diff --git a/.github/workflows/ci_docs.yml b/.github/workflows/ci_docs.yml
index 34219ac61..d93052c04 100644
--- a/.github/workflows/ci_docs.yml
+++ b/.github/workflows/ci_docs.yml
@@ -34,13 +34,7 @@ jobs:
- uses: actions/setup-python@v5
with:
python-version: 3.8
-
- - name: Cache pip
- uses: actions/cache@v4
- with:
- path: ~/.cache/pip
- key: pip-${{ hashFiles('requirements.txt') }}-${{ hashFiles('_requirements/docs.txt') }}
- restore-keys: pip-
+ cache: pip
- name: Install Texlive & tree
run: |
@@ -60,7 +54,7 @@ jobs:
head=$(git rev-parse origin/"${{ github.base_ref }}")
git diff --name-only $head --output=master-diff.txt
python .actions/assistant.py group-folders master-diff.txt
- printf "Changed folders:\n"
+ printf "Changed folders:\n----------------\n"
cat changed-folders.txt
- name: Count changed notebooks
diff --git a/_docs/source/conf.py b/_docs/source/conf.py
index ce0d984c6..45a0a3161 100644
--- a/_docs/source/conf.py
+++ b/_docs/source/conf.py
@@ -240,4 +240,7 @@
linkcheck_exclude_documents = []
# ignore the following relative links (false positive errors during linkcheck)
-linkcheck_ignore = []
+linkcheck_ignore = [
+ # Implicit generation and generalization methods for energy-based models
+ "https://openai.com/index/energy-based-models/",
+]
diff --git a/course_UvA-DL/03-initialization-and-optimization/Initialization_and_Optimization.py b/course_UvA-DL/03-initialization-and-optimization/Initialization_and_Optimization.py
index fef7cae2c..4625ca66e 100644
--- a/course_UvA-DL/03-initialization-and-optimization/Initialization_and_Optimization.py
+++ b/course_UvA-DL/03-initialization-and-optimization/Initialization_and_Optimization.py
@@ -524,7 +524,7 @@ def xavier_init(model):
#
# Thus, we see that we have an additional factor of 1/2 in the equation, so that our desired weight variance becomes $2/d_x$.
# This gives us the Kaiming initialization (see [He, K. et al.
-# (2015)](https://arxiv.org/pdf/1502.01852.pdf)).
+# (2015)](https://arxiv.org/abs/1502.01852)).
# Note that the Kaiming initialization does not use the harmonic mean between input and output size.
# In their paper (Section 2.2, Backward Propagation, last paragraph), they argue that using $d_x$ or $d_y$ both lead to stable gradients throughout the network, and only depend on the overall input and output size of the network.
# Hence, we can use here only the input $d_x$:
@@ -1098,7 +1098,7 @@ def comb_func(w1, w2):
# The short answer: no.
# There are many papers saying that in certain situations, SGD (with momentum) generalizes better where Adam often tends to overfit [5,6].
# This is related to the idea of finding wider optima.
-# For instance, see the illustration of different optima below (credit: [Keskar et al., 2017](https://arxiv.org/pdf/1609.04836.pdf)):
+# For instance, see the illustration of different optima below (credit: [Keskar et al., 2017](https://arxiv.org/abs/1609.04836)):
#
#  #
@@ -1128,7 +1128,7 @@ def comb_func(w1, w2):
# "Understanding the difficulty of training deep feedforward neural networks."
# Proceedings of the thirteenth international conference on artificial intelligence and statistics.
# 2010.
-# [link](http://proceedings.mlr.press/v9/glorot10a/glorot10a.pdf)
+# [link](https://proceedings.mlr.press/v9/glorot10a)
#
# [2] He, Kaiming, et al.
# "Delving deep into rectifiers: Surpassing human-level performance on imagenet classification."
diff --git a/course_UvA-DL/04-inception-resnet-densenet/Inception_ResNet_DenseNet.py b/course_UvA-DL/04-inception-resnet-densenet/Inception_ResNet_DenseNet.py
index 6e2a2b2b5..704d13515 100644
--- a/course_UvA-DL/04-inception-resnet-densenet/Inception_ResNet_DenseNet.py
+++ b/course_UvA-DL/04-inception-resnet-densenet/Inception_ResNet_DenseNet.py
@@ -244,7 +244,7 @@ def configure_optimizers(self):
# We will support Adam or SGD as optimizers.
if self.hparams.optimizer_name == "Adam":
# AdamW is Adam with a correct implementation of weight decay (see here
- # for details: https://arxiv.org/pdf/1711.05101.pdf)
+ # for details: https://arxiv.org/abs/1711.05101)
optimizer = optim.AdamW(self.parameters(), **self.hparams.optimizer_hparams)
elif self.hparams.optimizer_name == "SGD":
optimizer = optim.SGD(self.parameters(), **self.hparams.optimizer_hparams)
@@ -875,8 +875,8 @@ def forward(self, x):
# One difference to the GoogleNet training is that we explicitly use SGD with Momentum as optimizer instead of Adam.
# Adam often leads to a slightly worse accuracy on plain, shallow ResNets.
# It is not 100% clear why Adam performs worse in this context, but one possible explanation is related to ResNet's loss surface.
-# ResNet has been shown to produce smoother loss surfaces than networks without skip connection (see [Li et al., 2018](https://arxiv.org/pdf/1712.09913.pdf) for details).
-# A possible visualization of the loss surface with/out skip connections is below (figure credit - [Li et al. ](https://arxiv.org/pdf/1712.09913.pdf)):
+# ResNet has been shown to produce smoother loss surfaces than networks without skip connection (see [Li et al., 2018](https://arxiv.org/abs/1712.09913) for details).
+# A possible visualization of the loss surface with/out skip connections is below (figure credit - [Li et al. ](https://arxiv.org/abs/1712.09913)):
#
#
#
@@ -1128,7 +1128,7 @@ def comb_func(w1, w2):
# "Understanding the difficulty of training deep feedforward neural networks."
# Proceedings of the thirteenth international conference on artificial intelligence and statistics.
# 2010.
-# [link](http://proceedings.mlr.press/v9/glorot10a/glorot10a.pdf)
+# [link](https://proceedings.mlr.press/v9/glorot10a)
#
# [2] He, Kaiming, et al.
# "Delving deep into rectifiers: Surpassing human-level performance on imagenet classification."
diff --git a/course_UvA-DL/04-inception-resnet-densenet/Inception_ResNet_DenseNet.py b/course_UvA-DL/04-inception-resnet-densenet/Inception_ResNet_DenseNet.py
index 6e2a2b2b5..704d13515 100644
--- a/course_UvA-DL/04-inception-resnet-densenet/Inception_ResNet_DenseNet.py
+++ b/course_UvA-DL/04-inception-resnet-densenet/Inception_ResNet_DenseNet.py
@@ -244,7 +244,7 @@ def configure_optimizers(self):
# We will support Adam or SGD as optimizers.
if self.hparams.optimizer_name == "Adam":
# AdamW is Adam with a correct implementation of weight decay (see here
- # for details: https://arxiv.org/pdf/1711.05101.pdf)
+ # for details: https://arxiv.org/abs/1711.05101)
optimizer = optim.AdamW(self.parameters(), **self.hparams.optimizer_hparams)
elif self.hparams.optimizer_name == "SGD":
optimizer = optim.SGD(self.parameters(), **self.hparams.optimizer_hparams)
@@ -875,8 +875,8 @@ def forward(self, x):
# One difference to the GoogleNet training is that we explicitly use SGD with Momentum as optimizer instead of Adam.
# Adam often leads to a slightly worse accuracy on plain, shallow ResNets.
# It is not 100% clear why Adam performs worse in this context, but one possible explanation is related to ResNet's loss surface.
-# ResNet has been shown to produce smoother loss surfaces than networks without skip connection (see [Li et al., 2018](https://arxiv.org/pdf/1712.09913.pdf) for details).
-# A possible visualization of the loss surface with/out skip connections is below (figure credit - [Li et al. ](https://arxiv.org/pdf/1712.09913.pdf)):
+# ResNet has been shown to produce smoother loss surfaces than networks without skip connection (see [Li et al., 2018](https://arxiv.org/abs/1712.09913) for details).
+# A possible visualization of the loss surface with/out skip connections is below (figure credit - [Li et al. ](https://arxiv.org/abs/1712.09913)):
#
#  #
diff --git a/course_UvA-DL/05-transformers-and-MH-attention/Transformers_MHAttention.py b/course_UvA-DL/05-transformers-and-MH-attention/Transformers_MHAttention.py
index f3ba2d528..6c84c8c9b 100644
--- a/course_UvA-DL/05-transformers-and-MH-attention/Transformers_MHAttention.py
+++ b/course_UvA-DL/05-transformers-and-MH-attention/Transformers_MHAttention.py
@@ -660,7 +660,7 @@ def forward(self, x):
# In fact, training a deep Transformer without learning rate warm-up can make the model diverge
# and achieve a much worse performance on training and testing.
# Take for instance the following plot by [Liu et al.
-# (2019)](https://arxiv.org/pdf/1908.03265.pdf) comparing Adam-vanilla (i.e. Adam without warm-up)
+# (2019)](https://arxiv.org/abs/1908.03265) comparing Adam-vanilla (i.e. Adam without warm-up)
# vs Adam with a warm-up:
#
#
#
diff --git a/course_UvA-DL/05-transformers-and-MH-attention/Transformers_MHAttention.py b/course_UvA-DL/05-transformers-and-MH-attention/Transformers_MHAttention.py
index f3ba2d528..6c84c8c9b 100644
--- a/course_UvA-DL/05-transformers-and-MH-attention/Transformers_MHAttention.py
+++ b/course_UvA-DL/05-transformers-and-MH-attention/Transformers_MHAttention.py
@@ -660,7 +660,7 @@ def forward(self, x):
# In fact, training a deep Transformer without learning rate warm-up can make the model diverge
# and achieve a much worse performance on training and testing.
# Take for instance the following plot by [Liu et al.
-# (2019)](https://arxiv.org/pdf/1908.03265.pdf) comparing Adam-vanilla (i.e. Adam without warm-up)
+# (2019)](https://arxiv.org/abs/1908.03265) comparing Adam-vanilla (i.e. Adam without warm-up)
# vs Adam with a warm-up:
#
#  diff --git a/course_UvA-DL/06-graph-neural-networks/GNN_overview.py b/course_UvA-DL/06-graph-neural-networks/GNN_overview.py
index 5b53866f0..ab818f1df 100644
--- a/course_UvA-DL/06-graph-neural-networks/GNN_overview.py
+++ b/course_UvA-DL/06-graph-neural-networks/GNN_overview.py
@@ -750,7 +750,7 @@ def print_results(result_dict):
# Tutorials and papers for this topic include:
#
# * [PyTorch Geometric example](https://github.com/rusty1s/pytorch_geometric/blob/master/examples/link_pred.py)
-# * [Graph Neural Networks: A Review of Methods and Applications](https://arxiv.org/pdf/1812.08434.pdf), Zhou et al.
+# * [Graph Neural Networks: A Review of Methods and Applications](https://arxiv.org/abs/1812.08434), Zhou et al.
# 2019
# * [Link Prediction Based on Graph Neural Networks](https://papers.nips.cc/paper/2018/file/53f0d7c537d99b3824f0f99d62ea2428-Paper.pdf), Zhang and Chen, 2018.
diff --git a/course_UvA-DL/09-normalizing-flows/NF_image_modeling.py b/course_UvA-DL/09-normalizing-flows/NF_image_modeling.py
index 9b0c02e67..fe4177f4c 100644
--- a/course_UvA-DL/09-normalizing-flows/NF_image_modeling.py
+++ b/course_UvA-DL/09-normalizing-flows/NF_image_modeling.py
@@ -1396,7 +1396,7 @@ def visualize_dequant_distribution(model: ImageFlow, imgs: Tensor, title: str =
# and we have the guarantee that every possible input $x$ has a corresponding latent vector $z$.
# However, even beyond continuous inputs and images, flows can be applied and allow us to exploit
# the data structure in latent space, as e.g. on graphs for the task of molecule generation [6].
-# Recent advances in [Neural ODEs](https://arxiv.org/pdf/1806.07366.pdf) allow a flow with infinite number of layers,
+# Recent advances in [Neural ODEs](https://arxiv.org/abs/1806.07366) allow a flow with infinite number of layers,
# called Continuous Normalizing Flows, whose potential is yet to fully explore.
# Overall, normalizing flows are an exciting research area which will continue over the next couple of years.
diff --git a/course_UvA-DL/10-autoregressive-image-modeling/Autoregressive_Image_Modeling.py b/course_UvA-DL/10-autoregressive-image-modeling/Autoregressive_Image_Modeling.py
index 3367a1496..7c329b6f4 100644
--- a/course_UvA-DL/10-autoregressive-image-modeling/Autoregressive_Image_Modeling.py
+++ b/course_UvA-DL/10-autoregressive-image-modeling/Autoregressive_Image_Modeling.py
@@ -18,10 +18,10 @@
# For instance, in autoregressive models, we cannot interpolate between two images because of the lack of a latent representation.
# We will explore and discuss these benefits and drawbacks alongside with our implementation.
#
-# Our implementation will focus on the [PixelCNN](https://arxiv.org/pdf/1606.05328.pdf) [2] model which has been discussed in detail in the lecture.
+# Our implementation will focus on the [PixelCNN](https://arxiv.org/abs/1606.05328) [2] model which has been discussed in detail in the lecture.
# Most current SOTA models use PixelCNN as their fundamental architecture,
# and various additions have been proposed to improve the performance
-# (e.g. [PixelCNN++](https://arxiv.org/pdf/1701.05517.pdf) and [PixelSNAIL](http://proceedings.mlr.press/v80/chen18h/chen18h.pdf)).
+# (e.g. [PixelCNN++](https://arxiv.org/abs/1701.05517) and [PixelSNAIL](http://proceedings.mlr.press/v80/chen18h/chen18h.pdf)).
# Hence, implementing PixelCNN is a good starting point for our short tutorial.
#
# First of all, we need to import our standard libraries. Similarly as in
@@ -173,7 +173,7 @@ def show_imgs(imgs):
# If we now want to apply this to our convolutions, we need to ensure that the prediction of pixel 1
# is not influenced by its own "true" input, and all pixels on its right and in any lower row.
# In convolutions, this means that we want to set those entries of the weight matrix to zero that take pixels on the right and below into account.
-# As an example for a 5x5 kernel, see a mask below (figure credit - [Aaron van den Oord](https://arxiv.org/pdf/1606.05328.pdf)):
+# As an example for a 5x5 kernel, see a mask below (figure credit - [Aaron van den Oord](https://arxiv.org/abs/1606.05328)):
#
#
diff --git a/course_UvA-DL/06-graph-neural-networks/GNN_overview.py b/course_UvA-DL/06-graph-neural-networks/GNN_overview.py
index 5b53866f0..ab818f1df 100644
--- a/course_UvA-DL/06-graph-neural-networks/GNN_overview.py
+++ b/course_UvA-DL/06-graph-neural-networks/GNN_overview.py
@@ -750,7 +750,7 @@ def print_results(result_dict):
# Tutorials and papers for this topic include:
#
# * [PyTorch Geometric example](https://github.com/rusty1s/pytorch_geometric/blob/master/examples/link_pred.py)
-# * [Graph Neural Networks: A Review of Methods and Applications](https://arxiv.org/pdf/1812.08434.pdf), Zhou et al.
+# * [Graph Neural Networks: A Review of Methods and Applications](https://arxiv.org/abs/1812.08434), Zhou et al.
# 2019
# * [Link Prediction Based on Graph Neural Networks](https://papers.nips.cc/paper/2018/file/53f0d7c537d99b3824f0f99d62ea2428-Paper.pdf), Zhang and Chen, 2018.
diff --git a/course_UvA-DL/09-normalizing-flows/NF_image_modeling.py b/course_UvA-DL/09-normalizing-flows/NF_image_modeling.py
index 9b0c02e67..fe4177f4c 100644
--- a/course_UvA-DL/09-normalizing-flows/NF_image_modeling.py
+++ b/course_UvA-DL/09-normalizing-flows/NF_image_modeling.py
@@ -1396,7 +1396,7 @@ def visualize_dequant_distribution(model: ImageFlow, imgs: Tensor, title: str =
# and we have the guarantee that every possible input $x$ has a corresponding latent vector $z$.
# However, even beyond continuous inputs and images, flows can be applied and allow us to exploit
# the data structure in latent space, as e.g. on graphs for the task of molecule generation [6].
-# Recent advances in [Neural ODEs](https://arxiv.org/pdf/1806.07366.pdf) allow a flow with infinite number of layers,
+# Recent advances in [Neural ODEs](https://arxiv.org/abs/1806.07366) allow a flow with infinite number of layers,
# called Continuous Normalizing Flows, whose potential is yet to fully explore.
# Overall, normalizing flows are an exciting research area which will continue over the next couple of years.
diff --git a/course_UvA-DL/10-autoregressive-image-modeling/Autoregressive_Image_Modeling.py b/course_UvA-DL/10-autoregressive-image-modeling/Autoregressive_Image_Modeling.py
index 3367a1496..7c329b6f4 100644
--- a/course_UvA-DL/10-autoregressive-image-modeling/Autoregressive_Image_Modeling.py
+++ b/course_UvA-DL/10-autoregressive-image-modeling/Autoregressive_Image_Modeling.py
@@ -18,10 +18,10 @@
# For instance, in autoregressive models, we cannot interpolate between two images because of the lack of a latent representation.
# We will explore and discuss these benefits and drawbacks alongside with our implementation.
#
-# Our implementation will focus on the [PixelCNN](https://arxiv.org/pdf/1606.05328.pdf) [2] model which has been discussed in detail in the lecture.
+# Our implementation will focus on the [PixelCNN](https://arxiv.org/abs/1606.05328) [2] model which has been discussed in detail in the lecture.
# Most current SOTA models use PixelCNN as their fundamental architecture,
# and various additions have been proposed to improve the performance
-# (e.g. [PixelCNN++](https://arxiv.org/pdf/1701.05517.pdf) and [PixelSNAIL](http://proceedings.mlr.press/v80/chen18h/chen18h.pdf)).
+# (e.g. [PixelCNN++](https://arxiv.org/abs/1701.05517) and [PixelSNAIL](http://proceedings.mlr.press/v80/chen18h/chen18h.pdf)).
# Hence, implementing PixelCNN is a good starting point for our short tutorial.
#
# First of all, we need to import our standard libraries. Similarly as in
@@ -173,7 +173,7 @@ def show_imgs(imgs):
# If we now want to apply this to our convolutions, we need to ensure that the prediction of pixel 1
# is not influenced by its own "true" input, and all pixels on its right and in any lower row.
# In convolutions, this means that we want to set those entries of the weight matrix to zero that take pixels on the right and below into account.
-# As an example for a 5x5 kernel, see a mask below (figure credit - [Aaron van den Oord](https://arxiv.org/pdf/1606.05328.pdf)):
+# As an example for a 5x5 kernel, see a mask below (figure credit - [Aaron van den Oord](https://arxiv.org/abs/1606.05328)):
#
#  #
@@ -217,10 +217,10 @@ def forward(self, x):
#
# To build our own autoregressive image model, we could simply stack a few masked convolutions on top of each other.
# This was actually the case for the original PixelCNN model, discussed in the paper
-# [Pixel Recurrent Neural Networks](https://arxiv.org/pdf/1601.06759.pdf), but this leads to a considerable issue.
+# [Pixel Recurrent Neural Networks](https://arxiv.org/abs/1601.06759), but this leads to a considerable issue.
# When sequentially applying a couple of masked convolutions, the receptive field of a pixel
# show to have a "blind spot" on the right upper side, as shown in the figure below
-# (figure credit - [Aaron van den Oord et al. ](https://arxiv.org/pdf/1606.05328.pdf)):
+# (figure credit - [Aaron van den Oord et al. ](https://arxiv.org/abs/1606.05328)):
#
#
#
@@ -217,10 +217,10 @@ def forward(self, x):
#
# To build our own autoregressive image model, we could simply stack a few masked convolutions on top of each other.
# This was actually the case for the original PixelCNN model, discussed in the paper
-# [Pixel Recurrent Neural Networks](https://arxiv.org/pdf/1601.06759.pdf), but this leads to a considerable issue.
+# [Pixel Recurrent Neural Networks](https://arxiv.org/abs/1601.06759), but this leads to a considerable issue.
# When sequentially applying a couple of masked convolutions, the receptive field of a pixel
# show to have a "blind spot" on the right upper side, as shown in the figure below
-# (figure credit - [Aaron van den Oord et al. ](https://arxiv.org/pdf/1606.05328.pdf)):
+# (figure credit - [Aaron van den Oord et al. ](https://arxiv.org/abs/1606.05328)):
#
#  #
@@ -447,7 +447,7 @@ def show_center_recep_field(img, out):
# For visualizing the receptive field, we assumed a very simplified stack of vertical and horizontal convolutions.
# Obviously, there are more sophisticated ways of doing it, and PixelCNN uses gated convolutions for this.
# Specifically, the Gated Convolution block in PixelCNN looks as follows
-# (figure credit - [Aaron van den Oord et al. ](https://arxiv.org/pdf/1606.05328.pdf)):
+# (figure credit - [Aaron van den Oord et al. ](https://arxiv.org/abs/1606.05328)):
#
#
#
@@ -447,7 +447,7 @@ def show_center_recep_field(img, out):
# For visualizing the receptive field, we assumed a very simplified stack of vertical and horizontal convolutions.
# Obviously, there are more sophisticated ways of doing it, and PixelCNN uses gated convolutions for this.
# Specifically, the Gated Convolution block in PixelCNN looks as follows
-# (figure credit - [Aaron van den Oord et al. ](https://arxiv.org/pdf/1606.05328.pdf)):
+# (figure credit - [Aaron van den Oord et al. ](https://arxiv.org/abs/1606.05328)):
#
#  #
@@ -508,7 +508,7 @@ def forward(self, v_stack, h_stack):
# The architecture consists of multiple stacked GatedMaskedConv blocks, where we add an additional dilation factor to a few convolutions.
# This is used to increase the receptive field of the model and allows to take a larger context into account during generation.
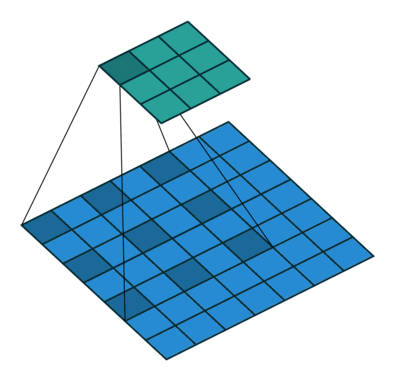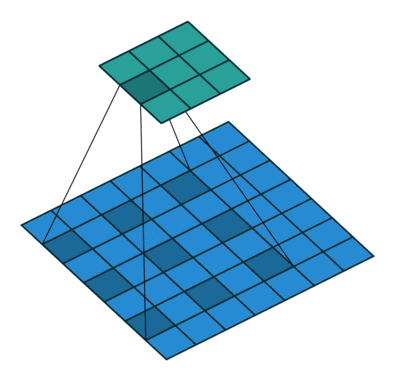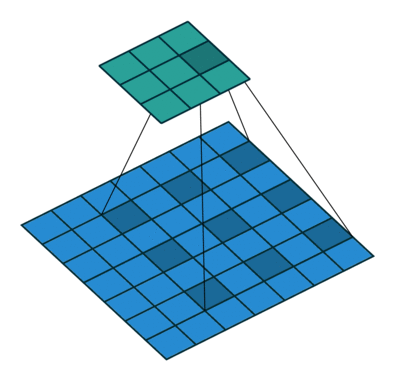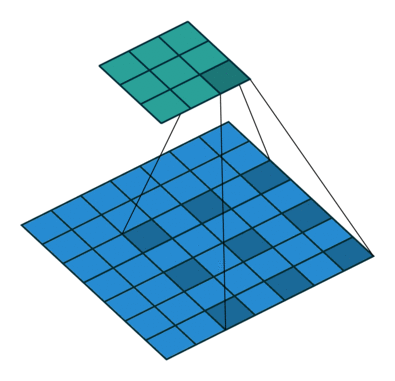
# As a reminder, dilation on a convolution works looks as follows
-# (figure credit - [Vincent Dumoulin and Francesco Visin](https://arxiv.org/pdf/1603.07285.pdf)):
+# (figure credit - [Vincent Dumoulin and Francesco Visin](https://arxiv.org/abs/1603.07285)):
#
#
#
@@ -508,7 +508,7 @@ def forward(self, v_stack, h_stack):
# The architecture consists of multiple stacked GatedMaskedConv blocks, where we add an additional dilation factor to a few convolutions.
# This is used to increase the receptive field of the model and allows to take a larger context into account during generation.
# As a reminder, dilation on a convolution works looks as follows
-# (figure credit - [Vincent Dumoulin and Francesco Visin](https://arxiv.org/pdf/1603.07285.pdf)):
+# (figure credit - [Vincent Dumoulin and Francesco Visin](https://arxiv.org/abs/1603.07285)):
#
#  #
@@ -659,7 +659,7 @@ def test_step(self, batch, batch_idx):
# %% [markdown]
# The visualization shows that for predicting any pixel, we can take almost half of the image into account.
# However, keep in mind that this is the "theoretical" receptive field and not necessarily
-# the [effective receptive field](https://arxiv.org/pdf/1701.04128.pdf), which is usually much smaller.
+# the [effective receptive field](https://arxiv.org/abs/1701.04128), which is usually much smaller.
# For a stronger model, we should therefore try to increase the receptive
# field even further. Especially, for the pixel on the bottom right, the
# very last pixel, we would be allowed to take into account the whole
@@ -873,7 +873,7 @@ def autocomplete_image(img):
# Interestingly, the pixel values 64, 128 and 191 also stand out which is likely due to the quantization used during the creation of the dataset.
# For RGB images, we would also see two peaks around 0 and 255,
# but the values in between would be much more frequent than in MNIST
-# (see Figure 1 in the [PixelCNN++](https://arxiv.org/pdf/1701.05517.pdf) for a visualization on CIFAR10).
+# (see Figure 1 in the [PixelCNN++](https://arxiv.org/abs/1701.05517) for a visualization on CIFAR10).
#
# Next, we can visualize the distribution our model predicts (in average):
diff --git a/course_UvA-DL/11-vision-transformer/Vision_Transformer.py b/course_UvA-DL/11-vision-transformer/Vision_Transformer.py
index fd7a6d45a..6606b0ef6 100644
--- a/course_UvA-DL/11-vision-transformer/Vision_Transformer.py
+++ b/course_UvA-DL/11-vision-transformer/Vision_Transformer.py
@@ -515,7 +515,7 @@ def train_model(**kwargs):
# Dosovitskiy, Alexey, et al.
# "An image is worth 16x16 words: Transformers for image recognition at scale."
# International Conference on Representation Learning (2021).
-# [link](https://arxiv.org/pdf/2010.11929.pdf)
+# [link](https://arxiv.org/abs/2010.11929)
#
# Chen, Xiangning, et al.
# "When Vision Transformers Outperform ResNets without Pretraining or Strong Data Augmentations."
diff --git a/course_UvA-DL/12-meta-learning/Meta_Learning.py b/course_UvA-DL/12-meta-learning/Meta_Learning.py
index 6cb110823..f4a266f84 100644
--- a/course_UvA-DL/12-meta-learning/Meta_Learning.py
+++ b/course_UvA-DL/12-meta-learning/Meta_Learning.py
@@ -1,6 +1,6 @@
# %% [markdown]
#
-# Meta-Learning offers solutions to these situations, and we will discuss three popular algorithms: __Prototypical Networks__ ([Snell et al., 2017](https://arxiv.org/pdf/1703.05175.pdf)), __Model-Agnostic Meta-Learning / MAML__ ([Finn et al., 2017](http://proceedings.mlr.press/v70/finn17a.html)), and __Proto-MAML__ ([Triantafillou et al., 2020](https://openreview.net/pdf?id=rkgAGAVKPr)).
+# Meta-Learning offers solutions to these situations, and we will discuss three popular algorithms: __Prototypical Networks__ ([Snell et al., 2017](https://arxiv.org/abs/1703.05175)), __Model-Agnostic Meta-Learning / MAML__ ([Finn et al., 2017](http://proceedings.mlr.press/v70/finn17a.html)), and __Proto-MAML__ ([Triantafillou et al., 2020](https://openreview.net/pdf?id=rkgAGAVKPr)).
# We will focus on the task of few-shot classification where the training and test set have distinct sets of classes.
# For instance, we would train the model on the binary classifications of cats-birds and flowers-bikes, but during test time, the model would need to learn from 4 examples each the difference between dogs and otters, two classes we have not seen during training (Figure credit - [Lilian Weng](https://lilianweng.github.io/lil-log/2018/11/30/meta-learning.html)).
#
@@ -418,7 +418,7 @@ def split_batch(imgs, targets):
# $$\mathbf{v}_c=\frac{1}{|S_c|}\sum_{(\mathbf{x}_i,y_i)\in S_c}f_{\theta}(\mathbf{x}_i)$$
#
# where $S_c$ is the part of the support set $S$ for which $y_i=c$, and $\mathbf{v}_c$ represents the _prototype_ of class $c$.
-# The prototype calculation is visualized below for a 2-dimensional feature space and 3 classes (Figure credit - [Snell et al.](https://arxiv.org/pdf/1703.05175.pdf)).
+# The prototype calculation is visualized below for a 2-dimensional feature space and 3 classes (Figure credit - [Snell et al.](https://arxiv.org/abs/1703.05175)).
# The colored dots represent encoded support elements with color-corresponding class label, and the black dots next to the class label are the averaged prototypes.
#
#
#
@@ -659,7 +659,7 @@ def test_step(self, batch, batch_idx):
# %% [markdown]
# The visualization shows that for predicting any pixel, we can take almost half of the image into account.
# However, keep in mind that this is the "theoretical" receptive field and not necessarily
-# the [effective receptive field](https://arxiv.org/pdf/1701.04128.pdf), which is usually much smaller.
+# the [effective receptive field](https://arxiv.org/abs/1701.04128), which is usually much smaller.
# For a stronger model, we should therefore try to increase the receptive
# field even further. Especially, for the pixel on the bottom right, the
# very last pixel, we would be allowed to take into account the whole
@@ -873,7 +873,7 @@ def autocomplete_image(img):
# Interestingly, the pixel values 64, 128 and 191 also stand out which is likely due to the quantization used during the creation of the dataset.
# For RGB images, we would also see two peaks around 0 and 255,
# but the values in between would be much more frequent than in MNIST
-# (see Figure 1 in the [PixelCNN++](https://arxiv.org/pdf/1701.05517.pdf) for a visualization on CIFAR10).
+# (see Figure 1 in the [PixelCNN++](https://arxiv.org/abs/1701.05517) for a visualization on CIFAR10).
#
# Next, we can visualize the distribution our model predicts (in average):
diff --git a/course_UvA-DL/11-vision-transformer/Vision_Transformer.py b/course_UvA-DL/11-vision-transformer/Vision_Transformer.py
index fd7a6d45a..6606b0ef6 100644
--- a/course_UvA-DL/11-vision-transformer/Vision_Transformer.py
+++ b/course_UvA-DL/11-vision-transformer/Vision_Transformer.py
@@ -515,7 +515,7 @@ def train_model(**kwargs):
# Dosovitskiy, Alexey, et al.
# "An image is worth 16x16 words: Transformers for image recognition at scale."
# International Conference on Representation Learning (2021).
-# [link](https://arxiv.org/pdf/2010.11929.pdf)
+# [link](https://arxiv.org/abs/2010.11929)
#
# Chen, Xiangning, et al.
# "When Vision Transformers Outperform ResNets without Pretraining or Strong Data Augmentations."
diff --git a/course_UvA-DL/12-meta-learning/Meta_Learning.py b/course_UvA-DL/12-meta-learning/Meta_Learning.py
index 6cb110823..f4a266f84 100644
--- a/course_UvA-DL/12-meta-learning/Meta_Learning.py
+++ b/course_UvA-DL/12-meta-learning/Meta_Learning.py
@@ -1,6 +1,6 @@
# %% [markdown]
#
-# Meta-Learning offers solutions to these situations, and we will discuss three popular algorithms: __Prototypical Networks__ ([Snell et al., 2017](https://arxiv.org/pdf/1703.05175.pdf)), __Model-Agnostic Meta-Learning / MAML__ ([Finn et al., 2017](http://proceedings.mlr.press/v70/finn17a.html)), and __Proto-MAML__ ([Triantafillou et al., 2020](https://openreview.net/pdf?id=rkgAGAVKPr)).
+# Meta-Learning offers solutions to these situations, and we will discuss three popular algorithms: __Prototypical Networks__ ([Snell et al., 2017](https://arxiv.org/abs/1703.05175)), __Model-Agnostic Meta-Learning / MAML__ ([Finn et al., 2017](http://proceedings.mlr.press/v70/finn17a.html)), and __Proto-MAML__ ([Triantafillou et al., 2020](https://openreview.net/pdf?id=rkgAGAVKPr)).
# We will focus on the task of few-shot classification where the training and test set have distinct sets of classes.
# For instance, we would train the model on the binary classifications of cats-birds and flowers-bikes, but during test time, the model would need to learn from 4 examples each the difference between dogs and otters, two classes we have not seen during training (Figure credit - [Lilian Weng](https://lilianweng.github.io/lil-log/2018/11/30/meta-learning.html)).
#
@@ -418,7 +418,7 @@ def split_batch(imgs, targets):
# $$\mathbf{v}_c=\frac{1}{|S_c|}\sum_{(\mathbf{x}_i,y_i)\in S_c}f_{\theta}(\mathbf{x}_i)$$
#
# where $S_c$ is the part of the support set $S$ for which $y_i=c$, and $\mathbf{v}_c$ represents the _prototype_ of class $c$.
-# The prototype calculation is visualized below for a 2-dimensional feature space and 3 classes (Figure credit - [Snell et al.](https://arxiv.org/pdf/1703.05175.pdf)).
+# The prototype calculation is visualized below for a 2-dimensional feature space and 3 classes (Figure credit - [Snell et al.](https://arxiv.org/abs/1703.05175)).
# The colored dots represent encoded support elements with color-corresponding class label, and the black dots next to the class label are the averaged prototypes.
#
#  @@ -1329,7 +1329,7 @@ def test_protomaml(model, dataset, k_shot=4):
# [1] Snell, Jake, Kevin Swersky, and Richard S. Zemel.
# "Prototypical networks for few-shot learning."
# NeurIPS 2017.
-# ([link](https://arxiv.org/pdf/1703.05175.pdf))
+# ([link](https://arxiv.org/abs/1703.05175))
#
# [2] Chelsea Finn, Pieter Abbeel, Sergey Levine.
# "Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks."
diff --git a/lightning_examples/finetuning-scheduler/finetuning-scheduler.py b/lightning_examples/finetuning-scheduler/finetuning-scheduler.py
index 9b69ddaae..22128320d 100644
--- a/lightning_examples/finetuning-scheduler/finetuning-scheduler.py
+++ b/lightning_examples/finetuning-scheduler/finetuning-scheduler.py
@@ -611,18 +611,18 @@ def train() -> None:
# %% [markdown]
# ## Footnotes
#
-# - [Howard, J., & Ruder, S. (2018)](https://arxiv.org/pdf/1801.06146.pdf). Fine-tuned Language
+# - [Howard, J., & Ruder, S. (2018)](https://arxiv.org/abs/1801.06146). Fine-tuned Language
# Models for Text Classification. ArXiv, abs/1801.06146. [↩](#Scheduled-Fine-Tuning-with-the-Fine-Tuning-Scheduler-Extension)
-# - [Chronopoulou, A., Baziotis, C., & Potamianos, A. (2019)](https://arxiv.org/pdf/1902.10547.pdf).
+# - [Chronopoulou, A., Baziotis, C., & Potamianos, A. (2019)](https://arxiv.org/abs/1902.10547).
# An embarrassingly simple approach for transfer learning from pretrained language models. arXiv
# preprint arXiv:1902.10547. [↩](#Scheduled-Fine-Tuning-with-the-Fine-Tuning-Scheduler-Extension)
-# - [Peters, M. E., Ruder, S., & Smith, N. A. (2019)](https://arxiv.org/pdf/1903.05987.pdf). To tune or not to
+# - [Peters, M. E., Ruder, S., & Smith, N. A. (2019)](https://arxiv.org/abs/1903.05987). To tune or not to
# tune? adapting pretrained representations to diverse tasks. arXiv preprint arXiv:1903.05987. [↩](#Scheduled-Fine-Tuning-with-the-Fine-Tuning-Scheduler-Extension)
-# - [Sivaprasad, P. T., Mai, F., Vogels, T., Jaggi, M., & Fleuret, F. (2020)](https://arxiv.org/pdf/1910.11758.pdf).
+# - [Sivaprasad, P. T., Mai, F., Vogels, T., Jaggi, M., & Fleuret, F. (2020)](https://arxiv.org/abs/1910.11758).
# Optimizer benchmarking needs to account for hyperparameter tuning. In International Conference on Machine Learning
# (pp. 9036-9045). PMLR. [↩](#Optimizer-Configuration)
-# - [Mosbach, M., Andriushchenko, M., & Klakow, D. (2020)](https://arxiv.org/pdf/2006.04884.pdf). On the stability of
+# - [Mosbach, M., Andriushchenko, M., & Klakow, D. (2020)](https://arxiv.org/abs/2006.04884). On the stability of
# fine-tuning bert: Misconceptions, explanations, and strong baselines. arXiv preprint arXiv:2006.04884. [↩](#Optimizer-Configuration)
-# - [Loshchilov, I., & Hutter, F. (2016)](https://arxiv.org/pdf/1608.03983.pdf). Sgdr: Stochastic gradient descent with
+# - [Loshchilov, I., & Hutter, F. (2016)](https://arxiv.org/abs/1608.03983). Sgdr: Stochastic gradient descent with
# warm restarts. arXiv preprint arXiv:1608.03983. [↩](#LR-Scheduler-Configuration)
#
@@ -1329,7 +1329,7 @@ def test_protomaml(model, dataset, k_shot=4):
# [1] Snell, Jake, Kevin Swersky, and Richard S. Zemel.
# "Prototypical networks for few-shot learning."
# NeurIPS 2017.
-# ([link](https://arxiv.org/pdf/1703.05175.pdf))
+# ([link](https://arxiv.org/abs/1703.05175))
#
# [2] Chelsea Finn, Pieter Abbeel, Sergey Levine.
# "Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks."
diff --git a/lightning_examples/finetuning-scheduler/finetuning-scheduler.py b/lightning_examples/finetuning-scheduler/finetuning-scheduler.py
index 9b69ddaae..22128320d 100644
--- a/lightning_examples/finetuning-scheduler/finetuning-scheduler.py
+++ b/lightning_examples/finetuning-scheduler/finetuning-scheduler.py
@@ -611,18 +611,18 @@ def train() -> None:
# %% [markdown]
# ## Footnotes
#
-# - [Howard, J., & Ruder, S. (2018)](https://arxiv.org/pdf/1801.06146.pdf). Fine-tuned Language
+# - [Howard, J., & Ruder, S. (2018)](https://arxiv.org/abs/1801.06146). Fine-tuned Language
# Models for Text Classification. ArXiv, abs/1801.06146. [↩](#Scheduled-Fine-Tuning-with-the-Fine-Tuning-Scheduler-Extension)
-# - [Chronopoulou, A., Baziotis, C., & Potamianos, A. (2019)](https://arxiv.org/pdf/1902.10547.pdf).
+# - [Chronopoulou, A., Baziotis, C., & Potamianos, A. (2019)](https://arxiv.org/abs/1902.10547).
# An embarrassingly simple approach for transfer learning from pretrained language models. arXiv
# preprint arXiv:1902.10547. [↩](#Scheduled-Fine-Tuning-with-the-Fine-Tuning-Scheduler-Extension)
-# - [Peters, M. E., Ruder, S., & Smith, N. A. (2019)](https://arxiv.org/pdf/1903.05987.pdf). To tune or not to
+# - [Peters, M. E., Ruder, S., & Smith, N. A. (2019)](https://arxiv.org/abs/1903.05987). To tune or not to
# tune? adapting pretrained representations to diverse tasks. arXiv preprint arXiv:1903.05987. [↩](#Scheduled-Fine-Tuning-with-the-Fine-Tuning-Scheduler-Extension)
-# - [Sivaprasad, P. T., Mai, F., Vogels, T., Jaggi, M., & Fleuret, F. (2020)](https://arxiv.org/pdf/1910.11758.pdf).
+# - [Sivaprasad, P. T., Mai, F., Vogels, T., Jaggi, M., & Fleuret, F. (2020)](https://arxiv.org/abs/1910.11758).
# Optimizer benchmarking needs to account for hyperparameter tuning. In International Conference on Machine Learning
# (pp. 9036-9045). PMLR. [↩](#Optimizer-Configuration)
-# - [Mosbach, M., Andriushchenko, M., & Klakow, D. (2020)](https://arxiv.org/pdf/2006.04884.pdf). On the stability of
+# - [Mosbach, M., Andriushchenko, M., & Klakow, D. (2020)](https://arxiv.org/abs/2006.04884). On the stability of
# fine-tuning bert: Misconceptions, explanations, and strong baselines. arXiv preprint arXiv:2006.04884. [↩](#Optimizer-Configuration)
-# - [Loshchilov, I., & Hutter, F. (2016)](https://arxiv.org/pdf/1608.03983.pdf). Sgdr: Stochastic gradient descent with
+# - [Loshchilov, I., & Hutter, F. (2016)](https://arxiv.org/abs/1608.03983). Sgdr: Stochastic gradient descent with
# warm restarts. arXiv preprint arXiv:1608.03983. [↩](#LR-Scheduler-Configuration)
#