diff --git a/content/en/blog/clusterpedia-0.1.0.md b/content/en/blog/clusterpedia-0.1.0.md
new file mode 100644
index 00000000..87df2379
--- /dev/null
+++ b/content/en/blog/clusterpedia-0.1.0.md
@@ -0,0 +1,154 @@
+---
+title: Clusterpedia v0.1.0 Release — four important functions
+date: 2022-02-16
+---
+**This is the first release of** [**Clusterpedia**](https://clusterpedia.io) **🥳🥳🥳, and it also means that it is officially in the iteration phase.**
+
+Compared to the initial [v0.0.8](https://github.com/clusterpedia-io/clusterpedia/tree/v0.0.8) and [v0.0.9-alpha](https://github.com/clusterpedia-io/clusterpedia/tree/v0.0.9-alpha), v0.1.0 add a lot of features and makes some incompatible updates.
+
+>If upgrading from v0.0.9-alpha or v0.0.8, you can refer to [Upgrade to Clusterpedia 0.1.0](/blog/2022/02/15/upgrade-to-clusterpedia-0.1.0/)
+
+# Features Preview
+|Role|Search Label Key|URL Query|
+|:-|:-|:-|
+|Filter cluster names|`search.clusterpedia.io/clusters`|`clusters`|
+|Filter namespaces|`search.clusterpedia.io/namespaces`|`namespaces`|
+|Filter resource names|`search.clusterpedia.io/names`|`names`|
+|Specified Owner UID|`internalstorage.clusterpedia.io/owner-uid`|\-|
+|Specified Owner Seniority|`internalstorage.clusterpedia.io/owner-seniority`|`ownerSeniority`|
+|Order by fields|`search.clusterpedia.io/orderby`|`orderby`|
+|Set page size|`search.clusterpedia.io/size`|`limit`|
+|Set page offset|`search.clusterpedia.io/offset`|`continue`|
+|Response include Continue|`search.clusterpedia.io/with-continue`|`withContinue`|
+|Response include remaining count|`search.clusterpedia.io/with-remaining-count`|`withRemainingCount`|
+
+Native `Label Selector` and enhanced `Field Selector` supported in addition to search label.
+
+# Important Features
+Let's start with the more important features that have been added in 0.1.0
+
+* The number of remaining items carried in response data
+* Added warnning when searching for resources in a `Not Ready` cluster
+* Enhancements to the native FieldSelector
+* Search by Parent or Ancestor Owner
+
+## Warnning alert on resource search
+
+When a cluster is not ready for some reason, resources are often not synchronised properly either.
+
+Warnning alerts are used to alert users of cluster exceptions when searching for resources within the cluster, and the resources searched may not be accurate in real time.
+
+ $ kubectl get pediacluster
+ NAME APISERVER VERSION STATUS
+ cluster-1 https://10.6.100.10:6443 v1.22.2 ClusterSynchroStop
+
+ $ kubectl --cluster cluster-1 get pods
+ Warning: cluster-1 is not ready and the resources obtained may be inaccurate, reason: ClusterSynchroStop
+ CLUSTER NAME READY STATUS RESTARTS AGE
+ cluster-1 fake-pod-698dfbbd5b-64fsx 1/1 Running 0 68d
+ cluster-1 fake-pod-698dfbbd5b-9ftzh 1/1 Running 0 39d
+ cluster-1 fake-pod-698dfbbd5b-rk74p 1/1 Running 0 39d
+ cluster-1 quickstart-ingress-nginx-admission-create--1-kxlnn 0/1 Completed 0 126d
+
+## Field Selector
+
+Native Kubernetes currently only supports field filtering on `metadata.name` and `metadata.namespace`, and the operators only support =, !=, ==\`, which is very limited.
+
+Although some specific resources will support some special fields, the use is still rather limited
+
+ # kubernetes/pkg
+ $ grep AddFieldLabelConversionFunc . -r
+ ./apis/core/v1/conversion.go: err := scheme.AddFieldLabelConversionFunc(SchemeGroupVersion.WithKind("Pod"),
+ ./apis/core/v1/conversion.go: err = scheme.AddFieldLabelConversionFunc(SchemeGroupVersion.WithKind("Node"),
+ ./apis/core/v1/conversion.go: err = scheme.AddFieldLabelConversionFunc(SchemeGroupVersion.WithKind("ReplicationController"),
+ ./apis/core/v1/conversion.go: return scheme.AddFieldLabelConversionFunc(SchemeGroupVersion.WithKind("Event"),
+ ./apis/core/v1/conversion.go: return scheme.AddFieldLabelConversionFunc(SchemeGroupVersion.WithKind("Namespace"),
+ ./apis/core/v1/conversion.go: return scheme.AddFieldLabelConversionFunc(SchemeGroupVersion.WithKind("Secret"),
+ ./apis/certificates/v1/conversion.go: return scheme.AddFieldLabelConversionFunc(SchemeGroupVersion.WithKind("CertificateSigningRequest"),
+ ./apis/certificates/v1beta1/conversion.go: return scheme.AddFieldLabelConversionFunc(SchemeGroupVersion.WithKind("CertificateSigningRequest"),
+ ./apis/batch/v1/conversion.go: return scheme.AddFieldLabelConversionFunc(SchemeGroupVersion.WithKind("Job"),
+ ./apis/batch/v1beta1/conversion.go: err = scheme.AddFieldLabelConversionFunc(SchemeGroupVersion.WithKind(kind),
+ ./apis/events/v1/conversion.go: return scheme.AddFieldLabelConversionFunc(SchemeGroupVersion.WithKind("Event"),
+ ./apis/events/v1beta1/conversion.go: return scheme.AddFieldLabelConversionFunc(SchemeGroupVersion.WithKind("Event"),
+ ./apis/apps/v1beta2/conversion.go: if err := scheme.AddFieldLabelConversionFunc(SchemeGroupVersion.WithKind("StatefulSet"),
+ ./apis/apps/v1beta1/conversion.go: if err := scheme.AddFieldLabelConversionFunc(SchemeGroupVersion.WithKind("StatefulSet"),
+
+Clusterpedia provides more powerful features based on the compatibility with existing Field Selector features, and supports the same operators as Label Selector: `!`, `=`, `!=`, `==`, `in`, `notin`.
+
+For example, we can filter by annotations, like label selector
+
+ kubectl get deploy --field-selector="metadata.annotations['test.io'] in (value1, value2)"
+
+[Lean More](https://clusterpedia.io/docs/usage/search/multi-cluster/#field-selector)
+
+## Search by Parent or Ancestor Owner
+
+There will usually be an Owner relationship between Kubernetes resources.
+
+ apiVersion: v1
+ kind: Pod
+ metadata:
+ ownerReferences:
+ - apiVersion: apps/v1
+ blockOwnerDeletion: true
+ controller: true
+ kind: ReplicaSet
+ name: fake-pod-698dfbbd5b
+ uid: d5bf2bdd-47d2-4932-84fb-98bde486d244
+
+Searching by Owner is a very useful search function, and Clusterpedia also supports the seniority advancement of Owner to search for grandparents and even higher seniority.
+
+By searching by Owner, we can query all Pods under Deployment at once, without having to query ReplicaSet in between
+
+>Currently only supports query by Owner UID. The feature of using Owner Name for queries is still under discussion, we can join the discussion in the [issue: Support for searching resources by owner](https://github.com/clusterpedia-io/clusterpedia/issues/49)
+
+ $ DEPLOY_UID=$(kubectl --cluster cluster-1 get deploy fake-deploy -o jsonpath="{.metadata.uid}")
+ $ kubectl --cluster cluster-1 get pods -l \
+ "internalstorage.clusterpedia.io/owner-uid=$DEPLOY_UID,\
+ internalstorage.clusterpedia.io/owner-seniority=1"
+
+[Lean More](https://clusterpedia.io/docs/usage/search/multi-cluster/#search-by-parent-or-ancestor-owner)
+
+## The number of remaining items carried in response data
+
+**In some UI cases, it is often necessary to get the total number of resources in the current search condition.**
+
+The RemainingItemCount field exists in the [ListMeta](https://pkg.go.dev/k8s.io/apimachinery/pkg/apis/meta/v1#ListMeta) of the Kubernetes List response.
+
+ type ListMeta struct {
+ ...
+
+ // remainingItemCount is the number of subsequent items in the list which are not included in this
+ // list response. If the list request contained label or field selectors, then the number of
+ // remaining items is unknown and the field will be left unset and omitted during serialization.
+ // If the list is complete (either because it is not chunking or because this is the last chunk),
+ // then there are no more remaining items and this field will be left unset and omitted during
+ // serialization.
+ // Servers older than v1.15 do not set this field.
+ // The intended use of the remainingItemCount is *estimating* the size of a collection. Clients
+ // should not rely on the remainingItemCount to be set or to be exact.
+ // +optional
+ RemainingItemCount *int64 `json:"remainingItemCount,omitempty" protobuf:"bytes,4,opt,name=remainingItemCount"`
+ }
+
+By reusing this field, the total number of resources can be returned in a Kubernetes OpenAPI-compatible manner:
+
+**offset + len(list.items) + list.metadata.remainingItemCount**
+
+>Use with Paging
+
+ $ kubectl get --raw="/apis/clusterpedia.io/v1beta1/resources/apis/apps/v1/deployments?withRemainingCount&limit=1" | jq
+ {
+ "kind": "DeploymentList",
+ "apiVersion": "apps/v1",
+ "metadata": {
+ "remainingItemCount": 23
+ },
+ "items": [
+ ...
+ ]
+ }
+
+[Lean More](https://clusterpedia.io/docs/usage/search/multi-cluster/#response-with-remaining-count)
+
+# [Realease v0.1.0](https://github.com/clusterpedia-io/clusterpedia/releases/tag/v0.1.0)
diff --git a/content/en/blog/clusterpedia-0.2.0.md b/content/en/blog/clusterpedia-0.2.0.md
new file mode 100644
index 00000000..aac4f00c
--- /dev/null
+++ b/content/en/blog/clusterpedia-0.2.0.md
@@ -0,0 +1,178 @@
+---
+title: Clusterpedia v0.2.0 Release
+date: 2022-04-12
+---
+## Use helm to install
+
+Users can already use Helm to install Clusterpedia:
+
+ $ helm install clusterpedia . \
+ --namespace clusterpedia-system \
+ --create-namespace \
+ --set persistenceMatchNode={{ LOCAL_PV_NODE }} \
+ # --set installCRDs=true
+
+[Lean More](https://github.com/clusterpedia-io/clusterpedia/tree/main/charts)
+
+## Use the Kube Config to import a cluster
+
+For v0.1.0, users need to Configure the address for the imported cluster and the authentication information.
+
+ apiVersion: cluster.clusterpedia.io/v1alpha2
+ kind: PediaCluster
+ metadata:
+ name: cluster-example
+ spec:
+ apiserver: "https://10.30.43.43:6443"
+ caData:
+ tokenData:
+ certData:
+ keyData:
+ syncResources: []
+
+In v0.2.0, the `PediaCluster` added the `spec.kubeconfig` field so that users can use `kube config` to import the cluster directly.
+
+First you need to base64 encode the kube config for the imported cluster.
+
+ $ base64 ./kubeconfig.yaml
+
+Set the content after the base64 to PediaCluster `spec.kubeconfig`, in addition `spec.apiserver` and other authentication fields don’t need to set.
+
+ apiVersion: cluster.clusterpedia.io/v1alpha2
+ kind: PediaCluster
+ metadata:
+ name: cluster-example
+ spec:
+ kubeconfig: **base64 kubeconfig**
+ syncResources: []
+
+However, since the cluster address is configured in kube config, the **APIServer** is empty when you use kubectl get pediacluster.
+
+ $ kubectl get pediacluster
+ NAME APISERVER VERSION STATUS
+ cluster-example v1.22.2 Healthy
+
+Mutating addmission webhooks will be added in the future to automatically set `spec.apiserver`, currently if you want to show the cluster apiserver address when `kubectl get pediacluster`, then you need to manually configure the `spec.apiserver` field additionally.
+
+## New Search Feature
+
+### Search by creation time interval
+
+|Description|Search Label Key|URL Query|
+|:-|:-|:-|
+|Since|search.clusterpedia.io/since|since|
+|Before|search.clusterpedia.io/before|before|
+
+The creation time interval used for the search is left closed and right open, **since <= creation time < before**.
+
+There are four formats for creation time:
+
+1. `Unix Timestamp` for ease of use will distinguish between units of `s` or `ms` based on the length of the timestamp. The 10-bit timestamp is in seconds, the 13-bit timestamp is in milliseconds.
+2. `RFC3339` *2006-01-02T15:04:05Z* or *2006-01-02T15:04:05+08:00*
+3. `UTC Date` *2006-01-02*
+4. `UTC Datetime` *2006-01-02 15:04:05*
+
+>Because of the limitation of the kube label selector, the search label only supports `Unix Timestamp` and `UTC Date`.
+>
+>All formats are available using the url query method.
+
+Look at what resources are under the default namespace
+
+ $ kubectl --cluster clusterpedia get pods
+ CLUSTER NAME READY STATUS RESTARTS AGE
+ cluster-example quickstart-ingress-nginx-admission-create--1-kxlnn 0/1 Completed 0 171d
+ cluster-example fake-pod-698dfbbd5b-wvtvw 1/1 Running 0 8d
+ cluster-example fake-pod-698dfbbd5b-74cjx 1/1 Running 0 21d
+ cluster-example fake-pod-698dfbbd5b-tmcw7 1/1 Running 0 8d
+
+We use the creation time to filter the resources.
+
+ $ kubectl --cluster clusterpedia get pods -l "search.clusterpedia.io/since=2022-03-20"
+ CLUSTER NAME READY STATUS RESTARTS AGE
+ cluster-example fake-pod-698dfbbd5b-wvtvw 1/1 Running 0 8d
+ cluster-example fake-pod-698dfbbd5b-tmcw7 1/1 Running 0 8d
+
+
+ $ kubectl --cluster clusterpedia get pods -l "search.clusterpedia.io/before=2022-03-20"
+ CLUSTER NAME READY STATUS RESTARTS AGE
+ cluster-example quickstart-ingress-nginx-admission-create--1-kxlnn 0/1 Completed 0 171d
+ cluster-example fake-pod-698dfbbd5b-74cjx 1/1 Running 0 21d
+
+### Search by Owner Name
+
+As of v0.1.0, we can specify ancestor or parent `Owner UID` to query resources, but `Owner UID` is not convenient to use, after all, you still need to know the UID of the Owner resource in advance.
+
+In v0.2.0, we support querying directly with `Owner Name`, and the Owner query has been moved from experimental to released functionality, the prefix of **Search Label** has been upgraded from *internalstorage.c lusterpedia.io* to \*search.clusterpedia.io \*, and URL Query is provided.
+
+|Role|search label key|url query|
+|:-|:-|:-|
+|Specified Owner UID|search.clusterpedia.io/owner-uid|ownerUID|
+|Specified Owner Name|search.clusterpedia.io/owner-name|ownerName|
+|SPecified Owner Group Resource|search.clusterpedia.io/owner-gr|ownerGR|
+|Specified Owner Seniority|`internalstorage.clusterpedia.io/owner-seniority`|`ownerSeniority`|
+
+>Note that when specifying `Owner UID`, `Owner Name` and `Owner Group Resource` will be ignored.
+
+ $ kubectl --cluster cluster-example get pods -l \
+ "search.clusterpedia.io/owner-name=fake-pod, \
+ search.clusterpedia.io/owner-seniority=1"
+ CLUSTER NAME READY STATUS RESTARTS AGE
+ cluster-example fake-pod-698dfbbd5b-wvtvw 1/1 Running 0 8d
+ cluster-example fake-pod-698dfbbd5b-74cjx 1/1 Running 0 21d
+ cluster-example fake-pod-698dfbbd5b-tmcw7 1/1 Running 0 8d
+
+**In addition, to avoid multiple types of owner resources in some cases, we can use the** `Owner Group Resource` **to restrict the type of owner.**
+
+ $ kubectl --cluster cluster-example get pods -l \
+ "search.clusterpedia.io/owner-name=fake-pod,\
+ search.clusterpedia.io/owner-gr=deployments.apps,\
+ search.clusterpedia.io/owner-seniority=1"
+ ... some output
+
+### Fuzzy Search base on resource names
+
+Since fuzzy search needs to be discussed further, it is temporarily provided as an experimental feature.
+
+Only the Search Label method is supported, URL Query isn’t supported. |Role| search label key|url query| | -- | --------------- | ------- | |Fuzzy Search for resource name|internalstorage.clusterpedia.io/fuzzy-name|-|
+
+ $ kubectl --cluster clusterpedia get deployments -l "internalstorage.clusterpedia.io/fuzzy-name=fake"
+ CLUSTER NAME READY UP-TO-DATE AVAILABLE AGE
+ cluster-example fake-pod 3/3 3 3 113d
+
+You can use the in operator to pass multiple fuzzy arguments, so that you can filter out resources that have all strings in their names.
+
+## Other Features
+
+In v0.1.0, searching the resources allow the number of remaining resources to be returned so that the user can calculate the total number of resources.
+
+This feature has been enhanced in v0.2.0. When offset is too large, `remainingItemCount` may be negative, ensuring that the total number of resources can always be calculated.
+
+[Lean More](https://clusterpedia.io/docs/usage/search/multi-cluster/#response-with-remaining-count)
+
+## [Release Notes](https://github.com/clusterpedia-io/clusterpedia/releases)
+
+* Support of using Helm Charts for installation ([\#53](https://github.com/clusterpedia-io/clusterpedia/pull/53), [\#125](https://github.com/clusterpedia-io/clusterpedia/pull/125), @calvin0327, @wzshiming)
+* `PediaCluster` supports for importing a cluster using the kubeconfig ([\#115](https://github.com/clusterpedia-io/clusterpedia/pull/115), @wzshiming)
+
+### APIServer
+
+* Support for filtering resources by a period of creation ([\#113](https://github.com/clusterpedia-io/clusterpedia/pull/113), @cleverhu)
+* Support for searching for resources by an Owner name. Now, the feature of `Search by Owner` is officially released. ([\#91](https://github.com/clusterpedia-io/clusterpedia/pull/91), @Iceber)
+
+### Default Storage Layer
+
+* Support for fuzzy search by a resource name ([\#117](https://github.com/clusterpedia-io/clusterpedia/pull/117), @cleverhu)
+* `RemainingItemCount` can be a negative number. We can still use `offset + len(items) + remainingItemCount` to calculate the total amount of resources if the `Offset` is too large. ([\#123](https://github.com/clusterpedia-io/clusterpedia/pull/123), @cleverhu)
+
+### Bug Fixes
+
+* Fixed unnecessary `json.Unmarshal` and improved performance when searching ([\#89](https://github.com/clusterpedia-io/clusterpedia/pull/89), [\#92](https://github.com/clusterpedia-io/clusterpedia/pull/92), @Iceber)
+
+### Deprecation
+
+* `Search by Owner` has been released as an official feature. `internalstorage.clusterpedia.io/owner-name` and `internalstorage.clusterpedia.io/owner-seniority` will be removed in the next release. ([\#91](https://github.com/clusterpedia-io/clusterpedia/pull/91), @Iceber)
+
+### Other
+
+* `golangci-lint` is used as a static checking tool ([\#86](https://github.com/clusterpedia-io/clusterpedia/pull/86), [\#88](https://github.com/clusterpedia-io/clusterpedia/pull/88), @Iceber)
+* Added CI Workloads such as static checking and unit testing for code [\#87](https://github.com/clusterpedia-io/clusterpedia/pull/87), @Iceber)
diff --git a/content/zh/blog/clusterpedia-0.1.0.md b/content/zh/blog/clusterpedia-0.1.0.md
new file mode 100644
index 00000000..2edb0136
--- /dev/null
+++ b/content/zh/blog/clusterpedia-0.1.0.md
@@ -0,0 +1,113 @@
+---
+title: 首发|Clusterpedia 0.1.0 四大重要功能
+date: 2022-02-16
+---
+
+**Clusterpedia 第一个版本 -- Clusterpedia 0.1.0 正式发布**,即日起进入版本迭代阶段。相比于初期的 0.0.8 和 0.0.9-alpha,0.1.0 添加了很多功能,并且做了一些不兼容的更新。
+
+如果由 0.0.9-alpha 升级的话,可以参考 [Upgrade to Clusterpedia 0.1.0](/blog/2022/02/15/upgrade-to-clusterpedia-0.1.0/)
+
+## 重要功能
+我们先介绍一下在 0.1.0 中增加的四大重要的功能:
+* **对 Not Ready 的集群进行资源检索时,增加了 Warning 提醒**
+* **增强了原生 Field Selector 的能力**
+* **根据父辈或者祖辈的 Owner 来进行查询**
+* **响应数据携带 remaining item count**
+
+[v0.1.0 Release Notes](https://github.com/clusterpedia-io/clusterpedia/releases/tag/v0.1.0)
+
+## 资源检索时的 Warning 提醒
+集群由于某些原因处于非 Ready 的状态时,资源通常也无法正常同步,在获取到该集群内的资源时,会通过 Warnning 提醒来告知用户集群异常,并且获取到的资源可能并不是实时准确的。
+
+```bash
+$ kubectl get pediacluster
+NAME APISERVER VERSION STATUS
+cluster-1 https://10.6.100.10:6443 v1.22.2 ClusterSynchroStop
+
+$ kubectl --cluster cluster-1 get pods
+Warning: cluster-1 is not ready and the resources obtained may be inaccurate, reason: ClusterSynchroStop
+CLUSTER NAME READY STATUS RESTARTS AGE
+cluster-1 fake-pod-698dfbbd5b-64fsx 1/1 Running 0 68d
+cluster-1 fake-pod-698dfbbd5b-9ftzh 1/1 Running 0 39d
+cluster-1 fake-pod-698dfbbd5b-rk74p 1/1 Running 0 39d
+cluster-1 quickstart-ingress-nginx-admission-create--1-kxlnn 0/1 Completed 0 126d
+```
+
+## 强化 Field Selector
+原生 kubernetes 对于 Field Selector 的支持非常有限,默认只支持 metadata.namespace 和 metadata.name 字段的过滤,尽管一些特定的资源会支持一些特殊的字段,但是使用起来还是比较局限,操作符只能支持 =, ==, !=。
+
+Clusterpedia 在兼容原生 Field Selector 的基础上,不仅仅支持了更加灵活的字段过滤,还支持和 Label Selector 相同的操作符:!, =, !=, ==, in, notin。
+
+例如我们可以像 label selector 一样,通过 annotations 过滤资源。
+```bash
+kubectl get deploy --field-selector="metadata.annotations['test.io'] in (value1, value2)"
+```
+[Lean More](/docs/usage/search/multi-cluster/#field-selector)
+
+
+## 根据父辈或者祖辈 Owner 进行查询
+Kubernetes 资源之间通常会存在一种 Owner 关系, 例如:
+```yaml
+apiVersion: v1
+kind: Pod
+metadata:
+ ownerReferences:
+ - apiVersion: apps/v1
+ blockOwnerDeletion: true
+ controller: true
+ kind: ReplicaSet
+ name: fake-pod-698dfbbd5b
+ uid: d5bf2bdd-47d2-4932-84fb-98bde486d244
+```
+Clusterpedia 不仅支持根据 Owner 查询,还支持对 Owner 进行辈分提升来根据祖辈或者更高辈分的 Owner 来检索资源。
+
+例如可以通过 Deployment 获取相应的所有 pods。
+> 当前暂时只支持通过Owner UID 来查询资源, 使用 Owner Name 来进行查询的功能尚在讨论中,可以在 issue: Support for searching resources by owner 参与讨论。
+> v0.2.0 中已经支持通过 Owner name 进行查询
+
+```bash
+$ DEPLOY_UID=$(kubectl --cluster cluster-1 get deploy fake-deploy -o jsonpath="{.metadata.uid}")
+$ kubectl --cluster cluster-1 get pods -l \
+ "internalstorage.clusterpedia.io/owner-uid=$DEPLOY_UID,\
+ internalstorage.clusterpedia.io/owner-seniority=1"
+```
+[Lean More](/docs/usage/search/multi-cluster/#search-by-parent-or-ancestor-owner)
+
+## 响应数据内携带剩余资源数量
+在一些 UI 场景下,往往需要获取当前检索条件下的资源总量。
+
+Kubernetes 响应的 ListMeta 中 RemainingItemCount 字段表示剩余的资源数量。
+```go
+type ListMeta struct {
+ ...
+
+ // remainingItemCount is the number of subsequent items in the list which are not included in this
+ // list response. If the list request contained label or field selectors, then the number of
+ // remaining items is unknown and the field will be left unset and omitted during serialization.
+ // If the list is complete (either because it is not chunking or because this is the last chunk),
+ // then there are no more remaining items and this field will be left unset and omitted during
+ // serialization.
+ // Servers older than v1.15 do not set this field.
+ // The intended use of the remainingItemCount is *estimating* the size of a collection. Clients
+ // should not rely on the remainingItemCount to be set or to be exact.
+ // +optional
+ RemainingItemCount *int64 `json:"remainingItemCount,omitempty" protobuf:"bytes,4,opt,name=remainingItemCount"`
+}
+```
+复用 ListMeta.RemainingItemCount,通过简单计算便可以获取当前检索条件下的资源总量: **total = offset + len(list.items) + list.metadata.remainingItemCount**
+> 该功能需要搭配分页功能一起使用
+
+```bash
+$ kubectl get --raw="/apis/clusterpedia.io/v1beta1/resources/apis/apps/v1/deployments?withRemainingCount&limit=1" | jq
+{
+ "kind": "DeploymentList",
+ "apiVersion": "apps/v1",
+ "metadata": {
+ "remainingItemCount": 24
+ },
+ "items": [
+ ...
+ ]
+}
+```
+[Lean More](/docs/usage/search/multi-cluster/#response-with-remaining-count)
diff --git a/content/zh/blog/clusterpedia-0.2.0.md b/content/zh/blog/clusterpedia-0.2.0.md
new file mode 100644
index 00000000..b704c3ea
--- /dev/null
+++ b/content/zh/blog/clusterpedia-0.2.0.md
@@ -0,0 +1,159 @@
+---
+title: Clusterpedia v0.2.0 发布
+date: 2022-04-12
+---
+## 使用 kube config 来接入集群
+v0.1.0 时,用户需要分别填写被接入集群的 apiserver 地址,以及访问集群时的认证信息
+```yaml
+apiVersion: cluster.clusterpedia.io/v1alpha2
+kind: PediaCluster
+metadata:
+ name: cluster-example
+spec:
+ apiserver: "https://10.30.43.43:6443"
+ caData:
+ tokenData:
+ certData:
+ keyData:
+ syncResources: []
+```
+
+在 v0.2.0 中 `PediaCluster` 增加了 `spec.kubeconfig` 字段,用户可以直接使用 kube config 来接入集群。
+
+首先 base64 集群的 *kube config*:
+```bash
+$ base64 ./kubeconfig.yaml
+```
+然后填充到 PediaCluster 的 `spec.kubeconfig` 字段中
+```yaml
+apiVersion: cluster.clusterpedia.io/v1alpha2
+kind: PediaCluster
+metadata:
+ name: cluster-example
+spec:
+ kubeconfig: **base64 kubeconfig**
+ syncResources: []
+```
+在使用 *kube config* 时,不需要填写 `spec.apiserver` 以及其他认证字段。
+
+需要注意,使用 `kubectl get pediacluster` 查看接入的集群列表时,**APISERVER** 不会显示集群地址
+```bash
+$ kubectl get pediacluster
+NAME APISERVER VERSION STATUS
+cluster-example v1.22.2 Healthy
+```
+如果需要显示,那么需要额外手动设置 `spec.kubeconfig`,未来会添加 Mutating Admission Webhook 来解析 kubeconfig 并自动填充 `spec.apiserver` 字段。
+
+## 新增的检索功能
+### 通过资源的创建时间来过滤资源
+| 作用 | Search Label Key | URL Query |
+| ---- | ---------------- | --------- |
+| Since | search.clusterpedia.io/since | since |
+| Before | search.clusterpedia.io/before | before |
+
+创建时间的区间采用左闭右开的规则,**since <= creation time < before**。
+
+时间格式支持 4 种:
+1. `Unix 时间戳格式` 为了方便使用会根据时间戳的长度来区分单位为 s 还是 ms。 10 位时间戳单位为秒,13 位时间戳单位为毫秒。
+2. `RFC3339` 2006-01-02T15:04:05Z or 2006-01-02T15:04:05+08:00
+3. `UTC Date` 2006-01-02
+4. `UTC Datetime` 2006-01-02 15:04:05
+
+> 由于 Kube Label Selector 的限制,Search Label 只支持使用 Unix 时间戳和 UTC Data 的格式
+> URL Query 可以使用四种格式
+
+首先查看一下当前都有哪些资源
+```bash
+$ kubectl --cluster clusterpedia get pods
+CLUSTER NAME READY STATUS RESTARTS AGE
+cluster-example quickstart-ingress-nginx-admission-create--1-kxlnn 0/1 Completed 0 171d
+cluster-example fake-pod-698dfbbd5b-wvtvw 1/1 Running 0 8d
+cluster-example fake-pod-698dfbbd5b-74cjx 1/1 Running 0 21d
+cluster-example fake-pod-698dfbbd5b-tmcw7 1/1 Running 0 8d
+```
+
+我们使用创建时间来过滤资源
+```bash
+$ kubectl --cluster clusterpedia get pods -l "search.clusterpedia.io/since=2022-03-20"
+CLUSTER NAME READY STATUS RESTARTS AGE
+cluster-example fake-pod-698dfbbd5b-wvtvw 1/1 Running 0 8d
+cluster-example fake-pod-698dfbbd5b-tmcw7 1/1 Running 0 8d
+
+
+$ kubectl --cluster clusterpedia get pods -l "search.clusterpedia.io/before=2022-03-20"
+CLUSTER NAME READY STATUS RESTARTS AGE
+cluster-example quickstart-ingress-nginx-admission-create--1-kxlnn 0/1 Completed 0 171d
+cluster-example fake-pod-698dfbbd5b-74cjx 1/1 Running 0 21d
+```
+
+### 使用 Owner Name 检索
+在 v0.1.0 时,我们可以指定祖辈或者父辈 `Owner UID` 来查询资源,不过 `Owner UID` 使用起来并不方便,毕竟还需要提前得知 Owner 资源的 UID。
+
+在 v0.2.0 版本中,支持直接使用 `Owner Name` 来查询,并且 Owner 查询由实验性功能进入到正式功能,Search Label 的前缀也由 *internalstorage.clusterpedia.io* 升级为 *search.clusterpedia.io*,并且提供了 URL Query。
+
+| 作用 | Search Label Key | URL Query |
+| ---- | ---------------- | --------- |
+|指定 Owner UID|search.clusterpedia.io/owner-uid|ownerUID|
+|指定 Owner Name|search.clusterpedia.io/owner-name|ownerName|
+|指定 Owner Group Resource|search.clusterpedia.io/owner-gr|ownerGR|
+|指定 Owner 辈分|internalstorage.clusterpedia.io/owner-seniority|ownerSeniority|
+
+> 如果用户同时指定了 `Owner UID` 和 `Owner Name`,那么 `Owner Name` 会被忽略。
+
+```bash
+$ kubectl --cluster cluster-example get pods -l \
+ "search.clusterpedia.io/owner-name=fake-pod, \
+ search.clusterpedia.io/owner-seniority=1"
+CLUSTER NAME READY STATUS RESTARTS AGE
+cluster-example fake-pod-698dfbbd5b-wvtvw 1/1 Running 0 8d
+cluster-example fake-pod-698dfbbd5b-74cjx 1/1 Running 0 21d
+cluster-example fake-pod-698dfbbd5b-tmcw7 1/1 Running 0 8d
+```
+
+**另外为了避免某些情况下,owner 资源存在多种类型,我们可以使用 `Owner Group Resource` 来限制 Owner 的类型。**
+```bash
+$ kubectl --cluster cluster-example get pods -l \
+ "search.clusterpedia.io/owner-name=fake-pod,\
+ search.clusterpedia.io/owner-gr=deployments.apps,\
+ search.clusterpedia.io/owner-seniority=1"
+... some output
+```
+
+### 根据资源名称的模糊搜索
+模糊搜索是一个非常常用的功能,当前暂时只提供了资源名称上的模糊搜索,由于还需要更多功能上的讨论,暂时作为试验性功能
+| 作用 | Search Label Key | URL Query |
+| ---- | ---------------- | --------- |
+| 根据资源名称进行模糊搜索| internalstorage.clusterpedia.io/fuzzy-name | - |
+
+```bash
+$ kubectl --cluster clusterpedia get deployments -l "internalstorage.clusterpedia.io/fuzzy-name=fake"
+CLUSTER NAME READY UP-TO-DATE AVAILABLE AGE
+cluster-example fake-pod 3/3 3 3 113d
+```
+可以使用 `in` 操作符来指定多个参数,这样可以过滤出名字包含所有模糊字符串的资源。
+
+## 其他功能
+在 v0.1.0 中,查询资源列表时,允许返回的剩余的资源数量,这样用户可以通过计算就能得知当前检索添加下的资源总量。
+
+在 v0.2.0 中对该功能进行了强化, 当分页查询的 `Offset` 参数过大时,`ReaminingItemCount` 可以为负数,
+这样可以保证通过 **`offset + len(list.items) + list.metadata.remainingItemCount`** 总是可以计算出正确的资源总量。
+
+
+# [发布日志](https://github.com/clusterpedia-io/clusterpedia/releases/tag/v0.2.0)
+## What's New
+* 支持使用 Helm 部署 ([#53](https://github.com/clusterpedia-io/clusterpedia/pull/53), [#125](https://github.com/clusterpedia-io/clusterpedia/pull/125), @calvin0327, @wzshiming)
+* PediaCluster 支持使用 kube config 来接入集群 ([#115](https://github.com/clusterpedia-io/clusterpedia/pull/115), @wzshiming)
+
+### APIServer
+* 支持通过创建时间的区间来过滤资源 ([#113](https://github.com/clusterpedia-io/clusterpedia/pull/113), @cleverhu)
+* 支持根据 Owner 的名字来检索资源,并且 Owner 查询成为 clusterpedia 的正式功能,同时支持 Search Label 和 URL Query ([#91](https://github.com/clusterpedia-io/clusterpedia/pull/91), @Iceber)
+
+### Default Storage Layer
+* 支持根据资源名称的模糊搜索 ([#117](https://github.com/clusterpedia-io/clusterpedia/pull/117), @cleverhu)
+* RemainingItemCount 可以为负数,在 Offset 过大时依然可以使用 `offset + len(items) + remainingItemCount` 来计算资源总量。([#123](https://github.com/clusterpedia-io/clusterpedia/pull/123), @cleverhu)
+
+#### Bug Fixes
+* 修复由于不必要的反序列化导致的 cpu 损耗,提升了查询时的性能 ([#89](https://github.com/clusterpedia-io/clusterpedia/pull/89), [#92](https://github.com/clusterpedia-io/clusterpedia/pull/92), @Iceber)
+
+#### Deprecation
+* Owner 查询已移动到正式功能,用于 Owner 查询的试验性 Search Label —— `internalstorage.clusterpedia.io/owner-name` 和 `internalstorage.clusterpedia.io/owner-seniority` 会在下一个版本被移除 ([#91](https://github.com/clusterpedia-io/clusterpedia/pull/91), @Iceber)
diff --git a/content/zh/blog/csdn.md b/content/zh/blog/csdn.md
new file mode 100644
index 00000000..9158f6a6
--- /dev/null
+++ b/content/zh/blog/csdn.md
@@ -0,0 +1,17 @@
+---
+title: Clusterpedia 上榜| CSDN IT 技术影响力之星
+date: 2022-04-01
+---
+

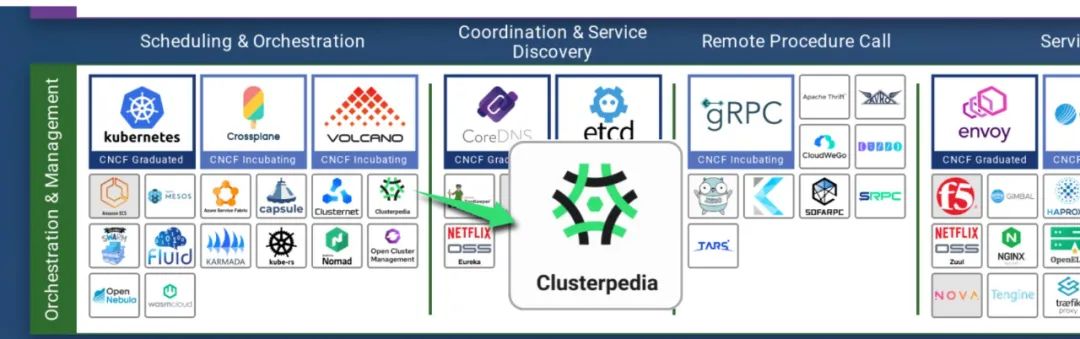 +
+---
+
+CNCF 全称 Cloud Native Computing Foundation (云原生计算基金会),隶属于 Linux 基金会,成立于 2015 年 12 月,是非营利性组织,致力于培育和维护一个厂商中立的开源生态系统,来推广云原生技术,普及云原生应用。
+
+云原生全景图由 CNCF 从 2016 年 12 月开始维护,汇总了社区成熟和使用范围较广、具有最佳实践的产品和方案,并加以分类,为企业构建云原生体系提供参考,在云生态研发、运维领域具有广泛影响力。
diff --git a/content/zh/blog/search-by-multi-cluster.md b/content/zh/blog/search-by-multi-cluster.md
new file mode 100644
index 00000000..6d2916d2
--- /dev/null
+++ b/content/zh/blog/search-by-multi-cluster.md
@@ -0,0 +1,34 @@
+---
+title: 视频讲解|Clusterpedia -- 多云环境下的资源复杂检索
+date: 2022-03-01
+---
+
+Clusterpedia 的发起人 --「Daocloud 道客」的云原生研发工程师蔡威,为大家详细介绍 Clusterpedia 在资源检索上提供的功能,让大家可以直观的了解到使用 Clusterepdia 可以解决哪些问题。
+
+
+
+## Clusterpedia 多集群资源检索神器
+随着云原生技术的发展、承载业务量的增加以及集群规模的不断扩大,单个 Kubernetes 集群已经无法满足很多企业的需求,我们在逐渐的步入多云时代,多集群内部资源管理和检索变得越发复杂和困难。
+
+由此,社区不断出现了很多优秀的的开源项目,例如用于集群生命周期管理的 cluster api,以及多云应用管理的 karmada, clusternet 等。而 Clusterpedia 便是建立在这些云管平台之上,为用户提供多集群资源的复杂检索。
+
+在单集群中,我们通常使用 kubectl 来查看资源,或者直接访问 Kubernetes 的 OpenAPI,在代码中也可以借助 client-go 来对资源进行检索。
+
+而在多集群环境下,Clusterpedia 通过兼容 Kubernetes OpenAPI ,用户可以依然使用单集群的方式,来对多集群资源进行复杂检索,无需从每个集群中拉取数据到本地进行过滤。
+
+当然 Clusterpedia 的能力并不仅仅只是检索查看,未来还会支持对资源的简单控制,就像 wiki 同样支持编辑词条一样。Clusterpedia 具有许多特性和功能:
+
+* 支持复杂的检索条件,过滤条件,排序,分页等等
+* 支持查询资源时请求附带关系资源
+* 统一主集群和多集群资源检索入口
+* 兼容 kubernetes OpenAPI, 可以直接使用 kubectl 进行多集群检索, 而无需第三方插件或者工具
+* 兼容收集不同版本的集群资源,不受主集群版本约束,
+* 资源收集高性能,低内存
+* 根据集群当前的健康状态,自动启停资源收集
+* 插件化存储层,用户可以根据自己需求使用其他存储组件来自定义存储层
+* 高可用
+
+## 下期内容
+除了支持多集群的复杂检索,Clusterpedia 还有很多其他优点,例如通过聚合式 API 来统一主集群和多集群资源的访问入口,在实时同步子集群资源时的低内存占用以及弱网优化,另外还有通过插件化存储层来解耦对存储组件的依赖。
+
+下一期将为大家介绍具体设计和实现原理,详细解读 Clusterpedia 的优点,敬请期待。
+
+---
+
+CNCF 全称 Cloud Native Computing Foundation (云原生计算基金会),隶属于 Linux 基金会,成立于 2015 年 12 月,是非营利性组织,致力于培育和维护一个厂商中立的开源生态系统,来推广云原生技术,普及云原生应用。
+
+云原生全景图由 CNCF 从 2016 年 12 月开始维护,汇总了社区成熟和使用范围较广、具有最佳实践的产品和方案,并加以分类,为企业构建云原生体系提供参考,在云生态研发、运维领域具有广泛影响力。
diff --git a/content/zh/blog/search-by-multi-cluster.md b/content/zh/blog/search-by-multi-cluster.md
new file mode 100644
index 00000000..6d2916d2
--- /dev/null
+++ b/content/zh/blog/search-by-multi-cluster.md
@@ -0,0 +1,34 @@
+---
+title: 视频讲解|Clusterpedia -- 多云环境下的资源复杂检索
+date: 2022-03-01
+---
+
+Clusterpedia 的发起人 --「Daocloud 道客」的云原生研发工程师蔡威,为大家详细介绍 Clusterpedia 在资源检索上提供的功能,让大家可以直观的了解到使用 Clusterepdia 可以解决哪些问题。
+
+
+
+## Clusterpedia 多集群资源检索神器
+随着云原生技术的发展、承载业务量的增加以及集群规模的不断扩大,单个 Kubernetes 集群已经无法满足很多企业的需求,我们在逐渐的步入多云时代,多集群内部资源管理和检索变得越发复杂和困难。
+
+由此,社区不断出现了很多优秀的的开源项目,例如用于集群生命周期管理的 cluster api,以及多云应用管理的 karmada, clusternet 等。而 Clusterpedia 便是建立在这些云管平台之上,为用户提供多集群资源的复杂检索。
+
+在单集群中,我们通常使用 kubectl 来查看资源,或者直接访问 Kubernetes 的 OpenAPI,在代码中也可以借助 client-go 来对资源进行检索。
+
+而在多集群环境下,Clusterpedia 通过兼容 Kubernetes OpenAPI ,用户可以依然使用单集群的方式,来对多集群资源进行复杂检索,无需从每个集群中拉取数据到本地进行过滤。
+
+当然 Clusterpedia 的能力并不仅仅只是检索查看,未来还会支持对资源的简单控制,就像 wiki 同样支持编辑词条一样。Clusterpedia 具有许多特性和功能:
+
+* 支持复杂的检索条件,过滤条件,排序,分页等等
+* 支持查询资源时请求附带关系资源
+* 统一主集群和多集群资源检索入口
+* 兼容 kubernetes OpenAPI, 可以直接使用 kubectl 进行多集群检索, 而无需第三方插件或者工具
+* 兼容收集不同版本的集群资源,不受主集群版本约束,
+* 资源收集高性能,低内存
+* 根据集群当前的健康状态,自动启停资源收集
+* 插件化存储层,用户可以根据自己需求使用其他存储组件来自定义存储层
+* 高可用
+
+## 下期内容
+除了支持多集群的复杂检索,Clusterpedia 还有很多其他优点,例如通过聚合式 API 来统一主集群和多集群资源的访问入口,在实时同步子集群资源时的低内存占用以及弱网优化,另外还有通过插件化存储层来解耦对存储组件的依赖。
+
+下一期将为大家介绍具体设计和实现原理,详细解读 Clusterpedia 的优点,敬请期待。
