From d47819dae18f16bd8394e72e7b27b8f0c80f0c53 Mon Sep 17 00:00:00 2001
From: Steven Liu <59462357+stevhliu@users.noreply.github.com>
Date: Tue, 25 Feb 2025 14:19:01 -0800
Subject: [PATCH 1/7] Create model-repo-layout.md
---
docs/hub/model-repo-layout.md | 60 +++++++++++++++++++++++++++++++++++
1 file changed, 60 insertions(+)
create mode 100644 docs/hub/model-repo-layout.md
diff --git a/docs/hub/model-repo-layout.md b/docs/hub/model-repo-layout.md
new file mode 100644
index 000000000..9acf7fd56
--- /dev/null
+++ b/docs/hub/model-repo-layout.md
@@ -0,0 +1,60 @@
+# Model repository files
+
+A model repository holds all the files required to initialize a pretrained model for inference or training. The repository directory structure and files may vary depending on the library integration, but this guide covers what to expect in a Transformers or Diffusers model repository.
+
+## Transformers
+
+A [Transformers](https://hf.co/docs/transformers/index) model repository generally contains model files and preprocessor files.
+
+
+

+
+

+
+

+
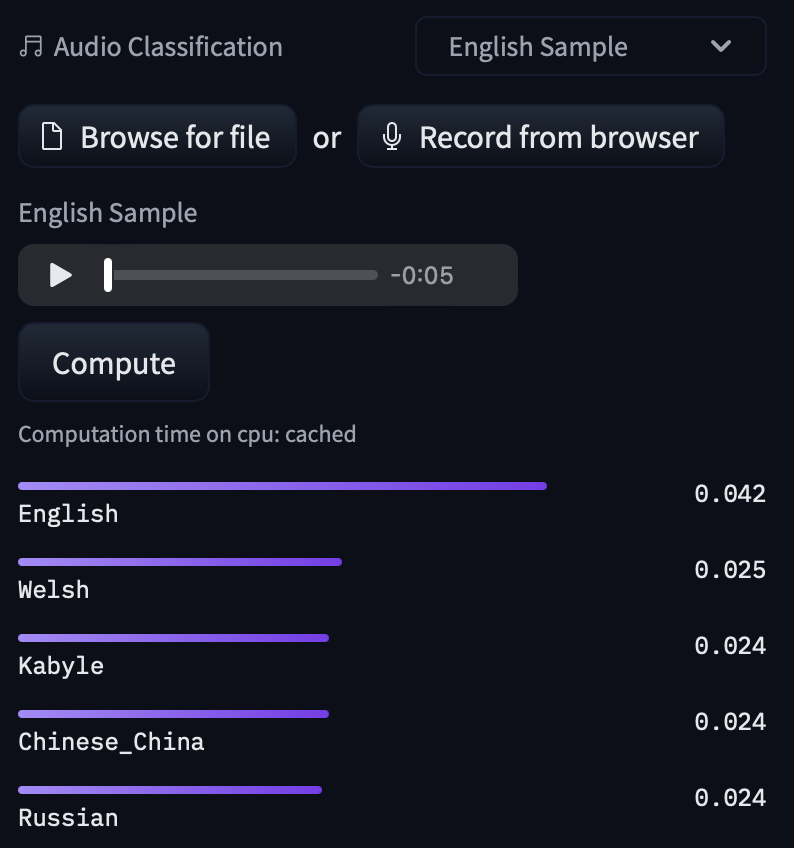 +## Transformers repository files
+
+A [Transformers](https://hf.co/docs/transformers/index) model repository generally contains model files and preprocessor files.
+
+
+## Transformers repository files
+
+A [Transformers](https://hf.co/docs/transformers/index) model repository generally contains model files and preprocessor files.
+
+
+
+
+
+
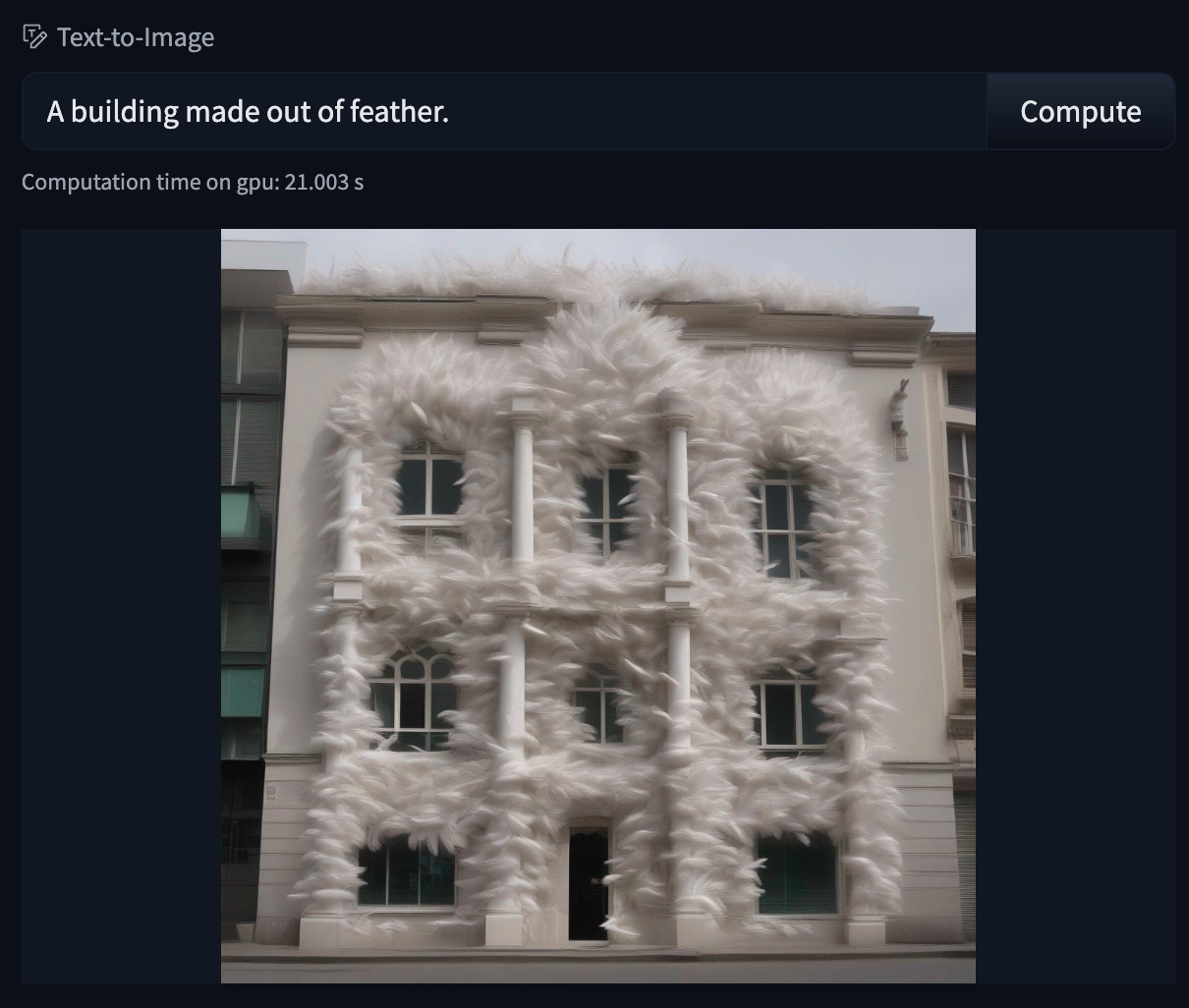 +## Diffusers repository files
+
+A [Diffusers](https://hf.co/docs/diffusers/index) model repository contains all the required model sub-components such as the variational autoencoder for encoding images and decoding latents, text encoder, transformer model, and more. These sub-components are organized into a multi-folder layout.
+
+
+## Diffusers repository files
+
+A [Diffusers](https://hf.co/docs/diffusers/index) model repository contains all the required model sub-components such as the variational autoencoder for encoding images and decoding latents, text encoder, transformer model, and more. These sub-components are organized into a multi-folder layout.
+
+
+
+
-
-
-
-
-
-