diff --git a/tutorials/W2D4_Macrolearning/W2D4_Intro.ipynb b/tutorials/W2D4_Macrolearning/W2D4_Intro.ipynb
index 7ed56f51f..e5deb386c 100644
--- a/tutorials/W2D4_Macrolearning/W2D4_Intro.ipynb
+++ b/tutorials/W2D4_Macrolearning/W2D4_Intro.ipynb
@@ -49,6 +49,17 @@
"feedback_prefix = \"W2D4_Intro\""
]
},
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "# Macrolearning\n",
+ "\n",
+ "Over the last two weeks in this NeuroAI course, we've focused on numerous aspects of learning mechanisms, inductive biases and how generalization is implemented as a fundamental property of successful learning systems. Back in Day 2 we looked at the topic of \"Comparing Tasks\" and Leila Wehbe introduced the idea of learning at multiple temporal scales. This idea was explored fairly lightly back then, but today we're going to go much deeper into this idea of learning of a macro-level of time and in a Reinforcement Learning framework. What does it mean about learning across the scale of biological evolution and at the species level? That's what today is all about. We hope you enjoy this fascinating topic!"
+ ]
+ },
{
"cell_type": "markdown",
"metadata": {
@@ -57,7 +68,7 @@
"source": [
"## Prerequisites\n",
"\n",
- "For this day, it would be beneficial to have prior experience working with the `pytorch` modeling package, as the last tutorials are going to be concentrated on defining architecture and training rules using this framework. For Tutorials 4 & 5, you might find yourself more comfortable if you are familiar with the reinforcement learning paradigm and with the Actor-Critic model, in particular. Actually, Tutorial 4 will elaborate on the agent already introduced previously in the last tutorial of Day 2, completing the discussion of meta-learning."
+ "For this day, it would be beneficial to have prior experience working with the `pytorch` modeling package, as the last tutorials are going to be concentrated on defining architecture and training rules using this framework. For Tutorials 4 & 5, you might find yourself more comfortable if you are familiar with the reinforcement learning paradigm and with the Actor-Critic model, in particular. Actually, Tutorial 4 will elaborate on the agent already introduced previously in the last tutorial of Day 2, completing the discussion of meta-learning. It might also be useful to revisit the recording in Tutorial 3 of Day 2, specifically related to the idea of Partially-Observable Markov Decision Processes (POMDPs)."
]
},
{
@@ -206,7 +217,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.9.19"
+ "version": "3.9.22"
}
},
"nbformat": 4,
diff --git a/tutorials/W2D4_Macrolearning/W2D4_Tutorial1.ipynb b/tutorials/W2D4_Macrolearning/W2D4_Tutorial1.ipynb
index 9d074b3c5..c38f39d37 100644
--- a/tutorials/W2D4_Macrolearning/W2D4_Tutorial1.ipynb
+++ b/tutorials/W2D4_Macrolearning/W2D4_Tutorial1.ipynb
@@ -24,9 +24,9 @@
"\n",
"__Content creators:__ Hlib Solodzhuk, Ximeng Mao, Grace Lindsay\n",
"\n",
- "__Content reviewers:__ Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Hlib Solodzhuk, Ximeng Mao, Samuele Bolotta, Grace Lindsay\n",
+ "__Content reviewers:__ Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Hlib Solodzhuk, Ximeng Mao, Samuele Bolotta, Grace Lindsay, Alex Murphy\n",
"\n",
- "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk\n"
+ "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk, Alex Murphy\n"
]
},
{
@@ -44,13 +44,13 @@
"\n",
"In this tutorial, we will explore the problems that arise from *distribution shifts*. Distribution shifts occur when the testing data distribution deviates from the training data distribution; that is, when a model is evaluated on data that somehow differs from what it was trained on.\n",
"\n",
- "There are many ways that testing data can differ from training data. Two broad categories of distribution shifts are: **covariate shift** and **concept shift**.\n",
+ "There are many ways that testing data can differ from training data. Two broad categories of distribution shifts are: **covariate shift** and **concept shift**. While we expect most of you to be familiar with the term *concept*, the term *covariate* is used in different ways in different fields and we want to clarify the specific usage we will be using in this tutorial. Unlike in the world of statistics, where a covariate might be a confounding variable, or specifically a continuous predictor feature, when talking about distribution shifts in machine learning, the term *covariate* is synonymous with any input **feature** (regardless of its causal status towards predicting the desired output of the model).\n",
"\n",
- "In covariate shift, the distribution of input features changes. For example, consider a dog/cat classification task where the model was trained to differentiate between real photos of pets while the testing dataset consists entirely of cartoon characters.\n",
+ "In covariate shift, the distribution of input features, $P(X)$ changes. For example, consider a dog/cat classification task where the model was trained to differentiate these classes using real photos of pets, while the testing dataset represents the same dog/cat classification task, but using images of cartoon characters exclusively.\n",
"\n",
- "Concept shift, as its name suggests, involves a conceptual change in the relationship between features and the desired output. For example, a recommendation system may learn a user's preferences, but then those preferences change.\n",
+ "Concept shift, as its name suggests, involves a conceptual change in the relationship between features and the desired output, $P(Y|X)$. For example, a recommendation system may learn a user's preferences, but then those preferences change. It's the mapping from features to outputs that is shifting, while the distribution of the inputs, $P(X)$ remains the same.\n",
"\n",
- "We will explore both types of shifts using a simple function that represents the relationship between the day of the year and the price of fruits in the local market!"
+ "We will explore both types of shifts using a simple function that represents the relationship between the day of the year and the price of fruits in a local market!"
]
},
{
@@ -325,7 +325,7 @@
"\n",
"# Section 1: Covariate shift\n",
"\n",
- "In this section, we are going to discuss the case of covariate shift in distribution - when the distribution of features (usually denoted by $\\mathbf{x}$) differs in the training and testing data."
+ "In this section, we are going to discuss covariate shifts (a major type of distribution shift). Covariate shift arises when the distribution of features, $P(X)$, differs between the training and testing data. This could be when the style of input is different (e.g. real photos vs cartoon illustrations). Another example is when looking at house price predictions. If you train on data from rural areas and test on data from urban areas, the distributions of inputs are not consistent (houses might be small and high-priced in urban areas that are in an excellent location, but no such examples of small houses being high-priced will exist in the rural data)."
]
},
{
@@ -342,9 +342,9 @@
"\n",
"$$f(x) = A x^{2} + B sin(\\pi x + \\phi) + C$$\n",
"\n",
- "This equation suggests quadratic annual behavior (with summer months being at the bottom of the parabola) as well as bi-weekly seasonality introduced by the $sin(\\pi x)$ term (with top values being the days where there is supply of fresh fruits to the market). Variables $A, B, \\phi \\:\\: \\text{and} \\:\\: C$ allow us to tune the day-price relation in different scenarios (for example, we will observe the role of $\\phi$ in the second section of the tutorial). For this particular case, let us set $A = 0.005$, $B = 0.1$, $\\phi = 0$ and $C = 1$.\n",
+ "This equation suggests quadratic annual behavior (with summer months being at the bottom of the parabola) as well as bi-weekly seasonality introduced by the $sin(\\pi x)$ term (with top values being the days where there is supply of fresh fruits to the market). Variables $A, B, \\phi \\:\\: \\text{and} \\:\\: C$ allow us to tune the day-price relation in different scenarios. We will observe the role of $\\phi$ in the second section of the tutorial. For this particular case, let us set $A = 0.005$, $B = 0.1$, $\\phi = 0$ and $C = 1$.\n",
"\n",
- "At first, let's take a look at the data - we will plot it.\n"
+ "Let's first take a look at the data by plotting it so we can orient ourselves to the input data used in this task.\n"
]
},
{
@@ -752,9 +752,9 @@
"\n",
"# Section 2: Concept shift\n",
"\n",
- "Estimated time to reach this point from the start of the tutorial: 15 minutes\n",
+ "*Estimated time to reach this point from the start of the tutorial: 15 minutes*\n",
"\n",
- "In this section, we are going to explore another case of distribution shift, which is different in nature from covariate shift: concept shift."
+ "In this section, we are going to explore another case of distribution shift, which is different in nature from covariate shift: concept shift. This is when the distribution of the inputs, $P(X)$ remains stable, but the mapping from features to predictions, $P(Y|X)$, differs between training and testing data distributions."
]
},
{
@@ -773,7 +773,7 @@
"\n",
"Answer
\n",
"
\n",
- "Yes, indeed, it involves a sinusoidal phase shift — we only need to change the $\\phi$ value.\n",
+ "Yes, indeed, it involves a sinusoidal phase shift — we only need to change the phi value.\n",
" \n",
"\n",
"Let's take a look at how well the model generalizes to this unexpected change as well."
@@ -849,7 +849,7 @@
"execution": {}
},
"source": [
- "Indeed, the model's predictions are capturing the original phase, not the phase-shifted function. Well, it's somewhat expected: we fixed values of features (in this case, week number), trained at first on one set of output values (prices), and then changed the outputs to measure the model's performance. It's obvious that the model will perform badly. Still, it's important to notice the effect of concept shift and this translation between conceptual effect and its impact on modeling. "
+ "The model's predictions are capturing the original phase, not the phase-shifted function. Well, it's somewhat expected: we fixed values of features (in this case, week number), trained at first on one set of output values (prices), and then changed the outputs to measure the model's performance. It's obvious that the model will perform badly. Still, it's important to notice the effect of concept shift and this translation between conceptual effect and its impact on modeling."
]
},
{
@@ -937,7 +937,20 @@
"Here's what we learned:\n",
"\n",
"1. Covariate and concept shifts are two different types of data distribution shifts.\n",
- "2. Distribution shifts negatively impact model performance.\n",
+ "2. Distribution shifts negatively impact model performance."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "# The Big Picture\n",
+ "\n",
+ "Distribution shifts are a huge issue in modern ML systems. Awareness of the fundamental idea behind how these shifts can happen is increasingly important, the more that these systems take on roles that impact systems that we interact with in our daily lives. During COVID-19, product replenishment systems failed spectacularly because there was an underlying shift (panic buying of certain items) that the model did not expect and this caused a huge problem for systems that relied on statistical predictions in the company pipeline.\n",
+ "\n",
+ "In NeuroAI, the distribution shifts can happen in numerous places. For example, training a model on sets of neurons that belong to different brain areas or perhaps the same distribution of neurons that differ due to a confounding third factor, that renders the training and test distribution of features to be different. Awareness of potential distribution shifts is incredibly important and should be something systems are continuosly monitoring. NeuroAI currently lags behind in its adoption of evaluations that monitor these kinds of issues. Our goal is to bring this attention more to the forefront so that in your careers as NeuroAI practioners, you are aware of the necessary factors that can affect the models you build.\n",
"\n",
"In the next tutorials, we are going to address the question of generalization—what are the techniques and methods to deal with poor generalization performance due to distribution shifts."
]
@@ -971,7 +984,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.9.19"
+ "version": "3.9.22"
}
},
"nbformat": 4,
diff --git a/tutorials/W2D4_Macrolearning/W2D4_Tutorial2.ipynb b/tutorials/W2D4_Macrolearning/W2D4_Tutorial2.ipynb
index 560ae914f..78d590e83 100644
--- a/tutorials/W2D4_Macrolearning/W2D4_Tutorial2.ipynb
+++ b/tutorials/W2D4_Macrolearning/W2D4_Tutorial2.ipynb
@@ -25,9 +25,9 @@
"\n",
"__Content creators:__ Hlib Solodzhuk, Ximeng Mao, Grace Lindsay\n",
"\n",
- "__Content reviewers:__ Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Hlib Solodzhuk, Ximeng Mao, Samuele Bolotta, Grace Lindsay\n",
+ "__Content reviewers:__ Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Hlib Solodzhuk, Ximeng Mao, Samuele Bolotta, Grace Lindsay, Alex Murphy\n",
"\n",
- "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk\n"
+ "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk, Alex Murphy\n"
]
},
{
@@ -43,7 +43,7 @@
"\n",
"*Estimated timing of tutorial: 25 minutes*\n",
"\n",
- "In this tutorial, you will observe how further training on new data or tasks causes forgetting of past tasks. You will also explore how different learning schedules impact performance."
+ "In this tutorial, we wil discover how further training on new data or tasks causes forgetting of past tasks. This is like the idea of learning a new idea by replacing an old one. This is a huge issue with the current AI models and deep neural networks and a very active area of research in the ML community. We are going to explore the problem in more detail and investigate some further issues connected to this idea, for example, how different learning schedules impact performance."
]
},
{
@@ -305,9 +305,9 @@
"source": [
"---\n",
"\n",
- "# Section 1: Catastrophic forgetting\n",
+ "# Section 1: Catastrophic Forgetting\n",
"\n",
- "In this section, we will discuss the concept of continual learning and argue that training on new data does not guarantee that the model will remember the relationships on which it was trained earlier. \n",
+ "In this section, we will discuss the concept of continual learning and argue that training on new data does not guarantee that the model will remember how to handle the tasks it was trained on earlier. First it's important to state that there are multiple ways to train some ML models. Often a model will take a training dataset and run a learning algorithm over it in a few steps and derive a solution resulting in a trained model. This is what happens in analytical solutions for linear regression, in Support Vector Machine training etc. In other cases, models can learn by being iteratively updated with single data points (or batches). This type of model can support **online learning** and it is specifically these models that have the potential to undergo catastrophic forgetting. Modern deep neural networks are all online learners, as are methods that are trained with variants of gradient descent. The problems of continual learning only exist for models that can be paused and then resumed with new training data, which has the potential to interact with a previous model that was also trained on prior data.\n",
"\n",
"- Catastrophic forgetting occurs when a neural network, or any machine learning model, forgets the information it previously learned upon learning new data. This is particularly problematic in scenarios where a model needs to perform well across multiple types of data or tasks that evolve over time.\n",
"\n",
@@ -322,7 +322,9 @@
"source": [
"## Coding Exercise 1: Fitting new data\n",
"\n",
- "Let's assume now that we want our model to predict not only the summer prices but also the autumn ones. We have already trained the MLP to predict summer months effectively but observed that it performs poorly during the autumn period. Let's try to make the model learn new information about the prices and see whether it can remember both. First, we will need to retrain the model for this tutorial on summer days."
+ "We're back at the fruit stall. Recall the modelling problem from Tutorial 1. Let's assume now that we want our model to predict not only the summer prices but also the autumn ones. We have already trained the MLP to predict summer months effectively but observed that it performs poorly during the autumn period. Let's try to make the model learn new information about the prices and see whether it can remember both.\n",
+ "\n",
+ "First, we will need to retrain the model for this tutorial on summer days."
]
},
{
@@ -523,7 +525,9 @@
"\n",
"In sequential joint training, epochs of each data type are alternated. So, for example, the first epoch will be the $K$ examples from summer data, and then the second will be the $K$ examples from autumn data, then the summer data again, then autumn again, and so on.\n",
"\n",
- "Please complete the partial fits for the corresponding data to implement sequential joint training in the coding exercise. We are using the `partial_fit` function to control the number of times the model \"meets\" data. With every new iteration, the model isn't a new one; it is partially fitted for all previous epochs."
+ "Please complete the partial fits for the corresponding data to implement sequential joint training in the coding exercise. We are using the `partial_fit` function to specify individual updates to the model. The `scikit-learn` library typically exposes a `fit` API whose goal is to specify full training on a dataset. However, if control over sequential training is desired, where you want to specify individual batches of data of a certain type, then models that expose a `partial_fit` function are great ways to accomplish this. In the language of training deep learning models, `fit` is similar to `train_model()` while `partial_fit` is more similar to `update_batch()`.\n",
+ "\n",
+ "Every call to `partial_fit` takes the model from the previous call and continually updates the parameters from the previous step, in the same way that in deep neural networks, each batch update builds upon the adjusted network weights from the previous backpropagation step."
]
},
{
@@ -861,6 +865,21 @@
"- [A Comprehensive Survey of Continual Learning: Theory, Method and Application](https://arxiv.org/pdf/2302.00487)\n",
"- [Brain-inspired replay for continual learning with artificial neural networks](https://www.nature.com/articles/s41467-020-17866-2)"
]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "# The Big Picture\n",
+ "\n",
+ "What causes catastrophic forgetting? If we train tasks continually (one after the other) and not in a joint fashion, it implies the overwriting of old knowledge (information) with new knowledge (information). That doesn't seem to happen in biological systems, so is there a lesson we can take from psychology and neuroscience to better handle catastrophic forgetting? Information seems to be distributed across all weights for this ovwerwriting to happen. Large LLM models have developed one solution, the so-called Mixture-of-Experts Model. This is where a routing mechanism decides what sections of a neural network become active for each tasks. Is that a viable solution? These models are gigantic and extremely computationally expensive. We think there is scope to be more brain-like without requiring such vast computational giants.\n",
+ "\n",
+ "If you're interested in learning more, the topics we covered today are also often referred to as the **Stability-Plasticity Dilemma**. A search for that term will certainly bring you to many recent advances in exploring this idea. \n",
+ "\n",
+ "But before you do that, let's first prepare ourselves for the next tutorial on Meta-Learning. See you there!"
+ ]
}
],
"metadata": {
@@ -891,7 +910,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.9.19"
+ "version": "3.9.22"
}
},
"nbformat": 4,
diff --git a/tutorials/W2D4_Macrolearning/W2D4_Tutorial3.ipynb b/tutorials/W2D4_Macrolearning/W2D4_Tutorial3.ipynb
index e5189e801..490c9aaa0 100644
--- a/tutorials/W2D4_Macrolearning/W2D4_Tutorial3.ipynb
+++ b/tutorials/W2D4_Macrolearning/W2D4_Tutorial3.ipynb
@@ -25,9 +25,9 @@
"\n",
"__Content creators:__ Hlib Solodzhuk, Ximeng Mao, Grace Lindsay\n",
"\n",
- "__Content reviewers:__ Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Hlib Solodzhuk, Ximeng Mao, Samuele Bolotta, Grace Lindsay\n",
+ "__Content reviewers:__ Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Hlib Solodzhuk, Ximeng Mao, Samuele Bolotta, Grace Lindsay, Alex Murphy\n",
"\n",
- "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk"
+ "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk, Alex Murphy"
]
},
{
@@ -378,7 +378,7 @@
" \"\"\"Load weights of the model from file or as defined architecture.\n",
" \"\"\"\n",
" if isinstance(model, str):\n",
- " return torch.load(model)\n",
+ " return torch.load(model, weights_only=False)\n",
" return model\n",
"\n",
" def deep_clone_model(self, model):\n",
@@ -650,7 +650,7 @@
"\n",
"In this section, we introduce the meta-learning approach. We will discuss its main components and then focus on defining the task before proceeding to training.\n",
"\n",
- "The idea behind meta-learning is that we can \"learn to learn\". Meta-learning is a phrase that is used to describe a lot of different approaches to making more flexible and adaptable systems. The MAML approach is essentially finding good initialization weights, and because those initial weights are learned based on the task set, the model is technically \"learning to find a good place to learn from\". \"Learning to learn\" is a shorter, snappier description that can encompass many different meta-learning approaches."
+ "The idea behind meta-learning is that we can *learn to learn*. Meta-learning is a phrase that is used to describe a lot of different approaches to making more flexible and adaptable systems. The MAML approach is essentially finding good initialization weights, and because those initial weights are learned based on the task set, the model is technically \"learning to find a good place to learn from\". *Learning to learn* is a shorter, snappier description that can encompass many different meta-learning approaches."
]
},
{
@@ -669,9 +669,10 @@
"\n",
"$$f(x) = A x^{2} + B sin(\\pi x + \\phi) + C$$\n",
"\n",
+ "Please see Tutorial 1 if you are unsure about the role of these parameters as that is where they are described in detail.\n",
"Thus, a particular task is a tuple of assigned values. For example, $A = 0.005$, $B = 0.5$, $\\phi = 0$ and $C = 0$.\n",
"\n",
- "You will implement `FruitSupplyDataset`, which enables the generation of a particular instance of the task. We will use it as an extension of `torch.utils.data.Dataset` to load data during training."
+ "You will implement `FruitSupplyDataset`, which enables the generation of a particular instance of the task. This is an extension (subclass) of `torch.utils.data.Dataset` to load data during training. PyTorch `Dataset` objects can be subclassed and its behavior customized as long as you define the initialiser, `__len__` and `__getitem__` methods."
]
},
{
@@ -1269,9 +1270,9 @@
"execution": {}
},
"source": [
- "To achieve the required level of performance, set `num_epochs` in the cell below to 100000, which would take the model at least one hour to train. Thus, at the start of the tutorial, we presented you with the already trained model `SummerAutumnModel.pt`. Ensure you can see it in the same folder as your tutorial notebook.\n",
+ "To achieve the required level of performance, set `num_epochs` in the cell below to 100,000, which would take the model at least one hour to train. Thus, at the start of the tutorial, we presented you with the already trained model `SummerAutumnModel.pt`. Ensure you can see it in the same folder as your tutorial notebook.\n",
"\n",
- "Below, we perform training for 1000 epochs so that you can still run your first meta-learning experiment and verify the correctness of the implementation!"
+ "Below, we perform training for 1,000 epochs so that you can still run your first meta-learning experiment and verify the correctness of the implementation!"
]
},
{
@@ -1426,7 +1427,7 @@
"source": [
"## Coding Exercise 3: Fine-tuning model\n",
"\n",
- "Now, we would like to evaluate the learning ability of the meta-learned model by fine-tuning it to a particular task. For that, we clone the model parameters and perform a couple of gradient descent steps on a small amount of data for two specific tasks:\n",
+ "Now, we would like to evaluate the learning ability of the meta-learned model by fine-tuning it to a particular task. For that, we clone (copy) the model parameters and perform a couple of gradient descent steps on a small amount of data for two specific tasks:\n",
"\n",
"$$A = 0.005, B = 0.1, \\phi = 0, C = 1$$\n",
"$$A = -0.005, B = 0.1, \\phi = 0, C = 4$$\n",
@@ -1709,7 +1710,8 @@
},
"source": [
"---\n",
- "# Summary\n",
+ "\n",
+ "# The Big Picture\n",
"\n",
"*Estimated timing of tutorial: 50 minutes*\n",
"\n",
@@ -1717,7 +1719,9 @@
"\n",
"1. Meta-learning aims to create a model that can quickly learn any task from a distribution.\n",
"\n",
- "2. To achieve this, it uses inner and outer learning loops to find base parameters from which a small number of gradient steps can lead to good performance on any task."
+ "2. To achieve this, it uses inner and outer learning loops to find base parameters from which a small number of gradient steps can lead to good performance on any task.\n",
+ "\n",
+ "Please take some time to reflect on the inner workings of this algorithm and how this aims to solve the problems we've highlighted over the previous tutorials. What is it specifically about the distinction between task-specific and base weights that decouples the effects that previously might have led to catastrophic forgetting? There are numerous ways you can think about this, but we hope you use time in your tutorial groups to exchange ideas and compare your own thoughts. Developing these intuitions is a key skill we would like you to develop as budding NeuroAI researchers!"
]
}
],
@@ -1749,7 +1753,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.9.19"
+ "version": "3.9.22"
}
},
"nbformat": 4,
diff --git a/tutorials/W2D4_Macrolearning/W2D4_Tutorial4.ipynb b/tutorials/W2D4_Macrolearning/W2D4_Tutorial4.ipynb
index 3283804d7..c36c131f1 100644
--- a/tutorials/W2D4_Macrolearning/W2D4_Tutorial4.ipynb
+++ b/tutorials/W2D4_Macrolearning/W2D4_Tutorial4.ipynb
@@ -25,9 +25,9 @@
"\n",
"__Content creators:__ Hlib Solodzhuk, Ximeng Mao, Grace Lindsay\n",
"\n",
- "__Content reviewers:__ Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Hlib Solodzhuk, Ximeng Mao, Samuele Bolotta, Grace Lindsay\n",
+ "__Content reviewers:__ Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Hlib Solodzhuk, Ximeng Mao, Samuele Bolotta, Grace Lindsay, Alex Murphy\n",
"\n",
- "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk\n"
+ "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk, Alex Murphy\n"
]
},
{
@@ -218,6 +218,41 @@
" plt.show()"
]
},
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Set device (GPU or CPU)\n",
+ "\n",
+ "def set_device():\n",
+ " \"\"\"\n",
+ " Determines and sets the computational device for PyTorch operations based on the availability of a CUDA-capable GPU.\n",
+ "\n",
+ " Outputs:\n",
+ " - device (str): The device that PyTorch will use for computations ('cuda' or 'cpu'). This string can be directly used\n",
+ " in PyTorch operations to specify the device.\n",
+ " \"\"\"\n",
+ "\n",
+ " device = \"cuda\" if torch.cuda.is_available() else \"cpu\"\n",
+ " if device != \"cuda\":\n",
+ " print(\"GPU is not enabled in this notebook. \\n\"\n",
+ " \"If you want to enable it, in the menu under `Runtime` -> \\n\"\n",
+ " \"`Hardware accelerator.` and select `GPU` from the dropdown menu\")\n",
+ " else:\n",
+ " print(\"GPU is enabled in this notebook. \\n\"\n",
+ " \"If you want to disable it, in the menu under `Runtime` -> \\n\"\n",
+ " \"`Hardware accelerator.` and select `None` from the dropdown menu\")\n",
+ "\n",
+ " return device\n",
+ "\n",
+ "device = set_device()"
+ ]
+ },
{
"cell_type": "code",
"execution_count": null,
@@ -418,41 +453,6 @@
" fid.write(r.content) # Write the downloaded content to a file"
]
},
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Set device (GPU or CPU)\n",
- "\n",
- "def set_device():\n",
- " \"\"\"\n",
- " Determines and sets the computational device for PyTorch operations based on the availability of a CUDA-capable GPU.\n",
- "\n",
- " Outputs:\n",
- " - device (str): The device that PyTorch will use for computations ('cuda' or 'cpu'). This string can be directly used\n",
- " in PyTorch operations to specify the device.\n",
- " \"\"\"\n",
- "\n",
- " device = \"cuda\" if torch.cuda.is_available() else \"cpu\"\n",
- " if device != \"cuda\":\n",
- " print(\"GPU is not enabled in this notebook. \\n\"\n",
- " \"If you want to enable it, in the menu under `Runtime` -> \\n\"\n",
- " \"`Hardware accelerator.` and select `GPU` from the dropdown menu\")\n",
- " else:\n",
- " print(\"GPU is enabled in this notebook. \\n\"\n",
- " \"If you want to disable it, in the menu under `Runtime` -> \\n\"\n",
- " \"`Hardware accelerator.` and select `None` from the dropdown menu\")\n",
- "\n",
- " return device\n",
- "\n",
- "device = set_device()"
- ]
- },
{
"cell_type": "code",
"execution_count": null,
@@ -686,7 +686,7 @@
"execution": {}
},
"source": [
- "Any RL system consists of an agent who tries to succeed in a task by observing the state of the environment, executing an action, and receiving the outcome (reward).\n",
+ "Any RL system consists of an agent who tries to succeed in a task by observing the state of the environment, executing an action, and receiving the outcome (reward) based on its action. The environment is the source of the reward signal in the RL framework.\n",
"\n",
"First, we will define the environment for this task."
]
@@ -768,7 +768,10 @@
"execution": {}
},
"source": [
- "**For now, simply run all the cells in this section without exploring the content. You can come back to look through the code if you have time after completing all the tutorials.**\n",
+ "For now, simply run all the cells in this section without exploring the content. You can come back to look through the code if you have time after completing all the tutorials.\n",
+ "\n",
+ "\n",
+ " (Click to expand)
\n",
"\n",
"The dummy agent's strategy doesn't use object identity, which is key to consistently selecting the right action. Let's see if we can do better than the dummy agent's strategy. After defining the environment, observing the agent's behavior, and implementing such a simple policy, it is the right time to remind ourselves about more sophisticated agent architectures capable of learning the environment's dynamics. For this, we will use the Advantage Actor-Critic (A2C) algorithm.\n",
"\n",
@@ -776,7 +779,9 @@
"\n",
"The architecture of the agent is as follows: it receives the previous state, previous reward, and previously chosen action as input, which is linearly projected to the `hidden_size` (this creates an embedding); then, its core consists of recurrent `LSTM` cells, their number is exactly `hidden_size`. Right after this RNN layer, there are two distinct linear projections: one for the actor (output dimension coincides with the number of actions; for the Harlow experiment, it is 2) and the other for the critic (outputs one value).\n",
"\n",
- "We don't propose an exercise to code for the agent; when you have time, simply go through the cell below to understand the implementation."
+ "We don't propose an exercise to code for the agent; when you have time, simply go through the cell below to understand the implementation. \n",
+ " \n",
+ " "
]
},
{
@@ -1118,7 +1123,7 @@
"execution": {}
},
"source": [
- "## Coding Exercise 1: Agent's Rate to Learn\n",
+ "## Agent's Rate to Learn\n",
"\n",
"As introduced in the video, the Baldwin effect argues that we don't inherit the features/weights that make us good at specific tasks but rather the ability to learn quickly to gain the needed features in the context of the tasks we face during our own lifetime. This way, evolution works like the outer loop in a meta-learning context.\n",
"\n",
@@ -1141,7 +1146,7 @@
"\n",
"At first, we sample a bunch of tasks from the environment (different pairs of objects; line [2]). The crucial concept involved in this algorithm is preserved in line [4], where for each new task, we don't start with updated parameters but with the ones we had before training and evaluating the agent. Then, we perform training for the defined number of gradient steps and evaluate the agent's performance on this same task (we have defined this function in the second section of the tutorial; it basically covers lines [5] - [9]). One task is not enough to evaluate the agent's ability to learn quickly — this is why we sampled a bunch of them, and the general score for the agent is defined as the sum of rewards for all tasks.\n",
"\n",
- "In the coding exercise, you are invited to complete the implementation of the evaluation of a randomly created agent on 10 tasks (thus, the maximum score that can be obtained is: 10 (number of tasks) x 20 (number of evaluation trials per task) = 200). In the next section of the tutorial, we will provide the evolutionary framework in which we are going to learn \"base\" or \"starting\" weights.\n",
+ "In the cell below, which we have written for you, you can see the implementation of the evaluation of a randomly created agent on 10 tasks (thus, the maximum score that can be obtained is: 10 (number of tasks) x 20 (number of evaluation trials per task) = 200). In the next section of the tutorial, we will provide the evolutionary framework in which we are going to learn \"base\" or \"starting\" weights.\n",
"\n",
"Observe the box plot of the scores as well as their sum."
]
@@ -1154,58 +1159,6 @@
},
"outputs": [],
"source": [
- "def evaluate_individual(env, agent, optimizer_func, num_tasks = 10, num_gradient_steps = 25, num_trials = 6, num_evaluation_trials = 20):\n",
- " \"\"\"Training and evaluation for agent in Harlow experiment environment for the bunch of tasks (thus measuring overall potential for agent's generalization across the tasks).\n",
- " Evaluation goes only after all gradient steps.\n",
- "\n",
- " Inputs:\n",
- " - env (HarlowExperimentEnv): environment.\n",
- " - agent (ActorCritic): particular instance of Actor Critic agent to train.\n",
- " - optimizer_func (torch.Optim): optimizer to use for training.\n",
- " - num_tasks (int, default = 10): number of tasks to evaluate agent on.\n",
- " - num_gradient_steps (int, default = 25): number of gradient steps to perform.\n",
- " - num_trials (int, default = 6): number of times the agent is exposed to the environment per gradient step to be trained .\n",
- " - num_evaluation_trials (int, default = 20): number of times the agent is exposed to the environment to evaluate it (no training happend during this phase).\n",
- "\n",
- " Outputs:\n",
- " - scores (list): list of scores obtained during evaluation on the specific tasks.\n",
- " \"\"\"\n",
- " ###################################################################\n",
- " ## Fill out the following then remove\n",
- " raise NotImplementedError(\"Student exercise: complete evaluation function with Baldwin effect in mind.\")\n",
- " ###################################################################\n",
- " scores = []\n",
- " for _ in range(num_tasks): #lines[2-3]; notice that environment resets inside `train_evaluate_agent`\n",
- " agent_copy = copy.deepcopy(...) #line[4]; remember that we don't want to change agent's parameters!\n",
- " score = train_evaluate_agent(env, ..., optimizer_func, num_gradient_steps, num_trials, num_evaluation_trials)\n",
- " scores.append(score)\n",
- " return np.sum(scores), scores\n",
- "\n",
- "set_seed(42)\n",
- "\n",
- "#define environment\n",
- "env = HarlowExperimentEnv()\n",
- "\n",
- "#define agent and optimizer\n",
- "agent = ActorCritic(hidden_size = 20)\n",
- "optimizer_func = optim.RMSprop\n",
- "\n",
- "#calculate score\n",
- "total_score, scores = evaluate_individual(env, agent, optimizer_func)\n",
- "print(f\"Total score is {total_score}.\")\n",
- "plot_boxplot_scores(scores)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# to_remove solution\n",
- "\n",
"def evaluate_individual(env, agent, optimizer_func, num_tasks = 10, num_gradient_steps = 25, num_trials = 6, num_evaluation_trials = 20):\n",
" \"\"\"Training and evaluation for agent in Harlow experiment environment for the bunch of tasks (thus measuring overall potential for agent's generalization across the tasks).\n",
" Evaluation goes only after all gradient steps.\n",
@@ -1273,11 +1226,13 @@
"execution": {}
},
"source": [
- "## Coding Exercise 2: Genetic Algorithm\n",
+ "## Coding Exercise 1: Genetic Algorithm\n",
+ "\n",
+ "Genetic algorithms (GA) mimic some of the evolutionary processes while generating better and better (= more desired) individuals in the population. At first, we initialize a population that consists of randomly defined agents (so we have a list of `population_size` A2C agents, which will, in the very end, evolve into agents that quickly learn the new task from the Harlow experiment environment).\n",
"\n",
- "Genetic algorithms (GA) mimic some of the evolutionary processes while generating better and better (= more desired) individuals in the population. At first, we initialize a population that consists of randomly defined agents (so we have a list of `population_size` A2C agents, which will, in the very end, evolve into agents that quickly learn the new task from the Harlow experiment environment). Each epoch (which is the classical term for machine learning) is defined as a generation in GA as we generate new individuals in the population. For each generation, we choose top-score individuals from the population (of size `tournament_size`; it should be big enough to preserve diversity and not too big for selecting top-score ones; this is exactly where selection occurs and it is the only such place in the whole algorithm) and then we select a random batch of these high-performing individuals of size `parents_num`. From those, we create offspring of size `new_generation_new_individuals`, which will replace random individuals from the population. Notice that we replace random individuals with new ones without comparing their performance (it is just one of the paradigms in genetic algorithms). We continue running generations until we are happy with the best-fit individual appearing in the population or until we run out of time (reaching the maximum number of generations).\n",
+ "Each epoch (which is the classical term for machine learning) is defined as a generation in GA as we generate new individuals in the population. For each generation, we choose top-score individuals from the population (of size `tournament_size`). The population size should be big enough to preserve diversity and not too big for selecting top-score ones. This is exactly where selection occurs and it is the only such place in the whole algorithm. We then we select a random batch of these high-performing individuals of size `parents_num`. From those, we create offspring of size `new_generation_new_individuals`, which will replace random individuals from the population. Notice that we replace random individuals with new ones without comparing their performance (it is just one of the paradigms in genetic algorithms). We continue running generations until we are happy with the best-fit individual appearing in the population or until we run out of time. We end when we reach the maximum number of generations.\n",
"\n",
- "The funniest part happens when we create offspring—simulating evolutionary processes, we randomly select two parents (two agents), and for each of the layers in their networks, we randomly select which one will go to the child (simulating crossing over), and then we add Gaussian noise to each of the layers (simulating mutation).\n",
+ "The most interesting part happens when we create offspring—simulating evolutionary processes, we randomly select two parents (two agents), and for each of the layers in their networks, we randomly select which one will go to the child (simulating crossing over), and then we add Gaussian noise to each of the layers (simulating mutation).\n",
"\n",
"The following cells consist of 3 functions:\n",
"\n",
@@ -1677,17 +1632,6 @@
"plot_two_boxplot_scores(newbie_scores, experienced_scores)"
]
},
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "## Why biology needs meta-learning\n",
- "\n",
- "If aspects of the environment change over time, previously learned hard-coded strategies might not work anymore. Still, as in the previous tutorial, these changes share similar features across the tasks. The Harlow experiment illustrates that although there is no direct instruction on how to obtain the maximum possible reward, and the environment's state changes with each new pair of objects, the agent is still able to capture the meta-structure of the experiment—the reward is associated with the object, not its relative placement. Only one trial is needed to identify which of the two new objects is rewarded."
- ]
- },
{
"cell_type": "code",
"execution_count": null,
@@ -1791,6 +1735,19 @@
"\n",
"4. This process creates agents that can quickly find the rewarding object in a Harlow experiment."
]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "# The Big Picture\n",
+ "\n",
+ "If aspects of the environment change over time, previously learned hard-coded strategies might not work anymore. Still, as in the previous tutorial, these changes share similar features across the tasks. The Harlow experiment illustrates that although there is no direct instruction on how to obtain the maximum possible reward, and the environment's state changes with each new pair of objects, the agent is still able to capture the meta-structure of the experiment—the reward is associated with the object, not its relative placement. Only one trial is needed to identify which of the two new objects is rewarded.\n",
+ "\n",
+ "Earlier in this tutorial, we instructed you to skip over the implementation and rationale behind the A2C code. If you have some extra time, why not jump back above and give that section a read in full? Either now or later at your own discretion. We just wanted to remind you that further details were given (but we initially asked you to skip over). If anything is unclear at this stage, it could be a good way to fill in some gaps in your knowledge."
+ ]
}
],
"metadata": {
@@ -1821,7 +1778,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.9.19"
+ "version": "3.9.22"
}
},
"nbformat": 4,
diff --git a/tutorials/W2D4_Macrolearning/W2D4_Tutorial5.ipynb b/tutorials/W2D4_Macrolearning/W2D4_Tutorial5.ipynb
index 9657edbf0..2d927f020 100644
--- a/tutorials/W2D4_Macrolearning/W2D4_Tutorial5.ipynb
+++ b/tutorials/W2D4_Macrolearning/W2D4_Tutorial5.ipynb
@@ -16,7 +16,7 @@
"execution": {}
},
"source": [
- "# Tutorial 5: Replay\n",
+ "# (Bonus) Tutorial 5: Replay\n",
"\n",
"**Week 2, Day 4: Macro-Learning**\n",
"\n",
@@ -24,9 +24,9 @@
"\n",
"__Content creators:__ Hlib Solodzhuk, Ximeng Mao, Grace Lindsay\n",
"\n",
- "__Content reviewers:__ Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Hlib Solodzhuk, Ximeng Mao, Grace Lindsay\n",
+ "__Content reviewers:__ Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Hlib Solodzhuk, Ximeng Mao, Grace Lindsay, Alex Murphy\n",
"\n",
- "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk\n"
+ "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk, Alex Murphy\n"
]
},
{
@@ -42,7 +42,9 @@
"\n",
"*Estimated timing of tutorial: 40 minutes*\n",
"\n",
- "In this tutorial, you will discover what replay is and how it helps with continual learning."
+ "Replay in reinforcement learning (RL) refers to the process where agents revisit and learn from past experiences stored in memory, rather than solely from new interactions with their environment. This mirrors how mammals, particularly during sleep, reactivate neural patterns from recent experiences to consolidate memories and extract generalizable patterns. In artificial RL systems, *experience replay* enables more efficient learning by breaking temporal correlations between consecutive experiences and allowing multiple learning updates from single experiences (runs of a series of steps in an RL experiment). This biologically inspired approach has proven crucial for deep RL algorithms like DQN, demonstrating how computational models can both draw from and inform our understanding of biological intelligence.\n",
+ "\n",
+ "In this tutorial, you will discover what replay is and how it helps to solve the continual learning problem we've been investigating over today's tutorials."
]
},
{
@@ -575,9 +577,9 @@
"source": [
"---\n",
"\n",
- "# Section 1: Changing Environment\n",
+ "# Section 1: A Changing Environment\n",
"\n",
- "As mentioned in the video, to study replay, we need to use a slightly different task inspired by the Harlow task, which creates an incentive to remember past data. In this section, we will introduce this new task environment, which replicates the game you played."
+ "As mentioned in the video, to study replay, we need to use a slightly different task inspired by the Harlow task, which creates an incentive to remember past data. In this section, we will introduce this new task environment, which is modelled in a similar way to the game you played in Section 0, above."
]
},
{
@@ -590,7 +592,7 @@
"\n",
"For this tutorial, each state will be represented by its color (via its RGB values; thus, it is a vector of 3 values), and each color is associated with a stable reward that remains unchanged over time (the rewards will correspond to the position of the color in the rainbow).\n",
"\n",
- "While the reward associated with each color does not change over time, the colors presented to the agent will change. Specifically, on each trial, the agent is presented with two colors and should choose the one associated with a higher reward. Initially (in 'mode 1'), colors will be chosen from a set of 3 possible colors. Over time, one of these colors will be replaced by another, creating a different set of three possible colors ('mode 2'). This constitutes a covariate distribution shift and may cause the agent to forget the reward associated with the dropped color."
+ "While the reward associated with each color does not change over time, the colors presented to the agent will change. Specifically, on each trial, the agent is presented with two colors and should choose the one associated with a higher reward. Initially (in 'mode 1'), colors will be chosen from a set of 3 possible colors. Over time, one of these colors will be replaced by another, creating a different set of three possible colors ('mode 2'). This constitutes a distribution shift (specifically: **covariate shift**, which I'm sure you all could instantly recognize!) This may cause the agent to forget the reward associated with the color that was replaced. This would be an instance of catastrophic forgetting in our continual learning setting."
]
},
{
@@ -726,7 +728,7 @@
"source": [
"---\n",
"\n",
- "# Section 2: A2C Agent in Changing Environment\n",
+ "# Section 2: A2C Agent in a Changing Environment\n",
"\n",
"*Estimated timing to here from start of tutorial: 10 minutes*\n",
"\n",
@@ -1004,7 +1006,28 @@
"source": [
"No specific patterns here; the only notable observation (which is also expected) is that whenever colors are close in their rewards, the agent makes more mistakes with those.\n",
"\n",
- "Notice that the blue color is missing, as it is indeed excluded from the first mode. Let us evaluate the agent in the second mode."
+ "Notice that the blue color is missing, as it is indeed excluded from the first mode, as indicated in the code above (repeated here for clarity):\n",
+ "\n",
+ "```python\n",
+ "first_mode = [\"red\", \"yellow\", \"green\"]\n",
+ "second_mode = [\"red\", \"green\", \"blue\"]\n",
+ "```\n",
+ "\n",
+ "Also, notice that the color red was never chosen, as it was never a maximum-reward color. Recall the reward values for the specific colors (again, reproducted below for clarity).\n",
+ "\n",
+ "```python\n",
+ "color_names_rewards = {\n",
+ " \"red\": 1,\n",
+ " \"yellow\": 2,\n",
+ " \"green\": 3,\n",
+ " \"blue\": 4\n",
+ "}\n",
+ "```\n",
+ "\n",
+ "This is why, in the confusion matrix, we never see the color red being picked. In both modes, red always exists in company with a color that has a higher reward.\n",
+ "\n",
+ "\n",
+ "With the details of the confusion matrix hopefully a bit clearer, let us evaluate the agent in the second mode."
]
},
{
@@ -1177,7 +1200,7 @@
"\n",
"*Estimated timing to here from start of tutorial: 25 minutes*\n",
"\n",
- "This section discusses the underlying biological reasoning behind the replay buffer and proposes its code implementation."
+ "This section discusses the underlying biological inspiration behind the replay buffer and proposes a way that in can be implemented in code and used to tackle the issue of catastrophic forgetting during continual learning."
]
},
{
@@ -1554,6 +1577,19 @@
"- Reinforcement learning also suffers from forgetting after learning a new distribution.\n",
"- Replay is a biologically-inspired way to learn from memories of past actions and rewards, thus preventing forgetting."
]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "# The Big Picture\n",
+ "\n",
+ "Replay mechanisms serve as a foundational bridge between past and present knowledge in both biological and artificial learning systems, enabling the critical ability to learn continuously without catastrophically forgetting previous skills. By selectively revisiting and consolidating important experiences, replay helps systems extract generalizable patterns that extend beyond specific tasks or contexts. In biological systems, hippocampal replay during sleep and rest periods allows the brain to transfer episodic memories to neocortical regions where they can inform future behavior across varied situations. Similarly, in artificial systems, experience replay buffers and generative replay techniques significantly improve an agent's ability to transfer knowledge across domains and protect against overfitting to recent experiences.\n",
+ "\n",
+ "We hope that you have found today's tutorials on Macrolearning insightful. There is a lot of material we covered today and we're almost at the end of the course! Tomorrow, our final day of content, will introduce some exciting concepts that are still unsolved and so its appropriately named \"Mysteries\". We will look into more speculative attempts to tackle some of the larger / grander outstanding questions in NeuroAI."
+ ]
}
],
"metadata": {
@@ -1584,7 +1620,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.9.19"
+ "version": "3.9.22"
}
},
"nbformat": 4,
diff --git a/tutorials/W2D4_Macrolearning/instructor/W2D4_Intro.ipynb b/tutorials/W2D4_Macrolearning/instructor/W2D4_Intro.ipynb
index 7ed56f51f..e5deb386c 100644
--- a/tutorials/W2D4_Macrolearning/instructor/W2D4_Intro.ipynb
+++ b/tutorials/W2D4_Macrolearning/instructor/W2D4_Intro.ipynb
@@ -49,6 +49,17 @@
"feedback_prefix = \"W2D4_Intro\""
]
},
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "# Macrolearning\n",
+ "\n",
+ "Over the last two weeks in this NeuroAI course, we've focused on numerous aspects of learning mechanisms, inductive biases and how generalization is implemented as a fundamental property of successful learning systems. Back in Day 2 we looked at the topic of \"Comparing Tasks\" and Leila Wehbe introduced the idea of learning at multiple temporal scales. This idea was explored fairly lightly back then, but today we're going to go much deeper into this idea of learning of a macro-level of time and in a Reinforcement Learning framework. What does it mean about learning across the scale of biological evolution and at the species level? That's what today is all about. We hope you enjoy this fascinating topic!"
+ ]
+ },
{
"cell_type": "markdown",
"metadata": {
@@ -57,7 +68,7 @@
"source": [
"## Prerequisites\n",
"\n",
- "For this day, it would be beneficial to have prior experience working with the `pytorch` modeling package, as the last tutorials are going to be concentrated on defining architecture and training rules using this framework. For Tutorials 4 & 5, you might find yourself more comfortable if you are familiar with the reinforcement learning paradigm and with the Actor-Critic model, in particular. Actually, Tutorial 4 will elaborate on the agent already introduced previously in the last tutorial of Day 2, completing the discussion of meta-learning."
+ "For this day, it would be beneficial to have prior experience working with the `pytorch` modeling package, as the last tutorials are going to be concentrated on defining architecture and training rules using this framework. For Tutorials 4 & 5, you might find yourself more comfortable if you are familiar with the reinforcement learning paradigm and with the Actor-Critic model, in particular. Actually, Tutorial 4 will elaborate on the agent already introduced previously in the last tutorial of Day 2, completing the discussion of meta-learning. It might also be useful to revisit the recording in Tutorial 3 of Day 2, specifically related to the idea of Partially-Observable Markov Decision Processes (POMDPs)."
]
},
{
@@ -206,7 +217,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.9.19"
+ "version": "3.9.22"
}
},
"nbformat": 4,
diff --git a/tutorials/W2D4_Macrolearning/instructor/W2D4_Tutorial1.ipynb b/tutorials/W2D4_Macrolearning/instructor/W2D4_Tutorial1.ipynb
index a833834fc..370066489 100644
--- a/tutorials/W2D4_Macrolearning/instructor/W2D4_Tutorial1.ipynb
+++ b/tutorials/W2D4_Macrolearning/instructor/W2D4_Tutorial1.ipynb
@@ -24,9 +24,9 @@
"\n",
"__Content creators:__ Hlib Solodzhuk, Ximeng Mao, Grace Lindsay\n",
"\n",
- "__Content reviewers:__ Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Hlib Solodzhuk, Ximeng Mao, Samuele Bolotta, Grace Lindsay\n",
+ "__Content reviewers:__ Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Hlib Solodzhuk, Ximeng Mao, Samuele Bolotta, Grace Lindsay, Alex Murphy\n",
"\n",
- "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk\n"
+ "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk, Alex Murphy\n"
]
},
{
@@ -44,13 +44,13 @@
"\n",
"In this tutorial, we will explore the problems that arise from *distribution shifts*. Distribution shifts occur when the testing data distribution deviates from the training data distribution; that is, when a model is evaluated on data that somehow differs from what it was trained on.\n",
"\n",
- "There are many ways that testing data can differ from training data. Two broad categories of distribution shifts are: **covariate shift** and **concept shift**.\n",
+ "There are many ways that testing data can differ from training data. Two broad categories of distribution shifts are: **covariate shift** and **concept shift**. While we expect most of you to be familiar with the term *concept*, the term *covariate* is used in different ways in different fields and we want to clarify the specific usage we will be using in this tutorial. Unlike in the world of statistics, where a covariate might be a confounding variable, or specifically a continuous predictor feature, when talking about distribution shifts in machine learning, the term *covariate* is synonymous with any input **feature** (regardless of its causal status towards predicting the desired output of the model).\n",
"\n",
- "In covariate shift, the distribution of input features changes. For example, consider a dog/cat classification task where the model was trained to differentiate between real photos of pets while the testing dataset consists entirely of cartoon characters.\n",
+ "In covariate shift, the distribution of input features, $P(X)$ changes. For example, consider a dog/cat classification task where the model was trained to differentiate these classes using real photos of pets, while the testing dataset represents the same dog/cat classification task, but using images of cartoon characters exclusively.\n",
"\n",
- "Concept shift, as its name suggests, involves a conceptual change in the relationship between features and the desired output. For example, a recommendation system may learn a user's preferences, but then those preferences change.\n",
+ "Concept shift, as its name suggests, involves a conceptual change in the relationship between features and the desired output, $P(Y|X)$. For example, a recommendation system may learn a user's preferences, but then those preferences change. It's the mapping from features to outputs that is shifting, while the distribution of the inputs, $P(X)$ remains the same.\n",
"\n",
- "We will explore both types of shifts using a simple function that represents the relationship between the day of the year and the price of fruits in the local market!"
+ "We will explore both types of shifts using a simple function that represents the relationship between the day of the year and the price of fruits in a local market!"
]
},
{
@@ -325,7 +325,7 @@
"\n",
"# Section 1: Covariate shift\n",
"\n",
- "In this section, we are going to discuss the case of covariate shift in distribution - when the distribution of features (usually denoted by $\\mathbf{x}$) differs in the training and testing data."
+ "In this section, we are going to discuss covariate shifts (a major type of distribution shift). Covariate shift arises when the distribution of features, $P(X)$, differs between the training and testing data. This could be when the style of input is different (e.g. real photos vs cartoon illustrations). Another example is when looking at house price predictions. If you train on data from rural areas and test on data from urban areas, the distributions of inputs are not consistent (houses might be small and high-priced in urban areas that are in an excellent location, but no such examples of small houses being high-priced will exist in the rural data)."
]
},
{
@@ -342,9 +342,9 @@
"\n",
"$$f(x) = A x^{2} + B sin(\\pi x + \\phi) + C$$\n",
"\n",
- "This equation suggests quadratic annual behavior (with summer months being at the bottom of the parabola) as well as bi-weekly seasonality introduced by the $sin(\\pi x)$ term (with top values being the days where there is supply of fresh fruits to the market). Variables $A, B, \\phi \\:\\: \\text{and} \\:\\: C$ allow us to tune the day-price relation in different scenarios (for example, we will observe the role of $\\phi$ in the second section of the tutorial). For this particular case, let us set $A = 0.005$, $B = 0.1$, $\\phi = 0$ and $C = 1$.\n",
+ "This equation suggests quadratic annual behavior (with summer months being at the bottom of the parabola) as well as bi-weekly seasonality introduced by the $sin(\\pi x)$ term (with top values being the days where there is supply of fresh fruits to the market). Variables $A, B, \\phi \\:\\: \\text{and} \\:\\: C$ allow us to tune the day-price relation in different scenarios. We will observe the role of $\\phi$ in the second section of the tutorial. For this particular case, let us set $A = 0.005$, $B = 0.1$, $\\phi = 0$ and $C = 1$.\n",
"\n",
- "At first, let's take a look at the data - we will plot it.\n"
+ "Let's first take a look at the data by plotting it so we can orient ourselves to the input data used in this task.\n"
]
},
{
@@ -756,9 +756,9 @@
"\n",
"# Section 2: Concept shift\n",
"\n",
- "Estimated time to reach this point from the start of the tutorial: 15 minutes\n",
+ "*Estimated time to reach this point from the start of the tutorial: 15 minutes*\n",
"\n",
- "In this section, we are going to explore another case of distribution shift, which is different in nature from covariate shift: concept shift."
+ "In this section, we are going to explore another case of distribution shift, which is different in nature from covariate shift: concept shift. This is when the distribution of the inputs, $P(X)$ remains stable, but the mapping from features to predictions, $P(Y|X)$, differs between training and testing data distributions."
]
},
{
@@ -777,7 +777,7 @@
"\n",
"Answer
\n",
"
\n",
- "Yes, indeed, it involves a sinusoidal phase shift — we only need to change the $\\phi$ value.\n",
+ "Yes, indeed, it involves a sinusoidal phase shift — we only need to change the phi value.\n",
" \n",
"\n",
"Let's take a look at how well the model generalizes to this unexpected change as well."
@@ -853,7 +853,7 @@
"execution": {}
},
"source": [
- "Indeed, the model's predictions are capturing the original phase, not the phase-shifted function. Well, it's somewhat expected: we fixed values of features (in this case, week number), trained at first on one set of output values (prices), and then changed the outputs to measure the model's performance. It's obvious that the model will perform badly. Still, it's important to notice the effect of concept shift and this translation between conceptual effect and its impact on modeling. "
+ "The model's predictions are capturing the original phase, not the phase-shifted function. Well, it's somewhat expected: we fixed values of features (in this case, week number), trained at first on one set of output values (prices), and then changed the outputs to measure the model's performance. It's obvious that the model will perform badly. Still, it's important to notice the effect of concept shift and this translation between conceptual effect and its impact on modeling."
]
},
{
@@ -941,7 +941,20 @@
"Here's what we learned:\n",
"\n",
"1. Covariate and concept shifts are two different types of data distribution shifts.\n",
- "2. Distribution shifts negatively impact model performance.\n",
+ "2. Distribution shifts negatively impact model performance."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "# The Big Picture\n",
+ "\n",
+ "Distribution shifts are a huge issue in modern ML systems. Awareness of the fundamental idea behind how these shifts can happen is increasingly important, the more that these systems take on roles that impact systems that we interact with in our daily lives. During COVID-19, product replenishment systems failed spectacularly because there was an underlying shift (panic buying of certain items) that the model did not expect and this caused a huge problem for systems that relied on statistical predictions in the company pipeline.\n",
+ "\n",
+ "In NeuroAI, the distribution shifts can happen in numerous places. For example, training a model on sets of neurons that belong to different brain areas or perhaps the same distribution of neurons that differ due to a confounding third factor, that renders the training and test distribution of features to be different. Awareness of potential distribution shifts is incredibly important and should be something systems are continuosly monitoring. NeuroAI currently lags behind in its adoption of evaluations that monitor these kinds of issues. Our goal is to bring this attention more to the forefront so that in your careers as NeuroAI practioners, you are aware of the necessary factors that can affect the models you build.\n",
"\n",
"In the next tutorials, we are going to address the question of generalization—what are the techniques and methods to deal with poor generalization performance due to distribution shifts."
]
@@ -975,7 +988,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.9.19"
+ "version": "3.9.22"
}
},
"nbformat": 4,
diff --git a/tutorials/W2D4_Macrolearning/instructor/W2D4_Tutorial2.ipynb b/tutorials/W2D4_Macrolearning/instructor/W2D4_Tutorial2.ipynb
index e2c7f59c0..94817e1b7 100644
--- a/tutorials/W2D4_Macrolearning/instructor/W2D4_Tutorial2.ipynb
+++ b/tutorials/W2D4_Macrolearning/instructor/W2D4_Tutorial2.ipynb
@@ -25,9 +25,9 @@
"\n",
"__Content creators:__ Hlib Solodzhuk, Ximeng Mao, Grace Lindsay\n",
"\n",
- "__Content reviewers:__ Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Hlib Solodzhuk, Ximeng Mao, Samuele Bolotta, Grace Lindsay\n",
+ "__Content reviewers:__ Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Hlib Solodzhuk, Ximeng Mao, Samuele Bolotta, Grace Lindsay, Alex Murphy\n",
"\n",
- "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk\n"
+ "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk, Alex Murphy\n"
]
},
{
@@ -43,7 +43,7 @@
"\n",
"*Estimated timing of tutorial: 25 minutes*\n",
"\n",
- "In this tutorial, you will observe how further training on new data or tasks causes forgetting of past tasks. You will also explore how different learning schedules impact performance."
+ "In this tutorial, we wil discover how further training on new data or tasks causes forgetting of past tasks. This is like the idea of learning a new idea by replacing an old one. This is a huge issue with the current AI models and deep neural networks and a very active area of research in the ML community. We are going to explore the problem in more detail and investigate some further issues connected to this idea, for example, how different learning schedules impact performance."
]
},
{
@@ -305,9 +305,9 @@
"source": [
"---\n",
"\n",
- "# Section 1: Catastrophic forgetting\n",
+ "# Section 1: Catastrophic Forgetting\n",
"\n",
- "In this section, we will discuss the concept of continual learning and argue that training on new data does not guarantee that the model will remember the relationships on which it was trained earlier. \n",
+ "In this section, we will discuss the concept of continual learning and argue that training on new data does not guarantee that the model will remember how to handle the tasks it was trained on earlier. First it's important to state that there are multiple ways to train some ML models. Often a model will take a training dataset and run a learning algorithm over it in a few steps and derive a solution resulting in a trained model. This is what happens in analytical solutions for linear regression, in Support Vector Machine training etc. In other cases, models can learn by being iteratively updated with single data points (or batches). This type of model can support **online learning** and it is specifically these models that have the potential to undergo catastrophic forgetting. Modern deep neural networks are all online learners, as are methods that are trained with variants of gradient descent. The problems of continual learning only exist for models that can be paused and then resumed with new training data, which has the potential to interact with a previous model that was also trained on prior data.\n",
"\n",
"- Catastrophic forgetting occurs when a neural network, or any machine learning model, forgets the information it previously learned upon learning new data. This is particularly problematic in scenarios where a model needs to perform well across multiple types of data or tasks that evolve over time.\n",
"\n",
@@ -322,7 +322,9 @@
"source": [
"## Coding Exercise 1: Fitting new data\n",
"\n",
- "Let's assume now that we want our model to predict not only the summer prices but also the autumn ones. We have already trained the MLP to predict summer months effectively but observed that it performs poorly during the autumn period. Let's try to make the model learn new information about the prices and see whether it can remember both. First, we will need to retrain the model for this tutorial on summer days."
+ "We're back at the fruit stall. Recall the modelling problem from Tutorial 1. Let's assume now that we want our model to predict not only the summer prices but also the autumn ones. We have already trained the MLP to predict summer months effectively but observed that it performs poorly during the autumn period. Let's try to make the model learn new information about the prices and see whether it can remember both.\n",
+ "\n",
+ "First, we will need to retrain the model for this tutorial on summer days."
]
},
{
@@ -525,7 +527,9 @@
"\n",
"In sequential joint training, epochs of each data type are alternated. So, for example, the first epoch will be the $K$ examples from summer data, and then the second will be the $K$ examples from autumn data, then the summer data again, then autumn again, and so on.\n",
"\n",
- "Please complete the partial fits for the corresponding data to implement sequential joint training in the coding exercise. We are using the `partial_fit` function to control the number of times the model \"meets\" data. With every new iteration, the model isn't a new one; it is partially fitted for all previous epochs."
+ "Please complete the partial fits for the corresponding data to implement sequential joint training in the coding exercise. We are using the `partial_fit` function to specify individual updates to the model. The `scikit-learn` library typically exposes a `fit` API whose goal is to specify full training on a dataset. However, if control over sequential training is desired, where you want to specify individual batches of data of a certain type, then models that expose a `partial_fit` function are great ways to accomplish this. In the language of training deep learning models, `fit` is similar to `train_model()` while `partial_fit` is more similar to `update_batch()`.\n",
+ "\n",
+ "Every call to `partial_fit` takes the model from the previous call and continually updates the parameters from the previous step, in the same way that in deep neural networks, each batch update builds upon the adjusted network weights from the previous backpropagation step."
]
},
{
@@ -867,6 +871,21 @@
"- [A Comprehensive Survey of Continual Learning: Theory, Method and Application](https://arxiv.org/pdf/2302.00487)\n",
"- [Brain-inspired replay for continual learning with artificial neural networks](https://www.nature.com/articles/s41467-020-17866-2)"
]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "# The Big Picture\n",
+ "\n",
+ "What causes catastrophic forgetting? If we train tasks continually (one after the other) and not in a joint fashion, it implies the overwriting of old knowledge (information) with new knowledge (information). That doesn't seem to happen in biological systems, so is there a lesson we can take from psychology and neuroscience to better handle catastrophic forgetting? Information seems to be distributed across all weights for this ovwerwriting to happen. Large LLM models have developed one solution, the so-called Mixture-of-Experts Model. This is where a routing mechanism decides what sections of a neural network become active for each tasks. Is that a viable solution? These models are gigantic and extremely computationally expensive. We think there is scope to be more brain-like without requiring such vast computational giants.\n",
+ "\n",
+ "If you're interested in learning more, the topics we covered today are also often referred to as the **Stability-Plasticity Dilemma**. A search for that term will certainly bring you to many recent advances in exploring this idea. \n",
+ "\n",
+ "But before you do that, let's first prepare ourselves for the next tutorial on Meta-Learning. See you there!"
+ ]
}
],
"metadata": {
@@ -897,7 +916,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.9.19"
+ "version": "3.9.22"
}
},
"nbformat": 4,
diff --git a/tutorials/W2D4_Macrolearning/instructor/W2D4_Tutorial3.ipynb b/tutorials/W2D4_Macrolearning/instructor/W2D4_Tutorial3.ipynb
index 0c6738153..a2af66c57 100644
--- a/tutorials/W2D4_Macrolearning/instructor/W2D4_Tutorial3.ipynb
+++ b/tutorials/W2D4_Macrolearning/instructor/W2D4_Tutorial3.ipynb
@@ -25,9 +25,9 @@
"\n",
"__Content creators:__ Hlib Solodzhuk, Ximeng Mao, Grace Lindsay\n",
"\n",
- "__Content reviewers:__ Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Hlib Solodzhuk, Ximeng Mao, Samuele Bolotta, Grace Lindsay\n",
+ "__Content reviewers:__ Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Hlib Solodzhuk, Ximeng Mao, Samuele Bolotta, Grace Lindsay, Alex Murphy\n",
"\n",
- "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk"
+ "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk, Alex Murphy"
]
},
{
@@ -378,7 +378,7 @@
" \"\"\"Load weights of the model from file or as defined architecture.\n",
" \"\"\"\n",
" if isinstance(model, str):\n",
- " return torch.load(model)\n",
+ " return torch.load(model, weights_only=False)\n",
" return model\n",
"\n",
" def deep_clone_model(self, model):\n",
@@ -650,7 +650,7 @@
"\n",
"In this section, we introduce the meta-learning approach. We will discuss its main components and then focus on defining the task before proceeding to training.\n",
"\n",
- "The idea behind meta-learning is that we can \"learn to learn\". Meta-learning is a phrase that is used to describe a lot of different approaches to making more flexible and adaptable systems. The MAML approach is essentially finding good initialization weights, and because those initial weights are learned based on the task set, the model is technically \"learning to find a good place to learn from\". \"Learning to learn\" is a shorter, snappier description that can encompass many different meta-learning approaches."
+ "The idea behind meta-learning is that we can *learn to learn*. Meta-learning is a phrase that is used to describe a lot of different approaches to making more flexible and adaptable systems. The MAML approach is essentially finding good initialization weights, and because those initial weights are learned based on the task set, the model is technically \"learning to find a good place to learn from\". *Learning to learn* is a shorter, snappier description that can encompass many different meta-learning approaches."
]
},
{
@@ -669,9 +669,10 @@
"\n",
"$$f(x) = A x^{2} + B sin(\\pi x + \\phi) + C$$\n",
"\n",
+ "Please see Tutorial 1 if you are unsure about the role of these parameters as that is where they are described in detail.\n",
"Thus, a particular task is a tuple of assigned values. For example, $A = 0.005$, $B = 0.5$, $\\phi = 0$ and $C = 0$.\n",
"\n",
- "You will implement `FruitSupplyDataset`, which enables the generation of a particular instance of the task. We will use it as an extension of `torch.utils.data.Dataset` to load data during training."
+ "You will implement `FruitSupplyDataset`, which enables the generation of a particular instance of the task. This is an extension (subclass) of `torch.utils.data.Dataset` to load data during training. PyTorch `Dataset` objects can be subclassed and its behavior customized as long as you define the initialiser, `__len__` and `__getitem__` methods."
]
},
{
@@ -1273,9 +1274,9 @@
"execution": {}
},
"source": [
- "To achieve the required level of performance, set `num_epochs` in the cell below to 100000, which would take the model at least one hour to train. Thus, at the start of the tutorial, we presented you with the already trained model `SummerAutumnModel.pt`. Ensure you can see it in the same folder as your tutorial notebook.\n",
+ "To achieve the required level of performance, set `num_epochs` in the cell below to 100,000, which would take the model at least one hour to train. Thus, at the start of the tutorial, we presented you with the already trained model `SummerAutumnModel.pt`. Ensure you can see it in the same folder as your tutorial notebook.\n",
"\n",
- "Below, we perform training for 1000 epochs so that you can still run your first meta-learning experiment and verify the correctness of the implementation!"
+ "Below, we perform training for 1,000 epochs so that you can still run your first meta-learning experiment and verify the correctness of the implementation!"
]
},
{
@@ -1430,7 +1431,7 @@
"source": [
"## Coding Exercise 3: Fine-tuning model\n",
"\n",
- "Now, we would like to evaluate the learning ability of the meta-learned model by fine-tuning it to a particular task. For that, we clone the model parameters and perform a couple of gradient descent steps on a small amount of data for two specific tasks:\n",
+ "Now, we would like to evaluate the learning ability of the meta-learned model by fine-tuning it to a particular task. For that, we clone (copy) the model parameters and perform a couple of gradient descent steps on a small amount of data for two specific tasks:\n",
"\n",
"$$A = 0.005, B = 0.1, \\phi = 0, C = 1$$\n",
"$$A = -0.005, B = 0.1, \\phi = 0, C = 4$$\n",
@@ -1715,7 +1716,8 @@
},
"source": [
"---\n",
- "# Summary\n",
+ "\n",
+ "# The Big Picture\n",
"\n",
"*Estimated timing of tutorial: 50 minutes*\n",
"\n",
@@ -1723,7 +1725,9 @@
"\n",
"1. Meta-learning aims to create a model that can quickly learn any task from a distribution.\n",
"\n",
- "2. To achieve this, it uses inner and outer learning loops to find base parameters from which a small number of gradient steps can lead to good performance on any task."
+ "2. To achieve this, it uses inner and outer learning loops to find base parameters from which a small number of gradient steps can lead to good performance on any task.\n",
+ "\n",
+ "Please take some time to reflect on the inner workings of this algorithm and how this aims to solve the problems we've highlighted over the previous tutorials. What is it specifically about the distinction between task-specific and base weights that decouples the effects that previously might have led to catastrophic forgetting? There are numerous ways you can think about this, but we hope you use time in your tutorial groups to exchange ideas and compare your own thoughts. Developing these intuitions is a key skill we would like you to develop as budding NeuroAI researchers!"
]
}
],
@@ -1755,7 +1759,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.9.19"
+ "version": "3.9.22"
}
},
"nbformat": 4,
diff --git a/tutorials/W2D4_Macrolearning/instructor/W2D4_Tutorial4.ipynb b/tutorials/W2D4_Macrolearning/instructor/W2D4_Tutorial4.ipynb
index d0e80b525..3e193426f 100644
--- a/tutorials/W2D4_Macrolearning/instructor/W2D4_Tutorial4.ipynb
+++ b/tutorials/W2D4_Macrolearning/instructor/W2D4_Tutorial4.ipynb
@@ -25,9 +25,9 @@
"\n",
"__Content creators:__ Hlib Solodzhuk, Ximeng Mao, Grace Lindsay\n",
"\n",
- "__Content reviewers:__ Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Hlib Solodzhuk, Ximeng Mao, Samuele Bolotta, Grace Lindsay\n",
+ "__Content reviewers:__ Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Hlib Solodzhuk, Ximeng Mao, Samuele Bolotta, Grace Lindsay, Alex Murphy\n",
"\n",
- "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk\n"
+ "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk, Alex Murphy\n"
]
},
{
@@ -218,6 +218,41 @@
" plt.show()"
]
},
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Set device (GPU or CPU)\n",
+ "\n",
+ "def set_device():\n",
+ " \"\"\"\n",
+ " Determines and sets the computational device for PyTorch operations based on the availability of a CUDA-capable GPU.\n",
+ "\n",
+ " Outputs:\n",
+ " - device (str): The device that PyTorch will use for computations ('cuda' or 'cpu'). This string can be directly used\n",
+ " in PyTorch operations to specify the device.\n",
+ " \"\"\"\n",
+ "\n",
+ " device = \"cuda\" if torch.cuda.is_available() else \"cpu\"\n",
+ " if device != \"cuda\":\n",
+ " print(\"GPU is not enabled in this notebook. \\n\"\n",
+ " \"If you want to enable it, in the menu under `Runtime` -> \\n\"\n",
+ " \"`Hardware accelerator.` and select `GPU` from the dropdown menu\")\n",
+ " else:\n",
+ " print(\"GPU is enabled in this notebook. \\n\"\n",
+ " \"If you want to disable it, in the menu under `Runtime` -> \\n\"\n",
+ " \"`Hardware accelerator.` and select `None` from the dropdown menu\")\n",
+ "\n",
+ " return device\n",
+ "\n",
+ "device = set_device()"
+ ]
+ },
{
"cell_type": "code",
"execution_count": null,
@@ -418,41 +453,6 @@
" fid.write(r.content) # Write the downloaded content to a file"
]
},
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Set device (GPU or CPU)\n",
- "\n",
- "def set_device():\n",
- " \"\"\"\n",
- " Determines and sets the computational device for PyTorch operations based on the availability of a CUDA-capable GPU.\n",
- "\n",
- " Outputs:\n",
- " - device (str): The device that PyTorch will use for computations ('cuda' or 'cpu'). This string can be directly used\n",
- " in PyTorch operations to specify the device.\n",
- " \"\"\"\n",
- "\n",
- " device = \"cuda\" if torch.cuda.is_available() else \"cpu\"\n",
- " if device != \"cuda\":\n",
- " print(\"GPU is not enabled in this notebook. \\n\"\n",
- " \"If you want to enable it, in the menu under `Runtime` -> \\n\"\n",
- " \"`Hardware accelerator.` and select `GPU` from the dropdown menu\")\n",
- " else:\n",
- " print(\"GPU is enabled in this notebook. \\n\"\n",
- " \"If you want to disable it, in the menu under `Runtime` -> \\n\"\n",
- " \"`Hardware accelerator.` and select `None` from the dropdown menu\")\n",
- "\n",
- " return device\n",
- "\n",
- "device = set_device()"
- ]
- },
{
"cell_type": "code",
"execution_count": null,
@@ -686,7 +686,7 @@
"execution": {}
},
"source": [
- "Any RL system consists of an agent who tries to succeed in a task by observing the state of the environment, executing an action, and receiving the outcome (reward).\n",
+ "Any RL system consists of an agent who tries to succeed in a task by observing the state of the environment, executing an action, and receiving the outcome (reward) based on its action. The environment is the source of the reward signal in the RL framework.\n",
"\n",
"First, we will define the environment for this task."
]
@@ -768,7 +768,10 @@
"execution": {}
},
"source": [
- "**For now, simply run all the cells in this section without exploring the content. You can come back to look through the code if you have time after completing all the tutorials.**\n",
+ "For now, simply run all the cells in this section without exploring the content. You can come back to look through the code if you have time after completing all the tutorials.\n",
+ "\n",
+ "\n",
+ " (Click to expand)
\n",
"\n",
"The dummy agent's strategy doesn't use object identity, which is key to consistently selecting the right action. Let's see if we can do better than the dummy agent's strategy. After defining the environment, observing the agent's behavior, and implementing such a simple policy, it is the right time to remind ourselves about more sophisticated agent architectures capable of learning the environment's dynamics. For this, we will use the Advantage Actor-Critic (A2C) algorithm.\n",
"\n",
@@ -776,7 +779,9 @@
"\n",
"The architecture of the agent is as follows: it receives the previous state, previous reward, and previously chosen action as input, which is linearly projected to the `hidden_size` (this creates an embedding); then, its core consists of recurrent `LSTM` cells, their number is exactly `hidden_size`. Right after this RNN layer, there are two distinct linear projections: one for the actor (output dimension coincides with the number of actions; for the Harlow experiment, it is 2) and the other for the critic (outputs one value).\n",
"\n",
- "We don't propose an exercise to code for the agent; when you have time, simply go through the cell below to understand the implementation."
+ "We don't propose an exercise to code for the agent; when you have time, simply go through the cell below to understand the implementation. \n",
+ " \n",
+ " "
]
},
{
@@ -1118,7 +1123,7 @@
"execution": {}
},
"source": [
- "## Coding Exercise 1: Agent's Rate to Learn\n",
+ "## Agent's Rate to Learn\n",
"\n",
"As introduced in the video, the Baldwin effect argues that we don't inherit the features/weights that make us good at specific tasks but rather the ability to learn quickly to gain the needed features in the context of the tasks we face during our own lifetime. This way, evolution works like the outer loop in a meta-learning context.\n",
"\n",
@@ -1141,63 +1146,11 @@
"\n",
"At first, we sample a bunch of tasks from the environment (different pairs of objects; line [2]). The crucial concept involved in this algorithm is preserved in line [4], where for each new task, we don't start with updated parameters but with the ones we had before training and evaluating the agent. Then, we perform training for the defined number of gradient steps and evaluate the agent's performance on this same task (we have defined this function in the second section of the tutorial; it basically covers lines [5] - [9]). One task is not enough to evaluate the agent's ability to learn quickly — this is why we sampled a bunch of them, and the general score for the agent is defined as the sum of rewards for all tasks.\n",
"\n",
- "In the coding exercise, you are invited to complete the implementation of the evaluation of a randomly created agent on 10 tasks (thus, the maximum score that can be obtained is: 10 (number of tasks) x 20 (number of evaluation trials per task) = 200). In the next section of the tutorial, we will provide the evolutionary framework in which we are going to learn \"base\" or \"starting\" weights.\n",
+ "In the cell below, which we have written for you, you can see the implementation of the evaluation of a randomly created agent on 10 tasks (thus, the maximum score that can be obtained is: 10 (number of tasks) x 20 (number of evaluation trials per task) = 200). In the next section of the tutorial, we will provide the evolutionary framework in which we are going to learn \"base\" or \"starting\" weights.\n",
"\n",
"Observe the box plot of the scores as well as their sum."
]
},
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "execution": {}
- },
- "source": [
- "```python\n",
- "def evaluate_individual(env, agent, optimizer_func, num_tasks = 10, num_gradient_steps = 25, num_trials = 6, num_evaluation_trials = 20):\n",
- " \"\"\"Training and evaluation for agent in Harlow experiment environment for the bunch of tasks (thus measuring overall potential for agent's generalization across the tasks).\n",
- " Evaluation goes only after all gradient steps.\n",
- "\n",
- " Inputs:\n",
- " - env (HarlowExperimentEnv): environment.\n",
- " - agent (ActorCritic): particular instance of Actor Critic agent to train.\n",
- " - optimizer_func (torch.Optim): optimizer to use for training.\n",
- " - num_tasks (int, default = 10): number of tasks to evaluate agent on.\n",
- " - num_gradient_steps (int, default = 25): number of gradient steps to perform.\n",
- " - num_trials (int, default = 6): number of times the agent is exposed to the environment per gradient step to be trained .\n",
- " - num_evaluation_trials (int, default = 20): number of times the agent is exposed to the environment to evaluate it (no training happend during this phase).\n",
- "\n",
- " Outputs:\n",
- " - scores (list): list of scores obtained during evaluation on the specific tasks.\n",
- " \"\"\"\n",
- " ###################################################################\n",
- " ## Fill out the following then remove\n",
- " raise NotImplementedError(\"Student exercise: complete evaluation function with Baldwin effect in mind.\")\n",
- " ###################################################################\n",
- " scores = []\n",
- " for _ in range(num_tasks): #lines[2-3]; notice that environment resets inside `train_evaluate_agent`\n",
- " agent_copy = copy.deepcopy(...) #line[4]; remember that we don't want to change agent's parameters!\n",
- " score = train_evaluate_agent(env, ..., optimizer_func, num_gradient_steps, num_trials, num_evaluation_trials)\n",
- " scores.append(score)\n",
- " return np.sum(scores), scores\n",
- "\n",
- "set_seed(42)\n",
- "\n",
- "#define environment\n",
- "env = HarlowExperimentEnv()\n",
- "\n",
- "#define agent and optimizer\n",
- "agent = ActorCritic(hidden_size = 20)\n",
- "optimizer_func = optim.RMSprop\n",
- "\n",
- "#calculate score\n",
- "total_score, scores = evaluate_individual(env, agent, optimizer_func)\n",
- "print(f\"Total score is {total_score}.\")\n",
- "plot_boxplot_scores(scores)\n",
- "\n",
- "```"
- ]
- },
{
"cell_type": "code",
"execution_count": null,
@@ -1206,8 +1159,6 @@
},
"outputs": [],
"source": [
- "# to_remove solution\n",
- "\n",
"def evaluate_individual(env, agent, optimizer_func, num_tasks = 10, num_gradient_steps = 25, num_trials = 6, num_evaluation_trials = 20):\n",
" \"\"\"Training and evaluation for agent in Harlow experiment environment for the bunch of tasks (thus measuring overall potential for agent's generalization across the tasks).\n",
" Evaluation goes only after all gradient steps.\n",
@@ -1275,11 +1226,13 @@
"execution": {}
},
"source": [
- "## Coding Exercise 2: Genetic Algorithm\n",
+ "## Coding Exercise 1: Genetic Algorithm\n",
+ "\n",
+ "Genetic algorithms (GA) mimic some of the evolutionary processes while generating better and better (= more desired) individuals in the population. At first, we initialize a population that consists of randomly defined agents (so we have a list of `population_size` A2C agents, which will, in the very end, evolve into agents that quickly learn the new task from the Harlow experiment environment).\n",
"\n",
- "Genetic algorithms (GA) mimic some of the evolutionary processes while generating better and better (= more desired) individuals in the population. At first, we initialize a population that consists of randomly defined agents (so we have a list of `population_size` A2C agents, which will, in the very end, evolve into agents that quickly learn the new task from the Harlow experiment environment). Each epoch (which is the classical term for machine learning) is defined as a generation in GA as we generate new individuals in the population. For each generation, we choose top-score individuals from the population (of size `tournament_size`; it should be big enough to preserve diversity and not too big for selecting top-score ones; this is exactly where selection occurs and it is the only such place in the whole algorithm) and then we select a random batch of these high-performing individuals of size `parents_num`. From those, we create offspring of size `new_generation_new_individuals`, which will replace random individuals from the population. Notice that we replace random individuals with new ones without comparing their performance (it is just one of the paradigms in genetic algorithms). We continue running generations until we are happy with the best-fit individual appearing in the population or until we run out of time (reaching the maximum number of generations).\n",
+ "Each epoch (which is the classical term for machine learning) is defined as a generation in GA as we generate new individuals in the population. For each generation, we choose top-score individuals from the population (of size `tournament_size`). The population size should be big enough to preserve diversity and not too big for selecting top-score ones. This is exactly where selection occurs and it is the only such place in the whole algorithm. We then we select a random batch of these high-performing individuals of size `parents_num`. From those, we create offspring of size `new_generation_new_individuals`, which will replace random individuals from the population. Notice that we replace random individuals with new ones without comparing their performance (it is just one of the paradigms in genetic algorithms). We continue running generations until we are happy with the best-fit individual appearing in the population or until we run out of time. We end when we reach the maximum number of generations.\n",
"\n",
- "The funniest part happens when we create offspring—simulating evolutionary processes, we randomly select two parents (two agents), and for each of the layers in their networks, we randomly select which one will go to the child (simulating crossing over), and then we add Gaussian noise to each of the layers (simulating mutation).\n",
+ "The most interesting part happens when we create offspring—simulating evolutionary processes, we randomly select two parents (two agents), and for each of the layers in their networks, we randomly select which one will go to the child (simulating crossing over), and then we add Gaussian noise to each of the layers (simulating mutation).\n",
"\n",
"The following cells consist of 3 functions:\n",
"\n",
@@ -1681,17 +1634,6 @@
"plot_two_boxplot_scores(newbie_scores, experienced_scores)"
]
},
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "## Why biology needs meta-learning\n",
- "\n",
- "If aspects of the environment change over time, previously learned hard-coded strategies might not work anymore. Still, as in the previous tutorial, these changes share similar features across the tasks. The Harlow experiment illustrates that although there is no direct instruction on how to obtain the maximum possible reward, and the environment's state changes with each new pair of objects, the agent is still able to capture the meta-structure of the experiment—the reward is associated with the object, not its relative placement. Only one trial is needed to identify which of the two new objects is rewarded."
- ]
- },
{
"cell_type": "code",
"execution_count": null,
@@ -1795,6 +1737,19 @@
"\n",
"4. This process creates agents that can quickly find the rewarding object in a Harlow experiment."
]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "# The Big Picture\n",
+ "\n",
+ "If aspects of the environment change over time, previously learned hard-coded strategies might not work anymore. Still, as in the previous tutorial, these changes share similar features across the tasks. The Harlow experiment illustrates that although there is no direct instruction on how to obtain the maximum possible reward, and the environment's state changes with each new pair of objects, the agent is still able to capture the meta-structure of the experiment—the reward is associated with the object, not its relative placement. Only one trial is needed to identify which of the two new objects is rewarded.\n",
+ "\n",
+ "Earlier in this tutorial, we instructed you to skip over the implementation and rationale behind the A2C code. If you have some extra time, why not jump back above and give that section a read in full? Either now or later at your own discretion. We just wanted to remind you that further details were given (but we initially asked you to skip over). If anything is unclear at this stage, it could be a good way to fill in some gaps in your knowledge."
+ ]
}
],
"metadata": {
@@ -1825,7 +1780,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.9.19"
+ "version": "3.9.22"
}
},
"nbformat": 4,
diff --git a/tutorials/W2D4_Macrolearning/instructor/W2D4_Tutorial5.ipynb b/tutorials/W2D4_Macrolearning/instructor/W2D4_Tutorial5.ipynb
index a8a81962e..ec2aef229 100644
--- a/tutorials/W2D4_Macrolearning/instructor/W2D4_Tutorial5.ipynb
+++ b/tutorials/W2D4_Macrolearning/instructor/W2D4_Tutorial5.ipynb
@@ -16,7 +16,7 @@
"execution": {}
},
"source": [
- "# Tutorial 5: Replay\n",
+ "# (Bonus) Tutorial 5: Replay\n",
"\n",
"**Week 2, Day 4: Macro-Learning**\n",
"\n",
@@ -24,9 +24,9 @@
"\n",
"__Content creators:__ Hlib Solodzhuk, Ximeng Mao, Grace Lindsay\n",
"\n",
- "__Content reviewers:__ Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Hlib Solodzhuk, Ximeng Mao, Grace Lindsay\n",
+ "__Content reviewers:__ Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Hlib Solodzhuk, Ximeng Mao, Grace Lindsay, Alex Murphy\n",
"\n",
- "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk\n"
+ "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk, Alex Murphy\n"
]
},
{
@@ -42,7 +42,9 @@
"\n",
"*Estimated timing of tutorial: 40 minutes*\n",
"\n",
- "In this tutorial, you will discover what replay is and how it helps with continual learning."
+ "Replay in reinforcement learning (RL) refers to the process where agents revisit and learn from past experiences stored in memory, rather than solely from new interactions with their environment. This mirrors how mammals, particularly during sleep, reactivate neural patterns from recent experiences to consolidate memories and extract generalizable patterns. In artificial RL systems, *experience replay* enables more efficient learning by breaking temporal correlations between consecutive experiences and allowing multiple learning updates from single experiences (runs of a series of steps in an RL experiment). This biologically inspired approach has proven crucial for deep RL algorithms like DQN, demonstrating how computational models can both draw from and inform our understanding of biological intelligence.\n",
+ "\n",
+ "In this tutorial, you will discover what replay is and how it helps to solve the continual learning problem we've been investigating over today's tutorials."
]
},
{
@@ -575,9 +577,9 @@
"source": [
"---\n",
"\n",
- "# Section 1: Changing Environment\n",
+ "# Section 1: A Changing Environment\n",
"\n",
- "As mentioned in the video, to study replay, we need to use a slightly different task inspired by the Harlow task, which creates an incentive to remember past data. In this section, we will introduce this new task environment, which replicates the game you played."
+ "As mentioned in the video, to study replay, we need to use a slightly different task inspired by the Harlow task, which creates an incentive to remember past data. In this section, we will introduce this new task environment, which is modelled in a similar way to the game you played in Section 0, above."
]
},
{
@@ -590,7 +592,7 @@
"\n",
"For this tutorial, each state will be represented by its color (via its RGB values; thus, it is a vector of 3 values), and each color is associated with a stable reward that remains unchanged over time (the rewards will correspond to the position of the color in the rainbow).\n",
"\n",
- "While the reward associated with each color does not change over time, the colors presented to the agent will change. Specifically, on each trial, the agent is presented with two colors and should choose the one associated with a higher reward. Initially (in 'mode 1'), colors will be chosen from a set of 3 possible colors. Over time, one of these colors will be replaced by another, creating a different set of three possible colors ('mode 2'). This constitutes a covariate distribution shift and may cause the agent to forget the reward associated with the dropped color."
+ "While the reward associated with each color does not change over time, the colors presented to the agent will change. Specifically, on each trial, the agent is presented with two colors and should choose the one associated with a higher reward. Initially (in 'mode 1'), colors will be chosen from a set of 3 possible colors. Over time, one of these colors will be replaced by another, creating a different set of three possible colors ('mode 2'). This constitutes a distribution shift (specifically: **covariate shift**, which I'm sure you all could instantly recognize!) This may cause the agent to forget the reward associated with the color that was replaced. This would be an instance of catastrophic forgetting in our continual learning setting."
]
},
{
@@ -726,7 +728,7 @@
"source": [
"---\n",
"\n",
- "# Section 2: A2C Agent in Changing Environment\n",
+ "# Section 2: A2C Agent in a Changing Environment\n",
"\n",
"*Estimated timing to here from start of tutorial: 10 minutes*\n",
"\n",
@@ -1004,7 +1006,28 @@
"source": [
"No specific patterns here; the only notable observation (which is also expected) is that whenever colors are close in their rewards, the agent makes more mistakes with those.\n",
"\n",
- "Notice that the blue color is missing, as it is indeed excluded from the first mode. Let us evaluate the agent in the second mode."
+ "Notice that the blue color is missing, as it is indeed excluded from the first mode, as indicated in the code above (repeated here for clarity):\n",
+ "\n",
+ "```python\n",
+ "first_mode = [\"red\", \"yellow\", \"green\"]\n",
+ "second_mode = [\"red\", \"green\", \"blue\"]\n",
+ "```\n",
+ "\n",
+ "Also, notice that the color red was never chosen, as it was never a maximum-reward color. Recall the reward values for the specific colors (again, reproducted below for clarity).\n",
+ "\n",
+ "```python\n",
+ "color_names_rewards = {\n",
+ " \"red\": 1,\n",
+ " \"yellow\": 2,\n",
+ " \"green\": 3,\n",
+ " \"blue\": 4\n",
+ "}\n",
+ "```\n",
+ "\n",
+ "This is why, in the confusion matrix, we never see the color red being picked. In both modes, red always exists in company with a color that has a higher reward.\n",
+ "\n",
+ "\n",
+ "With the details of the confusion matrix hopefully a bit clearer, let us evaluate the agent in the second mode."
]
},
{
@@ -1177,7 +1200,7 @@
"\n",
"*Estimated timing to here from start of tutorial: 25 minutes*\n",
"\n",
- "This section discusses the underlying biological reasoning behind the replay buffer and proposes its code implementation."
+ "This section discusses the underlying biological inspiration behind the replay buffer and proposes a way that in can be implemented in code and used to tackle the issue of catastrophic forgetting during continual learning."
]
},
{
@@ -1556,6 +1579,19 @@
"- Reinforcement learning also suffers from forgetting after learning a new distribution.\n",
"- Replay is a biologically-inspired way to learn from memories of past actions and rewards, thus preventing forgetting."
]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "# The Big Picture\n",
+ "\n",
+ "Replay mechanisms serve as a foundational bridge between past and present knowledge in both biological and artificial learning systems, enabling the critical ability to learn continuously without catastrophically forgetting previous skills. By selectively revisiting and consolidating important experiences, replay helps systems extract generalizable patterns that extend beyond specific tasks or contexts. In biological systems, hippocampal replay during sleep and rest periods allows the brain to transfer episodic memories to neocortical regions where they can inform future behavior across varied situations. Similarly, in artificial systems, experience replay buffers and generative replay techniques significantly improve an agent's ability to transfer knowledge across domains and protect against overfitting to recent experiences.\n",
+ "\n",
+ "We hope that you have found today's tutorials on Macrolearning insightful. There is a lot of material we covered today and we're almost at the end of the course! Tomorrow, our final day of content, will introduce some exciting concepts that are still unsolved and so its appropriately named \"Mysteries\". We will look into more speculative attempts to tackle some of the larger / grander outstanding questions in NeuroAI."
+ ]
}
],
"metadata": {
@@ -1586,7 +1622,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.9.19"
+ "version": "3.9.22"
}
},
"nbformat": 4,
diff --git a/tutorials/W2D4_Macrolearning/solutions/W2D4_Tutorial4_Solution_a47b2770.py b/tutorials/W2D4_Macrolearning/solutions/W2D4_Tutorial4_Solution_a47b2770.py
deleted file mode 100644
index 644e45c7d..000000000
--- a/tutorials/W2D4_Macrolearning/solutions/W2D4_Tutorial4_Solution_a47b2770.py
+++ /dev/null
@@ -1,38 +0,0 @@
-
-def evaluate_individual(env, agent, optimizer_func, num_tasks = 10, num_gradient_steps = 25, num_trials = 6, num_evaluation_trials = 20):
- """Training and evaluation for agent in Harlow experiment environment for the bunch of tasks (thus measuring overall potential for agent's generalization across the tasks).
- Evaluation goes only after all gradient steps.
-
- Inputs:
- - env (HarlowExperimentEnv): environment.
- - agent (ActorCritic): particular instance of Actor Critic agent to train.
- - optimizer_func (torch.Optim): optimizer to use for training.
- - num_tasks (int, default = 10): number of tasks to evaluate agent on.
- - num_gradient_steps (int, default = 25): number of gradient steps to perform.
- - num_trials (int, default = 6): number of times the agent is exposed to the environment per gradient step to be trained .
- - num_evaluation_trials (int, default = 20): number of times the agent is exposed to the environment to evaluate it (no training happend during this phase).
-
- Outputs:
- - score (int): total score.
- - scores (list): list of scores obtained during evaluation on the specific tasks.
- """
- scores = []
- for _ in range(num_tasks): #lines[2-3]; notice that environment resets inside `train_evaluate_agent`
- agent_copy = copy.deepcopy(agent) #line[4]; remember that we don't want to change agent's parameters!
- score = train_evaluate_agent(env, agent_copy, optimizer_func, num_gradient_steps, num_trials, num_evaluation_trials)
- scores.append(score)
- return np.sum(scores), scores
-
-set_seed(42)
-
-#define environment
-env = HarlowExperimentEnv()
-
-#define agent and optimizer
-agent = ActorCritic(hidden_size = 20)
-optimizer_func = optim.RMSprop
-
-#calculate score
-total_score, scores = evaluate_individual(env, agent, optimizer_func)
-print(f"Total score is {total_score}.")
-plot_boxplot_scores(scores)
\ No newline at end of file
diff --git a/tutorials/W2D4_Macrolearning/static/W2D4_Tutorial2_Solution_07232036_53.png b/tutorials/W2D4_Macrolearning/static/W2D4_Tutorial2_Solution_07232036_53.png
new file mode 100644
index 000000000..96e1bdbb1
Binary files /dev/null and b/tutorials/W2D4_Macrolearning/static/W2D4_Tutorial2_Solution_07232036_53.png differ
diff --git a/tutorials/W2D4_Macrolearning/static/W2D4_Tutorial2_Solution_07232036_54.png b/tutorials/W2D4_Macrolearning/static/W2D4_Tutorial2_Solution_07232036_54.png
index 96e1bdbb1..403f40984 100644
Binary files a/tutorials/W2D4_Macrolearning/static/W2D4_Tutorial2_Solution_07232036_54.png and b/tutorials/W2D4_Macrolearning/static/W2D4_Tutorial2_Solution_07232036_54.png differ
diff --git a/tutorials/W2D4_Macrolearning/static/W2D4_Tutorial2_Solution_07232036_55.png b/tutorials/W2D4_Macrolearning/static/W2D4_Tutorial2_Solution_07232036_55.png
deleted file mode 100644
index 403f40984..000000000
Binary files a/tutorials/W2D4_Macrolearning/static/W2D4_Tutorial2_Solution_07232036_55.png and /dev/null differ
diff --git a/tutorials/W2D4_Macrolearning/static/W2D4_Tutorial4_Solution_a47b2770_1.png b/tutorials/W2D4_Macrolearning/static/W2D4_Tutorial4_Solution_a47b2770_1.png
deleted file mode 100644
index 75ee0e91e..000000000
Binary files a/tutorials/W2D4_Macrolearning/static/W2D4_Tutorial4_Solution_a47b2770_1.png and /dev/null differ
diff --git a/tutorials/W2D4_Macrolearning/student/W2D4_Intro.ipynb b/tutorials/W2D4_Macrolearning/student/W2D4_Intro.ipynb
index 7ed56f51f..e5deb386c 100644
--- a/tutorials/W2D4_Macrolearning/student/W2D4_Intro.ipynb
+++ b/tutorials/W2D4_Macrolearning/student/W2D4_Intro.ipynb
@@ -49,6 +49,17 @@
"feedback_prefix = \"W2D4_Intro\""
]
},
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "# Macrolearning\n",
+ "\n",
+ "Over the last two weeks in this NeuroAI course, we've focused on numerous aspects of learning mechanisms, inductive biases and how generalization is implemented as a fundamental property of successful learning systems. Back in Day 2 we looked at the topic of \"Comparing Tasks\" and Leila Wehbe introduced the idea of learning at multiple temporal scales. This idea was explored fairly lightly back then, but today we're going to go much deeper into this idea of learning of a macro-level of time and in a Reinforcement Learning framework. What does it mean about learning across the scale of biological evolution and at the species level? That's what today is all about. We hope you enjoy this fascinating topic!"
+ ]
+ },
{
"cell_type": "markdown",
"metadata": {
@@ -57,7 +68,7 @@
"source": [
"## Prerequisites\n",
"\n",
- "For this day, it would be beneficial to have prior experience working with the `pytorch` modeling package, as the last tutorials are going to be concentrated on defining architecture and training rules using this framework. For Tutorials 4 & 5, you might find yourself more comfortable if you are familiar with the reinforcement learning paradigm and with the Actor-Critic model, in particular. Actually, Tutorial 4 will elaborate on the agent already introduced previously in the last tutorial of Day 2, completing the discussion of meta-learning."
+ "For this day, it would be beneficial to have prior experience working with the `pytorch` modeling package, as the last tutorials are going to be concentrated on defining architecture and training rules using this framework. For Tutorials 4 & 5, you might find yourself more comfortable if you are familiar with the reinforcement learning paradigm and with the Actor-Critic model, in particular. Actually, Tutorial 4 will elaborate on the agent already introduced previously in the last tutorial of Day 2, completing the discussion of meta-learning. It might also be useful to revisit the recording in Tutorial 3 of Day 2, specifically related to the idea of Partially-Observable Markov Decision Processes (POMDPs)."
]
},
{
@@ -206,7 +217,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.9.19"
+ "version": "3.9.22"
}
},
"nbformat": 4,
diff --git a/tutorials/W2D4_Macrolearning/student/W2D4_Tutorial1.ipynb b/tutorials/W2D4_Macrolearning/student/W2D4_Tutorial1.ipynb
index cb87ed721..09cca803e 100644
--- a/tutorials/W2D4_Macrolearning/student/W2D4_Tutorial1.ipynb
+++ b/tutorials/W2D4_Macrolearning/student/W2D4_Tutorial1.ipynb
@@ -24,9 +24,9 @@
"\n",
"__Content creators:__ Hlib Solodzhuk, Ximeng Mao, Grace Lindsay\n",
"\n",
- "__Content reviewers:__ Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Hlib Solodzhuk, Ximeng Mao, Samuele Bolotta, Grace Lindsay\n",
+ "__Content reviewers:__ Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Hlib Solodzhuk, Ximeng Mao, Samuele Bolotta, Grace Lindsay, Alex Murphy\n",
"\n",
- "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk\n"
+ "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk, Alex Murphy\n"
]
},
{
@@ -44,13 +44,13 @@
"\n",
"In this tutorial, we will explore the problems that arise from *distribution shifts*. Distribution shifts occur when the testing data distribution deviates from the training data distribution; that is, when a model is evaluated on data that somehow differs from what it was trained on.\n",
"\n",
- "There are many ways that testing data can differ from training data. Two broad categories of distribution shifts are: **covariate shift** and **concept shift**.\n",
+ "There are many ways that testing data can differ from training data. Two broad categories of distribution shifts are: **covariate shift** and **concept shift**. While we expect most of you to be familiar with the term *concept*, the term *covariate* is used in different ways in different fields and we want to clarify the specific usage we will be using in this tutorial. Unlike in the world of statistics, where a covariate might be a confounding variable, or specifically a continuous predictor feature, when talking about distribution shifts in machine learning, the term *covariate* is synonymous with any input **feature** (regardless of its causal status towards predicting the desired output of the model).\n",
"\n",
- "In covariate shift, the distribution of input features changes. For example, consider a dog/cat classification task where the model was trained to differentiate between real photos of pets while the testing dataset consists entirely of cartoon characters.\n",
+ "In covariate shift, the distribution of input features, $P(X)$ changes. For example, consider a dog/cat classification task where the model was trained to differentiate these classes using real photos of pets, while the testing dataset represents the same dog/cat classification task, but using images of cartoon characters exclusively.\n",
"\n",
- "Concept shift, as its name suggests, involves a conceptual change in the relationship between features and the desired output. For example, a recommendation system may learn a user's preferences, but then those preferences change.\n",
+ "Concept shift, as its name suggests, involves a conceptual change in the relationship between features and the desired output, $P(Y|X)$. For example, a recommendation system may learn a user's preferences, but then those preferences change. It's the mapping from features to outputs that is shifting, while the distribution of the inputs, $P(X)$ remains the same.\n",
"\n",
- "We will explore both types of shifts using a simple function that represents the relationship between the day of the year and the price of fruits in the local market!"
+ "We will explore both types of shifts using a simple function that represents the relationship between the day of the year and the price of fruits in a local market!"
]
},
{
@@ -325,7 +325,7 @@
"\n",
"# Section 1: Covariate shift\n",
"\n",
- "In this section, we are going to discuss the case of covariate shift in distribution - when the distribution of features (usually denoted by $\\mathbf{x}$) differs in the training and testing data."
+ "In this section, we are going to discuss covariate shifts (a major type of distribution shift). Covariate shift arises when the distribution of features, $P(X)$, differs between the training and testing data. This could be when the style of input is different (e.g. real photos vs cartoon illustrations). Another example is when looking at house price predictions. If you train on data from rural areas and test on data from urban areas, the distributions of inputs are not consistent (houses might be small and high-priced in urban areas that are in an excellent location, but no such examples of small houses being high-priced will exist in the rural data)."
]
},
{
@@ -342,9 +342,9 @@
"\n",
"$$f(x) = A x^{2} + B sin(\\pi x + \\phi) + C$$\n",
"\n",
- "This equation suggests quadratic annual behavior (with summer months being at the bottom of the parabola) as well as bi-weekly seasonality introduced by the $sin(\\pi x)$ term (with top values being the days where there is supply of fresh fruits to the market). Variables $A, B, \\phi \\:\\: \\text{and} \\:\\: C$ allow us to tune the day-price relation in different scenarios (for example, we will observe the role of $\\phi$ in the second section of the tutorial). For this particular case, let us set $A = 0.005$, $B = 0.1$, $\\phi = 0$ and $C = 1$.\n",
+ "This equation suggests quadratic annual behavior (with summer months being at the bottom of the parabola) as well as bi-weekly seasonality introduced by the $sin(\\pi x)$ term (with top values being the days where there is supply of fresh fruits to the market). Variables $A, B, \\phi \\:\\: \\text{and} \\:\\: C$ allow us to tune the day-price relation in different scenarios. We will observe the role of $\\phi$ in the second section of the tutorial. For this particular case, let us set $A = 0.005$, $B = 0.1$, $\\phi = 0$ and $C = 1$.\n",
"\n",
- "At first, let's take a look at the data - we will plot it.\n"
+ "Let's first take a look at the data by plotting it so we can orient ourselves to the input data used in this task.\n"
]
},
{
@@ -697,9 +697,9 @@
"\n",
"# Section 2: Concept shift\n",
"\n",
- "Estimated time to reach this point from the start of the tutorial: 15 minutes\n",
+ "*Estimated time to reach this point from the start of the tutorial: 15 minutes*\n",
"\n",
- "In this section, we are going to explore another case of distribution shift, which is different in nature from covariate shift: concept shift."
+ "In this section, we are going to explore another case of distribution shift, which is different in nature from covariate shift: concept shift. This is when the distribution of the inputs, $P(X)$ remains stable, but the mapping from features to predictions, $P(Y|X)$, differs between training and testing data distributions."
]
},
{
@@ -718,7 +718,7 @@
"\n",
"Answer
\n",
"
\n",
- "Yes, indeed, it involves a sinusoidal phase shift — we only need to change the $\\phi$ value.\n",
+ "Yes, indeed, it involves a sinusoidal phase shift — we only need to change the phi value.\n",
" \n",
"\n",
"Let's take a look at how well the model generalizes to this unexpected change as well."
@@ -794,7 +794,7 @@
"execution": {}
},
"source": [
- "Indeed, the model's predictions are capturing the original phase, not the phase-shifted function. Well, it's somewhat expected: we fixed values of features (in this case, week number), trained at first on one set of output values (prices), and then changed the outputs to measure the model's performance. It's obvious that the model will perform badly. Still, it's important to notice the effect of concept shift and this translation between conceptual effect and its impact on modeling. "
+ "The model's predictions are capturing the original phase, not the phase-shifted function. Well, it's somewhat expected: we fixed values of features (in this case, week number), trained at first on one set of output values (prices), and then changed the outputs to measure the model's performance. It's obvious that the model will perform badly. Still, it's important to notice the effect of concept shift and this translation between conceptual effect and its impact on modeling."
]
},
{
@@ -874,7 +874,20 @@
"Here's what we learned:\n",
"\n",
"1. Covariate and concept shifts are two different types of data distribution shifts.\n",
- "2. Distribution shifts negatively impact model performance.\n",
+ "2. Distribution shifts negatively impact model performance."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "# The Big Picture\n",
+ "\n",
+ "Distribution shifts are a huge issue in modern ML systems. Awareness of the fundamental idea behind how these shifts can happen is increasingly important, the more that these systems take on roles that impact systems that we interact with in our daily lives. During COVID-19, product replenishment systems failed spectacularly because there was an underlying shift (panic buying of certain items) that the model did not expect and this caused a huge problem for systems that relied on statistical predictions in the company pipeline.\n",
+ "\n",
+ "In NeuroAI, the distribution shifts can happen in numerous places. For example, training a model on sets of neurons that belong to different brain areas or perhaps the same distribution of neurons that differ due to a confounding third factor, that renders the training and test distribution of features to be different. Awareness of potential distribution shifts is incredibly important and should be something systems are continuosly monitoring. NeuroAI currently lags behind in its adoption of evaluations that monitor these kinds of issues. Our goal is to bring this attention more to the forefront so that in your careers as NeuroAI practioners, you are aware of the necessary factors that can affect the models you build.\n",
"\n",
"In the next tutorials, we are going to address the question of generalization—what are the techniques and methods to deal with poor generalization performance due to distribution shifts."
]
@@ -908,7 +921,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.9.19"
+ "version": "3.9.22"
}
},
"nbformat": 4,
diff --git a/tutorials/W2D4_Macrolearning/student/W2D4_Tutorial2.ipynb b/tutorials/W2D4_Macrolearning/student/W2D4_Tutorial2.ipynb
index 75735cc9e..e1f017654 100644
--- a/tutorials/W2D4_Macrolearning/student/W2D4_Tutorial2.ipynb
+++ b/tutorials/W2D4_Macrolearning/student/W2D4_Tutorial2.ipynb
@@ -25,9 +25,9 @@
"\n",
"__Content creators:__ Hlib Solodzhuk, Ximeng Mao, Grace Lindsay\n",
"\n",
- "__Content reviewers:__ Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Hlib Solodzhuk, Ximeng Mao, Samuele Bolotta, Grace Lindsay\n",
+ "__Content reviewers:__ Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Hlib Solodzhuk, Ximeng Mao, Samuele Bolotta, Grace Lindsay, Alex Murphy\n",
"\n",
- "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk\n"
+ "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk, Alex Murphy\n"
]
},
{
@@ -43,7 +43,7 @@
"\n",
"*Estimated timing of tutorial: 25 minutes*\n",
"\n",
- "In this tutorial, you will observe how further training on new data or tasks causes forgetting of past tasks. You will also explore how different learning schedules impact performance."
+ "In this tutorial, we wil discover how further training on new data or tasks causes forgetting of past tasks. This is like the idea of learning a new idea by replacing an old one. This is a huge issue with the current AI models and deep neural networks and a very active area of research in the ML community. We are going to explore the problem in more detail and investigate some further issues connected to this idea, for example, how different learning schedules impact performance."
]
},
{
@@ -305,9 +305,9 @@
"source": [
"---\n",
"\n",
- "# Section 1: Catastrophic forgetting\n",
+ "# Section 1: Catastrophic Forgetting\n",
"\n",
- "In this section, we will discuss the concept of continual learning and argue that training on new data does not guarantee that the model will remember the relationships on which it was trained earlier. \n",
+ "In this section, we will discuss the concept of continual learning and argue that training on new data does not guarantee that the model will remember how to handle the tasks it was trained on earlier. First it's important to state that there are multiple ways to train some ML models. Often a model will take a training dataset and run a learning algorithm over it in a few steps and derive a solution resulting in a trained model. This is what happens in analytical solutions for linear regression, in Support Vector Machine training etc. In other cases, models can learn by being iteratively updated with single data points (or batches). This type of model can support **online learning** and it is specifically these models that have the potential to undergo catastrophic forgetting. Modern deep neural networks are all online learners, as are methods that are trained with variants of gradient descent. The problems of continual learning only exist for models that can be paused and then resumed with new training data, which has the potential to interact with a previous model that was also trained on prior data.\n",
"\n",
"- Catastrophic forgetting occurs when a neural network, or any machine learning model, forgets the information it previously learned upon learning new data. This is particularly problematic in scenarios where a model needs to perform well across multiple types of data or tasks that evolve over time.\n",
"\n",
@@ -322,7 +322,9 @@
"source": [
"## Coding Exercise 1: Fitting new data\n",
"\n",
- "Let's assume now that we want our model to predict not only the summer prices but also the autumn ones. We have already trained the MLP to predict summer months effectively but observed that it performs poorly during the autumn period. Let's try to make the model learn new information about the prices and see whether it can remember both. First, we will need to retrain the model for this tutorial on summer days."
+ "We're back at the fruit stall. Recall the modelling problem from Tutorial 1. Let's assume now that we want our model to predict not only the summer prices but also the autumn ones. We have already trained the MLP to predict summer months effectively but observed that it performs poorly during the autumn period. Let's try to make the model learn new information about the prices and see whether it can remember both.\n",
+ "\n",
+ "First, we will need to retrain the model for this tutorial on summer days."
]
},
{
@@ -506,7 +508,9 @@
"\n",
"In sequential joint training, epochs of each data type are alternated. So, for example, the first epoch will be the $K$ examples from summer data, and then the second will be the $K$ examples from autumn data, then the summer data again, then autumn again, and so on.\n",
"\n",
- "Please complete the partial fits for the corresponding data to implement sequential joint training in the coding exercise. We are using the `partial_fit` function to control the number of times the model \"meets\" data. With every new iteration, the model isn't a new one; it is partially fitted for all previous epochs."
+ "Please complete the partial fits for the corresponding data to implement sequential joint training in the coding exercise. We are using the `partial_fit` function to specify individual updates to the model. The `scikit-learn` library typically exposes a `fit` API whose goal is to specify full training on a dataset. However, if control over sequential training is desired, where you want to specify individual batches of data of a certain type, then models that expose a `partial_fit` function are great ways to accomplish this. In the language of training deep learning models, `fit` is similar to `train_model()` while `partial_fit` is more similar to `update_batch()`.\n",
+ "\n",
+ "Every call to `partial_fit` takes the model from the previous call and continually updates the parameters from the previous step, in the same way that in deep neural networks, each batch update builds upon the adjusted network weights from the previous backpropagation step."
]
},
{
@@ -691,9 +695,9 @@
"\n",
"*Example output:*\n",
"\n",
- "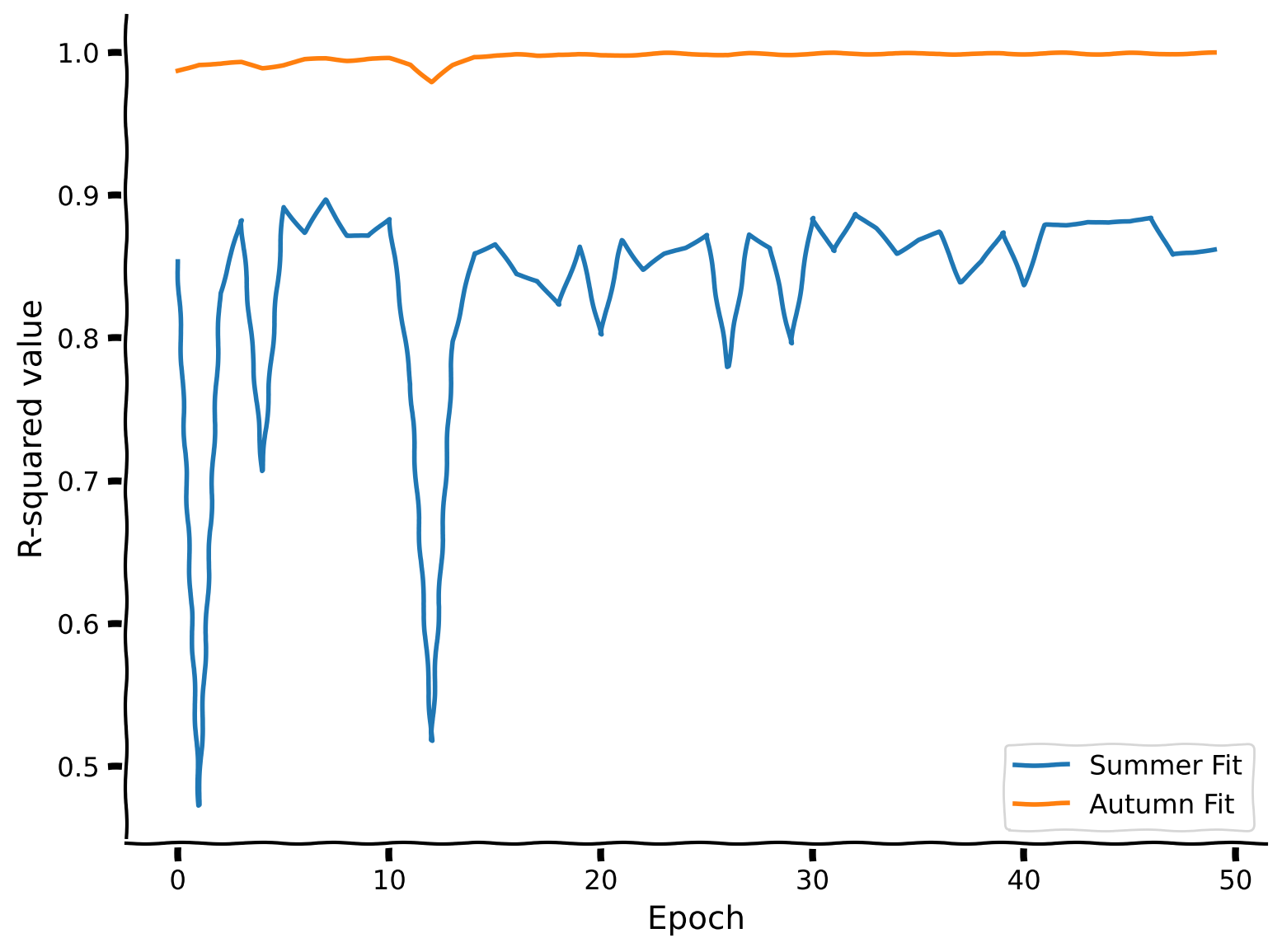 \n",
+ "
\n",
+ " \n",
"\n",
- "
\n",
"\n",
- "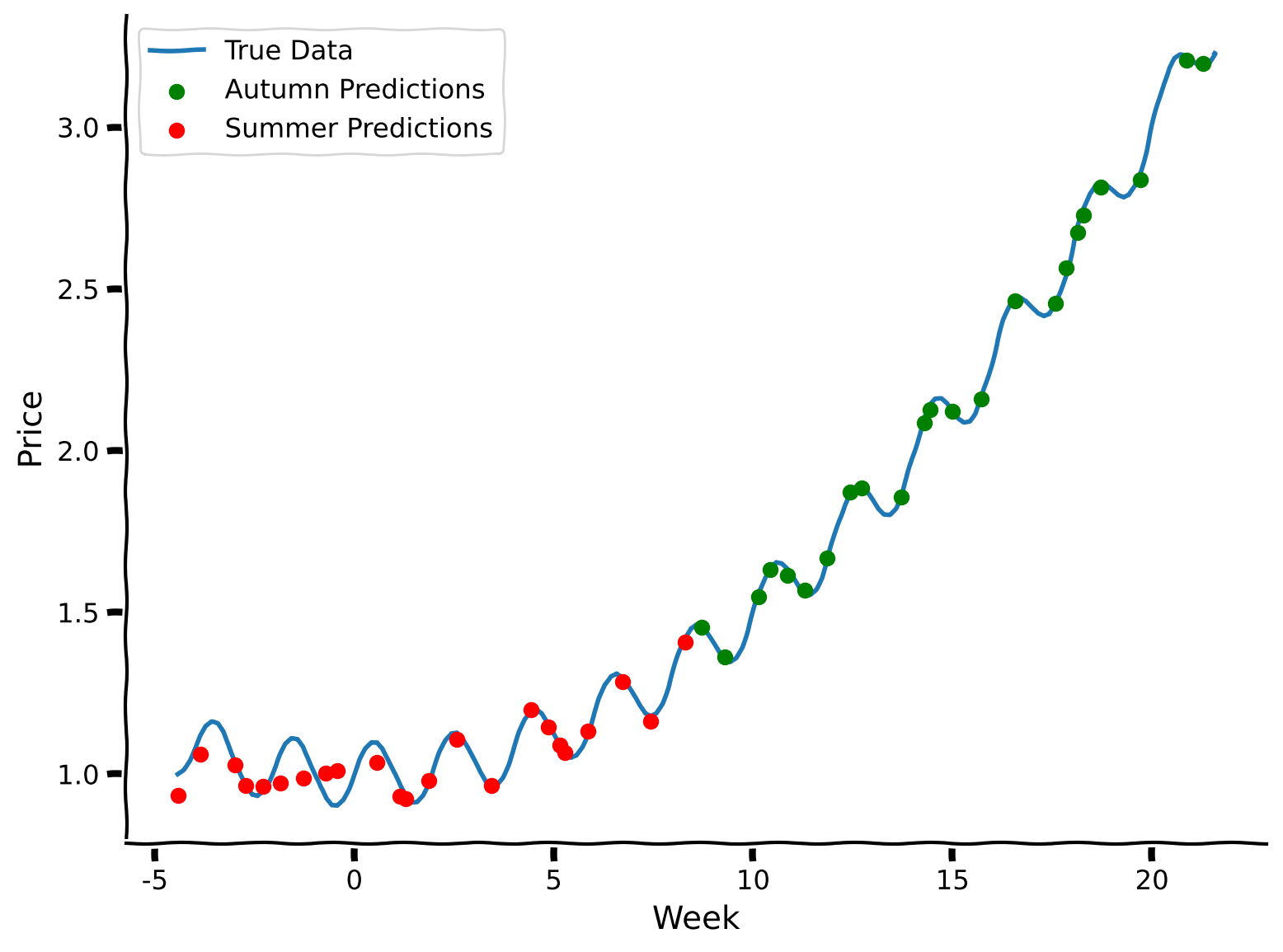 \n",
+ "\n",
"\n"
]
},
@@ -744,6 +748,21 @@
"- [A Comprehensive Survey of Continual Learning: Theory, Method and Application](https://arxiv.org/pdf/2302.00487)\n",
"- [Brain-inspired replay for continual learning with artificial neural networks](https://www.nature.com/articles/s41467-020-17866-2)"
]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "# The Big Picture\n",
+ "\n",
+ "What causes catastrophic forgetting? If we train tasks continually (one after the other) and not in a joint fashion, it implies the overwriting of old knowledge (information) with new knowledge (information). That doesn't seem to happen in biological systems, so is there a lesson we can take from psychology and neuroscience to better handle catastrophic forgetting? Information seems to be distributed across all weights for this ovwerwriting to happen. Large LLM models have developed one solution, the so-called Mixture-of-Experts Model. This is where a routing mechanism decides what sections of a neural network become active for each tasks. Is that a viable solution? These models are gigantic and extremely computationally expensive. We think there is scope to be more brain-like without requiring such vast computational giants.\n",
+ "\n",
+ "If you're interested in learning more, the topics we covered today are also often referred to as the **Stability-Plasticity Dilemma**. A search for that term will certainly bring you to many recent advances in exploring this idea. \n",
+ "\n",
+ "But before you do that, let's first prepare ourselves for the next tutorial on Meta-Learning. See you there!"
+ ]
}
],
"metadata": {
@@ -774,7 +793,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.9.19"
+ "version": "3.9.22"
}
},
"nbformat": 4,
diff --git a/tutorials/W2D4_Macrolearning/student/W2D4_Tutorial3.ipynb b/tutorials/W2D4_Macrolearning/student/W2D4_Tutorial3.ipynb
index 4fa3c10b1..f0a79d6ff 100644
--- a/tutorials/W2D4_Macrolearning/student/W2D4_Tutorial3.ipynb
+++ b/tutorials/W2D4_Macrolearning/student/W2D4_Tutorial3.ipynb
@@ -25,9 +25,9 @@
"\n",
"__Content creators:__ Hlib Solodzhuk, Ximeng Mao, Grace Lindsay\n",
"\n",
- "__Content reviewers:__ Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Hlib Solodzhuk, Ximeng Mao, Samuele Bolotta, Grace Lindsay\n",
+ "__Content reviewers:__ Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Hlib Solodzhuk, Ximeng Mao, Samuele Bolotta, Grace Lindsay, Alex Murphy\n",
"\n",
- "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk"
+ "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk, Alex Murphy"
]
},
{
@@ -378,7 +378,7 @@
" \"\"\"Load weights of the model from file or as defined architecture.\n",
" \"\"\"\n",
" if isinstance(model, str):\n",
- " return torch.load(model)\n",
+ " return torch.load(model, weights_only=False)\n",
" return model\n",
"\n",
" def deep_clone_model(self, model):\n",
@@ -650,7 +650,7 @@
"\n",
"In this section, we introduce the meta-learning approach. We will discuss its main components and then focus on defining the task before proceeding to training.\n",
"\n",
- "The idea behind meta-learning is that we can \"learn to learn\". Meta-learning is a phrase that is used to describe a lot of different approaches to making more flexible and adaptable systems. The MAML approach is essentially finding good initialization weights, and because those initial weights are learned based on the task set, the model is technically \"learning to find a good place to learn from\". \"Learning to learn\" is a shorter, snappier description that can encompass many different meta-learning approaches."
+ "The idea behind meta-learning is that we can *learn to learn*. Meta-learning is a phrase that is used to describe a lot of different approaches to making more flexible and adaptable systems. The MAML approach is essentially finding good initialization weights, and because those initial weights are learned based on the task set, the model is technically \"learning to find a good place to learn from\". *Learning to learn* is a shorter, snappier description that can encompass many different meta-learning approaches."
]
},
{
@@ -669,9 +669,10 @@
"\n",
"$$f(x) = A x^{2} + B sin(\\pi x + \\phi) + C$$\n",
"\n",
+ "Please see Tutorial 1 if you are unsure about the role of these parameters as that is where they are described in detail.\n",
"Thus, a particular task is a tuple of assigned values. For example, $A = 0.005$, $B = 0.5$, $\\phi = 0$ and $C = 0$.\n",
"\n",
- "You will implement `FruitSupplyDataset`, which enables the generation of a particular instance of the task. We will use it as an extension of `torch.utils.data.Dataset` to load data during training."
+ "You will implement `FruitSupplyDataset`, which enables the generation of a particular instance of the task. This is an extension (subclass) of `torch.utils.data.Dataset` to load data during training. PyTorch `Dataset` objects can be subclassed and its behavior customized as long as you define the initialiser, `__len__` and `__getitem__` methods."
]
},
{
@@ -1130,9 +1131,9 @@
"execution": {}
},
"source": [
- "To achieve the required level of performance, set `num_epochs` in the cell below to 100000, which would take the model at least one hour to train. Thus, at the start of the tutorial, we presented you with the already trained model `SummerAutumnModel.pt`. Ensure you can see it in the same folder as your tutorial notebook.\n",
+ "To achieve the required level of performance, set `num_epochs` in the cell below to 100,000, which would take the model at least one hour to train. Thus, at the start of the tutorial, we presented you with the already trained model `SummerAutumnModel.pt`. Ensure you can see it in the same folder as your tutorial notebook.\n",
"\n",
- "Below, we perform training for 1000 epochs so that you can still run your first meta-learning experiment and verify the correctness of the implementation!"
+ "Below, we perform training for 1,000 epochs so that you can still run your first meta-learning experiment and verify the correctness of the implementation!"
]
},
{
@@ -1287,7 +1288,7 @@
"source": [
"## Coding Exercise 3: Fine-tuning model\n",
"\n",
- "Now, we would like to evaluate the learning ability of the meta-learned model by fine-tuning it to a particular task. For that, we clone the model parameters and perform a couple of gradient descent steps on a small amount of data for two specific tasks:\n",
+ "Now, we would like to evaluate the learning ability of the meta-learned model by fine-tuning it to a particular task. For that, we clone (copy) the model parameters and perform a couple of gradient descent steps on a small amount of data for two specific tasks:\n",
"\n",
"$$A = 0.005, B = 0.1, \\phi = 0, C = 1$$\n",
"$$A = -0.005, B = 0.1, \\phi = 0, C = 4$$\n",
@@ -1545,7 +1546,8 @@
},
"source": [
"---\n",
- "# Summary\n",
+ "\n",
+ "# The Big Picture\n",
"\n",
"*Estimated timing of tutorial: 50 minutes*\n",
"\n",
@@ -1553,7 +1555,9 @@
"\n",
"1. Meta-learning aims to create a model that can quickly learn any task from a distribution.\n",
"\n",
- "2. To achieve this, it uses inner and outer learning loops to find base parameters from which a small number of gradient steps can lead to good performance on any task."
+ "2. To achieve this, it uses inner and outer learning loops to find base parameters from which a small number of gradient steps can lead to good performance on any task.\n",
+ "\n",
+ "Please take some time to reflect on the inner workings of this algorithm and how this aims to solve the problems we've highlighted over the previous tutorials. What is it specifically about the distinction between task-specific and base weights that decouples the effects that previously might have led to catastrophic forgetting? There are numerous ways you can think about this, but we hope you use time in your tutorial groups to exchange ideas and compare your own thoughts. Developing these intuitions is a key skill we would like you to develop as budding NeuroAI researchers!"
]
}
],
@@ -1585,7 +1589,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.9.19"
+ "version": "3.9.22"
}
},
"nbformat": 4,
diff --git a/tutorials/W2D4_Macrolearning/student/W2D4_Tutorial4.ipynb b/tutorials/W2D4_Macrolearning/student/W2D4_Tutorial4.ipynb
index 5a5c8b7b4..545546044 100644
--- a/tutorials/W2D4_Macrolearning/student/W2D4_Tutorial4.ipynb
+++ b/tutorials/W2D4_Macrolearning/student/W2D4_Tutorial4.ipynb
@@ -25,9 +25,9 @@
"\n",
"__Content creators:__ Hlib Solodzhuk, Ximeng Mao, Grace Lindsay\n",
"\n",
- "__Content reviewers:__ Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Hlib Solodzhuk, Ximeng Mao, Samuele Bolotta, Grace Lindsay\n",
+ "__Content reviewers:__ Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Hlib Solodzhuk, Ximeng Mao, Samuele Bolotta, Grace Lindsay, Alex Murphy\n",
"\n",
- "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk\n"
+ "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk, Alex Murphy\n"
]
},
{
@@ -218,6 +218,41 @@
" plt.show()"
]
},
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Set device (GPU or CPU)\n",
+ "\n",
+ "def set_device():\n",
+ " \"\"\"\n",
+ " Determines and sets the computational device for PyTorch operations based on the availability of a CUDA-capable GPU.\n",
+ "\n",
+ " Outputs:\n",
+ " - device (str): The device that PyTorch will use for computations ('cuda' or 'cpu'). This string can be directly used\n",
+ " in PyTorch operations to specify the device.\n",
+ " \"\"\"\n",
+ "\n",
+ " device = \"cuda\" if torch.cuda.is_available() else \"cpu\"\n",
+ " if device != \"cuda\":\n",
+ " print(\"GPU is not enabled in this notebook. \\n\"\n",
+ " \"If you want to enable it, in the menu under `Runtime` -> \\n\"\n",
+ " \"`Hardware accelerator.` and select `GPU` from the dropdown menu\")\n",
+ " else:\n",
+ " print(\"GPU is enabled in this notebook. \\n\"\n",
+ " \"If you want to disable it, in the menu under `Runtime` -> \\n\"\n",
+ " \"`Hardware accelerator.` and select `None` from the dropdown menu\")\n",
+ "\n",
+ " return device\n",
+ "\n",
+ "device = set_device()"
+ ]
+ },
{
"cell_type": "code",
"execution_count": null,
@@ -418,41 +453,6 @@
" fid.write(r.content) # Write the downloaded content to a file"
]
},
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Set device (GPU or CPU)\n",
- "\n",
- "def set_device():\n",
- " \"\"\"\n",
- " Determines and sets the computational device for PyTorch operations based on the availability of a CUDA-capable GPU.\n",
- "\n",
- " Outputs:\n",
- " - device (str): The device that PyTorch will use for computations ('cuda' or 'cpu'). This string can be directly used\n",
- " in PyTorch operations to specify the device.\n",
- " \"\"\"\n",
- "\n",
- " device = \"cuda\" if torch.cuda.is_available() else \"cpu\"\n",
- " if device != \"cuda\":\n",
- " print(\"GPU is not enabled in this notebook. \\n\"\n",
- " \"If you want to enable it, in the menu under `Runtime` -> \\n\"\n",
- " \"`Hardware accelerator.` and select `GPU` from the dropdown menu\")\n",
- " else:\n",
- " print(\"GPU is enabled in this notebook. \\n\"\n",
- " \"If you want to disable it, in the menu under `Runtime` -> \\n\"\n",
- " \"`Hardware accelerator.` and select `None` from the dropdown menu\")\n",
- "\n",
- " return device\n",
- "\n",
- "device = set_device()"
- ]
- },
{
"cell_type": "code",
"execution_count": null,
@@ -686,7 +686,7 @@
"execution": {}
},
"source": [
- "Any RL system consists of an agent who tries to succeed in a task by observing the state of the environment, executing an action, and receiving the outcome (reward).\n",
+ "Any RL system consists of an agent who tries to succeed in a task by observing the state of the environment, executing an action, and receiving the outcome (reward) based on its action. The environment is the source of the reward signal in the RL framework.\n",
"\n",
"First, we will define the environment for this task."
]
@@ -768,7 +768,10 @@
"execution": {}
},
"source": [
- "**For now, simply run all the cells in this section without exploring the content. You can come back to look through the code if you have time after completing all the tutorials.**\n",
+ "For now, simply run all the cells in this section without exploring the content. You can come back to look through the code if you have time after completing all the tutorials.\n",
+ "\n",
+ "
\n",
+ "\n",
"\n"
]
},
@@ -744,6 +748,21 @@
"- [A Comprehensive Survey of Continual Learning: Theory, Method and Application](https://arxiv.org/pdf/2302.00487)\n",
"- [Brain-inspired replay for continual learning with artificial neural networks](https://www.nature.com/articles/s41467-020-17866-2)"
]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "# The Big Picture\n",
+ "\n",
+ "What causes catastrophic forgetting? If we train tasks continually (one after the other) and not in a joint fashion, it implies the overwriting of old knowledge (information) with new knowledge (information). That doesn't seem to happen in biological systems, so is there a lesson we can take from psychology and neuroscience to better handle catastrophic forgetting? Information seems to be distributed across all weights for this ovwerwriting to happen. Large LLM models have developed one solution, the so-called Mixture-of-Experts Model. This is where a routing mechanism decides what sections of a neural network become active for each tasks. Is that a viable solution? These models are gigantic and extremely computationally expensive. We think there is scope to be more brain-like without requiring such vast computational giants.\n",
+ "\n",
+ "If you're interested in learning more, the topics we covered today are also often referred to as the **Stability-Plasticity Dilemma**. A search for that term will certainly bring you to many recent advances in exploring this idea. \n",
+ "\n",
+ "But before you do that, let's first prepare ourselves for the next tutorial on Meta-Learning. See you there!"
+ ]
}
],
"metadata": {
@@ -774,7 +793,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.9.19"
+ "version": "3.9.22"
}
},
"nbformat": 4,
diff --git a/tutorials/W2D4_Macrolearning/student/W2D4_Tutorial3.ipynb b/tutorials/W2D4_Macrolearning/student/W2D4_Tutorial3.ipynb
index 4fa3c10b1..f0a79d6ff 100644
--- a/tutorials/W2D4_Macrolearning/student/W2D4_Tutorial3.ipynb
+++ b/tutorials/W2D4_Macrolearning/student/W2D4_Tutorial3.ipynb
@@ -25,9 +25,9 @@
"\n",
"__Content creators:__ Hlib Solodzhuk, Ximeng Mao, Grace Lindsay\n",
"\n",
- "__Content reviewers:__ Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Hlib Solodzhuk, Ximeng Mao, Samuele Bolotta, Grace Lindsay\n",
+ "__Content reviewers:__ Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Hlib Solodzhuk, Ximeng Mao, Samuele Bolotta, Grace Lindsay, Alex Murphy\n",
"\n",
- "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk"
+ "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk, Alex Murphy"
]
},
{
@@ -378,7 +378,7 @@
" \"\"\"Load weights of the model from file or as defined architecture.\n",
" \"\"\"\n",
" if isinstance(model, str):\n",
- " return torch.load(model)\n",
+ " return torch.load(model, weights_only=False)\n",
" return model\n",
"\n",
" def deep_clone_model(self, model):\n",
@@ -650,7 +650,7 @@
"\n",
"In this section, we introduce the meta-learning approach. We will discuss its main components and then focus on defining the task before proceeding to training.\n",
"\n",
- "The idea behind meta-learning is that we can \"learn to learn\". Meta-learning is a phrase that is used to describe a lot of different approaches to making more flexible and adaptable systems. The MAML approach is essentially finding good initialization weights, and because those initial weights are learned based on the task set, the model is technically \"learning to find a good place to learn from\". \"Learning to learn\" is a shorter, snappier description that can encompass many different meta-learning approaches."
+ "The idea behind meta-learning is that we can *learn to learn*. Meta-learning is a phrase that is used to describe a lot of different approaches to making more flexible and adaptable systems. The MAML approach is essentially finding good initialization weights, and because those initial weights are learned based on the task set, the model is technically \"learning to find a good place to learn from\". *Learning to learn* is a shorter, snappier description that can encompass many different meta-learning approaches."
]
},
{
@@ -669,9 +669,10 @@
"\n",
"$$f(x) = A x^{2} + B sin(\\pi x + \\phi) + C$$\n",
"\n",
+ "Please see Tutorial 1 if you are unsure about the role of these parameters as that is where they are described in detail.\n",
"Thus, a particular task is a tuple of assigned values. For example, $A = 0.005$, $B = 0.5$, $\\phi = 0$ and $C = 0$.\n",
"\n",
- "You will implement `FruitSupplyDataset`, which enables the generation of a particular instance of the task. We will use it as an extension of `torch.utils.data.Dataset` to load data during training."
+ "You will implement `FruitSupplyDataset`, which enables the generation of a particular instance of the task. This is an extension (subclass) of `torch.utils.data.Dataset` to load data during training. PyTorch `Dataset` objects can be subclassed and its behavior customized as long as you define the initialiser, `__len__` and `__getitem__` methods."
]
},
{
@@ -1130,9 +1131,9 @@
"execution": {}
},
"source": [
- "To achieve the required level of performance, set `num_epochs` in the cell below to 100000, which would take the model at least one hour to train. Thus, at the start of the tutorial, we presented you with the already trained model `SummerAutumnModel.pt`. Ensure you can see it in the same folder as your tutorial notebook.\n",
+ "To achieve the required level of performance, set `num_epochs` in the cell below to 100,000, which would take the model at least one hour to train. Thus, at the start of the tutorial, we presented you with the already trained model `SummerAutumnModel.pt`. Ensure you can see it in the same folder as your tutorial notebook.\n",
"\n",
- "Below, we perform training for 1000 epochs so that you can still run your first meta-learning experiment and verify the correctness of the implementation!"
+ "Below, we perform training for 1,000 epochs so that you can still run your first meta-learning experiment and verify the correctness of the implementation!"
]
},
{
@@ -1287,7 +1288,7 @@
"source": [
"## Coding Exercise 3: Fine-tuning model\n",
"\n",
- "Now, we would like to evaluate the learning ability of the meta-learned model by fine-tuning it to a particular task. For that, we clone the model parameters and perform a couple of gradient descent steps on a small amount of data for two specific tasks:\n",
+ "Now, we would like to evaluate the learning ability of the meta-learned model by fine-tuning it to a particular task. For that, we clone (copy) the model parameters and perform a couple of gradient descent steps on a small amount of data for two specific tasks:\n",
"\n",
"$$A = 0.005, B = 0.1, \\phi = 0, C = 1$$\n",
"$$A = -0.005, B = 0.1, \\phi = 0, C = 4$$\n",
@@ -1545,7 +1546,8 @@
},
"source": [
"---\n",
- "# Summary\n",
+ "\n",
+ "# The Big Picture\n",
"\n",
"*Estimated timing of tutorial: 50 minutes*\n",
"\n",
@@ -1553,7 +1555,9 @@
"\n",
"1. Meta-learning aims to create a model that can quickly learn any task from a distribution.\n",
"\n",
- "2. To achieve this, it uses inner and outer learning loops to find base parameters from which a small number of gradient steps can lead to good performance on any task."
+ "2. To achieve this, it uses inner and outer learning loops to find base parameters from which a small number of gradient steps can lead to good performance on any task.\n",
+ "\n",
+ "Please take some time to reflect on the inner workings of this algorithm and how this aims to solve the problems we've highlighted over the previous tutorials. What is it specifically about the distinction between task-specific and base weights that decouples the effects that previously might have led to catastrophic forgetting? There are numerous ways you can think about this, but we hope you use time in your tutorial groups to exchange ideas and compare your own thoughts. Developing these intuitions is a key skill we would like you to develop as budding NeuroAI researchers!"
]
}
],
@@ -1585,7 +1589,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.9.19"
+ "version": "3.9.22"
}
},
"nbformat": 4,
diff --git a/tutorials/W2D4_Macrolearning/student/W2D4_Tutorial4.ipynb b/tutorials/W2D4_Macrolearning/student/W2D4_Tutorial4.ipynb
index 5a5c8b7b4..545546044 100644
--- a/tutorials/W2D4_Macrolearning/student/W2D4_Tutorial4.ipynb
+++ b/tutorials/W2D4_Macrolearning/student/W2D4_Tutorial4.ipynb
@@ -25,9 +25,9 @@
"\n",
"__Content creators:__ Hlib Solodzhuk, Ximeng Mao, Grace Lindsay\n",
"\n",
- "__Content reviewers:__ Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Hlib Solodzhuk, Ximeng Mao, Samuele Bolotta, Grace Lindsay\n",
+ "__Content reviewers:__ Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Hlib Solodzhuk, Ximeng Mao, Samuele Bolotta, Grace Lindsay, Alex Murphy\n",
"\n",
- "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk\n"
+ "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk, Alex Murphy\n"
]
},
{
@@ -218,6 +218,41 @@
" plt.show()"
]
},
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Set device (GPU or CPU)\n",
+ "\n",
+ "def set_device():\n",
+ " \"\"\"\n",
+ " Determines and sets the computational device for PyTorch operations based on the availability of a CUDA-capable GPU.\n",
+ "\n",
+ " Outputs:\n",
+ " - device (str): The device that PyTorch will use for computations ('cuda' or 'cpu'). This string can be directly used\n",
+ " in PyTorch operations to specify the device.\n",
+ " \"\"\"\n",
+ "\n",
+ " device = \"cuda\" if torch.cuda.is_available() else \"cpu\"\n",
+ " if device != \"cuda\":\n",
+ " print(\"GPU is not enabled in this notebook. \\n\"\n",
+ " \"If you want to enable it, in the menu under `Runtime` -> \\n\"\n",
+ " \"`Hardware accelerator.` and select `GPU` from the dropdown menu\")\n",
+ " else:\n",
+ " print(\"GPU is enabled in this notebook. \\n\"\n",
+ " \"If you want to disable it, in the menu under `Runtime` -> \\n\"\n",
+ " \"`Hardware accelerator.` and select `None` from the dropdown menu\")\n",
+ "\n",
+ " return device\n",
+ "\n",
+ "device = set_device()"
+ ]
+ },
{
"cell_type": "code",
"execution_count": null,
@@ -418,41 +453,6 @@
" fid.write(r.content) # Write the downloaded content to a file"
]
},
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Set device (GPU or CPU)\n",
- "\n",
- "def set_device():\n",
- " \"\"\"\n",
- " Determines and sets the computational device for PyTorch operations based on the availability of a CUDA-capable GPU.\n",
- "\n",
- " Outputs:\n",
- " - device (str): The device that PyTorch will use for computations ('cuda' or 'cpu'). This string can be directly used\n",
- " in PyTorch operations to specify the device.\n",
- " \"\"\"\n",
- "\n",
- " device = \"cuda\" if torch.cuda.is_available() else \"cpu\"\n",
- " if device != \"cuda\":\n",
- " print(\"GPU is not enabled in this notebook. \\n\"\n",
- " \"If you want to enable it, in the menu under `Runtime` -> \\n\"\n",
- " \"`Hardware accelerator.` and select `GPU` from the dropdown menu\")\n",
- " else:\n",
- " print(\"GPU is enabled in this notebook. \\n\"\n",
- " \"If you want to disable it, in the menu under `Runtime` -> \\n\"\n",
- " \"`Hardware accelerator.` and select `None` from the dropdown menu\")\n",
- "\n",
- " return device\n",
- "\n",
- "device = set_device()"
- ]
- },
{
"cell_type": "code",
"execution_count": null,
@@ -686,7 +686,7 @@
"execution": {}
},
"source": [
- "Any RL system consists of an agent who tries to succeed in a task by observing the state of the environment, executing an action, and receiving the outcome (reward).\n",
+ "Any RL system consists of an agent who tries to succeed in a task by observing the state of the environment, executing an action, and receiving the outcome (reward) based on its action. The environment is the source of the reward signal in the RL framework.\n",
"\n",
"First, we will define the environment for this task."
]
@@ -768,7 +768,10 @@
"execution": {}
},
"source": [
- "**For now, simply run all the cells in this section without exploring the content. You can come back to look through the code if you have time after completing all the tutorials.**\n",
+ "For now, simply run all the cells in this section without exploring the content. You can come back to look through the code if you have time after completing all the tutorials.\n",
+ "\n",
+ "\n",
+ " (Click to expand)
\n",
"\n",
"The dummy agent's strategy doesn't use object identity, which is key to consistently selecting the right action. Let's see if we can do better than the dummy agent's strategy. After defining the environment, observing the agent's behavior, and implementing such a simple policy, it is the right time to remind ourselves about more sophisticated agent architectures capable of learning the environment's dynamics. For this, we will use the Advantage Actor-Critic (A2C) algorithm.\n",
"\n",
@@ -776,7 +779,9 @@
"\n",
"The architecture of the agent is as follows: it receives the previous state, previous reward, and previously chosen action as input, which is linearly projected to the `hidden_size` (this creates an embedding); then, its core consists of recurrent `LSTM` cells, their number is exactly `hidden_size`. Right after this RNN layer, there are two distinct linear projections: one for the actor (output dimension coincides with the number of actions; for the Harlow experiment, it is 2) and the other for the critic (outputs one value).\n",
"\n",
- "We don't propose an exercise to code for the agent; when you have time, simply go through the cell below to understand the implementation."
+ "We don't propose an exercise to code for the agent; when you have time, simply go through the cell below to understand the implementation. \n",
+ " \n",
+ " "
]
},
{
@@ -1118,7 +1123,7 @@
"execution": {}
},
"source": [
- "## Coding Exercise 1: Agent's Rate to Learn\n",
+ "## Agent's Rate to Learn\n",
"\n",
"As introduced in the video, the Baldwin effect argues that we don't inherit the features/weights that make us good at specific tasks but rather the ability to learn quickly to gain the needed features in the context of the tasks we face during our own lifetime. This way, evolution works like the outer loop in a meta-learning context.\n",
"\n",
@@ -1141,7 +1146,7 @@
"\n",
"At first, we sample a bunch of tasks from the environment (different pairs of objects; line [2]). The crucial concept involved in this algorithm is preserved in line [4], where for each new task, we don't start with updated parameters but with the ones we had before training and evaluating the agent. Then, we perform training for the defined number of gradient steps and evaluate the agent's performance on this same task (we have defined this function in the second section of the tutorial; it basically covers lines [5] - [9]). One task is not enough to evaluate the agent's ability to learn quickly — this is why we sampled a bunch of them, and the general score for the agent is defined as the sum of rewards for all tasks.\n",
"\n",
- "In the coding exercise, you are invited to complete the implementation of the evaluation of a randomly created agent on 10 tasks (thus, the maximum score that can be obtained is: 10 (number of tasks) x 20 (number of evaluation trials per task) = 200). In the next section of the tutorial, we will provide the evolutionary framework in which we are going to learn \"base\" or \"starting\" weights.\n",
+ "In the cell below, which we have written for you, you can see the implementation of the evaluation of a randomly created agent on 10 tasks (thus, the maximum score that can be obtained is: 10 (number of tasks) x 20 (number of evaluation trials per task) = 200). In the next section of the tutorial, we will provide the evolutionary framework in which we are going to learn \"base\" or \"starting\" weights.\n",
"\n",
"Observe the box plot of the scores as well as their sum."
]
@@ -1168,16 +1173,13 @@
" - num_evaluation_trials (int, default = 20): number of times the agent is exposed to the environment to evaluate it (no training happend during this phase).\n",
"\n",
" Outputs:\n",
+ " - score (int): total score.\n",
" - scores (list): list of scores obtained during evaluation on the specific tasks.\n",
" \"\"\"\n",
- " ###################################################################\n",
- " ## Fill out the following then remove\n",
- " raise NotImplementedError(\"Student exercise: complete evaluation function with Baldwin effect in mind.\")\n",
- " ###################################################################\n",
" scores = []\n",
" for _ in range(num_tasks): #lines[2-3]; notice that environment resets inside `train_evaluate_agent`\n",
- " agent_copy = copy.deepcopy(...) #line[4]; remember that we don't want to change agent's parameters!\n",
- " score = train_evaluate_agent(env, ..., optimizer_func, num_gradient_steps, num_trials, num_evaluation_trials)\n",
+ " agent_copy = copy.deepcopy(agent) #line[4]; remember that we don't want to change agent's parameters!\n",
+ " score = train_evaluate_agent(env, agent_copy, optimizer_func, num_gradient_steps, num_trials, num_evaluation_trials)\n",
" scores.append(score)\n",
" return np.sum(scores), scores\n",
"\n",
@@ -1196,21 +1198,6 @@
"plot_boxplot_scores(scores)"
]
},
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "execution": {}
- },
- "source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D4_Macrolearning/solutions/W2D4_Tutorial4_Solution_a47b2770.py)\n",
- "\n",
- "*Example output:*\n",
- "\n",
- "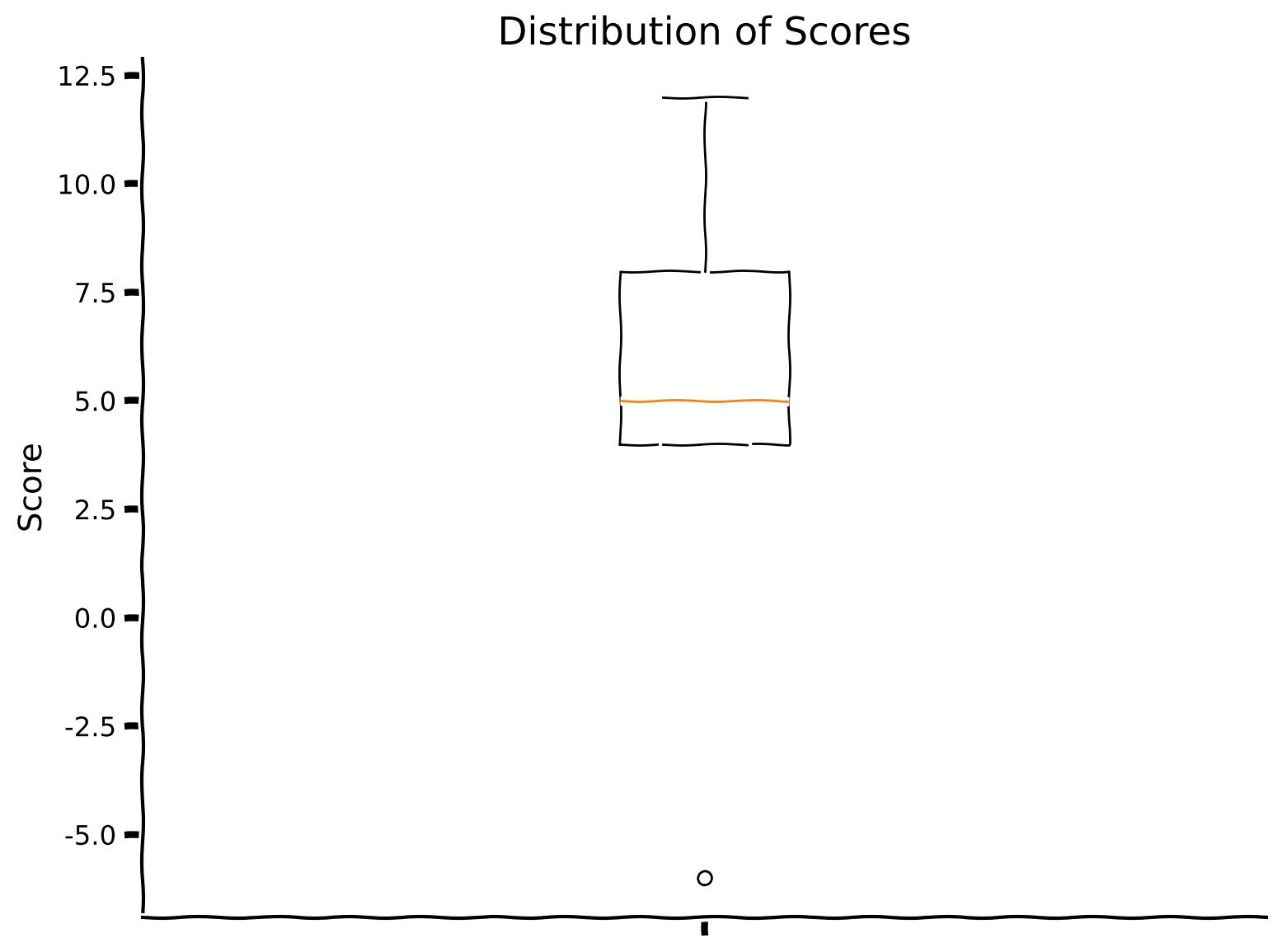 \n",
- "\n"
- ]
- },
{
"cell_type": "markdown",
"metadata": {
@@ -1239,11 +1226,13 @@
"execution": {}
},
"source": [
- "## Coding Exercise 2: Genetic Algorithm\n",
+ "## Coding Exercise 1: Genetic Algorithm\n",
+ "\n",
+ "Genetic algorithms (GA) mimic some of the evolutionary processes while generating better and better (= more desired) individuals in the population. At first, we initialize a population that consists of randomly defined agents (so we have a list of `population_size` A2C agents, which will, in the very end, evolve into agents that quickly learn the new task from the Harlow experiment environment).\n",
"\n",
- "Genetic algorithms (GA) mimic some of the evolutionary processes while generating better and better (= more desired) individuals in the population. At first, we initialize a population that consists of randomly defined agents (so we have a list of `population_size` A2C agents, which will, in the very end, evolve into agents that quickly learn the new task from the Harlow experiment environment). Each epoch (which is the classical term for machine learning) is defined as a generation in GA as we generate new individuals in the population. For each generation, we choose top-score individuals from the population (of size `tournament_size`; it should be big enough to preserve diversity and not too big for selecting top-score ones; this is exactly where selection occurs and it is the only such place in the whole algorithm) and then we select a random batch of these high-performing individuals of size `parents_num`. From those, we create offspring of size `new_generation_new_individuals`, which will replace random individuals from the population. Notice that we replace random individuals with new ones without comparing their performance (it is just one of the paradigms in genetic algorithms). We continue running generations until we are happy with the best-fit individual appearing in the population or until we run out of time (reaching the maximum number of generations).\n",
+ "Each epoch (which is the classical term for machine learning) is defined as a generation in GA as we generate new individuals in the population. For each generation, we choose top-score individuals from the population (of size `tournament_size`). The population size should be big enough to preserve diversity and not too big for selecting top-score ones. This is exactly where selection occurs and it is the only such place in the whole algorithm. We then we select a random batch of these high-performing individuals of size `parents_num`. From those, we create offspring of size `new_generation_new_individuals`, which will replace random individuals from the population. Notice that we replace random individuals with new ones without comparing their performance (it is just one of the paradigms in genetic algorithms). We continue running generations until we are happy with the best-fit individual appearing in the population or until we run out of time. We end when we reach the maximum number of generations.\n",
"\n",
- "The funniest part happens when we create offspring—simulating evolutionary processes, we randomly select two parents (two agents), and for each of the layers in their networks, we randomly select which one will go to the child (simulating crossing over), and then we add Gaussian noise to each of the layers (simulating mutation).\n",
+ "The most interesting part happens when we create offspring—simulating evolutionary processes, we randomly select two parents (two agents), and for each of the layers in their networks, we randomly select which one will go to the child (simulating crossing over), and then we add Gaussian noise to each of the layers (simulating mutation).\n",
"\n",
"The following cells consist of 3 functions:\n",
"\n",
@@ -1607,17 +1596,6 @@
"plot_two_boxplot_scores(newbie_scores, experienced_scores)"
]
},
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "## Why biology needs meta-learning\n",
- "\n",
- "If aspects of the environment change over time, previously learned hard-coded strategies might not work anymore. Still, as in the previous tutorial, these changes share similar features across the tasks. The Harlow experiment illustrates that although there is no direct instruction on how to obtain the maximum possible reward, and the environment's state changes with each new pair of objects, the agent is still able to capture the meta-structure of the experiment—the reward is associated with the object, not its relative placement. Only one trial is needed to identify which of the two new objects is rewarded."
- ]
- },
{
"cell_type": "code",
"execution_count": null,
@@ -1721,6 +1699,19 @@
"\n",
"4. This process creates agents that can quickly find the rewarding object in a Harlow experiment."
]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "# The Big Picture\n",
+ "\n",
+ "If aspects of the environment change over time, previously learned hard-coded strategies might not work anymore. Still, as in the previous tutorial, these changes share similar features across the tasks. The Harlow experiment illustrates that although there is no direct instruction on how to obtain the maximum possible reward, and the environment's state changes with each new pair of objects, the agent is still able to capture the meta-structure of the experiment—the reward is associated with the object, not its relative placement. Only one trial is needed to identify which of the two new objects is rewarded.\n",
+ "\n",
+ "Earlier in this tutorial, we instructed you to skip over the implementation and rationale behind the A2C code. If you have some extra time, why not jump back above and give that section a read in full? Either now or later at your own discretion. We just wanted to remind you that further details were given (but we initially asked you to skip over). If anything is unclear at this stage, it could be a good way to fill in some gaps in your knowledge."
+ ]
}
],
"metadata": {
@@ -1751,7 +1742,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.9.19"
+ "version": "3.9.22"
}
},
"nbformat": 4,
diff --git a/tutorials/W2D4_Macrolearning/student/W2D4_Tutorial5.ipynb b/tutorials/W2D4_Macrolearning/student/W2D4_Tutorial5.ipynb
index 709e4d0de..b09c71def 100644
--- a/tutorials/W2D4_Macrolearning/student/W2D4_Tutorial5.ipynb
+++ b/tutorials/W2D4_Macrolearning/student/W2D4_Tutorial5.ipynb
@@ -16,7 +16,7 @@
"execution": {}
},
"source": [
- "# Tutorial 5: Replay\n",
+ "# (Bonus) Tutorial 5: Replay\n",
"\n",
"**Week 2, Day 4: Macro-Learning**\n",
"\n",
@@ -24,9 +24,9 @@
"\n",
"__Content creators:__ Hlib Solodzhuk, Ximeng Mao, Grace Lindsay\n",
"\n",
- "__Content reviewers:__ Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Hlib Solodzhuk, Ximeng Mao, Grace Lindsay\n",
+ "__Content reviewers:__ Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Hlib Solodzhuk, Ximeng Mao, Grace Lindsay, Alex Murphy\n",
"\n",
- "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk\n"
+ "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk, Alex Murphy\n"
]
},
{
@@ -42,7 +42,9 @@
"\n",
"*Estimated timing of tutorial: 40 minutes*\n",
"\n",
- "In this tutorial, you will discover what replay is and how it helps with continual learning."
+ "Replay in reinforcement learning (RL) refers to the process where agents revisit and learn from past experiences stored in memory, rather than solely from new interactions with their environment. This mirrors how mammals, particularly during sleep, reactivate neural patterns from recent experiences to consolidate memories and extract generalizable patterns. In artificial RL systems, *experience replay* enables more efficient learning by breaking temporal correlations between consecutive experiences and allowing multiple learning updates from single experiences (runs of a series of steps in an RL experiment). This biologically inspired approach has proven crucial for deep RL algorithms like DQN, demonstrating how computational models can both draw from and inform our understanding of biological intelligence.\n",
+ "\n",
+ "In this tutorial, you will discover what replay is and how it helps to solve the continual learning problem we've been investigating over today's tutorials."
]
},
{
@@ -575,9 +577,9 @@
"source": [
"---\n",
"\n",
- "# Section 1: Changing Environment\n",
+ "# Section 1: A Changing Environment\n",
"\n",
- "As mentioned in the video, to study replay, we need to use a slightly different task inspired by the Harlow task, which creates an incentive to remember past data. In this section, we will introduce this new task environment, which replicates the game you played."
+ "As mentioned in the video, to study replay, we need to use a slightly different task inspired by the Harlow task, which creates an incentive to remember past data. In this section, we will introduce this new task environment, which is modelled in a similar way to the game you played in Section 0, above."
]
},
{
@@ -590,7 +592,7 @@
"\n",
"For this tutorial, each state will be represented by its color (via its RGB values; thus, it is a vector of 3 values), and each color is associated with a stable reward that remains unchanged over time (the rewards will correspond to the position of the color in the rainbow).\n",
"\n",
- "While the reward associated with each color does not change over time, the colors presented to the agent will change. Specifically, on each trial, the agent is presented with two colors and should choose the one associated with a higher reward. Initially (in 'mode 1'), colors will be chosen from a set of 3 possible colors. Over time, one of these colors will be replaced by another, creating a different set of three possible colors ('mode 2'). This constitutes a covariate distribution shift and may cause the agent to forget the reward associated with the dropped color."
+ "While the reward associated with each color does not change over time, the colors presented to the agent will change. Specifically, on each trial, the agent is presented with two colors and should choose the one associated with a higher reward. Initially (in 'mode 1'), colors will be chosen from a set of 3 possible colors. Over time, one of these colors will be replaced by another, creating a different set of three possible colors ('mode 2'). This constitutes a distribution shift (specifically: **covariate shift**, which I'm sure you all could instantly recognize!) This may cause the agent to forget the reward associated with the color that was replaced. This would be an instance of catastrophic forgetting in our continual learning setting."
]
},
{
@@ -726,7 +728,7 @@
"source": [
"---\n",
"\n",
- "# Section 2: A2C Agent in Changing Environment\n",
+ "# Section 2: A2C Agent in a Changing Environment\n",
"\n",
"*Estimated timing to here from start of tutorial: 10 minutes*\n",
"\n",
@@ -1004,7 +1006,28 @@
"source": [
"No specific patterns here; the only notable observation (which is also expected) is that whenever colors are close in their rewards, the agent makes more mistakes with those.\n",
"\n",
- "Notice that the blue color is missing, as it is indeed excluded from the first mode. Let us evaluate the agent in the second mode."
+ "Notice that the blue color is missing, as it is indeed excluded from the first mode, as indicated in the code above (repeated here for clarity):\n",
+ "\n",
+ "```python\n",
+ "first_mode = [\"red\", \"yellow\", \"green\"]\n",
+ "second_mode = [\"red\", \"green\", \"blue\"]\n",
+ "```\n",
+ "\n",
+ "Also, notice that the color red was never chosen, as it was never a maximum-reward color. Recall the reward values for the specific colors (again, reproducted below for clarity).\n",
+ "\n",
+ "```python\n",
+ "color_names_rewards = {\n",
+ " \"red\": 1,\n",
+ " \"yellow\": 2,\n",
+ " \"green\": 3,\n",
+ " \"blue\": 4\n",
+ "}\n",
+ "```\n",
+ "\n",
+ "This is why, in the confusion matrix, we never see the color red being picked. In both modes, red always exists in company with a color that has a higher reward.\n",
+ "\n",
+ "\n",
+ "With the details of the confusion matrix hopefully a bit clearer, let us evaluate the agent in the second mode."
]
},
{
@@ -1177,7 +1200,7 @@
"\n",
"*Estimated timing to here from start of tutorial: 25 minutes*\n",
"\n",
- "This section discusses the underlying biological reasoning behind the replay buffer and proposes its code implementation."
+ "This section discusses the underlying biological inspiration behind the replay buffer and proposes a way that in can be implemented in code and used to tackle the issue of catastrophic forgetting during continual learning."
]
},
{
@@ -1516,6 +1539,19 @@
"- Reinforcement learning also suffers from forgetting after learning a new distribution.\n",
"- Replay is a biologically-inspired way to learn from memories of past actions and rewards, thus preventing forgetting."
]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "# The Big Picture\n",
+ "\n",
+ "Replay mechanisms serve as a foundational bridge between past and present knowledge in both biological and artificial learning systems, enabling the critical ability to learn continuously without catastrophically forgetting previous skills. By selectively revisiting and consolidating important experiences, replay helps systems extract generalizable patterns that extend beyond specific tasks or contexts. In biological systems, hippocampal replay during sleep and rest periods allows the brain to transfer episodic memories to neocortical regions where they can inform future behavior across varied situations. Similarly, in artificial systems, experience replay buffers and generative replay techniques significantly improve an agent's ability to transfer knowledge across domains and protect against overfitting to recent experiences.\n",
+ "\n",
+ "We hope that you have found today's tutorials on Macrolearning insightful. There is a lot of material we covered today and we're almost at the end of the course! Tomorrow, our final day of content, will introduce some exciting concepts that are still unsolved and so its appropriately named \"Mysteries\". We will look into more speculative attempts to tackle some of the larger / grander outstanding questions in NeuroAI."
+ ]
}
],
"metadata": {
@@ -1546,7 +1582,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.9.19"
+ "version": "3.9.22"
}
},
"nbformat": 4,
\n",
- "\n"
- ]
- },
{
"cell_type": "markdown",
"metadata": {
@@ -1239,11 +1226,13 @@
"execution": {}
},
"source": [
- "## Coding Exercise 2: Genetic Algorithm\n",
+ "## Coding Exercise 1: Genetic Algorithm\n",
+ "\n",
+ "Genetic algorithms (GA) mimic some of the evolutionary processes while generating better and better (= more desired) individuals in the population. At first, we initialize a population that consists of randomly defined agents (so we have a list of `population_size` A2C agents, which will, in the very end, evolve into agents that quickly learn the new task from the Harlow experiment environment).\n",
"\n",
- "Genetic algorithms (GA) mimic some of the evolutionary processes while generating better and better (= more desired) individuals in the population. At first, we initialize a population that consists of randomly defined agents (so we have a list of `population_size` A2C agents, which will, in the very end, evolve into agents that quickly learn the new task from the Harlow experiment environment). Each epoch (which is the classical term for machine learning) is defined as a generation in GA as we generate new individuals in the population. For each generation, we choose top-score individuals from the population (of size `tournament_size`; it should be big enough to preserve diversity and not too big for selecting top-score ones; this is exactly where selection occurs and it is the only such place in the whole algorithm) and then we select a random batch of these high-performing individuals of size `parents_num`. From those, we create offspring of size `new_generation_new_individuals`, which will replace random individuals from the population. Notice that we replace random individuals with new ones without comparing their performance (it is just one of the paradigms in genetic algorithms). We continue running generations until we are happy with the best-fit individual appearing in the population or until we run out of time (reaching the maximum number of generations).\n",
+ "Each epoch (which is the classical term for machine learning) is defined as a generation in GA as we generate new individuals in the population. For each generation, we choose top-score individuals from the population (of size `tournament_size`). The population size should be big enough to preserve diversity and not too big for selecting top-score ones. This is exactly where selection occurs and it is the only such place in the whole algorithm. We then we select a random batch of these high-performing individuals of size `parents_num`. From those, we create offspring of size `new_generation_new_individuals`, which will replace random individuals from the population. Notice that we replace random individuals with new ones without comparing their performance (it is just one of the paradigms in genetic algorithms). We continue running generations until we are happy with the best-fit individual appearing in the population or until we run out of time. We end when we reach the maximum number of generations.\n",
"\n",
- "The funniest part happens when we create offspring—simulating evolutionary processes, we randomly select two parents (two agents), and for each of the layers in their networks, we randomly select which one will go to the child (simulating crossing over), and then we add Gaussian noise to each of the layers (simulating mutation).\n",
+ "The most interesting part happens when we create offspring—simulating evolutionary processes, we randomly select two parents (two agents), and for each of the layers in their networks, we randomly select which one will go to the child (simulating crossing over), and then we add Gaussian noise to each of the layers (simulating mutation).\n",
"\n",
"The following cells consist of 3 functions:\n",
"\n",
@@ -1607,17 +1596,6 @@
"plot_two_boxplot_scores(newbie_scores, experienced_scores)"
]
},
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "## Why biology needs meta-learning\n",
- "\n",
- "If aspects of the environment change over time, previously learned hard-coded strategies might not work anymore. Still, as in the previous tutorial, these changes share similar features across the tasks. The Harlow experiment illustrates that although there is no direct instruction on how to obtain the maximum possible reward, and the environment's state changes with each new pair of objects, the agent is still able to capture the meta-structure of the experiment—the reward is associated with the object, not its relative placement. Only one trial is needed to identify which of the two new objects is rewarded."
- ]
- },
{
"cell_type": "code",
"execution_count": null,
@@ -1721,6 +1699,19 @@
"\n",
"4. This process creates agents that can quickly find the rewarding object in a Harlow experiment."
]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "# The Big Picture\n",
+ "\n",
+ "If aspects of the environment change over time, previously learned hard-coded strategies might not work anymore. Still, as in the previous tutorial, these changes share similar features across the tasks. The Harlow experiment illustrates that although there is no direct instruction on how to obtain the maximum possible reward, and the environment's state changes with each new pair of objects, the agent is still able to capture the meta-structure of the experiment—the reward is associated with the object, not its relative placement. Only one trial is needed to identify which of the two new objects is rewarded.\n",
+ "\n",
+ "Earlier in this tutorial, we instructed you to skip over the implementation and rationale behind the A2C code. If you have some extra time, why not jump back above and give that section a read in full? Either now or later at your own discretion. We just wanted to remind you that further details were given (but we initially asked you to skip over). If anything is unclear at this stage, it could be a good way to fill in some gaps in your knowledge."
+ ]
}
],
"metadata": {
@@ -1751,7 +1742,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.9.19"
+ "version": "3.9.22"
}
},
"nbformat": 4,
diff --git a/tutorials/W2D4_Macrolearning/student/W2D4_Tutorial5.ipynb b/tutorials/W2D4_Macrolearning/student/W2D4_Tutorial5.ipynb
index 709e4d0de..b09c71def 100644
--- a/tutorials/W2D4_Macrolearning/student/W2D4_Tutorial5.ipynb
+++ b/tutorials/W2D4_Macrolearning/student/W2D4_Tutorial5.ipynb
@@ -16,7 +16,7 @@
"execution": {}
},
"source": [
- "# Tutorial 5: Replay\n",
+ "# (Bonus) Tutorial 5: Replay\n",
"\n",
"**Week 2, Day 4: Macro-Learning**\n",
"\n",
@@ -24,9 +24,9 @@
"\n",
"__Content creators:__ Hlib Solodzhuk, Ximeng Mao, Grace Lindsay\n",
"\n",
- "__Content reviewers:__ Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Hlib Solodzhuk, Ximeng Mao, Grace Lindsay\n",
+ "__Content reviewers:__ Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Hlib Solodzhuk, Ximeng Mao, Grace Lindsay, Alex Murphy\n",
"\n",
- "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk\n"
+ "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk, Alex Murphy\n"
]
},
{
@@ -42,7 +42,9 @@
"\n",
"*Estimated timing of tutorial: 40 minutes*\n",
"\n",
- "In this tutorial, you will discover what replay is and how it helps with continual learning."
+ "Replay in reinforcement learning (RL) refers to the process where agents revisit and learn from past experiences stored in memory, rather than solely from new interactions with their environment. This mirrors how mammals, particularly during sleep, reactivate neural patterns from recent experiences to consolidate memories and extract generalizable patterns. In artificial RL systems, *experience replay* enables more efficient learning by breaking temporal correlations between consecutive experiences and allowing multiple learning updates from single experiences (runs of a series of steps in an RL experiment). This biologically inspired approach has proven crucial for deep RL algorithms like DQN, demonstrating how computational models can both draw from and inform our understanding of biological intelligence.\n",
+ "\n",
+ "In this tutorial, you will discover what replay is and how it helps to solve the continual learning problem we've been investigating over today's tutorials."
]
},
{
@@ -575,9 +577,9 @@
"source": [
"---\n",
"\n",
- "# Section 1: Changing Environment\n",
+ "# Section 1: A Changing Environment\n",
"\n",
- "As mentioned in the video, to study replay, we need to use a slightly different task inspired by the Harlow task, which creates an incentive to remember past data. In this section, we will introduce this new task environment, which replicates the game you played."
+ "As mentioned in the video, to study replay, we need to use a slightly different task inspired by the Harlow task, which creates an incentive to remember past data. In this section, we will introduce this new task environment, which is modelled in a similar way to the game you played in Section 0, above."
]
},
{
@@ -590,7 +592,7 @@
"\n",
"For this tutorial, each state will be represented by its color (via its RGB values; thus, it is a vector of 3 values), and each color is associated with a stable reward that remains unchanged over time (the rewards will correspond to the position of the color in the rainbow).\n",
"\n",
- "While the reward associated with each color does not change over time, the colors presented to the agent will change. Specifically, on each trial, the agent is presented with two colors and should choose the one associated with a higher reward. Initially (in 'mode 1'), colors will be chosen from a set of 3 possible colors. Over time, one of these colors will be replaced by another, creating a different set of three possible colors ('mode 2'). This constitutes a covariate distribution shift and may cause the agent to forget the reward associated with the dropped color."
+ "While the reward associated with each color does not change over time, the colors presented to the agent will change. Specifically, on each trial, the agent is presented with two colors and should choose the one associated with a higher reward. Initially (in 'mode 1'), colors will be chosen from a set of 3 possible colors. Over time, one of these colors will be replaced by another, creating a different set of three possible colors ('mode 2'). This constitutes a distribution shift (specifically: **covariate shift**, which I'm sure you all could instantly recognize!) This may cause the agent to forget the reward associated with the color that was replaced. This would be an instance of catastrophic forgetting in our continual learning setting."
]
},
{
@@ -726,7 +728,7 @@
"source": [
"---\n",
"\n",
- "# Section 2: A2C Agent in Changing Environment\n",
+ "# Section 2: A2C Agent in a Changing Environment\n",
"\n",
"*Estimated timing to here from start of tutorial: 10 minutes*\n",
"\n",
@@ -1004,7 +1006,28 @@
"source": [
"No specific patterns here; the only notable observation (which is also expected) is that whenever colors are close in their rewards, the agent makes more mistakes with those.\n",
"\n",
- "Notice that the blue color is missing, as it is indeed excluded from the first mode. Let us evaluate the agent in the second mode."
+ "Notice that the blue color is missing, as it is indeed excluded from the first mode, as indicated in the code above (repeated here for clarity):\n",
+ "\n",
+ "```python\n",
+ "first_mode = [\"red\", \"yellow\", \"green\"]\n",
+ "second_mode = [\"red\", \"green\", \"blue\"]\n",
+ "```\n",
+ "\n",
+ "Also, notice that the color red was never chosen, as it was never a maximum-reward color. Recall the reward values for the specific colors (again, reproducted below for clarity).\n",
+ "\n",
+ "```python\n",
+ "color_names_rewards = {\n",
+ " \"red\": 1,\n",
+ " \"yellow\": 2,\n",
+ " \"green\": 3,\n",
+ " \"blue\": 4\n",
+ "}\n",
+ "```\n",
+ "\n",
+ "This is why, in the confusion matrix, we never see the color red being picked. In both modes, red always exists in company with a color that has a higher reward.\n",
+ "\n",
+ "\n",
+ "With the details of the confusion matrix hopefully a bit clearer, let us evaluate the agent in the second mode."
]
},
{
@@ -1177,7 +1200,7 @@
"\n",
"*Estimated timing to here from start of tutorial: 25 minutes*\n",
"\n",
- "This section discusses the underlying biological reasoning behind the replay buffer and proposes its code implementation."
+ "This section discusses the underlying biological inspiration behind the replay buffer and proposes a way that in can be implemented in code and used to tackle the issue of catastrophic forgetting during continual learning."
]
},
{
@@ -1516,6 +1539,19 @@
"- Reinforcement learning also suffers from forgetting after learning a new distribution.\n",
"- Replay is a biologically-inspired way to learn from memories of past actions and rewards, thus preventing forgetting."
]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "# The Big Picture\n",
+ "\n",
+ "Replay mechanisms serve as a foundational bridge between past and present knowledge in both biological and artificial learning systems, enabling the critical ability to learn continuously without catastrophically forgetting previous skills. By selectively revisiting and consolidating important experiences, replay helps systems extract generalizable patterns that extend beyond specific tasks or contexts. In biological systems, hippocampal replay during sleep and rest periods allows the brain to transfer episodic memories to neocortical regions where they can inform future behavior across varied situations. Similarly, in artificial systems, experience replay buffers and generative replay techniques significantly improve an agent's ability to transfer knowledge across domains and protect against overfitting to recent experiences.\n",
+ "\n",
+ "We hope that you have found today's tutorials on Macrolearning insightful. There is a lot of material we covered today and we're almost at the end of the course! Tomorrow, our final day of content, will introduce some exciting concepts that are still unsolved and so its appropriately named \"Mysteries\". We will look into more speculative attempts to tackle some of the larger / grander outstanding questions in NeuroAI."
+ ]
}
],
"metadata": {
@@ -1546,7 +1582,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.9.19"
+ "version": "3.9.22"
}
},
"nbformat": 4,