diff --git "a/Data Structure/baco/\354\236\220\353\260\224 \354\236\220\353\243\214\352\265\254\354\241\260(\353\260\260\354\227\264,\354\227\260\352\262\260\353\246\254\354\212\244\355\212\270,\354\212\244\355\203\235,\355\201\220).md" "b/Data Structure/jecheol/\354\236\220\353\260\224 \354\236\220\353\243\214\352\265\254\354\241\260(\353\260\260\354\227\264,\354\227\260\352\262\260\353\246\254\354\212\244\355\212\270,\354\212\244\355\203\235,\355\201\220).md"
similarity index 100%
rename from "Data Structure/baco/\354\236\220\353\260\224 \354\236\220\353\243\214\352\265\254\354\241\260(\353\260\260\354\227\264,\354\227\260\352\262\260\353\246\254\354\212\244\355\212\270,\354\212\244\355\203\235,\355\201\220).md"
rename to "Data Structure/jecheol/\354\236\220\353\260\224 \354\236\220\353\243\214\352\265\254\354\241\260(\353\260\260\354\227\264,\354\227\260\352\262\260\353\246\254\354\212\244\355\212\270,\354\212\244\355\203\235,\355\201\220).md"
diff --git "a/DataBase/jecheol/MySQL\353\241\234 \354\235\264\355\225\264\355\225\230\353\212\224 \353\215\260\354\235\264\355\204\260\353\262\240\354\235\264\354\212\244 1 - \354\235\264\355\225\264\354\231\200 \354\204\244\352\263\204.md" "b/DataBase/jecheol/MySQL\353\241\234 \354\235\264\355\225\264\355\225\230\353\212\224 \353\215\260\354\235\264\355\204\260\353\262\240\354\235\264\354\212\244 1 - \354\235\264\355\225\264\354\231\200 \354\204\244\352\263\204.md"
new file mode 100644
index 0000000..a64324f
--- /dev/null
+++ "b/DataBase/jecheol/MySQL\353\241\234 \354\235\264\355\225\264\355\225\230\353\212\224 \353\215\260\354\235\264\355\204\260\353\262\240\354\235\264\354\212\244 1 - \354\235\264\355\225\264\354\231\200 \354\204\244\352\263\204.md"
@@ -0,0 +1,220 @@
+_메인 출처 : (도서) MySQL로 배우는 데이터베이스 개론과 실습_
+_참고 링크 : [medium.com](https://medium.com/@claire_logan/3-relational-data-model-examples-c9f70c61588c)_
+
+_데이터베이스는 많은 종류가 있지만, 우리는 MySQL을 기준으로 관계형 데이터베이스를 학습하고 있으므로 앞으로 서술되는 많은 내용은 관계형 데이터베이스에 대한 내용입니다._
+
+## 데이터베이스란
+
+**데이터베이스는 조직에서 필요한 정보를 관리하기 위해 논리적으로 연관된 데이터를 구조적으로 통합해 둔 것입니다.** 즉, 데이터베이스는 구조화된 데이터 덩어리를 의미하며, MySQL이나 Oracle DB와 같은 것들은 데이터베이스를 관리하는 데이터베이스 "관리 시스템"입니다. Database Management System(DBMS)는 데이터 관리를 아날로그식으로 장부에 적어서 관리하던 시대를 지나, 디지털화되면서 데이터를 잘 관리할 수 있는 시스템의 필요에 따라 탄생하였습니다.
+
+데이터베이스 시스템은 데이터의 검색과 변경 작업 등을 주로 수행하기 위해 디자인되어 있습니다. 우리가 흔히 말하는 Create, Read, Update, Delete와 같은 작업을 말이죠.
+
+이제 그럼 엄격하게 한 번만 짚고 넘어가겠습니다.
+
+데이터베이스(관리하고자 하는 데이터 덩어리)를 디지털 환경에서 관리하기 위해서는 데이터베이스 시스템을 구축해야 합니다. 데이터베이스 시스템은 다음 3가지 요소로 구성됩니다.
+
+- 데이터베이스 관리 프로그램 DataBase Management System(DBMS; MySQL workbench 등)
+- 데이터베이스
+- 데이터 모델 (schema)
+
+관계형 데이터베이스는 많은 데이터를 효과적으로 관리하기 위해 입력되는 데이터의 양식을 정의합니다.
+
+우리가 c언어에서 구조체를 정의하거나, 자바에서 객체를 선언하듯이, 관리하고자 하는 데이터들은 연관성으로 연결하면 하나의 모델로 묶을 수 있습니다. 가령 "고객의 이름", "고객의 이메일"과 같은 정보는 "고객"의 정보의 속성값이라고 이해해볼 수 있는 거죠. 관계형 데이터베이스에서는 이런 연관성을 갖는 데이터들을 그룹화하여 관리합니다. 이런 각 그룹들은 Relation이라고 칭하는데, 이게 실제 데이터베이스 상에서는 마치 도표처럼 보여서 Table이라고 더 많이 부릅니다. 이렇게 여러 테이블이 하나의 관계형 데이터베이스에 생성될텐데, 각각 하나의 테이블을 정의하는 걸 모델링이라고 합니다.
+
+그럼 이런 테이블에 데이터가 들어가는 모양은 어떨까요?
+
+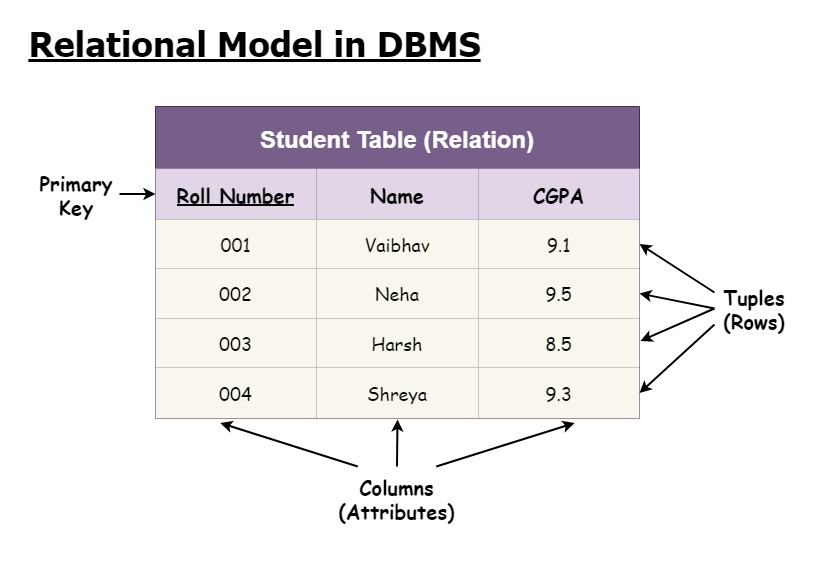
+위 그림을 보면 왜 Table이라고 부르는지 바로 이해가 되실 겁니다. 마치 수학에서 많이 보던 '표'처럼 생겼죠? 이렇게 테이블에 정의된 속성값 양식에 따라 데이터가 각각 저장되고, 각각의 데이터는 tuple 또는 row 또는 record라고 부릅니다. 뭐로 불러도 상관 없을 정도로 혼용하는 것 같습니다. 그리고 각 속성은 attribute라고 하기도 하고 column이라고도 합니다. 그리고 각 튜플을 명확히 구분하기 위한 식별자인 Primary key라는 것도 있습니다. 이는 아래 KEY 파트에서 좀 더 다루겠습니다.
+
+## 키 (KEY) : 데이터베이스 레코드 식별자
+관계 데이터베이스에서 key는 테이블의 많은 튜플들 중 특정 튜플을 식별할 때 사용하는 속성입니다. 관계 데이터베이스에서는 중복되는 데이터라는게 존재할 수 없기 때문에 구분자가 반드시 하나는 필요하거든요.
+
+이 키는 각 튜플을 구분하는 역할도 하고, 릴레이션 간 관계를 맺을 때에도 사용합니다. 한번 이에 대하여 정리해 보겠습니다.
+
+#### 슈퍼키
+슈퍼키(Super key)는 튜플을 유일하게 식별할 수 있는 하나의 속성 혹은 속성의 집합입니다. 튜플을 유일하게 식별할 수 있는 값이면 모두 슈퍼키가 될 수 있습니다. 다음 예시와 함께 이해해 보겠습니다.
+
+
+각 속성에 대한 설명은 다음과 같습니다.
+- id : 모든 튜플이 고유하게 갖는 임의의 유니크 숫자 값이다.
+- name : 이름을 담고 있으므로, 동명 이인에 대하여는 중복되는 데이터이다.
+- email : 이메일은 회원의 중복 가입 여부를 판단하는 값으로 사용되는 유니크 값이다.
+
+그럼 슈퍼키는 어떻게 될까요? 나열하면 다음과 같습니다.
+```text
+(id), (email), (id,name), (id,email), (email, name), (id,name,email)
+```
+
+즉, 반드시 구분될 수 있는 값이 있는 거라면 그 값을 포함하는 부분집합도 슈퍼키가 될 수 있다는 겁니다. 하지만 보시다시피 슈퍼키 구성에는 `name`과 같이 단독으로는 튜플을 식별할 수 없는 속성도 포함되는 것을 허용하므로 슈퍼키 구성 속성이 많아지는 걸 열어두게 되고, 만약 이렇게 많은 속성을 한번에 묶어서 키로 관리하게 되면 관계 표현이 복잡하고 사용성이 떨어집니다. 따라서 이는 개념적인 영역에만 머물게 되고, 실질적으로는 튜플을 식별할 수 있는 최소한의 속성 집합을 사용하게 되는 게 일반적입니다.
+
+#### 후보키
+후보키(Candidate key)는 모든 속성이 단독으로 튜플을 식별할 수 있어야 하는 속성의 집합입니다. 단독으로도 구분되니, 그 속성들의 집합으로는 더 당연히 각 튜플이 구분되겠죠. 즉 슈퍼키 중 `(id, name)`과 같은 경우는 후보키가 될 수 없습니다.
+
+이는 슈퍼키는 복잡성이 높아 보통 실제로 활용되지 않는 개념이고, 데이터베이스에 대한 이야기를 할 때 기본적으로 key라고 칭하면 이 후보키를 의미하는 것이 일반적입니다.
+
+그럼 다시 이미지를 참고해서 후보키를 뽑아볼까요?
+
+후보키는 다음과 같습니다.
+```text
+(id), (email), (id,email)
+```
+
+위에서 언급은 안 했었는데, `(id, email)`처럼 두 개 이상의 속성으로 이루어진 키를 복합키(composite key)라고 합니다. 이에 대하여는 FK에서 다시 다루겠습니다.
+
+#### 기본키
+기본키(Primary key)란 여러 후보키 중 선정된 하나의 대표 키를 의미합니다. 위에서 테이블에 대하여 설명할 때 있던 Primary key가 바로 기본키입니다.
+
+후보키 중 하나를 선정하여 "각 튜플을 이 속성값으로 구분하겠다" 지정하는 겁니다. 모든 테이블은 반드시 하나의 PK를 설정해줘야 하며, 이는 null이 될 수 없는 값이여야 합니다. 그래서 보통은 1,2,3,4,...와 같은 패턴으로 자동으로 각 튜플을 넘버링하는 값을 PK로 종종 설정합니다.
+
+다음은 무결성 조건 외에 기본키를 설정할 때 고려해야 하는 특징입니다.
+- Uniqueness : 다른 Row로부터 식별이 가능하도록 유일한 값일 것
+- Stability : 수정이 일어나지 않을 것.
+- Irreducibility : (비환원성) 복합키를 사용한다면 그 키의 어느 칼럼이건 수정하는 순간 PK의 유일성이 깨질 수 있으니 주의할 것
+- Simplicity : (sequence number와 같이) 가급적 읽기 쉽고, 기억되기 쉬운 값을
+
+_pk auto increment 전략은 위 특징을 충족하는 간편한 방법이지만, 만약 저처럼 "항상 auto increment를 하는 게 능사는 아닐 것 같은데?"와 같은 의문을 품고 사는 사람이라면 이 [링크](https://findstar.pe.kr/2022/10/14/resource-id-generation/)가 도움이 될 수 있을 것 같습니다._
+
+
+위 예시를 다시 보면, roll number라는 속성이 PK로 설정되어 있는데, 이게 1,2,3,4... 로 증가 수열을 이루며 모든 튜플에 대하여 식별자 역할을 해주고 있는 걸 확인할 수 있습니다. 1부터 시작하고 계속 1씩 증가시켜주니 절대 중복되지도, null이 되지도 않으니 PK로 선정되기에 딱인 것으로 보이네요.
+
+**추가로, PK 설정시 자연키(natural key)와 인공키(artificial key)라는 개념도 존재합니다.**
+자연키는 일반적으로 "주민등록번호"처럼 세상에 의미를 갖고 자연스럽게 존재하는 유니크한 key 데이터를 의미합니다. 과거에는 이를 PK로 설정하기도 했다고 하고, 이러한 자연키들을 복합키로 묶어서 종종 PK로 설정했다고 합니다.
+
+하지만 오늘날에는 위의 roll number와 같이 시스템에서 자동으로 생성하는 식별자 역할만을 위한 인공 키(aritificial key)를 별도 속성으로 추가하여 PK로 사용하는 일이 많아졌습니다. 이는 여러 목적이 있는데요.
+- ORM 기술이 보편화되면서 복합키 사용이 내부적으로 쿼리를 처리할 때 복잡성을 증가시키기도 하고,
+- PK와 같은 ID 데이터가 클라이언트에 노출될 수 있는 상황도 많은데 "주민등록번호"와 같은 의미가 있는 데이터를 외부에 노출시키는 것이 보안상 문제가 발생하기도 하며,
+- 가령 어떤 테이블은 유니크한 데이터가 전혀 없어서 PK 선정이 까다롭기 때문입니다.
+
+따라서 요즘은 인공키를 이용하여 PK를 설정하는 것이 일반적이고, 이는 다른 데이터 대신 PK 역할을 수행하는 key라 하여 대리키(surrogate key)라고도 부릅니다.
+
+#### 대체키
+대체키(alternate key)는 기본키로 선정되지 못한 후보키를 일컫습니다. 위 예시에서 Users 테이블의 id를 PK로 설정했다면 email이 대체키가 되겠네요. 이건 중요 개념이 아니라서 이쯤 하겠습니다.
+
+#### 외래키
+외래키(foreign key)는 다른 테이블의 기본키를 참조하는 속성을 의미합니다. 서비스를 구성하다 보면 유저 정보 외에도 많은 정보가 있을 겁니다. 우리가 자주 사용하는 인스타그램만 하더라도 "포스트"라는 테이블이 있다고 하면, 이미지들과 좋아요 개수, 댓글 개수와 같은 정보들이 있을 수 있겠죠.
+
+근데 내 게시글에 좋아요를 누른 유저들의 정보는 어떻게 저장해야 할까요? 게시글 테이블의 한 속성에 여러 유저 테이블 row를 저장하는 리스트를 둘 수 있을까요? 여기서 왜 관계형 데이터베이스가 "관계형" 데이터베이스인지 밝혀집니다. 관계형 데이터베이스에서는 이를 테이블 간 "관계 설정"으로 풀어냈습니다.
+
+
+
+
+위 사진에서 보면 Members, Member Signups, Class Schedule, Classes, Instructors, Types 와 같은 테이블이 있습니다. 그리고 각각 id라는 PK를 갖고 있습니다. 이제 또 보이는 것이 foreign key(FK)인데요. 잘 보시면 각 FK는 다른 테이블의 PK와 연결되어 있는 것을 확인할 수 있습니다. 그럼 예시에 있는 가장 간단한 예시인 class schedule과 instructor 테이블 간의 관계를 통해 FK로 구현하는 현상을 설명해 보겠습니다.
+
+- classe schedule은 어떤 클래스가 몇시에 시작하고 몇시에 끝나는지 나타낸다.
+- instructors는 각 클래스에 참여하는 강사의 이름을 나타낸다.
+- 한 강사가 여러 수업에 참여하는 경우, 강사 테이블에 참여 수업 리스트를 속성으로 지정하지 않고, class schedule에서 강사의 PK값을 저장하여 참여 강사 정보를 저장한다.
+
+이처럼 속성에 리스트를 두는 방식 보다는 각 데이터 간의 관계성을 담을 수 있도록 FK라는 속성값을 두게 하여 효과적으로 데이터를 관리할 수 있도록 구현한 게 관계형 데이터베이스의 가장 큰 특징입니다.
+
+그 외 FK에서 알아야 하는 특징은 2개 정도 더 있습니다.
+- FK는 반드시 다른 테이블의 PK일 필요는 없고, 자신의 PK를 FK로 참조하여 User 간 팔로우, 팔로워 등을 구현할 때에도 사용될 수 있습니다.
+- FK는 PK와 달리 NULL을 허용할 수 있습니다. 이게 튜플의 식별자가 아니기 때문이며, 단순히 관계를 갖는 여부에 따라 데이터를 추가하고 말고를 설정하는 속성이기 때문입니다. 물론, not null로 운영할수도 있으니, 이는 설계 단계에서 자율적으로 정책 설정을 하면 됩니다.
+
+_물론, 실무에서는 데이터 규모가 상당히 크고, 그 관계가 매우 복잡하다보니 FK 설정으로 인한 무결성 제약조건을 관리하는 것이 불편하여 의도적으로 FK를 사용하지 않는 경우도 있다고 합니다. 이는 관리의 편의성을 바탕으로 서비스 설계 단계에서 고려해볼 수 있는 사안이지만, 성능적인 측면에서는 FK를 적절하게 사용하는 게 일반적인 경우에서는 더욱 좋기 때문에 장단을 고려하여 적절한 설계를 하는 것이 우리 개발자들의 몫인 것으로 보입니다._
+
+### 무결성 제약조건
+key를 이용하여 데이터베이스에 저장된 데이터의 일관성과 정확성을 지키기 위해 지켜야 하는 조건들을 의미합니다. 당연히 지켜져야 하는 내용이고, 이런 조건이 있는 이유는 각 키의 목적을 이해하면 모두 자명한 내용이라 간단하게만 정리하고 넘어가겠습니다.
+
+- 도메인 무결성 제약조건
+ - 테이블에 저장되는 각 튜플이 갖는 각 속성값은 테이블 칼럼에 지정된 값만 가져야 한다는 조건이다.
+ - 도메인 무결성을 체크하기 위해 각 데이터의 data type, null 여부, 기본값 등을 체크한다.
+ - 만약 Users(id, age) 이라는 테이블이 있고, age 속성에 대하여 int, not null 조건이 매겨져 있다면 (1) 정수형 외에 문자열과 같은 데이터가 입력되지는 않았는지, (2) null이 입력되지는 않았는지 등을 체크한다.
+- 개체 무결성 제약조건
+ - 모든 테이블은 pk를 가져야 하며, 지정된 기본키가 유니크한 값이며, NULL 값을 가져서는 안 된다는 조건이다.
+ - **기본키 제약조건**이라고도 한다.
+ - 만약 Users(id, age) 테이블에서 id 값을 null로 입력하면 개체 무결성 제약조건이 위배되어 에러가 발생한다. 참고로, pk 설정시 unique 설정은 기본값으로 들어간다.
+- 참조 무결성 제약조건
+ - 참조하는 테이블(자식 테이블)의 FK가 참조받는 테이블(부모 테이블)의 PK여야 한다.
+ - (당연하지만) FK에 입력되는 값은 참조 PK의 도메인 무결성을 준수해야 한다.
+ - 부모 테이블에서 참조되는 튜플의 PK는 자식 테이블이 존재하는 한 삭제되거나 수정될 수 없다.
+ - 참조에 NULL pointing이 되지 않도록 막는 조건이라고 이해하면 된다.
+
+## 관계 데이터 모델 (ERD)
+
+ERD(Entity-Relationship Diagram)는 데이터 모델링을 할 때에 각 릴레이션의 관계성을 설정하는 논리적 설계 시 사용하는 양식을 의미합니다.
+
+
+
+위에서 사각형이 우리가 지금까지 봤던 table(relation), 동그라미가 각 table이 같는 속성값들입니다.
+
+
+그 중에서 밑 줄이 그어진 속성이 PK입니다.
+
+
+
+그리고 남은 게 이제 다이아몬드 모양이죠? 저게 바로 관계성을 나타내는 겁니다. 연결된 라인의 개수가 2개인지 1개인지에 따라서도 필수인지 optional인지에 대한 정보를 나타내며, 1인지 n 또는 m인지는 1대1 관계인지, 1대다 관계인지 등을 나타내는데, 이는 논리적으로는 이해하기가 오히려 어려우므로 스키마 설계에서 다시 다루겠습니다. (미리 궁금하다면 [링크](https://en.wikipedia.org/wiki/Entity%E2%80%93relationship_model) 참고해주세용)
+
+주목할 점은, ERD를 작성함으로써 관계성에 영어로 코멘트를 달아줌으로써 각 테이블이 어떤 의미의 관계성을 갖고 유기적으로 연결되어 있는지를 정의할 수 있다는 겁니다. 이 과정을 통해 스키마 작성시 더욱 명확하게 데이터 구조를 이해할 수 있게 됩니다. 더욱 명료하게 이해할수록 스키마 구조화가 더 효율적이고 정확하겠죠. 따라서 ERD를 구성해보는 것은 복잡한 데이터베이스 설계를 위해서는 가장 단순하면서도 효과적인 논리적 모델링 방법이라고 할 수 있겠습니다.
+
+## 정규화
+
+데이터베이스는 두 가지 이상의 정보가 한 릴레이션에 저장되어 있을 때 이상현상이 발생한다. 따라서 이상현상을 방지하지 위해 릴레이션 내에 있는 중복 데이터를 분리하는 작업이 필요하고, 이를 "정규화(Normalization)"라고 한다.
+
+정규화 과정은 기본적으로 제 1 정규형, 제 2 정규형, 제 3 정규형, BCNF(Boyce Codd Normal Form), 제 4 정규형, 제 5 정규형까지 총 6가지가 있다. 이를 모두 수행해야만 이상현상이 해결되는 것은 아니고, 대부분의 이상현상은 제 3 정규형 또는 BCNF까지 수행하면 없어진다고 한다. 따라서 제 4 정규형과 제 5 정규형에 대한 설명은 나보다 더 전문적인 분들의 설명이 적힌 [링크](https://code-lab1.tistory.com/270)로 대신하고, 그 전까지 간단하게 짚고 넘어가겠다.
+
+#### 제 1 정규형
+릴레이션 내의 속성값이 atomic해야 한다는 규칙을 준수하는 형태이다. 이는 사실 기본적인 처리로, 관계형 데이터베이스를 사용하기 위해 당연히 이뤄진다. 다음 이미지를 봐 보자.
+
+위 이미지를 보면 "STUD_PHONE" 속성값이 여러개 들어가 있는 걸 볼 수 있다. 관계형 데이터베이스에서는 각 속성에 하나의 값만 가질 수 있으므로 이를 하나씩 가질 수 있도록 수정해줘야 한다.
+
+단순하게 말해서, 관계형 데이터베이스의 가장 기본적인 특징인 하나의 칼럼에는 하나의 속성값만 들어갈 수 있다는 조건을 만족시키는 것이 제 1 정규화다.
+
+#### 제 2 정규형
+모든 nonprime attributes가 pk에 대해 완전 함수 종속이면 제 2정규형이다.
+- 완전 함수 종속 : A와 B가 릴레이션 R의 속성이라고 할 때, A -> B 종속성이 성립할 때, B가 A의 속성 전체에 함수 종속하고 부분집합 속성에 함수 종속하지 않을 경우 완전 함수 종속이라고 한다.
+즉, 부분 함수 종속이 없는 형태의 테이블이여야 한다. 이는 도메인에 대한 이해를 바탕으로 이뤄진다.
+
+다음 예시를 봐 보자.
+```text
+STUD_NO COURSE_NO COURSE_FEE
+1 C1 1000
+2 C2 1500
+1 C4 2000
+4 C3 1000
+4 C1 1000
+2 C5 2000
+출처 : geeksforgeeks
+```
+위 예시에서 COURSE FEE는 COURSE NO에만 종속적이며, 이를 부분 함수 종속이라고 한다. 따라서 부분 함수 종속을 제거해주면 제 2 정규형이 된다.
+
+```text
+ ****Table 1**** ****Table 2****
+STUD_NO COURSE_NO COURSE_NO COURSE_FEE
+1 C1 C1 1000
+2 C2 C2 1500
+1 C4 C3 1000
+4 C3 C4 2000
+4 C1 C5 2000
+2 C5
+출처 : geeksforgeeks
+```
+
+조금 더 복잡한 예시로는 다음 예시가 있다.
+- EMP_PROJ(SSN*, Pnumber*, hours, ename, pname, plocation)은
+
+ - hours는 (ssn,pnumber)에 종속적
+ - ename은 ssn에만 종속적 (부분 함수 종속)
+ - pname, plocation은 pnumber에만 종속적 (부분 함수 종속)
+
+ → 부분 함수 종속을 갖는 nonprime attribute를 별도 테이블로 분리해주면 됨
+
+단순하게 말해서, 같은 테이블로 구성해야 하는 것만 같은 테이블로 구성하는 것이 제 2 정규화다.
+
+#### 제 3 정규형
+제 2 정규형을 만족하면서, 어떤 nonprime attribute도 이행종속성(transitive dependency)이 없으면 제 3 정규형이다.
+
+즉, 모든 nonprime attribute가 릴레이션 R의 모든 키에 완전 함수 종속이면서, 모든 키에 이행종속성이 없어야 한다.
+
+- 이행종속성이란 X → Y라는 종속성이 있을 때, 테이블 내의 모든 속성이 기본 키에만 의존하며, 다른 후보 키에 의존하지 않는다.
+- LOTS(id, county_name, lot_number, area, price)라고 할 때, id를 보면 area가 결정되는데, area만 봐도 price를 알면 안된다. (이런게 이행 종속)
+
+ ⇒ 이럴때에는 area와 price를 별도의 테이블로 분리하고, fk를 할당해줘서 join할 수 있게 해두면 된다. (제3정규화)
+
+#### BCNF
+- R(A,B,C)가 있고, A, B가 key라고 할 때, A,B,를 보면 C라고 판단할 수 있고, C를 볼 때 B가 B라고 판단할 수 있으면 3NF이지만 BCNF가 아닌 경우이다. C → B가 안되어야 BCNF이다.
+- 예시를 보면, TEACH(student, course, instructor) 테이블이 있고, 그 함수 종속성이 FD1: {student, course} → Instructor, FD2 : Instructor → course라고 할 때 (Instructor, student), (Instructor, course)로 쪼개야 BCNF를 만족한다.
+
+## 마무리
+여기까지 Database에 대한 간단한 이해와, 설계 단계에서 고려해야 하는 KEY에 대한 지식, 그리고 ERD와 정규화에 대하여 이해해 봤습니다. 정규화는 과도하게 진행될 경우 JOIN연산을 너무 많이 수행해야 하므로 이상 현상만 피할 수 있게 적절히 하는 것이 중요합니다. 이를 고려하여 ERD를 잘 작성해서 DB를 모델링 한 뒤에 스키마를 제작하면 됩니다.
+
+다음에는 DB 스키마를 한번 코드로 짜 보겠습니다. 감사합니다.
\ No newline at end of file
diff --git "a/DataBase/jecheol/SQL Injection \354\212\244\355\201\254\353\236\251.md" "b/DataBase/jecheol/SQL Injection \354\212\244\355\201\254\353\236\251.md"
new file mode 100644
index 0000000..3f37d1a
--- /dev/null
+++ "b/DataBase/jecheol/SQL Injection \354\212\244\355\201\254\353\236\251.md"
@@ -0,0 +1,2 @@
+
+[링크](https://noirstar.tistory.com/264)
diff --git "a/DataBase/minhyeok/ERD_\354\240\225\352\267\234\355\231\224\352\263\274\354\240\225.md" "b/DataBase/minhyeok/ERD_\354\240\225\352\267\234\355\231\224\352\263\274\354\240\225.md"
new file mode 100644
index 0000000..f109cee
--- /dev/null
+++ "b/DataBase/minhyeok/ERD_\354\240\225\352\267\234\355\231\224\352\263\274\354\240\225.md"
@@ -0,0 +1,109 @@
+# ERD (Entity Relationship Diagram)
+
+## 개념
+ 개체-관계 모델. 테이블간의 관계를 설명해주는 다이어그램이라고 볼 수 있으며, 이를 통해 프로젝트에서 사용되는 DB의 구조를 한눈에 파악할 수 있습니다.
+ 즉, API를 효율적으로 뽑아내기 위한 모델 구조도라고 생각하면 됩니다.
+
+
+
+
+## 중요성
+
+ ERD는 복잡한 데이터 구조와 관계를 시각적으로 표현함으로써, 데이터베이스 설계를 명확하고 이해하기 쉽게 만들어줍니다. 또한, ERD를 통해 데이터의 무결성과 일관성을 보장할 수 있습니다.
+
+
+
+# 정규화 과정
+
+## 개념
+
+ 정규화는 데이터베이스에서 중복을 최소화하고, 데이터를 구조적으로 표현하기 위해 사용하는 과정입니다. 이를 통해 데이터의 무결성과 효율성을 높일 수 있습니다.
+
+## 원칙
+
+ 정규화는 중복된 데이터를 제거하고, 데이터를 논리적으로 구조화하는 것을 목표로 합니다. 이를 위해 여러 단계의 정규형을 거치게 됩니다.
+
+## 특징
+
+- 데이터 조회시 조인 증가 => 필요에 따라 반정규화 진행
+
+- 업무 변경시에도 모델의 유연성 향상
+
+- 엔터티 의미 해석 명확
+
+- 테이블 수 증가
+
+- 모델의 독립성 향상
+
+
+
+## 제 1 정규화
+
+- 모든 속성값이 원자값으로만 되어 있음
+
+## 제 2 정규화
+
+- 모든 속성은 기본키에 완전 함수 종속 만족
+- 부분적 함수 종속성 제거
+- 그러나 기본키가 속성 하나로만 구성되어있으면 Pass
+
+
+
+- 학생번호와 강좌이름 속성으로 구성된 기본키
+
+- 하지만 강좌명에 따라 강의실이 결정되는 부분 함수 종속이 존재
+
+- 따라서, 강좌명을 기본키로하는 테이블을 생성하여 수강 테이블, 강의실 테이블로 분리하여 제 2정규화 조건 충족
+
+## 제 3 정규화
+
+- 이행함수 종속성 제거
+
+- 이행적 종속이란 A -> B, B -> C 이면 A -> C 라는 것을 의미한다.
+
+
+
+
+
+- 학생번호에 따라 수강료가 결정되는 이상한 상황이 발생함.
+
+- 또한, 강좌가 2만원이라는 것이 중복된다.
+
+- 수강료는 강좌에 따라 결정되야 하므로 이행함수 종속성을 제거한다.
+
+- 다음과 같이 계절수강 테이블, 수강료 테이블을 나누었다.
+
+
+
+
+
+## BCNF 정규화
+
+- 모든 결정자가 후보키인 정규형을 뜻한다.
+- 제 3 정규화까지 진행한 테이블의 모든 결정자가 후보키가 되도록 테이블을 분리시킨다.
+
+ - 결정자란?
+
+ 한 속성의 값이 다른 속성의 값을 결정짓는다면, 그 속성을 '결정자'라고 한다.
+
+
+
+
+
+- 이 테이블에서 각 튜플을 구분할 수 있는 학생번호와 특강이름이 기본키이다.
+
+- 따라서 학생번호와 특강이름으로 해당 교수를 알 수 있다.
+
+- 그런데 마찬가지로 교수를 알면 특강 이름을 알 수 있다.
+
+- 교수는 특강이름을 알 수 있는 결정자인데 후보키가 아닌 상황이 발생함.
+
+- 모든 결정자가 후보키이어야한다는 BCNF 정규화 조건을 충족시키지 못함.
+
+
+
+
+
+
+
+- 그래서 다음과 같이 특강신청 테이블, 특강 교수 테이블로 나누어 문제를 해결.
diff --git a/DataBase/minhyeok/JOIN.md b/DataBase/minhyeok/JOIN.md
new file mode 100644
index 0000000..3504fba
--- /dev/null
+++ b/DataBase/minhyeok/JOIN.md
@@ -0,0 +1,148 @@
+# 조인이란?
+
+ 두 개 이상의 테이블에서 필요한 데이터를 가져와서 하나의 결과 집합으로 결합하는 연산입니다. 조인을 사용하면 여러 테이블에 분산된 데이터를 효율적으로 조회할 수 있습니다.
+
+## 종류
+
+
+
+
+
+### Inner Join(내부 조인)
+
+ 두 테이블의 교집합을 반환합니다. 즉, 조인 조건에 맞는 행만 결과로 반환하며, 조건에 맞지 않는 행은 제외됩니다.
+
+
+
+
+
+
+
+
+### Left Outer Join(왼쪽 외부 조인)
+
+ 왼쪽 테이블의 모든 행과 오른쪽 테이블에서 조인 조건에 맞는 행을 반환합니다. 오른쪽 테이블에 매칭되는 행이 없는 경우에는 NULL 값을 반환합니다.
+
+ SELECT A.ID, B.ID, A.NAME, B.NAME
+ FROM Table A, Table B
+ WHERE A.ID = B.ID(+);
+
+
+
+
+### Right Outer Join(오른쪽 외부 조인)
+
+ 오른쪽 테이블의 모든 행과 왼쪽 테이블에서 조인 조건에 맞는 행을 반환합니다. 왼쪽 테이블에 매칭되는 행이 없는 경우에는 NULL 값을 반환합니다.
+
+ SELECT A.ID, B.ID, A.NAME, B.NAME
+ FROM Table A, Table B
+ WHERE A.ID(+) = B.ID;
+
+
+
+
+
+
+
+### Full Outer Join(전체 외부 조인)
+
+ 왼쪽 테이블과 오른쪽 테이블의 합집합을 반환합니다. 양쪽 테이블에서 조인 조건에 맞는 행을 반환하며, 매칭되는 행이 없는 경우에는 NULL 값을 반환합니다.
+
+
+### Inner Join VS Outer Join
+
+ 댓글이 있는 게시물만 보여줘라 VS 댓글이 없는 게시물도 보여줘라
+
+
+
+
+# Nested Loop Join(중첩 조인)
+
+ 두 테이블을 조인하는 가장 기본적인 방법으로 하나의 테이블을 기준으로 기준 테이블의 행 마다 다른 테이블의 모든 행을 검색하는 방식. => 이중 for문과 유사
+
+## 사용 케이스
+
+- 작은 테이블 간의 조인이나, 인덱스가 적용된 테이블에 효과적
+
+## 작동 방식
+
+
+
+- Table A가 Outer Table(선행 테이블), Driving Table(구동 테이블)
+
+- Table B가 Inner Table(후행 테이블), Driven Table
+
+1. 외부 테이블의 첫 번째 행을 가져옵니다.
+
+2. 내부 테이블의 모든 행을 검색하면서, 조인 조건에 맞는 행을 찾습니다.
+
+3. 조건에 맞는 모든 행을 찾았다면, 외부 테이블의 다음 행으로 이동하고, 내부 테이블의 검색을 다시 시작합니다.
+
+4. 외부 테이블의 모든 행을 검사할 때까지 이 과정을 반복합니다.
+
+### 그런데, 후행 테이블을 Index화 한다면 모든 테이블을 검색하지도 않아도 되어 속도를 빠르게 할 수 있다.
+
+- index는 도서관의 도서 분류라고 보면 됨 => 모든 자료를 검색하지 않아도 된다.
+
+
+
+- Drivng Table의 범위가 작을수록 수행속도가 빨라진다. 따라서 Driving Table을 어떤 테이블로 설정하는지가 중요하다.
+
+
+
+# Sort Merge Join
+
+ 각 테이블을 조인 키에 따라 정렬한 후, 두 테이블을 병합하면서 조인을 수행하는 방식
+
+## 사용 케이스
+
+- 두 테이블이 이미 정렬된 상태거나, 정렬된 인덱스가 존재할 때 효과적
+
+- 출력해야 할 결과 값이 많을 때
+
+
+
+## 작동 방식
+
+1. 선행 테이블에서 조건을 만족하는 행을 찾고 조인 키를 기준으로 정렬
+
+2. 후행 테이블에서도 같은 작업
+
+3. Join 수행
+
+## Hash Join
+
+ 해싱 기법을 이용하여 조인을 수행하는 기법이다.
+
+
+
+## 작동 방식
+
+1. 선행 테이블에서 조건을 만족하는 행을 찾는다.
+
+2. 선행 테이블의 조인 키로 해시함수를 적용하여 테이블을 생성한다. 이때, 조인 컬럼과 select 절에서 필요로 하는 컬럼도 함께 저장한다.
+
+3. 1,2를 반복 수행한다.
+
+4. 후행 테이블에서 조건을 만족하는 행을 찾는다.
+
+5. 후행 테이블의 조인 키로 해시 함수를 적용하여 해당하는 버킷을 찾는다. => 조인 키를 이용하여 실제 조인된 데이터를 찾는다.
+
+6. 조인 성공시 추출버퍼에 넣는다.
+
+## 사용 케이스
+
+- 조인 컬럼에 인덱스를 사용하지 않는다. 따라서, 조인 컬럼 인덱스가 없는 경우에도 사용가능하다.
+
+- 해시 함수를 이용하여 조인을 하기 때문에 동등 연산 조인에서 사용한다. => 해시 함수가 적용될 때 동일한 값은 항상 같은 값으로 해싱 되기 때문.
+
+## 특징
+
+- 조인 시 해시 테이블을 메모리에 생성해야 한다.
+
+- 생성된 해시 테이블의 크기가 메모리 적재 크기보다 커지면 임시 영역(디스크)에 저장한다. 이 과정은 추가적인 작업이 필요.
+
+- 따라서, 결과 행의 수가 적은 것을 선행 테이블로 사용하는 것이 좋다.
+
+- 해시 테이블을 만든 선행 테이블을 빌드 테이블이라고 하며, 후행 테이블을 프로브 테이블이라고 한다.
diff --git a/DataBase/minhyeok/SQL Injection.md b/DataBase/minhyeok/SQL Injection.md
new file mode 100644
index 0000000..b53dd1f
--- /dev/null
+++ b/DataBase/minhyeok/SQL Injection.md
@@ -0,0 +1,89 @@
+# SQL Injection 이란?
+
+ 악의적인 사용자가 보안상 취약점을 이용하여 이득을 얻기 위해 SQL 쿼리문을 조작하여 DB가 비정상적인 동작을 하도록 유도하는 행위이다. 공격이 비교적 쉬우나, 큰 피해를 입힐 수 있어 많은 주의가 필요하다.
+
+# 종류
+
+
+
+
+
+- 입력값에 대한 검증이 없을 때 발생
+
+- 특정 SQL 구문을 주입하여 WHERE 절을 참으로 만들고, 뒤의 구문을 주석 처리하여 모든 정보를 조회
+
+- 이로 인해 가장 먼저 만들어진 계정으로 로그인에 성공할수도 있다. (관리자 계정) => 추가적인 피해
+
+
+## Union based SQL Injection
+
+
+
+
+
+- Union 키워드를 사용하여 정상적인 쿼리문에 추가적인 쿼리문을 주입
+
+- 이를 통해 원하는 쿼리문을 실행할 수 있게 된다.
+
+- 두가지 조건이 필요 하나는 Union 하는 두 테이블의 컬럼 수가 같아야 하고, 데이터 형이 같아야 한다.
+
+## Blind SQL Injection
+
+
+
+
+
+- 데이터베이스로부터 특정한 값이나 데이터를 전달받지 않고, 단순히 참과 거짓의 정보만 알 수 있을 때 사용
+
+- Boolean based는 로그인 성공과 실패 메시지를 이용하여 DB의 테이블 정보 등을 추출해 낼 수 있다.
+
+## Time based
+
+
+
+
+
+- 서버의 응답 시간을 이용하여 데이터베이스의 정보를 유추하는 기법.
+
+## Stored Procedure SQL Injection
+
+- 저장 프로시저를 이용하여 SQL Injection을 수행하는 방법
+
+- 특히 MS-SQL의 xp_cmdshell과 같은 특정 저장 프로시저를 이용하여 윈도우 명령어를 사용할 수 있다.
+
+## Mass SQL Injection
+
+- 한 번의 공격으로 다량의 데이터베이스를 조작하여 큰 피해를 입히는 방법
+
+- 주로 MS-SQL을 사용하는 ASP 기반 웹 애플리케이션에서 많이 사용되며, 쿼리문은 HEX 인코딩 방식으로 인코딩하여 공격
+
+
+
+# 대응방법
+
+## 입력 값에 대한 검증
+
+- 사용자로부터 입력 받은 값에 대한 검증은 필수
+
+- 이때 화이트리스트 기반의 검증이 필요하며, 블랙리스트 기반의 검증은 빠진 항목 하나로 인해 공격에 성공할 위험
+
+- 공격 키워드와는 의미 없는 단어로 치환
+
+## Prepared Statement 구문 사용
+
+- 사용자의 입력 값을 문자열로 인식하게 하여 전체 쿼리문이 공격자의 의도대로 작동하지 않도록 하는 방법
+
+- DBMS가 미리 컴파일하여 실행하지 않고 대기하며, 사용자의 입력은 이미 의미 없는 단순 문자열로 인식
+
+## Error Message 노출 금지
+
+- 데이터베이스 에러 발생 시, 에러가 발생한 쿼리문과 함께 에러에 관한 내용을 반환하면, 이를 통해 테이블명 및 컬럼명 그리고 쿼리문이 노출될 수 있다.
+
+- 따라서, 사용자에게 보여줄 수 있는 페이지를 제작하거나 메시지박스를 띄우는 등의 방법으로 에러 메시지의 노출을 막아야 한다.
+
+## 웹 방화벽 사용
+
+- 웹 공격 방어에 특화된 웹 방화벽의 사용은 효과적인 보안 방법 중 하나
+
+- 웹 방화벽은 소프트웨어 형, 하드웨어 형, 프록시 형 등의 종류가 있으며, 각각의 방법은 서버에 직접 설치하거나, 네트워크 상에서 서버 앞 단에 하드웨어 장비로 구성하거나, DNS 서버 주소를 웹 방화벽으로 바꾸는 등의 방식으로 운용된다.
+
diff --git "a/DataBase/minhyeok/\353\215\260\354\235\264\355\204\260\353\262\240\354\235\264\354\212\244 \352\270\260\353\263\270.md" "b/DataBase/minhyeok/\353\215\260\354\235\264\355\204\260\353\262\240\354\235\264\354\212\244 \352\270\260\353\263\270.md"
new file mode 100644
index 0000000..fef671b
--- /dev/null
+++ "b/DataBase/minhyeok/\353\215\260\354\235\264\355\204\260\353\262\240\354\235\264\354\212\244 \352\270\260\353\263\270.md"
@@ -0,0 +1,180 @@
+# 데이터베이스란?
+
+ 관련성을 가진 데이터들의 집합을 의미합니다.
+
+## 특징
+
+1. 실시간 접근성(Real-Time Accessibility): 실시간 처리에 의한 응답이 가능해야 한다.
+
+2. 계속적인 변화(Continuous Evolution): 새로운 데이터의 삽입(Insert), 삭제(Delete), 갱신(Update)로 항상 최신의 데이터를 유지한다.
+
+3. 동시 공용(Concurrent Sharing): 다수의 사용자가 동시에 같은 내용의 데이터를 이용할 수 있어야 한다.
+
+4. 내용에 의한 참조(Content Reference): 데이터베이스에 있는 데이터를 참조할 때 사용자의 요구에 따른 데이터 내용으로 데이터를 찾는다.
+
+
+
+# ★ SQL 언어
+
+
+
+표준 SQL이라는 공통된 SQL을 사용하지만, 각자의 언어도 있다.
+
+
+- DDL(Data Definition Language)
+
+ 데이터베이스의 스키마를 정의하거나 변경하는 데 사용됩니다.
+
+ 주요 명령어
+
+ - CREATE(테이블 생성)
+
+ CREATE TABLE students (
+ id NUMBER,
+ name VARCHAR2(100),
+ age NUMBER,
+ PRIMARY KEY (id)
+ );
+
+ - ALTER(테이블 변경)
+
+ ALTER TABLE students ADD email VARCHAR2(100);
+
+ - DROP(테이블 삭제)
+
+ DROP TABLE students;
+
+
+- DML(Data Manipulation Language)
+
+ 데이터를 조작하는 데 사용됩니다.
+
+ 주요 명령어
+
+ - SELECT(데이터 조회)
+
+ SELECT * FROM students;
+
+ SELECT name, age FROM students WHERE age > 20;
+
+ - INSERT(데이터 삽입)
+
+ INSERT INTO students (id, name, age) VALUES (1, 'Kim', 21);
+
+ - UPDATE(데이터 수정)
+
+ UPDATE students SET age = 22 WHERE id = 1;
+
+ - DELETE(데이터 삭제)
+
+ DELETE FROM students WHERE id = 1;
+
+- DCL(Data Control Language)
+
+ 데이터베이스에 대한 접근 권한을 관리하는 데 사용됩니다.
+
+ 주요 명령어
+
+ - GRANT(권한 부여)
+
+ GRANT SELECT, INSERT ON students TO user1;
+
+ - REVOKE(권한 제거)
+
+ REVOKE INSERT ON students FROM user1;
+
+
+- TCL(Transaction Control Language)
+
+ 데이터베이스의 트랜잭션을 관리하는 데 사용됩니다.
+
+ ### ★ 트랜잭션 원자성의 중요성
+
+ - 트랜잭션의 원자성(Atomicity)은 데이터베이스 트랜잭션이 DB에 모두 반영되거나, 아니면 전혀 반영되지 않아야 함을 의미
+
+ - 예를 들어, 은행 계좌 이체할 때 A 계좌에서 돈을 출금하여, B 계좌에 입금하려는데
+ A 계좌 출금만 수행되고 B 계좌에는 입금이 수행이 안되면 문제가 생긴다. 따라서, 여러 연산을 하나로 묶어서 하나라도 실패한다면 Rollback을 해야하기 때문에 Transaction이 필요하다.
+
+ 주요 명령어
+
+ - COMMIT(트랜잭션 확정)
+
+ 현재 트랜잭션에서 수행한 모든 변경사항을 데이터베이스에 영구적으로 저장합니다.
+
+ - ROLLBACK(트랜잭션 취소)
+
+ 현재 트랜잭션에서 수행한 모든 변경사항을 취소하고, 트랜잭션을 시작하기 전 상태로 되돌립니다.
+
+ - SAVEPOINT(트랜잭션 저장점 설정)
+
+ 현재 트랜잭션 내에서 특정 지점을 표시하여, 나중에 ROLLBACK 명령어를 사용할 때 이 지점으로 되돌아갈 수 있게 합니다. SAVEPOINT 명령어를 실행한 후에 수행한 SQL 문은 ROLLBACK TO SAVEPOINT 명령어를 사용하여 취소할 수 있습니다.
+
+ SAVEPOINT savepoint_name;
+
+ ROLLBACK TO SAVEPOINT savepoint_name;
+
+## ★ Delete, Truncate(DDL), Drop 차이점
+
+
+
+
+
+||DROP|TRUNCATE|DELETE|
+|---|---|---|---|
+|COMMIT|자동|자동|수동|
+|ROLLBACK|X|X|COMMIT 이전으로|
+|STORAGE|Storage 삭제 (테이블 스키마 삭제)|최초 테이블 생성 시 할당된 Storage만 남기고 삭제 (테이블 스키마 유지)|데이터 모두 DELETE 해도 Storage 삭제X|
+|수행 시|테이블 정의 자체 삭제|테이블 생성 상태로 회귀|데이터만 삭제|
+|예제|DROP TABLE STUDENT|TRUNCATE TABLE STUDENT|DELETE FROM STUDENT|
+|로그|안남김|안남김|남김|
+|속도|빠름|빠름|느림|
+
+
+
+# DBMS란?
+
+ 데이터베이스를 관리하는 소프트웨어
+
+
+
+## DBMS 특징
+
+- 데이터 독립성
+
+ DBMS는 물리적 데이터 독립성과 논리적 데이터 독립성을 제공합니다. 이는 데이터의 물리적 저장 구조가 변경되더라도 응용 프로그램에는 영향을 주지 않으며, 반대로 응용 프로그램의 변경이 데이터베이스에 영향을 주지 않음을 보장합니다.
+
+- 데이터 무결성
+
+ DBMS는 데이터의 정확성과 일관성을 유지하기 위한 규칙을 설정하고 강제하는 무결성 규칙을 제공합니다.
+
+- 데이터 보안
+
+ DBMS는 데이터의 접근 권한을 제어하여 민감한 데이터를 보호합니다.
+
+- 데이터 백업 및 복구
+
+ DBMS는 데이터 손실을 방지하기 위해 데이터를 백업하고, 시스템 장애 후에 데이터를 복구하는 기능을 제공합니다.
+
+- 동시성 제어
+
+ DBMS는 여러 사용자가 동시에 데이터베이스에 접근할 때 발생할 수 있는 문제를 관리하고, 데이터의 일관성을 유지합니다.
+
+- 데이터 추상화
+
+ DBMS는 데이터의 물리적 저장 구조를 숨기고 사용자에게 논리적인 데이터 뷰만을 제공함으로써, 사용자가 데이터를 쉽게 이해하고 사용할 수 있게 합니다.
+
+## 테이블 용어 정리
+
+https://inpa.tistory.com/entry/DB-%F0%9F%93%9A-%ED%85%8C%EC%9D%B4%EB%B8%94-%EC%9A%A9%EC%96%B4-%F0%9F%95%B5%EF%B8%8F-%EC%A0%95%EB%A6%AC
+
+
+
+## 면접 질문
+
+Q. DELETE , TRUNCATE , DROP의 차이점에 대해 말해보아라.
+
+ DELETE는 테이블에서 특정 행을 삭제하는 명령어로 삭제하려는 행을 지정할 수 있습니다. 또한, 로그에 기록되므로 삭제 후에도 롤백이 가능하고, commit이 필요합니다.
+
+ TRUNCATE는 테이블의 모든 행을 빠르게 삭제하는 명령어로 테이블의 모든 데이터를 한 번에 삭제합니다. 그러나 테이블 자체의 구조는 그대로 유지됩니다. 또한, 로그를 남기지 않기 때문에, 한 번 수행하면 롤백이 불가능합니다. commit이 불필요합니다.
+
+ DROP은 테이블 자체를 완전히 삭제하는 명령어입니다. 테이블에 속한 모든 데이터뿐만 아니라, 구조, 인덱스, 트리거, 제약 조건 등도 모두 삭제됩니다. 또한, 로그를 남기지 않아서 롤백이 불가능합니다. commit이 불필요합니다.
\ No newline at end of file
diff --git "a/DataBase/minhyeok/\355\202\244 \354\242\205\353\245\230.md" "b/DataBase/minhyeok/\355\202\244 \354\242\205\353\245\230.md"
new file mode 100644
index 0000000..f74487e
--- /dev/null
+++ "b/DataBase/minhyeok/\355\202\244 \354\242\205\353\245\230.md"
@@ -0,0 +1,53 @@
+# 키 종류 및 예시
+
+## 기본키 (Primary Key)
+
+특징: 릴레이션에서 각 튜플을 유일하게 식별할 수 있는 속성 또는 속성의 집합입니다. 기본키는 NULL 값을 가질 수 없으며, 중복된 값을 가질 수 없습니다.
+
+예시: 학생 테이블에서 학번, 사원 테이블에서 사원번호 등
+
+- 대부분 후보키 중 좀 더 자연스러운 것을 기본키로 택함
+
+ 예를들어, 학생정보 테이블에서 학생ID 또는 사용하는 마우스 모델넘버로 튜플을 구분할 수 있다고 가정해보자. 둘 다 기본키가 될 수 있지만 학생 정보 테이블에 좀 더 자연스러운 학생 ID를 기본키로 채택한다.
+
+## 외래키 (Foreign Key)
+
+특징: 한 테이블의 필드 중 다른 테이블의 기본키를 참조하는 것을 외래키라고 합니다. 외래키를 통해 릴레이션 간의 연결성과 무결성이 유지됩니다.
+
+예시: 학생 테이블에서 학과코드(학과 테이블의 기본키를 참조)
+
+## 후보키 (Candidate Key)
+
+특징: 기본키로 선택될 수 있는 모든 키를 말합니다.
+
+예시: 학생 테이블에서 학번, 주민등록번호 등
+
+## 대체키 (Alternate Key)
+
+특징: 후보키 중에서 기본키를 제외한 나머지 키를 말합니다. 이 키들은 기본키로 선택되지 않았지만, 기본키로 사용될 수 있는 속성을 가지고 있습니다.
+
+예시: 학생 테이블에서 주민등록번호(학번이 기본키로 선택된 경우)
+
+## 슈퍼키 (Super Key)
+
+특징: 릴레이션에서 튜플을 유일하게 식별할 수 있는 속성 또는 속성의 집합입니다. 슈퍼키는 후보키를 포함하며, 기본키를 포함한 모든 속성의 집합도 슈퍼키가 될 수 있습니다.
+
+예시: 학생 테이블에서 {학번}, {학번, 이름}, {학번, 주민등록번호, 학과코드} 등 (학번이 들어간 모든 조합)
+
+
+
+
+
+- 최소성과 유일성
+
+ - 최소성
+
+ 튜플을 유일하게 식별할 수 있는 속성 집합에서 어떠한 속성도 제거할 수 없는 상태를 의미
+
+ {학번}만으로 각 튜플을 구분할 수 있으면 최소성 인정
+
+ {학번}만으로 구분할 수 없고, {학번,이름} 으로 구분해야만 한다면 {학번,이름}이 최소성 만족
+
+ - 유일성
+
+ 특정 컬럼(속성)의 값이 각 행(Row, 튜플)마다 중복되지 않고 각각 다르게 유일하게 구별되는 성질
\ No newline at end of file
diff --git a/DataBase/yerin/week1.md b/DataBase/yerin/week1.md
new file mode 100644
index 0000000..04bb9af
--- /dev/null
+++ b/DataBase/yerin/week1.md
@@ -0,0 +1,385 @@
+# DB 1주차
+https://hyper-hotel-11e.notion.site/DB-1-75604ccc24b34c899a271dedcfff8425?pvs=4
+
+# 📌데이터 베이스 기본
+
+## 🔸DB
+
+데이터의 집합
+
+## 🔸DBMS
+
+**데이터베이스를 관리하고 운영하는 소프트웨어를 DBMS(Database Management System)**라고 한다. 다양한 데이터가 저장되어 있는 데이터베이스는 여러 명의 사용자나 응용 프로그램과 공유하고 동시에 접근이 가능해야 한다.
+
+## 🔸기본 용어
+
+
+
+
+
+### 릴레이션 = 테이블 = (스키마 + 인스턴스)
+
+### 스키마
+
+- 스키마는 관계형 데이터베이스에서 기본 구조를 정의하는 것
+- 스키마는 테이블의 첫 행인 헤더를 나타내며, 속성, 자료타입 등의 정보를 담고 있다.
+
+### 인스턴스
+
+- 인스턴스는 테이블에서 실제로 저장된 데이터
+
+### Tuple(튜플) = Row(행)
+
+- 튜플은 릴레이션에서 행(가로)의 개수
+- 위 그림에서 튜플의 개수는 3입니다
+
+### Attribute(속성) = Column(열)
+
+- 속성은 릴레이션에서 열(세로)의 개수
+- 위 그림 속성의 개수는 3입니다
+
+### 도메인
+
+- 도메인은 속성이 가질 수 있는 값의 집합
+- 예를 들면 성별이라는 속성에는 male, female 2가지 도메인이 존재
+
+# 📌키
+
+### Key란?
+
+릴레이션에서는 수많은 튜플들이 있다. 릴레이션에 많은 튜플이 존재하며 각 튜플들에는 중복되는 값이 발생할 수 있다.
+
+예를 들어 이름, 나이, 사는곳 등이 중복될 수 있는데, 이때 각각의 튜플을 구분하기 위한 기준이 되는 속성이 필요하다. 이것을 "키"라고 하며 속성 또는 속성들의 집합으로 표현할 수 있다.
+
+### **최소성 & 유일성**
+
+**유일성 : 하나의 키값으로 튜플을 유일하게 식별할 수 있는 성질**
+
+여러개의 튜플이 존재할 때 각각의 튜플을 서로 구분할 수 있어야함. 한마디로 각각의 튜플은 유일해야 함. 예를 들어 (주민번호, 나이, 사는곳, 혈액형)이라는 속성이 있을 때 나이, 사는곳, 혈액형은 중복 가능한 속성임. 하지만 주민번호는 모두 다르기 때문에 절대 중복될 수 없다. 이렇게 각각의 튜플을 구분할 수 있는 성질을 유일성이라고 한다.
+
+**최소성 : 키를 구성하는 속성들 중 꼭 필요한 최소한의 속성들로만 키를 구성하는 성질**
+
+ 키를 구성하는 속성들이 진짜 각 튜플을 구분하는데 꼭 필요한 속성들로만 구성되어 있나?를 의미한다. 굳이 없어도 될 속성들을 넣지 말자. 예를 들어 다음과 같은 키(주민번호, 이름, 나이)가 있다면, 물론 현재의 키는 각 튜플을 구분할 수 있다. 하지만 이름, 나이를 빼고 주민번호만으로 각 튜플을 유일하게 식별할 수 있다. 이때 이름, 나이를 빼면 해당 키는 최소성을 만족한다.
+
+- 슈퍼 키(Super Key) : 유일성을 만족하는 키
+- 복합 키(Composite Key) : 2개 이상의 속성(attribute)를 사용한 키
+- 후보 키(Candidate key) : 유일성과 최소성을 만족하는 키. 기본키가 될 수 있는 후보이기 때문에 후보키라고 불린다.
+- 기본 키(Primary key) : 후보 키에서 선택된 키. NULL값이 들어갈 수 없으며, 기본키로 선택된 속성(Attribute)은 동일한 값이 들어갈 수가 없다.
+ 1. 널 값을 가질 수 있는 속성이 포함된 후보키는 기본키로 부적절 합니다.
+ 2. 값이 자주 변경될 수 있는 속성이 포함된 후보키는 기본키로 부적절 합니다.
+ 3. 단순한 후보키를 기본키로 선택합니다.
+- 대체 키(Surrogate key) : 후보 키 중에 기본 키로 선택되지 않은 키.
+- 외래 키(Foreign Key) : 어떤 테이블 간의 기본 키(Primary key)를 참조하는 속성이다. 테이블들 간의 관계를 나타내기 위해서 사용된다.
+
+### 데이터베이스 무결성
+
+- ***개체 무결성 Entity Integrity***
+ - 첫번째 조건 : 기본키를 구성하는 속성은 `null`값을 가질 수 없다
+ - 두번째 조건 : 기본키를 구성하는 속성은 다른 레코드와 `중복`될 수 없다.
+- ***참조 무결성 Referential Integrity***
+ - 외래키를 구성하는 속성은 참조 릴레이션(테이블)의 `기본키` 값과 동일해야한다.
+
+ ex) A릴레이션의 기본키(학번)에 3이 없는데 B릴레이션에서 A릴레이션을 참조하고자 할 때 외래키 값에 3을 입력하는 경우 참조 무결성 위반
+
+ (FK는 참조하는 릴레이션의 PK값 혹은 NULL을 가져야함)
+
+- ***도메인 무결성 Domain Integrity***
+ - 속성값은 속성이 정의된 도메인의 범위를 벗어날 수 없다.
+
+ ex) 예를 들어 <강의> 릴레이션의 '과목명' 속성에는 영어, 수학, 국어 세 가지만 입력되도록 유효값이 지정된 경우 반드시 해당 값만 입력해야 한다.
+
+
+
+# 📌ERD & 정규화
+
+## 🔸ERD
+
+ERD(Entity Relationship Diagram)는 요구 분석 사항에서 얻은 엔티티와 속성들의 관계를 그림으로 나타낸 개체-관계 모델이다
+
+테이블과의 관계를 설명하는 다이어그램이며, 이를 통해 프로젝트에서 사용하는 데이터베이스의 구조를 한눈에 파악할 수 있다
+
+### ERD 관계
+
+entity의 관계를 나타낼때 선을 이어 관계를 나타내는데,
+
+실선과 점선으로 나뉘어진다.
+
+- 실선은 식별자 관계
+
+ 부모 테이블의 기본키를 자식 테이블이 가지고 있으며 이를 기본키로 사용하는 경우
+
+- 점선은 비식별자 관계
+
+ 부모 테이블의 기본키를 자식테이블이 가지고 있지만 이를 기본키로 사용하지 않을 때 사용
+
+
+### ERD Carinality & 필수참여 조건
+
+Cardinality는 한 개체에서 발생할 수 있는 발생 횟수를 정의하며, 다른 개체에서 발생할 수 있는 발생 횟수와 연관된다
+
+- One to one → 1:1
+- One to many → 1:M
+- Many to One → M:1
+- Many to many → M:N
+
+필수참여 조건이란 엔티티와 엔티티의 관계를 나타낼 때 한 엔티티가 다른 엔티티를 필수적으로 가지고 있는지 안그래도 되는지를 나타낼 때 사용한다.
+
+- 연결선의 끝부분이 O ⇒ 선택참여로 있어도 되고 없어도 된다.
+- 연결선의 끝부분이 | ⇒필수참여로 반드시 있어야 한다.
+- 연결선의 끝부분이 세갈래 ⇒ 1개 이상을 의미한다.
+
+### 1:1
+
+
+
+한 명의 학생은 하나의 신체 정보를 갖는다.
+
+### 1:M
+
+
+
+한 명의 학생은 여러 개의 취미를 가질 수도 있다.
+
+### M:N
+
+
+
+TV는 삼성, LG 등 여러 제조업체를 가질 수 있다.
+
+한 제조업체는 TV 뿐만 아니라 세탁기, 핸드폰 등을 만들 수 있다.
+
+
+
+
+
+나누기 전 엔티티의 각 PK를 FK로 갖는다.
+
+
+
+### ERD 관계의 참여도
+
+관계선 각 측의 끝자락에 기호를 표시한다.
+
+'|' 표시가 있는 곳은 반드시 있어야 하는 개체. (필수)
+
+'O' 표시가 있다면 없어도 되는 개체. (선택)
+
+
+
+취미를 가진 학생이 있을 수도 있고, 취미가 없는 학생이 있을 수도 있다.
+
+어떤 학생이 취미를 갖는데 그 학생이 존재하지 않는 건 말이 안 된다.
+
+---
+
+## 🔸정규화
+
+정규화(Normalization)의 기본 목표는 테이블 간에 중복된 데이터를 허용하지 않는다는 것이다. 중복된 데이터를 허용하지 않음으로써 무결성(Integrity)를 유지할 수 있으며, DB의 저장 용량 역시 줄일 수 있다.
+
+
+
+### 제 1 정규형
+
+- 모든 속성은 원자 값을 가져야 함
+- 다중 값을 가질 수 있는 속성은 분리되어야 함
+
+
+
+
+
+### 제 2 정규형
+
+- 제 1 정규화를 진행한 테이블에 대해 완전 함수 종속을 만족하도록 테이블을 분해하는 것 (완전 함수 종속이라는 것은 기본키의 부분집합이 결정자가 되어선 안된다는 것을 의미한다.)
+
+
+
+기본키 : 학생번호, 강좌이름 (복합키)
+
+학생번호, 강좌이름 ⇒ 성적 결정
+
+강좌이름(기본키의 부분집합) ⇒ 강의실 결정
+
+즉, 기본키의 부분키인 강좌이름이 결정자이기 때문에 강의실을 분해하여 별도의 테이블로 관리함으로써 제2 정규형을 만족시킬 수 있다.
+
+
+
+### 제 3 정규형
+
+- 제 2 정규형을 만족하고 일반 속성들간에도 종속관계가 존재하지 않아야 함
+- 제2 정규화를 진행한 테이블에 대해 이행적 종속을 없애도록 테이블을 분해하는 것이다. (이행적 종속이라는 것은 A -> B, B -> C가 성립할 때 A -> C가 성립되는 것을 의미한다.)
+
+
+
+기존의 테이블에서 학생 번호는 강좌 이름을 결정하고 있고, 강좌 이름은 수강료를 결정하고 있다. 그렇기 때문에 이를 (학생 번호, 강좌 이름) 테이블과 (강좌 이름, 수강료) 테이블로 분해해야 한다.이행적 종속을 제거하는 이유는 비교적 간단하다. 예를 들어 501번 학생이 수강하는 강좌가 스포츠경영학으로 변경되었다고 하자. 이행적 종속이 존재한다면 501번의 학생은 스포츠경영학이라는 수업을 20000원이라는 수강료로 듣게 된다. 물론 강좌 이름에 맞게 수강료를 다시 변경할 수 있지만, 이러한 번거로움을 해결하기 위해 제3 정규화를 하는 것이다.즉, 학생 번호를 통해 강좌 이름을 참조하고, 강좌 이름으로 수강료를 참조하도록 테이블을 분해해야 하며 그 결과는 다음의 그림과 같다.
+
+
+
+### BCNF 정규화
+
+- 제 3 정규형을 좀 더 강화한 버전으로, 3 정규형을 만족하면서 모든 결정자가 후보키 집합에 속해야한다. 즉, 후보키 집합에 없는 칼럼이 결정자가 되어서는 안 된다.
+
+
+
+학생번호, 과목 → 지도교수 (O)
+
+과목 → 지도교수 (X)
+
+지도교수 → 과목 (O) ⇒ 후보키 집합이 아닌 지도교수가 결정자가 됨.
+
+
+
+보통 정규화는 BCNF 까지만 하는 경우가 많다고 한다.
+
+그 이상 정규화를 하면 정규화의 단점이 나타날 수도 있어서.
+
+# 📌JOIN
+
+## JOIN이란?
+
+PK-FK로 연관된 두 테이블을 묶어 하나의 테이블로 만드는 방법.
+
+서로 관계있는 데이터가 여러 테이블로 나뉘어 저장되므로, 각 테이블에 저장된 데이터를 효과적으로 검색이 가능하다.
+
+## JOIN 종류
+
+
+
+### inner join
+
+**두 테이블에서 ‘공통된 값’을 가지고 있는 행들만을 반환**
+
+
+
+```jsx
+SELECT *
+FROM 테이블1
+INNER JOIN 테이블2
+ON 테이블1.열 = 테이블2.열;
+```
+
+
+
+### outer join
+
+**두 테이블에서 ‘공통된 값을 가지지 않는 행들’도 반환**
+
+Left outer Join, Right outer Join, Full outer Join
+
+**Left outer Join**
+
+’왼쪽 테이블의 모든 행’과 ‘오른쪽 테이블에서 왼쪽 테이블과 공통된 값’을 가지고 있는 행들을 반환
+
+만약 오른쪽 테이블에서 공통된 값을 가지고 있는 행이 없다면 NULL 값을 반환
+
+
+
+```jsx
+SELECT *
+FROM 테이블1
+LEFT JOIN 테이블2
+ON 테이블1.열 = 테이블2.열;
+```
+
+
+
+**Right outer Join**
+
+Left Join과 반대로 ‘오른쪽 테이블의 모든 행’과 ‘왼쪽 테이블에서 오른쪽 테이블과 공통된 값’을 가지고 있는 행들을 반환한다. 만약 왼쪽 테이블에서 공통된 값을 가지고 있는 행이 없다면 NULL 값을 반환
+
+
+
+```jsx
+SELECT *
+FROM 테이블1
+RIGHT JOIN 테이블2
+ON 테이블1.열 = 테이블2.열;
+```
+
+
+
+**Full outer Join**
+
+두 테이블에서 ‘모든 값’을 반환
+
+만약 공통된 값을 가지고 있지 않는 행이 있다면 NULL 값을 반환합니다.
+
+
+
+```jsx
+SELECT *
+FROM 테이블1
+FULL OUTER JOIN 테이블2
+ON 테이블1.열 = 테이블2.열;
+```
+
+
+
+# 📌SQL Injection
+
+## SQL Injection이란?
+
+웹 사이트의 보안상 허점을 이용해 특정 SQL 쿼리 문을 전송하여 공격자가 원하는 데이터베이스의 중요한 정보를 가져오는 해킹 기법. 클라이언트가 입력한 데이터를 제대로 필터링 하지 못하는 경우 발생하며, 공격 난이도가 쉬운데 비해 피해 규모가 큼.
+
+## 공격 종류 및 방법
+
+- Error based SQL Injection
+
+ 논리적 에러를 이용 / 가장 대중적인 공격 기법
+
+ ex)
+
+ 로그인
+
+ 정상접근 -> Select * from cliend where name='anjinma' and password='12345'
+
+ SQL Injection -> Select * from client where name='anjinma' and password=' or '1'='1'
+
+ ' or '1'='1'를 넣어서 1과 1이 같아서 항상 참이므로 로그인에 성공하게 된다.
+
+- Union based SQL Injection
+
+ Union 명령어를 이용
+
+ Union Injection을 성공하기 위해서는 Union 하는 두 테이블의 컬럼 수가 같아야 하고, 데이터 형이 같아야 함.
+
+ ex)
+
+ 어떤 게시글 테이블에서 제목과 내용을 출력하는 쿼리문이 있을때 id와 password를 요청하는 쿼리를 union 키워드와 함께 넣어주고 인젝션이 성공하게 되면 사용자의 개인정보가 게시글과 함께 화면에 보이게 된다
+
+- Blind SQL Injection - Boolean based SQL Injection
+
+ 데이터베이스로부터 특정한 값이나 데이터를 전달받지 않고, 단순히 참과 거짓의 정보만 알 수 있을 때 사용. 로그인 폼에 SQL Injection이 가능하다고 가정 했을 때, 서버가 응답하는 로그인 성공과 로그인 실패 메시지를 이용하여, DB의 테이블 정보 등을 추출해 낼 수 있다.
+
+- Blind SQL Injection - Time based SQL Injection
+
+ Time Based SQL Injection 도 마찬가지로 서버로부터 특정한 응답 대신에 참 혹은 거짓의 응답을 통해서 데이터베이스의 정보를 유추하는 기법
+
+- Stored Procedure SQL Injection
+
+ 저장 프로시저는 일련의 쿼리들을 모아 하나의 함수처럼 사용하기 위한 것. 공격에 사용되는 대표적인 저장 프로시저는 윈도우 명령어를 사용할 수 있게 되어 있다. 공격난이도가 높으나 공격자가 시스템 권한을 획득해서 공격에 성공한다면, 서버에 직접적인 피해를 입힐 수 있는 공격
+
+- Mass SQL Injection
+
+ 보통 데이터베이스 값을 변조하여 데이터베이스에 악성스크립트를 삽입하고, 사용자들이 변조된 사이트에 접속 시 좀비PC로 감염되게 합니다. 이렇게 감염된 좀비 PC들은 DDoS 공격에 사용됩니다.
+
+
+## 대응방법
+
+- 웹방화벽 사용
+- 에러 메시지 노출 금지
+
+ 에러 발생 시 따로 처리를 해주지 않았다면, 에러가 발생한 쿼리문과 함께 에러에 관한 내용을 반환해주는데 여기서 테이블명 및 컬럼명 그리고 쿼리문이 노출이 될 수 있기 때문에, 데이터 베이스에 대한 오류발생 시 사용자에게 보여줄 수 있는 페이지를 제작 혹은 메시지박스를 띄우도록 해야한다.
+
+- Prepared Statement 구문사용
+
+ Prepared Statement 구문을 사용하게 되면, 사용자의 입력 값이 데이터베이스의 파라미터로 들어가기 전에DBMS가 미리 컴파일 하여 실행하지 않고 대기합니다. 그 후 사용자의 입력 값을 문자열로 인식하게 하여 공격쿼리가 들어간다고 하더라도, 사용자의 입력은 이미 의미 없는 단순 문자열 이기 때문에 전체 쿼리문도 공격자의 의도대로 작동하지 않습니다.
+
+
+ inner join과 outer join의 차이를 설명해주시고 실제 프로젝트에서 어떤 상황에서 사용을 해봤는지 경험에 빗대어 설명해주세요.
+
+inner join 은 서로 연관된 내용만 검색하는 조인 방법입니다. A와 B에 대해 수행하는 것은, A와 B의 교집합을 말합니다. 벤다이어그램으로 그렸을 때 교차되는 부분입니다. outer join 은 한 쪽에는 데이터가 있고 한 쪽에는 데이터가 없는 경우, 데이터가 있는 쪽의 내용을 전부 출력하는 방법입니다.
+
+A와 B에 대해 수행하는 것은, A와 B의 합집합을 말합니다. 벤다이어그램으로 그렸을 때 합집합 부분입니다. outer join에는 LEFT OUTER JOIN, RIGHT OUTER JOIN, FULL OUTER JOIN이 있습니다.
\ No newline at end of file
diff --git "a/Network/jecheol/\354\233\271 \355\206\265\354\213\240\354\235\204 \354\234\204\355\225\234 \353\204\244\355\212\270\354\233\214\355\201\254 \354\235\264\355\225\264\355\225\230\352\270\260 1 - OSI 7 layer.md" "b/Network/jecheol/\354\233\271 \355\206\265\354\213\240\354\235\204 \354\234\204\355\225\234 \353\204\244\355\212\270\354\233\214\355\201\254 \354\235\264\355\225\264\355\225\230\352\270\260 1 - OSI 7 layer.md"
new file mode 100644
index 0000000..75b895b
--- /dev/null
+++ "b/Network/jecheol/\354\233\271 \355\206\265\354\213\240\354\235\204 \354\234\204\355\225\234 \353\204\244\355\212\270\354\233\214\355\201\254 \354\235\264\355\225\264\355\225\230\352\270\260 1 - OSI 7 layer.md"
@@ -0,0 +1,87 @@
+## 네트워크가 뭐지요?
+
+네트워크는 유선 또는 무선으로 여러 컴퓨터들을 연결하는 것을 의미한다. 어릴적 스타크래프트를 한 사람들은 LAN이라는 용어가 익숙할 것이다. LAN은 지역 네트워크를 이용하는 것으로, 지역망을 구축하기만 하면 인터넷을 통하지 않고도 컴퓨터끼리 통신하여 게임을 즐길 수 있었다. 사실 우린 어릴적 의식하고 사용하지 않았지만, 스타크래프트는 네트워크에 대하여 노골적으로 전문적인 이해를 요구했던 것 같다.
+
+
+
+이처럼 LAN은 가정이나 회사 등 특정 영역에 존재하는 컴퓨터를 연결하는 네트워크를 의미하고, 이러한 LAN을 연결하는 걸 Wide Area Network라 하여 WAN이라고 한다. 정말 정말 대부분의 경우에는 인터넷을 이용하여 WAN을 연결한다.
+
+## 서버와 클라이언트
+
+네트워크는 한마디로 통신이기 때문에, 두 컴퓨터가 등장해야 한다. 우리는 일반적으로 통신하는 두 컴퓨터를 서버와 클라이언트라는 개념으로 표현한다. 이에 대하여 간단하게 좀 더 이해해보자.
+
+서비스를 제공하는 프로그램이 서버(server)이며 이를 수행하는 컴퓨터가 서버 컴퓨터이다. 우리가 생각하는 서버는 보통 아래 사진과 같은 공간에 잔뜩 있는 컴퓨터 자체를 의미하지만, 엄밀하게 말하면 그 컴퓨터들이 구동하는 "서비스를 제공하는 프로그램"이 서버다.
+
+
+
+그럼 클라이언트는 뭘까? 바로 우리, 즉 서비스를 받을 고객님이다. 정확히는, 서비스를 요청하는 프로그램을 클라이언트(client)라고 말한다. 일반적으로 우리는 클라이언트의 입장에서 브라우저(클라이언트 프로그램)나 카카오톡과 같은 메신저 앱(클라이언트 프로그램)을 통해 네이버, 카카오, 구글 등에 검색이나 메시지 서비스를 요청하고 제공받는 개념이라고 생각하면 된다.
+
+기본적으로 클라이언트가 특정 서비스를 요청하면 서버는 해당 요청을 처리하고 처리 결과를 응답해주는 방식으로 통신이 이루어진다.
+
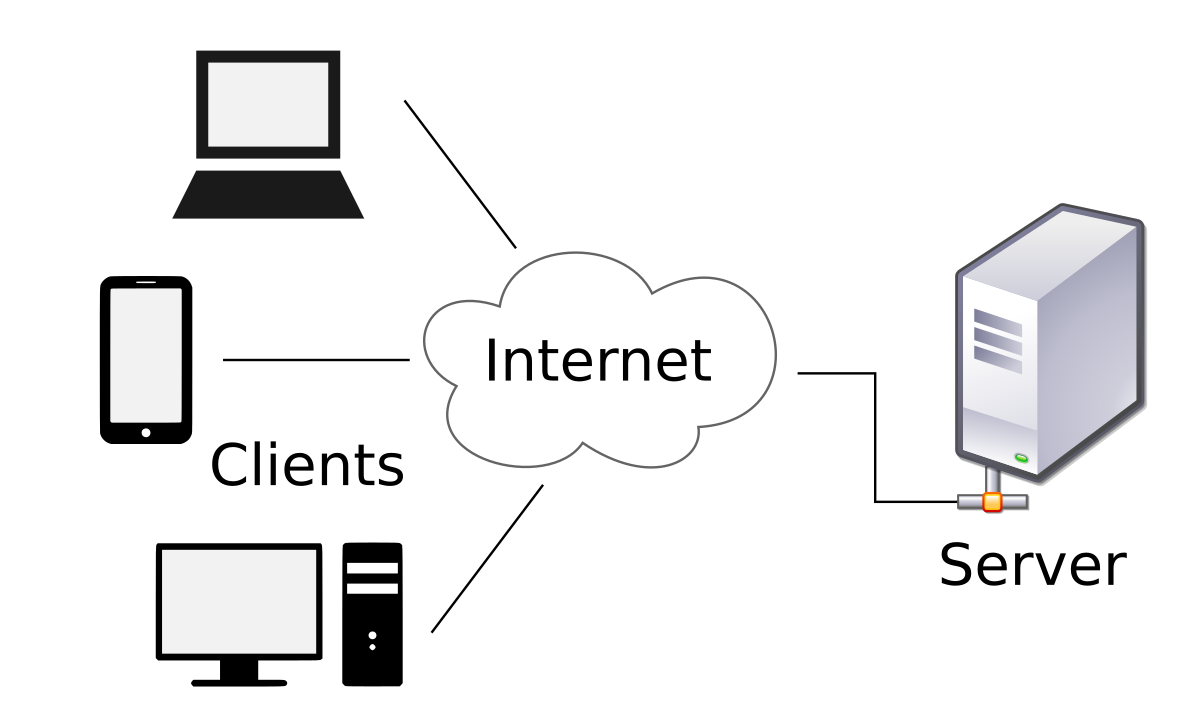
+
+
+## OSI 7 Layer를 통해 통신 과정 들여다보기
+
+자, 단순하게는 클라이언트가 서버에 요청하면, 서버가 해당 요청에 대한 응답을 준다는 것 까지는 이해했다. 그렇다면 예시 코드를 통해 도대체 어떤 일이 발생하는지 논리적인 단계별로 쪼개어 확실하게 이해해보자.
+
+구글 검색창에 "Google"이라고 검색하는 상황을 가정해보자.
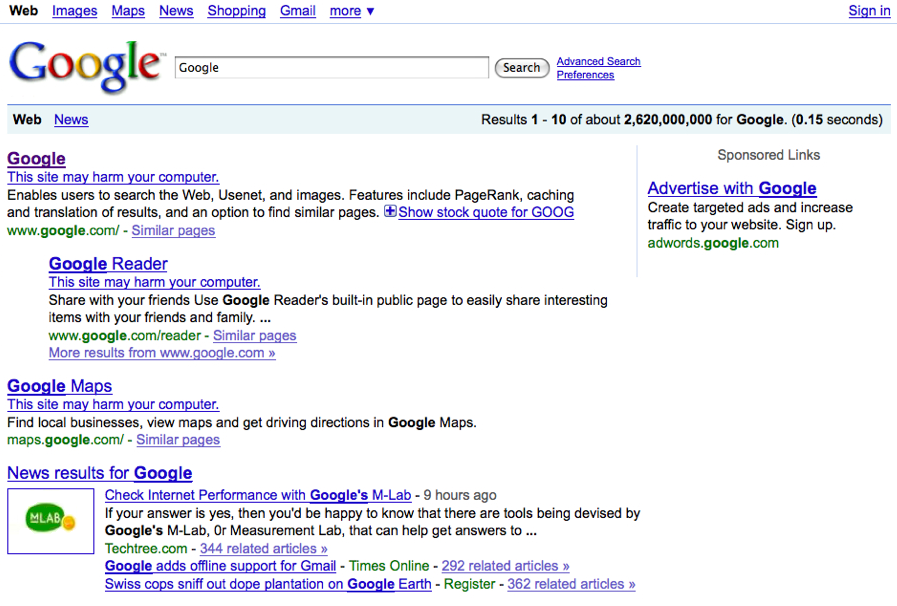
+
+
+
+우리 클라이언트는 단순하게 구글이라는 메인 페이지에서 Google이라고 문자열을 입력한 뒤, 검색 버튼을 누르기만 하면 된다. 그러면 이 요청에 대한 검색 결과를 구글에서 전달해 주는 것이다. 이 과정을 한번 분석해보자. 분석을 위해서는 OSI 7 Layer라는 것에 대하여 알아야 한다.
+
+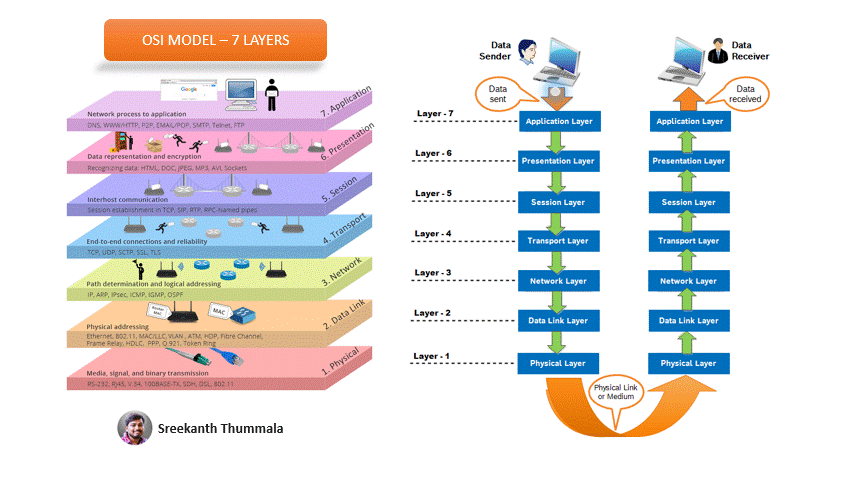
+
+위 그림은 OSI 7 Layer에 대한 간단한 내용과, 이를 바탕으로 통신 과정을 설명하고 있는 그림이다. 먼저 과정을 이해하고 각 계층이 하는 일에 대하여 알아보자.
+
+많은 분야가 그러하겠지만, 우리는 단순히 구글 검색창에 "Google"이라는 문자열을 입력하여 검색 버튼을 눌렀을 뿐이지만, 이 검색이라는 서비스 요청을 네트워크를 통해 전달하는 과정은 OSI 모델 기준으로 7단계를 거쳐 이루어진다.
+
+OSI 7 Layer를 기준으로 내 컴퓨터에서 공유기(라우터), 그리고 상대 컴퓨터(서버 컴퓨터)까지 도달하는 과정을 이해해보자. (하나하나 작성하기에는 번거로우니 GPT4에게 물어봤다. 잘 알려준 것 같다.)
+
+1. **내 컴퓨터**
+ - **응용 계층**: 브라우저에서 "Google"을 검색하려는 요청이 생성됩니다.
+ - **표현 계층**: 이 요청은 적절한 형식으로 변환(인코딩)됩니다.
+ - **세션 계층**: 이 요청을 처리하기 위한 통신 세션(TCP 세션)이 생성됩니다.
+ - **전송 계층**: 요청 정보를 세그먼트로 나누고, 이 때 TCP 헤더가 추가되며, 이 헤더에는 소스 포트와 목적지 포트 정보가 포함됩니다.
+ - **네트워크 계층**: 세그먼트를 패킷으로 변환하고, 이 때 IP 헤더가 추가되며, 이 헤더에는 소스 IP와 목적지 IP 정보가 포함됩니다.
+ - **데이터 링크 계층**: 패킷을 프레임으로 변환하고, 이 때 이더넷 헤더가 추가되며, 이 헤더에는 소스 MAC 주소와 목적지 MAC 주소(이 경우 라우터의 MAC 주소) 정보가 포함됩니다.
+ - **물리 계층**: 프레임을 전기 신호로 변환하여 네트워크 케이블을 통해 라우터로 전송합니다.
+2. **라우터**(공유기)
+ - **물리 계층**: 라우터는 네트워크 케이블을 통해 전기 신호로 받은 데이터를 디지털 신호로 변환합니다.
+ - **데이터 링크 계층**: 디지털 신호를 프레임으로 변환하고 MAC 주소를 확인합니다.
+ - **네트워크 계층**: 프레임을 패킷으로 변환하고, IP 주소를 확인한 후 라우팅 테이블에 따라 패킷을 다음 목적지(구글 서버)로 전송합니다.
+3. **구글 서버 컴퓨터**
+ - **물리 계층 ~ 네트워크 계층**: 이 과정은 라우터에서의 수신 과정과 동일합니다.
+ - **전송 계층**: 패킷을 세그먼트로 변환하고, 포트 번호를 확인하여 해당 서비스(웹 서버)로 전달합니다.
+ - **세션 계층 ~ 응용 계층**: 세그먼트를 데이터로 변환하고, 웹 서버가 이를 처리하여 "Google" 검색 결과를 생성합니다.
+4. **구글 서버 라우터**: 이 과정은 "내 컴퓨터"에서의 송신 과정과 동일하나, 이번에는 검색 결과를 포함하는 HTTP 응답이 전송됩니다.
+
+5. **내 컴퓨터의 라우터**: 이 과정은 "라우터"에서의 수신 과정과 동일하며, 패킷이 내 컴퓨터로 전송됩니다.
+
+6. **내 컴퓨터**: 이 과정은 "구글 서버 컴퓨터"에서의 수신 과정과 동일하나, 이번에는 HTTP 응답을 받아 웹 브라우저가 이를 처리하여 사용자에게 "Google" 검색 결과를 보여줍니다.
+
+
+
+즉, 송신 과정에서는 위 사진의 application layer에서 physical layer로 내려갔다가 라우터로 보내고, 라우터는 보통 network layer, data link layer, physical layer로 구성되어 IP 주소를 바탕으로 다음 스위치나 라우터 MAC 주소를 갖고 길을 찾아갈 수 있게 해주며, 이런 과정을 여러번 거쳐 목적지 서버 프로그램까지 도착하게 되는게 데이터 전송 과정이다. 응답은 역순으로 보면 된다. 물론 한번 통신을 수립한 길은 해당 길 정보를 각 라우터가 기억하여, 나중에는 더욱 빠르게 통신이 이루어진다. 우리가 한번 가본 길은 익숙하게 가는 거랑 똑같다.
+
+추가로, 각 레이어는 대표하는 프로토콜(Protocol)들이 있다. 여기서 프로토콜이란 통신 문법이라고 이해하면 된다. 우리가 한국어를 사용하여 대화를 할 때, 정해진 어순이 있듯이, 컴퓨터끼리도 전기 신호를 데이터화하여 통신하기 위해서는 일정한 규약을 바탕으로 통신을 하게 된다. 프로토콜에는 Application layer의 HTTP, Transport Layer의 TCP, Network Layer의 IP 프로토콜 등이 있다. 각 프로토콜은 독립적으로 골라먹는게 아니라, 유기적으로 연결되어 있다. 보통 TCP/IP는 묶어서 말하고, HTTP도 HTTP/1.1, HTTP/2 버전은 TCP기반으로 통신을 한다. 근데 [HTTP/3는 UDP 기반으로 통신을 한다](https://easy-code-yo.tistory.com/80)고 하니 이것도 알아두자.
+
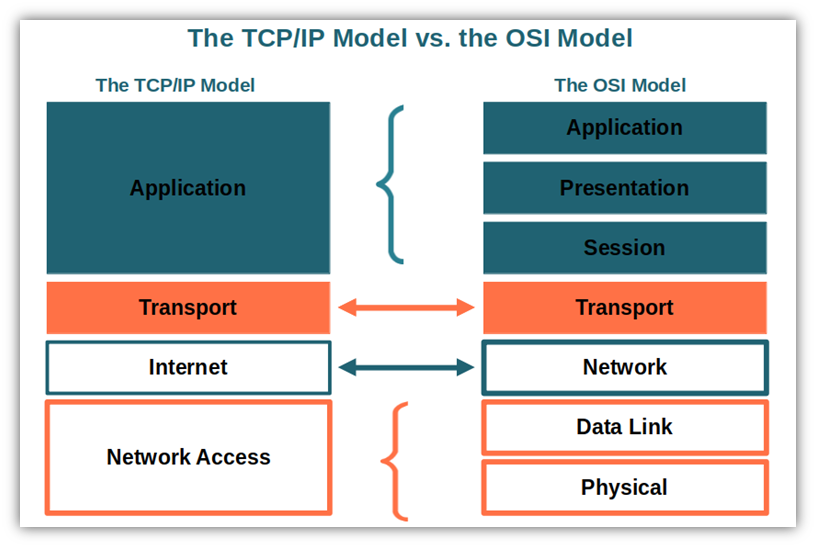
+## TCP/IP Stack
+
+사실 근데, 위 OSI 7 Layer보다는 실제로는 TCP/IP Stack이라고 부르는 통신 모델이 더 실질적으로 잘 와닿는 개념이라고 한다. 나 또한 이 의견에 동의한다. 레이어가 조금 더 뭉툭하게(?) 구분되어있긴 한데, 그렇기 때문에 좀 더 이해하기에 편안하고 통신을 이해하는 것에도 더 무난하게 느껴진다.
+
+TCP/IP stack은 Application Layer, Transport Layer, Internet Layer, Link Layer 4가지로 분류한다.
+
+
+
+OSI 모델을 이해했으니 이를 기준으로 이해하자면, 위와 같이 매핑된다. 각 역할은 매핑되는 개념으로 갈무리 할 수 있을 것 같고, 추가로 알아야 하는 건 여기서 TCP/IP stack의 application layer 부분이 유저모드 환경에서 수행되며, transport layer와 internet layer는 OS의 커널 모드에서 수행되는 레이어라는 것이다. 우리는 application 레벨에서 코드를 통해 통신을 수립할 수 있게 잘 설정해두면 해당 코드를 수행하면서 커널 영역에서 위 작업들을 수행하는 것이라 이해할 수 있다. (커널이 뭔지 잘 모르는 분들에게 소소한 안내를 하자면, 커널은 개발자가 컨트롤할 수 없는 운영체제의 소스코드 중 일부로, 하드웨어를 제어하는 데에 사용되는 코드들이 주를 이루고 있는 영역이다. 운영체제의 커널 코드에 Transport layer와 Internet Layer의 작업을 수행하는 코드가 적혀있다고 이해하면 충분하다.) [참고](https://brewagebear.github.io/linux-kernel-internal-3/)
+
+## 마무리
+
+
+
+처음에 단계별로 이해하기엔 OSI 7 Layer가 더 적절할 것 같아서 이를 기준으로 위에서 설명했지만, 앞으로는 TCP/IP 스택을 기준으로 설명할 것 같다. 따라서 이를 기준으로 대략 마무리를 해보자면,
+
+- 통신 과정에서 송수신하는 데이터는 layer들을 거치며 당장 목적지로 가기 위한 정보를 header에 담아 포장되면서(?) 데이터를 보낸다.
+- 각 레이어는 각각의 논리적 통신 과정에 따라 프로세스 간 통신인 HTTP, 노드 간 통신인 TCP/UDP 와 같은 통신 방식(프로토콜)들을 가지고 있다.
+- Application layer 작업은 OS의 유저 모드, Transport layer와 Internet Layer는 Kernel 모드에서 이루어진다.
\ No newline at end of file
diff --git "a/Network/jecheol/\354\233\271 \355\206\265\354\213\240\354\235\204 \354\234\204\355\225\234 \353\204\244\355\212\270\354\233\214\355\201\254 \354\235\264\355\225\264\355\225\230\352\270\260 2 - TCP.md" "b/Network/jecheol/\354\233\271 \355\206\265\354\213\240\354\235\204 \354\234\204\355\225\234 \353\204\244\355\212\270\354\233\214\355\201\254 \354\235\264\355\225\264\355\225\230\352\270\260 2 - TCP.md"
new file mode 100644
index 0000000..b6da905
--- /dev/null
+++ "b/Network/jecheol/\354\233\271 \355\206\265\354\213\240\354\235\204 \354\234\204\355\225\234 \353\204\244\355\212\270\354\233\214\355\201\254 \354\235\264\355\225\264\355\225\230\352\270\260 2 - TCP.md"
@@ -0,0 +1,252 @@
+
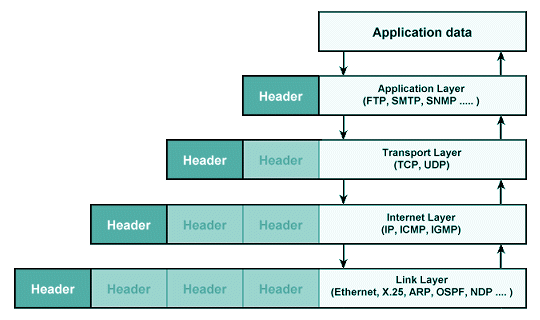
+지난 시간에 OSI 7 Layer나 TCP/IP Stack에 대하여 다뤘다. 여러 레이어를 거치며 통신이 이루어진다고만 이해해도 일단은 괜찮다 더 중요한 건, 통신의 목적이 되는 "중요 데이터"를 어떻게 주고받는가 이다. 이렇게 통신의 목적이 되는 중요 데이터를 어떤 규약으로 통신하는가를 담당하는 레이어는 Transport Layer이다. 전송 레이어라고도 하며, 여기에는 `TCP`와 `UDP`라는 두 개의 프로토콜이 메인을 이루고 있다. 이에 대하여 잘 이해하면, 네트워크에서 가장 중요한 것 중 하나를 이해했다고 해도 과언이 아니다. 따라서 차근차근 transport 레이어의 전송 프로토콜인 TCP, UDP에 대하여 자바 코드로 이해해볼 예정이다. 이번 시간에는 TCP 위주로 확인해보자.
+
+## TCP
+
+TCP는 전송 계층 프로토콜의 가장 중요한 데이터 통신 프로토콜이다. 이는 연결형 프로토콜로, 상대 프로세스와 연결을 수립한 뒤 데이터를 주고받는 방식으로 이루어진다. 통신을 하기 전에 연결 요청과 연결 수락 과정을 거치면 통신 회선이 고정되어 데이터가 전달된다. 이를 통해 전달되는 데이터는 순서대로 전달되며 손실이 발생하지 않도록 컨트롤된다.
+
+- 연결형 프로토콜
+- 연결 수립 후 통신 회선이 고정되어 데이터 전달
+- 데이터 순서를 보장, 패킷 손실 방지 컨트롤 O
+
+간단하게 연결 수립과 끝맺음에 대하여 사진으로 갈무리하고 넘어가려고 한다. TCP는 3-way handshake라는 과정으로 연결을 수립하고 4-way handshake라는 과정으로 연결을 끝낸다. handshake란 악수라는 의미로, 서로 합의 하에 연결 관계를 수립하고 일련의 데이터를 보낸 뒤 연결을 끝냄으로써 통신을 마치는 과정을 악수로 시작해서 악수로 끝나는 사람간의 대화처럼 표현한 거라고 이해할 수 있다.
+
+
+
+연결을 수립하는 3-way handshake는 이처럼 편도 3번의 `SYN`, `ACK` 패킷을 주고받음으로써 수행된다. `SYN`이란 synchronize를 떠올리며 의미를 이해할 수 있는데, 의역하자면 "데이터 보낼건데, 나랑 연결할래?"와 같은 의미로 이해하면 된다. `ACK`은 acknowledge로 이해하면 되고, 알겠다/패킷 잘 받았다는 응답의 의미를 담는 패킷이다. 그리고 서버 입장에서도 `SYN`을 보냄으로써 "데이터 받을 수 있는데, 연결할래?"와 같이 회신을 보내준다. 그러면 client에서 최종 `SYN`에 대한 `ACK`을 보냄으로써 두 노드 간 TCP 연결이 수립된다.
+
+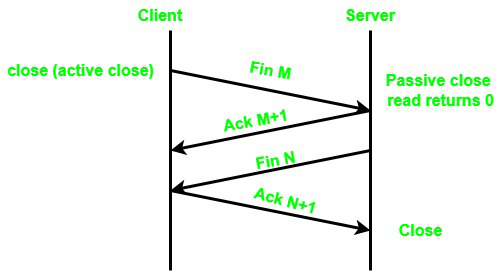
+
+TCP 통신을 끝내는 건 4번의 `SYN`, `ACK` 패킷을 통신해줘야 해서 4-way handshake라고 부른다. 그 이유는, 한참 데이터가 통신되고 있는 과정에서 client는 자기가 보낼 건 다 보냈다는 의미에서 통신 종료를 의미하는 `Fin` 패킷을 보내는 것인데, 데이터를 받고 있던 입장에서는 아직 모든 패킷이 수신되지 않은 상태일 수 있기 때문이다. 따라서 최초 `FIN`에 대한 `ACK`을 일단 보냄으로써 `FIN` 패킷이 잘 수신되었음을 나타낸 뒤, 나중에 모든 패킷이 정상적으로 수신되었음이 확인된 뒤, 서버에서 `FIN` 패킷을 클라이언트에 보내어 진짜 종료를 나타내고, 이에 client가 `ACK`을 보냄으로써 통신이 종료하게 된다.
+
+TCP는 대표적으로 웹 통신에 지배적으로 사용되는 통신 프로토콜인 HTTP/1.1과 HTTP/2 에 사용된다.(이 사실 만으로 TCP가 웹 통신에서 중요한 이유는 충분히 설명되었다 생각한다.) HTTP를 잘 모른다면, 웹 브라우저가 웹 서버와 통신할 때 보통 TCP를 사용한다고 이해하면 된다. 그 외에도 이메일 전송(SMTP), 파일 전송(FTP)에도 TCP가 사용된다. 이와 유사한 개념으로, 흔히들 우리는 TCP와 함께 네트워크 레이어의 IP 프로토콜을 같이 묶어서 TCP/IP라고 하는데, 이는 두 프로토콜이 항상 세트로 사용되기 때문이다. 각 레이어는 유기적으로 연결되어 하나의 통신 과정일 뿐이므로 공부할때에는 논리적으로 구분하더라도, 모두 분리된 개념이 아니라 하나로 통하는 것임을 명심해야 한다.
+
+### 자바에서는 이를 어떻게 코드로 구현하나요?
+
+자바에서는 TCP 통신을 수립하기 위해 `java.net` 패키지의 `ServerSocket`과 `Socket`클래스를 제공한다. 말 그대로, `ServerSocket` 클래스가 TCP 연결을 수락하는 서버 쪽 클래스고, `Socket`은 클라이언트 쪽에서 TCP 통신 연결을 요청하기 위해서도 쓰이고, 서버와 클라이언트 둘 다 데이터를 주고 받을 때 사용하는 클래스이다.
+
+```java
+// 방법 1
+ServerSocket serverSocket = new ServerSocket(15000); // port 번호 : 15000
+
+// 방법 2
+ServerSocket serverSocket = new ServerSocket();
+serverSocket.bind(new InetSocketAddress(15000));
+```
+
+기본적으로 자바 코드로 TCP 서버를 구축하기 위해서는 `ServerSocket` 객체를 생성해야 연결 요청을 수락할 수 있다. 이 객체를 사용하기 위해서는 프로세스 port 번호를 바인딩해줘야 하는데, 편한 방법은 객체를 생성할 때 해당 데이터를 통신할 서버 프로세스 port 번호를 생성자 argument로 지정해주는 것이다. 이렇게 서버 프로세스와 `ServerSocket` 객체가 바인딩 되었으며, client의 TCP 연결 요청 수락을 위한 준비가 끝난 것이다. (만약 서버 컴퓨터에 IP가 여러개로 할당되어 있다면, `InetSocketAddress`의 parameter에 특정 IP 주소를 지정해주면 된다.)
+
+```java
+// server
+Socket server = serverSocket.accept(); // 클라이언트의 연결 요청을 기다림
+
+// client
+Socket client = new Socket("localhost", 15000); // 해당 IP 주소와 port로 TCP 연결
+```
+
+`.accept()` 메서드를 수행하면 client의 연결 요청이 들어올 때 까지 프로세스가 블락되며, 요청이 들어오면 해당 요청을 받으며 Socket 객체를 반환한다. 이 과정에서 두 노드 간 TCP 연결이 수립된 것이며, Socket 객체는 상대 프로세스의 Port 번호는 물론, 상대 호스트의 IP 주소까지 갖고 있다. 이는 다음과 같이 확인이 가능하다.
+
+```java
+InetSocketAddress isa = (InetSocketAddress) socket.getRemoteSocketAddress();
+String clientIp = isa.getHostName(); // 클라이언트 IP 주소
+int clientPort = isa.getPort(); // 클라이언트 Port 번호
+```
+
+위 로직 중 `socket.getRemoteSocketAddress();`를 통해 `RemoteSocketAddress`라는 추상 클래스로 형변환된 변수를 반환받을 수 있는데, 이를 상속하여 구현한 클래스가 `InetSocketAddress`이다. 따라서 구현체 타입으로 다운캐스팅을 통해 해당 구현 클래스가 갖는 메서드를 사용할 수 있도록 한 코드이다.
+
+```java
+serverSocket.close(); // 서버 소켓 종료
+```
+
+`serverSocket` 객체의 `close()` 메서드를 통해 TCP 서버를 종료할 수 있으며, 이를 통해 socket에 바인딩 해 뒀던 port 번호를 언바인딩할 수 있다. 이렇게 한 이후에야 다른 프로그램에서 다시 해당 Port 번호를 사용할 수 있게 된다. (그 전에는 바인딩되어있는 프로세스가 있는 거라서 불가능)
+
+### TCP 통신으로 Echo 구현하기
+
+네트워크를 배우는 과정에서 한번쯤은 해보는, TCP 기반으로 echo를 제공하는 서버와 클라이언트 코드를 작성해 보자.
+
+아래 코드는 로컬호스트의 15000번 포트를 이용하여 TCP 통신으로 echo 서비스를 제공하는 서버와 이를 이용하는 클라이언트를 구현한 내용이다.
+
+**TCP 기반 Socket Server**
+
+TCP 방식은 당연히 서버가 먼저 실행되어 기다리고 있는 상황에서 client가 실행되어 데이터를 전송하고 이를 echo로 받는 시나리오에서만 가능하다. 따라서 SocketServer를 기준으로 먼저 서술하겠다.
+
+```java
+public class TCPServer {
+ private static ServerSocket serverSocket = null;
+
+ public static void main(String[] args) throws IOException {
+ // tcp socker server start
+ startServer();
+
+ // set quit condition
+ System.out.println("서버를 종료하려면 q를 입력하시오.");
+ BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
+ while (true) {
+ String input = br.readLine();
+ if (input.equals("q")) {
+ break;
+ }
+ }
+ br.close();
+
+ // terminate socket server
+ stopServer();
+ }
+
+ public static void startServer() {
+ // define worker thread
+ Thread thread = new Thread(() -> {
+ try {
+ // serverSocket generated & port bound
+ System.out.println("server : start");
+ serverSocket = new ServerSocket(15000);
+ System.out.println("server : bind port");
+
+ while (true) {
+ System.out.println("================================");
+ System.out.println("server : wait for client request");
+
+ // wait for establishing connection
+ Socket socket = serverSocket.accept();
+
+ // get informations of tcp connection host
+ InetSocketAddress isa = (InetSocketAddress) socket.getRemoteSocketAddress();
+ String clientIp = isa.getHostName();
+ System.out.println("server : clientIP " + clientIp + " connected");
+ // get data from client
+ byte[] buffer = new byte[1024];
+ InputStream inputStream = socket.getInputStream();
+ int input = inputStream.read(buffer);
+ String data = new String(buffer, 0, input, "UTF-8");
+ System.out.println("server : read data -> " + data);
+
+ // send echo data to client
+ DataOutputStream dataOutputStream = new DataOutputStream(socket.getOutputStream());
+ dataOutputStream.writeUTF(data);
+ dataOutputStream.flush();
+ System.out.println("server : send echo -> " + data);
+
+ // data transfer using tcp ended
+ socket.close();
+ System.out.println("server : clientIP " + clientIp + " connetion closed");
+ }
+
+ } catch (IOException e) {
+ throw new RuntimeException(e);
+ }
+ });
+ // worker thread start
+ thread.start();
+ }
+
+ public static void stopServer() {
+ try {
+ serverSocket.close();
+ System.out.printf("server : close");
+ } catch (IOException e) {
+ throw new RuntimeException(e);
+ }
+ }
+}
+```
+
+코드가 어렵진 않으니 간단하게만 설명하겠다. 기본적으로 클라이언트에서 데이터를 보내면 바이트 단위로 전달되는 해당 데이터를 버퍼를 이용하여 받아두도록 작성되어 있다. (만약 버퍼를 사용하지 않으면 바이트 하나하나 받아야 하므로 성능이 매우 느리다. 하지만 이 데이터를 메모리에 잠시 쌓아두면서 덩어리로 한번에 많은 양씩을 처리하게 되면 훨씬 성능이 빨라지게 된다. 즉, 버퍼는 CPU의 처리량을 끌어올리기 위해 고안된 아이디어로, 바이트 하나하나 디스크에 저장하거나 입출력하는 방식은 CPU 연산 성능을 최적으로 사용할 수 없어 메모리에 잠시 데이터를 보관하여 한번에 여러 데이터를 처리할 수 있도록 하는 방법을 의미한다.) 이렇게 받은 데이터를 매개값으로 하여 OutputStream의 `write()`메서드를 호출하면 echo 서비스를 구현할 수 있다. 위 코드에서는 설명과 조금 달리, 인코딩 과정을 좀 더 간편하게 처리하기 위해 `new DataInputStream()`을 이용하고 있다.
+
+
+**TCP 기반 클라이언트**
+
+```java
+public class TCPClient {
+ public static void main(String[] args) {
+ try {
+ Socket socket = new Socket("localhost", 15000);
+
+ System.out.println("client : server connected!");
+
+ // send data
+ String data = "자바로 네트워크 이해하기!!!";
+ byte[] bytes = data.getBytes("UTF-8");
+ OutputStream outputStream = socket.getOutputStream();
+ outputStream.write(bytes);
+ outputStream.flush();
+ System.out.println("client : send data -> " + bytes);
+
+ // receive echo
+ DataInputStream dataInputStream = new DataInputStream(socket.getInputStream());
+ String echo = dataInputStream.readUTF();
+ System.out.println("client : receive echo -> " + echo);
+
+ socket.close();
+ System.out.println("client : close");
+
+ } catch (UnknownHostException e) {
+ // IP 주소 잘못된 경우
+ throw new RuntimeException(e);
+ } catch (IOException e) {
+ // 해당 포트에 연결이 어려운 경우
+ throw new RuntimeException(e);
+ }
+ }
+}
+```
+
+클라이언트도 서버와 유사하게 구성하고 있으므로, 자세한 설명은 생략한다.
+
+위 코드를 통해 알 수 있는 건 다음과 같다.
+- TCP는 연결을 수립한 뒤 데이터를 통신하는 프로토콜
+- IP 주소와 포트 정보를 갖는 소켓을 이용하여 입출력을 통해 (논리적) 통신을 수행
+- 통신은 바이트 단위로 이루어지는 것이 기본이며, 이러한 통신의 성능 향상을 위해 수신 측에서는 버퍼를 사용
+
+## TCP의 흐름 제어, 혼잡 제어
+
+TCP는 연결을 수립한 신뢰성 있는 통신 방식을 위해 만들어졌다. 데이터의 손실이나 순서의 보장을 위해 상대방과 연결을 수립하고, 통신 패킷들에 대한 상대 노드의 응답을 활용하여 전송 흐름 제어와 혼잡 제어를 수행한다.
+
+### 흐름 제어
+
+수신측의 데이터 처리 속도에 비해 송신측의 전송 속도가 빠르다면 문제가 발생한다. 수신 측에서 제한한 저장 용량을 초과한 이후에 데이터가 수신되면 손실이 발생할 수 있고, 이는 재요청을 해야 하므로 통신 오버헤드가 발생한다. 따라서 통신 흐름을 적절하게 가져가야 한다.
+
+1. stop and wait : 패킷 하나하나 `ACK`(응답)을 받아야만 다음 패킷을 보내주는 방식. 이를 통해 수신 노드가 준비된 경우에만 데이터를 보내줄 수 있게 된다.
+ 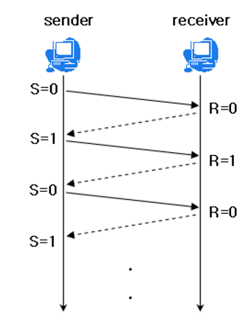
+2. sliding window : 수신 측에서 설정한 버퍼(윈도우)의 크기만큼 송신 측에서 `ACK`을 기다리지 않고 여러 세그먼트를 전송하는 pipelined protocols 방식이다.(버퍼 사이즈는 3-way handshake과정에서 수신 호스트의 receive window size에 송신 호스트가 window size를 맞추게 됨) `ACK`데이터를 카운트하여 window를 늘려가며 전송을 하게 된다. 즉, 일정 크기만큼은 응답을 기다리지 않고 계속 전송을 하며, 윈도우는 설정된 버퍼 사이즈보다 항상 작거나 같은 크기로 유지되면서 응답을 받는 개수만큼 윈도우를 늘려가며 데이터를 전송하는 방식으로 이어진다.
+
+ 
+
+ sliding windoe는 flow control을 수행할 때 다음 두 가지 방식으로 처리할 수 있다.
+
+ - Go Back N : 기본적으로 수신 호스트는 cumulative ack만을(=최종으로 받은 패킷이 뭐다.라는 말 만을 할 수 있다.) 보낼 수 있다. 따라서 sender는 timer를 가지고 ack 수신 timeout이 발생하는 패킷부터 다시 "전부" 패킷을 전송하는 방식을 의미한다. 따라서 n개만큼 다시 돌아가서 보낸다는 의미로 go back n 이라고 칭한다.
+
+ - Selective Repeat : 수신 호스트에서 각 수신 패킷에 대하여 individual ack을 보낼 수 있는 상황에서, sender host에서 timout이 발생한 패킷에 대하여만 패킷을 재전송해주는 방식을 말한다. 이는 두 호스트가 SACK(selective acknowledgement)을 지원해야 하며, TCP 헤더의 옵션 필드를 활용하여 SACK을 사용한다는 정보(option kind = 5)를 지정해야 하고, 손실된 패킷의 left edge, right edge 정보를 담아 보내어 이를 sender가 체크하여 재전송할 수 있게 한다.
+
+### 혼잡 제어
+
+세상에 호스트 단 두대만 통신을 하는 게 아니라 정말 수없이 많은 호스트가 거의 동시에 정말 많은 데이터를 통신하고 있는 상황에서, 만약 너무 빈번하게 패킷 재전송이 일어나는 경우가 발생하면 특정 라우터에 데이터는 계속 몰리게 될 거고, 이는 더 많은 재전송을 유발하는 등 극심한 통신 오버헤드를 유발할 수 있다. 이는 결국 오버플로우, 데이터 손실을 유발하므로, 상대방 호스트의 사정만을 고려하여 통신을 진행할 수 없다. 따라서 네트워크 혼잡을 고려하여 데이터 패킷 송신 속도를 제어해야 하며, 이를 혼잡 제어(Congestion control)라고 한다.
+
+혼잡 제어를 구성하는 방식은 초기의 극단적인 방식인 Tahoe와 그를 개선한 Reno, 그리고 그 이후의 VEGAS, CUBIC, Hybla등 오늘날의 네트워크 환경에 맞게 더욱 개선된 여러 알고리즘이 존재한다. 이 글에서의 설명은 이 중에서 오늘날 congestion control의 가장 기본적인 형태인 Reno를 기준으로 설명한다.
+
+혼잡 제어는 다음 3단계가 있다.
+- Slow start
+- Congestion Avoidance
+- Fast Retransmit
+- Fast Recovery
+
+
+
+- slow start
+통신을 시작하는 과정에서 패킷을 하나씩 보내면서, 패킷이 문제없이 도착하면 각각의 ACK 패킷마다 window size(MSS)를 2배씩 늘려준다. 이렇게 전송 속도를 지수 함수 꼴로 증가시켜서 빠르게(exponentially fast) window size를 확보한다.
+
+- Congestion Avoidance
+윈도우 사이즈가 일정 크기가 되면(ssthresh ; slow start threshold) 혼잡 회피 단계로 지정하여, 윈도우 크기를 선형으로 증가시킨다. 가장 초기의 ssthresh는 slow start 단계를 충분히 확보하기 위해 큰 값으로 지정되며, 이후 congestion이 발생할 때마다 window size를 절반으로 줄이면서 ssthresh를 동적으로 조절하며 통신이 수행된다.
+
+- fast recovery
+만약 송수신 과정에서 `ACK` 패킷 수신이 정상적으로 이루어진다는 시간을 초과하여 timeout이 발생하거나, 송신 과정에서 패킷이 유실되어 수신 측에서 특정 패킷이 아직 수신되지 않았다는 의미의 duplicate ack이 3번 연속으로 발생하는 경우를 네트워크 상태가 congestion에 있다고 판단한다. 이런 이벤트가 발생했을 때 송신 window size를 절반으로 줄이고 congestion avoidance로 다시 돌아가서 다시 window size를 선형으로 증가시키며 congestion을 감지하는 과정을 반복하는데, 이를 fast recovery라고 한다.
+
+- fast retransmit
+데이터를 송수신하는 과정에서 패킷 손실이 발생한 것에 대하여, 손실 패킷만을 재전송하는 것을 의미한다. 이는 flow control과 마찬가지로 초창기에는 go back n을 사용하였지만, selective repeat을 지원하는 호스트가 많아짐에 따라 오늘날에는 이를 주로 이용한다.
+
+### 참고 : AIMD란?
+
+위에서 설명한 Tahoe, 그리고 Reno는 AIMD라는 네트워크 혼잡 제어 방법의 기본 원칙을 의미합니다. 여기서 AIMD는 Additive Increase와 Multiplicative Decrease를 의미합니다.
+- Additive Increase : 혼잡이 발생하지 않는다면 데이터의 전송 속도를 선형적으로 증가시킨다. (= 윈도우 사이즈를 선형적으로 증가시킨다.)
+- Multiplicative Decrease : 패킷 손실을 감지하면 congestion이 있다고 판단하고, 윈도우 사이즈를 감축시켜서 전송 속도를 줄이는 기법을 의미합니다.
+
+이는 Tahoe와 Reno라는 방식을 고안하는 데 기본이 된 원칙이며, 참고만 하면 될 듯 합니다.
\ No newline at end of file
diff --git "a/Network/jecheol/\354\233\271 \355\206\265\354\213\240\354\235\204 \354\234\204\355\225\234 \353\204\244\355\212\270\354\233\214\355\201\254 \354\235\264\355\225\264\355\225\230\352\270\260 3 - QUIC (UDP).md" "b/Network/jecheol/\354\233\271 \355\206\265\354\213\240\354\235\204 \354\234\204\355\225\234 \353\204\244\355\212\270\354\233\214\355\201\254 \354\235\264\355\225\264\355\225\230\352\270\260 3 - QUIC (UDP).md"
new file mode 100644
index 0000000..ff9f7dd
--- /dev/null
+++ "b/Network/jecheol/\354\233\271 \355\206\265\354\213\240\354\235\204 \354\234\204\355\225\234 \353\204\244\355\212\270\354\233\214\355\201\254 \354\235\264\355\225\264\355\225\230\352\270\260 3 - QUIC (UDP).md"
@@ -0,0 +1,90 @@
+우리는 보통 TCP와 견주어 UDP를 많이 학습합니다. **UDP의 대표적 특징**으로는 아래 항목들이 있습니다.
+
+- 비연결형 프로토콜이다.
+- TCP와 달리 handshake를 하지 않아 속도'는' 빠르다.
+- 하지만 패킷의 유실 관리나 순서 보장을 하지 않아 **신뢰성 있는 통신이 불가능**하다.
+- 주로 **DNS**에 IP 주소 요청할 때, **DHCP**에 사용된다.
+
+개인적으로는 오늘날에는 인터넷 속도도 빠르다보니 신뢰성 있는 통신의 가치가 더 높다고 생각하여 현대 사회에서 대부분의 통신은 TCP 기반으로 이루어질 것이라 생각하였습니다. 실제로 웹 통신에서는 HTTP 통신이 가장 많이 쓰이는데 이게 기본적으로 TCP 기반으로 알려져 있죠. 근데 다시 네트워크를 공부하다가 신기한 사실을 알아냈습니다.
+
+#### **충격적이게도 모든 HTTP가 TCP로 이뤄지진 않는다는 것입니다!**
+
+
+
+엥? HTTP/1.1과 HTTP/2까지는 분명 TCP로 이뤄진다고 알고 있었습니다. [참고](https://en.wikipedia.org/wiki/HTTP/2#Differences_from_HTTP/1.1)
+
+근데... **HTTP/3부터는 QUIC 기반으로 통신**을 한다고 하는 걸 알게 되었고, 이 **QUIC가 UDP 기반**이라고 합니다. 이는 이미 우리도 모르는 사이에 많이 쓰이고 있는 것 같더라고요! (사실 엄밀히 말하면 QUIC가 등장하고, 이를 사용하는 HTTP를 HTTP/3로 칭하기로 했다고 합니다.)
+
+
+
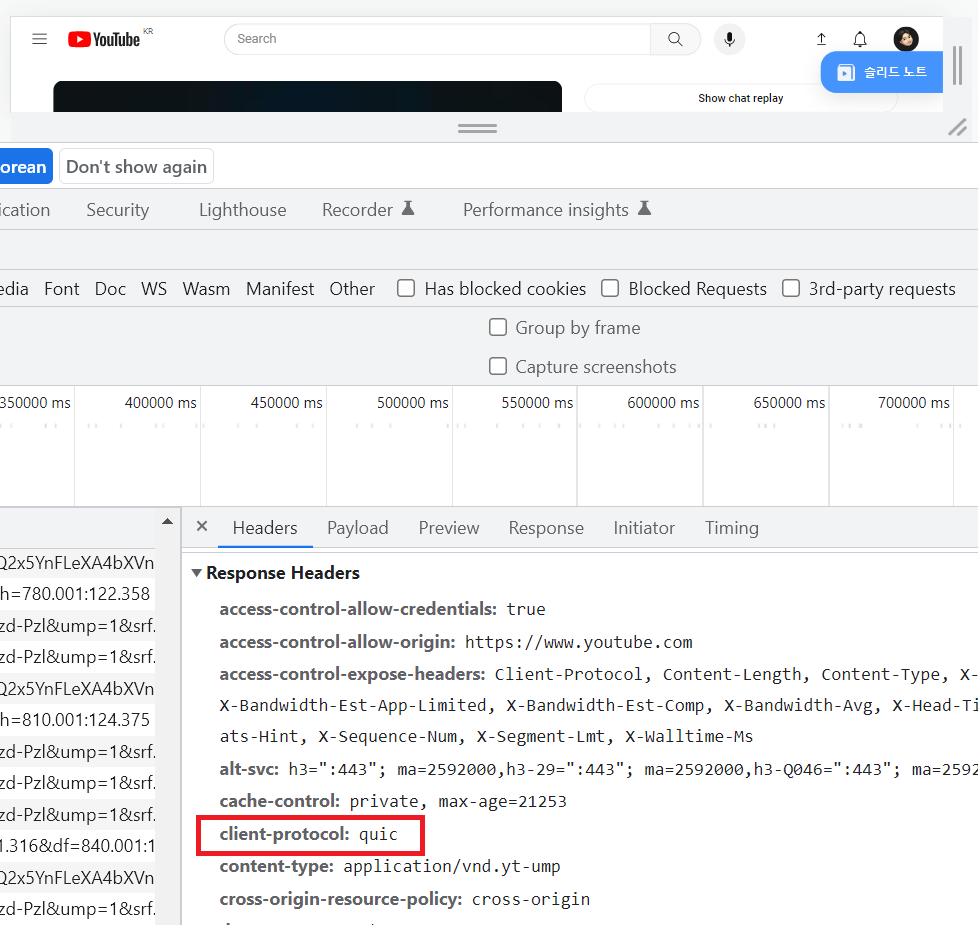
+위 사진은 유튜브 사이트에서 영상을 눌러 개발자 도구를 통해 확인한 모습인데요. **유튜브 영상을 시청할 때에도 QUIC를 통해 통신**하고 있음을 알 수 있었습니다.
+
+근데 또 유튜브 영상은 실시간 스트리밍도 아니라서 굳이 속도에 집착할 필욘 없을 것이거든요. 신뢰성 있는 통신을 통해 설정한 고화질을 제공해야 하기도 하구요.
+
+넵 맞습니다. **QUIC 프로토콜**은 UDP의 **빠른 통신** 속도와 TCP의 **신뢰성을 보장**하는 통신 두 가지 장점을 **둘 다 챙긴 프로토콜**입니다. 그럼 이게 어떻게 된 일인지 한번 확인하시죠.
+
+### QUIC (Quick UDP Internet Connections) 란,
+
+**UDP를 베이스로 하고 멀티플렉스와 보안을 지원하는 전송 계층 프로토콜**로, 구글의 짐 로스킨가 처음 설계하여 2012년 구현되었습니다. 이후 2021년에 표준화되어 현재 크롬에서부터 구글 서버에 이르는 모든 연결의 절반 이상에 QUIC가 사용된다고 하며, 현존하는 대부분의 브라우저들 또한 기본적으로 QUIC를 사용하여 통신하고 있습니다.
+
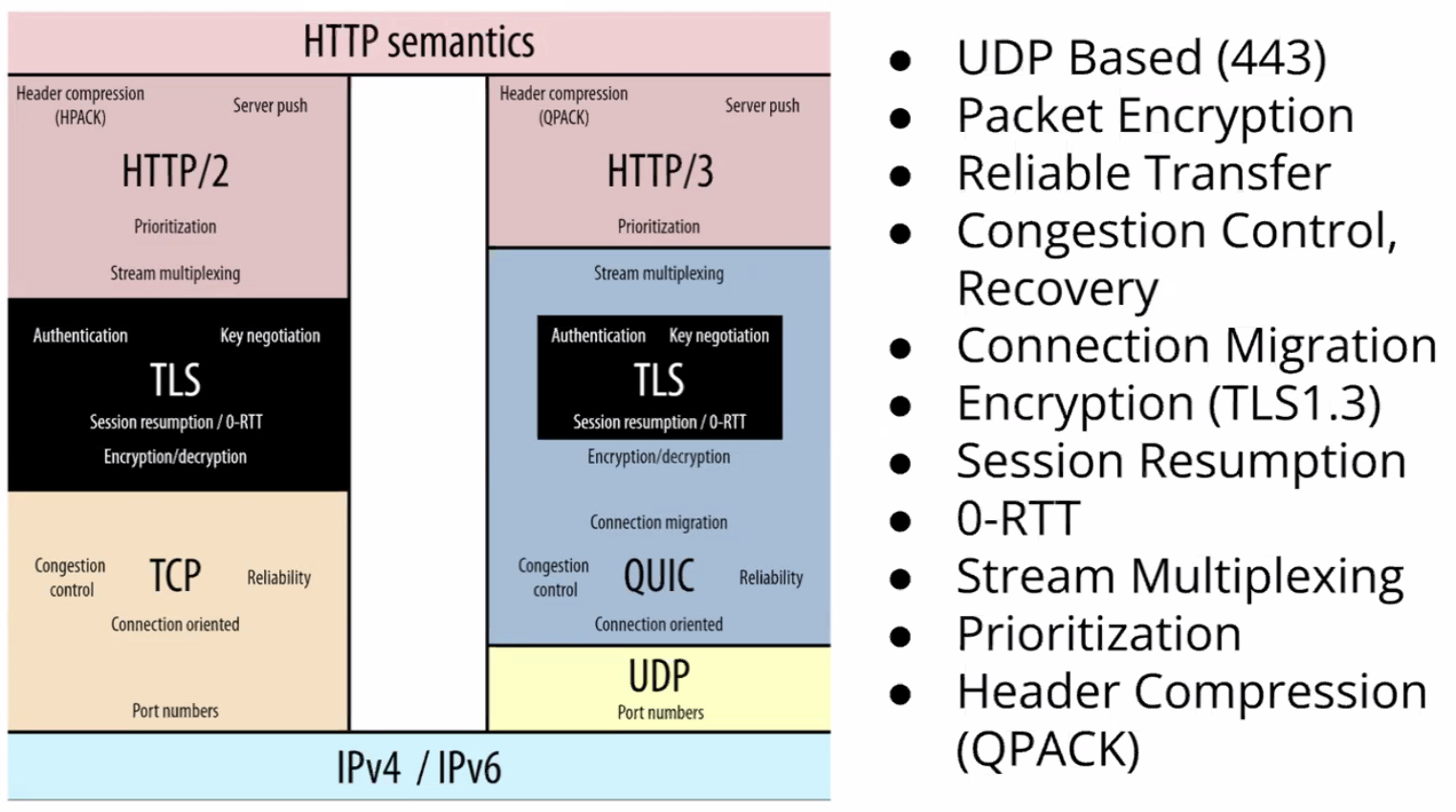
+
+
+위 사진은 QUIC를 검색하면 쉽게 보이는 HTTP/2와 HTTP/3를 비교하는 사진입니다. 이를 통해 알 수 있는 사실은 다음과 같습니다.
+
+- **HTTP/2에서 지원하는 기능은 대체로 전부 지원**한다. (header compression, server push, session resumption, congestion control, **connnection oriented**, etc.)
+- stream multiplexing을 UDP 기반으로 구현하여 HTTP/2까지 존재하던 **HOLB문제를 해결**하였다.
+- TLS가 TCP와 별도의 레이어로 구분되어있던 것과 달리, HTTP/3에서는 **TLS를 QUIC의 기본 스펙으로 지원**된다.
+
+### QUIC의 핵심적인 장점은 다음과 같습니다.
+
+#### **멀티플렉싱**
+
+이게 뭔지, 뭐가 좋은지 알기 위해서는 HTTP/1.1로 거슬러 올라가서 통신 방식을 이해해야 합니다.
+
+**HTTP/1.1**에서는 통신 성능 향상을 위해 하나의 커넥션 안에서 이전 요청에 대한 응답을 기다리지 않고 다음 요청을 연속적으로 보내는 **파이프라이닝을 지원**하고 있었습니다. 하지만 TCP 프로토콜의 구조상 **응답 순서는 보장되어야 하기 때문에** **첫 번째 요청에 대한 응답이 너무 오래 걸리면, 이후 요청에 대한 응답도 무작정 대기되는 비효율이 발생**하게 됩니다. 이걸 Head Of Line Blocking (HOLB) 문제라고 칭합니다.
+
+이를 해결하고자 기존에는 **Domain Sharding(도메인 샤딩)이라는 방법을 사용**하였습니다. 도메인 명을 여러개로 설정하여 같은 서버에 이미지나 css, js와 같은 static files를 병렬로 요청하여 각 도메인 명에 여러 커넥션을 맺어서 리소스를 병렬적으로 수신하겠다는 목적으로 고안된 방법입니다. 즉, 성능 개선을 위해 여러 TCP 연결을 수립하여 사용한 겁니다. 하지만 브라우저별로 도메인 커넥션 갯수 제한이 존재하였고, 결국 **근본적인 해결은 하지 못했습니다.**
+
+**HTTP/2**에서는 HTTP/1.1과 달리 한 개의 TCP 연결에서 여러 요청과 응답을 동시에 전송할 수 있게 하는 **멀티플렉싱을 지원**하였습니다. 즉, 클라이언트와 서버 사이에 TCP 연결이 수립되면 **하나의 TCP 연결 안에 여러 개의 독립적인 양방향 데이터 흐름을 확보할 수 있는 멀티 '스트림'을 생성하는 방식**입니다. 각각의 스트림은 요청이나 응답을 담은 HTTP 메시지를 주고 받습니다. 이 메시지는 네트워크를 통해 전송하는 단위인 '프레임'으로 분할되어 서로 다른 스트림을 타고 시퀀스 넘버를 바탕으로 병렬적으로 타고 갈 수 있게 되었습니다. 전송 과정에서도 스트림에 정수 가중치를 설정하여 스트림 우선순위를 부여할 수 있어서 수신 측에서는 우선순위가 높은 응답을 먼저 받을 수 있게 됩니다. 이를 통해 전체 요청 및 응답에 대한 다중화를 구현하였고, 기존 HTTP/1.1에서 발생했었던 HOLB를 해결할 수 있게 됩니다.
+
+하지만, HTTP/2에서도 TCP 통신 방식에 따라 피할 수 없는 다른 HOLB 이슈가 존재했습니다. TCP 통신은 신뢰성 있는 통신을 구현하고자 유실된 패킷을 재전송하는 기능을 제공하고 있는데, 만약 **TCP 통신에서 하나의 커넥션 내에서 패킷 유실이 발생하면, 결국은 하나의 TCP 연결 안에서는 스트림 1개가 유실 패킷을 재전송할때까지 나머지 N개의 스트림이 대기 상태로 돌입되는 문제**입니다.
+
+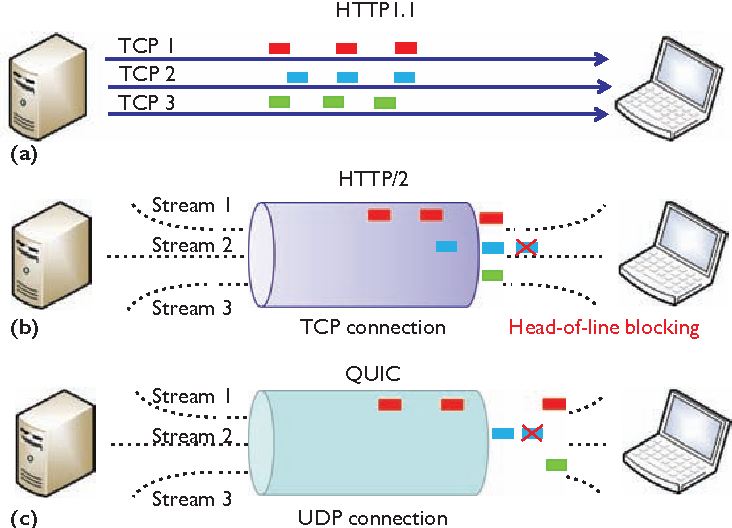
+
+출처: FAUN (HTTP/2 and HTTP/3)
+
+**QUIC**는 기본적으로 UDP 기반으로 데이터를 전송하므로 TCP 방식으로 인해 발생하는 고유의 **HOLB 문제를 해결**하였습니다. QUIC는 수립한 커넥션 안에서 통신을 수행할 때 **각 스트림을 UDP 방식으로 독립적으로 다중화하여 전송**하므로 **패킷 유실이 발생하였을 때 다른 스트림의 데이터 전달을 차단하지 않아 HOLB 이슈가 발생하지 않습니다.** 이로써 성능 좋은 멀티플렉싱을 이뤄냈습니다.
+
+#### **0 RTT 통신**
+
+**TCP는** 기본적으로 TLS와 별개로 고안된 보안 프로토콜이므로, HTTP/2까지는 TCP 위에서 동작하였습니다. 즉, **HTTP/2 까지는 TCP 핸드셰이크를 통한 연결 수립과 TLS 핸드셰이크를 통한 보안 연결 수립이 별도로 이뤄져야 했으므로 N번의 round trip을 수행해야만 했습니다.**
+
+하지만 **QUIC에서는 연결 수립을 하는 과정을 한 번의 통신으로 하고자 했으며,** 어차피 연결이 되지 않으면 암호화된 메세지를 읽을 수 없을 테니 **바로 enciphered data(통신의 목적이 되는 데이터)를 쏴버립니다.**
+
+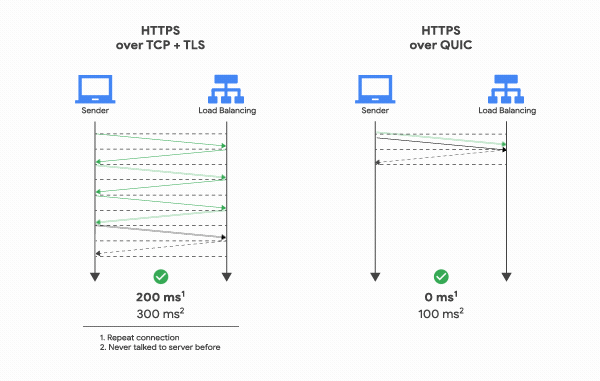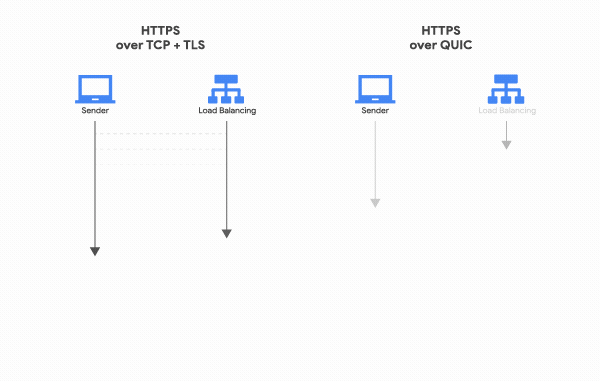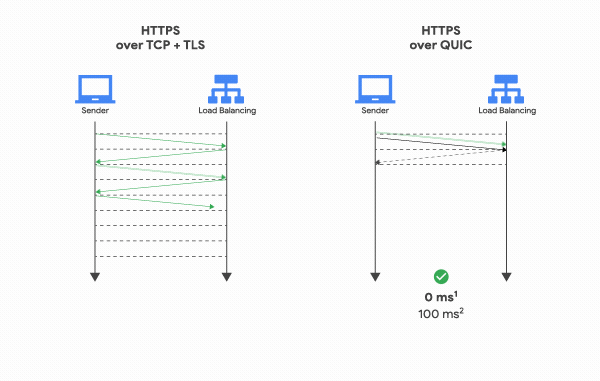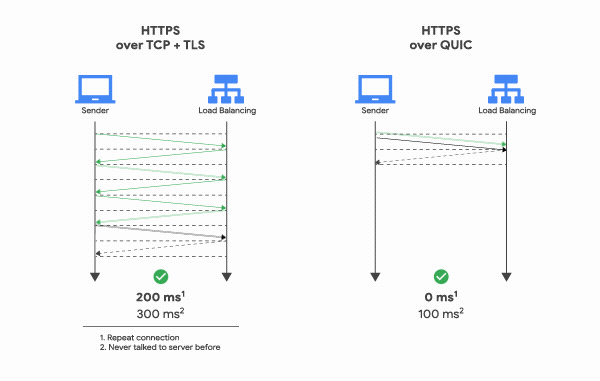
+
+출처 : Medium (what is HTTP/3?)
+
+따라서 이론상 **0 RTT**만으로 통신이 이뤄질 수 있도록 구현된 방식이 QUIC입니다.
+
+### 마무리
+
+위 사항 외에도 Connection migration을 지원한다는 것도 제 입장에서는 신기한 포인트였습니다. 이건 HTTP/2에서 이미 지원한 기능이라고 하는데, 간단하게 말하면 패킷 헤더에 Connection ID를 갖고 있어서 클라이언트의 IP 주소가 달라져서 커넥션을 재수립 하더라도 이전에 전송중이던 데이터를 받을 수 있게 하는 기능이라고 합니다. 오늘날 인터넷 연결이 케이블로만 되지 않고, 셀룰러 데이터와 와이파이를 오가는 형태가 빈번하다보니 반드시 필요한 기능인 것 같은데, 이를 알기 전까진 IP가 변경되는 상황에 대하여 네트워크 통신이 어떻게 유지되는지 깊게 고민해보지 않았기에 신기했습니다.
+
+TCP는 헤더를 가득가득 이용하여 신뢰성 있는 통신을 제공하다보니 더 최적화하기에 한계점을 느끼고 있었다 합니다. 이에 반하여, UDP는 처음엔 홀대받았지만 사실은 개척되지 않은 노다지 땅과 같은 영역이었던 거죠. 그래서 이를 기반으로 신뢰성 있는 통신을 구축하여 기존 통신 방식에서 더 최적화된 솔루션을 도출할 수 있었다고 합니다. 세상엔 참 스마트한 사람이 많은 것 같습니다.
+
+**정리하자면,**
+
+QUIC는 강력한 장점으로 인해 이미 HTTP 통신의 주인공으로 자리매김하고 있지만, (언제나 그렇듯) 아직 지원하지 않는 서버가 좀 있어서 브라우저는 HTTP 이전 버전들의 사용까지 모두 지원하고 있다!
+
+이제는 TCP만이 신뢰성 있는 통신을 한다고 말하기 어려울 것 같다(?)!!
+
+참고 :
+
+[https://truesparrow.com/blog/http2-will-stay-even-after-http3-and-quic/](https://truesparrow.com/blog/http2-will-stay-even-after-http3-and-quic/)
+
+[https://ko.wikipedia.org/wiki/QUIC](https://ko.wikipedia.org/wiki/QUIC)
+
+[https://bentist.tistory.com/36](https://bentist.tistory.com/36)
+
+[https://appleg1226.tistory.com/61](https://appleg1226.tistory.com/61)
\ No newline at end of file
diff --git a/Network/minhyeok/DHCP.md b/Network/minhyeok/DHCP.md
new file mode 100644
index 0000000..edf53de
--- /dev/null
+++ b/Network/minhyeok/DHCP.md
@@ -0,0 +1,69 @@
+# DHCP
+## DHCP란?
+ DHCP는 Dynamic Host Configuration Protocol의 약자로, 컴퓨터 네트워크에서 호스트의 IP 주소와 그 외 관련된 설정을 자동으로 할당해주는 프로토콜이다.
+
+## DHCP의 목적
+- 초기 인터넷에서는 호스트에게 IP 주소를 할당하기 위해 수동으로 설정
+
+- 또한, 호스트가 나가고 들어올때마다 재배치가 필요하였음
+
+- 각 호스트 IP를 추적해야하고 수동이기 때문에 번거로워 자동으로 IP를 할당해주는 DHCP 등장
+
+## 장점
+
+
+1. 자동화
+
+ DHCP는 IP 주소를 자동으로 할당하므로, 네트워크 관리자가 각각의 장치에 수동으로 IP 주소를 설정할 필요가 없다.
+
+2. IP 주소 관리 효율성
+
+ IP 주소를 동적으로 할당하므로 IP 주소의 낭비를 줄일 수 있다.
+
+3. 네트워크 설정의 단순화
+
+ DHCP는 IP 주소 외에도 서브넷 마스크, 기본 게이트웨이, DNS 서버 등의 정보도 자동으로 설정할 수 있다.
+
+## 단점
+
+1. 서버 의존성
+
+ DHCP 서버가 작동하지 않으면 새로운 장치는 IP 주소를 받을 수 없으므로 네트워크 접속에 문제를 일으킬 수 있다.
+
+2. 보안 문제
+
+ DHCP는 IP 주소를 무작위로 배정하므로, 특정 장치를 추적하기 어렵다. 따라서 보안에 취약할 수 있다.
+
+3. IP 주소 변경
+
+ DHCP는 IP 주소를 임시로 할당하므로, 장치가 네트워크에 재접속할 때마다 IP 주소가 바뀔 수 있다. 이는 일부 애플리케이션에서 문제가 될 수 있다.
+
+ - 일부 애플리케이션과 서비스는 특정 IP 주소에 바인딩되어 작동하는 경우가 있다. 예를 들어, 웹 서버나 데이터베이스 서버, FTP 서버 등의 서비스는 특정 IP 주소를 통해 접근되거나, 고정된 IP 주소를 통해 외부와 통신하는 경우가 많다. 때문에 변경된 IP에 접근이 실패하는 경우가 생길 수 있다.
+
+
+## IP 주소 할당 과정
+
+
+
+
+
+- DORA (DHCP Discover, Offer, Request, Acknowledgement)라고 부르기도 한다.
+
+1. DHCP Discover
+
+ 클라이언트가 네트워크에 브로드캐스트 메시지를 보내 DHCP 서버를 찾는다. 이 메시지는 클라이언트의 MAC 주소와 함께 전송되며, 클라이언트가 IP 주소를 필요로 한다는 것을 알리는 신호다.
+
+2. DHCP Offer
+
+ DHCP 서버가 이 메시지를 받으면, 사용 가능한 IP 주소와 함께, 서브넷 마스크, DNS 서버 주소, 라우터(게이트웨이) 주소, IP 주소 임대 기간 등의 정보를 제안하는 메시지를 보낸다.
+
+3. DHCP Request
+
+ 클라이언트는 제안받은 주소를 수락하고, 이를 DHCP 서버에 알리는 요청 메시지를 보낸다. 이 메시지에는 클라이언트가 수락한 IP 주소와 네트워크 설정 정보가 포함된다.
+
+4. DHCP Acknowledgement (ACK)
+
+ DHCP 서버는 IP 주소 할당을 확정하고, 이에 대한 정보를 포함한 ACK 메시지를 클라이언트에게 보낸다. 이 메시지에는 할당된 IP 주소, 서브넷 마스크, DNS 서버 주소, 라우터 주소, IP 주소 임대 기간 등의 정보가 포함된다.
+
+## 참조
+https://jwprogramming.tistory.com/35
\ No newline at end of file
diff --git a/Network/minhyeok/IP.md b/Network/minhyeok/IP.md
new file mode 100644
index 0000000..700cb37
--- /dev/null
+++ b/Network/minhyeok/IP.md
@@ -0,0 +1,181 @@
+## IPv4 & IPv6
+
+### IPv4
+- 32비트를 주소로 사용
+
+- .으로 구분 된 4개의 10진수로 표현
+
+ ex) 192.68.32.5
+
+- 2^32개 약 43억개를 ip주소로 사용가능
+
+- 헤더는 20바이트로, 옵션 필드가 있어서 복잡하고 처리가 느릴 수 있다
+
+- IPsec라는 보안 프로토콜이 선택사항
+
+### IPv6 도입 이유
+
+- IPv4만으로는 부족하다고 생각되어 2^128 (=거의 무한대) 에 가까운 IPv6가 도입됨
+
+### IPv6
+
+128비트를 주소로 사용
+
+- : 으로 구분 된 8개의 16진수
+
+ ex) 2001:230:abcd:ffff:0000:0000:ffff:1111
+
+- 2^128개를 주소로 사용 가능
+
+- 주소를 16진수로 표현
+
+- 헤더는 40바이트로, 옵션 필드가 없어서 처리가 빠르며, 라우팅 효율성과 성능이 향상
+
+- IPsec가 표준으로 포함되어 있어서, 데이터의 무결성, 기밀성, 인증 기능을 제공
+
+### IPv6 도입 지연 원인
+
+- 업그레이드 비용
+
+ - 하드웨어 장비 교체, 소프트웨어 업데이트, 테스트, 교육 등에 많은 비용이 든다.
+
+- 호환성 문제
+
+ - IPv4와 IPv6는 직접적으로 호환되지 않기 때문에 IPv6를 완전히 도입하려면 네트워크의 모든 컴포넌트를 업그레이드하거나 적절하게 구성해야 한다.
+
+- 필요성 부족
+
+ - IPv4 주소 공간이 부족한 문제는 NAT(Network Address Translation)와 같은 기술로 어느 정도 해결할 수 있다.
+
+- 기술적 복잡성
+
+ - IPv6 주소는 IPv4 주소보다 길고 복잡하여 사람이 이해하거나 기억하기 어렵다.
+
+- 보안 문제
+
+ - 새로운 프로토콜은 항상 새로운 보안 위협을 가져올 수 있습니다. IPv6에 대한 완전한 이해 없이 네트워크를 IPv6로 전환하면, 예상치 못한 보안 문제가 발생할 수 있다.
+
+## 고정 IP & 유동 IP
+
+### 고정 IP
+ - 특징
+
+ - 고정 IP는 네트워크 장치에 한 번 할당되면 변경되지 않는 IP 주소이다.
+
+ - 서버와 같이 항상 동일한 IP 주소를 유지해야 하는 장치에 주로 사용된다.
+
+ - 고정 IP를 사용하면 원격에서 장치에 접근하기 쉽고, 일관된 네트워크 연결을 유지할 수 있다.
+
+ - 그러나 고정 IP는 추가 비용이 발생할 수 있고, 보안 위협에 노출될 수 있다.
+
+### 유동 IP
+ - 등장 배경
+
+ - 인터넷 사용자가 증가하고 주소 공간이 부족해졌다.
+
+ - 이를 해결하기 위해 ip주소를 동적으로 할당해주는 DHCP가 등장하였고, 유동 ip 개념이 나오게 되었다.
+
+ - 특징
+
+ - 장치가 네트워크에 연결될 때마다 DHCP (Dynamic Host Configuration Protocol) 등의 프로토콜을 통해 새로운 IP 주소를 할당받는 방식.
+
+ - 사용하지 않는 IP 주소가 다른 장치에 재할당될 수 있기 때문에 효율적.
+
+ - 왜냐하면 IP 주소가 자주 변경되기 때문에 외부 공격자가 특정 IP 주소를 타겟으로 설정하기 어렵기 때문에 보안성이 높다.
+
+
+## 공인 IP & 사설 IP
+
+
+
+### 공인 IP
+- 인터넷상에서 유일한게 식별되는 IP 주소
+
+- ISP로 부터 주소를 할당 받음
+
+- 인터넷상의 다른 장치와 통신할 때 공인 IP를 사용
+
+ ex) 웹 서버나, 이메일과 같이 외부에서 접근이 필요한 서버
+
+### 사설 IP
+- 로컬상에서 유일하게 식별되는 IP 주소
+
+- DHCP로 부터 자동으로 할당 받음
+
+- 일반적으로 가정이나 사무실등 작은 네트워크에서 사용
+
+### 공인/사설 IP 사용의 장점
+
+- 사설 ip를 사용하면 같은 주소를 여러 네트워크에서 사용가능하므로 주소 공간을 효율적으로 사용할 수 있다.
+
+- 사설 ip주소는 외부에서 접근할 수 없기 때문에 네트워크 보안이 강화된다.
+
+### NAT
+- 통신을 하기 위해 사설 ip를 공인 ip로 변환해주거나 반대의 경우로 변환해주는 것.
+
+## 서브넷
+
+
+
+
+### A 클래스
+
+네트워크 앞자리 0 시작
+
+0xxx xxxx. hhhh hhhh. hhhh hhhh. hhhh hhhh
+
+네트워크 주소 범위 : 0 ~ 127
+
+호스트 주소 범위 : 0.0.0 ~ 255.255.255
+
+네트워크 할당 개수 : (2^7)-1 개 (127은 제외)
+
+호스트 할당 개수 : (2^24)-2 개
+
+
+### B 클래스
+
+네트워크 앞자리 10 시작
+
+10xx xxxx. xxxx xxxx. hhhh hhhh. hhhh hhhh
+
+네트워크 주소 범위 : 128.0 ~ 191.255
+
+호스트 주소 범위 : 0.0 ~ 255.255
+
+네트워크 할당 개수 : 2^14 개
+
+가능한 호스트 주소 수 : (2^16) - 2개
+
+
+
+### C 클래스
+
+네트워크 앞자리 110 시작
+
+110x xxxx. xxxx xxxx. xxxx xxxx. hhhh hhhh
+
+네트워크 주소 범위 : 192.0.0 ~ 223.255.255
+
+호스트 주소 범위 : 0 ~ 255
+
+네트워크 할당 개수 : 2^21 개
+
+가능한 호스트 주소 수 : (2^8) - 2개
+
+- D는 멀티캐스트 주소, E는 연구용 주소(미래계획)
+
+
+
+## 질문
+Q. 예를들어 A Class의 네트워크 주소에서 호스트가 사용할 수 있는 주소는 2^24-2이다.
+-2를 하는 이유는?
+
+A. 14이라는 네트워크 주소를 받았다면 첫번째, 14.000.000.000은 네트워크 자체를 식별할 수 있는 주소로 사용되어야 하기 때문에 호스트 주소로 쓰지못한다. 두번째, 14.255.255.255는 브로드캐스트 주소로 해당 네트워크의 모든 호스트들에게 데이터를 보낼 때 사용하므로 호스트 주소로 사용하지 못한다. 때문에 호스트가 사용할 수 있는 주소는 2^24 - 2개이다.
+
+
+## 참조
+
+https://github.com/im-d-team/Dev-Docs/blob/master/Network/IP.md
+
+https://nordvpn.com/ko/blog/public-ip-and-private-ip/
\ No newline at end of file
diff --git "a/Network/minhyeok/MAC_ARP_\354\212\244\354\234\204\354\271\230_\354\230\244\353\245\230 \354\262\264\355\201\254.md" "b/Network/minhyeok/MAC_ARP_\354\212\244\354\234\204\354\271\230_\354\230\244\353\245\230 \354\262\264\355\201\254.md"
new file mode 100644
index 0000000..a3e5b7f
--- /dev/null
+++ "b/Network/minhyeok/MAC_ARP_\354\212\244\354\234\204\354\271\230_\354\230\244\353\245\230 \354\262\264\355\201\254.md"
@@ -0,0 +1,184 @@
+# MAC(Media Access Control)이란?
+
+ 네트워크 장비가 데이터를 교환하는 데 사용되는 고유한 식별자
+
+## MAC의 특징
+
+- 6바이트(48비트)의 길이를 가지며, 이는 전 세계적으로 고유한 값이다. 이 주소는 보통 12자리의 16진수로 표현되며, 예를 들어 '00:0a:95:9d:68:16'와 같은 형태를 가진다.
+
+- 첫 6자리는 '제조사 코드'이고, 이는 각 네트워크 장비 제조사에게 할당된 고유한 값이다. 이를 OUI(Organizationally Unique Identifier)라고도 부른다. 뒤의 6자리는 '일련번호'로, 이는 제조사가 장비를 생산할 때마다 고유하게 부여하는 값이다.
+
+- 네트워크에서 데이터 패킷을 전송할 때, 패킷의 헤더에는 목적지와 출발지의 MAC 주소가 포함된다. 이렇게 하면 네트워크 내의 장비들이 데이터를 정확하게 전송하고 받을 수 있다.
+
+- 장비의 하드웨어에 내장되어 있으므로, 장비가 변경되지 않는 한 일반적으로 변경되지 않는다. 이는 IP 주소와는 대조적인 특징이다. IP 주소는 네트워크 상황에 따라 변경될 수 있다.
+
+### MAC 주소 스푸핑
+- 네트워크 장비의 실제 MAC 주소를 다른 MAC 주소로 변경하는 행위
+- 공격자는 네트워크에서 허용된 장비의 MAC 주소를 알아낸다. 그런 다음, 공격자는 자신의 장비의 MAC 주소를 그 주소로 변경한다. 이렇게 하면, 네트워크는 공격자의 장비를 허용된 장비로 인식하게 된다.
+
+- 해결법
+
+ - MAC 주소 필터링
+
+ - 특정 MAC 주소를 가진 장비만 네트워크에 접근하도록 허용하거나, 특정 MAC 주소를 가진 장비의 접근을 차단하는 방법이다. 이 기법은 네트워크에 접근할 수 있는 장비를 제한하여 보안을 강화하는 데 사용된다.
+
+
+
+# ARP(Address Resolution Protocol)이란?
+
+ 주소 결정 프로토콜로 불리고, IP주소(논리적 주소)를 Mac주소(물리적 주소)로 대응하기 위해 만들어진 프로토콜.
+
+## 등장 배경
+
+IP주소만으로 통신할 수 없고, 긴 Mac주소를 모두 기억하기엔 리소스 낭비가 있기 때문에 IP주소를 알면 Mac주소를 추적할 수 있는 ARP가 만들어짐
+
+## ARP 과정
+
+
+
+
+
+1. PC-A => Laptop-A
+
+ - 자신의 Mac/IP주소와 목적지 IP주소를 패킷에 담고 목적지 MAC주소를 FF-FF-FF-FF-FF-FF로 설정하여 브로드캐스트 요청을 한다.
+
+ |Source MAC|Source IP|Destination MAC|Destination IP|
+ |---|---|---|---|
+ |00-0A-0B-0C-00-00|192.168.1.1|FF-FF-FF-FF-FF-FF|192.168.1.4|
+
+2. Switch-A
+ - Switch는 이 요청을 받고 자신의 테이블에 PC-A의 MAC주소를 저장한다. 만약 Laptop-A의 Mac주소가 없을 경우 브로드캐스트를 진행한다.
+
+3. PC-B, PC-C
+
+ - PC-B, PC-C는 브로드캐스트를 받고 목적지 MAC이 자신이 아니라면 폐기처리한다.
+
+4. Laptop-A => PC-A
+
+ - Laptop-A는 목적지 MAC이 자신인 걸 확인하고 다음과 같은 ARP-Reply 패킷을 보낸다.
+
+ |Source MAC|Source IP|Destination MAC|Destination IP|
+ |---|---|---|---|
+ |00-2B-3B-4A-11-11|192.168.1.4|00-0A-0B-0C-00-00|192.168.1.1|
+
+5. Switch-A
+
+ - Switch는 Laptop-A의 MAC주소를 테이블에 기록하고 PC-A에 전달한다.
+
+6. PC-A와 Laptop-A
+
+ - 서로의 IP,MAC 주소를 파악했으므로 통신 가능
+
+## 네트워크 스위치
+
+ 네트워크 내의 트래픽을 MAC 주소를 기반으로 효율적으로 전송하며, 여러 장치들을 연결하여 통신이 가능하도록 하는 네트워크 장비
+
+### 특징
+
+1. MAC 주소 기반 전송
+
+ 스위치는 연결된 각 장치의 MAC(Media Access Control) 주소를 학습하고 이를 기반으로 정보를 전달한다. 장치가 데이터를 보내면, 스위치는 이 데이터의 출발지 MAC 주소를 확인하고 MAC 주소 테이블에 저장한다. 이후 같은 MAC 주소를 가진 장치로 데이터가 오면, 스위치는 이 데이터를 해당 장치로 바로 전송한다.
+
+2. 프레임 스위칭
+
+ 스위치는 네트워크 프레임을 받아 목적지 MAC 주소에 해당하는 포트로 전달한다. 이는 네트워크의 효율성을 높이고, 데이터 충돌을 최소화하는 데 도움이 된다.
+
+3. 네트워크 세분화
+
+ 충돌 도메인은 스위치나 허브 등의 네트워크 장치에 의해 결정된다. 스위치를 통해 네트워크를 세분화하면, 한 세그먼트에서 데이터 충돌이 발생해도 다른 세그먼트에는 영향을 미치지 않아 전체 네트워크의 성능 저하를 방지할 수 있다.
+
+ - 충돌 도메인이란?
+
+ 네트워크에서 데이터 패킷이 동시에 전송될 때 발생할 수 있는 '충돌'이 발생할 수 있는 영역을 의미한다.
+
+4. 풀 더플렉스 통신(전이중 통신)
+
+ 스위치는 풀 더플렉스 통신을 지원하여, 동시에 데이터를 송수신 할 수 있다.
+
+ - 통신 방식 종류
+
+
+
+## Physical Layer(물리 계층)
+
+### 물리 계층이란?
+
+ 물리 계층은 네트워크의 실제 데이터 전송을 담당하며, 비트 단위의 정보를 전기적 신호로 변환해 네트워크 장비들 간에 전송하는 역할을 합니다.
+
+### 구성 기기
+
+- NIC(Network Interface Card)
+
+ 네트워크에 연결하기 위한 하드웨어로, USB 포트와 연결하는 USB 타입, 마더 보드에 내장되어 있는 온보드 타입 등이 있습니다. 모든 네트워크 단말은 애플리케이션과 운영체제가 처리한 패킷을 NIC를 이용해 LAN 케이블이나 전파로 보냅니다.
+
+- 리피터(repeater)
+
+ 전송 거리가 길면 파형이 훼손됩니다. 이러한 훼손된 파형을 증폭해 정돈한 뒤 다른 쪽으로 전송하는 기기입니다.
+
+- 리피터 허브(repeater hub)
+
+ 전달받은 패킷의 복사본을 그대로 다른 모든 포트에 전송하는 기기입니다. 이제는 L2 스위치로 대체되어 잘 사용하지 않습니다.
+
+- 미디어 컨버터(media converter)
+
+ 전기 신호와 광 신호를 서로 교환하는 기기입니다.
+
+- 액세스 포인트(access point)
+
+ 패킷을 전파로 변조/복조하는 기기로, 무선과 유선 사이의 다리 역할을 합니다.
+
+
+
+
+# 로드 밸런싱
+
+## 로드 밸런싱이란?
+
+ 로드 밸런싱(load balancing)은 네트워크 트래픽이나 애플리케이션 요청을 다수의 서버나 네트워크 경로로 분산시키는 기술이다.
+
+## 특징
+
+- 시스템의 성능을 향상시키고, 가용성을 높이며, 응답 시간을 줄이는 데 도움이 됩니다.
+
+- 로드 밸런싱은 여러 서버가 동일한 작업을 수행할 수 있도록 설계된 시스템에서 특히 중요
+
+- 하나의 서버에 과도한 부하가 몰리지 않도록, 요청을 여러 서버에 균등하게 분산시킴으로써, 각 서버의 부하를 줄이고 전체 시스템의 가용성을 높이는 역할
+
+
+## 방법
+
+라운드 로빈(Round Robin)
+
+ 요청을 순차적으로 서버에 분배하는 방식.
+
+Least Connections
+
+ 현재 가장 적은 수의 연결을 가진 서버에 요청을 보낸다. 각 서버의 부하를 고려하여 분배하는 방식.
+
+IP Hash
+
+ 클라이언트의 IP 주소를 해시하여 특정 서버에 요청을 할당하는 방식. 특정 클라이언트 요청을 항상 동일한 서버로 전송하도록 보장한다.
+
+URL Hash:
+
+ 요청의 URL을 해시하여 요청을 서버에 분배하는 방식.
+
+## 면접 질문
+
+Q . ARP 과정 설명
+
+1. 먼저, 송신자는 자신이 보내려는 대상의 IP 주소를 알고 있지만, MAC 주소를 모르는 경우 ARP 요청을 보냅니다. 메시지에는 송신자의 IP와 MAC 주소, 그리고 대상의 IP 주소가 포함되어 있습니다.
+
+2. 메세지는 스위치를 통해 네트워크 상의 모든 디바이스에게 브로드캐스트로 전송됩니다.
+
+3. 모든 디바이스는 이 ARP 요청 메시지를 받지만, 대상 IP 주소가 자신의 IP 주소와 일치하는 디바이스만이 응답하고, 아닌 경우는 드랍합니다.
+
+4. 이 디바이스는 자신의 MAC 주소를 포함한 ARP 응답 메시지를 스위치를 통해 송신자에게 보냅니다.
+
+5. 이 과정에서 스위치는 table에 양 측의 Mac주소를 저장합니다.
+
+5. 송신자는 이 ARP 응답을 받아서 대상의 MAC 주소를 알게 되고, 이를 이용해 데이터를 전송하게 됩니다.
+
+## 참조
+
+https://daengsik.tistory.com/15
\ No newline at end of file
diff --git "a/Network/minhyeok/TCP \354\227\260\352\262\260 \355\225\264\354\240\234 \352\263\274\354\240\225.md" "b/Network/minhyeok/TCP \354\227\260\352\262\260 \355\225\264\354\240\234 \352\263\274\354\240\225.md"
new file mode 100644
index 0000000..2515e8b
--- /dev/null
+++ "b/Network/minhyeok/TCP \354\227\260\352\262\260 \355\225\264\354\240\234 \352\263\274\354\240\225.md"
@@ -0,0 +1,52 @@
+# TCP 연결 해제 과정
+### TCP란?
+- Transprot Layer의 프로토콜
+- 연결지향적
+- 신뢰성이 높음
+- 패킷 전달이 순서적, 안정적, 에러 없이 교환하는 것이 목표
+
+## 3-Way-Handshake (연결 과정)
+ - 데이터를 주고 받기 전에 안정적으로 데이터를 주고 받을 수 있을 지 클라이언트와 서버측 간 세션을 수립하는 과정
+
+
+
+ ### Flag 정보
+ - SYN(연결 설정) : 세그먼트로 나누어진 패킷의 순서 // 초기에 랜덤값으로 보내짐
+ - ACK(응답 확인) : 수신자가 성공적으로 값을 받은 것을 알리기 위해 사용
+ - FIN(연결 해제) : 세션 연결 종료시 사용. 전송할 데이터가 없음을 알림
+
+ ### 과정
+
+ 1. Client => Servcer
+ - tcp 헤더 안에 syn패킷에 (클라이언트 seq 임의의 숫자)을 보낸다
+
+ 2. Server => Client
+ server는 이를 받고 syn과 ack패킷을 보낸다. ack으로 클라이언트의 seq에 +1을 한 값을 보내고, 서버 seq을 보낸다.
+
+ 3. Client => Server
+ 응답으로 ack패킷을 보내고 server로 부터 받은 seq에 1을 더한 값을 보낸다.
+
+## 4-Way-Handshake (해제 과정)
+ - 세션을 종료하기 위해 수행되는 과정
+
+
+
+1. Client => Server
+- close()을 호출하여 FIN패킷 보냄
+
+2. Server => Client
+- ACK패킷 보내고, 남은 데이터를 마저 보낸다.
+
+3. Server => Client
+- 잔여 데이터를 모두 보낸 뒤 close() 호출하여 FIN 패킷을 보낸다
+
+4. Client => Server
+- FIN 패킷을 받고, 아직 다 오지 않은 데이터를 받기 위해 TIME_WAIT 상태 유지(기본 240초)
+- 240초 뒤에 닫음
+
+## 질문
+Q. TCP 연결 후 3-way-handshake 를 주고 받는 과정에서 seq 번호를 랜덤으로 설정하는 이유는?
+
+A. 첫번째 이유로는 이전 연결에서 재전송되거나, 지연된 패킷이 현재 연결에 혼돈을 줄 수 있기 때문입니다. 두번째는 보안상의 이유입니다. seq 번호가 예측이 가능하다면 공격자는 이를 이용하여 tcp연결을 하이재킹하거나 가짜 패킷을 삽입할 수 있습니다.
+
+but 한번 연결된 이후로는 seq 번호가 순차적으로 증가
\ No newline at end of file
diff --git "a/Network/minhyeok/\353\235\274\354\232\260\355\214\205.md" "b/Network/minhyeok/\353\235\274\354\232\260\355\214\205.md"
new file mode 100644
index 0000000..3a8db0b
--- /dev/null
+++ "b/Network/minhyeok/\353\235\274\354\232\260\355\214\205.md"
@@ -0,0 +1,119 @@
+## 라우팅
+
+ 라우팅이란 네트워크에서 정보를 효율적으로 전달하는 방법을 결정하는 과정이다.
+
+## 라우팅 테이블
+
+각 목적지까지의 최적 경로와 그 경로를 통해 전달할 다음 홉의 주소 등의 정보를 담고 있다.
+
+## 라우팅 프로토콜
+
+라우팅 테이블을 생성하고, 유지하며, 업데이트하고, 전달하는 역할을 한다.
+
+
+
+
+## 라우팅 프로토콜의 분류
+
+- 정보 갱신 방식
+ - 정적 라우팅 프로토콜
+
+ - 라우팅 테이블을 수동으로 설정하고 유지한다.
+
+ - 동적 라우팅 프로토콜
+
+ - 네트워크 상황에 따라 자동으로 라우팅 테이블을 업데이트한다.
+
+- 라우팅 범위
+ - 내부 라우팅 프로토콜(IGP)
+
+ - 같은 관리하에 있는 라우터의 집합(AS, Autonomous System) 내에서 라우팅을 담당한다.
+
+ - 외부 라우팅 프로토콜(EGP)
+
+ - 서로 다른 AS 간에 사용된다.
+
+ - AS란?
+
+ - 인터넷은 여러 기관이나 단체가 독립적으로 운영하는 네트워크들이 라우터에 의해 연결되어 복잡한 네트워크를 이루고 있다. 이렇게 독립적으로 운영되는 네트워크를 '자율 시스템'이라고 부른다.
+
+- 라우팅 테이블 관리 방식
+ - 거리 벡터 방식
+
+ - 라우팅 테이블에 목적지까지의 거리와 방향만을 기록
+
+ - 링크 상태 방식
+
+ - 라우터가 목적지까지의 모든 경로를 라우팅 테이블에 기록
+
+ - 하이브리드 방식
+
+ - 이 두 가지를 혼합한 방식이다.
+
+## Static과 Dynamic 라우팅 프로토콜 비교
+- 정적 라우팅 프로토콜
+
+ - 라우팅 경로를 수동으로 설정하고, 이 경로가 변경되지 않는다.
+ - 이 방식은 설정이 간단하고 네트워크 트래픽을 예측할 수 있지만, 네트워크의 변화에 빠르게 대응하기 어렵다.
+
+- 동적 라우팅 프로토콜
+
+ - 라우팅 경로를 네트워크 상황에 따라 자동으로 변경한다.
+ - 이 방식은 네트워크의 변화에 유연하게 대응할 수 있지만, 라우팅 프로토콜의 복잡성과 네트워크 오버헤드가 증가할 수 있다.
+
+## 라우팅 프로토콜 상세 설명
+
+- RIP(Routing Information Protocol)
+ - 거리 벡터 방식을 사용하며, 각 네트워크 간의 홉 카운트를 기반으로 최적 경로를 결정한다.
+ - 소규모 망에 주로 사용
+
+- OSPF(Open Shortest Path First)
+ - 링크 상태 방식을 사용하여 라우터의 계층 구조와 AS 구성을 고려하여 최적 경로를 찾는다.
+ - 대규모 망(도메인 내부)에 주로 사용
+
+- BGP(Border Gateway Protocol)
+
+ - 경로 벡터 방식을 사용하여, 다른 AS로의 경로를 결정한다.
+ - 대규모 (도메인 간)에 주로 사용
+
+## 라우팅 프로토콜 비교
+
+- Distance-Vector, Link-State, Path-Vector의 세 가지 방식은 업데이트 대상, 시점, 경로 선택 방법, 메트릭, 대표 프로토콜 등에서 차이가 있다.
+ - 메트릭이란?
+ - 동적 라우팅 프로토콜들이 최적의 경로를 선택하는 기준을 메트릭이라고 한다.
+
+- Distance-Vector(거리 벡터)
+
+ - 업데이트는 인접 라우터에 대해 이루어지며, 벨만-포드 알고리즘을 사용하여 경로를 선택한다.
+ - RIP와 IGRP 등이 이에 해당한다.
+ - 메트릭으로는 홉 카운트가 사용된다.
+ - 홉 카운트란?
+
+ 네트워크에서 소스 노드로부터 목적지 노드까지 패킷이 거치는 라우터나 스위치 등의 중간 지점의 개수를 나타낸다.
+
+- Link-State(링크 상태)
+ - 업데이트는 링크의 상태 변화가 발생할 때 모든 라우터에 대해 이루어진다.
+ - 다익스트라 알고리즘을 사용하여 경로를 선택하며, 메트릭으로는 홉 수, 대역폭, 지연 시간 등이 사용된다.
+ - OSPF와 EIGRP 등이 이에 해당한다.
+
+- Path-Vector(경로 벡터)
+
+ - 업데이트는 링크의 상태 변화가 발생할 때 BGP 이웃에 대해 이루어진다.
+ - BGP가 이에 해당한다.
+ - 정책 기반으로 경로를 선택한다.
+
+ - 정책 기반이란?
+
+ 경로 선택이 그냥 거리나 비용에만 의존하는 게 아니라, 특정 정책을 따라 결정된다는 걸 뜻한다.
+
+ 이 정책은 네트워크 관리자가 설정하는데, 예를 들면 특정 AS(자율 시스템)를 거치는 경로를 선호하거나, 특정 AS를 피하도록 정할 수 있다. 이런 정책들은 비즈니스 계약이나 트래픽 관리, 보안 같은 다양한 요인에 따라 결정된다.
+
+ 인터넷의 다양한 네트워크 사이에서 라우팅 정보를 주고받으면서, 이런 다양한 정책에 따라 경로를 선택한다. 이게 각 네트워크가 자기네 트래픽을 최적으로 관리할 수 있게 도와준다.
+
+
+## 참조
+https://daengsik.tistory.com/44
+
+https://github.com/alstjgg/cs-study/blob/main/%EB%84%A4%ED%8A%B8%EC%9B%8C%ED%81%AC/%EB%9D%BC%EC%9A%B0%ED%8C%85.md
+
+http://jidum.com/jidums/view.do?jidumId=433
\ No newline at end of file
diff --git "a/Network/minhyeok/\354\230\244\353\245\230\354\240\234\354\226\264 \355\235\220\353\246\204\354\240\234\354\226\264.md" "b/Network/minhyeok/\354\230\244\353\245\230\354\240\234\354\226\264 \355\235\220\353\246\204\354\240\234\354\226\264.md"
new file mode 100644
index 0000000..d96ba7a
--- /dev/null
+++ "b/Network/minhyeok/\354\230\244\353\245\230\354\240\234\354\226\264 \355\235\220\353\246\204\354\240\234\354\226\264.md"
@@ -0,0 +1,128 @@
+# 흐름제어
+
+- 송신측과 수신측의 데이터 처리 속도의 차이를 조절하는 것 (수신측 데이터 처리 속도 기준으로 송신측을 조절)
+
+### 데이터 전송 과정
+
+1. Application Layer: 송신측 Application Layer에서 데이터를 소켓에 입력합니다.
+2. Transport Layer: 이 데이터를 세그먼트로 감싸 Network Layer에 전달합니다.
+3. 이 세그먼트는 수신측 노드로 전송되며, 이 과정에서 송신측의 Send Buffer와 수신측의 Receive Buffer에 각각 데이터가 저장됩니다.
+4. 수신측 Application Layer가 준비되면, Receive Buffer에 있는 데이터를 읽기 시작합니다.
+
+- 여기서 흐름 제어의 핵심은 Receive Buffer가 넘치지 않도록 관리하는 것입니다. 이를 위해 수신측은 RWND(Receive Window, 즉 Receive Buffer의 남은 공간)를 송신측에 계속해서 피드백합니다. 이렇게 함으로써 송신측은 수신측이 처리할 수 있는 데이터의 양을 적절히 조절할 수 있게 됩니다.
+
+## Stop and Wait
+
+
+
+### 특징
+- 송신측에서는 전송한 패킷에 대한 응답을 받아야지만 다음 패킷을 보냄
+- 비효율적
+
+## Sliding Window
+
+### 특징
+
+- 수신측에서 설정한 윈도우 크기만큼 송신측에서 패킷을 보낸다.
+- 3-way-handshake 과정에서 보낸 tcp 헤더에 수신측의 윈도우 사이즈가 포함되어 있음.
+- 수신측에서 응답을 받지 않아도 계속해서 패킷을 전송할 수 있다. => 보다 효율적
+
+### 동작 방식
+- 먼저 윈도우에 포함되는 모든 패킷을 전송하고, 그 패킷들의 전달이 확인(ACK)되는대로 이 윈도우를 옆으로 옮김으로써 그 다음 패킷들을 전송
+
+
+
+### 동작 과정
+
+1. 송신측에서는 3-way-handshake에서 전달받은 헤더 정보에 있는 window-size 정보를 토대로 7만큼 설정
+2. 0,1,2,3,4,5,6 패킷을 보냄
+3. 수신측에서 ack응답으로 버퍼에 2개를 더 받을 수 있다는 정보를 보냄
+4. 송신측에서 ack을 수신하여 window-size를 2개 더늘리고 데이터 2개를 더 보냄
+5. 반복
+
+
+
+# 혼잡제어
+
+- 네트워크의 데이터 처리 능력에 따라 송신측의 데이터 전송 속도를 조절하는 것
+- 라우터에 데이터가 몰릴 경우, 라우터는 모든 데이터를 처리할 수 없게 되고, 이로 인해 데이터의 오버플로우나 손실이 발생할 수 있습니다.
+- 이런 상황을 방지하기 위해 데이터의 전송 속도를 조절해야 합니다.
+- 흐름제어가 송신측과 수신측 사이의 전송속도를 다룬다면, 혼잡제어는 호스트와 라우터를 포함한 보다 넓은 관점에서 전송 문제를 다루게 됩니다.
+
+### 패킷 유실되는 경우 (문제 상황)
+1. 3 duplicate acks
+ - 동일한 ack 응답을 3번 받은 경우 => 특정 패킷이 전송되지 않았다
+ - 상대적으로 가벼운 문제
+2. time out
+ - 전송된 패킷이 유실되거나, ack 응답을 못받음
+ - 상대적으로 치명적인 문제
+
+## AIMD
+
+
+### 특징
+
+ - AIMD는 TCP의 기본 혼잡 제어 알고리즘이다.
+ - 패킷 전송을 시작할 때 윈도우 크기를 1부터 시작하여, 각 패킷이 성공적으로 도착할 때마다 윈도우 크기를 1씩 증가시킨다.
+ - 하지만 패킷 전송에 실패하거나 일정 시간이 지나면 윈도우 크기를 절반으로 줄인다.
+ - 이 방법의 장점은 여러 호스트가 네트워크를 공유할 때, 시간이 지나면 모든 호스트가 평형 상태로 수렴하게 되는 점이다.
+
+ => 패킷 손실이 발생할 경우 모든 호스트가 동시에 윈도우 크기를 줄이기 때문
+
+ - 단점은 네트워크의 혼잡 상태를 미리 감지하지 못하고, 네트워크의 초반 대역폭을 충분히 활용하지 못하는 점이다.
+
+## Slow Start
+
+### 특징
+- tcp 연결이 처음 시작될 때, 패킷 손실이 됐을 때 사용
+- 1RTT에서 ack를 받은 응답개수만큼 +1하여 window size를 늘림
+### RTT란?
+송신측에서 패킷을 전송하고 수신측에서 보낸 ack값을 다시 송신측에서 수신하는 것을 한 싸이클로 잡는것
+
+
+
+ ex) 패킷 2개를 보내고 응답으로 2개를 다 받았다고 치면 => 다음 번엔 패킷을 4개를 보낸다
+ 패킷을 4개 보내고 응답으로 4개를 받았다면 => 다음 번엔 패킷을 8개를 보낸다 => 2의 지수승으로 증가
+
+- Time Out이나 3 Duplicated ACK 상황이 오면 window size를 1로 다시 조정한다.
+- 처음 데이터 전송이 늦는다는 단점
+
+
+## Fast Retransmit(빠른 재전송)
+- Fast Retransmit은 패킷 손실을 빠르게 감지하고 처리하는 방법이다. 패킷이 손실되면 수신 측에서는 동일한 ACK를 세 번 보내게 되는데, 이를 감지하면 해당 패킷을 즉시 재전송한다.
+
+
+
+## Fast Recovery(빠른 회복)
+- Fast Recovery는 Fast Retransmit 이후에 이어지는 과정으로, 패킷이 재전송된 후에는 네트워크가 혼잡하다고 가정하고 윈도우 크기를 줄인다. 이때 윈도우 크기를 현재 윈도우 크기의 절반으로 줄이고, 이 값을 새로운 임계점으로 설정한다.
+
+## TCP 혼잡제어 3단계
+
+
+- TCP의 혼잡 제어는 주로 세 가지 단계로 이루어진다.
+- 송신자가 한 번에 보낼 수 있는 최대 패킷 크기를 MSS(Maximum Segment Size)라고 부른다.
+
+1. Slow Start 단계: 이 단계는 네트워크가 아직 혼잡하지 않은 상태를 가리킨다. 이 때, MSS를 지수적으로 증가시킨다.
+
+2. Additive Increase 단계: 이 단계는 MSS의 값이 임계값에 도달한 상태를 의미한다. 이때, MSS를 선형적으로 증가시킨다. 초기의 임계값은 사전에 정해진 값이거나, 패킷의 전송 속도를 나타내는 MSS/RTT를 통해 설정할 수 있다. 때로는 다른 TCP 연결의 임계값을 참조하기도 한다.
+
+3. Multiplicative Decrease 단계: 이 단계는 패킷 유실을 감지하고 MSS를 줄이는 과정을 포함한다. Timeout이 발생하면 MSS를 1로, 3회의 중복 ACKs가 감지되는 경우에는 MSS를 절반으로 줄인다. 이처럼 큰 폭으로 윈도우 크기를 줄이는 것은 네트워크 혼잡을 신속하게 해결하기 위함이다.
+
+## TCP Tahoe
+- Timeout과 3회의 중복 ACKs를 동일하게 처리
+
+
+
+
+## TCP Reno
+- Timeout 발생 시 MSS를 1로, 3회의 중복 ACKs가 발생한 경우에는 MSS를 절반으로 줄인다.
+
+
+
+### 참조
+
+https://www.brianstorti.com/tcp-flow-control/
+
+https://yeoneeds.tistory.com/25
+
+https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Network/TCP%20(%ED%9D%90%EB%A6%84%EC%A0%9C%EC%96%B4%ED%98%BC%EC%9E%A1%EC%A0%9C%EC%96%B4).md
diff --git "a/Network/minhyeok/\354\233\271 \355\206\265\354\213\240 \355\235\220\353\246\204.md" "b/Network/minhyeok/\354\233\271 \355\206\265\354\213\240 \355\235\220\353\246\204.md"
new file mode 100644
index 0000000..1920aed
--- /dev/null
+++ "b/Network/minhyeok/\354\233\271 \355\206\265\354\213\240 \355\235\220\353\246\204.md"
@@ -0,0 +1,41 @@
+# 웹 통신 전체 흐름
+
+
+1. 사용자의 통신 요청
+
+ 이용자는 웹 브라우저를 통해 구글의 웹페이지를 요청하고, 이 과정은 애플리케이션 계층에서 시작된다. 여기서 HTTP, HTTPS와 같은 프로토콜이 사용되며, 이용자의 요청 정보가 생성된다.
+
+2. DNS 해석
+
+ 이용자의 컴퓨터는 구글의 도메인 이름을 IP 주소로 변환하기 위해 DNS 서버를 조회한다. 이 과정에서 이용자의 컴퓨터는 DNS Query를 생성하고 이를 DNS 서버에게 전송한다. DNS 서버는 이 Query를 해석하여 해당 도메인의 IP 주소를 반환한다.
+
+3. TCP 연결
+
+ HTTPS는 TCP 프로토콜을 사용하므로, 이용자의 컴퓨터와 구글 서버 사이에는 TCP 연결이 설정된다. 이 과정에서는 3-way-handshake라는 절차가 이루어져 연결이 확립된다.
+
+4. 데이터 캡슐화
+
+ 응용계층에서 html 데이터 요청을 http 메세지에 담아서 보낸다.
+
+ 전송계층에서 이 메세지에 tcp 헤더를 붙인다. 여기에는 출발포트번호, 목적지포트번호, 시퀀스 번호등이 있다.
+
+ 네트워크 계층에서는 출발지와 목적지IP 주소 정보가 담겨있는 IP헤더가 붙는다.
+
+ 데이터 링크 계층에서는 이더넷 헤더와 트레일러가 추가된다. 이더넷 헤더에는 목적지, 출발지 MAC 주소가 있고, 트레일러에는 데이터의 무결성을 확인하는 오류 검출 코드가 있다.
+
+5. 스위치에서의 처리
+
+ 데이터 패킷은 스위치에 도착하면 역캡슐화되고, 이더넷 헤더에 기록된 목적지 MAC 주소를 바탕으로 다음 목적지를 결정한다. 스위치는 자신의 MAC 주소 테이블을 참조하여 이를 결정하며, 데이터 패킷은 다시 캡슐화되어 라우터로 전송된다.
+
+6. 라우터에서의 처리
+
+ 라우터에서는 데이터 패킷을 역캡슐화하고, IP 헤더에 기록된 목적지 IP 주소를 바탕으로 다음 목적지를 결정한다. 라우터는 자신의 라우팅 테이블을 참조하여 이를 결정하며, 필요에 따라 출발지 IP를 라우터의 공인 IP로 변경할 수 있다. 데이터 패킷은 다시 캡슐화되어 다음 목적지로 전송된다.
+
+7. 서버에서의 처리
+
+ 데이터 패킷이 최종 목적지인 서버에 도착하면, 서버는 패킷을 역캡슐화하고 각 계층에서 필요한 처리를 수행한다. 이 과정에서는 패킷의 무결성 검사, 전송 오류 확인 등 다양한 작업이 이루어진다.
+
+8. 애플리케이션 계층에서 이용자의 웹페이지 요청을 처리하고 응답을 생성하여 이용자에게 전송한다.
+
+
+
diff --git "a/Network/minseo/3 -Way Handshake & 4 -Way Handshake/TCP UDP\354\231\200 3 -Way Handshake & 4 -Way Handshake .md" "b/Network/minseo/3 -Way Handshake & 4 -Way Handshake/TCP UDP\354\231\200 3 -Way Handshake & 4 -Way Handshake .md"
index 123b5fd..7647eb1 100644
--- "a/Network/minseo/3 -Way Handshake & 4 -Way Handshake/TCP UDP\354\231\200 3 -Way Handshake & 4 -Way Handshake .md"
+++ "b/Network/minseo/3 -Way Handshake & 4 -Way Handshake/TCP UDP\354\231\200 3 -Way Handshake & 4 -Way Handshake .md"
@@ -6,7 +6,7 @@
```c
int main(){
- sock = socket(AF_INFT, SOCK_STREAM, 0);
+ sock = socket(AF_INFT, SOCK_STREAM, 0) ;
..
bind( ~)
..
diff --git a/Network/minseo/DHCP&NAT/DHCP NAT .md b/Network/minseo/DHCP&NAT/DHCP NAT .md
new file mode 100644
index 0000000..4bde01b
--- /dev/null
+++ b/Network/minseo/DHCP&NAT/DHCP NAT .md
@@ -0,0 +1,135 @@
+# DHCP/NAT
+
+IP 주소 부족의 문제를 해결하기 위해 적은 IP 주소를 동적으로 활용한다는 점에서 NAT는 DHCP와 비슷한 느낌으로 다가올 수 있다. 그렇지만, 이 둘은 근본적으로 다른 개념입니다. 먼저, DHCP와 NAT의 개념은 각각 IP 주소를 **할당**하고, IP 주소를 **매핑(변환)**하는 것이다
+
+DHCP에서는 호스트가 하나의 IP 주소를 받아 그 주소를 이용해 통신하고,
+
+NAT는 자신이 사용하는 주소로 보낸 패킷이 그 주소와 매핑되는 주소로 다시 쓰여지는 과정이라는 점에서 근본적인 차이가 있다.
+
+# NAT (Network Address Translation)
+
+네트워크의 **IP 주소를 관리하거나, IP 주소를 변경**하고 싶을 때 이용한다.
+
+### **NAT를 사용하는 목적**
+
+1. **인터넷의 공인 IP주소를 절약할 수 있다.**
+
+
+
+인터넷의 공인 IP주소는 한정되어 있기 때문에 이를 공유할 수 있도록 하는 것이 필요하다. **NAT를 이용하면 사설 IP 주소를 사용하면서 이를 공인 IP주소와 상호 변환 할 수 있도록 하여, 공인 IP주소를 다수가 함께 사용하게 함**으로써 이를 절약할 수 있다는 것이다.
+
+즉 회사와 같은 곳에서 내부에서는 사설 IP 주소를 통하여 그들끼리 통신하고 회사 밖 인터넷은 회사의 IP로써 통신하는 구조에서 사용된다 볼 수 있겠다.
+
+1. **인터넷이란 공공망과 연결되는 사용자들의 고유한 사설망을 침입자들로부터 보호할 수있다.**
+
+공개된 인터넷과 사설망 사이에 **방화벽(Firewall)**를 설치하여 외부 공격으로부터 사용자의 통신망을 보호하는 기본적인 수단을 활용할 수 있다.
+
+이 때 외부 통신망 즉 인터넷망과 연결하는 장비인 라우터에 NAT를 설정할 경우, Space 내부에서는 private address, 외부에서는 public address를 사용할 수 있고 필요시에 이를 서로 변환할 수 있다.
+
+따라서 외부 침입자가 공격하기 위해서는 사설망의 내부 사설 IP주소를 알아야 하기 때문에 공격이 불가능해지므로 내부 네트워크를 보호할 수 있다.
+
+# DHCP (Dynamic Host Configulation Protocol)
+
+DHCP란 호스트의 **IP주소와 각종 TCP/IP 기본 설정을 클라이언트에게 자동적으로 제공해주는 프로토콜**을말한다.
+
+DHCP에 대한 표준은 RFC문서에 정의되어 있으며, DHCP는 네트워크에 사용되는 IP주소를 DHCP서버가 중앙집중식으로 관리하는 **클라이언트/서버 모델**을 사용하게 된다. DHCP지원 클라이언트는 **네트워크 부팅과정**에서 DHCP서버에 IP주소를 요청하고 이를 얻을 수 있다.
+
+네트워크 안에 컴퓨터에 자동으로 네임 서버 주소, IP주소, 게이트웨이 주소를 **할당**해주는 것을 의미하고, 해당 클라이언트에게 **일정 기간 임대를 하는 동적 주소 할당 프로토콜**이다.
+
+따라서 호스트가 빈번하게 접속을 연결하고 다시 갱신하는 가정 인터넷 접속 네트워크 및 **무선랜(LAN)**에서 폭 넓게 사용된다.
+
+**DHCP장점**
+
+PC의 수가 많거나 PC 자체 변동사항이 많은 경우 IP 설정이 자동으로 되기 때문에 효율적으로 사용 가능하고, IP를 자동으로 할당해주기 때문에 IP 충돌을 막을 수 있다.
+
+**DHCP단점**
+
+DHCP 서버에 의존되기 때문에 서버가 다운되면 IP 할당이 제대로 이루어지지 않는다.
+
+## DHCP 구성
+
+### **1) DHCP서버**
+
+ DHCP서버는 네트워크 인터페이스를 위해서 **IP주소를 가지고 있는 서버에서 실행되는 프로그램**으로
+
+**일정한 범위의 IP주소를 다른 클라이언트에게 할당하여 자동으로 설정하게 해주는 역할**을 한다. **DHCP서버는 클라이언트에게 할당된 IP주소를 변경없이 유**지해 줄 수 있다.**클라이언트에게 IP 할당 요청이 들어오면 IP를 부여해주고 할당 가능한 IP들을 관리**해주게 됩니다.
+
+### **2) DHCP클라이언트**
+
+클라이언트들은 시스템이 시작하면 DHCP서버에 자신의 시스템을 위한 IP주소를 요청하고, DHCP 서버로부터 IP주소를 부여받으면 TCP/IP 설정은 초기화되고 다른 호스트와 TCP/IP를 사용해서 통신을 할 수 있다.
+
+**즉, 서버에게 IP를 할당받으면 TCP/IP 통신을 할 수 있다.**
+
+### DHCP 프로토콜의 원리
+
+ DHCP를 통한 IP 주소 할당은 **“임대”**라는 개념을 가지고 있는데
+
+ 이는 DHCP 서버가 IP 주소를 영구적으로 단말에 할당하는 것이 아니고 **임대기간(IP Lease Time)**을 명시하여 그 기간 동안만 단말이 IP 주소를 사용하도록 하는 것이다.
+
+단말은 임대기간 이후에도 계속 해당 IP 주소를 사용하고자 한다면 **IP 주소 임대기간 연장(IP Address Renewal)**을 DHCP 서버에 요청해야 하고 또한 단말은 임대 받은 IP 주소가 더 이상 필요치 않게 되면 **IP 주소 반납 절차(IP Address Release)**를 수행하게 된다.
+
+[https://t1.daumcdn.net/cfile/tistory/2519193C5715E03427](https://t1.daumcdn.net/cfile/tistory/2519193C5715E03427)
+
+이제 단발 (DHCP client)이 DHCP 서버로 부터 IP 주소를 할당(임대)받는 절차에 대해서 알아보자.
+
+## DHCP 연결 과정
+
+
+
+### **1) DHCP 서버 발견 (DHCP Server Discover)**
+
+새롭게 도착한 호스트는 자신이 접속할 네트워크의 DHCP 서버 주소를 알지 못한다.
+
+따라서 서버 발견 메세지(포트67, UDP 메세지)를 **브로드캐스트 IP주소 (출발지 주소: 0.0.0.0. 목적지: 255.255.255.255.)**로 캡슐화하여 서브넷 상의 모든 노드로 전송한다.
+
+**[주요 파라미터]**
+
+- Client Mac : 단말의 MAC 주소
+
+### **2) DHCP 서버 제공 (DHCP Server Offer)**
+
+DHCP 발견 메세지를 받은 DHCP 서버는 DHCP 제공 메세지를 이용해 클라이언트로 브로드 캐스트 한다.
+
+**단말브로드캐스트 메시지** (Destination MAC = FF:FF:FF:FF:FF:FF)이거나 **유니캐스트**일수 있다.
+
+이는 단말이 보낸 DHCP Discover 메시지 내의 Broadcast Flag의 값에 따라 달라지는데, 이 Flag=1이면 DHCP 서버는 DHCP Offer 메시지를 Broadcast로, Flag=0이면 Unicast로 보내게 된다
+
+서버 제공 메세지는 클라이언트에게 제공될 IP주소 네트워크 마스크, 도메인, 이름 , IP 주소 임대기간 등의 클라이언트 설정 파라미터 값들이 포함된다.
+
+**[주요 파라미터]**
+
+- Client MAC: 단말의 MAC 주소
+- Your IP: 단말에 할당(임대)할 IP 주소
+- Subnet Mask (Option 1)
+- Router (Option 3): 단말의 Default Gateway IP 주소
+- DNS (Option 6): DNS 서버 IP 주소
+- IP Lease Time (Option 51): 단말이 IP 주소(Your IP)를 사용(임대)할 수 있는 기간(시간)
+- DHCP Server Identifier (Option 54): 본 메시지(DHCP Offer)를 보낸 DHCP 서버의 주소. 2개 이상의 DHCP 서버가 DHCP Offer를 보낼 수 있으므로 각 DHCP 서버는 자신의 IP 주소를 본 필드에 넣어서 단말에 보냄
+
+### 3) DHCP 요청 (DHCP Request)
+
+IP 할당을 요쳥한 새 호스트는 하나 이상의 DHCP 서버 제공 메세지를 받고 그 중 가장 최적의 서버를 선택한 후 그 서버측으로 DHCP 요청 메세지를 보낸디.
+
+**[주요 파라미터]**
+
+- Client MAC: 단말의 MAC 주소
+- Requested IP Address (Option 50): 난 이 IP 주소를 사용하겠다. (DHCP Offer의 Your IP 주소가 여기에 들어감)
+- DHCP Server Identifier (Option 54): 2대 이상의 DHCP 서버가 DHCP Offer를 보낸 경우, 단말은 이 중에 마음에 드는 DHCP 서버 하나를 고르게 되고, 그 서버의 IP 주소가 여기에 들어감. 즉, DHCP Server Identifier에 명시된DHCP서버에게"DHCP Request"메시지를 보내어 단말 IP 주소를 포함한 네트워크 정보를 얻는 것
+
+### 4) DHCP Ack (Acknowledgement)
+
+서버는 DHCP 요청 메세지에 대해 요청된 설정을 확인하는 ACK 메세지를 전송한다.
+
+단말브로드캐스트 메시지 (Destination MAC = FF:FF:FF:FF:FF:FF) 혹은 유니캐스트일수 있으며 이는 단말이 보낸 DHCP Request 메시지 내의 Broadcast Flag=1이면 DHCP 서버는 DHCP Ack 메시지를 Broadcast로, Flag=0이면 Unicast로 보내게 된다.
+
+**[주요 파라미터]**
+
+- Client MAC: 단말의 MAC 주소
+- Your IP: 단말에 할당(임대)할 IP 주소
+- Subnet Mask (Option 1)
+- Router (Option 3): 단말의 Default Gateway IP 주소
+- DNS (Option 6): DNS 서버 IP 주소
+- IP Lease Time (Option 51): 단말이 본 IP 주소(Your IP)를 사용(임대)할 수 있는 기간(시간
+- DHCP Server Identifier (Option 54): 본 메시지(DHCP Ack)를 보낸 DHCP 서버의 주소
+
+이렇게 DHCP Ack를 수신한 단말은 이제 IP 주소를 포함한 네트워크 정보를 획득(임대)하였고, 이제 인터넷 사용이 가능하게 된다.
\ No newline at end of file
diff --git a/Network/minseo/DHCP&NAT/DHCP NAT/Untitled 1.png b/Network/minseo/DHCP&NAT/DHCP NAT/Untitled 1.png
new file mode 100644
index 0000000..e5c5324
Binary files /dev/null and b/Network/minseo/DHCP&NAT/DHCP NAT/Untitled 1.png differ
diff --git a/Network/minseo/DHCP&NAT/DHCP NAT/Untitled.png b/Network/minseo/DHCP&NAT/DHCP NAT/Untitled.png
new file mode 100644
index 0000000..915688c
Binary files /dev/null and b/Network/minseo/DHCP&NAT/DHCP NAT/Untitled.png differ
diff --git a/Network/minseo/IP .md b/Network/minseo/IP .md
index 6254533..498f592 100644
--- a/Network/minseo/IP .md
+++ b/Network/minseo/IP .md
@@ -12,7 +12,7 @@
3계층은 다른 네트워크 대역,
-멀리 떨어진 곳에 존재하는 네트워크까지 어떻게 데이터를 전달할지 제어하는 일을 담당한다.
+멀리 떨어진 곳에 존재하는 네트워크까지 어떻게 데이터를 전달할지 제어하는 일을 담당한다 .

diff --git "a/Network/minseo/TCP \355\235\220\353\246\204\354\240\234\354\226\264 & \355\230\274\354\236\241\354\240\234\354\226\264/TCP \355\235\220\353\246\204\354\240\234\354\226\264 & \355\230\274\354\236\241\354\240\234\354\226\264 .md" "b/Network/minseo/TCP \355\235\220\353\246\204\354\240\234\354\226\264 & \355\230\274\354\236\241\354\240\234\354\226\264/TCP \355\235\220\353\246\204\354\240\234\354\226\264 & \355\230\274\354\236\241\354\240\234\354\226\264 .md"
index 6540cde..ca733f6 100644
--- "a/Network/minseo/TCP \355\235\220\353\246\204\354\240\234\354\226\264 & \355\230\274\354\236\241\354\240\234\354\226\264/TCP \355\235\220\353\246\204\354\240\234\354\226\264 & \355\230\274\354\236\241\354\240\234\354\226\264 .md"
+++ "b/Network/minseo/TCP \355\235\220\353\246\204\354\240\234\354\226\264 & \355\230\274\354\236\241\354\240\234\354\226\264/TCP \355\235\220\353\246\204\354\240\234\354\226\264 & \355\230\274\354\236\241\354\240\234\354\226\264 .md"
@@ -17,7 +17,7 @@
# 흐름제어
- 송신측과 수신측 사이의 데이터 처리 속도 차이를 해결하기 위한 기법이다
-- 송신 측의 전송량 > 수신측의 처리량인 경우, 패킷이 수신 측의 큐를 넘어 손실될 수 있어서 송신측 패킷 전송량을 제어해줘야 한다.
+- 송신 측의 전송량 > 수신측의 처리량인 경우 , 패킷이 수신 측의 큐를 넘어 손실될 수 있어서 송신측 패킷 전송량을 제어해줘야 한다.
## 1. Stop and Wait (정지-대기)
diff --git "a/Network/minseo/WEB \355\206\265\354\213\240 \354\240\204\354\262\264 \355\235\220\353\246\204.md" "b/Network/minseo/WEB \355\206\265\354\213\240 \354\240\204\354\262\264 \355\235\220\353\246\204.md"
new file mode 100644
index 0000000..537be02
--- /dev/null
+++ "b/Network/minseo/WEB \355\206\265\354\213\240 \354\240\204\354\262\264 \355\235\220\353\246\204.md"
@@ -0,0 +1,61 @@
+# WEB 통신 전체 흐름
+
+주소창에 url을 입력했을때 통신의 흐름에 대해 알아보자.
+
+웹 통신의 흐름을 보기 전에 알아야할 개념이 있다.
+
+## IP 주소
+
+컴퓨터 네트워크에서 장치들이 서로를 인식하고 통신을 하기 위해서 사용하는 특수한 번호
+
+→ 현재 사용하는 IPv4는 128.0.0.1과 같은 32비트 수로 구성되어 있다.
+
+## Domain Name
+
+IP 주소를 문자로 표현한 주소
+
+→ **DNS : IP주소와 도메인 이름의 매핑 정보를 담는 데이터베이스**
+
+# 작동 방식
+
+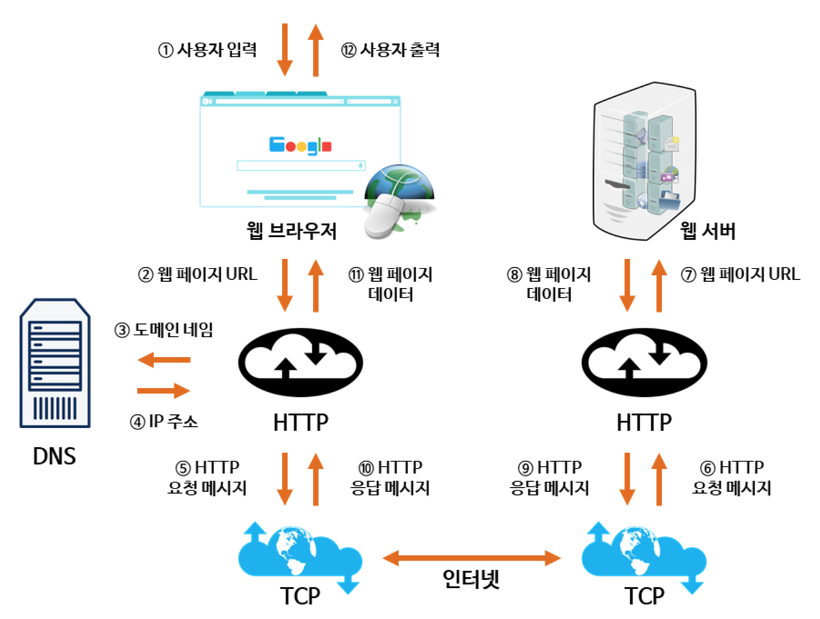
+
+1. 사용자가 브라우저에 **도메인 이름을 입력**한다.
+2. **DNS서버**에서 사용자가 입력한 Domain name을 검색하고, **매핑되는 IP주소**를 찾는다. 사용자가 입력한 URL 정보와 함께 리턴한다.
+3. IP주소는 HTTP 프로토콜을 이용해서 **HTTP 요청 메세지를 생성**한다.
+4. 생성된 HTTP 요청 메세지는 TCP 프로토콜을 사용해서 인터넷을 거쳐 **해당 IP 주소의 컴퓨터(서버)로** 전송된다.
+5. 서버는 클라이언트의 요청을 승인하고, 응답 메세지를 전송한다.
+6. 도착한 HTTP 응답 메세지는 HTTP 프로토콜을 사용하여 **웹페이지 데이터로 변환**되고, 웹 브라우저의 출력에 의해 사용자가 볼 수 있다.
+
+# DNS 서버의 주소 찾기
+
+## DHCP
+
+- Dynamic Host Configuration Protocol
+
+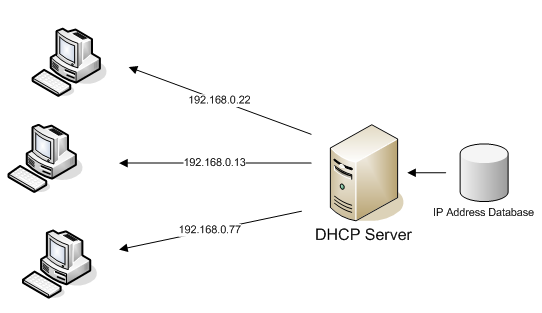
+
+- 호스트의 IP 주소와 TCP/IP 설정을 클라이언트에 의해 자동으로 제공하는 응용 계층 프로토콜
+
+ → 사용자는 DHCP 서버에서 자신의 IP 주소, 가장 가까운 라우터의 IP 주소, 가장 가까운 **DNS 서버의 주소**를 받는다.
+
+
+## ARP
+
+- Address Resolution Protocol
+- 네트워크상에서 IP 주소를 물리적 네트워크 주소로 바인딩시키기 위해 사용하는 프로토콜
+- DHCP로 얻은 라우터의 IP 주소를 MAC 주소로 변환
+
+# DNS 서버에서 IP 정보 수신
+
+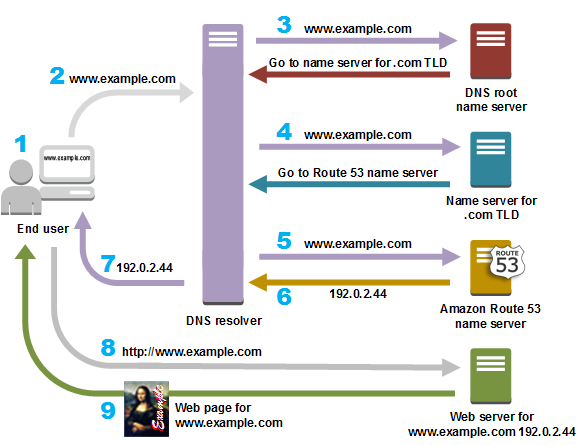
+
+- 사용자가 웹 브라우저 주소창에 www.example.com을 입력
+- www.example.com에 대한 요청이 인터넷 서비스 제공업체(ISP)가 관리하는 DNS 해석기로 라우팅
+- DNS 해석기는 요청을 DNS 루트 이름 서버에 전달
+- DNS 해석기는 요청을 .com 도메인 TLD(Top-level Domain) 네임 서버 중 하나에 다시 전달
+- DNS 해석기는 요청을 Route 53 네임 서버에 다시 전달
+- Route 53 네임 서버는 www.example.com 레코드를 찾아 IP주소를 DNS 해석기로 반환
+- DNS 해석기는 웹 브라우저에 IP주소 반환
+
+DNS 서버는 계층화 구조를 이루는데, 최상단 계층인 가장 뒷쪽(.com, .kr 등등)을 담당하는 DNS 서버는 **전세계에 13개 뿐**이다.
\ No newline at end of file
diff --git "a/Network/minseo/link layer/link layer (MAC ARP \354\212\244\354\234\204\354\271\230 \354\230\244\353\245\230 \354\262\264\355\201\254).md" "b/Network/minseo/link layer/link layer (MAC ARP \354\212\244\354\234\204\354\271\230 \354\230\244\353\245\230 \354\262\264\355\201\254).md"
new file mode 100644
index 0000000..56e0e89
--- /dev/null
+++ "b/Network/minseo/link layer/link layer (MAC ARP \354\212\244\354\234\204\354\271\230 \354\230\244\353\245\230 \354\262\264\355\201\254).md"
@@ -0,0 +1,130 @@
+# link layer (MAC / ARP / 스위치 / 오류 체크)
+
+- 데이터 링크 계층은 **직접 연결된** 서로 다른 2개의 네트워킹 장치 간의 데이터 전송을 담당한다.
+- Network 장비 간에 **신호를 주고받는 규칙**을 정하는 계층
+ - 대표적으로 Ethernet 프로토콜이 존재
+- Network 기기 간에 **Data 전송 + 물리 주소를 결정**
+- Data들을 Network 전송 방식에 맞게 **단위화(Framing)**해서, 해당 단위를 전송
+ - 전송되는 Data를 프레임이라 한다
+- Data Link layer에서 최종적으로 **이더넷 헤더/트레일러**가 붙는다.
+
+링크계층에서 제공하는 서비스들을 살펴보자
+
+## 주요 기능
+
+**1) 프레이밍 (Framing)**
+
+링크계층에서 일단 제공하는 가장중요한 서비스는 **프레이밍-프레임을** 만드는 것이다.
+
+**물리 계층으로 부터 받은 신호들을 조합**해서 **프래임단위**의 **정해진 크기의 Data Unit**으로 만들어서 처리
+
+프레임으로 만드는 작업을해서 데이터그램이 위쪽에서 내려와 캡슐화를 해서 프레임으로 만들게된다.
+
+링크계층에서 사용하는 헤더와 트레일러,
+
+트레일러는 앞뒤로 붙이는 메터데이터라고 생각해면 된다.
+
+**2) 오류제어 (Error Control)**
+
+Farme 전송 시 발생하는 오류들을 복원하거나 재전송
+
+**3) 흐름 제어 (Flow control)**
+
+-송수신측 간에 Data를 주고 받을 때 **적당한 양의 Data를 송수신**할 수 있도록 Data의 흐름을 제어
+
+**4) 접근 제어 (Access Control)**
+
+매체 상에 기기가 여러 개 존재할 때 **데이터 전송 여부를 결정**
+
+**5) 동기화 (Sysnchronization)**
+
+- Frame 구분자 (특별한 비트 패턴)
+
+---
+
+링크계층에는 2가지 종류가 있다.
+
+## 링크 계층의 종류
+
+**1) Point-to-point link**
+
+
+
+위 그림처럼 노드들 간에 dedicated 된 link를 사용하는 방식이다.
+
+빠르고 보안성이 높다는 장점이 있지만, 패킷의 경로가 길어지거나, 네트워크 카드가 여러개 필요하는 등 효율성이 떨어진다는 단점이 있다.
+
+이 경우, 신뢰성 있는 전달이나 flow control 등과 같은 Data link control 기능만 제공하면 된다.
+
+**2) Broadcast link**
+
+
+
+여러 노드들이 하나의 공유된 link를 사용하는 방식이다.
+
+효율적이라는 장점이 있지만, 보안이 약하고, 여러 노드가 동시에 신호를 보낼 경우 변조될 가능성이 존재한다는 단점이 있다.
+
+이 경우, 위 그림과 같이 Data link control 기능 뿐만 아니라, 여러 신호가 섞이는 것을 방지하기 위한 Media access control 기능도 필요하다.
+
+### **Link layer 프로토콜은 OS 커널과 네트워크 카드에도 일부 구현되어 있다.**
+
+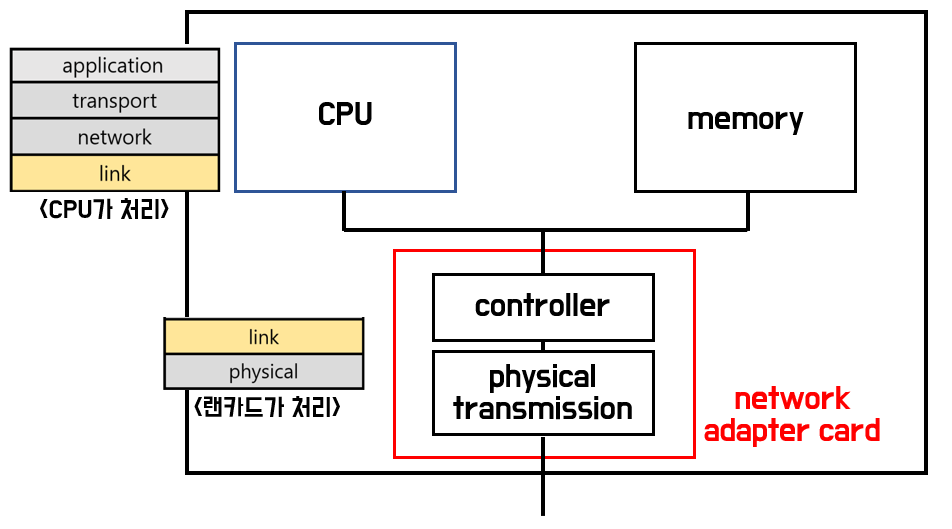
+
+위 그림처럼, 특정 application에서 트래픽을 보내고 싶을때, CPU를 통해 appilcation과 OS 커널에 구현된 프로토콜을 따라 내려오다, link layer를 거칠 때 네트워크 카드를 거치는 것을 확인할 수 있다.
+
+이후 네트워크 카드의 physical transmission 인터페이스를 통해 실제 물리적인 신호가 전달되는 것이다.
+
+# MAC 주소
+
+%20e25ccc6dacd944eba88db685fd1ffefb/%25E1%2584%2589%25E1%2585%25B3%25E1%2584%258F%25E1%2585%25B3%25E1%2584%2585%25E1%2585%25B5%25E1%2586%25AB%25E1%2584%2589%25E1%2585%25A3%25E1%2586%25BA_2024-02-03_%25E1%2584%258B%25E1%2585%25A9%25E1%2584%2592%25E1%2585%25AE_4.06.51.png)
+
+- **랜 카드를 제조할 떄 정해지는 물리적 주소**
+- **전 세계에서 유일한 번호**로 할당됨
+- 총 **48비트**의 숫자로 구성됨
+ - 앞 24 비트: 랜 카드 제조사 번호
+ - 뒤 24 비트 : 제조사가 랜 카드에 붙인 일련 번호
+
+ 네트워크 장비 혹은 컴퓨터는 모두 MAC주소를 갖는다. 그런데 왜 MAC 주소가 필요할까?
+
+ %20e25ccc6dacd944eba88db685fd1ffefb/%25E1%2584%2589%25E1%2585%25B3%25E1%2584%258F%25E1%2585%25B3%25E1%2584%2585%25E1%2585%25B5%25E1%2586%25AB%25E1%2584%2589%25E1%2585%25A3%25E1%2586%25BA_2024-02-03_%25E1%2584%258B%25E1%2585%25A9%25E1%2584%2592%25E1%2585%25AE_4.41.15.png)
+
+ %20e25ccc6dacd944eba88db685fd1ffefb/%25E1%2584%2589%25E1%2585%25B3%25E1%2584%258F%25E1%2585%25B3%25E1%2584%2585%25E1%2585%25B5%25E1%2586%25AB%25E1%2584%2589%25E1%2585%25A3%25E1%2586%25BA_2024-02-03_%25E1%2584%258B%25E1%2585%25A9%25E1%2584%2592%25E1%2585%25AE_4.42.10.png)
+
+
+# 스위치 (Switch)
+
+%20e25ccc6dacd944eba88db685fd1ffefb/%25E1%2584%2589%25E1%2585%25B3%25E1%2584%258F%25E1%2585%25B3%25E1%2584%2585%25E1%2585%25B5%25E1%2586%25AB%25E1%2584%2589%25E1%2585%25A3%25E1%2586%25BA_2024-02-03_%25E1%2584%258B%25E1%2585%25A9%25E1%2584%2592%25E1%2585%25AE_4.08.30.png)
+
+- Lv2 (데이터 링크)에서 동작
+- Layer 2 Switch/ Swtiching Hub라고 불린다
+- 스위치 내부에는 **MAC 주소 테이블** 존재
+
+### MAC 주소 테이블 (MAC Address Table)
+
+스위치의 포트번호 + 포트에 연결된 컴퓨터의 MAC 주소가 등록되는 DB
+
+- MAC 주소 학습을 통해서 MAC 주소 테이블에 해당 포트 + MAC 주소를 저장
+- 초기 상태에는 아무것도 등록 x
+
+### 스위치 기능
+
+1. **MAC 주소학습 (Learning)**
+ - 목적지 MAC 주소가 추가된 Frame 전송
+ - Frame이 스위치를 지나칠 때, MAC 주소 테이블에 출발지 MAC 주소가 등록
+
+2. **플러딩 (Flooding)**
+ - 목적지 MAC 주소가 MAC 주소 테이블에 등록되지 않은 경우
+ - 출발지를 제외한 포트에 연결된 모든 컴퓨터에 Frame이 전송
+
+3. **포워딩 (Forwarding)**
+ - 스위치가 목적지 MAC주소를 보유하고 있을 때, 그대로 목적지 포트로 Frame을 전송
+ - 나머지 포트는 필터링 되어서 Frame 전송 x
+
+4. **필터링 (Filterling)**
+ - 스위치가 목적지 MAC주소를 보유하고 있어서 해당 주소가 아닌 포트로는 Frame 전송 x
+
+5. **에이징 (Aging)**
+ - 스위치는 MAC 주소를 학습해서 MAC 테이블에 저장
+ - MAC 주소는 기본적으로 300초동안 MAC 테이블에 저장
+ - 300초 내에 Frame이 들어오지 않으면 해당 MAC 주소는 지워진다.
+ - 시간은 조정 가능
\ No newline at end of file
diff --git "a/Network/minseo/link layer/link layer (MAC ARP \354\212\244\354\234\204\354\271\230 \354\230\244\353\245\230 \354\262\264\355\201\254)/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_4.06.51.png" "b/Network/minseo/link layer/link layer (MAC ARP \354\212\244\354\234\204\354\271\230 \354\230\244\353\245\230 \354\262\264\355\201\254)/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_4.06.51.png"
new file mode 100644
index 0000000..d58eb86
Binary files /dev/null and "b/Network/minseo/link layer/link layer (MAC ARP \354\212\244\354\234\204\354\271\230 \354\230\244\353\245\230 \354\262\264\355\201\254)/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_4.06.51.png" differ
diff --git "a/Network/minseo/link layer/link layer (MAC ARP \354\212\244\354\234\204\354\271\230 \354\230\244\353\245\230 \354\262\264\355\201\254)/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_4.08.30.png" "b/Network/minseo/link layer/link layer (MAC ARP \354\212\244\354\234\204\354\271\230 \354\230\244\353\245\230 \354\262\264\355\201\254)/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_4.08.30.png"
new file mode 100644
index 0000000..5fa3c87
Binary files /dev/null and "b/Network/minseo/link layer/link layer (MAC ARP \354\212\244\354\234\204\354\271\230 \354\230\244\353\245\230 \354\262\264\355\201\254)/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_4.08.30.png" differ
diff --git "a/Network/minseo/link layer/link layer (MAC ARP \354\212\244\354\234\204\354\271\230 \354\230\244\353\245\230 \354\262\264\355\201\254)/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_4.41.15.png" "b/Network/minseo/link layer/link layer (MAC ARP \354\212\244\354\234\204\354\271\230 \354\230\244\353\245\230 \354\262\264\355\201\254)/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_4.41.15.png"
new file mode 100644
index 0000000..b0f9451
Binary files /dev/null and "b/Network/minseo/link layer/link layer (MAC ARP \354\212\244\354\234\204\354\271\230 \354\230\244\353\245\230 \354\262\264\355\201\254)/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_4.41.15.png" differ
diff --git "a/Network/minseo/link layer/link layer (MAC ARP \354\212\244\354\234\204\354\271\230 \354\230\244\353\245\230 \354\262\264\355\201\254)/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_4.42.10.png" "b/Network/minseo/link layer/link layer (MAC ARP \354\212\244\354\234\204\354\271\230 \354\230\244\353\245\230 \354\262\264\355\201\254)/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_4.42.10.png"
new file mode 100644
index 0000000..668c0c4
Binary files /dev/null and "b/Network/minseo/link layer/link layer (MAC ARP \354\212\244\354\234\204\354\271\230 \354\230\244\353\245\230 \354\262\264\355\201\254)/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_4.42.10.png" differ
diff --git "a/Network/minseo/loadBalancing/\353\241\234\353\223\234 \353\260\270\353\237\260\354\213\261 .md" "b/Network/minseo/loadBalancing/\353\241\234\353\223\234 \353\260\270\353\237\260\354\213\261 .md"
new file mode 100644
index 0000000..cb852f8
--- /dev/null
+++ "b/Network/minseo/loadBalancing/\353\241\234\353\223\234 \353\260\270\353\237\260\354\213\261 .md"
@@ -0,0 +1,91 @@
+# 로드 밸런싱
+
+# 로드밸런서란?
+
+### **1. 로드밸런서(Load Balancer)**
+
+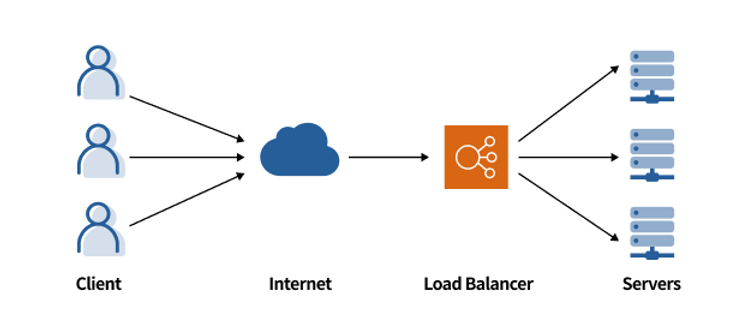
+
+로드밸런서(Load Balancer)는 **클라이언트와 서버 그룹 사이에 위치해 서버에 가해지는 트래픽을 여러 대의 서버에 고르게 분신(=밸런싱)하여 특정 서버의 부하(=로드)를 덜어준다.** 서버가 하나인데 많은 트래픽이 몰릴 경우 부하를 감당하지 못하고, 서버가 다운되어 서비스가 작동을 멈출 수 있다. 이런 문제를 해결하기 위해서 **Scale up(스케일업)과 Scale out(스케일아웃) 방식 중 한 가지**를 사용해 해결한다.
+
+**그렇다면 로드밸런싱은 모든 경우에 항상 필요할까요?**
+
+로드밸런싱은 여러 대의 서버를 두고 서비스를 제공하는 분산 처리 시스템에서 필요한 기술이다.
+
+서비스의 제공 초기단계라면 적은 수의 클라이언트로 인해 서버 한 대로 요청에 응답하는 것이 가능하지만,
+
+사업의 규모가 확장되고, 클라이언트의 수가 늘어나게 되면 기본 서버만으로는 정상적인 서비스가 불가능하다.
+
+이처럼 증가하 트래픽에 대처할 수 있는 방법은 크게 2가지다.
+
+### **2. 스케일 업과 스케일 아웃**
+
+
+
+**스케일 업(Scale Up)**은 **기존 서버 자체의 성능을 향상시키는 방법**으로 이는 CPU나 메모리를 업그레이드하는 것과 같은 작업을 포함한다. 반
+
+**스케일 아웃(Scale Out)**은 존 서버와 동일하거나 낮은 성능의 서버를 두 대 이상 증설하여 운영하는 것과 같다. 즉 **트래픽이나 작업을 여러 대의 컴퓨터나 서버에 분산시켜 처리하는 방법이**다.
+
+각각의 방법은 장단점이 있어 어떤 방법이 더 적합한지 판단해야 한다.
+
+| | 스케일 업 | 스케일 아웃 |
+| --- | --- | --- |
+| 확장성 | 성능 확장에 한계 존재 | 지속적 확장이 가능 |
+| 서버 비용 | 성능 증가에 따른 비용 증가 폭 큼
+일반적으로 비용 부담이 큰 편 | 비교적 저렴한 서버를 사용하므로, 일반적으로 비용 부담이 적음 |
+| 관리 편의성 | 스케일 업에 따른 큰 변화 없음 | 서버 대수가 늘어날수록 관리 편의성 떨어짐 |
+| 운영 비용 | 스케일 업에 따른 큰 변화 없음 | 서버 대수가 늘어날수록 운영 비용 증가 |
+| 장애 영향 | 한 대의 서버에 부하가 집중되므로 장애 시 다운 타임 발생 | 부하가 여러 서버에 분산되어 처리됨으로 장애 시 전면 장애 가능성 적음 |
+
+# 로드밸런싱 알고리즘
+
+### **1. 정적 로드 밸런싱**
+
+**1) 라운드 로빈 방식(Round Robin Method)**
+
+클라이언트의 요청을 여러 대의 서버에 순차적으로 분배하는 방식이다. 클라이언트의 요청을 순서대로 분배하기 때문에 서버들이 동일 스펙을 가지고 있고, 서버와의 연결(세션)이 오래 지속되지 않는 경우 활용하기 적합하다.
+
+- A, B, C의 서버를 가지고 있을 경우 A → B → C → A 순서대로 순회합니다.
+
+**2) 가중치 기반 라운드 로빈 방식(Weighted Round Robin Method)**
+
+각각의 서버마다 가중치(Weight)를 매기고 가중치가 높은 서버에 클라이언트의 요청을 먼저 배분합니다. 여러 서버가 같은 사양이 아니고, 특정 서버의 스펙이 더 좋은 경우 해당 서버의 가중치를 높게 매겨 트래픽 처리량을 늘릴 수 있습니다.
+
+- 서버 A의 가중치 = 8, 서버 B의 가중치 = 2, 서버 C의 가중치 = 3
+ - → 서버 A에 8개, 서버 B에 2개, 서버 C에 3개의 Request를 할당합니다.
+
+**3) IP 해시 방식(IP Hash Method)**
+
+IP 해시 방식에서 로드밸런서는 클라이언트 IP 주소에 대해 해싱이라고 하는 수학적인 계산을 수행합니다. 클라이언트 IP 주소를 숫자로 변환한 다음 개별 서버에 매핑합니다. 사용자 IP를 해싱하여 부하를 분산하기 때문에 사용자가 항상 동일한 서버로 연결되는 것을 보장합니다.
+
+### **2. 동적 로드 밸런싱**
+
+**1) 최소 연결 방법(Least Connection Method)**
+
+최소 연결 방법에서 로드 밸런서는 활성 연결이 가장 적은 서버를 확인하고 해당 서버로 트래픽을 전송합니다. 이 방법에서는 모든 연결에 모든 서버에 대해 동일한 처리 능력이 필요하다고 가정합니다. 서버에 분배된 트래픽들이 일정하지 않은 경우에 적합하다.
+
+**2) 최소 응답 시간 방법(Least Response Time Method)**
+
+서버의 현재 연결 상태와 응답 시간을 모두 고려하여, 가장 짧은 응답 시간을 보내는 서버로 트래픽을 할당합니다. 각 서버의 가용 가능한 리소스와 성능, 처리 중인 데이터양 등이 상이할 경우 적합합니다. 조건에 잘 들어맞는 서버가 있을 시 여유 있는 서버보다 먼저 할당됩니다. 로드 밸런서는 이 알고리즘을 사용하여 모든 사용자에게 더 빠른 서비스를 보장합니다.
+
+**부하분산에는 L4로드밸런서와 L7 로드밸런서가 가장많이 활용된다.**
+
+그 이유는 L4 로드밸런서부터 포트정보를 바탕으로 로드를 분산하는 것이 가능하기 때문이다. 한 대의 서버에 각기 다른 포트 번호를 부여하여 다수의 서버 프로그램을 운영하는 경우라면 최소 L4 로드밸런서 이상을 사용해야 만 한다.
+
+# L4 로드밸런싱과 L7로드 밸런싱
+
+
+
+L4 로드밸런서는 네트워크 계층(IP.IPX)이나 트랜스포트 계층(TCP,UDP)의 정보를 바탕으로 로드를 분산한다.
+
+IP주소나 포트번호, MAC주소, 전송 프로토콜에 따라 트래픽을 나누는 것이 가능하다.
+
+반면 L7 로드밸런서의 경우 애플리케이션 계층 (HTTP, FTP, SMTP)에서 로드를 분산하기 때문에 HTTP헤더, 쿠키 등과 같은 사용자의 요청을 기준으로 특정 서버에 트래픽을 분산하는 것이 가능하다.
+
+쉽게 말해 패킷의 내용을 확인하고 그 내용에 따라 로드를 특정 서버에 분배하는 것이 가능한 것이다.
+
+위 그림과 같이 URL에 따라 부하를 분산시키거나, HTTP 헤더의 쿠키 값에 따라 부하를 분산하는 등
+
+클라이언트의 요청을 보다 세분화하여 서버에 전달 할 수 있다. 또한 L7 로드밸런서의 경우 특정한 패턴을 지닌 바이러스를 감지해 네트워크를 보호할 수 있으며 Dos/DDoS 과 같은 비정상적인 트래픽을 필터링할 수 있어 네트워크 보안 분야에서도 활용되고 있다.
+
+
\ No newline at end of file
diff --git "a/Network/minseo/loadBalancing/\353\241\234\353\223\234 \353\260\270\353\237\260\354\213\261/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_2.43.33.png" "b/Network/minseo/loadBalancing/\353\241\234\353\223\234 \353\260\270\353\237\260\354\213\261/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_2.43.33.png"
new file mode 100644
index 0000000..356f944
Binary files /dev/null and "b/Network/minseo/loadBalancing/\353\241\234\353\223\234 \353\260\270\353\237\260\354\213\261/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_2.43.33.png" differ
diff --git "a/Network/minseo/loadBalancing/\353\241\234\353\223\234 \353\260\270\353\237\260\354\213\261/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_2.44.27.png" "b/Network/minseo/loadBalancing/\353\241\234\353\223\234 \353\260\270\353\237\260\354\213\261/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_2.44.27.png"
new file mode 100644
index 0000000..5c4b4a2
Binary files /dev/null and "b/Network/minseo/loadBalancing/\353\241\234\353\223\234 \353\260\270\353\237\260\354\213\261/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_2.44.27.png" differ
diff --git a/Network/minseo/physicalLayer/physical layer.md b/Network/minseo/physicalLayer/physical layer.md
new file mode 100644
index 0000000..7a86dfc
--- /dev/null
+++ b/Network/minseo/physicalLayer/physical layer.md
@@ -0,0 +1,27 @@
+# physical layer
+
+
+
+### 주된 기능
+
+1) 비트 단위의 데이터 전송
+
+2) 내트워크 장비로 데이터를 전기신호로 출력
+
+3) 데이터 링크 계층의 데이터 통신 기능을 원활하게 수행하도록 물리적인 연결 설정과 유지 및 해제기능과 관계
+
+단, Physical Layer은 단지 데이터를 전달만 할뿐 이 데이터가 무엇인지, 어떤 에러가 있는지, 어떻게 보내는 것이 더 효과적인지 하는 것은 전혀 관여하지 않음
+
+Physical Layer에 관련되는 프로토콜은 DTE/DCE 인터페이스로 규정한다.
+
+DTE/DCE 인터페이스?
+
+변복조기, DSU 등 통신 회선에 연결되는 장치의 퍼스널 컴퓨터 또는 단말기 사이를 연결하는 신호선, 커넥터에 대해 규정
+
+### Physical Layer의 대표적인 장비
+
+1) 통신 케이블
+
+2) 리퍼터
+
+3) 허브
\ No newline at end of file
diff --git a/Network/minseo/physicalLayer/physical layer/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_3.34.45.png b/Network/minseo/physicalLayer/physical layer/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_3.34.45.png
new file mode 100644
index 0000000..6eedf73
Binary files /dev/null and b/Network/minseo/physicalLayer/physical layer/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_3.34.45.png differ
diff --git "a/Network/minseo/routing&router/\353\235\274\354\232\260\355\214\205 & \353\235\274\354\232\260\355\204\260/Untitled 1.png" "b/Network/minseo/routing&router/\353\235\274\354\232\260\355\214\205 & \353\235\274\354\232\260\355\204\260/Untitled 1.png"
new file mode 100644
index 0000000..4a0239d
Binary files /dev/null and "b/Network/minseo/routing&router/\353\235\274\354\232\260\355\214\205 & \353\235\274\354\232\260\355\204\260/Untitled 1.png" differ
diff --git "a/Network/minseo/routing&router/\353\235\274\354\232\260\355\214\205 & \353\235\274\354\232\260\355\204\260/Untitled.png" "b/Network/minseo/routing&router/\353\235\274\354\232\260\355\214\205 & \353\235\274\354\232\260\355\204\260/Untitled.png"
new file mode 100644
index 0000000..2f0a6b5
Binary files /dev/null and "b/Network/minseo/routing&router/\353\235\274\354\232\260\355\214\205 & \353\235\274\354\232\260\355\204\260/Untitled.png" differ
diff --git "a/Network/minseo/routing&router/\353\235\274\354\232\260\355\214\205 & \353\235\274\354\232\260\355\204\260md" "b/Network/minseo/routing&router/\353\235\274\354\232\260\355\214\205 & \353\235\274\354\232\260\355\204\260md"
new file mode 100644
index 0000000..8683cdd
--- /dev/null
+++ "b/Network/minseo/routing&router/\353\235\274\354\232\260\355\214\205 & \353\235\274\354\232\260\355\204\260md"
@@ -0,0 +1,159 @@
+# 라우팅 & 라우터
+
+# 라우팅이란?
+
+라우터(router)는 패킷(packet)의 목적지 주소를 확인하고, 목적지와 연결되는 인터페이스로 전송하는 역할을 한다.
+
+
+
+말 그대로 Route(경로)를 선택하여 데이터가 전달될 수 있게 하는 것을 말하는데 이 경로를 최단거리, 최단시간에 전달될 수 있게 하는 것이 핵심적인 내용이다.
+
+이와 같은 라우터의 기능을 라우팅(routing)이라고 합니다. 특히, IP 라우팅이란 패킷의 목적지 IP 주소를 참조하여 길을 찾아주는 것이다.
+
+예를 들어 인천에는 여러 가지 경로가 존재하는데, 이 많은 경로 중에 하나를 선택하여 이동하는 것을 라우팅이라 한다.
+
+# 경로 선택
+
+당연히도 라우터는 특정 데이터(패킷)의 목적지인 IP주소에 대한 정보를 갖고 있어야 스위칭이 가능하다.
+
+내가 부산에 사는데 서울이 어딘지도 모른다면 어디로 가야하는지 모를수밖에 없겠죠. 또, 길이 어떻게 생겨먹었는지도 알아야 할 것이고, 어디가 교통량이 많고 적은지, 어떤 톨 게이트를 거쳐야 하는지 등 알아야 할 정보가 많을겁니다.
+
+라우팅 또한 최적의 경로를 선택하기 위해서는 이러한 정보들을 알고, 활용해야 합니다. 다음과 같은 요소들이 라우팅 경로 결정에 사용된다.
+
+- 토폴로지
+- 트래픽
+- 링크 비용
+- 메시지
+- 라우팅 테이블
+
+# **라우팅 프로토콜의 구분과 종류**
+
+해당 목적지에 대한 정보를 알아야 하며 그 정보에 따라 패킷을 전달한다. 그래서 라우터들은 목적지에 대한 경로 정보를 이웃 라우터들과 공유하게 된다. 이 때 교환하는 것을 라우팅 프로토콜이라 한다.
+
+
+
+라우터는 다른 라우터들로부터 라우팅 정보를 수신한 다음 그 중에서 최적의 경로를 선택하여 라우팅 테이블에 저장한다. 라우팅 테이블이란 목적지 네트워크 및 목적지 네트워크와 연결되는 인터페이스를 기록한 데이터베이스이다.
+
+## **정보 갱신 방법에 따른 구분**
+
+라우팅 경로는 동적 경로(dynamic route)와 정적 겅로(static route)가 있다.
+
+| 구분 | 특징 |
+| --- | --- |
+| 정적 라우팅(Static Routing) | - 네트워크 관리자가 경로를 수동으로 직접 지정해 주는 방식. - 구성이 간단하고, 원하는 경로로 패킷을 보낼 수 있음. - 단일 경로에 적합하여 Stub Network 에 주로 적용. - 네트워크 구성 변화에 수동적임. - 관리 부담의 증가 및 경로 장애 발생시에 라우팅이 불가능함. |
+| 동적 라우팅(Dynamic Routing) | - 장비가 자동으로 경로를 지정함. - 네트워크 변화를 인지하여 경로를 재구성할 수 있음. - 다중경로 네트워크에 적합함. - 라우팅 프로토콜(routing protocol)을 사용하여 동적으로 알아낸 경로 |
+
+수동(고정) 경로 설정과 적응 경로 설정의 차이다.
+
+ 부산→서울 이동 경로를 생각했을때, 나는 무조건 정해진 길로만 가겠다! 와 차막히면 돌아가지 뭐,, 네비게이션이 안내 해 주는대로 가자~~ 정도의 차이라고 생각하시면 됩니다.
+
+## **내/외부에 따른 구분**
+
+**같은 네트워크 관리자가 관리하는 라우터들과 일정 규모의 집합을 AS(Autonomus System)** 이라 칭하는데, 이 규모에 따라 구분하는 방식
+
+| 구분 | 특징 |
+| --- | --- |
+| IGP(Interior Gateway Protocol) | - AS 내에서의 라우팅을 담당하는 프로토콜. |
+| EGP(Exterior Gateway Protocol) | - 서로 다른 AS간 사용되는 프로토콜. |
+
+마치 내부망, 외부망을 구분짓는 것과 느낌이 비슷한데, 이 구분이 망 구성이 중점이 되는것이 아니고 관리자나 관리 업체가 중점이 되는것이 차이점입니다.
+
+예를들어 KT가 관리하는 라우터들은 KT 입장에서는 IGP를 사용하고 SK가 관리하는 라우터들과는 EGP를 사용하게 되는겁니다.
+
+## **테이블 관리 방법에 따른 구분**
+
+| 구분 | 특징 |
+| --- | --- |
+| Distance VectorAlgorithm | - 최단 거리를 홉 수로 판단함. - 주기적으로 라우팅 테이블을 교환함. |
+| Link StateAlgorithm | - 대역폭, 지연시간, 토폴로지를 참고하여 Cost를 책정함. - 라우터가 목적지까지 가는 경로를 모든 라우팅 테이블에 기록함. |
+| Hybrid RoutingAlgorithm | - 거리벡터, 링크상태를 복합적으로 사용한 방식. - Cisco 독점 프로토콜. |
+
+부산→서울 이동을 생각했을 때, 나는 톨 게이트를 최대한 적게 지나가는 경로로 가겠다! 하는것이 거리벡터, 나는 교통량이 적은 곳으로 최대한 빨리 가보겠다! 하는것이 링크상태방식이다.
+
+링크상태 방식에서 말하는 비용(Cost)은 금전적 의미가 아니고 **통신 속도**를 의미한다. 비용이 낮을수록 대역폭이 크다던가, 지연시간이 낮다던가 하는 것으로 빨리 전달할 수 있으면 비용이 낮다고 판단한다.
+
+거리 벡터는 거리, 방향을 중점으로 최단거리 계산을 위해 Bellman-Ford 알고리즘을 사용합니다.
+
+링크 상태는 라우터들이 정보를 주고받아 전체 토폴로지를 그리며 Dijkstra's 알고리즘을 사용합니다.
+
+# 패킷
+
+이렇게 라우팅 테이블이 만들어지면 해당 라우터는 특정 목적지 네트워크로 가는 패킷을 라우팅시킬 수 있다.
+
+라우터가 패킷을 수신하고, 라우팅 테이블에 따라 정해진 목적지 인터페이스로 해당 패킷을 전송하게 된다.
+
+## 1. 패킷의 처리
+
+**1) 패킷의 발송**
+
+이러한 IP패킷이 네트워크가 통과 시킬 수 있는 최대 바이트보다 클 경우에는 `단편화(Fragmentation)`시켜 보내게 되는데 그 단편화 정보도 IP패킷의 헤더에 저장하여 보내게 된다.
+
+**2) 최종 목적지**
+
+단편화된 패킷을 받은 목적지에서는 다면, 단편들을 모아서 **하나의 온전한 패킷을 조립한다.** 여기서 만약 하나의 온전한 패킷으로 조립이 불가능 하다면 모두 폐기시키고 이를 송신지에게 `CMP(Internet Control Message Protocol)메세지`를 보내게 된다.
+
+## 2. 패킷의 전달
+
+**1) 직접전달(Direct delivery)**
+
+패킷의 송신지와 목적지가 동일한 네트워크에 연결되어 있을 때 직접전달하는 경우.
+
+**2) 간접전달(Indirect delivery)**
+
+패킷이 최종 목적지에 전달될 때까지 라우터에서 라우터로 전달되는 경우.
+
+### 3. 라우팅 테이블
+
+우리가 어떤 웹사이트에 접속을 한다고 했을 때 송신측의 네트워크 계층에서는 데이터 앞쪽에 정보를 담은 헤더(header)를 붙이게 된다.
+
+**여기서 네트워크 계층에 데이터가 어디로 가야할지 경로를 설정할 수 있도록 `표 형태`로 구성되어 있는 것**을 `라우팅 테이블` 이라고 한다.
+
+즉, 목적지로 갈때 최적의 경로가 표로 구성되어 있는 것을 라우팅 테이블이라고 하고 이를 참조하여 IP패킷을 보내게 되어있다.
+
+이러한 라우팅 테이블은 처음 송신지에서 보낼때만 참조하는 것이 아니라 네트워크를 통해 이동하다가 **중간 장치들인 스위치나 라우터에서도 라우팅 테이블을 참조**하여 패킷을 보낸다.
+
+**1) 라우팅 프로토콜**
+
+라우팅 테이블을 만들어 주는 것이 바로 `라우팅 프로토콜`이다. 라우팅 프로토콜에서 라우팅 정보를 주고 받음으로써 이를 판단해 라우팅 테이블을 만들게 된다.
+
+**2) 패킷의 전달 방법**
+
+- **이웃노드명시(Next-hop method)**
+
+ 라우팅 테이블은 전체 경로상의 라우터를 명시하지 않고 `다음 라우터`만 명시한다.
+
+ 
+
+ - A -> R1 -> R2 -> B 와 같이 전체 경로를 명시하는 것이 아니라 A는 R1만 명시!*(과도한 메모리사용으로 비효율적이기 때문!)*
+
+- **네트워크 주소 명시(Network specific method)**
+
+ IP주소는 크게 `네트워크ID`와 `호스트ID`로 구성되어 있는데 여기서 네트워크ID를 기반으로 호스트ID를 할당하기 때문에 만약 특정 기관이라면 그 안에 있는 모든 컴퓨터들은 네트워크ID가 모두 동일하게 된다.
+
+ 이렇듯 목적지로 IP패킷을 전달할때 동일한 네트워크에 연결된 컴퓨터들을 하나하나 모두 명시하는 것이 아니라 **목적지 네트워크 주소만 명시하여 보내는 것**을 네트워크 주소 명시라고 한다.
+
+ 이처럼 간단하게 표기하게 되면 테이블 사이즈가 줄어들게 되고 이 효과로 빠른 검색과 메모리 효율성을 높일 수 있다.
+
+ > 호스트 주소 명시(Host-specific method)
+ >
+ >
+ > `특별한 목적`이 있는 경우라면 라우팅 테이블에 목적지 컴퓨터 주소를 직접 명시할수 있다! -> 관리자가 직접 입력해야함 (ex. 보안목적 등..)
+ >
+
+- **디폴트 지정(Default method)**
+
+ 인터넷에 있는 모든 목적지를 지정할 수 없음으로 지정된 목적지 이외의 모든 지역을 지정하는 라우팅 엔트리를 `디폴트(Default)`라고 한다.(내가 지정한거 외에는 다 얘한테 보내!)
+
+ > 보통 네트워크 주소가 0.0.0.0으로 표기 됨!
+ >
+
+**3) 라우팅 프로토콜의 종류**
+
+**(1) 유니캐스트 라우팅 프로토콜** = 보통의 그냥 라우팅 프로토콜
+
+- `일대일 통신`을 말함
+- 디지털 서명(Digital Signature)목적지가 하나이며 라우팅 정보를 교환하여 라우팅 테이블을 구축하는 형태
+
+**(2) 멀티캐스트 라우팅 프로토콜**
+
+- 송신지는 하나, 수신지는 여러개인 시스템으로 목적지가 동일한 그룹에 속한 여러 호스트가 될 수 있다.
\ No newline at end of file
diff --git "a/Network/minseo/tcp connection && socket/TCP Connection\352\263\274 Socket .md" "b/Network/minseo/tcp connection && socket/TCP Connection\352\263\274 Socket .md"
index af1f9ba..e462dbc 100644
--- "a/Network/minseo/tcp connection && socket/TCP Connection\352\263\274 Socket .md"
+++ "b/Network/minseo/tcp connection && socket/TCP Connection\352\263\274 Socket .md"
@@ -9,7 +9,7 @@
### TCP/IP stack
-**TCP/IP stack은 인터넷이 발명되면서 함께 개발된 프로토콜 스택이다.**
+**TCP/IP stack은 인터넷이 발명되면서 함께 개발된 프로토콜 스택이다 .**
- IETF에서 인터넷 표준을 관리한다.(RFC)
- TCP, UDP, IP.. 스펙은 RFC에서 정의한다.
diff --git a/Network/yerin/tcp_and_ip.md b/Network/yerin/tcp_and_ip.md
new file mode 100644
index 0000000..5e22aae
--- /dev/null
+++ b/Network/yerin/tcp_and_ip.md
@@ -0,0 +1,354 @@
+# 네트워크 2주차
+
+https://hyper-hotel-11e.notion.site/2-6287a99bb3984c248c4823c0a4c012ed?pvs=4
+
+# 📌TCP
+
+## UDP
+
+UDP에도 오류를 감지하는 기능은 있다. ⇒ Checksum으로.
+
+근데 감지만 하고, TCP와 달리 오류를 정정하거나 재전송하는 메커니즘을 제공하진 않는다.
+
+정정안해줄거면 왜 굳이 감지를 해줄까?
+
+⇒ 과도한 체크섬 오류는 네트워크 장비의 문제나 데이터 경로상의 문제를 나타내줌.
+
+⇒ Application layer에서 필요하면 선택적으로 재요청하게끔 적어도 알려는 준다는 느낌
+
+## TCP
+
+네트워크 통신에서 신뢰적인 연결방식을 사용한다는 특징이 있다.
+
+TCP는 기본적으로 unreliable network에서, reliable network (reliable data transfer)를 보장할 수 있도록 하는 프로토콜이다.
+
+TCP 통신을 하다보면 Segment 전송에 에러가 생기는 경우가 있다.
+
+- Loss - 손실 문제
+- Corruption - bit error
+- Congestion - 네트워크 혼잡 문제
+
+Solution ⇒ ACK, Checksum, Time-out, Retransmission, Seq #
+
+TCP는 이 에러들을 정정해줘야하고, 흐름과 혼잡을 제어해야한다. 왜냐하면 신뢰적인 연결방식을 사용하는 프로토콜이니까. TCP 프로토콜의 흐름제어와 혼잡제어 방식을 이해하기위해서는 몇가지 용어들과 과정들을 알아야한다.
+
+### ACK
+
+ACK(Acknowledgements) : 리시버가 센더에게 OK 잘 왔음이라고 답해주는 것
+
+ack은 리시버가 센더에게 잘 받았다고 전달해주는 메시지 개념인데, 이 ack 또한 센더한테 전달될때 에러가 날 수 있음. 이때 센더입장에서는 “못 받았나보네, 다시 보내야지” 하면서 첫번째 Segment를 다시 보냄. 그러면 리시버 입장에서는 첫번째 segment를 받은 상태이기 때문에 위 센더가 다시 보낸 값을 두번째 segment로 인식하게 됨. 이러한 문제를 해결하기 위해 Sequence Number 개념이 탄생.
+
+sequence number로 전달할 segment의 순서를 구분하게됨.
+
+### TCP Header
+
+https://blog.kakaocdn.net/dn/b2OtbA/btqAMlJTLi1/CTJcSSlZ7qzxlBrmgc5Pb1/img.png
+
+
+
+TCP flag(URG, ACK, PSH, RST, SYN, FIN)
+
+FLAG 순서 - | URG | ACK | PSH | RST | SYN | FIN |
+
+### ACK(Acknowledgement) - Ack : 응답
+
+상대로부터 패킷을 받았다는 걸 알려주는 패킷
+
+### SYN(Synchronization:동기화) - S : 연결 요청 플래그
+
+TCP 에서 세션을 성립할 때 가장먼저 보내는 패킷, 시퀀스 번호를 임의적으로 설정하여 세션을 연결하는 데에 사용되며 초기에 시퀀스 번호 (ISN) 를 보내게 된다.
+
+### FIN(Finish) - F : 종료
+
+연결 종료 요청세션 연결을 종료시킬 때 사용. 더이상 전송할 데이터가 없음을 나타냄
+
+### RST(Reset) - R : 리셋
+
+연결 종료재설정(Reset)을 하는 과정, 양방향에서 동시에 일어나는 중단 작업
+
+비 정상적인 세션 연결 끊기. 현재 접속하고 있는 곳과 즉시 연결을 끊고자 할 때 사용
+
+## 🔸TCP 3 way handshaking (연결)
+
+
+
+서버 listen() 상태
+
+1. 클라이언트 connect(), C->S 접속요청 패킷 SYN(M) 전송
+
+2. 서버 accept(), S->C 요청 수락 패킷 ACK(M+1), SYN(N) 전송
+
+3. 클라이언트 connect(), C->S 요청 수락 확인 패킷 ACK(N+1) 전송
+
+### 연결 성립
+
+## 🔸TCP 4 way handshaking (해제)
+
+
+
+1. C->S 연결 종료요청 FIN FLAG 전송
+
+2. S->C 종료 수락 메시지 ACK 전송
+
+일시적 TIME_OUT (데이터를 모두 보낼 때 까지)
+
+3. S->C 연결 종료 FIN FLAG 전송
+
+4. C->S 확인 메시지 ACK 전송
+
+서버 소켓 연결 close(), 클라이언트 일정 시간 동안 TIME_WAIT (잉여패킷 대기)
+
+### 연결 해제
+
+## 🔸TCP 흐름제어
+
+ **Window** : 윈도우는 메모리 버퍼의 일정 영역이라고 생각하면 된다. TCP/IP를 사용하는 모든 호스트들은 송신하기 위한 것과 수신하기 위한 2개의 Window를 가지고 있다. 호스트들은 실제 데이터를 보내기 전에 '3 way handshaking'을 통해 리시버의 receive window size에 자신의 send window size를 맞추게 된다.
+
+### **TCP Buffer**
+
+
+
+흐름 제어는 송신 측과 수신 측의 TCP 버퍼 크기 차이로 인해 생기는 데이터 처리 속도 차이를 해결하기 위한 기법이다.
+
+수신측에서 제한된 저장 용량을 초과한 이후에 도착하는 데이터는 손실 될 수 있으며, 만약 손실 된다면 불필요하게 응답과 데이터 전송이 송/수신 측 간에 빈번이 발생한다.
+
+이러한 위험을 줄이기 위해 송신 측의 데이터 전송량을 수신측에 따라 조절해야한다.
+
+흐름제어기법
+
+### 1. stop and wait
+
+매번 전송한 패킷에 대해 확인 응답(ACK)를 받으면 다음 패킷을 전송하는 방법이다. 그러나 패킷을 하나씩 보내기 때문에 비효율적인 방법이다.
+
+⇒ 파이프라이닝 형식을 사용해 효율성을 높임
+
+**슬라이딩 윈도우**
+
+- Go-back-N (슬라이딩 윈도우 방식을 이용한 오류제어 기법)
+- Selevtive Repeat (슬라이딩 윈도우 방식을 이용한 오류제어 기법)
+
+### 2. Sliding Window
+
+리시버는 rwnd 값을 포함한 tcp header를 센더에게 전달되는 segment에 담아 보내기 때문에 센더는 리시버의 rwnd값에 따라 in-flight 값을 제한할 수 있다.
+
+window size만큼 순서대로 모두 보내고, ack이 오면 그만큼 윈도우 이동하는 방식
+
+## 🔸TCP 혼잡제어
+
+센더의 데이터는 지역망이나 인터넷으로 연결된 대형 네트워크를 통해 전달된다. 만약 데이터가 한 곳으로 몰릴 경우, 자신에게 온 데이터를 모두 처리할 수 없게 된다. 이런 경우 혼잡으로 인한 오버플로우나 데이터 손실이 발생한다.
+
+따라서 이러한 네트워크의 혼잡을 피하기 위해 센더측에서 보내는 데이터의 전송속도를 강제로 줄이게 되는데, 이러한 작업을 혼잡제어라고 한다.
+
+TCP Tahoe와 Reno 등 혼잡 제어 정책들은 공통적으로 `혼잡이 발생하면 윈도우 크기를 줄이거나, 혹은 증가시키지 않으며 혼잡을 회피한다` 라는 전제를 깔고 있다.
+
+TCP Tahoe와 Reno 정책을 알아보기전에 몇가지 혼잡제어 방식과 관련 용어들을 알아야한다.
+
+1. **Timeout**
+
+여러 가지 요인으로 인해 센더가 보낸 데이터 자체가 유실되었거나,
+
+리시버가 응답으로 보낸 ACK이 유실되는 경우 센더가 설정해놓은 timeout에 걸리게 된다.
+
+1. **3 Duplicate ACKs**
+
+!https://blog.kakaocdn.net/dn/ci8GSU/btrlpLaCuUk/KHpoUNv1tRnEHPzOtXd4Gk/img.png
+
+ 중복 ACK 3개를 받으면 문제가 있다고 판단하여 해당 패킷을 재전송한다. 해당 기법을 `빠른 재전송` 이라고 부르며, 센더는 자신이 설정한 타임 아웃 시간이 지나지 않았어도 바로 해당 패킷을 재전송할 수 있기 때문에 보다 빠른 전송률을 유지할 수 있게 된다.
+
+1. ****AIMD(Additive Increase / Multiplicative Decrease)****
+ - 문제가 발생하기 전까지 cwnd 1씩 증가
+ - 문제가 발생하면 cwnd를 절반으로 감소
+
+ 문제점은 초기에 네트워크의 높은 대역폭을 사용하지 못하여 오랜 시간이 걸리게 되고, 네트워크가 혼잡해지는 상황을 미리 감지하지 못한다. 즉, 네트워크가 혼잡해지고 나서야 대역폭을 줄이는 방식이다.
+
+2. ****Slow Start****
+ - Slow Start 방식은 AIMD와 마찬가지로 패킷을 하나씩 보내면서 시작하고, 패킷이 문제없이 도착하면 각각의 ACK 패킷마다 window size를 1씩 늘려준다. 즉, 한 주기가 지나면 window size가 2배로 된다.
+ - 전송속도는 AIMD에 반해 지수 함수 꼴로 증가한다. 대신에 혼잡 현상이 발생하면 window size를 1로 떨어뜨리게 된다.
+
+ 
+
+
+**Slow Start 임계점 (ssthresh)**
+
+
+
+ `Slow Start Threshold(ssthresh)` 여기까지만 Slow Start를 사용하겠다는 의미를 가진다.
+
+Slow Start를 사용하며 윈도우 크기를 지수적으로 증가시키다보면 어느 순간부터는 윈도우 크기가 기하급수적으로 늘어나서 제어하기가 힘들다. 또한, 네트워크의 혼잡이 예상되는 상황에서 빠르게 값을 증가시키기 보다는 조금씩 증가시키는 편이 훨씬 안전하다.
+
+그래서 특정한 임계점을 정해 놓고, 그 임계점이 넘어가면 AIMD 방식을 사용하여 선형적으로 윈도우를 증가시킨다.
+
+(이 임계점은 계속 초기값을 가지는 건 아님. loss event가 발생하면 그 발생했을때의 cwnd의 절반 사이즈로 세팅됨)
+
+1. **Fast Recovery**
+
+혼잡한 상태가 되면 window size를 1이 아닌 반으로 줄이고 선형증가시키는 방법이다. 이 정책까지 적용하면 혼잡 상황을 한번 겪고 나서부터는 순수한 AIMD 방식으로 동작하게 된다.
+
+### TCP Tahoe
+
+
+
+이 정책은 한 번 혼잡 상황이 발생한 지점을 기억하고 그 지점이 가까워지지 않도록 합리적으로 조절하고 있다. 하지만, 초반의 Slow Start 구간에 윈도우 크기를 늘릴 때 오래 걸린다는 단점이 있고, 혼잡 상황이 발생했을 때 다시 윈도우 크기를 1에서부터 시작해야 한다는 단점이 있다.
+
+### TCP Reno
+
+
+
+TCP Reno는 TCP Tahoe 이후에 나온 정책으로, Tahoe와 마찬가지로 Slow Start로 시작하여 임계점을 넘어서면 AIMD을 사용한다. 다만, Tahoe와는 다르게 3 ACK Duplicated와 Timeout 혼잡 상황을 구분한다.
+
+Reno는 3개의 중복 ACK가 발생했을 때, 윈도우 크기를 1로 줄이는 것이 아니라 AIMD처럼 반으로만 줄이고 sshthresh를 줄어든 윈도우 값으로 정하게 된다. 이 방식을 `빠른 회복`이라고 부른다.
+
+그러나 Timeout에 의해서 데이터가 손실되면 Tahoe와 마찬가지로 윈도우 크기를 바로 1로 줄여버리고 Slow Start를 진행한다. 이때 ssthresh를 변경하지는 않는다.
+
+즉, Reno는 ACK 중복은 Timeout에 비해 그리 큰 혼잡이 아니라고 가정하고 혼잡 윈도우 크기를 1로 줄이지도 않는다는 점에서 혼잡 상황의 우선 순위를 둔 정책이라 볼 수 있다.
+
+
+
+---
+
+# 📌IP (Internet Protocol)
+
+> 인터넷 프로토콜의 약자로 송신 호스트와 수신 호스트가 패킷 교환 네트워크에서 정보를 주고받는데 사용하는 정보 위주의 규약
+>
+
+- 인터넷에서 데이터를 송수신하기 위한 주요 프로토콜
+- 데이터를 소스에서 목적지까지 전달
+- 비신뢰성과 비연결성
+- 패킷 전송과 정확한 순서를 보장하기 위해 TCP 프로토콜을 이용
+
+**고정 IP**
+
+- 컴퓨터가 고정적으로 가지고 있는 IP이다.
+- 한 번 부여받으면 **반납하기 전까지 변하지 않는다**.
+- 주로 인터넷 사이트를 운영할 때 사용한다.
+
+**유동 IP**
+
+- 컴퓨터에 고정된 IP를 부여하지 않고 **IP 갱신 주기가 되었을 때 ISP로부터 할당받는 IP**이다.
+- 사용하지 않는 IP를 수거하는 방식이다.
+ - 더 많은 사용자에게 인터넷 서비스를 제공할 수 있다.
+
+**공인 IP**
+
+- **외부에 공개된 IP**다.
+- 해킹의 위험이 있기에 보안 프로그램이 필요하다.
+
+**사설 IP**
+
+- **외부에서 접근할 수 없는 IP**다.
+- 주로 일반 가정 또는 회사 내부에서 사용한다.
+- 공인 IP가 할당된 라우터나 공유기를 통해 사설 IP가 할당된다.
+
+## IPv4
+
+
+
+IPv4 주소는 전세계적으로 관리되는 32bit의 유효한 자원으로 8 bits 씩 나눠져서 일부는 Network, 다른 일부는 Host의 번호를 표현하는데 사용된다. 네트워크 부분은 특정 네트워크를 식별하고, 호스트 부분은 그 네트워크 내의 특정 장치를 식별한다.
+
+- 주소는 점으로 구분된 네 개의 숫자(예: 192.168.0.1)로 표현
+- 인터넷 상에서 장치를 식별하는 데 사용 ⇒ IPv4 주소는 고유해야 함
+
+### IPv4 주소 고갈 & 대응 방안
+
+원인 : 인터넷의 지속적인 성장과 연결되는 장치의 증가
+
+IPv4 주소는 32비트로 구성되어 있어, 이론적으로 약 42억 개(2의 32승)의 고유한 주소만 제공 가능
+
+**대응 방안**
+
+ (IPv6가 근본적인 주소 고갈 대응 방안이라고 할 수 있고, 나머지는 IPv4 주소 공간을 보다 효율적으로 관리하고 활용하기 위한 임시 방안이라고 할 수 있다.)
+
+1. Subnetting & CIDR
+2. NAT
+3. DHCP
+4. IPv6
+
+## IPv6
+
+IPv4의 고갈 문제를 해결하기 위해 IPv6가 등장하였다.
+
+총 128비트로 각 16비트씩 8자리로 각 자리는 ‘:’(콜론)으로 구분한다.
+
+ex) 2001:0DB8:1000:0000:0000:0000:1111:2222
+
+총 2^128 의 IP 주소를 만들어낸다.
+
+### IPv4와의 차이점
+
+---
+
+1. **주소 체계 및 길이**
+
+- **IPv4**:
+ - 32비트 주소 체계
+ - 주소는 점으로 구분된 십진수 형식으로 표시 / 예: 192.168.1.1
+- **IPv6**:
+ - 128비트 주소 체계를 사용하여, 거의 무한에 가까운 주소 공간을 제공
+ - 주소는 콜론으로 구분된 16진수 형식으로 표시됩니다. / 예: 2001:0db8:85a3:0000:0000:8a2e:0370:7334
+
+
+**2. 주소 할당 및 관리**
+
+- **IPv4**:
+ - 정적(수동) 또는 동적(DHCP) 방식으로 주소 할당
+ - 주소 공간의 제한으로 인해 주소 할당을 효율적으로 해야한다.
+- **IPv6**:
+ - 주소의 풍부함으로 인해 주소 할당에 있어 더 많은 유연성을 가짐
+
+
+**3. 보안**
+
+- **IPv4**:
+ - 기본적으로 보안 기능이 내장되어 있지 않습니다.
+ - 보안을 위해 IPsec과 같은 별도의 프로토콜을 사용할 수 있으나, 선택적입니다.
+
+ (IPsec은 Host-to-Host와 Network-to-Network간의 Data Flow를 암호화 시키는 Protocol Suite)
+
+- **IPv6**:
+ - 보안을 위한 IPsec이 기본적으로 내장되어 있어, 보다 향상된 보안 기능을 제공합니다.
+
+ (참고로, 초창기 모든 IPv6는 IPsec를 필수적으로 지원하게 되어 있어 IPv6 Network의 높은 보안성을 기대하였으나, 낮은 Network Processor를 가진 IPv6 Nodes로 인하여 IPsec의 기능이 "Recommended" 수준으로 하향 조정 되었다. 하지만, IPsec이 "Option"으로 지원이 되는 IPv4 Network에 비하여 IPv6 Network이 여전히 높은 보안성을 가진다.)
+
+
+**4. 헤더 형식 및 처리**
+
+- **IPv4**:
+ - 헤더가 상대적으로 복잡하고 옵션 필드가 있어 처리가 더 복잡함
+ - 헤더 길이가 가변적
+
+- **IPv6**:
+ - 헤더 구조가 간소화되어 있고, 대부분 고정 길이
+ - checksum x (DataLink Layer에서 오류를 검사하기 때문에 IP 패킷의 빠른 처리를 위해 삭제)
+
+
+**5. fragmentation 단편화**
+
+Fragmentation은 데이터 패킷을 네트워크를 통해 전송할 때 발생하는 과정으로, 큰 데이터 패킷을 더 작은 단위로 나누는 것
+
+왜?
+
+MTU라는 한 번에 전송할 수 있는 데이터의 최대 크기를 나타내는 단위가 있는데, 네트워크 경로상 각 네트워크 세그먼트의 MTU보다 보내려는 데이터 패킷 크기가 크다면 그 패킷은 네트워크를 통과할 수 없다. 따라서 데이터 패킷은 MTU 크기에 맞게 여러 개의 작은 패킷으로 분할되어야 한다.
+
+- **IPv4**:
+ - 출발/목적지 또는 중간 라우터에서 수행
+- **IPv6**:
+ - 송신자만 수행하며, 중간 라우터에서는 수행x
+
+ 단편화 & 재결합 과정은 시간이 소요되는 일이므로 라우터에서 수행을 하지 않음으로써 네트워크 효율성이 증가
+
+
+---
+
+
+
+# 면접질문
+
+## TCP의 등장을 IP와 연결지어 설명하라.
+
+
+ IP는 데이터가 소스에서 목적지까지 도달하는 것만을 책임지며, 데이터의 순서, 무결성, 신뢰성 등에 대해서는 보장하지 않습니다.
+ IP에서 오류가 발생한다면 ICMP에서 오류가 발생했음을 알려주긴 하지만 ICMP는 알려주기만 할 뿐 대처를 해주지 않기 때문에 IP보다 위에서 오류에 대한 처리를 해줘야 합니다. 즉 이를 Transport layer에서 해결을 해주어야합니다.
+
+ 따라서, TCP는 IP의 기능을 보완하고, 다양한 네트워크 애플리케이션과 서비스의 요구 사항을 충족시키기 위해 도입되었습니다.
+
+ - ICMP : 인터넷 제어 메시지 프로토콜로 네트워크 컴퓨터 위에서 돌아가는 운영체제에서 오류 메시지를 전송받는데 주로 쓰임. ICMP는 문제를 알리지만, 문제 해결은 해주지 않는다.
\ No newline at end of file
diff --git a/Network/yerin/week3.md b/Network/yerin/week3.md
new file mode 100644
index 0000000..9852f2c
--- /dev/null
+++ b/Network/yerin/week3.md
@@ -0,0 +1,301 @@
+# 네트워크 3주차
+https://hyper-hotel-11e.notion.site/3-b7fe25e9a1464e0ea6e7367c59099129?pvs=4
+
+# 📌Router & Routing
+
+Network Layer의 핵심 : Routing & Forwarding
+
+== 라우터의 역할
+
+### **Routing**
+
+ "어디로 가야 하는가?"
+
+라우팅은 네트워크의 여러 경로 중에서 특정 목적지로 데이터 패킷을 보내기 위한 최적의 경로를 결정하는 과정
+
+⇒ **라우팅 알고리즘**에 의해 결정됨
+
+global & static ⇒ link state 알고리즘
+
+- 모든 라우터가 모든 연결사항을 알 때
+- 전체 구조와 링크 상태 파악
+- 변화가 아주 느리게 발생
+- 문제 발생 시 전체 정보를 알기 때문에 문제 지점만 제거하면 됨
+
+decentralized & dynamic ⇒ distance vector 알고리즘
+
+- 이웃의 정보만 공유
+- 각 router가 알아서 처리
+- 다소 변화가 빠름
+- 이상한 정보를 믿고 전파할 수도 있음
+
+### **Forwarding**
+
+ "이 패킷을 어떻게 그곳으로 보내는가?"
+
+포워딩은 라우터가 라우팅 테이블의 결정에 따라 실제로 데이터 패킷을 다음 홉(다음 네트워크 장비로 이동) 또는 최종 목적지로 전달하는 과정
+
+
+
+# 📌DHCP
+
+host는 어떻게 ip주소를 얻지?
+
+DHCP로.. 동적으로 서버로부터 주소를 얻을 수 있음
+
+⇒ 재사용 가능
+
+
+
+과정
+
+1. 호스트가 ‘DHCP discover’ msg를 broadcast 함
+2. dhcp 서버가 “DHCP offer’ msg 응답
+3. host가 “DHCP request’ msg로 ip 주소 요청
+4. DHCP 서버가 “DHCP ack” msg로 주소 응답
+
+DHCP가 돌려주는 것
+
+- IP주소 할당
+- first-hop router(인터넷으로 나가기 위한 첫 관문)의 주소
+- DNS 서버의 이름과 IP주소
+- network mask ( == subnet mask)
+
+> 공유기 = 라우터의 기능을 포함한 장치
+일반 가정집에서는 공유기가 DHCP서버를 탑재하고 있어서
+이 경우에는 HOST(기기)와 공유기가 통신을 하면서 IP주소를 할당 받고 First-hop-router의 주소 정보는 곧 DHCP서버(공유기)의 주소 정보가 됨.
+그런데 큰 조직이나 기업 환경에서 사용되는 고급 라우터들은 네트워크 구성이 복잡해서 DHCP 서버 기능은 별도의 전용 서버에 의해 처리하는 경우들이 있음. 이럴 때는 First-hop-router와 DHCP서버 주소가 다름.
+>
+
+# 📌NAT(Network Address Translation)
+
+NAT는 IPv4의 주소 부족 문제를 해결하기 위한 하나의 간접적인 방법으로,
+
+주로 사설 네트워크 주소를 사용하는 망에서
+
+외부의 공인 망(예를 들면 인터넷)과의 통신을 위해서 네트워크 주소를 변환하는 것.
+
+즉 내부 망에서는 사설 IP 주소를 사용하여 통신을 하고,
+
+외부 망과의 통신 시에는 NAT를 거쳐 공인 IP 주소로 자동 변환됨.
+
+과정
+
+
+
+
+
+### Port Forwarding
+
+별도의 설정이 없다면,
+
+외부 아이피가 접속을 시도해올 때, 내부의 어떤 프로세스(서비스) 또는 기기와 연결할 지 알 수 없어서 접근이 불가능하다.
+
+그래서 특정 프로세스(서비스) 또는 기기에 접근하기 위해
+
+포트 포워딩을 통해 `외부 아이피 : 특정 포트` 가 접속하면 `내부 아이피 : 특정 포트`로 맵핑해준다.
+
+> 예를 들어서..
+집에서 내가 서버를 하나 켜놨음.
+외부에서 접속 가능하게 하고싶음.
+근데 우리집 공유기에 연결된 기기 5개임.
+포트포워딩 없이는 외부에서 서버를 켜놓은 내 기기를 찾아올 수 없음.
+그래서 외부에서 IP주소:8080 포트로 요청을 보내면 무조건 내 기기로 오도록 포트포워딩함.
+외부에서 우리집 공유기의 공인 IP 주소와 8080번 포트로 웹 요청을 보냄
+공유기는 이를 내부 네트워크의 웹 서버 IP 주소와 포트로 포워딩함.
+연결 완료
+>
+
+# 📌Link Layer
+
+- Frame 단위
+- 안전한 통신의 흐름을 관리
+- 에러검출, 에러 수정, 흐름 제어 수행
+- 스위치, 이더넷
+
+## Error Check
+
+- Parity checking 방식 - single bit error
+- Cyclic redundancy check 방식 - burst errors
+
+## MAC addr & ARP
+
+### **MAC addr**
+
+IP 주소는 네트워크 계층(Network Layer)에서 사용되는 주소다.
+
+MAC 주소는 데이터 링크 계층에서 사용되고, LAN에서 목적지와 통신하기 위한 실질적인 주소이다.
+
+48bit (16진수)
+
+MAC주소 = unique한 주민번호 / Portability (LAN 카드 옮기면 됨)
+
+IP주소 = 우편주소
+
+
+
+### ARP (Address Resolution Protocol)
+
+네트워크 상에서 IP 주소를 MAC 주소로 대응시키기 위해 사용되는 프로토콜
+
+IP 주소와 MAC 주소를 일대일 매칭 시켜 LAN에서 목적지를 찾아갈 수 있도록 해줌.
+
+모든 host와 router는 ARP Table을 가짐
+
+ARP table - IP주소, MAC주소, TTL 정보를 대응시켜 정리한 테이블
+
+**1️⃣ ARP - 같은 LAN**
+
+예시) A가 B에게 datagram을 보내려함.
+
+1. A는 B의 IP주소는 알지만 MAC주소는 모름
+2. A가 ARP 쿼리(A의 MAC주소 + B의 IP주소)를 broadcast함
+3. B가 받으면 A한테 자신의 MAC주소를 반환 (Unicast로 A에게만)
+4. A는 ARP table에 IP-MAC pair 저장
+5. 이제 A는 B의 IP주소와 MAC주소를 아니까 보내기만 하면 됨
+
+2️⃣ **ARP - 다른 LAN**
+
+예시) A가 R을 거쳐 B에 datagram을 보내려함.
+
+1. 다른 LAN임을 파악 ⇒ src(dest) IP &(op) subnet-mask = net ID / src와 dest net ID비교
+2. A는 B의 IP주소 알고, DHCP를 통해 R의 IP주소도 알고, same LAN ARP를 통해 R의 MAC주소도 안다.
+3. A는 IP datagram 생성 (src IP, dest IP)하고, 이게 link layer에서 encapsulate하고 header에는 A의 MAC주소와 DEST로는 R의 MAC주소를 포함해서 frame을 생성함
+4. LINK layer에서 A가 R로 전송됨
+5. R은 받은 Frame의 헤더를 벗기고 net layer에서 datagram을 확인하고 최종 dest IP 확인
+6. R은 ARP를 통해 B의 MAC 주소를 알아내 DEST MAC으로 두고 다시 frame 생성해서 보냄
+
+## Ethernet
+
+하나의 인터넷 회선에 다수의 시스템이 유/무선 통신장비 공유기, 허브 등을 통해
+
+랜선 및 통신 포트에 연결되어 통신이 가능한 네트워크 구조
+
+- 전세계 학교, 가정, 사무실에서 가장 많이 활용되는 네트워크 규격
+- CSMA / CD방식
+
+ 회선에서는 아주 짧은 시간동안 데이터 송/수신을 제어 및 처리함.
+
+ 1. 보내는 사람은 케이블의 신호와 이력을 확인
+ 2. 다른 사람에게 신호가 흐르고 있지않음을 확인 후 전송
+ 3. 전송 중에도 파형에 의해 다른 사람의 송신과 충돌하지 않는지를 감시
+ 4. 만약 충돌발생 ⇒ 일정량 전송 후 중단하고, 일정 시간의 딜레이를 두어 전송을 재시작
+
+## Switch
+
+Ethernet을 사용하여 네트워크 내에서 데이터를 효율적으로 전송하는 데 사용되는 물리적 장치
+
+- MAC주소에 맞게 Frame 전송
+- Forwarding Table 가짐 (Mac 주소 - Interface - ttl 대응)
+- Self-learning (어떤 host가 어떤 Interface를 사용했는지 알아서 인지)
+
+Switch의 Self-learning & Forwarding 과정 예시
+
+
+
+# **📌Physical Layer**
+
+- 전기적, 기계적, 기능적인 특성을 이용해서 통신 케이블로 데이터를 전송하는 **물리적인 장비**
+- 단지 데이터 전기적인 신호(0,1)로 변환해서 주고받는 기능만 할 뿐
+- 통신 단위 : **비트(Bit) /** **1과 0 으로 표현됨** (On, Off 상태)
+- 통신 케이블, 허브 등
+
+# 📌WEB 통신 흐름
+
+### 구글페이지에 접속하는 과정
+
+- 인터넷 연결 - DHCP(IP주소 할당)
+ 1. 접속하는 노트북은 IP주소 필요
+ 2. DHCP - UDP - IP - ETH 로 이루어진 frame을 DHCP request
+ 3. broadcast ⇒ DHCP 서버가 받음
+ 4. 서버측에서 Demuxed 함
+ 5. DHCP ACK [ client IP주소, first-hop-router IP주소, DNS name & IP주소 ] 생성
+ 6. 다시 encapsulate 하고, self-learning한 스위치를 통해 client에게 전달 ⇒ client demuxed
+ 7. client는 성공적으로 DHCP ACK를 받아 IP주소를 할당받음
+- 구글 주소 파악 - APR / DNS / 라우팅 프로토콜
+ 1. DNS서버는 LAN에 있지 않으므로 라우터를 거쳐야함. 이 말은 즉슨 Frame을 라우터로 보내야하고 그럴거면 mac dest addr이 라우터의 mac addr이어야하니 APR 필요
+ 2. DNS-UDP-IP-ETH로 encapsulate된 DNS 쿼리 생성 (아직 전송 못함)
+ 3. client가 라우터 IP주소 정보를 담은 ARP query를 broadcast함. (이때, DHCP에 의해 first-hop-router의 IP주소를 알고 있는 상태)
+ 4. 해당 라우터가 받아서 MAC주소를 ARP reply함.
+ 5. 이제 MAC주소도 알았으니 DNS 쿼리를 포함한 frame을 전송할 수 있게됨.
+ 6. 라우터에서 라우팅 프로토콜에 의해 라우트된 path로 포워딩되어 DNS서버에 접근
+ 7. DNS 서버측에서 demuxed 하고 구글의 IP주소를 응답으로 client에게 보내줌
+ 8. 성공적으로 그 응답을 client가 받아 구글 주소를 알게 됨
+- TCP 3WAY handshaking
+ 1. client - TCP socket OPEN
+ 2. TCP SYN segment를 서버에게 보냄
+ 3. 서버는 TCP SYNACK을 보냄
+ 4. TCP 연결 완료
+- HTTP 요청, 응답
+ 1. TCP socket을 통해 HTTP 요청 보냄
+ 2. 요청을 포함하고있는 datagram이 구글서버에 route됨
+ 3. 구글서버가 웹페이지를 HTTP reply로 응답보냄
+ 4. datagram이 client에게 route됨
+ 5. 이제 웹페이지가 보임
+
+# 📌로드밸런싱
+
+
+
+둘 이상의 CPU 혹은 저장장치와 같은 컴퓨터 자원들에게 작업을 나누는 것
+
+요즘 시대에는 웹사이트에 접속하는 인원이 급격히 늘어나게 되었다.
+
+따라서 이 사람들에 대해 모든 트래픽을 감당하기엔 1대의 서버로는 부족하다. 대응 방안으로 하드웨어의 성능을 올리거나(Scale-up) 여러대의 서버가 나눠서 일하도록 만드는 것(Scale-out)이 있다. 하드웨어 향상 비용이 더욱 비싸기도 하고, 서버가 여러대면 무중단 서비스를 제공하는 환경 구성이 용이하므로 Scale-out이 효과적이다. 이때 여러 서버에게 균등하게 트래픽을 분산시켜주는 것이 바로 **로드밸런싱**이다.
+
+**로드밸런싱**은 분산식 웹 서비스로, 여러 서버에 부하(Load)를 나누어주는 역할을 한다. Load Balancer를 클라이언트와 서버 사이에 두고, 부하가 일어나지 않도록 여러 서버에 분산시켜주는 방식이다. 서비스를 운영하는 사이트의 규모에 따라 웹 서버를 추가로 증설하면서 로드 밸런서로 관리해주면 웹 서버의 부하를 해결할 수 있다.
+
+### 로드 밸런서가 서버를 선택하는 방식
+
+- 라운드 로빈(Round Robin) : 서버로 들어온 요청을 순서대로 돌아가며 배정하는 방식
+- Least Connections : 연결 개수가 가장 적은 서버 선택 (트래픽으로 인해 세션이 길어지는 경우 권장)
+- IP Hashing : 사용자 IP를 해싱하여 분배 (특정 사용자가 항상 같은 서버로 연결되는 것 보장)
+- Least Response Time : 가장 짧은 응답 시간을 보내는 서버로 트래픽을 할당하는 방식
+- Bandwidth : 서버들과의 대역폭을 고려하여 서버에 트래픽을 할당
+
+### **L4 로드 밸런서**
+
+네트워크 계층이나 전송 계층의 정보를 바탕으로 로드를 분산
+
+즉, IP 주소, 포트번호, MAC 주소, 전송 프로토콜 등에 따라 트래픽을 분산
+
+- 패킷의 내용을 확인하지 않고 로드를 분산하므로 속도가 빠르고 효율이 높음.
+- 데이터의 내용을 복호화할 필요가 없기에 안전.
+- L7 로드밸런서보다 가격이 저렴.
+
+### **L7 로드 밸런서**
+
+어플리케이션 계층에서 로드를 분산
+
+HTTP 헤더, 쿠키 등과 같은 사용자 요청을 기준으로 특정 서버에 트래픽을 분산
+
+L4 기능 + 패킷의 내용을 확인하고 그 내용에 따라 로드를 특정 서버에 분배
+
+- 캐싱(Cashing) 기능을 제공.
+- L4 로드밸런서에 비해 비쌈. (패킷의 내용을 복호화하여야 하므로)
+- 공격자가 로드밸런서를 통해 클라이언트의 데이터에 접근할 수 있는 보안상의 위험성 존재
+
+- ⭐ CORS와 해결 방법을 말씀해주세요.
+
+ cors란 교차 오리진을 허용해주는 정책으로, client와 server의 origin이 다를 때 리소스 공유를 허용해주는 정책입니다. 기본적으로는 sop정책에 의해 같은 오리진일때에만 리소스를 공유할 수 있도록 브라우저에서 막고 있지만, cors정책을 잘 이용한다면 다른 오리진에서도 리소스를 공유할 수 있게 됩니다.
+
+ 가장 기본적인 방법으로는 서버측에서 응답 헤더의 access control allow origin값에 허용된 출처 값을 설정해주는 방식이 있습니다. 또한 서버와 클라이언트가 로컬호스트를 사용하고 있는 개발환경에서 클라이언트 측이 webpack devserver proxy 설정에서 프록싱을 통해 CORS 정책을 우회하는 방식도 있는데요. 예를들어 클라이언트가 localhost:3000이고 서버가 localhost:8080일때,
+ 클라이언트가 proxy 서버주소를 localhost:8080으로 설정해놓으면 클라이언트에서 api로 보내는 요청은 주소를 8080으로 바꿔서 보내겠다 라는 뜻이 되면서 마치 CORS 정책을 지킨 것처럼 브라우저를 속이면서도 우리는 원하는 서버와 자유롭게 통신을 할 수 있습니다.
+
+
+- ⭐ 쿠키와 세션 차이에 대해 설명해주세요.
+
+ HTTP 프로토콜은 **Connectionless**하고, 상태정보를 유지하지 않는(**Stateless**) 특징이 있습니다. 이러한 특징 덕분에 리소스의 낭비를 크게 줄여주지만, 매 통신마다 클라이언트가 인증을 필요로하게 됩니다. 쿠키와 세션은 이 단점을 보완하는 기술입니다.
+
+ 두 기술의 가장 큰 차이는 저장 위치로, **쿠키는 클라이언트에 세션은 서버에 저장**됩니다. 그래서 쿠키는 빠르지만 보안이 취약하게 되고, 세션은 느리지만 상대적으로 보안성이 좋습니다. 또 쿠키는 브라우저가 종료되어도 남아있게 되고, 세션은 삭제된다는 차이도 있습니다.
+
+ 일반적으로 **보안성이 중요할 때는 세션**을, **종료 시에도 유지되도록 하려면 쿠키**를 사용하는 등 두 기술을 병행해서 활용하게 됩니다. 이때 세션의 경우 서버 자원을 사용하게 된다는 점에서 사용자가 많아지면 자원 관리면에서 문제가 발생하니 유의해야 하기도 합니다. 따라서 쿠키와 세션을 적절한 요소 및 기능에 사용할 수 있어야 서버 자원의 낭비를 막고 웹사이트의 속도를 높일 수 있습니다.
+
diff --git a/Network/yoojin/flow control-and-congestion control.md b/Network/yoojin/flow control-and-congestion control.md
new file mode 100644
index 0000000..8d0f15e
--- /dev/null
+++ b/Network/yoojin/flow control-and-congestion control.md
@@ -0,0 +1,86 @@
+## **흐름 제어**
+
+- 송신 측과 수신 측은 모두 데이터를 저장할 수 있는 버퍼를 가지고 있다.
+- 수신 측이 자신의 버퍼 안에 있는 데이터를 처리하는 속도보다 **송신 측이 데이터를 전송하는 속도가 더 빠르다면, 당연히 수신 측의 버퍼는 언젠가 꽉 차버릴 것이다. 수신 측에서 제한된 저장 용량을 초과한 이후에 도착하는 패킷은 손실될 수 있으며, 만약 손실된다면 불필요한 추가 패킷 전송이 발생하게 된다.**
+- 따라서 송신 측은 수신 측의 데이터 처리 속도를 파악하고 자신이 얼마나 빠르게, 많은 데이터를 전송할 지 결정해야한다. → 이것이 바로 TCP의 흐름 제어
+- 정리하자면, 흐름 제어는 **송신 측과 수신 측의 TCP 버퍼 크기 차이로 인해 생기는 데이터 처리 속도 차이를 해결하기 위한 기법**이다.
+
+### **Stop and Wait**
+
+이름 그대로 **상대방에게 데이터를 보낸 후 잘 받았다는 응답이 올 때까지 기다리는 모든 방식**을 통칭하는 말이다. **매번 전송한 패킷에 대해 확인 응답(ACK)을 받은 후에 다음 패킷을 전송**한다.
+
+
+
+그러나 패킷을 하나씩 보내기 때문에 **비효율적**인 방법이다.
+
+### **Sliding Window**
+
+- 앞서 살펴봤듯이 Stop and Wait를 사용하여 흐름 제어를 하게되면 비효율적인 부분이 있기 때문에, 오늘날의 TCP는 특별한 경우가 아닌 이상 대부분 슬라이딩 윈도우(Sliding Window) 방식을 사용한다.
+- 슬라이딩 윈도우는 **수신 측이 한 번에 처리할 수 있는 데이터를 정해놓고 그때 그때 수신 측의 데이터 처리 상황을 송신 측에 알려줘서 데이터의 흐름을 제어하는 방식**이다. **수신 측에서 설정한 윈도우 크기 만큼,** **송신 측에서 확인 응답(ACK) 없이 패킷을 전송**할 수 있게하여 데이터 흐름을 동적으로 조절한다.
+- Stop and Wait과 가장 큰 차이점은 송신 측이 **수신 측이 처리할 수 있는 데이터의 양을 알고 있다**는 점이다.
+
+
+
+**윈도우(Window)**
+
+송신 측과 수신 측은 각각 데이터를 담을 수 있는 버퍼를 가지고 있고, 별도로 **윈도우**라는 일종의 마스킹 도구를 가지고 있다. 이때 송신 측은 이 윈도우에 들어있는 데이터를 수신 측의 응답이 없어도 연속적으로 보낼 수 있다.
+
+
+
+최초의 **윈도우 크기는 호스트들의 3-way handshake를 통해 수신 측 윈도우 크기로 설정**되며, 이후 수신 측의 버퍼에 남아있는 공간에 따라 변한다. 윈도우 크기는 수신 측에서 송신 측으로 확인 응답(ACK)을 보낼 때 TCP 헤더(window size)에 담아서 보낸다. 이때 송신 측과 수신 측은 자신의 현재 버퍼 크기를 서로에게 알려주게 되고, 송신 측은 수신 측이 보내준 버퍼 크기를 사용하여 자신의 윈도우 크기를 정하게 된다.
+
+
+
+**동작 방식**
+
+윈도우에 포함된 패킷을 계속 전송하고, 수신 측으로부터 확인 응답(ACK)이 오면, 윈도우를 옆으로 옮겨 다음 패킷들을 전송한다.
+
+즉, **송신 TCP는 ACK을 받기 전까지 윈도우 크기 만큼의 세그먼트를 연속해서 전송**할 수 있다.
+
+
+
+## **혼잡 제어**
+
+- 데이터의 양이 라우터가 처리할 수 있는 양을 초과하면, 초과된 데이터는 라우터가 처리하지 못한다. 이때 송신 측에서는 라우터가 처리하지 못한 데이터를 손실 데이터로 간주하고 계속 재전송하여 네트워크를 혼잡하게 한다.
+- 이와 같은 **네트워크의 혼잡을 피하기 위하여 송신 측에서 보내는 데이터의 전송 속도를 강제로 줄이게 되는데**, 이러한 작업을 혼잡 제어(Congestion Control)이라고 한다.
+- 정리하자면, **흐름 제어**는 **송 수신 측 사이의 패킷 수를 제어하는 기능**이라 할 수 있으며, **혼잡 제어**는 **네트워크 내의 패킷 수를 조절하여 네트워크의 오버플로우를 방지하는 기능**이다.
+
+### **AIMD (Additive Increase/Multiplicative Decrease)**
+
+한글로 직역하면 합 증가/곱 감소 방식이다. **AIMD 방식은 처음에 패킷을 하나씩 보내고, 문제 없이 도착하면 윈도우의 크기를 1씩 증가시켜가며 전송한다. 만약 전송에 실패하거나 일정 시간을 넘기면 윈도우의 크기를 반으로 줄인다.**
+
+ 다만, 윈도우의 크기를 굉장히 조금씩 늘리기 때문에 네트워크의 모든 대역을 활용하여 제대로 된 속도로 통신하기까지 시간이 오래 걸린다는 단점이 있다.
+
+
+
+### **Slow Start(느린 시작)**
+
+앞서 얘기했듯이 AIMD 방식은 윈도우 크기를 선형적으로 증가시키기 때문에 제대로 된 속도가 나오기까지 시간이 오래 걸린다.
+
+반면 Slow Start는 윈도우의 크기를 1, 2, 4, 8, ...과 같이 **지수적으로 증가**시키다가 혼잡이 감지되면 **윈도우의 크기를 1로 줄이는 방식이다.**
+
+이 방식은 보낸 데이터의 ACK가 도착할 때마다 윈도우의 크기를 증가시키기 때문에 처음에는 윈도우 크기가 조금 느리게 증가할지라도, 시간이 가면 갈수록 윈도우의 크기가 점점 빠르게 증가한다는 장점이 있다.
+
+
+
+### **Fast Retransmit(빠른 재전송)**
+
+패킷을 받는 수신자 입장에서는 세그먼트로 분할된 내용들이 **순서대로 도착하지 않는 경우**가 생길 수 있다. 이러한 상황이 발생했을 때 **수신 측에서는 순서대로 잘 도착한 마지막 패킷의 다음 순번을 ACK 패킷에 실어서 보낸다.** 그리고 이런 **중복 ACK를 3개 받으면 재전송이 이루어진다.** 송신 측은 자신이 설정한 타임 아웃 시간이 지나지 않았어도 바로 해당 패킷을 재전송할 수 있기 때문에 보다 빠른 재전송률을 유지할 수 있다.
+
+
+예시
+
+- 세그먼트 1을 수신하면 수신자는 다음에 세그먼트 **2를 요청하는 확인**을 보낸다. (원래 ACK)
+
+- 세그먼트 3을 수신하면 수신자는 다음에 세그먼트 **2를 요청하는 확인**을 보낸다. (첫 번째 중복 ACK)
+
+- 세그먼트 4를 수신하면 수신자는 다음에 세그먼트 **2를 요청하는 확인**을 보낸다. (두 번째 중복 ACK)
+
+- 세그먼트 5를 수신하면 수신자는 다음에 세그먼트 **2를 요청하는 확인**을 보낸다. (세 번째 중복 ACK)
+
+
+### **Fast Recovery(빠른 회복)**
+
+빠른 회복은 혼잡한 상태가 되면 윈도우 크기를 1로 줄이지 않고, 반으로 줄이고 선형 증가시키는 방법이다. 이 방법을 적용하면 혼잡 상황을 한 번 겪고나서부터는 AIMD 방식으로 동작한다.
+
+
\ No newline at end of file
diff --git a/Network/yoojin/img/TCP 3,4-Way Handshake_1.png b/Network/yoojin/img/TCP 3,4-Way Handshake_1.png
new file mode 100644
index 0000000..e66c42c
Binary files /dev/null and b/Network/yoojin/img/TCP 3,4-Way Handshake_1.png differ
diff --git a/Network/yoojin/img/TCP 3,4-Way Handshake_2.png b/Network/yoojin/img/TCP 3,4-Way Handshake_2.png
new file mode 100644
index 0000000..2618e63
Binary files /dev/null and b/Network/yoojin/img/TCP 3,4-Way Handshake_2.png differ
diff --git a/Network/yoojin/img/flow control-and-congestion control_1.png b/Network/yoojin/img/flow control-and-congestion control_1.png
new file mode 100644
index 0000000..f8f31b5
Binary files /dev/null and b/Network/yoojin/img/flow control-and-congestion control_1.png differ
diff --git a/Network/yoojin/img/flow control-and-congestion control_2.png b/Network/yoojin/img/flow control-and-congestion control_2.png
new file mode 100644
index 0000000..8970298
Binary files /dev/null and b/Network/yoojin/img/flow control-and-congestion control_2.png differ
diff --git a/Network/yoojin/img/flow control-and-congestion control_3.png b/Network/yoojin/img/flow control-and-congestion control_3.png
new file mode 100644
index 0000000..8256a11
Binary files /dev/null and b/Network/yoojin/img/flow control-and-congestion control_3.png differ
diff --git a/Network/yoojin/img/flow control-and-congestion control_4.png b/Network/yoojin/img/flow control-and-congestion control_4.png
new file mode 100644
index 0000000..a42a071
Binary files /dev/null and b/Network/yoojin/img/flow control-and-congestion control_4.png differ
diff --git a/Network/yoojin/img/flow control-and-congestion control_5.png b/Network/yoojin/img/flow control-and-congestion control_5.png
new file mode 100644
index 0000000..5579a24
Binary files /dev/null and b/Network/yoojin/img/flow control-and-congestion control_5.png differ
diff --git a/Network/yoojin/img/flow control-and-congestion control_6.png b/Network/yoojin/img/flow control-and-congestion control_6.png
new file mode 100644
index 0000000..e1775b9
Binary files /dev/null and b/Network/yoojin/img/flow control-and-congestion control_6.png differ
diff --git a/Network/yoojin/img/ip_1.png b/Network/yoojin/img/ip_1.png
new file mode 100644
index 0000000..61ecac6
Binary files /dev/null and b/Network/yoojin/img/ip_1.png differ
diff --git a/Network/yoojin/img/ip_2.png b/Network/yoojin/img/ip_2.png
new file mode 100644
index 0000000..36ca6c5
Binary files /dev/null and b/Network/yoojin/img/ip_2.png differ
diff --git a/Network/yoojin/ip.md b/Network/yoojin/ip.md
new file mode 100644
index 0000000..82fb22f
--- /dev/null
+++ b/Network/yoojin/ip.md
@@ -0,0 +1,83 @@
+**네트워크 간의 통신을 하려면, IP 주소가 필요!**
+
+### IP 주소란?
+
+IP 주소는 **인터넷 서비스 제공자(ISP)** 에게 받을 수 있다. IP 버전에는 **IPv4**와 **IPv6**가 있다.
+
+IP 주소에는 **공인 IP 주소**와 **사설 IP 주소**가 있다. 공인 IP 주소는 **인터넷 서비스 제공자(ISP)** 가 제공한다. **공인 IP 주소**와 **사설 IP 주소**는 모두 2진수의 **32비트**를 동일하게 사용하고 있다.
+
+> IP 주소가 왜 두 종류나 필요할까?
+>
+>
+> IPv4 주소는 위에서 말했듯이 주소의 수가 고갈되고 있다. 그래서 인터넷에 직접 연결되는 컴퓨터나 라우터에는 **공인 IP 주소**를 할당하고, 회사나 가정의 랜에 있는 컴퓨터는 **사설 IP 주소**를 할당하는 정책을 사용하고 있다.
+>
+
+예를 들어 아래 사진과 같이 랜 안에 컴퓨터가 여러 대 있다면 공인 IP 주소는 사용할 수 있는 숫자가 제한되므로 컴퓨터 한 대당 공인 IP 주소를 하나씩 할당하기 어렵다. 그래서 우선 인터넷 서비스 제공자(ISP)가 제공하는 **공인 IP 주소**는 라우터에만 할당하고, **랜 안에 있는 컴퓨터에는 랜의 네트워크 관리자가 자유롭게 사설 IP 주소를 할당**하거나 라우터의 **DHCP 기능을 사용하여 IP 주소를 자동으로 할당**한다. 그러면 **공인 IP 주소 한 개로 랜 안에 있는 컴퓨터 세대에 인터넷을 모두 연결할 수 있는 환경**을 만들 수 있다.
+
+
+
+> **DHCP**는 Dynamic Host Configuration Protocol의 약어로 IP 주소를 자동으로 할당하는 프로토콜 이다.
+>
+
+
+> IP 주소는 **네트워크 ID**와 **호스트 ID**로 나눠져 있다.
+>
+>
+> 네트워크 ID는 어떤 네트워크인지를 나타내고, 호스트 ID는 해당 네트워크의 어느 컴퓨터인지를 나타낸다. 이 두 가지 정보가 합쳐져, IP 주소가 된다.
+>
+
+
+
+## IP 주소의 클래스 구조
+
+**IP 주소는, 네트워크의 규모에 따라 A~E 클래스로 나누어져 있다.**
+
+### IP 주소 클래스란?
+
+IPv4의 IP 주소는 32비트다. 이 비트를 옥탯 단위로 끊어서 **네트워크 ID**를 크게 만들거나 **호스트 ID**를 작게 만들어 네트워크 크기를 조정할 수도 있다. 네트워크 크기는 **클래스**라는 개념으로 구분하고 있다.
+
+| 클래스 이름 | 내용 | 네트워크 ID 크기 | 호스트 ID |
+| --- | --- | --- | --- |
+| A 클래스 | 대규모 네트워크 주소 | 8비트 | 24비트 |
+| B 클래스 | 중형 네트워크 주소 | 16비트 | 16비트 |
+| C 클래스 | 소규모 네트워크 주소 | 24비트 | 8비트 |
+| D 클래스 | 멀티캐스트(multicast) 주소 | x | x |
+| E 클래스 | 연규 및 특수용도 주소 | x | x |
+
+| 종류 | 공인 IP 주소의 범위 | 사설 IP 주소의 범위 |
+| --- | --- | --- |
+| A 클래스 | 1.0.0.0~9.255.255.255 | 10.0.0.0~10.255.255.255 |
+| | 11.0.0.0~126.255.255.255 | |
+| B 클래스 | 128.0.0.0~172.15.255.255 | 172.16.0.0~172.31.255.255 |
+| | 172.32.0.0~191.255.255.255 | |
+| C 클래스 | 192.0.0.0~192.167.255.255 | 192.168.0.0~192.168.255.255 |
+| | 192.169.0.0~223.255.255.255 | |
+
+> 사설 IP 주소는, 절대로 공인 IP 주소로 사용할 수 없다
+>
+
+> **가정의 랜**에서는, 주로 **C 클래스의 사설 IP 주소인 192.168.ㅁ.ㅁ**이다. (네트워크 ID.호스트 ID)
+>
+
+
+
+## 네트워크 주소와 브로드캐스트 주소의 구조
+
+### 네트워크 주소와 브로드캐스트 주소란?
+
+IP 주소에는 **네트워크 주소**와 **브로드캐스트 주소**가 있다.
+
+> 이 두 주소는 특별한 주소로, 컴퓨터나 라우터가 자신의 IP로 사용하면 안된다.
+>
+
+**예를 들어** C 클래스 사설 IP 주소가 있다고 가정하자.
+
+그러면 IP 주소의 범위는 192.168.0.0~192.168.255.255이다. 이것은 256개의 네트워크 ID에, 각각 호스트 ID가 256개가 있는 것이다. 그럼 이제 아래 사진을 보자.
+
+
+
+이 사진은 256개의 네트워크 ID 중에서 하나인, 192.168.1.0~192.168.1.255 (→ 같은 네트워크!) 부분이다. 같은 네트워크 ID의 호스트 주소이므로 네트워크 주소는 192.168.1로 당연히 같다. 그러면 이제 **첫 번째 호스트 ID인 192.168.1.0**은 **네트워크 주소**이고, **마지막 호스트 ID인 192.168.1.255**는 **브로드캐스트 주소**이다.
+
+**네트워크 주소**는 전체 네트워크에서 **작은 네트워크**를 식별하는 데 사용되고, 호스트 ID가 10진수로 0이면 그 **네트워크 전체를 대표하는 주소**가 되는거다. 쉽게 말해 전체 네트워크 대표 주소라고 생각하자.
+
+**브로드캐스트 주소**는 네트워크에 있는 컴퓨터나 장비 모두에게 **한 번에 데이터를 전송**하는 데 사용되는 전용 IP 주소다. **예를 들어** 192.168.1.1의 데이터를 192.168.1.2~192.168.1.254 모두에게 전송하고 싶으면, 전송할 데이터를 192.168.1.255에게 보내면 된다.
\ No newline at end of file
diff --git a/Network/yoojin/tcp 3,4-way handshake.md b/Network/yoojin/tcp 3,4-way handshake.md
new file mode 100644
index 0000000..4a8a6fe
--- /dev/null
+++ b/Network/yoojin/tcp 3,4-way handshake.md
@@ -0,0 +1,64 @@
+## **3-way Handshake**
+
+**3-Way Handshake는 TCP/IP프로토콜을 이용해서 통신을 하는 응용프로그램이 데이터를 전송하기 전에 먼저 정확한 전송을 보장하기 위해 상대방 컴퓨터와 사전에 세션을 수립하는 과정을 의미한다.**
+
+TCP 3 way handshake를 간단히 표현하면 다음과 같다.
+
+1. A -> B : 내 말 들려?
+2. B -> A : 잘 들려. 내 말은 들려?
+3. A -> B : 잘 들려!
+
+
+
+- SYN (synchronize sequence numbers) - ***연결 설정***. 연결 확인을 위해 보내는 무작위의 숫자값 (내 말 잘 들려?)
+- ACK (acknowledgements) - ***응답 확인***. Client 혹은 Server로부터 받은 **SYN에 1을 더해** SYN을 잘 받았다는 ACK (잘 들려)
+
+**[STEP 1]**
+
+**클라이언트는 서버와 커넥션을 연결하기 위해 SYN(x) 을 보낸다.**
+
+**[STEP 2]**
+
+**서버가 SYN(x)을 받고, 클라이언트로 받았다는 신호인 ACK(x+1)와 SYN(y) 패킷을 보낸다.**
+
+**[STEP 3]**
+
+**클라이언트는 서버의 응답은 ACK(x+1)와 SYN(y) 패킷을 받고, ACK(y+1)를 서버로 보낸다.**
+
+
+
+## **4-way Handshake**
+
+3 way handshake와 반대로 **연결을 해제**할 때 주고 받는 확인작업이다. 이 역시 4번의 확인과정을 거친다고 하여 4 way handshake라고 부른다.
+
+TCP 4 way handshake를 간단히 표현하면 다음과 같다.
+
+1. A -> B: 나는 다 보냈어. 이제 끊자!
+2. B -> A: 알겠어! 잠시만~
+3. B -> A: 나도 끊을게!
+4. A -> B: 알겠어!
+
+
+
+- FIN (Finish) - ***연결 해제***. TCP 연결을 종료하겠다는 메시지
+
+**[STEP 1]**
+
+클라이언트는 서버에게 연결을 종료한다는 **FIN** 플래그를 보낸다.
+
+**[STEP 2]**
+
+서버는 FIN 플래그를 받고, 일단 확인했다는 **ACK**를 클라이언트에게 보내고 **모든 데이터를 보낼 때까지 기다리는 `CLOSE_WAIT` 상태**에 들어간다.
+
+→ **Client가 데이터 전송을 마쳤다고 하더라도 Server는 아직 보낼 데이터가 남아있을 수 있기 때문에**
+
+**[STEP 3]**
+
+서버가 **데이터를 모두 보냈다면,** 서버는 연결 종료에 합의 한다는 의미로 **FIN** 패킷을 클라이언트에게 보낸다.
+
+**[STEP 4]**
+
+- 클라이언트는 FIN을 받고, 확인했다는 **ACK**를 서버에게 보낸다.
+- 클라이언트는, **아직 서버로부터 받지 못한 데이터가 있을 수 있으므로,** `TIME_WAIT`을 통해 기다린다.
+
+ → **TIME_WAIT** 시간이 끝나면, `CLOSED` 상태가 된다.
\ No newline at end of file
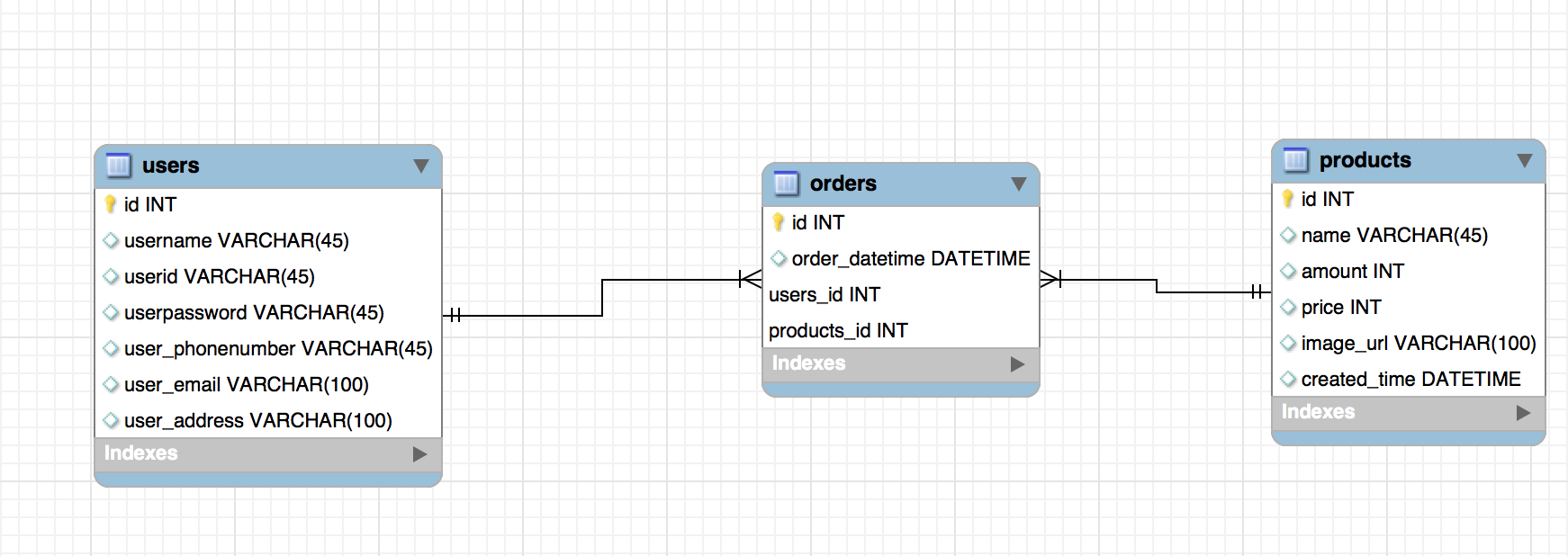 +
+
+## 중요성
+
+ ERD는 복잡한 데이터 구조와 관계를 시각적으로 표현함으로써, 데이터베이스 설계를 명확하고 이해하기 쉽게 만들어줍니다. 또한, ERD를 통해 데이터의 무결성과 일관성을 보장할 수 있습니다.
+
+
+
+
+## 중요성
+
+ ERD는 복잡한 데이터 구조와 관계를 시각적으로 표현함으로써, 데이터베이스 설계를 명확하고 이해하기 쉽게 만들어줍니다. 또한, ERD를 통해 데이터의 무결성과 일관성을 보장할 수 있습니다.
+
+ +
+
+
+ +
+
+
+ +
+
+### Left Outer Join(왼쪽 외부 조인)
+
+ 왼쪽 테이블의 모든 행과 오른쪽 테이블에서 조인 조건에 맞는 행을 반환합니다. 오른쪽 테이블에 매칭되는 행이 없는 경우에는 NULL 값을 반환합니다.
+
+ SELECT A.ID, B.ID, A.NAME, B.NAME
+ FROM Table A, Table B
+ WHERE A.ID = B.ID(+);
+
+
+
+
+### Left Outer Join(왼쪽 외부 조인)
+
+ 왼쪽 테이블의 모든 행과 오른쪽 테이블에서 조인 조건에 맞는 행을 반환합니다. 오른쪽 테이블에 매칭되는 행이 없는 경우에는 NULL 값을 반환합니다.
+
+ SELECT A.ID, B.ID, A.NAME, B.NAME
+ FROM Table A, Table B
+ WHERE A.ID = B.ID(+);
+
+ +
+
+### Right Outer Join(오른쪽 외부 조인)
+
+ 오른쪽 테이블의 모든 행과 왼쪽 테이블에서 조인 조건에 맞는 행을 반환합니다. 왼쪽 테이블에 매칭되는 행이 없는 경우에는 NULL 값을 반환합니다.
+
+ SELECT A.ID, B.ID, A.NAME, B.NAME
+ FROM Table A, Table B
+ WHERE A.ID(+) = B.ID;
+
+
+
+
+### Right Outer Join(오른쪽 외부 조인)
+
+ 오른쪽 테이블의 모든 행과 왼쪽 테이블에서 조인 조건에 맞는 행을 반환합니다. 왼쪽 테이블에 매칭되는 행이 없는 경우에는 NULL 값을 반환합니다.
+
+ SELECT A.ID, B.ID, A.NAME, B.NAME
+ FROM Table A, Table B
+ WHERE A.ID(+) = B.ID;
+
+ +
+
+
+ +
+### Full Outer Join(전체 외부 조인)
+
+ 왼쪽 테이블과 오른쪽 테이블의 합집합을 반환합니다. 양쪽 테이블에서 조인 조건에 맞는 행을 반환하며, 매칭되는 행이 없는 경우에는 NULL 값을 반환합니다.
+
+
+### Inner Join VS Outer Join
+
+ 댓글이 있는 게시물만 보여줘라 VS 댓글이 없는 게시물도 보여줘라
+
+
+
+
+### Full Outer Join(전체 외부 조인)
+
+ 왼쪽 테이블과 오른쪽 테이블의 합집합을 반환합니다. 양쪽 테이블에서 조인 조건에 맞는 행을 반환하며, 매칭되는 행이 없는 경우에는 NULL 값을 반환합니다.
+
+
+### Inner Join VS Outer Join
+
+ 댓글이 있는 게시물만 보여줘라 VS 댓글이 없는 게시물도 보여줘라
+
+
+ +
+- Table A가 Outer Table(선행 테이블), Driving Table(구동 테이블)
+
+- Table B가 Inner Table(후행 테이블), Driven Table
+
+1. 외부 테이블의 첫 번째 행을 가져옵니다.
+
+2. 내부 테이블의 모든 행을 검색하면서, 조인 조건에 맞는 행을 찾습니다.
+
+3. 조건에 맞는 모든 행을 찾았다면, 외부 테이블의 다음 행으로 이동하고, 내부 테이블의 검색을 다시 시작합니다.
+
+4. 외부 테이블의 모든 행을 검사할 때까지 이 과정을 반복합니다.
+
+### 그런데, 후행 테이블을 Index화 한다면 모든 테이블을 검색하지도 않아도 되어 속도를 빠르게 할 수 있다.
+
+- index는 도서관의 도서 분류라고 보면 됨 => 모든 자료를 검색하지 않아도 된다.
+
+
+
+- Table A가 Outer Table(선행 테이블), Driving Table(구동 테이블)
+
+- Table B가 Inner Table(후행 테이블), Driven Table
+
+1. 외부 테이블의 첫 번째 행을 가져옵니다.
+
+2. 내부 테이블의 모든 행을 검색하면서, 조인 조건에 맞는 행을 찾습니다.
+
+3. 조건에 맞는 모든 행을 찾았다면, 외부 테이블의 다음 행으로 이동하고, 내부 테이블의 검색을 다시 시작합니다.
+
+4. 외부 테이블의 모든 행을 검사할 때까지 이 과정을 반복합니다.
+
+### 그런데, 후행 테이블을 Index화 한다면 모든 테이블을 검색하지도 않아도 되어 속도를 빠르게 할 수 있다.
+
+- index는 도서관의 도서 분류라고 보면 됨 => 모든 자료를 검색하지 않아도 된다.
+
+ +
+- Drivng Table의 범위가 작을수록 수행속도가 빨라진다. 따라서 Driving Table을 어떤 테이블로 설정하는지가 중요하다.
+
+
+
+- Drivng Table의 범위가 작을수록 수행속도가 빨라진다. 따라서 Driving Table을 어떤 테이블로 설정하는지가 중요하다.
+
+ +
+## 작동 방식
+
+1. 선행 테이블에서 조건을 만족하는 행을 찾고 조인 키를 기준으로 정렬
+
+2. 후행 테이블에서도 같은 작업
+
+3. Join 수행
+
+## Hash Join
+
+ 해싱 기법을 이용하여 조인을 수행하는 기법이다.
+
+
+
+## 작동 방식
+
+1. 선행 테이블에서 조건을 만족하는 행을 찾고 조인 키를 기준으로 정렬
+
+2. 후행 테이블에서도 같은 작업
+
+3. Join 수행
+
+## Hash Join
+
+ 해싱 기법을 이용하여 조인을 수행하는 기법이다.
+
+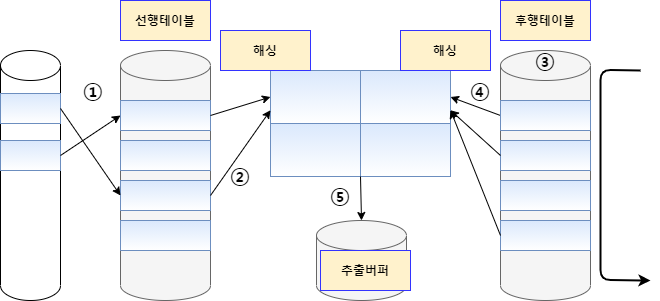 +
+## 작동 방식
+
+1. 선행 테이블에서 조건을 만족하는 행을 찾는다.
+
+2. 선행 테이블의 조인 키로 해시함수를 적용하여 테이블을 생성한다. 이때, 조인 컬럼과 select 절에서 필요로 하는 컬럼도 함께 저장한다.
+
+3. 1,2를 반복 수행한다.
+
+4. 후행 테이블에서 조건을 만족하는 행을 찾는다.
+
+5. 후행 테이블의 조인 키로 해시 함수를 적용하여 해당하는 버킷을 찾는다. => 조인 키를 이용하여 실제 조인된 데이터를 찾는다.
+
+6. 조인 성공시 추출버퍼에 넣는다.
+
+## 사용 케이스
+
+- 조인 컬럼에 인덱스를 사용하지 않는다. 따라서, 조인 컬럼 인덱스가 없는 경우에도 사용가능하다.
+
+- 해시 함수를 이용하여 조인을 하기 때문에 동등 연산 조인에서 사용한다. => 해시 함수가 적용될 때 동일한 값은 항상 같은 값으로 해싱 되기 때문.
+
+## 특징
+
+- 조인 시 해시 테이블을 메모리에 생성해야 한다.
+
+- 생성된 해시 테이블의 크기가 메모리 적재 크기보다 커지면 임시 영역(디스크)에 저장한다. 이 과정은 추가적인 작업이 필요.
+
+- 따라서, 결과 행의 수가 적은 것을 선행 테이블로 사용하는 것이 좋다.
+
+- 해시 테이블을 만든 선행 테이블을 빌드 테이블이라고 하며, 후행 테이블을 프로브 테이블이라고 한다.
diff --git a/DataBase/minhyeok/SQL Injection.md b/DataBase/minhyeok/SQL Injection.md
new file mode 100644
index 0000000..b53dd1f
--- /dev/null
+++ b/DataBase/minhyeok/SQL Injection.md
@@ -0,0 +1,89 @@
+# SQL Injection 이란?
+
+ 악의적인 사용자가 보안상 취약점을 이용하여 이득을 얻기 위해 SQL 쿼리문을 조작하여 DB가 비정상적인 동작을 하도록 유도하는 행위이다. 공격이 비교적 쉬우나, 큰 피해를 입힐 수 있어 많은 주의가 필요하다.
+
+# 종류
+
+
+
+## 작동 방식
+
+1. 선행 테이블에서 조건을 만족하는 행을 찾는다.
+
+2. 선행 테이블의 조인 키로 해시함수를 적용하여 테이블을 생성한다. 이때, 조인 컬럼과 select 절에서 필요로 하는 컬럼도 함께 저장한다.
+
+3. 1,2를 반복 수행한다.
+
+4. 후행 테이블에서 조건을 만족하는 행을 찾는다.
+
+5. 후행 테이블의 조인 키로 해시 함수를 적용하여 해당하는 버킷을 찾는다. => 조인 키를 이용하여 실제 조인된 데이터를 찾는다.
+
+6. 조인 성공시 추출버퍼에 넣는다.
+
+## 사용 케이스
+
+- 조인 컬럼에 인덱스를 사용하지 않는다. 따라서, 조인 컬럼 인덱스가 없는 경우에도 사용가능하다.
+
+- 해시 함수를 이용하여 조인을 하기 때문에 동등 연산 조인에서 사용한다. => 해시 함수가 적용될 때 동일한 값은 항상 같은 값으로 해싱 되기 때문.
+
+## 특징
+
+- 조인 시 해시 테이블을 메모리에 생성해야 한다.
+
+- 생성된 해시 테이블의 크기가 메모리 적재 크기보다 커지면 임시 영역(디스크)에 저장한다. 이 과정은 추가적인 작업이 필요.
+
+- 따라서, 결과 행의 수가 적은 것을 선행 테이블로 사용하는 것이 좋다.
+
+- 해시 테이블을 만든 선행 테이블을 빌드 테이블이라고 하며, 후행 테이블을 프로브 테이블이라고 한다.
diff --git a/DataBase/minhyeok/SQL Injection.md b/DataBase/minhyeok/SQL Injection.md
new file mode 100644
index 0000000..b53dd1f
--- /dev/null
+++ b/DataBase/minhyeok/SQL Injection.md
@@ -0,0 +1,89 @@
+# SQL Injection 이란?
+
+ 악의적인 사용자가 보안상 취약점을 이용하여 이득을 얻기 위해 SQL 쿼리문을 조작하여 DB가 비정상적인 동작을 하도록 유도하는 행위이다. 공격이 비교적 쉬우나, 큰 피해를 입힐 수 있어 많은 주의가 필요하다.
+
+# 종류
+
+ +
+
+
+ +
+
+
+ +
+
+
+ +
+
+
+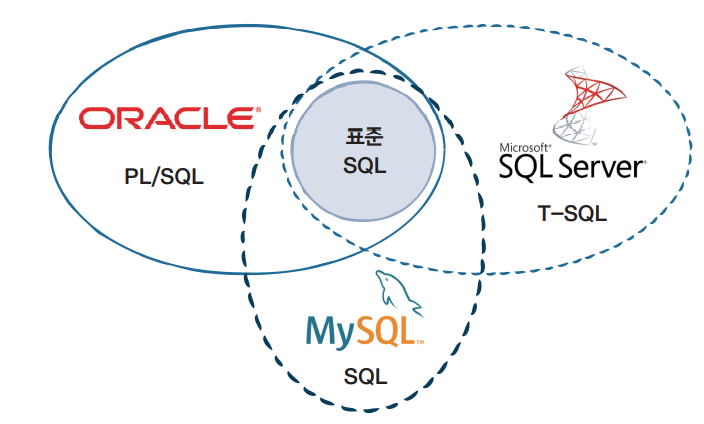 +
+표준 SQL이라는 공통된 SQL을 사용하지만, 각자의 언어도 있다.
+
+
+- DDL(Data Definition Language)
+
+ 데이터베이스의 스키마를 정의하거나 변경하는 데 사용됩니다.
+
+ 주요 명령어
+
+ - CREATE(테이블 생성)
+
+ CREATE TABLE students (
+ id NUMBER,
+ name VARCHAR2(100),
+ age NUMBER,
+ PRIMARY KEY (id)
+ );
+
+ - ALTER(테이블 변경)
+
+ ALTER TABLE students ADD email VARCHAR2(100);
+
+ - DROP(테이블 삭제)
+
+ DROP TABLE students;
+
+
+- DML(Data Manipulation Language)
+
+ 데이터를 조작하는 데 사용됩니다.
+
+ 주요 명령어
+
+ - SELECT(데이터 조회)
+
+ SELECT * FROM students;
+
+ SELECT name, age FROM students WHERE age > 20;
+
+ - INSERT(데이터 삽입)
+
+ INSERT INTO students (id, name, age) VALUES (1, 'Kim', 21);
+
+ - UPDATE(데이터 수정)
+
+ UPDATE students SET age = 22 WHERE id = 1;
+
+ - DELETE(데이터 삭제)
+
+ DELETE FROM students WHERE id = 1;
+
+- DCL(Data Control Language)
+
+ 데이터베이스에 대한 접근 권한을 관리하는 데 사용됩니다.
+
+ 주요 명령어
+
+ - GRANT(권한 부여)
+
+ GRANT SELECT, INSERT ON students TO user1;
+
+ - REVOKE(권한 제거)
+
+ REVOKE INSERT ON students FROM user1;
+
+
+- TCL(Transaction Control Language)
+
+ 데이터베이스의 트랜잭션을 관리하는 데 사용됩니다.
+
+ ### ★ 트랜잭션 원자성의 중요성
+
+ - 트랜잭션의 원자성(Atomicity)은 데이터베이스 트랜잭션이 DB에 모두 반영되거나, 아니면 전혀 반영되지 않아야 함을 의미
+
+ - 예를 들어, 은행 계좌 이체할 때 A 계좌에서 돈을 출금하여, B 계좌에 입금하려는데
+ A 계좌 출금만 수행되고 B 계좌에는 입금이 수행이 안되면 문제가 생긴다. 따라서, 여러 연산을 하나로 묶어서 하나라도 실패한다면 Rollback을 해야하기 때문에 Transaction이 필요하다.
+
+ 주요 명령어
+
+ - COMMIT(트랜잭션 확정)
+
+ 현재 트랜잭션에서 수행한 모든 변경사항을 데이터베이스에 영구적으로 저장합니다.
+
+ - ROLLBACK(트랜잭션 취소)
+
+ 현재 트랜잭션에서 수행한 모든 변경사항을 취소하고, 트랜잭션을 시작하기 전 상태로 되돌립니다.
+
+ - SAVEPOINT(트랜잭션 저장점 설정)
+
+ 현재 트랜잭션 내에서 특정 지점을 표시하여, 나중에 ROLLBACK 명령어를 사용할 때 이 지점으로 되돌아갈 수 있게 합니다. SAVEPOINT 명령어를 실행한 후에 수행한 SQL 문은 ROLLBACK TO SAVEPOINT 명령어를 사용하여 취소할 수 있습니다.
+
+ SAVEPOINT savepoint_name;
+
+ ROLLBACK TO SAVEPOINT savepoint_name;
+
+## ★ Delete, Truncate(DDL), Drop 차이점
+
+
+
+표준 SQL이라는 공통된 SQL을 사용하지만, 각자의 언어도 있다.
+
+
+- DDL(Data Definition Language)
+
+ 데이터베이스의 스키마를 정의하거나 변경하는 데 사용됩니다.
+
+ 주요 명령어
+
+ - CREATE(테이블 생성)
+
+ CREATE TABLE students (
+ id NUMBER,
+ name VARCHAR2(100),
+ age NUMBER,
+ PRIMARY KEY (id)
+ );
+
+ - ALTER(테이블 변경)
+
+ ALTER TABLE students ADD email VARCHAR2(100);
+
+ - DROP(테이블 삭제)
+
+ DROP TABLE students;
+
+
+- DML(Data Manipulation Language)
+
+ 데이터를 조작하는 데 사용됩니다.
+
+ 주요 명령어
+
+ - SELECT(데이터 조회)
+
+ SELECT * FROM students;
+
+ SELECT name, age FROM students WHERE age > 20;
+
+ - INSERT(데이터 삽입)
+
+ INSERT INTO students (id, name, age) VALUES (1, 'Kim', 21);
+
+ - UPDATE(데이터 수정)
+
+ UPDATE students SET age = 22 WHERE id = 1;
+
+ - DELETE(데이터 삭제)
+
+ DELETE FROM students WHERE id = 1;
+
+- DCL(Data Control Language)
+
+ 데이터베이스에 대한 접근 권한을 관리하는 데 사용됩니다.
+
+ 주요 명령어
+
+ - GRANT(권한 부여)
+
+ GRANT SELECT, INSERT ON students TO user1;
+
+ - REVOKE(권한 제거)
+
+ REVOKE INSERT ON students FROM user1;
+
+
+- TCL(Transaction Control Language)
+
+ 데이터베이스의 트랜잭션을 관리하는 데 사용됩니다.
+
+ ### ★ 트랜잭션 원자성의 중요성
+
+ - 트랜잭션의 원자성(Atomicity)은 데이터베이스 트랜잭션이 DB에 모두 반영되거나, 아니면 전혀 반영되지 않아야 함을 의미
+
+ - 예를 들어, 은행 계좌 이체할 때 A 계좌에서 돈을 출금하여, B 계좌에 입금하려는데
+ A 계좌 출금만 수행되고 B 계좌에는 입금이 수행이 안되면 문제가 생긴다. 따라서, 여러 연산을 하나로 묶어서 하나라도 실패한다면 Rollback을 해야하기 때문에 Transaction이 필요하다.
+
+ 주요 명령어
+
+ - COMMIT(트랜잭션 확정)
+
+ 현재 트랜잭션에서 수행한 모든 변경사항을 데이터베이스에 영구적으로 저장합니다.
+
+ - ROLLBACK(트랜잭션 취소)
+
+ 현재 트랜잭션에서 수행한 모든 변경사항을 취소하고, 트랜잭션을 시작하기 전 상태로 되돌립니다.
+
+ - SAVEPOINT(트랜잭션 저장점 설정)
+
+ 현재 트랜잭션 내에서 특정 지점을 표시하여, 나중에 ROLLBACK 명령어를 사용할 때 이 지점으로 되돌아갈 수 있게 합니다. SAVEPOINT 명령어를 실행한 후에 수행한 SQL 문은 ROLLBACK TO SAVEPOINT 명령어를 사용하여 취소할 수 있습니다.
+
+ SAVEPOINT savepoint_name;
+
+ ROLLBACK TO SAVEPOINT savepoint_name;
+
+## ★ Delete, Truncate(DDL), Drop 차이점
+
+ +
+
+
+ +
+## DBMS 특징
+
+- 데이터 독립성
+
+ DBMS는 물리적 데이터 독립성과 논리적 데이터 독립성을 제공합니다. 이는 데이터의 물리적 저장 구조가 변경되더라도 응용 프로그램에는 영향을 주지 않으며, 반대로 응용 프로그램의 변경이 데이터베이스에 영향을 주지 않음을 보장합니다.
+
+- 데이터 무결성
+
+ DBMS는 데이터의 정확성과 일관성을 유지하기 위한 규칙을 설정하고 강제하는 무결성 규칙을 제공합니다.
+
+- 데이터 보안
+
+ DBMS는 데이터의 접근 권한을 제어하여 민감한 데이터를 보호합니다.
+
+- 데이터 백업 및 복구
+
+ DBMS는 데이터 손실을 방지하기 위해 데이터를 백업하고, 시스템 장애 후에 데이터를 복구하는 기능을 제공합니다.
+
+- 동시성 제어
+
+ DBMS는 여러 사용자가 동시에 데이터베이스에 접근할 때 발생할 수 있는 문제를 관리하고, 데이터의 일관성을 유지합니다.
+
+- 데이터 추상화
+
+ DBMS는 데이터의 물리적 저장 구조를 숨기고 사용자에게 논리적인 데이터 뷰만을 제공함으로써, 사용자가 데이터를 쉽게 이해하고 사용할 수 있게 합니다.
+
+## 테이블 용어 정리
+
+https://inpa.tistory.com/entry/DB-%F0%9F%93%9A-%ED%85%8C%EC%9D%B4%EB%B8%94-%EC%9A%A9%EC%96%B4-%F0%9F%95%B5%EF%B8%8F-%EC%A0%95%EB%A6%AC
+
+
+
+## DBMS 특징
+
+- 데이터 독립성
+
+ DBMS는 물리적 데이터 독립성과 논리적 데이터 독립성을 제공합니다. 이는 데이터의 물리적 저장 구조가 변경되더라도 응용 프로그램에는 영향을 주지 않으며, 반대로 응용 프로그램의 변경이 데이터베이스에 영향을 주지 않음을 보장합니다.
+
+- 데이터 무결성
+
+ DBMS는 데이터의 정확성과 일관성을 유지하기 위한 규칙을 설정하고 강제하는 무결성 규칙을 제공합니다.
+
+- 데이터 보안
+
+ DBMS는 데이터의 접근 권한을 제어하여 민감한 데이터를 보호합니다.
+
+- 데이터 백업 및 복구
+
+ DBMS는 데이터 손실을 방지하기 위해 데이터를 백업하고, 시스템 장애 후에 데이터를 복구하는 기능을 제공합니다.
+
+- 동시성 제어
+
+ DBMS는 여러 사용자가 동시에 데이터베이스에 접근할 때 발생할 수 있는 문제를 관리하고, 데이터의 일관성을 유지합니다.
+
+- 데이터 추상화
+
+ DBMS는 데이터의 물리적 저장 구조를 숨기고 사용자에게 논리적인 데이터 뷰만을 제공함으로써, 사용자가 데이터를 쉽게 이해하고 사용할 수 있게 합니다.
+
+## 테이블 용어 정리
+
+https://inpa.tistory.com/entry/DB-%F0%9F%93%9A-%ED%85%8C%EC%9D%B4%EB%B8%94-%EC%9A%A9%EC%96%B4-%F0%9F%95%B5%EF%B8%8F-%EC%A0%95%EB%A6%AC
+
+ +
+
+
+ +
+
+
+ +
+### 공인 IP
+- 인터넷상에서 유일한게 식별되는 IP 주소
+
+- ISP로 부터 주소를 할당 받음
+
+- 인터넷상의 다른 장치와 통신할 때 공인 IP를 사용
+
+ ex) 웹 서버나, 이메일과 같이 외부에서 접근이 필요한 서버
+
+### 사설 IP
+- 로컬상에서 유일하게 식별되는 IP 주소
+
+- DHCP로 부터 자동으로 할당 받음
+
+- 일반적으로 가정이나 사무실등 작은 네트워크에서 사용
+
+### 공인/사설 IP 사용의 장점
+
+- 사설 ip를 사용하면 같은 주소를 여러 네트워크에서 사용가능하므로 주소 공간을 효율적으로 사용할 수 있다.
+
+- 사설 ip주소는 외부에서 접근할 수 없기 때문에 네트워크 보안이 강화된다.
+
+### NAT
+- 통신을 하기 위해 사설 ip를 공인 ip로 변환해주거나 반대의 경우로 변환해주는 것.
+
+## 서브넷
+
+
+
+### 공인 IP
+- 인터넷상에서 유일한게 식별되는 IP 주소
+
+- ISP로 부터 주소를 할당 받음
+
+- 인터넷상의 다른 장치와 통신할 때 공인 IP를 사용
+
+ ex) 웹 서버나, 이메일과 같이 외부에서 접근이 필요한 서버
+
+### 사설 IP
+- 로컬상에서 유일하게 식별되는 IP 주소
+
+- DHCP로 부터 자동으로 할당 받음
+
+- 일반적으로 가정이나 사무실등 작은 네트워크에서 사용
+
+### 공인/사설 IP 사용의 장점
+
+- 사설 ip를 사용하면 같은 주소를 여러 네트워크에서 사용가능하므로 주소 공간을 효율적으로 사용할 수 있다.
+
+- 사설 ip주소는 외부에서 접근할 수 없기 때문에 네트워크 보안이 강화된다.
+
+### NAT
+- 통신을 하기 위해 사설 ip를 공인 ip로 변환해주거나 반대의 경우로 변환해주는 것.
+
+## 서브넷
+
+ +
+
+### A 클래스
+
+네트워크 앞자리 0 시작
+
+0xxx xxxx. hhhh hhhh. hhhh hhhh. hhhh hhhh
+
+네트워크 주소 범위 : 0 ~ 127
+
+호스트 주소 범위 : 0.0.0 ~ 255.255.255
+
+네트워크 할당 개수 : (2^7)-1 개 (127은 제외)
+
+호스트 할당 개수 : (2^24)-2 개
+
+
+### B 클래스
+
+네트워크 앞자리 10 시작
+
+10xx xxxx. xxxx xxxx. hhhh hhhh. hhhh hhhh
+
+네트워크 주소 범위 : 128.0 ~ 191.255
+
+호스트 주소 범위 : 0.0 ~ 255.255
+
+네트워크 할당 개수 : 2^14 개
+
+가능한 호스트 주소 수 : (2^16) - 2개
+
+
+
+### C 클래스
+
+네트워크 앞자리 110 시작
+
+110x xxxx. xxxx xxxx. xxxx xxxx. hhhh hhhh
+
+네트워크 주소 범위 : 192.0.0 ~ 223.255.255
+
+호스트 주소 범위 : 0 ~ 255
+
+네트워크 할당 개수 : 2^21 개
+
+가능한 호스트 주소 수 : (2^8) - 2개
+
+- D는 멀티캐스트 주소, E는 연구용 주소(미래계획)
+
+
+
+## 질문
+Q. 예를들어 A Class의 네트워크 주소에서 호스트가 사용할 수 있는 주소는 2^24-2이다.
+-2를 하는 이유는?
+
+A. 14이라는 네트워크 주소를 받았다면 첫번째, 14.000.000.000은 네트워크 자체를 식별할 수 있는 주소로 사용되어야 하기 때문에 호스트 주소로 쓰지못한다. 두번째, 14.255.255.255는 브로드캐스트 주소로 해당 네트워크의 모든 호스트들에게 데이터를 보낼 때 사용하므로 호스트 주소로 사용하지 못한다. 때문에 호스트가 사용할 수 있는 주소는 2^24 - 2개이다.
+
+
+## 참조
+
+https://github.com/im-d-team/Dev-Docs/blob/master/Network/IP.md
+
+https://nordvpn.com/ko/blog/public-ip-and-private-ip/
\ No newline at end of file
diff --git "a/Network/minhyeok/MAC_ARP_\354\212\244\354\234\204\354\271\230_\354\230\244\353\245\230 \354\262\264\355\201\254.md" "b/Network/minhyeok/MAC_ARP_\354\212\244\354\234\204\354\271\230_\354\230\244\353\245\230 \354\262\264\355\201\254.md"
new file mode 100644
index 0000000..a3e5b7f
--- /dev/null
+++ "b/Network/minhyeok/MAC_ARP_\354\212\244\354\234\204\354\271\230_\354\230\244\353\245\230 \354\262\264\355\201\254.md"
@@ -0,0 +1,184 @@
+# MAC(Media Access Control)이란?
+
+ 네트워크 장비가 데이터를 교환하는 데 사용되는 고유한 식별자
+
+## MAC의 특징
+
+- 6바이트(48비트)의 길이를 가지며, 이는 전 세계적으로 고유한 값이다. 이 주소는 보통 12자리의 16진수로 표현되며, 예를 들어 '00:0a:95:9d:68:16'와 같은 형태를 가진다.
+
+- 첫 6자리는 '제조사 코드'이고, 이는 각 네트워크 장비 제조사에게 할당된 고유한 값이다. 이를 OUI(Organizationally Unique Identifier)라고도 부른다. 뒤의 6자리는 '일련번호'로, 이는 제조사가 장비를 생산할 때마다 고유하게 부여하는 값이다.
+
+- 네트워크에서 데이터 패킷을 전송할 때, 패킷의 헤더에는 목적지와 출발지의 MAC 주소가 포함된다. 이렇게 하면 네트워크 내의 장비들이 데이터를 정확하게 전송하고 받을 수 있다.
+
+- 장비의 하드웨어에 내장되어 있으므로, 장비가 변경되지 않는 한 일반적으로 변경되지 않는다. 이는 IP 주소와는 대조적인 특징이다. IP 주소는 네트워크 상황에 따라 변경될 수 있다.
+
+### MAC 주소 스푸핑
+- 네트워크 장비의 실제 MAC 주소를 다른 MAC 주소로 변경하는 행위
+- 공격자는 네트워크에서 허용된 장비의 MAC 주소를 알아낸다. 그런 다음, 공격자는 자신의 장비의 MAC 주소를 그 주소로 변경한다. 이렇게 하면, 네트워크는 공격자의 장비를 허용된 장비로 인식하게 된다.
+
+- 해결법
+
+ - MAC 주소 필터링
+
+ - 특정 MAC 주소를 가진 장비만 네트워크에 접근하도록 허용하거나, 특정 MAC 주소를 가진 장비의 접근을 차단하는 방법이다. 이 기법은 네트워크에 접근할 수 있는 장비를 제한하여 보안을 강화하는 데 사용된다.
+
+
+
+
+### A 클래스
+
+네트워크 앞자리 0 시작
+
+0xxx xxxx. hhhh hhhh. hhhh hhhh. hhhh hhhh
+
+네트워크 주소 범위 : 0 ~ 127
+
+호스트 주소 범위 : 0.0.0 ~ 255.255.255
+
+네트워크 할당 개수 : (2^7)-1 개 (127은 제외)
+
+호스트 할당 개수 : (2^24)-2 개
+
+
+### B 클래스
+
+네트워크 앞자리 10 시작
+
+10xx xxxx. xxxx xxxx. hhhh hhhh. hhhh hhhh
+
+네트워크 주소 범위 : 128.0 ~ 191.255
+
+호스트 주소 범위 : 0.0 ~ 255.255
+
+네트워크 할당 개수 : 2^14 개
+
+가능한 호스트 주소 수 : (2^16) - 2개
+
+
+
+### C 클래스
+
+네트워크 앞자리 110 시작
+
+110x xxxx. xxxx xxxx. xxxx xxxx. hhhh hhhh
+
+네트워크 주소 범위 : 192.0.0 ~ 223.255.255
+
+호스트 주소 범위 : 0 ~ 255
+
+네트워크 할당 개수 : 2^21 개
+
+가능한 호스트 주소 수 : (2^8) - 2개
+
+- D는 멀티캐스트 주소, E는 연구용 주소(미래계획)
+
+
+
+## 질문
+Q. 예를들어 A Class의 네트워크 주소에서 호스트가 사용할 수 있는 주소는 2^24-2이다.
+-2를 하는 이유는?
+
+A. 14이라는 네트워크 주소를 받았다면 첫번째, 14.000.000.000은 네트워크 자체를 식별할 수 있는 주소로 사용되어야 하기 때문에 호스트 주소로 쓰지못한다. 두번째, 14.255.255.255는 브로드캐스트 주소로 해당 네트워크의 모든 호스트들에게 데이터를 보낼 때 사용하므로 호스트 주소로 사용하지 못한다. 때문에 호스트가 사용할 수 있는 주소는 2^24 - 2개이다.
+
+
+## 참조
+
+https://github.com/im-d-team/Dev-Docs/blob/master/Network/IP.md
+
+https://nordvpn.com/ko/blog/public-ip-and-private-ip/
\ No newline at end of file
diff --git "a/Network/minhyeok/MAC_ARP_\354\212\244\354\234\204\354\271\230_\354\230\244\353\245\230 \354\262\264\355\201\254.md" "b/Network/minhyeok/MAC_ARP_\354\212\244\354\234\204\354\271\230_\354\230\244\353\245\230 \354\262\264\355\201\254.md"
new file mode 100644
index 0000000..a3e5b7f
--- /dev/null
+++ "b/Network/minhyeok/MAC_ARP_\354\212\244\354\234\204\354\271\230_\354\230\244\353\245\230 \354\262\264\355\201\254.md"
@@ -0,0 +1,184 @@
+# MAC(Media Access Control)이란?
+
+ 네트워크 장비가 데이터를 교환하는 데 사용되는 고유한 식별자
+
+## MAC의 특징
+
+- 6바이트(48비트)의 길이를 가지며, 이는 전 세계적으로 고유한 값이다. 이 주소는 보통 12자리의 16진수로 표현되며, 예를 들어 '00:0a:95:9d:68:16'와 같은 형태를 가진다.
+
+- 첫 6자리는 '제조사 코드'이고, 이는 각 네트워크 장비 제조사에게 할당된 고유한 값이다. 이를 OUI(Organizationally Unique Identifier)라고도 부른다. 뒤의 6자리는 '일련번호'로, 이는 제조사가 장비를 생산할 때마다 고유하게 부여하는 값이다.
+
+- 네트워크에서 데이터 패킷을 전송할 때, 패킷의 헤더에는 목적지와 출발지의 MAC 주소가 포함된다. 이렇게 하면 네트워크 내의 장비들이 데이터를 정확하게 전송하고 받을 수 있다.
+
+- 장비의 하드웨어에 내장되어 있으므로, 장비가 변경되지 않는 한 일반적으로 변경되지 않는다. 이는 IP 주소와는 대조적인 특징이다. IP 주소는 네트워크 상황에 따라 변경될 수 있다.
+
+### MAC 주소 스푸핑
+- 네트워크 장비의 실제 MAC 주소를 다른 MAC 주소로 변경하는 행위
+- 공격자는 네트워크에서 허용된 장비의 MAC 주소를 알아낸다. 그런 다음, 공격자는 자신의 장비의 MAC 주소를 그 주소로 변경한다. 이렇게 하면, 네트워크는 공격자의 장비를 허용된 장비로 인식하게 된다.
+
+- 해결법
+
+ - MAC 주소 필터링
+
+ - 특정 MAC 주소를 가진 장비만 네트워크에 접근하도록 허용하거나, 특정 MAC 주소를 가진 장비의 접근을 차단하는 방법이다. 이 기법은 네트워크에 접근할 수 있는 장비를 제한하여 보안을 강화하는 데 사용된다.
+
+ +
+
+
+ +
+## Physical Layer(물리 계층)
+
+### 물리 계층이란?
+
+ 물리 계층은 네트워크의 실제 데이터 전송을 담당하며, 비트 단위의 정보를 전기적 신호로 변환해 네트워크 장비들 간에 전송하는 역할을 합니다.
+
+### 구성 기기
+
+- NIC(Network Interface Card)
+
+ 네트워크에 연결하기 위한 하드웨어로, USB 포트와 연결하는 USB 타입, 마더 보드에 내장되어 있는 온보드 타입 등이 있습니다. 모든 네트워크 단말은 애플리케이션과 운영체제가 처리한 패킷을 NIC를 이용해 LAN 케이블이나 전파로 보냅니다.
+
+- 리피터(repeater)
+
+ 전송 거리가 길면 파형이 훼손됩니다. 이러한 훼손된 파형을 증폭해 정돈한 뒤 다른 쪽으로 전송하는 기기입니다.
+
+- 리피터 허브(repeater hub)
+
+ 전달받은 패킷의 복사본을 그대로 다른 모든 포트에 전송하는 기기입니다. 이제는 L2 스위치로 대체되어 잘 사용하지 않습니다.
+
+- 미디어 컨버터(media converter)
+
+ 전기 신호와 광 신호를 서로 교환하는 기기입니다.
+
+- 액세스 포인트(access point)
+
+ 패킷을 전파로 변조/복조하는 기기로, 무선과 유선 사이의 다리 역할을 합니다.
+
+
+
+## Physical Layer(물리 계층)
+
+### 물리 계층이란?
+
+ 물리 계층은 네트워크의 실제 데이터 전송을 담당하며, 비트 단위의 정보를 전기적 신호로 변환해 네트워크 장비들 간에 전송하는 역할을 합니다.
+
+### 구성 기기
+
+- NIC(Network Interface Card)
+
+ 네트워크에 연결하기 위한 하드웨어로, USB 포트와 연결하는 USB 타입, 마더 보드에 내장되어 있는 온보드 타입 등이 있습니다. 모든 네트워크 단말은 애플리케이션과 운영체제가 처리한 패킷을 NIC를 이용해 LAN 케이블이나 전파로 보냅니다.
+
+- 리피터(repeater)
+
+ 전송 거리가 길면 파형이 훼손됩니다. 이러한 훼손된 파형을 증폭해 정돈한 뒤 다른 쪽으로 전송하는 기기입니다.
+
+- 리피터 허브(repeater hub)
+
+ 전달받은 패킷의 복사본을 그대로 다른 모든 포트에 전송하는 기기입니다. 이제는 L2 스위치로 대체되어 잘 사용하지 않습니다.
+
+- 미디어 컨버터(media converter)
+
+ 전기 신호와 광 신호를 서로 교환하는 기기입니다.
+
+- 액세스 포인트(access point)
+
+ 패킷을 전파로 변조/복조하는 기기로, 무선과 유선 사이의 다리 역할을 합니다.
+
+ +
+ ### Flag 정보
+ - SYN(연결 설정) : 세그먼트로 나누어진 패킷의 순서 // 초기에 랜덤값으로 보내짐
+ - ACK(응답 확인) : 수신자가 성공적으로 값을 받은 것을 알리기 위해 사용
+ - FIN(연결 해제) : 세션 연결 종료시 사용. 전송할 데이터가 없음을 알림
+
+ ### 과정
+
+ 1. Client => Servcer
+ - tcp 헤더 안에 syn패킷에 (클라이언트 seq 임의의 숫자)을 보낸다
+
+ 2. Server => Client
+ server는 이를 받고 syn과 ack패킷을 보낸다. ack으로 클라이언트의 seq에 +1을 한 값을 보내고, 서버 seq을 보낸다.
+
+ 3. Client => Server
+ 응답으로 ack패킷을 보내고 server로 부터 받은 seq에 1을 더한 값을 보낸다.
+
+## 4-Way-Handshake (해제 과정)
+ - 세션을 종료하기 위해 수행되는 과정
+
+
+
+ ### Flag 정보
+ - SYN(연결 설정) : 세그먼트로 나누어진 패킷의 순서 // 초기에 랜덤값으로 보내짐
+ - ACK(응답 확인) : 수신자가 성공적으로 값을 받은 것을 알리기 위해 사용
+ - FIN(연결 해제) : 세션 연결 종료시 사용. 전송할 데이터가 없음을 알림
+
+ ### 과정
+
+ 1. Client => Servcer
+ - tcp 헤더 안에 syn패킷에 (클라이언트 seq 임의의 숫자)을 보낸다
+
+ 2. Server => Client
+ server는 이를 받고 syn과 ack패킷을 보낸다. ack으로 클라이언트의 seq에 +1을 한 값을 보내고, 서버 seq을 보낸다.
+
+ 3. Client => Server
+ 응답으로 ack패킷을 보내고 server로 부터 받은 seq에 1을 더한 값을 보낸다.
+
+## 4-Way-Handshake (해제 과정)
+ - 세션을 종료하기 위해 수행되는 과정
+
+  +
+1. Client => Server
+- close()을 호출하여 FIN패킷 보냄
+
+2. Server => Client
+- ACK패킷 보내고, 남은 데이터를 마저 보낸다.
+
+3. Server => Client
+- 잔여 데이터를 모두 보낸 뒤 close() 호출하여 FIN 패킷을 보낸다
+
+4. Client => Server
+- FIN 패킷을 받고, 아직 다 오지 않은 데이터를 받기 위해 TIME_WAIT 상태 유지(기본 240초)
+- 240초 뒤에 닫음
+
+## 질문
+Q. TCP 연결 후 3-way-handshake 를 주고 받는 과정에서 seq 번호를 랜덤으로 설정하는 이유는?
+
+A. 첫번째 이유로는 이전 연결에서 재전송되거나, 지연된 패킷이 현재 연결에 혼돈을 줄 수 있기 때문입니다. 두번째는 보안상의 이유입니다. seq 번호가 예측이 가능하다면 공격자는 이를 이용하여 tcp연결을 하이재킹하거나 가짜 패킷을 삽입할 수 있습니다.
+
+but 한번 연결된 이후로는 seq 번호가 순차적으로 증가
\ No newline at end of file
diff --git "a/Network/minhyeok/\353\235\274\354\232\260\355\214\205.md" "b/Network/minhyeok/\353\235\274\354\232\260\355\214\205.md"
new file mode 100644
index 0000000..3a8db0b
--- /dev/null
+++ "b/Network/minhyeok/\353\235\274\354\232\260\355\214\205.md"
@@ -0,0 +1,119 @@
+## 라우팅
+
+ 라우팅이란 네트워크에서 정보를 효율적으로 전달하는 방법을 결정하는 과정이다.
+
+## 라우팅 테이블
+
+각 목적지까지의 최적 경로와 그 경로를 통해 전달할 다음 홉의 주소 등의 정보를 담고 있다.
+
+## 라우팅 프로토콜
+
+라우팅 테이블을 생성하고, 유지하며, 업데이트하고, 전달하는 역할을 한다.
+
+
+
+1. Client => Server
+- close()을 호출하여 FIN패킷 보냄
+
+2. Server => Client
+- ACK패킷 보내고, 남은 데이터를 마저 보낸다.
+
+3. Server => Client
+- 잔여 데이터를 모두 보낸 뒤 close() 호출하여 FIN 패킷을 보낸다
+
+4. Client => Server
+- FIN 패킷을 받고, 아직 다 오지 않은 데이터를 받기 위해 TIME_WAIT 상태 유지(기본 240초)
+- 240초 뒤에 닫음
+
+## 질문
+Q. TCP 연결 후 3-way-handshake 를 주고 받는 과정에서 seq 번호를 랜덤으로 설정하는 이유는?
+
+A. 첫번째 이유로는 이전 연결에서 재전송되거나, 지연된 패킷이 현재 연결에 혼돈을 줄 수 있기 때문입니다. 두번째는 보안상의 이유입니다. seq 번호가 예측이 가능하다면 공격자는 이를 이용하여 tcp연결을 하이재킹하거나 가짜 패킷을 삽입할 수 있습니다.
+
+but 한번 연결된 이후로는 seq 번호가 순차적으로 증가
\ No newline at end of file
diff --git "a/Network/minhyeok/\353\235\274\354\232\260\355\214\205.md" "b/Network/minhyeok/\353\235\274\354\232\260\355\214\205.md"
new file mode 100644
index 0000000..3a8db0b
--- /dev/null
+++ "b/Network/minhyeok/\353\235\274\354\232\260\355\214\205.md"
@@ -0,0 +1,119 @@
+## 라우팅
+
+ 라우팅이란 네트워크에서 정보를 효율적으로 전달하는 방법을 결정하는 과정이다.
+
+## 라우팅 테이블
+
+각 목적지까지의 최적 경로와 그 경로를 통해 전달할 다음 홉의 주소 등의 정보를 담고 있다.
+
+## 라우팅 프로토콜
+
+라우팅 테이블을 생성하고, 유지하며, 업데이트하고, 전달하는 역할을 한다.
+
+ +
+### 특징
+- 송신측에서는 전송한 패킷에 대한 응답을 받아야지만 다음 패킷을 보냄
+- 비효율적
+
+## Sliding Window
+
+### 특징
+
+- 수신측에서 설정한 윈도우 크기만큼 송신측에서 패킷을 보낸다.
+- 3-way-handshake 과정에서 보낸 tcp 헤더에 수신측의 윈도우 사이즈가 포함되어 있음.
+- 수신측에서 응답을 받지 않아도 계속해서 패킷을 전송할 수 있다. => 보다 효율적
+
+### 동작 방식
+- 먼저 윈도우에 포함되는 모든 패킷을 전송하고, 그 패킷들의 전달이 확인(ACK)되는대로 이 윈도우를 옆으로 옮김으로써 그 다음 패킷들을 전송
+
+
+
+### 특징
+- 송신측에서는 전송한 패킷에 대한 응답을 받아야지만 다음 패킷을 보냄
+- 비효율적
+
+## Sliding Window
+
+### 특징
+
+- 수신측에서 설정한 윈도우 크기만큼 송신측에서 패킷을 보낸다.
+- 3-way-handshake 과정에서 보낸 tcp 헤더에 수신측의 윈도우 사이즈가 포함되어 있음.
+- 수신측에서 응답을 받지 않아도 계속해서 패킷을 전송할 수 있다. => 보다 효율적
+
+### 동작 방식
+- 먼저 윈도우에 포함되는 모든 패킷을 전송하고, 그 패킷들의 전달이 확인(ACK)되는대로 이 윈도우를 옆으로 옮김으로써 그 다음 패킷들을 전송
+
+ +
+### 동작 과정
+
+1. 송신측에서는 3-way-handshake에서 전달받은 헤더 정보에 있는 window-size 정보를 토대로 7만큼 설정
+2. 0,1,2,3,4,5,6 패킷을 보냄
+3. 수신측에서 ack응답으로 버퍼에 2개를 더 받을 수 있다는 정보를 보냄
+4. 송신측에서 ack을 수신하여 window-size를 2개 더늘리고 데이터 2개를 더 보냄
+5. 반복
+
+
+
+### 동작 과정
+
+1. 송신측에서는 3-way-handshake에서 전달받은 헤더 정보에 있는 window-size 정보를 토대로 7만큼 설정
+2. 0,1,2,3,4,5,6 패킷을 보냄
+3. 수신측에서 ack응답으로 버퍼에 2개를 더 받을 수 있다는 정보를 보냄
+4. 송신측에서 ack을 수신하여 window-size를 2개 더늘리고 데이터 2개를 더 보냄
+5. 반복
+
+ +
+### 특징
+
+ - AIMD는 TCP의 기본 혼잡 제어 알고리즘이다.
+ - 패킷 전송을 시작할 때 윈도우 크기를 1부터 시작하여, 각 패킷이 성공적으로 도착할 때마다 윈도우 크기를 1씩 증가시킨다.
+ - 하지만 패킷 전송에 실패하거나 일정 시간이 지나면 윈도우 크기를 절반으로 줄인다.
+ - 이 방법의 장점은 여러 호스트가 네트워크를 공유할 때, 시간이 지나면 모든 호스트가 평형 상태로 수렴하게 되는 점이다.
+
+ => 패킷 손실이 발생할 경우 모든 호스트가 동시에 윈도우 크기를 줄이기 때문
+
+ - 단점은 네트워크의 혼잡 상태를 미리 감지하지 못하고, 네트워크의 초반 대역폭을 충분히 활용하지 못하는 점이다.
+
+## Slow Start
+
+### 특징
+- tcp 연결이 처음 시작될 때, 패킷 손실이 됐을 때 사용
+- 1RTT에서 ack를 받은 응답개수만큼 +1하여 window size를 늘림
+### RTT란?
+송신측에서 패킷을 전송하고 수신측에서 보낸 ack값을 다시 송신측에서 수신하는 것을 한 싸이클로 잡는것
+
+
+
+### 특징
+
+ - AIMD는 TCP의 기본 혼잡 제어 알고리즘이다.
+ - 패킷 전송을 시작할 때 윈도우 크기를 1부터 시작하여, 각 패킷이 성공적으로 도착할 때마다 윈도우 크기를 1씩 증가시킨다.
+ - 하지만 패킷 전송에 실패하거나 일정 시간이 지나면 윈도우 크기를 절반으로 줄인다.
+ - 이 방법의 장점은 여러 호스트가 네트워크를 공유할 때, 시간이 지나면 모든 호스트가 평형 상태로 수렴하게 되는 점이다.
+
+ => 패킷 손실이 발생할 경우 모든 호스트가 동시에 윈도우 크기를 줄이기 때문
+
+ - 단점은 네트워크의 혼잡 상태를 미리 감지하지 못하고, 네트워크의 초반 대역폭을 충분히 활용하지 못하는 점이다.
+
+## Slow Start
+
+### 특징
+- tcp 연결이 처음 시작될 때, 패킷 손실이 됐을 때 사용
+- 1RTT에서 ack를 받은 응답개수만큼 +1하여 window size를 늘림
+### RTT란?
+송신측에서 패킷을 전송하고 수신측에서 보낸 ack값을 다시 송신측에서 수신하는 것을 한 싸이클로 잡는것
+
+ +
+ ex) 패킷 2개를 보내고 응답으로 2개를 다 받았다고 치면 => 다음 번엔 패킷을 4개를 보낸다
+ 패킷을 4개 보내고 응답으로 4개를 받았다면 => 다음 번엔 패킷을 8개를 보낸다 => 2의 지수승으로 증가
+
+- Time Out이나 3 Duplicated ACK 상황이 오면 window size를 1로 다시 조정한다.
+- 처음 데이터 전송이 늦는다는 단점
+
+
+## Fast Retransmit(빠른 재전송)
+- Fast Retransmit은 패킷 손실을 빠르게 감지하고 처리하는 방법이다. 패킷이 손실되면 수신 측에서는 동일한 ACK를 세 번 보내게 되는데, 이를 감지하면 해당 패킷을 즉시 재전송한다.
+
+
+
+ ex) 패킷 2개를 보내고 응답으로 2개를 다 받았다고 치면 => 다음 번엔 패킷을 4개를 보낸다
+ 패킷을 4개 보내고 응답으로 4개를 받았다면 => 다음 번엔 패킷을 8개를 보낸다 => 2의 지수승으로 증가
+
+- Time Out이나 3 Duplicated ACK 상황이 오면 window size를 1로 다시 조정한다.
+- 처음 데이터 전송이 늦는다는 단점
+
+
+## Fast Retransmit(빠른 재전송)
+- Fast Retransmit은 패킷 손실을 빠르게 감지하고 처리하는 방법이다. 패킷이 손실되면 수신 측에서는 동일한 ACK를 세 번 보내게 되는데, 이를 감지하면 해당 패킷을 즉시 재전송한다.
+
+ +
+## Fast Recovery(빠른 회복)
+- Fast Recovery는 Fast Retransmit 이후에 이어지는 과정으로, 패킷이 재전송된 후에는 네트워크가 혼잡하다고 가정하고 윈도우 크기를 줄인다. 이때 윈도우 크기를 현재 윈도우 크기의 절반으로 줄이고, 이 값을 새로운 임계점으로 설정한다.
+
+## TCP 혼잡제어 3단계
+
+
+## Fast Recovery(빠른 회복)
+- Fast Recovery는 Fast Retransmit 이후에 이어지는 과정으로, 패킷이 재전송된 후에는 네트워크가 혼잡하다고 가정하고 윈도우 크기를 줄인다. 이때 윈도우 크기를 현재 윈도우 크기의 절반으로 줄이고, 이 값을 새로운 임계점으로 설정한다.
+
+## TCP 혼잡제어 3단계
+ +
+
+## TCP Reno
+- Timeout 발생 시 MSS를 1로, 3회의 중복 ACKs가 발생한 경우에는 MSS를 절반으로 줄인다.
+
+
+
+
+## TCP Reno
+- Timeout 발생 시 MSS를 1로, 3회의 중복 ACKs가 발생한 경우에는 MSS를 절반으로 줄인다.
+
+ +
+### 참조
+
+https://www.brianstorti.com/tcp-flow-control/
+
+https://yeoneeds.tistory.com/25
+
+https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Network/TCP%20(%ED%9D%90%EB%A6%84%EC%A0%9C%EC%96%B4%ED%98%BC%EC%9E%A1%EC%A0%9C%EC%96%B4).md
diff --git "a/Network/minhyeok/\354\233\271 \355\206\265\354\213\240 \355\235\220\353\246\204.md" "b/Network/minhyeok/\354\233\271 \355\206\265\354\213\240 \355\235\220\353\246\204.md"
new file mode 100644
index 0000000..1920aed
--- /dev/null
+++ "b/Network/minhyeok/\354\233\271 \355\206\265\354\213\240 \355\235\220\353\246\204.md"
@@ -0,0 +1,41 @@
+# 웹 통신 전체 흐름
+
+
+### 참조
+
+https://www.brianstorti.com/tcp-flow-control/
+
+https://yeoneeds.tistory.com/25
+
+https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Network/TCP%20(%ED%9D%90%EB%A6%84%EC%A0%9C%EC%96%B4%ED%98%BC%EC%9E%A1%EC%A0%9C%EC%96%B4).md
diff --git "a/Network/minhyeok/\354\233\271 \355\206\265\354\213\240 \355\235\220\353\246\204.md" "b/Network/minhyeok/\354\233\271 \355\206\265\354\213\240 \355\235\220\353\246\204.md"
new file mode 100644
index 0000000..1920aed
--- /dev/null
+++ "b/Network/minhyeok/\354\233\271 \355\206\265\354\213\240 \355\235\220\353\246\204.md"
@@ -0,0 +1,41 @@
+# 웹 통신 전체 흐름
+ +
+1. 사용자의 통신 요청
+
+ 이용자는 웹 브라우저를 통해 구글의 웹페이지를 요청하고, 이 과정은 애플리케이션 계층에서 시작된다. 여기서 HTTP, HTTPS와 같은 프로토콜이 사용되며, 이용자의 요청 정보가 생성된다.
+
+2. DNS 해석
+
+ 이용자의 컴퓨터는 구글의 도메인 이름을 IP 주소로 변환하기 위해 DNS 서버를 조회한다. 이 과정에서 이용자의 컴퓨터는 DNS Query를 생성하고 이를 DNS 서버에게 전송한다. DNS 서버는 이 Query를 해석하여 해당 도메인의 IP 주소를 반환한다.
+
+3. TCP 연결
+
+ HTTPS는 TCP 프로토콜을 사용하므로, 이용자의 컴퓨터와 구글 서버 사이에는 TCP 연결이 설정된다. 이 과정에서는 3-way-handshake라는 절차가 이루어져 연결이 확립된다.
+
+4. 데이터 캡슐화
+
+ 응용계층에서 html 데이터 요청을 http 메세지에 담아서 보낸다.
+
+ 전송계층에서 이 메세지에 tcp 헤더를 붙인다. 여기에는 출발포트번호, 목적지포트번호, 시퀀스 번호등이 있다.
+
+ 네트워크 계층에서는 출발지와 목적지IP 주소 정보가 담겨있는 IP헤더가 붙는다.
+
+ 데이터 링크 계층에서는 이더넷 헤더와 트레일러가 추가된다. 이더넷 헤더에는 목적지, 출발지 MAC 주소가 있고, 트레일러에는 데이터의 무결성을 확인하는 오류 검출 코드가 있다.
+
+5. 스위치에서의 처리
+
+ 데이터 패킷은 스위치에 도착하면 역캡슐화되고, 이더넷 헤더에 기록된 목적지 MAC 주소를 바탕으로 다음 목적지를 결정한다. 스위치는 자신의 MAC 주소 테이블을 참조하여 이를 결정하며, 데이터 패킷은 다시 캡슐화되어 라우터로 전송된다.
+
+6. 라우터에서의 처리
+
+ 라우터에서는 데이터 패킷을 역캡슐화하고, IP 헤더에 기록된 목적지 IP 주소를 바탕으로 다음 목적지를 결정한다. 라우터는 자신의 라우팅 테이블을 참조하여 이를 결정하며, 필요에 따라 출발지 IP를 라우터의 공인 IP로 변경할 수 있다. 데이터 패킷은 다시 캡슐화되어 다음 목적지로 전송된다.
+
+7. 서버에서의 처리
+
+ 데이터 패킷이 최종 목적지인 서버에 도착하면, 서버는 패킷을 역캡슐화하고 각 계층에서 필요한 처리를 수행한다. 이 과정에서는 패킷의 무결성 검사, 전송 오류 확인 등 다양한 작업이 이루어진다.
+
+8. 애플리케이션 계층에서 이용자의 웹페이지 요청을 처리하고 응답을 생성하여 이용자에게 전송한다.
+
+
+
+
+1. 사용자의 통신 요청
+
+ 이용자는 웹 브라우저를 통해 구글의 웹페이지를 요청하고, 이 과정은 애플리케이션 계층에서 시작된다. 여기서 HTTP, HTTPS와 같은 프로토콜이 사용되며, 이용자의 요청 정보가 생성된다.
+
+2. DNS 해석
+
+ 이용자의 컴퓨터는 구글의 도메인 이름을 IP 주소로 변환하기 위해 DNS 서버를 조회한다. 이 과정에서 이용자의 컴퓨터는 DNS Query를 생성하고 이를 DNS 서버에게 전송한다. DNS 서버는 이 Query를 해석하여 해당 도메인의 IP 주소를 반환한다.
+
+3. TCP 연결
+
+ HTTPS는 TCP 프로토콜을 사용하므로, 이용자의 컴퓨터와 구글 서버 사이에는 TCP 연결이 설정된다. 이 과정에서는 3-way-handshake라는 절차가 이루어져 연결이 확립된다.
+
+4. 데이터 캡슐화
+
+ 응용계층에서 html 데이터 요청을 http 메세지에 담아서 보낸다.
+
+ 전송계층에서 이 메세지에 tcp 헤더를 붙인다. 여기에는 출발포트번호, 목적지포트번호, 시퀀스 번호등이 있다.
+
+ 네트워크 계층에서는 출발지와 목적지IP 주소 정보가 담겨있는 IP헤더가 붙는다.
+
+ 데이터 링크 계층에서는 이더넷 헤더와 트레일러가 추가된다. 이더넷 헤더에는 목적지, 출발지 MAC 주소가 있고, 트레일러에는 데이터의 무결성을 확인하는 오류 검출 코드가 있다.
+
+5. 스위치에서의 처리
+
+ 데이터 패킷은 스위치에 도착하면 역캡슐화되고, 이더넷 헤더에 기록된 목적지 MAC 주소를 바탕으로 다음 목적지를 결정한다. 스위치는 자신의 MAC 주소 테이블을 참조하여 이를 결정하며, 데이터 패킷은 다시 캡슐화되어 라우터로 전송된다.
+
+6. 라우터에서의 처리
+
+ 라우터에서는 데이터 패킷을 역캡슐화하고, IP 헤더에 기록된 목적지 IP 주소를 바탕으로 다음 목적지를 결정한다. 라우터는 자신의 라우팅 테이블을 참조하여 이를 결정하며, 필요에 따라 출발지 IP를 라우터의 공인 IP로 변경할 수 있다. 데이터 패킷은 다시 캡슐화되어 다음 목적지로 전송된다.
+
+7. 서버에서의 처리
+
+ 데이터 패킷이 최종 목적지인 서버에 도착하면, 서버는 패킷을 역캡슐화하고 각 계층에서 필요한 처리를 수행한다. 이 과정에서는 패킷의 무결성 검사, 전송 오류 확인 등 다양한 작업이 이루어진다.
+
+8. 애플리케이션 계층에서 이용자의 웹페이지 요청을 처리하고 응답을 생성하여 이용자에게 전송한다.
+
+
+ diff --git "a/Network/minseo/3 -Way Handshake & 4 -Way Handshake/TCP UDP\354\231\200 3 -Way Handshake & 4 -Way Handshake .md" "b/Network/minseo/3 -Way Handshake & 4 -Way Handshake/TCP UDP\354\231\200 3 -Way Handshake & 4 -Way Handshake .md"
index 123b5fd..7647eb1 100644
--- "a/Network/minseo/3 -Way Handshake & 4 -Way Handshake/TCP UDP\354\231\200 3 -Way Handshake & 4 -Way Handshake .md"
+++ "b/Network/minseo/3 -Way Handshake & 4 -Way Handshake/TCP UDP\354\231\200 3 -Way Handshake & 4 -Way Handshake .md"
@@ -6,7 +6,7 @@
```c
int main(){
- sock = socket(AF_INFT, SOCK_STREAM, 0);
+ sock = socket(AF_INFT, SOCK_STREAM, 0) ;
..
bind( ~)
..
diff --git a/Network/minseo/DHCP&NAT/DHCP NAT .md b/Network/minseo/DHCP&NAT/DHCP NAT .md
new file mode 100644
index 0000000..4bde01b
--- /dev/null
+++ b/Network/minseo/DHCP&NAT/DHCP NAT .md
@@ -0,0 +1,135 @@
+# DHCP/NAT
+
+IP 주소 부족의 문제를 해결하기 위해 적은 IP 주소를 동적으로 활용한다는 점에서 NAT는 DHCP와 비슷한 느낌으로 다가올 수 있다. 그렇지만, 이 둘은 근본적으로 다른 개념입니다. 먼저, DHCP와 NAT의 개념은 각각 IP 주소를 **할당**하고, IP 주소를 **매핑(변환)**하는 것이다
+
+DHCP에서는 호스트가 하나의 IP 주소를 받아 그 주소를 이용해 통신하고,
+
+NAT는 자신이 사용하는 주소로 보낸 패킷이 그 주소와 매핑되는 주소로 다시 쓰여지는 과정이라는 점에서 근본적인 차이가 있다.
+
+# NAT (Network Address Translation)
+
+네트워크의 **IP 주소를 관리하거나, IP 주소를 변경**하고 싶을 때 이용한다.
+
+### **NAT를 사용하는 목적**
+
+1. **인터넷의 공인 IP주소를 절약할 수 있다.**
+
+
+
+인터넷의 공인 IP주소는 한정되어 있기 때문에 이를 공유할 수 있도록 하는 것이 필요하다. **NAT를 이용하면 사설 IP 주소를 사용하면서 이를 공인 IP주소와 상호 변환 할 수 있도록 하여, 공인 IP주소를 다수가 함께 사용하게 함**으로써 이를 절약할 수 있다는 것이다.
+
+즉 회사와 같은 곳에서 내부에서는 사설 IP 주소를 통하여 그들끼리 통신하고 회사 밖 인터넷은 회사의 IP로써 통신하는 구조에서 사용된다 볼 수 있겠다.
+
+1. **인터넷이란 공공망과 연결되는 사용자들의 고유한 사설망을 침입자들로부터 보호할 수있다.**
+
+공개된 인터넷과 사설망 사이에 **방화벽(Firewall)**를 설치하여 외부 공격으로부터 사용자의 통신망을 보호하는 기본적인 수단을 활용할 수 있다.
+
+이 때 외부 통신망 즉 인터넷망과 연결하는 장비인 라우터에 NAT를 설정할 경우, Space 내부에서는 private address, 외부에서는 public address를 사용할 수 있고 필요시에 이를 서로 변환할 수 있다.
+
+따라서 외부 침입자가 공격하기 위해서는 사설망의 내부 사설 IP주소를 알아야 하기 때문에 공격이 불가능해지므로 내부 네트워크를 보호할 수 있다.
+
+# DHCP (Dynamic Host Configulation Protocol)
+
+DHCP란 호스트의 **IP주소와 각종 TCP/IP 기본 설정을 클라이언트에게 자동적으로 제공해주는 프로토콜**을말한다.
+
+DHCP에 대한 표준은 RFC문서에 정의되어 있으며, DHCP는 네트워크에 사용되는 IP주소를 DHCP서버가 중앙집중식으로 관리하는 **클라이언트/서버 모델**을 사용하게 된다. DHCP지원 클라이언트는 **네트워크 부팅과정**에서 DHCP서버에 IP주소를 요청하고 이를 얻을 수 있다.
+
+네트워크 안에 컴퓨터에 자동으로 네임 서버 주소, IP주소, 게이트웨이 주소를 **할당**해주는 것을 의미하고, 해당 클라이언트에게 **일정 기간 임대를 하는 동적 주소 할당 프로토콜**이다.
+
+따라서 호스트가 빈번하게 접속을 연결하고 다시 갱신하는 가정 인터넷 접속 네트워크 및 **무선랜(LAN)**에서 폭 넓게 사용된다.
+
+**DHCP장점**
+
+PC의 수가 많거나 PC 자체 변동사항이 많은 경우 IP 설정이 자동으로 되기 때문에 효율적으로 사용 가능하고, IP를 자동으로 할당해주기 때문에 IP 충돌을 막을 수 있다.
+
+**DHCP단점**
+
+DHCP 서버에 의존되기 때문에 서버가 다운되면 IP 할당이 제대로 이루어지지 않는다.
+
+## DHCP 구성
+
+### **1) DHCP서버**
+
+ DHCP서버는 네트워크 인터페이스를 위해서 **IP주소를 가지고 있는 서버에서 실행되는 프로그램**으로
+
+**일정한 범위의 IP주소를 다른 클라이언트에게 할당하여 자동으로 설정하게 해주는 역할**을 한다. **DHCP서버는 클라이언트에게 할당된 IP주소를 변경없이 유**지해 줄 수 있다.**클라이언트에게 IP 할당 요청이 들어오면 IP를 부여해주고 할당 가능한 IP들을 관리**해주게 됩니다.
+
+### **2) DHCP클라이언트**
+
+클라이언트들은 시스템이 시작하면 DHCP서버에 자신의 시스템을 위한 IP주소를 요청하고, DHCP 서버로부터 IP주소를 부여받으면 TCP/IP 설정은 초기화되고 다른 호스트와 TCP/IP를 사용해서 통신을 할 수 있다.
+
+**즉, 서버에게 IP를 할당받으면 TCP/IP 통신을 할 수 있다.**
+
+### DHCP 프로토콜의 원리
+
+ DHCP를 통한 IP 주소 할당은 **“임대”**라는 개념을 가지고 있는데
+
+ 이는 DHCP 서버가 IP 주소를 영구적으로 단말에 할당하는 것이 아니고 **임대기간(IP Lease Time)**을 명시하여 그 기간 동안만 단말이 IP 주소를 사용하도록 하는 것이다.
+
+단말은 임대기간 이후에도 계속 해당 IP 주소를 사용하고자 한다면 **IP 주소 임대기간 연장(IP Address Renewal)**을 DHCP 서버에 요청해야 하고 또한 단말은 임대 받은 IP 주소가 더 이상 필요치 않게 되면 **IP 주소 반납 절차(IP Address Release)**를 수행하게 된다.
+
+[https://t1.daumcdn.net/cfile/tistory/2519193C5715E03427](https://t1.daumcdn.net/cfile/tistory/2519193C5715E03427)
+
+이제 단발 (DHCP client)이 DHCP 서버로 부터 IP 주소를 할당(임대)받는 절차에 대해서 알아보자.
+
+## DHCP 연결 과정
+
+
+
+### **1) DHCP 서버 발견 (DHCP Server Discover)**
+
+새롭게 도착한 호스트는 자신이 접속할 네트워크의 DHCP 서버 주소를 알지 못한다.
+
+따라서 서버 발견 메세지(포트67, UDP 메세지)를 **브로드캐스트 IP주소 (출발지 주소: 0.0.0.0. 목적지: 255.255.255.255.)**로 캡슐화하여 서브넷 상의 모든 노드로 전송한다.
+
+**[주요 파라미터]**
+
+- Client Mac : 단말의 MAC 주소
+
+### **2) DHCP 서버 제공 (DHCP Server Offer)**
+
+DHCP 발견 메세지를 받은 DHCP 서버는 DHCP 제공 메세지를 이용해 클라이언트로 브로드 캐스트 한다.
+
+**단말브로드캐스트 메시지** (Destination MAC = FF:FF:FF:FF:FF:FF)이거나 **유니캐스트**일수 있다.
+
+이는 단말이 보낸 DHCP Discover 메시지 내의 Broadcast Flag의 값에 따라 달라지는데, 이 Flag=1이면 DHCP 서버는 DHCP Offer 메시지를 Broadcast로, Flag=0이면 Unicast로 보내게 된다
+
+서버 제공 메세지는 클라이언트에게 제공될 IP주소 네트워크 마스크, 도메인, 이름 , IP 주소 임대기간 등의 클라이언트 설정 파라미터 값들이 포함된다.
+
+**[주요 파라미터]**
+
+- Client MAC: 단말의 MAC 주소
+- Your IP: 단말에 할당(임대)할 IP 주소
+- Subnet Mask (Option 1)
+- Router (Option 3): 단말의 Default Gateway IP 주소
+- DNS (Option 6): DNS 서버 IP 주소
+- IP Lease Time (Option 51): 단말이 IP 주소(Your IP)를 사용(임대)할 수 있는 기간(시간)
+- DHCP Server Identifier (Option 54): 본 메시지(DHCP Offer)를 보낸 DHCP 서버의 주소. 2개 이상의 DHCP 서버가 DHCP Offer를 보낼 수 있으므로 각 DHCP 서버는 자신의 IP 주소를 본 필드에 넣어서 단말에 보냄
+
+### 3) DHCP 요청 (DHCP Request)
+
+IP 할당을 요쳥한 새 호스트는 하나 이상의 DHCP 서버 제공 메세지를 받고 그 중 가장 최적의 서버를 선택한 후 그 서버측으로 DHCP 요청 메세지를 보낸디.
+
+**[주요 파라미터]**
+
+- Client MAC: 단말의 MAC 주소
+- Requested IP Address (Option 50): 난 이 IP 주소를 사용하겠다. (DHCP Offer의 Your IP 주소가 여기에 들어감)
+- DHCP Server Identifier (Option 54): 2대 이상의 DHCP 서버가 DHCP Offer를 보낸 경우, 단말은 이 중에 마음에 드는 DHCP 서버 하나를 고르게 되고, 그 서버의 IP 주소가 여기에 들어감. 즉, DHCP Server Identifier에 명시된DHCP서버에게"DHCP Request"메시지를 보내어 단말 IP 주소를 포함한 네트워크 정보를 얻는 것
+
+### 4) DHCP Ack (Acknowledgement)
+
+서버는 DHCP 요청 메세지에 대해 요청된 설정을 확인하는 ACK 메세지를 전송한다.
+
+단말브로드캐스트 메시지 (Destination MAC = FF:FF:FF:FF:FF:FF) 혹은 유니캐스트일수 있으며 이는 단말이 보낸 DHCP Request 메시지 내의 Broadcast Flag=1이면 DHCP 서버는 DHCP Ack 메시지를 Broadcast로, Flag=0이면 Unicast로 보내게 된다.
+
+**[주요 파라미터]**
+
+- Client MAC: 단말의 MAC 주소
+- Your IP: 단말에 할당(임대)할 IP 주소
+- Subnet Mask (Option 1)
+- Router (Option 3): 단말의 Default Gateway IP 주소
+- DNS (Option 6): DNS 서버 IP 주소
+- IP Lease Time (Option 51): 단말이 본 IP 주소(Your IP)를 사용(임대)할 수 있는 기간(시간
+- DHCP Server Identifier (Option 54): 본 메시지(DHCP Ack)를 보낸 DHCP 서버의 주소
+
+이렇게 DHCP Ack를 수신한 단말은 이제 IP 주소를 포함한 네트워크 정보를 획득(임대)하였고, 이제 인터넷 사용이 가능하게 된다.
\ No newline at end of file
diff --git a/Network/minseo/DHCP&NAT/DHCP NAT/Untitled 1.png b/Network/minseo/DHCP&NAT/DHCP NAT/Untitled 1.png
new file mode 100644
index 0000000..e5c5324
Binary files /dev/null and b/Network/minseo/DHCP&NAT/DHCP NAT/Untitled 1.png differ
diff --git a/Network/minseo/DHCP&NAT/DHCP NAT/Untitled.png b/Network/minseo/DHCP&NAT/DHCP NAT/Untitled.png
new file mode 100644
index 0000000..915688c
Binary files /dev/null and b/Network/minseo/DHCP&NAT/DHCP NAT/Untitled.png differ
diff --git a/Network/minseo/IP .md b/Network/minseo/IP .md
index 6254533..498f592 100644
--- a/Network/minseo/IP .md
+++ b/Network/minseo/IP .md
@@ -12,7 +12,7 @@
3계층은 다른 네트워크 대역,
-멀리 떨어진 곳에 존재하는 네트워크까지 어떻게 데이터를 전달할지 제어하는 일을 담당한다.
+멀리 떨어진 곳에 존재하는 네트워크까지 어떻게 데이터를 전달할지 제어하는 일을 담당한다 .

diff --git "a/Network/minseo/TCP \355\235\220\353\246\204\354\240\234\354\226\264 & \355\230\274\354\236\241\354\240\234\354\226\264/TCP \355\235\220\353\246\204\354\240\234\354\226\264 & \355\230\274\354\236\241\354\240\234\354\226\264 .md" "b/Network/minseo/TCP \355\235\220\353\246\204\354\240\234\354\226\264 & \355\230\274\354\236\241\354\240\234\354\226\264/TCP \355\235\220\353\246\204\354\240\234\354\226\264 & \355\230\274\354\236\241\354\240\234\354\226\264 .md"
index 6540cde..ca733f6 100644
--- "a/Network/minseo/TCP \355\235\220\353\246\204\354\240\234\354\226\264 & \355\230\274\354\236\241\354\240\234\354\226\264/TCP \355\235\220\353\246\204\354\240\234\354\226\264 & \355\230\274\354\236\241\354\240\234\354\226\264 .md"
+++ "b/Network/minseo/TCP \355\235\220\353\246\204\354\240\234\354\226\264 & \355\230\274\354\236\241\354\240\234\354\226\264/TCP \355\235\220\353\246\204\354\240\234\354\226\264 & \355\230\274\354\236\241\354\240\234\354\226\264 .md"
@@ -17,7 +17,7 @@
# 흐름제어
- 송신측과 수신측 사이의 데이터 처리 속도 차이를 해결하기 위한 기법이다
-- 송신 측의 전송량 > 수신측의 처리량인 경우, 패킷이 수신 측의 큐를 넘어 손실될 수 있어서 송신측 패킷 전송량을 제어해줘야 한다.
+- 송신 측의 전송량 > 수신측의 처리량인 경우 , 패킷이 수신 측의 큐를 넘어 손실될 수 있어서 송신측 패킷 전송량을 제어해줘야 한다.
## 1. Stop and Wait (정지-대기)
diff --git "a/Network/minseo/WEB \355\206\265\354\213\240 \354\240\204\354\262\264 \355\235\220\353\246\204.md" "b/Network/minseo/WEB \355\206\265\354\213\240 \354\240\204\354\262\264 \355\235\220\353\246\204.md"
new file mode 100644
index 0000000..537be02
--- /dev/null
+++ "b/Network/minseo/WEB \355\206\265\354\213\240 \354\240\204\354\262\264 \355\235\220\353\246\204.md"
@@ -0,0 +1,61 @@
+# WEB 통신 전체 흐름
+
+주소창에 url을 입력했을때 통신의 흐름에 대해 알아보자.
+
+웹 통신의 흐름을 보기 전에 알아야할 개념이 있다.
+
+## IP 주소
+
+컴퓨터 네트워크에서 장치들이 서로를 인식하고 통신을 하기 위해서 사용하는 특수한 번호
+
+→ 현재 사용하는 IPv4는 128.0.0.1과 같은 32비트 수로 구성되어 있다.
+
+## Domain Name
+
+IP 주소를 문자로 표현한 주소
+
+→ **DNS : IP주소와 도메인 이름의 매핑 정보를 담는 데이터베이스**
+
+# 작동 방식
+
+
+
+1. 사용자가 브라우저에 **도메인 이름을 입력**한다.
+2. **DNS서버**에서 사용자가 입력한 Domain name을 검색하고, **매핑되는 IP주소**를 찾는다. 사용자가 입력한 URL 정보와 함께 리턴한다.
+3. IP주소는 HTTP 프로토콜을 이용해서 **HTTP 요청 메세지를 생성**한다.
+4. 생성된 HTTP 요청 메세지는 TCP 프로토콜을 사용해서 인터넷을 거쳐 **해당 IP 주소의 컴퓨터(서버)로** 전송된다.
+5. 서버는 클라이언트의 요청을 승인하고, 응답 메세지를 전송한다.
+6. 도착한 HTTP 응답 메세지는 HTTP 프로토콜을 사용하여 **웹페이지 데이터로 변환**되고, 웹 브라우저의 출력에 의해 사용자가 볼 수 있다.
+
+# DNS 서버의 주소 찾기
+
+## DHCP
+
+- Dynamic Host Configuration Protocol
+
+
+
+- 호스트의 IP 주소와 TCP/IP 설정을 클라이언트에 의해 자동으로 제공하는 응용 계층 프로토콜
+
+ → 사용자는 DHCP 서버에서 자신의 IP 주소, 가장 가까운 라우터의 IP 주소, 가장 가까운 **DNS 서버의 주소**를 받는다.
+
+
+## ARP
+
+- Address Resolution Protocol
+- 네트워크상에서 IP 주소를 물리적 네트워크 주소로 바인딩시키기 위해 사용하는 프로토콜
+- DHCP로 얻은 라우터의 IP 주소를 MAC 주소로 변환
+
+# DNS 서버에서 IP 정보 수신
+
+
+
+- 사용자가 웹 브라우저 주소창에 www.example.com을 입력
+- www.example.com에 대한 요청이 인터넷 서비스 제공업체(ISP)가 관리하는 DNS 해석기로 라우팅
+- DNS 해석기는 요청을 DNS 루트 이름 서버에 전달
+- DNS 해석기는 요청을 .com 도메인 TLD(Top-level Domain) 네임 서버 중 하나에 다시 전달
+- DNS 해석기는 요청을 Route 53 네임 서버에 다시 전달
+- Route 53 네임 서버는 www.example.com 레코드를 찾아 IP주소를 DNS 해석기로 반환
+- DNS 해석기는 웹 브라우저에 IP주소 반환
+
+DNS 서버는 계층화 구조를 이루는데, 최상단 계층인 가장 뒷쪽(.com, .kr 등등)을 담당하는 DNS 서버는 **전세계에 13개 뿐**이다.
\ No newline at end of file
diff --git "a/Network/minseo/link layer/link layer (MAC ARP \354\212\244\354\234\204\354\271\230 \354\230\244\353\245\230 \354\262\264\355\201\254).md" "b/Network/minseo/link layer/link layer (MAC ARP \354\212\244\354\234\204\354\271\230 \354\230\244\353\245\230 \354\262\264\355\201\254).md"
new file mode 100644
index 0000000..56e0e89
--- /dev/null
+++ "b/Network/minseo/link layer/link layer (MAC ARP \354\212\244\354\234\204\354\271\230 \354\230\244\353\245\230 \354\262\264\355\201\254).md"
@@ -0,0 +1,130 @@
+# link layer (MAC / ARP / 스위치 / 오류 체크)
+
+- 데이터 링크 계층은 **직접 연결된** 서로 다른 2개의 네트워킹 장치 간의 데이터 전송을 담당한다.
+- Network 장비 간에 **신호를 주고받는 규칙**을 정하는 계층
+ - 대표적으로 Ethernet 프로토콜이 존재
+- Network 기기 간에 **Data 전송 + 물리 주소를 결정**
+- Data들을 Network 전송 방식에 맞게 **단위화(Framing)**해서, 해당 단위를 전송
+ - 전송되는 Data를 프레임이라 한다
+- Data Link layer에서 최종적으로 **이더넷 헤더/트레일러**가 붙는다.
+
+링크계층에서 제공하는 서비스들을 살펴보자
+
+## 주요 기능
+
+**1) 프레이밍 (Framing)**
+
+링크계층에서 일단 제공하는 가장중요한 서비스는 **프레이밍-프레임을** 만드는 것이다.
+
+**물리 계층으로 부터 받은 신호들을 조합**해서 **프래임단위**의 **정해진 크기의 Data Unit**으로 만들어서 처리
+
+프레임으로 만드는 작업을해서 데이터그램이 위쪽에서 내려와 캡슐화를 해서 프레임으로 만들게된다.
+
+링크계층에서 사용하는 헤더와 트레일러,
+
+트레일러는 앞뒤로 붙이는 메터데이터라고 생각해면 된다.
+
+**2) 오류제어 (Error Control)**
+
+Farme 전송 시 발생하는 오류들을 복원하거나 재전송
+
+**3) 흐름 제어 (Flow control)**
+
+-송수신측 간에 Data를 주고 받을 때 **적당한 양의 Data를 송수신**할 수 있도록 Data의 흐름을 제어
+
+**4) 접근 제어 (Access Control)**
+
+매체 상에 기기가 여러 개 존재할 때 **데이터 전송 여부를 결정**
+
+**5) 동기화 (Sysnchronization)**
+
+- Frame 구분자 (특별한 비트 패턴)
+
+---
+
+링크계층에는 2가지 종류가 있다.
+
+## 링크 계층의 종류
+
+**1) Point-to-point link**
+
+
+
+위 그림처럼 노드들 간에 dedicated 된 link를 사용하는 방식이다.
+
+빠르고 보안성이 높다는 장점이 있지만, 패킷의 경로가 길어지거나, 네트워크 카드가 여러개 필요하는 등 효율성이 떨어진다는 단점이 있다.
+
+이 경우, 신뢰성 있는 전달이나 flow control 등과 같은 Data link control 기능만 제공하면 된다.
+
+**2) Broadcast link**
+
+
+
+여러 노드들이 하나의 공유된 link를 사용하는 방식이다.
+
+효율적이라는 장점이 있지만, 보안이 약하고, 여러 노드가 동시에 신호를 보낼 경우 변조될 가능성이 존재한다는 단점이 있다.
+
+이 경우, 위 그림과 같이 Data link control 기능 뿐만 아니라, 여러 신호가 섞이는 것을 방지하기 위한 Media access control 기능도 필요하다.
+
+### **Link layer 프로토콜은 OS 커널과 네트워크 카드에도 일부 구현되어 있다.**
+
+
+
+위 그림처럼, 특정 application에서 트래픽을 보내고 싶을때, CPU를 통해 appilcation과 OS 커널에 구현된 프로토콜을 따라 내려오다, link layer를 거칠 때 네트워크 카드를 거치는 것을 확인할 수 있다.
+
+이후 네트워크 카드의 physical transmission 인터페이스를 통해 실제 물리적인 신호가 전달되는 것이다.
+
+# MAC 주소
+
+%20e25ccc6dacd944eba88db685fd1ffefb/%25E1%2584%2589%25E1%2585%25B3%25E1%2584%258F%25E1%2585%25B3%25E1%2584%2585%25E1%2585%25B5%25E1%2586%25AB%25E1%2584%2589%25E1%2585%25A3%25E1%2586%25BA_2024-02-03_%25E1%2584%258B%25E1%2585%25A9%25E1%2584%2592%25E1%2585%25AE_4.06.51.png)
+
+- **랜 카드를 제조할 떄 정해지는 물리적 주소**
+- **전 세계에서 유일한 번호**로 할당됨
+- 총 **48비트**의 숫자로 구성됨
+ - 앞 24 비트: 랜 카드 제조사 번호
+ - 뒤 24 비트 : 제조사가 랜 카드에 붙인 일련 번호
+
+ 네트워크 장비 혹은 컴퓨터는 모두 MAC주소를 갖는다. 그런데 왜 MAC 주소가 필요할까?
+
+ %20e25ccc6dacd944eba88db685fd1ffefb/%25E1%2584%2589%25E1%2585%25B3%25E1%2584%258F%25E1%2585%25B3%25E1%2584%2585%25E1%2585%25B5%25E1%2586%25AB%25E1%2584%2589%25E1%2585%25A3%25E1%2586%25BA_2024-02-03_%25E1%2584%258B%25E1%2585%25A9%25E1%2584%2592%25E1%2585%25AE_4.41.15.png)
+
+ %20e25ccc6dacd944eba88db685fd1ffefb/%25E1%2584%2589%25E1%2585%25B3%25E1%2584%258F%25E1%2585%25B3%25E1%2584%2585%25E1%2585%25B5%25E1%2586%25AB%25E1%2584%2589%25E1%2585%25A3%25E1%2586%25BA_2024-02-03_%25E1%2584%258B%25E1%2585%25A9%25E1%2584%2592%25E1%2585%25AE_4.42.10.png)
+
+
+# 스위치 (Switch)
+
+%20e25ccc6dacd944eba88db685fd1ffefb/%25E1%2584%2589%25E1%2585%25B3%25E1%2584%258F%25E1%2585%25B3%25E1%2584%2585%25E1%2585%25B5%25E1%2586%25AB%25E1%2584%2589%25E1%2585%25A3%25E1%2586%25BA_2024-02-03_%25E1%2584%258B%25E1%2585%25A9%25E1%2584%2592%25E1%2585%25AE_4.08.30.png)
+
+- Lv2 (데이터 링크)에서 동작
+- Layer 2 Switch/ Swtiching Hub라고 불린다
+- 스위치 내부에는 **MAC 주소 테이블** 존재
+
+### MAC 주소 테이블 (MAC Address Table)
+
+스위치의 포트번호 + 포트에 연결된 컴퓨터의 MAC 주소가 등록되는 DB
+
+- MAC 주소 학습을 통해서 MAC 주소 테이블에 해당 포트 + MAC 주소를 저장
+- 초기 상태에는 아무것도 등록 x
+
+### 스위치 기능
+
+1. **MAC 주소학습 (Learning)**
+ - 목적지 MAC 주소가 추가된 Frame 전송
+ - Frame이 스위치를 지나칠 때, MAC 주소 테이블에 출발지 MAC 주소가 등록
+
+2. **플러딩 (Flooding)**
+ - 목적지 MAC 주소가 MAC 주소 테이블에 등록되지 않은 경우
+ - 출발지를 제외한 포트에 연결된 모든 컴퓨터에 Frame이 전송
+
+3. **포워딩 (Forwarding)**
+ - 스위치가 목적지 MAC주소를 보유하고 있을 때, 그대로 목적지 포트로 Frame을 전송
+ - 나머지 포트는 필터링 되어서 Frame 전송 x
+
+4. **필터링 (Filterling)**
+ - 스위치가 목적지 MAC주소를 보유하고 있어서 해당 주소가 아닌 포트로는 Frame 전송 x
+
+5. **에이징 (Aging)**
+ - 스위치는 MAC 주소를 학습해서 MAC 테이블에 저장
+ - MAC 주소는 기본적으로 300초동안 MAC 테이블에 저장
+ - 300초 내에 Frame이 들어오지 않으면 해당 MAC 주소는 지워진다.
+ - 시간은 조정 가능
\ No newline at end of file
diff --git "a/Network/minseo/link layer/link layer (MAC ARP \354\212\244\354\234\204\354\271\230 \354\230\244\353\245\230 \354\262\264\355\201\254)/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_4.06.51.png" "b/Network/minseo/link layer/link layer (MAC ARP \354\212\244\354\234\204\354\271\230 \354\230\244\353\245\230 \354\262\264\355\201\254)/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_4.06.51.png"
new file mode 100644
index 0000000..d58eb86
Binary files /dev/null and "b/Network/minseo/link layer/link layer (MAC ARP \354\212\244\354\234\204\354\271\230 \354\230\244\353\245\230 \354\262\264\355\201\254)/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_4.06.51.png" differ
diff --git "a/Network/minseo/link layer/link layer (MAC ARP \354\212\244\354\234\204\354\271\230 \354\230\244\353\245\230 \354\262\264\355\201\254)/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_4.08.30.png" "b/Network/minseo/link layer/link layer (MAC ARP \354\212\244\354\234\204\354\271\230 \354\230\244\353\245\230 \354\262\264\355\201\254)/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_4.08.30.png"
new file mode 100644
index 0000000..5fa3c87
Binary files /dev/null and "b/Network/minseo/link layer/link layer (MAC ARP \354\212\244\354\234\204\354\271\230 \354\230\244\353\245\230 \354\262\264\355\201\254)/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_4.08.30.png" differ
diff --git "a/Network/minseo/link layer/link layer (MAC ARP \354\212\244\354\234\204\354\271\230 \354\230\244\353\245\230 \354\262\264\355\201\254)/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_4.41.15.png" "b/Network/minseo/link layer/link layer (MAC ARP \354\212\244\354\234\204\354\271\230 \354\230\244\353\245\230 \354\262\264\355\201\254)/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_4.41.15.png"
new file mode 100644
index 0000000..b0f9451
Binary files /dev/null and "b/Network/minseo/link layer/link layer (MAC ARP \354\212\244\354\234\204\354\271\230 \354\230\244\353\245\230 \354\262\264\355\201\254)/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_4.41.15.png" differ
diff --git "a/Network/minseo/link layer/link layer (MAC ARP \354\212\244\354\234\204\354\271\230 \354\230\244\353\245\230 \354\262\264\355\201\254)/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_4.42.10.png" "b/Network/minseo/link layer/link layer (MAC ARP \354\212\244\354\234\204\354\271\230 \354\230\244\353\245\230 \354\262\264\355\201\254)/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_4.42.10.png"
new file mode 100644
index 0000000..668c0c4
Binary files /dev/null and "b/Network/minseo/link layer/link layer (MAC ARP \354\212\244\354\234\204\354\271\230 \354\230\244\353\245\230 \354\262\264\355\201\254)/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_4.42.10.png" differ
diff --git "a/Network/minseo/loadBalancing/\353\241\234\353\223\234 \353\260\270\353\237\260\354\213\261 .md" "b/Network/minseo/loadBalancing/\353\241\234\353\223\234 \353\260\270\353\237\260\354\213\261 .md"
new file mode 100644
index 0000000..cb852f8
--- /dev/null
+++ "b/Network/minseo/loadBalancing/\353\241\234\353\223\234 \353\260\270\353\237\260\354\213\261 .md"
@@ -0,0 +1,91 @@
+# 로드 밸런싱
+
+# 로드밸런서란?
+
+### **1. 로드밸런서(Load Balancer)**
+
+
+
+로드밸런서(Load Balancer)는 **클라이언트와 서버 그룹 사이에 위치해 서버에 가해지는 트래픽을 여러 대의 서버에 고르게 분신(=밸런싱)하여 특정 서버의 부하(=로드)를 덜어준다.** 서버가 하나인데 많은 트래픽이 몰릴 경우 부하를 감당하지 못하고, 서버가 다운되어 서비스가 작동을 멈출 수 있다. 이런 문제를 해결하기 위해서 **Scale up(스케일업)과 Scale out(스케일아웃) 방식 중 한 가지**를 사용해 해결한다.
+
+**그렇다면 로드밸런싱은 모든 경우에 항상 필요할까요?**
+
+로드밸런싱은 여러 대의 서버를 두고 서비스를 제공하는 분산 처리 시스템에서 필요한 기술이다.
+
+서비스의 제공 초기단계라면 적은 수의 클라이언트로 인해 서버 한 대로 요청에 응답하는 것이 가능하지만,
+
+사업의 규모가 확장되고, 클라이언트의 수가 늘어나게 되면 기본 서버만으로는 정상적인 서비스가 불가능하다.
+
+이처럼 증가하 트래픽에 대처할 수 있는 방법은 크게 2가지다.
+
+### **2. 스케일 업과 스케일 아웃**
+
+
+
+**스케일 업(Scale Up)**은 **기존 서버 자체의 성능을 향상시키는 방법**으로 이는 CPU나 메모리를 업그레이드하는 것과 같은 작업을 포함한다. 반
+
+**스케일 아웃(Scale Out)**은 존 서버와 동일하거나 낮은 성능의 서버를 두 대 이상 증설하여 운영하는 것과 같다. 즉 **트래픽이나 작업을 여러 대의 컴퓨터나 서버에 분산시켜 처리하는 방법이**다.
+
+각각의 방법은 장단점이 있어 어떤 방법이 더 적합한지 판단해야 한다.
+
+| | 스케일 업 | 스케일 아웃 |
+| --- | --- | --- |
+| 확장성 | 성능 확장에 한계 존재 | 지속적 확장이 가능 |
+| 서버 비용 | 성능 증가에 따른 비용 증가 폭 큼
+일반적으로 비용 부담이 큰 편 | 비교적 저렴한 서버를 사용하므로, 일반적으로 비용 부담이 적음 |
+| 관리 편의성 | 스케일 업에 따른 큰 변화 없음 | 서버 대수가 늘어날수록 관리 편의성 떨어짐 |
+| 운영 비용 | 스케일 업에 따른 큰 변화 없음 | 서버 대수가 늘어날수록 운영 비용 증가 |
+| 장애 영향 | 한 대의 서버에 부하가 집중되므로 장애 시 다운 타임 발생 | 부하가 여러 서버에 분산되어 처리됨으로 장애 시 전면 장애 가능성 적음 |
+
+# 로드밸런싱 알고리즘
+
+### **1. 정적 로드 밸런싱**
+
+**1) 라운드 로빈 방식(Round Robin Method)**
+
+클라이언트의 요청을 여러 대의 서버에 순차적으로 분배하는 방식이다. 클라이언트의 요청을 순서대로 분배하기 때문에 서버들이 동일 스펙을 가지고 있고, 서버와의 연결(세션)이 오래 지속되지 않는 경우 활용하기 적합하다.
+
+- A, B, C의 서버를 가지고 있을 경우 A → B → C → A 순서대로 순회합니다.
+
+**2) 가중치 기반 라운드 로빈 방식(Weighted Round Robin Method)**
+
+각각의 서버마다 가중치(Weight)를 매기고 가중치가 높은 서버에 클라이언트의 요청을 먼저 배분합니다. 여러 서버가 같은 사양이 아니고, 특정 서버의 스펙이 더 좋은 경우 해당 서버의 가중치를 높게 매겨 트래픽 처리량을 늘릴 수 있습니다.
+
+- 서버 A의 가중치 = 8, 서버 B의 가중치 = 2, 서버 C의 가중치 = 3
+ - → 서버 A에 8개, 서버 B에 2개, 서버 C에 3개의 Request를 할당합니다.
+
+**3) IP 해시 방식(IP Hash Method)**
+
+IP 해시 방식에서 로드밸런서는 클라이언트 IP 주소에 대해 해싱이라고 하는 수학적인 계산을 수행합니다. 클라이언트 IP 주소를 숫자로 변환한 다음 개별 서버에 매핑합니다. 사용자 IP를 해싱하여 부하를 분산하기 때문에 사용자가 항상 동일한 서버로 연결되는 것을 보장합니다.
+
+### **2. 동적 로드 밸런싱**
+
+**1) 최소 연결 방법(Least Connection Method)**
+
+최소 연결 방법에서 로드 밸런서는 활성 연결이 가장 적은 서버를 확인하고 해당 서버로 트래픽을 전송합니다. 이 방법에서는 모든 연결에 모든 서버에 대해 동일한 처리 능력이 필요하다고 가정합니다. 서버에 분배된 트래픽들이 일정하지 않은 경우에 적합하다.
+
+**2) 최소 응답 시간 방법(Least Response Time Method)**
+
+서버의 현재 연결 상태와 응답 시간을 모두 고려하여, 가장 짧은 응답 시간을 보내는 서버로 트래픽을 할당합니다. 각 서버의 가용 가능한 리소스와 성능, 처리 중인 데이터양 등이 상이할 경우 적합합니다. 조건에 잘 들어맞는 서버가 있을 시 여유 있는 서버보다 먼저 할당됩니다. 로드 밸런서는 이 알고리즘을 사용하여 모든 사용자에게 더 빠른 서비스를 보장합니다.
+
+**부하분산에는 L4로드밸런서와 L7 로드밸런서가 가장많이 활용된다.**
+
+그 이유는 L4 로드밸런서부터 포트정보를 바탕으로 로드를 분산하는 것이 가능하기 때문이다. 한 대의 서버에 각기 다른 포트 번호를 부여하여 다수의 서버 프로그램을 운영하는 경우라면 최소 L4 로드밸런서 이상을 사용해야 만 한다.
+
+# L4 로드밸런싱과 L7로드 밸런싱
+
+
+
+L4 로드밸런서는 네트워크 계층(IP.IPX)이나 트랜스포트 계층(TCP,UDP)의 정보를 바탕으로 로드를 분산한다.
+
+IP주소나 포트번호, MAC주소, 전송 프로토콜에 따라 트래픽을 나누는 것이 가능하다.
+
+반면 L7 로드밸런서의 경우 애플리케이션 계층 (HTTP, FTP, SMTP)에서 로드를 분산하기 때문에 HTTP헤더, 쿠키 등과 같은 사용자의 요청을 기준으로 특정 서버에 트래픽을 분산하는 것이 가능하다.
+
+쉽게 말해 패킷의 내용을 확인하고 그 내용에 따라 로드를 특정 서버에 분배하는 것이 가능한 것이다.
+
+위 그림과 같이 URL에 따라 부하를 분산시키거나, HTTP 헤더의 쿠키 값에 따라 부하를 분산하는 등
+
+클라이언트의 요청을 보다 세분화하여 서버에 전달 할 수 있다. 또한 L7 로드밸런서의 경우 특정한 패턴을 지닌 바이러스를 감지해 네트워크를 보호할 수 있으며 Dos/DDoS 과 같은 비정상적인 트래픽을 필터링할 수 있어 네트워크 보안 분야에서도 활용되고 있다.
+
+
\ No newline at end of file
diff --git "a/Network/minseo/loadBalancing/\353\241\234\353\223\234 \353\260\270\353\237\260\354\213\261/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_2.43.33.png" "b/Network/minseo/loadBalancing/\353\241\234\353\223\234 \353\260\270\353\237\260\354\213\261/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_2.43.33.png"
new file mode 100644
index 0000000..356f944
Binary files /dev/null and "b/Network/minseo/loadBalancing/\353\241\234\353\223\234 \353\260\270\353\237\260\354\213\261/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_2.43.33.png" differ
diff --git "a/Network/minseo/loadBalancing/\353\241\234\353\223\234 \353\260\270\353\237\260\354\213\261/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_2.44.27.png" "b/Network/minseo/loadBalancing/\353\241\234\353\223\234 \353\260\270\353\237\260\354\213\261/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_2.44.27.png"
new file mode 100644
index 0000000..5c4b4a2
Binary files /dev/null and "b/Network/minseo/loadBalancing/\353\241\234\353\223\234 \353\260\270\353\237\260\354\213\261/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_2.44.27.png" differ
diff --git a/Network/minseo/physicalLayer/physical layer.md b/Network/minseo/physicalLayer/physical layer.md
new file mode 100644
index 0000000..7a86dfc
--- /dev/null
+++ b/Network/minseo/physicalLayer/physical layer.md
@@ -0,0 +1,27 @@
+# physical layer
+
+
+
+### 주된 기능
+
+1) 비트 단위의 데이터 전송
+
+2) 내트워크 장비로 데이터를 전기신호로 출력
+
+3) 데이터 링크 계층의 데이터 통신 기능을 원활하게 수행하도록 물리적인 연결 설정과 유지 및 해제기능과 관계
+
+단, Physical Layer은 단지 데이터를 전달만 할뿐 이 데이터가 무엇인지, 어떤 에러가 있는지, 어떻게 보내는 것이 더 효과적인지 하는 것은 전혀 관여하지 않음
+
+Physical Layer에 관련되는 프로토콜은 DTE/DCE 인터페이스로 규정한다.
+
+DTE/DCE 인터페이스?
+
+변복조기, DSU 등 통신 회선에 연결되는 장치의 퍼스널 컴퓨터 또는 단말기 사이를 연결하는 신호선, 커넥터에 대해 규정
+
+### Physical Layer의 대표적인 장비
+
+1) 통신 케이블
+
+2) 리퍼터
+
+3) 허브
\ No newline at end of file
diff --git a/Network/minseo/physicalLayer/physical layer/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_3.34.45.png b/Network/minseo/physicalLayer/physical layer/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_3.34.45.png
new file mode 100644
index 0000000..6eedf73
Binary files /dev/null and b/Network/minseo/physicalLayer/physical layer/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_3.34.45.png differ
diff --git "a/Network/minseo/routing&router/\353\235\274\354\232\260\355\214\205 & \353\235\274\354\232\260\355\204\260/Untitled 1.png" "b/Network/minseo/routing&router/\353\235\274\354\232\260\355\214\205 & \353\235\274\354\232\260\355\204\260/Untitled 1.png"
new file mode 100644
index 0000000..4a0239d
Binary files /dev/null and "b/Network/minseo/routing&router/\353\235\274\354\232\260\355\214\205 & \353\235\274\354\232\260\355\204\260/Untitled 1.png" differ
diff --git "a/Network/minseo/routing&router/\353\235\274\354\232\260\355\214\205 & \353\235\274\354\232\260\355\204\260/Untitled.png" "b/Network/minseo/routing&router/\353\235\274\354\232\260\355\214\205 & \353\235\274\354\232\260\355\204\260/Untitled.png"
new file mode 100644
index 0000000..2f0a6b5
Binary files /dev/null and "b/Network/minseo/routing&router/\353\235\274\354\232\260\355\214\205 & \353\235\274\354\232\260\355\204\260/Untitled.png" differ
diff --git "a/Network/minseo/routing&router/\353\235\274\354\232\260\355\214\205 & \353\235\274\354\232\260\355\204\260md" "b/Network/minseo/routing&router/\353\235\274\354\232\260\355\214\205 & \353\235\274\354\232\260\355\204\260md"
new file mode 100644
index 0000000..8683cdd
--- /dev/null
+++ "b/Network/minseo/routing&router/\353\235\274\354\232\260\355\214\205 & \353\235\274\354\232\260\355\204\260md"
@@ -0,0 +1,159 @@
+# 라우팅 & 라우터
+
+# 라우팅이란?
+
+라우터(router)는 패킷(packet)의 목적지 주소를 확인하고, 목적지와 연결되는 인터페이스로 전송하는 역할을 한다.
+
+
+
+말 그대로 Route(경로)를 선택하여 데이터가 전달될 수 있게 하는 것을 말하는데 이 경로를 최단거리, 최단시간에 전달될 수 있게 하는 것이 핵심적인 내용이다.
+
+이와 같은 라우터의 기능을 라우팅(routing)이라고 합니다. 특히, IP 라우팅이란 패킷의 목적지 IP 주소를 참조하여 길을 찾아주는 것이다.
+
+예를 들어 인천에는 여러 가지 경로가 존재하는데, 이 많은 경로 중에 하나를 선택하여 이동하는 것을 라우팅이라 한다.
+
+# 경로 선택
+
+당연히도 라우터는 특정 데이터(패킷)의 목적지인 IP주소에 대한 정보를 갖고 있어야 스위칭이 가능하다.
+
+내가 부산에 사는데 서울이 어딘지도 모른다면 어디로 가야하는지 모를수밖에 없겠죠. 또, 길이 어떻게 생겨먹었는지도 알아야 할 것이고, 어디가 교통량이 많고 적은지, 어떤 톨 게이트를 거쳐야 하는지 등 알아야 할 정보가 많을겁니다.
+
+라우팅 또한 최적의 경로를 선택하기 위해서는 이러한 정보들을 알고, 활용해야 합니다. 다음과 같은 요소들이 라우팅 경로 결정에 사용된다.
+
+- 토폴로지
+- 트래픽
+- 링크 비용
+- 메시지
+- 라우팅 테이블
+
+# **라우팅 프로토콜의 구분과 종류**
+
+해당 목적지에 대한 정보를 알아야 하며 그 정보에 따라 패킷을 전달한다. 그래서 라우터들은 목적지에 대한 경로 정보를 이웃 라우터들과 공유하게 된다. 이 때 교환하는 것을 라우팅 프로토콜이라 한다.
+
+
+
+라우터는 다른 라우터들로부터 라우팅 정보를 수신한 다음 그 중에서 최적의 경로를 선택하여 라우팅 테이블에 저장한다. 라우팅 테이블이란 목적지 네트워크 및 목적지 네트워크와 연결되는 인터페이스를 기록한 데이터베이스이다.
+
+## **정보 갱신 방법에 따른 구분**
+
+라우팅 경로는 동적 경로(dynamic route)와 정적 겅로(static route)가 있다.
+
+| 구분 | 특징 |
+| --- | --- |
+| 정적 라우팅(Static Routing) | - 네트워크 관리자가 경로를 수동으로 직접 지정해 주는 방식. - 구성이 간단하고, 원하는 경로로 패킷을 보낼 수 있음. - 단일 경로에 적합하여 Stub Network 에 주로 적용. - 네트워크 구성 변화에 수동적임. - 관리 부담의 증가 및 경로 장애 발생시에 라우팅이 불가능함. |
+| 동적 라우팅(Dynamic Routing) | - 장비가 자동으로 경로를 지정함. - 네트워크 변화를 인지하여 경로를 재구성할 수 있음. - 다중경로 네트워크에 적합함. - 라우팅 프로토콜(routing protocol)을 사용하여 동적으로 알아낸 경로 |
+
+수동(고정) 경로 설정과 적응 경로 설정의 차이다.
+
+ 부산→서울 이동 경로를 생각했을때, 나는 무조건 정해진 길로만 가겠다! 와 차막히면 돌아가지 뭐,, 네비게이션이 안내 해 주는대로 가자~~ 정도의 차이라고 생각하시면 됩니다.
+
+## **내/외부에 따른 구분**
+
+**같은 네트워크 관리자가 관리하는 라우터들과 일정 규모의 집합을 AS(Autonomus System)** 이라 칭하는데, 이 규모에 따라 구분하는 방식
+
+| 구분 | 특징 |
+| --- | --- |
+| IGP(Interior Gateway Protocol) | - AS 내에서의 라우팅을 담당하는 프로토콜. |
+| EGP(Exterior Gateway Protocol) | - 서로 다른 AS간 사용되는 프로토콜. |
+
+마치 내부망, 외부망을 구분짓는 것과 느낌이 비슷한데, 이 구분이 망 구성이 중점이 되는것이 아니고 관리자나 관리 업체가 중점이 되는것이 차이점입니다.
+
+예를들어 KT가 관리하는 라우터들은 KT 입장에서는 IGP를 사용하고 SK가 관리하는 라우터들과는 EGP를 사용하게 되는겁니다.
+
+## **테이블 관리 방법에 따른 구분**
+
+| 구분 | 특징 |
+| --- | --- |
+| Distance VectorAlgorithm | - 최단 거리를 홉 수로 판단함. - 주기적으로 라우팅 테이블을 교환함. |
+| Link StateAlgorithm | - 대역폭, 지연시간, 토폴로지를 참고하여 Cost를 책정함. - 라우터가 목적지까지 가는 경로를 모든 라우팅 테이블에 기록함. |
+| Hybrid RoutingAlgorithm | - 거리벡터, 링크상태를 복합적으로 사용한 방식. - Cisco 독점 프로토콜. |
+
+부산→서울 이동을 생각했을 때, 나는 톨 게이트를 최대한 적게 지나가는 경로로 가겠다! 하는것이 거리벡터, 나는 교통량이 적은 곳으로 최대한 빨리 가보겠다! 하는것이 링크상태방식이다.
+
+링크상태 방식에서 말하는 비용(Cost)은 금전적 의미가 아니고 **통신 속도**를 의미한다. 비용이 낮을수록 대역폭이 크다던가, 지연시간이 낮다던가 하는 것으로 빨리 전달할 수 있으면 비용이 낮다고 판단한다.
+
+거리 벡터는 거리, 방향을 중점으로 최단거리 계산을 위해 Bellman-Ford 알고리즘을 사용합니다.
+
+링크 상태는 라우터들이 정보를 주고받아 전체 토폴로지를 그리며 Dijkstra's 알고리즘을 사용합니다.
+
+# 패킷
+
+이렇게 라우팅 테이블이 만들어지면 해당 라우터는 특정 목적지 네트워크로 가는 패킷을 라우팅시킬 수 있다.
+
+라우터가 패킷을 수신하고, 라우팅 테이블에 따라 정해진 목적지 인터페이스로 해당 패킷을 전송하게 된다.
+
+## 1. 패킷의 처리
+
+**1) 패킷의 발송**
+
+이러한 IP패킷이 네트워크가 통과 시킬 수 있는 최대 바이트보다 클 경우에는 `단편화(Fragmentation)`시켜 보내게 되는데 그 단편화 정보도 IP패킷의 헤더에 저장하여 보내게 된다.
+
+**2) 최종 목적지**
+
+단편화된 패킷을 받은 목적지에서는 다면, 단편들을 모아서 **하나의 온전한 패킷을 조립한다.** 여기서 만약 하나의 온전한 패킷으로 조립이 불가능 하다면 모두 폐기시키고 이를 송신지에게 `CMP(Internet Control Message Protocol)메세지`를 보내게 된다.
+
+## 2. 패킷의 전달
+
+**1) 직접전달(Direct delivery)**
+
+패킷의 송신지와 목적지가 동일한 네트워크에 연결되어 있을 때 직접전달하는 경우.
+
+**2) 간접전달(Indirect delivery)**
+
+패킷이 최종 목적지에 전달될 때까지 라우터에서 라우터로 전달되는 경우.
+
+### 3. 라우팅 테이블
+
+우리가 어떤 웹사이트에 접속을 한다고 했을 때 송신측의 네트워크 계층에서는 데이터 앞쪽에 정보를 담은 헤더(header)를 붙이게 된다.
+
+**여기서 네트워크 계층에 데이터가 어디로 가야할지 경로를 설정할 수 있도록 `표 형태`로 구성되어 있는 것**을 `라우팅 테이블` 이라고 한다.
+
+즉, 목적지로 갈때 최적의 경로가 표로 구성되어 있는 것을 라우팅 테이블이라고 하고 이를 참조하여 IP패킷을 보내게 되어있다.
+
+이러한 라우팅 테이블은 처음 송신지에서 보낼때만 참조하는 것이 아니라 네트워크를 통해 이동하다가 **중간 장치들인 스위치나 라우터에서도 라우팅 테이블을 참조**하여 패킷을 보낸다.
+
+**1) 라우팅 프로토콜**
+
+라우팅 테이블을 만들어 주는 것이 바로 `라우팅 프로토콜`이다. 라우팅 프로토콜에서 라우팅 정보를 주고 받음으로써 이를 판단해 라우팅 테이블을 만들게 된다.
+
+**2) 패킷의 전달 방법**
+
+- **이웃노드명시(Next-hop method)**
+
+ 라우팅 테이블은 전체 경로상의 라우터를 명시하지 않고 `다음 라우터`만 명시한다.
+
+ 
+
+ - A -> R1 -> R2 -> B 와 같이 전체 경로를 명시하는 것이 아니라 A는 R1만 명시!*(과도한 메모리사용으로 비효율적이기 때문!)*
+
+- **네트워크 주소 명시(Network specific method)**
+
+ IP주소는 크게 `네트워크ID`와 `호스트ID`로 구성되어 있는데 여기서 네트워크ID를 기반으로 호스트ID를 할당하기 때문에 만약 특정 기관이라면 그 안에 있는 모든 컴퓨터들은 네트워크ID가 모두 동일하게 된다.
+
+ 이렇듯 목적지로 IP패킷을 전달할때 동일한 네트워크에 연결된 컴퓨터들을 하나하나 모두 명시하는 것이 아니라 **목적지 네트워크 주소만 명시하여 보내는 것**을 네트워크 주소 명시라고 한다.
+
+ 이처럼 간단하게 표기하게 되면 테이블 사이즈가 줄어들게 되고 이 효과로 빠른 검색과 메모리 효율성을 높일 수 있다.
+
+ > 호스트 주소 명시(Host-specific method)
+ >
+ >
+ > `특별한 목적`이 있는 경우라면 라우팅 테이블에 목적지 컴퓨터 주소를 직접 명시할수 있다! -> 관리자가 직접 입력해야함 (ex. 보안목적 등..)
+ >
+
+- **디폴트 지정(Default method)**
+
+ 인터넷에 있는 모든 목적지를 지정할 수 없음으로 지정된 목적지 이외의 모든 지역을 지정하는 라우팅 엔트리를 `디폴트(Default)`라고 한다.(내가 지정한거 외에는 다 얘한테 보내!)
+
+ > 보통 네트워크 주소가 0.0.0.0으로 표기 됨!
+ >
+
+**3) 라우팅 프로토콜의 종류**
+
+**(1) 유니캐스트 라우팅 프로토콜** = 보통의 그냥 라우팅 프로토콜
+
+- `일대일 통신`을 말함
+- 디지털 서명(Digital Signature)목적지가 하나이며 라우팅 정보를 교환하여 라우팅 테이블을 구축하는 형태
+
+**(2) 멀티캐스트 라우팅 프로토콜**
+
+- 송신지는 하나, 수신지는 여러개인 시스템으로 목적지가 동일한 그룹에 속한 여러 호스트가 될 수 있다.
\ No newline at end of file
diff --git "a/Network/minseo/tcp connection && socket/TCP Connection\352\263\274 Socket .md" "b/Network/minseo/tcp connection && socket/TCP Connection\352\263\274 Socket .md"
index af1f9ba..e462dbc 100644
--- "a/Network/minseo/tcp connection && socket/TCP Connection\352\263\274 Socket .md"
+++ "b/Network/minseo/tcp connection && socket/TCP Connection\352\263\274 Socket .md"
@@ -9,7 +9,7 @@
### TCP/IP stack
-**TCP/IP stack은 인터넷이 발명되면서 함께 개발된 프로토콜 스택이다.**
+**TCP/IP stack은 인터넷이 발명되면서 함께 개발된 프로토콜 스택이다 .**
- IETF에서 인터넷 표준을 관리한다.(RFC)
- TCP, UDP, IP.. 스펙은 RFC에서 정의한다.
diff --git a/Network/yerin/tcp_and_ip.md b/Network/yerin/tcp_and_ip.md
new file mode 100644
index 0000000..5e22aae
--- /dev/null
+++ b/Network/yerin/tcp_and_ip.md
@@ -0,0 +1,354 @@
+# 네트워크 2주차
+
+https://hyper-hotel-11e.notion.site/2-6287a99bb3984c248c4823c0a4c012ed?pvs=4
+
+# 📌TCP
+
+## UDP
+
+UDP에도 오류를 감지하는 기능은 있다. ⇒ Checksum으로.
+
+근데 감지만 하고, TCP와 달리 오류를 정정하거나 재전송하는 메커니즘을 제공하진 않는다.
+
+정정안해줄거면 왜 굳이 감지를 해줄까?
+
+⇒ 과도한 체크섬 오류는 네트워크 장비의 문제나 데이터 경로상의 문제를 나타내줌.
+
+⇒ Application layer에서 필요하면 선택적으로 재요청하게끔 적어도 알려는 준다는 느낌
+
+## TCP
+
+네트워크 통신에서 신뢰적인 연결방식을 사용한다는 특징이 있다.
+
+TCP는 기본적으로 unreliable network에서, reliable network (reliable data transfer)를 보장할 수 있도록 하는 프로토콜이다.
+
+TCP 통신을 하다보면 Segment 전송에 에러가 생기는 경우가 있다.
+
+- Loss - 손실 문제
+- Corruption - bit error
+- Congestion - 네트워크 혼잡 문제
+
+Solution ⇒ ACK, Checksum, Time-out, Retransmission, Seq #
+
+TCP는 이 에러들을 정정해줘야하고, 흐름과 혼잡을 제어해야한다. 왜냐하면 신뢰적인 연결방식을 사용하는 프로토콜이니까. TCP 프로토콜의 흐름제어와 혼잡제어 방식을 이해하기위해서는 몇가지 용어들과 과정들을 알아야한다.
+
+### ACK
+
+ACK(Acknowledgements) : 리시버가 센더에게 OK 잘 왔음이라고 답해주는 것
+
+ack은 리시버가 센더에게 잘 받았다고 전달해주는 메시지 개념인데, 이 ack 또한 센더한테 전달될때 에러가 날 수 있음. 이때 센더입장에서는 “못 받았나보네, 다시 보내야지” 하면서 첫번째 Segment를 다시 보냄. 그러면 리시버 입장에서는 첫번째 segment를 받은 상태이기 때문에 위 센더가 다시 보낸 값을 두번째 segment로 인식하게 됨. 이러한 문제를 해결하기 위해 Sequence Number 개념이 탄생.
+
+sequence number로 전달할 segment의 순서를 구분하게됨.
+
+### TCP Header
+
+https://blog.kakaocdn.net/dn/b2OtbA/btqAMlJTLi1/CTJcSSlZ7qzxlBrmgc5Pb1/img.png
+
+
+
+TCP flag(URG, ACK, PSH, RST, SYN, FIN)
+
+FLAG 순서 - | URG | ACK | PSH | RST | SYN | FIN |
+
+### ACK(Acknowledgement) - Ack : 응답
+
+상대로부터 패킷을 받았다는 걸 알려주는 패킷
+
+### SYN(Synchronization:동기화) - S : 연결 요청 플래그
+
+TCP 에서 세션을 성립할 때 가장먼저 보내는 패킷, 시퀀스 번호를 임의적으로 설정하여 세션을 연결하는 데에 사용되며 초기에 시퀀스 번호 (ISN) 를 보내게 된다.
+
+### FIN(Finish) - F : 종료
+
+연결 종료 요청세션 연결을 종료시킬 때 사용. 더이상 전송할 데이터가 없음을 나타냄
+
+### RST(Reset) - R : 리셋
+
+연결 종료재설정(Reset)을 하는 과정, 양방향에서 동시에 일어나는 중단 작업
+
+비 정상적인 세션 연결 끊기. 현재 접속하고 있는 곳과 즉시 연결을 끊고자 할 때 사용
+
+## 🔸TCP 3 way handshaking (연결)
+
+
+
+서버 listen() 상태
+
+1. 클라이언트 connect(), C->S 접속요청 패킷 SYN(M) 전송
+
+2. 서버 accept(), S->C 요청 수락 패킷 ACK(M+1), SYN(N) 전송
+
+3. 클라이언트 connect(), C->S 요청 수락 확인 패킷 ACK(N+1) 전송
+
+### 연결 성립
+
+## 🔸TCP 4 way handshaking (해제)
+
+
+
+1. C->S 연결 종료요청 FIN FLAG 전송
+
+2. S->C 종료 수락 메시지 ACK 전송
+
+일시적 TIME_OUT (데이터를 모두 보낼 때 까지)
+
+3. S->C 연결 종료 FIN FLAG 전송
+
+4. C->S 확인 메시지 ACK 전송
+
+서버 소켓 연결 close(), 클라이언트 일정 시간 동안 TIME_WAIT (잉여패킷 대기)
+
+### 연결 해제
+
+## 🔸TCP 흐름제어
+
+ **Window** : 윈도우는 메모리 버퍼의 일정 영역이라고 생각하면 된다. TCP/IP를 사용하는 모든 호스트들은 송신하기 위한 것과 수신하기 위한 2개의 Window를 가지고 있다. 호스트들은 실제 데이터를 보내기 전에 '3 way handshaking'을 통해 리시버의 receive window size에 자신의 send window size를 맞추게 된다.
+
+### **TCP Buffer**
+
+
+
+흐름 제어는 송신 측과 수신 측의 TCP 버퍼 크기 차이로 인해 생기는 데이터 처리 속도 차이를 해결하기 위한 기법이다.
+
+수신측에서 제한된 저장 용량을 초과한 이후에 도착하는 데이터는 손실 될 수 있으며, 만약 손실 된다면 불필요하게 응답과 데이터 전송이 송/수신 측 간에 빈번이 발생한다.
+
+이러한 위험을 줄이기 위해 송신 측의 데이터 전송량을 수신측에 따라 조절해야한다.
+
+흐름제어기법
+
+### 1. stop and wait
+
+매번 전송한 패킷에 대해 확인 응답(ACK)를 받으면 다음 패킷을 전송하는 방법이다. 그러나 패킷을 하나씩 보내기 때문에 비효율적인 방법이다.
+
+⇒ 파이프라이닝 형식을 사용해 효율성을 높임
+
+**슬라이딩 윈도우**
+
+- Go-back-N (슬라이딩 윈도우 방식을 이용한 오류제어 기법)
+- Selevtive Repeat (슬라이딩 윈도우 방식을 이용한 오류제어 기법)
+
+### 2. Sliding Window
+
+리시버는 rwnd 값을 포함한 tcp header를 센더에게 전달되는 segment에 담아 보내기 때문에 센더는 리시버의 rwnd값에 따라 in-flight 값을 제한할 수 있다.
+
+window size만큼 순서대로 모두 보내고, ack이 오면 그만큼 윈도우 이동하는 방식
+
+## 🔸TCP 혼잡제어
+
+센더의 데이터는 지역망이나 인터넷으로 연결된 대형 네트워크를 통해 전달된다. 만약 데이터가 한 곳으로 몰릴 경우, 자신에게 온 데이터를 모두 처리할 수 없게 된다. 이런 경우 혼잡으로 인한 오버플로우나 데이터 손실이 발생한다.
+
+따라서 이러한 네트워크의 혼잡을 피하기 위해 센더측에서 보내는 데이터의 전송속도를 강제로 줄이게 되는데, 이러한 작업을 혼잡제어라고 한다.
+
+TCP Tahoe와 Reno 등 혼잡 제어 정책들은 공통적으로 `혼잡이 발생하면 윈도우 크기를 줄이거나, 혹은 증가시키지 않으며 혼잡을 회피한다` 라는 전제를 깔고 있다.
+
+TCP Tahoe와 Reno 정책을 알아보기전에 몇가지 혼잡제어 방식과 관련 용어들을 알아야한다.
+
+1. **Timeout**
+
+여러 가지 요인으로 인해 센더가 보낸 데이터 자체가 유실되었거나,
+
+리시버가 응답으로 보낸 ACK이 유실되는 경우 센더가 설정해놓은 timeout에 걸리게 된다.
+
+1. **3 Duplicate ACKs**
+
+!https://blog.kakaocdn.net/dn/ci8GSU/btrlpLaCuUk/KHpoUNv1tRnEHPzOtXd4Gk/img.png
+
+ 중복 ACK 3개를 받으면 문제가 있다고 판단하여 해당 패킷을 재전송한다. 해당 기법을 `빠른 재전송` 이라고 부르며, 센더는 자신이 설정한 타임 아웃 시간이 지나지 않았어도 바로 해당 패킷을 재전송할 수 있기 때문에 보다 빠른 전송률을 유지할 수 있게 된다.
+
+1. ****AIMD(Additive Increase / Multiplicative Decrease)****
+ - 문제가 발생하기 전까지 cwnd 1씩 증가
+ - 문제가 발생하면 cwnd를 절반으로 감소
+
+ 문제점은 초기에 네트워크의 높은 대역폭을 사용하지 못하여 오랜 시간이 걸리게 되고, 네트워크가 혼잡해지는 상황을 미리 감지하지 못한다. 즉, 네트워크가 혼잡해지고 나서야 대역폭을 줄이는 방식이다.
+
+2. ****Slow Start****
+ - Slow Start 방식은 AIMD와 마찬가지로 패킷을 하나씩 보내면서 시작하고, 패킷이 문제없이 도착하면 각각의 ACK 패킷마다 window size를 1씩 늘려준다. 즉, 한 주기가 지나면 window size가 2배로 된다.
+ - 전송속도는 AIMD에 반해 지수 함수 꼴로 증가한다. 대신에 혼잡 현상이 발생하면 window size를 1로 떨어뜨리게 된다.
+
+ 
+
+
+**Slow Start 임계점 (ssthresh)**
+
+
+
+ `Slow Start Threshold(ssthresh)` 여기까지만 Slow Start를 사용하겠다는 의미를 가진다.
+
+Slow Start를 사용하며 윈도우 크기를 지수적으로 증가시키다보면 어느 순간부터는 윈도우 크기가 기하급수적으로 늘어나서 제어하기가 힘들다. 또한, 네트워크의 혼잡이 예상되는 상황에서 빠르게 값을 증가시키기 보다는 조금씩 증가시키는 편이 훨씬 안전하다.
+
+그래서 특정한 임계점을 정해 놓고, 그 임계점이 넘어가면 AIMD 방식을 사용하여 선형적으로 윈도우를 증가시킨다.
+
+(이 임계점은 계속 초기값을 가지는 건 아님. loss event가 발생하면 그 발생했을때의 cwnd의 절반 사이즈로 세팅됨)
+
+1. **Fast Recovery**
+
+혼잡한 상태가 되면 window size를 1이 아닌 반으로 줄이고 선형증가시키는 방법이다. 이 정책까지 적용하면 혼잡 상황을 한번 겪고 나서부터는 순수한 AIMD 방식으로 동작하게 된다.
+
+### TCP Tahoe
+
+
+
+이 정책은 한 번 혼잡 상황이 발생한 지점을 기억하고 그 지점이 가까워지지 않도록 합리적으로 조절하고 있다. 하지만, 초반의 Slow Start 구간에 윈도우 크기를 늘릴 때 오래 걸린다는 단점이 있고, 혼잡 상황이 발생했을 때 다시 윈도우 크기를 1에서부터 시작해야 한다는 단점이 있다.
+
+### TCP Reno
+
+
+
+TCP Reno는 TCP Tahoe 이후에 나온 정책으로, Tahoe와 마찬가지로 Slow Start로 시작하여 임계점을 넘어서면 AIMD을 사용한다. 다만, Tahoe와는 다르게 3 ACK Duplicated와 Timeout 혼잡 상황을 구분한다.
+
+Reno는 3개의 중복 ACK가 발생했을 때, 윈도우 크기를 1로 줄이는 것이 아니라 AIMD처럼 반으로만 줄이고 sshthresh를 줄어든 윈도우 값으로 정하게 된다. 이 방식을 `빠른 회복`이라고 부른다.
+
+그러나 Timeout에 의해서 데이터가 손실되면 Tahoe와 마찬가지로 윈도우 크기를 바로 1로 줄여버리고 Slow Start를 진행한다. 이때 ssthresh를 변경하지는 않는다.
+
+즉, Reno는 ACK 중복은 Timeout에 비해 그리 큰 혼잡이 아니라고 가정하고 혼잡 윈도우 크기를 1로 줄이지도 않는다는 점에서 혼잡 상황의 우선 순위를 둔 정책이라 볼 수 있다.
+
+
+
+---
+
+# 📌IP (Internet Protocol)
+
+> 인터넷 프로토콜의 약자로 송신 호스트와 수신 호스트가 패킷 교환 네트워크에서 정보를 주고받는데 사용하는 정보 위주의 규약
+>
+
+- 인터넷에서 데이터를 송수신하기 위한 주요 프로토콜
+- 데이터를 소스에서 목적지까지 전달
+- 비신뢰성과 비연결성
+- 패킷 전송과 정확한 순서를 보장하기 위해 TCP 프로토콜을 이용
+
+**고정 IP**
+
+- 컴퓨터가 고정적으로 가지고 있는 IP이다.
+- 한 번 부여받으면 **반납하기 전까지 변하지 않는다**.
+- 주로 인터넷 사이트를 운영할 때 사용한다.
+
+**유동 IP**
+
+- 컴퓨터에 고정된 IP를 부여하지 않고 **IP 갱신 주기가 되었을 때 ISP로부터 할당받는 IP**이다.
+- 사용하지 않는 IP를 수거하는 방식이다.
+ - 더 많은 사용자에게 인터넷 서비스를 제공할 수 있다.
+
+**공인 IP**
+
+- **외부에 공개된 IP**다.
+- 해킹의 위험이 있기에 보안 프로그램이 필요하다.
+
+**사설 IP**
+
+- **외부에서 접근할 수 없는 IP**다.
+- 주로 일반 가정 또는 회사 내부에서 사용한다.
+- 공인 IP가 할당된 라우터나 공유기를 통해 사설 IP가 할당된다.
+
+## IPv4
+
+
+
+IPv4 주소는 전세계적으로 관리되는 32bit의 유효한 자원으로 8 bits 씩 나눠져서 일부는 Network, 다른 일부는 Host의 번호를 표현하는데 사용된다. 네트워크 부분은 특정 네트워크를 식별하고, 호스트 부분은 그 네트워크 내의 특정 장치를 식별한다.
+
+- 주소는 점으로 구분된 네 개의 숫자(예: 192.168.0.1)로 표현
+- 인터넷 상에서 장치를 식별하는 데 사용 ⇒ IPv4 주소는 고유해야 함
+
+### IPv4 주소 고갈 & 대응 방안
+
+원인 : 인터넷의 지속적인 성장과 연결되는 장치의 증가
+
+IPv4 주소는 32비트로 구성되어 있어, 이론적으로 약 42억 개(2의 32승)의 고유한 주소만 제공 가능
+
+**대응 방안**
+
+ (IPv6가 근본적인 주소 고갈 대응 방안이라고 할 수 있고, 나머지는 IPv4 주소 공간을 보다 효율적으로 관리하고 활용하기 위한 임시 방안이라고 할 수 있다.)
+
+1. Subnetting & CIDR
+2. NAT
+3. DHCP
+4. IPv6
+
+## IPv6
+
+IPv4의 고갈 문제를 해결하기 위해 IPv6가 등장하였다.
+
+총 128비트로 각 16비트씩 8자리로 각 자리는 ‘:’(콜론)으로 구분한다.
+
+ex) 2001:0DB8:1000:0000:0000:0000:1111:2222
+
+총 2^128 의 IP 주소를 만들어낸다.
+
+### IPv4와의 차이점
+
+---
+
+1. **주소 체계 및 길이**
+
+- **IPv4**:
+ - 32비트 주소 체계
+ - 주소는 점으로 구분된 십진수 형식으로 표시 / 예: 192.168.1.1
+- **IPv6**:
+ - 128비트 주소 체계를 사용하여, 거의 무한에 가까운 주소 공간을 제공
+ - 주소는 콜론으로 구분된 16진수 형식으로 표시됩니다. / 예: 2001:0db8:85a3:0000:0000:8a2e:0370:7334
+
+
+**2. 주소 할당 및 관리**
+
+- **IPv4**:
+ - 정적(수동) 또는 동적(DHCP) 방식으로 주소 할당
+ - 주소 공간의 제한으로 인해 주소 할당을 효율적으로 해야한다.
+- **IPv6**:
+ - 주소의 풍부함으로 인해 주소 할당에 있어 더 많은 유연성을 가짐
+
+
+**3. 보안**
+
+- **IPv4**:
+ - 기본적으로 보안 기능이 내장되어 있지 않습니다.
+ - 보안을 위해 IPsec과 같은 별도의 프로토콜을 사용할 수 있으나, 선택적입니다.
+
+ (IPsec은 Host-to-Host와 Network-to-Network간의 Data Flow를 암호화 시키는 Protocol Suite)
+
+- **IPv6**:
+ - 보안을 위한 IPsec이 기본적으로 내장되어 있어, 보다 향상된 보안 기능을 제공합니다.
+
+ (참고로, 초창기 모든 IPv6는 IPsec를 필수적으로 지원하게 되어 있어 IPv6 Network의 높은 보안성을 기대하였으나, 낮은 Network Processor를 가진 IPv6 Nodes로 인하여 IPsec의 기능이 "Recommended" 수준으로 하향 조정 되었다. 하지만, IPsec이 "Option"으로 지원이 되는 IPv4 Network에 비하여 IPv6 Network이 여전히 높은 보안성을 가진다.)
+
+
+**4. 헤더 형식 및 처리**
+
+- **IPv4**:
+ - 헤더가 상대적으로 복잡하고 옵션 필드가 있어 처리가 더 복잡함
+ - 헤더 길이가 가변적
+
+- **IPv6**:
+ - 헤더 구조가 간소화되어 있고, 대부분 고정 길이
+ - checksum x (DataLink Layer에서 오류를 검사하기 때문에 IP 패킷의 빠른 처리를 위해 삭제)
+
+
+**5. fragmentation 단편화**
+
+Fragmentation은 데이터 패킷을 네트워크를 통해 전송할 때 발생하는 과정으로, 큰 데이터 패킷을 더 작은 단위로 나누는 것
+
+왜?
+
+MTU라는 한 번에 전송할 수 있는 데이터의 최대 크기를 나타내는 단위가 있는데, 네트워크 경로상 각 네트워크 세그먼트의 MTU보다 보내려는 데이터 패킷 크기가 크다면 그 패킷은 네트워크를 통과할 수 없다. 따라서 데이터 패킷은 MTU 크기에 맞게 여러 개의 작은 패킷으로 분할되어야 한다.
+
+- **IPv4**:
+ - 출발/목적지 또는 중간 라우터에서 수행
+- **IPv6**:
+ - 송신자만 수행하며, 중간 라우터에서는 수행x
+
+ 단편화 & 재결합 과정은 시간이 소요되는 일이므로 라우터에서 수행을 하지 않음으로써 네트워크 효율성이 증가
+
+
+---
+
diff --git "a/Network/minseo/3 -Way Handshake & 4 -Way Handshake/TCP UDP\354\231\200 3 -Way Handshake & 4 -Way Handshake .md" "b/Network/minseo/3 -Way Handshake & 4 -Way Handshake/TCP UDP\354\231\200 3 -Way Handshake & 4 -Way Handshake .md"
index 123b5fd..7647eb1 100644
--- "a/Network/minseo/3 -Way Handshake & 4 -Way Handshake/TCP UDP\354\231\200 3 -Way Handshake & 4 -Way Handshake .md"
+++ "b/Network/minseo/3 -Way Handshake & 4 -Way Handshake/TCP UDP\354\231\200 3 -Way Handshake & 4 -Way Handshake .md"
@@ -6,7 +6,7 @@
```c
int main(){
- sock = socket(AF_INFT, SOCK_STREAM, 0);
+ sock = socket(AF_INFT, SOCK_STREAM, 0) ;
..
bind( ~)
..
diff --git a/Network/minseo/DHCP&NAT/DHCP NAT .md b/Network/minseo/DHCP&NAT/DHCP NAT .md
new file mode 100644
index 0000000..4bde01b
--- /dev/null
+++ b/Network/minseo/DHCP&NAT/DHCP NAT .md
@@ -0,0 +1,135 @@
+# DHCP/NAT
+
+IP 주소 부족의 문제를 해결하기 위해 적은 IP 주소를 동적으로 활용한다는 점에서 NAT는 DHCP와 비슷한 느낌으로 다가올 수 있다. 그렇지만, 이 둘은 근본적으로 다른 개념입니다. 먼저, DHCP와 NAT의 개념은 각각 IP 주소를 **할당**하고, IP 주소를 **매핑(변환)**하는 것이다
+
+DHCP에서는 호스트가 하나의 IP 주소를 받아 그 주소를 이용해 통신하고,
+
+NAT는 자신이 사용하는 주소로 보낸 패킷이 그 주소와 매핑되는 주소로 다시 쓰여지는 과정이라는 점에서 근본적인 차이가 있다.
+
+# NAT (Network Address Translation)
+
+네트워크의 **IP 주소를 관리하거나, IP 주소를 변경**하고 싶을 때 이용한다.
+
+### **NAT를 사용하는 목적**
+
+1. **인터넷의 공인 IP주소를 절약할 수 있다.**
+
+
+
+인터넷의 공인 IP주소는 한정되어 있기 때문에 이를 공유할 수 있도록 하는 것이 필요하다. **NAT를 이용하면 사설 IP 주소를 사용하면서 이를 공인 IP주소와 상호 변환 할 수 있도록 하여, 공인 IP주소를 다수가 함께 사용하게 함**으로써 이를 절약할 수 있다는 것이다.
+
+즉 회사와 같은 곳에서 내부에서는 사설 IP 주소를 통하여 그들끼리 통신하고 회사 밖 인터넷은 회사의 IP로써 통신하는 구조에서 사용된다 볼 수 있겠다.
+
+1. **인터넷이란 공공망과 연결되는 사용자들의 고유한 사설망을 침입자들로부터 보호할 수있다.**
+
+공개된 인터넷과 사설망 사이에 **방화벽(Firewall)**를 설치하여 외부 공격으로부터 사용자의 통신망을 보호하는 기본적인 수단을 활용할 수 있다.
+
+이 때 외부 통신망 즉 인터넷망과 연결하는 장비인 라우터에 NAT를 설정할 경우, Space 내부에서는 private address, 외부에서는 public address를 사용할 수 있고 필요시에 이를 서로 변환할 수 있다.
+
+따라서 외부 침입자가 공격하기 위해서는 사설망의 내부 사설 IP주소를 알아야 하기 때문에 공격이 불가능해지므로 내부 네트워크를 보호할 수 있다.
+
+# DHCP (Dynamic Host Configulation Protocol)
+
+DHCP란 호스트의 **IP주소와 각종 TCP/IP 기본 설정을 클라이언트에게 자동적으로 제공해주는 프로토콜**을말한다.
+
+DHCP에 대한 표준은 RFC문서에 정의되어 있으며, DHCP는 네트워크에 사용되는 IP주소를 DHCP서버가 중앙집중식으로 관리하는 **클라이언트/서버 모델**을 사용하게 된다. DHCP지원 클라이언트는 **네트워크 부팅과정**에서 DHCP서버에 IP주소를 요청하고 이를 얻을 수 있다.
+
+네트워크 안에 컴퓨터에 자동으로 네임 서버 주소, IP주소, 게이트웨이 주소를 **할당**해주는 것을 의미하고, 해당 클라이언트에게 **일정 기간 임대를 하는 동적 주소 할당 프로토콜**이다.
+
+따라서 호스트가 빈번하게 접속을 연결하고 다시 갱신하는 가정 인터넷 접속 네트워크 및 **무선랜(LAN)**에서 폭 넓게 사용된다.
+
+**DHCP장점**
+
+PC의 수가 많거나 PC 자체 변동사항이 많은 경우 IP 설정이 자동으로 되기 때문에 효율적으로 사용 가능하고, IP를 자동으로 할당해주기 때문에 IP 충돌을 막을 수 있다.
+
+**DHCP단점**
+
+DHCP 서버에 의존되기 때문에 서버가 다운되면 IP 할당이 제대로 이루어지지 않는다.
+
+## DHCP 구성
+
+### **1) DHCP서버**
+
+ DHCP서버는 네트워크 인터페이스를 위해서 **IP주소를 가지고 있는 서버에서 실행되는 프로그램**으로
+
+**일정한 범위의 IP주소를 다른 클라이언트에게 할당하여 자동으로 설정하게 해주는 역할**을 한다. **DHCP서버는 클라이언트에게 할당된 IP주소를 변경없이 유**지해 줄 수 있다.**클라이언트에게 IP 할당 요청이 들어오면 IP를 부여해주고 할당 가능한 IP들을 관리**해주게 됩니다.
+
+### **2) DHCP클라이언트**
+
+클라이언트들은 시스템이 시작하면 DHCP서버에 자신의 시스템을 위한 IP주소를 요청하고, DHCP 서버로부터 IP주소를 부여받으면 TCP/IP 설정은 초기화되고 다른 호스트와 TCP/IP를 사용해서 통신을 할 수 있다.
+
+**즉, 서버에게 IP를 할당받으면 TCP/IP 통신을 할 수 있다.**
+
+### DHCP 프로토콜의 원리
+
+ DHCP를 통한 IP 주소 할당은 **“임대”**라는 개념을 가지고 있는데
+
+ 이는 DHCP 서버가 IP 주소를 영구적으로 단말에 할당하는 것이 아니고 **임대기간(IP Lease Time)**을 명시하여 그 기간 동안만 단말이 IP 주소를 사용하도록 하는 것이다.
+
+단말은 임대기간 이후에도 계속 해당 IP 주소를 사용하고자 한다면 **IP 주소 임대기간 연장(IP Address Renewal)**을 DHCP 서버에 요청해야 하고 또한 단말은 임대 받은 IP 주소가 더 이상 필요치 않게 되면 **IP 주소 반납 절차(IP Address Release)**를 수행하게 된다.
+
+[https://t1.daumcdn.net/cfile/tistory/2519193C5715E03427](https://t1.daumcdn.net/cfile/tistory/2519193C5715E03427)
+
+이제 단발 (DHCP client)이 DHCP 서버로 부터 IP 주소를 할당(임대)받는 절차에 대해서 알아보자.
+
+## DHCP 연결 과정
+
+
+
+### **1) DHCP 서버 발견 (DHCP Server Discover)**
+
+새롭게 도착한 호스트는 자신이 접속할 네트워크의 DHCP 서버 주소를 알지 못한다.
+
+따라서 서버 발견 메세지(포트67, UDP 메세지)를 **브로드캐스트 IP주소 (출발지 주소: 0.0.0.0. 목적지: 255.255.255.255.)**로 캡슐화하여 서브넷 상의 모든 노드로 전송한다.
+
+**[주요 파라미터]**
+
+- Client Mac : 단말의 MAC 주소
+
+### **2) DHCP 서버 제공 (DHCP Server Offer)**
+
+DHCP 발견 메세지를 받은 DHCP 서버는 DHCP 제공 메세지를 이용해 클라이언트로 브로드 캐스트 한다.
+
+**단말브로드캐스트 메시지** (Destination MAC = FF:FF:FF:FF:FF:FF)이거나 **유니캐스트**일수 있다.
+
+이는 단말이 보낸 DHCP Discover 메시지 내의 Broadcast Flag의 값에 따라 달라지는데, 이 Flag=1이면 DHCP 서버는 DHCP Offer 메시지를 Broadcast로, Flag=0이면 Unicast로 보내게 된다
+
+서버 제공 메세지는 클라이언트에게 제공될 IP주소 네트워크 마스크, 도메인, 이름 , IP 주소 임대기간 등의 클라이언트 설정 파라미터 값들이 포함된다.
+
+**[주요 파라미터]**
+
+- Client MAC: 단말의 MAC 주소
+- Your IP: 단말에 할당(임대)할 IP 주소
+- Subnet Mask (Option 1)
+- Router (Option 3): 단말의 Default Gateway IP 주소
+- DNS (Option 6): DNS 서버 IP 주소
+- IP Lease Time (Option 51): 단말이 IP 주소(Your IP)를 사용(임대)할 수 있는 기간(시간)
+- DHCP Server Identifier (Option 54): 본 메시지(DHCP Offer)를 보낸 DHCP 서버의 주소. 2개 이상의 DHCP 서버가 DHCP Offer를 보낼 수 있으므로 각 DHCP 서버는 자신의 IP 주소를 본 필드에 넣어서 단말에 보냄
+
+### 3) DHCP 요청 (DHCP Request)
+
+IP 할당을 요쳥한 새 호스트는 하나 이상의 DHCP 서버 제공 메세지를 받고 그 중 가장 최적의 서버를 선택한 후 그 서버측으로 DHCP 요청 메세지를 보낸디.
+
+**[주요 파라미터]**
+
+- Client MAC: 단말의 MAC 주소
+- Requested IP Address (Option 50): 난 이 IP 주소를 사용하겠다. (DHCP Offer의 Your IP 주소가 여기에 들어감)
+- DHCP Server Identifier (Option 54): 2대 이상의 DHCP 서버가 DHCP Offer를 보낸 경우, 단말은 이 중에 마음에 드는 DHCP 서버 하나를 고르게 되고, 그 서버의 IP 주소가 여기에 들어감. 즉, DHCP Server Identifier에 명시된DHCP서버에게"DHCP Request"메시지를 보내어 단말 IP 주소를 포함한 네트워크 정보를 얻는 것
+
+### 4) DHCP Ack (Acknowledgement)
+
+서버는 DHCP 요청 메세지에 대해 요청된 설정을 확인하는 ACK 메세지를 전송한다.
+
+단말브로드캐스트 메시지 (Destination MAC = FF:FF:FF:FF:FF:FF) 혹은 유니캐스트일수 있으며 이는 단말이 보낸 DHCP Request 메시지 내의 Broadcast Flag=1이면 DHCP 서버는 DHCP Ack 메시지를 Broadcast로, Flag=0이면 Unicast로 보내게 된다.
+
+**[주요 파라미터]**
+
+- Client MAC: 단말의 MAC 주소
+- Your IP: 단말에 할당(임대)할 IP 주소
+- Subnet Mask (Option 1)
+- Router (Option 3): 단말의 Default Gateway IP 주소
+- DNS (Option 6): DNS 서버 IP 주소
+- IP Lease Time (Option 51): 단말이 본 IP 주소(Your IP)를 사용(임대)할 수 있는 기간(시간
+- DHCP Server Identifier (Option 54): 본 메시지(DHCP Ack)를 보낸 DHCP 서버의 주소
+
+이렇게 DHCP Ack를 수신한 단말은 이제 IP 주소를 포함한 네트워크 정보를 획득(임대)하였고, 이제 인터넷 사용이 가능하게 된다.
\ No newline at end of file
diff --git a/Network/minseo/DHCP&NAT/DHCP NAT/Untitled 1.png b/Network/minseo/DHCP&NAT/DHCP NAT/Untitled 1.png
new file mode 100644
index 0000000..e5c5324
Binary files /dev/null and b/Network/minseo/DHCP&NAT/DHCP NAT/Untitled 1.png differ
diff --git a/Network/minseo/DHCP&NAT/DHCP NAT/Untitled.png b/Network/minseo/DHCP&NAT/DHCP NAT/Untitled.png
new file mode 100644
index 0000000..915688c
Binary files /dev/null and b/Network/minseo/DHCP&NAT/DHCP NAT/Untitled.png differ
diff --git a/Network/minseo/IP .md b/Network/minseo/IP .md
index 6254533..498f592 100644
--- a/Network/minseo/IP .md
+++ b/Network/minseo/IP .md
@@ -12,7 +12,7 @@
3계층은 다른 네트워크 대역,
-멀리 떨어진 곳에 존재하는 네트워크까지 어떻게 데이터를 전달할지 제어하는 일을 담당한다.
+멀리 떨어진 곳에 존재하는 네트워크까지 어떻게 데이터를 전달할지 제어하는 일을 담당한다 .

diff --git "a/Network/minseo/TCP \355\235\220\353\246\204\354\240\234\354\226\264 & \355\230\274\354\236\241\354\240\234\354\226\264/TCP \355\235\220\353\246\204\354\240\234\354\226\264 & \355\230\274\354\236\241\354\240\234\354\226\264 .md" "b/Network/minseo/TCP \355\235\220\353\246\204\354\240\234\354\226\264 & \355\230\274\354\236\241\354\240\234\354\226\264/TCP \355\235\220\353\246\204\354\240\234\354\226\264 & \355\230\274\354\236\241\354\240\234\354\226\264 .md"
index 6540cde..ca733f6 100644
--- "a/Network/minseo/TCP \355\235\220\353\246\204\354\240\234\354\226\264 & \355\230\274\354\236\241\354\240\234\354\226\264/TCP \355\235\220\353\246\204\354\240\234\354\226\264 & \355\230\274\354\236\241\354\240\234\354\226\264 .md"
+++ "b/Network/minseo/TCP \355\235\220\353\246\204\354\240\234\354\226\264 & \355\230\274\354\236\241\354\240\234\354\226\264/TCP \355\235\220\353\246\204\354\240\234\354\226\264 & \355\230\274\354\236\241\354\240\234\354\226\264 .md"
@@ -17,7 +17,7 @@
# 흐름제어
- 송신측과 수신측 사이의 데이터 처리 속도 차이를 해결하기 위한 기법이다
-- 송신 측의 전송량 > 수신측의 처리량인 경우, 패킷이 수신 측의 큐를 넘어 손실될 수 있어서 송신측 패킷 전송량을 제어해줘야 한다.
+- 송신 측의 전송량 > 수신측의 처리량인 경우 , 패킷이 수신 측의 큐를 넘어 손실될 수 있어서 송신측 패킷 전송량을 제어해줘야 한다.
## 1. Stop and Wait (정지-대기)
diff --git "a/Network/minseo/WEB \355\206\265\354\213\240 \354\240\204\354\262\264 \355\235\220\353\246\204.md" "b/Network/minseo/WEB \355\206\265\354\213\240 \354\240\204\354\262\264 \355\235\220\353\246\204.md"
new file mode 100644
index 0000000..537be02
--- /dev/null
+++ "b/Network/minseo/WEB \355\206\265\354\213\240 \354\240\204\354\262\264 \355\235\220\353\246\204.md"
@@ -0,0 +1,61 @@
+# WEB 통신 전체 흐름
+
+주소창에 url을 입력했을때 통신의 흐름에 대해 알아보자.
+
+웹 통신의 흐름을 보기 전에 알아야할 개념이 있다.
+
+## IP 주소
+
+컴퓨터 네트워크에서 장치들이 서로를 인식하고 통신을 하기 위해서 사용하는 특수한 번호
+
+→ 현재 사용하는 IPv4는 128.0.0.1과 같은 32비트 수로 구성되어 있다.
+
+## Domain Name
+
+IP 주소를 문자로 표현한 주소
+
+→ **DNS : IP주소와 도메인 이름의 매핑 정보를 담는 데이터베이스**
+
+# 작동 방식
+
+
+
+1. 사용자가 브라우저에 **도메인 이름을 입력**한다.
+2. **DNS서버**에서 사용자가 입력한 Domain name을 검색하고, **매핑되는 IP주소**를 찾는다. 사용자가 입력한 URL 정보와 함께 리턴한다.
+3. IP주소는 HTTP 프로토콜을 이용해서 **HTTP 요청 메세지를 생성**한다.
+4. 생성된 HTTP 요청 메세지는 TCP 프로토콜을 사용해서 인터넷을 거쳐 **해당 IP 주소의 컴퓨터(서버)로** 전송된다.
+5. 서버는 클라이언트의 요청을 승인하고, 응답 메세지를 전송한다.
+6. 도착한 HTTP 응답 메세지는 HTTP 프로토콜을 사용하여 **웹페이지 데이터로 변환**되고, 웹 브라우저의 출력에 의해 사용자가 볼 수 있다.
+
+# DNS 서버의 주소 찾기
+
+## DHCP
+
+- Dynamic Host Configuration Protocol
+
+
+
+- 호스트의 IP 주소와 TCP/IP 설정을 클라이언트에 의해 자동으로 제공하는 응용 계층 프로토콜
+
+ → 사용자는 DHCP 서버에서 자신의 IP 주소, 가장 가까운 라우터의 IP 주소, 가장 가까운 **DNS 서버의 주소**를 받는다.
+
+
+## ARP
+
+- Address Resolution Protocol
+- 네트워크상에서 IP 주소를 물리적 네트워크 주소로 바인딩시키기 위해 사용하는 프로토콜
+- DHCP로 얻은 라우터의 IP 주소를 MAC 주소로 변환
+
+# DNS 서버에서 IP 정보 수신
+
+
+
+- 사용자가 웹 브라우저 주소창에 www.example.com을 입력
+- www.example.com에 대한 요청이 인터넷 서비스 제공업체(ISP)가 관리하는 DNS 해석기로 라우팅
+- DNS 해석기는 요청을 DNS 루트 이름 서버에 전달
+- DNS 해석기는 요청을 .com 도메인 TLD(Top-level Domain) 네임 서버 중 하나에 다시 전달
+- DNS 해석기는 요청을 Route 53 네임 서버에 다시 전달
+- Route 53 네임 서버는 www.example.com 레코드를 찾아 IP주소를 DNS 해석기로 반환
+- DNS 해석기는 웹 브라우저에 IP주소 반환
+
+DNS 서버는 계층화 구조를 이루는데, 최상단 계층인 가장 뒷쪽(.com, .kr 등등)을 담당하는 DNS 서버는 **전세계에 13개 뿐**이다.
\ No newline at end of file
diff --git "a/Network/minseo/link layer/link layer (MAC ARP \354\212\244\354\234\204\354\271\230 \354\230\244\353\245\230 \354\262\264\355\201\254).md" "b/Network/minseo/link layer/link layer (MAC ARP \354\212\244\354\234\204\354\271\230 \354\230\244\353\245\230 \354\262\264\355\201\254).md"
new file mode 100644
index 0000000..56e0e89
--- /dev/null
+++ "b/Network/minseo/link layer/link layer (MAC ARP \354\212\244\354\234\204\354\271\230 \354\230\244\353\245\230 \354\262\264\355\201\254).md"
@@ -0,0 +1,130 @@
+# link layer (MAC / ARP / 스위치 / 오류 체크)
+
+- 데이터 링크 계층은 **직접 연결된** 서로 다른 2개의 네트워킹 장치 간의 데이터 전송을 담당한다.
+- Network 장비 간에 **신호를 주고받는 규칙**을 정하는 계층
+ - 대표적으로 Ethernet 프로토콜이 존재
+- Network 기기 간에 **Data 전송 + 물리 주소를 결정**
+- Data들을 Network 전송 방식에 맞게 **단위화(Framing)**해서, 해당 단위를 전송
+ - 전송되는 Data를 프레임이라 한다
+- Data Link layer에서 최종적으로 **이더넷 헤더/트레일러**가 붙는다.
+
+링크계층에서 제공하는 서비스들을 살펴보자
+
+## 주요 기능
+
+**1) 프레이밍 (Framing)**
+
+링크계층에서 일단 제공하는 가장중요한 서비스는 **프레이밍-프레임을** 만드는 것이다.
+
+**물리 계층으로 부터 받은 신호들을 조합**해서 **프래임단위**의 **정해진 크기의 Data Unit**으로 만들어서 처리
+
+프레임으로 만드는 작업을해서 데이터그램이 위쪽에서 내려와 캡슐화를 해서 프레임으로 만들게된다.
+
+링크계층에서 사용하는 헤더와 트레일러,
+
+트레일러는 앞뒤로 붙이는 메터데이터라고 생각해면 된다.
+
+**2) 오류제어 (Error Control)**
+
+Farme 전송 시 발생하는 오류들을 복원하거나 재전송
+
+**3) 흐름 제어 (Flow control)**
+
+-송수신측 간에 Data를 주고 받을 때 **적당한 양의 Data를 송수신**할 수 있도록 Data의 흐름을 제어
+
+**4) 접근 제어 (Access Control)**
+
+매체 상에 기기가 여러 개 존재할 때 **데이터 전송 여부를 결정**
+
+**5) 동기화 (Sysnchronization)**
+
+- Frame 구분자 (특별한 비트 패턴)
+
+---
+
+링크계층에는 2가지 종류가 있다.
+
+## 링크 계층의 종류
+
+**1) Point-to-point link**
+
+
+
+위 그림처럼 노드들 간에 dedicated 된 link를 사용하는 방식이다.
+
+빠르고 보안성이 높다는 장점이 있지만, 패킷의 경로가 길어지거나, 네트워크 카드가 여러개 필요하는 등 효율성이 떨어진다는 단점이 있다.
+
+이 경우, 신뢰성 있는 전달이나 flow control 등과 같은 Data link control 기능만 제공하면 된다.
+
+**2) Broadcast link**
+
+
+
+여러 노드들이 하나의 공유된 link를 사용하는 방식이다.
+
+효율적이라는 장점이 있지만, 보안이 약하고, 여러 노드가 동시에 신호를 보낼 경우 변조될 가능성이 존재한다는 단점이 있다.
+
+이 경우, 위 그림과 같이 Data link control 기능 뿐만 아니라, 여러 신호가 섞이는 것을 방지하기 위한 Media access control 기능도 필요하다.
+
+### **Link layer 프로토콜은 OS 커널과 네트워크 카드에도 일부 구현되어 있다.**
+
+
+
+위 그림처럼, 특정 application에서 트래픽을 보내고 싶을때, CPU를 통해 appilcation과 OS 커널에 구현된 프로토콜을 따라 내려오다, link layer를 거칠 때 네트워크 카드를 거치는 것을 확인할 수 있다.
+
+이후 네트워크 카드의 physical transmission 인터페이스를 통해 실제 물리적인 신호가 전달되는 것이다.
+
+# MAC 주소
+
+%20e25ccc6dacd944eba88db685fd1ffefb/%25E1%2584%2589%25E1%2585%25B3%25E1%2584%258F%25E1%2585%25B3%25E1%2584%2585%25E1%2585%25B5%25E1%2586%25AB%25E1%2584%2589%25E1%2585%25A3%25E1%2586%25BA_2024-02-03_%25E1%2584%258B%25E1%2585%25A9%25E1%2584%2592%25E1%2585%25AE_4.06.51.png)
+
+- **랜 카드를 제조할 떄 정해지는 물리적 주소**
+- **전 세계에서 유일한 번호**로 할당됨
+- 총 **48비트**의 숫자로 구성됨
+ - 앞 24 비트: 랜 카드 제조사 번호
+ - 뒤 24 비트 : 제조사가 랜 카드에 붙인 일련 번호
+
+ 네트워크 장비 혹은 컴퓨터는 모두 MAC주소를 갖는다. 그런데 왜 MAC 주소가 필요할까?
+
+ %20e25ccc6dacd944eba88db685fd1ffefb/%25E1%2584%2589%25E1%2585%25B3%25E1%2584%258F%25E1%2585%25B3%25E1%2584%2585%25E1%2585%25B5%25E1%2586%25AB%25E1%2584%2589%25E1%2585%25A3%25E1%2586%25BA_2024-02-03_%25E1%2584%258B%25E1%2585%25A9%25E1%2584%2592%25E1%2585%25AE_4.41.15.png)
+
+ %20e25ccc6dacd944eba88db685fd1ffefb/%25E1%2584%2589%25E1%2585%25B3%25E1%2584%258F%25E1%2585%25B3%25E1%2584%2585%25E1%2585%25B5%25E1%2586%25AB%25E1%2584%2589%25E1%2585%25A3%25E1%2586%25BA_2024-02-03_%25E1%2584%258B%25E1%2585%25A9%25E1%2584%2592%25E1%2585%25AE_4.42.10.png)
+
+
+# 스위치 (Switch)
+
+%20e25ccc6dacd944eba88db685fd1ffefb/%25E1%2584%2589%25E1%2585%25B3%25E1%2584%258F%25E1%2585%25B3%25E1%2584%2585%25E1%2585%25B5%25E1%2586%25AB%25E1%2584%2589%25E1%2585%25A3%25E1%2586%25BA_2024-02-03_%25E1%2584%258B%25E1%2585%25A9%25E1%2584%2592%25E1%2585%25AE_4.08.30.png)
+
+- Lv2 (데이터 링크)에서 동작
+- Layer 2 Switch/ Swtiching Hub라고 불린다
+- 스위치 내부에는 **MAC 주소 테이블** 존재
+
+### MAC 주소 테이블 (MAC Address Table)
+
+스위치의 포트번호 + 포트에 연결된 컴퓨터의 MAC 주소가 등록되는 DB
+
+- MAC 주소 학습을 통해서 MAC 주소 테이블에 해당 포트 + MAC 주소를 저장
+- 초기 상태에는 아무것도 등록 x
+
+### 스위치 기능
+
+1. **MAC 주소학습 (Learning)**
+ - 목적지 MAC 주소가 추가된 Frame 전송
+ - Frame이 스위치를 지나칠 때, MAC 주소 테이블에 출발지 MAC 주소가 등록
+
+2. **플러딩 (Flooding)**
+ - 목적지 MAC 주소가 MAC 주소 테이블에 등록되지 않은 경우
+ - 출발지를 제외한 포트에 연결된 모든 컴퓨터에 Frame이 전송
+
+3. **포워딩 (Forwarding)**
+ - 스위치가 목적지 MAC주소를 보유하고 있을 때, 그대로 목적지 포트로 Frame을 전송
+ - 나머지 포트는 필터링 되어서 Frame 전송 x
+
+4. **필터링 (Filterling)**
+ - 스위치가 목적지 MAC주소를 보유하고 있어서 해당 주소가 아닌 포트로는 Frame 전송 x
+
+5. **에이징 (Aging)**
+ - 스위치는 MAC 주소를 학습해서 MAC 테이블에 저장
+ - MAC 주소는 기본적으로 300초동안 MAC 테이블에 저장
+ - 300초 내에 Frame이 들어오지 않으면 해당 MAC 주소는 지워진다.
+ - 시간은 조정 가능
\ No newline at end of file
diff --git "a/Network/minseo/link layer/link layer (MAC ARP \354\212\244\354\234\204\354\271\230 \354\230\244\353\245\230 \354\262\264\355\201\254)/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_4.06.51.png" "b/Network/minseo/link layer/link layer (MAC ARP \354\212\244\354\234\204\354\271\230 \354\230\244\353\245\230 \354\262\264\355\201\254)/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_4.06.51.png"
new file mode 100644
index 0000000..d58eb86
Binary files /dev/null and "b/Network/minseo/link layer/link layer (MAC ARP \354\212\244\354\234\204\354\271\230 \354\230\244\353\245\230 \354\262\264\355\201\254)/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_4.06.51.png" differ
diff --git "a/Network/minseo/link layer/link layer (MAC ARP \354\212\244\354\234\204\354\271\230 \354\230\244\353\245\230 \354\262\264\355\201\254)/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_4.08.30.png" "b/Network/minseo/link layer/link layer (MAC ARP \354\212\244\354\234\204\354\271\230 \354\230\244\353\245\230 \354\262\264\355\201\254)/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_4.08.30.png"
new file mode 100644
index 0000000..5fa3c87
Binary files /dev/null and "b/Network/minseo/link layer/link layer (MAC ARP \354\212\244\354\234\204\354\271\230 \354\230\244\353\245\230 \354\262\264\355\201\254)/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_4.08.30.png" differ
diff --git "a/Network/minseo/link layer/link layer (MAC ARP \354\212\244\354\234\204\354\271\230 \354\230\244\353\245\230 \354\262\264\355\201\254)/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_4.41.15.png" "b/Network/minseo/link layer/link layer (MAC ARP \354\212\244\354\234\204\354\271\230 \354\230\244\353\245\230 \354\262\264\355\201\254)/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_4.41.15.png"
new file mode 100644
index 0000000..b0f9451
Binary files /dev/null and "b/Network/minseo/link layer/link layer (MAC ARP \354\212\244\354\234\204\354\271\230 \354\230\244\353\245\230 \354\262\264\355\201\254)/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_4.41.15.png" differ
diff --git "a/Network/minseo/link layer/link layer (MAC ARP \354\212\244\354\234\204\354\271\230 \354\230\244\353\245\230 \354\262\264\355\201\254)/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_4.42.10.png" "b/Network/minseo/link layer/link layer (MAC ARP \354\212\244\354\234\204\354\271\230 \354\230\244\353\245\230 \354\262\264\355\201\254)/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_4.42.10.png"
new file mode 100644
index 0000000..668c0c4
Binary files /dev/null and "b/Network/minseo/link layer/link layer (MAC ARP \354\212\244\354\234\204\354\271\230 \354\230\244\353\245\230 \354\262\264\355\201\254)/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_4.42.10.png" differ
diff --git "a/Network/minseo/loadBalancing/\353\241\234\353\223\234 \353\260\270\353\237\260\354\213\261 .md" "b/Network/minseo/loadBalancing/\353\241\234\353\223\234 \353\260\270\353\237\260\354\213\261 .md"
new file mode 100644
index 0000000..cb852f8
--- /dev/null
+++ "b/Network/minseo/loadBalancing/\353\241\234\353\223\234 \353\260\270\353\237\260\354\213\261 .md"
@@ -0,0 +1,91 @@
+# 로드 밸런싱
+
+# 로드밸런서란?
+
+### **1. 로드밸런서(Load Balancer)**
+
+
+
+로드밸런서(Load Balancer)는 **클라이언트와 서버 그룹 사이에 위치해 서버에 가해지는 트래픽을 여러 대의 서버에 고르게 분신(=밸런싱)하여 특정 서버의 부하(=로드)를 덜어준다.** 서버가 하나인데 많은 트래픽이 몰릴 경우 부하를 감당하지 못하고, 서버가 다운되어 서비스가 작동을 멈출 수 있다. 이런 문제를 해결하기 위해서 **Scale up(스케일업)과 Scale out(스케일아웃) 방식 중 한 가지**를 사용해 해결한다.
+
+**그렇다면 로드밸런싱은 모든 경우에 항상 필요할까요?**
+
+로드밸런싱은 여러 대의 서버를 두고 서비스를 제공하는 분산 처리 시스템에서 필요한 기술이다.
+
+서비스의 제공 초기단계라면 적은 수의 클라이언트로 인해 서버 한 대로 요청에 응답하는 것이 가능하지만,
+
+사업의 규모가 확장되고, 클라이언트의 수가 늘어나게 되면 기본 서버만으로는 정상적인 서비스가 불가능하다.
+
+이처럼 증가하 트래픽에 대처할 수 있는 방법은 크게 2가지다.
+
+### **2. 스케일 업과 스케일 아웃**
+
+
+
+**스케일 업(Scale Up)**은 **기존 서버 자체의 성능을 향상시키는 방법**으로 이는 CPU나 메모리를 업그레이드하는 것과 같은 작업을 포함한다. 반
+
+**스케일 아웃(Scale Out)**은 존 서버와 동일하거나 낮은 성능의 서버를 두 대 이상 증설하여 운영하는 것과 같다. 즉 **트래픽이나 작업을 여러 대의 컴퓨터나 서버에 분산시켜 처리하는 방법이**다.
+
+각각의 방법은 장단점이 있어 어떤 방법이 더 적합한지 판단해야 한다.
+
+| | 스케일 업 | 스케일 아웃 |
+| --- | --- | --- |
+| 확장성 | 성능 확장에 한계 존재 | 지속적 확장이 가능 |
+| 서버 비용 | 성능 증가에 따른 비용 증가 폭 큼
+일반적으로 비용 부담이 큰 편 | 비교적 저렴한 서버를 사용하므로, 일반적으로 비용 부담이 적음 |
+| 관리 편의성 | 스케일 업에 따른 큰 변화 없음 | 서버 대수가 늘어날수록 관리 편의성 떨어짐 |
+| 운영 비용 | 스케일 업에 따른 큰 변화 없음 | 서버 대수가 늘어날수록 운영 비용 증가 |
+| 장애 영향 | 한 대의 서버에 부하가 집중되므로 장애 시 다운 타임 발생 | 부하가 여러 서버에 분산되어 처리됨으로 장애 시 전면 장애 가능성 적음 |
+
+# 로드밸런싱 알고리즘
+
+### **1. 정적 로드 밸런싱**
+
+**1) 라운드 로빈 방식(Round Robin Method)**
+
+클라이언트의 요청을 여러 대의 서버에 순차적으로 분배하는 방식이다. 클라이언트의 요청을 순서대로 분배하기 때문에 서버들이 동일 스펙을 가지고 있고, 서버와의 연결(세션)이 오래 지속되지 않는 경우 활용하기 적합하다.
+
+- A, B, C의 서버를 가지고 있을 경우 A → B → C → A 순서대로 순회합니다.
+
+**2) 가중치 기반 라운드 로빈 방식(Weighted Round Robin Method)**
+
+각각의 서버마다 가중치(Weight)를 매기고 가중치가 높은 서버에 클라이언트의 요청을 먼저 배분합니다. 여러 서버가 같은 사양이 아니고, 특정 서버의 스펙이 더 좋은 경우 해당 서버의 가중치를 높게 매겨 트래픽 처리량을 늘릴 수 있습니다.
+
+- 서버 A의 가중치 = 8, 서버 B의 가중치 = 2, 서버 C의 가중치 = 3
+ - → 서버 A에 8개, 서버 B에 2개, 서버 C에 3개의 Request를 할당합니다.
+
+**3) IP 해시 방식(IP Hash Method)**
+
+IP 해시 방식에서 로드밸런서는 클라이언트 IP 주소에 대해 해싱이라고 하는 수학적인 계산을 수행합니다. 클라이언트 IP 주소를 숫자로 변환한 다음 개별 서버에 매핑합니다. 사용자 IP를 해싱하여 부하를 분산하기 때문에 사용자가 항상 동일한 서버로 연결되는 것을 보장합니다.
+
+### **2. 동적 로드 밸런싱**
+
+**1) 최소 연결 방법(Least Connection Method)**
+
+최소 연결 방법에서 로드 밸런서는 활성 연결이 가장 적은 서버를 확인하고 해당 서버로 트래픽을 전송합니다. 이 방법에서는 모든 연결에 모든 서버에 대해 동일한 처리 능력이 필요하다고 가정합니다. 서버에 분배된 트래픽들이 일정하지 않은 경우에 적합하다.
+
+**2) 최소 응답 시간 방법(Least Response Time Method)**
+
+서버의 현재 연결 상태와 응답 시간을 모두 고려하여, 가장 짧은 응답 시간을 보내는 서버로 트래픽을 할당합니다. 각 서버의 가용 가능한 리소스와 성능, 처리 중인 데이터양 등이 상이할 경우 적합합니다. 조건에 잘 들어맞는 서버가 있을 시 여유 있는 서버보다 먼저 할당됩니다. 로드 밸런서는 이 알고리즘을 사용하여 모든 사용자에게 더 빠른 서비스를 보장합니다.
+
+**부하분산에는 L4로드밸런서와 L7 로드밸런서가 가장많이 활용된다.**
+
+그 이유는 L4 로드밸런서부터 포트정보를 바탕으로 로드를 분산하는 것이 가능하기 때문이다. 한 대의 서버에 각기 다른 포트 번호를 부여하여 다수의 서버 프로그램을 운영하는 경우라면 최소 L4 로드밸런서 이상을 사용해야 만 한다.
+
+# L4 로드밸런싱과 L7로드 밸런싱
+
+
+
+L4 로드밸런서는 네트워크 계층(IP.IPX)이나 트랜스포트 계층(TCP,UDP)의 정보를 바탕으로 로드를 분산한다.
+
+IP주소나 포트번호, MAC주소, 전송 프로토콜에 따라 트래픽을 나누는 것이 가능하다.
+
+반면 L7 로드밸런서의 경우 애플리케이션 계층 (HTTP, FTP, SMTP)에서 로드를 분산하기 때문에 HTTP헤더, 쿠키 등과 같은 사용자의 요청을 기준으로 특정 서버에 트래픽을 분산하는 것이 가능하다.
+
+쉽게 말해 패킷의 내용을 확인하고 그 내용에 따라 로드를 특정 서버에 분배하는 것이 가능한 것이다.
+
+위 그림과 같이 URL에 따라 부하를 분산시키거나, HTTP 헤더의 쿠키 값에 따라 부하를 분산하는 등
+
+클라이언트의 요청을 보다 세분화하여 서버에 전달 할 수 있다. 또한 L7 로드밸런서의 경우 특정한 패턴을 지닌 바이러스를 감지해 네트워크를 보호할 수 있으며 Dos/DDoS 과 같은 비정상적인 트래픽을 필터링할 수 있어 네트워크 보안 분야에서도 활용되고 있다.
+
+
\ No newline at end of file
diff --git "a/Network/minseo/loadBalancing/\353\241\234\353\223\234 \353\260\270\353\237\260\354\213\261/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_2.43.33.png" "b/Network/minseo/loadBalancing/\353\241\234\353\223\234 \353\260\270\353\237\260\354\213\261/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_2.43.33.png"
new file mode 100644
index 0000000..356f944
Binary files /dev/null and "b/Network/minseo/loadBalancing/\353\241\234\353\223\234 \353\260\270\353\237\260\354\213\261/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_2.43.33.png" differ
diff --git "a/Network/minseo/loadBalancing/\353\241\234\353\223\234 \353\260\270\353\237\260\354\213\261/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_2.44.27.png" "b/Network/minseo/loadBalancing/\353\241\234\353\223\234 \353\260\270\353\237\260\354\213\261/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_2.44.27.png"
new file mode 100644
index 0000000..5c4b4a2
Binary files /dev/null and "b/Network/minseo/loadBalancing/\353\241\234\353\223\234 \353\260\270\353\237\260\354\213\261/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_2.44.27.png" differ
diff --git a/Network/minseo/physicalLayer/physical layer.md b/Network/minseo/physicalLayer/physical layer.md
new file mode 100644
index 0000000..7a86dfc
--- /dev/null
+++ b/Network/minseo/physicalLayer/physical layer.md
@@ -0,0 +1,27 @@
+# physical layer
+
+
+
+### 주된 기능
+
+1) 비트 단위의 데이터 전송
+
+2) 내트워크 장비로 데이터를 전기신호로 출력
+
+3) 데이터 링크 계층의 데이터 통신 기능을 원활하게 수행하도록 물리적인 연결 설정과 유지 및 해제기능과 관계
+
+단, Physical Layer은 단지 데이터를 전달만 할뿐 이 데이터가 무엇인지, 어떤 에러가 있는지, 어떻게 보내는 것이 더 효과적인지 하는 것은 전혀 관여하지 않음
+
+Physical Layer에 관련되는 프로토콜은 DTE/DCE 인터페이스로 규정한다.
+
+DTE/DCE 인터페이스?
+
+변복조기, DSU 등 통신 회선에 연결되는 장치의 퍼스널 컴퓨터 또는 단말기 사이를 연결하는 신호선, 커넥터에 대해 규정
+
+### Physical Layer의 대표적인 장비
+
+1) 통신 케이블
+
+2) 리퍼터
+
+3) 허브
\ No newline at end of file
diff --git a/Network/minseo/physicalLayer/physical layer/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_3.34.45.png b/Network/minseo/physicalLayer/physical layer/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_3.34.45.png
new file mode 100644
index 0000000..6eedf73
Binary files /dev/null and b/Network/minseo/physicalLayer/physical layer/%E1%84%89%E1%85%B3%E1%84%8F%E1%85%B3%E1%84%85%E1%85%B5%E1%86%AB%E1%84%89%E1%85%A3%E1%86%BA_2024-02-03_%E1%84%8B%E1%85%A9%E1%84%92%E1%85%AE_3.34.45.png differ
diff --git "a/Network/minseo/routing&router/\353\235\274\354\232\260\355\214\205 & \353\235\274\354\232\260\355\204\260/Untitled 1.png" "b/Network/minseo/routing&router/\353\235\274\354\232\260\355\214\205 & \353\235\274\354\232\260\355\204\260/Untitled 1.png"
new file mode 100644
index 0000000..4a0239d
Binary files /dev/null and "b/Network/minseo/routing&router/\353\235\274\354\232\260\355\214\205 & \353\235\274\354\232\260\355\204\260/Untitled 1.png" differ
diff --git "a/Network/minseo/routing&router/\353\235\274\354\232\260\355\214\205 & \353\235\274\354\232\260\355\204\260/Untitled.png" "b/Network/minseo/routing&router/\353\235\274\354\232\260\355\214\205 & \353\235\274\354\232\260\355\204\260/Untitled.png"
new file mode 100644
index 0000000..2f0a6b5
Binary files /dev/null and "b/Network/minseo/routing&router/\353\235\274\354\232\260\355\214\205 & \353\235\274\354\232\260\355\204\260/Untitled.png" differ
diff --git "a/Network/minseo/routing&router/\353\235\274\354\232\260\355\214\205 & \353\235\274\354\232\260\355\204\260md" "b/Network/minseo/routing&router/\353\235\274\354\232\260\355\214\205 & \353\235\274\354\232\260\355\204\260md"
new file mode 100644
index 0000000..8683cdd
--- /dev/null
+++ "b/Network/minseo/routing&router/\353\235\274\354\232\260\355\214\205 & \353\235\274\354\232\260\355\204\260md"
@@ -0,0 +1,159 @@
+# 라우팅 & 라우터
+
+# 라우팅이란?
+
+라우터(router)는 패킷(packet)의 목적지 주소를 확인하고, 목적지와 연결되는 인터페이스로 전송하는 역할을 한다.
+
+
+
+말 그대로 Route(경로)를 선택하여 데이터가 전달될 수 있게 하는 것을 말하는데 이 경로를 최단거리, 최단시간에 전달될 수 있게 하는 것이 핵심적인 내용이다.
+
+이와 같은 라우터의 기능을 라우팅(routing)이라고 합니다. 특히, IP 라우팅이란 패킷의 목적지 IP 주소를 참조하여 길을 찾아주는 것이다.
+
+예를 들어 인천에는 여러 가지 경로가 존재하는데, 이 많은 경로 중에 하나를 선택하여 이동하는 것을 라우팅이라 한다.
+
+# 경로 선택
+
+당연히도 라우터는 특정 데이터(패킷)의 목적지인 IP주소에 대한 정보를 갖고 있어야 스위칭이 가능하다.
+
+내가 부산에 사는데 서울이 어딘지도 모른다면 어디로 가야하는지 모를수밖에 없겠죠. 또, 길이 어떻게 생겨먹었는지도 알아야 할 것이고, 어디가 교통량이 많고 적은지, 어떤 톨 게이트를 거쳐야 하는지 등 알아야 할 정보가 많을겁니다.
+
+라우팅 또한 최적의 경로를 선택하기 위해서는 이러한 정보들을 알고, 활용해야 합니다. 다음과 같은 요소들이 라우팅 경로 결정에 사용된다.
+
+- 토폴로지
+- 트래픽
+- 링크 비용
+- 메시지
+- 라우팅 테이블
+
+# **라우팅 프로토콜의 구분과 종류**
+
+해당 목적지에 대한 정보를 알아야 하며 그 정보에 따라 패킷을 전달한다. 그래서 라우터들은 목적지에 대한 경로 정보를 이웃 라우터들과 공유하게 된다. 이 때 교환하는 것을 라우팅 프로토콜이라 한다.
+
+
+
+라우터는 다른 라우터들로부터 라우팅 정보를 수신한 다음 그 중에서 최적의 경로를 선택하여 라우팅 테이블에 저장한다. 라우팅 테이블이란 목적지 네트워크 및 목적지 네트워크와 연결되는 인터페이스를 기록한 데이터베이스이다.
+
+## **정보 갱신 방법에 따른 구분**
+
+라우팅 경로는 동적 경로(dynamic route)와 정적 겅로(static route)가 있다.
+
+| 구분 | 특징 |
+| --- | --- |
+| 정적 라우팅(Static Routing) | - 네트워크 관리자가 경로를 수동으로 직접 지정해 주는 방식. - 구성이 간단하고, 원하는 경로로 패킷을 보낼 수 있음. - 단일 경로에 적합하여 Stub Network 에 주로 적용. - 네트워크 구성 변화에 수동적임. - 관리 부담의 증가 및 경로 장애 발생시에 라우팅이 불가능함. |
+| 동적 라우팅(Dynamic Routing) | - 장비가 자동으로 경로를 지정함. - 네트워크 변화를 인지하여 경로를 재구성할 수 있음. - 다중경로 네트워크에 적합함. - 라우팅 프로토콜(routing protocol)을 사용하여 동적으로 알아낸 경로 |
+
+수동(고정) 경로 설정과 적응 경로 설정의 차이다.
+
+ 부산→서울 이동 경로를 생각했을때, 나는 무조건 정해진 길로만 가겠다! 와 차막히면 돌아가지 뭐,, 네비게이션이 안내 해 주는대로 가자~~ 정도의 차이라고 생각하시면 됩니다.
+
+## **내/외부에 따른 구분**
+
+**같은 네트워크 관리자가 관리하는 라우터들과 일정 규모의 집합을 AS(Autonomus System)** 이라 칭하는데, 이 규모에 따라 구분하는 방식
+
+| 구분 | 특징 |
+| --- | --- |
+| IGP(Interior Gateway Protocol) | - AS 내에서의 라우팅을 담당하는 프로토콜. |
+| EGP(Exterior Gateway Protocol) | - 서로 다른 AS간 사용되는 프로토콜. |
+
+마치 내부망, 외부망을 구분짓는 것과 느낌이 비슷한데, 이 구분이 망 구성이 중점이 되는것이 아니고 관리자나 관리 업체가 중점이 되는것이 차이점입니다.
+
+예를들어 KT가 관리하는 라우터들은 KT 입장에서는 IGP를 사용하고 SK가 관리하는 라우터들과는 EGP를 사용하게 되는겁니다.
+
+## **테이블 관리 방법에 따른 구분**
+
+| 구분 | 특징 |
+| --- | --- |
+| Distance VectorAlgorithm | - 최단 거리를 홉 수로 판단함. - 주기적으로 라우팅 테이블을 교환함. |
+| Link StateAlgorithm | - 대역폭, 지연시간, 토폴로지를 참고하여 Cost를 책정함. - 라우터가 목적지까지 가는 경로를 모든 라우팅 테이블에 기록함. |
+| Hybrid RoutingAlgorithm | - 거리벡터, 링크상태를 복합적으로 사용한 방식. - Cisco 독점 프로토콜. |
+
+부산→서울 이동을 생각했을 때, 나는 톨 게이트를 최대한 적게 지나가는 경로로 가겠다! 하는것이 거리벡터, 나는 교통량이 적은 곳으로 최대한 빨리 가보겠다! 하는것이 링크상태방식이다.
+
+링크상태 방식에서 말하는 비용(Cost)은 금전적 의미가 아니고 **통신 속도**를 의미한다. 비용이 낮을수록 대역폭이 크다던가, 지연시간이 낮다던가 하는 것으로 빨리 전달할 수 있으면 비용이 낮다고 판단한다.
+
+거리 벡터는 거리, 방향을 중점으로 최단거리 계산을 위해 Bellman-Ford 알고리즘을 사용합니다.
+
+링크 상태는 라우터들이 정보를 주고받아 전체 토폴로지를 그리며 Dijkstra's 알고리즘을 사용합니다.
+
+# 패킷
+
+이렇게 라우팅 테이블이 만들어지면 해당 라우터는 특정 목적지 네트워크로 가는 패킷을 라우팅시킬 수 있다.
+
+라우터가 패킷을 수신하고, 라우팅 테이블에 따라 정해진 목적지 인터페이스로 해당 패킷을 전송하게 된다.
+
+## 1. 패킷의 처리
+
+**1) 패킷의 발송**
+
+이러한 IP패킷이 네트워크가 통과 시킬 수 있는 최대 바이트보다 클 경우에는 `단편화(Fragmentation)`시켜 보내게 되는데 그 단편화 정보도 IP패킷의 헤더에 저장하여 보내게 된다.
+
+**2) 최종 목적지**
+
+단편화된 패킷을 받은 목적지에서는 다면, 단편들을 모아서 **하나의 온전한 패킷을 조립한다.** 여기서 만약 하나의 온전한 패킷으로 조립이 불가능 하다면 모두 폐기시키고 이를 송신지에게 `CMP(Internet Control Message Protocol)메세지`를 보내게 된다.
+
+## 2. 패킷의 전달
+
+**1) 직접전달(Direct delivery)**
+
+패킷의 송신지와 목적지가 동일한 네트워크에 연결되어 있을 때 직접전달하는 경우.
+
+**2) 간접전달(Indirect delivery)**
+
+패킷이 최종 목적지에 전달될 때까지 라우터에서 라우터로 전달되는 경우.
+
+### 3. 라우팅 테이블
+
+우리가 어떤 웹사이트에 접속을 한다고 했을 때 송신측의 네트워크 계층에서는 데이터 앞쪽에 정보를 담은 헤더(header)를 붙이게 된다.
+
+**여기서 네트워크 계층에 데이터가 어디로 가야할지 경로를 설정할 수 있도록 `표 형태`로 구성되어 있는 것**을 `라우팅 테이블` 이라고 한다.
+
+즉, 목적지로 갈때 최적의 경로가 표로 구성되어 있는 것을 라우팅 테이블이라고 하고 이를 참조하여 IP패킷을 보내게 되어있다.
+
+이러한 라우팅 테이블은 처음 송신지에서 보낼때만 참조하는 것이 아니라 네트워크를 통해 이동하다가 **중간 장치들인 스위치나 라우터에서도 라우팅 테이블을 참조**하여 패킷을 보낸다.
+
+**1) 라우팅 프로토콜**
+
+라우팅 테이블을 만들어 주는 것이 바로 `라우팅 프로토콜`이다. 라우팅 프로토콜에서 라우팅 정보를 주고 받음으로써 이를 판단해 라우팅 테이블을 만들게 된다.
+
+**2) 패킷의 전달 방법**
+
+- **이웃노드명시(Next-hop method)**
+
+ 라우팅 테이블은 전체 경로상의 라우터를 명시하지 않고 `다음 라우터`만 명시한다.
+
+ 
+
+ - A -> R1 -> R2 -> B 와 같이 전체 경로를 명시하는 것이 아니라 A는 R1만 명시!*(과도한 메모리사용으로 비효율적이기 때문!)*
+
+- **네트워크 주소 명시(Network specific method)**
+
+ IP주소는 크게 `네트워크ID`와 `호스트ID`로 구성되어 있는데 여기서 네트워크ID를 기반으로 호스트ID를 할당하기 때문에 만약 특정 기관이라면 그 안에 있는 모든 컴퓨터들은 네트워크ID가 모두 동일하게 된다.
+
+ 이렇듯 목적지로 IP패킷을 전달할때 동일한 네트워크에 연결된 컴퓨터들을 하나하나 모두 명시하는 것이 아니라 **목적지 네트워크 주소만 명시하여 보내는 것**을 네트워크 주소 명시라고 한다.
+
+ 이처럼 간단하게 표기하게 되면 테이블 사이즈가 줄어들게 되고 이 효과로 빠른 검색과 메모리 효율성을 높일 수 있다.
+
+ > 호스트 주소 명시(Host-specific method)
+ >
+ >
+ > `특별한 목적`이 있는 경우라면 라우팅 테이블에 목적지 컴퓨터 주소를 직접 명시할수 있다! -> 관리자가 직접 입력해야함 (ex. 보안목적 등..)
+ >
+
+- **디폴트 지정(Default method)**
+
+ 인터넷에 있는 모든 목적지를 지정할 수 없음으로 지정된 목적지 이외의 모든 지역을 지정하는 라우팅 엔트리를 `디폴트(Default)`라고 한다.(내가 지정한거 외에는 다 얘한테 보내!)
+
+ > 보통 네트워크 주소가 0.0.0.0으로 표기 됨!
+ >
+
+**3) 라우팅 프로토콜의 종류**
+
+**(1) 유니캐스트 라우팅 프로토콜** = 보통의 그냥 라우팅 프로토콜
+
+- `일대일 통신`을 말함
+- 디지털 서명(Digital Signature)목적지가 하나이며 라우팅 정보를 교환하여 라우팅 테이블을 구축하는 형태
+
+**(2) 멀티캐스트 라우팅 프로토콜**
+
+- 송신지는 하나, 수신지는 여러개인 시스템으로 목적지가 동일한 그룹에 속한 여러 호스트가 될 수 있다.
\ No newline at end of file
diff --git "a/Network/minseo/tcp connection && socket/TCP Connection\352\263\274 Socket .md" "b/Network/minseo/tcp connection && socket/TCP Connection\352\263\274 Socket .md"
index af1f9ba..e462dbc 100644
--- "a/Network/minseo/tcp connection && socket/TCP Connection\352\263\274 Socket .md"
+++ "b/Network/minseo/tcp connection && socket/TCP Connection\352\263\274 Socket .md"
@@ -9,7 +9,7 @@
### TCP/IP stack
-**TCP/IP stack은 인터넷이 발명되면서 함께 개발된 프로토콜 스택이다.**
+**TCP/IP stack은 인터넷이 발명되면서 함께 개발된 프로토콜 스택이다 .**
- IETF에서 인터넷 표준을 관리한다.(RFC)
- TCP, UDP, IP.. 스펙은 RFC에서 정의한다.
diff --git a/Network/yerin/tcp_and_ip.md b/Network/yerin/tcp_and_ip.md
new file mode 100644
index 0000000..5e22aae
--- /dev/null
+++ b/Network/yerin/tcp_and_ip.md
@@ -0,0 +1,354 @@
+# 네트워크 2주차
+
+https://hyper-hotel-11e.notion.site/2-6287a99bb3984c248c4823c0a4c012ed?pvs=4
+
+# 📌TCP
+
+## UDP
+
+UDP에도 오류를 감지하는 기능은 있다. ⇒ Checksum으로.
+
+근데 감지만 하고, TCP와 달리 오류를 정정하거나 재전송하는 메커니즘을 제공하진 않는다.
+
+정정안해줄거면 왜 굳이 감지를 해줄까?
+
+⇒ 과도한 체크섬 오류는 네트워크 장비의 문제나 데이터 경로상의 문제를 나타내줌.
+
+⇒ Application layer에서 필요하면 선택적으로 재요청하게끔 적어도 알려는 준다는 느낌
+
+## TCP
+
+네트워크 통신에서 신뢰적인 연결방식을 사용한다는 특징이 있다.
+
+TCP는 기본적으로 unreliable network에서, reliable network (reliable data transfer)를 보장할 수 있도록 하는 프로토콜이다.
+
+TCP 통신을 하다보면 Segment 전송에 에러가 생기는 경우가 있다.
+
+- Loss - 손실 문제
+- Corruption - bit error
+- Congestion - 네트워크 혼잡 문제
+
+Solution ⇒ ACK, Checksum, Time-out, Retransmission, Seq #
+
+TCP는 이 에러들을 정정해줘야하고, 흐름과 혼잡을 제어해야한다. 왜냐하면 신뢰적인 연결방식을 사용하는 프로토콜이니까. TCP 프로토콜의 흐름제어와 혼잡제어 방식을 이해하기위해서는 몇가지 용어들과 과정들을 알아야한다.
+
+### ACK
+
+ACK(Acknowledgements) : 리시버가 센더에게 OK 잘 왔음이라고 답해주는 것
+
+ack은 리시버가 센더에게 잘 받았다고 전달해주는 메시지 개념인데, 이 ack 또한 센더한테 전달될때 에러가 날 수 있음. 이때 센더입장에서는 “못 받았나보네, 다시 보내야지” 하면서 첫번째 Segment를 다시 보냄. 그러면 리시버 입장에서는 첫번째 segment를 받은 상태이기 때문에 위 센더가 다시 보낸 값을 두번째 segment로 인식하게 됨. 이러한 문제를 해결하기 위해 Sequence Number 개념이 탄생.
+
+sequence number로 전달할 segment의 순서를 구분하게됨.
+
+### TCP Header
+
+https://blog.kakaocdn.net/dn/b2OtbA/btqAMlJTLi1/CTJcSSlZ7qzxlBrmgc5Pb1/img.png
+
+
+
+TCP flag(URG, ACK, PSH, RST, SYN, FIN)
+
+FLAG 순서 - | URG | ACK | PSH | RST | SYN | FIN |
+
+### ACK(Acknowledgement) - Ack : 응답
+
+상대로부터 패킷을 받았다는 걸 알려주는 패킷
+
+### SYN(Synchronization:동기화) - S : 연결 요청 플래그
+
+TCP 에서 세션을 성립할 때 가장먼저 보내는 패킷, 시퀀스 번호를 임의적으로 설정하여 세션을 연결하는 데에 사용되며 초기에 시퀀스 번호 (ISN) 를 보내게 된다.
+
+### FIN(Finish) - F : 종료
+
+연결 종료 요청세션 연결을 종료시킬 때 사용. 더이상 전송할 데이터가 없음을 나타냄
+
+### RST(Reset) - R : 리셋
+
+연결 종료재설정(Reset)을 하는 과정, 양방향에서 동시에 일어나는 중단 작업
+
+비 정상적인 세션 연결 끊기. 현재 접속하고 있는 곳과 즉시 연결을 끊고자 할 때 사용
+
+## 🔸TCP 3 way handshaking (연결)
+
+
+
+서버 listen() 상태
+
+1. 클라이언트 connect(), C->S 접속요청 패킷 SYN(M) 전송
+
+2. 서버 accept(), S->C 요청 수락 패킷 ACK(M+1), SYN(N) 전송
+
+3. 클라이언트 connect(), C->S 요청 수락 확인 패킷 ACK(N+1) 전송
+
+### 연결 성립
+
+## 🔸TCP 4 way handshaking (해제)
+
+
+
+1. C->S 연결 종료요청 FIN FLAG 전송
+
+2. S->C 종료 수락 메시지 ACK 전송
+
+일시적 TIME_OUT (데이터를 모두 보낼 때 까지)
+
+3. S->C 연결 종료 FIN FLAG 전송
+
+4. C->S 확인 메시지 ACK 전송
+
+서버 소켓 연결 close(), 클라이언트 일정 시간 동안 TIME_WAIT (잉여패킷 대기)
+
+### 연결 해제
+
+## 🔸TCP 흐름제어
+
+ **Window** : 윈도우는 메모리 버퍼의 일정 영역이라고 생각하면 된다. TCP/IP를 사용하는 모든 호스트들은 송신하기 위한 것과 수신하기 위한 2개의 Window를 가지고 있다. 호스트들은 실제 데이터를 보내기 전에 '3 way handshaking'을 통해 리시버의 receive window size에 자신의 send window size를 맞추게 된다.
+
+### **TCP Buffer**
+
+
+
+흐름 제어는 송신 측과 수신 측의 TCP 버퍼 크기 차이로 인해 생기는 데이터 처리 속도 차이를 해결하기 위한 기법이다.
+
+수신측에서 제한된 저장 용량을 초과한 이후에 도착하는 데이터는 손실 될 수 있으며, 만약 손실 된다면 불필요하게 응답과 데이터 전송이 송/수신 측 간에 빈번이 발생한다.
+
+이러한 위험을 줄이기 위해 송신 측의 데이터 전송량을 수신측에 따라 조절해야한다.
+
+흐름제어기법
+
+### 1. stop and wait
+
+매번 전송한 패킷에 대해 확인 응답(ACK)를 받으면 다음 패킷을 전송하는 방법이다. 그러나 패킷을 하나씩 보내기 때문에 비효율적인 방법이다.
+
+⇒ 파이프라이닝 형식을 사용해 효율성을 높임
+
+**슬라이딩 윈도우**
+
+- Go-back-N (슬라이딩 윈도우 방식을 이용한 오류제어 기법)
+- Selevtive Repeat (슬라이딩 윈도우 방식을 이용한 오류제어 기법)
+
+### 2. Sliding Window
+
+리시버는 rwnd 값을 포함한 tcp header를 센더에게 전달되는 segment에 담아 보내기 때문에 센더는 리시버의 rwnd값에 따라 in-flight 값을 제한할 수 있다.
+
+window size만큼 순서대로 모두 보내고, ack이 오면 그만큼 윈도우 이동하는 방식
+
+## 🔸TCP 혼잡제어
+
+센더의 데이터는 지역망이나 인터넷으로 연결된 대형 네트워크를 통해 전달된다. 만약 데이터가 한 곳으로 몰릴 경우, 자신에게 온 데이터를 모두 처리할 수 없게 된다. 이런 경우 혼잡으로 인한 오버플로우나 데이터 손실이 발생한다.
+
+따라서 이러한 네트워크의 혼잡을 피하기 위해 센더측에서 보내는 데이터의 전송속도를 강제로 줄이게 되는데, 이러한 작업을 혼잡제어라고 한다.
+
+TCP Tahoe와 Reno 등 혼잡 제어 정책들은 공통적으로 `혼잡이 발생하면 윈도우 크기를 줄이거나, 혹은 증가시키지 않으며 혼잡을 회피한다` 라는 전제를 깔고 있다.
+
+TCP Tahoe와 Reno 정책을 알아보기전에 몇가지 혼잡제어 방식과 관련 용어들을 알아야한다.
+
+1. **Timeout**
+
+여러 가지 요인으로 인해 센더가 보낸 데이터 자체가 유실되었거나,
+
+리시버가 응답으로 보낸 ACK이 유실되는 경우 센더가 설정해놓은 timeout에 걸리게 된다.
+
+1. **3 Duplicate ACKs**
+
+!https://blog.kakaocdn.net/dn/ci8GSU/btrlpLaCuUk/KHpoUNv1tRnEHPzOtXd4Gk/img.png
+
+ 중복 ACK 3개를 받으면 문제가 있다고 판단하여 해당 패킷을 재전송한다. 해당 기법을 `빠른 재전송` 이라고 부르며, 센더는 자신이 설정한 타임 아웃 시간이 지나지 않았어도 바로 해당 패킷을 재전송할 수 있기 때문에 보다 빠른 전송률을 유지할 수 있게 된다.
+
+1. ****AIMD(Additive Increase / Multiplicative Decrease)****
+ - 문제가 발생하기 전까지 cwnd 1씩 증가
+ - 문제가 발생하면 cwnd를 절반으로 감소
+
+ 문제점은 초기에 네트워크의 높은 대역폭을 사용하지 못하여 오랜 시간이 걸리게 되고, 네트워크가 혼잡해지는 상황을 미리 감지하지 못한다. 즉, 네트워크가 혼잡해지고 나서야 대역폭을 줄이는 방식이다.
+
+2. ****Slow Start****
+ - Slow Start 방식은 AIMD와 마찬가지로 패킷을 하나씩 보내면서 시작하고, 패킷이 문제없이 도착하면 각각의 ACK 패킷마다 window size를 1씩 늘려준다. 즉, 한 주기가 지나면 window size가 2배로 된다.
+ - 전송속도는 AIMD에 반해 지수 함수 꼴로 증가한다. 대신에 혼잡 현상이 발생하면 window size를 1로 떨어뜨리게 된다.
+
+ 
+
+
+**Slow Start 임계점 (ssthresh)**
+
+
+
+ `Slow Start Threshold(ssthresh)` 여기까지만 Slow Start를 사용하겠다는 의미를 가진다.
+
+Slow Start를 사용하며 윈도우 크기를 지수적으로 증가시키다보면 어느 순간부터는 윈도우 크기가 기하급수적으로 늘어나서 제어하기가 힘들다. 또한, 네트워크의 혼잡이 예상되는 상황에서 빠르게 값을 증가시키기 보다는 조금씩 증가시키는 편이 훨씬 안전하다.
+
+그래서 특정한 임계점을 정해 놓고, 그 임계점이 넘어가면 AIMD 방식을 사용하여 선형적으로 윈도우를 증가시킨다.
+
+(이 임계점은 계속 초기값을 가지는 건 아님. loss event가 발생하면 그 발생했을때의 cwnd의 절반 사이즈로 세팅됨)
+
+1. **Fast Recovery**
+
+혼잡한 상태가 되면 window size를 1이 아닌 반으로 줄이고 선형증가시키는 방법이다. 이 정책까지 적용하면 혼잡 상황을 한번 겪고 나서부터는 순수한 AIMD 방식으로 동작하게 된다.
+
+### TCP Tahoe
+
+
+
+이 정책은 한 번 혼잡 상황이 발생한 지점을 기억하고 그 지점이 가까워지지 않도록 합리적으로 조절하고 있다. 하지만, 초반의 Slow Start 구간에 윈도우 크기를 늘릴 때 오래 걸린다는 단점이 있고, 혼잡 상황이 발생했을 때 다시 윈도우 크기를 1에서부터 시작해야 한다는 단점이 있다.
+
+### TCP Reno
+
+
+
+TCP Reno는 TCP Tahoe 이후에 나온 정책으로, Tahoe와 마찬가지로 Slow Start로 시작하여 임계점을 넘어서면 AIMD을 사용한다. 다만, Tahoe와는 다르게 3 ACK Duplicated와 Timeout 혼잡 상황을 구분한다.
+
+Reno는 3개의 중복 ACK가 발생했을 때, 윈도우 크기를 1로 줄이는 것이 아니라 AIMD처럼 반으로만 줄이고 sshthresh를 줄어든 윈도우 값으로 정하게 된다. 이 방식을 `빠른 회복`이라고 부른다.
+
+그러나 Timeout에 의해서 데이터가 손실되면 Tahoe와 마찬가지로 윈도우 크기를 바로 1로 줄여버리고 Slow Start를 진행한다. 이때 ssthresh를 변경하지는 않는다.
+
+즉, Reno는 ACK 중복은 Timeout에 비해 그리 큰 혼잡이 아니라고 가정하고 혼잡 윈도우 크기를 1로 줄이지도 않는다는 점에서 혼잡 상황의 우선 순위를 둔 정책이라 볼 수 있다.
+
+
+
+---
+
+# 📌IP (Internet Protocol)
+
+> 인터넷 프로토콜의 약자로 송신 호스트와 수신 호스트가 패킷 교환 네트워크에서 정보를 주고받는데 사용하는 정보 위주의 규약
+>
+
+- 인터넷에서 데이터를 송수신하기 위한 주요 프로토콜
+- 데이터를 소스에서 목적지까지 전달
+- 비신뢰성과 비연결성
+- 패킷 전송과 정확한 순서를 보장하기 위해 TCP 프로토콜을 이용
+
+**고정 IP**
+
+- 컴퓨터가 고정적으로 가지고 있는 IP이다.
+- 한 번 부여받으면 **반납하기 전까지 변하지 않는다**.
+- 주로 인터넷 사이트를 운영할 때 사용한다.
+
+**유동 IP**
+
+- 컴퓨터에 고정된 IP를 부여하지 않고 **IP 갱신 주기가 되었을 때 ISP로부터 할당받는 IP**이다.
+- 사용하지 않는 IP를 수거하는 방식이다.
+ - 더 많은 사용자에게 인터넷 서비스를 제공할 수 있다.
+
+**공인 IP**
+
+- **외부에 공개된 IP**다.
+- 해킹의 위험이 있기에 보안 프로그램이 필요하다.
+
+**사설 IP**
+
+- **외부에서 접근할 수 없는 IP**다.
+- 주로 일반 가정 또는 회사 내부에서 사용한다.
+- 공인 IP가 할당된 라우터나 공유기를 통해 사설 IP가 할당된다.
+
+## IPv4
+
+
+
+IPv4 주소는 전세계적으로 관리되는 32bit의 유효한 자원으로 8 bits 씩 나눠져서 일부는 Network, 다른 일부는 Host의 번호를 표현하는데 사용된다. 네트워크 부분은 특정 네트워크를 식별하고, 호스트 부분은 그 네트워크 내의 특정 장치를 식별한다.
+
+- 주소는 점으로 구분된 네 개의 숫자(예: 192.168.0.1)로 표현
+- 인터넷 상에서 장치를 식별하는 데 사용 ⇒ IPv4 주소는 고유해야 함
+
+### IPv4 주소 고갈 & 대응 방안
+
+원인 : 인터넷의 지속적인 성장과 연결되는 장치의 증가
+
+IPv4 주소는 32비트로 구성되어 있어, 이론적으로 약 42억 개(2의 32승)의 고유한 주소만 제공 가능
+
+**대응 방안**
+
+ (IPv6가 근본적인 주소 고갈 대응 방안이라고 할 수 있고, 나머지는 IPv4 주소 공간을 보다 효율적으로 관리하고 활용하기 위한 임시 방안이라고 할 수 있다.)
+
+1. Subnetting & CIDR
+2. NAT
+3. DHCP
+4. IPv6
+
+## IPv6
+
+IPv4의 고갈 문제를 해결하기 위해 IPv6가 등장하였다.
+
+총 128비트로 각 16비트씩 8자리로 각 자리는 ‘:’(콜론)으로 구분한다.
+
+ex) 2001:0DB8:1000:0000:0000:0000:1111:2222
+
+총 2^128 의 IP 주소를 만들어낸다.
+
+### IPv4와의 차이점
+
+---
+
+1. **주소 체계 및 길이**
+
+- **IPv4**:
+ - 32비트 주소 체계
+ - 주소는 점으로 구분된 십진수 형식으로 표시 / 예: 192.168.1.1
+- **IPv6**:
+ - 128비트 주소 체계를 사용하여, 거의 무한에 가까운 주소 공간을 제공
+ - 주소는 콜론으로 구분된 16진수 형식으로 표시됩니다. / 예: 2001:0db8:85a3:0000:0000:8a2e:0370:7334
+
+
+**2. 주소 할당 및 관리**
+
+- **IPv4**:
+ - 정적(수동) 또는 동적(DHCP) 방식으로 주소 할당
+ - 주소 공간의 제한으로 인해 주소 할당을 효율적으로 해야한다.
+- **IPv6**:
+ - 주소의 풍부함으로 인해 주소 할당에 있어 더 많은 유연성을 가짐
+
+
+**3. 보안**
+
+- **IPv4**:
+ - 기본적으로 보안 기능이 내장되어 있지 않습니다.
+ - 보안을 위해 IPsec과 같은 별도의 프로토콜을 사용할 수 있으나, 선택적입니다.
+
+ (IPsec은 Host-to-Host와 Network-to-Network간의 Data Flow를 암호화 시키는 Protocol Suite)
+
+- **IPv6**:
+ - 보안을 위한 IPsec이 기본적으로 내장되어 있어, 보다 향상된 보안 기능을 제공합니다.
+
+ (참고로, 초창기 모든 IPv6는 IPsec를 필수적으로 지원하게 되어 있어 IPv6 Network의 높은 보안성을 기대하였으나, 낮은 Network Processor를 가진 IPv6 Nodes로 인하여 IPsec의 기능이 "Recommended" 수준으로 하향 조정 되었다. 하지만, IPsec이 "Option"으로 지원이 되는 IPv4 Network에 비하여 IPv6 Network이 여전히 높은 보안성을 가진다.)
+
+
+**4. 헤더 형식 및 처리**
+
+- **IPv4**:
+ - 헤더가 상대적으로 복잡하고 옵션 필드가 있어 처리가 더 복잡함
+ - 헤더 길이가 가변적
+
+- **IPv6**:
+ - 헤더 구조가 간소화되어 있고, 대부분 고정 길이
+ - checksum x (DataLink Layer에서 오류를 검사하기 때문에 IP 패킷의 빠른 처리를 위해 삭제)
+
+
+**5. fragmentation 단편화**
+
+Fragmentation은 데이터 패킷을 네트워크를 통해 전송할 때 발생하는 과정으로, 큰 데이터 패킷을 더 작은 단위로 나누는 것
+
+왜?
+
+MTU라는 한 번에 전송할 수 있는 데이터의 최대 크기를 나타내는 단위가 있는데, 네트워크 경로상 각 네트워크 세그먼트의 MTU보다 보내려는 데이터 패킷 크기가 크다면 그 패킷은 네트워크를 통과할 수 없다. 따라서 데이터 패킷은 MTU 크기에 맞게 여러 개의 작은 패킷으로 분할되어야 한다.
+
+- **IPv4**:
+ - 출발/목적지 또는 중간 라우터에서 수행
+- **IPv6**:
+ - 송신자만 수행하며, 중간 라우터에서는 수행x
+
+ 단편화 & 재결합 과정은 시간이 소요되는 일이므로 라우터에서 수행을 하지 않음으로써 네트워크 효율성이 증가
+
+
+---
+