
@@ -101,7 +101,8 @@ image
OmniGen has some interesting features, such as visual reasoning, as shown in the example below.
-```py
+
+```python
prompt="If the woman is thirsty, what should she take? Find it in the image and highlight it in blue.
![]()
<|image_1|>"
input_images=[load_image("https://raw.githubusercontent.com/VectorSpaceLab/OmniGen/main/imgs/docs_img/edit.png")]
image = pipe(
@@ -110,20 +111,20 @@ image = pipe(
guidance_scale=2,
img_guidance_scale=1.6,
use_input_image_size_as_output=True,
- generator=torch.Generator(device="cpu").manual_seed(0)).images[0]
-image
+ generator=torch.Generator(device="cpu").manual_seed(0)
+).images[0]
+image.save("output.png")
```
+

-
## Controllable generation
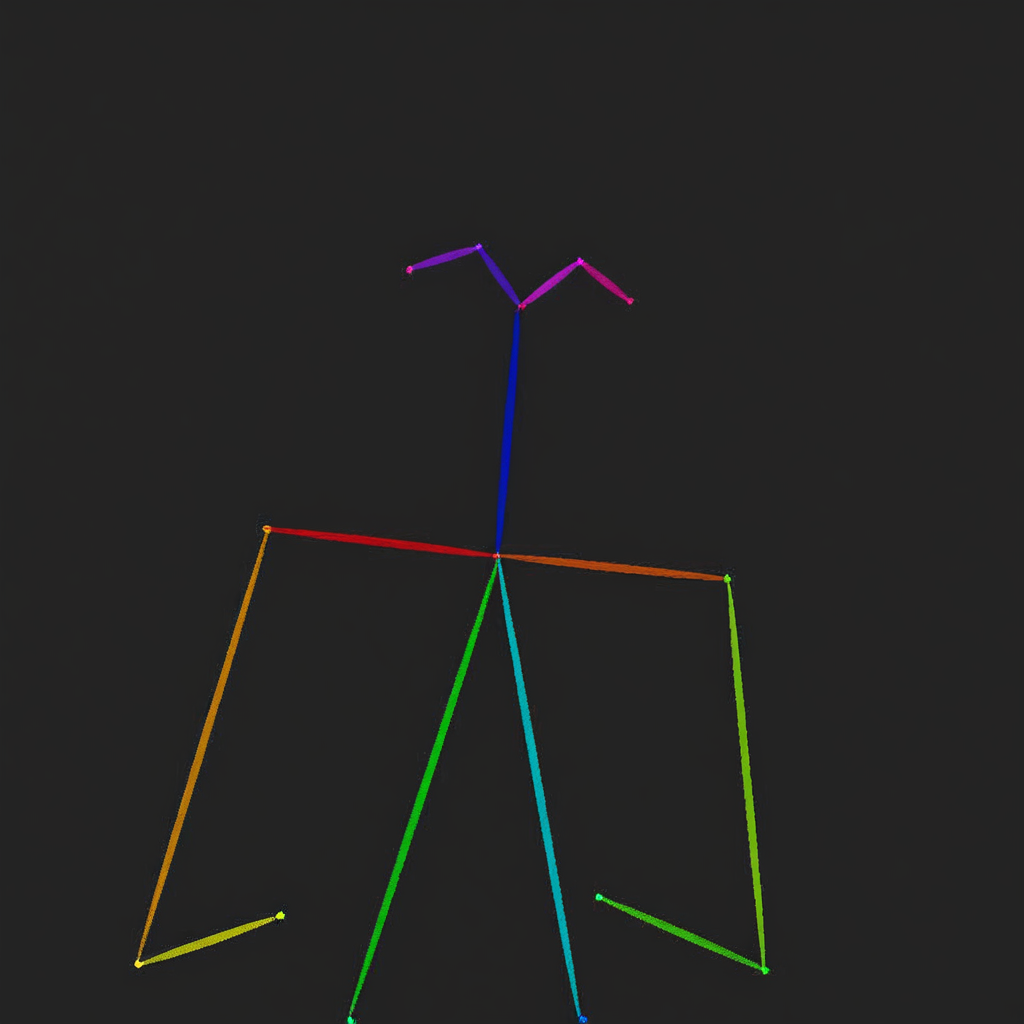
- OmniGen can handle several classic computer vision tasks.
- As shown below, OmniGen can detect human skeletons in input images, which can be used as control conditions to generate new images.
+OmniGen can handle several classic computer vision tasks. As shown below, OmniGen can detect human skeletons in input images, which can be used as control conditions to generate new images.
-```py
+```python
import torch
from diffusers import OmniGenPipeline
from diffusers.utils import load_image
@@ -142,8 +143,9 @@ image1 = pipe(
guidance_scale=2,
img_guidance_scale=1.6,
use_input_image_size_as_output=True,
- generator=torch.Generator(device="cpu").manual_seed(333)).images[0]
-image1
+ generator=torch.Generator(device="cpu").manual_seed(333)
+).images[0]
+image1.save("image1.png")
prompt="Generate a new photo using the following picture and text as conditions:
![]()
<|image_1|>\n A young boy is sitting on a sofa in the library, holding a book. His hair is neatly combed, and a faint smile plays on his lips, with a few freckles scattered across his cheeks. The library is quiet, with rows of shelves filled with books stretching out behind him."
input_images=[load_image("https://raw.githubusercontent.com/VectorSpaceLab/OmniGen/main/imgs/docs_img/skeletal.png")]
@@ -153,8 +155,9 @@ image2 = pipe(
guidance_scale=2,
img_guidance_scale=1.6,
use_input_image_size_as_output=True,
- generator=torch.Generator(device="cpu").manual_seed(333)).images[0]
-image2
+ generator=torch.Generator(device="cpu").manual_seed(333)
+).images[0]
+image2.save("image2.png")
```
@@ -174,7 +177,8 @@ image2
OmniGen can also directly use relevant information from input images to generate new images.
-```py
+
+```python
import torch
from diffusers import OmniGenPipeline
from diffusers.utils import load_image
@@ -193,9 +197,11 @@ image = pipe(
guidance_scale=2,
img_guidance_scale=1.6,
use_input_image_size_as_output=True,
- generator=torch.Generator(device="cpu").manual_seed(0)).images[0]
-image
+ generator=torch.Generator(device="cpu").manual_seed(0)
+).images[0]
+image.save("output.png")
```
+

@@ -203,13 +209,12 @@ image
-
## ID and object preserving
OmniGen can generate multiple images based on the people and objects in the input image and supports inputting multiple images simultaneously.
Additionally, OmniGen can extract desired objects from an image containing multiple objects based on instructions.
-```py
+```python
import torch
from diffusers import OmniGenPipeline
from diffusers.utils import load_image
@@ -231,9 +236,11 @@ image = pipe(
width=1024,
guidance_scale=2.5,
img_guidance_scale=1.6,
- generator=torch.Generator(device="cpu").manual_seed(666)).images[0]
-image
+ generator=torch.Generator(device="cpu").manual_seed(666)
+).images[0]
+image.save("output.png")
```
+

@@ -249,7 +256,6 @@ image
-
```py
import torch
from diffusers import OmniGenPipeline
@@ -261,7 +267,6 @@ pipe = OmniGenPipeline.from_pretrained(
)
pipe.to("cuda")
-
prompt="A woman is walking down the street, wearing a white long-sleeve blouse with lace details on the sleeves, paired with a blue pleated skirt. The woman is
![]()
<|image_1|>. The long-sleeve blouse and a pleated skirt are
![]()
<|image_2|>."
input_image_1 = load_image("https://raw.githubusercontent.com/VectorSpaceLab/OmniGen/main/imgs/docs_img/emma.jpeg")
input_image_2 = load_image("https://raw.githubusercontent.com/VectorSpaceLab/OmniGen/main/imgs/docs_img/dress.jpg")
@@ -273,8 +278,9 @@ image = pipe(
width=1024,
guidance_scale=2.5,
img_guidance_scale=1.6,
- generator=torch.Generator(device="cpu").manual_seed(666)).images[0]
-image
+ generator=torch.Generator(device="cpu").manual_seed(666)
+).images[0]
+image.save("output.png")
```
@@ -292,13 +298,12 @@ image
-
-## Optimization when inputting multiple images
+## Optimization when using multiple images
For text-to-image task, OmniGen requires minimal memory and time costs (9GB memory and 31s for a 1024x1024 image on A800 GPU).
However, when using input images, the computational cost increases.
-Here are some guidelines to help you reduce computational costs when inputting multiple images. The experiments are conducted on an A800 GPU with two input images.
+Here are some guidelines to help you reduce computational costs when using multiple images. The experiments are conducted on an A800 GPU with two input images.
Like other pipelines, you can reduce memory usage by offloading the model: `pipe.enable_model_cpu_offload()` or `pipe.enable_sequential_cpu_offload() `.
In OmniGen, you can also decrease computational overhead by reducing the `max_input_image_size`.
@@ -310,5 +315,3 @@ The memory consumption for different image sizes is shown in the table below:
| max_input_image_size=512 | 17GB |
| max_input_image_size=256 | 14GB |
-
-
diff --git a/src/diffusers/models/transformers/transformer_omnigen.py b/src/diffusers/models/transformers/transformer_omnigen.py
index 480f97d56385..7a05f49826aa 100644
--- a/src/diffusers/models/transformers/transformer_omnigen.py
+++ b/src/diffusers/models/transformers/transformer_omnigen.py
@@ -16,9 +16,8 @@
from typing import Dict, List, Optional, Tuple, Union
import torch
+import torch.nn as nn
import torch.nn.functional as F
-import torch.utils.checkpoint
-from torch import nn
from ...configuration_utils import ConfigMixin, register_to_config
from ...utils import logging
From aa32b86858de58a7baf4b5021ea8911d7c80aa5b Mon Sep 17 00:00:00 2001
From: Aryan
Date: Wed, 12 Feb 2025 09:21:16 +0100
Subject: [PATCH 58/58] apply review suggestion
---
src/diffusers/models/transformers/transformer_omnigen.py | 6 +++---
1 file changed, 3 insertions(+), 3 deletions(-)
diff --git a/src/diffusers/models/transformers/transformer_omnigen.py b/src/diffusers/models/transformers/transformer_omnigen.py
index 7a05f49826aa..8d5d1b3f8fea 100644
--- a/src/diffusers/models/transformers/transformer_omnigen.py
+++ b/src/diffusers/models/transformers/transformer_omnigen.py
@@ -424,9 +424,9 @@ def forward(
hidden_states = self.patch_embedding(hidden_states, is_input_image=False)
num_tokens_for_output_image = hidden_states.size(1)
- time_token = self.time_token(self.time_proj(timestep).to(hidden_states.dtype)).unsqueeze(1)
- timestep_proj = self.time_proj(timestep)
- temb = self.t_embedder(timestep_proj.type_as(hidden_states))
+ timestep_proj = self.time_proj(timestep).type_as(hidden_states)
+ time_token = self.time_token(timestep_proj).unsqueeze(1)
+ temb = self.t_embedder(timestep_proj)
condition_tokens = self._get_multimodal_embeddings(input_ids, input_img_latents, input_image_sizes)
if condition_tokens is not None:
 +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+ +
+ +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+