Releases: kengz/SLM-Lab
v5.0.2
SAC Atari Benchmarks - All 58 Games
Complete SAC Atari benchmark across all 58 games (2M frames, 4 seeds each).
- Single universal spec (
sac_atari.json): training_iter=3, Categorical, AdamW lr=3e-4 - A2C+PPO+SAC comparison plots for all 58 games
- Results graduated to public SLM-Lab/benchmark HF dataset
- Streamlined CLAUDE.md and benchmark skill with data lifecycle docs
- Removed stale SAC PER and sac_pong specs
Best SAC games: CrazyClimber 81839, Atlantis 64097, VideoPinball 22541
Worst SAC games: Tennis -374, FishingDerby -77, DoubleDunk -44, Enduro 0, Freeway 0
SAC generally underperforms PPO on Atari (wins ~10/58 games), useful as negative result.
v5.0.1
SLM-Lab v5.0.0 - Gymnasium Migration & Complete Benchmark Suite
Major modernization release that updates SLM-Lab from OpenAI Gym to Gymnasium, migrates to modern Python tooling (uv), and validates all algorithms across 70+ environments.
Key Changes
- Gymnasium migration with correct
terminated/truncatedhandling - Modern toolchain:
uv+pyproject.toml, Python 3.12+, PyTorch 2.8+ - Simplified specs: No more
bodysection or array wrappers - Complete benchmark validation: 7 algorithms × 4 environment categories
- Cloud training support via dstack + HuggingFace
Benchmark Results
| Algorithm | Classic | Box2D | MuJoCo | Atari |
|---|---|---|---|---|
| REINFORCE | ✅ | — | — | — |
| SARSA | ✅ | — | — | — |
| DQN | ✅ | ✅ | — | — |
| DDQN+PER | ✅ | ✅ | — | — |
| A2C | ✅ | ✅ 54 games | ||
| PPO | ✅ | ✅ | ✅ 11 envs | ✅ 54 games |
| SAC | ✅ | ✅ | ✅ 11 envs | — |
Atari benchmarks use ALE v5 with sticky actions (repeat_action_probability=0.25), following Machado et al. (2018) research best practices.
Breaking Changes
- Environment names:
CartPole-v0→CartPole-v1,PongNoFrameskip-v4→ALE/Pong-v5 - Spec format simplified:
agent: [{...}]→agent: {...} bodysection removed, attributes moved toagent- Roboschool → MuJoCo (
RoboschoolHopper-v1→Hopper-v5)
Quick Start
# Install
uv sync && uv tool install --editable .
# Run
slm-lab run spec.json spec_name trainBook Readers
For exact code from Foundations of Deep Reinforcement Learning, use:
git checkout v4.1.1See CHANGELOG.md for full details.
upgrade plotly, replace orca with kaleido
What's Changed
Full Changelog: v4.2.3...v4.2.4
Contributors
Assets 2
fix GPU installation and assignment issue
What's Changed
- Added Algorithms config files for VideoPinball-v0 game by @dd-iuonac in #488
- fix build for new RTX GPUs by @kengz and @Karl-Grantham in #496
- remove the
reinforce_pong.jsonspec to prevent confusion in #499
New Contributors
- @dd-iuonac made their first contribution in #488
- @Karl-Grantham for help with debugging #496
Full Changelog: v4.2.2...v4.2.3
Contributors
Assets 2
Improve Installation / Colab notebook
Improve Installation Stability
🙌 Thanks to @Nickfagiano help with debugging.
- #487 update installation to work with MacOS BigSur
- #487 improve setup with Conda path guard
- #487 lock
atari-pyversion to 0.2.6 for safety
Google Colab/Jupyter
🙌 Thanks to @piosif97 for helping.
Windows setup
🙌 Thanks to @vladimirnitu and @steindaian for providing the PDF.
Update installation
Update installation
Dependencies and systems around SLM Lab has changed and caused some breakages. This release fixes these installation issues.
- #461, #476 update to
homebrew/cask(thanks @ben-e, @amjadmajid ) - #463 add pybullet to dependencies (thanks @rafapi)
- #483 fix missing install command in Arch Linux setup (thanks @sebimarkgraf)
- #485 update GitHub Actions CI to v2
- #485 fix demo spec to use strict json
Resume mode, Plotly and PyTorch update, OnPolicyCrossEntropy memory
Resume mode
- #455 adds
train@resume mode and refactors theenjoymode. See PR for detailed info.
train@ usage example
Specify train mode as train@{predir}, where {predir} is the data directory of the last training run, or simply use latest` to use the latest. e.g.:
python run_lab.py slm_lab/spec/benchmark/reinforce/reinforce_cartpole.json reinforce_cartpole train
# terminate run before its completion
# optionally edit the spec file in a past-future-consistent manner
# run resume with either of the commands:
python run_lab.py slm_lab/spec/benchmark/reinforce/reinforce_cartpole.json reinforce_cartpole train@latest
# or to use a specific run folder
python run_lab.py slm_lab/spec/benchmark/reinforce/reinforce_cartpole.json reinforce_cartpole train@data/reinforce_cartpole_2020_04_13_232521enjoy mode refactor
The train@ resume mode API allows for the enjoy mode to be refactored. Both share similar syntax. Continuing with the example above, to enjoy a train model, we now use:
python run_lab.py slm_lab/spec/benchmark/reinforce/reinforce_cartpole.json reinforce_cartpole enjoy@data/reinforce_cartpole_2020_04_13_232521/reinforce_cartpole_t0_s0_spec.jsonPlotly and PyTorch update
- #453 updates Plotly to 4.5.4 and PyTorch to 1.3.1.
- #454 explicitly shuts down Plotly orca server after plotting to prevent zombie processes
PPO batch size optimization
- #453 adds chunking to allow PPO to run on larger batch size by breaking up the forward loop.
New OnPolicyCrossEntropy memory
Discrete SAC benchmark update
Discrete SAC benchmark update
| Env. \ Alg. | DQN | DDQN+PER | A2C (GAE) | A2C (n-step) | PPO | SAC |
Breakout graph |
80.88 | 182 | 377 | 398 | 443 | 3.51* |
Pong graph |
18.48 | 20.5 | 19.31 | 19.56 | 20.58 | 19.87* |
Seaquest graph |
1185 | 4405 | 1070 | 1684 | 1715 | 171* |
Qbert graph |
5494 | 11426 | 12405 | 13590 | 13460 | 923* |
LunarLander graph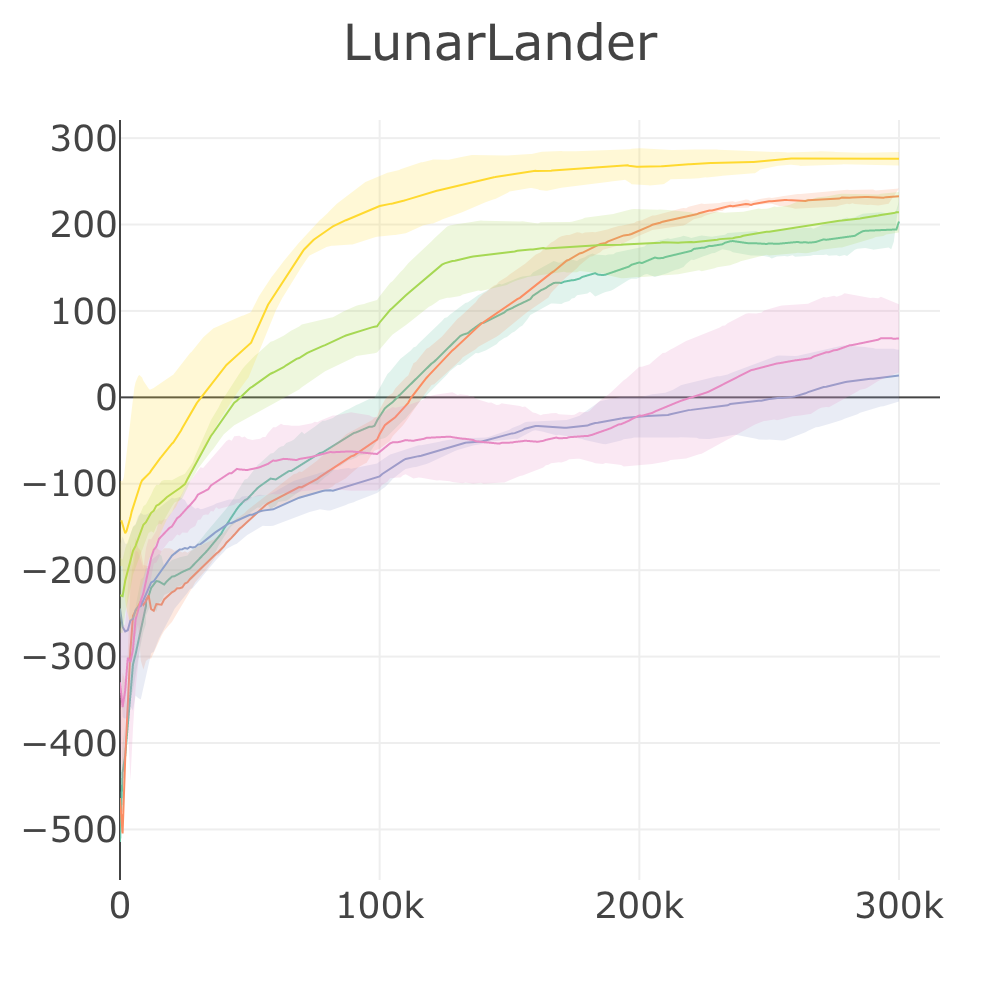 |
192 | 233 | 25.21 | 68.23 | 214 | 276 |
UnityHallway graph |
-0.32 | 0.27 | 0.08 | -0.96 | 0.73 | 0.01 |
UnityPushBlock graph |
4.88 | 4.93 | 4.68 | 4.93 | 4.97 | -0.70 |
Episode score at the end of training attained by SLM Lab implementations on discrete-action control problems. Reported episode scores are the average over the last 100 checkpoints, and then averaged over 4 Sessions. A Random baseline with score averaged over 100 episodes is included. Results marked with
*were trained using the hybrid synchronous/asynchronous version of SAC to parallelize and speed up training time. For SAC, Breakout, Pong and Seaquest were trained for 2M frames instead of 10M frames.
For the full Atari benchmark, see Atari Benchmark
RAdam+Lookahead optim, TensorBoard, Full Benchmark Upload
This marks a stable release of SLM Lab with full benchmark results
RAdam+Lookahead optimizer
- Lookahead + RAdam optimizer significantly improves the performance of some RL algorithms (A2C (n-step), PPO) on continuous domain problems, but does not improve (A2C (GAE), SAC). #416
TensorBoard
- Add TensorBoard in body to auto-log summary variables, graph, network parameter histograms, action histogram. To launch TensorBoard, run
tensorboard --logdir=dataafter a session/trial is completed. Example screenshot:
Full Benchmark Upload
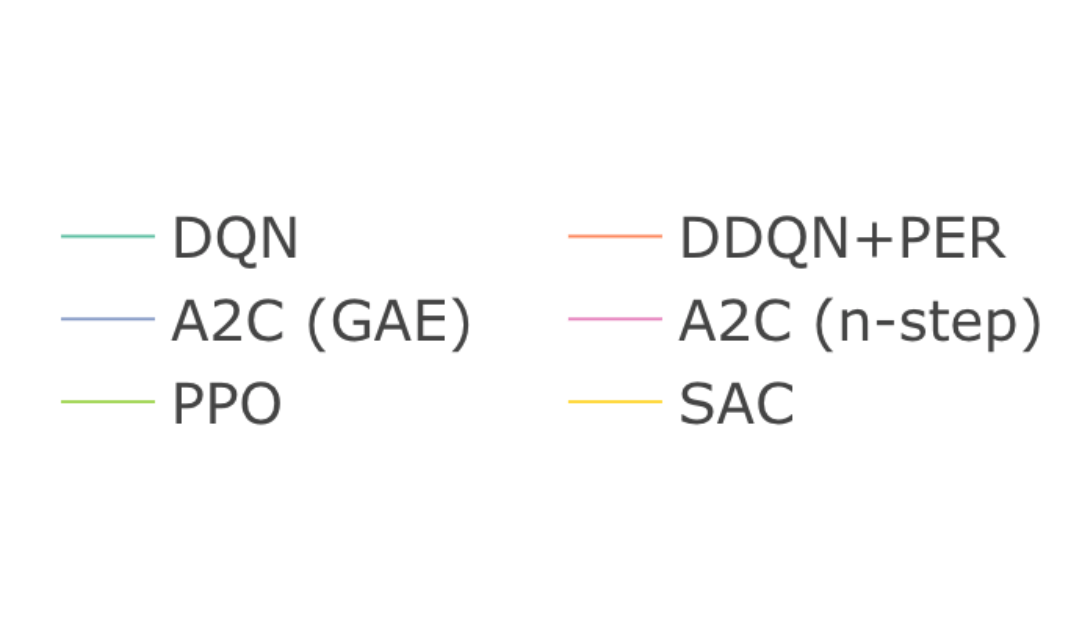
Plot Legend
Discrete Benchmark
| Env. \ Alg. | DQN | DDQN+PER | A2C (GAE) | A2C (n-step) | PPO | SAC |
Breakout graph |
80.88 | 182 | 377 | 398 | 443 | - |
Pong graph |
18.48 | 20.5 | 19.31 | 19.56 | 20.58 | 19.87* |
Seaquest graph |
1185 | 4405 | 1070 | 1684 | 1715 | - |
Qbert graph |
5494 | 11426 | 12405 | 13590 | 13460 | 214* |
LunarLander graph |
192 | 233 | 25.21 | 68.23 | 214 | 276 |
UnityHallway graph |
-0.32 | 0.27 | 0.08 | -0.96 | 0.73 | - |
UnityPushBlock graph |
4.88 | 4.93 | 4.68 | 4.93 | 4.97 | - |
Episode score at the end of training attained by SLM Lab implementations on discrete-action control problems. Reported episode scores are the average over the last 100 checkpoints, and then averaged over 4 Sessions. Results marked with
*were trained using the hybrid synchronous/asynchronous version of SAC to parallelize and speed up training time.
For the full Atari benchmark, see Atari Benchmark
Continuous Benchmark
| Env. \ Alg. | A2C (GAE) | A2C (n-step) | PPO | SAC |
RoboschoolAnt graph |
787 | 1396 | 1843 | 2915 |
RoboschoolAtlasForwardWalk graph |
59.87 | 88.04 | 172 | 800 |
RoboschoolHalfCheetah graph |
712 | 439 | 1960 | 2497 |
RoboschoolHopper graph |
710 | 285 | 2042 | 2045 |
RoboschoolInvertedDoublePendulum graph |
996 | 4410 | 8076 | 8085 |
RoboschoolInvertedPendulum graph |
995 | 978 | 986 | 941 |
RoboschoolReacher graph |
12.9 | 10.16 | 19.51 | 19.99 |
RoboschoolWalker2d graph |
280 | 220 | 1660 | 1894 |
RoboschoolHumanoid graph |
99.31 | 54.58 | 2388 | 2621* |
RoboschoolHumanoidFlagrun graph |
73.57 | 178 | 2014 | 2056* |
RoboschoolHumanoidFlagrunHarder graph |
-429 | 253 | 680 | 280* |
Unity3DBall graph |
33.48 | 53.46 | 78.24 | 98.44 |
Unity3DBallHard graph |
62.92 | 71.92 | 91.41 | 97.06 |
Episode score at the end of training attained by SLM Lab implementations on continuous control problems. Reported episode scores are the average over the last 100 checkpoints, and then averaged over 4 Sessions. Results marked with
*require 50M-100M frames, so we use the hybrid synchronous/asynchronous version of SAC to parallelize and speed up training time.
Atari Benchmark
- Upload PR #427
- Dropbox data: DQN
- Dropbox data: DDQN+PER
- Dropbox data: A2C (GAE)
- Dropbox data: A2C (n-step)
- Dropbox data: PPO
- Dropbox data: all Atari graphs
| Env. \ Alg. | DQN | DDQN+PER | A2C (GAE) | A2C (n-step) | PPO |
Adventure graph |
-0.94 | -0.92 | -0.77 | -0.85 | -0.3 |
AirRaid graph |
1876 | 3974 | 4202 | 3557 | 4028 |
Alien graph |
822 | 1574 | 1519 | 1627 | 1413 |
Amidar graph |
90.95 | 431 | 577 | 418 | 795 |
Assault graph |
1392 | 2567 | 3366 | 3312 | 3619 |
Asterix graph |
1253 | 6866 | 5559 | 5223 | 6132 |
Asteroids graph |
439 | 426 | 2951 | 2147 | 2186 |
Atlantis graph |
68679 | 644810 | 2747371 | 2259733 | 2148077 |
BankHeist graph |
131 | 623 | 855 | 1170 | 1183 |
BattleZone graph |
6564 | 6395 | 4336 | 4533 | 13649 |
BeamRider graph<img src="https://user-images.githubusercontent.com/8... |