|
| 1 | +# Training Factorization Machine with FTRL on Spark on Angel |
| 2 | + |
| 3 | +> FM(Factorization Machine) is an algorithm based on matrix decomposition which can predict any real-valued vector. |
| 4 | +
|
| 5 | +> Its main advantages include: |
| 6 | +
|
| 7 | +- can handle highly sparse data; |
| 8 | +- linear computational complexity |
| 9 | + |
| 10 | +> FTRL (Follow-the-regularized-leader) is an optimization algorithm which is widely deployed by online learning. Employing FTRL is easy in Spark-on-Angel and you can train a model with billions, even ten billions, dimensions once you have enough machines. |
| 11 | +
|
| 12 | +Here, we will use FTRL Optimizer to update the parameters of FM. |
| 13 | + |
| 14 | +If you are not familiar with how to programming on Spark-on-Angel, please first refer to [Programming Guide for Spark-on-Angel](https://github.com/Angel-ML/angel/blob/master/docs/programmers_guide/spark_on_angel_programing_guide_en.md); |
| 15 | + |
| 16 | +## Factorization Model |
| 17 | + |
| 18 | +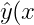=b+\sum_{i=1}^n{w_ix_i}+\sum_{i=1}^{n-1}\sum_{j=i+1}^n<v_i,v_j>x_ix_j) |
| 19 | + |
| 20 | +where 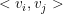 is the dot of two k-dimension vector: |
| 21 | + |
| 22 | +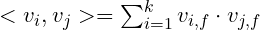 |
| 23 | + |
| 24 | +model parameters: |
| 25 | + |
| 26 | +, where n is the number of feature, 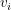 represents feature i composed by k factors, k is a hyperparameter that determines the factorization. |
| 27 | + |
| 28 | + |
| 29 | +## Using the FTRL-FM |
| 30 | + |
| 31 | +```scala |
| 32 | + |
| 33 | +import com.tencent.angel.ml.math2.utils.RowType |
| 34 | +import org.apache.spark.angel.ml.online_learning.FtrlFM |
| 35 | + |
| 36 | +// allocate a ftrl optimizer with (lambda1, lambda2, alpha, beta) |
| 37 | +val optim = new FtrlFM(lambda1, lambda2, alpha, beta) |
| 38 | +// initializing the model |
| 39 | +optim.init(dim, factor) |
| 40 | +``` |
| 41 | + |
| 42 | +There are four hyper-parameters for the FTRL optimizer, which are lambda1, lambda2, alpha and beta. We allocate a FTRL optimizer with these four hyper-parameters. The next step is to initialized a FtrlFM model. There are two matrixs for FtrlFM, including `first` and `second`, the `first` contains the z, n and w in which z and n are used to init or update parameter w in FM, the `second` contains the z, n and v in which z and n are used to init or update parameter v in FM. In the aboving code, we allocate `first` a sparse distributed matrix with 3 rows and dim columns, and allocate `second` a sparse distributed matrix with 3 * factor rows and dim columns. |
| 43 | + |
| 44 | +### set the dimension |
| 45 | +In the scenaro of online learning, the index of features can be range from (int.min, int.max), which is usually generated by a hash function. In Spark-on-Angel, you can set the dim=-1 when your feature index range from (int.min, int.max) and rowType is sparse. If the feature index range from [0, n), you can set the dim=n. |
| 46 | + |
| 47 | + |
| 48 | +## Training with Spark |
| 49 | + |
| 50 | +### loading data |
| 51 | +Using the interface of RDD to load data and parse them to vectors. |
| 52 | + |
| 53 | +```scala |
| 54 | +val data = sc.textFile(input).repartition(partNum) |
| 55 | + .map(s => (DataLoader.parseIntFloat(s, dim), DataLoader.parseLabel(s, false))) |
| 56 | + .map { |
| 57 | + f => |
| 58 | + f._1.setY(f._2) |
| 59 | + f._1 |
| 60 | + } |
| 61 | +``` |
| 62 | +### training model |
| 63 | + |
| 64 | +```scala |
| 65 | +val size = data.count() |
| 66 | +for (epoch <- 1 to numEpoch) { |
| 67 | + val totalLoss = data.mapPartitions { |
| 68 | + case iterator => |
| 69 | + // for each partition |
| 70 | + val loss = iterator |
| 71 | + .sliding(batchSize, batchSize) |
| 72 | + .zipWithIndex |
| 73 | + .map(f => optim.optimize(f._2, f_1.toArray)).sum |
| 74 | + Iterator.single(loss) |
| 75 | + }.sum() |
| 76 | + println(s"epoch=$epoch loss=${totalLoss / size}") |
| 77 | +} |
| 78 | +``` |
| 79 | + |
| 80 | + |
| 81 | +### saving model |
| 82 | + |
| 83 | +```scala |
| 84 | +output = "hdfs://xxx" |
| 85 | +optim.weight |
| 86 | +optim.save(output + "/back") |
| 87 | +optim.saveWeight(output) |
| 88 | +``` |
| 89 | + |
| 90 | +### Submit Command |
| 91 | + |
| 92 | +```shell |
| 93 | +source ./bin/spark-on-angel-env.sh |
| 94 | + |
| 95 | +$SPARK_HOME/bin/spark-submit \ |
| 96 | + --master yarn-cluster \ |
| 97 | + --conf spark.yarn.allocation.am.maxMemory=55g \ |
| 98 | + --conf spark.yarn.allocation.executor.maxMemory=55g \ |
| 99 | + --conf spark.driver.maxResultSize=20g \ |
| 100 | + --conf spark.kryoserializer.buffer.max=2000m\ |
| 101 | + --conf spark.ps.jars=$SONA_ANGEL_JARS \ |
| 102 | + --conf spark.ps.instances=1 \ |
| 103 | + --conf spark.ps.cores=2 \ |
| 104 | + --conf spark.ps.memory=5g \ |
| 105 | + --conf spark.ps.log.level=INFO \ |
| 106 | + --conf spark.offline.evaluate=200\ |
| 107 | + --jars $SONA_SPARK_JARS \ |
| 108 | + --name "FTRLFM on Spark-on-Angel" \ |
| 109 | + --driver-memory 5g \ |
| 110 | + --num-executors 5 \ |
| 111 | + --executor-cores 2 \ |
| 112 | + --executor-memory 2g \ |
| 113 | + --class org.apache.spark.angel.examples.online_learning.FtrlFMExample \ |
| 114 | + ./lib/angelml-${SONA_VERSION}.jar \ |
| 115 | + input:$input modelPath:$model dim:$dim batchSize:$batchSize actionType:train factor:5 |
| 116 | +``` |
| 117 | +[detail parameters](../../angelml/src/main/scala/org/apache/spark/angel/examples/online_learning/FtrlFMExample.scala) |
0 commit comments