diff --git a/tutorials/README.md b/tutorials/README.md
index e5bcba111..6f7d39c4b 100644
--- a/tutorials/README.md
+++ b/tutorials/README.md
@@ -120,6 +120,8 @@ Slides: [Intro](https://mfr.ca-1.osf.io/render?url=https://osf.io/nxzar/?direct%
| Tutorial 1 | [](https://colab.research.google.com/github/neuromatch/NeuroAI_Course/blob/main/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial1.ipynb) | [](https://kaggle.com/kernels/welcome?src=https://raw.githubusercontent.com/neuromatch/NeuroAI_Course/main/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial1.ipynb) | [](https://nbviewer.jupyter.org/github/neuromatch/NeuroAI_Course/blob/main/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial1.ipynb?flush_cache=true) |
| Tutorial 2 | [](https://colab.research.google.com/github/neuromatch/NeuroAI_Course/blob/main/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial2.ipynb) | [](https://kaggle.com/kernels/welcome?src=https://raw.githubusercontent.com/neuromatch/NeuroAI_Course/main/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial2.ipynb) | [](https://nbviewer.jupyter.org/github/neuromatch/NeuroAI_Course/blob/main/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial2.ipynb?flush_cache=true) |
| Tutorial 3 | [](https://colab.research.google.com/github/neuromatch/NeuroAI_Course/blob/main/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial3.ipynb) | [](https://kaggle.com/kernels/welcome?src=https://raw.githubusercontent.com/neuromatch/NeuroAI_Course/main/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial3.ipynb) | [](https://nbviewer.jupyter.org/github/neuromatch/NeuroAI_Course/blob/main/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial3.ipynb?flush_cache=true) |
+| Tutorial 4 | [](https://colab.research.google.com/github/neuromatch/NeuroAI_Course/blob/main/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial4.ipynb) | [](https://kaggle.com/kernels/welcome?src=https://raw.githubusercontent.com/neuromatch/NeuroAI_Course/main/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial4.ipynb) | [](https://nbviewer.jupyter.org/github/neuromatch/NeuroAI_Course/blob/main/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial4.ipynb?flush_cache=true) |
+| Tutorial 5 | [](https://colab.research.google.com/github/neuromatch/NeuroAI_Course/blob/main/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial5.ipynb) | [](https://kaggle.com/kernels/welcome?src=https://raw.githubusercontent.com/neuromatch/NeuroAI_Course/main/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial5.ipynb) | [](https://nbviewer.jupyter.org/github/neuromatch/NeuroAI_Course/blob/main/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial5.ipynb?flush_cache=true) |
| Outro | [](https://colab.research.google.com/github/neuromatch/NeuroAI_Course/blob/main/tutorials/W2D2_NeuroSymbolicMethods/W2D2_Outro.ipynb) | [](https://kaggle.com/kernels/welcome?src=https://raw.githubusercontent.com/neuromatch/NeuroAI_Course/main/tutorials/W2D2_NeuroSymbolicMethods/W2D2_Outro.ipynb) | [](https://nbviewer.jupyter.org/github/neuromatch/NeuroAI_Course/blob/main/tutorials/W2D2_NeuroSymbolicMethods/W2D2_Outro.ipynb?flush_cache=true) |
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/README.md b/tutorials/W2D2_NeuroSymbolicMethods/README.md
index 09ab68d0d..582dc5fb5 100644
--- a/tutorials/W2D2_NeuroSymbolicMethods/README.md
+++ b/tutorials/W2D2_NeuroSymbolicMethods/README.md
@@ -8,6 +8,8 @@
| Tutorial 1 | [](https://colab.research.google.com/github/neuromatch/NeuroAI_Course/blob/main/tutorials/W2D2_NeuroSymbolicMethods/instructor/W2D2_Tutorial1.ipynb) | [](https://kaggle.com/kernels/welcome?src=https://raw.githubusercontent.com/neuromatch/NeuroAI_Course/main/tutorials/W2D2_NeuroSymbolicMethods/instructor/W2D2_Tutorial1.ipynb) | [](https://nbviewer.jupyter.org/github/neuromatch/NeuroAI_Course/blob/main/tutorials/W2D2_NeuroSymbolicMethods/instructor/W2D2_Tutorial1.ipynb?flush_cache=true) |
| Tutorial 2 | [](https://colab.research.google.com/github/neuromatch/NeuroAI_Course/blob/main/tutorials/W2D2_NeuroSymbolicMethods/instructor/W2D2_Tutorial2.ipynb) | [](https://kaggle.com/kernels/welcome?src=https://raw.githubusercontent.com/neuromatch/NeuroAI_Course/main/tutorials/W2D2_NeuroSymbolicMethods/instructor/W2D2_Tutorial2.ipynb) | [](https://nbviewer.jupyter.org/github/neuromatch/NeuroAI_Course/blob/main/tutorials/W2D2_NeuroSymbolicMethods/instructor/W2D2_Tutorial2.ipynb?flush_cache=true) |
| Tutorial 3 | [](https://colab.research.google.com/github/neuromatch/NeuroAI_Course/blob/main/tutorials/W2D2_NeuroSymbolicMethods/instructor/W2D2_Tutorial3.ipynb) | [](https://kaggle.com/kernels/welcome?src=https://raw.githubusercontent.com/neuromatch/NeuroAI_Course/main/tutorials/W2D2_NeuroSymbolicMethods/instructor/W2D2_Tutorial3.ipynb) | [](https://nbviewer.jupyter.org/github/neuromatch/NeuroAI_Course/blob/main/tutorials/W2D2_NeuroSymbolicMethods/instructor/W2D2_Tutorial3.ipynb?flush_cache=true) |
+| Tutorial 4 | [](https://colab.research.google.com/github/neuromatch/NeuroAI_Course/blob/main/tutorials/W2D2_NeuroSymbolicMethods/instructor/W2D2_Tutorial4.ipynb) | [](https://kaggle.com/kernels/welcome?src=https://raw.githubusercontent.com/neuromatch/NeuroAI_Course/main/tutorials/W2D2_NeuroSymbolicMethods/instructor/W2D2_Tutorial4.ipynb) | [](https://nbviewer.jupyter.org/github/neuromatch/NeuroAI_Course/blob/main/tutorials/W2D2_NeuroSymbolicMethods/instructor/W2D2_Tutorial4.ipynb?flush_cache=true) |
+| Tutorial 5 | [](https://colab.research.google.com/github/neuromatch/NeuroAI_Course/blob/main/tutorials/W2D2_NeuroSymbolicMethods/instructor/W2D2_Tutorial5.ipynb) | [](https://kaggle.com/kernels/welcome?src=https://raw.githubusercontent.com/neuromatch/NeuroAI_Course/main/tutorials/W2D2_NeuroSymbolicMethods/instructor/W2D2_Tutorial5.ipynb) | [](https://nbviewer.jupyter.org/github/neuromatch/NeuroAI_Course/blob/main/tutorials/W2D2_NeuroSymbolicMethods/instructor/W2D2_Tutorial5.ipynb?flush_cache=true) |
| Outro | [](https://colab.research.google.com/github/neuromatch/NeuroAI_Course/blob/main/tutorials/W2D2_NeuroSymbolicMethods/W2D2_Outro.ipynb) | [](https://kaggle.com/kernels/welcome?src=https://raw.githubusercontent.com/neuromatch/NeuroAI_Course/main/tutorials/W2D2_NeuroSymbolicMethods/W2D2_Outro.ipynb) | [](https://nbviewer.jupyter.org/github/neuromatch/NeuroAI_Course/blob/main/tutorials/W2D2_NeuroSymbolicMethods/W2D2_Outro.ipynb?flush_cache=true) |
@@ -19,5 +21,7 @@
| Tutorial 1 | [](https://colab.research.google.com/github/neuromatch/NeuroAI_Course/blob/main/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial1.ipynb) | [](https://kaggle.com/kernels/welcome?src=https://raw.githubusercontent.com/neuromatch/NeuroAI_Course/main/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial1.ipynb) | [](https://nbviewer.jupyter.org/github/neuromatch/NeuroAI_Course/blob/main/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial1.ipynb?flush_cache=true) |
| Tutorial 2 | [](https://colab.research.google.com/github/neuromatch/NeuroAI_Course/blob/main/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial2.ipynb) | [](https://kaggle.com/kernels/welcome?src=https://raw.githubusercontent.com/neuromatch/NeuroAI_Course/main/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial2.ipynb) | [](https://nbviewer.jupyter.org/github/neuromatch/NeuroAI_Course/blob/main/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial2.ipynb?flush_cache=true) |
| Tutorial 3 | [](https://colab.research.google.com/github/neuromatch/NeuroAI_Course/blob/main/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial3.ipynb) | [](https://kaggle.com/kernels/welcome?src=https://raw.githubusercontent.com/neuromatch/NeuroAI_Course/main/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial3.ipynb) | [](https://nbviewer.jupyter.org/github/neuromatch/NeuroAI_Course/blob/main/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial3.ipynb?flush_cache=true) |
+| Tutorial 4 | [](https://colab.research.google.com/github/neuromatch/NeuroAI_Course/blob/main/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial4.ipynb) | [](https://kaggle.com/kernels/welcome?src=https://raw.githubusercontent.com/neuromatch/NeuroAI_Course/main/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial4.ipynb) | [](https://nbviewer.jupyter.org/github/neuromatch/NeuroAI_Course/blob/main/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial4.ipynb?flush_cache=true) |
+| Tutorial 5 | [](https://colab.research.google.com/github/neuromatch/NeuroAI_Course/blob/main/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial5.ipynb) | [](https://kaggle.com/kernels/welcome?src=https://raw.githubusercontent.com/neuromatch/NeuroAI_Course/main/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial5.ipynb) | [](https://nbviewer.jupyter.org/github/neuromatch/NeuroAI_Course/blob/main/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial5.ipynb?flush_cache=true) |
| Outro | [](https://colab.research.google.com/github/neuromatch/NeuroAI_Course/blob/main/tutorials/W2D2_NeuroSymbolicMethods/W2D2_Outro.ipynb) | [](https://kaggle.com/kernels/welcome?src=https://raw.githubusercontent.com/neuromatch/NeuroAI_Course/main/tutorials/W2D2_NeuroSymbolicMethods/W2D2_Outro.ipynb) | [](https://nbviewer.jupyter.org/github/neuromatch/NeuroAI_Course/blob/main/tutorials/W2D2_NeuroSymbolicMethods/W2D2_Outro.ipynb?flush_cache=true) |
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/W2D2_Intro.ipynb b/tutorials/W2D2_NeuroSymbolicMethods/W2D2_Intro.ipynb
index 218b77e69..5a0275059 100644
--- a/tutorials/W2D2_NeuroSymbolicMethods/W2D2_Intro.ipynb
+++ b/tutorials/W2D2_NeuroSymbolicMethods/W2D2_Intro.ipynb
@@ -18,7 +18,9 @@
}
},
"source": [
- "# Intro"
+ "# W2D2 - Neurosymbolic Methods and Cognitive Architectures \n",
+ "\n",
+ "Welcome to the day on Neurosymbolic Methods and Cognitive Architectures. This year we have some new content to introduce to you from the fascinating work by Chris Eliasmith and Michael Furlong. We're going to look at methods that use symbolic manipulation in order to learn how to model data in a way that is more brain-like and generalizes well to stimuli out of distribution. We're also going to look in some detail at a model they have created, called SPAUN. Please consider the note in the prerequisite cell below and try to have a basic understanding of those listed topics before getting into the details. The topic will be much clearer having brushed up on those topics. We'll now pass it over to Chris and Michael to tell you all about neurosymbolic methods and cognitive architectures!"
]
},
{
@@ -123,7 +125,7 @@
" return tab_contents\n",
"\n",
"\n",
- "video_ids = [('Youtube', 'RKKUfo0dVnY'), ('Bilibili', 'BV11D421M7Hy')]\n",
+ "video_ids = [('Youtube', 'W1jsRycDYXQ'), ('Bilibili', 'BV15V7jz8EAj')]\n",
"tab_contents = display_videos(video_ids, W=854, H=480)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
@@ -172,7 +174,7 @@
"from ipywidgets import widgets\n",
"out = widgets.Output()\n",
"\n",
- "link_id = \"nxzar\"\n",
+ "link_id = \"9w836\"\n",
"\n",
"with out:\n",
" print(f\"If you want to download the slides: https://osf.io/download/{link_id}/\")\n",
@@ -209,7 +211,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.9.19"
+ "version": "3.9.22"
}
},
"nbformat": 4,
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/W2D2_Tutorial1.ipynb b/tutorials/W2D2_NeuroSymbolicMethods/W2D2_Tutorial1.ipynb
index d97ac6c98..8e895d5cd 100644
--- a/tutorials/W2D2_NeuroSymbolicMethods/W2D2_Tutorial1.ipynb
+++ b/tutorials/W2D2_NeuroSymbolicMethods/W2D2_Tutorial1.ipynb
@@ -25,9 +25,9 @@
"\n",
"__Content creators:__ P. Michael Furlong, Chris Eliasmith\n",
"\n",
- "__Content reviewers:__ Hlib Solodzhuk, Patrick Mineault, Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi\n",
+ "__Content reviewers:__ Hlib Solodzhuk, Patrick Mineault, Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Alex Murphy\n",
"\n",
- "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk\n"
+ "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk, Alex Murphy\n"
]
},
{
@@ -43,7 +43,7 @@
"\n",
"*Estimated timing of tutorial: 1 hour*\n",
"\n",
- "In this tutorial we will introduce vector symbolic algebra and discuss its main operations."
+ "In this tutorial we will introduce the concept of a vector symbolic algebra (VSA) and discuss its main operations and we will give you some demonstrations on a simple set of concepts (shapes and their colors) in order to let you see and play around with concept manipulations in this VSA! Let's get started!"
]
},
{
@@ -59,7 +59,7 @@
"# @markdown These are the slides for the videos in all tutorials today\n",
"\n",
"from IPython.display import IFrame\n",
- "link_id = \"2szmk\"\n",
+ "link_id = \"jybuw\"\n",
"\n",
"print(f\"If you want to download the slides: 'https://osf.io/download/{link_id}'\")\n",
"\n",
@@ -73,8 +73,11 @@
},
"source": [
"---\n",
- "# Setup\n",
- "\n"
+ "# Setup (Colab Users: Please Read)\n",
+ "\n",
+ "Note that because this tutorial relies on some special Python packages, these packages have requirements for specific versions of common scientific libraries, such as `numpy`. If you're in Google Colab, then as of May 2025, this comes with a later version (2.0.2) pre-installed. We require an older version (we'll be installing `1.24.4`). This causes Colab to force a session restart and then re-running of the installation cells for the new version to take effect. When you run the cell below, you will be prompted to restart the session. This is *entirely expected* and you haven't done anything wrong. Simply click 'Restart' and then run the cells as normal. \n",
+ "\n",
+ "An additional error might sometimes arise where an exception is raised connected to a missing element of NumPy. If this occurs, please restart the session and re-run the cells as normal and this error will go away. Updated versions of the affected libraries are expected out soon, but sadly not in time for the preparation of this material. We thank you for your understanding."
]
},
{
@@ -88,7 +91,10 @@
"source": [
"# @title Install and import feedback gadget\n",
"\n",
- "!pip install --quiet numpy matplotlib ipywidgets scipy vibecheck\n",
+ "!pip install git+https://github.com/neuromatch/sspspace@neuromatch --quiet\n",
+ "!pip install numpy==1.24.4\n",
+ "!pip install nengo_spa==2.0.0\n",
+ "!pip install --quiet matplotlib ipywidgets scipy vibecheck\n",
"\n",
"from vibecheck import DatatopsContentReviewContainer\n",
"def content_review(notebook_section: str):\n",
@@ -106,30 +112,6 @@
"feedback_prefix = \"W2D2_T1\""
]
},
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Notice that exactly the `neuromatch` branch of `sspspace` should be installed! Otherwise, some of the functionality won't work."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Install dependencies\n",
- "\n",
- "# Install sspspace\n",
- "!pip install git+https://github.com/neuromatch/sspspace@neuromatch --quiet"
- ]
- },
{
"cell_type": "code",
"execution_count": null,
@@ -153,6 +135,7 @@
"\n",
"#modeling\n",
"import sspspace\n",
+ "import nengo_spa as spa\n",
"from scipy.special import softmax"
]
},
@@ -284,7 +267,7 @@
" - title (str): title of the plot.\n",
" \"\"\"\n",
" with plt.xkcd():\n",
- " plt.plot(x_range, sim_mat)\n",
+ " plt.plot(x_range, sims)\n",
" plt.xlabel('x')\n",
" plt.ylabel('Similarity')\n",
" plt.title(title)"
@@ -313,90 +296,6 @@
"set_seed(seed = 42)"
]
},
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Helper functions\n",
- "\n",
- "# mainly contains solutions to exercises for correct plot output; please don't take a look!\n",
- "set_seed(42)\n",
- "\n",
- "vector_length = 1024\n",
- "symbol_names = ['circle','square','triangle']\n",
- "discrete_space = sspspace.DiscreteSPSpace(symbol_names, ssp_dim=vector_length, optimize = False)\n",
- "\n",
- "circle = discrete_space.encode('circle')\n",
- "square = discrete_space.encode('square')\n",
- "triangle = discrete_space.encode('triangle')\n",
- "\n",
- "shape = (circle + square + triangle).normalize()\n",
- "\n",
- "shape_sim_mat = np.zeros((4,4))\n",
- "\n",
- "shape_sim_mat[0,0] = (circle | circle).item()\n",
- "shape_sim_mat[1,1] = (square | square).item()\n",
- "shape_sim_mat[2,2] = (triangle | triangle).item()\n",
- "shape_sim_mat[3,3] = (shape | shape).item()\n",
- "\n",
- "shape_sim_mat[0,1] = shape_sim_mat[1,0] = (circle | square).item()\n",
- "shape_sim_mat[0,2] = shape_sim_mat[2,0] = (circle | triangle).item()\n",
- "shape_sim_mat[0,3] = shape_sim_mat[3,0] = (circle | shape).item()\n",
- "\n",
- "shape_sim_mat[1,2] = shape_sim_mat[2,1] = (square | triangle).item()\n",
- "shape_sim_mat[1,3] = shape_sim_mat[3,1] = (square | shape).item()\n",
- "\n",
- "shape_sim_mat[2,3] = shape_sim_mat[3,2] = (triangle | shape).item()\n",
- "\n",
- "new_symbol_names = ['circle','square','triangle', 'red', 'blue', 'green']\n",
- "new_discrete_space = sspspace.DiscreteSPSpace(new_symbol_names, ssp_dim=vector_length, optimize=False)\n",
- "\n",
- "objs = {n:new_discrete_space.encode(np.array([n])) for n in new_symbol_names}\n",
- "\n",
- "objs['red*circle'] = objs['red'] * objs['circle']\n",
- "objs['blue*triangle'] = objs['blue'] * objs['triangle']\n",
- "objs['green*square'] = objs['green'] * objs['square']\n",
- "\n",
- "new_object_names = ['red','red^','red*circle','circle','circle^']\n",
- "new_objs = objs.copy()\n",
- "\n",
- "new_objs['red^'] = new_objs['red*circle'] * ~new_objs['circle']\n",
- "new_objs['circle^'] = new_objs['red*circle'] * ~new_objs['red']\n",
- "\n",
- "axis_vectors = ['one']\n",
- "\n",
- "encoder = sspspace.DiscreteSPSpace(axis_vectors, ssp_dim=1024, optimize=False)\n",
- "\n",
- "vocab = {w:encoder.encode(w) for w in axis_vectors}\n",
- "\n",
- "integers = [vocab['one']]\n",
- "\n",
- "max_int = 5\n",
- "for i in range(2, max_int + 1):\n",
- " integers.append(integers[-1] * vocab['one'])\n",
- "\n",
- "integers = np.array(integers).squeeze()\n",
- "integer_sims = integers @ integers.T\n",
- "\n",
- "five_unbind_two = sspspace.SSP(integers[4]) * ~sspspace.SSP(integers[1])\n",
- "five_unbind_two_sims = five_unbind_two @ integers.T\n",
- "\n",
- "new_encoder = sspspace.RandomSSPSpace(domain_dim=1, ssp_dim=1024)\n",
- "\n",
- "xs = np.linspace(-4,4,401)[:,None]\n",
- "phis = new_encoder.encode(xs)\n",
- "\n",
- "real_line_sims = phis[200, :] @ phis.T\n",
- "\n",
- "phi_shifted = phis[200,:][None,:] * new_encoder.encode([[np.pi/2]])\n",
- "shifted_real_line_sims = phi_shifted.flatten() @ phis.T"
- ]
- },
{
"cell_type": "markdown",
"metadata": {
@@ -485,11 +384,27 @@
"source": [
"## Coding Exercise 1: Concepts as High-Dimensional Vectors\n",
"\n",
- "In an arbitrary space of concepts, we will represent the ideas of 'circle,' 'square,' and triangle.' For that, we will use the SSP space library (`sspspace`) to map identifiers for the concepts (strings of their names in this case) into high-dimensional vectors of unit length. It means that for each `name`, we will uniquely identify $\\mathbf{v}$ where $||\\mathbf{v}|| = 1$.\n",
+ "In an arbitrary space of concepts, we will represent the ideas of `CIRCLE`, `SQUARE` and `TRIANGLE`. For that, we will make a vocabulary that map identifiers of the concepts (strings of their names in this case) into high-dimensional vectors of unit length. It means that for each `name`, we will uniquely identify $\\mathbf{v}$ where $||\\mathbf{v}|| = 1$.\n",
"\n",
"In this exercise, check that, indeed, vectors are of unit length."
]
},
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "from nengo_spa.algebras.hrr_algebra import HrrProperties, HrrAlgebra\n",
+ "from nengo_spa.vector_generation import VectorsWithProperties\n",
+ "def make_vocabulary(vector_length):\n",
+ " vec_generator = VectorsWithProperties(vector_length, algebra=HrrAlgebra(), properties = [HrrProperties.UNITARY, HrrProperties.POSITIVE])\n",
+ " vocab = spa.Vocabulary(vector_length, pointer_gen=vec_generator)\n",
+ " return vocab"
+ ]
+ },
{
"cell_type": "code",
"execution_count": null,
@@ -510,16 +425,19 @@
"set_seed(42)\n",
"\n",
"vector_length = 1024\n",
- "symbol_names = ['circle','square','triangle']\n",
- "discrete_space = sspspace.DiscreteSPSpace(symbol_names, ssp_dim=vector_length, optimize = False)\n",
+ "symbol_names = ['CIRCLE','SQUARE','TRIANGLE']\n",
+ "\n",
+ "vocab = make_vocabulary(vector_length)\n",
+ "vocab.populate(';'.join(symbol_names))\n",
+ "print(list(vocab.keys()))\n",
"\n",
- "circle = discrete_space.encode('circle')\n",
- "square = discrete_space.encode('square')\n",
- "triangle = discrete_space.encode('triangle')\n",
+ "circle = vocab['CIRCLE']\n",
+ "square = vocab['SQUARE']\n",
+ "triangle = vocab['TRIANGLE']\n",
"\n",
- "print('|circle| =', np.linalg.norm(circle))\n",
- "print('|triangle| =', np.linalg.norm(...))\n",
- "print('|square| =', ...)"
+ "print('|circle| =', np.linalg.norm(circle.v))\n",
+ "print('|triangle| =', np.linalg.norm(square.v))\n",
+ "print('|square| =', np.linalg.norm(triangle.v))"
]
},
{
@@ -535,16 +453,19 @@
"set_seed(42)\n",
"\n",
"vector_length = 1024\n",
- "symbol_names = ['circle','square','triangle']\n",
- "discrete_space = sspspace.DiscreteSPSpace(symbol_names, ssp_dim=vector_length, optimize = False)\n",
+ "symbol_names = ['CIRCLE','SQUARE','TRIANGLE']\n",
"\n",
- "circle = discrete_space.encode('circle')\n",
- "square = discrete_space.encode('square')\n",
- "triangle = discrete_space.encode('triangle')\n",
+ "vocab = make_vocabulary(vector_length)\n",
+ "vocab.populate(';'.join(symbol_names))\n",
+ "print(list(vocab.keys()))\n",
"\n",
- "print('|circle| =', np.linalg.norm(circle))\n",
- "print('|triangle| =', np.linalg.norm(triangle))\n",
- "print('|square| =', np.linalg.norm(square))"
+ "circle = vocab['CIRCLE']\n",
+ "square = vocab['SQUARE']\n",
+ "triangle = vocab['TRIANGLE']\n",
+ "\n",
+ "print('|circle| =', np.linalg.norm(circle.v))\n",
+ "print('|triangle| =', np.linalg.norm(square.v))\n",
+ "print('|square| =', np.linalg.norm(triangle.v))"
]
},
{
@@ -564,7 +485,7 @@
},
"outputs": [],
"source": [
- "plot_vectors([circle, square, triangle], symbol_names)"
+ "plot_vectors([circle.v, square.v, triangle.v], symbol_names)"
]
},
{
@@ -573,13 +494,13 @@
"execution": {}
},
"source": [
- "As vectors are assigned randomly, the images do not display any meaningful structure.\n",
+ "As vectors are initialized randomly, it's perfectly expected that there is no visual connection to how we would represent or expect those concepts to be represented.\n",
"\n",
- "One of the most useful properties of random high-dimensional vectors is that they are approximately orthogonal. This is an important aspect for vector symbolic algebras (VSAs) since we will use the vector dot product to measure similarity between objects encoded as random, high-dimensional vectors. \n",
+ "One of the extremely useful properties of random high-dimensional vectors is that they are approximately orthogonal. This is an important aspect for vector symbolic algebras (VSAs), since we will use the vector dot product to measure similarity between objects encoded as random, high-dimensional vectors.\n",
"\n",
- "Discrete objects are either the same or different, so we expect similarity would be either 1 (the same) or 0 (not the same). Given how we select the vectors that represent discrete symbols if they are the same, they will have the dot product of 1, and if they are different concepts, then they will have a dot product of (approximately) 0.\n",
+ "Discrete objects are either the same or different, so we expect similarity would be either 1 (the same) or 0 (not the same). Given how we select the vectors that represent discrete symbols, if they are the same they will have the dot product of 1 and if they are different concepts, then they will have a dot product of (approximately) 0. This is due to the approximate orthogonality of randomly selected high-dimensional vectors.\n",
"\n",
- "Below, we use the | operator to indicate similarity. This is borrowed from the bra-ket notation in physics, i.e.,\n",
+ "Below we use the | operator to indicate similarity. This is borrowed from the bra-ket notation in physics, i.e.,\n",
"\n",
"$$\n",
"\\mathbf{a}\\cdot\\mathbf{b} = \\langle \\mathbf{a} \\mid \\mathbf{b}\\rangle\n",
@@ -596,17 +517,17 @@
},
"outputs": [],
"source": [
- "concepts_sim_mat = np.zeros((3,3))\n",
+ "sim_mat = np.zeros((3,3))\n",
"\n",
- "concepts_sim_mat[0,0] = (circle | circle).item()\n",
- "concepts_sim_mat[1,1] = (square | square).item()\n",
- "concepts_sim_mat[2,2] = (triangle | triangle).item()\n",
+ "sim_mat[0,0] = spa.dot(circle, circle)\n",
+ "sim_mat[1,1] = spa.dot(square, square)\n",
+ "sim_mat[2,2] = spa.dot(triangle, triangle)\n",
"\n",
- "concepts_sim_mat[0,1] = concepts_sim_mat[1,0] = (circle | square).item()\n",
- "concepts_sim_mat[0,2] = concepts_sim_mat[2,0] = (circle | triangle).item()\n",
- "concepts_sim_mat[1,2] = concepts_sim_mat[2,1] = (square | triangle).item()\n",
+ "sim_mat[0,1] = sim_mat[1,0] = spa.dot(circle, square)\n",
+ "sim_mat[0,2] = sim_mat[2,0] = spa.dot(circle, triangle)\n",
+ "sim_mat[1,2] = sim_mat[2,1] = spa.dot(square, triangle)\n",
"\n",
- "plot_similarity_matrix(concepts_sim_mat, symbol_names)"
+ "plot_similarity_matrix(sim_mat, symbol_names)"
]
},
{
@@ -618,6 +539,34 @@
"As you can see from the above figure, the three randomly selected vectors are approximately orthogonal. This will be important later when we go to make more complicated objects from our vectors."
]
},
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "### Coding Exercise 1 Discussion\n",
+ "\n",
+ "1. How would you provide intuitive reasoning (or rigorous mathematical proof) behind the fact that random high-dimensional vectors (note that each of the components is drawn from uniform distribution with zero mean) approximately orthogonal?"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "#to_remove explanation\n",
+ "\n",
+ "\"\"\"\n",
+ "Discussion: How would you provide intuitive reasoning or rigorous mathematical proof behind the fact that random high-dimensional vectors (note that each of the components is drawn from uniform distribution with zero mean) approximately orthogonal?\n",
+ "\n",
+ "Observe that as each of the components are independent and they are sampled from distribution with zero mean, it means that expected value of dot product E(x*y) = E(\\sum_i x_i * y_i) = (linearity of expectation) \\sum_i E(x_i * y_i) = (independence) \\sum_i (E(x_i) * E(y_i)) = 0.\n",
+ "\"\"\";"
+ ]
+ },
{
"cell_type": "code",
"execution_count": null,
@@ -732,7 +681,7 @@
},
"outputs": [],
"source": [
- "shape = (circle + square + triangle).normalize()"
+ "shape = (circle + square + triangle).normalized()"
]
},
{
@@ -759,21 +708,20 @@
"raise NotImplementedError(\"Student exercise: complete calcualtion of similarity matrix.\")\n",
"###################################################################\n",
"\n",
- "shape_sim_mat = np.zeros((4,4))\n",
- "\n",
- "shape_sim_mat[0,0] = (circle | circle).item()\n",
- "shape_sim_mat[1,1] = (square | square).item()\n",
- "shape_sim_mat[2,2] = (triangle | ...).item()\n",
- "shape_sim_mat[3,3] = (shape | ...).item()\n",
+ "sim_mat = np.zeros((4,4))\n",
"\n",
- "shape_sim_mat[0,1] = shape_sim_mat[1,0] = (circle | square).item()\n",
- "shape_sim_mat[0,2] = shape_sim_mat[2,0] = (circle | triangle).item()\n",
- "shape_sim_mat[0,3] = shape_sim_mat[3,0] = (circle | shape).item()\n",
+ "sim_mat[0,0] = spa.dot(circle, circle)\n",
+ "sim_mat[1,1] = spa.dot(square, square)\n",
+ "sim_mat[2,2] = spa.dot(triangle, ...)\n",
+ "sim_mat[3,3] = spa.dot(shape, ...)\n",
"\n",
- "shape_sim_mat[1,2] = shape_sim_mat[2,1] = (square | triangle).item()\n",
- "shape_sim_mat[1,3] = shape_sim_mat[3,1] = (square | shape).item()\n",
+ "sim_mat[0,1] = sim_mat[1,0] = spa.dot(circle, square)\n",
+ "sim_mat[0,2] = sim_mat[2,0] = spa.dot(circle, triangle)\n",
+ "sim_mat[0,3] = sim_mat[3,0] = spa.dot(circle, shape)\n",
"\n",
- "shape_sim_mat[2,3] = shape_sim_mat[3,2] = (... | ...).item()"
+ "sim_mat[1,2] = sim_mat[2,1] = spa.dot(square, triangle)\n",
+ "sim_mat[1,3] = sim_mat[3,1] = spa.dot(square, shape)\n",
+ "sim_mat[2,3] = sim_mat[3,2] = spa.dot(..., shape)"
]
},
{
@@ -786,21 +734,20 @@
"source": [
"# to_remove solution\n",
"\n",
- "shape_sim_mat = np.zeros((4,4))\n",
+ "sim_mat = np.zeros((4,4))\n",
"\n",
- "shape_sim_mat[0,0] = (circle | circle).item()\n",
- "shape_sim_mat[1,1] = (square | square).item()\n",
- "shape_sim_mat[2,2] = (triangle | triangle).item()\n",
- "shape_sim_mat[3,3] = (shape | shape).item()\n",
+ "sim_mat[0,0] = spa.dot(circle, circle)\n",
+ "sim_mat[1,1] = spa.dot(square, square)\n",
+ "sim_mat[2,2] = spa.dot(triangle, triangle)\n",
+ "sim_mat[3,3] = spa.dot(shape, shape)\n",
"\n",
- "shape_sim_mat[0,1] = shape_sim_mat[1,0] = (circle | square).item()\n",
- "shape_sim_mat[0,2] = shape_sim_mat[2,0] = (circle | triangle).item()\n",
- "shape_sim_mat[0,3] = shape_sim_mat[3,0] = (circle | shape).item()\n",
+ "sim_mat[0,1] = sim_mat[1,0] = spa.dot(circle, square)\n",
+ "sim_mat[0,2] = sim_mat[2,0] = spa.dot(circle, triangle)\n",
+ "sim_mat[0,3] = sim_mat[3,0] = spa.dot(circle, shape)\n",
"\n",
- "shape_sim_mat[1,2] = shape_sim_mat[2,1] = (square | triangle).item()\n",
- "shape_sim_mat[1,3] = shape_sim_mat[3,1] = (square | shape).item()\n",
- "\n",
- "shape_sim_mat[2,3] = shape_sim_mat[3,2] = (triangle | shape).item()"
+ "sim_mat[1,2] = sim_mat[2,1] = spa.dot(square, triangle)\n",
+ "sim_mat[1,3] = sim_mat[3,1] = spa.dot(square, shape)\n",
+ "sim_mat[2,3] = sim_mat[3,2] = spa.dot(triangle, shape)"
]
},
{
@@ -811,7 +758,7 @@
},
"outputs": [],
"source": [
- "plot_similarity_matrix(shape_sim_mat, symbol_names + [\"shape\"], values = True)"
+ "plot_similarity_matrix(sim_mat, symbol_names + [\"shape\"], values = True)"
]
},
{
@@ -876,7 +823,7 @@
"\n",
"Estimated timing to here from start of tutorial: 20 minutes\n",
"\n",
- "In this section, we will talk about binding, an operation that takes two vectors and produces a new vector that is *not* similar to either of its constituent elements.\n",
+ "In this section we will talk about binding - an operation that takes two vectors and produces a new vector that is *not* similar to either of it's constituent elements.\n",
"\n",
"Binding and unbinding are implemented using circular convolution. Luckily, that is implemented for you inside the SSPSpace library. If you would like a refresher on convolution, this [Three Blue One Brown video](https://www.youtube.com/watch?v=KuXjwB4LzSA) is a good place to start."
]
@@ -969,10 +916,9 @@
"source": [
"set_seed(42)\n",
"\n",
- "new_symbol_names = ['circle','square','triangle', 'red', 'blue', 'green']\n",
- "new_discrete_space = sspspace.DiscreteSPSpace(new_symbol_names, ssp_dim=vector_length, optimize=False)\n",
- "\n",
- "objs = {n:new_discrete_space.encode(np.array([n])) for n in new_symbol_names}"
+ "symbol_names = ['CIRCLE','SQUARE','TRIANGLE', 'RED', 'BLUE', 'GREEN']\n",
+ "vocab = make_vocabulary(vector_length)\n",
+ "vocab.populate(';'.join(symbol_names))"
]
},
{
@@ -981,27 +927,12 @@
"execution": {}
},
"source": [
- "Now, we are going to take two of the objects to make new ones: a red circle, a blue triangle, and a green square.\n",
+ "Now we are going to take two of the objects to make new ones: a red circle, a blue triangle and a green square.\n",
"\n",
- "We will combine the two primitive objects using the binding operation, which for us is implemented using circular convolution, and we denote it by \n",
- "\n",
- "\\begin{align*}\n",
+ "We will combine the two primitive objects using the binding operation, which for us is implemented using circular convolution, and we denote it by\n",
+ "$$\n",
" a \\circledast b\n",
- "\\end{align*}\n",
- "\n",
- "\n",
- "Mathematical details
\n",
- "\n",
- "The circular convolution of two vectors $\\mathbf{a}$ and $\\mathbf{b} \\in \\mathbb{R}^N$ is defined as:\n",
- "\n",
- "$$c_j = a \\circledast b = \\sum_{k=1}^{N} a_k b_{1 + (j-k) \\mod N}$$\n",
- "\n",
- "where $N$ is the length of the vectors, and $j$ is the index of the output vector. It's often more convenient to calculate the circular convolution in the Fourier domain. The circular convolution is equivalent to the element-wise product of the Fourier transforms of the two vectors, followed by an inverse Fourier transform:\n",
- "\n",
- "$$a \\circledast b = \\mathcal{F}^{-1}(\\mathcal{F}(\\mathbf{a}) \\odot \\mathcal{F}(\\mathbf{b}))$$\n",
- "where $\\mathcal{F}$ is the Fourier transform, $\\odot$ is the element-wise product, and $\\mathcal{F}^{-1}$ is the inverse Fourier transform. The equivalence between these two formulations is a consequence of the [convolution theorem](https://en.wikipedia.org/wiki/Convolution_theorem).\n",
- "\n",
- " \n",
+ "$$\n",
"\n",
"In the cell below, complete the missing concepts and then observe the computed similarity matrix."
]
@@ -1019,9 +950,9 @@
"raise NotImplementedError(\"Student exercise: complete derivation of new objects using binding operation.\")\n",
"###################################################################\n",
"\n",
- "objs['red*circle'] = objs['red'] * objs['circle']\n",
- "objs['blue*triangle'] = ... * objs['triangle']\n",
- "objs['green*square'] = objs['green'] * ..."
+ "vocab.add('RED_CIRCLE', vocab['RED'] * vocab['CIRCLE'])\n",
+ "vocab.add('BLUE_TRIANGLE', vocab['BLUE'] * ...)\n",
+ "vocab.add('GREEN_SQUARE', ... * vocab['SQUARE'])"
]
},
{
@@ -1034,9 +965,9 @@
"source": [
"# to_remove solution\n",
"\n",
- "objs['red*circle'] = objs['red'] * objs['circle']\n",
- "objs['blue*triangle'] = objs['blue'] * objs['triangle']\n",
- "objs['green*square'] = objs['green'] * objs['square']"
+ "vocab.add('RED_CIRCLE', vocab['RED'] * vocab['CIRCLE'])\n",
+ "vocab.add('BLUE_TRIANGLE', vocab['BLUE'] * vocab['TRIANGLE'])\n",
+ "vocab.add('GREEN_SQUARE', vocab['GREEN'] * vocab['SQUARE'])"
]
},
{
@@ -1056,14 +987,14 @@
},
"outputs": [],
"source": [
- "object_names = list(objs.keys())\n",
- "obj_sims = np.zeros((len(object_names), len(object_names)))\n",
+ "object_names = list(vocab.keys())\n",
+ "sims = np.zeros((len(object_names), len(object_names)))\n",
"\n",
"for name_idx, name in enumerate(object_names):\n",
" for other_idx in range(name_idx, len(object_names)):\n",
- " obj_sims[name_idx, other_idx] = obj_sims[other_idx, name_idx] = (objs[name] | objs[object_names[other_idx]]).item()\n",
+ " sims[name_idx, other_idx] = sims[other_idx, name_idx] = spa.dot(vocab[name], vocab[object_names[other_idx]])\n",
"\n",
- "plot_similarity_matrix(obj_sims, object_names)"
+ "plot_similarity_matrix(sims, object_names)"
]
},
{
@@ -1094,117 +1025,22 @@
"execution": {}
},
"source": [
- "## Coding Exercise 4: Foundations of Colorful Shapes"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Video 4: Unbinding\n",
- "\n",
- "from ipywidgets import widgets\n",
- "from IPython.display import YouTubeVideo\n",
- "from IPython.display import IFrame\n",
- "from IPython.display import display\n",
- "\n",
- "class PlayVideo(IFrame):\n",
- " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
- " self.id = id\n",
- " if source == 'Bilibili':\n",
- " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
- " elif source == 'Osf':\n",
- " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
- " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
- "\n",
- "def display_videos(video_ids, W=400, H=300, fs=1):\n",
- " tab_contents = []\n",
- " for i, video_id in enumerate(video_ids):\n",
- " out = widgets.Output()\n",
- " with out:\n",
- " if video_ids[i][0] == 'Youtube':\n",
- " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
- " height=H, fs=fs, rel=0)\n",
- " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
- " else:\n",
- " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
- " height=H, fs=fs, autoplay=False)\n",
- " if video_ids[i][0] == 'Bilibili':\n",
- " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
- " elif video_ids[i][0] == 'Osf':\n",
- " print(f'Video available at https://osf.io/{video.id}')\n",
- " display(video)\n",
- " tab_contents.append(out)\n",
- " return tab_contents\n",
+ "## Coding Exercise 4: Foundations of Colorful Shapes\n",
"\n",
- "video_ids = [('Youtube', 'vHHX98jBvk8'), ('Bilibili', 'BV1gZ421g7XT')]\n",
- "tab_contents = display_videos(video_ids, W=854, H=480)\n",
- "tabs = widgets.Tab()\n",
- "tabs.children = tab_contents\n",
- "for i in range(len(tab_contents)):\n",
- " tabs.set_title(i, video_ids[i][0])\n",
- "display(tabs)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_unbinding\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "We can also undo the binding operation, which we call unbinding. It is implemented by binding with the pseudo-inverse of the vector we wish to unbind. We denote the pseudo-inverse of the vector using the ~ symbol.\n",
+ "We can also undo the binding operation, which we call unbinding. It is implemented by binding with the pseduo-inverse of the vector we wish to unbind. We denote the pseudoinverse of the vector using the ~ symbol.\n",
"\n",
- "The SSPSpace library implements the pseudo-inverse for you, but the pseudo-inverse of a vector $\\mathbf{x} = (x_{0},\\ldots, x_{d-1})$ is defined:\n",
+ "The SSPSpace library implements the pseudo-inverse for you, but the pseudo-inverse of a vector $\\mathbf{x} = (x_{1},\\ldots, x_{d})$ is defined:\n",
"\n",
- "$$\\sim\\mathbf{x} = \\left(x_{0},x_{d-1},x_{d-2},\\ldots,x_{1}\\right)$$\n",
+ "$$\\sim\\mathbf{x} = \\left(x_{1},x_{d},x_{d-1},\\ldots,x_{2}\\right)$$\n",
"\n",
"\n",
- "Consider the example of our red circle. If we want to recover the shape of the object, we will unbind from it the color:\n",
+ "Consider the example of our red circle. If we wanted to recover the shape of the object, we will unbind from it the color:\n",
"\n",
"$$\n",
"(\\mathtt{red} \\circledast \\mathtt{circle}) \\circledast \\sim \\mathtt{red} \\approx \\mathtt{circle}\n",
"$$\n",
"\n",
- "\n",
- "Mathematical details
\n",
- "\n",
- "By the definition of the pseudo-inverse and circular convolution, we have:\n",
- "\n",
- "$$\\mathbf{x} \\, \\circledast \\sim \\mathbf{x} = \n",
- "\\sum_{k=1}^{N} x_k x_{1 + (j + k - 2) \\mod N} \\approx \\delta_j$$\n",
- "\n",
- "where $\\delta_j$ is the Kronecker delta function. This is:\n",
- "\n",
- "* exactly equal to 1 when $j=1$. This is because the vectors in SSP have a norm of 1.\n",
- "* approximately 0 otherwise. This is because the vectors in SSP are random, and so a vector is approximately orthogonal to a shifted version of itself.\n",
- "\n",
- "The Kronecker delta is the identity function for the circular convolution, and circular convolutions commute, hence:\n",
- "\n",
- "$$\n",
- "(\\mathtt{a} \\circledast \\mathtt{b}) \\circledast \\sim \\mathtt{a} = \\mathtt{b} \\circledast (\\mathtt{a} \\circledast \\sim \\mathtt{a}) \\approx \\mathtt{b} \\circledast \\delta = \\mathtt{b}\n",
- "$$\n",
- "\n",
- " \n",
- "\n",
- "In the cell below, unbind the color and shape, and then observe the similarity matrix."
+ "In the cell below unbind color and shape, and then observe the similarity matrix."
]
},
{
@@ -1215,24 +1051,18 @@
},
"outputs": [],
"source": [
- "new_object_names = ['red','red^','red*circle','circle','circle^']\n",
- "new_objs = objs\n",
+ "object_names = ['RED','EST_RED','RED_CIRCLE','CIRCLE','EST_CIRCLE']\n",
"\n",
"###################################################################\n",
"## Fill out the following then remove\n",
"raise NotImplementedError(\"Student exercise: complete derivation of default objects using pseudoinverse.\")\n",
"###################################################################\n",
"\n",
- "new_objs['red^'] = new_objs['red*circle'] * ~new_objs['circle']\n",
- "new_objs['circle^'] = new_objs[...] * ~new_objs[...]\n",
- "\n",
- "new_obj_sims = np.zeros((len(new_object_names), len(new_object_names)))\n",
- "\n",
- "for name_idx, name in enumerate(new_object_names):\n",
- " for other_idx in range(name_idx, len(new_object_names)):\n",
- " new_obj_sims[name_idx, other_idx] = new_obj_sims[other_idx, name_idx] = (new_objs[name] | new_objs[new_object_names[other_idx]]).item()\n",
+ "# to_remove solution\n",
+ "object_names = ['RED','EST_RED','RED_CIRCLE','CIRCLE','EST_CIRCLE']\n",
"\n",
- "plot_similarity_matrix(new_obj_sims, new_object_names, values = True)"
+ "vocab.add('EST_RED', (... * ...).normalized())\n",
+ "vocab.add('EST_CIRCLE', (vocab['RED_CIRCLE'] * ~vocab['RED']).normalized())"
]
},
{
@@ -1244,19 +1074,28 @@
"outputs": [],
"source": [
"# to_remove solution\n",
- "new_object_names = ['red','red^','red*circle','circle','circle^']\n",
- "new_objs = objs\n",
+ "object_names = ['RED','EST_RED','RED_CIRCLE','CIRCLE','EST_CIRCLE']\n",
"\n",
- "new_objs['red^'] = new_objs['red*circle'] * ~new_objs['circle']\n",
- "new_objs['circle^'] = new_objs['red*circle'] * ~new_objs['red']\n",
- "\n",
- "new_obj_sims = np.zeros((len(new_object_names), len(new_object_names)))\n",
+ "vocab.add('EST_RED', (vocab['RED_CIRCLE'] * ~vocab['CIRCLE']).normalized())\n",
+ "vocab.add('EST_CIRCLE', (vocab['RED_CIRCLE'] * ~vocab['RED']).normalized())"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "sims = np.zeros((len(object_names), len(object_names)))\n",
"\n",
- "for name_idx, name in enumerate(new_object_names):\n",
- " for other_idx in range(name_idx, len(new_object_names)):\n",
- " new_obj_sims[name_idx, other_idx] = new_obj_sims[other_idx, name_idx] = (new_objs[name] | new_objs[new_object_names[other_idx]]).item()\n",
+ "for name_idx, name in enumerate(object_names):\n",
+ " for other_idx in range(name_idx, len(object_names)):\n",
+ " sims[name_idx, other_idx] = spa.dot(vocab[name], vocab[object_names[other_idx]])\n",
+ " sims[other_idx, name_idx] = sims[name_idx, other_idx]\n",
"\n",
- "plot_similarity_matrix(new_obj_sims, new_object_names, values = True)"
+ "plot_similarity_matrix(sims, object_names, values = True)"
]
},
{
@@ -1307,7 +1146,7 @@
},
"outputs": [],
"source": [
- "# @title Video 5: Cleanup\n",
+ "# @title Video 4: Cleanup\n",
"\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
@@ -1373,13 +1212,11 @@
"source": [
"## Coding Exercise 5: Cleanup Memories To Find The Best-Fit\n",
"\n",
- "In the process of computing with VSAs, the vectors themselves can become corrupted due to noise, because we implement these systems with spiking neurons, or due to approximations like using the pseudo-inverse for unbinding, or because noise gets added when we operate on complex structures.\n",
+ "In the process of computing with VSAs, the vectors themselves can become corrupted, due to noise, because we implement these systems with spiking neurons, or due to the approximations like using the pseudo inverse for unbinding, or because noise gets added when we operate on complex structures.\n",
"\n",
- "To address this problem, we employ \"cleanup memories.\" These are lots of ways to implement these systems, but today, we're going to do it with a single hidden layer neural network. Let's start with a sequence of symbols, say $\\texttt{fire-fighter},\\texttt{math-teacher},\\texttt{sales-manager},$ and so on, in that fashion, and create a new vector that is a corrupted combination of all three. We will then use a cleanup memory to find the best-fitting vector in our vocabulary.\n",
+ "To address this problem we employ \"cleanup memories\". There are lots of ways to implement these systems, but today we're going to do it with a single hidden layer neural network. Lets start with a sequence of symbols, say $\\texttt{fire-fighter},\\texttt{math-teacher},\\texttt{sales-manager},$ and so on, in that fashion, and create a new vector that is a corrupted combination of all three. We will then use a clean up memory to find the best fitting vector in our vocabulary.\n",
"\n",
- "In the cell below, you will see the definition of `noisy_vector`, your task is to complete the calculation of similarity values for this vector and all default ones.\n",
- "\n",
- "Here, we introduce another graphical way to represent the similarity: by putting a similarity value on the y-axis (instead of the box in the grid) and representing each of the objects by line (the x-axis stays the same, and similarity takes place between the corresponding label on the x-axis and line-object)."
+ "In the cell below you will see the definition of `noisy_vector`, your task is to complete the calculation of similarity values for this vector and all default ones.\n"
]
},
{
@@ -1394,6 +1231,7 @@
"## Fill out the following then remove\n",
"raise NotImplementedError(\"Student exercise: complete similarities calculation between noisy vector and given symbols.\")\n",
"###################################################################\n",
+ "\n",
"set_seed(42)\n",
"\n",
"symbol_names = ['fire-fighter','math-teacher','sales-manager']\n",
@@ -1403,9 +1241,7 @@
"\n",
"noisy_vector = 0.2 * vocab['fire-fighter'] + 0.15 * vocab['math-teacher'] + 0.3 * vocab['sales-manager']\n",
"\n",
- "sims = np.array([noisy_vector | vocab[...] for name in ...]).squeeze()\n",
- "\n",
- "plot_line_similarity_matrix(sims, symbol_names, multiple_objects = False, title = 'Similarity - pre cleanup')"
+ "sims = np.array([noisy_vector | vocab[...] for name in ...]).squeeze()"
]
},
{
@@ -1427,9 +1263,7 @@
"\n",
"noisy_vector = 0.2 * vocab['fire-fighter'] + 0.15 * vocab['math-teacher'] + 0.3 * vocab['sales-manager']\n",
"\n",
- "sims = np.array([noisy_vector | vocab[name] for name in symbol_names]).squeeze()\n",
- "\n",
- "plot_line_similarity_matrix(sims, symbol_names, multiple_objects = False, title = 'Similarity - pre cleanup')"
+ "sims = np.array([noisy_vector | vocab[name] for name in symbol_names]).squeeze()"
]
},
{
@@ -1438,19 +1272,13 @@
"execution": {}
},
"source": [
- "Conceptually, with a discrete vocabulary, we can clean up a vector by finding the reference vector that's closest to the noisy vector and replacing it:\n",
- "\n",
- "$$\\text{cleanup}(\\boldsymbol{x}) = \\arg\\max_{\\boldsymbol{w} \\in \\text{vocab}} \\boldsymbol{x} \\cdot \\boldsymbol{w}$$\n",
+ "Now let's construct a simple neural network that does cleanup. We will construct the network, instead of learning it. The input weights will be the vectors in the vocabulary, and we will place a softmax function on the hidden layer (although we can use more biologically plausible activiations) and the output weights will again be the vectors representing the symbols in the vocabulary.\n",
"\n",
- "Now, let's construct a simple one-hidden layer neural network that does cleanup using a soft version of this operation, replacing the max operation with a softmax. The input weights will be the vectors in the vocabulary, and we will place a softmax function on the hidden layer. The output weights will again be the vectors representing the symbols in the vocabulary.\n",
+ "For efficient implementation of similarity calculation inside network, we will use `np.einsum()` function. Typically, it is used as `output = np.einsum('dim_inp1, dim_inp2 -> dim_out', input1, input2)`\n",
"\n",
- "To snap the corrupted vectors back to the vocabulary, we'll apply this operation:\n",
+ "In this notation, `nd,md->nm` is the einsum \"equation\" or \"subscript notation\" which describes what operation should be performed. In this particular case, it states that the first input tensor is of shape `(n, d)` while the second is of shape `(m, d)` and the result of operation is of shape `(n, m)` (note that `n` and `m` can coincide). The operation itself performs the following calcualtion: `output[n, m] = sum(input1[n, d] * input2[m, d])`, meaning that in our case it will calculate all pairwise dot products - exactly what we need for similarity!\n",
"\n",
- "$$\\text{cleanup}(\\boldsymbol{x}) = \\text{softmax}(T \\cdot \\boldsymbol{x} \\boldsymbol{W}^T) \\boldsymbol{W}$$\n",
- "\n",
- "Where $T$ is the temperature parameter, and $\\boldsymbol{W}$ is the matrix of vectors in the vocabulary. As $T \\to \\infty$, this operation converges to the original hard max cleanup operation. Your task is to complete the `__call__` function. Then, we calculate the similarity between the obtained vector and the ones in the vocabulary.\n",
- "\n",
- "Observe the result and compare it to the pre-cleanup metrics."
+ "Your task is to complete `__call__` function. Then we calculate similarity between obtained vector and the ones in the vocabulary."
]
},
{
@@ -1471,24 +1299,18 @@
"class Cleanup:\n",
" def __init__(self, vocab, temperature=1e5):\n",
" self.weights = np.array([vocab[k] for k in vocab.keys()]).squeeze()\n",
- " self.temp = temperature\n",
+ " self.temp = ...\n",
" def __call__(self, x):\n",
- " ###################################################################\n",
- " ## Fill out the following then remove\n",
- " raise NotImplementedError(\"Student exercise: complete similarity calculation between input vector and weights of the network.\")\n",
- " ###################################################################\n",
- " sims = ...\n",
- " max_sim = softmax(sims * self.temp, axis=1)\n",
- " return sspspace.SSP(...) #sspspace.SSP() wrapper is necessary for further bitwise comparison, it doesn't change the result vector\n",
+ " sims = np.einsum(...)\n",
+ " max_sim = softmax(sims * self.temp, axis=0)\n",
+ " return sspspace.SSP(np.einsum('nd,nm->md', self.weights, max_sim))\n",
"\n",
"\n",
"cleanup = Cleanup(vocab)\n",
"\n",
"clean_vector = cleanup(noisy_vector)\n",
"\n",
- "clean_sims = np.array([clean_vector | vocab[name] for name in symbol_names]).squeeze()\n",
- "\n",
- "plot_double_line_similarity_matrix([sims, clean_sims], symbol_names, ['Noisy Similarity', 'Clean Similarity'], title = 'Similarity - post cleanup')"
+ "clean_sims = np.array([clean_vector | vocab[name] for name in symbol_names]).squeeze()"
]
},
{
@@ -1508,17 +1330,35 @@
" self.weights = np.array([vocab[k] for k in vocab.keys()]).squeeze()\n",
" self.temp = temperature\n",
" def __call__(self, x):\n",
- " sims = x @ self.weights.T\n",
- " max_sim = softmax(sims * self.temp, axis=1)\n",
- " return sspspace.SSP(max_sim @ self.weights) #sspspace.SSP() wrapper is necessary for further bitwise comparison, it doesn't change the result vector\n",
+ " sims = np.einsum('nd,md->nm', self.weights, x)\n",
+ " max_sim = softmax(sims * self.temp, axis=0)\n",
+ " return sspspace.SSP(np.einsum('nd,nm->md', self.weights, max_sim))\n",
"\n",
"\n",
"cleanup = Cleanup(vocab)\n",
"\n",
"clean_vector = cleanup(noisy_vector)\n",
"\n",
- "clean_sims = np.array([clean_vector | vocab[name] for name in symbol_names]).squeeze()\n",
- "\n",
+ "clean_sims = np.array([clean_vector | vocab[name] for name in symbol_names]).squeeze()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Observe the result with comparison to the pre cleanup metrics."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
"plot_double_line_similarity_matrix([sims, clean_sims], symbol_names, ['Noisy Similarity', 'Clean Similarity'], title = 'Similarity - post cleanup')"
]
},
@@ -1528,7 +1368,7 @@
"execution": {}
},
"source": [
- "For the scenario where we have a discrete, known vocabulary, we can do this cleanup with a single feed-forward network, and we don't need to learn any of the synaptic weights."
+ "We can do this cleanup with a single, feed-forward network, and we don't need to learn any of the synaptic weights if we know what the appropriate vocabulary is."
]
},
{
@@ -1566,7 +1406,7 @@
},
"outputs": [],
"source": [
- "# @title Video 6: Iterated Binding\n",
+ "# @title Video 5: Iterated Binding\n",
"\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
@@ -1632,22 +1472,22 @@
"source": [
"## Coding Exercise 6: Representing Numbers\n",
"\n",
- "It is often useful to be able to represent numbers. For example, we may want to represent the position of an object in a list, or we may want to represent the coordinates of an object in a grid. To do this, we use the binding operator to construct a vector that represents a number. We start by picking what we refer to as an \"axis vector,\" let's call it $\\texttt{one}$, and then iteratively apply binding like this:\n",
+ "It is often useful to be able to represent numbers. For example, we may want to represent the position of an object in a list, or we may want to represent the coordinates of an object in a grid. To do this we use the binding operator to construct a vector that represents a number. We start by picking what we refer to as an \"axis vector\", let's call it $\\texttt{one}$, and then iteratively apply binding, like this:\n",
"\n",
"$$\n",
- "\\texttt{two} = \\texttt{one}\\circledast\\texttt{one} \n",
+ "\\texttt{two} = \\texttt{one}\\circledast\\texttt{one}\n",
"$$\n",
"$$\n",
"\\texttt{three} = \\texttt{two}\\circledast\\texttt{one} = \\texttt{one}\\circledast\\texttt{one}\\circledast\\texttt{one}\n",
"$$\n",
"\n",
- "and so on. We extend that to arbitrary integers, $n$, by writing:\n",
+ "and so on. We extend that to arbitrary integers, $n$, by writing:\n",
"\n",
"$$\n",
"\\phi[n] = \\underset{i=1}{\\overset{n}{\\circledast}}\\texttt{one}\n",
"$$\n",
"\n",
- "Let's try that now and see how similarity between iteratively bound vectors develops. In the cell below, you should complete the missing part, which implements the iterative binding mechanism."
+ "Let's try that now and see how similarity between iteratively bound vectors develops. In the cell below you should complete missing part which implements iterative binding mechanism."
]
},
{
@@ -1666,20 +1506,19 @@
"set_seed(42)\n",
"\n",
"#define axis vector\n",
- "axis_vectors = ['one']\n",
- "\n",
- "encoder = sspspace.DiscreteSPSpace(axis_vectors, ssp_dim=1024, optimize=False)\n",
- "\n",
+ "axis_vectors = ['ONE']\n",
"#vocabulary\n",
- "vocab = {w:encoder.encode(w) for w in axis_vectors}\n",
+ "vocab = make_vocabulary(vector_length)\n",
+ "# vocab = spa.Vocabulary(vector_length)\n",
+ "vocab.populate(';'.join(axis_vectors))\n",
"\n",
"#we will add new vectors to this list\n",
- "integers = [vocab['one']]\n",
+ "integers = [vocab['ONE']]\n",
"\n",
"max_int = 5\n",
"for i in range(2, max_int + 1):\n",
" #bind one more \"one\" to the previous integer to get the new one\n",
- " integers.append(integers[-1] * vocab[...])"
+ " integers.append((integers[-1] * vocab[...]).normalized())"
]
},
{
@@ -1690,24 +1529,22 @@
},
"outputs": [],
"source": [
- "#to_remove solution\n",
"set_seed(42)\n",
"\n",
"#define axis vector\n",
- "axis_vectors = ['one']\n",
- "\n",
- "encoder = sspspace.DiscreteSPSpace(axis_vectors, ssp_dim=1024, optimize=False)\n",
- "\n",
+ "axis_vectors = ['ONE']\n",
"#vocabulary\n",
- "vocab = {w:encoder.encode(w) for w in axis_vectors}\n",
+ "vocab = make_vocabulary(vector_length)\n",
+ "# vocab = spa.Vocabulary(vector_length)\n",
+ "vocab.populate(';'.join(axis_vectors))\n",
"\n",
"#we will add new vectors to this list\n",
- "integers = [vocab['one']]\n",
+ "integers = [vocab['ONE']]\n",
"\n",
"max_int = 5\n",
"for i in range(2, max_int + 1):\n",
" #bind one more \"one\" to the previous integer to get the new one\n",
- " integers.append(integers[-1] * vocab['one'])"
+ " integers.append((integers[-1] * vocab['ONE']).normalized())"
]
},
{
@@ -1716,7 +1553,7 @@
"execution": {}
},
"source": [
- "Now, we will observe the similarity metric between the obtained vectors. "
+ "Now, we will observe the similarity metric between the obtained vectors. In order to efficienty implement it, we will use already introduced `np.einsum` function. Notice, that in this particual notation, `sims = integers @ integers.T`"
]
},
{
@@ -1727,8 +1564,10 @@
},
"outputs": [],
"source": [
- "integers = np.array(integers).squeeze()\n",
- "integer_sims = integers @ integers.T"
+ "sims = np.zeros((len(integers), len(integers)))\n",
+ "for i_idx, i in enumerate(integers):\n",
+ " for j_idx, j in enumerate(integers):\n",
+ " sims[i_idx, j_idx] = spa.dot(i,j)"
]
},
{
@@ -1739,7 +1578,7 @@
},
"outputs": [],
"source": [
- "plot_similarity_matrix(integer_sims, [i for i in range(1, 6)], values = True)"
+ "plot_similarity_matrix(sims, [i for i in range(1, 6)], values = True)"
]
},
{
@@ -1759,7 +1598,7 @@
},
"outputs": [],
"source": [
- "plot_line_similarity_matrix(integer_sims, range(1, 6), multiple_objects = True, labels = [f'$\\phi$[{idx+1}]' for idx in range(5)], title = \"Similarity for digits\")"
+ "plot_line_similarity_matrix(sims, range(1, 6), multiple_objects = True, labels = [f'$\\phi$[{idx+1}]' for idx in range(5)], title = \"Similarity for digits\")"
]
},
{
@@ -1768,9 +1607,9 @@
"execution": {}
},
"source": [
- "What we can see here is that each number acts like its own vector; they are highly dissimilar, but we can still do arithmetic with them. Let's see what happens when we unbind $\\texttt{two}$ from $\\texttt{five}$.\n",
+ "What we can see here is that each number acts like it's own vector, they are highly dissimilar, but we can still do arithmetic with them. Let's see what happens when we unbind $\\texttt{two}$ from $\\texttt{five}$.\n",
"\n",
- "In the cell below you are invited to complete the missing parts (be attentive! python is zero-indexed, thus you need to choose the correct indices)."
+ "In the cell below you are invited to complete the missing parts (be attentive! python is zero-indexed, thus you need to choose correct indices)."
]
},
{
@@ -1786,8 +1625,8 @@
"raise NotImplementedError(\"Student exercise: unbinding of two from five.\")\n",
"###################################################################\n",
"\n",
- "five_unbind_two = sspspace.SSP(integers[...]) * ~sspspace.SSP(integers[...])\n",
- "five_unbind_two_sims = five_unbind_two @ integers.T"
+ "five_unbind_two = integers[4] * ~integers[...]\n",
+ "sims = np.array([spa.dot(five_unbind_two, i) for i in ...])"
]
},
{
@@ -1800,8 +1639,8 @@
"source": [
"#to_remove solution\n",
"\n",
- "five_unbind_two = sspspace.SSP(integers[4]) * ~sspspace.SSP(integers[1])\n",
- "five_unbind_two_sims = five_unbind_two @ integers.T"
+ "five_unbind_two = integers[4] * ~integers[1]\n",
+ "sims = np.array([spa.dot(five_unbind_two, i) for i in integers])"
]
},
{
@@ -1812,7 +1651,7 @@
},
"outputs": [],
"source": [
- "plot_line_similarity_matrix(five_unbind_two_sims, range(1, 6), multiple_objects = False, title = '$(\\phi[5]\\circledast \\phi[2]^{-1}) \\cdot \\phi[n]$')"
+ "plot_line_similarity_matrix(sims, range(1, 6), multiple_objects = False, title = '$(\\phi[5]\\circledast \\phi[2]^{-1}) \\cdot \\phi[n]$')"
]
},
{
@@ -1843,74 +1682,8 @@
"execution": {}
},
"source": [
- "## Coding Exercise 7: Beyond Binding Integers"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Video 7: Fractional Binding\n",
- "\n",
- "from ipywidgets import widgets\n",
- "from IPython.display import YouTubeVideo\n",
- "from IPython.display import IFrame\n",
- "from IPython.display import display\n",
- "\n",
- "class PlayVideo(IFrame):\n",
- " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
- " self.id = id\n",
- " if source == 'Bilibili':\n",
- " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
- " elif source == 'Osf':\n",
- " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
- " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
- "\n",
- "def display_videos(video_ids, W=400, H=300, fs=1):\n",
- " tab_contents = []\n",
- " for i, video_id in enumerate(video_ids):\n",
- " out = widgets.Output()\n",
- " with out:\n",
- " if video_ids[i][0] == 'Youtube':\n",
- " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
- " height=H, fs=fs, rel=0)\n",
- " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
- " else:\n",
- " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
- " height=H, fs=fs, autoplay=False)\n",
- " if video_ids[i][0] == 'Bilibili':\n",
- " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
- " elif video_ids[i][0] == 'Osf':\n",
- " print(f'Video available at https://osf.io/{video.id}')\n",
- " display(video)\n",
- " tab_contents.append(out)\n",
- " return tab_contents\n",
- "\n",
- "video_ids = [('Youtube', 'mTIodqegq_4'), ('Bilibili', 'BV1b4421Q7mS')]\n",
- "tab_contents = display_videos(video_ids, W=854, H=480)\n",
- "tabs = widgets.Tab()\n",
- "tabs.children = tab_contents\n",
- "for i in range(len(tab_contents)):\n",
- " tabs.set_title(i, video_ids[i][0])\n",
- "display(tabs)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_fractional_binding\")"
+ "## Background Material\n",
+ "### Coding Exercise 7: Beyond Binding Integers"
]
},
{
@@ -1919,7 +1692,7 @@
"execution": {}
},
"source": [
- "This is all well and good, but sometimes, we want to encode values that are not integers. Is there an easy way to do this? You'll be surprised to learn that the answer is: yes.\n",
+ "This is all well and good, but sometimes we want to encode values that are not integers. Is there an easy way to do this? You'll be surprised to learn that the answer is: yes.\n",
"\n",
"We actually use the same technique, but we recognize that iterated binding can be implemented in the Fourier domain:\n",
"\n",
@@ -1927,45 +1700,22 @@
"\\phi[n] = \\mathcal{F}^{-1}\\left\\{\\mathcal{F}\\left\\{\\texttt{one}\\right\\}^{n}\\right\\}\n",
"$$\n",
"\n",
- "where the power of $n$ in the Fourier domain is applied element-wise to the vector. To encode real-valued data, we simply let the integer value, $n$, be a real-valued vector, $x$, and we let the axis vector be a randomly generated vector, $X$. \n",
+ "where the power of $n$ in the Fourier domain is applied element-wise to the vector. To encode real-valued data we simply let the integer value, $n$, be a real-valued vector, $x$, and we let the axis vector be a randomly generated vector, $X$.\n",
"\n",
"$$\n",
"\\phi(x) = \\mathcal{F}^{-1}\\left\\{\\mathcal{F}\\left\\{X\\right\\}^{x}\\right\\}\n",
"$$\n",
"\n",
- "We call vectors that represent real-valued data Spatial Semantic Pointers (SSPs). We can also extend this to multi-dimensional data by binding different SSPs together.\n",
+ "We call vectors that represent real-valued data Spatial Semantic Pointers (SSPs). We can also extend this to multi-dimensional data by binding different SSPs together.\n",
"\n",
"$$\n",
"\\phi(x,y) = \\phi_{X}(x) \\circledast \\phi_{Y}(y)\n",
"$$\n",
"\n",
"\n",
- "In the $\\texttt{sspspace}$ library, we provide an encoder for real- and integer-valued data, and we'll demonstrate it next by encoding a bunch of points in the range $[-4,4]$ and comparing their value to $0$, encoded with SSP.\n",
- "\n",
- "In the cell below, you should complete the similarity calculation by injecting the correct index for the $0$ element (observe that it is right in the middle of the encoded array)."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete similarity calculation: correct index for `0` and array.\")\n",
- "###################################################################\n",
- "\n",
- "set_seed(42)\n",
- "new_encoder = sspspace.RandomSSPSpace(domain_dim=1, ssp_dim=1024)\n",
- "\n",
- "xs = np.linspace(-4,4,401)[:,None] #we expect the encoded values to be two-dimensional in `encoder.encode()` so we add extra dimension\n",
- "phis = new_encoder.encode(xs)\n",
+ "In the $\\texttt{sspspace}$ library we provide an encoder for real- and integer-valued data, and we'll demonstrate it next by encoding a bunch of points in the range $[-4,4]$ and comparing their value to $0$, encoded a SSP.\n",
"\n",
- "#`0` element is right in the middle of phis array! notice that we have 401 samples inside it\n",
- "real_line_sims = phis[..., :] @ phis.T"
+ "In the cell below you should complete similarity calculation by injecting correct index for $0$ element (observe that it is right in the middle of encoded array)."
]
},
{
@@ -1976,16 +1726,16 @@
},
"outputs": [],
"source": [
- "#to_remove solution\n",
- "\n",
"set_seed(42)\n",
- "new_encoder = sspspace.RandomSSPSpace(domain_dim=1, ssp_dim=1024)\n",
+ "vocab = make_vocabulary(vector_length)\n",
+ "vocab.populate('X')\n",
"\n",
+ "X = vocab['X'].abs()\n",
"xs = np.linspace(-4,4,401)[:,None] #we expect the encoded values to be two-dimensional in `encoder.encode()` so we add extra dimension\n",
- "phis = new_encoder.encode(xs)\n",
+ "phis = [(X**x) for x in xs]\n",
"\n",
"#`0` element is right in the middle of phis array! notice that we have 401 samples inside it\n",
- "real_line_sims = phis[200, :] @ phis.T"
+ "sims = np.array([spa.dot(phis[200], p) for p in phis])"
]
},
{
@@ -1996,7 +1746,7 @@
},
"outputs": [],
"source": [
- "plot_real_valued_line_similarity(real_line_sims, xs, title = '$\\phi(x)\\cdot\\phi(0)$')"
+ "plot_real_valued_line_similarity(sims, xs, title = '$\\phi(x)\\cdot\\phi(0)$')"
]
},
{
@@ -2005,9 +1755,9 @@
"execution": {}
},
"source": [
- "As with the integers, we can update the values post-encoding through the binding operation. Let's look at the similarity between all the points in the range $[-4,4]$, this time with the value $\\pi/2$, but we will shift it by binding the origin with the desired shift value.\n",
+ "As with the integers, we can update the values, post-encoding through the binding operation. Let's look at the similarity between all the points in the range $[-4,4]$ this time with the value $\\pi/2$, but we will shift it by binding the origin with the desired shift value.\n",
"\n",
- "In the cell below, you need to provide the value for which we are going to shift the origin."
+ "In the cell below you need to provide the value by which we are going to shift the origin."
]
},
{
@@ -2023,8 +1773,8 @@
"raise NotImplementedError(\"Student exercise: provide value to shift and observe the usage of the operation.\")\n",
"###################################################################\n",
"\n",
- "phi_shifted = phis[200,:][None,:] * new_encoder.encode([[...]])\n",
- "shifted_real_line_sims = phi_shifted.flatten() @ phis.T"
+ "phi_shifted = phis[200] * X**-3.1\n",
+ "sims = np.array([spa.dot(...) for p in phis])"
]
},
{
@@ -2037,8 +1787,8 @@
"source": [
"#to_remove solution\n",
"\n",
- "phi_shifted = phis[200,:][None,:] * new_encoder.encode([[np.pi/2]])\n",
- "shifted_real_line_sims = phi_shifted.flatten() @ phis.T"
+ "phi_shifted = phis[200] * X**-3.1\n",
+ "sims = np.array([spa.dot(phi_shifted, p) for p in phis])"
]
},
{
@@ -2049,7 +1799,7 @@
},
"outputs": [],
"source": [
- "plot_real_valued_line_similarity(shifted_real_line_sims, xs, title = '$\\phi(x)\\cdot(\\phi(0)\\circledast\\phi(\\pi/2))$')"
+ "plot_real_valued_line_similarity(sims, xs, title = '$\\phi(x)\\cdot(\\phi(0)\\circledast\\phi(\\pi/2))$')"
]
},
{
@@ -2069,8 +1819,8 @@
},
"outputs": [],
"source": [
- "new_phi_shifted = phis[200,:][None,:] * new_encoder.encode([[-1.5*np.pi]])\n",
- "new_shifted_real_line_sims = new_phi_shifted.flatten() @ phis.T"
+ "phi_shifted = phis[200] * X**(-1.5*np.pi)\n",
+ "sims = np.array([spa.dot(phi_shifted, p) for p in phis])"
]
},
{
@@ -2081,7 +1831,7 @@
},
"outputs": [],
"source": [
- "plot_real_valued_line_similarity(new_shifted_real_line_sims, xs, title = '$\\phi(x)\\cdot(\\phi(0)\\circledast\\phi(-1.5\\pi))$')"
+ "plot_real_valued_line_similarity(sims, xs, title = '$\\phi(x)\\cdot(\\phi(0)\\circledast\\phi(-1.5\\pi))$')"
]
},
{
@@ -2090,7 +1840,7 @@
"execution": {}
},
"source": [
- "We will go on to use these encodings to build spatial maps in Tutorial 3."
+ "We will go on to use these encodings to build spatial maps in Tutorial 5 (Bonus)."
]
},
{
@@ -2101,7 +1851,7 @@
"source": [
"### Coding Exercise 7 Discussion\n",
"\n",
- "1. How would you explain the lines `sims = vector @ phis.T` in the previous coding exercises?"
+ "1. How would you explain the usage of `d,md->m` in `np.einsum()` function in the previous coding exercise?"
]
},
{
@@ -2115,9 +1865,9 @@
"#to_remove explanation\n",
"\n",
"\"\"\"\n",
- "Discussion: How would you explain the lines `sims = vector @ phis.T` in the previous coding exercises?\n",
+ "Discussion: How would you explain the usage of `d,md->m` in `np.einsum()` function in the previous coding exercise?\n",
"\n",
- "We compute the similarity of `vector` to all the other references `phi` using the dot product. `vector` has shape `d` and phis has shape `m x d`, where `m` is the number of references. This yields `m` similarity values, one for each reference.\n",
+ "`d` is the dimensionality of the vector; we compute similariy of one vector (representing `0` object) with other `m` vectors of the same dimension `d` (thus `md`); as the result we receive `m` values of similarity.\n",
"\"\"\";"
]
},
@@ -2130,20 +1880,7 @@
},
"outputs": [],
"source": [
- "# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_beyond_bidning_integers\")"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Video 8: Iterated Binding Conclusion\n",
+ "# @title Video 6: Iterated Binding Conclusion\n",
"\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
@@ -2215,11 +1952,9 @@
"In this tutorial, we developed the toolbox of the main operations on the vector symbolic algebra. In particular, it includes:\n",
"- similarity operation (|), which measures how similar the two vectors are (by calculating their dot product);\n",
"- bundling (+), which creates new set-like objects using vector addition;\n",
- "- binding ($\\circledast$), which creates a new combined representation of the two given objects using circular convolution;\n",
- "- unbinding (~), which allows to derive a pure object from the bound representation by unbinding another one that stands in the pair;\n",
- "- cleanup, which tries to identify the most similar vector in the vocabulary with multiple possible implementations.\n",
- "- iterated binding, which allows one to \"count\" by iteratively binding an axis vector with itself.\n",
- "- encoding real-valued data using fractional binding.\n",
+ "- binding ($\\circledast$), which creates new combined representation of the two given objects using circular convolution;\n",
+ "- unbinding (~), which allows to derive pure object from the binded representation by unbinding another one which stands in the pair;\n",
+ "- cleanup, which tries to identify the most similar vector in the vocabulary, with multiple possible implementations.\n",
"\n",
"In the following tutorials, we will take a look at how we can use these tools to create more complicated structures and derive useful information from them."
]
@@ -2253,7 +1988,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.9.19"
+ "version": "3.9.22"
}
},
"nbformat": 4,
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/W2D2_Tutorial2.ipynb b/tutorials/W2D2_NeuroSymbolicMethods/W2D2_Tutorial2.ipynb
index 7f0ebac02..bc9d5a14c 100644
--- a/tutorials/W2D2_NeuroSymbolicMethods/W2D2_Tutorial2.ipynb
+++ b/tutorials/W2D2_NeuroSymbolicMethods/W2D2_Tutorial2.ipynb
@@ -25,9 +25,9 @@
"\n",
"__Content creators:__ P. Michael Furlong, Chris Eliasmith\n",
"\n",
- "__Content reviewers:__ Hlib Solodzhuk, Patrick Mineault, Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi\n",
+ "__Content reviewers:__ Hlib Solodzhuk, Patrick Mineault, Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Alex Murphy\n",
"\n",
- "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk\n"
+ "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk, Alex Murphy\n"
]
},
{
@@ -41,7 +41,7 @@
"\n",
"# Tutorial Objectives\n",
"\n",
- "*Estimated timing of tutorial: 50 minutes*\n",
+ "*Estimated timing of tutorial: 20 minutes*\n",
"\n",
"This tutorial will present you with a couple of play-examples on the usage of basic operations of vector symbolic algebras while generalizing to the new knowledge."
]
@@ -59,7 +59,7 @@
"# @markdown These are the slides for the videos in all tutorials today\n",
"\n",
"from IPython.display import IFrame\n",
- "link_id = \"2szmk\"\n",
+ "link_id = \"jybuw\"\n",
"\n",
"print(f\"If you want to download the slides: 'https://osf.io/download/{link_id}'\")\n",
"\n",
@@ -73,8 +73,11 @@
},
"source": [
"---\n",
- "# Setup\n",
- "\n"
+ "# Setup (Colab Users: Please Read)\n",
+ "\n",
+ "Note that because this tutorial relies on some special Python packages, these packages have requirements for specific versions of common scientific libraries, such as `numpy`. If you're in Google Colab, then as of May 2025, this comes with a later version (2.0.2) pre-installed. We require an older version (we'll be installing `1.24.4`). This causes Colab to force a session restart and then re-running of the installation cells for the new version to take effect. When you run the cell below, you will be prompted to restart the session. This is *entirely expected* and you haven't done anything wrong. Simply click 'Restart' and then run the cells as normal. \n",
+ "\n",
+ "An additional error might sometimes arise where an exception is raised connected to a missing element of NumPy. If this occurs, please restart the session and re-run the cells as normal and this error will go away. Updated versions of the affected libraries are expected out soon, but sadly not in time for the preparation of this material. We thank you for your understanding."
]
},
{
@@ -86,9 +89,27 @@
},
"outputs": [],
"source": [
- "# @title Install and import feedback gadget\n",
+ "# @title Install dependencies\n",
"\n",
- "!pip install --quiet numpy matplotlib ipywidgets scipy scikit-learn vibecheck\n",
+ "!pip install numpy==1.24.4 --quiet\n",
+ "!pip install scikit-learn==1.6.1 --quiet\n",
+ "!pip install scipy==1.15.3 --quiet\n",
+ "!pip install git+https://github.com/neuromatch/sspspace@neuromatch --no-deps --quiet\n",
+ "!pip install nengo==4.0.0 --quiet\n",
+ "!pip install nengo_spa==2.0.0 --quiet\n",
+ "!pip install --quiet matplotlib ipywidgets vibecheck"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Install and import feedback gadget\n",
"\n",
"from vibecheck import DatatopsContentReviewContainer\n",
"def content_review(notebook_section: str):\n",
@@ -106,30 +127,6 @@
"feedback_prefix = \"W2D2_T2\""
]
},
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Notice that exactly the `neuromatch` branch of `sspspace` should be installed! Otherwise, some of the functionality (like `optimize` parameter in the `DiscreteSPSpace` initialization) won't work."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Install dependencies\n",
- "\n",
- "# Install sspspace\n",
- "!pip install git+https://github.com/neuromatch/sspspace@neuromatch --quiet"
- ]
- },
{
"cell_type": "code",
"execution_count": null,
@@ -155,7 +152,15 @@
"import sspspace\n",
"from scipy.special import softmax\n",
"from sklearn.metrics import log_loss\n",
- "from sklearn.neural_network import MLPRegressor"
+ "from sklearn.neural_network import MLPRegressor\n",
+ "\n",
+ "import nengo_spa as spa\n",
+ "from nengo_spa.algebras.hrr_algebra import HrrProperties, HrrAlgebra\n",
+ "from nengo_spa.vector_generation import VectorsWithProperties\n",
+ "def make_vocabulary(vector_length):\n",
+ " vec_generator = VectorsWithProperties(vector_length, algebra=HrrAlgebra(), properties = [HrrProperties.UNITARY, HrrProperties.POSITIVE])\n",
+ " vocab = spa.Vocabulary(vector_length, pointer_gen=vec_generator)\n",
+ " return vocab"
]
},
{
@@ -341,9 +346,9 @@
"source": [
"---\n",
"\n",
- "# Section 1: Analogies. Part 1\n",
+ "# Section 1: Wason Card Task\n",
"\n",
- "In this section we will construct a simple analogy using Vector Symbolic Algebras. The question we are going to try and solve is \"King is to the queen as the prince is to X.\""
+ "One of the powerful benefits of using these structured representations is being able to generalize to other circumstances. To demonstrate this, we are going to show you this in a simple task."
]
},
{
@@ -355,7 +360,7 @@
},
"outputs": [],
"source": [
- "# @title Video 1: Analogy 1\n",
+ "# @title Video 1: Wason Card Task Intro\n",
"\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
@@ -391,7 +396,7 @@
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
- "video_ids = [('Youtube', '2tR4fHvL1Jk'), ('Bilibili', 'BV1fS411P7Ez')]\n",
+ "video_ids = [('Youtube', 'BAju3MNHCq8'), ('Bilibili', 'BV1Qf421X7MB')]\n",
"tab_contents = display_videos(video_ids, W=854, H=480)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
@@ -410,7 +415,7 @@
"outputs": [],
"source": [
"# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_analogy_part_one\")"
+ "content_review(f\"{feedback_prefix}_wason_card_task_intro\")"
]
},
{
@@ -419,25 +424,31 @@
"execution": {}
},
"source": [
- "## Coding Exercise 1: Royal Relationships\n",
+ "## Coding Exercise 1: Wason Card Task\n",
"\n",
- "We're going to start by considering our vocabulary. We will use the basic discrete concepts of monarch, heir, male, and female."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Let's create the objects we know about by combinatorially expanding the space: \n",
+ "We are going to test the generalization property on the Wason Card Task, where a person is told a rule of the form \"if the card is even, then the back is blue\", they are then presented with a number of cards with either an odd number, an even number, a red back, or a blue back. The participant is asked which cards they have to flip to determine that the rule is true.\n",
+ "\n",
+ "In this case, the participant needs to flip only the even card(s), and any card where the back is not blue, as the rule does not state whether or not odd numbers can have blue backs, and a red-backed card with an even number would violate the rule. We can get this from Boolean logic:\n",
+ "\n",
+ "$$\n",
+ "\\mathrm{even} \\implies \\mathrm{blue}\n",
+ "$$\n",
+ "\n",
+ "which is equal to \n",
+ "\n",
+ "$$ \n",
+ "\\neg \\mathrm{even} \\vee \\mathrm{blue}\n",
+ "$$\n",
+ "\n",
+ "where $\\neg$ means a logical not. If we want to find cards that violate the rule, then we negate the rule, providing:\n",
+ "\n",
+ "$$ \n",
+ "\\neg (\\neg \\mathrm{even} \\vee \\mathrm{blue}) = \\mathrm{even} \\wedge \\neg \\mathrm{blue}.\n",
+ "$$\n",
"\n",
- "1. King is a male monarch\n",
- "2. Queen is a female monarch\n",
- "3. Prince is a male heir\n",
- "4. Princess is a female heir\n",
+ "Hence the cards that can violate the rule are even and not blue. \n",
"\n",
- "Complete the missing parts of the code to obtain correct representations of new concepts."
+ "At first, we will define all needed concepts. For all noun concepts we would also like to have `not concept` presented in the space, please complete missing code parts."
]
},
{
@@ -448,22 +459,23 @@
},
"outputs": [],
"source": [
+ "set_seed(42)\n",
+ "vector_length = 1024\n",
+ "\n",
+ "card_states = ['RED','BLUE','ODD','EVEN','NOT','GREEN','PRIME','IMPLIES','ANT','RELATION','CONS']\n",
+ "vocab = make_vocabulary(vector_length)\n",
+ "vocab.populate(';'.join(card_states))\n",
+ "\n",
"###################################################################\n",
"## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete correct relations for creating new concepts.\")\n",
+ "raise NotImplementedError(\"Student exercise: complete creating `not x` concepts.\")\n",
"###################################################################\n",
"\n",
- "set_seed(42)\n",
- "\n",
- "symbol_names = ['monarch','heir','male','female']\n",
- "discrete_space = sspspace.DiscreteSPSpace(symbol_names, ssp_dim=1024, optimize=False)\n",
- "\n",
- "objs = {n:discrete_space.encode(n) for n in symbol_names}\n",
+ "for a in ['RED','BLUE','ODD','EVEN','GREEN','PRIME']:\n",
+ " vocab.add(f'NOT_{a}', vocab['NOT'] * vocab[a])\n",
"\n",
- "objs['king'] = objs['monarch'] * objs['male']\n",
- "objs['queen'] = objs['monarch'] * ...\n",
- "objs['prince'] = objs['heir'] * objs['male']\n",
- "objs['princess'] = ... * objs['female']"
+ "action_names = ['RED','BLUE','ODD','EVEN','GREEN','PRIME','NOT_RED','NOT_BLUE','NOT_ODD','NOT_EVEN','NOT_GREEN','NOT_PRIME']\n",
+ "action_space = np.array([vocab[x].v for x in action_names]).squeeze()"
]
},
{
@@ -475,18 +487,19 @@
"outputs": [],
"source": [
"#to_remove solution\n",
- "\n",
"set_seed(42)\n",
+ "vector_length = 1024\n",
"\n",
- "symbol_names = ['monarch','heir','male','female']\n",
- "discrete_space = sspspace.DiscreteSPSpace(symbol_names, ssp_dim=1024, optimize=False)\n",
+ "card_states = ['RED','BLUE','ODD','EVEN','NOT','GREEN','PRIME','IMPLIES','ANT','RELATION','CONS']\n",
+ "vocab = make_vocabulary(vector_length)\n",
+ "vocab.populate(';'.join(card_states))\n",
"\n",
- "objs = {n:discrete_space.encode(n) for n in symbol_names}\n",
"\n",
- "objs['king'] = objs['monarch'] * objs['male']\n",
- "objs['queen'] = objs['monarch'] * objs['female']\n",
- "objs['prince'] = objs['heir'] * objs['male']\n",
- "objs['princess'] = objs['heir'] * objs['female']"
+ "for a in ['RED','BLUE','ODD','EVEN','GREEN','PRIME']:\n",
+ " vocab.add(f'NOT_{a}', vocab['NOT'] * vocab[a])\n",
+ "\n",
+ "action_names = ['RED','BLUE','ODD','EVEN','GREEN','PRIME','NOT_RED','NOT_BLUE','NOT_ODD','NOT_EVEN','NOT_GREEN','NOT_PRIME']\n",
+ "action_space = np.array([vocab[x].v for x in action_names]).squeeze()"
]
},
{
@@ -495,9 +508,27 @@
"execution": {}
},
"source": [
- "Now, we can take an explicit approach. We know that the conversion from king to queen is to unbind male and bind female, so let's apply that to our prince object and see what we uncover. \n",
+ "Now, we are going to set up a simple perceptron-style learning rule, using the HRR (Holographic Reduced Representations) algebra. We are going to learn a target transformation, $T$, such that given a learning rule, $A^{*} = T\\circledast R$, where $A^{*}$ is the antecedant value bundled with $\\texttt{not}$ bound with the consequent value, because we are trying to learn the cards that can violate the rule, described above, and $R$ is the rule to be learned. \n",
+ "\n",
+ "Rules themselves are going to be composed like the data structures representing different countries in the previous section. `ant`, `relation` and `cons` are extra concepts which define the structure and which will bind to the specific instances. \n",
+ "\n",
+ "If we have a rule, $X \\implies Y$, then we would create the VSA representation:\n",
+ "\n",
+ "$$R = \\texttt{ant}\\circledast X + \\texttt{relation}\\circledast \\text{implies} + \\texttt{cons} \\circledast Y$$,\n",
+ "\n",
+ "and the ideal output is:\n",
+ "\n",
+ "$$\n",
+ "A^{*} = X + \\texttt{not}\\circledast Y\n",
+ "$$\n",
"\n",
- "At first, in the cell below, let's recover `queen` from `king` by constructing a new `query` concept, which represents the unbinding of `male` and the binding of `female.` Then, let's see if this new query object bears any similarity to anything in our vocabulary."
+ "\n",
+ "\n",
+ "\n",
+ "In the cell below, let us define two rules:\n",
+ "\n",
+ "$$\\text{blue} \\implies \\text{even}$$\n",
+ "$$\\text{odd} \\implies \\text{green}$$"
]
},
{
@@ -510,19 +541,13 @@
"source": [
"###################################################################\n",
"## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete correct relation for creating `query` object to compare with `queen`.\")\n",
+ "raise NotImplementedError(\"Student exercise: complete creating rules as defined above.\")\n",
"###################################################################\n",
"\n",
- "objs['queen_query'] = (objs[...] * ~objs[...]) * objs[...]\n",
- "\n",
- "object_names = list(objs.keys())\n",
- "sims = np.zeros((len(object_names), len(object_names)))\n",
- "\n",
- "for name_idx, name in enumerate(object_names):\n",
- " for other_idx in range(name_idx, len(object_names)):\n",
- " sims[name_idx, other_idx] = sims[other_idx, name_idx] = (objs[name] | objs[object_names[other_idx]]).item()\n",
- "\n",
- "plot_similarity_matrix(sims, object_names, values = True)"
+ "rules = [\n",
+ " (vocab['ANT'] * vocab['BLUE'] + vocab['RELATION'] * vocab['IMPLIES'] + vocab['CONS'] * vocab[...]).normalized(),\n",
+ " (vocab[...] * vocab[...] + vocab[...] * vocab[...] + vocab[...] * vocab[...]).normalized(),\n",
+ "]"
]
},
{
@@ -535,16 +560,10 @@
"source": [
"#to_remove solution\n",
"\n",
- "objs['queen_query'] = (objs['king'] * ~objs['male']) * objs['female']\n",
- "\n",
- "object_names = list(objs.keys())\n",
- "sims = np.zeros((len(object_names), len(object_names)))\n",
- "\n",
- "for name_idx, name in enumerate(object_names):\n",
- " for other_idx in range(name_idx, len(object_names)):\n",
- " sims[name_idx, other_idx] = sims[other_idx, name_idx] = (objs[name] | objs[object_names[other_idx]]).item()\n",
- "\n",
- "plot_similarity_matrix(sims, object_names, values = True)"
+ "rules = [\n",
+ " (vocab['ANT'] * vocab['BLUE'] + vocab['RELATION'] * vocab['IMPLIES'] + vocab['CONS'] * vocab['EVEN']).normalized(),\n",
+ " (vocab['ANT'] * vocab['ODD'] + vocab['RELATION'] * vocab['IMPLIES'] + vocab['CONS'] * vocab['GREEN']).normalized(),\n",
+ "]"
]
},
{
@@ -553,40 +572,13 @@
"execution": {}
},
"source": [
- "The above similarity plot shows that applying that operation successfully converts king to queen. Let's apply it to 'prince' and see what happens. Now, `query` should represent the `princess` concept."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "objs['princess_query'] = (objs['prince'] * ~objs['male']) * objs['female']\n",
+ "Now, we are ready to derive the transformation! For that, we will iterate through the rules and solutions for specified number of iterations and update it as the following:\n",
"\n",
- "object_names = list(objs.keys())\n",
- "sims = np.zeros((len(object_names), len(object_names)))\n",
- "\n",
- "for name_idx, name in enumerate(object_names):\n",
- " for other_idx in range(name_idx, len(object_names)):\n",
- " sims[name_idx, other_idx] = sims[other_idx, name_idx] = (objs[name] | objs[object_names[other_idx]]).item()\n",
- "\n",
- "plot_similarity_matrix(sims, object_names, values = True)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Here, we have successfully recovered the princess, completing the analogy.\n",
+ "$$\\Delta T \\leftarrow T - \\text{lr}*(A^{*} \\circledast \\sim R)$$\n",
"\n",
- "This approach, however, requires explicit knowledge of the construction of the objects. Let's see if we can just work with the concepts of 'king,' 'queen,' and 'prince' directly.\n",
+ "where $\\text{lr}$ is learning rate constant value. Ultimately, we want $A^{*} = T\\circledast R$, so we unbind $R$ to recorver the desired transform, and use the learning rule to update our current estimated transform.\n",
"\n",
- "In the cell below, construct the `princess` concept using only `king,` `queen`, and `prince.`"
+ "We will also compute loss progression over the time and log loss function between perfect similarity (ones only for antecedance value and not consequent one) and the one we obtain between prediciton for current transformation and full action space. Complete missing parts of the code in the next cell to complete training."
]
},
{
@@ -599,18 +591,50 @@
"source": [
"###################################################################\n",
"## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete correct relation for creating `query` object to compare with `princess`.\")\n",
+ "raise NotImplementedError(\"Student exercise: complete training loop.\")\n",
"###################################################################\n",
"\n",
- "objs['new_princess_query'] = (objs[...] * ~objs[...]) * objs[...]\n",
+ "num_iters = 500\n",
+ "losses = []\n",
+ "sims = []\n",
+ "lr = 1e-1\n",
+ "ant_names = [\"BLUE\", \"ODD\"]\n",
+ "cons_names = [\"EVEN\", \"GREEN\"]\n",
+ "vector_length = 1024\n",
+ "\n",
+ "transform = np.zeros((vector_length))\n",
+ "for i in range(num_iters):\n",
+ " loss = 0\n",
+ " for rule, ant_name, cons_name in zip(rules, ant_names, cons_names):\n",
+ "\n",
+ " #perfect similarity\n",
+ " y_true = np.eye(len(action_names))[action_names.index(ant_name),:] + np.eye(len(action_names))[4+action_names.index(cons_name),:]\n",
+ "\n",
+ " #prediction with current transform (a_hat = transform * rule)\n",
+ " a_hat = spa.SemanticPointer(transform) * ...\n",
+ "\n",
+ " #similarity with current transform\n",
+ " sim_mat = np.einsum('nd,d->n', action_space, a_hat.v)\n",
+ "\n",
+ " #cleanup\n",
+ " y_hat = softmax(sim_mat)\n",
+ "\n",
+ " #true solution (a* = ant_name + not * cons_name)\n",
+ " a_true = (vocab[ant_name] + vocab['NOT']*vocab[...]).normalized()\n",
+ "\n",
+ " #calculate loss\n",
+ " loss += log_loss(y_true, y_hat)\n",
"\n",
- "sims = np.zeros((len(object_names), len(object_names)))\n",
+ " #update transform (T <- T - lr * (A* * (~rule)))\n",
+ " transform -= (lr) * (transform - (... * ~rule).v)\n",
+ " transform = transform / np.linalg.norm(transform)\n",
"\n",
- "for name_idx, name in enumerate(object_names):\n",
- " for other_idx in range(name_idx, len(object_names)):\n",
- " sims[name_idx, other_idx] = sims[other_idx, name_idx] = (objs[name] | objs[object_names[other_idx]]).item()\n",
+ " #save predicted similarities if it is last iteration\n",
+ " if i == num_iters - 1:\n",
+ " sims.append(sim_mat)\n",
"\n",
- "plot_similarity_matrix(sims, object_names, values = True)"
+ " #save loss\n",
+ " losses.append(np.copy(loss))"
]
},
{
@@ -623,29 +647,47 @@
"source": [
"#to_remove solution\n",
"\n",
- "objs['new_princess_query'] = (objs['prince'] * ~objs['king']) * objs['queen']\n",
- "object_names = list(objs.keys())\n",
+ "num_iters = 500\n",
+ "losses = []\n",
+ "sims = []\n",
+ "lr = 1e-1\n",
+ "ant_names = [\"BLUE\", \"ODD\"]\n",
+ "cons_names = [\"EVEN\", \"GREEN\"]\n",
+ "vector_length = 1024\n",
"\n",
- "sims = np.zeros((len(object_names), len(object_names)))\n",
+ "transform = np.zeros((vector_length))\n",
+ "for i in range(num_iters):\n",
+ " loss = 0\n",
+ " for rule, ant_name, cons_name in zip(rules, ant_names, cons_names):\n",
"\n",
- "for name_idx, name in enumerate(object_names):\n",
- " for other_idx in range(name_idx, len(object_names)):\n",
- " sims[name_idx, other_idx] = sims[other_idx, name_idx] = (objs[name] | objs[object_names[other_idx]]).item()\n",
+ " #perfect similarity\n",
+ " y_true = np.eye(len(action_names))[action_names.index(ant_name),:] + np.eye(len(action_names))[4+action_names.index(cons_name),:]\n",
"\n",
- "plot_similarity_matrix(sims, object_names, values = True)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Again, we see that we have recovered the princess by using our analogy.\n",
+ " #prediction with current transform (a_hat = transform * rule)\n",
+ " a_hat = spa.SemanticPointer(transform) * rule\n",
+ "\n",
+ " #similarity with current transform\n",
+ " sim_mat = np.einsum('nd,d->n', action_space, a_hat.v)\n",
+ "\n",
+ " #cleanup\n",
+ " y_hat = softmax(sim_mat)\n",
+ "\n",
+ " #true solution (a* = ant_name + not * cons_name)\n",
+ " a_true = (vocab[ant_name] + vocab['NOT']*vocab[cons_name]).normalized()\n",
+ "\n",
+ " #calculate loss\n",
+ " loss += log_loss(y_true, y_hat)\n",
+ "\n",
+ " #update transform (T <- T - lr * (A* * (~rule)))\n",
+ " transform -= (lr) * (transform - (a_true * ~rule).v)\n",
+ " transform = transform / np.linalg.norm(transform)\n",
"\n",
- "That said, the above depends on knowing that the representations are constructed using binding. Can we do something similar through the bundling operation? Let's try that out.\n",
+ " #save predicted similarities if it is last iteration\n",
+ " if i == num_iters - 1:\n",
+ " sims.append(sim_mat)\n",
"\n",
- "Reassing concept definitions using bundling operation."
+ " #save loss\n",
+ " losses.append(np.copy(loss))"
]
},
{
@@ -656,14 +698,8 @@
},
"outputs": [],
"source": [
- "set_seed(42)\n",
- "\n",
- "bundle_objs = {n:discrete_space.encode(n) for n in symbol_names}\n",
- "\n",
- "bundle_objs['king'] = (bundle_objs['monarch'] + bundle_objs['male']).normalize()\n",
- "bundle_objs['queen'] = (bundle_objs['monarch'] + bundle_objs['female']).normalize()\n",
- "bundle_objs['prince'] = (bundle_objs['heir'] + bundle_objs['male']).normalize()\n",
- "bundle_objs['princess'] = (bundle_objs['heir'] + bundle_objs['female']).normalize()"
+ "plt.figure(figsize=(15,5))\n",
+ "plot_training_and_choice(losses, sims, ant_names, cons_names, action_names)"
]
},
{
@@ -672,9 +708,7 @@
"execution": {}
},
"source": [
- "But now that we are using an additive model, we need to take a different approach. Instead of unbinding the king and binding the queen, we subtract the king and add the queen to find the princess from the prince.\n",
- "\n",
- "Complete the code to reflect the updated mechanism."
+ "Let's see what happens when we test it on a new rule it hasn't seen before. This time we will use the rule that $\\text{red} \\implies \\text{prime}$. Your task is to complete new rule in the cell below and observe the results."
]
},
{
@@ -687,10 +721,16 @@
"source": [
"###################################################################\n",
"## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete correct relation for creating `query` object to compare with `princess`.\")\n",
+ "raise NotImplementedError(\"Student exercise: complete new rule and predict for it.\")\n",
"###################################################################\n",
"\n",
- "bundle_objs['princess_query'] = (bundle_objs[...] - bundle_objs[...]) + bundle_objs[...]"
+ "new_rule = (vocab['ANT'] * vocab[...] + vocab['RELATION'] * ... + vocab['CONS'] * vocab[...]).normalized()\n",
+ "\n",
+ "#apply transform on new rule to test the generalization of the transform\n",
+ "a_hat = spa.SemanticPointer(transform) * ...\n",
+ "\n",
+ "new_sims = np.einsum('nd,d->n', action_space, a_hat.v)\n",
+ "y_hat = softmax(new_sims)"
]
},
{
@@ -703,7 +743,13 @@
"source": [
"#to_remove solution\n",
"\n",
- "bundle_objs['princess_query'] = (bundle_objs['prince'] - bundle_objs['king']) + bundle_objs['queen']"
+ "new_rule = (vocab['ANT'] * vocab['RED'] + vocab['RELATION'] * vocab['IMPLIES'] + vocab['CONS'] * vocab['PRIME']).normalized()\n",
+ "\n",
+ "#apply transform on new rule to test the generalization of the transform\n",
+ "a_hat = spa.SemanticPointer(transform) * new_rule\n",
+ "\n",
+ "new_sims = np.einsum('nd,d->n', action_space, a_hat.v)\n",
+ "y_hat = softmax(new_sims)"
]
},
{
@@ -714,15 +760,8 @@
},
"outputs": [],
"source": [
- "object_names = list(bundle_objs.keys())\n",
- "\n",
- "sims = np.zeros((len(object_names), len(object_names)))\n",
- "\n",
- "for name_idx, name in enumerate(object_names):\n",
- " for other_idx in range(name_idx, len(object_names)):\n",
- " sims[name_idx, other_idx] = sims[other_idx, name_idx] = (bundle_objs[name] | bundle_objs[object_names[other_idx]]).item()\n",
- "\n",
- "plot_similarity_matrix(sims, object_names, values = True)"
+ "plt.figure(figsize=(7,5))\n",
+ "plot_choice([new_sims], [\"RED\"], [\"PRIME\"], action_names)"
]
},
{
@@ -731,725 +770,73 @@
"execution": {}
},
"source": [
- "This is a messier similarity plot due to the fact that the bundled representations interact with all their constituent parts in the vocabulary. That said, we see that 'princess' is still most similar to the query vector. \n",
- "\n",
- "This approach is more like what we would expect from a `word2vec` embedding."
+ "Let's compare how a standard MLP that isn't aware of the structure in the representation performs. Here, features are going to be the rules and output - solutions. Complete the code below."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
- "cellView": "form",
"execution": {}
},
"outputs": [],
"source": [
- "# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_royal_relationships\")"
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete MLP training.\")\n",
+ "###################################################################\n",
+ "\n",
+ "#features - rules\n",
+ "X_train = np.array(...).squeeze()\n",
+ "\n",
+ "#output - a* for each rule\n",
+ "y_train = np.array([\n",
+ " (vocab[ant_names[0]] + vocab['NOT']*vocab[cons_names[0]]).normalized().v,\n",
+ " (vocab[ant_names[1]] + vocab['NOT']*vocab[cons_names[1]]).normalized().v,\n",
+ "]).squeeze()\n",
+ "\n",
+ "regr = MLPRegressor(random_state=1, hidden_layer_sizes=(1024,1024), max_iter=1000).fit(..., ...)\n",
+ "\n",
+ "a_mlp = regr.predict(new_rule.v[None,:])\n",
+ "\n",
+ "mlp_sims = np.einsum('nd,md->nm', action_space, a_mlp)"
]
},
{
- "cell_type": "markdown",
+ "cell_type": "code",
+ "execution_count": null,
"metadata": {
"execution": {}
},
+ "outputs": [],
"source": [
- "---\n",
+ "#to_remove solution\n",
+ "\n",
+ "#features - rules\n",
+ "X_train = np.array([r.v for r in rules]).squeeze()\n",
+ "\n",
+ "#output - a* for each rule\n",
+ "y_train = np.array([\n",
+ " (vocab[ant_names[0]] + vocab['NOT']*vocab[cons_names[0]]).normalized().v,\n",
+ " (vocab[ant_names[1]] + vocab['NOT']*vocab[cons_names[1]]).normalized().v,\n",
+ "]).squeeze()\n",
"\n",
- "# Section 2: Analogies. Part 2\n",
+ "regr = MLPRegressor(random_state=1, hidden_layer_sizes=(1024,1024), max_iter=1000).fit(X_train, y_train)\n",
"\n",
- "Estimated timing to here from start of tutorial: 15 minutes\n",
+ "a_mlp = regr.predict(new_rule.v[None,:])\n",
"\n",
- "In this section, we will construct a database of data structures that describe different countries. Materials are adopted from [Kanerva (2010)](https://cdn.aaai.org/ocs/2243/2243-9566-1-PB.pdf)."
+ "mlp_sims = np.einsum('nd,md->nm', action_space, a_mlp)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
- "cellView": "form",
"execution": {}
},
"outputs": [],
"source": [
- "# @title Video 2: Analogy 2\n",
- "\n",
- "from ipywidgets import widgets\n",
- "from IPython.display import YouTubeVideo\n",
- "from IPython.display import IFrame\n",
- "from IPython.display import display\n",
- "\n",
- "class PlayVideo(IFrame):\n",
- " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
- " self.id = id\n",
- " if source == 'Bilibili':\n",
- " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
- " elif source == 'Osf':\n",
- " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
- " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
- "\n",
- "def display_videos(video_ids, W=400, H=300, fs=1):\n",
- " tab_contents = []\n",
- " for i, video_id in enumerate(video_ids):\n",
- " out = widgets.Output()\n",
- " with out:\n",
- " if video_ids[i][0] == 'Youtube':\n",
- " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
- " height=H, fs=fs, rel=0)\n",
- " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
- " else:\n",
- " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
- " height=H, fs=fs, autoplay=False)\n",
- " if video_ids[i][0] == 'Bilibili':\n",
- " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
- " elif video_ids[i][0] == 'Osf':\n",
- " print(f'Video available at https://osf.io/{video.id}')\n",
- " display(video)\n",
- " tab_contents.append(out)\n",
- " return tab_contents\n",
- "\n",
- "video_ids = [('Youtube', 'OB3hzhM7Ois'), ('Bilibili', 'BV1TZ421g7G5')]\n",
- "tab_contents = display_videos(video_ids, W=854, H=480)\n",
- "tabs = widgets.Tab()\n",
- "tabs.children = tab_contents\n",
- "for i in range(len(tab_contents)):\n",
- " tabs.set_title(i, video_ids[i][0])\n",
- "display(tabs)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_analogy_part_two\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "## Coding Exercise 2: Dollar of Mexico\n",
- "\n",
- "This is going to be a little more involved because to construct the data structure, we are going to need vectors that not only represent values that we are reasoning about, but also vectors that represent different roles data can play. This is sometimes called a slot-filler representation or a key-value representation.\n",
- "\n",
- "At first, let us define concepts and cleanup object. Then, we will define `canada` and `mexico` concepts by integrating the available information together. You will be provided with a `canada` object and your task is to complete for `mexico` one. Note that:\n",
- "\n",
- "* We bind `currency` to the relevant currency for that country (`dollar` for Canada, `peso` for Mexico)\n",
- "* We bind `capital` to the relevant capital for that country (`Ottawa` for Canada, `Mexico City` for Mexico)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete `mexico` concept.\")\n",
- "###################################################################\n",
- "\n",
- "set_seed(42)\n",
- "\n",
- "new_symbol_names = ['dollar', 'peso', 'ottawa', 'mexico-city', 'currency', 'capital']\n",
- "new_discrete_space = sspspace.DiscreteSPSpace(new_symbol_names, ssp_dim=1024, optimize=False)\n",
- "\n",
- "new_objs = {n:new_discrete_space.encode(n) for n in new_symbol_names}\n",
- "\n",
- "cleanup = sspspace.Cleanup(new_objs)\n",
- "\n",
- "new_objs['canada'] = ((new_objs['currency'] * new_objs['dollar']) + (new_objs['capital'] * new_objs['ottawa'])).normalize()\n",
- "new_objs['mexico'] = ((new_objs['currency'] * ...) + (new_objs['capital'] * ...)).normalize()"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "#to_remove solution\n",
- "\n",
- "set_seed(42)\n",
- "\n",
- "new_symbol_names = ['dollar', 'peso', 'ottawa', 'mexico-city', 'currency', 'capital']\n",
- "new_discrete_space = sspspace.DiscreteSPSpace(new_symbol_names, ssp_dim=1024, optimize=False)\n",
- "\n",
- "new_objs = {n:new_discrete_space.encode(n) for n in new_symbol_names}\n",
- "\n",
- "cleanup = sspspace.Cleanup(new_objs)\n",
- "\n",
- "new_objs['canada'] = ((new_objs['currency'] * new_objs['dollar']) + (new_objs['capital'] * new_objs['ottawa'])).normalize()\n",
- "new_objs['mexico'] = ((new_objs['currency'] * new_objs['peso']) + (new_objs['capital'] * new_objs['mexico-city'])).normalize()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "We would like to find out Mexico's currency. Complete the code for constructing a `query` which will help us do that. Note that we are using a cleanup operation (feel free to remove it and compare the results)."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete `query` concept which will be similar to currency in Mexico.\")\n",
- "###################################################################\n",
- "\n",
- "objs['peso_query'] = cleanup(~new_objs[...] * new_objs[...] * new_objs['mexico'])\n",
- "\n",
- "object_names = list(new_objs.keys())\n",
- "sims = np.zeros((len(object_names), len(object_names)))\n",
- "\n",
- "for name_idx, name in enumerate(object_names):\n",
- " for other_idx in range(name_idx, len(object_names)):\n",
- " sims[name_idx, other_idx] = sims[other_idx, name_idx] = (new_objs[name] | new_objs[object_names[other_idx]]).item()\n",
- "\n",
- "plot_similarity_matrix(sims, object_names)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "#to_remove solution\n",
- "\n",
- "new_objs['peso_query'] = cleanup(~new_objs['canada'] * new_objs['dollar'] * new_objs['mexico'])\n",
- "\n",
- "object_names = list(new_objs.keys())\n",
- "sims = np.zeros((len(object_names), len(object_names)))\n",
- "\n",
- "for name_idx, name in enumerate(object_names):\n",
- " for other_idx in range(name_idx, len(object_names)):\n",
- " sims[name_idx, other_idx] = sims[other_idx, name_idx] = (new_objs[name] | new_objs[object_names[other_idx]]).item()\n",
- "\n",
- "plot_similarity_matrix(sims, object_names)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "After cleanup, the query vector is the most similar to the `peso` object in the vocabulary, correctly answering the question. \n",
- "\n",
- "Note, however, that the similarity is not perfectly equal to 1. This is due to the scale factors applied to the composite vectors `canada` and `mexico`, to ensure they remain unit vectors, and due to cross talk. Crosstalk is a symptom of the fact that we are binding and unbinding bundles of vector symbols to produce the resultant query vector. The constituent vectors are not perfectly orthogonal (i.e., having a dot product of zero), and as such, the terms in the bundle interact when we measure similarity between them."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_dolar_of_mexico\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "---\n",
- "\n",
- "# Section 3: Wason Card Task\n",
- "\n",
- "Estimated timing to here from start of tutorial: 25 minutes\n",
- "\n",
- "One of the powerful benefits of using these structured representations is being able to generalize to other circumstances. To demonstrate this, we are going to show you this in a simple task."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Video 3: Wason Card Task Intro\n",
- "\n",
- "from ipywidgets import widgets\n",
- "from IPython.display import YouTubeVideo\n",
- "from IPython.display import IFrame\n",
- "from IPython.display import display\n",
- "\n",
- "class PlayVideo(IFrame):\n",
- " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
- " self.id = id\n",
- " if source == 'Bilibili':\n",
- " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
- " elif source == 'Osf':\n",
- " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
- " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
- "\n",
- "def display_videos(video_ids, W=400, H=300, fs=1):\n",
- " tab_contents = []\n",
- " for i, video_id in enumerate(video_ids):\n",
- " out = widgets.Output()\n",
- " with out:\n",
- " if video_ids[i][0] == 'Youtube':\n",
- " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
- " height=H, fs=fs, rel=0)\n",
- " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
- " else:\n",
- " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
- " height=H, fs=fs, autoplay=False)\n",
- " if video_ids[i][0] == 'Bilibili':\n",
- " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
- " elif video_ids[i][0] == 'Osf':\n",
- " print(f'Video available at https://osf.io/{video.id}')\n",
- " display(video)\n",
- " tab_contents.append(out)\n",
- " return tab_contents\n",
- "\n",
- "video_ids = [('Youtube', 'BAju3MNHCq8'), ('Bilibili', 'BV1Qf421X7MB')]\n",
- "tab_contents = display_videos(video_ids, W=854, H=480)\n",
- "tabs = widgets.Tab()\n",
- "tabs.children = tab_contents\n",
- "for i in range(len(tab_contents)):\n",
- " tabs.set_title(i, video_ids[i][0])\n",
- "display(tabs)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_wason_card_task_intro\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "## Coding Exercise 3: Wason Card Task\n",
- "\n",
- "We are going to test the generalization property on the Wason Card Task, where a person is told a rule of the form \"if the card is even, then the back is blue\", they are then presented with a number of cards with either an odd number, an even number, a red back, or a blue back. The participant is asked which cards they have to flip to determine that the rule is true.\n",
- "\n",
- "In this case, the participant needs to flip only the even card(s), and any card where the back is not blue, as the rule does not state whether or not odd numbers can have blue backs, and a red-backed card with an even number would violate the rule. We can get this from Boolean logic:\n",
- "\n",
- "$$\n",
- "\\mathrm{even} \\implies \\mathrm{blue}\n",
- "$$\n",
- "\n",
- "which is equal to \n",
- "\n",
- "$$ \n",
- "\\neg \\mathrm{even} \\vee \\mathrm{blue}\n",
- "$$\n",
- "\n",
- "where $\\neg$ means a logical not and $\\vee$ means logical or. If we want to find cards that violate the rule, then we negate the rule, providing:\n",
- "\n",
- "$$ \n",
- "\\neg (\\neg \\mathrm{even} \\vee \\mathrm{blue}) = \\mathrm{even} \\wedge \\neg \\mathrm{blue}.\n",
- "$$\n",
- "\n",
- "Where $\\wedge$ is the logical and. Hence, the cards that can violate the rule are either even or not blue. \n",
- "\n",
- "At first, we will define all the needed concepts. For all noun concepts, we would also like to have `not concept` presented in the space; please complete missing code parts."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "set_seed(42)\n",
- "\n",
- "card_states = ['red','blue','odd','even','not','green','prime','implies','ant','relation','cons']\n",
- "encoder = sspspace.DiscreteSPSpace(card_states, ssp_dim=1024, optimize=False)\n",
- "vocab = {c:encoder.encode(c) for c in card_states}\n",
- "\n",
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete creating `not x` concepts.\")\n",
- "###################################################################\n",
- "\n",
- "for a in ['red','blue','odd','even','green','prime']:\n",
- " vocab[f'not*{a}'] = vocab[...] * vocab[a]\n",
- "\n",
- "action_names = ['red','blue','odd','even','green','prime','not*red','not*blue','not*odd','not*even','not*green','not*prime']\n",
- "action_space = np.array([vocab[x] for x in action_names]).squeeze()"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "#to_remove solution\n",
- "\n",
- "set_seed(42)\n",
- "\n",
- "card_states = ['red','blue','odd','even','not','green','prime','implies','ant','relation','cons']\n",
- "encoder = sspspace.DiscreteSPSpace(card_states, ssp_dim=1024, optimize=False)\n",
- "vocab = {c:encoder.encode(c) for c in card_states}\n",
- "\n",
- "for a in ['red','blue','odd','even','green','prime']:\n",
- " vocab[f'not*{a}'] = vocab['not'] * vocab[a]\n",
- "\n",
- "action_names = ['red','blue','odd','even','green','prime','not*red','not*blue','not*odd','not*even','not*green','not*prime']\n",
- "action_space = np.array([vocab[x] for x in action_names]).squeeze()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Now, we are going to set up a simple perceptron-style learning rule using the HRR (Holographic Reduced Representations) algebra. We are going to learn a target transformation, $T$, such that given a learning rule, $A^{*} = T\\circledast R$. Here:\n",
- "\n",
- "* $R$ is the rule to be learned\n",
- "* $A^{*}$ is the antecedent value bundled with $\\texttt{not}$ bound with the consequent value. This is because we are trying to learn the cards that can *violate* the rule.\n",
- "\n",
- "Rules themselves are going to be composed like the data structures representing different countries in the previous section. `ant`, `relation`, and `cons` are extra concepts that define the structure and which will bind to the specific instances (think of them as anchor concepts which got bound to the specific instances). \n",
- "\n",
- "If we have a rule, $X \\implies Y$, then we would create the VSA representation:\n",
- "\n",
- "$$ R = \\texttt{ant} \\circledast X + \\texttt{relation} \\circledast \\texttt{implies} + \\texttt{cons} \\circledast Y $$\n",
- "\n",
- "and the ideal output is:\n",
- "\n",
- "$$\n",
- "A^{*} = X + \\texttt{not}\\circledast Y\n",
- "$$\n",
- "\n",
- "In the cell below, let us define two rules:\n",
- "\n",
- "$$\\text{blue} \\implies \\text{even}$$\n",
- "$$\\text{odd} \\implies \\text{green}$$"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete creating rules as defined above.\")\n",
- "###################################################################\n",
- "\n",
- "rules = [\n",
- " (vocab['ant'] * vocab['blue'] + vocab['relation'] * vocab['implies'] + vocab['cons'] * vocab[...]).normalize(),\n",
- " (vocab[...] * vocab[...] + vocab[...] * vocab[...] + vocab[...] * vocab[...]).normalize(),\n",
- "]"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "#to_remove solution\n",
- "\n",
- "rules = [\n",
- " (vocab['ant'] * vocab['blue'] + vocab['relation'] * vocab['implies'] + vocab['cons'] * vocab['even']).normalize(),\n",
- " (vocab['ant'] * vocab['odd'] + vocab['relation'] * vocab['implies'] + vocab['cons'] * vocab['green']).normalize(),\n",
- "]"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Now, we are ready to derive the transformation! For that, we will iterate through the rules and solutions for a specified number of iterations and update it as the following:\n",
- "\n",
- "$$ T \\leftarrow T - \\text{lr} (T - A^{} \\circledast \\sim R)$$\n",
- "\n",
- "where $\\text{lr}$ is learning rate constant value. Ultimately, we want $A^{*} = T\\circledast R$, so we unbind $R$ to recover the desired transform and use the learning rule to update our current estimated transform.\n",
- "\n",
- "We will also compute loss progression over time and log the loss function between perfect similarity (ones only for antecedence value and not consequent one) and the one we obtain between prediction for current transformation and full action space. Complete the missing parts of the code in the next cell to complete training."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete training loop.\")\n",
- "###################################################################\n",
- "\n",
- "num_iters = 500\n",
- "losses = []\n",
- "sims = []\n",
- "lr = 1e-1\n",
- "ant_names = [\"blue\", \"odd\"]\n",
- "cons_names = [\"even\", \"green\"]\n",
- "\n",
- "transform = np.zeros((1,encoder.ssp_dim))\n",
- "for i in range(num_iters):\n",
- " loss = 0\n",
- " for rule, ant_name, cons_name in zip(rules, ant_names, cons_names):\n",
- "\n",
- " #perfect similarity\n",
- " y_true = np.eye(len(action_names))[action_names.index(ant_name),:] + np.eye(len(action_names))[4+action_names.index(cons_name),:]\n",
- "\n",
- " #prediction with current transform (a_hat = transform * rule)\n",
- " a_hat = sspspace.SSP(transform) * ...\n",
- "\n",
- " #similarity with current transform\n",
- " sim_mat = action_space @ a_hat.T\n",
- "\n",
- " #cleanup\n",
- " y_hat = softmax(sim_mat)\n",
- "\n",
- " #true solution (a* = ant_name + not * cons_name)\n",
- " a_true = (vocab[ant_name] + vocab['not']*vocab[...]).normalize()\n",
- "\n",
- " #calculate loss\n",
- " loss += log_loss(y_true, y_hat)\n",
- "\n",
- " #update transform (T <- T - lr * (T - A* * (~rule)))\n",
- " transform -= (lr) * (... - np.array(... * ~...))\n",
- " transform = transform / np.linalg.norm(transform)\n",
- "\n",
- " #save predicted similarities if it is last iteration\n",
- " if i == num_iters - 1:\n",
- " sims.append(sim_mat)\n",
- "\n",
- " #save loss\n",
- " losses.append(np.copy(loss))\n",
- "\n",
- "plot_training_and_choice(losses, sims, ant_names, cons_names, action_names)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "#to_remove solution\n",
- "\n",
- "num_iters = 500\n",
- "losses = []\n",
- "sims = []\n",
- "lr = 1e-1\n",
- "ant_names = [\"blue\", \"odd\"]\n",
- "cons_names = [\"even\", \"green\"]\n",
- "\n",
- "transform = np.zeros((1,encoder.ssp_dim))\n",
- "for i in range(num_iters):\n",
- " loss = 0\n",
- " for rule, ant_name, cons_name in zip(rules, ant_names, cons_names):\n",
- "\n",
- " #perfect similarity\n",
- " y_true = np.eye(len(action_names))[action_names.index(ant_name),:] + np.eye(len(action_names))[4+action_names.index(cons_name),:]\n",
- "\n",
- " #prediction with current transform (a_hat = transform * rule)\n",
- " a_hat = sspspace.SSP(transform) * rule\n",
- "\n",
- " #similarity with current transform\n",
- " sim_mat = action_space @ a_hat.T\n",
- "\n",
- " #cleanup\n",
- " y_hat = softmax(sim_mat)\n",
- "\n",
- " #true solution (a* = ant_name + not * cons_name)\n",
- " a_true = (vocab[ant_name] + vocab['not']*vocab[cons_name]).normalize()\n",
- "\n",
- " #calculate loss\n",
- " loss += log_loss(y_true, y_hat)\n",
- "\n",
- " #update transform (T <- T - lr * (T - A* * (~rule)))\n",
- " transform -= (lr) * (transform - np.array(a_true * ~rule))\n",
- " transform = transform / np.linalg.norm(transform)\n",
- "\n",
- " #save predicted similarities if it is last iteration\n",
- " if i == num_iters - 1:\n",
- " sims.append(sim_mat)\n",
- "\n",
- " #save loss\n",
- " losses.append(np.copy(loss))\n",
- "\n",
- "plot_training_and_choice(losses, sims, ant_names, cons_names, action_names)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Let's see what happens when we test it on a new rule it hasn't seen before. This time, we will use the rule that $\\text{red} \\implies \\text{prime}$. Your task is to complete the new rule in the cell below and observe the results."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete new rule and predict for it.\")\n",
- "###################################################################\n",
- "\n",
- "new_rule = (vocab['ant'] * vocab[...] + vocab['relation'] * ... + vocab['cons'] * vocab[...]).normalize()\n",
- "\n",
- "#apply transform on new rule to test the generalization of the transform\n",
- "a_hat = sspspace.SSP(transform) * ...\n",
- "\n",
- "new_sims = action_space @ a_hat.T\n",
- "y_hat = softmax(new_sims)\n",
- "\n",
- "plot_choice([new_sims], [\"red\"], [\"prime\"], action_names)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "#to_remove solution\n",
- "\n",
- "new_rule = (vocab['ant'] * vocab['red'] + vocab['relation'] * vocab['implies'] + vocab['cons'] * vocab['prime']).normalize()\n",
- "\n",
- "#apply transform on new rule to test the generalization of the transform\n",
- "a_hat = sspspace.SSP(transform) * new_rule\n",
- "\n",
- "new_sims = action_space @ a_hat.T\n",
- "y_hat = softmax(new_sims)\n",
- "\n",
- "plot_choice([new_sims], [\"red\"], [\"prime\"], action_names)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Let's compare how a standard MLP that isn't aware of the structure in the representation performs. Here, features are going to be the rules and output - solutions. Complete the code below."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete MLP training.\")\n",
- "###################################################################\n",
- "\n",
- "#features - rules\n",
- "X_train = np.array(...).squeeze()\n",
- "\n",
- "#output - a* for each rule\n",
- "y_train = np.array([\n",
- " (vocab[ant_names[0]] + vocab['not']*vocab[cons_names[0]]).normalize(),\n",
- " (vocab[ant_names[1]] + vocab['not']*vocab[cons_names[1]]).normalize(),\n",
- "]).squeeze()\n",
- "\n",
- "regr = MLPRegressor(random_state=1, hidden_layer_sizes=(1024,1024), max_iter=1000).fit(..., ...)\n",
- "\n",
- "a_mlp = regr.predict(new_rule)\n",
- "\n",
- "mlp_sims = action_space @ a_mlp.T\n",
- "\n",
- "plot_choice([mlp_sims], [\"red\"], [\"prime\"], action_names)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "#to_remove solution\n",
- "\n",
- "#features - rules\n",
- "X_train = np.array(rules).squeeze()\n",
- "\n",
- "#output - a* for each rule\n",
- "y_train = np.array([\n",
- " (vocab[ant_names[0]] + vocab['not']*vocab[cons_names[0]]).normalize(),\n",
- " (vocab[ant_names[1]] + vocab['not']*vocab[cons_names[1]]).normalize(),\n",
- "]).squeeze()\n",
- "\n",
- "regr = MLPRegressor(random_state=1, hidden_layer_sizes=(1024,1024), max_iter=1000).fit(X_train, y_train)\n",
- "\n",
- "a_mlp = regr.predict(new_rule)\n",
- "\n",
- "mlp_sims = action_space @ a_mlp.T\n",
- "\n",
- "plot_choice([mlp_sims], [\"red\"], [\"prime\"], action_names)"
+ "plot_choice([mlp_sims], [\"RED\"], [\"PRIME\"], action_names)"
]
},
{
@@ -1483,7 +870,7 @@
},
"outputs": [],
"source": [
- "# @title Video 4: Wason Card Task Outro\n",
+ "# @title Video 2: Wason Card Task Outro\n",
"\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
@@ -1548,11 +935,11 @@
},
"source": [
"---\n",
- "# Summary\n",
+ "# The Big Picture\n",
"\n",
- "*Estimated timing of tutorial: 45 minutes*\n",
+ "What we saw in this tutorial is the power of generalization at work, that the two top responses were indeed GREEN and NOT PRIME, as Michael outlined in the Outro video. The theme of generalization is the cornerstone of this course and one of the most fundamental aspects we want to convey to you in your NeuroAI journey with us. This tutorial highlights yet another way in which this can be achieved, through the special language of VSA. The MLP does not have access to the structural components and fails to generalize on this task. This is one of the key benefits of the VSA method, where the connection to learning underlying structures allows for generalization to occur. \n",
"\n",
- "In this tutorial, we observed three scenarios where we used the basic operations to solve different analogies and engage in structured learning. The next final tutorial will show us how to use structure to impose inductive biases and how to use continuous representations to represent mixtures of discrete and continuous objects."
+ "We have a bonus tutorial today (Tutorial 4) that covers some other cases connected to analogies, which will help to clarify and demonstrate the power of VSAs even more. We really encourage you to check out that material and then maybe revisit this tutorial if you had any trouble following along. "
]
}
],
@@ -1584,7 +971,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.9.19"
+ "version": "3.9.22"
}
},
"nbformat": 4,
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/W2D2_Tutorial3.ipynb b/tutorials/W2D2_NeuroSymbolicMethods/W2D2_Tutorial3.ipynb
index a259155e3..28d1917db 100644
--- a/tutorials/W2D2_NeuroSymbolicMethods/W2D2_Tutorial3.ipynb
+++ b/tutorials/W2D2_NeuroSymbolicMethods/W2D2_Tutorial3.ipynb
@@ -17,7 +17,7 @@
"execution": {}
},
"source": [
- "# Tutorial 3: Representations in continuous space\n",
+ "# Tutorial 3: Question Answering with Memory\n",
"\n",
"**Week 2, Day 2: Neuro-Symbolic Methods**\n",
"\n",
@@ -25,9 +25,9 @@
"\n",
"__Content creators:__ P. Michael Furlong, Chris Eliasmith\n",
"\n",
- "__Content reviewers:__ Hlib Solodzhuk, Patrick Mineault, Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi\n",
+ "__Content reviewers:__ Konstantine Tsafatinos, Xaq Pitkow, Alex Murphy\n",
"\n",
- "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk"
+ "__Production editors:__ Konstantine Tsafatinos, Xaq Pitkow, Alex Murphy"
]
},
{
@@ -37,13 +37,11 @@
},
"source": [
"___\n",
- "\n",
- "\n",
"# Tutorial Objectives\n",
"\n",
- "*Estimated timing of tutorial: 40 minutes*\n",
+ "This model shows a form of question answering with memory. You will bind two features (color and shape) by circular convolution and store them in a memory population. Then you will provide a cue to the model at a later time to determine either one of the features by deconvolution. This model exhibits better cognitive ability since the answers to the questions are provided at a later time and not at the same time as the questions themselves. These operations use the primitives we introduced in Tutorial 1. Please make sure you have worked through previous tutorials so you can understand how operations such as circular convolution can implement binding of concepts.\n",
"\n",
- "In this tutorial, you will observe how the VSA methods can be applied in structures and environments to allow for efficient generalization."
+ "**Note:** While we present a simplified interface using the Semantc Pointer Architecture, all the computations underlying the model you build are implemented using spiking neurons!"
]
},
{
@@ -59,7 +57,7 @@
"# @markdown These are the slides for the videos in all tutorials today\n",
"\n",
"from IPython.display import IFrame\n",
- "link_id = \"2szmk\"\n",
+ "link_id = \"jybuw\"\n",
"\n",
"print(f\"If you want to download the slides: 'https://osf.io/download/{link_id}'\")\n",
"\n",
@@ -73,8 +71,11 @@
},
"source": [
"---\n",
- "# Setup\n",
- "\n"
+ "# Setup (Colab Users: Please Read)\n",
+ "\n",
+ "Note that because this tutorial relies on some special Python packages, these packages have requirements for specific versions of common scientific libraries, such as `numpy`. If you're in Google Colab, then as of May 2025, this comes with a later version (2.0.2) pre-installed. We require an older version (we'll be installing `1.24.4`). This causes Colab to force a session restart and then re-running of the installation cells for the new version to take effect. When you run the cell below, you will be prompted to restart the session. This is *entirely expected* and you haven't done anything wrong. Simply click 'Restart' and then run the cells as normal. \n",
+ "\n",
+ "An additional error might sometimes arise where an exception is raised connected to a missing element of NumPy. If this occurs, please restart the session and re-run the cells as normal and this error will go away. Updated versions of the affected libraries are expected out soon, but sadly not in time for the preparation of this material. We thank you for your understanding."
]
},
{
@@ -86,9 +87,23 @@
},
"outputs": [],
"source": [
- "# @title Install and import feedback gadget\n",
+ "# @title Install dependencies\n",
"\n",
- "!pip install --quiet jupyter numpy matplotlib ipywidgets scikit-learn tqdm vibecheck\n",
+ "!pip install numpy==1.24.4 --quiet\n",
+ "!pip install nengo nengo-spa nengo-gui --quiet\n",
+ "!pip install matplotlib vibecheck --quiet"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Install and import feedback gadget\n",
"\n",
"from vibecheck import DatatopsContentReviewContainer\n",
"def content_review(notebook_section: str):\n",
@@ -106,30 +121,6 @@
"feedback_prefix = \"W2D2_T3\""
]
},
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Notice that exactly the `neuromatch` branch of `sspspace` should be installed! Otherwise, some of the functionality (like `optimize` parameter in the `DiscreteSPSpace` initialization) won't work."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Install dependencies\n",
- "\n",
- "# Install sspspace\n",
- "!pip install git+https://github.com/neuromatch/sspspace@neuromatch --quiet"
- ]
- },
{
"cell_type": "code",
"execution_count": null,
@@ -141,22 +132,16 @@
"source": [
"# @title Imports\n",
"\n",
- "#working with data\n",
- "import numpy as np\n",
- "\n",
- "#plotting\n",
"import matplotlib.pyplot as plt\n",
+ "import numpy as np\n",
"import logging\n",
"\n",
- "#interactive display\n",
- "import ipywidgets as widgets\n",
+ "%matplotlib inline\n",
"\n",
- "#modeling\n",
- "import sspspace\n",
- "from sklearn.linear_model import LinearRegression\n",
- "from sklearn.model_selection import train_test_split\n",
+ "import nengo\n",
+ "import nengo_spa as spa\n",
"\n",
- "from tqdm.notebook import tqdm as tqdm"
+ "seed = 0"
]
},
{
@@ -178,129 +163,14 @@
]
},
{
- "cell_type": "code",
- "execution_count": null,
+ "cell_type": "markdown",
"metadata": {
- "cellView": "form",
"execution": {}
},
- "outputs": [],
"source": [
- "# @title Plotting functions\n",
- "\n",
- "def plot_3d_function(X, Y, zs, titles):\n",
- " \"\"\"Plot 3D function.\n",
- "\n",
- " Inputs:\n",
- " - X (list): list of np.ndarray of x-values.\n",
- " - Y (list): list of np.ndarray of y-values.\n",
- " - zs (list): list of np.ndarray of z-values.\n",
- " - titles (list): list of titles of the plot.\n",
- " \"\"\"\n",
- " with plt.xkcd():\n",
- " fig = plt.figure(figsize=(8, 8))\n",
- " for index, (x, y, z) in enumerate(zip(X, Y, zs)):\n",
- " fig.add_subplot(1, len(X), index + 1, projection='3d')\n",
- " plt.gca().plot_surface(x,y,z.reshape(x.shape),cmap='plasma', antialiased=False, linewidth=0)\n",
- " plt.xlabel(r'$x_{1}$')\n",
- " plt.ylabel(r'$x_{2}$')\n",
- " plt.gca().set_zlabel(r'$f(\\mathbf{x})$')\n",
- " plt.title(titles[index])\n",
- " plt.show()\n",
- "\n",
- "def plot_performance(bound_performance, bundle_performance, training_samples, title):\n",
- " \"\"\"Plot RMSE values for two different representations of the input data.\n",
- "\n",
- " Inputs:\n",
- " - bound_performance (list): list of RMSE for bound representation.\n",
- " - bundle_performance (list): list of RMSE for bundle representation.\n",
- " - training_samples (list): x-axis.\n",
- " - title (str): title of the plot.\n",
- " \"\"\"\n",
- " with plt.xkcd():\n",
- " plt.plot(training_samples, bound_performance, label='Bound Representation')\n",
- " plt.plot(training_samples, bundle_performance, label='Bundling Representation', ls='--')\n",
- " plt.legend()\n",
- " plt.title(title)\n",
- " plt.ylabel('RMSE (a.u.)')\n",
- " plt.xlabel('# Training samples')\n",
- "\n",
- "def plot_2d_similarity(sims, obj_names, size, title_argmax = False):\n",
- " \"\"\"\n",
- " Plot 2D similarity between query points (grid) and the ones associated with the objects.\n",
- "\n",
- " Inputs:\n",
- " - sims (list): list of similarity values for each of the objects.\n",
- " - obj_names (list): list of object names.\n",
- " - size (tuple): to reshape the similarities.\n",
- " - title_argmax (bool, default = False): looks for the point coordinates as arg max from all similarity value.\n",
- " \"\"\"\n",
- " ticks = [0, 24, 49, 74, 99]\n",
- " ticklabels = [-5, -2, 0, 2, 5]\n",
- " with plt.xkcd():\n",
- " for obj_idx, obj in enumerate(obj_names):\n",
- " plt.subplot(1, len(obj_names), 1 + obj_idx)\n",
- " plt.imshow(np.array(sims[obj_idx].reshape(size)), origin='lower', vmin=-1, vmax=1)\n",
- " plt.gca().set_xticks(ticks)\n",
- " plt.gca().set_xticklabels(ticklabels)\n",
- " if obj_idx == 0:\n",
- " plt.gca().set_yticks(ticks)\n",
- " plt.gca().set_yticklabels(ticklabels)\n",
- " else:\n",
- " plt.gca().set_yticks([])\n",
- " if not title_argmax:\n",
- " plt.title(f'{obj}, {positions[obj_idx]}')\n",
- " else:\n",
- " plt.title(f'{obj}, {query_xs[sims[obj_idx].argmax()]}')\n",
- "\n",
- "def plot_unbinding_objects_map(sims, positions, query_xs, size):\n",
- " \"\"\"\n",
- " Plot 2D similarity between query points (grid) and the unbinded from the objects map.\n",
- "\n",
- " Inputs:\n",
- " - sims (np.ndarray): similarity values for each of the query points with the map.\n",
- " - positions (np.ndarray): positions of the objects.\n",
- " - query_xs (np.ndarray): grid points.\n",
- " - size (tuple): to reshape the similarities.\n",
- "\n",
- " \"\"\"\n",
- " ticks = [0,24,49,74,99]\n",
- " ticklabels = [-5,-2,0,2,5]\n",
- " with plt.xkcd():\n",
- " plt.imshow(sims.reshape(size), origin='lower')\n",
- "\n",
- " for idx, marker in enumerate(['o','s','^']):\n",
- " plt.scatter(*get_coordinate(positions[idx,:], query_xs, size), marker=marker,s=100)\n",
- "\n",
- " plt.gca().set_xticks(ticks)\n",
- " plt.gca().set_xticklabels(ticklabels)\n",
- " plt.gca().set_yticks(ticks)\n",
- " plt.gca().set_yticklabels(ticklabels)\n",
- " plt.title(f'All Object Locations')\n",
- " plt.show()\n",
- "\n",
- "def plot_unbinding_positions_map(sims, positions, obj_names):\n",
- " \"\"\"\n",
- " Plot 2D similarity between query points (grid) and the unbinded from the positions map.\n",
- "\n",
- " Inputs:\n",
- " - sims (np.ndarray): similarity values for each of the query points with the map.\n",
- " - positions (np.ndarray): test positions to query.\n",
- " - obj_names (list): names of the objects for labels.\n",
- " - size (tuple): to reshape the similarities.\n",
- " \"\"\"\n",
- " with plt.xkcd():\n",
- " plt.figure(figsize=(8, 4))\n",
- " for pos_idx, pos in enumerate(positions):\n",
- " plt.subplot(1,len(test_positions), 1+pos_idx)\n",
- " plt.bar([1,2,3], sims[pos_idx])\n",
- " plt.ylim([-0.3, 1.05])\n",
- " plt.gca().set_xticks([1,2,3])\n",
- " plt.gca().set_xticklabels(obj_names, rotation=90)\n",
- " if pos_idx != 0:\n",
- " plt.gca().set_yticks([])\n",
- " plt.title(f'Symbols at\\n{pos}')\n",
- " plt.show()"
+ "# Intro\n",
+ "\n",
+ "Michael will give an introductory overview to the notion of performing question answering in the VSA setup we have been working with today.\n"
]
},
{
@@ -312,113 +182,49 @@
},
"outputs": [],
"source": [
- "# @title Set random seed\n",
+ "# @title Video 1: Introduction\n",
"\n",
- "import random\n",
- "import numpy as np\n",
+ "from ipywidgets import widgets\n",
+ "from IPython.display import YouTubeVideo\n",
+ "from IPython.display import IFrame\n",
+ "from IPython.display import display\n",
"\n",
- "def set_seed(seed=None):\n",
- " if seed is None:\n",
- " seed = np.random.choice(2 ** 32)\n",
- " random.seed(seed)\n",
- " np.random.seed(seed)\n",
+ "class PlayVideo(IFrame):\n",
+ " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
+ " self.id = id\n",
+ " if source == 'Bilibili':\n",
+ " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
+ " elif source == 'Osf':\n",
+ " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
+ " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
- "set_seed(seed = 42)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Helper functions\n",
- "\n",
- "def get_model(xs, ys, train_size):\n",
- " \"\"\"Fit linear regression to the given data.\n",
- "\n",
- " Inputs:\n",
- " - xs (np.ndarray): input data.\n",
- " - ys (np.ndarray): output data.\n",
- " - train_size (float): fraction of data to use for train.\n",
- " \"\"\"\n",
- " X_train, _, y_train, _ = train_test_split(xs, ys, random_state=1, train_size=train_size)\n",
- " return LinearRegression().fit(X_train, y_train)\n",
- "\n",
- "def get_coordinate(x, positions, target_shape):\n",
- " \"\"\"Return the closest column and row coordinates for the given position.\n",
- "\n",
- " Inputs:\n",
- " - x (np.ndarray): query position.\n",
- " - positions (np.ndarray): all positions.\n",
- " - target_shape (tuple): shape of the grid.\n",
- "\n",
- " Outputs:\n",
- " - coordinates (tuple): column and row positions.\n",
- " \"\"\"\n",
- " idx = np.argmin(np.linalg.norm(x - positions, axis=1))\n",
- " c = idx % target_shape[1]\n",
- " r = idx // target_shape[1]\n",
- " return (c,r)\n",
- "\n",
- "def rastrigin_solution(x):\n",
- " \"\"\"Compute Rastrigin function for given array of d-dimenstional vectors.\n",
- "\n",
- " Inputs:\n",
- " - x (np.ndarray of shape (n, d)): n d-dimensional vectors.\n",
- "\n",
- " Outputs:\n",
- " - y (np.ndarray of shape (n, 1)): Rastrigin function value for each of the vectors.\n",
- " \"\"\"\n",
- " return 10 * x.shape[1] + np.sum(x**2 - 10 * np.cos(2*np.pi*x), axis=1)\n",
- "\n",
- "def non_separable_solution(x):\n",
- " \"\"\"Compute non-separable function for given array of 2-dimenstional vectors.\n",
- "\n",
- " Inputs:\n",
- " - x (np.ndarray of shape (n, 2)): n 2-dimensional vectors.\n",
- "\n",
- " Outputs:\n",
- " - y (np.ndarray of shape (n, 1)): non-separable function value for each of the vectors.\n",
- " \"\"\"\n",
- " return np.sin(np.multiply(x[:, 0], x[:, 1]))\n",
- "\n",
- "x0_rastrigin = np.linspace(-5.12, 5.12, 100)\n",
- "X_rastrigin, Y_rastrigin = np.meshgrid(x0_rastrigin,x0_rastrigin)\n",
- "xs_rastrigin = np.vstack((X_rastrigin.flatten(), Y_rastrigin.flatten())).T\n",
- "ys_rastrigin = rastrigin_solution(xs_rastrigin)\n",
- "\n",
- "x0_non_separable = np.linspace(-4, 4, 100)\n",
- "X_non_separable, Y_non_separable = np.meshgrid(x0_non_separable,x0_non_separable)\n",
- "xs_non_separable = np.vstack((X_non_separable.flatten(), Y_non_separable.flatten())).T\n",
- "ys_non_separable = non_separable_solution(xs_non_separable)\n",
- "\n",
- "set_seed(42)\n",
- "\n",
- "obj_names = ['circle','square','triangle']\n",
- "discrete_space = sspspace.DiscreteSPSpace(obj_names, ssp_dim=1024)\n",
- "\n",
- "objs = {n:discrete_space.encode(n) for n in obj_names}\n",
- "\n",
- "ssp_space = sspspace.RandomSSPSpace(domain_dim=2, ssp_dim=1024)\n",
- "positions = np.array([[0, -2],\n",
- " [-2, 3],\n",
- " [3, 2]\n",
- " ])\n",
- "ssps = {n:ssp_space.encode(x) for n, x in zip(obj_names, positions)}\n",
- "\n",
- "dim0 = np.linspace(-5, 5, 101)\n",
- "dim1 = np.linspace(-5, 5, 101)\n",
- "X,Y = np.meshgrid(dim0, dim1)\n",
- "\n",
- "query_xs = np.vstack((X.flatten(), Y.flatten())).T\n",
- "query_ssps = ssp_space.encode(query_xs)\n",
- "\n",
- "bound_objects = [objs[n] * ssps[n] for n in obj_names]\n",
- "ssp_map = sspspace.SSP(np.sum(bound_objects, axis=0))"
+ "def display_videos(video_ids, W=400, H=300, fs=1):\n",
+ " tab_contents = []\n",
+ " for i, video_id in enumerate(video_ids):\n",
+ " out = widgets.Output()\n",
+ " with out:\n",
+ " if video_ids[i][0] == 'Youtube':\n",
+ " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
+ " height=H, fs=fs, rel=0)\n",
+ " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
+ " else:\n",
+ " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
+ " height=H, fs=fs, autoplay=False)\n",
+ " if video_ids[i][0] == 'Bilibili':\n",
+ " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
+ " elif video_ids[i][0] == 'Osf':\n",
+ " print(f'Video available at https://osf.io/{video.id}')\n",
+ " display(video)\n",
+ " tab_contents.append(out)\n",
+ " return tab_contents\n",
+ "\n",
+ "video_ids = [('Youtube', 'YX-CM-vuxAc'), ('Bilibili', 'BV1VV7jz8EXa')]\n",
+ "tab_contents = display_videos(video_ids, W=854, H=480)\n",
+ "tabs = widgets.Tab()\n",
+ "tabs.children = tab_contents\n",
+ "for i in range(len(tab_contents)):\n",
+ " tabs.set_title(i, video_ids[i][0])\n",
+ "display(tabs)"
]
},
{
@@ -427,11 +233,9 @@
"execution": {}
},
"source": [
- "---\n",
+ "## Nengo & Question Answering\n",
"\n",
- "# Section 1: Sample Efficient Learning\n",
- "\n",
- "In this section, we will take a look at how imposing an inductive bias on our feature space can result in more sample-efficient learning. "
+ "Nengo is a tool used to implement spiking and dynamic neural network systems. We will shortly introduce the basics of Nengo so you have a clear idea of how it works, what it can do and how we will be using it throughout this tutorial (and other tutorials) today. We're then going to see how Nengo can be used on the application of Question Answering and then hand over to you to complete some interesting coding exercises to help you develop a feel for how to work with a basic example. These tools in your NeuroAI toolkit should then be a great start for you to continue learning about these methods and applying them to your your scientific questions and interests."
]
},
{
@@ -443,7 +247,7 @@
},
"outputs": [],
"source": [
- "# @title Video 1: Function Learning and Inductive Bias\n",
+ "# @title Video 2: Introduction to Nengo\n",
"\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
@@ -479,7 +283,7 @@
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
- "video_ids = [('Youtube', 'KDKmDjMxU7Q'), ('Bilibili', 'BV1GM4m1S7kT')]\n",
+ "video_ids = [('Youtube', 'FTIu-ariSyE'), ('Bilibili', 'BV1YV7jz8EfS')]\n",
"tab_contents = display_videos(video_ids, W=854, H=480)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
@@ -489,68 +293,68 @@
]
},
{
- "cell_type": "code",
- "execution_count": null,
+ "cell_type": "markdown",
"metadata": {
- "cellView": "form",
"execution": {}
},
- "outputs": [],
"source": [
- "# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_function_learning_and_inductive_bias\")"
+ "# Section 1: Define the input functions\n",
+ "\n",
+ "The color input will ``RED`` and then ``BLUE`` for 0.25 seconds each before being turned off. In the same way the shape input will be ``CIRCLE`` and then ``SQUARE`` for 0.25 seconds each. Thus, the network will bind alternatingly ``RED`` * ``CIRCLE`` and ``BLUE`` * ``SQUARE`` for 0.5 seconds each.\n",
+ "\n",
+ "The cue for deconvolving bound semantic pointers will be turned off for 0.5 seconds and then cycles through ``CIRCLE``, ``RED``, ``SQUARE``, and ``BLUE`` within one second."
]
},
{
- "cell_type": "markdown",
+ "cell_type": "code",
+ "execution_count": null,
"metadata": {
"execution": {}
},
+ "outputs": [],
"source": [
- "## Coding Exercise 1: Additive Function\n",
+ "def color_input(t):\n",
+ " if t < 0.25:\n",
+ " return \"RED\"\n",
+ " elif t < 0.5:\n",
+ " return \"BLUE\"\n",
+ " else:\n",
+ " return \"0\"\n",
"\n",
"\n",
- "We will start with an additive function, the Rastrigin function, defined \n",
+ "def shape_input(t):\n",
+ " if t < 0.25:\n",
+ " return \"CIRCLE\"\n",
+ " elif t < 0.5:\n",
+ " return \"SQUARE\"\n",
+ " else:\n",
+ " return \"0\"\n",
"\n",
- "\\begin{align*}\n",
- "f(\\mathbf{x}) = 10d + \\sum_{i=1}^{d} (x_{i}^{2} - 10 \\cos(2 \\pi x_{i}))\n",
- "\\end{align*}\n",
"\n",
- "where $d$ is the dimensionality of the input vector. In the cell below, complete missing parts of the function which computes values of the Rastrigin function given the input array."
+ "def cue_input(t):\n",
+ " if t < 0.5:\n",
+ " return \"0\"\n",
+ " sequence = [\"0\", \"CIRCLE\", \"RED\", \"0\", \"SQUARE\", \"BLUE\"]\n",
+ " idx = int(((t - 0.5) // (1.0 / len(sequence))) % len(sequence))\n",
+ " return sequence[idx]"
]
},
{
- "cell_type": "code",
- "execution_count": null,
+ "cell_type": "markdown",
"metadata": {
"execution": {}
},
- "outputs": [],
"source": [
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete the Rastrigin function.\")\n",
- "###################################################################\n",
- "\n",
- "def rastrigin(x):\n",
- " \"\"\"Compute Rastrigin function for given array of d-dimenstional vectors.\n",
- "\n",
- " Inputs:\n",
- " - x (np.ndarray of shape (n, d)): n d-dimensional vectors.\n",
- "\n",
- " Outputs:\n",
- " - y (np.ndarray of shape (n, 1)): Rastrigin function value for each of the vectors.\n",
- " \"\"\"\n",
- " return 10 * x.shape[1] + np.sum(... - 10 * np.cos(2*np.pi*...), axis=1)\n",
+ "# Create the model\n",
"\n",
- "# this code creates 10000 2-dimensional vectors which are going to be served as input to the function (thus, output is of shape (10000, 1))\n",
- "x0_rastrigin = np.linspace(-5.12, 5.12, 100)\n",
- "X_rastrigin, Y_rastrigin = np.meshgrid(x0_rastrigin,x0_rastrigin)\n",
- "xs_rastrigin = np.vstack((X_rastrigin.flatten(), Y_rastrigin.flatten())).T\n",
+ "Below we define a simple network compute the question answering. Note that the state labelled ``conv`` has the following arguments:\n",
+ "```python\n",
+ "conv = spa.State(dimensions, subdimensions=4, feedback=1.0, feedback_synapse=0.4)\n",
+ "```\n",
"\n",
- "ys_rastrigin = rastrigin(xs_rastrigin)\n",
+ "```feedback=1.0``` determines the strength of a recurrent connection that provides memory. ```feedback_synapse=0.4``` provides a time constant on a low-pass filter that models the synapses of the recurrent connection.\n",
"\n",
- "plot_3d_function([X_rastrigin],[Y_rastrigin], [ys_rastrigin.reshape(X_rastrigin.shape)], ['Rastrigin Function'])"
+ "``Transcode`` objects are modules provided by the Nengo programming framework to allow interaction with the outside world. They represent the interface between functions and the network, and execute simulus functions at runtime."
]
},
{
@@ -561,27 +365,21 @@
},
"outputs": [],
"source": [
- "#to_remove solution\n",
+ "# Number of dimensions for the Semantic Pointers\n",
+ "dimensions = 32\n",
"\n",
- "def rastrigin(x):\n",
- " \"\"\"Compute Rastrigin function for given array of d-dimenstional vectors.\n",
+ "model = spa.Network(label=\"Simple question answering\", seed=seed)\n",
"\n",
- " Inputs:\n",
- " - x (np.ndarray of shape (n, d)): n d-dimensional vectors.\n",
+ "with model:\n",
+ " color_in = spa.Transcode(color_input, output_vocab=dimensions)\n",
+ " shape_in = spa.Transcode(shape_input, output_vocab=dimensions)\n",
+ " bound = spa.State(dimensions, subdimensions=4, feedback=1.0, feedback_synapse=0.4) # conv\n",
+ " cue = spa.Transcode(cue_input, output_vocab=dimensions)\n",
+ " out = spa.State(dimensions)\n",
"\n",
- " Outputs:\n",
- " - y (np.ndarray of shape (n, 1)): Rastrigin function value for each of the vectors.\n",
- " \"\"\"\n",
- " return 10 * x.shape[1] + np.sum(x**2 - 10 * np.cos(2*np.pi*x), axis=1)\n",
- "\n",
- "# this code creates 10000 2-dimensional vectors which are going to be served as input to the function (thus, output is of shape (10000, 1))\n",
- "x0_rastrigin = np.linspace(-5.12, 5.12, 100)\n",
- "X_rastrigin, Y_rastrigin = np.meshgrid(x0_rastrigin,x0_rastrigin)\n",
- "xs_rastrigin = np.vstack((X_rastrigin.flatten(), Y_rastrigin.flatten())).T\n",
- "\n",
- "ys_rastrigin = rastrigin(xs_rastrigin)\n",
- "\n",
- "plot_3d_function([X_rastrigin],[Y_rastrigin], [ys_rastrigin.reshape(X_rastrigin.shape)], ['Rastrigin Function'])"
+ " # Connect the buffers\n",
+ " color_in * shape_in >> bound\n",
+ " bound * ~cue >> out"
]
},
{
@@ -590,10 +388,11 @@
"execution": {}
},
"source": [
- "Now, we are going to see which of the inductive biases (suggested mechanism underlying input data) will be more efficient in training the linear regression to get values of the Rastrigin function. We will consider two representations:\n",
+ "# Probe the Model\n",
+ "\n",
+ "Next we are going to probe different parts of the model to record their state during operation. Probes are analogous to sensors used in performing electrophysiological experiments, and their readout acts like a low-pass filter, smoothing the activity through the `synapse` member. Here we specify the low pass filter to have a time constant of `0.03`\n",
"\n",
- "* **Bound**: We encode 2D input vectors `xs` as bound vectors\n",
- "* **Bundled**: We encode 1D input vectors separately and use bundling and then bundle them together"
+ "We will create probes for all the components in the model: `color_in`, `shape_in`, `cue`, `conv`, and `out`. Specifically, we will probe the `output` member of each of these objects, as the Transcode and State objects represent more complex networks that are implemented in Nengo."
]
},
{
@@ -604,64 +403,67 @@
},
"outputs": [],
"source": [
- "set_seed(42)\n",
- "\n",
- "ssp_space = sspspace.RandomSSPSpace(domain_dim=2, ssp_dim=1024)\n",
- "bound_phis = ssp_space.encode(xs_rastrigin)\n",
- "\n",
- "ssp_space0 = sspspace.RandomSSPSpace(domain_dim=1, ssp_dim=1024)\n",
- "ssp_space1 = sspspace.RandomSSPSpace(domain_dim=1, ssp_dim=1024)\n",
- "\n",
- "#remember that input to `encode` should be 2-dimensional, thus we need to create extra dimension by applying [:,None]\n",
- "bundle_phis = ssp_space0.encode(xs_rastrigin[:, 0][:, None]) + ssp_space1.encode(xs_rastrigin[:, 1][:, None])"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Now, let us define modeling attributes: we will have a few different `train_sizes`, and we will fit a linear regression for each of them in a loop. Then, for each of the models, we will evaluate its fit based on RMSE loss on the test set."
+ "with model:\n",
+ " model.config[nengo.Probe].synapse = nengo.Lowpass(0.03)\n",
+ " p_color_in = nengo.Probe(color_in.output)\n",
+ " p_shape_in = nengo.Probe(shape_in.output)\n",
+ " p_cue = nengo.Probe(cue.output)\n",
+ " p_bound = nengo.Probe(bound.output)\n",
+ " p_out = nengo.Probe(out.output)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
+ "cellView": "form",
"execution": {}
},
"outputs": [],
"source": [
- "def loss(y_true, y_pred):\n",
- " \"\"\"Calculate RMSE loss between true and predicted values (note, that loss is not normalized by the shape).\n",
- "\n",
- " Inputs:\n",
- " - y_true (np.ndarray): true values.\n",
- " - y_pred (np.ndarray): predicted values.\n",
- "\n",
- " Outputs:\n",
- " - loss (float): loss value.\n",
- " \"\"\"\n",
- " return np.sqrt(np.mean((y_true - y_pred) ** 2))\n",
- "\n",
- "def test_performance(xs, ys, train_sizes):\n",
- " \"\"\"Fit linear regression to the provided data and evaluate the performance with RMSE loss for different test sizes.\n",
- "\n",
- " Inputs:\n",
- " - xs (np.ndarray): input data.\n",
- " - ys (np.ndarray): output data.\n",
- " - train_size (list): list of the train sizes.\n",
- " \"\"\"\n",
- " performance = []\n",
- "\n",
- " models = []\n",
- " for train_size in tqdm(train_sizes):\n",
- " X_train, X_test, y_train, y_test = train_test_split(xs, ys, random_state=1, train_size=train_size)\n",
- " regr = LinearRegression().fit(X_train, y_train)\n",
- " performance.append(np.copy(loss(y_test, regr.predict(X_test))))\n",
- " models.append(regr)\n",
- " return performance, models"
+ "# @title Video 3: Working Memory Functionality\n",
+ "\n",
+ "from ipywidgets import widgets\n",
+ "from IPython.display import YouTubeVideo\n",
+ "from IPython.display import IFrame\n",
+ "from IPython.display import display\n",
+ "\n",
+ "class PlayVideo(IFrame):\n",
+ " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
+ " self.id = id\n",
+ " if source == 'Bilibili':\n",
+ " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
+ " elif source == 'Osf':\n",
+ " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
+ " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
+ "\n",
+ "def display_videos(video_ids, W=400, H=300, fs=1):\n",
+ " tab_contents = []\n",
+ " for i, video_id in enumerate(video_ids):\n",
+ " out = widgets.Output()\n",
+ " with out:\n",
+ " if video_ids[i][0] == 'Youtube':\n",
+ " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
+ " height=H, fs=fs, rel=0)\n",
+ " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
+ " else:\n",
+ " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
+ " height=H, fs=fs, autoplay=False)\n",
+ " if video_ids[i][0] == 'Bilibili':\n",
+ " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
+ " elif video_ids[i][0] == 'Osf':\n",
+ " print(f'Video available at https://osf.io/{video.id}')\n",
+ " display(video)\n",
+ " tab_contents.append(out)\n",
+ " return tab_contents\n",
+ "\n",
+ "video_ids = [('Youtube', 'i7mc_Z03pew'), ('Bilibili', 'BV1jK7jzNEr7')]\n",
+ "tab_contents = display_videos(video_ids, W=854, H=480)\n",
+ "tabs = widgets.Tab()\n",
+ "tabs.children = tab_contents\n",
+ "for i in range(len(tab_contents)):\n",
+ " tabs.set_title(i, video_ids[i][0])\n",
+ "display(tabs)"
]
},
{
@@ -670,7 +472,11 @@
"execution": {}
},
"source": [
- "Now, we are ready to train the models on two different inductive biases of the input data."
+ "# Run the model\n",
+ "\n",
+ "Now you will run the model using the programmatic Nengo interface. It will produce plots that compare similarity between different terms in our vocabulary (``RED``,``BLUE``,``CIRCLE``,``SQUARE``) and the states of the different elements of the networks. \n",
+ "\n",
+ "Remember: when the module is representing a state in our vocabularity, the similarity should increase towards 1."
]
},
{
@@ -681,11 +487,8 @@
},
"outputs": [],
"source": [
- "train_sizes = np.linspace(0.25, 0.9, 5)\n",
- "bound_performance, bound_models = test_performance(bound_phis, ys_rastrigin, train_sizes)\n",
- "bundle_performance, bundle_models = test_performance(bundle_phis, ys_rastrigin, train_sizes)\n",
- "plot_performance(bound_performance, bundle_performance, train_sizes * bound_phis.shape[0], \"Rastrigin function - RMSE\")\n",
- "plt.ylim((-1, 20))"
+ "with nengo.Simulator(model) as sim:\n",
+ " sim.run(3.0)"
]
},
{
@@ -694,7 +497,9 @@
"execution": {}
},
"source": [
- "What a drastic difference! Let us evaluate visually the performance when training on 3,000 train points."
+ "# Plot the results\n",
+ "\n",
+ "After we run the simulator, it will store the data from the probes we created earlier. Each of the probe objects above, say `p_bound` which records the output of the binding operation, `bound`, are keys for a dictionary of data stored in the simulator."
]
},
{
@@ -705,13 +510,35 @@
},
"outputs": [],
"source": [
- "bound_model = bound_models[0]\n",
- "bundled_model = bundle_models[0]\n",
+ "plt.figure(figsize=(10, 10))\n",
+ "vocab = model.vocabs[dimensions]\n",
"\n",
- "ys_hat_rastrigin_bound = bound_model.predict(bound_phis)\n",
- "ys_hat_rastrigin_bundled = bundled_model.predict(bundle_phis)\n",
+ "plt.subplot(5, 1, 1)\n",
+ "plt.plot(sim.trange(), spa.similarity(sim.data[p_color_in], vocab))\n",
+ "plt.legend(vocab.keys(), fontsize=\"x-small\")\n",
+ "plt.ylabel(\"color\")\n",
"\n",
- "plot_3d_function([X_rastrigin, X_rastrigin, X_rastrigin], [Y_rastrigin, Y_rastrigin, Y_rastrigin], [ys_rastrigin.reshape(X_rastrigin.shape), ys_hat_rastrigin_bound.reshape(X_rastrigin.shape), ys_hat_rastrigin_bundled.reshape(X_rastrigin.shape)], ['Rastrigin Function - True', 'Bound', 'Bundled'])"
+ "plt.subplot(5, 1, 2)\n",
+ "plt.plot(sim.trange(), spa.similarity(sim.data[p_shape_in], vocab))\n",
+ "plt.legend(vocab.keys(), fontsize=\"x-small\")\n",
+ "plt.ylabel(\"shape\")\n",
+ "\n",
+ "plt.subplot(5, 1, 3)\n",
+ "plt.plot(sim.trange(), spa.similarity(sim.data[p_cue], vocab))\n",
+ "plt.legend(vocab.keys(), fontsize=\"x-small\")\n",
+ "plt.ylabel(\"cue\")\n",
+ "\n",
+ "plt.subplot(5, 1, 4)\n",
+ "for pointer in [\"RED * CIRCLE\", \"BLUE * SQUARE\"]:\n",
+ " plt.plot(sim.trange(), vocab.parse(pointer).dot(sim.data[p_bound].T), label=pointer)\n",
+ "plt.legend(fontsize=\"x-small\")\n",
+ "plt.ylabel(\"Bound\")\n",
+ "\n",
+ "plt.subplot(5, 1, 5)\n",
+ "plt.plot(sim.trange(), spa.similarity(sim.data[p_out], vocab))\n",
+ "plt.legend(vocab.keys(), fontsize=\"x-small\")\n",
+ "plt.ylabel(\"Output\")\n",
+ "plt.xlabel(\"time [s]\")"
]
},
{
@@ -720,26 +547,67 @@
"execution": {}
},
"source": [
- "### Coding Exercise 1 Discussion\n",
+ "The plots of shape, color, and convolved show that first `RED * CIRCLE` and then `BLUE * SQUARE` will be loaded into the convolved buffer so after 0.5 seconds it represents the superposition `RED * CIRCLE + BLUE * SQUARE`.\n",
+ "\n",
+ "The last plot shows that the output is most similar to the semantic pointer bound to the current cue. For example, when RED and CIRCLE are being convolved and the cue is CIRCLE, the output is most similar to RED. Thus, it is possible to unbind semantic pointers from the superposition stored in convolved.\n",
"\n",
- "1. Why do you think the bundled representation is superior for the Rastrigin function?"
+ "You can see the effect of the memory unit in the model above because, even after the stimulus is turned off, the model is still able to answer the questions posed to it by the ``cue`` element.\n",
+ "\n",
+ "You can also see the effect of the neural implementation in the noise in the output signal.\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
+ "cellView": "form",
"execution": {}
},
"outputs": [],
"source": [
- "#to_remove explanation\n",
+ "# @title Video 4: Results Walthrough\n",
+ "\n",
+ "from ipywidgets import widgets\n",
+ "from IPython.display import YouTubeVideo\n",
+ "from IPython.display import IFrame\n",
+ "from IPython.display import display\n",
+ "\n",
+ "class PlayVideo(IFrame):\n",
+ " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
+ " self.id = id\n",
+ " if source == 'Bilibili':\n",
+ " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
+ " elif source == 'Osf':\n",
+ " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
+ " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
- "\"\"\"\n",
- "Discussion: Why do you think the bundled representation is superior for the Rastrigin function?\n",
+ "def display_videos(video_ids, W=400, H=300, fs=1):\n",
+ " tab_contents = []\n",
+ " for i, video_id in enumerate(video_ids):\n",
+ " out = widgets.Output()\n",
+ " with out:\n",
+ " if video_ids[i][0] == 'Youtube':\n",
+ " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
+ " height=H, fs=fs, rel=0)\n",
+ " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
+ " else:\n",
+ " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
+ " height=H, fs=fs, autoplay=False)\n",
+ " if video_ids[i][0] == 'Bilibili':\n",
+ " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
+ " elif video_ids[i][0] == 'Osf':\n",
+ " print(f'Video available at https://osf.io/{video.id}')\n",
+ " display(video)\n",
+ " tab_contents.append(out)\n",
+ " return tab_contents\n",
"\n",
- "The Rastrigin function is a superposition of independent functions of the input variable dimensions. The bundled representation is a superposition of a high-dimensional representation of the input dimensions, making it easier to learn this function, which is additive. For the bound representation, we have to learn a mapping from each tuple of input values to the appropriate output value, meaning more samples are required to approximate the function.\n",
- "\"\"\";"
+ "video_ids = [('Youtube', '3f0UqEm9Gzo'), ('Bilibili', 'BV17K7jzNEr3')]\n",
+ "tab_contents = display_videos(video_ids, W=854, H=480)\n",
+ "tabs = widgets.Tab()\n",
+ "tabs.children = tab_contents\n",
+ "for i in range(len(tab_contents)):\n",
+ " tabs.set_title(i, video_ids[i][0])\n",
+ "display(tabs)"
]
},
{
@@ -752,7 +620,7 @@
"outputs": [],
"source": [
"# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_additive_function\")"
+ "content_review(f\"{feedback_prefix}_results_walkthrough\")"
]
},
{
@@ -761,44 +629,9 @@
"execution": {}
},
"source": [
- "## Coding Exercise 2: Non-separable Function\n",
- "\n",
- "Now, let's consider a non-separable function: a function $f(x_1, x_2)$ that cannot be described as the sum of two one-dimensional functions $g(x_1)$ and $h_1$. We will examine this function over the domain $[-4,4]^{2}$:\n",
- "\n",
- "$$f(\\mathbf{x}) = \\sin(x_{1}x_{2})$$\n",
- "\n",
- "Fill in the missing parts of the code to get the correct calculation of the defined function."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete the non-separable function.\")\n",
- "###################################################################\n",
- "\n",
- "def non_separable(x):\n",
- " \"\"\"Compute non-separable function for given array of 2-dimenstional vectors.\n",
- "\n",
- " Inputs:\n",
- " - x (np.ndarray of shape (n, 2)): n 2-dimensional vectors.\n",
+ "## Coding Exercise \n",
"\n",
- " Outputs:\n",
- " - y (np.ndarray of shape (n, 1)): non-separable function value for each of the vectors.\n",
- " \"\"\"\n",
- " return np.sin(np.multiply(x[:, ...], x[:, ...]))\n",
- "\n",
- "x0_non_separable = np.linspace(-4, 4, 100)\n",
- "X_non_separable, Y_non_separable = np.meshgrid(x0_non_separable,x0_non_separable)\n",
- "xs_non_separable = np.vstack((X_non_separable.flatten(), Y_non_separable.flatten())).T\n",
- "\n",
- "ys_non_separable = non_separable(xs_non_separable)"
+ "**QUESTION** Try adding the concept of a ``GREEN * SQUARE`` to the model. Run the simulation for 5 seconds and compare the plots."
]
},
{
@@ -809,35 +642,20 @@
},
"outputs": [],
"source": [
- "#to_remove solution\n",
- "\n",
- "def non_separable(x):\n",
- " \"\"\"Compute non-separable function for given array of 2-dimenstional vectors.\n",
- "\n",
- " Inputs:\n",
- " - x (np.ndarray of shape (n, 2)): n 2-dimensional vectors.\n",
- "\n",
- " Outputs:\n",
- " - y (np.ndarray of shape (n, 1)): non-separable function value for each of the vectors.\n",
- " \"\"\"\n",
- " return np.sin(np.multiply(x[:, 0], x[:, 1]))\n",
- "\n",
- "x0_non_separable = np.linspace(-4, 4, 100)\n",
- "X_non_separable, Y_non_separable = np.meshgrid(x0_non_separable,x0_non_separable)\n",
- "xs_non_separable = np.vstack((X_non_separable.flatten(), Y_non_separable.flatten())).T\n",
- "\n",
- "ys_non_separable = non_separable(xs_non_separable)"
+ "# Student code completion here"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
+ "cellView": "form",
"execution": {}
},
"outputs": [],
"source": [
- "plot_3d_function([X_non_separable],[Y_non_separable], [ys_non_separable.reshape(X_non_separable.shape)], ['Nonseparable Function, $f(\\mathbf{x}) = \\sin(x_{1}x_{2})$'])"
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_green_square_coding\")"
]
},
{
@@ -846,592 +664,24 @@
"execution": {}
},
"source": [
- "### Coding Exercise 2 Discussion\n",
- "\n",
- "1. Can you guess by the nature of the function which of the representations will be more efficient?"
+ "---"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
+ "cellView": "form",
"execution": {}
},
"outputs": [],
"source": [
- "#to_remove explanation\n",
+ "# @title Video 5: Outro Video\n",
"\n",
- "\"\"\"\n",
- "Discussion: Can you guess which of the representations will be more efficient by the nature of the function?\n",
- "\n",
- "As the function is not separable, we expect the bound representation to perform better.\n",
- "\"\"\";"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "We will reuse previously defined spaces for encoding bound and bundled representations."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "bound_phis = ssp_space.encode(xs_non_separable)\n",
- "bundle_phis = ssp_space0.encode(xs_non_separable[:,0][:,None]) + ssp_space1.encode(xs_non_separable[:,1][:,None])\n",
- "\n",
- "train_sizes = np.linspace(0.25, 0.9, 5)\n",
- "bound_performance, bound_models = test_performance(bound_phis, ys_non_separable, train_sizes)\n",
- "bundle_performance, bundle_models = test_performance(bundle_phis, ys_non_separable, train_sizes)\n",
- "plot_performance(bound_performance, bundle_performance, train_sizes * bound_phis.shape[0], title = \"Non-separable function - RMSE\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Bundling representation can't achieve the same quality even when the number of samples is increased. This is because the function is non-separable, and the bundling representation can't capture the interaction between the two dimensions."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "bound_model = bound_models[0]\n",
- "bundle_model = bundle_models[0]\n",
- "\n",
- "ys_hat_bound = bound_model.predict(bound_phis)\n",
- "ys_hat_bundle = bundle_model.predict(bundle_phis)\n",
- "\n",
- "plot_3d_function([X_non_separable, X_non_separable, X_non_separable], [Y_non_separable, Y_non_separable, Y_non_separable], [ys_non_separable.reshape(X_non_separable.shape), ys_hat_bound.reshape(X_non_separable.shape), ys_hat_bundle.reshape(X_non_separable.shape)], ['Non-separable Function - True', 'Bound', 'Bundled'])"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "So, as we can see, when we pick the right inductive bias, we can do a better job."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_non_separable_function\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "---\n",
- "\n",
- "# Section 2: Representing Continuous Values\n",
- "\n",
- "Estimated timing to here from start of tutorial: 20 minutes\n",
- "\n",
- "In this section we will use a technique called Fractional Binding to represent continuous values to construct a map of objects distributed over a 2D space. "
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Video 2: Mapping Intro\n",
- "from ipywidgets import widgets\n",
- "from IPython.display import YouTubeVideo\n",
- "from IPython.display import IFrame\n",
- "from IPython.display import display\n",
- "\n",
- "class PlayVideo(IFrame):\n",
- " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
- " self.id = id\n",
- " if source == 'Bilibili':\n",
- " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
- " elif source == 'Osf':\n",
- " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
- " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
- "\n",
- "def display_videos(video_ids, W=400, H=300, fs=1):\n",
- " tab_contents = []\n",
- " for i, video_id in enumerate(video_ids):\n",
- " out = widgets.Output()\n",
- " with out:\n",
- " if video_ids[i][0] == 'Youtube':\n",
- " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
- " height=H, fs=fs, rel=0)\n",
- " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
- " else:\n",
- " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
- " height=H, fs=fs, autoplay=False)\n",
- " if video_ids[i][0] == 'Bilibili':\n",
- " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
- " elif video_ids[i][0] == 'Osf':\n",
- " print(f'Video available at https://osf.io/{video.id}')\n",
- " display(video)\n",
- " tab_contents.append(out)\n",
- " return tab_contents\n",
- "\n",
- "video_ids = [('Youtube', 's7MOusrbKXU'), ('Bilibili', 'BV1pi421i7iN')]\n",
- "tab_contents = display_videos(video_ids, W=854, H=480)\n",
- "tabs = widgets.Tab()\n",
- "tabs.children = tab_contents\n",
- "for i in range(len(tab_contents)):\n",
- " tabs.set_title(i, video_ids[i][0])\n",
- "display(tabs)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_mapping_intro\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "## Coding Exercise 3: Mixing Discrete Objects With Continuous Space\n",
- "\n",
- "We will store three objects in a vector representing a map. First, we will create 3 objects (a circle, square, and triangle), as we did before."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "set_seed(42)\n",
- "\n",
- "obj_names = ['circle','square','triangle']\n",
- "discrete_space = sspspace.DiscreteSPSpace(obj_names, ssp_dim=1024)\n",
- "\n",
- "objs = {n:discrete_space.encode(n) for n in obj_names}"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Next, we are going to create three locations where the objects will reside, and an encoder will transform those coordinates into an SSP representation."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "set_seed(42)\n",
- "\n",
- "ssp_space = sspspace.RandomSSPSpace(domain_dim=2, ssp_dim=1024)\n",
- "positions = np.array([[0, -2],\n",
- " [-2, 3],\n",
- " [3, 2]\n",
- " ])\n",
- "ssps = {n:ssp_space.encode(x) for n, x in zip(obj_names, positions)}"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Next, in order to see where things are on the map, we are going to compute the similarity between encoded places and points in the space. Your task is to complete the calculation of similarity values between all grid points with the one associated with the object."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "dim0 = np.linspace(-5, 5, 101)\n",
- "dim1 = np.linspace(-5, 5, 101)\n",
- "X,Y = np.meshgrid(dim0, dim1)\n",
- "\n",
- "query_xs = np.vstack((X.flatten(), Y.flatten())).T\n",
- "query_ssps = ssp_space.encode(query_xs)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete similarity calculation.\")\n",
- "###################################################################\n",
- "\n",
- "sims = []\n",
- "\n",
- "for obj_idx, obj in enumerate(obj_names):\n",
- " sims.append(... @ ssps[obj].flatten())\n",
- "\n",
- "plt.figure(figsize=(8, 2.4))\n",
- "plot_2d_similarity(sims, obj_names, (dim0.size, dim1.size))"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "#to_remove solution\n",
- "\n",
- "sims = []\n",
- "\n",
- "for obj_idx, obj in enumerate(obj_names):\n",
- " sims.append(query_ssps @ ssps[obj].flatten())\n",
- "\n",
- "plt.figure(figsize=(8, 2.4))\n",
- "plot_2d_similarity(sims, obj_names, (dim0.size, dim1.size))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Now, let's bind these positions with the objects and see how that changes similarity with the map positions. Complete binding operation in the cell below."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete binding operation for objects and corresponding positions.\")\n",
- "###################################################################\n",
- "\n",
- "#objects are located in `objs` and positions in `ssps`\n",
- "bound_objects = [... * ... for n in obj_names]\n",
- "\n",
- "sims = []\n",
- "\n",
- "for obj_idx, obj in enumerate(obj_names):\n",
- " sims.append(query_ssps @ bound_objects[obj_idx].flatten())\n",
- "\n",
- "plt.figure(figsize=(8, 2.4))\n",
- "plot_2d_similarity(sims, obj_names, (dim0.size, dim1.size))"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "#to_remove solution\n",
- "\n",
- "#objects are located in `objs` and positions in `ssps`\n",
- "bound_objects = [objs[n] * ssps[n] for n in obj_names]\n",
- "\n",
- "sims = []\n",
- "\n",
- "for obj_idx, obj in enumerate(obj_names):\n",
- " sims.append(query_ssps @ bound_objects[obj_idx].flatten())\n",
- "\n",
- "plt.figure(figsize=(8, 2.4))\n",
- "plot_2d_similarity(sims, obj_names, (dim0.size, dim1.size))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "As you can see, the similarity is destroyed, which is what we should expect.\n",
- "\n",
- "Next, we are going to create a map out of our bound objects:\n",
- "\n",
- "\\begin{align*}\n",
- "\\mathrm{map} = \\sum_{i=1}^{n} \\phi(x_{i})\\circledast obj_{i}\n",
- "\\end{align*}"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "set_seed(42)\n",
- "\n",
- "ssp_map = sspspace.SSP(np.sum(bound_objects, axis=0))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Now, we can query the map by unbinding the objects we care about. Your task is to complete the unbinding operation. Then, let's observe the resulting similarities."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete the unbinding operation.\")\n",
- "###################################################################\n",
- "\n",
- "objects_sims = []\n",
- "\n",
- "for obj_idx, obj_name in enumerate(obj_names):\n",
- " #query the object name by unbinding it from the map\n",
- " query_map = ssp_map * ~objs[...]\n",
- " objects_sims.append(query_ssps @ query_map.flatten())\n",
- "\n",
- "plot_2d_similarity(objects_sims, obj_names, (dim0.size, dim1.size), title_argmax = True)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "#to_remove solution\n",
- "\n",
- "objects_sims = []\n",
- "\n",
- "for obj_idx, obj_name in enumerate(obj_names):\n",
- " #query the object name by unbinding it from the map\n",
- " query_map = ssp_map * ~objs[obj_name]\n",
- " objects_sims.append(query_ssps @ query_map.flatten())\n",
- "\n",
- "plot_2d_similarity(objects_sims, obj_names, (dim0.size, dim1.size), title_argmax = True)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Let's look at what happens when we unbind all the symbols from the map at once. Complete bundling and unbinding operations in the following code cell."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete the bundling and unbinding operations.\")\n",
- "###################################################################\n",
- "\n",
- "# unifying bundled representation of all objects\n",
- "all_objs = (objs['circle'] + objs[...] + objs[...]).normalize()\n",
- "\n",
- "# unbind this unifying representation from the map\n",
- "query_map = ... * ~...\n",
- "\n",
- "sims = query_ssps @ query_map.flatten()\n",
- "size = (dim0.size,dim1.size)\n",
- "\n",
- "plot_unbinding_objects_map(sims, positions, query_xs, size)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "#to_remove solution\n",
- "# unifying bundled representation of all objects\n",
- "all_objs = (objs['circle'] + objs['square'] + objs['triangle']).normalize()\n",
- "\n",
- "# unbind this unifying representation from the map\n",
- "query_map = ssp_map * ~all_objs\n",
- "\n",
- "sims = query_ssps @ query_map.flatten()\n",
- "size = (dim0.size,dim1.size)\n",
- "\n",
- "plot_unbinding_objects_map(sims, positions, query_xs, size)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "We can also unbind positions and see what objects exist there. We will the locations where objects are located as test positions, as well as two distinct ones to compare. In the final exercise, you should complete the unbinding of the position's operation."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete the unbinding operations.\")\n",
- "###################################################################\n",
- "\n",
- "query_objs = np.vstack([objs[n] for n in obj_names])\n",
- "test_positions = np.vstack((positions, [0,0], [0,-1.5]))\n",
- "\n",
- "sims = []\n",
- "\n",
- "for pos_idx, pos in enumerate(test_positions):\n",
- " position_ssp = ssp_space.encode(pos[None,:]) #remember we need to have 2-dimensional vectors for `encode()` function\n",
- " #unbind positions from the map\n",
- " query_map = ... * ~...\n",
- " sims.append(query_objs @ query_map.flatten())\n",
- "\n",
- "plot_unbinding_positions_map(sims, test_positions, obj_names)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "#to_remove solution\n",
- "\n",
- "query_objs = np.vstack([objs[n] for n in obj_names])\n",
- "test_positions = np.vstack((positions, [0,0], [0,-1.5]))\n",
- "\n",
- "sims = []\n",
- "\n",
- "for pos_idx, pos in enumerate(test_positions):\n",
- " position_ssp = ssp_space.encode(pos[None,:]) #remember we need to have 2-dimensional vectors for `encode()` function\n",
- " #unbind positions from the map\n",
- " query_map = ssp_map * ~position_ssp\n",
- " sims.append(query_objs @ query_map.flatten())\n",
- "\n",
- "plot_unbinding_positions_map(sims, test_positions, obj_names)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "As you can see from the above plots, when we query each location, we can clearly identify the object stored at that location. \n",
- "\n",
- "When we query at the origin (where no object is present), we see that there is no strong candidate element. However, as we move closer to one of the objects (rightmost plot), the similarity starts to increase."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_mixing_discrete_objects_with_continuous_space\")"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Video 4: Mapping Outro\n",
- "from ipywidgets import widgets\n",
- "from IPython.display import YouTubeVideo\n",
- "from IPython.display import IFrame\n",
- "from IPython.display import display\n",
+ "from ipywidgets import widgets\n",
+ "from IPython.display import YouTubeVideo\n",
+ "from IPython.display import IFrame\n",
+ "from IPython.display import display\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
@@ -1462,7 +712,7 @@
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
- "video_ids = [('Youtube', 'mXNFWr_cap4'), ('Bilibili', 'BV1ND421u7gp')]\n",
+ "video_ids = [('Youtube', 'mWIfBl-4FKM'), ('Bilibili', 'BV1jK7jzNE1h')]\n",
"tab_contents = display_videos(video_ids, W=854, H=480)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
@@ -1481,7 +731,7 @@
"outputs": [],
"source": [
"# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_mapping_outro\")"
+ "content_review(f\"{feedback_prefix}_outro\")"
]
},
{
@@ -1491,94 +741,13 @@
},
"source": [
"---\n",
- "# Summary\n",
+ "# The Big Picture\n",
"\n",
- "*Estimated timing of tutorial: 40 minutes*"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Video 5: Conclusions\n",
- "from ipywidgets import widgets\n",
- "from IPython.display import YouTubeVideo\n",
- "from IPython.display import IFrame\n",
- "from IPython.display import display\n",
+ "You have now built a fairly simple cognitive model. A system that has an, albeit limited, vocabulary, expressed using a Vector Symbolic Algebra (VSA). Also, importantly, it is able to answer questions about it's experience, even though the experience has passed, thanks to its working memory. Working memory is a vital component of cognitive models, and while this is a simple system, you have now experienced working with the tools that underly SPAUN, the world's largest *functional* brain model. \n",
"\n",
- "class PlayVideo(IFrame):\n",
- " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
- " self.id = id\n",
- " if source == 'Bilibili':\n",
- " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
- " elif source == 'Osf':\n",
- " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
- " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
+ "Additionally, while you haven't explicitly worked with them, this model was implemented completely with spiking neurons. The Neural Engineering Framework, the mathematical tools that underpin Nengo, allow us to compile the program we wrote using the VSA into a network of neurons. If you look closely at the plots above, you can see that the lines are noisy. This is because they are smoothed (thanks to the probes' synapse) signals that represent the activity of the populations of neurons that implement our simple question answering model.\n",
"\n",
- "def display_videos(video_ids, W=400, H=300, fs=1):\n",
- " tab_contents = []\n",
- " for i, video_id in enumerate(video_ids):\n",
- " out = widgets.Output()\n",
- " with out:\n",
- " if video_ids[i][0] == 'Youtube':\n",
- " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
- " height=H, fs=fs, rel=0)\n",
- " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
- " else:\n",
- " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
- " height=H, fs=fs, autoplay=False)\n",
- " if video_ids[i][0] == 'Bilibili':\n",
- " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
- " elif video_ids[i][0] == 'Osf':\n",
- " print(f'Video available at https://osf.io/{video.id}')\n",
- " display(video)\n",
- " tab_contents.append(out)\n",
- " return tab_contents\n",
- "\n",
- "video_ids = [('Youtube', 'M6rRsdJdoYQ'), ('Bilibili', 'BV1wm421L7Se')]\n",
- "tab_contents = display_videos(video_ids, W=854, H=480)\n",
- "tabs = widgets.Tab()\n",
- "tabs.children = tab_contents\n",
- "for i in range(len(tab_contents)):\n",
- " tabs.set_title(i, video_ids[i][0])\n",
- "display(tabs)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Conclusion slides\n",
- "\n",
- "from IPython.display import IFrame\n",
- "link_id = \"pxqny\"\n",
- "\n",
- "print(f\"If you want to download the slides: 'https://osf.io/download/{link_id}'\")\n",
- "\n",
- "IFrame(src=f\"https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{link_id}/?direct%26mode=render\", width=854, height=480)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_conclusions\")"
+ "We have not one, but two extra bonus tutorials for today. These tutorials go into more depth on the basics around how to implement the notions of analogies in a VSA (Bonus Tutorial 4) and in Bonus Tutorial 5 we go through representations in continuous space. If you have any time left over, we encourage you to work your way through this extra material."
]
}
],
@@ -1610,7 +779,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.9.19"
+ "version": "3.9.22"
}
},
"nbformat": 4,
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/W2D2_Tutorial4.ipynb b/tutorials/W2D2_NeuroSymbolicMethods/W2D2_Tutorial4.ipynb
new file mode 100644
index 000000000..1986815d2
--- /dev/null
+++ b/tutorials/W2D2_NeuroSymbolicMethods/W2D2_Tutorial4.ipynb
@@ -0,0 +1,1039 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {},
+ "id": "view-in-github"
+ },
+ "source": [
+ "
 "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "# (BONUS) Tutorial 4: VSA Analogies\n",
+ "\n",
+ "**Week 2, Day 2: Neuro-Symbolic Methods**\n",
+ "\n",
+ "**By Neuromatch Academy**\n",
+ "\n",
+ "__Content creators:__ P. Michael Furlong, Chris Eliasmith\n",
+ "\n",
+ "__Content reviewers:__ Hlib Solodzhuk, Patrick Mineault, Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Alex Murphy\n",
+ "\n",
+ "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk, Alex Murphy\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "___\n",
+ "\n",
+ "\n",
+ "# Tutorial Objectives\n",
+ "\n",
+ "This tutorial will present you with a couple of toy examples using the basic operations of vector symbolic algebras. We will further show how these can generalize to new knowledge. If you are familiar with the basics of semantic algebra on word embeddings, you already understand the basics of what we'll be demonstrating in this tutorial. If not, don't worry, this tutorial is designed to be highly self-contained. If you're interested in learning more about word embedding algebra, then we encourage you to use your search engine of choice and learn more after completing the code exercises given below."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Tutorial slides\n",
+ "# @markdown These are the slides for the videos in all tutorials today\n",
+ "\n",
+ "from IPython.display import IFrame\n",
+ "link_id = \"jybuw\"\n",
+ "\n",
+ "print(f\"If you want to download the slides: 'https://osf.io/download/{link_id}'\")\n",
+ "\n",
+ "IFrame(src=f\"https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{link_id}/?direct%26mode=render\", width=854, height=480)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "---\n",
+ "# Setup (Colab Users: Please Read)\n",
+ "\n",
+ "Note that because this tutorial relies on some special Python packages, these packages have requirements for specific versions of common scientific libraries, such as `numpy`. If you're in Google Colab, then as of May 2025, this comes with a later version (2.0.2) pre-installed. We require an older version (we'll be installing `1.24.4`). This causes Colab to force a session restart and then re-running of the installation cells for the new version to take effect. When you run the cell below, you will be prompted to restart the session. This is *entirely expected* and you haven't done anything wrong. Simply click 'Restart' and then run the cells as normal. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Install dependencies and import feedback gadget\n",
+ "\n",
+ "!pip install numpy==1.24.4 --quiet\n",
+ "!pip install scikit-learn==1.6.1 --quiet\n",
+ "!pip install scipy==1.15.3 --quiet\n",
+ "!pip install git+https://github.com/neuromatch/sspspace@neuromatch --no-deps --quiet\n",
+ "!pip install nengo==4.0.0 --quiet\n",
+ "!pip install nengo_spa==2.0.0 --quiet\n",
+ "!pip install --quiet matplotlib ipywidgets vibecheck\n",
+ "!pip install --quiet numpy matplotlib ipywidgets scipy scikit-learn vibecheck\n",
+ "\n",
+ "from vibecheck import DatatopsContentReviewContainer\n",
+ "def content_review(notebook_section: str):\n",
+ " return DatatopsContentReviewContainer(\n",
+ " \"\", # No text prompt\n",
+ " notebook_section,\n",
+ " {\n",
+ " \"url\": \"https://pmyvdlilci.execute-api.us-east-1.amazonaws.com/klab\",\n",
+ " \"name\": \"neuromatch_neuroai\",\n",
+ " \"user_key\": \"wb2cxze8\",\n",
+ " },\n",
+ " ).render()\n",
+ "\n",
+ "\n",
+ "feedback_prefix = \"W2D2_T4\""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Notice that exactly the `neuromatch` branch of `sspspace` should be installed! Otherwise, some of the functionality (like `optimize` parameter in the `DiscreteSPSpace` initialization) won't work."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Imports\n",
+ "\n",
+ "#working with data\n",
+ "import numpy as np\n",
+ "\n",
+ "#plotting\n",
+ "import matplotlib.pyplot as plt\n",
+ "import logging\n",
+ "\n",
+ "#interactive display\n",
+ "# import ipywidgets as widgets\n",
+ "\n",
+ "#modeling\n",
+ "import sspspace\n",
+ "import nengo_spa as spa\n",
+ "from scipy.special import softmax\n",
+ "from sklearn.metrics import log_loss\n",
+ "from sklearn.neural_network import MLPRegressor\n",
+ "from nengo_spa.algebras.hrr_algebra import HrrProperties, HrrAlgebra\n",
+ "from nengo_spa.vector_generation import VectorsWithProperties\n",
+ "\n",
+ "def make_vocabulary(vector_length):\n",
+ " vec_generator = VectorsWithProperties(vector_length, algebra=HrrAlgebra(), properties = [HrrProperties.UNITARY, HrrProperties.POSITIVE])\n",
+ " vocab = spa.Vocabulary(vector_length, pointer_gen=vec_generator)\n",
+ " return vocab"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Figure settings\n",
+ "\n",
+ "logging.getLogger('matplotlib.font_manager').disabled = True\n",
+ "\n",
+ "%matplotlib inline\n",
+ "%config InlineBackend.figure_format = 'retina' # perfrom high definition rendering for images and plots\n",
+ "plt.style.use(\"https://raw.githubusercontent.com/NeuromatchAcademy/course-content/main/nma.mplstyle\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Plotting functions\n",
+ "\n",
+ "def plot_similarity_matrix(sim_mat, labels, values = False):\n",
+ " \"\"\"\n",
+ " Plot the similarity matrix between vectors.\n",
+ "\n",
+ " Inputs:\n",
+ " - sim_mat (numpy.ndarray): similarity matrix between vectors.\n",
+ " - labels (list of str): list of strings which represent concepts.\n",
+ " - values (bool): True if we would like to plot values of similarity too.\n",
+ " \"\"\"\n",
+ " with plt.xkcd():\n",
+ " plt.imshow(sim_mat, cmap='Greys')\n",
+ " plt.colorbar()\n",
+ " plt.xticks(np.arange(len(labels)), labels, rotation=45, ha=\"right\", rotation_mode=\"anchor\")\n",
+ " plt.yticks(np.arange(len(labels)), labels)\n",
+ " if values:\n",
+ " for x in range(sim_mat.shape[1]):\n",
+ " for y in range(sim_mat.shape[0]):\n",
+ " plt.text(x, y, f\"{sim_mat[y, x]:.2f}\", fontsize = 8, ha=\"center\", va=\"center\", color=\"green\")\n",
+ " plt.title('Similarity between vector-symbols')\n",
+ " plt.xlabel('Symbols')\n",
+ " plt.ylabel('Symbols')\n",
+ " plt.show()\n",
+ "\n",
+ "def plot_training_and_choice(losses, sims, ant_names, cons_names, action_names):\n",
+ " \"\"\"\n",
+ " Plot loss progression over training as well as predicted similarities for given rules / correct solutions.\n",
+ "\n",
+ " Inputs:\n",
+ " - losses (list): list of loss values.\n",
+ " - sims (list): list of similartiy matrices.\n",
+ " - ant_names (list): list of antecedance names.\n",
+ " - cons_names (list): list of consequent names.\n",
+ " - action_names (list): full list of concepts.\n",
+ " \"\"\"\n",
+ " with plt.xkcd():\n",
+ " plt.subplot(1, len(ant_names) + 1, 1)\n",
+ " plt.plot(losses)\n",
+ " plt.xlabel('Training number')\n",
+ " plt.ylabel('Loss')\n",
+ " plt.title('Training Error')\n",
+ " index = 1\n",
+ " for ant_name, cons_name, sim in zip(ant_names, cons_names, sims):\n",
+ " index += 1\n",
+ " plt.subplot(1, len(ant_names) + 1, index)\n",
+ " plt.bar(range(len(action_names)), sim.flatten())\n",
+ " plt.gca().set_xticks(range(len(action_names)))\n",
+ " plt.gca().set_xticklabels(action_names, rotation=90)\n",
+ " plt.title(f'{ant_name}, not*{cons_name}')\n",
+ "\n",
+ "def plot_choice(sims, ant_names, cons_names, action_names):\n",
+ " \"\"\"\n",
+ " Plot predicted similarities for given rules / correct solutions.\n",
+ " \"\"\"\n",
+ " with plt.xkcd():\n",
+ " index = 0\n",
+ " for ant_name, cons_name, sim in zip(ant_names, cons_names, sims):\n",
+ " index += 1\n",
+ " plt.subplot(1, len(ant_names) + 1, index)\n",
+ " plt.bar(range(len(action_names)), sim.flatten())\n",
+ " plt.gca().set_xticks(range(len(action_names)))\n",
+ " plt.gca().set_xticklabels(action_names, rotation=90)\n",
+ " plt.ylabel(\"Similarity\")\n",
+ " plt.title(f'{ant_name}, not*{cons_name}')"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Set random seed\n",
+ "\n",
+ "import random\n",
+ "import numpy as np\n",
+ "\n",
+ "def set_seed(seed=None):\n",
+ " if seed is None:\n",
+ " seed = np.random.choice(2 ** 32)\n",
+ " random.seed(seed)\n",
+ " np.random.seed(seed)\n",
+ "\n",
+ "set_seed(seed = 42)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Helper functions\n",
+ "\n",
+ "set_seed(42)\n",
+ "\n",
+ "symbol_names = ['monarch','heir','male','female']\n",
+ "discrete_space = sspspace.DiscreteSPSpace(symbol_names, ssp_dim=1024, optimize=False)\n",
+ "\n",
+ "objs = {n:discrete_space.encode(n) for n in symbol_names}\n",
+ "\n",
+ "objs['king'] = objs['monarch'] * objs['male']\n",
+ "objs['queen'] = objs['monarch'] * objs['female']\n",
+ "objs['prince'] = objs['heir'] * objs['male']\n",
+ "objs['princess'] = objs['heir'] * objs['female']\n",
+ "\n",
+ "bundle_objs = {n:discrete_space.encode(n) for n in symbol_names}\n",
+ "\n",
+ "bundle_objs['king'] = (bundle_objs['monarch'] + bundle_objs['male']).normalize()\n",
+ "bundle_objs['queen'] = (bundle_objs['monarch'] + bundle_objs['female']).normalize()\n",
+ "bundle_objs['prince'] = (bundle_objs['heir'] + bundle_objs['male']).normalize()\n",
+ "bundle_objs['princess'] = (bundle_objs['heir'] + bundle_objs['female']).normalize()\n",
+ "\n",
+ "bundle_objs['princess_query'] = (bundle_objs['prince'] - bundle_objs['king']) + bundle_objs['queen']\n",
+ "\n",
+ "new_symbol_names = ['dollar', 'peso', 'ottawa', 'mexico-city', 'currency', 'capital']\n",
+ "new_discrete_space = sspspace.DiscreteSPSpace(new_symbol_names, ssp_dim=1024, optimize=False)\n",
+ "\n",
+ "new_objs = {n:new_discrete_space.encode(n) for n in new_symbol_names}\n",
+ "\n",
+ "cleanup = sspspace.Cleanup(new_objs)\n",
+ "\n",
+ "new_objs['canada'] = ((new_objs['currency'] * new_objs['dollar']) + (new_objs['capital'] * new_objs['ottawa'])).normalize()\n",
+ "new_objs['mexico'] = ((new_objs['currency'] * new_objs['peso']) + (new_objs['capital'] * new_objs['mexico-city'])).normalize()\n",
+ "\n",
+ "card_states = ['red','blue','odd','even','not','green','prime','implies','ant','relation','cons']\n",
+ "encoder = sspspace.DiscreteSPSpace(card_states, ssp_dim=1024, optimize=False)\n",
+ "vocab = {c:encoder.encode(c) for c in card_states}\n",
+ "\n",
+ "for a in ['red','blue','odd','even','green','prime']:\n",
+ " vocab[f'not*{a}'] = vocab['not'] * vocab[a]\n",
+ "\n",
+ "action_names = ['red','blue','odd','even','green','prime','not*red','not*blue','not*odd','not*even','not*green','not*prime']\n",
+ "action_space = np.array([vocab[x] for x in action_names]).squeeze()\n",
+ "\n",
+ "rules = [\n",
+ " (vocab['ant'] * vocab['blue'] + vocab['relation'] * vocab['implies'] + vocab['cons'] * vocab['even']).normalize(),\n",
+ " (vocab['ant'] * vocab['odd'] + vocab['relation'] * vocab['implies'] + vocab['cons'] * vocab['green']).normalize(),\n",
+ "]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "---\n",
+ "\n",
+ "# Section 1: Analogies. Part 1\n",
+ "\n",
+ "In this section we will construct a simple analogy using Vector Symbolic Algebras. The question we are going to try and solve is \"King is to the queen as the prince is to X.\""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Video 1: Analogy 1\n",
+ "\n",
+ "from ipywidgets import widgets\n",
+ "from IPython.display import YouTubeVideo\n",
+ "from IPython.display import IFrame\n",
+ "from IPython.display import display\n",
+ "\n",
+ "class PlayVideo(IFrame):\n",
+ " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
+ " self.id = id\n",
+ " if source == 'Bilibili':\n",
+ " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
+ " elif source == 'Osf':\n",
+ " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
+ " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
+ "\n",
+ "def display_videos(video_ids, W=400, H=300, fs=1):\n",
+ " tab_contents = []\n",
+ " for i, video_id in enumerate(video_ids):\n",
+ " out = widgets.Output()\n",
+ " with out:\n",
+ " if video_ids[i][0] == 'Youtube':\n",
+ " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
+ " height=H, fs=fs, rel=0)\n",
+ " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
+ " else:\n",
+ " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
+ " height=H, fs=fs, autoplay=False)\n",
+ " if video_ids[i][0] == 'Bilibili':\n",
+ " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
+ " elif video_ids[i][0] == 'Osf':\n",
+ " print(f'Video available at https://osf.io/{video.id}')\n",
+ " display(video)\n",
+ " tab_contents.append(out)\n",
+ " return tab_contents\n",
+ "\n",
+ "video_ids = [('Youtube', '2tR4fHvL1Jk'), ('Bilibili', 'BV1fS411P7Ez')]\n",
+ "tab_contents = display_videos(video_ids, W=854, H=480)\n",
+ "tabs = widgets.Tab()\n",
+ "tabs.children = tab_contents\n",
+ "for i in range(len(tab_contents)):\n",
+ " tabs.set_title(i, video_ids[i][0])\n",
+ "display(tabs)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_analogy_part_one\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "## Coding Exercise 1: Royal Relationships\n",
+ "\n",
+ "We're going to start by considering our vocabulary. We will use the basic discrete concepts of monarch, heir, male, and female."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Let's create the objects we know about by combinatorially expanding the space: \n",
+ "\n",
+ "1. King is a male monarch\n",
+ "2. Queen is a female monarch\n",
+ "3. Prince is a male heir\n",
+ "4. Princess is a female heir\n",
+ "\n",
+ "Complete the missing parts of the code to obtain correct representations of new concepts."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "set_seed(42)\n",
+ "\n",
+ "vector_length = 1024\n",
+ "symbol_names = ['MONARCH', 'HEIR', 'MALE', 'FEMALE']\n",
+ "vocab = make_vocabulary(vector_length)\n",
+ "vocab.populate(';'.join(symbol_names))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete correct relations for creating new concepts.\")\n",
+ "\n",
+ "###################################################################\n",
+ "vocab.add('KING', vocab['MONARCH'] * vocab['MALE'])\n",
+ "vocab.add('QUEEN', vocab['MONARCH'] * ...)\n",
+ "vocab.add('PRINCE', vocab['HEIR'] * vocab['MALE'])\n",
+ "vocab.add('PRINCESS', ... * vocab['FEMALE'])"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "#to_remove solution\n",
+ "\n",
+ "vocab.add('KING', vocab['MONARCH'] * vocab['MALE'])\n",
+ "vocab.add('QUEEN', vocab['MONARCH'] * vocab['FEMALE'])\n",
+ "vocab.add('PRINCE', vocab['HEIR'] * vocab['MALE'])\n",
+ "vocab.add('PRINCESS', vocab['HEIR'] * vocab['FEMALE'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Now, we can take an explicit approach. We know that the conversion from king to queen is to unbind male and bind female, so let's apply that to our prince object and see what we uncover.\n",
+ "\n",
+ "At first, in the cell below, let's recover `queen` from `king` by constructing a new `query` concept, which represents the unbinding of `male` and the binding of `female.`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete correct relation for creating `query` object to compare with `queen`.\")\n",
+ "###################################################################\n",
+ "\n",
+ "vocab.add('QUERY_QUEEN', (vocab[...] * ~vocab[...]) * vocab[...])"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "#to_remove solution\n",
+ "\n",
+ "vocab.add('QUERY_QUEEN', (vocab['KING'] * ~vocab['MALE']) * vocab['FEMALE'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Then, let's see if this new query object bears any similarity to anything in our vocabulary."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "object_names = list(vocab.keys())\n",
+ "sims = np.zeros((len(object_names), len(object_names)))\n",
+ "\n",
+ "for name_idx, name in enumerate(object_names):\n",
+ " for other_idx in range(name_idx, len(object_names)):\n",
+ " sims[name_idx, other_idx] = sims[other_idx, name_idx] = spa.dot(vocab[name], vocab[object_names[other_idx]])\n",
+ "\n",
+ "plot_similarity_matrix(sims, object_names, values = True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "The above similarity plot shows that applying that operation successfully converts king to queen. Let's apply it to 'prince' and see what happens. Now, `query` should represent the `princess` concept."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "vocab.add('QUERY_PRINCESS', (vocab['PRINCE'] * ~vocab['MALE']) * vocab['FEMALE'])\n",
+ "\n",
+ "sims = np.zeros((len(object_names), len(object_names)))\n",
+ "\n",
+ "for name_idx, name in enumerate(object_names):\n",
+ " for other_idx in range(name_idx, len(object_names)):\n",
+ " sims[name_idx, other_idx] = sims[other_idx, name_idx] = spa.dot(vocab[name], vocab[object_names[other_idx]])\n",
+ "\n",
+ "plot_similarity_matrix(sims, object_names, values = True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Here, we have successfully recovered the princess, completing the analogy.\n",
+ "\n",
+ "This approach, however, requires explicit knowledge of the construction of the objects. Let's see if we can just work with the concepts of 'king,' 'queen,' and 'prince' directly.\n",
+ "\n",
+ "In the cell below, construct the `princess` concept using only `king,` `queen`, and `prince.`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete correct relation for creating `query` object to compare with `princess`.\")\n",
+ "###################################################################\n",
+ "\n",
+ "vocab.add('QUERY_PRINCESS_2', (vocab[...] * ~vocab[...]) * vocab[...])"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "#to_remove solution\n",
+ "\n",
+ "# objs['query'] = (objs['prince'] * ~objs['king']) * objs['queen']\n",
+ "vocab.add('QUERY_PRINCESS_2', (vocab['PRINCE'] * ~vocab['KING']) * vocab['QUEEN'])"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "object_names = list(vocab.keys())\n",
+ "sims = np.zeros((len(object_names), len(object_names)))\n",
+ "\n",
+ "for name_idx, name in enumerate(object_names):\n",
+ " for other_idx in range(name_idx, len(object_names)):\n",
+ " sims[name_idx, other_idx] = sims[other_idx, name_idx] = spa.dot(vocab[name], vocab[object_names[other_idx]])\n",
+ "\n",
+ "plot_similarity_matrix(sims, object_names, values = True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Again, we see that we have recovered the princess by using our analogy.\n",
+ "\n",
+ "That said, the above depends on knowing that the representations are constructed using binding. Can we do something similar through the bundling operation? Let's try that out.\n",
+ "\n",
+ "Reassing concept definitions using bundling operation."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "vocab = vocab.create_subset(['MONARCH','HEIR','FEMALE','MALE'])\n",
+ "vocab.add('KING', (vocab['MONARCH'] + vocab['MALE']).normalized())\n",
+ "vocab.add('QUEEN', (vocab['MONARCH'] + vocab['FEMALE']).normalized())\n",
+ "vocab.add('PRINCE', (vocab['HEIR'] + vocab['MALE']).normalized())\n",
+ "vocab.add('PRINCESS', (vocab['HEIR'] + vocab['FEMALE']).normalized())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "But now that we are using an additive model, we need to take a different approach. Instead of unbinding the king and binding the queen, we subtract the king and add the queen to find the princess from the prince.\n",
+ "\n",
+ "Complete the code to reflect the updated mechanism."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete correct relation for creating `query` object to compare with `princess`.\")\n",
+ "###################################################################\n",
+ "\n",
+ "vocab.add('QUERY_PRINCESS', ((vocab[...] - vocab[...]) + vocab[...]).normalized())"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "#to_remove solution\n",
+ "\n",
+ "vocab.add('QUERY_PRINCESS', ((vocab['PRINCE'] - vocab['KING']) + vocab['QUEEN']).normalized())"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "object_names = list(vocab.keys())\n",
+ "sims = np.zeros((len(object_names), len(object_names)))\n",
+ "\n",
+ "for name_idx, name in enumerate(object_names):\n",
+ " for other_idx in range(name_idx, len(object_names)):\n",
+ " sims[name_idx, other_idx] = sims[other_idx, name_idx] = spa.dot(vocab[name], vocab[object_names[other_idx]])\n",
+ "\n",
+ "plot_similarity_matrix(sims, object_names, values = True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "This is a messier similarity plot due to the fact that the bundled representations interact with all their constituent parts in the vocabulary. That said, we see that 'princess' is still most similar to the query vector. \n",
+ "\n",
+ "This approach is more like what we would expect from a `word2vec` embedding."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_royal_relationships\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "---\n",
+ "\n",
+ "# Section 2: Analogies (Part 2)\n",
+ "\n",
+ "Estimated timing to here from start of tutorial: 15 minutes\n",
+ "\n",
+ "In this section, we will construct a database of data structures that describe different countries. Materials are adopted from [Kanerva (2010)](https://cdn.aaai.org/ocs/2243/2243-9566-1-PB.pdf)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Video 2: Analogy 2\n",
+ "\n",
+ "from ipywidgets import widgets\n",
+ "from IPython.display import YouTubeVideo\n",
+ "from IPython.display import IFrame\n",
+ "from IPython.display import display\n",
+ "\n",
+ "class PlayVideo(IFrame):\n",
+ " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
+ " self.id = id\n",
+ " if source == 'Bilibili':\n",
+ " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
+ " elif source == 'Osf':\n",
+ " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
+ " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
+ "\n",
+ "def display_videos(video_ids, W=400, H=300, fs=1):\n",
+ " tab_contents = []\n",
+ " for i, video_id in enumerate(video_ids):\n",
+ " out = widgets.Output()\n",
+ " with out:\n",
+ " if video_ids[i][0] == 'Youtube':\n",
+ " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
+ " height=H, fs=fs, rel=0)\n",
+ " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
+ " else:\n",
+ " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
+ " height=H, fs=fs, autoplay=False)\n",
+ " if video_ids[i][0] == 'Bilibili':\n",
+ " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
+ " elif video_ids[i][0] == 'Osf':\n",
+ " print(f'Video available at https://osf.io/{video.id}')\n",
+ " display(video)\n",
+ " tab_contents.append(out)\n",
+ " return tab_contents\n",
+ "\n",
+ "video_ids = [('Youtube', 'OB3hzhM7Ois'), ('Bilibili', 'BV1TZ421g7G5')]\n",
+ "tab_contents = display_videos(video_ids, W=854, H=480)\n",
+ "tabs = widgets.Tab()\n",
+ "tabs.children = tab_contents\n",
+ "for i in range(len(tab_contents)):\n",
+ " tabs.set_title(i, video_ids[i][0])\n",
+ "display(tabs)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_analogy_part_two\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "## Coding Exercise 2: Dollar of Mexico\n",
+ "\n",
+ "This is going to be a little more involved, because to construct the data structure we are going to need vectors that don't just represent values that we are reasoning about, but also vectors that represent different roles data can play. This is sometimes called a slot-filler representation, or a key-value representation.\n",
+ "\n",
+ "At first, let us define concepts and cleanup object."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "set_seed(42)\n",
+ "\n",
+ "symbol_names = ['DOLLAR','PESO', 'OTTAWA','MEXICO_CITY','CURRENCY','CAPITAL']\n",
+ "vocab = make_vocabulary(vector_length)\n",
+ "vocab.populate(';'.join(symbol_names))\n",
+ "\n",
+ "cleanup = sspspace.Cleanup(vocab)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Now, we will define `Canada` and `Mexico` concepts by integrating the available information together. You will be provided with `Canada` object and your task is to complete for `Mexico` one."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete `mexico` concept.\")\n",
+ "###################################################################\n",
+ "\n",
+ "vocab.add('CANADA', (vocab['CURRENCY'] * vocab['DOLLAR'] + vocab['CAPITAL'] * vocab['OTTAWA']).normalized())\n",
+ "vocab.add('MEXICO', (vocab['CURRENCY'] * ... + vocab['CAPITAL'] * ...).normalized())"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "#to_remove solution\n",
+ "\n",
+ "vocab.add('CANADA', (vocab['CURRENCY'] * vocab['DOLLAR'] + vocab['CAPITAL'] * vocab['OTTAWA']).normalized())\n",
+ "vocab.add('MEXICO', (vocab['CURRENCY'] * vocab['PESO'] + vocab['CAPITAL'] * vocab['MEXICO_CITY']).normalized())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "We would like to find out Mexico's currency. Complete the code for constructing a `query` which will help us do that. Note that we are using a cleanup operation."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete `query` concept which will be similar to currency in Mexico.\")\n",
+ "###################################################################\n",
+ "\n",
+ "vocab.add('QUERY_MX_CURRENCY', vocab['MEXICO'] * ~(... * ~...))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "#to_remove solution\n",
+ "\n",
+ "vocab.add('QUERY_MX_CURRENCY', vocab['MEXICO'] * ~(vocab['CANADA'] * ~vocab['DOLLAR']))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "object_names = list(vocab.keys())\n",
+ "sims = np.zeros((len(object_names), len(object_names)))\n",
+ "\n",
+ "for name_idx, name in enumerate(object_names):\n",
+ " for other_idx in range(name_idx, len(object_names)):\n",
+ " sims[name_idx, other_idx] = sims[other_idx, name_idx] = spa.dot(vocab[name], vocab[object_names[other_idx]])\n",
+ "\n",
+ "plot_similarity_matrix(sims, object_names)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "After cleanup, the query vector is the most similar with the 'peso' object in the vocabularly, correctly answering the question. \n",
+ "\n",
+ "Note, however, that the similarity is not perfectly equal to 1. This is due to the scale factors applied to the composite vectors 'canada' and 'mexico', to ensure they remain unit vectors, and due to cross talk. Crosstalk is a symptom of the fact that we are binding and unbinding bundles of vector symbols to produce the resultant query vector. The constituent vectors are not perfectly orthogonal (i.e., having a dot product of zero) and as such the terms in the bundle interact when we measure similarity between them."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_dollar_of_mexico\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "---\n",
+ "# The Big Picture\n",
+ "\n",
+ "*Estimated timing of tutorial: 45 minutes*\n",
+ "\n",
+ "In this tutorial, we observed three scenarios where we used the basic operations to solve different analogies and engage in structured learning. Those of you familiar with word embeddings from Natural Language Processing (NLP) might already be familiar with the idea of interpretable semantics on vector representations. This bonus tutorial helps to show how this can be accomplished in a different way. The ability to recreate different phenomena in different paradigms often gives us a great way to compare and contrast model mechanisms and we hope that this bonus tutorial has given you a curiosity to dive a bit deeper and start experimenting further with what you can accomplish using these great open-source tools!"
+ ]
+ }
+ ],
+ "metadata": {
+ "colab": {
+ "collapsed_sections": [],
+ "include_colab_link": true,
+ "name": "W2D2_Tutorial4",
+ "provenance": [],
+ "toc_visible": true
+ },
+ "kernel": {
+ "display_name": "Python 3",
+ "language": "python",
+ "name": "python3"
+ },
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.9.22"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 4
+}
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/W2D2_Tutorial5.ipynb b/tutorials/W2D2_NeuroSymbolicMethods/W2D2_Tutorial5.ipynb
new file mode 100644
index 000000000..7f1a877e7
--- /dev/null
+++ b/tutorials/W2D2_NeuroSymbolicMethods/W2D2_Tutorial5.ipynb
@@ -0,0 +1,1613 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {},
+ "id": "view-in-github"
+ },
+ "source": [
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "# (Bonus) Tutorial 5: Representations in continuous space\n",
+ "\n",
+ "**Week 2, Day 2: Neuro-Symbolic Methods**\n",
+ "\n",
+ "**By Neuromatch Academy**\n",
+ "\n",
+ "__Content creators:__ P. Michael Furlong, Chris Eliasmith\n",
+ "\n",
+ "__Content reviewers:__ Hlib Solodzhuk, Patrick Mineault, Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Alex Murphy\n",
+ "\n",
+ "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk, Alex Murphy"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "___\n",
+ "\n",
+ "\n",
+ "# Tutorial Objectives\n",
+ "\n",
+ "*Estimated timing of tutorial: 40 minutes*\n",
+ "\n",
+ "In this tutorial, you will observe how the VSA methods can be applied in structures and environments to allow for efficient generalization."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Tutorial slides\n",
+ "# @markdown These are the slides for the videos in all tutorials today\n",
+ "\n",
+ "from IPython.display import IFrame\n",
+ "link_id = \"jybuw\"\n",
+ "\n",
+ "print(f\"If you want to download the slides: 'https://osf.io/download/{link_id}'\")\n",
+ "\n",
+ "IFrame(src=f\"https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{link_id}/?direct%26mode=render\", width=854, height=480)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "---\n",
+ "# Setup (Colab Users: Please Read)\n",
+ "\n",
+ "Note that because this tutorial relies on some special Python packages, these packages have requirements for specific versions of common scientific libraries, such as `numpy`. If you're in Google Colab, then as of May 2025, this comes with a later version (2.0.2) pre-installed. We require an older version (we'll be installing `1.24.4`). This causes Colab to force a session restart and then re-running of the installation cells for the new version to take effect. When you run the cell below, you will be prompted to restart the session. This is *entirely expected* and you haven't done anything wrong. Simply click 'Restart' and then run the cells as normal. \n",
+ "\n",
+ "An additional error might sometimes arise where an exception is raised connected to a missing element of NumPy. If this occurs, please restart the session and re-run the cells as normal and this error will go away. Updated versions of the affected libraries are expected out soon, but sadly not in time for the preparation of this material. We thank you for your understanding.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Install dependencies\n",
+ "\n",
+ "!pip install numpy==1.24.4 --quiet\n",
+ "!pip install scikit-learn==1.6.1 --quiet\n",
+ "!pip install scipy==1.15.3 --quiet\n",
+ "!pip install git+https://github.com/neuromatch/sspspace@neuromatch --no-deps --quiet\n",
+ "!pip install nengo==4.0.0 --quiet\n",
+ "!pip install nengo_spa==2.0.0 --quiet\n",
+ "!pip install --quiet matplotlib ipywidgets tqdm vibecheck"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Install and import feedback gadget\n",
+ "\n",
+ "from vibecheck import DatatopsContentReviewContainer\n",
+ "def content_review(notebook_section: str):\n",
+ " return DatatopsContentReviewContainer(\n",
+ " \"\", # No text prompt\n",
+ " notebook_section,\n",
+ " {\n",
+ " \"url\": \"https://pmyvdlilci.execute-api.us-east-1.amazonaws.com/klab\",\n",
+ " \"name\": \"neuromatch_neuroai\",\n",
+ " \"user_key\": \"wb2cxze8\",\n",
+ " },\n",
+ " ).render()\n",
+ "\n",
+ "\n",
+ "feedback_prefix = \"W2D2_T5\""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Imports\n",
+ "\n",
+ "#working with data\n",
+ "import numpy as np\n",
+ "import random\n",
+ "\n",
+ "#plotting\n",
+ "import matplotlib.pyplot as plt\n",
+ "import logging\n",
+ "\n",
+ "#interactive display\n",
+ "import ipywidgets as widgets\n",
+ "\n",
+ "#modeling\n",
+ "import sspspace\n",
+ "from sklearn.linear_model import LinearRegression\n",
+ "from sklearn.model_selection import train_test_split\n",
+ "\n",
+ "from tqdm.notebook import tqdm as tqdm"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Figure settings\n",
+ "\n",
+ "logging.getLogger('matplotlib.font_manager').disabled = True\n",
+ "\n",
+ "%matplotlib inline\n",
+ "%config InlineBackend.figure_format = 'retina' # perfrom high definition rendering for images and plots\n",
+ "plt.style.use(\"https://raw.githubusercontent.com/NeuromatchAcademy/course-content/main/nma.mplstyle\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Plotting functions\n",
+ "\n",
+ "def plot_3d_function(X, Y, zs, titles):\n",
+ " \"\"\"Plot 3D function.\n",
+ "\n",
+ " Inputs:\n",
+ " - X (list): list of np.ndarray of x-values.\n",
+ " - Y (list): list of np.ndarray of y-values.\n",
+ " - zs (list): list of np.ndarray of z-values.\n",
+ " - titles (list): list of titles of the plot.\n",
+ " \"\"\"\n",
+ " with plt.xkcd():\n",
+ " fig = plt.figure(figsize=(8, 8))\n",
+ " for index, (x, y, z) in enumerate(zip(X, Y, zs)):\n",
+ " fig.add_subplot(1, len(X), index + 1, projection='3d')\n",
+ " plt.gca().plot_surface(x,y,z.reshape(x.shape),cmap='plasma', antialiased=False, linewidth=0)\n",
+ " plt.xlabel(r'$x_{1}$')\n",
+ " plt.ylabel(r'$x_{2}$')\n",
+ " plt.gca().set_zlabel(r'$f(\\mathbf{x})$')\n",
+ " plt.title(titles[index])\n",
+ " plt.show()\n",
+ "\n",
+ "def plot_performance(bound_performance, bundle_performance, training_samples, title):\n",
+ " \"\"\"Plot RMSE values for two different representations of the input data.\n",
+ "\n",
+ " Inputs:\n",
+ " - bound_performance (list): list of RMSE for bound representation.\n",
+ " - bundle_performance (list): list of RMSE for bundle representation.\n",
+ " - training_samples (list): x-axis.\n",
+ " - title (str): title of the plot.\n",
+ " \"\"\"\n",
+ " with plt.xkcd():\n",
+ " plt.plot(training_samples, bound_performance, label='Bound Representation')\n",
+ " plt.plot(training_samples, bundle_performance, label='Bundling Representation', ls='--')\n",
+ " plt.legend()\n",
+ " plt.title(title)\n",
+ " plt.ylabel('RMSE (a.u.)')\n",
+ " plt.xlabel('# Training samples')\n",
+ "\n",
+ "def plot_2d_similarity(sims, obj_names, size, title_argmax = False):\n",
+ " \"\"\"\n",
+ " Plot 2D similarity between query points (grid) and the ones associated with the objects.\n",
+ "\n",
+ " Inputs:\n",
+ " - sims (list): list of similarity values for each of the objects.\n",
+ " - obj_names (list): list of object names.\n",
+ " - size (tuple): to reshape the similarities.\n",
+ " - title_argmax (bool, default = False): looks for the point coordinates as arg max from all similarity value.\n",
+ " \"\"\"\n",
+ " ticks = [0, 24, 49, 74, 99]\n",
+ " ticklabels = [-5, -2, 0, 2, 5]\n",
+ " with plt.xkcd():\n",
+ " for obj_idx, obj in enumerate(obj_names):\n",
+ " plt.subplot(1, len(obj_names), 1 + obj_idx)\n",
+ " plt.imshow(np.array(sims[obj_idx].reshape(size)), origin='lower', vmin=-1, vmax=1)\n",
+ " plt.gca().set_xticks(ticks)\n",
+ " plt.gca().set_xticklabels(ticklabels)\n",
+ " if obj_idx == 0:\n",
+ " plt.gca().set_yticks(ticks)\n",
+ " plt.gca().set_yticklabels(ticklabels)\n",
+ " else:\n",
+ " plt.gca().set_yticks([])\n",
+ " if not title_argmax:\n",
+ " plt.title(f'{obj}, {positions[obj_idx]}')\n",
+ " else:\n",
+ " plt.title(f'{obj}, {query_xs[sims[obj_idx].argmax()]}')\n",
+ "\n",
+ "def plot_unbinding_objects_map(sims, positions, query_xs, size):\n",
+ " \"\"\"\n",
+ " Plot 2D similarity between query points (grid) and the unbinded from the objects map.\n",
+ "\n",
+ " Inputs:\n",
+ " - sims (np.ndarray): similarity values for each of the query points with the map.\n",
+ " - positions (np.ndarray): positions of the objects.\n",
+ " - query_xs (np.ndarray): grid points.\n",
+ " - size (tuple): to reshape the similarities.\n",
+ "\n",
+ " \"\"\"\n",
+ " ticks = [0,24,49,74,99]\n",
+ " ticklabels = [-5,-2,0,2,5]\n",
+ " with plt.xkcd():\n",
+ " plt.imshow(sims.reshape(size), origin='lower')\n",
+ "\n",
+ " for idx, marker in enumerate(['o','s','^']):\n",
+ " plt.scatter(*get_coordinate(positions[idx,:], query_xs, size), marker=marker,s=100)\n",
+ "\n",
+ " plt.gca().set_xticks(ticks)\n",
+ " plt.gca().set_xticklabels(ticklabels)\n",
+ " plt.gca().set_yticks(ticks)\n",
+ " plt.gca().set_yticklabels(ticklabels)\n",
+ " plt.title(f'All Object Locations')\n",
+ " plt.show()\n",
+ "\n",
+ "def plot_unbinding_positions_map(sims, positions, obj_names):\n",
+ " \"\"\"\n",
+ " Plot 2D similarity between query points (grid) and the unbinded from the positions map.\n",
+ "\n",
+ " Inputs:\n",
+ " - sims (np.ndarray): similarity values for each of the query points with the map.\n",
+ " - positions (np.ndarray): test positions to query.\n",
+ " - obj_names (list): names of the objects for labels.\n",
+ " - size (tuple): to reshape the similarities.\n",
+ " \"\"\"\n",
+ " with plt.xkcd():\n",
+ " plt.figure(figsize=(8, 4))\n",
+ " for pos_idx, pos in enumerate(positions):\n",
+ " plt.subplot(1,len(test_positions), 1+pos_idx)\n",
+ " plt.bar([1,2,3], sims[pos_idx])\n",
+ " plt.ylim([-0.3, 1.05])\n",
+ " plt.gca().set_xticks([1,2,3])\n",
+ " plt.gca().set_xticklabels(obj_names, rotation=90)\n",
+ " if pos_idx != 0:\n",
+ " plt.gca().set_yticks([])\n",
+ " plt.title(f'Symbols at\\n{pos}')\n",
+ " plt.show()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Set random seed\n",
+ "\n",
+ "def set_seed(seed=None):\n",
+ " if seed is None:\n",
+ " seed = np.random.choice(2 ** 32)\n",
+ " random.seed(seed)\n",
+ " np.random.seed(seed)\n",
+ "\n",
+ "set_seed(seed = 42)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Helper functions\n",
+ "\n",
+ "def get_model(xs, ys, train_size):\n",
+ " \"\"\"Fit linear regression to the given data.\n",
+ "\n",
+ " Inputs:\n",
+ " - xs (np.ndarray): input data.\n",
+ " - ys (np.ndarray): output data.\n",
+ " - train_size (float): fraction of data to use for train.\n",
+ " \"\"\"\n",
+ " X_train, _, y_train, _ = train_test_split(xs, ys, random_state=1, train_size=train_size)\n",
+ " return LinearRegression().fit(X_train, y_train)\n",
+ "\n",
+ "def get_coordinate(x, positions, target_shape):\n",
+ " \"\"\"Return the closest column and row coordinates for the given position.\n",
+ "\n",
+ " Inputs:\n",
+ " - x (np.ndarray): query position.\n",
+ " - positions (np.ndarray): all positions.\n",
+ " - target_shape (tuple): shape of the grid.\n",
+ "\n",
+ " Outputs:\n",
+ " - coordinates (tuple): column and row positions.\n",
+ " \"\"\"\n",
+ " idx = np.argmin(np.linalg.norm(x - positions, axis=1))\n",
+ " c = idx % target_shape[1]\n",
+ " r = idx // target_shape[1]\n",
+ " return (c,r)\n",
+ "\n",
+ "def rastrigin_solution(x):\n",
+ " \"\"\"Compute Rastrigin function for given array of d-dimenstional vectors.\n",
+ "\n",
+ " Inputs:\n",
+ " - x (np.ndarray of shape (n, d)): n d-dimensional vectors.\n",
+ "\n",
+ " Outputs:\n",
+ " - y (np.ndarray of shape (n, 1)): Rastrigin function value for each of the vectors.\n",
+ " \"\"\"\n",
+ " return 10 * x.shape[1] + np.sum(x**2 - 10 * np.cos(2*np.pi*x), axis=1)\n",
+ "\n",
+ "def non_separable_solution(x):\n",
+ " \"\"\"Compute non-separable function for given array of 2-dimenstional vectors.\n",
+ "\n",
+ " Inputs:\n",
+ " - x (np.ndarray of shape (n, 2)): n 2-dimensional vectors.\n",
+ "\n",
+ " Outputs:\n",
+ " - y (np.ndarray of shape (n, 1)): non-separable function value for each of the vectors.\n",
+ " \"\"\"\n",
+ " return np.sin(np.multiply(x[:, 0], x[:, 1]))\n",
+ "\n",
+ "x0_rastrigin = np.linspace(-5.12, 5.12, 100)\n",
+ "X_rastrigin, Y_rastrigin = np.meshgrid(x0_rastrigin,x0_rastrigin)\n",
+ "xs_rastrigin = np.vstack((X_rastrigin.flatten(), Y_rastrigin.flatten())).T\n",
+ "ys_rastrigin = rastrigin_solution(xs_rastrigin)\n",
+ "\n",
+ "x0_non_separable = np.linspace(-4, 4, 100)\n",
+ "X_non_separable, Y_non_separable = np.meshgrid(x0_non_separable,x0_non_separable)\n",
+ "xs_non_separable = np.vstack((X_non_separable.flatten(), Y_non_separable.flatten())).T\n",
+ "ys_non_separable = non_separable_solution(xs_non_separable)\n",
+ "\n",
+ "set_seed(42)\n",
+ "\n",
+ "obj_names = ['circle','square','triangle']\n",
+ "discrete_space = sspspace.DiscreteSPSpace(obj_names, ssp_dim=1024)\n",
+ "\n",
+ "objs = {n:discrete_space.encode(n) for n in obj_names}\n",
+ "\n",
+ "ssp_space = sspspace.RandomSSPSpace(domain_dim=2, ssp_dim=1024)\n",
+ "positions = np.array([[0, -2],\n",
+ " [-2, 3],\n",
+ " [3, 2]\n",
+ " ])\n",
+ "ssps = {n:ssp_space.encode(x) for n, x in zip(obj_names, positions)}\n",
+ "\n",
+ "dim0 = np.linspace(-5, 5, 101)\n",
+ "dim1 = np.linspace(-5, 5, 101)\n",
+ "X,Y = np.meshgrid(dim0, dim1)\n",
+ "\n",
+ "query_xs = np.vstack((X.flatten(), Y.flatten())).T\n",
+ "query_ssps = ssp_space.encode(query_xs)\n",
+ "\n",
+ "bound_objects = [objs[n] * ssps[n] for n in obj_names]\n",
+ "ssp_map = sspspace.SSP(np.sum(bound_objects, axis=0))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "---\n",
+ "\n",
+ "# Section 1: Sample Efficient Learning\n",
+ "\n",
+ "In this section, we will take a look at how imposing an inductive bias on our feature space can result in more sample-efficient learning. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Video 1: Function Learning and Inductive Bias\n",
+ "\n",
+ "from ipywidgets import widgets\n",
+ "from IPython.display import YouTubeVideo\n",
+ "from IPython.display import IFrame\n",
+ "from IPython.display import display\n",
+ "\n",
+ "class PlayVideo(IFrame):\n",
+ " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
+ " self.id = id\n",
+ " if source == 'Bilibili':\n",
+ " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
+ " elif source == 'Osf':\n",
+ " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
+ " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
+ "\n",
+ "def display_videos(video_ids, W=400, H=300, fs=1):\n",
+ " tab_contents = []\n",
+ " for i, video_id in enumerate(video_ids):\n",
+ " out = widgets.Output()\n",
+ " with out:\n",
+ " if video_ids[i][0] == 'Youtube':\n",
+ " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
+ " height=H, fs=fs, rel=0)\n",
+ " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
+ " else:\n",
+ " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
+ " height=H, fs=fs, autoplay=False)\n",
+ " if video_ids[i][0] == 'Bilibili':\n",
+ " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
+ " elif video_ids[i][0] == 'Osf':\n",
+ " print(f'Video available at https://osf.io/{video.id}')\n",
+ " display(video)\n",
+ " tab_contents.append(out)\n",
+ " return tab_contents\n",
+ "\n",
+ "video_ids = [('Youtube', 'KDKmDjMxU7Q'), ('Bilibili', 'BV1GM4m1S7kT')]\n",
+ "tab_contents = display_videos(video_ids, W=854, H=480)\n",
+ "tabs = widgets.Tab()\n",
+ "tabs.children = tab_contents\n",
+ "for i in range(len(tab_contents)):\n",
+ " tabs.set_title(i, video_ids[i][0])\n",
+ "display(tabs)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_function_learning_and_inductive_bias\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "## Coding Exercise 1: Additive Function\n",
+ "\n",
+ "\n",
+ "We will start with an additive function, the Rastrigin function, defined \n",
+ "\n",
+ "\\begin{align*}\n",
+ "f(\\mathbf{x}) = 10d + \\sum_{i=1}^{d} (x_{i}^{2} - 10 \\cos(2 \\pi x_{i}))\n",
+ "\\end{align*}\n",
+ "\n",
+ "where $d$ is the dimensionality of the input vector. In the cell below, complete missing parts of the function which computes values of the Rastrigin function given the input array."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete the Rastrigin function.\")\n",
+ "###################################################################\n",
+ "\n",
+ "def rastrigin(x):\n",
+ " \"\"\"Compute Rastrigin function for given array of d-dimenstional vectors.\n",
+ "\n",
+ " Inputs:\n",
+ " - x (np.ndarray of shape (n, d)): n d-dimensional vectors.\n",
+ "\n",
+ " Outputs:\n",
+ " - y (np.ndarray of shape (n, 1)): Rastrigin function value for each of the vectors.\n",
+ " \"\"\"\n",
+ " return 10 * x.shape[1] + np.sum(... - 10 * np.cos(2*np.pi*...), axis=1)\n",
+ "\n",
+ "# this code creates 10000 2-dimensional vectors which are going to be served as input to the function (thus, output is of shape (10000, 1))\n",
+ "x0_rastrigin = np.linspace(-5.12, 5.12, 100)\n",
+ "X_rastrigin, Y_rastrigin = np.meshgrid(x0_rastrigin,x0_rastrigin)\n",
+ "xs_rastrigin = np.vstack((X_rastrigin.flatten(), Y_rastrigin.flatten())).T\n",
+ "\n",
+ "ys_rastrigin = rastrigin(xs_rastrigin)\n",
+ "\n",
+ "plot_3d_function([X_rastrigin],[Y_rastrigin], [ys_rastrigin.reshape(X_rastrigin.shape)], ['Rastrigin Function'])"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "#to_remove solution\n",
+ "\n",
+ "def rastrigin(x):\n",
+ " \"\"\"Compute Rastrigin function for given array of d-dimenstional vectors.\n",
+ "\n",
+ " Inputs:\n",
+ " - x (np.ndarray of shape (n, d)): n d-dimensional vectors.\n",
+ "\n",
+ " Outputs:\n",
+ " - y (np.ndarray of shape (n, 1)): Rastrigin function value for each of the vectors.\n",
+ " \"\"\"\n",
+ " return 10 * x.shape[1] + np.sum(x**2 - 10 * np.cos(2*np.pi*x), axis=1)\n",
+ "\n",
+ "# this code creates 10000 2-dimensional vectors which are going to be served as input to the function (thus, output is of shape (10000, 1))\n",
+ "x0_rastrigin = np.linspace(-5.12, 5.12, 100)\n",
+ "X_rastrigin, Y_rastrigin = np.meshgrid(x0_rastrigin,x0_rastrigin)\n",
+ "xs_rastrigin = np.vstack((X_rastrigin.flatten(), Y_rastrigin.flatten())).T\n",
+ "\n",
+ "ys_rastrigin = rastrigin(xs_rastrigin)\n",
+ "\n",
+ "plot_3d_function([X_rastrigin],[Y_rastrigin], [ys_rastrigin.reshape(X_rastrigin.shape)], ['Rastrigin Function'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Now, we are going to see which of the inductive biases (suggested mechanism underlying input data) will be more efficient in training the linear regression to get values of the Rastrigin function. We will consider two representations:\n",
+ "\n",
+ "* **Bound**: We encode 2D input vectors `xs` as bound vectors\n",
+ "* **Bundled**: We encode 1D input vectors separately and use bundling and then bundle them together"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "set_seed(42)\n",
+ "\n",
+ "ssp_space = sspspace.RandomSSPSpace(domain_dim=2, ssp_dim=1024)\n",
+ "bound_phis = ssp_space.encode(xs_rastrigin)\n",
+ "\n",
+ "ssp_space0 = sspspace.RandomSSPSpace(domain_dim=1, ssp_dim=1024)\n",
+ "ssp_space1 = sspspace.RandomSSPSpace(domain_dim=1, ssp_dim=1024)\n",
+ "\n",
+ "#remember that input to `encode` should be 2-dimensional, thus we need to create extra dimension by applying [:,None]\n",
+ "bundle_phis = ssp_space0.encode(xs_rastrigin[:, 0][:, None]) + ssp_space1.encode(xs_rastrigin[:, 1][:, None])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Now, let us define modeling attributes: we will have a few different `train_sizes`, and we will fit a linear regression for each of them in a loop. Then, for each of the models, we will evaluate its fit based on RMSE loss on the test set."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "def loss(y_true, y_pred):\n",
+ " \"\"\"Calculate RMSE loss between true and predicted values (note, that loss is not normalized by the shape).\n",
+ "\n",
+ " Inputs:\n",
+ " - y_true (np.ndarray): true values.\n",
+ " - y_pred (np.ndarray): predicted values.\n",
+ "\n",
+ " Outputs:\n",
+ " - loss (float): loss value.\n",
+ " \"\"\"\n",
+ " return np.sqrt(np.mean((y_true - y_pred) ** 2))\n",
+ "\n",
+ "def test_performance(xs, ys, train_sizes):\n",
+ " \"\"\"Fit linear regression to the provided data and evaluate the performance with RMSE loss for different test sizes.\n",
+ "\n",
+ " Inputs:\n",
+ " - xs (np.ndarray): input data.\n",
+ " - ys (np.ndarray): output data.\n",
+ " - train_size (list): list of the train sizes.\n",
+ " \"\"\"\n",
+ " performance = []\n",
+ "\n",
+ " models = []\n",
+ " for train_size in tqdm(train_sizes):\n",
+ " X_train, X_test, y_train, y_test = train_test_split(xs, ys, random_state=1, train_size=train_size)\n",
+ " regr = LinearRegression().fit(X_train, y_train)\n",
+ " performance.append(np.copy(loss(y_test, regr.predict(X_test))))\n",
+ " models.append(regr)\n",
+ " return performance, models"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Now, we are ready to train the models on two different inductive biases of the input data."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "train_sizes = np.linspace(0.25, 0.9, 5)\n",
+ "bound_performance, bound_models = test_performance(bound_phis, ys_rastrigin, train_sizes)\n",
+ "bundle_performance, bundle_models = test_performance(bundle_phis, ys_rastrigin, train_sizes)\n",
+ "plot_performance(bound_performance, bundle_performance, train_sizes * bound_phis.shape[0], \"Rastrigin function - RMSE\")\n",
+ "plt.ylim((-1, 20))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "What a drastic difference! Let us evaluate visually the performance when training on 3,000 train points."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "bound_model = bound_models[0]\n",
+ "bundled_model = bundle_models[0]\n",
+ "\n",
+ "ys_hat_rastrigin_bound = bound_model.predict(bound_phis)\n",
+ "ys_hat_rastrigin_bundled = bundled_model.predict(bundle_phis)\n",
+ "\n",
+ "plot_3d_function([X_rastrigin, X_rastrigin, X_rastrigin], [Y_rastrigin, Y_rastrigin, Y_rastrigin], [ys_rastrigin.reshape(X_rastrigin.shape), ys_hat_rastrigin_bound.reshape(X_rastrigin.shape), ys_hat_rastrigin_bundled.reshape(X_rastrigin.shape)], ['Rastrigin Function - True', 'Bound', 'Bundled'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "### Coding Exercise 1 Discussion\n",
+ "\n",
+ "1. Why do you think the bundled representation is superior for the Rastrigin function?"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "#to_remove explanation\n",
+ "\n",
+ "\"\"\"\n",
+ "Discussion: Why do you think the bundled representation is superior for the Rastrigin function?\n",
+ "\n",
+ "The Rastrigin function is a superposition of independent functions of the input variable dimensions. The bundled representation is a superposition of a high-dimensional representation of the input dimensions, making it easier to learn this function, which is additive. For the bound representation, we have to learn a mapping from each tuple of input values to the appropriate output value, meaning more samples are required to approximate the function.\n",
+ "\"\"\";"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_additive_function\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "## Coding Exercise 2: Non-separable Function\n",
+ "\n",
+ "Now, let's consider a non-separable function: a function $f(x_1, x_2)$ that cannot be described as the sum of two one-dimensional functions $g(x_1)$ and $h_1$. We will examine this function over the domain $[-4,4]^{2}$:\n",
+ "\n",
+ "$$f(\\mathbf{x}) = \\sin(x_{1}x_{2})$$\n",
+ "\n",
+ "Fill in the missing parts of the code to get the correct calculation of the defined function."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete the non-separable function.\")\n",
+ "###################################################################\n",
+ "\n",
+ "def non_separable(x):\n",
+ " \"\"\"Compute non-separable function for given array of 2-dimenstional vectors.\n",
+ "\n",
+ " Inputs:\n",
+ " - x (np.ndarray of shape (n, 2)): n 2-dimensional vectors.\n",
+ "\n",
+ " Outputs:\n",
+ " - y (np.ndarray of shape (n, 1)): non-separable function value for each of the vectors.\n",
+ " \"\"\"\n",
+ " return np.sin(np.multiply(x[:, ...], x[:, ...]))\n",
+ "\n",
+ "x0_non_separable = np.linspace(-4, 4, 100)\n",
+ "X_non_separable, Y_non_separable = np.meshgrid(x0_non_separable,x0_non_separable)\n",
+ "xs_non_separable = np.vstack((X_non_separable.flatten(), Y_non_separable.flatten())).T\n",
+ "\n",
+ "ys_non_separable = non_separable(xs_non_separable)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "#to_remove solution\n",
+ "\n",
+ "def non_separable(x):\n",
+ " \"\"\"Compute non-separable function for given array of 2-dimenstional vectors.\n",
+ "\n",
+ " Inputs:\n",
+ " - x (np.ndarray of shape (n, 2)): n 2-dimensional vectors.\n",
+ "\n",
+ " Outputs:\n",
+ " - y (np.ndarray of shape (n, 1)): non-separable function value for each of the vectors.\n",
+ " \"\"\"\n",
+ " return np.sin(np.multiply(x[:, 0], x[:, 1]))\n",
+ "\n",
+ "x0_non_separable = np.linspace(-4, 4, 100)\n",
+ "X_non_separable, Y_non_separable = np.meshgrid(x0_non_separable,x0_non_separable)\n",
+ "xs_non_separable = np.vstack((X_non_separable.flatten(), Y_non_separable.flatten())).T\n",
+ "\n",
+ "ys_non_separable = non_separable(xs_non_separable)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "plot_3d_function([X_non_separable],[Y_non_separable], [ys_non_separable.reshape(X_non_separable.shape)], ['Nonseparable Function, $f(\\mathbf{x}) = \\sin(x_{1}x_{2})$'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "### Coding Exercise 2 Discussion\n",
+ "\n",
+ "1. Can you guess by the nature of the function which of the representations will be more efficient?"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "#to_remove explanation\n",
+ "\n",
+ "\"\"\"\n",
+ "Discussion: Can you guess which of the representations will be more efficient by the nature of the function?\n",
+ "\n",
+ "As the function is not separable, we expect the bound representation to perform better.\n",
+ "\"\"\";"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "We will reuse previously defined spaces for encoding bound and bundled representations."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "bound_phis = ssp_space.encode(xs_non_separable)\n",
+ "bundle_phis = ssp_space0.encode(xs_non_separable[:,0][:,None]) + ssp_space1.encode(xs_non_separable[:,1][:,None])\n",
+ "\n",
+ "train_sizes = np.linspace(0.25, 0.9, 5)\n",
+ "bound_performance, bound_models = test_performance(bound_phis, ys_non_separable, train_sizes)\n",
+ "bundle_performance, bundle_models = test_performance(bundle_phis, ys_non_separable, train_sizes)\n",
+ "plot_performance(bound_performance, bundle_performance, train_sizes * bound_phis.shape[0], title = \"Non-separable function - RMSE\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Bundling representation can't achieve the same quality even when the number of samples is increased. This is because the function is non-separable, and the bundling representation can't capture the interaction between the two dimensions."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "bound_model = bound_models[0]\n",
+ "bundle_model = bundle_models[0]\n",
+ "\n",
+ "ys_hat_bound = bound_model.predict(bound_phis)\n",
+ "ys_hat_bundle = bundle_model.predict(bundle_phis)\n",
+ "\n",
+ "plot_3d_function([X_non_separable, X_non_separable, X_non_separable], [Y_non_separable, Y_non_separable, Y_non_separable], [ys_non_separable.reshape(X_non_separable.shape), ys_hat_bound.reshape(X_non_separable.shape), ys_hat_bundle.reshape(X_non_separable.shape)], ['Non-separable Function - True', 'Bound', 'Bundled'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "So, as we can see, when we pick the right inductive bias, we can do a better job."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_non_separable_function\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "---\n",
+ "\n",
+ "# Section 2: Representing Continuous Values\n",
+ "\n",
+ "Estimated timing to here from start of tutorial: 20 minutes\n",
+ "\n",
+ "In this section we will use a technique called Fractional Binding to represent continuous values to construct a map of objects distributed over a 2D space. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Video 2: Mapping Intro\n",
+ "from ipywidgets import widgets\n",
+ "from IPython.display import YouTubeVideo\n",
+ "from IPython.display import IFrame\n",
+ "from IPython.display import display\n",
+ "\n",
+ "class PlayVideo(IFrame):\n",
+ " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
+ " self.id = id\n",
+ " if source == 'Bilibili':\n",
+ " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
+ " elif source == 'Osf':\n",
+ " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
+ " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
+ "\n",
+ "def display_videos(video_ids, W=400, H=300, fs=1):\n",
+ " tab_contents = []\n",
+ " for i, video_id in enumerate(video_ids):\n",
+ " out = widgets.Output()\n",
+ " with out:\n",
+ " if video_ids[i][0] == 'Youtube':\n",
+ " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
+ " height=H, fs=fs, rel=0)\n",
+ " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
+ " else:\n",
+ " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
+ " height=H, fs=fs, autoplay=False)\n",
+ " if video_ids[i][0] == 'Bilibili':\n",
+ " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
+ " elif video_ids[i][0] == 'Osf':\n",
+ " print(f'Video available at https://osf.io/{video.id}')\n",
+ " display(video)\n",
+ " tab_contents.append(out)\n",
+ " return tab_contents\n",
+ "\n",
+ "video_ids = [('Youtube', 's7MOusrbKXU'), ('Bilibili', 'BV1pi421i7iN')]\n",
+ "tab_contents = display_videos(video_ids, W=854, H=480)\n",
+ "tabs = widgets.Tab()\n",
+ "tabs.children = tab_contents\n",
+ "for i in range(len(tab_contents)):\n",
+ " tabs.set_title(i, video_ids[i][0])\n",
+ "display(tabs)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_mapping_intro\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "## Coding Exercise 3: Mixing Discrete Objects With Continuous Space\n",
+ "\n",
+ "We will store three objects in a vector representing a map. First, we will create 3 objects (a circle, square, and triangle), as we did before."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "set_seed(42)\n",
+ "\n",
+ "obj_names = ['circle','square','triangle']\n",
+ "discrete_space = sspspace.DiscreteSPSpace(obj_names, ssp_dim=1024)\n",
+ "\n",
+ "objs = {n:discrete_space.encode(n) for n in obj_names}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Next, we are going to create three locations where the objects will reside, and an encoder will transform those coordinates into an SSP representation."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "set_seed(42)\n",
+ "\n",
+ "ssp_space = sspspace.RandomSSPSpace(domain_dim=2, ssp_dim=1024)\n",
+ "positions = np.array([[0, -2],\n",
+ " [-2, 3],\n",
+ " [3, 2]\n",
+ " ])\n",
+ "ssps = {n:ssp_space.encode(x) for n, x in zip(obj_names, positions)}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Next, in order to see where things are on the map, we are going to compute the similarity between encoded places and points in the space. Your task is to complete the calculation of similarity values between all grid points with the one associated with the object."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "dim0 = np.linspace(-5, 5, 101)\n",
+ "dim1 = np.linspace(-5, 5, 101)\n",
+ "X,Y = np.meshgrid(dim0, dim1)\n",
+ "\n",
+ "query_xs = np.vstack((X.flatten(), Y.flatten())).T\n",
+ "query_ssps = ssp_space.encode(query_xs)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete similarity calculation.\")\n",
+ "###################################################################\n",
+ "\n",
+ "sims = []\n",
+ "\n",
+ "for obj_idx, obj in enumerate(obj_names):\n",
+ " sims.append(... @ ssps[obj].flatten())\n",
+ "\n",
+ "plt.figure(figsize=(8, 2.4))\n",
+ "plot_2d_similarity(sims, obj_names, (dim0.size, dim1.size))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "#to_remove solution\n",
+ "\n",
+ "sims = []\n",
+ "\n",
+ "for obj_idx, obj in enumerate(obj_names):\n",
+ " sims.append(query_ssps @ ssps[obj].flatten())\n",
+ "\n",
+ "plt.figure(figsize=(8, 2.4))\n",
+ "plot_2d_similarity(sims, obj_names, (dim0.size, dim1.size))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Now, let's bind these positions with the objects and see how that changes similarity with the map positions. Complete binding operation in the cell below."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete binding operation for objects and corresponding positions.\")\n",
+ "###################################################################\n",
+ "\n",
+ "#objects are located in `objs` and positions in `ssps`\n",
+ "bound_objects = [... * ... for n in obj_names]\n",
+ "\n",
+ "sims = []\n",
+ "\n",
+ "for obj_idx, obj in enumerate(obj_names):\n",
+ " sims.append(query_ssps @ bound_objects[obj_idx].flatten())\n",
+ "\n",
+ "plt.figure(figsize=(8, 2.4))\n",
+ "plot_2d_similarity(sims, obj_names, (dim0.size, dim1.size))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "#to_remove solution\n",
+ "\n",
+ "#objects are located in `objs` and positions in `ssps`\n",
+ "bound_objects = [objs[n] * ssps[n] for n in obj_names]\n",
+ "\n",
+ "sims = []\n",
+ "\n",
+ "for obj_idx, obj in enumerate(obj_names):\n",
+ " sims.append(query_ssps @ bound_objects[obj_idx].flatten())\n",
+ "\n",
+ "plt.figure(figsize=(8, 2.4))\n",
+ "plot_2d_similarity(sims, obj_names, (dim0.size, dim1.size))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "As you can see, the similarity is destroyed, which is what we should expect.\n",
+ "\n",
+ "Next, we are going to create a map out of our bound objects:\n",
+ "\n",
+ "\\begin{align*}\n",
+ "\\mathrm{map} = \\sum_{i=1}^{n} \\phi(x_{i})\\circledast obj_{i}\n",
+ "\\end{align*}"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "set_seed(42)\n",
+ "\n",
+ "ssp_map = sspspace.SSP(np.sum(bound_objects, axis=0))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Now, we can query the map by unbinding the objects we care about. Your task is to complete the unbinding operation. Then, let's observe the resulting similarities."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete the unbinding operation.\")\n",
+ "###################################################################\n",
+ "\n",
+ "objects_sims = []\n",
+ "\n",
+ "for obj_idx, obj_name in enumerate(obj_names):\n",
+ " #query the object name by unbinding it from the map\n",
+ " query_map = ssp_map * ~objs[...]\n",
+ " objects_sims.append(query_ssps @ query_map.flatten())\n",
+ "\n",
+ "plot_2d_similarity(objects_sims, obj_names, (dim0.size, dim1.size), title_argmax = True)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "#to_remove solution\n",
+ "\n",
+ "objects_sims = []\n",
+ "\n",
+ "for obj_idx, obj_name in enumerate(obj_names):\n",
+ " #query the object name by unbinding it from the map\n",
+ " query_map = ssp_map * ~objs[obj_name]\n",
+ " objects_sims.append(query_ssps @ query_map.flatten())\n",
+ "\n",
+ "plot_2d_similarity(objects_sims, obj_names, (dim0.size, dim1.size), title_argmax = True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Let's look at what happens when we unbind all the symbols from the map at once. Complete bundling and unbinding operations in the following code cell."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete the bundling and unbinding operations.\")\n",
+ "###################################################################\n",
+ "\n",
+ "# unifying bundled representation of all objects\n",
+ "all_objs = (objs['circle'] + objs[...] + objs[...]).normalize()\n",
+ "\n",
+ "# unbind this unifying representation from the map\n",
+ "query_map = ... * ~...\n",
+ "\n",
+ "sims = query_ssps @ query_map.flatten()\n",
+ "size = (dim0.size,dim1.size)\n",
+ "\n",
+ "plot_unbinding_objects_map(sims, positions, query_xs, size)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "#to_remove solution\n",
+ "# unifying bundled representation of all objects\n",
+ "all_objs = (objs['circle'] + objs['square'] + objs['triangle']).normalize()\n",
+ "\n",
+ "# unbind this unifying representation from the map\n",
+ "query_map = ssp_map * ~all_objs\n",
+ "\n",
+ "sims = query_ssps @ query_map.flatten()\n",
+ "size = (dim0.size,dim1.size)\n",
+ "\n",
+ "plot_unbinding_objects_map(sims, positions, query_xs, size)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "We can also unbind positions and see what objects exist there. We will the locations where objects are located as test positions, as well as two distinct ones to compare. In the final exercise, you should complete the unbinding of the position's operation."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete the unbinding operations.\")\n",
+ "###################################################################\n",
+ "\n",
+ "query_objs = np.vstack([objs[n] for n in obj_names])\n",
+ "test_positions = np.vstack((positions, [0,0], [0,-1.5]))\n",
+ "\n",
+ "sims = []\n",
+ "\n",
+ "for pos_idx, pos in enumerate(test_positions):\n",
+ " position_ssp = ssp_space.encode(pos[None,:]) #remember we need to have 2-dimensional vectors for `encode()` function\n",
+ " #unbind positions from the map\n",
+ " query_map = ... * ~...\n",
+ " sims.append(query_objs @ query_map.flatten())\n",
+ "\n",
+ "plot_unbinding_positions_map(sims, test_positions, obj_names)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "#to_remove solution\n",
+ "\n",
+ "query_objs = np.vstack([objs[n] for n in obj_names])\n",
+ "test_positions = np.vstack((positions, [0,0], [0,-1.5]))\n",
+ "\n",
+ "sims = []\n",
+ "\n",
+ "for pos_idx, pos in enumerate(test_positions):\n",
+ " position_ssp = ssp_space.encode(pos[None,:]) #remember we need to have 2-dimensional vectors for `encode()` function\n",
+ " #unbind positions from the map\n",
+ " query_map = ssp_map * ~position_ssp\n",
+ " sims.append(query_objs @ query_map.flatten())\n",
+ "\n",
+ "plot_unbinding_positions_map(sims, test_positions, obj_names)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "As you can see from the above plots, when we query each location, we can clearly identify the object stored at that location. \n",
+ "\n",
+ "When we query at the origin (where no object is present), we see that there is no strong candidate element. However, as we move closer to one of the objects (rightmost plot), the similarity starts to increase."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_mixing_discrete_objects_with_continuous_space\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Video 4: Mapping Outro\n",
+ "from ipywidgets import widgets\n",
+ "from IPython.display import YouTubeVideo\n",
+ "from IPython.display import IFrame\n",
+ "from IPython.display import display\n",
+ "\n",
+ "class PlayVideo(IFrame):\n",
+ " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
+ " self.id = id\n",
+ " if source == 'Bilibili':\n",
+ " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
+ " elif source == 'Osf':\n",
+ " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
+ " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
+ "\n",
+ "def display_videos(video_ids, W=400, H=300, fs=1):\n",
+ " tab_contents = []\n",
+ " for i, video_id in enumerate(video_ids):\n",
+ " out = widgets.Output()\n",
+ " with out:\n",
+ " if video_ids[i][0] == 'Youtube':\n",
+ " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
+ " height=H, fs=fs, rel=0)\n",
+ " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
+ " else:\n",
+ " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
+ " height=H, fs=fs, autoplay=False)\n",
+ " if video_ids[i][0] == 'Bilibili':\n",
+ " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
+ " elif video_ids[i][0] == 'Osf':\n",
+ " print(f'Video available at https://osf.io/{video.id}')\n",
+ " display(video)\n",
+ " tab_contents.append(out)\n",
+ " return tab_contents\n",
+ "\n",
+ "video_ids = [('Youtube', 'mXNFWr_cap4'), ('Bilibili', 'BV1ND421u7gp')]\n",
+ "tab_contents = display_videos(video_ids, W=854, H=480)\n",
+ "tabs = widgets.Tab()\n",
+ "tabs.children = tab_contents\n",
+ "for i in range(len(tab_contents)):\n",
+ " tabs.set_title(i, video_ids[i][0])\n",
+ "display(tabs)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_mapping_outro\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "---\n",
+ "# Summary\n",
+ "\n",
+ "*Estimated timing of tutorial: 40 minutes*"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Video 5: Conclusions\n",
+ "from ipywidgets import widgets\n",
+ "from IPython.display import YouTubeVideo\n",
+ "from IPython.display import IFrame\n",
+ "from IPython.display import display\n",
+ "\n",
+ "class PlayVideo(IFrame):\n",
+ " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
+ " self.id = id\n",
+ " if source == 'Bilibili':\n",
+ " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
+ " elif source == 'Osf':\n",
+ " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
+ " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
+ "\n",
+ "def display_videos(video_ids, W=400, H=300, fs=1):\n",
+ " tab_contents = []\n",
+ " for i, video_id in enumerate(video_ids):\n",
+ " out = widgets.Output()\n",
+ " with out:\n",
+ " if video_ids[i][0] == 'Youtube':\n",
+ " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
+ " height=H, fs=fs, rel=0)\n",
+ " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
+ " else:\n",
+ " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
+ " height=H, fs=fs, autoplay=False)\n",
+ " if video_ids[i][0] == 'Bilibili':\n",
+ " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
+ " elif video_ids[i][0] == 'Osf':\n",
+ " print(f'Video available at https://osf.io/{video.id}')\n",
+ " display(video)\n",
+ " tab_contents.append(out)\n",
+ " return tab_contents\n",
+ "\n",
+ "video_ids = [('Youtube', 'M6rRsdJdoYQ'), ('Bilibili', 'BV1wm421L7Se')]\n",
+ "tab_contents = display_videos(video_ids, W=854, H=480)\n",
+ "tabs = widgets.Tab()\n",
+ "tabs.children = tab_contents\n",
+ "for i in range(len(tab_contents)):\n",
+ " tabs.set_title(i, video_ids[i][0])\n",
+ "display(tabs)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Conclusion slides\n",
+ "\n",
+ "from IPython.display import IFrame\n",
+ "link_id = \"pxqny\"\n",
+ "\n",
+ "print(f\"If you want to download the slides: 'https://osf.io/download/{link_id}'\")\n",
+ "\n",
+ "IFrame(src=f\"https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{link_id}/?direct%26mode=render\", width=854, height=480)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_conclusions\")"
+ ]
+ }
+ ],
+ "metadata": {
+ "colab": {
+ "collapsed_sections": [],
+ "include_colab_link": true,
+ "name": "W2D2_Tutorial5",
+ "provenance": [],
+ "toc_visible": true
+ },
+ "kernel": {
+ "display_name": "Python 3",
+ "language": "python",
+ "name": "python3"
+ },
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.9.22"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 4
+}
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/instructor/W2D2_Intro.ipynb b/tutorials/W2D2_NeuroSymbolicMethods/instructor/W2D2_Intro.ipynb
index 218b77e69..5a0275059 100644
--- a/tutorials/W2D2_NeuroSymbolicMethods/instructor/W2D2_Intro.ipynb
+++ b/tutorials/W2D2_NeuroSymbolicMethods/instructor/W2D2_Intro.ipynb
@@ -18,7 +18,9 @@
}
},
"source": [
- "# Intro"
+ "# W2D2 - Neurosymbolic Methods and Cognitive Architectures \n",
+ "\n",
+ "Welcome to the day on Neurosymbolic Methods and Cognitive Architectures. This year we have some new content to introduce to you from the fascinating work by Chris Eliasmith and Michael Furlong. We're going to look at methods that use symbolic manipulation in order to learn how to model data in a way that is more brain-like and generalizes well to stimuli out of distribution. We're also going to look in some detail at a model they have created, called SPAUN. Please consider the note in the prerequisite cell below and try to have a basic understanding of those listed topics before getting into the details. The topic will be much clearer having brushed up on those topics. We'll now pass it over to Chris and Michael to tell you all about neurosymbolic methods and cognitive architectures!"
]
},
{
@@ -123,7 +125,7 @@
" return tab_contents\n",
"\n",
"\n",
- "video_ids = [('Youtube', 'RKKUfo0dVnY'), ('Bilibili', 'BV11D421M7Hy')]\n",
+ "video_ids = [('Youtube', 'W1jsRycDYXQ'), ('Bilibili', 'BV15V7jz8EAj')]\n",
"tab_contents = display_videos(video_ids, W=854, H=480)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
@@ -172,7 +174,7 @@
"from ipywidgets import widgets\n",
"out = widgets.Output()\n",
"\n",
- "link_id = \"nxzar\"\n",
+ "link_id = \"9w836\"\n",
"\n",
"with out:\n",
" print(f\"If you want to download the slides: https://osf.io/download/{link_id}/\")\n",
@@ -209,7 +211,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.9.19"
+ "version": "3.9.22"
}
},
"nbformat": 4,
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/instructor/W2D2_Tutorial1.ipynb b/tutorials/W2D2_NeuroSymbolicMethods/instructor/W2D2_Tutorial1.ipynb
index 7fd099dc5..bc0a55646 100644
--- a/tutorials/W2D2_NeuroSymbolicMethods/instructor/W2D2_Tutorial1.ipynb
+++ b/tutorials/W2D2_NeuroSymbolicMethods/instructor/W2D2_Tutorial1.ipynb
@@ -25,9 +25,9 @@
"\n",
"__Content creators:__ P. Michael Furlong, Chris Eliasmith\n",
"\n",
- "__Content reviewers:__ Hlib Solodzhuk, Patrick Mineault, Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi\n",
+ "__Content reviewers:__ Hlib Solodzhuk, Patrick Mineault, Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Alex Murphy\n",
"\n",
- "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk\n"
+ "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk, Alex Murphy\n"
]
},
{
@@ -43,7 +43,7 @@
"\n",
"*Estimated timing of tutorial: 1 hour*\n",
"\n",
- "In this tutorial we will introduce vector symbolic algebra and discuss its main operations."
+ "In this tutorial we will introduce the concept of a vector symbolic algebra (VSA) and discuss its main operations and we will give you some demonstrations on a simple set of concepts (shapes and their colors) in order to let you see and play around with concept manipulations in this VSA! Let's get started!"
]
},
{
@@ -59,7 +59,7 @@
"# @markdown These are the slides for the videos in all tutorials today\n",
"\n",
"from IPython.display import IFrame\n",
- "link_id = \"2szmk\"\n",
+ "link_id = \"jybuw\"\n",
"\n",
"print(f\"If you want to download the slides: 'https://osf.io/download/{link_id}'\")\n",
"\n",
@@ -73,8 +73,11 @@
},
"source": [
"---\n",
- "# Setup\n",
- "\n"
+ "# Setup (Colab Users: Please Read)\n",
+ "\n",
+ "Note that because this tutorial relies on some special Python packages, these packages have requirements for specific versions of common scientific libraries, such as `numpy`. If you're in Google Colab, then as of May 2025, this comes with a later version (2.0.2) pre-installed. We require an older version (we'll be installing `1.24.4`). This causes Colab to force a session restart and then re-running of the installation cells for the new version to take effect. When you run the cell below, you will be prompted to restart the session. This is *entirely expected* and you haven't done anything wrong. Simply click 'Restart' and then run the cells as normal. \n",
+ "\n",
+ "An additional error might sometimes arise where an exception is raised connected to a missing element of NumPy. If this occurs, please restart the session and re-run the cells as normal and this error will go away. Updated versions of the affected libraries are expected out soon, but sadly not in time for the preparation of this material. We thank you for your understanding."
]
},
{
@@ -88,7 +91,10 @@
"source": [
"# @title Install and import feedback gadget\n",
"\n",
- "!pip install --quiet numpy matplotlib ipywidgets scipy vibecheck\n",
+ "!pip install git+https://github.com/neuromatch/sspspace@neuromatch --quiet\n",
+ "!pip install numpy==1.24.4\n",
+ "!pip install nengo_spa==2.0.0\n",
+ "!pip install --quiet matplotlib ipywidgets scipy vibecheck\n",
"\n",
"from vibecheck import DatatopsContentReviewContainer\n",
"def content_review(notebook_section: str):\n",
@@ -106,30 +112,6 @@
"feedback_prefix = \"W2D2_T1\""
]
},
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Notice that exactly the `neuromatch` branch of `sspspace` should be installed! Otherwise, some of the functionality won't work."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Install dependencies\n",
- "\n",
- "# Install sspspace\n",
- "!pip install git+https://github.com/neuromatch/sspspace@neuromatch --quiet"
- ]
- },
{
"cell_type": "code",
"execution_count": null,
@@ -153,6 +135,7 @@
"\n",
"#modeling\n",
"import sspspace\n",
+ "import nengo_spa as spa\n",
"from scipy.special import softmax"
]
},
@@ -284,7 +267,7 @@
" - title (str): title of the plot.\n",
" \"\"\"\n",
" with plt.xkcd():\n",
- " plt.plot(x_range, sim_mat)\n",
+ " plt.plot(x_range, sims)\n",
" plt.xlabel('x')\n",
" plt.ylabel('Similarity')\n",
" plt.title(title)"
@@ -313,90 +296,6 @@
"set_seed(seed = 42)"
]
},
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Helper functions\n",
- "\n",
- "# mainly contains solutions to exercises for correct plot output; please don't take a look!\n",
- "set_seed(42)\n",
- "\n",
- "vector_length = 1024\n",
- "symbol_names = ['circle','square','triangle']\n",
- "discrete_space = sspspace.DiscreteSPSpace(symbol_names, ssp_dim=vector_length, optimize = False)\n",
- "\n",
- "circle = discrete_space.encode('circle')\n",
- "square = discrete_space.encode('square')\n",
- "triangle = discrete_space.encode('triangle')\n",
- "\n",
- "shape = (circle + square + triangle).normalize()\n",
- "\n",
- "shape_sim_mat = np.zeros((4,4))\n",
- "\n",
- "shape_sim_mat[0,0] = (circle | circle).item()\n",
- "shape_sim_mat[1,1] = (square | square).item()\n",
- "shape_sim_mat[2,2] = (triangle | triangle).item()\n",
- "shape_sim_mat[3,3] = (shape | shape).item()\n",
- "\n",
- "shape_sim_mat[0,1] = shape_sim_mat[1,0] = (circle | square).item()\n",
- "shape_sim_mat[0,2] = shape_sim_mat[2,0] = (circle | triangle).item()\n",
- "shape_sim_mat[0,3] = shape_sim_mat[3,0] = (circle | shape).item()\n",
- "\n",
- "shape_sim_mat[1,2] = shape_sim_mat[2,1] = (square | triangle).item()\n",
- "shape_sim_mat[1,3] = shape_sim_mat[3,1] = (square | shape).item()\n",
- "\n",
- "shape_sim_mat[2,3] = shape_sim_mat[3,2] = (triangle | shape).item()\n",
- "\n",
- "new_symbol_names = ['circle','square','triangle', 'red', 'blue', 'green']\n",
- "new_discrete_space = sspspace.DiscreteSPSpace(new_symbol_names, ssp_dim=vector_length, optimize=False)\n",
- "\n",
- "objs = {n:new_discrete_space.encode(np.array([n])) for n in new_symbol_names}\n",
- "\n",
- "objs['red*circle'] = objs['red'] * objs['circle']\n",
- "objs['blue*triangle'] = objs['blue'] * objs['triangle']\n",
- "objs['green*square'] = objs['green'] * objs['square']\n",
- "\n",
- "new_object_names = ['red','red^','red*circle','circle','circle^']\n",
- "new_objs = objs.copy()\n",
- "\n",
- "new_objs['red^'] = new_objs['red*circle'] * ~new_objs['circle']\n",
- "new_objs['circle^'] = new_objs['red*circle'] * ~new_objs['red']\n",
- "\n",
- "axis_vectors = ['one']\n",
- "\n",
- "encoder = sspspace.DiscreteSPSpace(axis_vectors, ssp_dim=1024, optimize=False)\n",
- "\n",
- "vocab = {w:encoder.encode(w) for w in axis_vectors}\n",
- "\n",
- "integers = [vocab['one']]\n",
- "\n",
- "max_int = 5\n",
- "for i in range(2, max_int + 1):\n",
- " integers.append(integers[-1] * vocab['one'])\n",
- "\n",
- "integers = np.array(integers).squeeze()\n",
- "integer_sims = integers @ integers.T\n",
- "\n",
- "five_unbind_two = sspspace.SSP(integers[4]) * ~sspspace.SSP(integers[1])\n",
- "five_unbind_two_sims = five_unbind_two @ integers.T\n",
- "\n",
- "new_encoder = sspspace.RandomSSPSpace(domain_dim=1, ssp_dim=1024)\n",
- "\n",
- "xs = np.linspace(-4,4,401)[:,None]\n",
- "phis = new_encoder.encode(xs)\n",
- "\n",
- "real_line_sims = phis[200, :] @ phis.T\n",
- "\n",
- "phi_shifted = phis[200,:][None,:] * new_encoder.encode([[np.pi/2]])\n",
- "shifted_real_line_sims = phi_shifted.flatten() @ phis.T"
- ]
- },
{
"cell_type": "markdown",
"metadata": {
@@ -485,11 +384,27 @@
"source": [
"## Coding Exercise 1: Concepts as High-Dimensional Vectors\n",
"\n",
- "In an arbitrary space of concepts, we will represent the ideas of 'circle,' 'square,' and triangle.' For that, we will use the SSP space library (`sspspace`) to map identifiers for the concepts (strings of their names in this case) into high-dimensional vectors of unit length. It means that for each `name`, we will uniquely identify $\\mathbf{v}$ where $||\\mathbf{v}|| = 1$.\n",
+ "In an arbitrary space of concepts, we will represent the ideas of `CIRCLE`, `SQUARE` and `TRIANGLE`. For that, we will make a vocabulary that map identifiers of the concepts (strings of their names in this case) into high-dimensional vectors of unit length. It means that for each `name`, we will uniquely identify $\\mathbf{v}$ where $||\\mathbf{v}|| = 1$.\n",
"\n",
"In this exercise, check that, indeed, vectors are of unit length."
]
},
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "from nengo_spa.algebras.hrr_algebra import HrrProperties, HrrAlgebra\n",
+ "from nengo_spa.vector_generation import VectorsWithProperties\n",
+ "def make_vocabulary(vector_length):\n",
+ " vec_generator = VectorsWithProperties(vector_length, algebra=HrrAlgebra(), properties = [HrrProperties.UNITARY, HrrProperties.POSITIVE])\n",
+ " vocab = spa.Vocabulary(vector_length, pointer_gen=vec_generator)\n",
+ " return vocab"
+ ]
+ },
{
"cell_type": "markdown",
"metadata": {
@@ -510,16 +425,19 @@
"set_seed(42)\n",
"\n",
"vector_length = 1024\n",
- "symbol_names = ['circle','square','triangle']\n",
- "discrete_space = sspspace.DiscreteSPSpace(symbol_names, ssp_dim=vector_length, optimize = False)\n",
+ "symbol_names = ['CIRCLE','SQUARE','TRIANGLE']\n",
"\n",
- "circle = discrete_space.encode('circle')\n",
- "square = discrete_space.encode('square')\n",
- "triangle = discrete_space.encode('triangle')\n",
+ "vocab = make_vocabulary(vector_length)\n",
+ "vocab.populate(';'.join(symbol_names))\n",
+ "print(list(vocab.keys()))\n",
"\n",
- "print('|circle| =', np.linalg.norm(circle))\n",
- "print('|triangle| =', np.linalg.norm(...))\n",
- "print('|square| =', ...)\n",
+ "circle = vocab['CIRCLE']\n",
+ "square = vocab['SQUARE']\n",
+ "triangle = vocab['TRIANGLE']\n",
+ "\n",
+ "print('|circle| =', np.linalg.norm(circle.v))\n",
+ "print('|triangle| =', np.linalg.norm(square.v))\n",
+ "print('|square| =', np.linalg.norm(triangle.v))\n",
"\n",
"```"
]
@@ -537,16 +455,19 @@
"set_seed(42)\n",
"\n",
"vector_length = 1024\n",
- "symbol_names = ['circle','square','triangle']\n",
- "discrete_space = sspspace.DiscreteSPSpace(symbol_names, ssp_dim=vector_length, optimize = False)\n",
+ "symbol_names = ['CIRCLE','SQUARE','TRIANGLE']\n",
+ "\n",
+ "vocab = make_vocabulary(vector_length)\n",
+ "vocab.populate(';'.join(symbol_names))\n",
+ "print(list(vocab.keys()))\n",
"\n",
- "circle = discrete_space.encode('circle')\n",
- "square = discrete_space.encode('square')\n",
- "triangle = discrete_space.encode('triangle')\n",
+ "circle = vocab['CIRCLE']\n",
+ "square = vocab['SQUARE']\n",
+ "triangle = vocab['TRIANGLE']\n",
"\n",
- "print('|circle| =', np.linalg.norm(circle))\n",
- "print('|triangle| =', np.linalg.norm(triangle))\n",
- "print('|square| =', np.linalg.norm(square))"
+ "print('|circle| =', np.linalg.norm(circle.v))\n",
+ "print('|triangle| =', np.linalg.norm(square.v))\n",
+ "print('|square| =', np.linalg.norm(triangle.v))"
]
},
{
@@ -566,7 +487,7 @@
},
"outputs": [],
"source": [
- "plot_vectors([circle, square, triangle], symbol_names)"
+ "plot_vectors([circle.v, square.v, triangle.v], symbol_names)"
]
},
{
@@ -575,13 +496,13 @@
"execution": {}
},
"source": [
- "As vectors are assigned randomly, the images do not display any meaningful structure.\n",
+ "As vectors are initialized randomly, it's perfectly expected that there is no visual connection to how we would represent or expect those concepts to be represented.\n",
"\n",
- "One of the most useful properties of random high-dimensional vectors is that they are approximately orthogonal. This is an important aspect for vector symbolic algebras (VSAs) since we will use the vector dot product to measure similarity between objects encoded as random, high-dimensional vectors. \n",
+ "One of the extremely useful properties of random high-dimensional vectors is that they are approximately orthogonal. This is an important aspect for vector symbolic algebras (VSAs), since we will use the vector dot product to measure similarity between objects encoded as random, high-dimensional vectors.\n",
"\n",
- "Discrete objects are either the same or different, so we expect similarity would be either 1 (the same) or 0 (not the same). Given how we select the vectors that represent discrete symbols if they are the same, they will have the dot product of 1, and if they are different concepts, then they will have a dot product of (approximately) 0.\n",
+ "Discrete objects are either the same or different, so we expect similarity would be either 1 (the same) or 0 (not the same). Given how we select the vectors that represent discrete symbols, if they are the same they will have the dot product of 1 and if they are different concepts, then they will have a dot product of (approximately) 0. This is due to the approximate orthogonality of randomly selected high-dimensional vectors.\n",
"\n",
- "Below, we use the | operator to indicate similarity. This is borrowed from the bra-ket notation in physics, i.e.,\n",
+ "Below we use the | operator to indicate similarity. This is borrowed from the bra-ket notation in physics, i.e.,\n",
"\n",
"$$\n",
"\\mathbf{a}\\cdot\\mathbf{b} = \\langle \\mathbf{a} \\mid \\mathbf{b}\\rangle\n",
@@ -598,17 +519,17 @@
},
"outputs": [],
"source": [
- "concepts_sim_mat = np.zeros((3,3))\n",
+ "sim_mat = np.zeros((3,3))\n",
"\n",
- "concepts_sim_mat[0,0] = (circle | circle).item()\n",
- "concepts_sim_mat[1,1] = (square | square).item()\n",
- "concepts_sim_mat[2,2] = (triangle | triangle).item()\n",
+ "sim_mat[0,0] = spa.dot(circle, circle)\n",
+ "sim_mat[1,1] = spa.dot(square, square)\n",
+ "sim_mat[2,2] = spa.dot(triangle, triangle)\n",
"\n",
- "concepts_sim_mat[0,1] = concepts_sim_mat[1,0] = (circle | square).item()\n",
- "concepts_sim_mat[0,2] = concepts_sim_mat[2,0] = (circle | triangle).item()\n",
- "concepts_sim_mat[1,2] = concepts_sim_mat[2,1] = (square | triangle).item()\n",
+ "sim_mat[0,1] = sim_mat[1,0] = spa.dot(circle, square)\n",
+ "sim_mat[0,2] = sim_mat[2,0] = spa.dot(circle, triangle)\n",
+ "sim_mat[1,2] = sim_mat[2,1] = spa.dot(square, triangle)\n",
"\n",
- "plot_similarity_matrix(concepts_sim_mat, symbol_names)"
+ "plot_similarity_matrix(sim_mat, symbol_names)"
]
},
{
@@ -620,6 +541,34 @@
"As you can see from the above figure, the three randomly selected vectors are approximately orthogonal. This will be important later when we go to make more complicated objects from our vectors."
]
},
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "### Coding Exercise 1 Discussion\n",
+ "\n",
+ "1. How would you provide intuitive reasoning (or rigorous mathematical proof) behind the fact that random high-dimensional vectors (note that each of the components is drawn from uniform distribution with zero mean) approximately orthogonal?"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "#to_remove explanation\n",
+ "\n",
+ "\"\"\"\n",
+ "Discussion: How would you provide intuitive reasoning or rigorous mathematical proof behind the fact that random high-dimensional vectors (note that each of the components is drawn from uniform distribution with zero mean) approximately orthogonal?\n",
+ "\n",
+ "Observe that as each of the components are independent and they are sampled from distribution with zero mean, it means that expected value of dot product E(x*y) = E(\\sum_i x_i * y_i) = (linearity of expectation) \\sum_i E(x_i * y_i) = (independence) \\sum_i (E(x_i) * E(y_i)) = 0.\n",
+ "\"\"\";"
+ ]
+ },
{
"cell_type": "code",
"execution_count": null,
@@ -734,7 +683,7 @@
},
"outputs": [],
"source": [
- "shape = (circle + square + triangle).normalize()"
+ "shape = (circle + square + triangle).normalized()"
]
},
{
@@ -761,21 +710,20 @@
"raise NotImplementedError(\"Student exercise: complete calcualtion of similarity matrix.\")\n",
"###################################################################\n",
"\n",
- "shape_sim_mat = np.zeros((4,4))\n",
+ "sim_mat = np.zeros((4,4))\n",
"\n",
- "shape_sim_mat[0,0] = (circle | circle).item()\n",
- "shape_sim_mat[1,1] = (square | square).item()\n",
- "shape_sim_mat[2,2] = (triangle | ...).item()\n",
- "shape_sim_mat[3,3] = (shape | ...).item()\n",
+ "sim_mat[0,0] = spa.dot(circle, circle)\n",
+ "sim_mat[1,1] = spa.dot(square, square)\n",
+ "sim_mat[2,2] = spa.dot(triangle, ...)\n",
+ "sim_mat[3,3] = spa.dot(shape, ...)\n",
"\n",
- "shape_sim_mat[0,1] = shape_sim_mat[1,0] = (circle | square).item()\n",
- "shape_sim_mat[0,2] = shape_sim_mat[2,0] = (circle | triangle).item()\n",
- "shape_sim_mat[0,3] = shape_sim_mat[3,0] = (circle | shape).item()\n",
+ "sim_mat[0,1] = sim_mat[1,0] = spa.dot(circle, square)\n",
+ "sim_mat[0,2] = sim_mat[2,0] = spa.dot(circle, triangle)\n",
+ "sim_mat[0,3] = sim_mat[3,0] = spa.dot(circle, shape)\n",
"\n",
- "shape_sim_mat[1,2] = shape_sim_mat[2,1] = (square | triangle).item()\n",
- "shape_sim_mat[1,3] = shape_sim_mat[3,1] = (square | shape).item()\n",
- "\n",
- "shape_sim_mat[2,3] = shape_sim_mat[3,2] = (... | ...).item()\n",
+ "sim_mat[1,2] = sim_mat[2,1] = spa.dot(square, triangle)\n",
+ "sim_mat[1,3] = sim_mat[3,1] = spa.dot(square, shape)\n",
+ "sim_mat[2,3] = sim_mat[3,2] = spa.dot(..., shape)\n",
"\n",
"```"
]
@@ -790,21 +738,20 @@
"source": [
"# to_remove solution\n",
"\n",
- "shape_sim_mat = np.zeros((4,4))\n",
- "\n",
- "shape_sim_mat[0,0] = (circle | circle).item()\n",
- "shape_sim_mat[1,1] = (square | square).item()\n",
- "shape_sim_mat[2,2] = (triangle | triangle).item()\n",
- "shape_sim_mat[3,3] = (shape | shape).item()\n",
+ "sim_mat = np.zeros((4,4))\n",
"\n",
- "shape_sim_mat[0,1] = shape_sim_mat[1,0] = (circle | square).item()\n",
- "shape_sim_mat[0,2] = shape_sim_mat[2,0] = (circle | triangle).item()\n",
- "shape_sim_mat[0,3] = shape_sim_mat[3,0] = (circle | shape).item()\n",
+ "sim_mat[0,0] = spa.dot(circle, circle)\n",
+ "sim_mat[1,1] = spa.dot(square, square)\n",
+ "sim_mat[2,2] = spa.dot(triangle, triangle)\n",
+ "sim_mat[3,3] = spa.dot(shape, shape)\n",
"\n",
- "shape_sim_mat[1,2] = shape_sim_mat[2,1] = (square | triangle).item()\n",
- "shape_sim_mat[1,3] = shape_sim_mat[3,1] = (square | shape).item()\n",
+ "sim_mat[0,1] = sim_mat[1,0] = spa.dot(circle, square)\n",
+ "sim_mat[0,2] = sim_mat[2,0] = spa.dot(circle, triangle)\n",
+ "sim_mat[0,3] = sim_mat[3,0] = spa.dot(circle, shape)\n",
"\n",
- "shape_sim_mat[2,3] = shape_sim_mat[3,2] = (triangle | shape).item()"
+ "sim_mat[1,2] = sim_mat[2,1] = spa.dot(square, triangle)\n",
+ "sim_mat[1,3] = sim_mat[3,1] = spa.dot(square, shape)\n",
+ "sim_mat[2,3] = sim_mat[3,2] = spa.dot(triangle, shape)"
]
},
{
@@ -815,7 +762,7 @@
},
"outputs": [],
"source": [
- "plot_similarity_matrix(shape_sim_mat, symbol_names + [\"shape\"], values = True)"
+ "plot_similarity_matrix(sim_mat, symbol_names + [\"shape\"], values = True)"
]
},
{
@@ -880,7 +827,7 @@
"\n",
"Estimated timing to here from start of tutorial: 20 minutes\n",
"\n",
- "In this section, we will talk about binding, an operation that takes two vectors and produces a new vector that is *not* similar to either of its constituent elements.\n",
+ "In this section we will talk about binding - an operation that takes two vectors and produces a new vector that is *not* similar to either of it's constituent elements.\n",
"\n",
"Binding and unbinding are implemented using circular convolution. Luckily, that is implemented for you inside the SSPSpace library. If you would like a refresher on convolution, this [Three Blue One Brown video](https://www.youtube.com/watch?v=KuXjwB4LzSA) is a good place to start."
]
@@ -973,10 +920,9 @@
"source": [
"set_seed(42)\n",
"\n",
- "new_symbol_names = ['circle','square','triangle', 'red', 'blue', 'green']\n",
- "new_discrete_space = sspspace.DiscreteSPSpace(new_symbol_names, ssp_dim=vector_length, optimize=False)\n",
- "\n",
- "objs = {n:new_discrete_space.encode(np.array([n])) for n in new_symbol_names}"
+ "symbol_names = ['CIRCLE','SQUARE','TRIANGLE', 'RED', 'BLUE', 'GREEN']\n",
+ "vocab = make_vocabulary(vector_length)\n",
+ "vocab.populate(';'.join(symbol_names))"
]
},
{
@@ -985,27 +931,12 @@
"execution": {}
},
"source": [
- "Now, we are going to take two of the objects to make new ones: a red circle, a blue triangle, and a green square.\n",
+ "Now we are going to take two of the objects to make new ones: a red circle, a blue triangle and a green square.\n",
"\n",
- "We will combine the two primitive objects using the binding operation, which for us is implemented using circular convolution, and we denote it by \n",
- "\n",
- "\\begin{align*}\n",
+ "We will combine the two primitive objects using the binding operation, which for us is implemented using circular convolution, and we denote it by\n",
+ "$$\n",
" a \\circledast b\n",
- "\\end{align*}\n",
- "\n",
- "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "# (BONUS) Tutorial 4: VSA Analogies\n",
+ "\n",
+ "**Week 2, Day 2: Neuro-Symbolic Methods**\n",
+ "\n",
+ "**By Neuromatch Academy**\n",
+ "\n",
+ "__Content creators:__ P. Michael Furlong, Chris Eliasmith\n",
+ "\n",
+ "__Content reviewers:__ Hlib Solodzhuk, Patrick Mineault, Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Alex Murphy\n",
+ "\n",
+ "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk, Alex Murphy\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "___\n",
+ "\n",
+ "\n",
+ "# Tutorial Objectives\n",
+ "\n",
+ "This tutorial will present you with a couple of toy examples using the basic operations of vector symbolic algebras. We will further show how these can generalize to new knowledge. If you are familiar with the basics of semantic algebra on word embeddings, you already understand the basics of what we'll be demonstrating in this tutorial. If not, don't worry, this tutorial is designed to be highly self-contained. If you're interested in learning more about word embedding algebra, then we encourage you to use your search engine of choice and learn more after completing the code exercises given below."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Tutorial slides\n",
+ "# @markdown These are the slides for the videos in all tutorials today\n",
+ "\n",
+ "from IPython.display import IFrame\n",
+ "link_id = \"jybuw\"\n",
+ "\n",
+ "print(f\"If you want to download the slides: 'https://osf.io/download/{link_id}'\")\n",
+ "\n",
+ "IFrame(src=f\"https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{link_id}/?direct%26mode=render\", width=854, height=480)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "---\n",
+ "# Setup (Colab Users: Please Read)\n",
+ "\n",
+ "Note that because this tutorial relies on some special Python packages, these packages have requirements for specific versions of common scientific libraries, such as `numpy`. If you're in Google Colab, then as of May 2025, this comes with a later version (2.0.2) pre-installed. We require an older version (we'll be installing `1.24.4`). This causes Colab to force a session restart and then re-running of the installation cells for the new version to take effect. When you run the cell below, you will be prompted to restart the session. This is *entirely expected* and you haven't done anything wrong. Simply click 'Restart' and then run the cells as normal. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Install dependencies and import feedback gadget\n",
+ "\n",
+ "!pip install numpy==1.24.4 --quiet\n",
+ "!pip install scikit-learn==1.6.1 --quiet\n",
+ "!pip install scipy==1.15.3 --quiet\n",
+ "!pip install git+https://github.com/neuromatch/sspspace@neuromatch --no-deps --quiet\n",
+ "!pip install nengo==4.0.0 --quiet\n",
+ "!pip install nengo_spa==2.0.0 --quiet\n",
+ "!pip install --quiet matplotlib ipywidgets vibecheck\n",
+ "!pip install --quiet numpy matplotlib ipywidgets scipy scikit-learn vibecheck\n",
+ "\n",
+ "from vibecheck import DatatopsContentReviewContainer\n",
+ "def content_review(notebook_section: str):\n",
+ " return DatatopsContentReviewContainer(\n",
+ " \"\", # No text prompt\n",
+ " notebook_section,\n",
+ " {\n",
+ " \"url\": \"https://pmyvdlilci.execute-api.us-east-1.amazonaws.com/klab\",\n",
+ " \"name\": \"neuromatch_neuroai\",\n",
+ " \"user_key\": \"wb2cxze8\",\n",
+ " },\n",
+ " ).render()\n",
+ "\n",
+ "\n",
+ "feedback_prefix = \"W2D2_T4\""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Notice that exactly the `neuromatch` branch of `sspspace` should be installed! Otherwise, some of the functionality (like `optimize` parameter in the `DiscreteSPSpace` initialization) won't work."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Imports\n",
+ "\n",
+ "#working with data\n",
+ "import numpy as np\n",
+ "\n",
+ "#plotting\n",
+ "import matplotlib.pyplot as plt\n",
+ "import logging\n",
+ "\n",
+ "#interactive display\n",
+ "# import ipywidgets as widgets\n",
+ "\n",
+ "#modeling\n",
+ "import sspspace\n",
+ "import nengo_spa as spa\n",
+ "from scipy.special import softmax\n",
+ "from sklearn.metrics import log_loss\n",
+ "from sklearn.neural_network import MLPRegressor\n",
+ "from nengo_spa.algebras.hrr_algebra import HrrProperties, HrrAlgebra\n",
+ "from nengo_spa.vector_generation import VectorsWithProperties\n",
+ "\n",
+ "def make_vocabulary(vector_length):\n",
+ " vec_generator = VectorsWithProperties(vector_length, algebra=HrrAlgebra(), properties = [HrrProperties.UNITARY, HrrProperties.POSITIVE])\n",
+ " vocab = spa.Vocabulary(vector_length, pointer_gen=vec_generator)\n",
+ " return vocab"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Figure settings\n",
+ "\n",
+ "logging.getLogger('matplotlib.font_manager').disabled = True\n",
+ "\n",
+ "%matplotlib inline\n",
+ "%config InlineBackend.figure_format = 'retina' # perfrom high definition rendering for images and plots\n",
+ "plt.style.use(\"https://raw.githubusercontent.com/NeuromatchAcademy/course-content/main/nma.mplstyle\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Plotting functions\n",
+ "\n",
+ "def plot_similarity_matrix(sim_mat, labels, values = False):\n",
+ " \"\"\"\n",
+ " Plot the similarity matrix between vectors.\n",
+ "\n",
+ " Inputs:\n",
+ " - sim_mat (numpy.ndarray): similarity matrix between vectors.\n",
+ " - labels (list of str): list of strings which represent concepts.\n",
+ " - values (bool): True if we would like to plot values of similarity too.\n",
+ " \"\"\"\n",
+ " with plt.xkcd():\n",
+ " plt.imshow(sim_mat, cmap='Greys')\n",
+ " plt.colorbar()\n",
+ " plt.xticks(np.arange(len(labels)), labels, rotation=45, ha=\"right\", rotation_mode=\"anchor\")\n",
+ " plt.yticks(np.arange(len(labels)), labels)\n",
+ " if values:\n",
+ " for x in range(sim_mat.shape[1]):\n",
+ " for y in range(sim_mat.shape[0]):\n",
+ " plt.text(x, y, f\"{sim_mat[y, x]:.2f}\", fontsize = 8, ha=\"center\", va=\"center\", color=\"green\")\n",
+ " plt.title('Similarity between vector-symbols')\n",
+ " plt.xlabel('Symbols')\n",
+ " plt.ylabel('Symbols')\n",
+ " plt.show()\n",
+ "\n",
+ "def plot_training_and_choice(losses, sims, ant_names, cons_names, action_names):\n",
+ " \"\"\"\n",
+ " Plot loss progression over training as well as predicted similarities for given rules / correct solutions.\n",
+ "\n",
+ " Inputs:\n",
+ " - losses (list): list of loss values.\n",
+ " - sims (list): list of similartiy matrices.\n",
+ " - ant_names (list): list of antecedance names.\n",
+ " - cons_names (list): list of consequent names.\n",
+ " - action_names (list): full list of concepts.\n",
+ " \"\"\"\n",
+ " with plt.xkcd():\n",
+ " plt.subplot(1, len(ant_names) + 1, 1)\n",
+ " plt.plot(losses)\n",
+ " plt.xlabel('Training number')\n",
+ " plt.ylabel('Loss')\n",
+ " plt.title('Training Error')\n",
+ " index = 1\n",
+ " for ant_name, cons_name, sim in zip(ant_names, cons_names, sims):\n",
+ " index += 1\n",
+ " plt.subplot(1, len(ant_names) + 1, index)\n",
+ " plt.bar(range(len(action_names)), sim.flatten())\n",
+ " plt.gca().set_xticks(range(len(action_names)))\n",
+ " plt.gca().set_xticklabels(action_names, rotation=90)\n",
+ " plt.title(f'{ant_name}, not*{cons_name}')\n",
+ "\n",
+ "def plot_choice(sims, ant_names, cons_names, action_names):\n",
+ " \"\"\"\n",
+ " Plot predicted similarities for given rules / correct solutions.\n",
+ " \"\"\"\n",
+ " with plt.xkcd():\n",
+ " index = 0\n",
+ " for ant_name, cons_name, sim in zip(ant_names, cons_names, sims):\n",
+ " index += 1\n",
+ " plt.subplot(1, len(ant_names) + 1, index)\n",
+ " plt.bar(range(len(action_names)), sim.flatten())\n",
+ " plt.gca().set_xticks(range(len(action_names)))\n",
+ " plt.gca().set_xticklabels(action_names, rotation=90)\n",
+ " plt.ylabel(\"Similarity\")\n",
+ " plt.title(f'{ant_name}, not*{cons_name}')"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Set random seed\n",
+ "\n",
+ "import random\n",
+ "import numpy as np\n",
+ "\n",
+ "def set_seed(seed=None):\n",
+ " if seed is None:\n",
+ " seed = np.random.choice(2 ** 32)\n",
+ " random.seed(seed)\n",
+ " np.random.seed(seed)\n",
+ "\n",
+ "set_seed(seed = 42)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Helper functions\n",
+ "\n",
+ "set_seed(42)\n",
+ "\n",
+ "symbol_names = ['monarch','heir','male','female']\n",
+ "discrete_space = sspspace.DiscreteSPSpace(symbol_names, ssp_dim=1024, optimize=False)\n",
+ "\n",
+ "objs = {n:discrete_space.encode(n) for n in symbol_names}\n",
+ "\n",
+ "objs['king'] = objs['monarch'] * objs['male']\n",
+ "objs['queen'] = objs['monarch'] * objs['female']\n",
+ "objs['prince'] = objs['heir'] * objs['male']\n",
+ "objs['princess'] = objs['heir'] * objs['female']\n",
+ "\n",
+ "bundle_objs = {n:discrete_space.encode(n) for n in symbol_names}\n",
+ "\n",
+ "bundle_objs['king'] = (bundle_objs['monarch'] + bundle_objs['male']).normalize()\n",
+ "bundle_objs['queen'] = (bundle_objs['monarch'] + bundle_objs['female']).normalize()\n",
+ "bundle_objs['prince'] = (bundle_objs['heir'] + bundle_objs['male']).normalize()\n",
+ "bundle_objs['princess'] = (bundle_objs['heir'] + bundle_objs['female']).normalize()\n",
+ "\n",
+ "bundle_objs['princess_query'] = (bundle_objs['prince'] - bundle_objs['king']) + bundle_objs['queen']\n",
+ "\n",
+ "new_symbol_names = ['dollar', 'peso', 'ottawa', 'mexico-city', 'currency', 'capital']\n",
+ "new_discrete_space = sspspace.DiscreteSPSpace(new_symbol_names, ssp_dim=1024, optimize=False)\n",
+ "\n",
+ "new_objs = {n:new_discrete_space.encode(n) for n in new_symbol_names}\n",
+ "\n",
+ "cleanup = sspspace.Cleanup(new_objs)\n",
+ "\n",
+ "new_objs['canada'] = ((new_objs['currency'] * new_objs['dollar']) + (new_objs['capital'] * new_objs['ottawa'])).normalize()\n",
+ "new_objs['mexico'] = ((new_objs['currency'] * new_objs['peso']) + (new_objs['capital'] * new_objs['mexico-city'])).normalize()\n",
+ "\n",
+ "card_states = ['red','blue','odd','even','not','green','prime','implies','ant','relation','cons']\n",
+ "encoder = sspspace.DiscreteSPSpace(card_states, ssp_dim=1024, optimize=False)\n",
+ "vocab = {c:encoder.encode(c) for c in card_states}\n",
+ "\n",
+ "for a in ['red','blue','odd','even','green','prime']:\n",
+ " vocab[f'not*{a}'] = vocab['not'] * vocab[a]\n",
+ "\n",
+ "action_names = ['red','blue','odd','even','green','prime','not*red','not*blue','not*odd','not*even','not*green','not*prime']\n",
+ "action_space = np.array([vocab[x] for x in action_names]).squeeze()\n",
+ "\n",
+ "rules = [\n",
+ " (vocab['ant'] * vocab['blue'] + vocab['relation'] * vocab['implies'] + vocab['cons'] * vocab['even']).normalize(),\n",
+ " (vocab['ant'] * vocab['odd'] + vocab['relation'] * vocab['implies'] + vocab['cons'] * vocab['green']).normalize(),\n",
+ "]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "---\n",
+ "\n",
+ "# Section 1: Analogies. Part 1\n",
+ "\n",
+ "In this section we will construct a simple analogy using Vector Symbolic Algebras. The question we are going to try and solve is \"King is to the queen as the prince is to X.\""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Video 1: Analogy 1\n",
+ "\n",
+ "from ipywidgets import widgets\n",
+ "from IPython.display import YouTubeVideo\n",
+ "from IPython.display import IFrame\n",
+ "from IPython.display import display\n",
+ "\n",
+ "class PlayVideo(IFrame):\n",
+ " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
+ " self.id = id\n",
+ " if source == 'Bilibili':\n",
+ " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
+ " elif source == 'Osf':\n",
+ " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
+ " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
+ "\n",
+ "def display_videos(video_ids, W=400, H=300, fs=1):\n",
+ " tab_contents = []\n",
+ " for i, video_id in enumerate(video_ids):\n",
+ " out = widgets.Output()\n",
+ " with out:\n",
+ " if video_ids[i][0] == 'Youtube':\n",
+ " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
+ " height=H, fs=fs, rel=0)\n",
+ " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
+ " else:\n",
+ " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
+ " height=H, fs=fs, autoplay=False)\n",
+ " if video_ids[i][0] == 'Bilibili':\n",
+ " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
+ " elif video_ids[i][0] == 'Osf':\n",
+ " print(f'Video available at https://osf.io/{video.id}')\n",
+ " display(video)\n",
+ " tab_contents.append(out)\n",
+ " return tab_contents\n",
+ "\n",
+ "video_ids = [('Youtube', '2tR4fHvL1Jk'), ('Bilibili', 'BV1fS411P7Ez')]\n",
+ "tab_contents = display_videos(video_ids, W=854, H=480)\n",
+ "tabs = widgets.Tab()\n",
+ "tabs.children = tab_contents\n",
+ "for i in range(len(tab_contents)):\n",
+ " tabs.set_title(i, video_ids[i][0])\n",
+ "display(tabs)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_analogy_part_one\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "## Coding Exercise 1: Royal Relationships\n",
+ "\n",
+ "We're going to start by considering our vocabulary. We will use the basic discrete concepts of monarch, heir, male, and female."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Let's create the objects we know about by combinatorially expanding the space: \n",
+ "\n",
+ "1. King is a male monarch\n",
+ "2. Queen is a female monarch\n",
+ "3. Prince is a male heir\n",
+ "4. Princess is a female heir\n",
+ "\n",
+ "Complete the missing parts of the code to obtain correct representations of new concepts."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "set_seed(42)\n",
+ "\n",
+ "vector_length = 1024\n",
+ "symbol_names = ['MONARCH', 'HEIR', 'MALE', 'FEMALE']\n",
+ "vocab = make_vocabulary(vector_length)\n",
+ "vocab.populate(';'.join(symbol_names))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete correct relations for creating new concepts.\")\n",
+ "\n",
+ "###################################################################\n",
+ "vocab.add('KING', vocab['MONARCH'] * vocab['MALE'])\n",
+ "vocab.add('QUEEN', vocab['MONARCH'] * ...)\n",
+ "vocab.add('PRINCE', vocab['HEIR'] * vocab['MALE'])\n",
+ "vocab.add('PRINCESS', ... * vocab['FEMALE'])"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "#to_remove solution\n",
+ "\n",
+ "vocab.add('KING', vocab['MONARCH'] * vocab['MALE'])\n",
+ "vocab.add('QUEEN', vocab['MONARCH'] * vocab['FEMALE'])\n",
+ "vocab.add('PRINCE', vocab['HEIR'] * vocab['MALE'])\n",
+ "vocab.add('PRINCESS', vocab['HEIR'] * vocab['FEMALE'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Now, we can take an explicit approach. We know that the conversion from king to queen is to unbind male and bind female, so let's apply that to our prince object and see what we uncover.\n",
+ "\n",
+ "At first, in the cell below, let's recover `queen` from `king` by constructing a new `query` concept, which represents the unbinding of `male` and the binding of `female.`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete correct relation for creating `query` object to compare with `queen`.\")\n",
+ "###################################################################\n",
+ "\n",
+ "vocab.add('QUERY_QUEEN', (vocab[...] * ~vocab[...]) * vocab[...])"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "#to_remove solution\n",
+ "\n",
+ "vocab.add('QUERY_QUEEN', (vocab['KING'] * ~vocab['MALE']) * vocab['FEMALE'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Then, let's see if this new query object bears any similarity to anything in our vocabulary."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "object_names = list(vocab.keys())\n",
+ "sims = np.zeros((len(object_names), len(object_names)))\n",
+ "\n",
+ "for name_idx, name in enumerate(object_names):\n",
+ " for other_idx in range(name_idx, len(object_names)):\n",
+ " sims[name_idx, other_idx] = sims[other_idx, name_idx] = spa.dot(vocab[name], vocab[object_names[other_idx]])\n",
+ "\n",
+ "plot_similarity_matrix(sims, object_names, values = True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "The above similarity plot shows that applying that operation successfully converts king to queen. Let's apply it to 'prince' and see what happens. Now, `query` should represent the `princess` concept."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "vocab.add('QUERY_PRINCESS', (vocab['PRINCE'] * ~vocab['MALE']) * vocab['FEMALE'])\n",
+ "\n",
+ "sims = np.zeros((len(object_names), len(object_names)))\n",
+ "\n",
+ "for name_idx, name in enumerate(object_names):\n",
+ " for other_idx in range(name_idx, len(object_names)):\n",
+ " sims[name_idx, other_idx] = sims[other_idx, name_idx] = spa.dot(vocab[name], vocab[object_names[other_idx]])\n",
+ "\n",
+ "plot_similarity_matrix(sims, object_names, values = True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Here, we have successfully recovered the princess, completing the analogy.\n",
+ "\n",
+ "This approach, however, requires explicit knowledge of the construction of the objects. Let's see if we can just work with the concepts of 'king,' 'queen,' and 'prince' directly.\n",
+ "\n",
+ "In the cell below, construct the `princess` concept using only `king,` `queen`, and `prince.`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete correct relation for creating `query` object to compare with `princess`.\")\n",
+ "###################################################################\n",
+ "\n",
+ "vocab.add('QUERY_PRINCESS_2', (vocab[...] * ~vocab[...]) * vocab[...])"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "#to_remove solution\n",
+ "\n",
+ "# objs['query'] = (objs['prince'] * ~objs['king']) * objs['queen']\n",
+ "vocab.add('QUERY_PRINCESS_2', (vocab['PRINCE'] * ~vocab['KING']) * vocab['QUEEN'])"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "object_names = list(vocab.keys())\n",
+ "sims = np.zeros((len(object_names), len(object_names)))\n",
+ "\n",
+ "for name_idx, name in enumerate(object_names):\n",
+ " for other_idx in range(name_idx, len(object_names)):\n",
+ " sims[name_idx, other_idx] = sims[other_idx, name_idx] = spa.dot(vocab[name], vocab[object_names[other_idx]])\n",
+ "\n",
+ "plot_similarity_matrix(sims, object_names, values = True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Again, we see that we have recovered the princess by using our analogy.\n",
+ "\n",
+ "That said, the above depends on knowing that the representations are constructed using binding. Can we do something similar through the bundling operation? Let's try that out.\n",
+ "\n",
+ "Reassing concept definitions using bundling operation."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "vocab = vocab.create_subset(['MONARCH','HEIR','FEMALE','MALE'])\n",
+ "vocab.add('KING', (vocab['MONARCH'] + vocab['MALE']).normalized())\n",
+ "vocab.add('QUEEN', (vocab['MONARCH'] + vocab['FEMALE']).normalized())\n",
+ "vocab.add('PRINCE', (vocab['HEIR'] + vocab['MALE']).normalized())\n",
+ "vocab.add('PRINCESS', (vocab['HEIR'] + vocab['FEMALE']).normalized())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "But now that we are using an additive model, we need to take a different approach. Instead of unbinding the king and binding the queen, we subtract the king and add the queen to find the princess from the prince.\n",
+ "\n",
+ "Complete the code to reflect the updated mechanism."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete correct relation for creating `query` object to compare with `princess`.\")\n",
+ "###################################################################\n",
+ "\n",
+ "vocab.add('QUERY_PRINCESS', ((vocab[...] - vocab[...]) + vocab[...]).normalized())"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "#to_remove solution\n",
+ "\n",
+ "vocab.add('QUERY_PRINCESS', ((vocab['PRINCE'] - vocab['KING']) + vocab['QUEEN']).normalized())"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "object_names = list(vocab.keys())\n",
+ "sims = np.zeros((len(object_names), len(object_names)))\n",
+ "\n",
+ "for name_idx, name in enumerate(object_names):\n",
+ " for other_idx in range(name_idx, len(object_names)):\n",
+ " sims[name_idx, other_idx] = sims[other_idx, name_idx] = spa.dot(vocab[name], vocab[object_names[other_idx]])\n",
+ "\n",
+ "plot_similarity_matrix(sims, object_names, values = True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "This is a messier similarity plot due to the fact that the bundled representations interact with all their constituent parts in the vocabulary. That said, we see that 'princess' is still most similar to the query vector. \n",
+ "\n",
+ "This approach is more like what we would expect from a `word2vec` embedding."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_royal_relationships\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "---\n",
+ "\n",
+ "# Section 2: Analogies (Part 2)\n",
+ "\n",
+ "Estimated timing to here from start of tutorial: 15 minutes\n",
+ "\n",
+ "In this section, we will construct a database of data structures that describe different countries. Materials are adopted from [Kanerva (2010)](https://cdn.aaai.org/ocs/2243/2243-9566-1-PB.pdf)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Video 2: Analogy 2\n",
+ "\n",
+ "from ipywidgets import widgets\n",
+ "from IPython.display import YouTubeVideo\n",
+ "from IPython.display import IFrame\n",
+ "from IPython.display import display\n",
+ "\n",
+ "class PlayVideo(IFrame):\n",
+ " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
+ " self.id = id\n",
+ " if source == 'Bilibili':\n",
+ " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
+ " elif source == 'Osf':\n",
+ " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
+ " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
+ "\n",
+ "def display_videos(video_ids, W=400, H=300, fs=1):\n",
+ " tab_contents = []\n",
+ " for i, video_id in enumerate(video_ids):\n",
+ " out = widgets.Output()\n",
+ " with out:\n",
+ " if video_ids[i][0] == 'Youtube':\n",
+ " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
+ " height=H, fs=fs, rel=0)\n",
+ " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
+ " else:\n",
+ " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
+ " height=H, fs=fs, autoplay=False)\n",
+ " if video_ids[i][0] == 'Bilibili':\n",
+ " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
+ " elif video_ids[i][0] == 'Osf':\n",
+ " print(f'Video available at https://osf.io/{video.id}')\n",
+ " display(video)\n",
+ " tab_contents.append(out)\n",
+ " return tab_contents\n",
+ "\n",
+ "video_ids = [('Youtube', 'OB3hzhM7Ois'), ('Bilibili', 'BV1TZ421g7G5')]\n",
+ "tab_contents = display_videos(video_ids, W=854, H=480)\n",
+ "tabs = widgets.Tab()\n",
+ "tabs.children = tab_contents\n",
+ "for i in range(len(tab_contents)):\n",
+ " tabs.set_title(i, video_ids[i][0])\n",
+ "display(tabs)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_analogy_part_two\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "## Coding Exercise 2: Dollar of Mexico\n",
+ "\n",
+ "This is going to be a little more involved, because to construct the data structure we are going to need vectors that don't just represent values that we are reasoning about, but also vectors that represent different roles data can play. This is sometimes called a slot-filler representation, or a key-value representation.\n",
+ "\n",
+ "At first, let us define concepts and cleanup object."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "set_seed(42)\n",
+ "\n",
+ "symbol_names = ['DOLLAR','PESO', 'OTTAWA','MEXICO_CITY','CURRENCY','CAPITAL']\n",
+ "vocab = make_vocabulary(vector_length)\n",
+ "vocab.populate(';'.join(symbol_names))\n",
+ "\n",
+ "cleanup = sspspace.Cleanup(vocab)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Now, we will define `Canada` and `Mexico` concepts by integrating the available information together. You will be provided with `Canada` object and your task is to complete for `Mexico` one."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete `mexico` concept.\")\n",
+ "###################################################################\n",
+ "\n",
+ "vocab.add('CANADA', (vocab['CURRENCY'] * vocab['DOLLAR'] + vocab['CAPITAL'] * vocab['OTTAWA']).normalized())\n",
+ "vocab.add('MEXICO', (vocab['CURRENCY'] * ... + vocab['CAPITAL'] * ...).normalized())"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "#to_remove solution\n",
+ "\n",
+ "vocab.add('CANADA', (vocab['CURRENCY'] * vocab['DOLLAR'] + vocab['CAPITAL'] * vocab['OTTAWA']).normalized())\n",
+ "vocab.add('MEXICO', (vocab['CURRENCY'] * vocab['PESO'] + vocab['CAPITAL'] * vocab['MEXICO_CITY']).normalized())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "We would like to find out Mexico's currency. Complete the code for constructing a `query` which will help us do that. Note that we are using a cleanup operation."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete `query` concept which will be similar to currency in Mexico.\")\n",
+ "###################################################################\n",
+ "\n",
+ "vocab.add('QUERY_MX_CURRENCY', vocab['MEXICO'] * ~(... * ~...))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "#to_remove solution\n",
+ "\n",
+ "vocab.add('QUERY_MX_CURRENCY', vocab['MEXICO'] * ~(vocab['CANADA'] * ~vocab['DOLLAR']))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "object_names = list(vocab.keys())\n",
+ "sims = np.zeros((len(object_names), len(object_names)))\n",
+ "\n",
+ "for name_idx, name in enumerate(object_names):\n",
+ " for other_idx in range(name_idx, len(object_names)):\n",
+ " sims[name_idx, other_idx] = sims[other_idx, name_idx] = spa.dot(vocab[name], vocab[object_names[other_idx]])\n",
+ "\n",
+ "plot_similarity_matrix(sims, object_names)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "After cleanup, the query vector is the most similar with the 'peso' object in the vocabularly, correctly answering the question. \n",
+ "\n",
+ "Note, however, that the similarity is not perfectly equal to 1. This is due to the scale factors applied to the composite vectors 'canada' and 'mexico', to ensure they remain unit vectors, and due to cross talk. Crosstalk is a symptom of the fact that we are binding and unbinding bundles of vector symbols to produce the resultant query vector. The constituent vectors are not perfectly orthogonal (i.e., having a dot product of zero) and as such the terms in the bundle interact when we measure similarity between them."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_dollar_of_mexico\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "---\n",
+ "# The Big Picture\n",
+ "\n",
+ "*Estimated timing of tutorial: 45 minutes*\n",
+ "\n",
+ "In this tutorial, we observed three scenarios where we used the basic operations to solve different analogies and engage in structured learning. Those of you familiar with word embeddings from Natural Language Processing (NLP) might already be familiar with the idea of interpretable semantics on vector representations. This bonus tutorial helps to show how this can be accomplished in a different way. The ability to recreate different phenomena in different paradigms often gives us a great way to compare and contrast model mechanisms and we hope that this bonus tutorial has given you a curiosity to dive a bit deeper and start experimenting further with what you can accomplish using these great open-source tools!"
+ ]
+ }
+ ],
+ "metadata": {
+ "colab": {
+ "collapsed_sections": [],
+ "include_colab_link": true,
+ "name": "W2D2_Tutorial4",
+ "provenance": [],
+ "toc_visible": true
+ },
+ "kernel": {
+ "display_name": "Python 3",
+ "language": "python",
+ "name": "python3"
+ },
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.9.22"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 4
+}
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/W2D2_Tutorial5.ipynb b/tutorials/W2D2_NeuroSymbolicMethods/W2D2_Tutorial5.ipynb
new file mode 100644
index 000000000..7f1a877e7
--- /dev/null
+++ b/tutorials/W2D2_NeuroSymbolicMethods/W2D2_Tutorial5.ipynb
@@ -0,0 +1,1613 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {},
+ "id": "view-in-github"
+ },
+ "source": [
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "# (Bonus) Tutorial 5: Representations in continuous space\n",
+ "\n",
+ "**Week 2, Day 2: Neuro-Symbolic Methods**\n",
+ "\n",
+ "**By Neuromatch Academy**\n",
+ "\n",
+ "__Content creators:__ P. Michael Furlong, Chris Eliasmith\n",
+ "\n",
+ "__Content reviewers:__ Hlib Solodzhuk, Patrick Mineault, Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Alex Murphy\n",
+ "\n",
+ "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk, Alex Murphy"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "___\n",
+ "\n",
+ "\n",
+ "# Tutorial Objectives\n",
+ "\n",
+ "*Estimated timing of tutorial: 40 minutes*\n",
+ "\n",
+ "In this tutorial, you will observe how the VSA methods can be applied in structures and environments to allow for efficient generalization."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Tutorial slides\n",
+ "# @markdown These are the slides for the videos in all tutorials today\n",
+ "\n",
+ "from IPython.display import IFrame\n",
+ "link_id = \"jybuw\"\n",
+ "\n",
+ "print(f\"If you want to download the slides: 'https://osf.io/download/{link_id}'\")\n",
+ "\n",
+ "IFrame(src=f\"https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{link_id}/?direct%26mode=render\", width=854, height=480)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "---\n",
+ "# Setup (Colab Users: Please Read)\n",
+ "\n",
+ "Note that because this tutorial relies on some special Python packages, these packages have requirements for specific versions of common scientific libraries, such as `numpy`. If you're in Google Colab, then as of May 2025, this comes with a later version (2.0.2) pre-installed. We require an older version (we'll be installing `1.24.4`). This causes Colab to force a session restart and then re-running of the installation cells for the new version to take effect. When you run the cell below, you will be prompted to restart the session. This is *entirely expected* and you haven't done anything wrong. Simply click 'Restart' and then run the cells as normal. \n",
+ "\n",
+ "An additional error might sometimes arise where an exception is raised connected to a missing element of NumPy. If this occurs, please restart the session and re-run the cells as normal and this error will go away. Updated versions of the affected libraries are expected out soon, but sadly not in time for the preparation of this material. We thank you for your understanding.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Install dependencies\n",
+ "\n",
+ "!pip install numpy==1.24.4 --quiet\n",
+ "!pip install scikit-learn==1.6.1 --quiet\n",
+ "!pip install scipy==1.15.3 --quiet\n",
+ "!pip install git+https://github.com/neuromatch/sspspace@neuromatch --no-deps --quiet\n",
+ "!pip install nengo==4.0.0 --quiet\n",
+ "!pip install nengo_spa==2.0.0 --quiet\n",
+ "!pip install --quiet matplotlib ipywidgets tqdm vibecheck"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Install and import feedback gadget\n",
+ "\n",
+ "from vibecheck import DatatopsContentReviewContainer\n",
+ "def content_review(notebook_section: str):\n",
+ " return DatatopsContentReviewContainer(\n",
+ " \"\", # No text prompt\n",
+ " notebook_section,\n",
+ " {\n",
+ " \"url\": \"https://pmyvdlilci.execute-api.us-east-1.amazonaws.com/klab\",\n",
+ " \"name\": \"neuromatch_neuroai\",\n",
+ " \"user_key\": \"wb2cxze8\",\n",
+ " },\n",
+ " ).render()\n",
+ "\n",
+ "\n",
+ "feedback_prefix = \"W2D2_T5\""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Imports\n",
+ "\n",
+ "#working with data\n",
+ "import numpy as np\n",
+ "import random\n",
+ "\n",
+ "#plotting\n",
+ "import matplotlib.pyplot as plt\n",
+ "import logging\n",
+ "\n",
+ "#interactive display\n",
+ "import ipywidgets as widgets\n",
+ "\n",
+ "#modeling\n",
+ "import sspspace\n",
+ "from sklearn.linear_model import LinearRegression\n",
+ "from sklearn.model_selection import train_test_split\n",
+ "\n",
+ "from tqdm.notebook import tqdm as tqdm"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Figure settings\n",
+ "\n",
+ "logging.getLogger('matplotlib.font_manager').disabled = True\n",
+ "\n",
+ "%matplotlib inline\n",
+ "%config InlineBackend.figure_format = 'retina' # perfrom high definition rendering for images and plots\n",
+ "plt.style.use(\"https://raw.githubusercontent.com/NeuromatchAcademy/course-content/main/nma.mplstyle\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Plotting functions\n",
+ "\n",
+ "def plot_3d_function(X, Y, zs, titles):\n",
+ " \"\"\"Plot 3D function.\n",
+ "\n",
+ " Inputs:\n",
+ " - X (list): list of np.ndarray of x-values.\n",
+ " - Y (list): list of np.ndarray of y-values.\n",
+ " - zs (list): list of np.ndarray of z-values.\n",
+ " - titles (list): list of titles of the plot.\n",
+ " \"\"\"\n",
+ " with plt.xkcd():\n",
+ " fig = plt.figure(figsize=(8, 8))\n",
+ " for index, (x, y, z) in enumerate(zip(X, Y, zs)):\n",
+ " fig.add_subplot(1, len(X), index + 1, projection='3d')\n",
+ " plt.gca().plot_surface(x,y,z.reshape(x.shape),cmap='plasma', antialiased=False, linewidth=0)\n",
+ " plt.xlabel(r'$x_{1}$')\n",
+ " plt.ylabel(r'$x_{2}$')\n",
+ " plt.gca().set_zlabel(r'$f(\\mathbf{x})$')\n",
+ " plt.title(titles[index])\n",
+ " plt.show()\n",
+ "\n",
+ "def plot_performance(bound_performance, bundle_performance, training_samples, title):\n",
+ " \"\"\"Plot RMSE values for two different representations of the input data.\n",
+ "\n",
+ " Inputs:\n",
+ " - bound_performance (list): list of RMSE for bound representation.\n",
+ " - bundle_performance (list): list of RMSE for bundle representation.\n",
+ " - training_samples (list): x-axis.\n",
+ " - title (str): title of the plot.\n",
+ " \"\"\"\n",
+ " with plt.xkcd():\n",
+ " plt.plot(training_samples, bound_performance, label='Bound Representation')\n",
+ " plt.plot(training_samples, bundle_performance, label='Bundling Representation', ls='--')\n",
+ " plt.legend()\n",
+ " plt.title(title)\n",
+ " plt.ylabel('RMSE (a.u.)')\n",
+ " plt.xlabel('# Training samples')\n",
+ "\n",
+ "def plot_2d_similarity(sims, obj_names, size, title_argmax = False):\n",
+ " \"\"\"\n",
+ " Plot 2D similarity between query points (grid) and the ones associated with the objects.\n",
+ "\n",
+ " Inputs:\n",
+ " - sims (list): list of similarity values for each of the objects.\n",
+ " - obj_names (list): list of object names.\n",
+ " - size (tuple): to reshape the similarities.\n",
+ " - title_argmax (bool, default = False): looks for the point coordinates as arg max from all similarity value.\n",
+ " \"\"\"\n",
+ " ticks = [0, 24, 49, 74, 99]\n",
+ " ticklabels = [-5, -2, 0, 2, 5]\n",
+ " with plt.xkcd():\n",
+ " for obj_idx, obj in enumerate(obj_names):\n",
+ " plt.subplot(1, len(obj_names), 1 + obj_idx)\n",
+ " plt.imshow(np.array(sims[obj_idx].reshape(size)), origin='lower', vmin=-1, vmax=1)\n",
+ " plt.gca().set_xticks(ticks)\n",
+ " plt.gca().set_xticklabels(ticklabels)\n",
+ " if obj_idx == 0:\n",
+ " plt.gca().set_yticks(ticks)\n",
+ " plt.gca().set_yticklabels(ticklabels)\n",
+ " else:\n",
+ " plt.gca().set_yticks([])\n",
+ " if not title_argmax:\n",
+ " plt.title(f'{obj}, {positions[obj_idx]}')\n",
+ " else:\n",
+ " plt.title(f'{obj}, {query_xs[sims[obj_idx].argmax()]}')\n",
+ "\n",
+ "def plot_unbinding_objects_map(sims, positions, query_xs, size):\n",
+ " \"\"\"\n",
+ " Plot 2D similarity between query points (grid) and the unbinded from the objects map.\n",
+ "\n",
+ " Inputs:\n",
+ " - sims (np.ndarray): similarity values for each of the query points with the map.\n",
+ " - positions (np.ndarray): positions of the objects.\n",
+ " - query_xs (np.ndarray): grid points.\n",
+ " - size (tuple): to reshape the similarities.\n",
+ "\n",
+ " \"\"\"\n",
+ " ticks = [0,24,49,74,99]\n",
+ " ticklabels = [-5,-2,0,2,5]\n",
+ " with plt.xkcd():\n",
+ " plt.imshow(sims.reshape(size), origin='lower')\n",
+ "\n",
+ " for idx, marker in enumerate(['o','s','^']):\n",
+ " plt.scatter(*get_coordinate(positions[idx,:], query_xs, size), marker=marker,s=100)\n",
+ "\n",
+ " plt.gca().set_xticks(ticks)\n",
+ " plt.gca().set_xticklabels(ticklabels)\n",
+ " plt.gca().set_yticks(ticks)\n",
+ " plt.gca().set_yticklabels(ticklabels)\n",
+ " plt.title(f'All Object Locations')\n",
+ " plt.show()\n",
+ "\n",
+ "def plot_unbinding_positions_map(sims, positions, obj_names):\n",
+ " \"\"\"\n",
+ " Plot 2D similarity between query points (grid) and the unbinded from the positions map.\n",
+ "\n",
+ " Inputs:\n",
+ " - sims (np.ndarray): similarity values for each of the query points with the map.\n",
+ " - positions (np.ndarray): test positions to query.\n",
+ " - obj_names (list): names of the objects for labels.\n",
+ " - size (tuple): to reshape the similarities.\n",
+ " \"\"\"\n",
+ " with plt.xkcd():\n",
+ " plt.figure(figsize=(8, 4))\n",
+ " for pos_idx, pos in enumerate(positions):\n",
+ " plt.subplot(1,len(test_positions), 1+pos_idx)\n",
+ " plt.bar([1,2,3], sims[pos_idx])\n",
+ " plt.ylim([-0.3, 1.05])\n",
+ " plt.gca().set_xticks([1,2,3])\n",
+ " plt.gca().set_xticklabels(obj_names, rotation=90)\n",
+ " if pos_idx != 0:\n",
+ " plt.gca().set_yticks([])\n",
+ " plt.title(f'Symbols at\\n{pos}')\n",
+ " plt.show()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Set random seed\n",
+ "\n",
+ "def set_seed(seed=None):\n",
+ " if seed is None:\n",
+ " seed = np.random.choice(2 ** 32)\n",
+ " random.seed(seed)\n",
+ " np.random.seed(seed)\n",
+ "\n",
+ "set_seed(seed = 42)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Helper functions\n",
+ "\n",
+ "def get_model(xs, ys, train_size):\n",
+ " \"\"\"Fit linear regression to the given data.\n",
+ "\n",
+ " Inputs:\n",
+ " - xs (np.ndarray): input data.\n",
+ " - ys (np.ndarray): output data.\n",
+ " - train_size (float): fraction of data to use for train.\n",
+ " \"\"\"\n",
+ " X_train, _, y_train, _ = train_test_split(xs, ys, random_state=1, train_size=train_size)\n",
+ " return LinearRegression().fit(X_train, y_train)\n",
+ "\n",
+ "def get_coordinate(x, positions, target_shape):\n",
+ " \"\"\"Return the closest column and row coordinates for the given position.\n",
+ "\n",
+ " Inputs:\n",
+ " - x (np.ndarray): query position.\n",
+ " - positions (np.ndarray): all positions.\n",
+ " - target_shape (tuple): shape of the grid.\n",
+ "\n",
+ " Outputs:\n",
+ " - coordinates (tuple): column and row positions.\n",
+ " \"\"\"\n",
+ " idx = np.argmin(np.linalg.norm(x - positions, axis=1))\n",
+ " c = idx % target_shape[1]\n",
+ " r = idx // target_shape[1]\n",
+ " return (c,r)\n",
+ "\n",
+ "def rastrigin_solution(x):\n",
+ " \"\"\"Compute Rastrigin function for given array of d-dimenstional vectors.\n",
+ "\n",
+ " Inputs:\n",
+ " - x (np.ndarray of shape (n, d)): n d-dimensional vectors.\n",
+ "\n",
+ " Outputs:\n",
+ " - y (np.ndarray of shape (n, 1)): Rastrigin function value for each of the vectors.\n",
+ " \"\"\"\n",
+ " return 10 * x.shape[1] + np.sum(x**2 - 10 * np.cos(2*np.pi*x), axis=1)\n",
+ "\n",
+ "def non_separable_solution(x):\n",
+ " \"\"\"Compute non-separable function for given array of 2-dimenstional vectors.\n",
+ "\n",
+ " Inputs:\n",
+ " - x (np.ndarray of shape (n, 2)): n 2-dimensional vectors.\n",
+ "\n",
+ " Outputs:\n",
+ " - y (np.ndarray of shape (n, 1)): non-separable function value for each of the vectors.\n",
+ " \"\"\"\n",
+ " return np.sin(np.multiply(x[:, 0], x[:, 1]))\n",
+ "\n",
+ "x0_rastrigin = np.linspace(-5.12, 5.12, 100)\n",
+ "X_rastrigin, Y_rastrigin = np.meshgrid(x0_rastrigin,x0_rastrigin)\n",
+ "xs_rastrigin = np.vstack((X_rastrigin.flatten(), Y_rastrigin.flatten())).T\n",
+ "ys_rastrigin = rastrigin_solution(xs_rastrigin)\n",
+ "\n",
+ "x0_non_separable = np.linspace(-4, 4, 100)\n",
+ "X_non_separable, Y_non_separable = np.meshgrid(x0_non_separable,x0_non_separable)\n",
+ "xs_non_separable = np.vstack((X_non_separable.flatten(), Y_non_separable.flatten())).T\n",
+ "ys_non_separable = non_separable_solution(xs_non_separable)\n",
+ "\n",
+ "set_seed(42)\n",
+ "\n",
+ "obj_names = ['circle','square','triangle']\n",
+ "discrete_space = sspspace.DiscreteSPSpace(obj_names, ssp_dim=1024)\n",
+ "\n",
+ "objs = {n:discrete_space.encode(n) for n in obj_names}\n",
+ "\n",
+ "ssp_space = sspspace.RandomSSPSpace(domain_dim=2, ssp_dim=1024)\n",
+ "positions = np.array([[0, -2],\n",
+ " [-2, 3],\n",
+ " [3, 2]\n",
+ " ])\n",
+ "ssps = {n:ssp_space.encode(x) for n, x in zip(obj_names, positions)}\n",
+ "\n",
+ "dim0 = np.linspace(-5, 5, 101)\n",
+ "dim1 = np.linspace(-5, 5, 101)\n",
+ "X,Y = np.meshgrid(dim0, dim1)\n",
+ "\n",
+ "query_xs = np.vstack((X.flatten(), Y.flatten())).T\n",
+ "query_ssps = ssp_space.encode(query_xs)\n",
+ "\n",
+ "bound_objects = [objs[n] * ssps[n] for n in obj_names]\n",
+ "ssp_map = sspspace.SSP(np.sum(bound_objects, axis=0))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "---\n",
+ "\n",
+ "# Section 1: Sample Efficient Learning\n",
+ "\n",
+ "In this section, we will take a look at how imposing an inductive bias on our feature space can result in more sample-efficient learning. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Video 1: Function Learning and Inductive Bias\n",
+ "\n",
+ "from ipywidgets import widgets\n",
+ "from IPython.display import YouTubeVideo\n",
+ "from IPython.display import IFrame\n",
+ "from IPython.display import display\n",
+ "\n",
+ "class PlayVideo(IFrame):\n",
+ " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
+ " self.id = id\n",
+ " if source == 'Bilibili':\n",
+ " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
+ " elif source == 'Osf':\n",
+ " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
+ " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
+ "\n",
+ "def display_videos(video_ids, W=400, H=300, fs=1):\n",
+ " tab_contents = []\n",
+ " for i, video_id in enumerate(video_ids):\n",
+ " out = widgets.Output()\n",
+ " with out:\n",
+ " if video_ids[i][0] == 'Youtube':\n",
+ " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
+ " height=H, fs=fs, rel=0)\n",
+ " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
+ " else:\n",
+ " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
+ " height=H, fs=fs, autoplay=False)\n",
+ " if video_ids[i][0] == 'Bilibili':\n",
+ " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
+ " elif video_ids[i][0] == 'Osf':\n",
+ " print(f'Video available at https://osf.io/{video.id}')\n",
+ " display(video)\n",
+ " tab_contents.append(out)\n",
+ " return tab_contents\n",
+ "\n",
+ "video_ids = [('Youtube', 'KDKmDjMxU7Q'), ('Bilibili', 'BV1GM4m1S7kT')]\n",
+ "tab_contents = display_videos(video_ids, W=854, H=480)\n",
+ "tabs = widgets.Tab()\n",
+ "tabs.children = tab_contents\n",
+ "for i in range(len(tab_contents)):\n",
+ " tabs.set_title(i, video_ids[i][0])\n",
+ "display(tabs)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_function_learning_and_inductive_bias\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "## Coding Exercise 1: Additive Function\n",
+ "\n",
+ "\n",
+ "We will start with an additive function, the Rastrigin function, defined \n",
+ "\n",
+ "\\begin{align*}\n",
+ "f(\\mathbf{x}) = 10d + \\sum_{i=1}^{d} (x_{i}^{2} - 10 \\cos(2 \\pi x_{i}))\n",
+ "\\end{align*}\n",
+ "\n",
+ "where $d$ is the dimensionality of the input vector. In the cell below, complete missing parts of the function which computes values of the Rastrigin function given the input array."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete the Rastrigin function.\")\n",
+ "###################################################################\n",
+ "\n",
+ "def rastrigin(x):\n",
+ " \"\"\"Compute Rastrigin function for given array of d-dimenstional vectors.\n",
+ "\n",
+ " Inputs:\n",
+ " - x (np.ndarray of shape (n, d)): n d-dimensional vectors.\n",
+ "\n",
+ " Outputs:\n",
+ " - y (np.ndarray of shape (n, 1)): Rastrigin function value for each of the vectors.\n",
+ " \"\"\"\n",
+ " return 10 * x.shape[1] + np.sum(... - 10 * np.cos(2*np.pi*...), axis=1)\n",
+ "\n",
+ "# this code creates 10000 2-dimensional vectors which are going to be served as input to the function (thus, output is of shape (10000, 1))\n",
+ "x0_rastrigin = np.linspace(-5.12, 5.12, 100)\n",
+ "X_rastrigin, Y_rastrigin = np.meshgrid(x0_rastrigin,x0_rastrigin)\n",
+ "xs_rastrigin = np.vstack((X_rastrigin.flatten(), Y_rastrigin.flatten())).T\n",
+ "\n",
+ "ys_rastrigin = rastrigin(xs_rastrigin)\n",
+ "\n",
+ "plot_3d_function([X_rastrigin],[Y_rastrigin], [ys_rastrigin.reshape(X_rastrigin.shape)], ['Rastrigin Function'])"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "#to_remove solution\n",
+ "\n",
+ "def rastrigin(x):\n",
+ " \"\"\"Compute Rastrigin function for given array of d-dimenstional vectors.\n",
+ "\n",
+ " Inputs:\n",
+ " - x (np.ndarray of shape (n, d)): n d-dimensional vectors.\n",
+ "\n",
+ " Outputs:\n",
+ " - y (np.ndarray of shape (n, 1)): Rastrigin function value for each of the vectors.\n",
+ " \"\"\"\n",
+ " return 10 * x.shape[1] + np.sum(x**2 - 10 * np.cos(2*np.pi*x), axis=1)\n",
+ "\n",
+ "# this code creates 10000 2-dimensional vectors which are going to be served as input to the function (thus, output is of shape (10000, 1))\n",
+ "x0_rastrigin = np.linspace(-5.12, 5.12, 100)\n",
+ "X_rastrigin, Y_rastrigin = np.meshgrid(x0_rastrigin,x0_rastrigin)\n",
+ "xs_rastrigin = np.vstack((X_rastrigin.flatten(), Y_rastrigin.flatten())).T\n",
+ "\n",
+ "ys_rastrigin = rastrigin(xs_rastrigin)\n",
+ "\n",
+ "plot_3d_function([X_rastrigin],[Y_rastrigin], [ys_rastrigin.reshape(X_rastrigin.shape)], ['Rastrigin Function'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Now, we are going to see which of the inductive biases (suggested mechanism underlying input data) will be more efficient in training the linear regression to get values of the Rastrigin function. We will consider two representations:\n",
+ "\n",
+ "* **Bound**: We encode 2D input vectors `xs` as bound vectors\n",
+ "* **Bundled**: We encode 1D input vectors separately and use bundling and then bundle them together"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "set_seed(42)\n",
+ "\n",
+ "ssp_space = sspspace.RandomSSPSpace(domain_dim=2, ssp_dim=1024)\n",
+ "bound_phis = ssp_space.encode(xs_rastrigin)\n",
+ "\n",
+ "ssp_space0 = sspspace.RandomSSPSpace(domain_dim=1, ssp_dim=1024)\n",
+ "ssp_space1 = sspspace.RandomSSPSpace(domain_dim=1, ssp_dim=1024)\n",
+ "\n",
+ "#remember that input to `encode` should be 2-dimensional, thus we need to create extra dimension by applying [:,None]\n",
+ "bundle_phis = ssp_space0.encode(xs_rastrigin[:, 0][:, None]) + ssp_space1.encode(xs_rastrigin[:, 1][:, None])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Now, let us define modeling attributes: we will have a few different `train_sizes`, and we will fit a linear regression for each of them in a loop. Then, for each of the models, we will evaluate its fit based on RMSE loss on the test set."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "def loss(y_true, y_pred):\n",
+ " \"\"\"Calculate RMSE loss between true and predicted values (note, that loss is not normalized by the shape).\n",
+ "\n",
+ " Inputs:\n",
+ " - y_true (np.ndarray): true values.\n",
+ " - y_pred (np.ndarray): predicted values.\n",
+ "\n",
+ " Outputs:\n",
+ " - loss (float): loss value.\n",
+ " \"\"\"\n",
+ " return np.sqrt(np.mean((y_true - y_pred) ** 2))\n",
+ "\n",
+ "def test_performance(xs, ys, train_sizes):\n",
+ " \"\"\"Fit linear regression to the provided data and evaluate the performance with RMSE loss for different test sizes.\n",
+ "\n",
+ " Inputs:\n",
+ " - xs (np.ndarray): input data.\n",
+ " - ys (np.ndarray): output data.\n",
+ " - train_size (list): list of the train sizes.\n",
+ " \"\"\"\n",
+ " performance = []\n",
+ "\n",
+ " models = []\n",
+ " for train_size in tqdm(train_sizes):\n",
+ " X_train, X_test, y_train, y_test = train_test_split(xs, ys, random_state=1, train_size=train_size)\n",
+ " regr = LinearRegression().fit(X_train, y_train)\n",
+ " performance.append(np.copy(loss(y_test, regr.predict(X_test))))\n",
+ " models.append(regr)\n",
+ " return performance, models"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Now, we are ready to train the models on two different inductive biases of the input data."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "train_sizes = np.linspace(0.25, 0.9, 5)\n",
+ "bound_performance, bound_models = test_performance(bound_phis, ys_rastrigin, train_sizes)\n",
+ "bundle_performance, bundle_models = test_performance(bundle_phis, ys_rastrigin, train_sizes)\n",
+ "plot_performance(bound_performance, bundle_performance, train_sizes * bound_phis.shape[0], \"Rastrigin function - RMSE\")\n",
+ "plt.ylim((-1, 20))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "What a drastic difference! Let us evaluate visually the performance when training on 3,000 train points."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "bound_model = bound_models[0]\n",
+ "bundled_model = bundle_models[0]\n",
+ "\n",
+ "ys_hat_rastrigin_bound = bound_model.predict(bound_phis)\n",
+ "ys_hat_rastrigin_bundled = bundled_model.predict(bundle_phis)\n",
+ "\n",
+ "plot_3d_function([X_rastrigin, X_rastrigin, X_rastrigin], [Y_rastrigin, Y_rastrigin, Y_rastrigin], [ys_rastrigin.reshape(X_rastrigin.shape), ys_hat_rastrigin_bound.reshape(X_rastrigin.shape), ys_hat_rastrigin_bundled.reshape(X_rastrigin.shape)], ['Rastrigin Function - True', 'Bound', 'Bundled'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "### Coding Exercise 1 Discussion\n",
+ "\n",
+ "1. Why do you think the bundled representation is superior for the Rastrigin function?"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "#to_remove explanation\n",
+ "\n",
+ "\"\"\"\n",
+ "Discussion: Why do you think the bundled representation is superior for the Rastrigin function?\n",
+ "\n",
+ "The Rastrigin function is a superposition of independent functions of the input variable dimensions. The bundled representation is a superposition of a high-dimensional representation of the input dimensions, making it easier to learn this function, which is additive. For the bound representation, we have to learn a mapping from each tuple of input values to the appropriate output value, meaning more samples are required to approximate the function.\n",
+ "\"\"\";"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_additive_function\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "## Coding Exercise 2: Non-separable Function\n",
+ "\n",
+ "Now, let's consider a non-separable function: a function $f(x_1, x_2)$ that cannot be described as the sum of two one-dimensional functions $g(x_1)$ and $h_1$. We will examine this function over the domain $[-4,4]^{2}$:\n",
+ "\n",
+ "$$f(\\mathbf{x}) = \\sin(x_{1}x_{2})$$\n",
+ "\n",
+ "Fill in the missing parts of the code to get the correct calculation of the defined function."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete the non-separable function.\")\n",
+ "###################################################################\n",
+ "\n",
+ "def non_separable(x):\n",
+ " \"\"\"Compute non-separable function for given array of 2-dimenstional vectors.\n",
+ "\n",
+ " Inputs:\n",
+ " - x (np.ndarray of shape (n, 2)): n 2-dimensional vectors.\n",
+ "\n",
+ " Outputs:\n",
+ " - y (np.ndarray of shape (n, 1)): non-separable function value for each of the vectors.\n",
+ " \"\"\"\n",
+ " return np.sin(np.multiply(x[:, ...], x[:, ...]))\n",
+ "\n",
+ "x0_non_separable = np.linspace(-4, 4, 100)\n",
+ "X_non_separable, Y_non_separable = np.meshgrid(x0_non_separable,x0_non_separable)\n",
+ "xs_non_separable = np.vstack((X_non_separable.flatten(), Y_non_separable.flatten())).T\n",
+ "\n",
+ "ys_non_separable = non_separable(xs_non_separable)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "#to_remove solution\n",
+ "\n",
+ "def non_separable(x):\n",
+ " \"\"\"Compute non-separable function for given array of 2-dimenstional vectors.\n",
+ "\n",
+ " Inputs:\n",
+ " - x (np.ndarray of shape (n, 2)): n 2-dimensional vectors.\n",
+ "\n",
+ " Outputs:\n",
+ " - y (np.ndarray of shape (n, 1)): non-separable function value for each of the vectors.\n",
+ " \"\"\"\n",
+ " return np.sin(np.multiply(x[:, 0], x[:, 1]))\n",
+ "\n",
+ "x0_non_separable = np.linspace(-4, 4, 100)\n",
+ "X_non_separable, Y_non_separable = np.meshgrid(x0_non_separable,x0_non_separable)\n",
+ "xs_non_separable = np.vstack((X_non_separable.flatten(), Y_non_separable.flatten())).T\n",
+ "\n",
+ "ys_non_separable = non_separable(xs_non_separable)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "plot_3d_function([X_non_separable],[Y_non_separable], [ys_non_separable.reshape(X_non_separable.shape)], ['Nonseparable Function, $f(\\mathbf{x}) = \\sin(x_{1}x_{2})$'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "### Coding Exercise 2 Discussion\n",
+ "\n",
+ "1. Can you guess by the nature of the function which of the representations will be more efficient?"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "#to_remove explanation\n",
+ "\n",
+ "\"\"\"\n",
+ "Discussion: Can you guess which of the representations will be more efficient by the nature of the function?\n",
+ "\n",
+ "As the function is not separable, we expect the bound representation to perform better.\n",
+ "\"\"\";"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "We will reuse previously defined spaces for encoding bound and bundled representations."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "bound_phis = ssp_space.encode(xs_non_separable)\n",
+ "bundle_phis = ssp_space0.encode(xs_non_separable[:,0][:,None]) + ssp_space1.encode(xs_non_separable[:,1][:,None])\n",
+ "\n",
+ "train_sizes = np.linspace(0.25, 0.9, 5)\n",
+ "bound_performance, bound_models = test_performance(bound_phis, ys_non_separable, train_sizes)\n",
+ "bundle_performance, bundle_models = test_performance(bundle_phis, ys_non_separable, train_sizes)\n",
+ "plot_performance(bound_performance, bundle_performance, train_sizes * bound_phis.shape[0], title = \"Non-separable function - RMSE\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Bundling representation can't achieve the same quality even when the number of samples is increased. This is because the function is non-separable, and the bundling representation can't capture the interaction between the two dimensions."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "bound_model = bound_models[0]\n",
+ "bundle_model = bundle_models[0]\n",
+ "\n",
+ "ys_hat_bound = bound_model.predict(bound_phis)\n",
+ "ys_hat_bundle = bundle_model.predict(bundle_phis)\n",
+ "\n",
+ "plot_3d_function([X_non_separable, X_non_separable, X_non_separable], [Y_non_separable, Y_non_separable, Y_non_separable], [ys_non_separable.reshape(X_non_separable.shape), ys_hat_bound.reshape(X_non_separable.shape), ys_hat_bundle.reshape(X_non_separable.shape)], ['Non-separable Function - True', 'Bound', 'Bundled'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "So, as we can see, when we pick the right inductive bias, we can do a better job."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_non_separable_function\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "---\n",
+ "\n",
+ "# Section 2: Representing Continuous Values\n",
+ "\n",
+ "Estimated timing to here from start of tutorial: 20 minutes\n",
+ "\n",
+ "In this section we will use a technique called Fractional Binding to represent continuous values to construct a map of objects distributed over a 2D space. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Video 2: Mapping Intro\n",
+ "from ipywidgets import widgets\n",
+ "from IPython.display import YouTubeVideo\n",
+ "from IPython.display import IFrame\n",
+ "from IPython.display import display\n",
+ "\n",
+ "class PlayVideo(IFrame):\n",
+ " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
+ " self.id = id\n",
+ " if source == 'Bilibili':\n",
+ " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
+ " elif source == 'Osf':\n",
+ " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
+ " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
+ "\n",
+ "def display_videos(video_ids, W=400, H=300, fs=1):\n",
+ " tab_contents = []\n",
+ " for i, video_id in enumerate(video_ids):\n",
+ " out = widgets.Output()\n",
+ " with out:\n",
+ " if video_ids[i][0] == 'Youtube':\n",
+ " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
+ " height=H, fs=fs, rel=0)\n",
+ " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
+ " else:\n",
+ " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
+ " height=H, fs=fs, autoplay=False)\n",
+ " if video_ids[i][0] == 'Bilibili':\n",
+ " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
+ " elif video_ids[i][0] == 'Osf':\n",
+ " print(f'Video available at https://osf.io/{video.id}')\n",
+ " display(video)\n",
+ " tab_contents.append(out)\n",
+ " return tab_contents\n",
+ "\n",
+ "video_ids = [('Youtube', 's7MOusrbKXU'), ('Bilibili', 'BV1pi421i7iN')]\n",
+ "tab_contents = display_videos(video_ids, W=854, H=480)\n",
+ "tabs = widgets.Tab()\n",
+ "tabs.children = tab_contents\n",
+ "for i in range(len(tab_contents)):\n",
+ " tabs.set_title(i, video_ids[i][0])\n",
+ "display(tabs)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_mapping_intro\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "## Coding Exercise 3: Mixing Discrete Objects With Continuous Space\n",
+ "\n",
+ "We will store three objects in a vector representing a map. First, we will create 3 objects (a circle, square, and triangle), as we did before."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "set_seed(42)\n",
+ "\n",
+ "obj_names = ['circle','square','triangle']\n",
+ "discrete_space = sspspace.DiscreteSPSpace(obj_names, ssp_dim=1024)\n",
+ "\n",
+ "objs = {n:discrete_space.encode(n) for n in obj_names}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Next, we are going to create three locations where the objects will reside, and an encoder will transform those coordinates into an SSP representation."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "set_seed(42)\n",
+ "\n",
+ "ssp_space = sspspace.RandomSSPSpace(domain_dim=2, ssp_dim=1024)\n",
+ "positions = np.array([[0, -2],\n",
+ " [-2, 3],\n",
+ " [3, 2]\n",
+ " ])\n",
+ "ssps = {n:ssp_space.encode(x) for n, x in zip(obj_names, positions)}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Next, in order to see where things are on the map, we are going to compute the similarity between encoded places and points in the space. Your task is to complete the calculation of similarity values between all grid points with the one associated with the object."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "dim0 = np.linspace(-5, 5, 101)\n",
+ "dim1 = np.linspace(-5, 5, 101)\n",
+ "X,Y = np.meshgrid(dim0, dim1)\n",
+ "\n",
+ "query_xs = np.vstack((X.flatten(), Y.flatten())).T\n",
+ "query_ssps = ssp_space.encode(query_xs)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete similarity calculation.\")\n",
+ "###################################################################\n",
+ "\n",
+ "sims = []\n",
+ "\n",
+ "for obj_idx, obj in enumerate(obj_names):\n",
+ " sims.append(... @ ssps[obj].flatten())\n",
+ "\n",
+ "plt.figure(figsize=(8, 2.4))\n",
+ "plot_2d_similarity(sims, obj_names, (dim0.size, dim1.size))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "#to_remove solution\n",
+ "\n",
+ "sims = []\n",
+ "\n",
+ "for obj_idx, obj in enumerate(obj_names):\n",
+ " sims.append(query_ssps @ ssps[obj].flatten())\n",
+ "\n",
+ "plt.figure(figsize=(8, 2.4))\n",
+ "plot_2d_similarity(sims, obj_names, (dim0.size, dim1.size))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Now, let's bind these positions with the objects and see how that changes similarity with the map positions. Complete binding operation in the cell below."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete binding operation for objects and corresponding positions.\")\n",
+ "###################################################################\n",
+ "\n",
+ "#objects are located in `objs` and positions in `ssps`\n",
+ "bound_objects = [... * ... for n in obj_names]\n",
+ "\n",
+ "sims = []\n",
+ "\n",
+ "for obj_idx, obj in enumerate(obj_names):\n",
+ " sims.append(query_ssps @ bound_objects[obj_idx].flatten())\n",
+ "\n",
+ "plt.figure(figsize=(8, 2.4))\n",
+ "plot_2d_similarity(sims, obj_names, (dim0.size, dim1.size))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "#to_remove solution\n",
+ "\n",
+ "#objects are located in `objs` and positions in `ssps`\n",
+ "bound_objects = [objs[n] * ssps[n] for n in obj_names]\n",
+ "\n",
+ "sims = []\n",
+ "\n",
+ "for obj_idx, obj in enumerate(obj_names):\n",
+ " sims.append(query_ssps @ bound_objects[obj_idx].flatten())\n",
+ "\n",
+ "plt.figure(figsize=(8, 2.4))\n",
+ "plot_2d_similarity(sims, obj_names, (dim0.size, dim1.size))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "As you can see, the similarity is destroyed, which is what we should expect.\n",
+ "\n",
+ "Next, we are going to create a map out of our bound objects:\n",
+ "\n",
+ "\\begin{align*}\n",
+ "\\mathrm{map} = \\sum_{i=1}^{n} \\phi(x_{i})\\circledast obj_{i}\n",
+ "\\end{align*}"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "set_seed(42)\n",
+ "\n",
+ "ssp_map = sspspace.SSP(np.sum(bound_objects, axis=0))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Now, we can query the map by unbinding the objects we care about. Your task is to complete the unbinding operation. Then, let's observe the resulting similarities."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete the unbinding operation.\")\n",
+ "###################################################################\n",
+ "\n",
+ "objects_sims = []\n",
+ "\n",
+ "for obj_idx, obj_name in enumerate(obj_names):\n",
+ " #query the object name by unbinding it from the map\n",
+ " query_map = ssp_map * ~objs[...]\n",
+ " objects_sims.append(query_ssps @ query_map.flatten())\n",
+ "\n",
+ "plot_2d_similarity(objects_sims, obj_names, (dim0.size, dim1.size), title_argmax = True)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "#to_remove solution\n",
+ "\n",
+ "objects_sims = []\n",
+ "\n",
+ "for obj_idx, obj_name in enumerate(obj_names):\n",
+ " #query the object name by unbinding it from the map\n",
+ " query_map = ssp_map * ~objs[obj_name]\n",
+ " objects_sims.append(query_ssps @ query_map.flatten())\n",
+ "\n",
+ "plot_2d_similarity(objects_sims, obj_names, (dim0.size, dim1.size), title_argmax = True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Let's look at what happens when we unbind all the symbols from the map at once. Complete bundling and unbinding operations in the following code cell."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete the bundling and unbinding operations.\")\n",
+ "###################################################################\n",
+ "\n",
+ "# unifying bundled representation of all objects\n",
+ "all_objs = (objs['circle'] + objs[...] + objs[...]).normalize()\n",
+ "\n",
+ "# unbind this unifying representation from the map\n",
+ "query_map = ... * ~...\n",
+ "\n",
+ "sims = query_ssps @ query_map.flatten()\n",
+ "size = (dim0.size,dim1.size)\n",
+ "\n",
+ "plot_unbinding_objects_map(sims, positions, query_xs, size)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "#to_remove solution\n",
+ "# unifying bundled representation of all objects\n",
+ "all_objs = (objs['circle'] + objs['square'] + objs['triangle']).normalize()\n",
+ "\n",
+ "# unbind this unifying representation from the map\n",
+ "query_map = ssp_map * ~all_objs\n",
+ "\n",
+ "sims = query_ssps @ query_map.flatten()\n",
+ "size = (dim0.size,dim1.size)\n",
+ "\n",
+ "plot_unbinding_objects_map(sims, positions, query_xs, size)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "We can also unbind positions and see what objects exist there. We will the locations where objects are located as test positions, as well as two distinct ones to compare. In the final exercise, you should complete the unbinding of the position's operation."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete the unbinding operations.\")\n",
+ "###################################################################\n",
+ "\n",
+ "query_objs = np.vstack([objs[n] for n in obj_names])\n",
+ "test_positions = np.vstack((positions, [0,0], [0,-1.5]))\n",
+ "\n",
+ "sims = []\n",
+ "\n",
+ "for pos_idx, pos in enumerate(test_positions):\n",
+ " position_ssp = ssp_space.encode(pos[None,:]) #remember we need to have 2-dimensional vectors for `encode()` function\n",
+ " #unbind positions from the map\n",
+ " query_map = ... * ~...\n",
+ " sims.append(query_objs @ query_map.flatten())\n",
+ "\n",
+ "plot_unbinding_positions_map(sims, test_positions, obj_names)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "#to_remove solution\n",
+ "\n",
+ "query_objs = np.vstack([objs[n] for n in obj_names])\n",
+ "test_positions = np.vstack((positions, [0,0], [0,-1.5]))\n",
+ "\n",
+ "sims = []\n",
+ "\n",
+ "for pos_idx, pos in enumerate(test_positions):\n",
+ " position_ssp = ssp_space.encode(pos[None,:]) #remember we need to have 2-dimensional vectors for `encode()` function\n",
+ " #unbind positions from the map\n",
+ " query_map = ssp_map * ~position_ssp\n",
+ " sims.append(query_objs @ query_map.flatten())\n",
+ "\n",
+ "plot_unbinding_positions_map(sims, test_positions, obj_names)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "As you can see from the above plots, when we query each location, we can clearly identify the object stored at that location. \n",
+ "\n",
+ "When we query at the origin (where no object is present), we see that there is no strong candidate element. However, as we move closer to one of the objects (rightmost plot), the similarity starts to increase."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_mixing_discrete_objects_with_continuous_space\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Video 4: Mapping Outro\n",
+ "from ipywidgets import widgets\n",
+ "from IPython.display import YouTubeVideo\n",
+ "from IPython.display import IFrame\n",
+ "from IPython.display import display\n",
+ "\n",
+ "class PlayVideo(IFrame):\n",
+ " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
+ " self.id = id\n",
+ " if source == 'Bilibili':\n",
+ " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
+ " elif source == 'Osf':\n",
+ " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
+ " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
+ "\n",
+ "def display_videos(video_ids, W=400, H=300, fs=1):\n",
+ " tab_contents = []\n",
+ " for i, video_id in enumerate(video_ids):\n",
+ " out = widgets.Output()\n",
+ " with out:\n",
+ " if video_ids[i][0] == 'Youtube':\n",
+ " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
+ " height=H, fs=fs, rel=0)\n",
+ " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
+ " else:\n",
+ " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
+ " height=H, fs=fs, autoplay=False)\n",
+ " if video_ids[i][0] == 'Bilibili':\n",
+ " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
+ " elif video_ids[i][0] == 'Osf':\n",
+ " print(f'Video available at https://osf.io/{video.id}')\n",
+ " display(video)\n",
+ " tab_contents.append(out)\n",
+ " return tab_contents\n",
+ "\n",
+ "video_ids = [('Youtube', 'mXNFWr_cap4'), ('Bilibili', 'BV1ND421u7gp')]\n",
+ "tab_contents = display_videos(video_ids, W=854, H=480)\n",
+ "tabs = widgets.Tab()\n",
+ "tabs.children = tab_contents\n",
+ "for i in range(len(tab_contents)):\n",
+ " tabs.set_title(i, video_ids[i][0])\n",
+ "display(tabs)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_mapping_outro\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "---\n",
+ "# Summary\n",
+ "\n",
+ "*Estimated timing of tutorial: 40 minutes*"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Video 5: Conclusions\n",
+ "from ipywidgets import widgets\n",
+ "from IPython.display import YouTubeVideo\n",
+ "from IPython.display import IFrame\n",
+ "from IPython.display import display\n",
+ "\n",
+ "class PlayVideo(IFrame):\n",
+ " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
+ " self.id = id\n",
+ " if source == 'Bilibili':\n",
+ " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
+ " elif source == 'Osf':\n",
+ " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
+ " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
+ "\n",
+ "def display_videos(video_ids, W=400, H=300, fs=1):\n",
+ " tab_contents = []\n",
+ " for i, video_id in enumerate(video_ids):\n",
+ " out = widgets.Output()\n",
+ " with out:\n",
+ " if video_ids[i][0] == 'Youtube':\n",
+ " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
+ " height=H, fs=fs, rel=0)\n",
+ " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
+ " else:\n",
+ " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
+ " height=H, fs=fs, autoplay=False)\n",
+ " if video_ids[i][0] == 'Bilibili':\n",
+ " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
+ " elif video_ids[i][0] == 'Osf':\n",
+ " print(f'Video available at https://osf.io/{video.id}')\n",
+ " display(video)\n",
+ " tab_contents.append(out)\n",
+ " return tab_contents\n",
+ "\n",
+ "video_ids = [('Youtube', 'M6rRsdJdoYQ'), ('Bilibili', 'BV1wm421L7Se')]\n",
+ "tab_contents = display_videos(video_ids, W=854, H=480)\n",
+ "tabs = widgets.Tab()\n",
+ "tabs.children = tab_contents\n",
+ "for i in range(len(tab_contents)):\n",
+ " tabs.set_title(i, video_ids[i][0])\n",
+ "display(tabs)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Conclusion slides\n",
+ "\n",
+ "from IPython.display import IFrame\n",
+ "link_id = \"pxqny\"\n",
+ "\n",
+ "print(f\"If you want to download the slides: 'https://osf.io/download/{link_id}'\")\n",
+ "\n",
+ "IFrame(src=f\"https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{link_id}/?direct%26mode=render\", width=854, height=480)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_conclusions\")"
+ ]
+ }
+ ],
+ "metadata": {
+ "colab": {
+ "collapsed_sections": [],
+ "include_colab_link": true,
+ "name": "W2D2_Tutorial5",
+ "provenance": [],
+ "toc_visible": true
+ },
+ "kernel": {
+ "display_name": "Python 3",
+ "language": "python",
+ "name": "python3"
+ },
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.9.22"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 4
+}
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/instructor/W2D2_Intro.ipynb b/tutorials/W2D2_NeuroSymbolicMethods/instructor/W2D2_Intro.ipynb
index 218b77e69..5a0275059 100644
--- a/tutorials/W2D2_NeuroSymbolicMethods/instructor/W2D2_Intro.ipynb
+++ b/tutorials/W2D2_NeuroSymbolicMethods/instructor/W2D2_Intro.ipynb
@@ -18,7 +18,9 @@
}
},
"source": [
- "# Intro"
+ "# W2D2 - Neurosymbolic Methods and Cognitive Architectures \n",
+ "\n",
+ "Welcome to the day on Neurosymbolic Methods and Cognitive Architectures. This year we have some new content to introduce to you from the fascinating work by Chris Eliasmith and Michael Furlong. We're going to look at methods that use symbolic manipulation in order to learn how to model data in a way that is more brain-like and generalizes well to stimuli out of distribution. We're also going to look in some detail at a model they have created, called SPAUN. Please consider the note in the prerequisite cell below and try to have a basic understanding of those listed topics before getting into the details. The topic will be much clearer having brushed up on those topics. We'll now pass it over to Chris and Michael to tell you all about neurosymbolic methods and cognitive architectures!"
]
},
{
@@ -123,7 +125,7 @@
" return tab_contents\n",
"\n",
"\n",
- "video_ids = [('Youtube', 'RKKUfo0dVnY'), ('Bilibili', 'BV11D421M7Hy')]\n",
+ "video_ids = [('Youtube', 'W1jsRycDYXQ'), ('Bilibili', 'BV15V7jz8EAj')]\n",
"tab_contents = display_videos(video_ids, W=854, H=480)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
@@ -172,7 +174,7 @@
"from ipywidgets import widgets\n",
"out = widgets.Output()\n",
"\n",
- "link_id = \"nxzar\"\n",
+ "link_id = \"9w836\"\n",
"\n",
"with out:\n",
" print(f\"If you want to download the slides: https://osf.io/download/{link_id}/\")\n",
@@ -209,7 +211,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.9.19"
+ "version": "3.9.22"
}
},
"nbformat": 4,
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/instructor/W2D2_Tutorial1.ipynb b/tutorials/W2D2_NeuroSymbolicMethods/instructor/W2D2_Tutorial1.ipynb
index 7fd099dc5..bc0a55646 100644
--- a/tutorials/W2D2_NeuroSymbolicMethods/instructor/W2D2_Tutorial1.ipynb
+++ b/tutorials/W2D2_NeuroSymbolicMethods/instructor/W2D2_Tutorial1.ipynb
@@ -25,9 +25,9 @@
"\n",
"__Content creators:__ P. Michael Furlong, Chris Eliasmith\n",
"\n",
- "__Content reviewers:__ Hlib Solodzhuk, Patrick Mineault, Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi\n",
+ "__Content reviewers:__ Hlib Solodzhuk, Patrick Mineault, Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Alex Murphy\n",
"\n",
- "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk\n"
+ "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk, Alex Murphy\n"
]
},
{
@@ -43,7 +43,7 @@
"\n",
"*Estimated timing of tutorial: 1 hour*\n",
"\n",
- "In this tutorial we will introduce vector symbolic algebra and discuss its main operations."
+ "In this tutorial we will introduce the concept of a vector symbolic algebra (VSA) and discuss its main operations and we will give you some demonstrations on a simple set of concepts (shapes and their colors) in order to let you see and play around with concept manipulations in this VSA! Let's get started!"
]
},
{
@@ -59,7 +59,7 @@
"# @markdown These are the slides for the videos in all tutorials today\n",
"\n",
"from IPython.display import IFrame\n",
- "link_id = \"2szmk\"\n",
+ "link_id = \"jybuw\"\n",
"\n",
"print(f\"If you want to download the slides: 'https://osf.io/download/{link_id}'\")\n",
"\n",
@@ -73,8 +73,11 @@
},
"source": [
"---\n",
- "# Setup\n",
- "\n"
+ "# Setup (Colab Users: Please Read)\n",
+ "\n",
+ "Note that because this tutorial relies on some special Python packages, these packages have requirements for specific versions of common scientific libraries, such as `numpy`. If you're in Google Colab, then as of May 2025, this comes with a later version (2.0.2) pre-installed. We require an older version (we'll be installing `1.24.4`). This causes Colab to force a session restart and then re-running of the installation cells for the new version to take effect. When you run the cell below, you will be prompted to restart the session. This is *entirely expected* and you haven't done anything wrong. Simply click 'Restart' and then run the cells as normal. \n",
+ "\n",
+ "An additional error might sometimes arise where an exception is raised connected to a missing element of NumPy. If this occurs, please restart the session and re-run the cells as normal and this error will go away. Updated versions of the affected libraries are expected out soon, but sadly not in time for the preparation of this material. We thank you for your understanding."
]
},
{
@@ -88,7 +91,10 @@
"source": [
"# @title Install and import feedback gadget\n",
"\n",
- "!pip install --quiet numpy matplotlib ipywidgets scipy vibecheck\n",
+ "!pip install git+https://github.com/neuromatch/sspspace@neuromatch --quiet\n",
+ "!pip install numpy==1.24.4\n",
+ "!pip install nengo_spa==2.0.0\n",
+ "!pip install --quiet matplotlib ipywidgets scipy vibecheck\n",
"\n",
"from vibecheck import DatatopsContentReviewContainer\n",
"def content_review(notebook_section: str):\n",
@@ -106,30 +112,6 @@
"feedback_prefix = \"W2D2_T1\""
]
},
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Notice that exactly the `neuromatch` branch of `sspspace` should be installed! Otherwise, some of the functionality won't work."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Install dependencies\n",
- "\n",
- "# Install sspspace\n",
- "!pip install git+https://github.com/neuromatch/sspspace@neuromatch --quiet"
- ]
- },
{
"cell_type": "code",
"execution_count": null,
@@ -153,6 +135,7 @@
"\n",
"#modeling\n",
"import sspspace\n",
+ "import nengo_spa as spa\n",
"from scipy.special import softmax"
]
},
@@ -284,7 +267,7 @@
" - title (str): title of the plot.\n",
" \"\"\"\n",
" with plt.xkcd():\n",
- " plt.plot(x_range, sim_mat)\n",
+ " plt.plot(x_range, sims)\n",
" plt.xlabel('x')\n",
" plt.ylabel('Similarity')\n",
" plt.title(title)"
@@ -313,90 +296,6 @@
"set_seed(seed = 42)"
]
},
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Helper functions\n",
- "\n",
- "# mainly contains solutions to exercises for correct plot output; please don't take a look!\n",
- "set_seed(42)\n",
- "\n",
- "vector_length = 1024\n",
- "symbol_names = ['circle','square','triangle']\n",
- "discrete_space = sspspace.DiscreteSPSpace(symbol_names, ssp_dim=vector_length, optimize = False)\n",
- "\n",
- "circle = discrete_space.encode('circle')\n",
- "square = discrete_space.encode('square')\n",
- "triangle = discrete_space.encode('triangle')\n",
- "\n",
- "shape = (circle + square + triangle).normalize()\n",
- "\n",
- "shape_sim_mat = np.zeros((4,4))\n",
- "\n",
- "shape_sim_mat[0,0] = (circle | circle).item()\n",
- "shape_sim_mat[1,1] = (square | square).item()\n",
- "shape_sim_mat[2,2] = (triangle | triangle).item()\n",
- "shape_sim_mat[3,3] = (shape | shape).item()\n",
- "\n",
- "shape_sim_mat[0,1] = shape_sim_mat[1,0] = (circle | square).item()\n",
- "shape_sim_mat[0,2] = shape_sim_mat[2,0] = (circle | triangle).item()\n",
- "shape_sim_mat[0,3] = shape_sim_mat[3,0] = (circle | shape).item()\n",
- "\n",
- "shape_sim_mat[1,2] = shape_sim_mat[2,1] = (square | triangle).item()\n",
- "shape_sim_mat[1,3] = shape_sim_mat[3,1] = (square | shape).item()\n",
- "\n",
- "shape_sim_mat[2,3] = shape_sim_mat[3,2] = (triangle | shape).item()\n",
- "\n",
- "new_symbol_names = ['circle','square','triangle', 'red', 'blue', 'green']\n",
- "new_discrete_space = sspspace.DiscreteSPSpace(new_symbol_names, ssp_dim=vector_length, optimize=False)\n",
- "\n",
- "objs = {n:new_discrete_space.encode(np.array([n])) for n in new_symbol_names}\n",
- "\n",
- "objs['red*circle'] = objs['red'] * objs['circle']\n",
- "objs['blue*triangle'] = objs['blue'] * objs['triangle']\n",
- "objs['green*square'] = objs['green'] * objs['square']\n",
- "\n",
- "new_object_names = ['red','red^','red*circle','circle','circle^']\n",
- "new_objs = objs.copy()\n",
- "\n",
- "new_objs['red^'] = new_objs['red*circle'] * ~new_objs['circle']\n",
- "new_objs['circle^'] = new_objs['red*circle'] * ~new_objs['red']\n",
- "\n",
- "axis_vectors = ['one']\n",
- "\n",
- "encoder = sspspace.DiscreteSPSpace(axis_vectors, ssp_dim=1024, optimize=False)\n",
- "\n",
- "vocab = {w:encoder.encode(w) for w in axis_vectors}\n",
- "\n",
- "integers = [vocab['one']]\n",
- "\n",
- "max_int = 5\n",
- "for i in range(2, max_int + 1):\n",
- " integers.append(integers[-1] * vocab['one'])\n",
- "\n",
- "integers = np.array(integers).squeeze()\n",
- "integer_sims = integers @ integers.T\n",
- "\n",
- "five_unbind_two = sspspace.SSP(integers[4]) * ~sspspace.SSP(integers[1])\n",
- "five_unbind_two_sims = five_unbind_two @ integers.T\n",
- "\n",
- "new_encoder = sspspace.RandomSSPSpace(domain_dim=1, ssp_dim=1024)\n",
- "\n",
- "xs = np.linspace(-4,4,401)[:,None]\n",
- "phis = new_encoder.encode(xs)\n",
- "\n",
- "real_line_sims = phis[200, :] @ phis.T\n",
- "\n",
- "phi_shifted = phis[200,:][None,:] * new_encoder.encode([[np.pi/2]])\n",
- "shifted_real_line_sims = phi_shifted.flatten() @ phis.T"
- ]
- },
{
"cell_type": "markdown",
"metadata": {
@@ -485,11 +384,27 @@
"source": [
"## Coding Exercise 1: Concepts as High-Dimensional Vectors\n",
"\n",
- "In an arbitrary space of concepts, we will represent the ideas of 'circle,' 'square,' and triangle.' For that, we will use the SSP space library (`sspspace`) to map identifiers for the concepts (strings of their names in this case) into high-dimensional vectors of unit length. It means that for each `name`, we will uniquely identify $\\mathbf{v}$ where $||\\mathbf{v}|| = 1$.\n",
+ "In an arbitrary space of concepts, we will represent the ideas of `CIRCLE`, `SQUARE` and `TRIANGLE`. For that, we will make a vocabulary that map identifiers of the concepts (strings of their names in this case) into high-dimensional vectors of unit length. It means that for each `name`, we will uniquely identify $\\mathbf{v}$ where $||\\mathbf{v}|| = 1$.\n",
"\n",
"In this exercise, check that, indeed, vectors are of unit length."
]
},
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "from nengo_spa.algebras.hrr_algebra import HrrProperties, HrrAlgebra\n",
+ "from nengo_spa.vector_generation import VectorsWithProperties\n",
+ "def make_vocabulary(vector_length):\n",
+ " vec_generator = VectorsWithProperties(vector_length, algebra=HrrAlgebra(), properties = [HrrProperties.UNITARY, HrrProperties.POSITIVE])\n",
+ " vocab = spa.Vocabulary(vector_length, pointer_gen=vec_generator)\n",
+ " return vocab"
+ ]
+ },
{
"cell_type": "markdown",
"metadata": {
@@ -510,16 +425,19 @@
"set_seed(42)\n",
"\n",
"vector_length = 1024\n",
- "symbol_names = ['circle','square','triangle']\n",
- "discrete_space = sspspace.DiscreteSPSpace(symbol_names, ssp_dim=vector_length, optimize = False)\n",
+ "symbol_names = ['CIRCLE','SQUARE','TRIANGLE']\n",
"\n",
- "circle = discrete_space.encode('circle')\n",
- "square = discrete_space.encode('square')\n",
- "triangle = discrete_space.encode('triangle')\n",
+ "vocab = make_vocabulary(vector_length)\n",
+ "vocab.populate(';'.join(symbol_names))\n",
+ "print(list(vocab.keys()))\n",
"\n",
- "print('|circle| =', np.linalg.norm(circle))\n",
- "print('|triangle| =', np.linalg.norm(...))\n",
- "print('|square| =', ...)\n",
+ "circle = vocab['CIRCLE']\n",
+ "square = vocab['SQUARE']\n",
+ "triangle = vocab['TRIANGLE']\n",
+ "\n",
+ "print('|circle| =', np.linalg.norm(circle.v))\n",
+ "print('|triangle| =', np.linalg.norm(square.v))\n",
+ "print('|square| =', np.linalg.norm(triangle.v))\n",
"\n",
"```"
]
@@ -537,16 +455,19 @@
"set_seed(42)\n",
"\n",
"vector_length = 1024\n",
- "symbol_names = ['circle','square','triangle']\n",
- "discrete_space = sspspace.DiscreteSPSpace(symbol_names, ssp_dim=vector_length, optimize = False)\n",
+ "symbol_names = ['CIRCLE','SQUARE','TRIANGLE']\n",
+ "\n",
+ "vocab = make_vocabulary(vector_length)\n",
+ "vocab.populate(';'.join(symbol_names))\n",
+ "print(list(vocab.keys()))\n",
"\n",
- "circle = discrete_space.encode('circle')\n",
- "square = discrete_space.encode('square')\n",
- "triangle = discrete_space.encode('triangle')\n",
+ "circle = vocab['CIRCLE']\n",
+ "square = vocab['SQUARE']\n",
+ "triangle = vocab['TRIANGLE']\n",
"\n",
- "print('|circle| =', np.linalg.norm(circle))\n",
- "print('|triangle| =', np.linalg.norm(triangle))\n",
- "print('|square| =', np.linalg.norm(square))"
+ "print('|circle| =', np.linalg.norm(circle.v))\n",
+ "print('|triangle| =', np.linalg.norm(square.v))\n",
+ "print('|square| =', np.linalg.norm(triangle.v))"
]
},
{
@@ -566,7 +487,7 @@
},
"outputs": [],
"source": [
- "plot_vectors([circle, square, triangle], symbol_names)"
+ "plot_vectors([circle.v, square.v, triangle.v], symbol_names)"
]
},
{
@@ -575,13 +496,13 @@
"execution": {}
},
"source": [
- "As vectors are assigned randomly, the images do not display any meaningful structure.\n",
+ "As vectors are initialized randomly, it's perfectly expected that there is no visual connection to how we would represent or expect those concepts to be represented.\n",
"\n",
- "One of the most useful properties of random high-dimensional vectors is that they are approximately orthogonal. This is an important aspect for vector symbolic algebras (VSAs) since we will use the vector dot product to measure similarity between objects encoded as random, high-dimensional vectors. \n",
+ "One of the extremely useful properties of random high-dimensional vectors is that they are approximately orthogonal. This is an important aspect for vector symbolic algebras (VSAs), since we will use the vector dot product to measure similarity between objects encoded as random, high-dimensional vectors.\n",
"\n",
- "Discrete objects are either the same or different, so we expect similarity would be either 1 (the same) or 0 (not the same). Given how we select the vectors that represent discrete symbols if they are the same, they will have the dot product of 1, and if they are different concepts, then they will have a dot product of (approximately) 0.\n",
+ "Discrete objects are either the same or different, so we expect similarity would be either 1 (the same) or 0 (not the same). Given how we select the vectors that represent discrete symbols, if they are the same they will have the dot product of 1 and if they are different concepts, then they will have a dot product of (approximately) 0. This is due to the approximate orthogonality of randomly selected high-dimensional vectors.\n",
"\n",
- "Below, we use the | operator to indicate similarity. This is borrowed from the bra-ket notation in physics, i.e.,\n",
+ "Below we use the | operator to indicate similarity. This is borrowed from the bra-ket notation in physics, i.e.,\n",
"\n",
"$$\n",
"\\mathbf{a}\\cdot\\mathbf{b} = \\langle \\mathbf{a} \\mid \\mathbf{b}\\rangle\n",
@@ -598,17 +519,17 @@
},
"outputs": [],
"source": [
- "concepts_sim_mat = np.zeros((3,3))\n",
+ "sim_mat = np.zeros((3,3))\n",
"\n",
- "concepts_sim_mat[0,0] = (circle | circle).item()\n",
- "concepts_sim_mat[1,1] = (square | square).item()\n",
- "concepts_sim_mat[2,2] = (triangle | triangle).item()\n",
+ "sim_mat[0,0] = spa.dot(circle, circle)\n",
+ "sim_mat[1,1] = spa.dot(square, square)\n",
+ "sim_mat[2,2] = spa.dot(triangle, triangle)\n",
"\n",
- "concepts_sim_mat[0,1] = concepts_sim_mat[1,0] = (circle | square).item()\n",
- "concepts_sim_mat[0,2] = concepts_sim_mat[2,0] = (circle | triangle).item()\n",
- "concepts_sim_mat[1,2] = concepts_sim_mat[2,1] = (square | triangle).item()\n",
+ "sim_mat[0,1] = sim_mat[1,0] = spa.dot(circle, square)\n",
+ "sim_mat[0,2] = sim_mat[2,0] = spa.dot(circle, triangle)\n",
+ "sim_mat[1,2] = sim_mat[2,1] = spa.dot(square, triangle)\n",
"\n",
- "plot_similarity_matrix(concepts_sim_mat, symbol_names)"
+ "plot_similarity_matrix(sim_mat, symbol_names)"
]
},
{
@@ -620,6 +541,34 @@
"As you can see from the above figure, the three randomly selected vectors are approximately orthogonal. This will be important later when we go to make more complicated objects from our vectors."
]
},
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "### Coding Exercise 1 Discussion\n",
+ "\n",
+ "1. How would you provide intuitive reasoning (or rigorous mathematical proof) behind the fact that random high-dimensional vectors (note that each of the components is drawn from uniform distribution with zero mean) approximately orthogonal?"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "#to_remove explanation\n",
+ "\n",
+ "\"\"\"\n",
+ "Discussion: How would you provide intuitive reasoning or rigorous mathematical proof behind the fact that random high-dimensional vectors (note that each of the components is drawn from uniform distribution with zero mean) approximately orthogonal?\n",
+ "\n",
+ "Observe that as each of the components are independent and they are sampled from distribution with zero mean, it means that expected value of dot product E(x*y) = E(\\sum_i x_i * y_i) = (linearity of expectation) \\sum_i E(x_i * y_i) = (independence) \\sum_i (E(x_i) * E(y_i)) = 0.\n",
+ "\"\"\";"
+ ]
+ },
{
"cell_type": "code",
"execution_count": null,
@@ -734,7 +683,7 @@
},
"outputs": [],
"source": [
- "shape = (circle + square + triangle).normalize()"
+ "shape = (circle + square + triangle).normalized()"
]
},
{
@@ -761,21 +710,20 @@
"raise NotImplementedError(\"Student exercise: complete calcualtion of similarity matrix.\")\n",
"###################################################################\n",
"\n",
- "shape_sim_mat = np.zeros((4,4))\n",
+ "sim_mat = np.zeros((4,4))\n",
"\n",
- "shape_sim_mat[0,0] = (circle | circle).item()\n",
- "shape_sim_mat[1,1] = (square | square).item()\n",
- "shape_sim_mat[2,2] = (triangle | ...).item()\n",
- "shape_sim_mat[3,3] = (shape | ...).item()\n",
+ "sim_mat[0,0] = spa.dot(circle, circle)\n",
+ "sim_mat[1,1] = spa.dot(square, square)\n",
+ "sim_mat[2,2] = spa.dot(triangle, ...)\n",
+ "sim_mat[3,3] = spa.dot(shape, ...)\n",
"\n",
- "shape_sim_mat[0,1] = shape_sim_mat[1,0] = (circle | square).item()\n",
- "shape_sim_mat[0,2] = shape_sim_mat[2,0] = (circle | triangle).item()\n",
- "shape_sim_mat[0,3] = shape_sim_mat[3,0] = (circle | shape).item()\n",
+ "sim_mat[0,1] = sim_mat[1,0] = spa.dot(circle, square)\n",
+ "sim_mat[0,2] = sim_mat[2,0] = spa.dot(circle, triangle)\n",
+ "sim_mat[0,3] = sim_mat[3,0] = spa.dot(circle, shape)\n",
"\n",
- "shape_sim_mat[1,2] = shape_sim_mat[2,1] = (square | triangle).item()\n",
- "shape_sim_mat[1,3] = shape_sim_mat[3,1] = (square | shape).item()\n",
- "\n",
- "shape_sim_mat[2,3] = shape_sim_mat[3,2] = (... | ...).item()\n",
+ "sim_mat[1,2] = sim_mat[2,1] = spa.dot(square, triangle)\n",
+ "sim_mat[1,3] = sim_mat[3,1] = spa.dot(square, shape)\n",
+ "sim_mat[2,3] = sim_mat[3,2] = spa.dot(..., shape)\n",
"\n",
"```"
]
@@ -790,21 +738,20 @@
"source": [
"# to_remove solution\n",
"\n",
- "shape_sim_mat = np.zeros((4,4))\n",
- "\n",
- "shape_sim_mat[0,0] = (circle | circle).item()\n",
- "shape_sim_mat[1,1] = (square | square).item()\n",
- "shape_sim_mat[2,2] = (triangle | triangle).item()\n",
- "shape_sim_mat[3,3] = (shape | shape).item()\n",
+ "sim_mat = np.zeros((4,4))\n",
"\n",
- "shape_sim_mat[0,1] = shape_sim_mat[1,0] = (circle | square).item()\n",
- "shape_sim_mat[0,2] = shape_sim_mat[2,0] = (circle | triangle).item()\n",
- "shape_sim_mat[0,3] = shape_sim_mat[3,0] = (circle | shape).item()\n",
+ "sim_mat[0,0] = spa.dot(circle, circle)\n",
+ "sim_mat[1,1] = spa.dot(square, square)\n",
+ "sim_mat[2,2] = spa.dot(triangle, triangle)\n",
+ "sim_mat[3,3] = spa.dot(shape, shape)\n",
"\n",
- "shape_sim_mat[1,2] = shape_sim_mat[2,1] = (square | triangle).item()\n",
- "shape_sim_mat[1,3] = shape_sim_mat[3,1] = (square | shape).item()\n",
+ "sim_mat[0,1] = sim_mat[1,0] = spa.dot(circle, square)\n",
+ "sim_mat[0,2] = sim_mat[2,0] = spa.dot(circle, triangle)\n",
+ "sim_mat[0,3] = sim_mat[3,0] = spa.dot(circle, shape)\n",
"\n",
- "shape_sim_mat[2,3] = shape_sim_mat[3,2] = (triangle | shape).item()"
+ "sim_mat[1,2] = sim_mat[2,1] = spa.dot(square, triangle)\n",
+ "sim_mat[1,3] = sim_mat[3,1] = spa.dot(square, shape)\n",
+ "sim_mat[2,3] = sim_mat[3,2] = spa.dot(triangle, shape)"
]
},
{
@@ -815,7 +762,7 @@
},
"outputs": [],
"source": [
- "plot_similarity_matrix(shape_sim_mat, symbol_names + [\"shape\"], values = True)"
+ "plot_similarity_matrix(sim_mat, symbol_names + [\"shape\"], values = True)"
]
},
{
@@ -880,7 +827,7 @@
"\n",
"Estimated timing to here from start of tutorial: 20 minutes\n",
"\n",
- "In this section, we will talk about binding, an operation that takes two vectors and produces a new vector that is *not* similar to either of its constituent elements.\n",
+ "In this section we will talk about binding - an operation that takes two vectors and produces a new vector that is *not* similar to either of it's constituent elements.\n",
"\n",
"Binding and unbinding are implemented using circular convolution. Luckily, that is implemented for you inside the SSPSpace library. If you would like a refresher on convolution, this [Three Blue One Brown video](https://www.youtube.com/watch?v=KuXjwB4LzSA) is a good place to start."
]
@@ -973,10 +920,9 @@
"source": [
"set_seed(42)\n",
"\n",
- "new_symbol_names = ['circle','square','triangle', 'red', 'blue', 'green']\n",
- "new_discrete_space = sspspace.DiscreteSPSpace(new_symbol_names, ssp_dim=vector_length, optimize=False)\n",
- "\n",
- "objs = {n:new_discrete_space.encode(np.array([n])) for n in new_symbol_names}"
+ "symbol_names = ['CIRCLE','SQUARE','TRIANGLE', 'RED', 'BLUE', 'GREEN']\n",
+ "vocab = make_vocabulary(vector_length)\n",
+ "vocab.populate(';'.join(symbol_names))"
]
},
{
@@ -985,27 +931,12 @@
"execution": {}
},
"source": [
- "Now, we are going to take two of the objects to make new ones: a red circle, a blue triangle, and a green square.\n",
+ "Now we are going to take two of the objects to make new ones: a red circle, a blue triangle and a green square.\n",
"\n",
- "We will combine the two primitive objects using the binding operation, which for us is implemented using circular convolution, and we denote it by \n",
- "\n",
- "\\begin{align*}\n",
+ "We will combine the two primitive objects using the binding operation, which for us is implemented using circular convolution, and we denote it by\n",
+ "$$\n",
" a \\circledast b\n",
- "\\end{align*}\n",
- "\n",
- "\n",
- "Mathematical details
\n",
- "\n",
- "The circular convolution of two vectors $\\mathbf{a}$ and $\\mathbf{b} \\in \\mathbb{R}^N$ is defined as:\n",
- "\n",
- "$$c_j = a \\circledast b = \\sum_{k=1}^{N} a_k b_{1 + (j-k) \\mod N}$$\n",
- "\n",
- "where $N$ is the length of the vectors, and $j$ is the index of the output vector. It's often more convenient to calculate the circular convolution in the Fourier domain. The circular convolution is equivalent to the element-wise product of the Fourier transforms of the two vectors, followed by an inverse Fourier transform:\n",
- "\n",
- "$$a \\circledast b = \\mathcal{F}^{-1}(\\mathcal{F}(\\mathbf{a}) \\odot \\mathcal{F}(\\mathbf{b}))$$\n",
- "where $\\mathcal{F}$ is the Fourier transform, $\\odot$ is the element-wise product, and $\\mathcal{F}^{-1}$ is the inverse Fourier transform. The equivalence between these two formulations is a consequence of the [convolution theorem](https://en.wikipedia.org/wiki/Convolution_theorem).\n",
- "\n",
- " \n",
+ "$$\n",
"\n",
"In the cell below, complete the missing concepts and then observe the computed similarity matrix."
]
@@ -1023,9 +954,9 @@
"raise NotImplementedError(\"Student exercise: complete derivation of new objects using binding operation.\")\n",
"###################################################################\n",
"\n",
- "objs['red*circle'] = objs['red'] * objs['circle']\n",
- "objs['blue*triangle'] = ... * objs['triangle']\n",
- "objs['green*square'] = objs['green'] * ...\n",
+ "vocab.add('RED_CIRCLE', vocab['RED'] * vocab['CIRCLE'])\n",
+ "vocab.add('BLUE_TRIANGLE', vocab['BLUE'] * ...)\n",
+ "vocab.add('GREEN_SQUARE', ... * vocab['SQUARE'])\n",
"\n",
"```"
]
@@ -1040,9 +971,9 @@
"source": [
"# to_remove solution\n",
"\n",
- "objs['red*circle'] = objs['red'] * objs['circle']\n",
- "objs['blue*triangle'] = objs['blue'] * objs['triangle']\n",
- "objs['green*square'] = objs['green'] * objs['square']"
+ "vocab.add('RED_CIRCLE', vocab['RED'] * vocab['CIRCLE'])\n",
+ "vocab.add('BLUE_TRIANGLE', vocab['BLUE'] * vocab['TRIANGLE'])\n",
+ "vocab.add('GREEN_SQUARE', vocab['GREEN'] * vocab['SQUARE'])"
]
},
{
@@ -1062,14 +993,14 @@
},
"outputs": [],
"source": [
- "object_names = list(objs.keys())\n",
- "obj_sims = np.zeros((len(object_names), len(object_names)))\n",
+ "object_names = list(vocab.keys())\n",
+ "sims = np.zeros((len(object_names), len(object_names)))\n",
"\n",
"for name_idx, name in enumerate(object_names):\n",
" for other_idx in range(name_idx, len(object_names)):\n",
- " obj_sims[name_idx, other_idx] = obj_sims[other_idx, name_idx] = (objs[name] | objs[object_names[other_idx]]).item()\n",
+ " sims[name_idx, other_idx] = sims[other_idx, name_idx] = spa.dot(vocab[name], vocab[object_names[other_idx]])\n",
"\n",
- "plot_similarity_matrix(obj_sims, object_names)"
+ "plot_similarity_matrix(sims, object_names)"
]
},
{
@@ -1100,117 +1031,22 @@
"execution": {}
},
"source": [
- "## Coding Exercise 4: Foundations of Colorful Shapes"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Video 4: Unbinding\n",
- "\n",
- "from ipywidgets import widgets\n",
- "from IPython.display import YouTubeVideo\n",
- "from IPython.display import IFrame\n",
- "from IPython.display import display\n",
+ "## Coding Exercise 4: Foundations of Colorful Shapes\n",
"\n",
- "class PlayVideo(IFrame):\n",
- " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
- " self.id = id\n",
- " if source == 'Bilibili':\n",
- " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
- " elif source == 'Osf':\n",
- " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
- " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
- "\n",
- "def display_videos(video_ids, W=400, H=300, fs=1):\n",
- " tab_contents = []\n",
- " for i, video_id in enumerate(video_ids):\n",
- " out = widgets.Output()\n",
- " with out:\n",
- " if video_ids[i][0] == 'Youtube':\n",
- " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
- " height=H, fs=fs, rel=0)\n",
- " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
- " else:\n",
- " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
- " height=H, fs=fs, autoplay=False)\n",
- " if video_ids[i][0] == 'Bilibili':\n",
- " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
- " elif video_ids[i][0] == 'Osf':\n",
- " print(f'Video available at https://osf.io/{video.id}')\n",
- " display(video)\n",
- " tab_contents.append(out)\n",
- " return tab_contents\n",
- "\n",
- "video_ids = [('Youtube', 'vHHX98jBvk8'), ('Bilibili', 'BV1gZ421g7XT')]\n",
- "tab_contents = display_videos(video_ids, W=854, H=480)\n",
- "tabs = widgets.Tab()\n",
- "tabs.children = tab_contents\n",
- "for i in range(len(tab_contents)):\n",
- " tabs.set_title(i, video_ids[i][0])\n",
- "display(tabs)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_unbinding\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "We can also undo the binding operation, which we call unbinding. It is implemented by binding with the pseudo-inverse of the vector we wish to unbind. We denote the pseudo-inverse of the vector using the ~ symbol.\n",
+ "We can also undo the binding operation, which we call unbinding. It is implemented by binding with the pseduo-inverse of the vector we wish to unbind. We denote the pseudoinverse of the vector using the ~ symbol.\n",
"\n",
- "The SSPSpace library implements the pseudo-inverse for you, but the pseudo-inverse of a vector $\\mathbf{x} = (x_{0},\\ldots, x_{d-1})$ is defined:\n",
+ "The SSPSpace library implements the pseudo-inverse for you, but the pseudo-inverse of a vector $\\mathbf{x} = (x_{1},\\ldots, x_{d})$ is defined:\n",
"\n",
- "$$\\sim\\mathbf{x} = \\left(x_{0},x_{d-1},x_{d-2},\\ldots,x_{1}\\right)$$\n",
+ "$$\\sim\\mathbf{x} = \\left(x_{1},x_{d},x_{d-1},\\ldots,x_{2}\\right)$$\n",
"\n",
"\n",
- "Consider the example of our red circle. If we want to recover the shape of the object, we will unbind from it the color:\n",
+ "Consider the example of our red circle. If we wanted to recover the shape of the object, we will unbind from it the color:\n",
"\n",
"$$\n",
"(\\mathtt{red} \\circledast \\mathtt{circle}) \\circledast \\sim \\mathtt{red} \\approx \\mathtt{circle}\n",
"$$\n",
"\n",
- "\n",
- "Mathematical details
\n",
- "\n",
- "By the definition of the pseudo-inverse and circular convolution, we have:\n",
- "\n",
- "$$\\mathbf{x} \\, \\circledast \\sim \\mathbf{x} = \n",
- "\\sum_{k=1}^{N} x_k x_{1 + (j + k - 2) \\mod N} \\approx \\delta_j$$\n",
- "\n",
- "where $\\delta_j$ is the Kronecker delta function. This is:\n",
- "\n",
- "* exactly equal to 1 when $j=1$. This is because the vectors in SSP have a norm of 1.\n",
- "* approximately 0 otherwise. This is because the vectors in SSP are random, and so a vector is approximately orthogonal to a shifted version of itself.\n",
- "\n",
- "The Kronecker delta is the identity function for the circular convolution, and circular convolutions commute, hence:\n",
- "\n",
- "$$\n",
- "(\\mathtt{a} \\circledast \\mathtt{b}) \\circledast \\sim \\mathtt{a} = \\mathtt{b} \\circledast (\\mathtt{a} \\circledast \\sim \\mathtt{a}) \\approx \\mathtt{b} \\circledast \\delta = \\mathtt{b}\n",
- "$$\n",
- "\n",
- " \n",
- "\n",
- "In the cell below, unbind the color and shape, and then observe the similarity matrix."
+ "In the cell below unbind color and shape, and then observe the similarity matrix."
]
},
{
@@ -1221,24 +1057,18 @@
},
"source": [
"```python\n",
- "new_object_names = ['red','red^','red*circle','circle','circle^']\n",
- "new_objs = objs\n",
+ "object_names = ['RED','EST_RED','RED_CIRCLE','CIRCLE','EST_CIRCLE']\n",
"\n",
"###################################################################\n",
"## Fill out the following then remove\n",
"raise NotImplementedError(\"Student exercise: complete derivation of default objects using pseudoinverse.\")\n",
"###################################################################\n",
"\n",
- "new_objs['red^'] = new_objs['red*circle'] * ~new_objs['circle']\n",
- "new_objs['circle^'] = new_objs[...] * ~new_objs[...]\n",
- "\n",
- "new_obj_sims = np.zeros((len(new_object_names), len(new_object_names)))\n",
- "\n",
- "for name_idx, name in enumerate(new_object_names):\n",
- " for other_idx in range(name_idx, len(new_object_names)):\n",
- " new_obj_sims[name_idx, other_idx] = new_obj_sims[other_idx, name_idx] = (new_objs[name] | new_objs[new_object_names[other_idx]]).item()\n",
+ "# to_remove solution\n",
+ "object_names = ['RED','EST_RED','RED_CIRCLE','CIRCLE','EST_CIRCLE']\n",
"\n",
- "plot_similarity_matrix(new_obj_sims, new_object_names, values = True)\n",
+ "vocab.add('EST_RED', (... * ...).normalized())\n",
+ "vocab.add('EST_CIRCLE', (vocab['RED_CIRCLE'] * ~vocab['RED']).normalized())\n",
"\n",
"```"
]
@@ -1252,19 +1082,28 @@
"outputs": [],
"source": [
"# to_remove solution\n",
- "new_object_names = ['red','red^','red*circle','circle','circle^']\n",
- "new_objs = objs\n",
+ "object_names = ['RED','EST_RED','RED_CIRCLE','CIRCLE','EST_CIRCLE']\n",
"\n",
- "new_objs['red^'] = new_objs['red*circle'] * ~new_objs['circle']\n",
- "new_objs['circle^'] = new_objs['red*circle'] * ~new_objs['red']\n",
- "\n",
- "new_obj_sims = np.zeros((len(new_object_names), len(new_object_names)))\n",
+ "vocab.add('EST_RED', (vocab['RED_CIRCLE'] * ~vocab['CIRCLE']).normalized())\n",
+ "vocab.add('EST_CIRCLE', (vocab['RED_CIRCLE'] * ~vocab['RED']).normalized())"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "sims = np.zeros((len(object_names), len(object_names)))\n",
"\n",
- "for name_idx, name in enumerate(new_object_names):\n",
- " for other_idx in range(name_idx, len(new_object_names)):\n",
- " new_obj_sims[name_idx, other_idx] = new_obj_sims[other_idx, name_idx] = (new_objs[name] | new_objs[new_object_names[other_idx]]).item()\n",
+ "for name_idx, name in enumerate(object_names):\n",
+ " for other_idx in range(name_idx, len(object_names)):\n",
+ " sims[name_idx, other_idx] = spa.dot(vocab[name], vocab[object_names[other_idx]])\n",
+ " sims[other_idx, name_idx] = sims[name_idx, other_idx]\n",
"\n",
- "plot_similarity_matrix(new_obj_sims, new_object_names, values = True)"
+ "plot_similarity_matrix(sims, object_names, values = True)"
]
},
{
@@ -1315,7 +1154,7 @@
},
"outputs": [],
"source": [
- "# @title Video 5: Cleanup\n",
+ "# @title Video 4: Cleanup\n",
"\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
@@ -1381,13 +1220,11 @@
"source": [
"## Coding Exercise 5: Cleanup Memories To Find The Best-Fit\n",
"\n",
- "In the process of computing with VSAs, the vectors themselves can become corrupted due to noise, because we implement these systems with spiking neurons, or due to approximations like using the pseudo-inverse for unbinding, or because noise gets added when we operate on complex structures.\n",
+ "In the process of computing with VSAs, the vectors themselves can become corrupted, due to noise, because we implement these systems with spiking neurons, or due to the approximations like using the pseudo inverse for unbinding, or because noise gets added when we operate on complex structures.\n",
"\n",
- "To address this problem, we employ \"cleanup memories.\" These are lots of ways to implement these systems, but today, we're going to do it with a single hidden layer neural network. Let's start with a sequence of symbols, say $\\texttt{fire-fighter},\\texttt{math-teacher},\\texttt{sales-manager},$ and so on, in that fashion, and create a new vector that is a corrupted combination of all three. We will then use a cleanup memory to find the best-fitting vector in our vocabulary.\n",
+ "To address this problem we employ \"cleanup memories\". There are lots of ways to implement these systems, but today we're going to do it with a single hidden layer neural network. Lets start with a sequence of symbols, say $\\texttt{fire-fighter},\\texttt{math-teacher},\\texttt{sales-manager},$ and so on, in that fashion, and create a new vector that is a corrupted combination of all three. We will then use a clean up memory to find the best fitting vector in our vocabulary.\n",
"\n",
- "In the cell below, you will see the definition of `noisy_vector`, your task is to complete the calculation of similarity values for this vector and all default ones.\n",
- "\n",
- "Here, we introduce another graphical way to represent the similarity: by putting a similarity value on the y-axis (instead of the box in the grid) and representing each of the objects by line (the x-axis stays the same, and similarity takes place between the corresponding label on the x-axis and line-object)."
+ "In the cell below you will see the definition of `noisy_vector`, your task is to complete the calculation of similarity values for this vector and all default ones.\n"
]
},
{
@@ -1402,6 +1239,7 @@
"## Fill out the following then remove\n",
"raise NotImplementedError(\"Student exercise: complete similarities calculation between noisy vector and given symbols.\")\n",
"###################################################################\n",
+ "\n",
"set_seed(42)\n",
"\n",
"symbol_names = ['fire-fighter','math-teacher','sales-manager']\n",
@@ -1413,8 +1251,6 @@
"\n",
"sims = np.array([noisy_vector | vocab[...] for name in ...]).squeeze()\n",
"\n",
- "plot_line_similarity_matrix(sims, symbol_names, multiple_objects = False, title = 'Similarity - pre cleanup')\n",
- "\n",
"```"
]
},
@@ -1437,9 +1273,7 @@
"\n",
"noisy_vector = 0.2 * vocab['fire-fighter'] + 0.15 * vocab['math-teacher'] + 0.3 * vocab['sales-manager']\n",
"\n",
- "sims = np.array([noisy_vector | vocab[name] for name in symbol_names]).squeeze()\n",
- "\n",
- "plot_line_similarity_matrix(sims, symbol_names, multiple_objects = False, title = 'Similarity - pre cleanup')"
+ "sims = np.array([noisy_vector | vocab[name] for name in symbol_names]).squeeze()"
]
},
{
@@ -1448,19 +1282,13 @@
"execution": {}
},
"source": [
- "Conceptually, with a discrete vocabulary, we can clean up a vector by finding the reference vector that's closest to the noisy vector and replacing it:\n",
- "\n",
- "$$\\text{cleanup}(\\boldsymbol{x}) = \\arg\\max_{\\boldsymbol{w} \\in \\text{vocab}} \\boldsymbol{x} \\cdot \\boldsymbol{w}$$\n",
- "\n",
- "Now, let's construct a simple one-hidden layer neural network that does cleanup using a soft version of this operation, replacing the max operation with a softmax. The input weights will be the vectors in the vocabulary, and we will place a softmax function on the hidden layer. The output weights will again be the vectors representing the symbols in the vocabulary.\n",
+ "Now let's construct a simple neural network that does cleanup. We will construct the network, instead of learning it. The input weights will be the vectors in the vocabulary, and we will place a softmax function on the hidden layer (although we can use more biologically plausible activiations) and the output weights will again be the vectors representing the symbols in the vocabulary.\n",
"\n",
- "To snap the corrupted vectors back to the vocabulary, we'll apply this operation:\n",
+ "For efficient implementation of similarity calculation inside network, we will use `np.einsum()` function. Typically, it is used as `output = np.einsum('dim_inp1, dim_inp2 -> dim_out', input1, input2)`\n",
"\n",
- "$$\\text{cleanup}(\\boldsymbol{x}) = \\text{softmax}(T \\cdot \\boldsymbol{x} \\boldsymbol{W}^T) \\boldsymbol{W}$$\n",
+ "In this notation, `nd,md->nm` is the einsum \"equation\" or \"subscript notation\" which describes what operation should be performed. In this particular case, it states that the first input tensor is of shape `(n, d)` while the second is of shape `(m, d)` and the result of operation is of shape `(n, m)` (note that `n` and `m` can coincide). The operation itself performs the following calcualtion: `output[n, m] = sum(input1[n, d] * input2[m, d])`, meaning that in our case it will calculate all pairwise dot products - exactly what we need for similarity!\n",
"\n",
- "Where $T$ is the temperature parameter, and $\\boldsymbol{W}$ is the matrix of vectors in the vocabulary. As $T \\to \\infty$, this operation converges to the original hard max cleanup operation. Your task is to complete the `__call__` function. Then, we calculate the similarity between the obtained vector and the ones in the vocabulary.\n",
- "\n",
- "Observe the result and compare it to the pre-cleanup metrics."
+ "Your task is to complete `__call__` function. Then we calculate similarity between obtained vector and the ones in the vocabulary."
]
},
{
@@ -1481,15 +1309,11 @@
"class Cleanup:\n",
" def __init__(self, vocab, temperature=1e5):\n",
" self.weights = np.array([vocab[k] for k in vocab.keys()]).squeeze()\n",
- " self.temp = temperature\n",
+ " self.temp = ...\n",
" def __call__(self, x):\n",
- " ###################################################################\n",
- " ## Fill out the following then remove\n",
- " raise NotImplementedError(\"Student exercise: complete similarity calculation between input vector and weights of the network.\")\n",
- " ###################################################################\n",
- " sims = ...\n",
- " max_sim = softmax(sims * self.temp, axis=1)\n",
- " return sspspace.SSP(...) #sspspace.SSP() wrapper is necessary for further bitwise comparison, it doesn't change the result vector\n",
+ " sims = np.einsum(...)\n",
+ " max_sim = softmax(sims * self.temp, axis=0)\n",
+ " return sspspace.SSP(np.einsum('nd,nm->md', self.weights, max_sim))\n",
"\n",
"\n",
"cleanup = Cleanup(vocab)\n",
@@ -1498,8 +1322,6 @@
"\n",
"clean_sims = np.array([clean_vector | vocab[name] for name in symbol_names]).squeeze()\n",
"\n",
- "plot_double_line_similarity_matrix([sims, clean_sims], symbol_names, ['Noisy Similarity', 'Clean Similarity'], title = 'Similarity - post cleanup')\n",
- "\n",
"```"
]
},
@@ -1520,17 +1342,35 @@
" self.weights = np.array([vocab[k] for k in vocab.keys()]).squeeze()\n",
" self.temp = temperature\n",
" def __call__(self, x):\n",
- " sims = x @ self.weights.T\n",
- " max_sim = softmax(sims * self.temp, axis=1)\n",
- " return sspspace.SSP(max_sim @ self.weights) #sspspace.SSP() wrapper is necessary for further bitwise comparison, it doesn't change the result vector\n",
+ " sims = np.einsum('nd,md->nm', self.weights, x)\n",
+ " max_sim = softmax(sims * self.temp, axis=0)\n",
+ " return sspspace.SSP(np.einsum('nd,nm->md', self.weights, max_sim))\n",
"\n",
"\n",
"cleanup = Cleanup(vocab)\n",
"\n",
"clean_vector = cleanup(noisy_vector)\n",
"\n",
- "clean_sims = np.array([clean_vector | vocab[name] for name in symbol_names]).squeeze()\n",
- "\n",
+ "clean_sims = np.array([clean_vector | vocab[name] for name in symbol_names]).squeeze()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Observe the result with comparison to the pre cleanup metrics."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
"plot_double_line_similarity_matrix([sims, clean_sims], symbol_names, ['Noisy Similarity', 'Clean Similarity'], title = 'Similarity - post cleanup')"
]
},
@@ -1540,7 +1380,7 @@
"execution": {}
},
"source": [
- "For the scenario where we have a discrete, known vocabulary, we can do this cleanup with a single feed-forward network, and we don't need to learn any of the synaptic weights."
+ "We can do this cleanup with a single, feed-forward network, and we don't need to learn any of the synaptic weights if we know what the appropriate vocabulary is."
]
},
{
@@ -1578,7 +1418,7 @@
},
"outputs": [],
"source": [
- "# @title Video 6: Iterated Binding\n",
+ "# @title Video 5: Iterated Binding\n",
"\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
@@ -1644,32 +1484,32 @@
"source": [
"## Coding Exercise 6: Representing Numbers\n",
"\n",
- "It is often useful to be able to represent numbers. For example, we may want to represent the position of an object in a list, or we may want to represent the coordinates of an object in a grid. To do this, we use the binding operator to construct a vector that represents a number. We start by picking what we refer to as an \"axis vector,\" let's call it $\\texttt{one}$, and then iteratively apply binding like this:\n",
+ "It is often useful to be able to represent numbers. For example, we may want to represent the position of an object in a list, or we may want to represent the coordinates of an object in a grid. To do this we use the binding operator to construct a vector that represents a number. We start by picking what we refer to as an \"axis vector\", let's call it $\\texttt{one}$, and then iteratively apply binding, like this:\n",
"\n",
"$$\n",
- "\\texttt{two} = \\texttt{one}\\circledast\\texttt{one} \n",
+ "\\texttt{two} = \\texttt{one}\\circledast\\texttt{one}\n",
"$$\n",
"$$\n",
"\\texttt{three} = \\texttt{two}\\circledast\\texttt{one} = \\texttt{one}\\circledast\\texttt{one}\\circledast\\texttt{one}\n",
"$$\n",
"\n",
- "and so on. We extend that to arbitrary integers, $n$, by writing:\n",
+ "and so on. We extend that to arbitrary integers, $n$, by writing:\n",
"\n",
"$$\n",
"\\phi[n] = \\underset{i=1}{\\overset{n}{\\circledast}}\\texttt{one}\n",
"$$\n",
"\n",
- "Let's try that now and see how similarity between iteratively bound vectors develops. In the cell below, you should complete the missing part, which implements the iterative binding mechanism."
+ "Let's try that now and see how similarity between iteratively bound vectors develops. In the cell below you should complete missing part which implements iterative binding mechanism."
]
},
{
- "cell_type": "markdown",
+ "cell_type": "code",
+ "execution_count": null,
"metadata": {
- "colab_type": "text",
"execution": {}
},
+ "outputs": [],
"source": [
- "```python\n",
"###################################################################\n",
"## Fill out the following then remove\n",
"raise NotImplementedError(\"Student exercise: complete iterated binding.\")\n",
@@ -1678,22 +1518,19 @@
"set_seed(42)\n",
"\n",
"#define axis vector\n",
- "axis_vectors = ['one']\n",
- "\n",
- "encoder = sspspace.DiscreteSPSpace(axis_vectors, ssp_dim=1024, optimize=False)\n",
- "\n",
+ "axis_vectors = ['ONE']\n",
"#vocabulary\n",
- "vocab = {w:encoder.encode(w) for w in axis_vectors}\n",
+ "vocab = make_vocabulary(vector_length)\n",
+ "# vocab = spa.Vocabulary(vector_length)\n",
+ "vocab.populate(';'.join(axis_vectors))\n",
"\n",
"#we will add new vectors to this list\n",
- "integers = [vocab['one']]\n",
+ "integers = [vocab['ONE']]\n",
"\n",
"max_int = 5\n",
"for i in range(2, max_int + 1):\n",
" #bind one more \"one\" to the previous integer to get the new one\n",
- " integers.append(integers[-1] * vocab[...])\n",
- "\n",
- "```"
+ " integers.append((integers[-1] * vocab[...]).normalized())"
]
},
{
@@ -1704,24 +1541,22 @@
},
"outputs": [],
"source": [
- "#to_remove solution\n",
"set_seed(42)\n",
"\n",
"#define axis vector\n",
- "axis_vectors = ['one']\n",
- "\n",
- "encoder = sspspace.DiscreteSPSpace(axis_vectors, ssp_dim=1024, optimize=False)\n",
- "\n",
+ "axis_vectors = ['ONE']\n",
"#vocabulary\n",
- "vocab = {w:encoder.encode(w) for w in axis_vectors}\n",
+ "vocab = make_vocabulary(vector_length)\n",
+ "# vocab = spa.Vocabulary(vector_length)\n",
+ "vocab.populate(';'.join(axis_vectors))\n",
"\n",
"#we will add new vectors to this list\n",
- "integers = [vocab['one']]\n",
+ "integers = [vocab['ONE']]\n",
"\n",
"max_int = 5\n",
"for i in range(2, max_int + 1):\n",
" #bind one more \"one\" to the previous integer to get the new one\n",
- " integers.append(integers[-1] * vocab['one'])"
+ " integers.append((integers[-1] * vocab['ONE']).normalized())"
]
},
{
@@ -1730,7 +1565,7 @@
"execution": {}
},
"source": [
- "Now, we will observe the similarity metric between the obtained vectors. "
+ "Now, we will observe the similarity metric between the obtained vectors. In order to efficienty implement it, we will use already introduced `np.einsum` function. Notice, that in this particual notation, `sims = integers @ integers.T`"
]
},
{
@@ -1741,8 +1576,10 @@
},
"outputs": [],
"source": [
- "integers = np.array(integers).squeeze()\n",
- "integer_sims = integers @ integers.T"
+ "sims = np.zeros((len(integers), len(integers)))\n",
+ "for i_idx, i in enumerate(integers):\n",
+ " for j_idx, j in enumerate(integers):\n",
+ " sims[i_idx, j_idx] = spa.dot(i,j)"
]
},
{
@@ -1753,7 +1590,7 @@
},
"outputs": [],
"source": [
- "plot_similarity_matrix(integer_sims, [i for i in range(1, 6)], values = True)"
+ "plot_similarity_matrix(sims, [i for i in range(1, 6)], values = True)"
]
},
{
@@ -1773,7 +1610,7 @@
},
"outputs": [],
"source": [
- "plot_line_similarity_matrix(integer_sims, range(1, 6), multiple_objects = True, labels = [f'$\\phi$[{idx+1}]' for idx in range(5)], title = \"Similarity for digits\")"
+ "plot_line_similarity_matrix(sims, range(1, 6), multiple_objects = True, labels = [f'$\\phi$[{idx+1}]' for idx in range(5)], title = \"Similarity for digits\")"
]
},
{
@@ -1782,9 +1619,9 @@
"execution": {}
},
"source": [
- "What we can see here is that each number acts like its own vector; they are highly dissimilar, but we can still do arithmetic with them. Let's see what happens when we unbind $\\texttt{two}$ from $\\texttt{five}$.\n",
+ "What we can see here is that each number acts like it's own vector, they are highly dissimilar, but we can still do arithmetic with them. Let's see what happens when we unbind $\\texttt{two}$ from $\\texttt{five}$.\n",
"\n",
- "In the cell below you are invited to complete the missing parts (be attentive! python is zero-indexed, thus you need to choose the correct indices)."
+ "In the cell below you are invited to complete the missing parts (be attentive! python is zero-indexed, thus you need to choose correct indices)."
]
},
{
@@ -1800,8 +1637,8 @@
"raise NotImplementedError(\"Student exercise: unbinding of two from five.\")\n",
"###################################################################\n",
"\n",
- "five_unbind_two = sspspace.SSP(integers[...]) * ~sspspace.SSP(integers[...])\n",
- "five_unbind_two_sims = five_unbind_two @ integers.T\n",
+ "five_unbind_two = integers[4] * ~integers[...]\n",
+ "sims = np.array([spa.dot(five_unbind_two, i) for i in ...])\n",
"\n",
"```"
]
@@ -1816,8 +1653,8 @@
"source": [
"#to_remove solution\n",
"\n",
- "five_unbind_two = sspspace.SSP(integers[4]) * ~sspspace.SSP(integers[1])\n",
- "five_unbind_two_sims = five_unbind_two @ integers.T"
+ "five_unbind_two = integers[4] * ~integers[1]\n",
+ "sims = np.array([spa.dot(five_unbind_two, i) for i in integers])"
]
},
{
@@ -1828,7 +1665,7 @@
},
"outputs": [],
"source": [
- "plot_line_similarity_matrix(five_unbind_two_sims, range(1, 6), multiple_objects = False, title = '$(\\phi[5]\\circledast \\phi[2]^{-1}) \\cdot \\phi[n]$')"
+ "plot_line_similarity_matrix(sims, range(1, 6), multiple_objects = False, title = '$(\\phi[5]\\circledast \\phi[2]^{-1}) \\cdot \\phi[n]$')"
]
},
{
@@ -1859,74 +1696,8 @@
"execution": {}
},
"source": [
- "## Coding Exercise 7: Beyond Binding Integers"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Video 7: Fractional Binding\n",
- "\n",
- "from ipywidgets import widgets\n",
- "from IPython.display import YouTubeVideo\n",
- "from IPython.display import IFrame\n",
- "from IPython.display import display\n",
- "\n",
- "class PlayVideo(IFrame):\n",
- " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
- " self.id = id\n",
- " if source == 'Bilibili':\n",
- " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
- " elif source == 'Osf':\n",
- " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
- " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
- "\n",
- "def display_videos(video_ids, W=400, H=300, fs=1):\n",
- " tab_contents = []\n",
- " for i, video_id in enumerate(video_ids):\n",
- " out = widgets.Output()\n",
- " with out:\n",
- " if video_ids[i][0] == 'Youtube':\n",
- " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
- " height=H, fs=fs, rel=0)\n",
- " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
- " else:\n",
- " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
- " height=H, fs=fs, autoplay=False)\n",
- " if video_ids[i][0] == 'Bilibili':\n",
- " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
- " elif video_ids[i][0] == 'Osf':\n",
- " print(f'Video available at https://osf.io/{video.id}')\n",
- " display(video)\n",
- " tab_contents.append(out)\n",
- " return tab_contents\n",
- "\n",
- "video_ids = [('Youtube', 'mTIodqegq_4'), ('Bilibili', 'BV1b4421Q7mS')]\n",
- "tab_contents = display_videos(video_ids, W=854, H=480)\n",
- "tabs = widgets.Tab()\n",
- "tabs.children = tab_contents\n",
- "for i in range(len(tab_contents)):\n",
- " tabs.set_title(i, video_ids[i][0])\n",
- "display(tabs)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_fractional_binding\")"
+ "## Background Material\n",
+ "### Coding Exercise 7: Beyond Binding Integers"
]
},
{
@@ -1935,7 +1706,7 @@
"execution": {}
},
"source": [
- "This is all well and good, but sometimes, we want to encode values that are not integers. Is there an easy way to do this? You'll be surprised to learn that the answer is: yes.\n",
+ "This is all well and good, but sometimes we want to encode values that are not integers. Is there an easy way to do this? You'll be surprised to learn that the answer is: yes.\n",
"\n",
"We actually use the same technique, but we recognize that iterated binding can be implemented in the Fourier domain:\n",
"\n",
@@ -1943,47 +1714,22 @@
"\\phi[n] = \\mathcal{F}^{-1}\\left\\{\\mathcal{F}\\left\\{\\texttt{one}\\right\\}^{n}\\right\\}\n",
"$$\n",
"\n",
- "where the power of $n$ in the Fourier domain is applied element-wise to the vector. To encode real-valued data, we simply let the integer value, $n$, be a real-valued vector, $x$, and we let the axis vector be a randomly generated vector, $X$. \n",
+ "where the power of $n$ in the Fourier domain is applied element-wise to the vector. To encode real-valued data we simply let the integer value, $n$, be a real-valued vector, $x$, and we let the axis vector be a randomly generated vector, $X$.\n",
"\n",
"$$\n",
"\\phi(x) = \\mathcal{F}^{-1}\\left\\{\\mathcal{F}\\left\\{X\\right\\}^{x}\\right\\}\n",
"$$\n",
"\n",
- "We call vectors that represent real-valued data Spatial Semantic Pointers (SSPs). We can also extend this to multi-dimensional data by binding different SSPs together.\n",
+ "We call vectors that represent real-valued data Spatial Semantic Pointers (SSPs). We can also extend this to multi-dimensional data by binding different SSPs together.\n",
"\n",
"$$\n",
"\\phi(x,y) = \\phi_{X}(x) \\circledast \\phi_{Y}(y)\n",
"$$\n",
"\n",
"\n",
- "In the $\\texttt{sspspace}$ library, we provide an encoder for real- and integer-valued data, and we'll demonstrate it next by encoding a bunch of points in the range $[-4,4]$ and comparing their value to $0$, encoded with SSP.\n",
+ "In the $\\texttt{sspspace}$ library we provide an encoder for real- and integer-valued data, and we'll demonstrate it next by encoding a bunch of points in the range $[-4,4]$ and comparing their value to $0$, encoded a SSP.\n",
"\n",
- "In the cell below, you should complete the similarity calculation by injecting the correct index for the $0$ element (observe that it is right in the middle of the encoded array)."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "execution": {}
- },
- "source": [
- "```python\n",
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete similarity calculation: correct index for `0` and array.\")\n",
- "###################################################################\n",
- "\n",
- "set_seed(42)\n",
- "new_encoder = sspspace.RandomSSPSpace(domain_dim=1, ssp_dim=1024)\n",
- "\n",
- "xs = np.linspace(-4,4,401)[:,None] #we expect the encoded values to be two-dimensional in `encoder.encode()` so we add extra dimension\n",
- "phis = new_encoder.encode(xs)\n",
- "\n",
- "#`0` element is right in the middle of phis array! notice that we have 401 samples inside it\n",
- "real_line_sims = phis[..., :] @ phis.T\n",
- "\n",
- "```"
+ "In the cell below you should complete similarity calculation by injecting correct index for $0$ element (observe that it is right in the middle of encoded array)."
]
},
{
@@ -1994,16 +1740,16 @@
},
"outputs": [],
"source": [
- "#to_remove solution\n",
- "\n",
"set_seed(42)\n",
- "new_encoder = sspspace.RandomSSPSpace(domain_dim=1, ssp_dim=1024)\n",
+ "vocab = make_vocabulary(vector_length)\n",
+ "vocab.populate('X')\n",
"\n",
+ "X = vocab['X'].abs()\n",
"xs = np.linspace(-4,4,401)[:,None] #we expect the encoded values to be two-dimensional in `encoder.encode()` so we add extra dimension\n",
- "phis = new_encoder.encode(xs)\n",
+ "phis = [(X**x) for x in xs]\n",
"\n",
"#`0` element is right in the middle of phis array! notice that we have 401 samples inside it\n",
- "real_line_sims = phis[200, :] @ phis.T"
+ "sims = np.array([spa.dot(phis[200], p) for p in phis])"
]
},
{
@@ -2014,7 +1760,7 @@
},
"outputs": [],
"source": [
- "plot_real_valued_line_similarity(real_line_sims, xs, title = '$\\phi(x)\\cdot\\phi(0)$')"
+ "plot_real_valued_line_similarity(sims, xs, title = '$\\phi(x)\\cdot\\phi(0)$')"
]
},
{
@@ -2023,9 +1769,9 @@
"execution": {}
},
"source": [
- "As with the integers, we can update the values post-encoding through the binding operation. Let's look at the similarity between all the points in the range $[-4,4]$, this time with the value $\\pi/2$, but we will shift it by binding the origin with the desired shift value.\n",
+ "As with the integers, we can update the values, post-encoding through the binding operation. Let's look at the similarity between all the points in the range $[-4,4]$ this time with the value $\\pi/2$, but we will shift it by binding the origin with the desired shift value.\n",
"\n",
- "In the cell below, you need to provide the value for which we are going to shift the origin."
+ "In the cell below you need to provide the value by which we are going to shift the origin."
]
},
{
@@ -2041,8 +1787,8 @@
"raise NotImplementedError(\"Student exercise: provide value to shift and observe the usage of the operation.\")\n",
"###################################################################\n",
"\n",
- "phi_shifted = phis[200,:][None,:] * new_encoder.encode([[...]])\n",
- "shifted_real_line_sims = phi_shifted.flatten() @ phis.T\n",
+ "phi_shifted = phis[200] * X**-3.1\n",
+ "sims = np.array([spa.dot(...) for p in phis])\n",
"\n",
"```"
]
@@ -2057,8 +1803,8 @@
"source": [
"#to_remove solution\n",
"\n",
- "phi_shifted = phis[200,:][None,:] * new_encoder.encode([[np.pi/2]])\n",
- "shifted_real_line_sims = phi_shifted.flatten() @ phis.T"
+ "phi_shifted = phis[200] * X**-3.1\n",
+ "sims = np.array([spa.dot(phi_shifted, p) for p in phis])"
]
},
{
@@ -2069,7 +1815,7 @@
},
"outputs": [],
"source": [
- "plot_real_valued_line_similarity(shifted_real_line_sims, xs, title = '$\\phi(x)\\cdot(\\phi(0)\\circledast\\phi(\\pi/2))$')"
+ "plot_real_valued_line_similarity(sims, xs, title = '$\\phi(x)\\cdot(\\phi(0)\\circledast\\phi(\\pi/2))$')"
]
},
{
@@ -2089,8 +1835,8 @@
},
"outputs": [],
"source": [
- "new_phi_shifted = phis[200,:][None,:] * new_encoder.encode([[-1.5*np.pi]])\n",
- "new_shifted_real_line_sims = new_phi_shifted.flatten() @ phis.T"
+ "phi_shifted = phis[200] * X**(-1.5*np.pi)\n",
+ "sims = np.array([spa.dot(phi_shifted, p) for p in phis])"
]
},
{
@@ -2101,7 +1847,7 @@
},
"outputs": [],
"source": [
- "plot_real_valued_line_similarity(new_shifted_real_line_sims, xs, title = '$\\phi(x)\\cdot(\\phi(0)\\circledast\\phi(-1.5\\pi))$')"
+ "plot_real_valued_line_similarity(sims, xs, title = '$\\phi(x)\\cdot(\\phi(0)\\circledast\\phi(-1.5\\pi))$')"
]
},
{
@@ -2110,7 +1856,7 @@
"execution": {}
},
"source": [
- "We will go on to use these encodings to build spatial maps in Tutorial 3."
+ "We will go on to use these encodings to build spatial maps in Tutorial 5 (Bonus)."
]
},
{
@@ -2121,7 +1867,7 @@
"source": [
"### Coding Exercise 7 Discussion\n",
"\n",
- "1. How would you explain the lines `sims = vector @ phis.T` in the previous coding exercises?"
+ "1. How would you explain the usage of `d,md->m` in `np.einsum()` function in the previous coding exercise?"
]
},
{
@@ -2135,9 +1881,9 @@
"#to_remove explanation\n",
"\n",
"\"\"\"\n",
- "Discussion: How would you explain the lines `sims = vector @ phis.T` in the previous coding exercises?\n",
+ "Discussion: How would you explain the usage of `d,md->m` in `np.einsum()` function in the previous coding exercise?\n",
"\n",
- "We compute the similarity of `vector` to all the other references `phi` using the dot product. `vector` has shape `d` and phis has shape `m x d`, where `m` is the number of references. This yields `m` similarity values, one for each reference.\n",
+ "`d` is the dimensionality of the vector; we compute similariy of one vector (representing `0` object) with other `m` vectors of the same dimension `d` (thus `md`); as the result we receive `m` values of similarity.\n",
"\"\"\";"
]
},
@@ -2150,20 +1896,7 @@
},
"outputs": [],
"source": [
- "# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_beyond_bidning_integers\")"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Video 8: Iterated Binding Conclusion\n",
+ "# @title Video 6: Iterated Binding Conclusion\n",
"\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
@@ -2235,11 +1968,9 @@
"In this tutorial, we developed the toolbox of the main operations on the vector symbolic algebra. In particular, it includes:\n",
"- similarity operation (|), which measures how similar the two vectors are (by calculating their dot product);\n",
"- bundling (+), which creates new set-like objects using vector addition;\n",
- "- binding ($\\circledast$), which creates a new combined representation of the two given objects using circular convolution;\n",
- "- unbinding (~), which allows to derive a pure object from the bound representation by unbinding another one that stands in the pair;\n",
- "- cleanup, which tries to identify the most similar vector in the vocabulary with multiple possible implementations.\n",
- "- iterated binding, which allows one to \"count\" by iteratively binding an axis vector with itself.\n",
- "- encoding real-valued data using fractional binding.\n",
+ "- binding ($\\circledast$), which creates new combined representation of the two given objects using circular convolution;\n",
+ "- unbinding (~), which allows to derive pure object from the binded representation by unbinding another one which stands in the pair;\n",
+ "- cleanup, which tries to identify the most similar vector in the vocabulary, with multiple possible implementations.\n",
"\n",
"In the following tutorials, we will take a look at how we can use these tools to create more complicated structures and derive useful information from them."
]
@@ -2273,7 +2004,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.9.19"
+ "version": "3.9.22"
}
},
"nbformat": 4,
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/instructor/W2D2_Tutorial2.ipynb b/tutorials/W2D2_NeuroSymbolicMethods/instructor/W2D2_Tutorial2.ipynb
index bee1996a9..a299cf670 100644
--- a/tutorials/W2D2_NeuroSymbolicMethods/instructor/W2D2_Tutorial2.ipynb
+++ b/tutorials/W2D2_NeuroSymbolicMethods/instructor/W2D2_Tutorial2.ipynb
@@ -25,9 +25,9 @@
"\n",
"__Content creators:__ P. Michael Furlong, Chris Eliasmith\n",
"\n",
- "__Content reviewers:__ Hlib Solodzhuk, Patrick Mineault, Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi\n",
+ "__Content reviewers:__ Hlib Solodzhuk, Patrick Mineault, Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Alex Murphy\n",
"\n",
- "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk\n"
+ "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk, Alex Murphy\n"
]
},
{
@@ -41,7 +41,7 @@
"\n",
"# Tutorial Objectives\n",
"\n",
- "*Estimated timing of tutorial: 50 minutes*\n",
+ "*Estimated timing of tutorial: 20 minutes*\n",
"\n",
"This tutorial will present you with a couple of play-examples on the usage of basic operations of vector symbolic algebras while generalizing to the new knowledge."
]
@@ -59,7 +59,7 @@
"# @markdown These are the slides for the videos in all tutorials today\n",
"\n",
"from IPython.display import IFrame\n",
- "link_id = \"2szmk\"\n",
+ "link_id = \"jybuw\"\n",
"\n",
"print(f\"If you want to download the slides: 'https://osf.io/download/{link_id}'\")\n",
"\n",
@@ -73,8 +73,11 @@
},
"source": [
"---\n",
- "# Setup\n",
- "\n"
+ "# Setup (Colab Users: Please Read)\n",
+ "\n",
+ "Note that because this tutorial relies on some special Python packages, these packages have requirements for specific versions of common scientific libraries, such as `numpy`. If you're in Google Colab, then as of May 2025, this comes with a later version (2.0.2) pre-installed. We require an older version (we'll be installing `1.24.4`). This causes Colab to force a session restart and then re-running of the installation cells for the new version to take effect. When you run the cell below, you will be prompted to restart the session. This is *entirely expected* and you haven't done anything wrong. Simply click 'Restart' and then run the cells as normal. \n",
+ "\n",
+ "An additional error might sometimes arise where an exception is raised connected to a missing element of NumPy. If this occurs, please restart the session and re-run the cells as normal and this error will go away. Updated versions of the affected libraries are expected out soon, but sadly not in time for the preparation of this material. We thank you for your understanding."
]
},
{
@@ -86,9 +89,27 @@
},
"outputs": [],
"source": [
- "# @title Install and import feedback gadget\n",
+ "# @title Install dependencies\n",
"\n",
- "!pip install --quiet numpy matplotlib ipywidgets scipy scikit-learn vibecheck\n",
+ "!pip install numpy==1.24.4 --quiet\n",
+ "!pip install scikit-learn==1.6.1 --quiet\n",
+ "!pip install scipy==1.15.3 --quiet\n",
+ "!pip install git+https://github.com/neuromatch/sspspace@neuromatch --no-deps --quiet\n",
+ "!pip install nengo==4.0.0 --quiet\n",
+ "!pip install nengo_spa==2.0.0 --quiet\n",
+ "!pip install --quiet matplotlib ipywidgets vibecheck"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Install and import feedback gadget\n",
"\n",
"from vibecheck import DatatopsContentReviewContainer\n",
"def content_review(notebook_section: str):\n",
@@ -106,30 +127,6 @@
"feedback_prefix = \"W2D2_T2\""
]
},
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Notice that exactly the `neuromatch` branch of `sspspace` should be installed! Otherwise, some of the functionality (like `optimize` parameter in the `DiscreteSPSpace` initialization) won't work."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Install dependencies\n",
- "\n",
- "# Install sspspace\n",
- "!pip install git+https://github.com/neuromatch/sspspace@neuromatch --quiet"
- ]
- },
{
"cell_type": "code",
"execution_count": null,
@@ -155,7 +152,15 @@
"import sspspace\n",
"from scipy.special import softmax\n",
"from sklearn.metrics import log_loss\n",
- "from sklearn.neural_network import MLPRegressor"
+ "from sklearn.neural_network import MLPRegressor\n",
+ "\n",
+ "import nengo_spa as spa\n",
+ "from nengo_spa.algebras.hrr_algebra import HrrProperties, HrrAlgebra\n",
+ "from nengo_spa.vector_generation import VectorsWithProperties\n",
+ "def make_vocabulary(vector_length):\n",
+ " vec_generator = VectorsWithProperties(vector_length, algebra=HrrAlgebra(), properties = [HrrProperties.UNITARY, HrrProperties.POSITIVE])\n",
+ " vocab = spa.Vocabulary(vector_length, pointer_gen=vec_generator)\n",
+ " return vocab"
]
},
{
@@ -341,9 +346,9 @@
"source": [
"---\n",
"\n",
- "# Section 1: Analogies. Part 1\n",
+ "# Section 1: Wason Card Task\n",
"\n",
- "In this section we will construct a simple analogy using Vector Symbolic Algebras. The question we are going to try and solve is \"King is to the queen as the prince is to X.\""
+ "One of the powerful benefits of using these structured representations is being able to generalize to other circumstances. To demonstrate this, we are going to show you this in a simple task."
]
},
{
@@ -355,7 +360,7 @@
},
"outputs": [],
"source": [
- "# @title Video 1: Analogy 1\n",
+ "# @title Video 1: Wason Card Task Intro\n",
"\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
@@ -391,7 +396,7 @@
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
- "video_ids = [('Youtube', '2tR4fHvL1Jk'), ('Bilibili', 'BV1fS411P7Ez')]\n",
+ "video_ids = [('Youtube', 'BAju3MNHCq8'), ('Bilibili', 'BV1Qf421X7MB')]\n",
"tab_contents = display_videos(video_ids, W=854, H=480)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
@@ -410,7 +415,7 @@
"outputs": [],
"source": [
"# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_analogy_part_one\")"
+ "content_review(f\"{feedback_prefix}_wason_card_task_intro\")"
]
},
{
@@ -419,25 +424,31 @@
"execution": {}
},
"source": [
- "## Coding Exercise 1: Royal Relationships\n",
+ "## Coding Exercise 1: Wason Card Task\n",
"\n",
- "We're going to start by considering our vocabulary. We will use the basic discrete concepts of monarch, heir, male, and female."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Let's create the objects we know about by combinatorially expanding the space: \n",
+ "We are going to test the generalization property on the Wason Card Task, where a person is told a rule of the form \"if the card is even, then the back is blue\", they are then presented with a number of cards with either an odd number, an even number, a red back, or a blue back. The participant is asked which cards they have to flip to determine that the rule is true.\n",
+ "\n",
+ "In this case, the participant needs to flip only the even card(s), and any card where the back is not blue, as the rule does not state whether or not odd numbers can have blue backs, and a red-backed card with an even number would violate the rule. We can get this from Boolean logic:\n",
+ "\n",
+ "$$\n",
+ "\\mathrm{even} \\implies \\mathrm{blue}\n",
+ "$$\n",
+ "\n",
+ "which is equal to \n",
+ "\n",
+ "$$ \n",
+ "\\neg \\mathrm{even} \\vee \\mathrm{blue}\n",
+ "$$\n",
+ "\n",
+ "where $\\neg$ means a logical not. If we want to find cards that violate the rule, then we negate the rule, providing:\n",
+ "\n",
+ "$$ \n",
+ "\\neg (\\neg \\mathrm{even} \\vee \\mathrm{blue}) = \\mathrm{even} \\wedge \\neg \\mathrm{blue}.\n",
+ "$$\n",
"\n",
- "1. King is a male monarch\n",
- "2. Queen is a female monarch\n",
- "3. Prince is a male heir\n",
- "4. Princess is a female heir\n",
+ "Hence the cards that can violate the rule are even and not blue. \n",
"\n",
- "Complete the missing parts of the code to obtain correct representations of new concepts."
+ "At first, we will define all needed concepts. For all noun concepts we would also like to have `not concept` presented in the space, please complete missing code parts."
]
},
{
@@ -448,22 +459,23 @@
},
"source": [
"```python\n",
+ "set_seed(42)\n",
+ "vector_length = 1024\n",
+ "\n",
+ "card_states = ['RED','BLUE','ODD','EVEN','NOT','GREEN','PRIME','IMPLIES','ANT','RELATION','CONS']\n",
+ "vocab = make_vocabulary(vector_length)\n",
+ "vocab.populate(';'.join(card_states))\n",
+ "\n",
"###################################################################\n",
"## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete correct relations for creating new concepts.\")\n",
+ "raise NotImplementedError(\"Student exercise: complete creating `not x` concepts.\")\n",
"###################################################################\n",
"\n",
- "set_seed(42)\n",
- "\n",
- "symbol_names = ['monarch','heir','male','female']\n",
- "discrete_space = sspspace.DiscreteSPSpace(symbol_names, ssp_dim=1024, optimize=False)\n",
- "\n",
- "objs = {n:discrete_space.encode(n) for n in symbol_names}\n",
+ "for a in ['RED','BLUE','ODD','EVEN','GREEN','PRIME']:\n",
+ " vocab.add(f'NOT_{a}', vocab['NOT'] * vocab[a])\n",
"\n",
- "objs['king'] = objs['monarch'] * objs['male']\n",
- "objs['queen'] = objs['monarch'] * ...\n",
- "objs['prince'] = objs['heir'] * objs['male']\n",
- "objs['princess'] = ... * objs['female']\n",
+ "action_names = ['RED','BLUE','ODD','EVEN','GREEN','PRIME','NOT_RED','NOT_BLUE','NOT_ODD','NOT_EVEN','NOT_GREEN','NOT_PRIME']\n",
+ "action_space = np.array([vocab[x].v for x in action_names]).squeeze()\n",
"\n",
"```"
]
@@ -477,18 +489,19 @@
"outputs": [],
"source": [
"#to_remove solution\n",
- "\n",
"set_seed(42)\n",
+ "vector_length = 1024\n",
"\n",
- "symbol_names = ['monarch','heir','male','female']\n",
- "discrete_space = sspspace.DiscreteSPSpace(symbol_names, ssp_dim=1024, optimize=False)\n",
+ "card_states = ['RED','BLUE','ODD','EVEN','NOT','GREEN','PRIME','IMPLIES','ANT','RELATION','CONS']\n",
+ "vocab = make_vocabulary(vector_length)\n",
+ "vocab.populate(';'.join(card_states))\n",
"\n",
- "objs = {n:discrete_space.encode(n) for n in symbol_names}\n",
"\n",
- "objs['king'] = objs['monarch'] * objs['male']\n",
- "objs['queen'] = objs['monarch'] * objs['female']\n",
- "objs['prince'] = objs['heir'] * objs['male']\n",
- "objs['princess'] = objs['heir'] * objs['female']"
+ "for a in ['RED','BLUE','ODD','EVEN','GREEN','PRIME']:\n",
+ " vocab.add(f'NOT_{a}', vocab['NOT'] * vocab[a])\n",
+ "\n",
+ "action_names = ['RED','BLUE','ODD','EVEN','GREEN','PRIME','NOT_RED','NOT_BLUE','NOT_ODD','NOT_EVEN','NOT_GREEN','NOT_PRIME']\n",
+ "action_space = np.array([vocab[x].v for x in action_names]).squeeze()"
]
},
{
@@ -497,9 +510,27 @@
"execution": {}
},
"source": [
- "Now, we can take an explicit approach. We know that the conversion from king to queen is to unbind male and bind female, so let's apply that to our prince object and see what we uncover. \n",
+ "Now, we are going to set up a simple perceptron-style learning rule, using the HRR (Holographic Reduced Representations) algebra. We are going to learn a target transformation, $T$, such that given a learning rule, $A^{*} = T\\circledast R$, where $A^{*}$ is the antecedant value bundled with $\\texttt{not}$ bound with the consequent value, because we are trying to learn the cards that can violate the rule, described above, and $R$ is the rule to be learned. \n",
+ "\n",
+ "Rules themselves are going to be composed like the data structures representing different countries in the previous section. `ant`, `relation` and `cons` are extra concepts which define the structure and which will bind to the specific instances. \n",
+ "\n",
+ "If we have a rule, $X \\implies Y$, then we would create the VSA representation:\n",
+ "\n",
+ "$$R = \\texttt{ant}\\circledast X + \\texttt{relation}\\circledast \\text{implies} + \\texttt{cons} \\circledast Y$$,\n",
+ "\n",
+ "and the ideal output is:\n",
+ "\n",
+ "$$\n",
+ "A^{*} = X + \\texttt{not}\\circledast Y\n",
+ "$$\n",
"\n",
- "At first, in the cell below, let's recover `queen` from `king` by constructing a new `query` concept, which represents the unbinding of `male` and the binding of `female.` Then, let's see if this new query object bears any similarity to anything in our vocabulary."
+ "\n",
+ "\n",
+ "\n",
+ "In the cell below, let us define two rules:\n",
+ "\n",
+ "$$\\text{blue} \\implies \\text{even}$$\n",
+ "$$\\text{odd} \\implies \\text{green}$$"
]
},
{
@@ -512,19 +543,13 @@
"```python\n",
"###################################################################\n",
"## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete correct relation for creating `query` object to compare with `queen`.\")\n",
+ "raise NotImplementedError(\"Student exercise: complete creating rules as defined above.\")\n",
"###################################################################\n",
"\n",
- "objs['queen_query'] = (objs[...] * ~objs[...]) * objs[...]\n",
- "\n",
- "object_names = list(objs.keys())\n",
- "sims = np.zeros((len(object_names), len(object_names)))\n",
- "\n",
- "for name_idx, name in enumerate(object_names):\n",
- " for other_idx in range(name_idx, len(object_names)):\n",
- " sims[name_idx, other_idx] = sims[other_idx, name_idx] = (objs[name] | objs[object_names[other_idx]]).item()\n",
- "\n",
- "plot_similarity_matrix(sims, object_names, values = True)\n",
+ "rules = [\n",
+ " (vocab['ANT'] * vocab['BLUE'] + vocab['RELATION'] * vocab['IMPLIES'] + vocab['CONS'] * vocab[...]).normalized(),\n",
+ " (vocab[...] * vocab[...] + vocab[...] * vocab[...] + vocab[...] * vocab[...]).normalized(),\n",
+ "]\n",
"\n",
"```"
]
@@ -539,16 +564,10 @@
"source": [
"#to_remove solution\n",
"\n",
- "objs['queen_query'] = (objs['king'] * ~objs['male']) * objs['female']\n",
- "\n",
- "object_names = list(objs.keys())\n",
- "sims = np.zeros((len(object_names), len(object_names)))\n",
- "\n",
- "for name_idx, name in enumerate(object_names):\n",
- " for other_idx in range(name_idx, len(object_names)):\n",
- " sims[name_idx, other_idx] = sims[other_idx, name_idx] = (objs[name] | objs[object_names[other_idx]]).item()\n",
- "\n",
- "plot_similarity_matrix(sims, object_names, values = True)"
+ "rules = [\n",
+ " (vocab['ANT'] * vocab['BLUE'] + vocab['RELATION'] * vocab['IMPLIES'] + vocab['CONS'] * vocab['EVEN']).normalized(),\n",
+ " (vocab['ANT'] * vocab['ODD'] + vocab['RELATION'] * vocab['IMPLIES'] + vocab['CONS'] * vocab['GREEN']).normalized(),\n",
+ "]"
]
},
{
@@ -557,40 +576,13 @@
"execution": {}
},
"source": [
- "The above similarity plot shows that applying that operation successfully converts king to queen. Let's apply it to 'prince' and see what happens. Now, `query` should represent the `princess` concept."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "objs['princess_query'] = (objs['prince'] * ~objs['male']) * objs['female']\n",
+ "Now, we are ready to derive the transformation! For that, we will iterate through the rules and solutions for specified number of iterations and update it as the following:\n",
"\n",
- "object_names = list(objs.keys())\n",
- "sims = np.zeros((len(object_names), len(object_names)))\n",
- "\n",
- "for name_idx, name in enumerate(object_names):\n",
- " for other_idx in range(name_idx, len(object_names)):\n",
- " sims[name_idx, other_idx] = sims[other_idx, name_idx] = (objs[name] | objs[object_names[other_idx]]).item()\n",
- "\n",
- "plot_similarity_matrix(sims, object_names, values = True)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Here, we have successfully recovered the princess, completing the analogy.\n",
+ "$$\\Delta T \\leftarrow T - \\text{lr}*(A^{*} \\circledast \\sim R)$$\n",
"\n",
- "This approach, however, requires explicit knowledge of the construction of the objects. Let's see if we can just work with the concepts of 'king,' 'queen,' and 'prince' directly.\n",
+ "where $\\text{lr}$ is learning rate constant value. Ultimately, we want $A^{*} = T\\circledast R$, so we unbind $R$ to recorver the desired transform, and use the learning rule to update our current estimated transform.\n",
"\n",
- "In the cell below, construct the `princess` concept using only `king,` `queen`, and `prince.`"
+ "We will also compute loss progression over the time and log loss function between perfect similarity (ones only for antecedance value and not consequent one) and the one we obtain between prediciton for current transformation and full action space. Complete missing parts of the code in the next cell to complete training."
]
},
{
@@ -603,18 +595,50 @@
"```python\n",
"###################################################################\n",
"## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete correct relation for creating `query` object to compare with `princess`.\")\n",
+ "raise NotImplementedError(\"Student exercise: complete training loop.\")\n",
"###################################################################\n",
"\n",
- "objs['new_princess_query'] = (objs[...] * ~objs[...]) * objs[...]\n",
+ "num_iters = 500\n",
+ "losses = []\n",
+ "sims = []\n",
+ "lr = 1e-1\n",
+ "ant_names = [\"BLUE\", \"ODD\"]\n",
+ "cons_names = [\"EVEN\", \"GREEN\"]\n",
+ "vector_length = 1024\n",
+ "\n",
+ "transform = np.zeros((vector_length))\n",
+ "for i in range(num_iters):\n",
+ " loss = 0\n",
+ " for rule, ant_name, cons_name in zip(rules, ant_names, cons_names):\n",
+ "\n",
+ " #perfect similarity\n",
+ " y_true = np.eye(len(action_names))[action_names.index(ant_name),:] + np.eye(len(action_names))[4+action_names.index(cons_name),:]\n",
+ "\n",
+ " #prediction with current transform (a_hat = transform * rule)\n",
+ " a_hat = spa.SemanticPointer(transform) * ...\n",
+ "\n",
+ " #similarity with current transform\n",
+ " sim_mat = np.einsum('nd,d->n', action_space, a_hat.v)\n",
+ "\n",
+ " #cleanup\n",
+ " y_hat = softmax(sim_mat)\n",
+ "\n",
+ " #true solution (a* = ant_name + not * cons_name)\n",
+ " a_true = (vocab[ant_name] + vocab['NOT']*vocab[...]).normalized()\n",
+ "\n",
+ " #calculate loss\n",
+ " loss += log_loss(y_true, y_hat)\n",
"\n",
- "sims = np.zeros((len(object_names), len(object_names)))\n",
+ " #update transform (T <- T - lr * (A* * (~rule)))\n",
+ " transform -= (lr) * (transform - (... * ~rule).v)\n",
+ " transform = transform / np.linalg.norm(transform)\n",
"\n",
- "for name_idx, name in enumerate(object_names):\n",
- " for other_idx in range(name_idx, len(object_names)):\n",
- " sims[name_idx, other_idx] = sims[other_idx, name_idx] = (objs[name] | objs[object_names[other_idx]]).item()\n",
+ " #save predicted similarities if it is last iteration\n",
+ " if i == num_iters - 1:\n",
+ " sims.append(sim_mat)\n",
"\n",
- "plot_similarity_matrix(sims, object_names, values = True)\n",
+ " #save loss\n",
+ " losses.append(np.copy(loss))\n",
"\n",
"```"
]
@@ -629,29 +653,47 @@
"source": [
"#to_remove solution\n",
"\n",
- "objs['new_princess_query'] = (objs['prince'] * ~objs['king']) * objs['queen']\n",
- "object_names = list(objs.keys())\n",
+ "num_iters = 500\n",
+ "losses = []\n",
+ "sims = []\n",
+ "lr = 1e-1\n",
+ "ant_names = [\"BLUE\", \"ODD\"]\n",
+ "cons_names = [\"EVEN\", \"GREEN\"]\n",
+ "vector_length = 1024\n",
"\n",
- "sims = np.zeros((len(object_names), len(object_names)))\n",
+ "transform = np.zeros((vector_length))\n",
+ "for i in range(num_iters):\n",
+ " loss = 0\n",
+ " for rule, ant_name, cons_name in zip(rules, ant_names, cons_names):\n",
"\n",
- "for name_idx, name in enumerate(object_names):\n",
- " for other_idx in range(name_idx, len(object_names)):\n",
- " sims[name_idx, other_idx] = sims[other_idx, name_idx] = (objs[name] | objs[object_names[other_idx]]).item()\n",
+ " #perfect similarity\n",
+ " y_true = np.eye(len(action_names))[action_names.index(ant_name),:] + np.eye(len(action_names))[4+action_names.index(cons_name),:]\n",
"\n",
- "plot_similarity_matrix(sims, object_names, values = True)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Again, we see that we have recovered the princess by using our analogy.\n",
+ " #prediction with current transform (a_hat = transform * rule)\n",
+ " a_hat = spa.SemanticPointer(transform) * rule\n",
+ "\n",
+ " #similarity with current transform\n",
+ " sim_mat = np.einsum('nd,d->n', action_space, a_hat.v)\n",
+ "\n",
+ " #cleanup\n",
+ " y_hat = softmax(sim_mat)\n",
+ "\n",
+ " #true solution (a* = ant_name + not * cons_name)\n",
+ " a_true = (vocab[ant_name] + vocab['NOT']*vocab[cons_name]).normalized()\n",
+ "\n",
+ " #calculate loss\n",
+ " loss += log_loss(y_true, y_hat)\n",
"\n",
- "That said, the above depends on knowing that the representations are constructed using binding. Can we do something similar through the bundling operation? Let's try that out.\n",
+ " #update transform (T <- T - lr * (A* * (~rule)))\n",
+ " transform -= (lr) * (transform - (a_true * ~rule).v)\n",
+ " transform = transform / np.linalg.norm(transform)\n",
+ "\n",
+ " #save predicted similarities if it is last iteration\n",
+ " if i == num_iters - 1:\n",
+ " sims.append(sim_mat)\n",
"\n",
- "Reassing concept definitions using bundling operation."
+ " #save loss\n",
+ " losses.append(np.copy(loss))"
]
},
{
@@ -662,14 +704,8 @@
},
"outputs": [],
"source": [
- "set_seed(42)\n",
- "\n",
- "bundle_objs = {n:discrete_space.encode(n) for n in symbol_names}\n",
- "\n",
- "bundle_objs['king'] = (bundle_objs['monarch'] + bundle_objs['male']).normalize()\n",
- "bundle_objs['queen'] = (bundle_objs['monarch'] + bundle_objs['female']).normalize()\n",
- "bundle_objs['prince'] = (bundle_objs['heir'] + bundle_objs['male']).normalize()\n",
- "bundle_objs['princess'] = (bundle_objs['heir'] + bundle_objs['female']).normalize()"
+ "plt.figure(figsize=(15,5))\n",
+ "plot_training_and_choice(losses, sims, ant_names, cons_names, action_names)"
]
},
{
@@ -678,9 +714,7 @@
"execution": {}
},
"source": [
- "But now that we are using an additive model, we need to take a different approach. Instead of unbinding the king and binding the queen, we subtract the king and add the queen to find the princess from the prince.\n",
- "\n",
- "Complete the code to reflect the updated mechanism."
+ "Let's see what happens when we test it on a new rule it hasn't seen before. This time we will use the rule that $\\text{red} \\implies \\text{prime}$. Your task is to complete new rule in the cell below and observe the results."
]
},
{
@@ -693,10 +727,16 @@
"```python\n",
"###################################################################\n",
"## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete correct relation for creating `query` object to compare with `princess`.\")\n",
+ "raise NotImplementedError(\"Student exercise: complete new rule and predict for it.\")\n",
"###################################################################\n",
"\n",
- "bundle_objs['princess_query'] = (bundle_objs[...] - bundle_objs[...]) + bundle_objs[...]\n",
+ "new_rule = (vocab['ANT'] * vocab[...] + vocab['RELATION'] * ... + vocab['CONS'] * vocab[...]).normalized()\n",
+ "\n",
+ "#apply transform on new rule to test the generalization of the transform\n",
+ "a_hat = spa.SemanticPointer(transform) * ...\n",
+ "\n",
+ "new_sims = np.einsum('nd,d->n', action_space, a_hat.v)\n",
+ "y_hat = softmax(new_sims)\n",
"\n",
"```"
]
@@ -711,7 +751,13 @@
"source": [
"#to_remove solution\n",
"\n",
- "bundle_objs['princess_query'] = (bundle_objs['prince'] - bundle_objs['king']) + bundle_objs['queen']"
+ "new_rule = (vocab['ANT'] * vocab['RED'] + vocab['RELATION'] * vocab['IMPLIES'] + vocab['CONS'] * vocab['PRIME']).normalized()\n",
+ "\n",
+ "#apply transform on new rule to test the generalization of the transform\n",
+ "a_hat = spa.SemanticPointer(transform) * new_rule\n",
+ "\n",
+ "new_sims = np.einsum('nd,d->n', action_space, a_hat.v)\n",
+ "y_hat = softmax(new_sims)"
]
},
{
@@ -722,15 +768,8 @@
},
"outputs": [],
"source": [
- "object_names = list(bundle_objs.keys())\n",
- "\n",
- "sims = np.zeros((len(object_names), len(object_names)))\n",
- "\n",
- "for name_idx, name in enumerate(object_names):\n",
- " for other_idx in range(name_idx, len(object_names)):\n",
- " sims[name_idx, other_idx] = sims[other_idx, name_idx] = (bundle_objs[name] | bundle_objs[object_names[other_idx]]).item()\n",
- "\n",
- "plot_similarity_matrix(sims, object_names, values = True)"
+ "plt.figure(figsize=(7,5))\n",
+ "plot_choice([new_sims], [\"RED\"], [\"PRIME\"], action_names)"
]
},
{
@@ -739,711 +778,64 @@
"execution": {}
},
"source": [
- "This is a messier similarity plot due to the fact that the bundled representations interact with all their constituent parts in the vocabulary. That said, we see that 'princess' is still most similar to the query vector. \n",
- "\n",
- "This approach is more like what we would expect from a `word2vec` embedding."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_royal_relationships\")"
+ "Let's compare how a standard MLP that isn't aware of the structure in the representation performs. Here, features are going to be the rules and output - solutions. Complete the code below."
]
},
{
"cell_type": "markdown",
"metadata": {
+ "colab_type": "text",
"execution": {}
},
"source": [
- "---\n",
+ "```python\n",
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete MLP training.\")\n",
+ "###################################################################\n",
+ "\n",
+ "#features - rules\n",
+ "X_train = np.array(...).squeeze()\n",
+ "\n",
+ "#output - a* for each rule\n",
+ "y_train = np.array([\n",
+ " (vocab[ant_names[0]] + vocab['NOT']*vocab[cons_names[0]]).normalized().v,\n",
+ " (vocab[ant_names[1]] + vocab['NOT']*vocab[cons_names[1]]).normalized().v,\n",
+ "]).squeeze()\n",
+ "\n",
+ "regr = MLPRegressor(random_state=1, hidden_layer_sizes=(1024,1024), max_iter=1000).fit(..., ...)\n",
"\n",
- "# Section 2: Analogies. Part 2\n",
+ "a_mlp = regr.predict(new_rule.v[None,:])\n",
"\n",
- "Estimated timing to here from start of tutorial: 15 minutes\n",
+ "mlp_sims = np.einsum('nd,md->nm', action_space, a_mlp)\n",
"\n",
- "In this section, we will construct a database of data structures that describe different countries. Materials are adopted from [Kanerva (2010)](https://cdn.aaai.org/ocs/2243/2243-9566-1-PB.pdf)."
+ "```"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
- "cellView": "form",
"execution": {}
},
"outputs": [],
"source": [
- "# @title Video 2: Analogy 2\n",
+ "#to_remove solution\n",
"\n",
- "from ipywidgets import widgets\n",
- "from IPython.display import YouTubeVideo\n",
- "from IPython.display import IFrame\n",
- "from IPython.display import display\n",
- "\n",
- "class PlayVideo(IFrame):\n",
- " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
- " self.id = id\n",
- " if source == 'Bilibili':\n",
- " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
- " elif source == 'Osf':\n",
- " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
- " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
- "\n",
- "def display_videos(video_ids, W=400, H=300, fs=1):\n",
- " tab_contents = []\n",
- " for i, video_id in enumerate(video_ids):\n",
- " out = widgets.Output()\n",
- " with out:\n",
- " if video_ids[i][0] == 'Youtube':\n",
- " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
- " height=H, fs=fs, rel=0)\n",
- " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
- " else:\n",
- " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
- " height=H, fs=fs, autoplay=False)\n",
- " if video_ids[i][0] == 'Bilibili':\n",
- " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
- " elif video_ids[i][0] == 'Osf':\n",
- " print(f'Video available at https://osf.io/{video.id}')\n",
- " display(video)\n",
- " tab_contents.append(out)\n",
- " return tab_contents\n",
- "\n",
- "video_ids = [('Youtube', 'OB3hzhM7Ois'), ('Bilibili', 'BV1TZ421g7G5')]\n",
- "tab_contents = display_videos(video_ids, W=854, H=480)\n",
- "tabs = widgets.Tab()\n",
- "tabs.children = tab_contents\n",
- "for i in range(len(tab_contents)):\n",
- " tabs.set_title(i, video_ids[i][0])\n",
- "display(tabs)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_analogy_part_two\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "## Coding Exercise 2: Dollar of Mexico\n",
- "\n",
- "This is going to be a little more involved because to construct the data structure, we are going to need vectors that not only represent values that we are reasoning about, but also vectors that represent different roles data can play. This is sometimes called a slot-filler representation or a key-value representation.\n",
- "\n",
- "At first, let us define concepts and cleanup object. Then, we will define `canada` and `mexico` concepts by integrating the available information together. You will be provided with a `canada` object and your task is to complete for `mexico` one. Note that:\n",
- "\n",
- "* We bind `currency` to the relevant currency for that country (`dollar` for Canada, `peso` for Mexico)\n",
- "* We bind `capital` to the relevant capital for that country (`Ottawa` for Canada, `Mexico City` for Mexico)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "execution": {}
- },
- "source": [
- "```python\n",
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete `mexico` concept.\")\n",
- "###################################################################\n",
- "\n",
- "set_seed(42)\n",
- "\n",
- "new_symbol_names = ['dollar', 'peso', 'ottawa', 'mexico-city', 'currency', 'capital']\n",
- "new_discrete_space = sspspace.DiscreteSPSpace(new_symbol_names, ssp_dim=1024, optimize=False)\n",
- "\n",
- "new_objs = {n:new_discrete_space.encode(n) for n in new_symbol_names}\n",
- "\n",
- "cleanup = sspspace.Cleanup(new_objs)\n",
- "\n",
- "new_objs['canada'] = ((new_objs['currency'] * new_objs['dollar']) + (new_objs['capital'] * new_objs['ottawa'])).normalize()\n",
- "new_objs['mexico'] = ((new_objs['currency'] * ...) + (new_objs['capital'] * ...)).normalize()\n",
- "\n",
- "```"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "#to_remove solution\n",
- "\n",
- "set_seed(42)\n",
- "\n",
- "new_symbol_names = ['dollar', 'peso', 'ottawa', 'mexico-city', 'currency', 'capital']\n",
- "new_discrete_space = sspspace.DiscreteSPSpace(new_symbol_names, ssp_dim=1024, optimize=False)\n",
- "\n",
- "new_objs = {n:new_discrete_space.encode(n) for n in new_symbol_names}\n",
- "\n",
- "cleanup = sspspace.Cleanup(new_objs)\n",
- "\n",
- "new_objs['canada'] = ((new_objs['currency'] * new_objs['dollar']) + (new_objs['capital'] * new_objs['ottawa'])).normalize()\n",
- "new_objs['mexico'] = ((new_objs['currency'] * new_objs['peso']) + (new_objs['capital'] * new_objs['mexico-city'])).normalize()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "We would like to find out Mexico's currency. Complete the code for constructing a `query` which will help us do that. Note that we are using a cleanup operation (feel free to remove it and compare the results)."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "execution": {}
- },
- "source": [
- "```python\n",
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete `query` concept which will be similar to currency in Mexico.\")\n",
- "###################################################################\n",
- "\n",
- "objs['peso_query'] = cleanup(~new_objs[...] * new_objs[...] * new_objs['mexico'])\n",
- "\n",
- "object_names = list(new_objs.keys())\n",
- "sims = np.zeros((len(object_names), len(object_names)))\n",
- "\n",
- "for name_idx, name in enumerate(object_names):\n",
- " for other_idx in range(name_idx, len(object_names)):\n",
- " sims[name_idx, other_idx] = sims[other_idx, name_idx] = (new_objs[name] | new_objs[object_names[other_idx]]).item()\n",
- "\n",
- "plot_similarity_matrix(sims, object_names)\n",
- "\n",
- "```"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "#to_remove solution\n",
- "\n",
- "new_objs['peso_query'] = cleanup(~new_objs['canada'] * new_objs['dollar'] * new_objs['mexico'])\n",
- "\n",
- "object_names = list(new_objs.keys())\n",
- "sims = np.zeros((len(object_names), len(object_names)))\n",
- "\n",
- "for name_idx, name in enumerate(object_names):\n",
- " for other_idx in range(name_idx, len(object_names)):\n",
- " sims[name_idx, other_idx] = sims[other_idx, name_idx] = (new_objs[name] | new_objs[object_names[other_idx]]).item()\n",
- "\n",
- "plot_similarity_matrix(sims, object_names)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "After cleanup, the query vector is the most similar to the `peso` object in the vocabulary, correctly answering the question. \n",
- "\n",
- "Note, however, that the similarity is not perfectly equal to 1. This is due to the scale factors applied to the composite vectors `canada` and `mexico`, to ensure they remain unit vectors, and due to cross talk. Crosstalk is a symptom of the fact that we are binding and unbinding bundles of vector symbols to produce the resultant query vector. The constituent vectors are not perfectly orthogonal (i.e., having a dot product of zero), and as such, the terms in the bundle interact when we measure similarity between them."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_dolar_of_mexico\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "---\n",
- "\n",
- "# Section 3: Wason Card Task\n",
- "\n",
- "Estimated timing to here from start of tutorial: 25 minutes\n",
- "\n",
- "One of the powerful benefits of using these structured representations is being able to generalize to other circumstances. To demonstrate this, we are going to show you this in a simple task."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Video 3: Wason Card Task Intro\n",
- "\n",
- "from ipywidgets import widgets\n",
- "from IPython.display import YouTubeVideo\n",
- "from IPython.display import IFrame\n",
- "from IPython.display import display\n",
- "\n",
- "class PlayVideo(IFrame):\n",
- " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
- " self.id = id\n",
- " if source == 'Bilibili':\n",
- " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
- " elif source == 'Osf':\n",
- " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
- " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
- "\n",
- "def display_videos(video_ids, W=400, H=300, fs=1):\n",
- " tab_contents = []\n",
- " for i, video_id in enumerate(video_ids):\n",
- " out = widgets.Output()\n",
- " with out:\n",
- " if video_ids[i][0] == 'Youtube':\n",
- " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
- " height=H, fs=fs, rel=0)\n",
- " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
- " else:\n",
- " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
- " height=H, fs=fs, autoplay=False)\n",
- " if video_ids[i][0] == 'Bilibili':\n",
- " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
- " elif video_ids[i][0] == 'Osf':\n",
- " print(f'Video available at https://osf.io/{video.id}')\n",
- " display(video)\n",
- " tab_contents.append(out)\n",
- " return tab_contents\n",
- "\n",
- "video_ids = [('Youtube', 'BAju3MNHCq8'), ('Bilibili', 'BV1Qf421X7MB')]\n",
- "tab_contents = display_videos(video_ids, W=854, H=480)\n",
- "tabs = widgets.Tab()\n",
- "tabs.children = tab_contents\n",
- "for i in range(len(tab_contents)):\n",
- " tabs.set_title(i, video_ids[i][0])\n",
- "display(tabs)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_wason_card_task_intro\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "## Coding Exercise 3: Wason Card Task\n",
- "\n",
- "We are going to test the generalization property on the Wason Card Task, where a person is told a rule of the form \"if the card is even, then the back is blue\", they are then presented with a number of cards with either an odd number, an even number, a red back, or a blue back. The participant is asked which cards they have to flip to determine that the rule is true.\n",
- "\n",
- "In this case, the participant needs to flip only the even card(s), and any card where the back is not blue, as the rule does not state whether or not odd numbers can have blue backs, and a red-backed card with an even number would violate the rule. We can get this from Boolean logic:\n",
- "\n",
- "$$\n",
- "\\mathrm{even} \\implies \\mathrm{blue}\n",
- "$$\n",
- "\n",
- "which is equal to \n",
- "\n",
- "$$ \n",
- "\\neg \\mathrm{even} \\vee \\mathrm{blue}\n",
- "$$\n",
- "\n",
- "where $\\neg$ means a logical not and $\\vee$ means logical or. If we want to find cards that violate the rule, then we negate the rule, providing:\n",
- "\n",
- "$$ \n",
- "\\neg (\\neg \\mathrm{even} \\vee \\mathrm{blue}) = \\mathrm{even} \\wedge \\neg \\mathrm{blue}.\n",
- "$$\n",
- "\n",
- "Where $\\wedge$ is the logical and. Hence, the cards that can violate the rule are either even or not blue. \n",
- "\n",
- "At first, we will define all the needed concepts. For all noun concepts, we would also like to have `not concept` presented in the space; please complete missing code parts."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "execution": {}
- },
- "source": [
- "```python\n",
- "set_seed(42)\n",
- "\n",
- "card_states = ['red','blue','odd','even','not','green','prime','implies','ant','relation','cons']\n",
- "encoder = sspspace.DiscreteSPSpace(card_states, ssp_dim=1024, optimize=False)\n",
- "vocab = {c:encoder.encode(c) for c in card_states}\n",
- "\n",
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete creating `not x` concepts.\")\n",
- "###################################################################\n",
- "\n",
- "for a in ['red','blue','odd','even','green','prime']:\n",
- " vocab[f'not*{a}'] = vocab[...] * vocab[a]\n",
- "\n",
- "action_names = ['red','blue','odd','even','green','prime','not*red','not*blue','not*odd','not*even','not*green','not*prime']\n",
- "action_space = np.array([vocab[x] for x in action_names]).squeeze()\n",
- "\n",
- "```"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "#to_remove solution\n",
- "\n",
- "set_seed(42)\n",
- "\n",
- "card_states = ['red','blue','odd','even','not','green','prime','implies','ant','relation','cons']\n",
- "encoder = sspspace.DiscreteSPSpace(card_states, ssp_dim=1024, optimize=False)\n",
- "vocab = {c:encoder.encode(c) for c in card_states}\n",
- "\n",
- "for a in ['red','blue','odd','even','green','prime']:\n",
- " vocab[f'not*{a}'] = vocab['not'] * vocab[a]\n",
- "\n",
- "action_names = ['red','blue','odd','even','green','prime','not*red','not*blue','not*odd','not*even','not*green','not*prime']\n",
- "action_space = np.array([vocab[x] for x in action_names]).squeeze()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Now, we are going to set up a simple perceptron-style learning rule using the HRR (Holographic Reduced Representations) algebra. We are going to learn a target transformation, $T$, such that given a learning rule, $A^{*} = T\\circledast R$. Here:\n",
- "\n",
- "* $R$ is the rule to be learned\n",
- "* $A^{*}$ is the antecedent value bundled with $\\texttt{not}$ bound with the consequent value. This is because we are trying to learn the cards that can *violate* the rule.\n",
- "\n",
- "Rules themselves are going to be composed like the data structures representing different countries in the previous section. `ant`, `relation`, and `cons` are extra concepts that define the structure and which will bind to the specific instances (think of them as anchor concepts which got bound to the specific instances). \n",
- "\n",
- "If we have a rule, $X \\implies Y$, then we would create the VSA representation:\n",
- "\n",
- "$$ R = \\texttt{ant} \\circledast X + \\texttt{relation} \\circledast \\texttt{implies} + \\texttt{cons} \\circledast Y $$\n",
- "\n",
- "and the ideal output is:\n",
- "\n",
- "$$\n",
- "A^{*} = X + \\texttt{not}\\circledast Y\n",
- "$$\n",
- "\n",
- "In the cell below, let us define two rules:\n",
- "\n",
- "$$\\text{blue} \\implies \\text{even}$$\n",
- "$$\\text{odd} \\implies \\text{green}$$"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "execution": {}
- },
- "source": [
- "```python\n",
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete creating rules as defined above.\")\n",
- "###################################################################\n",
- "\n",
- "rules = [\n",
- " (vocab['ant'] * vocab['blue'] + vocab['relation'] * vocab['implies'] + vocab['cons'] * vocab[...]).normalize(),\n",
- " (vocab[...] * vocab[...] + vocab[...] * vocab[...] + vocab[...] * vocab[...]).normalize(),\n",
- "]\n",
- "\n",
- "```"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "#to_remove solution\n",
- "\n",
- "rules = [\n",
- " (vocab['ant'] * vocab['blue'] + vocab['relation'] * vocab['implies'] + vocab['cons'] * vocab['even']).normalize(),\n",
- " (vocab['ant'] * vocab['odd'] + vocab['relation'] * vocab['implies'] + vocab['cons'] * vocab['green']).normalize(),\n",
- "]"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Now, we are ready to derive the transformation! For that, we will iterate through the rules and solutions for a specified number of iterations and update it as the following:\n",
- "\n",
- "$$ T \\leftarrow T - \\text{lr} (T - A^{} \\circledast \\sim R)$$\n",
- "\n",
- "where $\\text{lr}$ is learning rate constant value. Ultimately, we want $A^{*} = T\\circledast R$, so we unbind $R$ to recover the desired transform and use the learning rule to update our current estimated transform.\n",
- "\n",
- "We will also compute loss progression over time and log the loss function between perfect similarity (ones only for antecedence value and not consequent one) and the one we obtain between prediction for current transformation and full action space. Complete the missing parts of the code in the next cell to complete training."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "execution": {}
- },
- "source": [
- "```python\n",
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete training loop.\")\n",
- "###################################################################\n",
- "\n",
- "num_iters = 500\n",
- "losses = []\n",
- "sims = []\n",
- "lr = 1e-1\n",
- "ant_names = [\"blue\", \"odd\"]\n",
- "cons_names = [\"even\", \"green\"]\n",
- "\n",
- "transform = np.zeros((1,encoder.ssp_dim))\n",
- "for i in range(num_iters):\n",
- " loss = 0\n",
- " for rule, ant_name, cons_name in zip(rules, ant_names, cons_names):\n",
- "\n",
- " #perfect similarity\n",
- " y_true = np.eye(len(action_names))[action_names.index(ant_name),:] + np.eye(len(action_names))[4+action_names.index(cons_name),:]\n",
- "\n",
- " #prediction with current transform (a_hat = transform * rule)\n",
- " a_hat = sspspace.SSP(transform) * ...\n",
- "\n",
- " #similarity with current transform\n",
- " sim_mat = action_space @ a_hat.T\n",
- "\n",
- " #cleanup\n",
- " y_hat = softmax(sim_mat)\n",
- "\n",
- " #true solution (a* = ant_name + not * cons_name)\n",
- " a_true = (vocab[ant_name] + vocab['not']*vocab[...]).normalize()\n",
- "\n",
- " #calculate loss\n",
- " loss += log_loss(y_true, y_hat)\n",
- "\n",
- " #update transform (T <- T - lr * (T - A* * (~rule)))\n",
- " transform -= (lr) * (... - np.array(... * ~...))\n",
- " transform = transform / np.linalg.norm(transform)\n",
- "\n",
- " #save predicted similarities if it is last iteration\n",
- " if i == num_iters - 1:\n",
- " sims.append(sim_mat)\n",
- "\n",
- " #save loss\n",
- " losses.append(np.copy(loss))\n",
- "\n",
- "plot_training_and_choice(losses, sims, ant_names, cons_names, action_names)\n",
- "\n",
- "```"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "#to_remove solution\n",
- "\n",
- "num_iters = 500\n",
- "losses = []\n",
- "sims = []\n",
- "lr = 1e-1\n",
- "ant_names = [\"blue\", \"odd\"]\n",
- "cons_names = [\"even\", \"green\"]\n",
- "\n",
- "transform = np.zeros((1,encoder.ssp_dim))\n",
- "for i in range(num_iters):\n",
- " loss = 0\n",
- " for rule, ant_name, cons_name in zip(rules, ant_names, cons_names):\n",
- "\n",
- " #perfect similarity\n",
- " y_true = np.eye(len(action_names))[action_names.index(ant_name),:] + np.eye(len(action_names))[4+action_names.index(cons_name),:]\n",
- "\n",
- " #prediction with current transform (a_hat = transform * rule)\n",
- " a_hat = sspspace.SSP(transform) * rule\n",
- "\n",
- " #similarity with current transform\n",
- " sim_mat = action_space @ a_hat.T\n",
- "\n",
- " #cleanup\n",
- " y_hat = softmax(sim_mat)\n",
- "\n",
- " #true solution (a* = ant_name + not * cons_name)\n",
- " a_true = (vocab[ant_name] + vocab['not']*vocab[cons_name]).normalize()\n",
- "\n",
- " #calculate loss\n",
- " loss += log_loss(y_true, y_hat)\n",
- "\n",
- " #update transform (T <- T - lr * (T - A* * (~rule)))\n",
- " transform -= (lr) * (transform - np.array(a_true * ~rule))\n",
- " transform = transform / np.linalg.norm(transform)\n",
- "\n",
- " #save predicted similarities if it is last iteration\n",
- " if i == num_iters - 1:\n",
- " sims.append(sim_mat)\n",
- "\n",
- " #save loss\n",
- " losses.append(np.copy(loss))\n",
- "\n",
- "plot_training_and_choice(losses, sims, ant_names, cons_names, action_names)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Let's see what happens when we test it on a new rule it hasn't seen before. This time, we will use the rule that $\\text{red} \\implies \\text{prime}$. Your task is to complete the new rule in the cell below and observe the results."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "execution": {}
- },
- "source": [
- "```python\n",
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete new rule and predict for it.\")\n",
- "###################################################################\n",
- "\n",
- "new_rule = (vocab['ant'] * vocab[...] + vocab['relation'] * ... + vocab['cons'] * vocab[...]).normalize()\n",
- "\n",
- "#apply transform on new rule to test the generalization of the transform\n",
- "a_hat = sspspace.SSP(transform) * ...\n",
- "\n",
- "new_sims = action_space @ a_hat.T\n",
- "y_hat = softmax(new_sims)\n",
- "\n",
- "plot_choice([new_sims], [\"red\"], [\"prime\"], action_names)\n",
- "\n",
- "```"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "#to_remove solution\n",
- "\n",
- "new_rule = (vocab['ant'] * vocab['red'] + vocab['relation'] * vocab['implies'] + vocab['cons'] * vocab['prime']).normalize()\n",
- "\n",
- "#apply transform on new rule to test the generalization of the transform\n",
- "a_hat = sspspace.SSP(transform) * new_rule\n",
- "\n",
- "new_sims = action_space @ a_hat.T\n",
- "y_hat = softmax(new_sims)\n",
- "\n",
- "plot_choice([new_sims], [\"red\"], [\"prime\"], action_names)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Let's compare how a standard MLP that isn't aware of the structure in the representation performs. Here, features are going to be the rules and output - solutions. Complete the code below."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "execution": {}
- },
- "source": [
- "```python\n",
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete MLP training.\")\n",
- "###################################################################\n",
- "\n",
- "#features - rules\n",
- "X_train = np.array(...).squeeze()\n",
+ "#features - rules\n",
+ "X_train = np.array([r.v for r in rules]).squeeze()\n",
"\n",
"#output - a* for each rule\n",
"y_train = np.array([\n",
- " (vocab[ant_names[0]] + vocab['not']*vocab[cons_names[0]]).normalize(),\n",
- " (vocab[ant_names[1]] + vocab['not']*vocab[cons_names[1]]).normalize(),\n",
+ " (vocab[ant_names[0]] + vocab['NOT']*vocab[cons_names[0]]).normalized().v,\n",
+ " (vocab[ant_names[1]] + vocab['NOT']*vocab[cons_names[1]]).normalized().v,\n",
"]).squeeze()\n",
"\n",
- "regr = MLPRegressor(random_state=1, hidden_layer_sizes=(1024,1024), max_iter=1000).fit(..., ...)\n",
- "\n",
- "a_mlp = regr.predict(new_rule)\n",
- "\n",
- "mlp_sims = action_space @ a_mlp.T\n",
+ "regr = MLPRegressor(random_state=1, hidden_layer_sizes=(1024,1024), max_iter=1000).fit(X_train, y_train)\n",
"\n",
- "plot_choice([mlp_sims], [\"red\"], [\"prime\"], action_names)\n",
+ "a_mlp = regr.predict(new_rule.v[None,:])\n",
"\n",
- "```"
+ "mlp_sims = np.einsum('nd,md->nm', action_space, a_mlp)"
]
},
{
@@ -1454,24 +846,7 @@
},
"outputs": [],
"source": [
- "#to_remove solution\n",
- "\n",
- "#features - rules\n",
- "X_train = np.array(rules).squeeze()\n",
- "\n",
- "#output - a* for each rule\n",
- "y_train = np.array([\n",
- " (vocab[ant_names[0]] + vocab['not']*vocab[cons_names[0]]).normalize(),\n",
- " (vocab[ant_names[1]] + vocab['not']*vocab[cons_names[1]]).normalize(),\n",
- "]).squeeze()\n",
- "\n",
- "regr = MLPRegressor(random_state=1, hidden_layer_sizes=(1024,1024), max_iter=1000).fit(X_train, y_train)\n",
- "\n",
- "a_mlp = regr.predict(new_rule)\n",
- "\n",
- "mlp_sims = action_space @ a_mlp.T\n",
- "\n",
- "plot_choice([mlp_sims], [\"red\"], [\"prime\"], action_names)"
+ "plot_choice([mlp_sims], [\"RED\"], [\"PRIME\"], action_names)"
]
},
{
@@ -1505,7 +880,7 @@
},
"outputs": [],
"source": [
- "# @title Video 4: Wason Card Task Outro\n",
+ "# @title Video 2: Wason Card Task Outro\n",
"\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
@@ -1570,11 +945,11 @@
},
"source": [
"---\n",
- "# Summary\n",
+ "# The Big Picture\n",
"\n",
- "*Estimated timing of tutorial: 45 minutes*\n",
+ "What we saw in this tutorial is the power of generalization at work, that the two top responses were indeed GREEN and NOT PRIME, as Michael outlined in the Outro video. The theme of generalization is the cornerstone of this course and one of the most fundamental aspects we want to convey to you in your NeuroAI journey with us. This tutorial highlights yet another way in which this can be achieved, through the special language of VSA. The MLP does not have access to the structural components and fails to generalize on this task. This is one of the key benefits of the VSA method, where the connection to learning underlying structures allows for generalization to occur. \n",
"\n",
- "In this tutorial, we observed three scenarios where we used the basic operations to solve different analogies and engage in structured learning. The next final tutorial will show us how to use structure to impose inductive biases and how to use continuous representations to represent mixtures of discrete and continuous objects."
+ "We have a bonus tutorial today (Tutorial 4) that covers some other cases connected to analogies, which will help to clarify and demonstrate the power of VSAs even more. We really encourage you to check out that material and then maybe revisit this tutorial if you had any trouble following along. "
]
}
],
@@ -1606,7 +981,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.9.19"
+ "version": "3.9.22"
}
},
"nbformat": 4,
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/instructor/W2D2_Tutorial3.ipynb b/tutorials/W2D2_NeuroSymbolicMethods/instructor/W2D2_Tutorial3.ipynb
index 3131b8d46..28d1917db 100644
--- a/tutorials/W2D2_NeuroSymbolicMethods/instructor/W2D2_Tutorial3.ipynb
+++ b/tutorials/W2D2_NeuroSymbolicMethods/instructor/W2D2_Tutorial3.ipynb
@@ -17,7 +17,7 @@
"execution": {}
},
"source": [
- "# Tutorial 3: Representations in continuous space\n",
+ "# Tutorial 3: Question Answering with Memory\n",
"\n",
"**Week 2, Day 2: Neuro-Symbolic Methods**\n",
"\n",
@@ -25,9 +25,9 @@
"\n",
"__Content creators:__ P. Michael Furlong, Chris Eliasmith\n",
"\n",
- "__Content reviewers:__ Hlib Solodzhuk, Patrick Mineault, Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi\n",
+ "__Content reviewers:__ Konstantine Tsafatinos, Xaq Pitkow, Alex Murphy\n",
"\n",
- "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk"
+ "__Production editors:__ Konstantine Tsafatinos, Xaq Pitkow, Alex Murphy"
]
},
{
@@ -37,13 +37,11 @@
},
"source": [
"___\n",
- "\n",
- "\n",
"# Tutorial Objectives\n",
"\n",
- "*Estimated timing of tutorial: 40 minutes*\n",
+ "This model shows a form of question answering with memory. You will bind two features (color and shape) by circular convolution and store them in a memory population. Then you will provide a cue to the model at a later time to determine either one of the features by deconvolution. This model exhibits better cognitive ability since the answers to the questions are provided at a later time and not at the same time as the questions themselves. These operations use the primitives we introduced in Tutorial 1. Please make sure you have worked through previous tutorials so you can understand how operations such as circular convolution can implement binding of concepts.\n",
"\n",
- "In this tutorial, you will observe how the VSA methods can be applied in structures and environments to allow for efficient generalization."
+ "**Note:** While we present a simplified interface using the Semantc Pointer Architecture, all the computations underlying the model you build are implemented using spiking neurons!"
]
},
{
@@ -59,7 +57,7 @@
"# @markdown These are the slides for the videos in all tutorials today\n",
"\n",
"from IPython.display import IFrame\n",
- "link_id = \"2szmk\"\n",
+ "link_id = \"jybuw\"\n",
"\n",
"print(f\"If you want to download the slides: 'https://osf.io/download/{link_id}'\")\n",
"\n",
@@ -73,8 +71,11 @@
},
"source": [
"---\n",
- "# Setup\n",
- "\n"
+ "# Setup (Colab Users: Please Read)\n",
+ "\n",
+ "Note that because this tutorial relies on some special Python packages, these packages have requirements for specific versions of common scientific libraries, such as `numpy`. If you're in Google Colab, then as of May 2025, this comes with a later version (2.0.2) pre-installed. We require an older version (we'll be installing `1.24.4`). This causes Colab to force a session restart and then re-running of the installation cells for the new version to take effect. When you run the cell below, you will be prompted to restart the session. This is *entirely expected* and you haven't done anything wrong. Simply click 'Restart' and then run the cells as normal. \n",
+ "\n",
+ "An additional error might sometimes arise where an exception is raised connected to a missing element of NumPy. If this occurs, please restart the session and re-run the cells as normal and this error will go away. Updated versions of the affected libraries are expected out soon, but sadly not in time for the preparation of this material. We thank you for your understanding."
]
},
{
@@ -86,9 +87,23 @@
},
"outputs": [],
"source": [
- "# @title Install and import feedback gadget\n",
+ "# @title Install dependencies\n",
"\n",
- "!pip install --quiet jupyter numpy matplotlib ipywidgets scikit-learn tqdm vibecheck\n",
+ "!pip install numpy==1.24.4 --quiet\n",
+ "!pip install nengo nengo-spa nengo-gui --quiet\n",
+ "!pip install matplotlib vibecheck --quiet"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Install and import feedback gadget\n",
"\n",
"from vibecheck import DatatopsContentReviewContainer\n",
"def content_review(notebook_section: str):\n",
@@ -106,30 +121,6 @@
"feedback_prefix = \"W2D2_T3\""
]
},
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Notice that exactly the `neuromatch` branch of `sspspace` should be installed! Otherwise, some of the functionality (like `optimize` parameter in the `DiscreteSPSpace` initialization) won't work."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Install dependencies\n",
- "\n",
- "# Install sspspace\n",
- "!pip install git+https://github.com/neuromatch/sspspace@neuromatch --quiet"
- ]
- },
{
"cell_type": "code",
"execution_count": null,
@@ -141,22 +132,16 @@
"source": [
"# @title Imports\n",
"\n",
- "#working with data\n",
- "import numpy as np\n",
- "\n",
- "#plotting\n",
"import matplotlib.pyplot as plt\n",
+ "import numpy as np\n",
"import logging\n",
"\n",
- "#interactive display\n",
- "import ipywidgets as widgets\n",
+ "%matplotlib inline\n",
"\n",
- "#modeling\n",
- "import sspspace\n",
- "from sklearn.linear_model import LinearRegression\n",
- "from sklearn.model_selection import train_test_split\n",
+ "import nengo\n",
+ "import nengo_spa as spa\n",
"\n",
- "from tqdm.notebook import tqdm as tqdm"
+ "seed = 0"
]
},
{
@@ -178,129 +163,14 @@
]
},
{
- "cell_type": "code",
- "execution_count": null,
+ "cell_type": "markdown",
"metadata": {
- "cellView": "form",
"execution": {}
},
- "outputs": [],
"source": [
- "# @title Plotting functions\n",
- "\n",
- "def plot_3d_function(X, Y, zs, titles):\n",
- " \"\"\"Plot 3D function.\n",
- "\n",
- " Inputs:\n",
- " - X (list): list of np.ndarray of x-values.\n",
- " - Y (list): list of np.ndarray of y-values.\n",
- " - zs (list): list of np.ndarray of z-values.\n",
- " - titles (list): list of titles of the plot.\n",
- " \"\"\"\n",
- " with plt.xkcd():\n",
- " fig = plt.figure(figsize=(8, 8))\n",
- " for index, (x, y, z) in enumerate(zip(X, Y, zs)):\n",
- " fig.add_subplot(1, len(X), index + 1, projection='3d')\n",
- " plt.gca().plot_surface(x,y,z.reshape(x.shape),cmap='plasma', antialiased=False, linewidth=0)\n",
- " plt.xlabel(r'$x_{1}$')\n",
- " plt.ylabel(r'$x_{2}$')\n",
- " plt.gca().set_zlabel(r'$f(\\mathbf{x})$')\n",
- " plt.title(titles[index])\n",
- " plt.show()\n",
- "\n",
- "def plot_performance(bound_performance, bundle_performance, training_samples, title):\n",
- " \"\"\"Plot RMSE values for two different representations of the input data.\n",
- "\n",
- " Inputs:\n",
- " - bound_performance (list): list of RMSE for bound representation.\n",
- " - bundle_performance (list): list of RMSE for bundle representation.\n",
- " - training_samples (list): x-axis.\n",
- " - title (str): title of the plot.\n",
- " \"\"\"\n",
- " with plt.xkcd():\n",
- " plt.plot(training_samples, bound_performance, label='Bound Representation')\n",
- " plt.plot(training_samples, bundle_performance, label='Bundling Representation', ls='--')\n",
- " plt.legend()\n",
- " plt.title(title)\n",
- " plt.ylabel('RMSE (a.u.)')\n",
- " plt.xlabel('# Training samples')\n",
- "\n",
- "def plot_2d_similarity(sims, obj_names, size, title_argmax = False):\n",
- " \"\"\"\n",
- " Plot 2D similarity between query points (grid) and the ones associated with the objects.\n",
- "\n",
- " Inputs:\n",
- " - sims (list): list of similarity values for each of the objects.\n",
- " - obj_names (list): list of object names.\n",
- " - size (tuple): to reshape the similarities.\n",
- " - title_argmax (bool, default = False): looks for the point coordinates as arg max from all similarity value.\n",
- " \"\"\"\n",
- " ticks = [0, 24, 49, 74, 99]\n",
- " ticklabels = [-5, -2, 0, 2, 5]\n",
- " with plt.xkcd():\n",
- " for obj_idx, obj in enumerate(obj_names):\n",
- " plt.subplot(1, len(obj_names), 1 + obj_idx)\n",
- " plt.imshow(np.array(sims[obj_idx].reshape(size)), origin='lower', vmin=-1, vmax=1)\n",
- " plt.gca().set_xticks(ticks)\n",
- " plt.gca().set_xticklabels(ticklabels)\n",
- " if obj_idx == 0:\n",
- " plt.gca().set_yticks(ticks)\n",
- " plt.gca().set_yticklabels(ticklabels)\n",
- " else:\n",
- " plt.gca().set_yticks([])\n",
- " if not title_argmax:\n",
- " plt.title(f'{obj}, {positions[obj_idx]}')\n",
- " else:\n",
- " plt.title(f'{obj}, {query_xs[sims[obj_idx].argmax()]}')\n",
- "\n",
- "def plot_unbinding_objects_map(sims, positions, query_xs, size):\n",
- " \"\"\"\n",
- " Plot 2D similarity between query points (grid) and the unbinded from the objects map.\n",
- "\n",
- " Inputs:\n",
- " - sims (np.ndarray): similarity values for each of the query points with the map.\n",
- " - positions (np.ndarray): positions of the objects.\n",
- " - query_xs (np.ndarray): grid points.\n",
- " - size (tuple): to reshape the similarities.\n",
- "\n",
- " \"\"\"\n",
- " ticks = [0,24,49,74,99]\n",
- " ticklabels = [-5,-2,0,2,5]\n",
- " with plt.xkcd():\n",
- " plt.imshow(sims.reshape(size), origin='lower')\n",
- "\n",
- " for idx, marker in enumerate(['o','s','^']):\n",
- " plt.scatter(*get_coordinate(positions[idx,:], query_xs, size), marker=marker,s=100)\n",
- "\n",
- " plt.gca().set_xticks(ticks)\n",
- " plt.gca().set_xticklabels(ticklabels)\n",
- " plt.gca().set_yticks(ticks)\n",
- " plt.gca().set_yticklabels(ticklabels)\n",
- " plt.title(f'All Object Locations')\n",
- " plt.show()\n",
- "\n",
- "def plot_unbinding_positions_map(sims, positions, obj_names):\n",
- " \"\"\"\n",
- " Plot 2D similarity between query points (grid) and the unbinded from the positions map.\n",
- "\n",
- " Inputs:\n",
- " - sims (np.ndarray): similarity values for each of the query points with the map.\n",
- " - positions (np.ndarray): test positions to query.\n",
- " - obj_names (list): names of the objects for labels.\n",
- " - size (tuple): to reshape the similarities.\n",
- " \"\"\"\n",
- " with plt.xkcd():\n",
- " plt.figure(figsize=(8, 4))\n",
- " for pos_idx, pos in enumerate(positions):\n",
- " plt.subplot(1,len(test_positions), 1+pos_idx)\n",
- " plt.bar([1,2,3], sims[pos_idx])\n",
- " plt.ylim([-0.3, 1.05])\n",
- " plt.gca().set_xticks([1,2,3])\n",
- " plt.gca().set_xticklabels(obj_names, rotation=90)\n",
- " if pos_idx != 0:\n",
- " plt.gca().set_yticks([])\n",
- " plt.title(f'Symbols at\\n{pos}')\n",
- " plt.show()"
+ "# Intro\n",
+ "\n",
+ "Michael will give an introductory overview to the notion of performing question answering in the VSA setup we have been working with today.\n"
]
},
{
@@ -312,113 +182,49 @@
},
"outputs": [],
"source": [
- "# @title Set random seed\n",
+ "# @title Video 1: Introduction\n",
"\n",
- "import random\n",
- "import numpy as np\n",
+ "from ipywidgets import widgets\n",
+ "from IPython.display import YouTubeVideo\n",
+ "from IPython.display import IFrame\n",
+ "from IPython.display import display\n",
"\n",
- "def set_seed(seed=None):\n",
- " if seed is None:\n",
- " seed = np.random.choice(2 ** 32)\n",
- " random.seed(seed)\n",
- " np.random.seed(seed)\n",
+ "class PlayVideo(IFrame):\n",
+ " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
+ " self.id = id\n",
+ " if source == 'Bilibili':\n",
+ " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
+ " elif source == 'Osf':\n",
+ " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
+ " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
- "set_seed(seed = 42)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Helper functions\n",
- "\n",
- "def get_model(xs, ys, train_size):\n",
- " \"\"\"Fit linear regression to the given data.\n",
- "\n",
- " Inputs:\n",
- " - xs (np.ndarray): input data.\n",
- " - ys (np.ndarray): output data.\n",
- " - train_size (float): fraction of data to use for train.\n",
- " \"\"\"\n",
- " X_train, _, y_train, _ = train_test_split(xs, ys, random_state=1, train_size=train_size)\n",
- " return LinearRegression().fit(X_train, y_train)\n",
- "\n",
- "def get_coordinate(x, positions, target_shape):\n",
- " \"\"\"Return the closest column and row coordinates for the given position.\n",
- "\n",
- " Inputs:\n",
- " - x (np.ndarray): query position.\n",
- " - positions (np.ndarray): all positions.\n",
- " - target_shape (tuple): shape of the grid.\n",
- "\n",
- " Outputs:\n",
- " - coordinates (tuple): column and row positions.\n",
- " \"\"\"\n",
- " idx = np.argmin(np.linalg.norm(x - positions, axis=1))\n",
- " c = idx % target_shape[1]\n",
- " r = idx // target_shape[1]\n",
- " return (c,r)\n",
- "\n",
- "def rastrigin_solution(x):\n",
- " \"\"\"Compute Rastrigin function for given array of d-dimenstional vectors.\n",
- "\n",
- " Inputs:\n",
- " - x (np.ndarray of shape (n, d)): n d-dimensional vectors.\n",
- "\n",
- " Outputs:\n",
- " - y (np.ndarray of shape (n, 1)): Rastrigin function value for each of the vectors.\n",
- " \"\"\"\n",
- " return 10 * x.shape[1] + np.sum(x**2 - 10 * np.cos(2*np.pi*x), axis=1)\n",
- "\n",
- "def non_separable_solution(x):\n",
- " \"\"\"Compute non-separable function for given array of 2-dimenstional vectors.\n",
- "\n",
- " Inputs:\n",
- " - x (np.ndarray of shape (n, 2)): n 2-dimensional vectors.\n",
- "\n",
- " Outputs:\n",
- " - y (np.ndarray of shape (n, 1)): non-separable function value for each of the vectors.\n",
- " \"\"\"\n",
- " return np.sin(np.multiply(x[:, 0], x[:, 1]))\n",
- "\n",
- "x0_rastrigin = np.linspace(-5.12, 5.12, 100)\n",
- "X_rastrigin, Y_rastrigin = np.meshgrid(x0_rastrigin,x0_rastrigin)\n",
- "xs_rastrigin = np.vstack((X_rastrigin.flatten(), Y_rastrigin.flatten())).T\n",
- "ys_rastrigin = rastrigin_solution(xs_rastrigin)\n",
- "\n",
- "x0_non_separable = np.linspace(-4, 4, 100)\n",
- "X_non_separable, Y_non_separable = np.meshgrid(x0_non_separable,x0_non_separable)\n",
- "xs_non_separable = np.vstack((X_non_separable.flatten(), Y_non_separable.flatten())).T\n",
- "ys_non_separable = non_separable_solution(xs_non_separable)\n",
- "\n",
- "set_seed(42)\n",
- "\n",
- "obj_names = ['circle','square','triangle']\n",
- "discrete_space = sspspace.DiscreteSPSpace(obj_names, ssp_dim=1024)\n",
- "\n",
- "objs = {n:discrete_space.encode(n) for n in obj_names}\n",
- "\n",
- "ssp_space = sspspace.RandomSSPSpace(domain_dim=2, ssp_dim=1024)\n",
- "positions = np.array([[0, -2],\n",
- " [-2, 3],\n",
- " [3, 2]\n",
- " ])\n",
- "ssps = {n:ssp_space.encode(x) for n, x in zip(obj_names, positions)}\n",
- "\n",
- "dim0 = np.linspace(-5, 5, 101)\n",
- "dim1 = np.linspace(-5, 5, 101)\n",
- "X,Y = np.meshgrid(dim0, dim1)\n",
- "\n",
- "query_xs = np.vstack((X.flatten(), Y.flatten())).T\n",
- "query_ssps = ssp_space.encode(query_xs)\n",
- "\n",
- "bound_objects = [objs[n] * ssps[n] for n in obj_names]\n",
- "ssp_map = sspspace.SSP(np.sum(bound_objects, axis=0))"
+ "def display_videos(video_ids, W=400, H=300, fs=1):\n",
+ " tab_contents = []\n",
+ " for i, video_id in enumerate(video_ids):\n",
+ " out = widgets.Output()\n",
+ " with out:\n",
+ " if video_ids[i][0] == 'Youtube':\n",
+ " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
+ " height=H, fs=fs, rel=0)\n",
+ " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
+ " else:\n",
+ " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
+ " height=H, fs=fs, autoplay=False)\n",
+ " if video_ids[i][0] == 'Bilibili':\n",
+ " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
+ " elif video_ids[i][0] == 'Osf':\n",
+ " print(f'Video available at https://osf.io/{video.id}')\n",
+ " display(video)\n",
+ " tab_contents.append(out)\n",
+ " return tab_contents\n",
+ "\n",
+ "video_ids = [('Youtube', 'YX-CM-vuxAc'), ('Bilibili', 'BV1VV7jz8EXa')]\n",
+ "tab_contents = display_videos(video_ids, W=854, H=480)\n",
+ "tabs = widgets.Tab()\n",
+ "tabs.children = tab_contents\n",
+ "for i in range(len(tab_contents)):\n",
+ " tabs.set_title(i, video_ids[i][0])\n",
+ "display(tabs)"
]
},
{
@@ -427,11 +233,9 @@
"execution": {}
},
"source": [
- "---\n",
+ "## Nengo & Question Answering\n",
"\n",
- "# Section 1: Sample Efficient Learning\n",
- "\n",
- "In this section, we will take a look at how imposing an inductive bias on our feature space can result in more sample-efficient learning. "
+ "Nengo is a tool used to implement spiking and dynamic neural network systems. We will shortly introduce the basics of Nengo so you have a clear idea of how it works, what it can do and how we will be using it throughout this tutorial (and other tutorials) today. We're then going to see how Nengo can be used on the application of Question Answering and then hand over to you to complete some interesting coding exercises to help you develop a feel for how to work with a basic example. These tools in your NeuroAI toolkit should then be a great start for you to continue learning about these methods and applying them to your your scientific questions and interests."
]
},
{
@@ -443,7 +247,7 @@
},
"outputs": [],
"source": [
- "# @title Video 1: Function Learning and Inductive Bias\n",
+ "# @title Video 2: Introduction to Nengo\n",
"\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
@@ -479,7 +283,7 @@
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
- "video_ids = [('Youtube', 'KDKmDjMxU7Q'), ('Bilibili', 'BV1GM4m1S7kT')]\n",
+ "video_ids = [('Youtube', 'FTIu-ariSyE'), ('Bilibili', 'BV1YV7jz8EfS')]\n",
"tab_contents = display_videos(video_ids, W=854, H=480)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
@@ -489,70 +293,68 @@
]
},
{
- "cell_type": "code",
- "execution_count": null,
+ "cell_type": "markdown",
"metadata": {
- "cellView": "form",
"execution": {}
},
- "outputs": [],
"source": [
- "# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_function_learning_and_inductive_bias\")"
+ "# Section 1: Define the input functions\n",
+ "\n",
+ "The color input will ``RED`` and then ``BLUE`` for 0.25 seconds each before being turned off. In the same way the shape input will be ``CIRCLE`` and then ``SQUARE`` for 0.25 seconds each. Thus, the network will bind alternatingly ``RED`` * ``CIRCLE`` and ``BLUE`` * ``SQUARE`` for 0.5 seconds each.\n",
+ "\n",
+ "The cue for deconvolving bound semantic pointers will be turned off for 0.5 seconds and then cycles through ``CIRCLE``, ``RED``, ``SQUARE``, and ``BLUE`` within one second."
]
},
{
- "cell_type": "markdown",
+ "cell_type": "code",
+ "execution_count": null,
"metadata": {
"execution": {}
},
+ "outputs": [],
"source": [
- "## Coding Exercise 1: Additive Function\n",
+ "def color_input(t):\n",
+ " if t < 0.25:\n",
+ " return \"RED\"\n",
+ " elif t < 0.5:\n",
+ " return \"BLUE\"\n",
+ " else:\n",
+ " return \"0\"\n",
"\n",
"\n",
- "We will start with an additive function, the Rastrigin function, defined \n",
+ "def shape_input(t):\n",
+ " if t < 0.25:\n",
+ " return \"CIRCLE\"\n",
+ " elif t < 0.5:\n",
+ " return \"SQUARE\"\n",
+ " else:\n",
+ " return \"0\"\n",
"\n",
- "\\begin{align*}\n",
- "f(\\mathbf{x}) = 10d + \\sum_{i=1}^{d} (x_{i}^{2} - 10 \\cos(2 \\pi x_{i}))\n",
- "\\end{align*}\n",
"\n",
- "where $d$ is the dimensionality of the input vector. In the cell below, complete missing parts of the function which computes values of the Rastrigin function given the input array."
+ "def cue_input(t):\n",
+ " if t < 0.5:\n",
+ " return \"0\"\n",
+ " sequence = [\"0\", \"CIRCLE\", \"RED\", \"0\", \"SQUARE\", \"BLUE\"]\n",
+ " idx = int(((t - 0.5) // (1.0 / len(sequence))) % len(sequence))\n",
+ " return sequence[idx]"
]
},
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"execution": {}
},
"source": [
- "```python\n",
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete the Rastrigin function.\")\n",
- "###################################################################\n",
- "\n",
- "def rastrigin(x):\n",
- " \"\"\"Compute Rastrigin function for given array of d-dimenstional vectors.\n",
+ "# Create the model\n",
"\n",
- " Inputs:\n",
- " - x (np.ndarray of shape (n, d)): n d-dimensional vectors.\n",
- "\n",
- " Outputs:\n",
- " - y (np.ndarray of shape (n, 1)): Rastrigin function value for each of the vectors.\n",
- " \"\"\"\n",
- " return 10 * x.shape[1] + np.sum(... - 10 * np.cos(2*np.pi*...), axis=1)\n",
- "\n",
- "# this code creates 10000 2-dimensional vectors which are going to be served as input to the function (thus, output is of shape (10000, 1))\n",
- "x0_rastrigin = np.linspace(-5.12, 5.12, 100)\n",
- "X_rastrigin, Y_rastrigin = np.meshgrid(x0_rastrigin,x0_rastrigin)\n",
- "xs_rastrigin = np.vstack((X_rastrigin.flatten(), Y_rastrigin.flatten())).T\n",
- "\n",
- "ys_rastrigin = rastrigin(xs_rastrigin)\n",
+ "Below we define a simple network compute the question answering. Note that the state labelled ``conv`` has the following arguments:\n",
+ "```python\n",
+ "conv = spa.State(dimensions, subdimensions=4, feedback=1.0, feedback_synapse=0.4)\n",
+ "```\n",
"\n",
- "plot_3d_function([X_rastrigin],[Y_rastrigin], [ys_rastrigin.reshape(X_rastrigin.shape)], ['Rastrigin Function'])\n",
+ "```feedback=1.0``` determines the strength of a recurrent connection that provides memory. ```feedback_synapse=0.4``` provides a time constant on a low-pass filter that models the synapses of the recurrent connection.\n",
"\n",
- "```"
+ "``Transcode`` objects are modules provided by the Nengo programming framework to allow interaction with the outside world. They represent the interface between functions and the network, and execute simulus functions at runtime."
]
},
{
@@ -563,27 +365,21 @@
},
"outputs": [],
"source": [
- "#to_remove solution\n",
+ "# Number of dimensions for the Semantic Pointers\n",
+ "dimensions = 32\n",
"\n",
- "def rastrigin(x):\n",
- " \"\"\"Compute Rastrigin function for given array of d-dimenstional vectors.\n",
+ "model = spa.Network(label=\"Simple question answering\", seed=seed)\n",
"\n",
- " Inputs:\n",
- " - x (np.ndarray of shape (n, d)): n d-dimensional vectors.\n",
+ "with model:\n",
+ " color_in = spa.Transcode(color_input, output_vocab=dimensions)\n",
+ " shape_in = spa.Transcode(shape_input, output_vocab=dimensions)\n",
+ " bound = spa.State(dimensions, subdimensions=4, feedback=1.0, feedback_synapse=0.4) # conv\n",
+ " cue = spa.Transcode(cue_input, output_vocab=dimensions)\n",
+ " out = spa.State(dimensions)\n",
"\n",
- " Outputs:\n",
- " - y (np.ndarray of shape (n, 1)): Rastrigin function value for each of the vectors.\n",
- " \"\"\"\n",
- " return 10 * x.shape[1] + np.sum(x**2 - 10 * np.cos(2*np.pi*x), axis=1)\n",
- "\n",
- "# this code creates 10000 2-dimensional vectors which are going to be served as input to the function (thus, output is of shape (10000, 1))\n",
- "x0_rastrigin = np.linspace(-5.12, 5.12, 100)\n",
- "X_rastrigin, Y_rastrigin = np.meshgrid(x0_rastrigin,x0_rastrigin)\n",
- "xs_rastrigin = np.vstack((X_rastrigin.flatten(), Y_rastrigin.flatten())).T\n",
- "\n",
- "ys_rastrigin = rastrigin(xs_rastrigin)\n",
- "\n",
- "plot_3d_function([X_rastrigin],[Y_rastrigin], [ys_rastrigin.reshape(X_rastrigin.shape)], ['Rastrigin Function'])"
+ " # Connect the buffers\n",
+ " color_in * shape_in >> bound\n",
+ " bound * ~cue >> out"
]
},
{
@@ -592,10 +388,11 @@
"execution": {}
},
"source": [
- "Now, we are going to see which of the inductive biases (suggested mechanism underlying input data) will be more efficient in training the linear regression to get values of the Rastrigin function. We will consider two representations:\n",
+ "# Probe the Model\n",
+ "\n",
+ "Next we are going to probe different parts of the model to record their state during operation. Probes are analogous to sensors used in performing electrophysiological experiments, and their readout acts like a low-pass filter, smoothing the activity through the `synapse` member. Here we specify the low pass filter to have a time constant of `0.03`\n",
"\n",
- "* **Bound**: We encode 2D input vectors `xs` as bound vectors\n",
- "* **Bundled**: We encode 1D input vectors separately and use bundling and then bundle them together"
+ "We will create probes for all the components in the model: `color_in`, `shape_in`, `cue`, `conv`, and `out`. Specifically, we will probe the `output` member of each of these objects, as the Transcode and State objects represent more complex networks that are implemented in Nengo."
]
},
{
@@ -606,64 +403,67 @@
},
"outputs": [],
"source": [
- "set_seed(42)\n",
- "\n",
- "ssp_space = sspspace.RandomSSPSpace(domain_dim=2, ssp_dim=1024)\n",
- "bound_phis = ssp_space.encode(xs_rastrigin)\n",
- "\n",
- "ssp_space0 = sspspace.RandomSSPSpace(domain_dim=1, ssp_dim=1024)\n",
- "ssp_space1 = sspspace.RandomSSPSpace(domain_dim=1, ssp_dim=1024)\n",
- "\n",
- "#remember that input to `encode` should be 2-dimensional, thus we need to create extra dimension by applying [:,None]\n",
- "bundle_phis = ssp_space0.encode(xs_rastrigin[:, 0][:, None]) + ssp_space1.encode(xs_rastrigin[:, 1][:, None])"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Now, let us define modeling attributes: we will have a few different `train_sizes`, and we will fit a linear regression for each of them in a loop. Then, for each of the models, we will evaluate its fit based on RMSE loss on the test set."
+ "with model:\n",
+ " model.config[nengo.Probe].synapse = nengo.Lowpass(0.03)\n",
+ " p_color_in = nengo.Probe(color_in.output)\n",
+ " p_shape_in = nengo.Probe(shape_in.output)\n",
+ " p_cue = nengo.Probe(cue.output)\n",
+ " p_bound = nengo.Probe(bound.output)\n",
+ " p_out = nengo.Probe(out.output)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
+ "cellView": "form",
"execution": {}
},
"outputs": [],
"source": [
- "def loss(y_true, y_pred):\n",
- " \"\"\"Calculate RMSE loss between true and predicted values (note, that loss is not normalized by the shape).\n",
- "\n",
- " Inputs:\n",
- " - y_true (np.ndarray): true values.\n",
- " - y_pred (np.ndarray): predicted values.\n",
- "\n",
- " Outputs:\n",
- " - loss (float): loss value.\n",
- " \"\"\"\n",
- " return np.sqrt(np.mean((y_true - y_pred) ** 2))\n",
- "\n",
- "def test_performance(xs, ys, train_sizes):\n",
- " \"\"\"Fit linear regression to the provided data and evaluate the performance with RMSE loss for different test sizes.\n",
- "\n",
- " Inputs:\n",
- " - xs (np.ndarray): input data.\n",
- " - ys (np.ndarray): output data.\n",
- " - train_size (list): list of the train sizes.\n",
- " \"\"\"\n",
- " performance = []\n",
- "\n",
- " models = []\n",
- " for train_size in tqdm(train_sizes):\n",
- " X_train, X_test, y_train, y_test = train_test_split(xs, ys, random_state=1, train_size=train_size)\n",
- " regr = LinearRegression().fit(X_train, y_train)\n",
- " performance.append(np.copy(loss(y_test, regr.predict(X_test))))\n",
- " models.append(regr)\n",
- " return performance, models"
+ "# @title Video 3: Working Memory Functionality\n",
+ "\n",
+ "from ipywidgets import widgets\n",
+ "from IPython.display import YouTubeVideo\n",
+ "from IPython.display import IFrame\n",
+ "from IPython.display import display\n",
+ "\n",
+ "class PlayVideo(IFrame):\n",
+ " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
+ " self.id = id\n",
+ " if source == 'Bilibili':\n",
+ " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
+ " elif source == 'Osf':\n",
+ " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
+ " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
+ "\n",
+ "def display_videos(video_ids, W=400, H=300, fs=1):\n",
+ " tab_contents = []\n",
+ " for i, video_id in enumerate(video_ids):\n",
+ " out = widgets.Output()\n",
+ " with out:\n",
+ " if video_ids[i][0] == 'Youtube':\n",
+ " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
+ " height=H, fs=fs, rel=0)\n",
+ " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
+ " else:\n",
+ " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
+ " height=H, fs=fs, autoplay=False)\n",
+ " if video_ids[i][0] == 'Bilibili':\n",
+ " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
+ " elif video_ids[i][0] == 'Osf':\n",
+ " print(f'Video available at https://osf.io/{video.id}')\n",
+ " display(video)\n",
+ " tab_contents.append(out)\n",
+ " return tab_contents\n",
+ "\n",
+ "video_ids = [('Youtube', 'i7mc_Z03pew'), ('Bilibili', 'BV1jK7jzNEr7')]\n",
+ "tab_contents = display_videos(video_ids, W=854, H=480)\n",
+ "tabs = widgets.Tab()\n",
+ "tabs.children = tab_contents\n",
+ "for i in range(len(tab_contents)):\n",
+ " tabs.set_title(i, video_ids[i][0])\n",
+ "display(tabs)"
]
},
{
@@ -672,7 +472,11 @@
"execution": {}
},
"source": [
- "Now, we are ready to train the models on two different inductive biases of the input data."
+ "# Run the model\n",
+ "\n",
+ "Now you will run the model using the programmatic Nengo interface. It will produce plots that compare similarity between different terms in our vocabulary (``RED``,``BLUE``,``CIRCLE``,``SQUARE``) and the states of the different elements of the networks. \n",
+ "\n",
+ "Remember: when the module is representing a state in our vocabularity, the similarity should increase towards 1."
]
},
{
@@ -683,11 +487,8 @@
},
"outputs": [],
"source": [
- "train_sizes = np.linspace(0.25, 0.9, 5)\n",
- "bound_performance, bound_models = test_performance(bound_phis, ys_rastrigin, train_sizes)\n",
- "bundle_performance, bundle_models = test_performance(bundle_phis, ys_rastrigin, train_sizes)\n",
- "plot_performance(bound_performance, bundle_performance, train_sizes * bound_phis.shape[0], \"Rastrigin function - RMSE\")\n",
- "plt.ylim((-1, 20))"
+ "with nengo.Simulator(model) as sim:\n",
+ " sim.run(3.0)"
]
},
{
@@ -696,7 +497,9 @@
"execution": {}
},
"source": [
- "What a drastic difference! Let us evaluate visually the performance when training on 3,000 train points."
+ "# Plot the results\n",
+ "\n",
+ "After we run the simulator, it will store the data from the probes we created earlier. Each of the probe objects above, say `p_bound` which records the output of the binding operation, `bound`, are keys for a dictionary of data stored in the simulator."
]
},
{
@@ -707,13 +510,35 @@
},
"outputs": [],
"source": [
- "bound_model = bound_models[0]\n",
- "bundled_model = bundle_models[0]\n",
+ "plt.figure(figsize=(10, 10))\n",
+ "vocab = model.vocabs[dimensions]\n",
"\n",
- "ys_hat_rastrigin_bound = bound_model.predict(bound_phis)\n",
- "ys_hat_rastrigin_bundled = bundled_model.predict(bundle_phis)\n",
+ "plt.subplot(5, 1, 1)\n",
+ "plt.plot(sim.trange(), spa.similarity(sim.data[p_color_in], vocab))\n",
+ "plt.legend(vocab.keys(), fontsize=\"x-small\")\n",
+ "plt.ylabel(\"color\")\n",
"\n",
- "plot_3d_function([X_rastrigin, X_rastrigin, X_rastrigin], [Y_rastrigin, Y_rastrigin, Y_rastrigin], [ys_rastrigin.reshape(X_rastrigin.shape), ys_hat_rastrigin_bound.reshape(X_rastrigin.shape), ys_hat_rastrigin_bundled.reshape(X_rastrigin.shape)], ['Rastrigin Function - True', 'Bound', 'Bundled'])"
+ "plt.subplot(5, 1, 2)\n",
+ "plt.plot(sim.trange(), spa.similarity(sim.data[p_shape_in], vocab))\n",
+ "plt.legend(vocab.keys(), fontsize=\"x-small\")\n",
+ "plt.ylabel(\"shape\")\n",
+ "\n",
+ "plt.subplot(5, 1, 3)\n",
+ "plt.plot(sim.trange(), spa.similarity(sim.data[p_cue], vocab))\n",
+ "plt.legend(vocab.keys(), fontsize=\"x-small\")\n",
+ "plt.ylabel(\"cue\")\n",
+ "\n",
+ "plt.subplot(5, 1, 4)\n",
+ "for pointer in [\"RED * CIRCLE\", \"BLUE * SQUARE\"]:\n",
+ " plt.plot(sim.trange(), vocab.parse(pointer).dot(sim.data[p_bound].T), label=pointer)\n",
+ "plt.legend(fontsize=\"x-small\")\n",
+ "plt.ylabel(\"Bound\")\n",
+ "\n",
+ "plt.subplot(5, 1, 5)\n",
+ "plt.plot(sim.trange(), spa.similarity(sim.data[p_out], vocab))\n",
+ "plt.legend(vocab.keys(), fontsize=\"x-small\")\n",
+ "plt.ylabel(\"Output\")\n",
+ "plt.xlabel(\"time [s]\")"
]
},
{
@@ -722,26 +547,67 @@
"execution": {}
},
"source": [
- "### Coding Exercise 1 Discussion\n",
+ "The plots of shape, color, and convolved show that first `RED * CIRCLE` and then `BLUE * SQUARE` will be loaded into the convolved buffer so after 0.5 seconds it represents the superposition `RED * CIRCLE + BLUE * SQUARE`.\n",
+ "\n",
+ "The last plot shows that the output is most similar to the semantic pointer bound to the current cue. For example, when RED and CIRCLE are being convolved and the cue is CIRCLE, the output is most similar to RED. Thus, it is possible to unbind semantic pointers from the superposition stored in convolved.\n",
"\n",
- "1. Why do you think the bundled representation is superior for the Rastrigin function?"
+ "You can see the effect of the memory unit in the model above because, even after the stimulus is turned off, the model is still able to answer the questions posed to it by the ``cue`` element.\n",
+ "\n",
+ "You can also see the effect of the neural implementation in the noise in the output signal.\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
+ "cellView": "form",
"execution": {}
},
"outputs": [],
"source": [
- "#to_remove explanation\n",
+ "# @title Video 4: Results Walthrough\n",
+ "\n",
+ "from ipywidgets import widgets\n",
+ "from IPython.display import YouTubeVideo\n",
+ "from IPython.display import IFrame\n",
+ "from IPython.display import display\n",
+ "\n",
+ "class PlayVideo(IFrame):\n",
+ " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
+ " self.id = id\n",
+ " if source == 'Bilibili':\n",
+ " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
+ " elif source == 'Osf':\n",
+ " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
+ " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
- "\"\"\"\n",
- "Discussion: Why do you think the bundled representation is superior for the Rastrigin function?\n",
+ "def display_videos(video_ids, W=400, H=300, fs=1):\n",
+ " tab_contents = []\n",
+ " for i, video_id in enumerate(video_ids):\n",
+ " out = widgets.Output()\n",
+ " with out:\n",
+ " if video_ids[i][0] == 'Youtube':\n",
+ " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
+ " height=H, fs=fs, rel=0)\n",
+ " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
+ " else:\n",
+ " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
+ " height=H, fs=fs, autoplay=False)\n",
+ " if video_ids[i][0] == 'Bilibili':\n",
+ " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
+ " elif video_ids[i][0] == 'Osf':\n",
+ " print(f'Video available at https://osf.io/{video.id}')\n",
+ " display(video)\n",
+ " tab_contents.append(out)\n",
+ " return tab_contents\n",
"\n",
- "The Rastrigin function is a superposition of independent functions of the input variable dimensions. The bundled representation is a superposition of a high-dimensional representation of the input dimensions, making it easier to learn this function, which is additive. For the bound representation, we have to learn a mapping from each tuple of input values to the appropriate output value, meaning more samples are required to approximate the function.\n",
- "\"\"\";"
+ "video_ids = [('Youtube', '3f0UqEm9Gzo'), ('Bilibili', 'BV17K7jzNEr3')]\n",
+ "tab_contents = display_videos(video_ids, W=854, H=480)\n",
+ "tabs = widgets.Tab()\n",
+ "tabs.children = tab_contents\n",
+ "for i in range(len(tab_contents)):\n",
+ " tabs.set_title(i, video_ids[i][0])\n",
+ "display(tabs)"
]
},
{
@@ -754,55 +620,18 @@
"outputs": [],
"source": [
"# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_additive_function\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "## Coding Exercise 2: Non-separable Function\n",
- "\n",
- "Now, let's consider a non-separable function: a function $f(x_1, x_2)$ that cannot be described as the sum of two one-dimensional functions $g(x_1)$ and $h_1$. We will examine this function over the domain $[-4,4]^{2}$:\n",
- "\n",
- "$$f(\\mathbf{x}) = \\sin(x_{1}x_{2})$$\n",
- "\n",
- "Fill in the missing parts of the code to get the correct calculation of the defined function."
+ "content_review(f\"{feedback_prefix}_results_walkthrough\")"
]
},
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"execution": {}
},
"source": [
- "```python\n",
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete the non-separable function.\")\n",
- "###################################################################\n",
- "\n",
- "def non_separable(x):\n",
- " \"\"\"Compute non-separable function for given array of 2-dimenstional vectors.\n",
- "\n",
- " Inputs:\n",
- " - x (np.ndarray of shape (n, 2)): n 2-dimensional vectors.\n",
+ "## Coding Exercise \n",
"\n",
- " Outputs:\n",
- " - y (np.ndarray of shape (n, 1)): non-separable function value for each of the vectors.\n",
- " \"\"\"\n",
- " return np.sin(np.multiply(x[:, ...], x[:, ...]))\n",
- "\n",
- "x0_non_separable = np.linspace(-4, 4, 100)\n",
- "X_non_separable, Y_non_separable = np.meshgrid(x0_non_separable,x0_non_separable)\n",
- "xs_non_separable = np.vstack((X_non_separable.flatten(), Y_non_separable.flatten())).T\n",
- "\n",
- "ys_non_separable = non_separable(xs_non_separable)\n",
- "\n",
- "```"
+ "**QUESTION** Try adding the concept of a ``GREEN * SQUARE`` to the model. Run the simulation for 5 seconds and compare the plots."
]
},
{
@@ -813,35 +642,20 @@
},
"outputs": [],
"source": [
- "#to_remove solution\n",
- "\n",
- "def non_separable(x):\n",
- " \"\"\"Compute non-separable function for given array of 2-dimenstional vectors.\n",
- "\n",
- " Inputs:\n",
- " - x (np.ndarray of shape (n, 2)): n 2-dimensional vectors.\n",
- "\n",
- " Outputs:\n",
- " - y (np.ndarray of shape (n, 1)): non-separable function value for each of the vectors.\n",
- " \"\"\"\n",
- " return np.sin(np.multiply(x[:, 0], x[:, 1]))\n",
- "\n",
- "x0_non_separable = np.linspace(-4, 4, 100)\n",
- "X_non_separable, Y_non_separable = np.meshgrid(x0_non_separable,x0_non_separable)\n",
- "xs_non_separable = np.vstack((X_non_separable.flatten(), Y_non_separable.flatten())).T\n",
- "\n",
- "ys_non_separable = non_separable(xs_non_separable)"
+ "# Student code completion here"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
+ "cellView": "form",
"execution": {}
},
"outputs": [],
"source": [
- "plot_3d_function([X_non_separable],[Y_non_separable], [ys_non_separable.reshape(X_non_separable.shape)], ['Nonseparable Function, $f(\\mathbf{x}) = \\sin(x_{1}x_{2})$'])"
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_green_square_coding\")"
]
},
{
@@ -850,602 +664,24 @@
"execution": {}
},
"source": [
- "### Coding Exercise 2 Discussion\n",
- "\n",
- "1. Can you guess by the nature of the function which of the representations will be more efficient?"
+ "---"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
+ "cellView": "form",
"execution": {}
},
"outputs": [],
"source": [
- "#to_remove explanation\n",
+ "# @title Video 5: Outro Video\n",
"\n",
- "\"\"\"\n",
- "Discussion: Can you guess which of the representations will be more efficient by the nature of the function?\n",
- "\n",
- "As the function is not separable, we expect the bound representation to perform better.\n",
- "\"\"\";"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "We will reuse previously defined spaces for encoding bound and bundled representations."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "bound_phis = ssp_space.encode(xs_non_separable)\n",
- "bundle_phis = ssp_space0.encode(xs_non_separable[:,0][:,None]) + ssp_space1.encode(xs_non_separable[:,1][:,None])\n",
- "\n",
- "train_sizes = np.linspace(0.25, 0.9, 5)\n",
- "bound_performance, bound_models = test_performance(bound_phis, ys_non_separable, train_sizes)\n",
- "bundle_performance, bundle_models = test_performance(bundle_phis, ys_non_separable, train_sizes)\n",
- "plot_performance(bound_performance, bundle_performance, train_sizes * bound_phis.shape[0], title = \"Non-separable function - RMSE\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Bundling representation can't achieve the same quality even when the number of samples is increased. This is because the function is non-separable, and the bundling representation can't capture the interaction between the two dimensions."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "bound_model = bound_models[0]\n",
- "bundle_model = bundle_models[0]\n",
- "\n",
- "ys_hat_bound = bound_model.predict(bound_phis)\n",
- "ys_hat_bundle = bundle_model.predict(bundle_phis)\n",
- "\n",
- "plot_3d_function([X_non_separable, X_non_separable, X_non_separable], [Y_non_separable, Y_non_separable, Y_non_separable], [ys_non_separable.reshape(X_non_separable.shape), ys_hat_bound.reshape(X_non_separable.shape), ys_hat_bundle.reshape(X_non_separable.shape)], ['Non-separable Function - True', 'Bound', 'Bundled'])"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "So, as we can see, when we pick the right inductive bias, we can do a better job."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_non_separable_function\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "---\n",
- "\n",
- "# Section 2: Representing Continuous Values\n",
- "\n",
- "Estimated timing to here from start of tutorial: 20 minutes\n",
- "\n",
- "In this section we will use a technique called Fractional Binding to represent continuous values to construct a map of objects distributed over a 2D space. "
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Video 2: Mapping Intro\n",
- "from ipywidgets import widgets\n",
- "from IPython.display import YouTubeVideo\n",
- "from IPython.display import IFrame\n",
- "from IPython.display import display\n",
- "\n",
- "class PlayVideo(IFrame):\n",
- " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
- " self.id = id\n",
- " if source == 'Bilibili':\n",
- " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
- " elif source == 'Osf':\n",
- " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
- " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
- "\n",
- "def display_videos(video_ids, W=400, H=300, fs=1):\n",
- " tab_contents = []\n",
- " for i, video_id in enumerate(video_ids):\n",
- " out = widgets.Output()\n",
- " with out:\n",
- " if video_ids[i][0] == 'Youtube':\n",
- " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
- " height=H, fs=fs, rel=0)\n",
- " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
- " else:\n",
- " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
- " height=H, fs=fs, autoplay=False)\n",
- " if video_ids[i][0] == 'Bilibili':\n",
- " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
- " elif video_ids[i][0] == 'Osf':\n",
- " print(f'Video available at https://osf.io/{video.id}')\n",
- " display(video)\n",
- " tab_contents.append(out)\n",
- " return tab_contents\n",
- "\n",
- "video_ids = [('Youtube', 's7MOusrbKXU'), ('Bilibili', 'BV1pi421i7iN')]\n",
- "tab_contents = display_videos(video_ids, W=854, H=480)\n",
- "tabs = widgets.Tab()\n",
- "tabs.children = tab_contents\n",
- "for i in range(len(tab_contents)):\n",
- " tabs.set_title(i, video_ids[i][0])\n",
- "display(tabs)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_mapping_intro\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "## Coding Exercise 3: Mixing Discrete Objects With Continuous Space\n",
- "\n",
- "We will store three objects in a vector representing a map. First, we will create 3 objects (a circle, square, and triangle), as we did before."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "set_seed(42)\n",
- "\n",
- "obj_names = ['circle','square','triangle']\n",
- "discrete_space = sspspace.DiscreteSPSpace(obj_names, ssp_dim=1024)\n",
- "\n",
- "objs = {n:discrete_space.encode(n) for n in obj_names}"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Next, we are going to create three locations where the objects will reside, and an encoder will transform those coordinates into an SSP representation."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "set_seed(42)\n",
- "\n",
- "ssp_space = sspspace.RandomSSPSpace(domain_dim=2, ssp_dim=1024)\n",
- "positions = np.array([[0, -2],\n",
- " [-2, 3],\n",
- " [3, 2]\n",
- " ])\n",
- "ssps = {n:ssp_space.encode(x) for n, x in zip(obj_names, positions)}"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Next, in order to see where things are on the map, we are going to compute the similarity between encoded places and points in the space. Your task is to complete the calculation of similarity values between all grid points with the one associated with the object."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "dim0 = np.linspace(-5, 5, 101)\n",
- "dim1 = np.linspace(-5, 5, 101)\n",
- "X,Y = np.meshgrid(dim0, dim1)\n",
- "\n",
- "query_xs = np.vstack((X.flatten(), Y.flatten())).T\n",
- "query_ssps = ssp_space.encode(query_xs)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "execution": {}
- },
- "source": [
- "```python\n",
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete similarity calculation.\")\n",
- "###################################################################\n",
- "\n",
- "sims = []\n",
- "\n",
- "for obj_idx, obj in enumerate(obj_names):\n",
- " sims.append(... @ ssps[obj].flatten())\n",
- "\n",
- "plt.figure(figsize=(8, 2.4))\n",
- "plot_2d_similarity(sims, obj_names, (dim0.size, dim1.size))\n",
- "\n",
- "```"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "#to_remove solution\n",
- "\n",
- "sims = []\n",
- "\n",
- "for obj_idx, obj in enumerate(obj_names):\n",
- " sims.append(query_ssps @ ssps[obj].flatten())\n",
- "\n",
- "plt.figure(figsize=(8, 2.4))\n",
- "plot_2d_similarity(sims, obj_names, (dim0.size, dim1.size))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Now, let's bind these positions with the objects and see how that changes similarity with the map positions. Complete binding operation in the cell below."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "execution": {}
- },
- "source": [
- "```python\n",
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete binding operation for objects and corresponding positions.\")\n",
- "###################################################################\n",
- "\n",
- "#objects are located in `objs` and positions in `ssps`\n",
- "bound_objects = [... * ... for n in obj_names]\n",
- "\n",
- "sims = []\n",
- "\n",
- "for obj_idx, obj in enumerate(obj_names):\n",
- " sims.append(query_ssps @ bound_objects[obj_idx].flatten())\n",
- "\n",
- "plt.figure(figsize=(8, 2.4))\n",
- "plot_2d_similarity(sims, obj_names, (dim0.size, dim1.size))\n",
- "\n",
- "```"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "#to_remove solution\n",
- "\n",
- "#objects are located in `objs` and positions in `ssps`\n",
- "bound_objects = [objs[n] * ssps[n] for n in obj_names]\n",
- "\n",
- "sims = []\n",
- "\n",
- "for obj_idx, obj in enumerate(obj_names):\n",
- " sims.append(query_ssps @ bound_objects[obj_idx].flatten())\n",
- "\n",
- "plt.figure(figsize=(8, 2.4))\n",
- "plot_2d_similarity(sims, obj_names, (dim0.size, dim1.size))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "As you can see, the similarity is destroyed, which is what we should expect.\n",
- "\n",
- "Next, we are going to create a map out of our bound objects:\n",
- "\n",
- "\\begin{align*}\n",
- "\\mathrm{map} = \\sum_{i=1}^{n} \\phi(x_{i})\\circledast obj_{i}\n",
- "\\end{align*}"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "set_seed(42)\n",
- "\n",
- "ssp_map = sspspace.SSP(np.sum(bound_objects, axis=0))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Now, we can query the map by unbinding the objects we care about. Your task is to complete the unbinding operation. Then, let's observe the resulting similarities."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "execution": {}
- },
- "source": [
- "```python\n",
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete the unbinding operation.\")\n",
- "###################################################################\n",
- "\n",
- "objects_sims = []\n",
- "\n",
- "for obj_idx, obj_name in enumerate(obj_names):\n",
- " #query the object name by unbinding it from the map\n",
- " query_map = ssp_map * ~objs[...]\n",
- " objects_sims.append(query_ssps @ query_map.flatten())\n",
- "\n",
- "plot_2d_similarity(objects_sims, obj_names, (dim0.size, dim1.size), title_argmax = True)\n",
- "\n",
- "```"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "#to_remove solution\n",
- "\n",
- "objects_sims = []\n",
- "\n",
- "for obj_idx, obj_name in enumerate(obj_names):\n",
- " #query the object name by unbinding it from the map\n",
- " query_map = ssp_map * ~objs[obj_name]\n",
- " objects_sims.append(query_ssps @ query_map.flatten())\n",
- "\n",
- "plot_2d_similarity(objects_sims, obj_names, (dim0.size, dim1.size), title_argmax = True)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Let's look at what happens when we unbind all the symbols from the map at once. Complete bundling and unbinding operations in the following code cell."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "execution": {}
- },
- "source": [
- "```python\n",
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete the bundling and unbinding operations.\")\n",
- "###################################################################\n",
- "\n",
- "# unifying bundled representation of all objects\n",
- "all_objs = (objs['circle'] + objs[...] + objs[...]).normalize()\n",
- "\n",
- "# unbind this unifying representation from the map\n",
- "query_map = ... * ~...\n",
- "\n",
- "sims = query_ssps @ query_map.flatten()\n",
- "size = (dim0.size,dim1.size)\n",
- "\n",
- "plot_unbinding_objects_map(sims, positions, query_xs, size)\n",
- "\n",
- "```"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "#to_remove solution\n",
- "# unifying bundled representation of all objects\n",
- "all_objs = (objs['circle'] + objs['square'] + objs['triangle']).normalize()\n",
- "\n",
- "# unbind this unifying representation from the map\n",
- "query_map = ssp_map * ~all_objs\n",
- "\n",
- "sims = query_ssps @ query_map.flatten()\n",
- "size = (dim0.size,dim1.size)\n",
- "\n",
- "plot_unbinding_objects_map(sims, positions, query_xs, size)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "We can also unbind positions and see what objects exist there. We will the locations where objects are located as test positions, as well as two distinct ones to compare. In the final exercise, you should complete the unbinding of the position's operation."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "execution": {}
- },
- "source": [
- "```python\n",
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete the unbinding operations.\")\n",
- "###################################################################\n",
- "\n",
- "query_objs = np.vstack([objs[n] for n in obj_names])\n",
- "test_positions = np.vstack((positions, [0,0], [0,-1.5]))\n",
- "\n",
- "sims = []\n",
- "\n",
- "for pos_idx, pos in enumerate(test_positions):\n",
- " position_ssp = ssp_space.encode(pos[None,:]) #remember we need to have 2-dimensional vectors for `encode()` function\n",
- " #unbind positions from the map\n",
- " query_map = ... * ~...\n",
- " sims.append(query_objs @ query_map.flatten())\n",
- "\n",
- "plot_unbinding_positions_map(sims, test_positions, obj_names)\n",
- "\n",
- "```"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "#to_remove solution\n",
- "\n",
- "query_objs = np.vstack([objs[n] for n in obj_names])\n",
- "test_positions = np.vstack((positions, [0,0], [0,-1.5]))\n",
- "\n",
- "sims = []\n",
- "\n",
- "for pos_idx, pos in enumerate(test_positions):\n",
- " position_ssp = ssp_space.encode(pos[None,:]) #remember we need to have 2-dimensional vectors for `encode()` function\n",
- " #unbind positions from the map\n",
- " query_map = ssp_map * ~position_ssp\n",
- " sims.append(query_objs @ query_map.flatten())\n",
- "\n",
- "plot_unbinding_positions_map(sims, test_positions, obj_names)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "As you can see from the above plots, when we query each location, we can clearly identify the object stored at that location. \n",
- "\n",
- "When we query at the origin (where no object is present), we see that there is no strong candidate element. However, as we move closer to one of the objects (rightmost plot), the similarity starts to increase."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_mixing_discrete_objects_with_continuous_space\")"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Video 4: Mapping Outro\n",
- "from ipywidgets import widgets\n",
- "from IPython.display import YouTubeVideo\n",
- "from IPython.display import IFrame\n",
- "from IPython.display import display\n",
+ "from ipywidgets import widgets\n",
+ "from IPython.display import YouTubeVideo\n",
+ "from IPython.display import IFrame\n",
+ "from IPython.display import display\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
@@ -1476,7 +712,7 @@
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
- "video_ids = [('Youtube', 'mXNFWr_cap4'), ('Bilibili', 'BV1ND421u7gp')]\n",
+ "video_ids = [('Youtube', 'mWIfBl-4FKM'), ('Bilibili', 'BV1jK7jzNE1h')]\n",
"tab_contents = display_videos(video_ids, W=854, H=480)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
@@ -1495,7 +731,7 @@
"outputs": [],
"source": [
"# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_mapping_outro\")"
+ "content_review(f\"{feedback_prefix}_outro\")"
]
},
{
@@ -1505,94 +741,13 @@
},
"source": [
"---\n",
- "# Summary\n",
+ "# The Big Picture\n",
"\n",
- "*Estimated timing of tutorial: 40 minutes*"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Video 5: Conclusions\n",
- "from ipywidgets import widgets\n",
- "from IPython.display import YouTubeVideo\n",
- "from IPython.display import IFrame\n",
- "from IPython.display import display\n",
+ "You have now built a fairly simple cognitive model. A system that has an, albeit limited, vocabulary, expressed using a Vector Symbolic Algebra (VSA). Also, importantly, it is able to answer questions about it's experience, even though the experience has passed, thanks to its working memory. Working memory is a vital component of cognitive models, and while this is a simple system, you have now experienced working with the tools that underly SPAUN, the world's largest *functional* brain model. \n",
"\n",
- "class PlayVideo(IFrame):\n",
- " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
- " self.id = id\n",
- " if source == 'Bilibili':\n",
- " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
- " elif source == 'Osf':\n",
- " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
- " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
- "\n",
- "def display_videos(video_ids, W=400, H=300, fs=1):\n",
- " tab_contents = []\n",
- " for i, video_id in enumerate(video_ids):\n",
- " out = widgets.Output()\n",
- " with out:\n",
- " if video_ids[i][0] == 'Youtube':\n",
- " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
- " height=H, fs=fs, rel=0)\n",
- " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
- " else:\n",
- " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
- " height=H, fs=fs, autoplay=False)\n",
- " if video_ids[i][0] == 'Bilibili':\n",
- " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
- " elif video_ids[i][0] == 'Osf':\n",
- " print(f'Video available at https://osf.io/{video.id}')\n",
- " display(video)\n",
- " tab_contents.append(out)\n",
- " return tab_contents\n",
- "\n",
- "video_ids = [('Youtube', 'M6rRsdJdoYQ'), ('Bilibili', 'BV1wm421L7Se')]\n",
- "tab_contents = display_videos(video_ids, W=854, H=480)\n",
- "tabs = widgets.Tab()\n",
- "tabs.children = tab_contents\n",
- "for i in range(len(tab_contents)):\n",
- " tabs.set_title(i, video_ids[i][0])\n",
- "display(tabs)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Conclusion slides\n",
- "\n",
- "from IPython.display import IFrame\n",
- "link_id = \"pxqny\"\n",
+ "Additionally, while you haven't explicitly worked with them, this model was implemented completely with spiking neurons. The Neural Engineering Framework, the mathematical tools that underpin Nengo, allow us to compile the program we wrote using the VSA into a network of neurons. If you look closely at the plots above, you can see that the lines are noisy. This is because they are smoothed (thanks to the probes' synapse) signals that represent the activity of the populations of neurons that implement our simple question answering model.\n",
"\n",
- "print(f\"If you want to download the slides: 'https://osf.io/download/{link_id}'\")\n",
- "\n",
- "IFrame(src=f\"https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{link_id}/?direct%26mode=render\", width=854, height=480)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_conclusions\")"
+ "We have not one, but two extra bonus tutorials for today. These tutorials go into more depth on the basics around how to implement the notions of analogies in a VSA (Bonus Tutorial 4) and in Bonus Tutorial 5 we go through representations in continuous space. If you have any time left over, we encourage you to work your way through this extra material."
]
}
],
@@ -1624,7 +779,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.9.19"
+ "version": "3.9.22"
}
},
"nbformat": 4,
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/instructor/W2D2_Tutorial4.ipynb b/tutorials/W2D2_NeuroSymbolicMethods/instructor/W2D2_Tutorial4.ipynb
new file mode 100644
index 000000000..71f95acd5
--- /dev/null
+++ b/tutorials/W2D2_NeuroSymbolicMethods/instructor/W2D2_Tutorial4.ipynb
@@ -0,0 +1,1051 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {},
+ "id": "view-in-github"
+ },
+ "source": [
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "# (BONUS) Tutorial 4: VSA Analogies\n",
+ "\n",
+ "**Week 2, Day 2: Neuro-Symbolic Methods**\n",
+ "\n",
+ "**By Neuromatch Academy**\n",
+ "\n",
+ "__Content creators:__ P. Michael Furlong, Chris Eliasmith\n",
+ "\n",
+ "__Content reviewers:__ Hlib Solodzhuk, Patrick Mineault, Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Alex Murphy\n",
+ "\n",
+ "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk, Alex Murphy\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "___\n",
+ "\n",
+ "\n",
+ "# Tutorial Objectives\n",
+ "\n",
+ "This tutorial will present you with a couple of toy examples using the basic operations of vector symbolic algebras. We will further show how these can generalize to new knowledge. If you are familiar with the basics of semantic algebra on word embeddings, you already understand the basics of what we'll be demonstrating in this tutorial. If not, don't worry, this tutorial is designed to be highly self-contained. If you're interested in learning more about word embedding algebra, then we encourage you to use your search engine of choice and learn more after completing the code exercises given below."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Tutorial slides\n",
+ "# @markdown These are the slides for the videos in all tutorials today\n",
+ "\n",
+ "from IPython.display import IFrame\n",
+ "link_id = \"jybuw\"\n",
+ "\n",
+ "print(f\"If you want to download the slides: 'https://osf.io/download/{link_id}'\")\n",
+ "\n",
+ "IFrame(src=f\"https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{link_id}/?direct%26mode=render\", width=854, height=480)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "---\n",
+ "# Setup (Colab Users: Please Read)\n",
+ "\n",
+ "Note that because this tutorial relies on some special Python packages, these packages have requirements for specific versions of common scientific libraries, such as `numpy`. If you're in Google Colab, then as of May 2025, this comes with a later version (2.0.2) pre-installed. We require an older version (we'll be installing `1.24.4`). This causes Colab to force a session restart and then re-running of the installation cells for the new version to take effect. When you run the cell below, you will be prompted to restart the session. This is *entirely expected* and you haven't done anything wrong. Simply click 'Restart' and then run the cells as normal. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Install dependencies and import feedback gadget\n",
+ "\n",
+ "!pip install numpy==1.24.4 --quiet\n",
+ "!pip install scikit-learn==1.6.1 --quiet\n",
+ "!pip install scipy==1.15.3 --quiet\n",
+ "!pip install git+https://github.com/neuromatch/sspspace@neuromatch --no-deps --quiet\n",
+ "!pip install nengo==4.0.0 --quiet\n",
+ "!pip install nengo_spa==2.0.0 --quiet\n",
+ "!pip install --quiet matplotlib ipywidgets vibecheck\n",
+ "!pip install --quiet numpy matplotlib ipywidgets scipy scikit-learn vibecheck\n",
+ "\n",
+ "from vibecheck import DatatopsContentReviewContainer\n",
+ "def content_review(notebook_section: str):\n",
+ " return DatatopsContentReviewContainer(\n",
+ " \"\", # No text prompt\n",
+ " notebook_section,\n",
+ " {\n",
+ " \"url\": \"https://pmyvdlilci.execute-api.us-east-1.amazonaws.com/klab\",\n",
+ " \"name\": \"neuromatch_neuroai\",\n",
+ " \"user_key\": \"wb2cxze8\",\n",
+ " },\n",
+ " ).render()\n",
+ "\n",
+ "\n",
+ "feedback_prefix = \"W2D2_T4\""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Notice that exactly the `neuromatch` branch of `sspspace` should be installed! Otherwise, some of the functionality (like `optimize` parameter in the `DiscreteSPSpace` initialization) won't work."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Imports\n",
+ "\n",
+ "#working with data\n",
+ "import numpy as np\n",
+ "\n",
+ "#plotting\n",
+ "import matplotlib.pyplot as plt\n",
+ "import logging\n",
+ "\n",
+ "#interactive display\n",
+ "# import ipywidgets as widgets\n",
+ "\n",
+ "#modeling\n",
+ "import sspspace\n",
+ "import nengo_spa as spa\n",
+ "from scipy.special import softmax\n",
+ "from sklearn.metrics import log_loss\n",
+ "from sklearn.neural_network import MLPRegressor\n",
+ "from nengo_spa.algebras.hrr_algebra import HrrProperties, HrrAlgebra\n",
+ "from nengo_spa.vector_generation import VectorsWithProperties\n",
+ "\n",
+ "def make_vocabulary(vector_length):\n",
+ " vec_generator = VectorsWithProperties(vector_length, algebra=HrrAlgebra(), properties = [HrrProperties.UNITARY, HrrProperties.POSITIVE])\n",
+ " vocab = spa.Vocabulary(vector_length, pointer_gen=vec_generator)\n",
+ " return vocab"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Figure settings\n",
+ "\n",
+ "logging.getLogger('matplotlib.font_manager').disabled = True\n",
+ "\n",
+ "%matplotlib inline\n",
+ "%config InlineBackend.figure_format = 'retina' # perfrom high definition rendering for images and plots\n",
+ "plt.style.use(\"https://raw.githubusercontent.com/NeuromatchAcademy/course-content/main/nma.mplstyle\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Plotting functions\n",
+ "\n",
+ "def plot_similarity_matrix(sim_mat, labels, values = False):\n",
+ " \"\"\"\n",
+ " Plot the similarity matrix between vectors.\n",
+ "\n",
+ " Inputs:\n",
+ " - sim_mat (numpy.ndarray): similarity matrix between vectors.\n",
+ " - labels (list of str): list of strings which represent concepts.\n",
+ " - values (bool): True if we would like to plot values of similarity too.\n",
+ " \"\"\"\n",
+ " with plt.xkcd():\n",
+ " plt.imshow(sim_mat, cmap='Greys')\n",
+ " plt.colorbar()\n",
+ " plt.xticks(np.arange(len(labels)), labels, rotation=45, ha=\"right\", rotation_mode=\"anchor\")\n",
+ " plt.yticks(np.arange(len(labels)), labels)\n",
+ " if values:\n",
+ " for x in range(sim_mat.shape[1]):\n",
+ " for y in range(sim_mat.shape[0]):\n",
+ " plt.text(x, y, f\"{sim_mat[y, x]:.2f}\", fontsize = 8, ha=\"center\", va=\"center\", color=\"green\")\n",
+ " plt.title('Similarity between vector-symbols')\n",
+ " plt.xlabel('Symbols')\n",
+ " plt.ylabel('Symbols')\n",
+ " plt.show()\n",
+ "\n",
+ "def plot_training_and_choice(losses, sims, ant_names, cons_names, action_names):\n",
+ " \"\"\"\n",
+ " Plot loss progression over training as well as predicted similarities for given rules / correct solutions.\n",
+ "\n",
+ " Inputs:\n",
+ " - losses (list): list of loss values.\n",
+ " - sims (list): list of similartiy matrices.\n",
+ " - ant_names (list): list of antecedance names.\n",
+ " - cons_names (list): list of consequent names.\n",
+ " - action_names (list): full list of concepts.\n",
+ " \"\"\"\n",
+ " with plt.xkcd():\n",
+ " plt.subplot(1, len(ant_names) + 1, 1)\n",
+ " plt.plot(losses)\n",
+ " plt.xlabel('Training number')\n",
+ " plt.ylabel('Loss')\n",
+ " plt.title('Training Error')\n",
+ " index = 1\n",
+ " for ant_name, cons_name, sim in zip(ant_names, cons_names, sims):\n",
+ " index += 1\n",
+ " plt.subplot(1, len(ant_names) + 1, index)\n",
+ " plt.bar(range(len(action_names)), sim.flatten())\n",
+ " plt.gca().set_xticks(range(len(action_names)))\n",
+ " plt.gca().set_xticklabels(action_names, rotation=90)\n",
+ " plt.title(f'{ant_name}, not*{cons_name}')\n",
+ "\n",
+ "def plot_choice(sims, ant_names, cons_names, action_names):\n",
+ " \"\"\"\n",
+ " Plot predicted similarities for given rules / correct solutions.\n",
+ " \"\"\"\n",
+ " with plt.xkcd():\n",
+ " index = 0\n",
+ " for ant_name, cons_name, sim in zip(ant_names, cons_names, sims):\n",
+ " index += 1\n",
+ " plt.subplot(1, len(ant_names) + 1, index)\n",
+ " plt.bar(range(len(action_names)), sim.flatten())\n",
+ " plt.gca().set_xticks(range(len(action_names)))\n",
+ " plt.gca().set_xticklabels(action_names, rotation=90)\n",
+ " plt.ylabel(\"Similarity\")\n",
+ " plt.title(f'{ant_name}, not*{cons_name}')"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Set random seed\n",
+ "\n",
+ "import random\n",
+ "import numpy as np\n",
+ "\n",
+ "def set_seed(seed=None):\n",
+ " if seed is None:\n",
+ " seed = np.random.choice(2 ** 32)\n",
+ " random.seed(seed)\n",
+ " np.random.seed(seed)\n",
+ "\n",
+ "set_seed(seed = 42)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Helper functions\n",
+ "\n",
+ "set_seed(42)\n",
+ "\n",
+ "symbol_names = ['monarch','heir','male','female']\n",
+ "discrete_space = sspspace.DiscreteSPSpace(symbol_names, ssp_dim=1024, optimize=False)\n",
+ "\n",
+ "objs = {n:discrete_space.encode(n) for n in symbol_names}\n",
+ "\n",
+ "objs['king'] = objs['monarch'] * objs['male']\n",
+ "objs['queen'] = objs['monarch'] * objs['female']\n",
+ "objs['prince'] = objs['heir'] * objs['male']\n",
+ "objs['princess'] = objs['heir'] * objs['female']\n",
+ "\n",
+ "bundle_objs = {n:discrete_space.encode(n) for n in symbol_names}\n",
+ "\n",
+ "bundle_objs['king'] = (bundle_objs['monarch'] + bundle_objs['male']).normalize()\n",
+ "bundle_objs['queen'] = (bundle_objs['monarch'] + bundle_objs['female']).normalize()\n",
+ "bundle_objs['prince'] = (bundle_objs['heir'] + bundle_objs['male']).normalize()\n",
+ "bundle_objs['princess'] = (bundle_objs['heir'] + bundle_objs['female']).normalize()\n",
+ "\n",
+ "bundle_objs['princess_query'] = (bundle_objs['prince'] - bundle_objs['king']) + bundle_objs['queen']\n",
+ "\n",
+ "new_symbol_names = ['dollar', 'peso', 'ottawa', 'mexico-city', 'currency', 'capital']\n",
+ "new_discrete_space = sspspace.DiscreteSPSpace(new_symbol_names, ssp_dim=1024, optimize=False)\n",
+ "\n",
+ "new_objs = {n:new_discrete_space.encode(n) for n in new_symbol_names}\n",
+ "\n",
+ "cleanup = sspspace.Cleanup(new_objs)\n",
+ "\n",
+ "new_objs['canada'] = ((new_objs['currency'] * new_objs['dollar']) + (new_objs['capital'] * new_objs['ottawa'])).normalize()\n",
+ "new_objs['mexico'] = ((new_objs['currency'] * new_objs['peso']) + (new_objs['capital'] * new_objs['mexico-city'])).normalize()\n",
+ "\n",
+ "card_states = ['red','blue','odd','even','not','green','prime','implies','ant','relation','cons']\n",
+ "encoder = sspspace.DiscreteSPSpace(card_states, ssp_dim=1024, optimize=False)\n",
+ "vocab = {c:encoder.encode(c) for c in card_states}\n",
+ "\n",
+ "for a in ['red','blue','odd','even','green','prime']:\n",
+ " vocab[f'not*{a}'] = vocab['not'] * vocab[a]\n",
+ "\n",
+ "action_names = ['red','blue','odd','even','green','prime','not*red','not*blue','not*odd','not*even','not*green','not*prime']\n",
+ "action_space = np.array([vocab[x] for x in action_names]).squeeze()\n",
+ "\n",
+ "rules = [\n",
+ " (vocab['ant'] * vocab['blue'] + vocab['relation'] * vocab['implies'] + vocab['cons'] * vocab['even']).normalize(),\n",
+ " (vocab['ant'] * vocab['odd'] + vocab['relation'] * vocab['implies'] + vocab['cons'] * vocab['green']).normalize(),\n",
+ "]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "---\n",
+ "\n",
+ "# Section 1: Analogies. Part 1\n",
+ "\n",
+ "In this section we will construct a simple analogy using Vector Symbolic Algebras. The question we are going to try and solve is \"King is to the queen as the prince is to X.\""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Video 1: Analogy 1\n",
+ "\n",
+ "from ipywidgets import widgets\n",
+ "from IPython.display import YouTubeVideo\n",
+ "from IPython.display import IFrame\n",
+ "from IPython.display import display\n",
+ "\n",
+ "class PlayVideo(IFrame):\n",
+ " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
+ " self.id = id\n",
+ " if source == 'Bilibili':\n",
+ " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
+ " elif source == 'Osf':\n",
+ " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
+ " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
+ "\n",
+ "def display_videos(video_ids, W=400, H=300, fs=1):\n",
+ " tab_contents = []\n",
+ " for i, video_id in enumerate(video_ids):\n",
+ " out = widgets.Output()\n",
+ " with out:\n",
+ " if video_ids[i][0] == 'Youtube':\n",
+ " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
+ " height=H, fs=fs, rel=0)\n",
+ " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
+ " else:\n",
+ " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
+ " height=H, fs=fs, autoplay=False)\n",
+ " if video_ids[i][0] == 'Bilibili':\n",
+ " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
+ " elif video_ids[i][0] == 'Osf':\n",
+ " print(f'Video available at https://osf.io/{video.id}')\n",
+ " display(video)\n",
+ " tab_contents.append(out)\n",
+ " return tab_contents\n",
+ "\n",
+ "video_ids = [('Youtube', '2tR4fHvL1Jk'), ('Bilibili', 'BV1fS411P7Ez')]\n",
+ "tab_contents = display_videos(video_ids, W=854, H=480)\n",
+ "tabs = widgets.Tab()\n",
+ "tabs.children = tab_contents\n",
+ "for i in range(len(tab_contents)):\n",
+ " tabs.set_title(i, video_ids[i][0])\n",
+ "display(tabs)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_analogy_part_one\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "## Coding Exercise 1: Royal Relationships\n",
+ "\n",
+ "We're going to start by considering our vocabulary. We will use the basic discrete concepts of monarch, heir, male, and female."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Let's create the objects we know about by combinatorially expanding the space: \n",
+ "\n",
+ "1. King is a male monarch\n",
+ "2. Queen is a female monarch\n",
+ "3. Prince is a male heir\n",
+ "4. Princess is a female heir\n",
+ "\n",
+ "Complete the missing parts of the code to obtain correct representations of new concepts."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "set_seed(42)\n",
+ "\n",
+ "vector_length = 1024\n",
+ "symbol_names = ['MONARCH', 'HEIR', 'MALE', 'FEMALE']\n",
+ "vocab = make_vocabulary(vector_length)\n",
+ "vocab.populate(';'.join(symbol_names))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {}
+ },
+ "source": [
+ "```python\n",
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete correct relations for creating new concepts.\")\n",
+ "\n",
+ "###################################################################\n",
+ "vocab.add('KING', vocab['MONARCH'] * vocab['MALE'])\n",
+ "vocab.add('QUEEN', vocab['MONARCH'] * ...)\n",
+ "vocab.add('PRINCE', vocab['HEIR'] * vocab['MALE'])\n",
+ "vocab.add('PRINCESS', ... * vocab['FEMALE'])\n",
+ "\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "#to_remove solution\n",
+ "\n",
+ "vocab.add('KING', vocab['MONARCH'] * vocab['MALE'])\n",
+ "vocab.add('QUEEN', vocab['MONARCH'] * vocab['FEMALE'])\n",
+ "vocab.add('PRINCE', vocab['HEIR'] * vocab['MALE'])\n",
+ "vocab.add('PRINCESS', vocab['HEIR'] * vocab['FEMALE'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Now, we can take an explicit approach. We know that the conversion from king to queen is to unbind male and bind female, so let's apply that to our prince object and see what we uncover.\n",
+ "\n",
+ "At first, in the cell below, let's recover `queen` from `king` by constructing a new `query` concept, which represents the unbinding of `male` and the binding of `female.`"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {}
+ },
+ "source": [
+ "```python\n",
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete correct relation for creating `query` object to compare with `queen`.\")\n",
+ "###################################################################\n",
+ "\n",
+ "vocab.add('QUERY_QUEEN', (vocab[...] * ~vocab[...]) * vocab[...])\n",
+ "\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "#to_remove solution\n",
+ "\n",
+ "vocab.add('QUERY_QUEEN', (vocab['KING'] * ~vocab['MALE']) * vocab['FEMALE'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Then, let's see if this new query object bears any similarity to anything in our vocabulary."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "object_names = list(vocab.keys())\n",
+ "sims = np.zeros((len(object_names), len(object_names)))\n",
+ "\n",
+ "for name_idx, name in enumerate(object_names):\n",
+ " for other_idx in range(name_idx, len(object_names)):\n",
+ " sims[name_idx, other_idx] = sims[other_idx, name_idx] = spa.dot(vocab[name], vocab[object_names[other_idx]])\n",
+ "\n",
+ "plot_similarity_matrix(sims, object_names, values = True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "The above similarity plot shows that applying that operation successfully converts king to queen. Let's apply it to 'prince' and see what happens. Now, `query` should represent the `princess` concept."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "vocab.add('QUERY_PRINCESS', (vocab['PRINCE'] * ~vocab['MALE']) * vocab['FEMALE'])\n",
+ "\n",
+ "sims = np.zeros((len(object_names), len(object_names)))\n",
+ "\n",
+ "for name_idx, name in enumerate(object_names):\n",
+ " for other_idx in range(name_idx, len(object_names)):\n",
+ " sims[name_idx, other_idx] = sims[other_idx, name_idx] = spa.dot(vocab[name], vocab[object_names[other_idx]])\n",
+ "\n",
+ "plot_similarity_matrix(sims, object_names, values = True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Here, we have successfully recovered the princess, completing the analogy.\n",
+ "\n",
+ "This approach, however, requires explicit knowledge of the construction of the objects. Let's see if we can just work with the concepts of 'king,' 'queen,' and 'prince' directly.\n",
+ "\n",
+ "In the cell below, construct the `princess` concept using only `king,` `queen`, and `prince.`"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {}
+ },
+ "source": [
+ "```python\n",
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete correct relation for creating `query` object to compare with `princess`.\")\n",
+ "###################################################################\n",
+ "\n",
+ "vocab.add('QUERY_PRINCESS_2', (vocab[...] * ~vocab[...]) * vocab[...])\n",
+ "\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "#to_remove solution\n",
+ "\n",
+ "# objs['query'] = (objs['prince'] * ~objs['king']) * objs['queen']\n",
+ "vocab.add('QUERY_PRINCESS_2', (vocab['PRINCE'] * ~vocab['KING']) * vocab['QUEEN'])"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "object_names = list(vocab.keys())\n",
+ "sims = np.zeros((len(object_names), len(object_names)))\n",
+ "\n",
+ "for name_idx, name in enumerate(object_names):\n",
+ " for other_idx in range(name_idx, len(object_names)):\n",
+ " sims[name_idx, other_idx] = sims[other_idx, name_idx] = spa.dot(vocab[name], vocab[object_names[other_idx]])\n",
+ "\n",
+ "plot_similarity_matrix(sims, object_names, values = True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Again, we see that we have recovered the princess by using our analogy.\n",
+ "\n",
+ "That said, the above depends on knowing that the representations are constructed using binding. Can we do something similar through the bundling operation? Let's try that out.\n",
+ "\n",
+ "Reassing concept definitions using bundling operation."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "vocab = vocab.create_subset(['MONARCH','HEIR','FEMALE','MALE'])\n",
+ "vocab.add('KING', (vocab['MONARCH'] + vocab['MALE']).normalized())\n",
+ "vocab.add('QUEEN', (vocab['MONARCH'] + vocab['FEMALE']).normalized())\n",
+ "vocab.add('PRINCE', (vocab['HEIR'] + vocab['MALE']).normalized())\n",
+ "vocab.add('PRINCESS', (vocab['HEIR'] + vocab['FEMALE']).normalized())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "But now that we are using an additive model, we need to take a different approach. Instead of unbinding the king and binding the queen, we subtract the king and add the queen to find the princess from the prince.\n",
+ "\n",
+ "Complete the code to reflect the updated mechanism."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {}
+ },
+ "source": [
+ "```python\n",
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete correct relation for creating `query` object to compare with `princess`.\")\n",
+ "###################################################################\n",
+ "\n",
+ "vocab.add('QUERY_PRINCESS', ((vocab[...] - vocab[...]) + vocab[...]).normalized())\n",
+ "\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "#to_remove solution\n",
+ "\n",
+ "vocab.add('QUERY_PRINCESS', ((vocab['PRINCE'] - vocab['KING']) + vocab['QUEEN']).normalized())"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "object_names = list(vocab.keys())\n",
+ "sims = np.zeros((len(object_names), len(object_names)))\n",
+ "\n",
+ "for name_idx, name in enumerate(object_names):\n",
+ " for other_idx in range(name_idx, len(object_names)):\n",
+ " sims[name_idx, other_idx] = sims[other_idx, name_idx] = spa.dot(vocab[name], vocab[object_names[other_idx]])\n",
+ "\n",
+ "plot_similarity_matrix(sims, object_names, values = True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "This is a messier similarity plot due to the fact that the bundled representations interact with all their constituent parts in the vocabulary. That said, we see that 'princess' is still most similar to the query vector. \n",
+ "\n",
+ "This approach is more like what we would expect from a `word2vec` embedding."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_royal_relationships\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "---\n",
+ "\n",
+ "# Section 2: Analogies (Part 2)\n",
+ "\n",
+ "Estimated timing to here from start of tutorial: 15 minutes\n",
+ "\n",
+ "In this section, we will construct a database of data structures that describe different countries. Materials are adopted from [Kanerva (2010)](https://cdn.aaai.org/ocs/2243/2243-9566-1-PB.pdf)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Video 2: Analogy 2\n",
+ "\n",
+ "from ipywidgets import widgets\n",
+ "from IPython.display import YouTubeVideo\n",
+ "from IPython.display import IFrame\n",
+ "from IPython.display import display\n",
+ "\n",
+ "class PlayVideo(IFrame):\n",
+ " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
+ " self.id = id\n",
+ " if source == 'Bilibili':\n",
+ " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
+ " elif source == 'Osf':\n",
+ " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
+ " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
+ "\n",
+ "def display_videos(video_ids, W=400, H=300, fs=1):\n",
+ " tab_contents = []\n",
+ " for i, video_id in enumerate(video_ids):\n",
+ " out = widgets.Output()\n",
+ " with out:\n",
+ " if video_ids[i][0] == 'Youtube':\n",
+ " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
+ " height=H, fs=fs, rel=0)\n",
+ " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
+ " else:\n",
+ " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
+ " height=H, fs=fs, autoplay=False)\n",
+ " if video_ids[i][0] == 'Bilibili':\n",
+ " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
+ " elif video_ids[i][0] == 'Osf':\n",
+ " print(f'Video available at https://osf.io/{video.id}')\n",
+ " display(video)\n",
+ " tab_contents.append(out)\n",
+ " return tab_contents\n",
+ "\n",
+ "video_ids = [('Youtube', 'OB3hzhM7Ois'), ('Bilibili', 'BV1TZ421g7G5')]\n",
+ "tab_contents = display_videos(video_ids, W=854, H=480)\n",
+ "tabs = widgets.Tab()\n",
+ "tabs.children = tab_contents\n",
+ "for i in range(len(tab_contents)):\n",
+ " tabs.set_title(i, video_ids[i][0])\n",
+ "display(tabs)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_analogy_part_two\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "## Coding Exercise 2: Dollar of Mexico\n",
+ "\n",
+ "This is going to be a little more involved, because to construct the data structure we are going to need vectors that don't just represent values that we are reasoning about, but also vectors that represent different roles data can play. This is sometimes called a slot-filler representation, or a key-value representation.\n",
+ "\n",
+ "At first, let us define concepts and cleanup object."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "set_seed(42)\n",
+ "\n",
+ "symbol_names = ['DOLLAR','PESO', 'OTTAWA','MEXICO_CITY','CURRENCY','CAPITAL']\n",
+ "vocab = make_vocabulary(vector_length)\n",
+ "vocab.populate(';'.join(symbol_names))\n",
+ "\n",
+ "cleanup = sspspace.Cleanup(vocab)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Now, we will define `Canada` and `Mexico` concepts by integrating the available information together. You will be provided with `Canada` object and your task is to complete for `Mexico` one."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {}
+ },
+ "source": [
+ "```python\n",
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete `mexico` concept.\")\n",
+ "###################################################################\n",
+ "\n",
+ "vocab.add('CANADA', (vocab['CURRENCY'] * vocab['DOLLAR'] + vocab['CAPITAL'] * vocab['OTTAWA']).normalized())\n",
+ "vocab.add('MEXICO', (vocab['CURRENCY'] * ... + vocab['CAPITAL'] * ...).normalized())\n",
+ "\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "#to_remove solution\n",
+ "\n",
+ "vocab.add('CANADA', (vocab['CURRENCY'] * vocab['DOLLAR'] + vocab['CAPITAL'] * vocab['OTTAWA']).normalized())\n",
+ "vocab.add('MEXICO', (vocab['CURRENCY'] * vocab['PESO'] + vocab['CAPITAL'] * vocab['MEXICO_CITY']).normalized())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "We would like to find out Mexico's currency. Complete the code for constructing a `query` which will help us do that. Note that we are using a cleanup operation."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {}
+ },
+ "source": [
+ "```python\n",
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete `query` concept which will be similar to currency in Mexico.\")\n",
+ "###################################################################\n",
+ "\n",
+ "vocab.add('QUERY_MX_CURRENCY', vocab['MEXICO'] * ~(... * ~...))\n",
+ "\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "#to_remove solution\n",
+ "\n",
+ "vocab.add('QUERY_MX_CURRENCY', vocab['MEXICO'] * ~(vocab['CANADA'] * ~vocab['DOLLAR']))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "object_names = list(vocab.keys())\n",
+ "sims = np.zeros((len(object_names), len(object_names)))\n",
+ "\n",
+ "for name_idx, name in enumerate(object_names):\n",
+ " for other_idx in range(name_idx, len(object_names)):\n",
+ " sims[name_idx, other_idx] = sims[other_idx, name_idx] = spa.dot(vocab[name], vocab[object_names[other_idx]])\n",
+ "\n",
+ "plot_similarity_matrix(sims, object_names)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "After cleanup, the query vector is the most similar with the 'peso' object in the vocabularly, correctly answering the question. \n",
+ "\n",
+ "Note, however, that the similarity is not perfectly equal to 1. This is due to the scale factors applied to the composite vectors 'canada' and 'mexico', to ensure they remain unit vectors, and due to cross talk. Crosstalk is a symptom of the fact that we are binding and unbinding bundles of vector symbols to produce the resultant query vector. The constituent vectors are not perfectly orthogonal (i.e., having a dot product of zero) and as such the terms in the bundle interact when we measure similarity between them."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_dollar_of_mexico\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "---\n",
+ "# The Big Picture\n",
+ "\n",
+ "*Estimated timing of tutorial: 45 minutes*\n",
+ "\n",
+ "In this tutorial, we observed three scenarios where we used the basic operations to solve different analogies and engage in structured learning. Those of you familiar with word embeddings from Natural Language Processing (NLP) might already be familiar with the idea of interpretable semantics on vector representations. This bonus tutorial helps to show how this can be accomplished in a different way. The ability to recreate different phenomena in different paradigms often gives us a great way to compare and contrast model mechanisms and we hope that this bonus tutorial has given you a curiosity to dive a bit deeper and start experimenting further with what you can accomplish using these great open-source tools!"
+ ]
+ }
+ ],
+ "metadata": {
+ "colab": {
+ "collapsed_sections": [],
+ "include_colab_link": true,
+ "name": "W2D2_Tutorial4",
+ "provenance": [],
+ "toc_visible": true
+ },
+ "kernel": {
+ "display_name": "Python 3",
+ "language": "python",
+ "name": "python3"
+ },
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.9.22"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 4
+}
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/instructor/W2D2_Tutorial5.ipynb b/tutorials/W2D2_NeuroSymbolicMethods/instructor/W2D2_Tutorial5.ipynb
new file mode 100644
index 000000000..c0dee63d8
--- /dev/null
+++ b/tutorials/W2D2_NeuroSymbolicMethods/instructor/W2D2_Tutorial5.ipynb
@@ -0,0 +1,1627 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {},
+ "id": "view-in-github"
+ },
+ "source": [
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "# (Bonus) Tutorial 5: Representations in continuous space\n",
+ "\n",
+ "**Week 2, Day 2: Neuro-Symbolic Methods**\n",
+ "\n",
+ "**By Neuromatch Academy**\n",
+ "\n",
+ "__Content creators:__ P. Michael Furlong, Chris Eliasmith\n",
+ "\n",
+ "__Content reviewers:__ Hlib Solodzhuk, Patrick Mineault, Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Alex Murphy\n",
+ "\n",
+ "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk, Alex Murphy"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "___\n",
+ "\n",
+ "\n",
+ "# Tutorial Objectives\n",
+ "\n",
+ "*Estimated timing of tutorial: 40 minutes*\n",
+ "\n",
+ "In this tutorial, you will observe how the VSA methods can be applied in structures and environments to allow for efficient generalization."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Tutorial slides\n",
+ "# @markdown These are the slides for the videos in all tutorials today\n",
+ "\n",
+ "from IPython.display import IFrame\n",
+ "link_id = \"jybuw\"\n",
+ "\n",
+ "print(f\"If you want to download the slides: 'https://osf.io/download/{link_id}'\")\n",
+ "\n",
+ "IFrame(src=f\"https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{link_id}/?direct%26mode=render\", width=854, height=480)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "---\n",
+ "# Setup (Colab Users: Please Read)\n",
+ "\n",
+ "Note that because this tutorial relies on some special Python packages, these packages have requirements for specific versions of common scientific libraries, such as `numpy`. If you're in Google Colab, then as of May 2025, this comes with a later version (2.0.2) pre-installed. We require an older version (we'll be installing `1.24.4`). This causes Colab to force a session restart and then re-running of the installation cells for the new version to take effect. When you run the cell below, you will be prompted to restart the session. This is *entirely expected* and you haven't done anything wrong. Simply click 'Restart' and then run the cells as normal. \n",
+ "\n",
+ "An additional error might sometimes arise where an exception is raised connected to a missing element of NumPy. If this occurs, please restart the session and re-run the cells as normal and this error will go away. Updated versions of the affected libraries are expected out soon, but sadly not in time for the preparation of this material. We thank you for your understanding.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Install dependencies\n",
+ "\n",
+ "!pip install numpy==1.24.4 --quiet\n",
+ "!pip install scikit-learn==1.6.1 --quiet\n",
+ "!pip install scipy==1.15.3 --quiet\n",
+ "!pip install git+https://github.com/neuromatch/sspspace@neuromatch --no-deps --quiet\n",
+ "!pip install nengo==4.0.0 --quiet\n",
+ "!pip install nengo_spa==2.0.0 --quiet\n",
+ "!pip install --quiet matplotlib ipywidgets tqdm vibecheck"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Install and import feedback gadget\n",
+ "\n",
+ "from vibecheck import DatatopsContentReviewContainer\n",
+ "def content_review(notebook_section: str):\n",
+ " return DatatopsContentReviewContainer(\n",
+ " \"\", # No text prompt\n",
+ " notebook_section,\n",
+ " {\n",
+ " \"url\": \"https://pmyvdlilci.execute-api.us-east-1.amazonaws.com/klab\",\n",
+ " \"name\": \"neuromatch_neuroai\",\n",
+ " \"user_key\": \"wb2cxze8\",\n",
+ " },\n",
+ " ).render()\n",
+ "\n",
+ "\n",
+ "feedback_prefix = \"W2D2_T5\""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Imports\n",
+ "\n",
+ "#working with data\n",
+ "import numpy as np\n",
+ "import random\n",
+ "\n",
+ "#plotting\n",
+ "import matplotlib.pyplot as plt\n",
+ "import logging\n",
+ "\n",
+ "#interactive display\n",
+ "import ipywidgets as widgets\n",
+ "\n",
+ "#modeling\n",
+ "import sspspace\n",
+ "from sklearn.linear_model import LinearRegression\n",
+ "from sklearn.model_selection import train_test_split\n",
+ "\n",
+ "from tqdm.notebook import tqdm as tqdm"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Figure settings\n",
+ "\n",
+ "logging.getLogger('matplotlib.font_manager').disabled = True\n",
+ "\n",
+ "%matplotlib inline\n",
+ "%config InlineBackend.figure_format = 'retina' # perfrom high definition rendering for images and plots\n",
+ "plt.style.use(\"https://raw.githubusercontent.com/NeuromatchAcademy/course-content/main/nma.mplstyle\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Plotting functions\n",
+ "\n",
+ "def plot_3d_function(X, Y, zs, titles):\n",
+ " \"\"\"Plot 3D function.\n",
+ "\n",
+ " Inputs:\n",
+ " - X (list): list of np.ndarray of x-values.\n",
+ " - Y (list): list of np.ndarray of y-values.\n",
+ " - zs (list): list of np.ndarray of z-values.\n",
+ " - titles (list): list of titles of the plot.\n",
+ " \"\"\"\n",
+ " with plt.xkcd():\n",
+ " fig = plt.figure(figsize=(8, 8))\n",
+ " for index, (x, y, z) in enumerate(zip(X, Y, zs)):\n",
+ " fig.add_subplot(1, len(X), index + 1, projection='3d')\n",
+ " plt.gca().plot_surface(x,y,z.reshape(x.shape),cmap='plasma', antialiased=False, linewidth=0)\n",
+ " plt.xlabel(r'$x_{1}$')\n",
+ " plt.ylabel(r'$x_{2}$')\n",
+ " plt.gca().set_zlabel(r'$f(\\mathbf{x})$')\n",
+ " plt.title(titles[index])\n",
+ " plt.show()\n",
+ "\n",
+ "def plot_performance(bound_performance, bundle_performance, training_samples, title):\n",
+ " \"\"\"Plot RMSE values for two different representations of the input data.\n",
+ "\n",
+ " Inputs:\n",
+ " - bound_performance (list): list of RMSE for bound representation.\n",
+ " - bundle_performance (list): list of RMSE for bundle representation.\n",
+ " - training_samples (list): x-axis.\n",
+ " - title (str): title of the plot.\n",
+ " \"\"\"\n",
+ " with plt.xkcd():\n",
+ " plt.plot(training_samples, bound_performance, label='Bound Representation')\n",
+ " plt.plot(training_samples, bundle_performance, label='Bundling Representation', ls='--')\n",
+ " plt.legend()\n",
+ " plt.title(title)\n",
+ " plt.ylabel('RMSE (a.u.)')\n",
+ " plt.xlabel('# Training samples')\n",
+ "\n",
+ "def plot_2d_similarity(sims, obj_names, size, title_argmax = False):\n",
+ " \"\"\"\n",
+ " Plot 2D similarity between query points (grid) and the ones associated with the objects.\n",
+ "\n",
+ " Inputs:\n",
+ " - sims (list): list of similarity values for each of the objects.\n",
+ " - obj_names (list): list of object names.\n",
+ " - size (tuple): to reshape the similarities.\n",
+ " - title_argmax (bool, default = False): looks for the point coordinates as arg max from all similarity value.\n",
+ " \"\"\"\n",
+ " ticks = [0, 24, 49, 74, 99]\n",
+ " ticklabels = [-5, -2, 0, 2, 5]\n",
+ " with plt.xkcd():\n",
+ " for obj_idx, obj in enumerate(obj_names):\n",
+ " plt.subplot(1, len(obj_names), 1 + obj_idx)\n",
+ " plt.imshow(np.array(sims[obj_idx].reshape(size)), origin='lower', vmin=-1, vmax=1)\n",
+ " plt.gca().set_xticks(ticks)\n",
+ " plt.gca().set_xticklabels(ticklabels)\n",
+ " if obj_idx == 0:\n",
+ " plt.gca().set_yticks(ticks)\n",
+ " plt.gca().set_yticklabels(ticklabels)\n",
+ " else:\n",
+ " plt.gca().set_yticks([])\n",
+ " if not title_argmax:\n",
+ " plt.title(f'{obj}, {positions[obj_idx]}')\n",
+ " else:\n",
+ " plt.title(f'{obj}, {query_xs[sims[obj_idx].argmax()]}')\n",
+ "\n",
+ "def plot_unbinding_objects_map(sims, positions, query_xs, size):\n",
+ " \"\"\"\n",
+ " Plot 2D similarity between query points (grid) and the unbinded from the objects map.\n",
+ "\n",
+ " Inputs:\n",
+ " - sims (np.ndarray): similarity values for each of the query points with the map.\n",
+ " - positions (np.ndarray): positions of the objects.\n",
+ " - query_xs (np.ndarray): grid points.\n",
+ " - size (tuple): to reshape the similarities.\n",
+ "\n",
+ " \"\"\"\n",
+ " ticks = [0,24,49,74,99]\n",
+ " ticklabels = [-5,-2,0,2,5]\n",
+ " with plt.xkcd():\n",
+ " plt.imshow(sims.reshape(size), origin='lower')\n",
+ "\n",
+ " for idx, marker in enumerate(['o','s','^']):\n",
+ " plt.scatter(*get_coordinate(positions[idx,:], query_xs, size), marker=marker,s=100)\n",
+ "\n",
+ " plt.gca().set_xticks(ticks)\n",
+ " plt.gca().set_xticklabels(ticklabels)\n",
+ " plt.gca().set_yticks(ticks)\n",
+ " plt.gca().set_yticklabels(ticklabels)\n",
+ " plt.title(f'All Object Locations')\n",
+ " plt.show()\n",
+ "\n",
+ "def plot_unbinding_positions_map(sims, positions, obj_names):\n",
+ " \"\"\"\n",
+ " Plot 2D similarity between query points (grid) and the unbinded from the positions map.\n",
+ "\n",
+ " Inputs:\n",
+ " - sims (np.ndarray): similarity values for each of the query points with the map.\n",
+ " - positions (np.ndarray): test positions to query.\n",
+ " - obj_names (list): names of the objects for labels.\n",
+ " - size (tuple): to reshape the similarities.\n",
+ " \"\"\"\n",
+ " with plt.xkcd():\n",
+ " plt.figure(figsize=(8, 4))\n",
+ " for pos_idx, pos in enumerate(positions):\n",
+ " plt.subplot(1,len(test_positions), 1+pos_idx)\n",
+ " plt.bar([1,2,3], sims[pos_idx])\n",
+ " plt.ylim([-0.3, 1.05])\n",
+ " plt.gca().set_xticks([1,2,3])\n",
+ " plt.gca().set_xticklabels(obj_names, rotation=90)\n",
+ " if pos_idx != 0:\n",
+ " plt.gca().set_yticks([])\n",
+ " plt.title(f'Symbols at\\n{pos}')\n",
+ " plt.show()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Set random seed\n",
+ "\n",
+ "def set_seed(seed=None):\n",
+ " if seed is None:\n",
+ " seed = np.random.choice(2 ** 32)\n",
+ " random.seed(seed)\n",
+ " np.random.seed(seed)\n",
+ "\n",
+ "set_seed(seed = 42)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Helper functions\n",
+ "\n",
+ "def get_model(xs, ys, train_size):\n",
+ " \"\"\"Fit linear regression to the given data.\n",
+ "\n",
+ " Inputs:\n",
+ " - xs (np.ndarray): input data.\n",
+ " - ys (np.ndarray): output data.\n",
+ " - train_size (float): fraction of data to use for train.\n",
+ " \"\"\"\n",
+ " X_train, _, y_train, _ = train_test_split(xs, ys, random_state=1, train_size=train_size)\n",
+ " return LinearRegression().fit(X_train, y_train)\n",
+ "\n",
+ "def get_coordinate(x, positions, target_shape):\n",
+ " \"\"\"Return the closest column and row coordinates for the given position.\n",
+ "\n",
+ " Inputs:\n",
+ " - x (np.ndarray): query position.\n",
+ " - positions (np.ndarray): all positions.\n",
+ " - target_shape (tuple): shape of the grid.\n",
+ "\n",
+ " Outputs:\n",
+ " - coordinates (tuple): column and row positions.\n",
+ " \"\"\"\n",
+ " idx = np.argmin(np.linalg.norm(x - positions, axis=1))\n",
+ " c = idx % target_shape[1]\n",
+ " r = idx // target_shape[1]\n",
+ " return (c,r)\n",
+ "\n",
+ "def rastrigin_solution(x):\n",
+ " \"\"\"Compute Rastrigin function for given array of d-dimenstional vectors.\n",
+ "\n",
+ " Inputs:\n",
+ " - x (np.ndarray of shape (n, d)): n d-dimensional vectors.\n",
+ "\n",
+ " Outputs:\n",
+ " - y (np.ndarray of shape (n, 1)): Rastrigin function value for each of the vectors.\n",
+ " \"\"\"\n",
+ " return 10 * x.shape[1] + np.sum(x**2 - 10 * np.cos(2*np.pi*x), axis=1)\n",
+ "\n",
+ "def non_separable_solution(x):\n",
+ " \"\"\"Compute non-separable function for given array of 2-dimenstional vectors.\n",
+ "\n",
+ " Inputs:\n",
+ " - x (np.ndarray of shape (n, 2)): n 2-dimensional vectors.\n",
+ "\n",
+ " Outputs:\n",
+ " - y (np.ndarray of shape (n, 1)): non-separable function value for each of the vectors.\n",
+ " \"\"\"\n",
+ " return np.sin(np.multiply(x[:, 0], x[:, 1]))\n",
+ "\n",
+ "x0_rastrigin = np.linspace(-5.12, 5.12, 100)\n",
+ "X_rastrigin, Y_rastrigin = np.meshgrid(x0_rastrigin,x0_rastrigin)\n",
+ "xs_rastrigin = np.vstack((X_rastrigin.flatten(), Y_rastrigin.flatten())).T\n",
+ "ys_rastrigin = rastrigin_solution(xs_rastrigin)\n",
+ "\n",
+ "x0_non_separable = np.linspace(-4, 4, 100)\n",
+ "X_non_separable, Y_non_separable = np.meshgrid(x0_non_separable,x0_non_separable)\n",
+ "xs_non_separable = np.vstack((X_non_separable.flatten(), Y_non_separable.flatten())).T\n",
+ "ys_non_separable = non_separable_solution(xs_non_separable)\n",
+ "\n",
+ "set_seed(42)\n",
+ "\n",
+ "obj_names = ['circle','square','triangle']\n",
+ "discrete_space = sspspace.DiscreteSPSpace(obj_names, ssp_dim=1024)\n",
+ "\n",
+ "objs = {n:discrete_space.encode(n) for n in obj_names}\n",
+ "\n",
+ "ssp_space = sspspace.RandomSSPSpace(domain_dim=2, ssp_dim=1024)\n",
+ "positions = np.array([[0, -2],\n",
+ " [-2, 3],\n",
+ " [3, 2]\n",
+ " ])\n",
+ "ssps = {n:ssp_space.encode(x) for n, x in zip(obj_names, positions)}\n",
+ "\n",
+ "dim0 = np.linspace(-5, 5, 101)\n",
+ "dim1 = np.linspace(-5, 5, 101)\n",
+ "X,Y = np.meshgrid(dim0, dim1)\n",
+ "\n",
+ "query_xs = np.vstack((X.flatten(), Y.flatten())).T\n",
+ "query_ssps = ssp_space.encode(query_xs)\n",
+ "\n",
+ "bound_objects = [objs[n] * ssps[n] for n in obj_names]\n",
+ "ssp_map = sspspace.SSP(np.sum(bound_objects, axis=0))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "---\n",
+ "\n",
+ "# Section 1: Sample Efficient Learning\n",
+ "\n",
+ "In this section, we will take a look at how imposing an inductive bias on our feature space can result in more sample-efficient learning. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Video 1: Function Learning and Inductive Bias\n",
+ "\n",
+ "from ipywidgets import widgets\n",
+ "from IPython.display import YouTubeVideo\n",
+ "from IPython.display import IFrame\n",
+ "from IPython.display import display\n",
+ "\n",
+ "class PlayVideo(IFrame):\n",
+ " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
+ " self.id = id\n",
+ " if source == 'Bilibili':\n",
+ " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
+ " elif source == 'Osf':\n",
+ " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
+ " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
+ "\n",
+ "def display_videos(video_ids, W=400, H=300, fs=1):\n",
+ " tab_contents = []\n",
+ " for i, video_id in enumerate(video_ids):\n",
+ " out = widgets.Output()\n",
+ " with out:\n",
+ " if video_ids[i][0] == 'Youtube':\n",
+ " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
+ " height=H, fs=fs, rel=0)\n",
+ " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
+ " else:\n",
+ " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
+ " height=H, fs=fs, autoplay=False)\n",
+ " if video_ids[i][0] == 'Bilibili':\n",
+ " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
+ " elif video_ids[i][0] == 'Osf':\n",
+ " print(f'Video available at https://osf.io/{video.id}')\n",
+ " display(video)\n",
+ " tab_contents.append(out)\n",
+ " return tab_contents\n",
+ "\n",
+ "video_ids = [('Youtube', 'KDKmDjMxU7Q'), ('Bilibili', 'BV1GM4m1S7kT')]\n",
+ "tab_contents = display_videos(video_ids, W=854, H=480)\n",
+ "tabs = widgets.Tab()\n",
+ "tabs.children = tab_contents\n",
+ "for i in range(len(tab_contents)):\n",
+ " tabs.set_title(i, video_ids[i][0])\n",
+ "display(tabs)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_function_learning_and_inductive_bias\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "## Coding Exercise 1: Additive Function\n",
+ "\n",
+ "\n",
+ "We will start with an additive function, the Rastrigin function, defined \n",
+ "\n",
+ "\\begin{align*}\n",
+ "f(\\mathbf{x}) = 10d + \\sum_{i=1}^{d} (x_{i}^{2} - 10 \\cos(2 \\pi x_{i}))\n",
+ "\\end{align*}\n",
+ "\n",
+ "where $d$ is the dimensionality of the input vector. In the cell below, complete missing parts of the function which computes values of the Rastrigin function given the input array."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {}
+ },
+ "source": [
+ "```python\n",
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete the Rastrigin function.\")\n",
+ "###################################################################\n",
+ "\n",
+ "def rastrigin(x):\n",
+ " \"\"\"Compute Rastrigin function for given array of d-dimenstional vectors.\n",
+ "\n",
+ " Inputs:\n",
+ " - x (np.ndarray of shape (n, d)): n d-dimensional vectors.\n",
+ "\n",
+ " Outputs:\n",
+ " - y (np.ndarray of shape (n, 1)): Rastrigin function value for each of the vectors.\n",
+ " \"\"\"\n",
+ " return 10 * x.shape[1] + np.sum(... - 10 * np.cos(2*np.pi*...), axis=1)\n",
+ "\n",
+ "# this code creates 10000 2-dimensional vectors which are going to be served as input to the function (thus, output is of shape (10000, 1))\n",
+ "x0_rastrigin = np.linspace(-5.12, 5.12, 100)\n",
+ "X_rastrigin, Y_rastrigin = np.meshgrid(x0_rastrigin,x0_rastrigin)\n",
+ "xs_rastrigin = np.vstack((X_rastrigin.flatten(), Y_rastrigin.flatten())).T\n",
+ "\n",
+ "ys_rastrigin = rastrigin(xs_rastrigin)\n",
+ "\n",
+ "plot_3d_function([X_rastrigin],[Y_rastrigin], [ys_rastrigin.reshape(X_rastrigin.shape)], ['Rastrigin Function'])\n",
+ "\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "#to_remove solution\n",
+ "\n",
+ "def rastrigin(x):\n",
+ " \"\"\"Compute Rastrigin function for given array of d-dimenstional vectors.\n",
+ "\n",
+ " Inputs:\n",
+ " - x (np.ndarray of shape (n, d)): n d-dimensional vectors.\n",
+ "\n",
+ " Outputs:\n",
+ " - y (np.ndarray of shape (n, 1)): Rastrigin function value for each of the vectors.\n",
+ " \"\"\"\n",
+ " return 10 * x.shape[1] + np.sum(x**2 - 10 * np.cos(2*np.pi*x), axis=1)\n",
+ "\n",
+ "# this code creates 10000 2-dimensional vectors which are going to be served as input to the function (thus, output is of shape (10000, 1))\n",
+ "x0_rastrigin = np.linspace(-5.12, 5.12, 100)\n",
+ "X_rastrigin, Y_rastrigin = np.meshgrid(x0_rastrigin,x0_rastrigin)\n",
+ "xs_rastrigin = np.vstack((X_rastrigin.flatten(), Y_rastrigin.flatten())).T\n",
+ "\n",
+ "ys_rastrigin = rastrigin(xs_rastrigin)\n",
+ "\n",
+ "plot_3d_function([X_rastrigin],[Y_rastrigin], [ys_rastrigin.reshape(X_rastrigin.shape)], ['Rastrigin Function'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Now, we are going to see which of the inductive biases (suggested mechanism underlying input data) will be more efficient in training the linear regression to get values of the Rastrigin function. We will consider two representations:\n",
+ "\n",
+ "* **Bound**: We encode 2D input vectors `xs` as bound vectors\n",
+ "* **Bundled**: We encode 1D input vectors separately and use bundling and then bundle them together"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "set_seed(42)\n",
+ "\n",
+ "ssp_space = sspspace.RandomSSPSpace(domain_dim=2, ssp_dim=1024)\n",
+ "bound_phis = ssp_space.encode(xs_rastrigin)\n",
+ "\n",
+ "ssp_space0 = sspspace.RandomSSPSpace(domain_dim=1, ssp_dim=1024)\n",
+ "ssp_space1 = sspspace.RandomSSPSpace(domain_dim=1, ssp_dim=1024)\n",
+ "\n",
+ "#remember that input to `encode` should be 2-dimensional, thus we need to create extra dimension by applying [:,None]\n",
+ "bundle_phis = ssp_space0.encode(xs_rastrigin[:, 0][:, None]) + ssp_space1.encode(xs_rastrigin[:, 1][:, None])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Now, let us define modeling attributes: we will have a few different `train_sizes`, and we will fit a linear regression for each of them in a loop. Then, for each of the models, we will evaluate its fit based on RMSE loss on the test set."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "def loss(y_true, y_pred):\n",
+ " \"\"\"Calculate RMSE loss between true and predicted values (note, that loss is not normalized by the shape).\n",
+ "\n",
+ " Inputs:\n",
+ " - y_true (np.ndarray): true values.\n",
+ " - y_pred (np.ndarray): predicted values.\n",
+ "\n",
+ " Outputs:\n",
+ " - loss (float): loss value.\n",
+ " \"\"\"\n",
+ " return np.sqrt(np.mean((y_true - y_pred) ** 2))\n",
+ "\n",
+ "def test_performance(xs, ys, train_sizes):\n",
+ " \"\"\"Fit linear regression to the provided data and evaluate the performance with RMSE loss for different test sizes.\n",
+ "\n",
+ " Inputs:\n",
+ " - xs (np.ndarray): input data.\n",
+ " - ys (np.ndarray): output data.\n",
+ " - train_size (list): list of the train sizes.\n",
+ " \"\"\"\n",
+ " performance = []\n",
+ "\n",
+ " models = []\n",
+ " for train_size in tqdm(train_sizes):\n",
+ " X_train, X_test, y_train, y_test = train_test_split(xs, ys, random_state=1, train_size=train_size)\n",
+ " regr = LinearRegression().fit(X_train, y_train)\n",
+ " performance.append(np.copy(loss(y_test, regr.predict(X_test))))\n",
+ " models.append(regr)\n",
+ " return performance, models"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Now, we are ready to train the models on two different inductive biases of the input data."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "train_sizes = np.linspace(0.25, 0.9, 5)\n",
+ "bound_performance, bound_models = test_performance(bound_phis, ys_rastrigin, train_sizes)\n",
+ "bundle_performance, bundle_models = test_performance(bundle_phis, ys_rastrigin, train_sizes)\n",
+ "plot_performance(bound_performance, bundle_performance, train_sizes * bound_phis.shape[0], \"Rastrigin function - RMSE\")\n",
+ "plt.ylim((-1, 20))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "What a drastic difference! Let us evaluate visually the performance when training on 3,000 train points."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "bound_model = bound_models[0]\n",
+ "bundled_model = bundle_models[0]\n",
+ "\n",
+ "ys_hat_rastrigin_bound = bound_model.predict(bound_phis)\n",
+ "ys_hat_rastrigin_bundled = bundled_model.predict(bundle_phis)\n",
+ "\n",
+ "plot_3d_function([X_rastrigin, X_rastrigin, X_rastrigin], [Y_rastrigin, Y_rastrigin, Y_rastrigin], [ys_rastrigin.reshape(X_rastrigin.shape), ys_hat_rastrigin_bound.reshape(X_rastrigin.shape), ys_hat_rastrigin_bundled.reshape(X_rastrigin.shape)], ['Rastrigin Function - True', 'Bound', 'Bundled'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "### Coding Exercise 1 Discussion\n",
+ "\n",
+ "1. Why do you think the bundled representation is superior for the Rastrigin function?"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "#to_remove explanation\n",
+ "\n",
+ "\"\"\"\n",
+ "Discussion: Why do you think the bundled representation is superior for the Rastrigin function?\n",
+ "\n",
+ "The Rastrigin function is a superposition of independent functions of the input variable dimensions. The bundled representation is a superposition of a high-dimensional representation of the input dimensions, making it easier to learn this function, which is additive. For the bound representation, we have to learn a mapping from each tuple of input values to the appropriate output value, meaning more samples are required to approximate the function.\n",
+ "\"\"\";"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_additive_function\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "## Coding Exercise 2: Non-separable Function\n",
+ "\n",
+ "Now, let's consider a non-separable function: a function $f(x_1, x_2)$ that cannot be described as the sum of two one-dimensional functions $g(x_1)$ and $h_1$. We will examine this function over the domain $[-4,4]^{2}$:\n",
+ "\n",
+ "$$f(\\mathbf{x}) = \\sin(x_{1}x_{2})$$\n",
+ "\n",
+ "Fill in the missing parts of the code to get the correct calculation of the defined function."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {}
+ },
+ "source": [
+ "```python\n",
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete the non-separable function.\")\n",
+ "###################################################################\n",
+ "\n",
+ "def non_separable(x):\n",
+ " \"\"\"Compute non-separable function for given array of 2-dimenstional vectors.\n",
+ "\n",
+ " Inputs:\n",
+ " - x (np.ndarray of shape (n, 2)): n 2-dimensional vectors.\n",
+ "\n",
+ " Outputs:\n",
+ " - y (np.ndarray of shape (n, 1)): non-separable function value for each of the vectors.\n",
+ " \"\"\"\n",
+ " return np.sin(np.multiply(x[:, ...], x[:, ...]))\n",
+ "\n",
+ "x0_non_separable = np.linspace(-4, 4, 100)\n",
+ "X_non_separable, Y_non_separable = np.meshgrid(x0_non_separable,x0_non_separable)\n",
+ "xs_non_separable = np.vstack((X_non_separable.flatten(), Y_non_separable.flatten())).T\n",
+ "\n",
+ "ys_non_separable = non_separable(xs_non_separable)\n",
+ "\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "#to_remove solution\n",
+ "\n",
+ "def non_separable(x):\n",
+ " \"\"\"Compute non-separable function for given array of 2-dimenstional vectors.\n",
+ "\n",
+ " Inputs:\n",
+ " - x (np.ndarray of shape (n, 2)): n 2-dimensional vectors.\n",
+ "\n",
+ " Outputs:\n",
+ " - y (np.ndarray of shape (n, 1)): non-separable function value for each of the vectors.\n",
+ " \"\"\"\n",
+ " return np.sin(np.multiply(x[:, 0], x[:, 1]))\n",
+ "\n",
+ "x0_non_separable = np.linspace(-4, 4, 100)\n",
+ "X_non_separable, Y_non_separable = np.meshgrid(x0_non_separable,x0_non_separable)\n",
+ "xs_non_separable = np.vstack((X_non_separable.flatten(), Y_non_separable.flatten())).T\n",
+ "\n",
+ "ys_non_separable = non_separable(xs_non_separable)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "plot_3d_function([X_non_separable],[Y_non_separable], [ys_non_separable.reshape(X_non_separable.shape)], ['Nonseparable Function, $f(\\mathbf{x}) = \\sin(x_{1}x_{2})$'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "### Coding Exercise 2 Discussion\n",
+ "\n",
+ "1. Can you guess by the nature of the function which of the representations will be more efficient?"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "#to_remove explanation\n",
+ "\n",
+ "\"\"\"\n",
+ "Discussion: Can you guess which of the representations will be more efficient by the nature of the function?\n",
+ "\n",
+ "As the function is not separable, we expect the bound representation to perform better.\n",
+ "\"\"\";"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "We will reuse previously defined spaces for encoding bound and bundled representations."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "bound_phis = ssp_space.encode(xs_non_separable)\n",
+ "bundle_phis = ssp_space0.encode(xs_non_separable[:,0][:,None]) + ssp_space1.encode(xs_non_separable[:,1][:,None])\n",
+ "\n",
+ "train_sizes = np.linspace(0.25, 0.9, 5)\n",
+ "bound_performance, bound_models = test_performance(bound_phis, ys_non_separable, train_sizes)\n",
+ "bundle_performance, bundle_models = test_performance(bundle_phis, ys_non_separable, train_sizes)\n",
+ "plot_performance(bound_performance, bundle_performance, train_sizes * bound_phis.shape[0], title = \"Non-separable function - RMSE\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Bundling representation can't achieve the same quality even when the number of samples is increased. This is because the function is non-separable, and the bundling representation can't capture the interaction between the two dimensions."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "bound_model = bound_models[0]\n",
+ "bundle_model = bundle_models[0]\n",
+ "\n",
+ "ys_hat_bound = bound_model.predict(bound_phis)\n",
+ "ys_hat_bundle = bundle_model.predict(bundle_phis)\n",
+ "\n",
+ "plot_3d_function([X_non_separable, X_non_separable, X_non_separable], [Y_non_separable, Y_non_separable, Y_non_separable], [ys_non_separable.reshape(X_non_separable.shape), ys_hat_bound.reshape(X_non_separable.shape), ys_hat_bundle.reshape(X_non_separable.shape)], ['Non-separable Function - True', 'Bound', 'Bundled'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "So, as we can see, when we pick the right inductive bias, we can do a better job."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_non_separable_function\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "---\n",
+ "\n",
+ "# Section 2: Representing Continuous Values\n",
+ "\n",
+ "Estimated timing to here from start of tutorial: 20 minutes\n",
+ "\n",
+ "In this section we will use a technique called Fractional Binding to represent continuous values to construct a map of objects distributed over a 2D space. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Video 2: Mapping Intro\n",
+ "from ipywidgets import widgets\n",
+ "from IPython.display import YouTubeVideo\n",
+ "from IPython.display import IFrame\n",
+ "from IPython.display import display\n",
+ "\n",
+ "class PlayVideo(IFrame):\n",
+ " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
+ " self.id = id\n",
+ " if source == 'Bilibili':\n",
+ " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
+ " elif source == 'Osf':\n",
+ " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
+ " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
+ "\n",
+ "def display_videos(video_ids, W=400, H=300, fs=1):\n",
+ " tab_contents = []\n",
+ " for i, video_id in enumerate(video_ids):\n",
+ " out = widgets.Output()\n",
+ " with out:\n",
+ " if video_ids[i][0] == 'Youtube':\n",
+ " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
+ " height=H, fs=fs, rel=0)\n",
+ " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
+ " else:\n",
+ " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
+ " height=H, fs=fs, autoplay=False)\n",
+ " if video_ids[i][0] == 'Bilibili':\n",
+ " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
+ " elif video_ids[i][0] == 'Osf':\n",
+ " print(f'Video available at https://osf.io/{video.id}')\n",
+ " display(video)\n",
+ " tab_contents.append(out)\n",
+ " return tab_contents\n",
+ "\n",
+ "video_ids = [('Youtube', 's7MOusrbKXU'), ('Bilibili', 'BV1pi421i7iN')]\n",
+ "tab_contents = display_videos(video_ids, W=854, H=480)\n",
+ "tabs = widgets.Tab()\n",
+ "tabs.children = tab_contents\n",
+ "for i in range(len(tab_contents)):\n",
+ " tabs.set_title(i, video_ids[i][0])\n",
+ "display(tabs)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_mapping_intro\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "## Coding Exercise 3: Mixing Discrete Objects With Continuous Space\n",
+ "\n",
+ "We will store three objects in a vector representing a map. First, we will create 3 objects (a circle, square, and triangle), as we did before."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "set_seed(42)\n",
+ "\n",
+ "obj_names = ['circle','square','triangle']\n",
+ "discrete_space = sspspace.DiscreteSPSpace(obj_names, ssp_dim=1024)\n",
+ "\n",
+ "objs = {n:discrete_space.encode(n) for n in obj_names}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Next, we are going to create three locations where the objects will reside, and an encoder will transform those coordinates into an SSP representation."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "set_seed(42)\n",
+ "\n",
+ "ssp_space = sspspace.RandomSSPSpace(domain_dim=2, ssp_dim=1024)\n",
+ "positions = np.array([[0, -2],\n",
+ " [-2, 3],\n",
+ " [3, 2]\n",
+ " ])\n",
+ "ssps = {n:ssp_space.encode(x) for n, x in zip(obj_names, positions)}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Next, in order to see where things are on the map, we are going to compute the similarity between encoded places and points in the space. Your task is to complete the calculation of similarity values between all grid points with the one associated with the object."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "dim0 = np.linspace(-5, 5, 101)\n",
+ "dim1 = np.linspace(-5, 5, 101)\n",
+ "X,Y = np.meshgrid(dim0, dim1)\n",
+ "\n",
+ "query_xs = np.vstack((X.flatten(), Y.flatten())).T\n",
+ "query_ssps = ssp_space.encode(query_xs)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {}
+ },
+ "source": [
+ "```python\n",
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete similarity calculation.\")\n",
+ "###################################################################\n",
+ "\n",
+ "sims = []\n",
+ "\n",
+ "for obj_idx, obj in enumerate(obj_names):\n",
+ " sims.append(... @ ssps[obj].flatten())\n",
+ "\n",
+ "plt.figure(figsize=(8, 2.4))\n",
+ "plot_2d_similarity(sims, obj_names, (dim0.size, dim1.size))\n",
+ "\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "#to_remove solution\n",
+ "\n",
+ "sims = []\n",
+ "\n",
+ "for obj_idx, obj in enumerate(obj_names):\n",
+ " sims.append(query_ssps @ ssps[obj].flatten())\n",
+ "\n",
+ "plt.figure(figsize=(8, 2.4))\n",
+ "plot_2d_similarity(sims, obj_names, (dim0.size, dim1.size))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Now, let's bind these positions with the objects and see how that changes similarity with the map positions. Complete binding operation in the cell below."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {}
+ },
+ "source": [
+ "```python\n",
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete binding operation for objects and corresponding positions.\")\n",
+ "###################################################################\n",
+ "\n",
+ "#objects are located in `objs` and positions in `ssps`\n",
+ "bound_objects = [... * ... for n in obj_names]\n",
+ "\n",
+ "sims = []\n",
+ "\n",
+ "for obj_idx, obj in enumerate(obj_names):\n",
+ " sims.append(query_ssps @ bound_objects[obj_idx].flatten())\n",
+ "\n",
+ "plt.figure(figsize=(8, 2.4))\n",
+ "plot_2d_similarity(sims, obj_names, (dim0.size, dim1.size))\n",
+ "\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "#to_remove solution\n",
+ "\n",
+ "#objects are located in `objs` and positions in `ssps`\n",
+ "bound_objects = [objs[n] * ssps[n] for n in obj_names]\n",
+ "\n",
+ "sims = []\n",
+ "\n",
+ "for obj_idx, obj in enumerate(obj_names):\n",
+ " sims.append(query_ssps @ bound_objects[obj_idx].flatten())\n",
+ "\n",
+ "plt.figure(figsize=(8, 2.4))\n",
+ "plot_2d_similarity(sims, obj_names, (dim0.size, dim1.size))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "As you can see, the similarity is destroyed, which is what we should expect.\n",
+ "\n",
+ "Next, we are going to create a map out of our bound objects:\n",
+ "\n",
+ "\\begin{align*}\n",
+ "\\mathrm{map} = \\sum_{i=1}^{n} \\phi(x_{i})\\circledast obj_{i}\n",
+ "\\end{align*}"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "set_seed(42)\n",
+ "\n",
+ "ssp_map = sspspace.SSP(np.sum(bound_objects, axis=0))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Now, we can query the map by unbinding the objects we care about. Your task is to complete the unbinding operation. Then, let's observe the resulting similarities."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {}
+ },
+ "source": [
+ "```python\n",
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete the unbinding operation.\")\n",
+ "###################################################################\n",
+ "\n",
+ "objects_sims = []\n",
+ "\n",
+ "for obj_idx, obj_name in enumerate(obj_names):\n",
+ " #query the object name by unbinding it from the map\n",
+ " query_map = ssp_map * ~objs[...]\n",
+ " objects_sims.append(query_ssps @ query_map.flatten())\n",
+ "\n",
+ "plot_2d_similarity(objects_sims, obj_names, (dim0.size, dim1.size), title_argmax = True)\n",
+ "\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "#to_remove solution\n",
+ "\n",
+ "objects_sims = []\n",
+ "\n",
+ "for obj_idx, obj_name in enumerate(obj_names):\n",
+ " #query the object name by unbinding it from the map\n",
+ " query_map = ssp_map * ~objs[obj_name]\n",
+ " objects_sims.append(query_ssps @ query_map.flatten())\n",
+ "\n",
+ "plot_2d_similarity(objects_sims, obj_names, (dim0.size, dim1.size), title_argmax = True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Let's look at what happens when we unbind all the symbols from the map at once. Complete bundling and unbinding operations in the following code cell."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {}
+ },
+ "source": [
+ "```python\n",
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete the bundling and unbinding operations.\")\n",
+ "###################################################################\n",
+ "\n",
+ "# unifying bundled representation of all objects\n",
+ "all_objs = (objs['circle'] + objs[...] + objs[...]).normalize()\n",
+ "\n",
+ "# unbind this unifying representation from the map\n",
+ "query_map = ... * ~...\n",
+ "\n",
+ "sims = query_ssps @ query_map.flatten()\n",
+ "size = (dim0.size,dim1.size)\n",
+ "\n",
+ "plot_unbinding_objects_map(sims, positions, query_xs, size)\n",
+ "\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "#to_remove solution\n",
+ "# unifying bundled representation of all objects\n",
+ "all_objs = (objs['circle'] + objs['square'] + objs['triangle']).normalize()\n",
+ "\n",
+ "# unbind this unifying representation from the map\n",
+ "query_map = ssp_map * ~all_objs\n",
+ "\n",
+ "sims = query_ssps @ query_map.flatten()\n",
+ "size = (dim0.size,dim1.size)\n",
+ "\n",
+ "plot_unbinding_objects_map(sims, positions, query_xs, size)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "We can also unbind positions and see what objects exist there. We will the locations where objects are located as test positions, as well as two distinct ones to compare. In the final exercise, you should complete the unbinding of the position's operation."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {}
+ },
+ "source": [
+ "```python\n",
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete the unbinding operations.\")\n",
+ "###################################################################\n",
+ "\n",
+ "query_objs = np.vstack([objs[n] for n in obj_names])\n",
+ "test_positions = np.vstack((positions, [0,0], [0,-1.5]))\n",
+ "\n",
+ "sims = []\n",
+ "\n",
+ "for pos_idx, pos in enumerate(test_positions):\n",
+ " position_ssp = ssp_space.encode(pos[None,:]) #remember we need to have 2-dimensional vectors for `encode()` function\n",
+ " #unbind positions from the map\n",
+ " query_map = ... * ~...\n",
+ " sims.append(query_objs @ query_map.flatten())\n",
+ "\n",
+ "plot_unbinding_positions_map(sims, test_positions, obj_names)\n",
+ "\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "#to_remove solution\n",
+ "\n",
+ "query_objs = np.vstack([objs[n] for n in obj_names])\n",
+ "test_positions = np.vstack((positions, [0,0], [0,-1.5]))\n",
+ "\n",
+ "sims = []\n",
+ "\n",
+ "for pos_idx, pos in enumerate(test_positions):\n",
+ " position_ssp = ssp_space.encode(pos[None,:]) #remember we need to have 2-dimensional vectors for `encode()` function\n",
+ " #unbind positions from the map\n",
+ " query_map = ssp_map * ~position_ssp\n",
+ " sims.append(query_objs @ query_map.flatten())\n",
+ "\n",
+ "plot_unbinding_positions_map(sims, test_positions, obj_names)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "As you can see from the above plots, when we query each location, we can clearly identify the object stored at that location. \n",
+ "\n",
+ "When we query at the origin (where no object is present), we see that there is no strong candidate element. However, as we move closer to one of the objects (rightmost plot), the similarity starts to increase."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_mixing_discrete_objects_with_continuous_space\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Video 4: Mapping Outro\n",
+ "from ipywidgets import widgets\n",
+ "from IPython.display import YouTubeVideo\n",
+ "from IPython.display import IFrame\n",
+ "from IPython.display import display\n",
+ "\n",
+ "class PlayVideo(IFrame):\n",
+ " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
+ " self.id = id\n",
+ " if source == 'Bilibili':\n",
+ " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
+ " elif source == 'Osf':\n",
+ " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
+ " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
+ "\n",
+ "def display_videos(video_ids, W=400, H=300, fs=1):\n",
+ " tab_contents = []\n",
+ " for i, video_id in enumerate(video_ids):\n",
+ " out = widgets.Output()\n",
+ " with out:\n",
+ " if video_ids[i][0] == 'Youtube':\n",
+ " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
+ " height=H, fs=fs, rel=0)\n",
+ " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
+ " else:\n",
+ " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
+ " height=H, fs=fs, autoplay=False)\n",
+ " if video_ids[i][0] == 'Bilibili':\n",
+ " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
+ " elif video_ids[i][0] == 'Osf':\n",
+ " print(f'Video available at https://osf.io/{video.id}')\n",
+ " display(video)\n",
+ " tab_contents.append(out)\n",
+ " return tab_contents\n",
+ "\n",
+ "video_ids = [('Youtube', 'mXNFWr_cap4'), ('Bilibili', 'BV1ND421u7gp')]\n",
+ "tab_contents = display_videos(video_ids, W=854, H=480)\n",
+ "tabs = widgets.Tab()\n",
+ "tabs.children = tab_contents\n",
+ "for i in range(len(tab_contents)):\n",
+ " tabs.set_title(i, video_ids[i][0])\n",
+ "display(tabs)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_mapping_outro\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "---\n",
+ "# Summary\n",
+ "\n",
+ "*Estimated timing of tutorial: 40 minutes*"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Video 5: Conclusions\n",
+ "from ipywidgets import widgets\n",
+ "from IPython.display import YouTubeVideo\n",
+ "from IPython.display import IFrame\n",
+ "from IPython.display import display\n",
+ "\n",
+ "class PlayVideo(IFrame):\n",
+ " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
+ " self.id = id\n",
+ " if source == 'Bilibili':\n",
+ " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
+ " elif source == 'Osf':\n",
+ " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
+ " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
+ "\n",
+ "def display_videos(video_ids, W=400, H=300, fs=1):\n",
+ " tab_contents = []\n",
+ " for i, video_id in enumerate(video_ids):\n",
+ " out = widgets.Output()\n",
+ " with out:\n",
+ " if video_ids[i][0] == 'Youtube':\n",
+ " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
+ " height=H, fs=fs, rel=0)\n",
+ " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
+ " else:\n",
+ " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
+ " height=H, fs=fs, autoplay=False)\n",
+ " if video_ids[i][0] == 'Bilibili':\n",
+ " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
+ " elif video_ids[i][0] == 'Osf':\n",
+ " print(f'Video available at https://osf.io/{video.id}')\n",
+ " display(video)\n",
+ " tab_contents.append(out)\n",
+ " return tab_contents\n",
+ "\n",
+ "video_ids = [('Youtube', 'M6rRsdJdoYQ'), ('Bilibili', 'BV1wm421L7Se')]\n",
+ "tab_contents = display_videos(video_ids, W=854, H=480)\n",
+ "tabs = widgets.Tab()\n",
+ "tabs.children = tab_contents\n",
+ "for i in range(len(tab_contents)):\n",
+ " tabs.set_title(i, video_ids[i][0])\n",
+ "display(tabs)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Conclusion slides\n",
+ "\n",
+ "from IPython.display import IFrame\n",
+ "link_id = \"pxqny\"\n",
+ "\n",
+ "print(f\"If you want to download the slides: 'https://osf.io/download/{link_id}'\")\n",
+ "\n",
+ "IFrame(src=f\"https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{link_id}/?direct%26mode=render\", width=854, height=480)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_conclusions\")"
+ ]
+ }
+ ],
+ "metadata": {
+ "colab": {
+ "collapsed_sections": [],
+ "include_colab_link": true,
+ "name": "W2D2_Tutorial5",
+ "provenance": [],
+ "toc_visible": true
+ },
+ "kernel": {
+ "display_name": "Python 3",
+ "language": "python",
+ "name": "python3"
+ },
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.9.22"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 4
+}
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_04cf23a5.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_04cf23a5.py
deleted file mode 100644
index 2f65a0ba0..000000000
--- a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_04cf23a5.py
+++ /dev/null
@@ -1,3 +0,0 @@
-
-five_unbind_two = sspspace.SSP(integers[4]) * ~sspspace.SSP(integers[1])
-five_unbind_two_sims = five_unbind_two @ integers.T
\ No newline at end of file
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_7024b3c7.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_0b0b7a2d.py
similarity index 75%
rename from tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_7024b3c7.py
rename to tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_0b0b7a2d.py
index b56269a1d..30a35ad04 100644
--- a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_7024b3c7.py
+++ b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_0b0b7a2d.py
@@ -8,6 +8,4 @@
noisy_vector = 0.2 * vocab['fire-fighter'] + 0.15 * vocab['math-teacher'] + 0.3 * vocab['sales-manager']
-sims = np.array([noisy_vector | vocab[name] for name in symbol_names]).squeeze()
-
-plot_line_similarity_matrix(sims, symbol_names, multiple_objects = False, title = 'Similarity - pre cleanup')
\ No newline at end of file
+sims = np.array([noisy_vector | vocab[name] for name in symbol_names]).squeeze()
\ No newline at end of file
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_15f690ab.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_15f690ab.py
new file mode 100644
index 000000000..bb47ac32d
--- /dev/null
+++ b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_15f690ab.py
@@ -0,0 +1,15 @@
+
+sim_mat = np.zeros((4,4))
+
+sim_mat[0,0] = spa.dot(circle, circle)
+sim_mat[1,1] = spa.dot(square, square)
+sim_mat[2,2] = spa.dot(triangle, triangle)
+sim_mat[3,3] = spa.dot(shape, shape)
+
+sim_mat[0,1] = sim_mat[1,0] = spa.dot(circle, square)
+sim_mat[0,2] = sim_mat[2,0] = spa.dot(circle, triangle)
+sim_mat[0,3] = sim_mat[3,0] = spa.dot(circle, shape)
+
+sim_mat[1,2] = sim_mat[2,1] = spa.dot(square, triangle)
+sim_mat[1,3] = sim_mat[3,1] = spa.dot(square, shape)
+sim_mat[2,3] = sim_mat[3,2] = spa.dot(triangle, shape)
\ No newline at end of file
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_3e9c4916.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_3e9c4916.py
new file mode 100644
index 000000000..4c5414b25
--- /dev/null
+++ b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_3e9c4916.py
@@ -0,0 +1,6 @@
+
+"""
+Discussion: How would you provide intuitive reasoning or rigorous mathematical proof behind the fact that random high-dimensional vectors (note that each of the components is drawn from uniform distribution with zero mean) approximately orthogonal?
+
+Observe that as each of the components are independent and they are sampled from distribution with zero mean, it means that expected value of dot product E(x*y) = E(\sum_i x_i * y_i) = (linearity of expectation) \sum_i E(x_i * y_i) = (independence) \sum_i (E(x_i) * E(y_i)) = 0.
+""";
\ No newline at end of file
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_513dd01a.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_513dd01a.py
new file mode 100644
index 000000000..44f8b8bde
--- /dev/null
+++ b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_513dd01a.py
@@ -0,0 +1,3 @@
+
+five_unbind_two = integers[4] * ~integers[1]
+sims = np.array([spa.dot(five_unbind_two, i) for i in integers])
\ No newline at end of file
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_708701bb.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_708701bb.py
deleted file mode 100644
index 0abc44450..000000000
--- a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_708701bb.py
+++ /dev/null
@@ -1,16 +0,0 @@
-
-shape_sim_mat = np.zeros((4,4))
-
-shape_sim_mat[0,0] = (circle | circle).item()
-shape_sim_mat[1,1] = (square | square).item()
-shape_sim_mat[2,2] = (triangle | triangle).item()
-shape_sim_mat[3,3] = (shape | shape).item()
-
-shape_sim_mat[0,1] = shape_sim_mat[1,0] = (circle | square).item()
-shape_sim_mat[0,2] = shape_sim_mat[2,0] = (circle | triangle).item()
-shape_sim_mat[0,3] = shape_sim_mat[3,0] = (circle | shape).item()
-
-shape_sim_mat[1,2] = shape_sim_mat[2,1] = (square | triangle).item()
-shape_sim_mat[1,3] = shape_sim_mat[3,1] = (square | shape).item()
-
-shape_sim_mat[2,3] = shape_sim_mat[3,2] = (triangle | shape).item()
\ No newline at end of file
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_87190668.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_87190668.py
deleted file mode 100644
index f36fb1eb6..000000000
--- a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_87190668.py
+++ /dev/null
@@ -1,6 +0,0 @@
-
-"""
-Discussion: How would you explain the lines `sims = vector @ phis.T` in the previous coding exercises?
-
-We compute the similarity of `vector` to all the other references `phi` using the dot product. `vector` has shape `d` and phis has shape `m x d`, where `m` is the number of references. This yields `m` similarity values, one for each reference.
-""";
\ No newline at end of file
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_99c595f2.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_99c595f2.py
new file mode 100644
index 000000000..8499b6862
--- /dev/null
+++ b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_99c595f2.py
@@ -0,0 +1,17 @@
+
+set_seed(42)
+
+vector_length = 1024
+symbol_names = ['CIRCLE','SQUARE','TRIANGLE']
+
+vocab = make_vocabulary(vector_length)
+vocab.populate(';'.join(symbol_names))
+print(list(vocab.keys()))
+
+circle = vocab['CIRCLE']
+square = vocab['SQUARE']
+triangle = vocab['TRIANGLE']
+
+print('|circle| =', np.linalg.norm(circle.v))
+print('|triangle| =', np.linalg.norm(square.v))
+print('|square| =', np.linalg.norm(triangle.v))
\ No newline at end of file
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_9bc21529.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_9bc21529.py
deleted file mode 100644
index edee3e9c0..000000000
--- a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_9bc21529.py
+++ /dev/null
@@ -1,13 +0,0 @@
-new_object_names = ['red','red^','red*circle','circle','circle^']
-new_objs = objs
-
-new_objs['red^'] = new_objs['red*circle'] * ~new_objs['circle']
-new_objs['circle^'] = new_objs['red*circle'] * ~new_objs['red']
-
-new_obj_sims = np.zeros((len(new_object_names), len(new_object_names)))
-
-for name_idx, name in enumerate(new_object_names):
- for other_idx in range(name_idx, len(new_object_names)):
- new_obj_sims[name_idx, other_idx] = new_obj_sims[other_idx, name_idx] = (new_objs[name] | new_objs[new_object_names[other_idx]]).item()
-
-plot_similarity_matrix(new_obj_sims, new_object_names, values = True)
\ No newline at end of file
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_a86d03c8.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_a86d03c8.py
deleted file mode 100644
index 6b32fd23a..000000000
--- a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_a86d03c8.py
+++ /dev/null
@@ -1,14 +0,0 @@
-
-set_seed(42)
-
-vector_length = 1024
-symbol_names = ['circle','square','triangle']
-discrete_space = sspspace.DiscreteSPSpace(symbol_names, ssp_dim=vector_length, optimize = False)
-
-circle = discrete_space.encode('circle')
-square = discrete_space.encode('square')
-triangle = discrete_space.encode('triangle')
-
-print('|circle| =', np.linalg.norm(circle))
-print('|triangle| =', np.linalg.norm(triangle))
-print('|square| =', np.linalg.norm(square))
\ No newline at end of file
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_b91a4ab5.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_b91a4ab5.py
new file mode 100644
index 000000000..83792bfbb
--- /dev/null
+++ b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_b91a4ab5.py
@@ -0,0 +1,6 @@
+
+"""
+Discussion: How would you explain the usage of `d,md->m` in `np.einsum()` function in the previous coding exercise?
+
+`d` is the dimensionality of the vector; we compute similariy of one vector (representing `0` object) with other `m` vectors of the same dimension `d` (thus `md`); as the result we receive `m` values of similarity.
+""";
\ No newline at end of file
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_ce5fc6c7.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_ce5fc6c7.py
new file mode 100644
index 000000000..b8fd9bf92
--- /dev/null
+++ b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_ce5fc6c7.py
@@ -0,0 +1,3 @@
+
+phi_shifted = phis[200] * X**-3.1
+sims = np.array([spa.dot(phi_shifted, p) for p in phis])
\ No newline at end of file
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_d25db2a0.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_d25db2a0.py
deleted file mode 100644
index 4d6fc9097..000000000
--- a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_d25db2a0.py
+++ /dev/null
@@ -1,3 +0,0 @@
-
-phi_shifted = phis[200,:][None,:] * new_encoder.encode([[np.pi/2]])
-shifted_real_line_sims = phi_shifted.flatten() @ phis.T
\ No newline at end of file
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_da1926e8.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_da1926e8.py
new file mode 100644
index 000000000..02c63c45c
--- /dev/null
+++ b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_da1926e8.py
@@ -0,0 +1,4 @@
+
+vocab.add('RED_CIRCLE', vocab['RED'] * vocab['CIRCLE'])
+vocab.add('BLUE_TRIANGLE', vocab['BLUE'] * vocab['TRIANGLE'])
+vocab.add('GREEN_SQUARE', vocab['GREEN'] * vocab['SQUARE'])
\ No newline at end of file
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_da811641.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_da811641.py
deleted file mode 100644
index e2816d430..000000000
--- a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_da811641.py
+++ /dev/null
@@ -1,20 +0,0 @@
-
-set_seed(42)
-
-class Cleanup:
- def __init__(self, vocab, temperature=1e5):
- self.weights = np.array([vocab[k] for k in vocab.keys()]).squeeze()
- self.temp = temperature
- def __call__(self, x):
- sims = x @ self.weights.T
- max_sim = softmax(sims * self.temp, axis=1)
- return sspspace.SSP(max_sim @ self.weights) #sspspace.SSP() wrapper is necessary for further bitwise comparison, it doesn't change the result vector
-
-
-cleanup = Cleanup(vocab)
-
-clean_vector = cleanup(noisy_vector)
-
-clean_sims = np.array([clean_vector | vocab[name] for name in symbol_names]).squeeze()
-
-plot_double_line_similarity_matrix([sims, clean_sims], symbol_names, ['Noisy Similarity', 'Clean Similarity'], title = 'Similarity - post cleanup')
\ No newline at end of file
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_db547f5d.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_db547f5d.py
new file mode 100644
index 000000000..ce76fc432
--- /dev/null
+++ b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_db547f5d.py
@@ -0,0 +1,4 @@
+object_names = ['RED','EST_RED','RED_CIRCLE','CIRCLE','EST_CIRCLE']
+
+vocab.add('EST_RED', (vocab['RED_CIRCLE'] * ~vocab['CIRCLE']).normalized())
+vocab.add('EST_CIRCLE', (vocab['RED_CIRCLE'] * ~vocab['RED']).normalized())
\ No newline at end of file
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_f0f796f7.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_f0f796f7.py
deleted file mode 100644
index 76d105532..000000000
--- a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_f0f796f7.py
+++ /dev/null
@@ -1,17 +0,0 @@
-set_seed(42)
-
-#define axis vector
-axis_vectors = ['one']
-
-encoder = sspspace.DiscreteSPSpace(axis_vectors, ssp_dim=1024, optimize=False)
-
-#vocabulary
-vocab = {w:encoder.encode(w) for w in axis_vectors}
-
-#we will add new vectors to this list
-integers = [vocab['one']]
-
-max_int = 5
-for i in range(2, max_int + 1):
- #bind one more "one" to the previous integer to get the new one
- integers.append(integers[-1] * vocab['one'])
\ No newline at end of file
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_f12d9c75.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_f12d9c75.py
new file mode 100644
index 000000000..a438a346b
--- /dev/null
+++ b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_f12d9c75.py
@@ -0,0 +1,18 @@
+
+set_seed(42)
+
+class Cleanup:
+ def __init__(self, vocab, temperature=1e5):
+ self.weights = np.array([vocab[k] for k in vocab.keys()]).squeeze()
+ self.temp = temperature
+ def __call__(self, x):
+ sims = np.einsum('nd,md->nm', self.weights, x)
+ max_sim = softmax(sims * self.temp, axis=0)
+ return sspspace.SSP(np.einsum('nd,nm->md', self.weights, max_sim))
+
+
+cleanup = Cleanup(vocab)
+
+clean_vector = cleanup(noisy_vector)
+
+clean_sims = np.array([clean_vector | vocab[name] for name in symbol_names]).squeeze()
\ No newline at end of file
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_f5f2174f.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_f5f2174f.py
deleted file mode 100644
index 31b8293da..000000000
--- a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_f5f2174f.py
+++ /dev/null
@@ -1,9 +0,0 @@
-
-set_seed(42)
-new_encoder = sspspace.RandomSSPSpace(domain_dim=1, ssp_dim=1024)
-
-xs = np.linspace(-4,4,401)[:,None] #we expect the encoded values to be two-dimensional in `encoder.encode()` so we add extra dimension
-phis = new_encoder.encode(xs)
-
-#`0` element is right in the middle of phis array! notice that we have 401 samples inside it
-real_line_sims = phis[200, :] @ phis.T
\ No newline at end of file
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_f9fa3af1.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_f9fa3af1.py
deleted file mode 100644
index 08b5bb145..000000000
--- a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_f9fa3af1.py
+++ /dev/null
@@ -1,4 +0,0 @@
-
-objs['red*circle'] = objs['red'] * objs['circle']
-objs['blue*triangle'] = objs['blue'] * objs['triangle']
-objs['green*square'] = objs['green'] * objs['square']
\ No newline at end of file
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_150dc068.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_150dc068.py
deleted file mode 100644
index 5688eff9f..000000000
--- a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_150dc068.py
+++ /dev/null
@@ -1,5 +0,0 @@
-
-rules = [
- (vocab['ant'] * vocab['blue'] + vocab['relation'] * vocab['implies'] + vocab['cons'] * vocab['even']).normalize(),
- (vocab['ant'] * vocab['odd'] + vocab['relation'] * vocab['implies'] + vocab['cons'] * vocab['green']).normalize(),
-]
\ No newline at end of file
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_3a819ce6.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_3a819ce6.py
new file mode 100644
index 000000000..1a2c043f6
--- /dev/null
+++ b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_3a819ce6.py
@@ -0,0 +1,8 @@
+
+new_rule = (vocab['ANT'] * vocab['RED'] + vocab['RELATION'] * vocab['IMPLIES'] + vocab['CONS'] * vocab['PRIME']).normalized()
+
+#apply transform on new rule to test the generalization of the transform
+a_hat = spa.SemanticPointer(transform) * new_rule
+
+new_sims = np.einsum('nd,d->n', action_space, a_hat.v)
+y_hat = softmax(new_sims)
\ No newline at end of file
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_47654e2f.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_47654e2f.py
deleted file mode 100644
index 741e83704..000000000
--- a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_47654e2f.py
+++ /dev/null
@@ -1,12 +0,0 @@
-
-set_seed(42)
-
-card_states = ['red','blue','odd','even','not','green','prime','implies','ant','relation','cons']
-encoder = sspspace.DiscreteSPSpace(card_states, ssp_dim=1024, optimize=False)
-vocab = {c:encoder.encode(c) for c in card_states}
-
-for a in ['red','blue','odd','even','green','prime']:
- vocab[f'not*{a}'] = vocab['not'] * vocab[a]
-
-action_names = ['red','blue','odd','even','green','prime','not*red','not*blue','not*odd','not*even','not*green','not*prime']
-action_space = np.array([vocab[x] for x in action_names]).squeeze()
\ No newline at end of file
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_adb53d43.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_550fd076.py
similarity index 61%
rename from tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_adb53d43.py
rename to tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_550fd076.py
index 33a97aa09..93d753d57 100644
--- a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_adb53d43.py
+++ b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_550fd076.py
@@ -3,10 +3,11 @@
losses = []
sims = []
lr = 1e-1
-ant_names = ["blue", "odd"]
-cons_names = ["even", "green"]
+ant_names = ["BLUE", "ODD"]
+cons_names = ["EVEN", "GREEN"]
+vector_length = 1024
-transform = np.zeros((1,encoder.ssp_dim))
+transform = np.zeros((vector_length))
for i in range(num_iters):
loss = 0
for rule, ant_name, cons_name in zip(rules, ant_names, cons_names):
@@ -15,22 +16,22 @@
y_true = np.eye(len(action_names))[action_names.index(ant_name),:] + np.eye(len(action_names))[4+action_names.index(cons_name),:]
#prediction with current transform (a_hat = transform * rule)
- a_hat = sspspace.SSP(transform) * rule
+ a_hat = spa.SemanticPointer(transform) * rule
#similarity with current transform
- sim_mat = action_space @ a_hat.T
+ sim_mat = np.einsum('nd,d->n', action_space, a_hat.v)
#cleanup
y_hat = softmax(sim_mat)
#true solution (a* = ant_name + not * cons_name)
- a_true = (vocab[ant_name] + vocab['not']*vocab[cons_name]).normalize()
+ a_true = (vocab[ant_name] + vocab['NOT']*vocab[cons_name]).normalized()
#calculate loss
loss += log_loss(y_true, y_hat)
- #update transform (T <- T - lr * (T - A* * (~rule)))
- transform -= (lr) * (transform - np.array(a_true * ~rule))
+ #update transform (T <- T - lr * (A* * (~rule)))
+ transform -= (lr) * (transform - (a_true * ~rule).v)
transform = transform / np.linalg.norm(transform)
#save predicted similarities if it is last iteration
@@ -38,6 +39,4 @@
sims.append(sim_mat)
#save loss
- losses.append(np.copy(loss))
-
-plot_training_and_choice(losses, sims, ant_names, cons_names, action_names)
\ No newline at end of file
+ losses.append(np.copy(loss))
\ No newline at end of file
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_6e6c0725.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_6e6c0725.py
deleted file mode 100644
index c89dffd20..000000000
--- a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_6e6c0725.py
+++ /dev/null
@@ -1,11 +0,0 @@
-
-objs['queen_query'] = (objs['king'] * ~objs['male']) * objs['female']
-
-object_names = list(objs.keys())
-sims = np.zeros((len(object_names), len(object_names)))
-
-for name_idx, name in enumerate(object_names):
- for other_idx in range(name_idx, len(object_names)):
- sims[name_idx, other_idx] = sims[other_idx, name_idx] = (objs[name] | objs[object_names[other_idx]]).item()
-
-plot_similarity_matrix(sims, object_names, values = True)
\ No newline at end of file
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_721e11a2.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_721e11a2.py
deleted file mode 100644
index d24329c3e..000000000
--- a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_721e11a2.py
+++ /dev/null
@@ -1,12 +0,0 @@
-
-set_seed(42)
-
-symbol_names = ['monarch','heir','male','female']
-discrete_space = sspspace.DiscreteSPSpace(symbol_names, ssp_dim=1024, optimize=False)
-
-objs = {n:discrete_space.encode(n) for n in symbol_names}
-
-objs['king'] = objs['monarch'] * objs['male']
-objs['queen'] = objs['monarch'] * objs['female']
-objs['prince'] = objs['heir'] * objs['male']
-objs['princess'] = objs['heir'] * objs['female']
\ No newline at end of file
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_923b3e73.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_923b3e73.py
deleted file mode 100644
index f387d4f7c..000000000
--- a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_923b3e73.py
+++ /dev/null
@@ -1,11 +0,0 @@
-
-new_objs['peso_query'] = cleanup(~new_objs['canada'] * new_objs['dollar'] * new_objs['mexico'])
-
-object_names = list(new_objs.keys())
-sims = np.zeros((len(object_names), len(object_names)))
-
-for name_idx, name in enumerate(object_names):
- for other_idx in range(name_idx, len(object_names)):
- sims[name_idx, other_idx] = sims[other_idx, name_idx] = (new_objs[name] | new_objs[object_names[other_idx]]).item()
-
-plot_similarity_matrix(sims, object_names)
\ No newline at end of file
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_9da10bdc.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_9da10bdc.py
deleted file mode 100644
index 997b4d351..000000000
--- a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_9da10bdc.py
+++ /dev/null
@@ -1,17 +0,0 @@
-
-#features - rules
-X_train = np.array(rules).squeeze()
-
-#output - a* for each rule
-y_train = np.array([
- (vocab[ant_names[0]] + vocab['not']*vocab[cons_names[0]]).normalize(),
- (vocab[ant_names[1]] + vocab['not']*vocab[cons_names[1]]).normalize(),
-]).squeeze()
-
-regr = MLPRegressor(random_state=1, hidden_layer_sizes=(1024,1024), max_iter=1000).fit(X_train, y_train)
-
-a_mlp = regr.predict(new_rule)
-
-mlp_sims = action_space @ a_mlp.T
-
-plot_choice([mlp_sims], ["red"], ["prime"], action_names)
\ No newline at end of file
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_a0e39449.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_a0e39449.py
new file mode 100644
index 000000000..c2755a2bf
--- /dev/null
+++ b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_a0e39449.py
@@ -0,0 +1,13 @@
+set_seed(42)
+vector_length = 1024
+
+card_states = ['RED','BLUE','ODD','EVEN','NOT','GREEN','PRIME','IMPLIES','ANT','RELATION','CONS']
+vocab = make_vocabulary(vector_length)
+vocab.populate(';'.join(card_states))
+
+
+for a in ['RED','BLUE','ODD','EVEN','GREEN','PRIME']:
+ vocab.add(f'NOT_{a}', vocab['NOT'] * vocab[a])
+
+action_names = ['RED','BLUE','ODD','EVEN','GREEN','PRIME','NOT_RED','NOT_BLUE','NOT_ODD','NOT_EVEN','NOT_GREEN','NOT_PRIME']
+action_space = np.array([vocab[x].v for x in action_names]).squeeze()
\ No newline at end of file
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_a8dd8a5d.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_a8dd8a5d.py
deleted file mode 100644
index 7baa621e6..000000000
--- a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_a8dd8a5d.py
+++ /dev/null
@@ -1,10 +0,0 @@
-
-new_rule = (vocab['ant'] * vocab['red'] + vocab['relation'] * vocab['implies'] + vocab['cons'] * vocab['prime']).normalize()
-
-#apply transform on new rule to test the generalization of the transform
-a_hat = sspspace.SSP(transform) * new_rule
-
-new_sims = action_space @ a_hat.T
-y_hat = softmax(new_sims)
-
-plot_choice([new_sims], ["red"], ["prime"], action_names)
\ No newline at end of file
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_bab79b64.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_bab79b64.py
new file mode 100644
index 000000000..13c72b0a7
--- /dev/null
+++ b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_bab79b64.py
@@ -0,0 +1,5 @@
+
+rules = [
+ (vocab['ANT'] * vocab['BLUE'] + vocab['RELATION'] * vocab['IMPLIES'] + vocab['CONS'] * vocab['EVEN']).normalized(),
+ (vocab['ANT'] * vocab['ODD'] + vocab['RELATION'] * vocab['IMPLIES'] + vocab['CONS'] * vocab['GREEN']).normalized(),
+]
\ No newline at end of file
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_c3859542.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_c3859542.py
deleted file mode 100644
index 3be7fe607..000000000
--- a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_c3859542.py
+++ /dev/null
@@ -1,11 +0,0 @@
-
-objs['new_princess_query'] = (objs['prince'] * ~objs['king']) * objs['queen']
-object_names = list(objs.keys())
-
-sims = np.zeros((len(object_names), len(object_names)))
-
-for name_idx, name in enumerate(object_names):
- for other_idx in range(name_idx, len(object_names)):
- sims[name_idx, other_idx] = sims[other_idx, name_idx] = (objs[name] | objs[object_names[other_idx]]).item()
-
-plot_similarity_matrix(sims, object_names, values = True)
\ No newline at end of file
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_cc0b7eb5.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_cc0b7eb5.py
new file mode 100644
index 000000000..542ff9ac0
--- /dev/null
+++ b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_cc0b7eb5.py
@@ -0,0 +1,15 @@
+
+#features - rules
+X_train = np.array([r.v for r in rules]).squeeze()
+
+#output - a* for each rule
+y_train = np.array([
+ (vocab[ant_names[0]] + vocab['NOT']*vocab[cons_names[0]]).normalized().v,
+ (vocab[ant_names[1]] + vocab['NOT']*vocab[cons_names[1]]).normalized().v,
+]).squeeze()
+
+regr = MLPRegressor(random_state=1, hidden_layer_sizes=(1024,1024), max_iter=1000).fit(X_train, y_train)
+
+a_mlp = regr.predict(new_rule.v[None,:])
+
+mlp_sims = np.einsum('nd,md->nm', action_space, a_mlp)
\ No newline at end of file
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_d2f142fd.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_d2f142fd.py
deleted file mode 100644
index 659bd7c07..000000000
--- a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_d2f142fd.py
+++ /dev/null
@@ -1,2 +0,0 @@
-
-bundle_objs['princess_query'] = (bundle_objs['prince'] - bundle_objs['king']) + bundle_objs['queen']
\ No newline at end of file
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_e3c85ed6.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_e3c85ed6.py
deleted file mode 100644
index ea69f7395..000000000
--- a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_e3c85ed6.py
+++ /dev/null
@@ -1,12 +0,0 @@
-
-set_seed(42)
-
-new_symbol_names = ['dollar', 'peso', 'ottawa', 'mexico-city', 'currency', 'capital']
-new_discrete_space = sspspace.DiscreteSPSpace(new_symbol_names, ssp_dim=1024, optimize=False)
-
-new_objs = {n:new_discrete_space.encode(n) for n in new_symbol_names}
-
-cleanup = sspspace.Cleanup(new_objs)
-
-new_objs['canada'] = ((new_objs['currency'] * new_objs['dollar']) + (new_objs['capital'] * new_objs['ottawa'])).normalize()
-new_objs['mexico'] = ((new_objs['currency'] * new_objs['peso']) + (new_objs['capital'] * new_objs['mexico-city'])).normalize()
\ No newline at end of file
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial4_Solution_603ce327.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial4_Solution_603ce327.py
new file mode 100644
index 000000000..8b0f74340
--- /dev/null
+++ b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial4_Solution_603ce327.py
@@ -0,0 +1,2 @@
+
+vocab.add('QUERY_MX_CURRENCY', vocab['MEXICO'] * ~(vocab['CANADA'] * ~vocab['DOLLAR']))
\ No newline at end of file
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial4_Solution_73f6dd01.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial4_Solution_73f6dd01.py
new file mode 100644
index 000000000..78a29d73a
--- /dev/null
+++ b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial4_Solution_73f6dd01.py
@@ -0,0 +1,2 @@
+
+vocab.add('QUERY_PRINCESS', ((vocab['PRINCE'] - vocab['KING']) + vocab['QUEEN']).normalized())
\ No newline at end of file
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial4_Solution_873dadc4.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial4_Solution_873dadc4.py
new file mode 100644
index 000000000..d36f11943
--- /dev/null
+++ b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial4_Solution_873dadc4.py
@@ -0,0 +1,5 @@
+
+vocab.add('KING', vocab['MONARCH'] * vocab['MALE'])
+vocab.add('QUEEN', vocab['MONARCH'] * vocab['FEMALE'])
+vocab.add('PRINCE', vocab['HEIR'] * vocab['MALE'])
+vocab.add('PRINCESS', vocab['HEIR'] * vocab['FEMALE'])
\ No newline at end of file
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial4_Solution_8ecc4392.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial4_Solution_8ecc4392.py
new file mode 100644
index 000000000..af525253b
--- /dev/null
+++ b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial4_Solution_8ecc4392.py
@@ -0,0 +1,2 @@
+
+vocab.add('QUERY_QUEEN', (vocab['KING'] * ~vocab['MALE']) * vocab['FEMALE'])
\ No newline at end of file
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial4_Solution_a848247a.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial4_Solution_a848247a.py
new file mode 100644
index 000000000..c1116c885
--- /dev/null
+++ b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial4_Solution_a848247a.py
@@ -0,0 +1,3 @@
+
+vocab.add('CANADA', (vocab['CURRENCY'] * vocab['DOLLAR'] + vocab['CAPITAL'] * vocab['OTTAWA']).normalized())
+vocab.add('MEXICO', (vocab['CURRENCY'] * vocab['PESO'] + vocab['CAPITAL'] * vocab['MEXICO_CITY']).normalized())
\ No newline at end of file
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial4_Solution_f2f03c67.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial4_Solution_f2f03c67.py
new file mode 100644
index 000000000..15867b386
--- /dev/null
+++ b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial4_Solution_f2f03c67.py
@@ -0,0 +1,3 @@
+
+# objs['query'] = (objs['prince'] * ~objs['king']) * objs['queen']
+vocab.add('QUERY_PRINCESS_2', (vocab['PRINCE'] * ~vocab['KING']) * vocab['QUEEN'])
\ No newline at end of file
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial3_Solution_1090e65a.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial5_Solution_1090e65a.py
similarity index 100%
rename from tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial3_Solution_1090e65a.py
rename to tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial5_Solution_1090e65a.py
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial3_Solution_2b4c5a99.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial5_Solution_2b4c5a99.py
similarity index 100%
rename from tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial3_Solution_2b4c5a99.py
rename to tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial5_Solution_2b4c5a99.py
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial3_Solution_57dcbce1.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial5_Solution_57dcbce1.py
similarity index 100%
rename from tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial3_Solution_57dcbce1.py
rename to tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial5_Solution_57dcbce1.py
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial3_Solution_730a75ed.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial5_Solution_730a75ed.py
similarity index 100%
rename from tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial3_Solution_730a75ed.py
rename to tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial5_Solution_730a75ed.py
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial3_Solution_8c79265f.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial5_Solution_8c79265f.py
similarity index 100%
rename from tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial3_Solution_8c79265f.py
rename to tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial5_Solution_8c79265f.py
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial3_Solution_99c56d84.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial5_Solution_99c56d84.py
similarity index 100%
rename from tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial3_Solution_99c56d84.py
rename to tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial5_Solution_99c56d84.py
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial3_Solution_b3d8f220.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial5_Solution_b3d8f220.py
similarity index 100%
rename from tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial3_Solution_b3d8f220.py
rename to tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial5_Solution_b3d8f220.py
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial3_Solution_bd7761a4.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial5_Solution_bd7761a4.py
similarity index 100%
rename from tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial3_Solution_bd7761a4.py
rename to tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial5_Solution_bd7761a4.py
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial3_Solution_cff4accc.py b/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial5_Solution_cff4accc.py
similarity index 100%
rename from tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial3_Solution_cff4accc.py
rename to tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial5_Solution_cff4accc.py
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial1_Solution_7024b3c7_0.png b/tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial1_Solution_7024b3c7_0.png
deleted file mode 100644
index 9ca136c73..000000000
Binary files a/tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial1_Solution_7024b3c7_0.png and /dev/null differ
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial1_Solution_9bc21529_0.png b/tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial1_Solution_9bc21529_0.png
deleted file mode 100644
index 8b0889090..000000000
Binary files a/tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial1_Solution_9bc21529_0.png and /dev/null differ
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial1_Solution_da811641_0.png b/tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial1_Solution_da811641_0.png
deleted file mode 100644
index 0e946a6d5..000000000
Binary files a/tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial1_Solution_da811641_0.png and /dev/null differ
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial2_Solution_6e6c0725_0.png b/tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial2_Solution_6e6c0725_0.png
deleted file mode 100644
index a6af2bcb4..000000000
Binary files a/tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial2_Solution_6e6c0725_0.png and /dev/null differ
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial2_Solution_923b3e73_0.png b/tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial2_Solution_923b3e73_0.png
deleted file mode 100644
index bbf7b9675..000000000
Binary files a/tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial2_Solution_923b3e73_0.png and /dev/null differ
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial2_Solution_9da10bdc_0.png b/tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial2_Solution_9da10bdc_0.png
deleted file mode 100644
index 1e77239ae..000000000
Binary files a/tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial2_Solution_9da10bdc_0.png and /dev/null differ
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial2_Solution_a8dd8a5d_0.png b/tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial2_Solution_a8dd8a5d_0.png
deleted file mode 100644
index d82ec5ddc..000000000
Binary files a/tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial2_Solution_a8dd8a5d_0.png and /dev/null differ
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial2_Solution_adb53d43_0.png b/tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial2_Solution_adb53d43_0.png
deleted file mode 100644
index 2365129e4..000000000
Binary files a/tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial2_Solution_adb53d43_0.png and /dev/null differ
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial2_Solution_c3859542_0.png b/tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial2_Solution_c3859542_0.png
deleted file mode 100644
index 541ee2d52..000000000
Binary files a/tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial2_Solution_c3859542_0.png and /dev/null differ
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial3_Solution_1090e65a_0.png b/tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial5_Solution_1090e65a_0.png
similarity index 100%
rename from tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial3_Solution_1090e65a_0.png
rename to tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial5_Solution_1090e65a_0.png
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial3_Solution_57dcbce1_0.png b/tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial5_Solution_57dcbce1_0.png
similarity index 100%
rename from tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial3_Solution_57dcbce1_0.png
rename to tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial5_Solution_57dcbce1_0.png
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial3_Solution_99c56d84_0.png b/tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial5_Solution_99c56d84_0.png
similarity index 100%
rename from tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial3_Solution_99c56d84_0.png
rename to tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial5_Solution_99c56d84_0.png
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial3_Solution_b3d8f220_0.png b/tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial5_Solution_b3d8f220_0.png
similarity index 100%
rename from tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial3_Solution_b3d8f220_0.png
rename to tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial5_Solution_b3d8f220_0.png
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial3_Solution_bd7761a4_0.png b/tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial5_Solution_bd7761a4_0.png
similarity index 100%
rename from tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial3_Solution_bd7761a4_0.png
rename to tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial5_Solution_bd7761a4_0.png
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial3_Solution_cff4accc_0.png b/tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial5_Solution_cff4accc_0.png
similarity index 100%
rename from tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial3_Solution_cff4accc_0.png
rename to tutorials/W2D2_NeuroSymbolicMethods/static/W2D2_Tutorial5_Solution_cff4accc_0.png
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Intro.ipynb b/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Intro.ipynb
index 218b77e69..5a0275059 100644
--- a/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Intro.ipynb
+++ b/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Intro.ipynb
@@ -18,7 +18,9 @@
}
},
"source": [
- "# Intro"
+ "# W2D2 - Neurosymbolic Methods and Cognitive Architectures \n",
+ "\n",
+ "Welcome to the day on Neurosymbolic Methods and Cognitive Architectures. This year we have some new content to introduce to you from the fascinating work by Chris Eliasmith and Michael Furlong. We're going to look at methods that use symbolic manipulation in order to learn how to model data in a way that is more brain-like and generalizes well to stimuli out of distribution. We're also going to look in some detail at a model they have created, called SPAUN. Please consider the note in the prerequisite cell below and try to have a basic understanding of those listed topics before getting into the details. The topic will be much clearer having brushed up on those topics. We'll now pass it over to Chris and Michael to tell you all about neurosymbolic methods and cognitive architectures!"
]
},
{
@@ -123,7 +125,7 @@
" return tab_contents\n",
"\n",
"\n",
- "video_ids = [('Youtube', 'RKKUfo0dVnY'), ('Bilibili', 'BV11D421M7Hy')]\n",
+ "video_ids = [('Youtube', 'W1jsRycDYXQ'), ('Bilibili', 'BV15V7jz8EAj')]\n",
"tab_contents = display_videos(video_ids, W=854, H=480)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
@@ -172,7 +174,7 @@
"from ipywidgets import widgets\n",
"out = widgets.Output()\n",
"\n",
- "link_id = \"nxzar\"\n",
+ "link_id = \"9w836\"\n",
"\n",
"with out:\n",
" print(f\"If you want to download the slides: https://osf.io/download/{link_id}/\")\n",
@@ -209,7 +211,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.9.19"
+ "version": "3.9.22"
}
},
"nbformat": 4,
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial1.ipynb b/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial1.ipynb
index 2d52ed034..9d8e0dae3 100644
--- a/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial1.ipynb
+++ b/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial1.ipynb
@@ -25,9 +25,9 @@
"\n",
"__Content creators:__ P. Michael Furlong, Chris Eliasmith\n",
"\n",
- "__Content reviewers:__ Hlib Solodzhuk, Patrick Mineault, Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi\n",
+ "__Content reviewers:__ Hlib Solodzhuk, Patrick Mineault, Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Alex Murphy\n",
"\n",
- "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk\n"
+ "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk, Alex Murphy\n"
]
},
{
@@ -43,7 +43,7 @@
"\n",
"*Estimated timing of tutorial: 1 hour*\n",
"\n",
- "In this tutorial we will introduce vector symbolic algebra and discuss its main operations."
+ "In this tutorial we will introduce the concept of a vector symbolic algebra (VSA) and discuss its main operations and we will give you some demonstrations on a simple set of concepts (shapes and their colors) in order to let you see and play around with concept manipulations in this VSA! Let's get started!"
]
},
{
@@ -59,7 +59,7 @@
"# @markdown These are the slides for the videos in all tutorials today\n",
"\n",
"from IPython.display import IFrame\n",
- "link_id = \"2szmk\"\n",
+ "link_id = \"jybuw\"\n",
"\n",
"print(f\"If you want to download the slides: 'https://osf.io/download/{link_id}'\")\n",
"\n",
@@ -73,8 +73,11 @@
},
"source": [
"---\n",
- "# Setup\n",
- "\n"
+ "# Setup (Colab Users: Please Read)\n",
+ "\n",
+ "Note that because this tutorial relies on some special Python packages, these packages have requirements for specific versions of common scientific libraries, such as `numpy`. If you're in Google Colab, then as of May 2025, this comes with a later version (2.0.2) pre-installed. We require an older version (we'll be installing `1.24.4`). This causes Colab to force a session restart and then re-running of the installation cells for the new version to take effect. When you run the cell below, you will be prompted to restart the session. This is *entirely expected* and you haven't done anything wrong. Simply click 'Restart' and then run the cells as normal. \n",
+ "\n",
+ "An additional error might sometimes arise where an exception is raised connected to a missing element of NumPy. If this occurs, please restart the session and re-run the cells as normal and this error will go away. Updated versions of the affected libraries are expected out soon, but sadly not in time for the preparation of this material. We thank you for your understanding."
]
},
{
@@ -88,7 +91,10 @@
"source": [
"# @title Install and import feedback gadget\n",
"\n",
- "!pip install --quiet numpy matplotlib ipywidgets scipy vibecheck\n",
+ "!pip install git+https://github.com/neuromatch/sspspace@neuromatch --quiet\n",
+ "!pip install numpy==1.24.4\n",
+ "!pip install nengo_spa==2.0.0\n",
+ "!pip install --quiet matplotlib ipywidgets scipy vibecheck\n",
"\n",
"from vibecheck import DatatopsContentReviewContainer\n",
"def content_review(notebook_section: str):\n",
@@ -106,30 +112,6 @@
"feedback_prefix = \"W2D2_T1\""
]
},
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Notice that exactly the `neuromatch` branch of `sspspace` should be installed! Otherwise, some of the functionality won't work."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Install dependencies\n",
- "\n",
- "# Install sspspace\n",
- "!pip install git+https://github.com/neuromatch/sspspace@neuromatch --quiet"
- ]
- },
{
"cell_type": "code",
"execution_count": null,
@@ -153,6 +135,7 @@
"\n",
"#modeling\n",
"import sspspace\n",
+ "import nengo_spa as spa\n",
"from scipy.special import softmax"
]
},
@@ -284,7 +267,7 @@
" - title (str): title of the plot.\n",
" \"\"\"\n",
" with plt.xkcd():\n",
- " plt.plot(x_range, sim_mat)\n",
+ " plt.plot(x_range, sims)\n",
" plt.xlabel('x')\n",
" plt.ylabel('Similarity')\n",
" plt.title(title)"
@@ -313,90 +296,6 @@
"set_seed(seed = 42)"
]
},
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Helper functions\n",
- "\n",
- "# mainly contains solutions to exercises for correct plot output; please don't take a look!\n",
- "set_seed(42)\n",
- "\n",
- "vector_length = 1024\n",
- "symbol_names = ['circle','square','triangle']\n",
- "discrete_space = sspspace.DiscreteSPSpace(symbol_names, ssp_dim=vector_length, optimize = False)\n",
- "\n",
- "circle = discrete_space.encode('circle')\n",
- "square = discrete_space.encode('square')\n",
- "triangle = discrete_space.encode('triangle')\n",
- "\n",
- "shape = (circle + square + triangle).normalize()\n",
- "\n",
- "shape_sim_mat = np.zeros((4,4))\n",
- "\n",
- "shape_sim_mat[0,0] = (circle | circle).item()\n",
- "shape_sim_mat[1,1] = (square | square).item()\n",
- "shape_sim_mat[2,2] = (triangle | triangle).item()\n",
- "shape_sim_mat[3,3] = (shape | shape).item()\n",
- "\n",
- "shape_sim_mat[0,1] = shape_sim_mat[1,0] = (circle | square).item()\n",
- "shape_sim_mat[0,2] = shape_sim_mat[2,0] = (circle | triangle).item()\n",
- "shape_sim_mat[0,3] = shape_sim_mat[3,0] = (circle | shape).item()\n",
- "\n",
- "shape_sim_mat[1,2] = shape_sim_mat[2,1] = (square | triangle).item()\n",
- "shape_sim_mat[1,3] = shape_sim_mat[3,1] = (square | shape).item()\n",
- "\n",
- "shape_sim_mat[2,3] = shape_sim_mat[3,2] = (triangle | shape).item()\n",
- "\n",
- "new_symbol_names = ['circle','square','triangle', 'red', 'blue', 'green']\n",
- "new_discrete_space = sspspace.DiscreteSPSpace(new_symbol_names, ssp_dim=vector_length, optimize=False)\n",
- "\n",
- "objs = {n:new_discrete_space.encode(np.array([n])) for n in new_symbol_names}\n",
- "\n",
- "objs['red*circle'] = objs['red'] * objs['circle']\n",
- "objs['blue*triangle'] = objs['blue'] * objs['triangle']\n",
- "objs['green*square'] = objs['green'] * objs['square']\n",
- "\n",
- "new_object_names = ['red','red^','red*circle','circle','circle^']\n",
- "new_objs = objs.copy()\n",
- "\n",
- "new_objs['red^'] = new_objs['red*circle'] * ~new_objs['circle']\n",
- "new_objs['circle^'] = new_objs['red*circle'] * ~new_objs['red']\n",
- "\n",
- "axis_vectors = ['one']\n",
- "\n",
- "encoder = sspspace.DiscreteSPSpace(axis_vectors, ssp_dim=1024, optimize=False)\n",
- "\n",
- "vocab = {w:encoder.encode(w) for w in axis_vectors}\n",
- "\n",
- "integers = [vocab['one']]\n",
- "\n",
- "max_int = 5\n",
- "for i in range(2, max_int + 1):\n",
- " integers.append(integers[-1] * vocab['one'])\n",
- "\n",
- "integers = np.array(integers).squeeze()\n",
- "integer_sims = integers @ integers.T\n",
- "\n",
- "five_unbind_two = sspspace.SSP(integers[4]) * ~sspspace.SSP(integers[1])\n",
- "five_unbind_two_sims = five_unbind_two @ integers.T\n",
- "\n",
- "new_encoder = sspspace.RandomSSPSpace(domain_dim=1, ssp_dim=1024)\n",
- "\n",
- "xs = np.linspace(-4,4,401)[:,None]\n",
- "phis = new_encoder.encode(xs)\n",
- "\n",
- "real_line_sims = phis[200, :] @ phis.T\n",
- "\n",
- "phi_shifted = phis[200,:][None,:] * new_encoder.encode([[np.pi/2]])\n",
- "shifted_real_line_sims = phi_shifted.flatten() @ phis.T"
- ]
- },
{
"cell_type": "markdown",
"metadata": {
@@ -485,11 +384,27 @@
"source": [
"## Coding Exercise 1: Concepts as High-Dimensional Vectors\n",
"\n",
- "In an arbitrary space of concepts, we will represent the ideas of 'circle,' 'square,' and triangle.' For that, we will use the SSP space library (`sspspace`) to map identifiers for the concepts (strings of their names in this case) into high-dimensional vectors of unit length. It means that for each `name`, we will uniquely identify $\\mathbf{v}$ where $||\\mathbf{v}|| = 1$.\n",
+ "In an arbitrary space of concepts, we will represent the ideas of `CIRCLE`, `SQUARE` and `TRIANGLE`. For that, we will make a vocabulary that map identifiers of the concepts (strings of their names in this case) into high-dimensional vectors of unit length. It means that for each `name`, we will uniquely identify $\\mathbf{v}$ where $||\\mathbf{v}|| = 1$.\n",
"\n",
"In this exercise, check that, indeed, vectors are of unit length."
]
},
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "from nengo_spa.algebras.hrr_algebra import HrrProperties, HrrAlgebra\n",
+ "from nengo_spa.vector_generation import VectorsWithProperties\n",
+ "def make_vocabulary(vector_length):\n",
+ " vec_generator = VectorsWithProperties(vector_length, algebra=HrrAlgebra(), properties = [HrrProperties.UNITARY, HrrProperties.POSITIVE])\n",
+ " vocab = spa.Vocabulary(vector_length, pointer_gen=vec_generator)\n",
+ " return vocab"
+ ]
+ },
{
"cell_type": "code",
"execution_count": null,
@@ -510,16 +425,19 @@
"set_seed(42)\n",
"\n",
"vector_length = 1024\n",
- "symbol_names = ['circle','square','triangle']\n",
- "discrete_space = sspspace.DiscreteSPSpace(symbol_names, ssp_dim=vector_length, optimize = False)\n",
+ "symbol_names = ['CIRCLE','SQUARE','TRIANGLE']\n",
"\n",
- "circle = discrete_space.encode('circle')\n",
- "square = discrete_space.encode('square')\n",
- "triangle = discrete_space.encode('triangle')\n",
+ "vocab = make_vocabulary(vector_length)\n",
+ "vocab.populate(';'.join(symbol_names))\n",
+ "print(list(vocab.keys()))\n",
"\n",
- "print('|circle| =', np.linalg.norm(circle))\n",
- "print('|triangle| =', np.linalg.norm(...))\n",
- "print('|square| =', ...)"
+ "circle = vocab['CIRCLE']\n",
+ "square = vocab['SQUARE']\n",
+ "triangle = vocab['TRIANGLE']\n",
+ "\n",
+ "print('|circle| =', np.linalg.norm(circle.v))\n",
+ "print('|triangle| =', np.linalg.norm(square.v))\n",
+ "print('|square| =', np.linalg.norm(triangle.v))"
]
},
{
@@ -529,7 +447,7 @@
"execution": {}
},
"source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_a86d03c8.py)\n",
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_99c595f2.py)\n",
"\n"
]
},
@@ -550,7 +468,7 @@
},
"outputs": [],
"source": [
- "plot_vectors([circle, square, triangle], symbol_names)"
+ "plot_vectors([circle.v, square.v, triangle.v], symbol_names)"
]
},
{
@@ -559,13 +477,13 @@
"execution": {}
},
"source": [
- "As vectors are assigned randomly, the images do not display any meaningful structure.\n",
+ "As vectors are initialized randomly, it's perfectly expected that there is no visual connection to how we would represent or expect those concepts to be represented.\n",
"\n",
- "One of the most useful properties of random high-dimensional vectors is that they are approximately orthogonal. This is an important aspect for vector symbolic algebras (VSAs) since we will use the vector dot product to measure similarity between objects encoded as random, high-dimensional vectors. \n",
+ "One of the extremely useful properties of random high-dimensional vectors is that they are approximately orthogonal. This is an important aspect for vector symbolic algebras (VSAs), since we will use the vector dot product to measure similarity between objects encoded as random, high-dimensional vectors.\n",
"\n",
- "Discrete objects are either the same or different, so we expect similarity would be either 1 (the same) or 0 (not the same). Given how we select the vectors that represent discrete symbols if they are the same, they will have the dot product of 1, and if they are different concepts, then they will have a dot product of (approximately) 0.\n",
+ "Discrete objects are either the same or different, so we expect similarity would be either 1 (the same) or 0 (not the same). Given how we select the vectors that represent discrete symbols, if they are the same they will have the dot product of 1 and if they are different concepts, then they will have a dot product of (approximately) 0. This is due to the approximate orthogonality of randomly selected high-dimensional vectors.\n",
"\n",
- "Below, we use the | operator to indicate similarity. This is borrowed from the bra-ket notation in physics, i.e.,\n",
+ "Below we use the | operator to indicate similarity. This is borrowed from the bra-ket notation in physics, i.e.,\n",
"\n",
"$$\n",
"\\mathbf{a}\\cdot\\mathbf{b} = \\langle \\mathbf{a} \\mid \\mathbf{b}\\rangle\n",
@@ -582,17 +500,17 @@
},
"outputs": [],
"source": [
- "concepts_sim_mat = np.zeros((3,3))\n",
+ "sim_mat = np.zeros((3,3))\n",
"\n",
- "concepts_sim_mat[0,0] = (circle | circle).item()\n",
- "concepts_sim_mat[1,1] = (square | square).item()\n",
- "concepts_sim_mat[2,2] = (triangle | triangle).item()\n",
+ "sim_mat[0,0] = spa.dot(circle, circle)\n",
+ "sim_mat[1,1] = spa.dot(square, square)\n",
+ "sim_mat[2,2] = spa.dot(triangle, triangle)\n",
"\n",
- "concepts_sim_mat[0,1] = concepts_sim_mat[1,0] = (circle | square).item()\n",
- "concepts_sim_mat[0,2] = concepts_sim_mat[2,0] = (circle | triangle).item()\n",
- "concepts_sim_mat[1,2] = concepts_sim_mat[2,1] = (square | triangle).item()\n",
+ "sim_mat[0,1] = sim_mat[1,0] = spa.dot(circle, square)\n",
+ "sim_mat[0,2] = sim_mat[2,0] = spa.dot(circle, triangle)\n",
+ "sim_mat[1,2] = sim_mat[2,1] = spa.dot(square, triangle)\n",
"\n",
- "plot_similarity_matrix(concepts_sim_mat, symbol_names)"
+ "plot_similarity_matrix(sim_mat, symbol_names)"
]
},
{
@@ -604,6 +522,28 @@
"As you can see from the above figure, the three randomly selected vectors are approximately orthogonal. This will be important later when we go to make more complicated objects from our vectors."
]
},
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "### Coding Exercise 1 Discussion\n",
+ "\n",
+ "1. How would you provide intuitive reasoning (or rigorous mathematical proof) behind the fact that random high-dimensional vectors (note that each of the components is drawn from uniform distribution with zero mean) approximately orthogonal?"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {}
+ },
+ "source": [
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_3e9c4916.py)\n",
+ "\n"
+ ]
+ },
{
"cell_type": "code",
"execution_count": null,
@@ -718,7 +658,7 @@
},
"outputs": [],
"source": [
- "shape = (circle + square + triangle).normalize()"
+ "shape = (circle + square + triangle).normalized()"
]
},
{
@@ -745,21 +685,20 @@
"raise NotImplementedError(\"Student exercise: complete calcualtion of similarity matrix.\")\n",
"###################################################################\n",
"\n",
- "shape_sim_mat = np.zeros((4,4))\n",
- "\n",
- "shape_sim_mat[0,0] = (circle | circle).item()\n",
- "shape_sim_mat[1,1] = (square | square).item()\n",
- "shape_sim_mat[2,2] = (triangle | ...).item()\n",
- "shape_sim_mat[3,3] = (shape | ...).item()\n",
+ "sim_mat = np.zeros((4,4))\n",
"\n",
- "shape_sim_mat[0,1] = shape_sim_mat[1,0] = (circle | square).item()\n",
- "shape_sim_mat[0,2] = shape_sim_mat[2,0] = (circle | triangle).item()\n",
- "shape_sim_mat[0,3] = shape_sim_mat[3,0] = (circle | shape).item()\n",
+ "sim_mat[0,0] = spa.dot(circle, circle)\n",
+ "sim_mat[1,1] = spa.dot(square, square)\n",
+ "sim_mat[2,2] = spa.dot(triangle, ...)\n",
+ "sim_mat[3,3] = spa.dot(shape, ...)\n",
"\n",
- "shape_sim_mat[1,2] = shape_sim_mat[2,1] = (square | triangle).item()\n",
- "shape_sim_mat[1,3] = shape_sim_mat[3,1] = (square | shape).item()\n",
+ "sim_mat[0,1] = sim_mat[1,0] = spa.dot(circle, square)\n",
+ "sim_mat[0,2] = sim_mat[2,0] = spa.dot(circle, triangle)\n",
+ "sim_mat[0,3] = sim_mat[3,0] = spa.dot(circle, shape)\n",
"\n",
- "shape_sim_mat[2,3] = shape_sim_mat[3,2] = (... | ...).item()"
+ "sim_mat[1,2] = sim_mat[2,1] = spa.dot(square, triangle)\n",
+ "sim_mat[1,3] = sim_mat[3,1] = spa.dot(square, shape)\n",
+ "sim_mat[2,3] = sim_mat[3,2] = spa.dot(..., shape)"
]
},
{
@@ -769,7 +708,7 @@
"execution": {}
},
"source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_708701bb.py)\n",
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_15f690ab.py)\n",
"\n"
]
},
@@ -781,7 +720,7 @@
},
"outputs": [],
"source": [
- "plot_similarity_matrix(shape_sim_mat, symbol_names + [\"shape\"], values = True)"
+ "plot_similarity_matrix(sim_mat, symbol_names + [\"shape\"], values = True)"
]
},
{
@@ -840,7 +779,7 @@
"\n",
"Estimated timing to here from start of tutorial: 20 minutes\n",
"\n",
- "In this section, we will talk about binding, an operation that takes two vectors and produces a new vector that is *not* similar to either of its constituent elements.\n",
+ "In this section we will talk about binding - an operation that takes two vectors and produces a new vector that is *not* similar to either of it's constituent elements.\n",
"\n",
"Binding and unbinding are implemented using circular convolution. Luckily, that is implemented for you inside the SSPSpace library. If you would like a refresher on convolution, this [Three Blue One Brown video](https://www.youtube.com/watch?v=KuXjwB4LzSA) is a good place to start."
]
@@ -933,10 +872,9 @@
"source": [
"set_seed(42)\n",
"\n",
- "new_symbol_names = ['circle','square','triangle', 'red', 'blue', 'green']\n",
- "new_discrete_space = sspspace.DiscreteSPSpace(new_symbol_names, ssp_dim=vector_length, optimize=False)\n",
- "\n",
- "objs = {n:new_discrete_space.encode(np.array([n])) for n in new_symbol_names}"
+ "symbol_names = ['CIRCLE','SQUARE','TRIANGLE', 'RED', 'BLUE', 'GREEN']\n",
+ "vocab = make_vocabulary(vector_length)\n",
+ "vocab.populate(';'.join(symbol_names))"
]
},
{
@@ -945,27 +883,12 @@
"execution": {}
},
"source": [
- "Now, we are going to take two of the objects to make new ones: a red circle, a blue triangle, and a green square.\n",
- "\n",
- "We will combine the two primitive objects using the binding operation, which for us is implemented using circular convolution, and we denote it by \n",
+ "Now we are going to take two of the objects to make new ones: a red circle, a blue triangle and a green square.\n",
"\n",
- "\\begin{align*}\n",
+ "We will combine the two primitive objects using the binding operation, which for us is implemented using circular convolution, and we denote it by\n",
+ "$$\n",
" a \\circledast b\n",
- "\\end{align*}\n",
- "\n",
- "\n",
- "Mathematical details
\n",
- "\n",
- "The circular convolution of two vectors $\\mathbf{a}$ and $\\mathbf{b} \\in \\mathbb{R}^N$ is defined as:\n",
- "\n",
- "$$c_j = a \\circledast b = \\sum_{k=1}^{N} a_k b_{1 + (j-k) \\mod N}$$\n",
- "\n",
- "where $N$ is the length of the vectors, and $j$ is the index of the output vector. It's often more convenient to calculate the circular convolution in the Fourier domain. The circular convolution is equivalent to the element-wise product of the Fourier transforms of the two vectors, followed by an inverse Fourier transform:\n",
- "\n",
- "$$a \\circledast b = \\mathcal{F}^{-1}(\\mathcal{F}(\\mathbf{a}) \\odot \\mathcal{F}(\\mathbf{b}))$$\n",
- "where $\\mathcal{F}$ is the Fourier transform, $\\odot$ is the element-wise product, and $\\mathcal{F}^{-1}$ is the inverse Fourier transform. The equivalence between these two formulations is a consequence of the [convolution theorem](https://en.wikipedia.org/wiki/Convolution_theorem).\n",
- "\n",
- " \n",
+ "$$\n",
"\n",
"In the cell below, complete the missing concepts and then observe the computed similarity matrix."
]
@@ -983,9 +906,9 @@
"raise NotImplementedError(\"Student exercise: complete derivation of new objects using binding operation.\")\n",
"###################################################################\n",
"\n",
- "objs['red*circle'] = objs['red'] * objs['circle']\n",
- "objs['blue*triangle'] = ... * objs['triangle']\n",
- "objs['green*square'] = objs['green'] * ..."
+ "vocab.add('RED_CIRCLE', vocab['RED'] * vocab['CIRCLE'])\n",
+ "vocab.add('BLUE_TRIANGLE', vocab['BLUE'] * ...)\n",
+ "vocab.add('GREEN_SQUARE', ... * vocab['SQUARE'])"
]
},
{
@@ -995,7 +918,7 @@
"execution": {}
},
"source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_f9fa3af1.py)\n",
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_da1926e8.py)\n",
"\n"
]
},
@@ -1016,14 +939,14 @@
},
"outputs": [],
"source": [
- "object_names = list(objs.keys())\n",
- "obj_sims = np.zeros((len(object_names), len(object_names)))\n",
+ "object_names = list(vocab.keys())\n",
+ "sims = np.zeros((len(object_names), len(object_names)))\n",
"\n",
"for name_idx, name in enumerate(object_names):\n",
" for other_idx in range(name_idx, len(object_names)):\n",
- " obj_sims[name_idx, other_idx] = obj_sims[other_idx, name_idx] = (objs[name] | objs[object_names[other_idx]]).item()\n",
+ " sims[name_idx, other_idx] = sims[other_idx, name_idx] = spa.dot(vocab[name], vocab[object_names[other_idx]])\n",
"\n",
- "plot_similarity_matrix(obj_sims, object_names)"
+ "plot_similarity_matrix(sims, object_names)"
]
},
{
@@ -1054,117 +977,22 @@
"execution": {}
},
"source": [
- "## Coding Exercise 4: Foundations of Colorful Shapes"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Video 4: Unbinding\n",
+ "## Coding Exercise 4: Foundations of Colorful Shapes\n",
"\n",
- "from ipywidgets import widgets\n",
- "from IPython.display import YouTubeVideo\n",
- "from IPython.display import IFrame\n",
- "from IPython.display import display\n",
- "\n",
- "class PlayVideo(IFrame):\n",
- " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
- " self.id = id\n",
- " if source == 'Bilibili':\n",
- " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
- " elif source == 'Osf':\n",
- " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
- " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
- "\n",
- "def display_videos(video_ids, W=400, H=300, fs=1):\n",
- " tab_contents = []\n",
- " for i, video_id in enumerate(video_ids):\n",
- " out = widgets.Output()\n",
- " with out:\n",
- " if video_ids[i][0] == 'Youtube':\n",
- " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
- " height=H, fs=fs, rel=0)\n",
- " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
- " else:\n",
- " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
- " height=H, fs=fs, autoplay=False)\n",
- " if video_ids[i][0] == 'Bilibili':\n",
- " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
- " elif video_ids[i][0] == 'Osf':\n",
- " print(f'Video available at https://osf.io/{video.id}')\n",
- " display(video)\n",
- " tab_contents.append(out)\n",
- " return tab_contents\n",
- "\n",
- "video_ids = [('Youtube', 'vHHX98jBvk8'), ('Bilibili', 'BV1gZ421g7XT')]\n",
- "tab_contents = display_videos(video_ids, W=854, H=480)\n",
- "tabs = widgets.Tab()\n",
- "tabs.children = tab_contents\n",
- "for i in range(len(tab_contents)):\n",
- " tabs.set_title(i, video_ids[i][0])\n",
- "display(tabs)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_unbinding\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "We can also undo the binding operation, which we call unbinding. It is implemented by binding with the pseudo-inverse of the vector we wish to unbind. We denote the pseudo-inverse of the vector using the ~ symbol.\n",
+ "We can also undo the binding operation, which we call unbinding. It is implemented by binding with the pseduo-inverse of the vector we wish to unbind. We denote the pseudoinverse of the vector using the ~ symbol.\n",
"\n",
- "The SSPSpace library implements the pseudo-inverse for you, but the pseudo-inverse of a vector $\\mathbf{x} = (x_{0},\\ldots, x_{d-1})$ is defined:\n",
+ "The SSPSpace library implements the pseudo-inverse for you, but the pseudo-inverse of a vector $\\mathbf{x} = (x_{1},\\ldots, x_{d})$ is defined:\n",
"\n",
- "$$\\sim\\mathbf{x} = \\left(x_{0},x_{d-1},x_{d-2},\\ldots,x_{1}\\right)$$\n",
+ "$$\\sim\\mathbf{x} = \\left(x_{1},x_{d},x_{d-1},\\ldots,x_{2}\\right)$$\n",
"\n",
"\n",
- "Consider the example of our red circle. If we want to recover the shape of the object, we will unbind from it the color:\n",
+ "Consider the example of our red circle. If we wanted to recover the shape of the object, we will unbind from it the color:\n",
"\n",
"$$\n",
"(\\mathtt{red} \\circledast \\mathtt{circle}) \\circledast \\sim \\mathtt{red} \\approx \\mathtt{circle}\n",
"$$\n",
"\n",
- "\n",
- "Mathematical details
\n",
- "\n",
- "By the definition of the pseudo-inverse and circular convolution, we have:\n",
- "\n",
- "$$\\mathbf{x} \\, \\circledast \\sim \\mathbf{x} = \n",
- "\\sum_{k=1}^{N} x_k x_{1 + (j + k - 2) \\mod N} \\approx \\delta_j$$\n",
- "\n",
- "where $\\delta_j$ is the Kronecker delta function. This is:\n",
- "\n",
- "* exactly equal to 1 when $j=1$. This is because the vectors in SSP have a norm of 1.\n",
- "* approximately 0 otherwise. This is because the vectors in SSP are random, and so a vector is approximately orthogonal to a shifted version of itself.\n",
- "\n",
- "The Kronecker delta is the identity function for the circular convolution, and circular convolutions commute, hence:\n",
- "\n",
- "$$\n",
- "(\\mathtt{a} \\circledast \\mathtt{b}) \\circledast \\sim \\mathtt{a} = \\mathtt{b} \\circledast (\\mathtt{a} \\circledast \\sim \\mathtt{a}) \\approx \\mathtt{b} \\circledast \\delta = \\mathtt{b}\n",
- "$$\n",
- "\n",
- " \n",
- "\n",
- "In the cell below, unbind the color and shape, and then observe the similarity matrix."
+ "In the cell below unbind color and shape, and then observe the similarity matrix."
]
},
{
@@ -1175,24 +1003,18 @@
},
"outputs": [],
"source": [
- "new_object_names = ['red','red^','red*circle','circle','circle^']\n",
- "new_objs = objs\n",
+ "object_names = ['RED','EST_RED','RED_CIRCLE','CIRCLE','EST_CIRCLE']\n",
"\n",
"###################################################################\n",
"## Fill out the following then remove\n",
"raise NotImplementedError(\"Student exercise: complete derivation of default objects using pseudoinverse.\")\n",
"###################################################################\n",
"\n",
- "new_objs['red^'] = new_objs['red*circle'] * ~new_objs['circle']\n",
- "new_objs['circle^'] = new_objs[...] * ~new_objs[...]\n",
- "\n",
- "new_obj_sims = np.zeros((len(new_object_names), len(new_object_names)))\n",
- "\n",
- "for name_idx, name in enumerate(new_object_names):\n",
- " for other_idx in range(name_idx, len(new_object_names)):\n",
- " new_obj_sims[name_idx, other_idx] = new_obj_sims[other_idx, name_idx] = (new_objs[name] | new_objs[new_object_names[other_idx]]).item()\n",
+ "# to_remove solution\n",
+ "object_names = ['RED','EST_RED','RED_CIRCLE','CIRCLE','EST_CIRCLE']\n",
"\n",
- "plot_similarity_matrix(new_obj_sims, new_object_names, values = True)"
+ "vocab.add('EST_RED', (... * ...).normalized())\n",
+ "vocab.add('EST_CIRCLE', (vocab['RED_CIRCLE'] * ~vocab['RED']).normalized())"
]
},
{
@@ -1202,12 +1024,26 @@
"execution": {}
},
"source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_9bc21529.py)\n",
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_db547f5d.py)\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "sims = np.zeros((len(object_names), len(object_names)))\n",
"\n",
- "*Example output:*\n",
+ "for name_idx, name in enumerate(object_names):\n",
+ " for other_idx in range(name_idx, len(object_names)):\n",
+ " sims[name_idx, other_idx] = spa.dot(vocab[name], vocab[object_names[other_idx]])\n",
+ " sims[other_idx, name_idx] = sims[name_idx, other_idx]\n",
"\n",
- "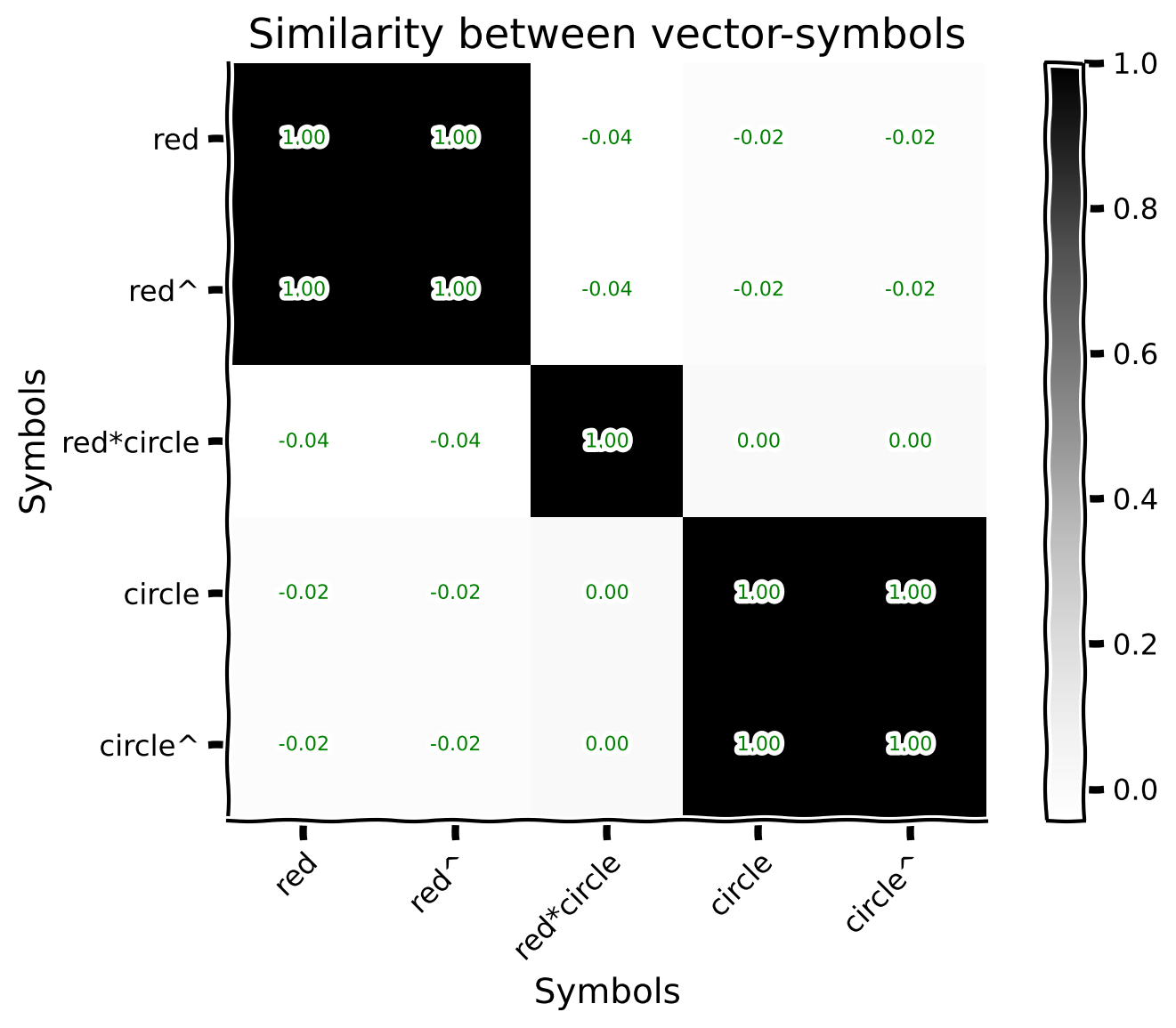 \n",
- "\n"
+ "plot_similarity_matrix(sims, object_names, values = True)"
]
},
{
@@ -1258,7 +1094,7 @@
},
"outputs": [],
"source": [
- "# @title Video 5: Cleanup\n",
+ "# @title Video 4: Cleanup\n",
"\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
@@ -1324,13 +1160,11 @@
"source": [
"## Coding Exercise 5: Cleanup Memories To Find The Best-Fit\n",
"\n",
- "In the process of computing with VSAs, the vectors themselves can become corrupted due to noise, because we implement these systems with spiking neurons, or due to approximations like using the pseudo-inverse for unbinding, or because noise gets added when we operate on complex structures.\n",
+ "In the process of computing with VSAs, the vectors themselves can become corrupted, due to noise, because we implement these systems with spiking neurons, or due to the approximations like using the pseudo inverse for unbinding, or because noise gets added when we operate on complex structures.\n",
"\n",
- "To address this problem, we employ \"cleanup memories.\" These are lots of ways to implement these systems, but today, we're going to do it with a single hidden layer neural network. Let's start with a sequence of symbols, say $\\texttt{fire-fighter},\\texttt{math-teacher},\\texttt{sales-manager},$ and so on, in that fashion, and create a new vector that is a corrupted combination of all three. We will then use a cleanup memory to find the best-fitting vector in our vocabulary.\n",
+ "To address this problem we employ \"cleanup memories\". There are lots of ways to implement these systems, but today we're going to do it with a single hidden layer neural network. Lets start with a sequence of symbols, say $\\texttt{fire-fighter},\\texttt{math-teacher},\\texttt{sales-manager},$ and so on, in that fashion, and create a new vector that is a corrupted combination of all three. We will then use a clean up memory to find the best fitting vector in our vocabulary.\n",
"\n",
- "In the cell below, you will see the definition of `noisy_vector`, your task is to complete the calculation of similarity values for this vector and all default ones.\n",
- "\n",
- "Here, we introduce another graphical way to represent the similarity: by putting a similarity value on the y-axis (instead of the box in the grid) and representing each of the objects by line (the x-axis stays the same, and similarity takes place between the corresponding label on the x-axis and line-object)."
+ "In the cell below you will see the definition of `noisy_vector`, your task is to complete the calculation of similarity values for this vector and all default ones.\n"
]
},
{
@@ -1345,6 +1179,7 @@
"## Fill out the following then remove\n",
"raise NotImplementedError(\"Student exercise: complete similarities calculation between noisy vector and given symbols.\")\n",
"###################################################################\n",
+ "\n",
"set_seed(42)\n",
"\n",
"symbol_names = ['fire-fighter','math-teacher','sales-manager']\n",
@@ -1354,9 +1189,7 @@
"\n",
"noisy_vector = 0.2 * vocab['fire-fighter'] + 0.15 * vocab['math-teacher'] + 0.3 * vocab['sales-manager']\n",
"\n",
- "sims = np.array([noisy_vector | vocab[...] for name in ...]).squeeze()\n",
- "\n",
- "plot_line_similarity_matrix(sims, symbol_names, multiple_objects = False, title = 'Similarity - pre cleanup')"
+ "sims = np.array([noisy_vector | vocab[...] for name in ...]).squeeze()"
]
},
{
@@ -1366,11 +1199,7 @@
"execution": {}
},
"source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_7024b3c7.py)\n",
- "\n",
- "*Example output:*\n",
- "\n",
- "
\n",
- "\n"
+ "plot_similarity_matrix(sims, object_names, values = True)"
]
},
{
@@ -1258,7 +1094,7 @@
},
"outputs": [],
"source": [
- "# @title Video 5: Cleanup\n",
+ "# @title Video 4: Cleanup\n",
"\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
@@ -1324,13 +1160,11 @@
"source": [
"## Coding Exercise 5: Cleanup Memories To Find The Best-Fit\n",
"\n",
- "In the process of computing with VSAs, the vectors themselves can become corrupted due to noise, because we implement these systems with spiking neurons, or due to approximations like using the pseudo-inverse for unbinding, or because noise gets added when we operate on complex structures.\n",
+ "In the process of computing with VSAs, the vectors themselves can become corrupted, due to noise, because we implement these systems with spiking neurons, or due to the approximations like using the pseudo inverse for unbinding, or because noise gets added when we operate on complex structures.\n",
"\n",
- "To address this problem, we employ \"cleanup memories.\" These are lots of ways to implement these systems, but today, we're going to do it with a single hidden layer neural network. Let's start with a sequence of symbols, say $\\texttt{fire-fighter},\\texttt{math-teacher},\\texttt{sales-manager},$ and so on, in that fashion, and create a new vector that is a corrupted combination of all three. We will then use a cleanup memory to find the best-fitting vector in our vocabulary.\n",
+ "To address this problem we employ \"cleanup memories\". There are lots of ways to implement these systems, but today we're going to do it with a single hidden layer neural network. Lets start with a sequence of symbols, say $\\texttt{fire-fighter},\\texttt{math-teacher},\\texttt{sales-manager},$ and so on, in that fashion, and create a new vector that is a corrupted combination of all three. We will then use a clean up memory to find the best fitting vector in our vocabulary.\n",
"\n",
- "In the cell below, you will see the definition of `noisy_vector`, your task is to complete the calculation of similarity values for this vector and all default ones.\n",
- "\n",
- "Here, we introduce another graphical way to represent the similarity: by putting a similarity value on the y-axis (instead of the box in the grid) and representing each of the objects by line (the x-axis stays the same, and similarity takes place between the corresponding label on the x-axis and line-object)."
+ "In the cell below you will see the definition of `noisy_vector`, your task is to complete the calculation of similarity values for this vector and all default ones.\n"
]
},
{
@@ -1345,6 +1179,7 @@
"## Fill out the following then remove\n",
"raise NotImplementedError(\"Student exercise: complete similarities calculation between noisy vector and given symbols.\")\n",
"###################################################################\n",
+ "\n",
"set_seed(42)\n",
"\n",
"symbol_names = ['fire-fighter','math-teacher','sales-manager']\n",
@@ -1354,9 +1189,7 @@
"\n",
"noisy_vector = 0.2 * vocab['fire-fighter'] + 0.15 * vocab['math-teacher'] + 0.3 * vocab['sales-manager']\n",
"\n",
- "sims = np.array([noisy_vector | vocab[...] for name in ...]).squeeze()\n",
- "\n",
- "plot_line_similarity_matrix(sims, symbol_names, multiple_objects = False, title = 'Similarity - pre cleanup')"
+ "sims = np.array([noisy_vector | vocab[...] for name in ...]).squeeze()"
]
},
{
@@ -1366,11 +1199,7 @@
"execution": {}
},
"source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_7024b3c7.py)\n",
- "\n",
- "*Example output:*\n",
- "\n",
- "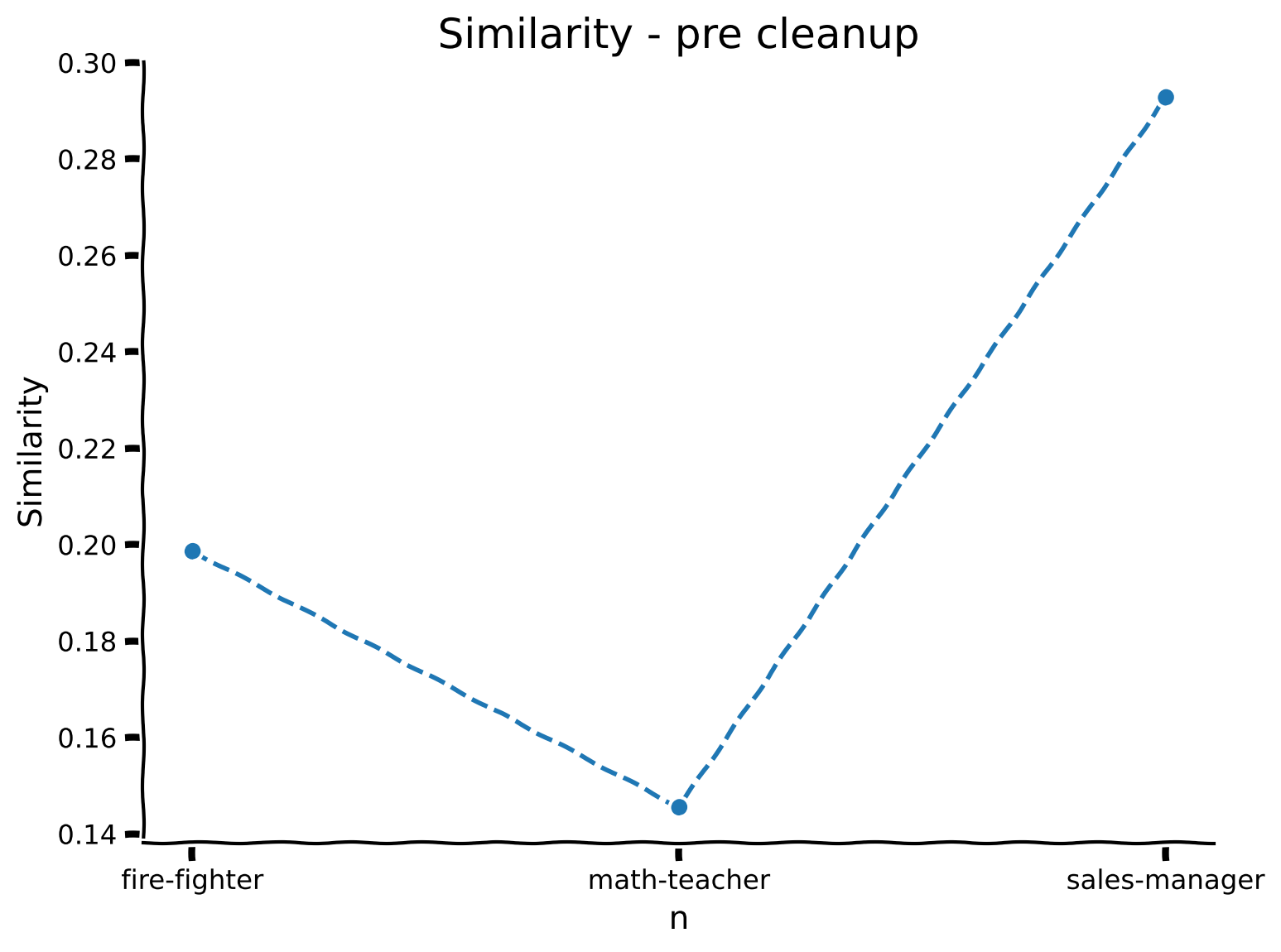 \n",
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_0b0b7a2d.py)\n",
"\n"
]
},
@@ -1380,19 +1209,13 @@
"execution": {}
},
"source": [
- "Conceptually, with a discrete vocabulary, we can clean up a vector by finding the reference vector that's closest to the noisy vector and replacing it:\n",
- "\n",
- "$$\\text{cleanup}(\\boldsymbol{x}) = \\arg\\max_{\\boldsymbol{w} \\in \\text{vocab}} \\boldsymbol{x} \\cdot \\boldsymbol{w}$$\n",
- "\n",
- "Now, let's construct a simple one-hidden layer neural network that does cleanup using a soft version of this operation, replacing the max operation with a softmax. The input weights will be the vectors in the vocabulary, and we will place a softmax function on the hidden layer. The output weights will again be the vectors representing the symbols in the vocabulary.\n",
+ "Now let's construct a simple neural network that does cleanup. We will construct the network, instead of learning it. The input weights will be the vectors in the vocabulary, and we will place a softmax function on the hidden layer (although we can use more biologically plausible activiations) and the output weights will again be the vectors representing the symbols in the vocabulary.\n",
"\n",
- "To snap the corrupted vectors back to the vocabulary, we'll apply this operation:\n",
+ "For efficient implementation of similarity calculation inside network, we will use `np.einsum()` function. Typically, it is used as `output = np.einsum('dim_inp1, dim_inp2 -> dim_out', input1, input2)`\n",
"\n",
- "$$\\text{cleanup}(\\boldsymbol{x}) = \\text{softmax}(T \\cdot \\boldsymbol{x} \\boldsymbol{W}^T) \\boldsymbol{W}$$\n",
+ "In this notation, `nd,md->nm` is the einsum \"equation\" or \"subscript notation\" which describes what operation should be performed. In this particular case, it states that the first input tensor is of shape `(n, d)` while the second is of shape `(m, d)` and the result of operation is of shape `(n, m)` (note that `n` and `m` can coincide). The operation itself performs the following calcualtion: `output[n, m] = sum(input1[n, d] * input2[m, d])`, meaning that in our case it will calculate all pairwise dot products - exactly what we need for similarity!\n",
"\n",
- "Where $T$ is the temperature parameter, and $\\boldsymbol{W}$ is the matrix of vectors in the vocabulary. As $T \\to \\infty$, this operation converges to the original hard max cleanup operation. Your task is to complete the `__call__` function. Then, we calculate the similarity between the obtained vector and the ones in the vocabulary.\n",
- "\n",
- "Observe the result and compare it to the pre-cleanup metrics."
+ "Your task is to complete `__call__` function. Then we calculate similarity between obtained vector and the ones in the vocabulary."
]
},
{
@@ -1413,24 +1236,18 @@
"class Cleanup:\n",
" def __init__(self, vocab, temperature=1e5):\n",
" self.weights = np.array([vocab[k] for k in vocab.keys()]).squeeze()\n",
- " self.temp = temperature\n",
+ " self.temp = ...\n",
" def __call__(self, x):\n",
- " ###################################################################\n",
- " ## Fill out the following then remove\n",
- " raise NotImplementedError(\"Student exercise: complete similarity calculation between input vector and weights of the network.\")\n",
- " ###################################################################\n",
- " sims = ...\n",
- " max_sim = softmax(sims * self.temp, axis=1)\n",
- " return sspspace.SSP(...) #sspspace.SSP() wrapper is necessary for further bitwise comparison, it doesn't change the result vector\n",
+ " sims = np.einsum(...)\n",
+ " max_sim = softmax(sims * self.temp, axis=0)\n",
+ " return sspspace.SSP(np.einsum('nd,nm->md', self.weights, max_sim))\n",
"\n",
"\n",
"cleanup = Cleanup(vocab)\n",
"\n",
"clean_vector = cleanup(noisy_vector)\n",
"\n",
- "clean_sims = np.array([clean_vector | vocab[name] for name in symbol_names]).squeeze()\n",
- "\n",
- "plot_double_line_similarity_matrix([sims, clean_sims], symbol_names, ['Noisy Similarity', 'Clean Similarity'], title = 'Similarity - post cleanup')"
+ "clean_sims = np.array([clean_vector | vocab[name] for name in symbol_names]).squeeze()"
]
},
{
@@ -1440,11 +1257,7 @@
"execution": {}
},
"source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_da811641.py)\n",
- "\n",
- "*Example output:*\n",
- "\n",
- "
\n",
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_0b0b7a2d.py)\n",
"\n"
]
},
@@ -1380,19 +1209,13 @@
"execution": {}
},
"source": [
- "Conceptually, with a discrete vocabulary, we can clean up a vector by finding the reference vector that's closest to the noisy vector and replacing it:\n",
- "\n",
- "$$\\text{cleanup}(\\boldsymbol{x}) = \\arg\\max_{\\boldsymbol{w} \\in \\text{vocab}} \\boldsymbol{x} \\cdot \\boldsymbol{w}$$\n",
- "\n",
- "Now, let's construct a simple one-hidden layer neural network that does cleanup using a soft version of this operation, replacing the max operation with a softmax. The input weights will be the vectors in the vocabulary, and we will place a softmax function on the hidden layer. The output weights will again be the vectors representing the symbols in the vocabulary.\n",
+ "Now let's construct a simple neural network that does cleanup. We will construct the network, instead of learning it. The input weights will be the vectors in the vocabulary, and we will place a softmax function on the hidden layer (although we can use more biologically plausible activiations) and the output weights will again be the vectors representing the symbols in the vocabulary.\n",
"\n",
- "To snap the corrupted vectors back to the vocabulary, we'll apply this operation:\n",
+ "For efficient implementation of similarity calculation inside network, we will use `np.einsum()` function. Typically, it is used as `output = np.einsum('dim_inp1, dim_inp2 -> dim_out', input1, input2)`\n",
"\n",
- "$$\\text{cleanup}(\\boldsymbol{x}) = \\text{softmax}(T \\cdot \\boldsymbol{x} \\boldsymbol{W}^T) \\boldsymbol{W}$$\n",
+ "In this notation, `nd,md->nm` is the einsum \"equation\" or \"subscript notation\" which describes what operation should be performed. In this particular case, it states that the first input tensor is of shape `(n, d)` while the second is of shape `(m, d)` and the result of operation is of shape `(n, m)` (note that `n` and `m` can coincide). The operation itself performs the following calcualtion: `output[n, m] = sum(input1[n, d] * input2[m, d])`, meaning that in our case it will calculate all pairwise dot products - exactly what we need for similarity!\n",
"\n",
- "Where $T$ is the temperature parameter, and $\\boldsymbol{W}$ is the matrix of vectors in the vocabulary. As $T \\to \\infty$, this operation converges to the original hard max cleanup operation. Your task is to complete the `__call__` function. Then, we calculate the similarity between the obtained vector and the ones in the vocabulary.\n",
- "\n",
- "Observe the result and compare it to the pre-cleanup metrics."
+ "Your task is to complete `__call__` function. Then we calculate similarity between obtained vector and the ones in the vocabulary."
]
},
{
@@ -1413,24 +1236,18 @@
"class Cleanup:\n",
" def __init__(self, vocab, temperature=1e5):\n",
" self.weights = np.array([vocab[k] for k in vocab.keys()]).squeeze()\n",
- " self.temp = temperature\n",
+ " self.temp = ...\n",
" def __call__(self, x):\n",
- " ###################################################################\n",
- " ## Fill out the following then remove\n",
- " raise NotImplementedError(\"Student exercise: complete similarity calculation between input vector and weights of the network.\")\n",
- " ###################################################################\n",
- " sims = ...\n",
- " max_sim = softmax(sims * self.temp, axis=1)\n",
- " return sspspace.SSP(...) #sspspace.SSP() wrapper is necessary for further bitwise comparison, it doesn't change the result vector\n",
+ " sims = np.einsum(...)\n",
+ " max_sim = softmax(sims * self.temp, axis=0)\n",
+ " return sspspace.SSP(np.einsum('nd,nm->md', self.weights, max_sim))\n",
"\n",
"\n",
"cleanup = Cleanup(vocab)\n",
"\n",
"clean_vector = cleanup(noisy_vector)\n",
"\n",
- "clean_sims = np.array([clean_vector | vocab[name] for name in symbol_names]).squeeze()\n",
- "\n",
- "plot_double_line_similarity_matrix([sims, clean_sims], symbol_names, ['Noisy Similarity', 'Clean Similarity'], title = 'Similarity - post cleanup')"
+ "clean_sims = np.array([clean_vector | vocab[name] for name in symbol_names]).squeeze()"
]
},
{
@@ -1440,11 +1257,7 @@
"execution": {}
},
"source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_da811641.py)\n",
- "\n",
- "*Example output:*\n",
- "\n",
- "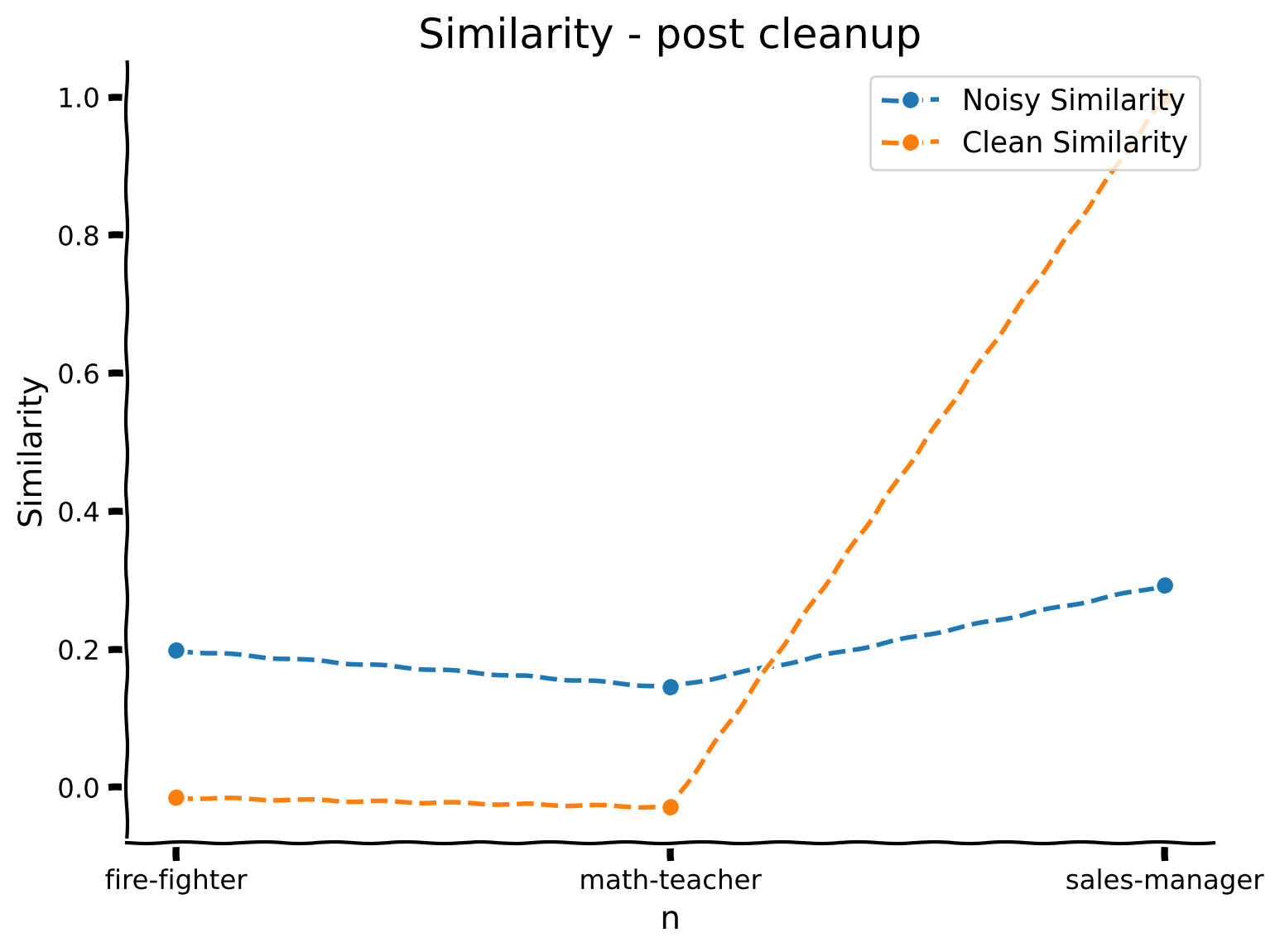 \n",
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_f12d9c75.py)\n",
"\n"
]
},
@@ -1454,7 +1267,27 @@
"execution": {}
},
"source": [
- "For the scenario where we have a discrete, known vocabulary, we can do this cleanup with a single feed-forward network, and we don't need to learn any of the synaptic weights."
+ "Observe the result with comparison to the pre cleanup metrics."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "plot_double_line_similarity_matrix([sims, clean_sims], symbol_names, ['Noisy Similarity', 'Clean Similarity'], title = 'Similarity - post cleanup')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "We can do this cleanup with a single, feed-forward network, and we don't need to learn any of the synaptic weights if we know what the appropriate vocabulary is."
]
},
{
@@ -1492,7 +1325,7 @@
},
"outputs": [],
"source": [
- "# @title Video 6: Iterated Binding\n",
+ "# @title Video 5: Iterated Binding\n",
"\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
@@ -1558,22 +1391,22 @@
"source": [
"## Coding Exercise 6: Representing Numbers\n",
"\n",
- "It is often useful to be able to represent numbers. For example, we may want to represent the position of an object in a list, or we may want to represent the coordinates of an object in a grid. To do this, we use the binding operator to construct a vector that represents a number. We start by picking what we refer to as an \"axis vector,\" let's call it $\\texttt{one}$, and then iteratively apply binding like this:\n",
+ "It is often useful to be able to represent numbers. For example, we may want to represent the position of an object in a list, or we may want to represent the coordinates of an object in a grid. To do this we use the binding operator to construct a vector that represents a number. We start by picking what we refer to as an \"axis vector\", let's call it $\\texttt{one}$, and then iteratively apply binding, like this:\n",
"\n",
"$$\n",
- "\\texttt{two} = \\texttt{one}\\circledast\\texttt{one} \n",
+ "\\texttt{two} = \\texttt{one}\\circledast\\texttt{one}\n",
"$$\n",
"$$\n",
"\\texttt{three} = \\texttt{two}\\circledast\\texttt{one} = \\texttt{one}\\circledast\\texttt{one}\\circledast\\texttt{one}\n",
"$$\n",
"\n",
- "and so on. We extend that to arbitrary integers, $n$, by writing:\n",
+ "and so on. We extend that to arbitrary integers, $n$, by writing:\n",
"\n",
"$$\n",
"\\phi[n] = \\underset{i=1}{\\overset{n}{\\circledast}}\\texttt{one}\n",
"$$\n",
"\n",
- "Let's try that now and see how similarity between iteratively bound vectors develops. In the cell below, you should complete the missing part, which implements the iterative binding mechanism."
+ "Let's try that now and see how similarity between iteratively bound vectors develops. In the cell below you should complete missing part which implements iterative binding mechanism."
]
},
{
@@ -1592,31 +1425,45 @@
"set_seed(42)\n",
"\n",
"#define axis vector\n",
- "axis_vectors = ['one']\n",
- "\n",
- "encoder = sspspace.DiscreteSPSpace(axis_vectors, ssp_dim=1024, optimize=False)\n",
- "\n",
+ "axis_vectors = ['ONE']\n",
"#vocabulary\n",
- "vocab = {w:encoder.encode(w) for w in axis_vectors}\n",
+ "vocab = make_vocabulary(vector_length)\n",
+ "# vocab = spa.Vocabulary(vector_length)\n",
+ "vocab.populate(';'.join(axis_vectors))\n",
"\n",
"#we will add new vectors to this list\n",
- "integers = [vocab['one']]\n",
+ "integers = [vocab['ONE']]\n",
"\n",
"max_int = 5\n",
"for i in range(2, max_int + 1):\n",
" #bind one more \"one\" to the previous integer to get the new one\n",
- " integers.append(integers[-1] * vocab[...])"
+ " integers.append((integers[-1] * vocab[...]).normalized())"
]
},
{
- "cell_type": "markdown",
+ "cell_type": "code",
+ "execution_count": null,
"metadata": {
- "colab_type": "text",
"execution": {}
},
+ "outputs": [],
"source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_f0f796f7.py)\n",
- "\n"
+ "set_seed(42)\n",
+ "\n",
+ "#define axis vector\n",
+ "axis_vectors = ['ONE']\n",
+ "#vocabulary\n",
+ "vocab = make_vocabulary(vector_length)\n",
+ "# vocab = spa.Vocabulary(vector_length)\n",
+ "vocab.populate(';'.join(axis_vectors))\n",
+ "\n",
+ "#we will add new vectors to this list\n",
+ "integers = [vocab['ONE']]\n",
+ "\n",
+ "max_int = 5\n",
+ "for i in range(2, max_int + 1):\n",
+ " #bind one more \"one\" to the previous integer to get the new one\n",
+ " integers.append((integers[-1] * vocab['ONE']).normalized())"
]
},
{
@@ -1625,7 +1472,7 @@
"execution": {}
},
"source": [
- "Now, we will observe the similarity metric between the obtained vectors. "
+ "Now, we will observe the similarity metric between the obtained vectors. In order to efficienty implement it, we will use already introduced `np.einsum` function. Notice, that in this particual notation, `sims = integers @ integers.T`"
]
},
{
@@ -1636,8 +1483,10 @@
},
"outputs": [],
"source": [
- "integers = np.array(integers).squeeze()\n",
- "integer_sims = integers @ integers.T"
+ "sims = np.zeros((len(integers), len(integers)))\n",
+ "for i_idx, i in enumerate(integers):\n",
+ " for j_idx, j in enumerate(integers):\n",
+ " sims[i_idx, j_idx] = spa.dot(i,j)"
]
},
{
@@ -1648,7 +1497,7 @@
},
"outputs": [],
"source": [
- "plot_similarity_matrix(integer_sims, [i for i in range(1, 6)], values = True)"
+ "plot_similarity_matrix(sims, [i for i in range(1, 6)], values = True)"
]
},
{
@@ -1668,7 +1517,7 @@
},
"outputs": [],
"source": [
- "plot_line_similarity_matrix(integer_sims, range(1, 6), multiple_objects = True, labels = [f'$\\phi$[{idx+1}]' for idx in range(5)], title = \"Similarity for digits\")"
+ "plot_line_similarity_matrix(sims, range(1, 6), multiple_objects = True, labels = [f'$\\phi$[{idx+1}]' for idx in range(5)], title = \"Similarity for digits\")"
]
},
{
@@ -1677,9 +1526,9 @@
"execution": {}
},
"source": [
- "What we can see here is that each number acts like its own vector; they are highly dissimilar, but we can still do arithmetic with them. Let's see what happens when we unbind $\\texttt{two}$ from $\\texttt{five}$.\n",
+ "What we can see here is that each number acts like it's own vector, they are highly dissimilar, but we can still do arithmetic with them. Let's see what happens when we unbind $\\texttt{two}$ from $\\texttt{five}$.\n",
"\n",
- "In the cell below you are invited to complete the missing parts (be attentive! python is zero-indexed, thus you need to choose the correct indices)."
+ "In the cell below you are invited to complete the missing parts (be attentive! python is zero-indexed, thus you need to choose correct indices)."
]
},
{
@@ -1695,8 +1544,8 @@
"raise NotImplementedError(\"Student exercise: unbinding of two from five.\")\n",
"###################################################################\n",
"\n",
- "five_unbind_two = sspspace.SSP(integers[...]) * ~sspspace.SSP(integers[...])\n",
- "five_unbind_two_sims = five_unbind_two @ integers.T"
+ "five_unbind_two = integers[4] * ~integers[...]\n",
+ "sims = np.array([spa.dot(five_unbind_two, i) for i in ...])"
]
},
{
@@ -1706,7 +1555,7 @@
"execution": {}
},
"source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_04cf23a5.py)\n",
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_513dd01a.py)\n",
"\n"
]
},
@@ -1718,7 +1567,7 @@
},
"outputs": [],
"source": [
- "plot_line_similarity_matrix(five_unbind_two_sims, range(1, 6), multiple_objects = False, title = '$(\\phi[5]\\circledast \\phi[2]^{-1}) \\cdot \\phi[n]$')"
+ "plot_line_similarity_matrix(sims, range(1, 6), multiple_objects = False, title = '$(\\phi[5]\\circledast \\phi[2]^{-1}) \\cdot \\phi[n]$')"
]
},
{
@@ -1749,74 +1598,8 @@
"execution": {}
},
"source": [
- "## Coding Exercise 7: Beyond Binding Integers"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Video 7: Fractional Binding\n",
- "\n",
- "from ipywidgets import widgets\n",
- "from IPython.display import YouTubeVideo\n",
- "from IPython.display import IFrame\n",
- "from IPython.display import display\n",
- "\n",
- "class PlayVideo(IFrame):\n",
- " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
- " self.id = id\n",
- " if source == 'Bilibili':\n",
- " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
- " elif source == 'Osf':\n",
- " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
- " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
- "\n",
- "def display_videos(video_ids, W=400, H=300, fs=1):\n",
- " tab_contents = []\n",
- " for i, video_id in enumerate(video_ids):\n",
- " out = widgets.Output()\n",
- " with out:\n",
- " if video_ids[i][0] == 'Youtube':\n",
- " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
- " height=H, fs=fs, rel=0)\n",
- " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
- " else:\n",
- " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
- " height=H, fs=fs, autoplay=False)\n",
- " if video_ids[i][0] == 'Bilibili':\n",
- " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
- " elif video_ids[i][0] == 'Osf':\n",
- " print(f'Video available at https://osf.io/{video.id}')\n",
- " display(video)\n",
- " tab_contents.append(out)\n",
- " return tab_contents\n",
- "\n",
- "video_ids = [('Youtube', 'mTIodqegq_4'), ('Bilibili', 'BV1b4421Q7mS')]\n",
- "tab_contents = display_videos(video_ids, W=854, H=480)\n",
- "tabs = widgets.Tab()\n",
- "tabs.children = tab_contents\n",
- "for i in range(len(tab_contents)):\n",
- " tabs.set_title(i, video_ids[i][0])\n",
- "display(tabs)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_fractional_binding\")"
+ "## Background Material\n",
+ "### Coding Exercise 7: Beyond Binding Integers"
]
},
{
@@ -1825,7 +1608,7 @@
"execution": {}
},
"source": [
- "This is all well and good, but sometimes, we want to encode values that are not integers. Is there an easy way to do this? You'll be surprised to learn that the answer is: yes.\n",
+ "This is all well and good, but sometimes we want to encode values that are not integers. Is there an easy way to do this? You'll be surprised to learn that the answer is: yes.\n",
"\n",
"We actually use the same technique, but we recognize that iterated binding can be implemented in the Fourier domain:\n",
"\n",
@@ -1833,22 +1616,22 @@
"\\phi[n] = \\mathcal{F}^{-1}\\left\\{\\mathcal{F}\\left\\{\\texttt{one}\\right\\}^{n}\\right\\}\n",
"$$\n",
"\n",
- "where the power of $n$ in the Fourier domain is applied element-wise to the vector. To encode real-valued data, we simply let the integer value, $n$, be a real-valued vector, $x$, and we let the axis vector be a randomly generated vector, $X$. \n",
+ "where the power of $n$ in the Fourier domain is applied element-wise to the vector. To encode real-valued data we simply let the integer value, $n$, be a real-valued vector, $x$, and we let the axis vector be a randomly generated vector, $X$.\n",
"\n",
"$$\n",
"\\phi(x) = \\mathcal{F}^{-1}\\left\\{\\mathcal{F}\\left\\{X\\right\\}^{x}\\right\\}\n",
"$$\n",
"\n",
- "We call vectors that represent real-valued data Spatial Semantic Pointers (SSPs). We can also extend this to multi-dimensional data by binding different SSPs together.\n",
+ "We call vectors that represent real-valued data Spatial Semantic Pointers (SSPs). We can also extend this to multi-dimensional data by binding different SSPs together.\n",
"\n",
"$$\n",
"\\phi(x,y) = \\phi_{X}(x) \\circledast \\phi_{Y}(y)\n",
"$$\n",
"\n",
"\n",
- "In the $\\texttt{sspspace}$ library, we provide an encoder for real- and integer-valued data, and we'll demonstrate it next by encoding a bunch of points in the range $[-4,4]$ and comparing their value to $0$, encoded with SSP.\n",
+ "In the $\\texttt{sspspace}$ library we provide an encoder for real- and integer-valued data, and we'll demonstrate it next by encoding a bunch of points in the range $[-4,4]$ and comparing their value to $0$, encoded a SSP.\n",
"\n",
- "In the cell below, you should complete the similarity calculation by injecting the correct index for the $0$ element (observe that it is right in the middle of the encoded array)."
+ "In the cell below you should complete similarity calculation by injecting correct index for $0$ element (observe that it is right in the middle of encoded array)."
]
},
{
@@ -1859,30 +1642,16 @@
},
"outputs": [],
"source": [
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete similarity calculation: correct index for `0` and array.\")\n",
- "###################################################################\n",
- "\n",
"set_seed(42)\n",
- "new_encoder = sspspace.RandomSSPSpace(domain_dim=1, ssp_dim=1024)\n",
+ "vocab = make_vocabulary(vector_length)\n",
+ "vocab.populate('X')\n",
"\n",
+ "X = vocab['X'].abs()\n",
"xs = np.linspace(-4,4,401)[:,None] #we expect the encoded values to be two-dimensional in `encoder.encode()` so we add extra dimension\n",
- "phis = new_encoder.encode(xs)\n",
+ "phis = [(X**x) for x in xs]\n",
"\n",
"#`0` element is right in the middle of phis array! notice that we have 401 samples inside it\n",
- "real_line_sims = phis[..., :] @ phis.T"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "execution": {}
- },
- "source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_f5f2174f.py)\n",
- "\n"
+ "sims = np.array([spa.dot(phis[200], p) for p in phis])"
]
},
{
@@ -1893,7 +1662,7 @@
},
"outputs": [],
"source": [
- "plot_real_valued_line_similarity(real_line_sims, xs, title = '$\\phi(x)\\cdot\\phi(0)$')"
+ "plot_real_valued_line_similarity(sims, xs, title = '$\\phi(x)\\cdot\\phi(0)$')"
]
},
{
@@ -1902,9 +1671,9 @@
"execution": {}
},
"source": [
- "As with the integers, we can update the values post-encoding through the binding operation. Let's look at the similarity between all the points in the range $[-4,4]$, this time with the value $\\pi/2$, but we will shift it by binding the origin with the desired shift value.\n",
+ "As with the integers, we can update the values, post-encoding through the binding operation. Let's look at the similarity between all the points in the range $[-4,4]$ this time with the value $\\pi/2$, but we will shift it by binding the origin with the desired shift value.\n",
"\n",
- "In the cell below, you need to provide the value for which we are going to shift the origin."
+ "In the cell below you need to provide the value by which we are going to shift the origin."
]
},
{
@@ -1920,8 +1689,8 @@
"raise NotImplementedError(\"Student exercise: provide value to shift and observe the usage of the operation.\")\n",
"###################################################################\n",
"\n",
- "phi_shifted = phis[200,:][None,:] * new_encoder.encode([[...]])\n",
- "shifted_real_line_sims = phi_shifted.flatten() @ phis.T"
+ "phi_shifted = phis[200] * X**-3.1\n",
+ "sims = np.array([spa.dot(...) for p in phis])"
]
},
{
@@ -1931,7 +1700,7 @@
"execution": {}
},
"source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_d25db2a0.py)\n",
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_ce5fc6c7.py)\n",
"\n"
]
},
@@ -1943,7 +1712,7 @@
},
"outputs": [],
"source": [
- "plot_real_valued_line_similarity(shifted_real_line_sims, xs, title = '$\\phi(x)\\cdot(\\phi(0)\\circledast\\phi(\\pi/2))$')"
+ "plot_real_valued_line_similarity(sims, xs, title = '$\\phi(x)\\cdot(\\phi(0)\\circledast\\phi(\\pi/2))$')"
]
},
{
@@ -1963,8 +1732,8 @@
},
"outputs": [],
"source": [
- "new_phi_shifted = phis[200,:][None,:] * new_encoder.encode([[-1.5*np.pi]])\n",
- "new_shifted_real_line_sims = new_phi_shifted.flatten() @ phis.T"
+ "phi_shifted = phis[200] * X**(-1.5*np.pi)\n",
+ "sims = np.array([spa.dot(phi_shifted, p) for p in phis])"
]
},
{
@@ -1975,7 +1744,7 @@
},
"outputs": [],
"source": [
- "plot_real_valued_line_similarity(new_shifted_real_line_sims, xs, title = '$\\phi(x)\\cdot(\\phi(0)\\circledast\\phi(-1.5\\pi))$')"
+ "plot_real_valued_line_similarity(sims, xs, title = '$\\phi(x)\\cdot(\\phi(0)\\circledast\\phi(-1.5\\pi))$')"
]
},
{
@@ -1984,7 +1753,7 @@
"execution": {}
},
"source": [
- "We will go on to use these encodings to build spatial maps in Tutorial 3."
+ "We will go on to use these encodings to build spatial maps in Tutorial 5 (Bonus)."
]
},
{
@@ -1995,7 +1764,7 @@
"source": [
"### Coding Exercise 7 Discussion\n",
"\n",
- "1. How would you explain the lines `sims = vector @ phis.T` in the previous coding exercises?"
+ "1. How would you explain the usage of `d,md->m` in `np.einsum()` function in the previous coding exercise?"
]
},
{
@@ -2005,7 +1774,7 @@
"execution": {}
},
"source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_87190668.py)\n",
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_b91a4ab5.py)\n",
"\n"
]
},
@@ -2018,20 +1787,7 @@
},
"outputs": [],
"source": [
- "# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_beyond_bidning_integers\")"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Video 8: Iterated Binding Conclusion\n",
+ "# @title Video 6: Iterated Binding Conclusion\n",
"\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
@@ -2103,11 +1859,9 @@
"In this tutorial, we developed the toolbox of the main operations on the vector symbolic algebra. In particular, it includes:\n",
"- similarity operation (|), which measures how similar the two vectors are (by calculating their dot product);\n",
"- bundling (+), which creates new set-like objects using vector addition;\n",
- "- binding ($\\circledast$), which creates a new combined representation of the two given objects using circular convolution;\n",
- "- unbinding (~), which allows to derive a pure object from the bound representation by unbinding another one that stands in the pair;\n",
- "- cleanup, which tries to identify the most similar vector in the vocabulary with multiple possible implementations.\n",
- "- iterated binding, which allows one to \"count\" by iteratively binding an axis vector with itself.\n",
- "- encoding real-valued data using fractional binding.\n",
+ "- binding ($\\circledast$), which creates new combined representation of the two given objects using circular convolution;\n",
+ "- unbinding (~), which allows to derive pure object from the binded representation by unbinding another one which stands in the pair;\n",
+ "- cleanup, which tries to identify the most similar vector in the vocabulary, with multiple possible implementations.\n",
"\n",
"In the following tutorials, we will take a look at how we can use these tools to create more complicated structures and derive useful information from them."
]
@@ -2141,7 +1895,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.9.19"
+ "version": "3.9.22"
}
},
"nbformat": 4,
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial2.ipynb b/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial2.ipynb
index 63b5a92b3..a2b9404dd 100644
--- a/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial2.ipynb
+++ b/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial2.ipynb
@@ -25,9 +25,9 @@
"\n",
"__Content creators:__ P. Michael Furlong, Chris Eliasmith\n",
"\n",
- "__Content reviewers:__ Hlib Solodzhuk, Patrick Mineault, Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi\n",
+ "__Content reviewers:__ Hlib Solodzhuk, Patrick Mineault, Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Alex Murphy\n",
"\n",
- "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk\n"
+ "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk, Alex Murphy\n"
]
},
{
@@ -41,7 +41,7 @@
"\n",
"# Tutorial Objectives\n",
"\n",
- "*Estimated timing of tutorial: 50 minutes*\n",
+ "*Estimated timing of tutorial: 20 minutes*\n",
"\n",
"This tutorial will present you with a couple of play-examples on the usage of basic operations of vector symbolic algebras while generalizing to the new knowledge."
]
@@ -59,7 +59,7 @@
"# @markdown These are the slides for the videos in all tutorials today\n",
"\n",
"from IPython.display import IFrame\n",
- "link_id = \"2szmk\"\n",
+ "link_id = \"jybuw\"\n",
"\n",
"print(f\"If you want to download the slides: 'https://osf.io/download/{link_id}'\")\n",
"\n",
@@ -73,8 +73,11 @@
},
"source": [
"---\n",
- "# Setup\n",
- "\n"
+ "# Setup (Colab Users: Please Read)\n",
+ "\n",
+ "Note that because this tutorial relies on some special Python packages, these packages have requirements for specific versions of common scientific libraries, such as `numpy`. If you're in Google Colab, then as of May 2025, this comes with a later version (2.0.2) pre-installed. We require an older version (we'll be installing `1.24.4`). This causes Colab to force a session restart and then re-running of the installation cells for the new version to take effect. When you run the cell below, you will be prompted to restart the session. This is *entirely expected* and you haven't done anything wrong. Simply click 'Restart' and then run the cells as normal. \n",
+ "\n",
+ "An additional error might sometimes arise where an exception is raised connected to a missing element of NumPy. If this occurs, please restart the session and re-run the cells as normal and this error will go away. Updated versions of the affected libraries are expected out soon, but sadly not in time for the preparation of this material. We thank you for your understanding."
]
},
{
@@ -86,9 +89,27 @@
},
"outputs": [],
"source": [
- "# @title Install and import feedback gadget\n",
+ "# @title Install dependencies\n",
"\n",
- "!pip install --quiet numpy matplotlib ipywidgets scipy scikit-learn vibecheck\n",
+ "!pip install numpy==1.24.4 --quiet\n",
+ "!pip install scikit-learn==1.6.1 --quiet\n",
+ "!pip install scipy==1.15.3 --quiet\n",
+ "!pip install git+https://github.com/neuromatch/sspspace@neuromatch --no-deps --quiet\n",
+ "!pip install nengo==4.0.0 --quiet\n",
+ "!pip install nengo_spa==2.0.0 --quiet\n",
+ "!pip install --quiet matplotlib ipywidgets vibecheck"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Install and import feedback gadget\n",
"\n",
"from vibecheck import DatatopsContentReviewContainer\n",
"def content_review(notebook_section: str):\n",
@@ -106,30 +127,6 @@
"feedback_prefix = \"W2D2_T2\""
]
},
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Notice that exactly the `neuromatch` branch of `sspspace` should be installed! Otherwise, some of the functionality (like `optimize` parameter in the `DiscreteSPSpace` initialization) won't work."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Install dependencies\n",
- "\n",
- "# Install sspspace\n",
- "!pip install git+https://github.com/neuromatch/sspspace@neuromatch --quiet"
- ]
- },
{
"cell_type": "code",
"execution_count": null,
@@ -155,7 +152,15 @@
"import sspspace\n",
"from scipy.special import softmax\n",
"from sklearn.metrics import log_loss\n",
- "from sklearn.neural_network import MLPRegressor"
+ "from sklearn.neural_network import MLPRegressor\n",
+ "\n",
+ "import nengo_spa as spa\n",
+ "from nengo_spa.algebras.hrr_algebra import HrrProperties, HrrAlgebra\n",
+ "from nengo_spa.vector_generation import VectorsWithProperties\n",
+ "def make_vocabulary(vector_length):\n",
+ " vec_generator = VectorsWithProperties(vector_length, algebra=HrrAlgebra(), properties = [HrrProperties.UNITARY, HrrProperties.POSITIVE])\n",
+ " vocab = spa.Vocabulary(vector_length, pointer_gen=vec_generator)\n",
+ " return vocab"
]
},
{
@@ -341,9 +346,9 @@
"source": [
"---\n",
"\n",
- "# Section 1: Analogies. Part 1\n",
+ "# Section 1: Wason Card Task\n",
"\n",
- "In this section we will construct a simple analogy using Vector Symbolic Algebras. The question we are going to try and solve is \"King is to the queen as the prince is to X.\""
+ "One of the powerful benefits of using these structured representations is being able to generalize to other circumstances. To demonstrate this, we are going to show you this in a simple task."
]
},
{
@@ -355,7 +360,7 @@
},
"outputs": [],
"source": [
- "# @title Video 1: Analogy 1\n",
+ "# @title Video 1: Wason Card Task Intro\n",
"\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
@@ -391,7 +396,7 @@
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
- "video_ids = [('Youtube', '2tR4fHvL1Jk'), ('Bilibili', 'BV1fS411P7Ez')]\n",
+ "video_ids = [('Youtube', 'BAju3MNHCq8'), ('Bilibili', 'BV1Qf421X7MB')]\n",
"tab_contents = display_videos(video_ids, W=854, H=480)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
@@ -410,7 +415,7 @@
"outputs": [],
"source": [
"# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_analogy_part_one\")"
+ "content_review(f\"{feedback_prefix}_wason_card_task_intro\")"
]
},
{
@@ -419,25 +424,31 @@
"execution": {}
},
"source": [
- "## Coding Exercise 1: Royal Relationships\n",
+ "## Coding Exercise 1: Wason Card Task\n",
"\n",
- "We're going to start by considering our vocabulary. We will use the basic discrete concepts of monarch, heir, male, and female."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Let's create the objects we know about by combinatorially expanding the space: \n",
+ "We are going to test the generalization property on the Wason Card Task, where a person is told a rule of the form \"if the card is even, then the back is blue\", they are then presented with a number of cards with either an odd number, an even number, a red back, or a blue back. The participant is asked which cards they have to flip to determine that the rule is true.\n",
+ "\n",
+ "In this case, the participant needs to flip only the even card(s), and any card where the back is not blue, as the rule does not state whether or not odd numbers can have blue backs, and a red-backed card with an even number would violate the rule. We can get this from Boolean logic:\n",
+ "\n",
+ "$$\n",
+ "\\mathrm{even} \\implies \\mathrm{blue}\n",
+ "$$\n",
+ "\n",
+ "which is equal to \n",
+ "\n",
+ "$$ \n",
+ "\\neg \\mathrm{even} \\vee \\mathrm{blue}\n",
+ "$$\n",
+ "\n",
+ "where $\\neg$ means a logical not. If we want to find cards that violate the rule, then we negate the rule, providing:\n",
+ "\n",
+ "$$ \n",
+ "\\neg (\\neg \\mathrm{even} \\vee \\mathrm{blue}) = \\mathrm{even} \\wedge \\neg \\mathrm{blue}.\n",
+ "$$\n",
"\n",
- "1. King is a male monarch\n",
- "2. Queen is a female monarch\n",
- "3. Prince is a male heir\n",
- "4. Princess is a female heir\n",
+ "Hence the cards that can violate the rule are even and not blue. \n",
"\n",
- "Complete the missing parts of the code to obtain correct representations of new concepts."
+ "At first, we will define all needed concepts. For all noun concepts we would also like to have `not concept` presented in the space, please complete missing code parts."
]
},
{
@@ -448,22 +459,23 @@
},
"outputs": [],
"source": [
+ "set_seed(42)\n",
+ "vector_length = 1024\n",
+ "\n",
+ "card_states = ['RED','BLUE','ODD','EVEN','NOT','GREEN','PRIME','IMPLIES','ANT','RELATION','CONS']\n",
+ "vocab = make_vocabulary(vector_length)\n",
+ "vocab.populate(';'.join(card_states))\n",
+ "\n",
"###################################################################\n",
"## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete correct relations for creating new concepts.\")\n",
+ "raise NotImplementedError(\"Student exercise: complete creating `not x` concepts.\")\n",
"###################################################################\n",
"\n",
- "set_seed(42)\n",
- "\n",
- "symbol_names = ['monarch','heir','male','female']\n",
- "discrete_space = sspspace.DiscreteSPSpace(symbol_names, ssp_dim=1024, optimize=False)\n",
- "\n",
- "objs = {n:discrete_space.encode(n) for n in symbol_names}\n",
+ "for a in ['RED','BLUE','ODD','EVEN','GREEN','PRIME']:\n",
+ " vocab.add(f'NOT_{a}', vocab['NOT'] * vocab[a])\n",
"\n",
- "objs['king'] = objs['monarch'] * objs['male']\n",
- "objs['queen'] = objs['monarch'] * ...\n",
- "objs['prince'] = objs['heir'] * objs['male']\n",
- "objs['princess'] = ... * objs['female']"
+ "action_names = ['RED','BLUE','ODD','EVEN','GREEN','PRIME','NOT_RED','NOT_BLUE','NOT_ODD','NOT_EVEN','NOT_GREEN','NOT_PRIME']\n",
+ "action_space = np.array([vocab[x].v for x in action_names]).squeeze()"
]
},
{
@@ -473,7 +485,7 @@
"execution": {}
},
"source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_721e11a2.py)\n",
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_a0e39449.py)\n",
"\n"
]
},
@@ -483,9 +495,27 @@
"execution": {}
},
"source": [
- "Now, we can take an explicit approach. We know that the conversion from king to queen is to unbind male and bind female, so let's apply that to our prince object and see what we uncover. \n",
+ "Now, we are going to set up a simple perceptron-style learning rule, using the HRR (Holographic Reduced Representations) algebra. We are going to learn a target transformation, $T$, such that given a learning rule, $A^{*} = T\\circledast R$, where $A^{*}$ is the antecedant value bundled with $\\texttt{not}$ bound with the consequent value, because we are trying to learn the cards that can violate the rule, described above, and $R$ is the rule to be learned. \n",
+ "\n",
+ "Rules themselves are going to be composed like the data structures representing different countries in the previous section. `ant`, `relation` and `cons` are extra concepts which define the structure and which will bind to the specific instances. \n",
"\n",
- "At first, in the cell below, let's recover `queen` from `king` by constructing a new `query` concept, which represents the unbinding of `male` and the binding of `female.` Then, let's see if this new query object bears any similarity to anything in our vocabulary."
+ "If we have a rule, $X \\implies Y$, then we would create the VSA representation:\n",
+ "\n",
+ "$$R = \\texttt{ant}\\circledast X + \\texttt{relation}\\circledast \\text{implies} + \\texttt{cons} \\circledast Y$$,\n",
+ "\n",
+ "and the ideal output is:\n",
+ "\n",
+ "$$\n",
+ "A^{*} = X + \\texttt{not}\\circledast Y\n",
+ "$$\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "In the cell below, let us define two rules:\n",
+ "\n",
+ "$$\\text{blue} \\implies \\text{even}$$\n",
+ "$$\\text{odd} \\implies \\text{green}$$"
]
},
{
@@ -498,19 +528,13 @@
"source": [
"###################################################################\n",
"## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete correct relation for creating `query` object to compare with `queen`.\")\n",
+ "raise NotImplementedError(\"Student exercise: complete creating rules as defined above.\")\n",
"###################################################################\n",
"\n",
- "objs['queen_query'] = (objs[...] * ~objs[...]) * objs[...]\n",
- "\n",
- "object_names = list(objs.keys())\n",
- "sims = np.zeros((len(object_names), len(object_names)))\n",
- "\n",
- "for name_idx, name in enumerate(object_names):\n",
- " for other_idx in range(name_idx, len(object_names)):\n",
- " sims[name_idx, other_idx] = sims[other_idx, name_idx] = (objs[name] | objs[object_names[other_idx]]).item()\n",
- "\n",
- "plot_similarity_matrix(sims, object_names, values = True)"
+ "rules = [\n",
+ " (vocab['ANT'] * vocab['BLUE'] + vocab['RELATION'] * vocab['IMPLIES'] + vocab['CONS'] * vocab[...]).normalized(),\n",
+ " (vocab[...] * vocab[...] + vocab[...] * vocab[...] + vocab[...] * vocab[...]).normalized(),\n",
+ "]"
]
},
{
@@ -520,11 +544,7 @@
"execution": {}
},
"source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_6e6c0725.py)\n",
- "\n",
- "*Example output:*\n",
- "\n",
- "
\n",
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_f12d9c75.py)\n",
"\n"
]
},
@@ -1454,7 +1267,27 @@
"execution": {}
},
"source": [
- "For the scenario where we have a discrete, known vocabulary, we can do this cleanup with a single feed-forward network, and we don't need to learn any of the synaptic weights."
+ "Observe the result with comparison to the pre cleanup metrics."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "plot_double_line_similarity_matrix([sims, clean_sims], symbol_names, ['Noisy Similarity', 'Clean Similarity'], title = 'Similarity - post cleanup')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "We can do this cleanup with a single, feed-forward network, and we don't need to learn any of the synaptic weights if we know what the appropriate vocabulary is."
]
},
{
@@ -1492,7 +1325,7 @@
},
"outputs": [],
"source": [
- "# @title Video 6: Iterated Binding\n",
+ "# @title Video 5: Iterated Binding\n",
"\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
@@ -1558,22 +1391,22 @@
"source": [
"## Coding Exercise 6: Representing Numbers\n",
"\n",
- "It is often useful to be able to represent numbers. For example, we may want to represent the position of an object in a list, or we may want to represent the coordinates of an object in a grid. To do this, we use the binding operator to construct a vector that represents a number. We start by picking what we refer to as an \"axis vector,\" let's call it $\\texttt{one}$, and then iteratively apply binding like this:\n",
+ "It is often useful to be able to represent numbers. For example, we may want to represent the position of an object in a list, or we may want to represent the coordinates of an object in a grid. To do this we use the binding operator to construct a vector that represents a number. We start by picking what we refer to as an \"axis vector\", let's call it $\\texttt{one}$, and then iteratively apply binding, like this:\n",
"\n",
"$$\n",
- "\\texttt{two} = \\texttt{one}\\circledast\\texttt{one} \n",
+ "\\texttt{two} = \\texttt{one}\\circledast\\texttt{one}\n",
"$$\n",
"$$\n",
"\\texttt{three} = \\texttt{two}\\circledast\\texttt{one} = \\texttt{one}\\circledast\\texttt{one}\\circledast\\texttt{one}\n",
"$$\n",
"\n",
- "and so on. We extend that to arbitrary integers, $n$, by writing:\n",
+ "and so on. We extend that to arbitrary integers, $n$, by writing:\n",
"\n",
"$$\n",
"\\phi[n] = \\underset{i=1}{\\overset{n}{\\circledast}}\\texttt{one}\n",
"$$\n",
"\n",
- "Let's try that now and see how similarity between iteratively bound vectors develops. In the cell below, you should complete the missing part, which implements the iterative binding mechanism."
+ "Let's try that now and see how similarity between iteratively bound vectors develops. In the cell below you should complete missing part which implements iterative binding mechanism."
]
},
{
@@ -1592,31 +1425,45 @@
"set_seed(42)\n",
"\n",
"#define axis vector\n",
- "axis_vectors = ['one']\n",
- "\n",
- "encoder = sspspace.DiscreteSPSpace(axis_vectors, ssp_dim=1024, optimize=False)\n",
- "\n",
+ "axis_vectors = ['ONE']\n",
"#vocabulary\n",
- "vocab = {w:encoder.encode(w) for w in axis_vectors}\n",
+ "vocab = make_vocabulary(vector_length)\n",
+ "# vocab = spa.Vocabulary(vector_length)\n",
+ "vocab.populate(';'.join(axis_vectors))\n",
"\n",
"#we will add new vectors to this list\n",
- "integers = [vocab['one']]\n",
+ "integers = [vocab['ONE']]\n",
"\n",
"max_int = 5\n",
"for i in range(2, max_int + 1):\n",
" #bind one more \"one\" to the previous integer to get the new one\n",
- " integers.append(integers[-1] * vocab[...])"
+ " integers.append((integers[-1] * vocab[...]).normalized())"
]
},
{
- "cell_type": "markdown",
+ "cell_type": "code",
+ "execution_count": null,
"metadata": {
- "colab_type": "text",
"execution": {}
},
+ "outputs": [],
"source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_f0f796f7.py)\n",
- "\n"
+ "set_seed(42)\n",
+ "\n",
+ "#define axis vector\n",
+ "axis_vectors = ['ONE']\n",
+ "#vocabulary\n",
+ "vocab = make_vocabulary(vector_length)\n",
+ "# vocab = spa.Vocabulary(vector_length)\n",
+ "vocab.populate(';'.join(axis_vectors))\n",
+ "\n",
+ "#we will add new vectors to this list\n",
+ "integers = [vocab['ONE']]\n",
+ "\n",
+ "max_int = 5\n",
+ "for i in range(2, max_int + 1):\n",
+ " #bind one more \"one\" to the previous integer to get the new one\n",
+ " integers.append((integers[-1] * vocab['ONE']).normalized())"
]
},
{
@@ -1625,7 +1472,7 @@
"execution": {}
},
"source": [
- "Now, we will observe the similarity metric between the obtained vectors. "
+ "Now, we will observe the similarity metric between the obtained vectors. In order to efficienty implement it, we will use already introduced `np.einsum` function. Notice, that in this particual notation, `sims = integers @ integers.T`"
]
},
{
@@ -1636,8 +1483,10 @@
},
"outputs": [],
"source": [
- "integers = np.array(integers).squeeze()\n",
- "integer_sims = integers @ integers.T"
+ "sims = np.zeros((len(integers), len(integers)))\n",
+ "for i_idx, i in enumerate(integers):\n",
+ " for j_idx, j in enumerate(integers):\n",
+ " sims[i_idx, j_idx] = spa.dot(i,j)"
]
},
{
@@ -1648,7 +1497,7 @@
},
"outputs": [],
"source": [
- "plot_similarity_matrix(integer_sims, [i for i in range(1, 6)], values = True)"
+ "plot_similarity_matrix(sims, [i for i in range(1, 6)], values = True)"
]
},
{
@@ -1668,7 +1517,7 @@
},
"outputs": [],
"source": [
- "plot_line_similarity_matrix(integer_sims, range(1, 6), multiple_objects = True, labels = [f'$\\phi$[{idx+1}]' for idx in range(5)], title = \"Similarity for digits\")"
+ "plot_line_similarity_matrix(sims, range(1, 6), multiple_objects = True, labels = [f'$\\phi$[{idx+1}]' for idx in range(5)], title = \"Similarity for digits\")"
]
},
{
@@ -1677,9 +1526,9 @@
"execution": {}
},
"source": [
- "What we can see here is that each number acts like its own vector; they are highly dissimilar, but we can still do arithmetic with them. Let's see what happens when we unbind $\\texttt{two}$ from $\\texttt{five}$.\n",
+ "What we can see here is that each number acts like it's own vector, they are highly dissimilar, but we can still do arithmetic with them. Let's see what happens when we unbind $\\texttt{two}$ from $\\texttt{five}$.\n",
"\n",
- "In the cell below you are invited to complete the missing parts (be attentive! python is zero-indexed, thus you need to choose the correct indices)."
+ "In the cell below you are invited to complete the missing parts (be attentive! python is zero-indexed, thus you need to choose correct indices)."
]
},
{
@@ -1695,8 +1544,8 @@
"raise NotImplementedError(\"Student exercise: unbinding of two from five.\")\n",
"###################################################################\n",
"\n",
- "five_unbind_two = sspspace.SSP(integers[...]) * ~sspspace.SSP(integers[...])\n",
- "five_unbind_two_sims = five_unbind_two @ integers.T"
+ "five_unbind_two = integers[4] * ~integers[...]\n",
+ "sims = np.array([spa.dot(five_unbind_two, i) for i in ...])"
]
},
{
@@ -1706,7 +1555,7 @@
"execution": {}
},
"source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_04cf23a5.py)\n",
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_513dd01a.py)\n",
"\n"
]
},
@@ -1718,7 +1567,7 @@
},
"outputs": [],
"source": [
- "plot_line_similarity_matrix(five_unbind_two_sims, range(1, 6), multiple_objects = False, title = '$(\\phi[5]\\circledast \\phi[2]^{-1}) \\cdot \\phi[n]$')"
+ "plot_line_similarity_matrix(sims, range(1, 6), multiple_objects = False, title = '$(\\phi[5]\\circledast \\phi[2]^{-1}) \\cdot \\phi[n]$')"
]
},
{
@@ -1749,74 +1598,8 @@
"execution": {}
},
"source": [
- "## Coding Exercise 7: Beyond Binding Integers"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Video 7: Fractional Binding\n",
- "\n",
- "from ipywidgets import widgets\n",
- "from IPython.display import YouTubeVideo\n",
- "from IPython.display import IFrame\n",
- "from IPython.display import display\n",
- "\n",
- "class PlayVideo(IFrame):\n",
- " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
- " self.id = id\n",
- " if source == 'Bilibili':\n",
- " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
- " elif source == 'Osf':\n",
- " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
- " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
- "\n",
- "def display_videos(video_ids, W=400, H=300, fs=1):\n",
- " tab_contents = []\n",
- " for i, video_id in enumerate(video_ids):\n",
- " out = widgets.Output()\n",
- " with out:\n",
- " if video_ids[i][0] == 'Youtube':\n",
- " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
- " height=H, fs=fs, rel=0)\n",
- " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
- " else:\n",
- " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
- " height=H, fs=fs, autoplay=False)\n",
- " if video_ids[i][0] == 'Bilibili':\n",
- " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
- " elif video_ids[i][0] == 'Osf':\n",
- " print(f'Video available at https://osf.io/{video.id}')\n",
- " display(video)\n",
- " tab_contents.append(out)\n",
- " return tab_contents\n",
- "\n",
- "video_ids = [('Youtube', 'mTIodqegq_4'), ('Bilibili', 'BV1b4421Q7mS')]\n",
- "tab_contents = display_videos(video_ids, W=854, H=480)\n",
- "tabs = widgets.Tab()\n",
- "tabs.children = tab_contents\n",
- "for i in range(len(tab_contents)):\n",
- " tabs.set_title(i, video_ids[i][0])\n",
- "display(tabs)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_fractional_binding\")"
+ "## Background Material\n",
+ "### Coding Exercise 7: Beyond Binding Integers"
]
},
{
@@ -1825,7 +1608,7 @@
"execution": {}
},
"source": [
- "This is all well and good, but sometimes, we want to encode values that are not integers. Is there an easy way to do this? You'll be surprised to learn that the answer is: yes.\n",
+ "This is all well and good, but sometimes we want to encode values that are not integers. Is there an easy way to do this? You'll be surprised to learn that the answer is: yes.\n",
"\n",
"We actually use the same technique, but we recognize that iterated binding can be implemented in the Fourier domain:\n",
"\n",
@@ -1833,22 +1616,22 @@
"\\phi[n] = \\mathcal{F}^{-1}\\left\\{\\mathcal{F}\\left\\{\\texttt{one}\\right\\}^{n}\\right\\}\n",
"$$\n",
"\n",
- "where the power of $n$ in the Fourier domain is applied element-wise to the vector. To encode real-valued data, we simply let the integer value, $n$, be a real-valued vector, $x$, and we let the axis vector be a randomly generated vector, $X$. \n",
+ "where the power of $n$ in the Fourier domain is applied element-wise to the vector. To encode real-valued data we simply let the integer value, $n$, be a real-valued vector, $x$, and we let the axis vector be a randomly generated vector, $X$.\n",
"\n",
"$$\n",
"\\phi(x) = \\mathcal{F}^{-1}\\left\\{\\mathcal{F}\\left\\{X\\right\\}^{x}\\right\\}\n",
"$$\n",
"\n",
- "We call vectors that represent real-valued data Spatial Semantic Pointers (SSPs). We can also extend this to multi-dimensional data by binding different SSPs together.\n",
+ "We call vectors that represent real-valued data Spatial Semantic Pointers (SSPs). We can also extend this to multi-dimensional data by binding different SSPs together.\n",
"\n",
"$$\n",
"\\phi(x,y) = \\phi_{X}(x) \\circledast \\phi_{Y}(y)\n",
"$$\n",
"\n",
"\n",
- "In the $\\texttt{sspspace}$ library, we provide an encoder for real- and integer-valued data, and we'll demonstrate it next by encoding a bunch of points in the range $[-4,4]$ and comparing their value to $0$, encoded with SSP.\n",
+ "In the $\\texttt{sspspace}$ library we provide an encoder for real- and integer-valued data, and we'll demonstrate it next by encoding a bunch of points in the range $[-4,4]$ and comparing their value to $0$, encoded a SSP.\n",
"\n",
- "In the cell below, you should complete the similarity calculation by injecting the correct index for the $0$ element (observe that it is right in the middle of the encoded array)."
+ "In the cell below you should complete similarity calculation by injecting correct index for $0$ element (observe that it is right in the middle of encoded array)."
]
},
{
@@ -1859,30 +1642,16 @@
},
"outputs": [],
"source": [
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete similarity calculation: correct index for `0` and array.\")\n",
- "###################################################################\n",
- "\n",
"set_seed(42)\n",
- "new_encoder = sspspace.RandomSSPSpace(domain_dim=1, ssp_dim=1024)\n",
+ "vocab = make_vocabulary(vector_length)\n",
+ "vocab.populate('X')\n",
"\n",
+ "X = vocab['X'].abs()\n",
"xs = np.linspace(-4,4,401)[:,None] #we expect the encoded values to be two-dimensional in `encoder.encode()` so we add extra dimension\n",
- "phis = new_encoder.encode(xs)\n",
+ "phis = [(X**x) for x in xs]\n",
"\n",
"#`0` element is right in the middle of phis array! notice that we have 401 samples inside it\n",
- "real_line_sims = phis[..., :] @ phis.T"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "execution": {}
- },
- "source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_f5f2174f.py)\n",
- "\n"
+ "sims = np.array([spa.dot(phis[200], p) for p in phis])"
]
},
{
@@ -1893,7 +1662,7 @@
},
"outputs": [],
"source": [
- "plot_real_valued_line_similarity(real_line_sims, xs, title = '$\\phi(x)\\cdot\\phi(0)$')"
+ "plot_real_valued_line_similarity(sims, xs, title = '$\\phi(x)\\cdot\\phi(0)$')"
]
},
{
@@ -1902,9 +1671,9 @@
"execution": {}
},
"source": [
- "As with the integers, we can update the values post-encoding through the binding operation. Let's look at the similarity between all the points in the range $[-4,4]$, this time with the value $\\pi/2$, but we will shift it by binding the origin with the desired shift value.\n",
+ "As with the integers, we can update the values, post-encoding through the binding operation. Let's look at the similarity between all the points in the range $[-4,4]$ this time with the value $\\pi/2$, but we will shift it by binding the origin with the desired shift value.\n",
"\n",
- "In the cell below, you need to provide the value for which we are going to shift the origin."
+ "In the cell below you need to provide the value by which we are going to shift the origin."
]
},
{
@@ -1920,8 +1689,8 @@
"raise NotImplementedError(\"Student exercise: provide value to shift and observe the usage of the operation.\")\n",
"###################################################################\n",
"\n",
- "phi_shifted = phis[200,:][None,:] * new_encoder.encode([[...]])\n",
- "shifted_real_line_sims = phi_shifted.flatten() @ phis.T"
+ "phi_shifted = phis[200] * X**-3.1\n",
+ "sims = np.array([spa.dot(...) for p in phis])"
]
},
{
@@ -1931,7 +1700,7 @@
"execution": {}
},
"source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_d25db2a0.py)\n",
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_ce5fc6c7.py)\n",
"\n"
]
},
@@ -1943,7 +1712,7 @@
},
"outputs": [],
"source": [
- "plot_real_valued_line_similarity(shifted_real_line_sims, xs, title = '$\\phi(x)\\cdot(\\phi(0)\\circledast\\phi(\\pi/2))$')"
+ "plot_real_valued_line_similarity(sims, xs, title = '$\\phi(x)\\cdot(\\phi(0)\\circledast\\phi(\\pi/2))$')"
]
},
{
@@ -1963,8 +1732,8 @@
},
"outputs": [],
"source": [
- "new_phi_shifted = phis[200,:][None,:] * new_encoder.encode([[-1.5*np.pi]])\n",
- "new_shifted_real_line_sims = new_phi_shifted.flatten() @ phis.T"
+ "phi_shifted = phis[200] * X**(-1.5*np.pi)\n",
+ "sims = np.array([spa.dot(phi_shifted, p) for p in phis])"
]
},
{
@@ -1975,7 +1744,7 @@
},
"outputs": [],
"source": [
- "plot_real_valued_line_similarity(new_shifted_real_line_sims, xs, title = '$\\phi(x)\\cdot(\\phi(0)\\circledast\\phi(-1.5\\pi))$')"
+ "plot_real_valued_line_similarity(sims, xs, title = '$\\phi(x)\\cdot(\\phi(0)\\circledast\\phi(-1.5\\pi))$')"
]
},
{
@@ -1984,7 +1753,7 @@
"execution": {}
},
"source": [
- "We will go on to use these encodings to build spatial maps in Tutorial 3."
+ "We will go on to use these encodings to build spatial maps in Tutorial 5 (Bonus)."
]
},
{
@@ -1995,7 +1764,7 @@
"source": [
"### Coding Exercise 7 Discussion\n",
"\n",
- "1. How would you explain the lines `sims = vector @ phis.T` in the previous coding exercises?"
+ "1. How would you explain the usage of `d,md->m` in `np.einsum()` function in the previous coding exercise?"
]
},
{
@@ -2005,7 +1774,7 @@
"execution": {}
},
"source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_87190668.py)\n",
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial1_Solution_b91a4ab5.py)\n",
"\n"
]
},
@@ -2018,20 +1787,7 @@
},
"outputs": [],
"source": [
- "# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_beyond_bidning_integers\")"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Video 8: Iterated Binding Conclusion\n",
+ "# @title Video 6: Iterated Binding Conclusion\n",
"\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
@@ -2103,11 +1859,9 @@
"In this tutorial, we developed the toolbox of the main operations on the vector symbolic algebra. In particular, it includes:\n",
"- similarity operation (|), which measures how similar the two vectors are (by calculating their dot product);\n",
"- bundling (+), which creates new set-like objects using vector addition;\n",
- "- binding ($\\circledast$), which creates a new combined representation of the two given objects using circular convolution;\n",
- "- unbinding (~), which allows to derive a pure object from the bound representation by unbinding another one that stands in the pair;\n",
- "- cleanup, which tries to identify the most similar vector in the vocabulary with multiple possible implementations.\n",
- "- iterated binding, which allows one to \"count\" by iteratively binding an axis vector with itself.\n",
- "- encoding real-valued data using fractional binding.\n",
+ "- binding ($\\circledast$), which creates new combined representation of the two given objects using circular convolution;\n",
+ "- unbinding (~), which allows to derive pure object from the binded representation by unbinding another one which stands in the pair;\n",
+ "- cleanup, which tries to identify the most similar vector in the vocabulary, with multiple possible implementations.\n",
"\n",
"In the following tutorials, we will take a look at how we can use these tools to create more complicated structures and derive useful information from them."
]
@@ -2141,7 +1895,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.9.19"
+ "version": "3.9.22"
}
},
"nbformat": 4,
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial2.ipynb b/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial2.ipynb
index 63b5a92b3..a2b9404dd 100644
--- a/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial2.ipynb
+++ b/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial2.ipynb
@@ -25,9 +25,9 @@
"\n",
"__Content creators:__ P. Michael Furlong, Chris Eliasmith\n",
"\n",
- "__Content reviewers:__ Hlib Solodzhuk, Patrick Mineault, Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi\n",
+ "__Content reviewers:__ Hlib Solodzhuk, Patrick Mineault, Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Alex Murphy\n",
"\n",
- "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk\n"
+ "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk, Alex Murphy\n"
]
},
{
@@ -41,7 +41,7 @@
"\n",
"# Tutorial Objectives\n",
"\n",
- "*Estimated timing of tutorial: 50 minutes*\n",
+ "*Estimated timing of tutorial: 20 minutes*\n",
"\n",
"This tutorial will present you with a couple of play-examples on the usage of basic operations of vector symbolic algebras while generalizing to the new knowledge."
]
@@ -59,7 +59,7 @@
"# @markdown These are the slides for the videos in all tutorials today\n",
"\n",
"from IPython.display import IFrame\n",
- "link_id = \"2szmk\"\n",
+ "link_id = \"jybuw\"\n",
"\n",
"print(f\"If you want to download the slides: 'https://osf.io/download/{link_id}'\")\n",
"\n",
@@ -73,8 +73,11 @@
},
"source": [
"---\n",
- "# Setup\n",
- "\n"
+ "# Setup (Colab Users: Please Read)\n",
+ "\n",
+ "Note that because this tutorial relies on some special Python packages, these packages have requirements for specific versions of common scientific libraries, such as `numpy`. If you're in Google Colab, then as of May 2025, this comes with a later version (2.0.2) pre-installed. We require an older version (we'll be installing `1.24.4`). This causes Colab to force a session restart and then re-running of the installation cells for the new version to take effect. When you run the cell below, you will be prompted to restart the session. This is *entirely expected* and you haven't done anything wrong. Simply click 'Restart' and then run the cells as normal. \n",
+ "\n",
+ "An additional error might sometimes arise where an exception is raised connected to a missing element of NumPy. If this occurs, please restart the session and re-run the cells as normal and this error will go away. Updated versions of the affected libraries are expected out soon, but sadly not in time for the preparation of this material. We thank you for your understanding."
]
},
{
@@ -86,9 +89,27 @@
},
"outputs": [],
"source": [
- "# @title Install and import feedback gadget\n",
+ "# @title Install dependencies\n",
"\n",
- "!pip install --quiet numpy matplotlib ipywidgets scipy scikit-learn vibecheck\n",
+ "!pip install numpy==1.24.4 --quiet\n",
+ "!pip install scikit-learn==1.6.1 --quiet\n",
+ "!pip install scipy==1.15.3 --quiet\n",
+ "!pip install git+https://github.com/neuromatch/sspspace@neuromatch --no-deps --quiet\n",
+ "!pip install nengo==4.0.0 --quiet\n",
+ "!pip install nengo_spa==2.0.0 --quiet\n",
+ "!pip install --quiet matplotlib ipywidgets vibecheck"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Install and import feedback gadget\n",
"\n",
"from vibecheck import DatatopsContentReviewContainer\n",
"def content_review(notebook_section: str):\n",
@@ -106,30 +127,6 @@
"feedback_prefix = \"W2D2_T2\""
]
},
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Notice that exactly the `neuromatch` branch of `sspspace` should be installed! Otherwise, some of the functionality (like `optimize` parameter in the `DiscreteSPSpace` initialization) won't work."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Install dependencies\n",
- "\n",
- "# Install sspspace\n",
- "!pip install git+https://github.com/neuromatch/sspspace@neuromatch --quiet"
- ]
- },
{
"cell_type": "code",
"execution_count": null,
@@ -155,7 +152,15 @@
"import sspspace\n",
"from scipy.special import softmax\n",
"from sklearn.metrics import log_loss\n",
- "from sklearn.neural_network import MLPRegressor"
+ "from sklearn.neural_network import MLPRegressor\n",
+ "\n",
+ "import nengo_spa as spa\n",
+ "from nengo_spa.algebras.hrr_algebra import HrrProperties, HrrAlgebra\n",
+ "from nengo_spa.vector_generation import VectorsWithProperties\n",
+ "def make_vocabulary(vector_length):\n",
+ " vec_generator = VectorsWithProperties(vector_length, algebra=HrrAlgebra(), properties = [HrrProperties.UNITARY, HrrProperties.POSITIVE])\n",
+ " vocab = spa.Vocabulary(vector_length, pointer_gen=vec_generator)\n",
+ " return vocab"
]
},
{
@@ -341,9 +346,9 @@
"source": [
"---\n",
"\n",
- "# Section 1: Analogies. Part 1\n",
+ "# Section 1: Wason Card Task\n",
"\n",
- "In this section we will construct a simple analogy using Vector Symbolic Algebras. The question we are going to try and solve is \"King is to the queen as the prince is to X.\""
+ "One of the powerful benefits of using these structured representations is being able to generalize to other circumstances. To demonstrate this, we are going to show you this in a simple task."
]
},
{
@@ -355,7 +360,7 @@
},
"outputs": [],
"source": [
- "# @title Video 1: Analogy 1\n",
+ "# @title Video 1: Wason Card Task Intro\n",
"\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
@@ -391,7 +396,7 @@
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
- "video_ids = [('Youtube', '2tR4fHvL1Jk'), ('Bilibili', 'BV1fS411P7Ez')]\n",
+ "video_ids = [('Youtube', 'BAju3MNHCq8'), ('Bilibili', 'BV1Qf421X7MB')]\n",
"tab_contents = display_videos(video_ids, W=854, H=480)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
@@ -410,7 +415,7 @@
"outputs": [],
"source": [
"# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_analogy_part_one\")"
+ "content_review(f\"{feedback_prefix}_wason_card_task_intro\")"
]
},
{
@@ -419,25 +424,31 @@
"execution": {}
},
"source": [
- "## Coding Exercise 1: Royal Relationships\n",
+ "## Coding Exercise 1: Wason Card Task\n",
"\n",
- "We're going to start by considering our vocabulary. We will use the basic discrete concepts of monarch, heir, male, and female."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Let's create the objects we know about by combinatorially expanding the space: \n",
+ "We are going to test the generalization property on the Wason Card Task, where a person is told a rule of the form \"if the card is even, then the back is blue\", they are then presented with a number of cards with either an odd number, an even number, a red back, or a blue back. The participant is asked which cards they have to flip to determine that the rule is true.\n",
+ "\n",
+ "In this case, the participant needs to flip only the even card(s), and any card where the back is not blue, as the rule does not state whether or not odd numbers can have blue backs, and a red-backed card with an even number would violate the rule. We can get this from Boolean logic:\n",
+ "\n",
+ "$$\n",
+ "\\mathrm{even} \\implies \\mathrm{blue}\n",
+ "$$\n",
+ "\n",
+ "which is equal to \n",
+ "\n",
+ "$$ \n",
+ "\\neg \\mathrm{even} \\vee \\mathrm{blue}\n",
+ "$$\n",
+ "\n",
+ "where $\\neg$ means a logical not. If we want to find cards that violate the rule, then we negate the rule, providing:\n",
+ "\n",
+ "$$ \n",
+ "\\neg (\\neg \\mathrm{even} \\vee \\mathrm{blue}) = \\mathrm{even} \\wedge \\neg \\mathrm{blue}.\n",
+ "$$\n",
"\n",
- "1. King is a male monarch\n",
- "2. Queen is a female monarch\n",
- "3. Prince is a male heir\n",
- "4. Princess is a female heir\n",
+ "Hence the cards that can violate the rule are even and not blue. \n",
"\n",
- "Complete the missing parts of the code to obtain correct representations of new concepts."
+ "At first, we will define all needed concepts. For all noun concepts we would also like to have `not concept` presented in the space, please complete missing code parts."
]
},
{
@@ -448,22 +459,23 @@
},
"outputs": [],
"source": [
+ "set_seed(42)\n",
+ "vector_length = 1024\n",
+ "\n",
+ "card_states = ['RED','BLUE','ODD','EVEN','NOT','GREEN','PRIME','IMPLIES','ANT','RELATION','CONS']\n",
+ "vocab = make_vocabulary(vector_length)\n",
+ "vocab.populate(';'.join(card_states))\n",
+ "\n",
"###################################################################\n",
"## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete correct relations for creating new concepts.\")\n",
+ "raise NotImplementedError(\"Student exercise: complete creating `not x` concepts.\")\n",
"###################################################################\n",
"\n",
- "set_seed(42)\n",
- "\n",
- "symbol_names = ['monarch','heir','male','female']\n",
- "discrete_space = sspspace.DiscreteSPSpace(symbol_names, ssp_dim=1024, optimize=False)\n",
- "\n",
- "objs = {n:discrete_space.encode(n) for n in symbol_names}\n",
+ "for a in ['RED','BLUE','ODD','EVEN','GREEN','PRIME']:\n",
+ " vocab.add(f'NOT_{a}', vocab['NOT'] * vocab[a])\n",
"\n",
- "objs['king'] = objs['monarch'] * objs['male']\n",
- "objs['queen'] = objs['monarch'] * ...\n",
- "objs['prince'] = objs['heir'] * objs['male']\n",
- "objs['princess'] = ... * objs['female']"
+ "action_names = ['RED','BLUE','ODD','EVEN','GREEN','PRIME','NOT_RED','NOT_BLUE','NOT_ODD','NOT_EVEN','NOT_GREEN','NOT_PRIME']\n",
+ "action_space = np.array([vocab[x].v for x in action_names]).squeeze()"
]
},
{
@@ -473,7 +485,7 @@
"execution": {}
},
"source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_721e11a2.py)\n",
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_a0e39449.py)\n",
"\n"
]
},
@@ -483,9 +495,27 @@
"execution": {}
},
"source": [
- "Now, we can take an explicit approach. We know that the conversion from king to queen is to unbind male and bind female, so let's apply that to our prince object and see what we uncover. \n",
+ "Now, we are going to set up a simple perceptron-style learning rule, using the HRR (Holographic Reduced Representations) algebra. We are going to learn a target transformation, $T$, such that given a learning rule, $A^{*} = T\\circledast R$, where $A^{*}$ is the antecedant value bundled with $\\texttt{not}$ bound with the consequent value, because we are trying to learn the cards that can violate the rule, described above, and $R$ is the rule to be learned. \n",
+ "\n",
+ "Rules themselves are going to be composed like the data structures representing different countries in the previous section. `ant`, `relation` and `cons` are extra concepts which define the structure and which will bind to the specific instances. \n",
"\n",
- "At first, in the cell below, let's recover `queen` from `king` by constructing a new `query` concept, which represents the unbinding of `male` and the binding of `female.` Then, let's see if this new query object bears any similarity to anything in our vocabulary."
+ "If we have a rule, $X \\implies Y$, then we would create the VSA representation:\n",
+ "\n",
+ "$$R = \\texttt{ant}\\circledast X + \\texttt{relation}\\circledast \\text{implies} + \\texttt{cons} \\circledast Y$$,\n",
+ "\n",
+ "and the ideal output is:\n",
+ "\n",
+ "$$\n",
+ "A^{*} = X + \\texttt{not}\\circledast Y\n",
+ "$$\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "In the cell below, let us define two rules:\n",
+ "\n",
+ "$$\\text{blue} \\implies \\text{even}$$\n",
+ "$$\\text{odd} \\implies \\text{green}$$"
]
},
{
@@ -498,19 +528,13 @@
"source": [
"###################################################################\n",
"## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete correct relation for creating `query` object to compare with `queen`.\")\n",
+ "raise NotImplementedError(\"Student exercise: complete creating rules as defined above.\")\n",
"###################################################################\n",
"\n",
- "objs['queen_query'] = (objs[...] * ~objs[...]) * objs[...]\n",
- "\n",
- "object_names = list(objs.keys())\n",
- "sims = np.zeros((len(object_names), len(object_names)))\n",
- "\n",
- "for name_idx, name in enumerate(object_names):\n",
- " for other_idx in range(name_idx, len(object_names)):\n",
- " sims[name_idx, other_idx] = sims[other_idx, name_idx] = (objs[name] | objs[object_names[other_idx]]).item()\n",
- "\n",
- "plot_similarity_matrix(sims, object_names, values = True)"
+ "rules = [\n",
+ " (vocab['ANT'] * vocab['BLUE'] + vocab['RELATION'] * vocab['IMPLIES'] + vocab['CONS'] * vocab[...]).normalized(),\n",
+ " (vocab[...] * vocab[...] + vocab[...] * vocab[...] + vocab[...] * vocab[...]).normalized(),\n",
+ "]"
]
},
{
@@ -520,11 +544,7 @@
"execution": {}
},
"source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_6e6c0725.py)\n",
- "\n",
- "*Example output:*\n",
- "\n",
- " \n",
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_bab79b64.py)\n",
"\n"
]
},
@@ -534,40 +554,13 @@
"execution": {}
},
"source": [
- "The above similarity plot shows that applying that operation successfully converts king to queen. Let's apply it to 'prince' and see what happens. Now, `query` should represent the `princess` concept."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "objs['princess_query'] = (objs['prince'] * ~objs['male']) * objs['female']\n",
- "\n",
- "object_names = list(objs.keys())\n",
- "sims = np.zeros((len(object_names), len(object_names)))\n",
- "\n",
- "for name_idx, name in enumerate(object_names):\n",
- " for other_idx in range(name_idx, len(object_names)):\n",
- " sims[name_idx, other_idx] = sims[other_idx, name_idx] = (objs[name] | objs[object_names[other_idx]]).item()\n",
+ "Now, we are ready to derive the transformation! For that, we will iterate through the rules and solutions for specified number of iterations and update it as the following:\n",
"\n",
- "plot_similarity_matrix(sims, object_names, values = True)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Here, we have successfully recovered the princess, completing the analogy.\n",
+ "$$\\Delta T \\leftarrow T - \\text{lr}*(A^{*} \\circledast \\sim R)$$\n",
"\n",
- "This approach, however, requires explicit knowledge of the construction of the objects. Let's see if we can just work with the concepts of 'king,' 'queen,' and 'prince' directly.\n",
+ "where $\\text{lr}$ is learning rate constant value. Ultimately, we want $A^{*} = T\\circledast R$, so we unbind $R$ to recorver the desired transform, and use the learning rule to update our current estimated transform.\n",
"\n",
- "In the cell below, construct the `princess` concept using only `king,` `queen`, and `prince.`"
+ "We will also compute loss progression over the time and log loss function between perfect similarity (ones only for antecedance value and not consequent one) and the one we obtain between prediciton for current transformation and full action space. Complete missing parts of the code in the next cell to complete training."
]
},
{
@@ -580,46 +573,61 @@
"source": [
"###################################################################\n",
"## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete correct relation for creating `query` object to compare with `princess`.\")\n",
+ "raise NotImplementedError(\"Student exercise: complete training loop.\")\n",
"###################################################################\n",
"\n",
- "objs['new_princess_query'] = (objs[...] * ~objs[...]) * objs[...]\n",
+ "num_iters = 500\n",
+ "losses = []\n",
+ "sims = []\n",
+ "lr = 1e-1\n",
+ "ant_names = [\"BLUE\", \"ODD\"]\n",
+ "cons_names = [\"EVEN\", \"GREEN\"]\n",
+ "vector_length = 1024\n",
+ "\n",
+ "transform = np.zeros((vector_length))\n",
+ "for i in range(num_iters):\n",
+ " loss = 0\n",
+ " for rule, ant_name, cons_name in zip(rules, ant_names, cons_names):\n",
"\n",
- "sims = np.zeros((len(object_names), len(object_names)))\n",
+ " #perfect similarity\n",
+ " y_true = np.eye(len(action_names))[action_names.index(ant_name),:] + np.eye(len(action_names))[4+action_names.index(cons_name),:]\n",
"\n",
- "for name_idx, name in enumerate(object_names):\n",
- " for other_idx in range(name_idx, len(object_names)):\n",
- " sims[name_idx, other_idx] = sims[other_idx, name_idx] = (objs[name] | objs[object_names[other_idx]]).item()\n",
+ " #prediction with current transform (a_hat = transform * rule)\n",
+ " a_hat = spa.SemanticPointer(transform) * ...\n",
"\n",
- "plot_similarity_matrix(sims, object_names, values = True)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "execution": {}
- },
- "source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_c3859542.py)\n",
+ " #similarity with current transform\n",
+ " sim_mat = np.einsum('nd,d->n', action_space, a_hat.v)\n",
+ "\n",
+ " #cleanup\n",
+ " y_hat = softmax(sim_mat)\n",
"\n",
- "*Example output:*\n",
+ " #true solution (a* = ant_name + not * cons_name)\n",
+ " a_true = (vocab[ant_name] + vocab['NOT']*vocab[...]).normalized()\n",
"\n",
- "
\n",
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_bab79b64.py)\n",
"\n"
]
},
@@ -534,40 +554,13 @@
"execution": {}
},
"source": [
- "The above similarity plot shows that applying that operation successfully converts king to queen. Let's apply it to 'prince' and see what happens. Now, `query` should represent the `princess` concept."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "objs['princess_query'] = (objs['prince'] * ~objs['male']) * objs['female']\n",
- "\n",
- "object_names = list(objs.keys())\n",
- "sims = np.zeros((len(object_names), len(object_names)))\n",
- "\n",
- "for name_idx, name in enumerate(object_names):\n",
- " for other_idx in range(name_idx, len(object_names)):\n",
- " sims[name_idx, other_idx] = sims[other_idx, name_idx] = (objs[name] | objs[object_names[other_idx]]).item()\n",
+ "Now, we are ready to derive the transformation! For that, we will iterate through the rules and solutions for specified number of iterations and update it as the following:\n",
"\n",
- "plot_similarity_matrix(sims, object_names, values = True)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Here, we have successfully recovered the princess, completing the analogy.\n",
+ "$$\\Delta T \\leftarrow T - \\text{lr}*(A^{*} \\circledast \\sim R)$$\n",
"\n",
- "This approach, however, requires explicit knowledge of the construction of the objects. Let's see if we can just work with the concepts of 'king,' 'queen,' and 'prince' directly.\n",
+ "where $\\text{lr}$ is learning rate constant value. Ultimately, we want $A^{*} = T\\circledast R$, so we unbind $R$ to recorver the desired transform, and use the learning rule to update our current estimated transform.\n",
"\n",
- "In the cell below, construct the `princess` concept using only `king,` `queen`, and `prince.`"
+ "We will also compute loss progression over the time and log loss function between perfect similarity (ones only for antecedance value and not consequent one) and the one we obtain between prediciton for current transformation and full action space. Complete missing parts of the code in the next cell to complete training."
]
},
{
@@ -580,46 +573,61 @@
"source": [
"###################################################################\n",
"## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete correct relation for creating `query` object to compare with `princess`.\")\n",
+ "raise NotImplementedError(\"Student exercise: complete training loop.\")\n",
"###################################################################\n",
"\n",
- "objs['new_princess_query'] = (objs[...] * ~objs[...]) * objs[...]\n",
+ "num_iters = 500\n",
+ "losses = []\n",
+ "sims = []\n",
+ "lr = 1e-1\n",
+ "ant_names = [\"BLUE\", \"ODD\"]\n",
+ "cons_names = [\"EVEN\", \"GREEN\"]\n",
+ "vector_length = 1024\n",
+ "\n",
+ "transform = np.zeros((vector_length))\n",
+ "for i in range(num_iters):\n",
+ " loss = 0\n",
+ " for rule, ant_name, cons_name in zip(rules, ant_names, cons_names):\n",
"\n",
- "sims = np.zeros((len(object_names), len(object_names)))\n",
+ " #perfect similarity\n",
+ " y_true = np.eye(len(action_names))[action_names.index(ant_name),:] + np.eye(len(action_names))[4+action_names.index(cons_name),:]\n",
"\n",
- "for name_idx, name in enumerate(object_names):\n",
- " for other_idx in range(name_idx, len(object_names)):\n",
- " sims[name_idx, other_idx] = sims[other_idx, name_idx] = (objs[name] | objs[object_names[other_idx]]).item()\n",
+ " #prediction with current transform (a_hat = transform * rule)\n",
+ " a_hat = spa.SemanticPointer(transform) * ...\n",
"\n",
- "plot_similarity_matrix(sims, object_names, values = True)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "execution": {}
- },
- "source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_c3859542.py)\n",
+ " #similarity with current transform\n",
+ " sim_mat = np.einsum('nd,d->n', action_space, a_hat.v)\n",
+ "\n",
+ " #cleanup\n",
+ " y_hat = softmax(sim_mat)\n",
"\n",
- "*Example output:*\n",
+ " #true solution (a* = ant_name + not * cons_name)\n",
+ " a_true = (vocab[ant_name] + vocab['NOT']*vocab[...]).normalized()\n",
"\n",
- "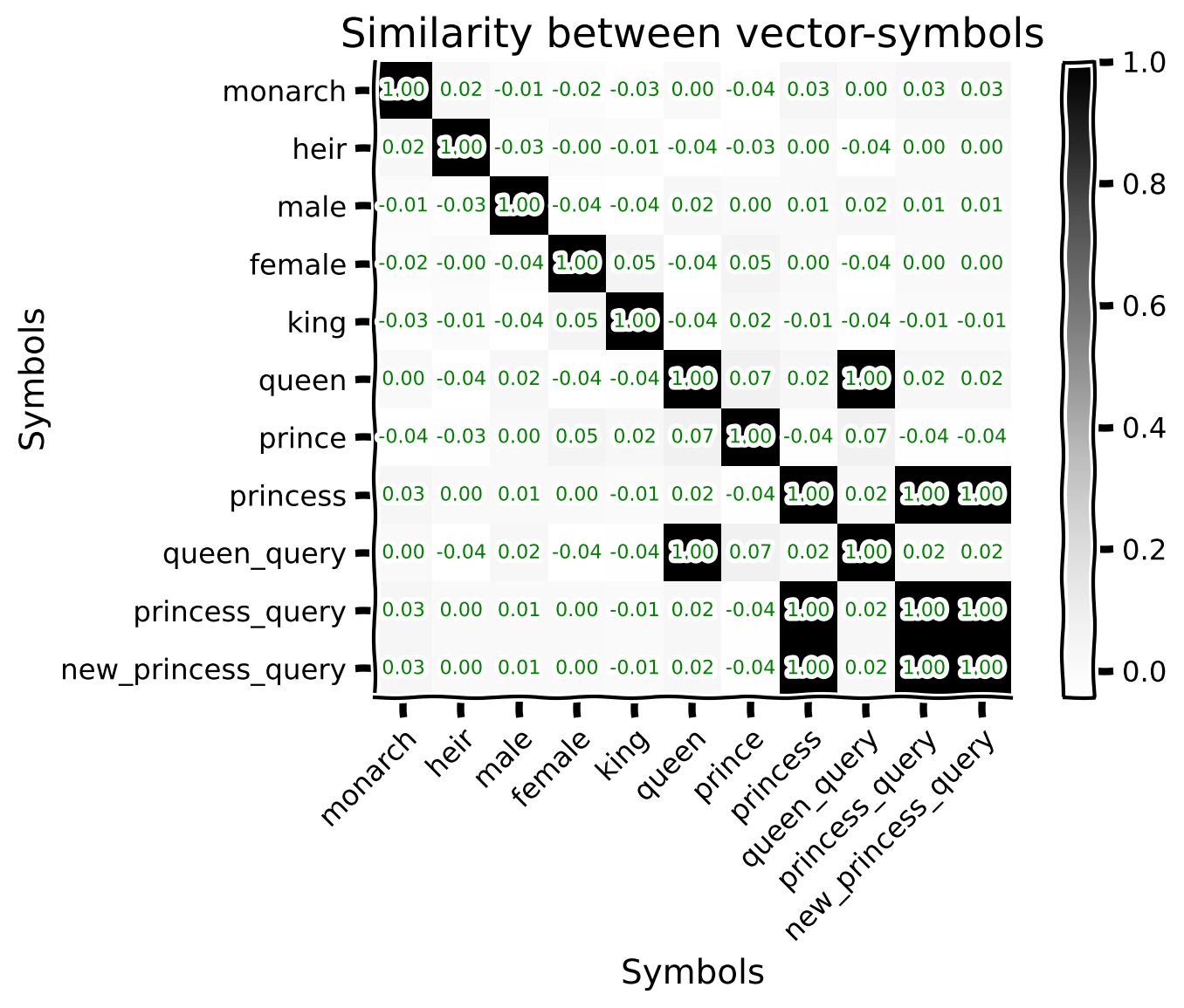 \n",
- "\n"
+ " #calculate loss\n",
+ " loss += log_loss(y_true, y_hat)\n",
+ "\n",
+ " #update transform (T <- T - lr * (A* * (~rule)))\n",
+ " transform -= (lr) * (transform - (... * ~rule).v)\n",
+ " transform = transform / np.linalg.norm(transform)\n",
+ "\n",
+ " #save predicted similarities if it is last iteration\n",
+ " if i == num_iters - 1:\n",
+ " sims.append(sim_mat)\n",
+ "\n",
+ " #save loss\n",
+ " losses.append(np.copy(loss))"
]
},
{
"cell_type": "markdown",
"metadata": {
+ "colab_type": "text",
"execution": {}
},
"source": [
- "Again, we see that we have recovered the princess by using our analogy.\n",
- "\n",
- "That said, the above depends on knowing that the representations are constructed using binding. Can we do something similar through the bundling operation? Let's try that out.\n",
- "\n",
- "Reassing concept definitions using bundling operation."
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_550fd076.py)\n",
+ "\n"
]
},
{
@@ -630,14 +638,8 @@
},
"outputs": [],
"source": [
- "set_seed(42)\n",
- "\n",
- "bundle_objs = {n:discrete_space.encode(n) for n in symbol_names}\n",
- "\n",
- "bundle_objs['king'] = (bundle_objs['monarch'] + bundle_objs['male']).normalize()\n",
- "bundle_objs['queen'] = (bundle_objs['monarch'] + bundle_objs['female']).normalize()\n",
- "bundle_objs['prince'] = (bundle_objs['heir'] + bundle_objs['male']).normalize()\n",
- "bundle_objs['princess'] = (bundle_objs['heir'] + bundle_objs['female']).normalize()"
+ "plt.figure(figsize=(15,5))\n",
+ "plot_training_and_choice(losses, sims, ant_names, cons_names, action_names)"
]
},
{
@@ -646,9 +648,7 @@
"execution": {}
},
"source": [
- "But now that we are using an additive model, we need to take a different approach. Instead of unbinding the king and binding the queen, we subtract the king and add the queen to find the princess from the prince.\n",
- "\n",
- "Complete the code to reflect the updated mechanism."
+ "Let's see what happens when we test it on a new rule it hasn't seen before. This time we will use the rule that $\\text{red} \\implies \\text{prime}$. Your task is to complete new rule in the cell below and observe the results."
]
},
{
@@ -661,10 +661,16 @@
"source": [
"###################################################################\n",
"## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete correct relation for creating `query` object to compare with `princess`.\")\n",
+ "raise NotImplementedError(\"Student exercise: complete new rule and predict for it.\")\n",
"###################################################################\n",
"\n",
- "bundle_objs['princess_query'] = (bundle_objs[...] - bundle_objs[...]) + bundle_objs[...]"
+ "new_rule = (vocab['ANT'] * vocab[...] + vocab['RELATION'] * ... + vocab['CONS'] * vocab[...]).normalized()\n",
+ "\n",
+ "#apply transform on new rule to test the generalization of the transform\n",
+ "a_hat = spa.SemanticPointer(transform) * ...\n",
+ "\n",
+ "new_sims = np.einsum('nd,d->n', action_space, a_hat.v)\n",
+ "y_hat = softmax(new_sims)"
]
},
{
@@ -674,7 +680,7 @@
"execution": {}
},
"source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_d2f142fd.py)\n",
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_3a819ce6.py)\n",
"\n"
]
},
@@ -686,15 +692,8 @@
},
"outputs": [],
"source": [
- "object_names = list(bundle_objs.keys())\n",
- "\n",
- "sims = np.zeros((len(object_names), len(object_names)))\n",
- "\n",
- "for name_idx, name in enumerate(object_names):\n",
- " for other_idx in range(name_idx, len(object_names)):\n",
- " sims[name_idx, other_idx] = sims[other_idx, name_idx] = (bundle_objs[name] | bundle_objs[object_names[other_idx]]).item()\n",
- "\n",
- "plot_similarity_matrix(sims, object_names, values = True)"
+ "plt.figure(figsize=(7,5))\n",
+ "plot_choice([new_sims], [\"RED\"], [\"PRIME\"], action_names)"
]
},
{
@@ -703,631 +702,58 @@
"execution": {}
},
"source": [
- "This is a messier similarity plot due to the fact that the bundled representations interact with all their constituent parts in the vocabulary. That said, we see that 'princess' is still most similar to the query vector. \n",
- "\n",
- "This approach is more like what we would expect from a `word2vec` embedding."
+ "Let's compare how a standard MLP that isn't aware of the structure in the representation performs. Here, features are going to be the rules and output - solutions. Complete the code below."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
- "cellView": "form",
"execution": {}
},
"outputs": [],
"source": [
- "# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_royal_relationships\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "---\n",
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete MLP training.\")\n",
+ "###################################################################\n",
+ "\n",
+ "#features - rules\n",
+ "X_train = np.array(...).squeeze()\n",
+ "\n",
+ "#output - a* for each rule\n",
+ "y_train = np.array([\n",
+ " (vocab[ant_names[0]] + vocab['NOT']*vocab[cons_names[0]]).normalized().v,\n",
+ " (vocab[ant_names[1]] + vocab['NOT']*vocab[cons_names[1]]).normalized().v,\n",
+ "]).squeeze()\n",
"\n",
- "# Section 2: Analogies. Part 2\n",
+ "regr = MLPRegressor(random_state=1, hidden_layer_sizes=(1024,1024), max_iter=1000).fit(..., ...)\n",
"\n",
- "Estimated timing to here from start of tutorial: 15 minutes\n",
+ "a_mlp = regr.predict(new_rule.v[None,:])\n",
"\n",
- "In this section, we will construct a database of data structures that describe different countries. Materials are adopted from [Kanerva (2010)](https://cdn.aaai.org/ocs/2243/2243-9566-1-PB.pdf)."
+ "mlp_sims = np.einsum('nd,md->nm', action_space, a_mlp)"
]
},
{
- "cell_type": "code",
- "execution_count": null,
+ "cell_type": "markdown",
"metadata": {
- "cellView": "form",
+ "colab_type": "text",
"execution": {}
},
- "outputs": [],
"source": [
- "# @title Video 2: Analogy 2\n",
- "\n",
- "from ipywidgets import widgets\n",
- "from IPython.display import YouTubeVideo\n",
- "from IPython.display import IFrame\n",
- "from IPython.display import display\n",
- "\n",
- "class PlayVideo(IFrame):\n",
- " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
- " self.id = id\n",
- " if source == 'Bilibili':\n",
- " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
- " elif source == 'Osf':\n",
- " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
- " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
- "\n",
- "def display_videos(video_ids, W=400, H=300, fs=1):\n",
- " tab_contents = []\n",
- " for i, video_id in enumerate(video_ids):\n",
- " out = widgets.Output()\n",
- " with out:\n",
- " if video_ids[i][0] == 'Youtube':\n",
- " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
- " height=H, fs=fs, rel=0)\n",
- " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
- " else:\n",
- " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
- " height=H, fs=fs, autoplay=False)\n",
- " if video_ids[i][0] == 'Bilibili':\n",
- " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
- " elif video_ids[i][0] == 'Osf':\n",
- " print(f'Video available at https://osf.io/{video.id}')\n",
- " display(video)\n",
- " tab_contents.append(out)\n",
- " return tab_contents\n",
- "\n",
- "video_ids = [('Youtube', 'OB3hzhM7Ois'), ('Bilibili', 'BV1TZ421g7G5')]\n",
- "tab_contents = display_videos(video_ids, W=854, H=480)\n",
- "tabs = widgets.Tab()\n",
- "tabs.children = tab_contents\n",
- "for i in range(len(tab_contents)):\n",
- " tabs.set_title(i, video_ids[i][0])\n",
- "display(tabs)"
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_cc0b7eb5.py)\n",
+ "\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
- "cellView": "form",
"execution": {}
},
"outputs": [],
"source": [
- "# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_analogy_part_two\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "## Coding Exercise 2: Dollar of Mexico\n",
- "\n",
- "This is going to be a little more involved because to construct the data structure, we are going to need vectors that not only represent values that we are reasoning about, but also vectors that represent different roles data can play. This is sometimes called a slot-filler representation or a key-value representation.\n",
- "\n",
- "At first, let us define concepts and cleanup object. Then, we will define `canada` and `mexico` concepts by integrating the available information together. You will be provided with a `canada` object and your task is to complete for `mexico` one. Note that:\n",
- "\n",
- "* We bind `currency` to the relevant currency for that country (`dollar` for Canada, `peso` for Mexico)\n",
- "* We bind `capital` to the relevant capital for that country (`Ottawa` for Canada, `Mexico City` for Mexico)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete `mexico` concept.\")\n",
- "###################################################################\n",
- "\n",
- "set_seed(42)\n",
- "\n",
- "new_symbol_names = ['dollar', 'peso', 'ottawa', 'mexico-city', 'currency', 'capital']\n",
- "new_discrete_space = sspspace.DiscreteSPSpace(new_symbol_names, ssp_dim=1024, optimize=False)\n",
- "\n",
- "new_objs = {n:new_discrete_space.encode(n) for n in new_symbol_names}\n",
- "\n",
- "cleanup = sspspace.Cleanup(new_objs)\n",
- "\n",
- "new_objs['canada'] = ((new_objs['currency'] * new_objs['dollar']) + (new_objs['capital'] * new_objs['ottawa'])).normalize()\n",
- "new_objs['mexico'] = ((new_objs['currency'] * ...) + (new_objs['capital'] * ...)).normalize()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "execution": {}
- },
- "source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_e3c85ed6.py)\n",
- "\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "We would like to find out Mexico's currency. Complete the code for constructing a `query` which will help us do that. Note that we are using a cleanup operation (feel free to remove it and compare the results)."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete `query` concept which will be similar to currency in Mexico.\")\n",
- "###################################################################\n",
- "\n",
- "objs['peso_query'] = cleanup(~new_objs[...] * new_objs[...] * new_objs['mexico'])\n",
- "\n",
- "object_names = list(new_objs.keys())\n",
- "sims = np.zeros((len(object_names), len(object_names)))\n",
- "\n",
- "for name_idx, name in enumerate(object_names):\n",
- " for other_idx in range(name_idx, len(object_names)):\n",
- " sims[name_idx, other_idx] = sims[other_idx, name_idx] = (new_objs[name] | new_objs[object_names[other_idx]]).item()\n",
- "\n",
- "plot_similarity_matrix(sims, object_names)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "execution": {}
- },
- "source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_923b3e73.py)\n",
- "\n",
- "*Example output:*\n",
- "\n",
- "
\n",
- "\n"
+ " #calculate loss\n",
+ " loss += log_loss(y_true, y_hat)\n",
+ "\n",
+ " #update transform (T <- T - lr * (A* * (~rule)))\n",
+ " transform -= (lr) * (transform - (... * ~rule).v)\n",
+ " transform = transform / np.linalg.norm(transform)\n",
+ "\n",
+ " #save predicted similarities if it is last iteration\n",
+ " if i == num_iters - 1:\n",
+ " sims.append(sim_mat)\n",
+ "\n",
+ " #save loss\n",
+ " losses.append(np.copy(loss))"
]
},
{
"cell_type": "markdown",
"metadata": {
+ "colab_type": "text",
"execution": {}
},
"source": [
- "Again, we see that we have recovered the princess by using our analogy.\n",
- "\n",
- "That said, the above depends on knowing that the representations are constructed using binding. Can we do something similar through the bundling operation? Let's try that out.\n",
- "\n",
- "Reassing concept definitions using bundling operation."
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_550fd076.py)\n",
+ "\n"
]
},
{
@@ -630,14 +638,8 @@
},
"outputs": [],
"source": [
- "set_seed(42)\n",
- "\n",
- "bundle_objs = {n:discrete_space.encode(n) for n in symbol_names}\n",
- "\n",
- "bundle_objs['king'] = (bundle_objs['monarch'] + bundle_objs['male']).normalize()\n",
- "bundle_objs['queen'] = (bundle_objs['monarch'] + bundle_objs['female']).normalize()\n",
- "bundle_objs['prince'] = (bundle_objs['heir'] + bundle_objs['male']).normalize()\n",
- "bundle_objs['princess'] = (bundle_objs['heir'] + bundle_objs['female']).normalize()"
+ "plt.figure(figsize=(15,5))\n",
+ "plot_training_and_choice(losses, sims, ant_names, cons_names, action_names)"
]
},
{
@@ -646,9 +648,7 @@
"execution": {}
},
"source": [
- "But now that we are using an additive model, we need to take a different approach. Instead of unbinding the king and binding the queen, we subtract the king and add the queen to find the princess from the prince.\n",
- "\n",
- "Complete the code to reflect the updated mechanism."
+ "Let's see what happens when we test it on a new rule it hasn't seen before. This time we will use the rule that $\\text{red} \\implies \\text{prime}$. Your task is to complete new rule in the cell below and observe the results."
]
},
{
@@ -661,10 +661,16 @@
"source": [
"###################################################################\n",
"## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete correct relation for creating `query` object to compare with `princess`.\")\n",
+ "raise NotImplementedError(\"Student exercise: complete new rule and predict for it.\")\n",
"###################################################################\n",
"\n",
- "bundle_objs['princess_query'] = (bundle_objs[...] - bundle_objs[...]) + bundle_objs[...]"
+ "new_rule = (vocab['ANT'] * vocab[...] + vocab['RELATION'] * ... + vocab['CONS'] * vocab[...]).normalized()\n",
+ "\n",
+ "#apply transform on new rule to test the generalization of the transform\n",
+ "a_hat = spa.SemanticPointer(transform) * ...\n",
+ "\n",
+ "new_sims = np.einsum('nd,d->n', action_space, a_hat.v)\n",
+ "y_hat = softmax(new_sims)"
]
},
{
@@ -674,7 +680,7 @@
"execution": {}
},
"source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_d2f142fd.py)\n",
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_3a819ce6.py)\n",
"\n"
]
},
@@ -686,15 +692,8 @@
},
"outputs": [],
"source": [
- "object_names = list(bundle_objs.keys())\n",
- "\n",
- "sims = np.zeros((len(object_names), len(object_names)))\n",
- "\n",
- "for name_idx, name in enumerate(object_names):\n",
- " for other_idx in range(name_idx, len(object_names)):\n",
- " sims[name_idx, other_idx] = sims[other_idx, name_idx] = (bundle_objs[name] | bundle_objs[object_names[other_idx]]).item()\n",
- "\n",
- "plot_similarity_matrix(sims, object_names, values = True)"
+ "plt.figure(figsize=(7,5))\n",
+ "plot_choice([new_sims], [\"RED\"], [\"PRIME\"], action_names)"
]
},
{
@@ -703,631 +702,58 @@
"execution": {}
},
"source": [
- "This is a messier similarity plot due to the fact that the bundled representations interact with all their constituent parts in the vocabulary. That said, we see that 'princess' is still most similar to the query vector. \n",
- "\n",
- "This approach is more like what we would expect from a `word2vec` embedding."
+ "Let's compare how a standard MLP that isn't aware of the structure in the representation performs. Here, features are going to be the rules and output - solutions. Complete the code below."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
- "cellView": "form",
"execution": {}
},
"outputs": [],
"source": [
- "# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_royal_relationships\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "---\n",
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete MLP training.\")\n",
+ "###################################################################\n",
+ "\n",
+ "#features - rules\n",
+ "X_train = np.array(...).squeeze()\n",
+ "\n",
+ "#output - a* for each rule\n",
+ "y_train = np.array([\n",
+ " (vocab[ant_names[0]] + vocab['NOT']*vocab[cons_names[0]]).normalized().v,\n",
+ " (vocab[ant_names[1]] + vocab['NOT']*vocab[cons_names[1]]).normalized().v,\n",
+ "]).squeeze()\n",
"\n",
- "# Section 2: Analogies. Part 2\n",
+ "regr = MLPRegressor(random_state=1, hidden_layer_sizes=(1024,1024), max_iter=1000).fit(..., ...)\n",
"\n",
- "Estimated timing to here from start of tutorial: 15 minutes\n",
+ "a_mlp = regr.predict(new_rule.v[None,:])\n",
"\n",
- "In this section, we will construct a database of data structures that describe different countries. Materials are adopted from [Kanerva (2010)](https://cdn.aaai.org/ocs/2243/2243-9566-1-PB.pdf)."
+ "mlp_sims = np.einsum('nd,md->nm', action_space, a_mlp)"
]
},
{
- "cell_type": "code",
- "execution_count": null,
+ "cell_type": "markdown",
"metadata": {
- "cellView": "form",
+ "colab_type": "text",
"execution": {}
},
- "outputs": [],
"source": [
- "# @title Video 2: Analogy 2\n",
- "\n",
- "from ipywidgets import widgets\n",
- "from IPython.display import YouTubeVideo\n",
- "from IPython.display import IFrame\n",
- "from IPython.display import display\n",
- "\n",
- "class PlayVideo(IFrame):\n",
- " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
- " self.id = id\n",
- " if source == 'Bilibili':\n",
- " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
- " elif source == 'Osf':\n",
- " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
- " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
- "\n",
- "def display_videos(video_ids, W=400, H=300, fs=1):\n",
- " tab_contents = []\n",
- " for i, video_id in enumerate(video_ids):\n",
- " out = widgets.Output()\n",
- " with out:\n",
- " if video_ids[i][0] == 'Youtube':\n",
- " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
- " height=H, fs=fs, rel=0)\n",
- " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
- " else:\n",
- " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
- " height=H, fs=fs, autoplay=False)\n",
- " if video_ids[i][0] == 'Bilibili':\n",
- " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
- " elif video_ids[i][0] == 'Osf':\n",
- " print(f'Video available at https://osf.io/{video.id}')\n",
- " display(video)\n",
- " tab_contents.append(out)\n",
- " return tab_contents\n",
- "\n",
- "video_ids = [('Youtube', 'OB3hzhM7Ois'), ('Bilibili', 'BV1TZ421g7G5')]\n",
- "tab_contents = display_videos(video_ids, W=854, H=480)\n",
- "tabs = widgets.Tab()\n",
- "tabs.children = tab_contents\n",
- "for i in range(len(tab_contents)):\n",
- " tabs.set_title(i, video_ids[i][0])\n",
- "display(tabs)"
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_cc0b7eb5.py)\n",
+ "\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
- "cellView": "form",
"execution": {}
},
"outputs": [],
"source": [
- "# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_analogy_part_two\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "## Coding Exercise 2: Dollar of Mexico\n",
- "\n",
- "This is going to be a little more involved because to construct the data structure, we are going to need vectors that not only represent values that we are reasoning about, but also vectors that represent different roles data can play. This is sometimes called a slot-filler representation or a key-value representation.\n",
- "\n",
- "At first, let us define concepts and cleanup object. Then, we will define `canada` and `mexico` concepts by integrating the available information together. You will be provided with a `canada` object and your task is to complete for `mexico` one. Note that:\n",
- "\n",
- "* We bind `currency` to the relevant currency for that country (`dollar` for Canada, `peso` for Mexico)\n",
- "* We bind `capital` to the relevant capital for that country (`Ottawa` for Canada, `Mexico City` for Mexico)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete `mexico` concept.\")\n",
- "###################################################################\n",
- "\n",
- "set_seed(42)\n",
- "\n",
- "new_symbol_names = ['dollar', 'peso', 'ottawa', 'mexico-city', 'currency', 'capital']\n",
- "new_discrete_space = sspspace.DiscreteSPSpace(new_symbol_names, ssp_dim=1024, optimize=False)\n",
- "\n",
- "new_objs = {n:new_discrete_space.encode(n) for n in new_symbol_names}\n",
- "\n",
- "cleanup = sspspace.Cleanup(new_objs)\n",
- "\n",
- "new_objs['canada'] = ((new_objs['currency'] * new_objs['dollar']) + (new_objs['capital'] * new_objs['ottawa'])).normalize()\n",
- "new_objs['mexico'] = ((new_objs['currency'] * ...) + (new_objs['capital'] * ...)).normalize()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "execution": {}
- },
- "source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_e3c85ed6.py)\n",
- "\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "We would like to find out Mexico's currency. Complete the code for constructing a `query` which will help us do that. Note that we are using a cleanup operation (feel free to remove it and compare the results)."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete `query` concept which will be similar to currency in Mexico.\")\n",
- "###################################################################\n",
- "\n",
- "objs['peso_query'] = cleanup(~new_objs[...] * new_objs[...] * new_objs['mexico'])\n",
- "\n",
- "object_names = list(new_objs.keys())\n",
- "sims = np.zeros((len(object_names), len(object_names)))\n",
- "\n",
- "for name_idx, name in enumerate(object_names):\n",
- " for other_idx in range(name_idx, len(object_names)):\n",
- " sims[name_idx, other_idx] = sims[other_idx, name_idx] = (new_objs[name] | new_objs[object_names[other_idx]]).item()\n",
- "\n",
- "plot_similarity_matrix(sims, object_names)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "execution": {}
- },
- "source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_923b3e73.py)\n",
- "\n",
- "*Example output:*\n",
- "\n",
- " \n",
- "\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "After cleanup, the query vector is the most similar to the `peso` object in the vocabulary, correctly answering the question. \n",
- "\n",
- "Note, however, that the similarity is not perfectly equal to 1. This is due to the scale factors applied to the composite vectors `canada` and `mexico`, to ensure they remain unit vectors, and due to cross talk. Crosstalk is a symptom of the fact that we are binding and unbinding bundles of vector symbols to produce the resultant query vector. The constituent vectors are not perfectly orthogonal (i.e., having a dot product of zero), and as such, the terms in the bundle interact when we measure similarity between them."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_dolar_of_mexico\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "---\n",
- "\n",
- "# Section 3: Wason Card Task\n",
- "\n",
- "Estimated timing to here from start of tutorial: 25 minutes\n",
- "\n",
- "One of the powerful benefits of using these structured representations is being able to generalize to other circumstances. To demonstrate this, we are going to show you this in a simple task."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Video 3: Wason Card Task Intro\n",
- "\n",
- "from ipywidgets import widgets\n",
- "from IPython.display import YouTubeVideo\n",
- "from IPython.display import IFrame\n",
- "from IPython.display import display\n",
- "\n",
- "class PlayVideo(IFrame):\n",
- " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
- " self.id = id\n",
- " if source == 'Bilibili':\n",
- " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
- " elif source == 'Osf':\n",
- " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
- " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
- "\n",
- "def display_videos(video_ids, W=400, H=300, fs=1):\n",
- " tab_contents = []\n",
- " for i, video_id in enumerate(video_ids):\n",
- " out = widgets.Output()\n",
- " with out:\n",
- " if video_ids[i][0] == 'Youtube':\n",
- " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
- " height=H, fs=fs, rel=0)\n",
- " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
- " else:\n",
- " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
- " height=H, fs=fs, autoplay=False)\n",
- " if video_ids[i][0] == 'Bilibili':\n",
- " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
- " elif video_ids[i][0] == 'Osf':\n",
- " print(f'Video available at https://osf.io/{video.id}')\n",
- " display(video)\n",
- " tab_contents.append(out)\n",
- " return tab_contents\n",
- "\n",
- "video_ids = [('Youtube', 'BAju3MNHCq8'), ('Bilibili', 'BV1Qf421X7MB')]\n",
- "tab_contents = display_videos(video_ids, W=854, H=480)\n",
- "tabs = widgets.Tab()\n",
- "tabs.children = tab_contents\n",
- "for i in range(len(tab_contents)):\n",
- " tabs.set_title(i, video_ids[i][0])\n",
- "display(tabs)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_wason_card_task_intro\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "## Coding Exercise 3: Wason Card Task\n",
- "\n",
- "We are going to test the generalization property on the Wason Card Task, where a person is told a rule of the form \"if the card is even, then the back is blue\", they are then presented with a number of cards with either an odd number, an even number, a red back, or a blue back. The participant is asked which cards they have to flip to determine that the rule is true.\n",
- "\n",
- "In this case, the participant needs to flip only the even card(s), and any card where the back is not blue, as the rule does not state whether or not odd numbers can have blue backs, and a red-backed card with an even number would violate the rule. We can get this from Boolean logic:\n",
- "\n",
- "$$\n",
- "\\mathrm{even} \\implies \\mathrm{blue}\n",
- "$$\n",
- "\n",
- "which is equal to \n",
- "\n",
- "$$ \n",
- "\\neg \\mathrm{even} \\vee \\mathrm{blue}\n",
- "$$\n",
- "\n",
- "where $\\neg$ means a logical not and $\\vee$ means logical or. If we want to find cards that violate the rule, then we negate the rule, providing:\n",
- "\n",
- "$$ \n",
- "\\neg (\\neg \\mathrm{even} \\vee \\mathrm{blue}) = \\mathrm{even} \\wedge \\neg \\mathrm{blue}.\n",
- "$$\n",
- "\n",
- "Where $\\wedge$ is the logical and. Hence, the cards that can violate the rule are either even or not blue. \n",
- "\n",
- "At first, we will define all the needed concepts. For all noun concepts, we would also like to have `not concept` presented in the space; please complete missing code parts."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "set_seed(42)\n",
- "\n",
- "card_states = ['red','blue','odd','even','not','green','prime','implies','ant','relation','cons']\n",
- "encoder = sspspace.DiscreteSPSpace(card_states, ssp_dim=1024, optimize=False)\n",
- "vocab = {c:encoder.encode(c) for c in card_states}\n",
- "\n",
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete creating `not x` concepts.\")\n",
- "###################################################################\n",
- "\n",
- "for a in ['red','blue','odd','even','green','prime']:\n",
- " vocab[f'not*{a}'] = vocab[...] * vocab[a]\n",
- "\n",
- "action_names = ['red','blue','odd','even','green','prime','not*red','not*blue','not*odd','not*even','not*green','not*prime']\n",
- "action_space = np.array([vocab[x] for x in action_names]).squeeze()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "execution": {}
- },
- "source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_47654e2f.py)\n",
- "\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Now, we are going to set up a simple perceptron-style learning rule using the HRR (Holographic Reduced Representations) algebra. We are going to learn a target transformation, $T$, such that given a learning rule, $A^{*} = T\\circledast R$. Here:\n",
- "\n",
- "* $R$ is the rule to be learned\n",
- "* $A^{*}$ is the antecedent value bundled with $\\texttt{not}$ bound with the consequent value. This is because we are trying to learn the cards that can *violate* the rule.\n",
- "\n",
- "Rules themselves are going to be composed like the data structures representing different countries in the previous section. `ant`, `relation`, and `cons` are extra concepts that define the structure and which will bind to the specific instances (think of them as anchor concepts which got bound to the specific instances). \n",
- "\n",
- "If we have a rule, $X \\implies Y$, then we would create the VSA representation:\n",
- "\n",
- "$$ R = \\texttt{ant} \\circledast X + \\texttt{relation} \\circledast \\texttt{implies} + \\texttt{cons} \\circledast Y $$\n",
- "\n",
- "and the ideal output is:\n",
- "\n",
- "$$\n",
- "A^{*} = X + \\texttt{not}\\circledast Y\n",
- "$$\n",
- "\n",
- "In the cell below, let us define two rules:\n",
- "\n",
- "$$\\text{blue} \\implies \\text{even}$$\n",
- "$$\\text{odd} \\implies \\text{green}$$"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete creating rules as defined above.\")\n",
- "###################################################################\n",
- "\n",
- "rules = [\n",
- " (vocab['ant'] * vocab['blue'] + vocab['relation'] * vocab['implies'] + vocab['cons'] * vocab[...]).normalize(),\n",
- " (vocab[...] * vocab[...] + vocab[...] * vocab[...] + vocab[...] * vocab[...]).normalize(),\n",
- "]"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "execution": {}
- },
- "source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_150dc068.py)\n",
- "\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Now, we are ready to derive the transformation! For that, we will iterate through the rules and solutions for a specified number of iterations and update it as the following:\n",
- "\n",
- "$$ T \\leftarrow T - \\text{lr} (T - A^{} \\circledast \\sim R)$$\n",
- "\n",
- "where $\\text{lr}$ is learning rate constant value. Ultimately, we want $A^{*} = T\\circledast R$, so we unbind $R$ to recover the desired transform and use the learning rule to update our current estimated transform.\n",
- "\n",
- "We will also compute loss progression over time and log the loss function between perfect similarity (ones only for antecedence value and not consequent one) and the one we obtain between prediction for current transformation and full action space. Complete the missing parts of the code in the next cell to complete training."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete training loop.\")\n",
- "###################################################################\n",
- "\n",
- "num_iters = 500\n",
- "losses = []\n",
- "sims = []\n",
- "lr = 1e-1\n",
- "ant_names = [\"blue\", \"odd\"]\n",
- "cons_names = [\"even\", \"green\"]\n",
- "\n",
- "transform = np.zeros((1,encoder.ssp_dim))\n",
- "for i in range(num_iters):\n",
- " loss = 0\n",
- " for rule, ant_name, cons_name in zip(rules, ant_names, cons_names):\n",
- "\n",
- " #perfect similarity\n",
- " y_true = np.eye(len(action_names))[action_names.index(ant_name),:] + np.eye(len(action_names))[4+action_names.index(cons_name),:]\n",
- "\n",
- " #prediction with current transform (a_hat = transform * rule)\n",
- " a_hat = sspspace.SSP(transform) * ...\n",
- "\n",
- " #similarity with current transform\n",
- " sim_mat = action_space @ a_hat.T\n",
- "\n",
- " #cleanup\n",
- " y_hat = softmax(sim_mat)\n",
- "\n",
- " #true solution (a* = ant_name + not * cons_name)\n",
- " a_true = (vocab[ant_name] + vocab['not']*vocab[...]).normalize()\n",
- "\n",
- " #calculate loss\n",
- " loss += log_loss(y_true, y_hat)\n",
- "\n",
- " #update transform (T <- T - lr * (T - A* * (~rule)))\n",
- " transform -= (lr) * (... - np.array(... * ~...))\n",
- " transform = transform / np.linalg.norm(transform)\n",
- "\n",
- " #save predicted similarities if it is last iteration\n",
- " if i == num_iters - 1:\n",
- " sims.append(sim_mat)\n",
- "\n",
- " #save loss\n",
- " losses.append(np.copy(loss))\n",
- "\n",
- "plot_training_and_choice(losses, sims, ant_names, cons_names, action_names)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "execution": {}
- },
- "source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_adb53d43.py)\n",
- "\n",
- "*Example output:*\n",
- "\n",
- "
\n",
- "\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "After cleanup, the query vector is the most similar to the `peso` object in the vocabulary, correctly answering the question. \n",
- "\n",
- "Note, however, that the similarity is not perfectly equal to 1. This is due to the scale factors applied to the composite vectors `canada` and `mexico`, to ensure they remain unit vectors, and due to cross talk. Crosstalk is a symptom of the fact that we are binding and unbinding bundles of vector symbols to produce the resultant query vector. The constituent vectors are not perfectly orthogonal (i.e., having a dot product of zero), and as such, the terms in the bundle interact when we measure similarity between them."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_dolar_of_mexico\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "---\n",
- "\n",
- "# Section 3: Wason Card Task\n",
- "\n",
- "Estimated timing to here from start of tutorial: 25 minutes\n",
- "\n",
- "One of the powerful benefits of using these structured representations is being able to generalize to other circumstances. To demonstrate this, we are going to show you this in a simple task."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Video 3: Wason Card Task Intro\n",
- "\n",
- "from ipywidgets import widgets\n",
- "from IPython.display import YouTubeVideo\n",
- "from IPython.display import IFrame\n",
- "from IPython.display import display\n",
- "\n",
- "class PlayVideo(IFrame):\n",
- " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
- " self.id = id\n",
- " if source == 'Bilibili':\n",
- " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
- " elif source == 'Osf':\n",
- " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
- " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
- "\n",
- "def display_videos(video_ids, W=400, H=300, fs=1):\n",
- " tab_contents = []\n",
- " for i, video_id in enumerate(video_ids):\n",
- " out = widgets.Output()\n",
- " with out:\n",
- " if video_ids[i][0] == 'Youtube':\n",
- " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
- " height=H, fs=fs, rel=0)\n",
- " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
- " else:\n",
- " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
- " height=H, fs=fs, autoplay=False)\n",
- " if video_ids[i][0] == 'Bilibili':\n",
- " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
- " elif video_ids[i][0] == 'Osf':\n",
- " print(f'Video available at https://osf.io/{video.id}')\n",
- " display(video)\n",
- " tab_contents.append(out)\n",
- " return tab_contents\n",
- "\n",
- "video_ids = [('Youtube', 'BAju3MNHCq8'), ('Bilibili', 'BV1Qf421X7MB')]\n",
- "tab_contents = display_videos(video_ids, W=854, H=480)\n",
- "tabs = widgets.Tab()\n",
- "tabs.children = tab_contents\n",
- "for i in range(len(tab_contents)):\n",
- " tabs.set_title(i, video_ids[i][0])\n",
- "display(tabs)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_wason_card_task_intro\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "## Coding Exercise 3: Wason Card Task\n",
- "\n",
- "We are going to test the generalization property on the Wason Card Task, where a person is told a rule of the form \"if the card is even, then the back is blue\", they are then presented with a number of cards with either an odd number, an even number, a red back, or a blue back. The participant is asked which cards they have to flip to determine that the rule is true.\n",
- "\n",
- "In this case, the participant needs to flip only the even card(s), and any card where the back is not blue, as the rule does not state whether or not odd numbers can have blue backs, and a red-backed card with an even number would violate the rule. We can get this from Boolean logic:\n",
- "\n",
- "$$\n",
- "\\mathrm{even} \\implies \\mathrm{blue}\n",
- "$$\n",
- "\n",
- "which is equal to \n",
- "\n",
- "$$ \n",
- "\\neg \\mathrm{even} \\vee \\mathrm{blue}\n",
- "$$\n",
- "\n",
- "where $\\neg$ means a logical not and $\\vee$ means logical or. If we want to find cards that violate the rule, then we negate the rule, providing:\n",
- "\n",
- "$$ \n",
- "\\neg (\\neg \\mathrm{even} \\vee \\mathrm{blue}) = \\mathrm{even} \\wedge \\neg \\mathrm{blue}.\n",
- "$$\n",
- "\n",
- "Where $\\wedge$ is the logical and. Hence, the cards that can violate the rule are either even or not blue. \n",
- "\n",
- "At first, we will define all the needed concepts. For all noun concepts, we would also like to have `not concept` presented in the space; please complete missing code parts."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "set_seed(42)\n",
- "\n",
- "card_states = ['red','blue','odd','even','not','green','prime','implies','ant','relation','cons']\n",
- "encoder = sspspace.DiscreteSPSpace(card_states, ssp_dim=1024, optimize=False)\n",
- "vocab = {c:encoder.encode(c) for c in card_states}\n",
- "\n",
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete creating `not x` concepts.\")\n",
- "###################################################################\n",
- "\n",
- "for a in ['red','blue','odd','even','green','prime']:\n",
- " vocab[f'not*{a}'] = vocab[...] * vocab[a]\n",
- "\n",
- "action_names = ['red','blue','odd','even','green','prime','not*red','not*blue','not*odd','not*even','not*green','not*prime']\n",
- "action_space = np.array([vocab[x] for x in action_names]).squeeze()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "execution": {}
- },
- "source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_47654e2f.py)\n",
- "\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Now, we are going to set up a simple perceptron-style learning rule using the HRR (Holographic Reduced Representations) algebra. We are going to learn a target transformation, $T$, such that given a learning rule, $A^{*} = T\\circledast R$. Here:\n",
- "\n",
- "* $R$ is the rule to be learned\n",
- "* $A^{*}$ is the antecedent value bundled with $\\texttt{not}$ bound with the consequent value. This is because we are trying to learn the cards that can *violate* the rule.\n",
- "\n",
- "Rules themselves are going to be composed like the data structures representing different countries in the previous section. `ant`, `relation`, and `cons` are extra concepts that define the structure and which will bind to the specific instances (think of them as anchor concepts which got bound to the specific instances). \n",
- "\n",
- "If we have a rule, $X \\implies Y$, then we would create the VSA representation:\n",
- "\n",
- "$$ R = \\texttt{ant} \\circledast X + \\texttt{relation} \\circledast \\texttt{implies} + \\texttt{cons} \\circledast Y $$\n",
- "\n",
- "and the ideal output is:\n",
- "\n",
- "$$\n",
- "A^{*} = X + \\texttt{not}\\circledast Y\n",
- "$$\n",
- "\n",
- "In the cell below, let us define two rules:\n",
- "\n",
- "$$\\text{blue} \\implies \\text{even}$$\n",
- "$$\\text{odd} \\implies \\text{green}$$"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete creating rules as defined above.\")\n",
- "###################################################################\n",
- "\n",
- "rules = [\n",
- " (vocab['ant'] * vocab['blue'] + vocab['relation'] * vocab['implies'] + vocab['cons'] * vocab[...]).normalize(),\n",
- " (vocab[...] * vocab[...] + vocab[...] * vocab[...] + vocab[...] * vocab[...]).normalize(),\n",
- "]"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "execution": {}
- },
- "source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_150dc068.py)\n",
- "\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Now, we are ready to derive the transformation! For that, we will iterate through the rules and solutions for a specified number of iterations and update it as the following:\n",
- "\n",
- "$$ T \\leftarrow T - \\text{lr} (T - A^{} \\circledast \\sim R)$$\n",
- "\n",
- "where $\\text{lr}$ is learning rate constant value. Ultimately, we want $A^{*} = T\\circledast R$, so we unbind $R$ to recover the desired transform and use the learning rule to update our current estimated transform.\n",
- "\n",
- "We will also compute loss progression over time and log the loss function between perfect similarity (ones only for antecedence value and not consequent one) and the one we obtain between prediction for current transformation and full action space. Complete the missing parts of the code in the next cell to complete training."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete training loop.\")\n",
- "###################################################################\n",
- "\n",
- "num_iters = 500\n",
- "losses = []\n",
- "sims = []\n",
- "lr = 1e-1\n",
- "ant_names = [\"blue\", \"odd\"]\n",
- "cons_names = [\"even\", \"green\"]\n",
- "\n",
- "transform = np.zeros((1,encoder.ssp_dim))\n",
- "for i in range(num_iters):\n",
- " loss = 0\n",
- " for rule, ant_name, cons_name in zip(rules, ant_names, cons_names):\n",
- "\n",
- " #perfect similarity\n",
- " y_true = np.eye(len(action_names))[action_names.index(ant_name),:] + np.eye(len(action_names))[4+action_names.index(cons_name),:]\n",
- "\n",
- " #prediction with current transform (a_hat = transform * rule)\n",
- " a_hat = sspspace.SSP(transform) * ...\n",
- "\n",
- " #similarity with current transform\n",
- " sim_mat = action_space @ a_hat.T\n",
- "\n",
- " #cleanup\n",
- " y_hat = softmax(sim_mat)\n",
- "\n",
- " #true solution (a* = ant_name + not * cons_name)\n",
- " a_true = (vocab[ant_name] + vocab['not']*vocab[...]).normalize()\n",
- "\n",
- " #calculate loss\n",
- " loss += log_loss(y_true, y_hat)\n",
- "\n",
- " #update transform (T <- T - lr * (T - A* * (~rule)))\n",
- " transform -= (lr) * (... - np.array(... * ~...))\n",
- " transform = transform / np.linalg.norm(transform)\n",
- "\n",
- " #save predicted similarities if it is last iteration\n",
- " if i == num_iters - 1:\n",
- " sims.append(sim_mat)\n",
- "\n",
- " #save loss\n",
- " losses.append(np.copy(loss))\n",
- "\n",
- "plot_training_and_choice(losses, sims, ant_names, cons_names, action_names)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "execution": {}
- },
- "source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_adb53d43.py)\n",
- "\n",
- "*Example output:*\n",
- "\n",
- " \n",
- "\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Let's see what happens when we test it on a new rule it hasn't seen before. This time, we will use the rule that $\\text{red} \\implies \\text{prime}$. Your task is to complete the new rule in the cell below and observe the results."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete new rule and predict for it.\")\n",
- "###################################################################\n",
- "\n",
- "new_rule = (vocab['ant'] * vocab[...] + vocab['relation'] * ... + vocab['cons'] * vocab[...]).normalize()\n",
- "\n",
- "#apply transform on new rule to test the generalization of the transform\n",
- "a_hat = sspspace.SSP(transform) * ...\n",
- "\n",
- "new_sims = action_space @ a_hat.T\n",
- "y_hat = softmax(new_sims)\n",
- "\n",
- "plot_choice([new_sims], [\"red\"], [\"prime\"], action_names)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "execution": {}
- },
- "source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_a8dd8a5d.py)\n",
- "\n",
- "*Example output:*\n",
- "\n",
- "
\n",
- "\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Let's see what happens when we test it on a new rule it hasn't seen before. This time, we will use the rule that $\\text{red} \\implies \\text{prime}$. Your task is to complete the new rule in the cell below and observe the results."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete new rule and predict for it.\")\n",
- "###################################################################\n",
- "\n",
- "new_rule = (vocab['ant'] * vocab[...] + vocab['relation'] * ... + vocab['cons'] * vocab[...]).normalize()\n",
- "\n",
- "#apply transform on new rule to test the generalization of the transform\n",
- "a_hat = sspspace.SSP(transform) * ...\n",
- "\n",
- "new_sims = action_space @ a_hat.T\n",
- "y_hat = softmax(new_sims)\n",
- "\n",
- "plot_choice([new_sims], [\"red\"], [\"prime\"], action_names)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "execution": {}
- },
- "source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_a8dd8a5d.py)\n",
- "\n",
- "*Example output:*\n",
- "\n",
- " \n",
- "\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Let's compare how a standard MLP that isn't aware of the structure in the representation performs. Here, features are going to be the rules and output - solutions. Complete the code below."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete MLP training.\")\n",
- "###################################################################\n",
- "\n",
- "#features - rules\n",
- "X_train = np.array(...).squeeze()\n",
- "\n",
- "#output - a* for each rule\n",
- "y_train = np.array([\n",
- " (vocab[ant_names[0]] + vocab['not']*vocab[cons_names[0]]).normalize(),\n",
- " (vocab[ant_names[1]] + vocab['not']*vocab[cons_names[1]]).normalize(),\n",
- "]).squeeze()\n",
- "\n",
- "regr = MLPRegressor(random_state=1, hidden_layer_sizes=(1024,1024), max_iter=1000).fit(..., ...)\n",
- "\n",
- "a_mlp = regr.predict(new_rule)\n",
- "\n",
- "mlp_sims = action_space @ a_mlp.T\n",
- "\n",
- "plot_choice([mlp_sims], [\"red\"], [\"prime\"], action_names)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "execution": {}
- },
- "source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_9da10bdc.py)\n",
- "\n",
- "*Example output:*\n",
- "\n",
- "
\n",
- "\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Let's compare how a standard MLP that isn't aware of the structure in the representation performs. Here, features are going to be the rules and output - solutions. Complete the code below."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete MLP training.\")\n",
- "###################################################################\n",
- "\n",
- "#features - rules\n",
- "X_train = np.array(...).squeeze()\n",
- "\n",
- "#output - a* for each rule\n",
- "y_train = np.array([\n",
- " (vocab[ant_names[0]] + vocab['not']*vocab[cons_names[0]]).normalize(),\n",
- " (vocab[ant_names[1]] + vocab['not']*vocab[cons_names[1]]).normalize(),\n",
- "]).squeeze()\n",
- "\n",
- "regr = MLPRegressor(random_state=1, hidden_layer_sizes=(1024,1024), max_iter=1000).fit(..., ...)\n",
- "\n",
- "a_mlp = regr.predict(new_rule)\n",
- "\n",
- "mlp_sims = action_space @ a_mlp.T\n",
- "\n",
- "plot_choice([mlp_sims], [\"red\"], [\"prime\"], action_names)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "execution": {}
- },
- "source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial2_Solution_9da10bdc.py)\n",
- "\n",
- "*Example output:*\n",
- "\n",
- "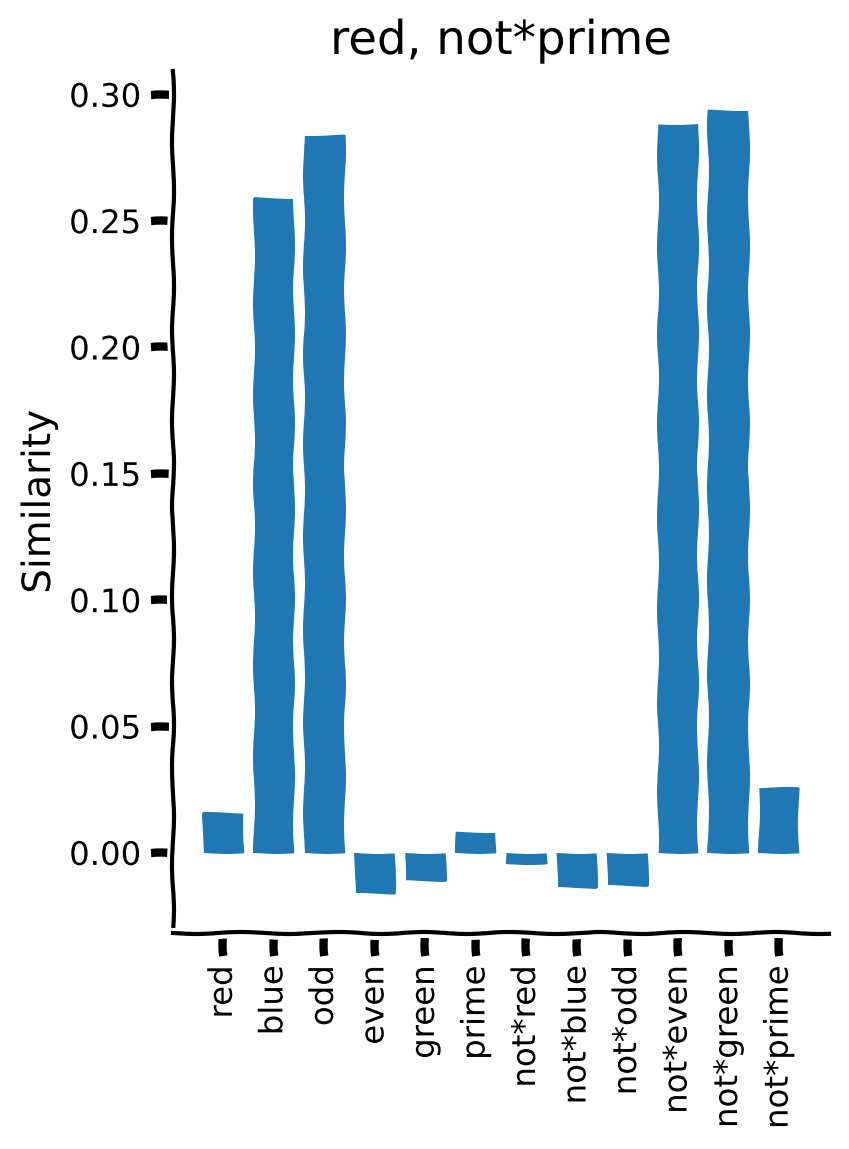 \n",
- "\n"
+ "plot_choice([mlp_sims], [\"RED\"], [\"PRIME\"], action_names)"
]
},
{
@@ -1361,7 +787,7 @@
},
"outputs": [],
"source": [
- "# @title Video 4: Wason Card Task Outro\n",
+ "# @title Video 2: Wason Card Task Outro\n",
"\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
@@ -1426,11 +852,11 @@
},
"source": [
"---\n",
- "# Summary\n",
+ "# The Big Picture\n",
"\n",
- "*Estimated timing of tutorial: 45 minutes*\n",
+ "What we saw in this tutorial is the power of generalization at work, that the two top responses were indeed GREEN and NOT PRIME, as Michael outlined in the Outro video. The theme of generalization is the cornerstone of this course and one of the most fundamental aspects we want to convey to you in your NeuroAI journey with us. This tutorial highlights yet another way in which this can be achieved, through the special language of VSA. The MLP does not have access to the structural components and fails to generalize on this task. This is one of the key benefits of the VSA method, where the connection to learning underlying structures allows for generalization to occur. \n",
"\n",
- "In this tutorial, we observed three scenarios where we used the basic operations to solve different analogies and engage in structured learning. The next final tutorial will show us how to use structure to impose inductive biases and how to use continuous representations to represent mixtures of discrete and continuous objects."
+ "We have a bonus tutorial today (Tutorial 4) that covers some other cases connected to analogies, which will help to clarify and demonstrate the power of VSAs even more. We really encourage you to check out that material and then maybe revisit this tutorial if you had any trouble following along. "
]
}
],
@@ -1462,7 +888,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.9.19"
+ "version": "3.9.22"
}
},
"nbformat": 4,
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial3.ipynb b/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial3.ipynb
index 21d44b84a..28d1917db 100644
--- a/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial3.ipynb
+++ b/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial3.ipynb
@@ -17,7 +17,7 @@
"execution": {}
},
"source": [
- "# Tutorial 3: Representations in continuous space\n",
+ "# Tutorial 3: Question Answering with Memory\n",
"\n",
"**Week 2, Day 2: Neuro-Symbolic Methods**\n",
"\n",
@@ -25,9 +25,9 @@
"\n",
"__Content creators:__ P. Michael Furlong, Chris Eliasmith\n",
"\n",
- "__Content reviewers:__ Hlib Solodzhuk, Patrick Mineault, Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi\n",
+ "__Content reviewers:__ Konstantine Tsafatinos, Xaq Pitkow, Alex Murphy\n",
"\n",
- "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk"
+ "__Production editors:__ Konstantine Tsafatinos, Xaq Pitkow, Alex Murphy"
]
},
{
@@ -37,13 +37,11 @@
},
"source": [
"___\n",
- "\n",
- "\n",
"# Tutorial Objectives\n",
"\n",
- "*Estimated timing of tutorial: 40 minutes*\n",
+ "This model shows a form of question answering with memory. You will bind two features (color and shape) by circular convolution and store them in a memory population. Then you will provide a cue to the model at a later time to determine either one of the features by deconvolution. This model exhibits better cognitive ability since the answers to the questions are provided at a later time and not at the same time as the questions themselves. These operations use the primitives we introduced in Tutorial 1. Please make sure you have worked through previous tutorials so you can understand how operations such as circular convolution can implement binding of concepts.\n",
"\n",
- "In this tutorial, you will observe how the VSA methods can be applied in structures and environments to allow for efficient generalization."
+ "**Note:** While we present a simplified interface using the Semantc Pointer Architecture, all the computations underlying the model you build are implemented using spiking neurons!"
]
},
{
@@ -59,7 +57,7 @@
"# @markdown These are the slides for the videos in all tutorials today\n",
"\n",
"from IPython.display import IFrame\n",
- "link_id = \"2szmk\"\n",
+ "link_id = \"jybuw\"\n",
"\n",
"print(f\"If you want to download the slides: 'https://osf.io/download/{link_id}'\")\n",
"\n",
@@ -73,8 +71,11 @@
},
"source": [
"---\n",
- "# Setup\n",
- "\n"
+ "# Setup (Colab Users: Please Read)\n",
+ "\n",
+ "Note that because this tutorial relies on some special Python packages, these packages have requirements for specific versions of common scientific libraries, such as `numpy`. If you're in Google Colab, then as of May 2025, this comes with a later version (2.0.2) pre-installed. We require an older version (we'll be installing `1.24.4`). This causes Colab to force a session restart and then re-running of the installation cells for the new version to take effect. When you run the cell below, you will be prompted to restart the session. This is *entirely expected* and you haven't done anything wrong. Simply click 'Restart' and then run the cells as normal. \n",
+ "\n",
+ "An additional error might sometimes arise where an exception is raised connected to a missing element of NumPy. If this occurs, please restart the session and re-run the cells as normal and this error will go away. Updated versions of the affected libraries are expected out soon, but sadly not in time for the preparation of this material. We thank you for your understanding."
]
},
{
@@ -86,9 +87,23 @@
},
"outputs": [],
"source": [
- "# @title Install and import feedback gadget\n",
+ "# @title Install dependencies\n",
"\n",
- "!pip install --quiet jupyter numpy matplotlib ipywidgets scikit-learn tqdm vibecheck\n",
+ "!pip install numpy==1.24.4 --quiet\n",
+ "!pip install nengo nengo-spa nengo-gui --quiet\n",
+ "!pip install matplotlib vibecheck --quiet"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Install and import feedback gadget\n",
"\n",
"from vibecheck import DatatopsContentReviewContainer\n",
"def content_review(notebook_section: str):\n",
@@ -106,30 +121,6 @@
"feedback_prefix = \"W2D2_T3\""
]
},
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Notice that exactly the `neuromatch` branch of `sspspace` should be installed! Otherwise, some of the functionality (like `optimize` parameter in the `DiscreteSPSpace` initialization) won't work."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Install dependencies\n",
- "\n",
- "# Install sspspace\n",
- "!pip install git+https://github.com/neuromatch/sspspace@neuromatch --quiet"
- ]
- },
{
"cell_type": "code",
"execution_count": null,
@@ -141,189 +132,16 @@
"source": [
"# @title Imports\n",
"\n",
- "#working with data\n",
- "import numpy as np\n",
- "\n",
- "#plotting\n",
"import matplotlib.pyplot as plt\n",
+ "import numpy as np\n",
"import logging\n",
"\n",
- "#interactive display\n",
- "import ipywidgets as widgets\n",
- "\n",
- "#modeling\n",
- "import sspspace\n",
- "from sklearn.linear_model import LinearRegression\n",
- "from sklearn.model_selection import train_test_split\n",
- "\n",
- "from tqdm.notebook import tqdm as tqdm"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Figure settings\n",
- "\n",
- "logging.getLogger('matplotlib.font_manager').disabled = True\n",
- "\n",
"%matplotlib inline\n",
- "%config InlineBackend.figure_format = 'retina' # perfrom high definition rendering for images and plots\n",
- "plt.style.use(\"https://raw.githubusercontent.com/NeuromatchAcademy/course-content/main/nma.mplstyle\")"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Plotting functions\n",
- "\n",
- "def plot_3d_function(X, Y, zs, titles):\n",
- " \"\"\"Plot 3D function.\n",
- "\n",
- " Inputs:\n",
- " - X (list): list of np.ndarray of x-values.\n",
- " - Y (list): list of np.ndarray of y-values.\n",
- " - zs (list): list of np.ndarray of z-values.\n",
- " - titles (list): list of titles of the plot.\n",
- " \"\"\"\n",
- " with plt.xkcd():\n",
- " fig = plt.figure(figsize=(8, 8))\n",
- " for index, (x, y, z) in enumerate(zip(X, Y, zs)):\n",
- " fig.add_subplot(1, len(X), index + 1, projection='3d')\n",
- " plt.gca().plot_surface(x,y,z.reshape(x.shape),cmap='plasma', antialiased=False, linewidth=0)\n",
- " plt.xlabel(r'$x_{1}$')\n",
- " plt.ylabel(r'$x_{2}$')\n",
- " plt.gca().set_zlabel(r'$f(\\mathbf{x})$')\n",
- " plt.title(titles[index])\n",
- " plt.show()\n",
- "\n",
- "def plot_performance(bound_performance, bundle_performance, training_samples, title):\n",
- " \"\"\"Plot RMSE values for two different representations of the input data.\n",
- "\n",
- " Inputs:\n",
- " - bound_performance (list): list of RMSE for bound representation.\n",
- " - bundle_performance (list): list of RMSE for bundle representation.\n",
- " - training_samples (list): x-axis.\n",
- " - title (str): title of the plot.\n",
- " \"\"\"\n",
- " with plt.xkcd():\n",
- " plt.plot(training_samples, bound_performance, label='Bound Representation')\n",
- " plt.plot(training_samples, bundle_performance, label='Bundling Representation', ls='--')\n",
- " plt.legend()\n",
- " plt.title(title)\n",
- " plt.ylabel('RMSE (a.u.)')\n",
- " plt.xlabel('# Training samples')\n",
- "\n",
- "def plot_2d_similarity(sims, obj_names, size, title_argmax = False):\n",
- " \"\"\"\n",
- " Plot 2D similarity between query points (grid) and the ones associated with the objects.\n",
- "\n",
- " Inputs:\n",
- " - sims (list): list of similarity values for each of the objects.\n",
- " - obj_names (list): list of object names.\n",
- " - size (tuple): to reshape the similarities.\n",
- " - title_argmax (bool, default = False): looks for the point coordinates as arg max from all similarity value.\n",
- " \"\"\"\n",
- " ticks = [0, 24, 49, 74, 99]\n",
- " ticklabels = [-5, -2, 0, 2, 5]\n",
- " with plt.xkcd():\n",
- " for obj_idx, obj in enumerate(obj_names):\n",
- " plt.subplot(1, len(obj_names), 1 + obj_idx)\n",
- " plt.imshow(np.array(sims[obj_idx].reshape(size)), origin='lower', vmin=-1, vmax=1)\n",
- " plt.gca().set_xticks(ticks)\n",
- " plt.gca().set_xticklabels(ticklabels)\n",
- " if obj_idx == 0:\n",
- " plt.gca().set_yticks(ticks)\n",
- " plt.gca().set_yticklabels(ticklabels)\n",
- " else:\n",
- " plt.gca().set_yticks([])\n",
- " if not title_argmax:\n",
- " plt.title(f'{obj}, {positions[obj_idx]}')\n",
- " else:\n",
- " plt.title(f'{obj}, {query_xs[sims[obj_idx].argmax()]}')\n",
- "\n",
- "def plot_unbinding_objects_map(sims, positions, query_xs, size):\n",
- " \"\"\"\n",
- " Plot 2D similarity between query points (grid) and the unbinded from the objects map.\n",
- "\n",
- " Inputs:\n",
- " - sims (np.ndarray): similarity values for each of the query points with the map.\n",
- " - positions (np.ndarray): positions of the objects.\n",
- " - query_xs (np.ndarray): grid points.\n",
- " - size (tuple): to reshape the similarities.\n",
- "\n",
- " \"\"\"\n",
- " ticks = [0,24,49,74,99]\n",
- " ticklabels = [-5,-2,0,2,5]\n",
- " with plt.xkcd():\n",
- " plt.imshow(sims.reshape(size), origin='lower')\n",
- "\n",
- " for idx, marker in enumerate(['o','s','^']):\n",
- " plt.scatter(*get_coordinate(positions[idx,:], query_xs, size), marker=marker,s=100)\n",
- "\n",
- " plt.gca().set_xticks(ticks)\n",
- " plt.gca().set_xticklabels(ticklabels)\n",
- " plt.gca().set_yticks(ticks)\n",
- " plt.gca().set_yticklabels(ticklabels)\n",
- " plt.title(f'All Object Locations')\n",
- " plt.show()\n",
- "\n",
- "def plot_unbinding_positions_map(sims, positions, obj_names):\n",
- " \"\"\"\n",
- " Plot 2D similarity between query points (grid) and the unbinded from the positions map.\n",
- "\n",
- " Inputs:\n",
- " - sims (np.ndarray): similarity values for each of the query points with the map.\n",
- " - positions (np.ndarray): test positions to query.\n",
- " - obj_names (list): names of the objects for labels.\n",
- " - size (tuple): to reshape the similarities.\n",
- " \"\"\"\n",
- " with plt.xkcd():\n",
- " plt.figure(figsize=(8, 4))\n",
- " for pos_idx, pos in enumerate(positions):\n",
- " plt.subplot(1,len(test_positions), 1+pos_idx)\n",
- " plt.bar([1,2,3], sims[pos_idx])\n",
- " plt.ylim([-0.3, 1.05])\n",
- " plt.gca().set_xticks([1,2,3])\n",
- " plt.gca().set_xticklabels(obj_names, rotation=90)\n",
- " if pos_idx != 0:\n",
- " plt.gca().set_yticks([])\n",
- " plt.title(f'Symbols at\\n{pos}')\n",
- " plt.show()"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Set random seed\n",
- "\n",
- "import random\n",
- "import numpy as np\n",
"\n",
- "def set_seed(seed=None):\n",
- " if seed is None:\n",
- " seed = np.random.choice(2 ** 32)\n",
- " random.seed(seed)\n",
- " np.random.seed(seed)\n",
+ "import nengo\n",
+ "import nengo_spa as spa\n",
"\n",
- "set_seed(seed = 42)"
+ "seed = 0"
]
},
{
@@ -335,566 +153,13 @@
},
"outputs": [],
"source": [
- "# @title Helper functions\n",
- "\n",
- "def get_model(xs, ys, train_size):\n",
- " \"\"\"Fit linear regression to the given data.\n",
- "\n",
- " Inputs:\n",
- " - xs (np.ndarray): input data.\n",
- " - ys (np.ndarray): output data.\n",
- " - train_size (float): fraction of data to use for train.\n",
- " \"\"\"\n",
- " X_train, _, y_train, _ = train_test_split(xs, ys, random_state=1, train_size=train_size)\n",
- " return LinearRegression().fit(X_train, y_train)\n",
- "\n",
- "def get_coordinate(x, positions, target_shape):\n",
- " \"\"\"Return the closest column and row coordinates for the given position.\n",
- "\n",
- " Inputs:\n",
- " - x (np.ndarray): query position.\n",
- " - positions (np.ndarray): all positions.\n",
- " - target_shape (tuple): shape of the grid.\n",
- "\n",
- " Outputs:\n",
- " - coordinates (tuple): column and row positions.\n",
- " \"\"\"\n",
- " idx = np.argmin(np.linalg.norm(x - positions, axis=1))\n",
- " c = idx % target_shape[1]\n",
- " r = idx // target_shape[1]\n",
- " return (c,r)\n",
- "\n",
- "def rastrigin_solution(x):\n",
- " \"\"\"Compute Rastrigin function for given array of d-dimenstional vectors.\n",
- "\n",
- " Inputs:\n",
- " - x (np.ndarray of shape (n, d)): n d-dimensional vectors.\n",
- "\n",
- " Outputs:\n",
- " - y (np.ndarray of shape (n, 1)): Rastrigin function value for each of the vectors.\n",
- " \"\"\"\n",
- " return 10 * x.shape[1] + np.sum(x**2 - 10 * np.cos(2*np.pi*x), axis=1)\n",
- "\n",
- "def non_separable_solution(x):\n",
- " \"\"\"Compute non-separable function for given array of 2-dimenstional vectors.\n",
- "\n",
- " Inputs:\n",
- " - x (np.ndarray of shape (n, 2)): n 2-dimensional vectors.\n",
- "\n",
- " Outputs:\n",
- " - y (np.ndarray of shape (n, 1)): non-separable function value for each of the vectors.\n",
- " \"\"\"\n",
- " return np.sin(np.multiply(x[:, 0], x[:, 1]))\n",
- "\n",
- "x0_rastrigin = np.linspace(-5.12, 5.12, 100)\n",
- "X_rastrigin, Y_rastrigin = np.meshgrid(x0_rastrigin,x0_rastrigin)\n",
- "xs_rastrigin = np.vstack((X_rastrigin.flatten(), Y_rastrigin.flatten())).T\n",
- "ys_rastrigin = rastrigin_solution(xs_rastrigin)\n",
- "\n",
- "x0_non_separable = np.linspace(-4, 4, 100)\n",
- "X_non_separable, Y_non_separable = np.meshgrid(x0_non_separable,x0_non_separable)\n",
- "xs_non_separable = np.vstack((X_non_separable.flatten(), Y_non_separable.flatten())).T\n",
- "ys_non_separable = non_separable_solution(xs_non_separable)\n",
- "\n",
- "set_seed(42)\n",
- "\n",
- "obj_names = ['circle','square','triangle']\n",
- "discrete_space = sspspace.DiscreteSPSpace(obj_names, ssp_dim=1024)\n",
- "\n",
- "objs = {n:discrete_space.encode(n) for n in obj_names}\n",
- "\n",
- "ssp_space = sspspace.RandomSSPSpace(domain_dim=2, ssp_dim=1024)\n",
- "positions = np.array([[0, -2],\n",
- " [-2, 3],\n",
- " [3, 2]\n",
- " ])\n",
- "ssps = {n:ssp_space.encode(x) for n, x in zip(obj_names, positions)}\n",
- "\n",
- "dim0 = np.linspace(-5, 5, 101)\n",
- "dim1 = np.linspace(-5, 5, 101)\n",
- "X,Y = np.meshgrid(dim0, dim1)\n",
- "\n",
- "query_xs = np.vstack((X.flatten(), Y.flatten())).T\n",
- "query_ssps = ssp_space.encode(query_xs)\n",
- "\n",
- "bound_objects = [objs[n] * ssps[n] for n in obj_names]\n",
- "ssp_map = sspspace.SSP(np.sum(bound_objects, axis=0))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "---\n",
- "\n",
- "# Section 1: Sample Efficient Learning\n",
- "\n",
- "In this section, we will take a look at how imposing an inductive bias on our feature space can result in more sample-efficient learning. "
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Video 1: Function Learning and Inductive Bias\n",
- "\n",
- "from ipywidgets import widgets\n",
- "from IPython.display import YouTubeVideo\n",
- "from IPython.display import IFrame\n",
- "from IPython.display import display\n",
- "\n",
- "class PlayVideo(IFrame):\n",
- " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
- " self.id = id\n",
- " if source == 'Bilibili':\n",
- " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
- " elif source == 'Osf':\n",
- " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
- " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
- "\n",
- "def display_videos(video_ids, W=400, H=300, fs=1):\n",
- " tab_contents = []\n",
- " for i, video_id in enumerate(video_ids):\n",
- " out = widgets.Output()\n",
- " with out:\n",
- " if video_ids[i][0] == 'Youtube':\n",
- " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
- " height=H, fs=fs, rel=0)\n",
- " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
- " else:\n",
- " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
- " height=H, fs=fs, autoplay=False)\n",
- " if video_ids[i][0] == 'Bilibili':\n",
- " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
- " elif video_ids[i][0] == 'Osf':\n",
- " print(f'Video available at https://osf.io/{video.id}')\n",
- " display(video)\n",
- " tab_contents.append(out)\n",
- " return tab_contents\n",
- "\n",
- "video_ids = [('Youtube', 'KDKmDjMxU7Q'), ('Bilibili', 'BV1GM4m1S7kT')]\n",
- "tab_contents = display_videos(video_ids, W=854, H=480)\n",
- "tabs = widgets.Tab()\n",
- "tabs.children = tab_contents\n",
- "for i in range(len(tab_contents)):\n",
- " tabs.set_title(i, video_ids[i][0])\n",
- "display(tabs)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_function_learning_and_inductive_bias\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "## Coding Exercise 1: Additive Function\n",
- "\n",
- "\n",
- "We will start with an additive function, the Rastrigin function, defined \n",
- "\n",
- "\\begin{align*}\n",
- "f(\\mathbf{x}) = 10d + \\sum_{i=1}^{d} (x_{i}^{2} - 10 \\cos(2 \\pi x_{i}))\n",
- "\\end{align*}\n",
- "\n",
- "where $d$ is the dimensionality of the input vector. In the cell below, complete missing parts of the function which computes values of the Rastrigin function given the input array."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete the Rastrigin function.\")\n",
- "###################################################################\n",
- "\n",
- "def rastrigin(x):\n",
- " \"\"\"Compute Rastrigin function for given array of d-dimenstional vectors.\n",
- "\n",
- " Inputs:\n",
- " - x (np.ndarray of shape (n, d)): n d-dimensional vectors.\n",
- "\n",
- " Outputs:\n",
- " - y (np.ndarray of shape (n, 1)): Rastrigin function value for each of the vectors.\n",
- " \"\"\"\n",
- " return 10 * x.shape[1] + np.sum(... - 10 * np.cos(2*np.pi*...), axis=1)\n",
- "\n",
- "# this code creates 10000 2-dimensional vectors which are going to be served as input to the function (thus, output is of shape (10000, 1))\n",
- "x0_rastrigin = np.linspace(-5.12, 5.12, 100)\n",
- "X_rastrigin, Y_rastrigin = np.meshgrid(x0_rastrigin,x0_rastrigin)\n",
- "xs_rastrigin = np.vstack((X_rastrigin.flatten(), Y_rastrigin.flatten())).T\n",
- "\n",
- "ys_rastrigin = rastrigin(xs_rastrigin)\n",
- "\n",
- "plot_3d_function([X_rastrigin],[Y_rastrigin], [ys_rastrigin.reshape(X_rastrigin.shape)], ['Rastrigin Function'])"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "execution": {}
- },
- "source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial3_Solution_bd7761a4.py)\n",
- "\n",
- "*Example output:*\n",
- "\n",
- "
\n",
- "\n"
+ "plot_choice([mlp_sims], [\"RED\"], [\"PRIME\"], action_names)"
]
},
{
@@ -1361,7 +787,7 @@
},
"outputs": [],
"source": [
- "# @title Video 4: Wason Card Task Outro\n",
+ "# @title Video 2: Wason Card Task Outro\n",
"\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
@@ -1426,11 +852,11 @@
},
"source": [
"---\n",
- "# Summary\n",
+ "# The Big Picture\n",
"\n",
- "*Estimated timing of tutorial: 45 minutes*\n",
+ "What we saw in this tutorial is the power of generalization at work, that the two top responses were indeed GREEN and NOT PRIME, as Michael outlined in the Outro video. The theme of generalization is the cornerstone of this course and one of the most fundamental aspects we want to convey to you in your NeuroAI journey with us. This tutorial highlights yet another way in which this can be achieved, through the special language of VSA. The MLP does not have access to the structural components and fails to generalize on this task. This is one of the key benefits of the VSA method, where the connection to learning underlying structures allows for generalization to occur. \n",
"\n",
- "In this tutorial, we observed three scenarios where we used the basic operations to solve different analogies and engage in structured learning. The next final tutorial will show us how to use structure to impose inductive biases and how to use continuous representations to represent mixtures of discrete and continuous objects."
+ "We have a bonus tutorial today (Tutorial 4) that covers some other cases connected to analogies, which will help to clarify and demonstrate the power of VSAs even more. We really encourage you to check out that material and then maybe revisit this tutorial if you had any trouble following along. "
]
}
],
@@ -1462,7 +888,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.9.19"
+ "version": "3.9.22"
}
},
"nbformat": 4,
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial3.ipynb b/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial3.ipynb
index 21d44b84a..28d1917db 100644
--- a/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial3.ipynb
+++ b/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial3.ipynb
@@ -17,7 +17,7 @@
"execution": {}
},
"source": [
- "# Tutorial 3: Representations in continuous space\n",
+ "# Tutorial 3: Question Answering with Memory\n",
"\n",
"**Week 2, Day 2: Neuro-Symbolic Methods**\n",
"\n",
@@ -25,9 +25,9 @@
"\n",
"__Content creators:__ P. Michael Furlong, Chris Eliasmith\n",
"\n",
- "__Content reviewers:__ Hlib Solodzhuk, Patrick Mineault, Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi\n",
+ "__Content reviewers:__ Konstantine Tsafatinos, Xaq Pitkow, Alex Murphy\n",
"\n",
- "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk"
+ "__Production editors:__ Konstantine Tsafatinos, Xaq Pitkow, Alex Murphy"
]
},
{
@@ -37,13 +37,11 @@
},
"source": [
"___\n",
- "\n",
- "\n",
"# Tutorial Objectives\n",
"\n",
- "*Estimated timing of tutorial: 40 minutes*\n",
+ "This model shows a form of question answering with memory. You will bind two features (color and shape) by circular convolution and store them in a memory population. Then you will provide a cue to the model at a later time to determine either one of the features by deconvolution. This model exhibits better cognitive ability since the answers to the questions are provided at a later time and not at the same time as the questions themselves. These operations use the primitives we introduced in Tutorial 1. Please make sure you have worked through previous tutorials so you can understand how operations such as circular convolution can implement binding of concepts.\n",
"\n",
- "In this tutorial, you will observe how the VSA methods can be applied in structures and environments to allow for efficient generalization."
+ "**Note:** While we present a simplified interface using the Semantc Pointer Architecture, all the computations underlying the model you build are implemented using spiking neurons!"
]
},
{
@@ -59,7 +57,7 @@
"# @markdown These are the slides for the videos in all tutorials today\n",
"\n",
"from IPython.display import IFrame\n",
- "link_id = \"2szmk\"\n",
+ "link_id = \"jybuw\"\n",
"\n",
"print(f\"If you want to download the slides: 'https://osf.io/download/{link_id}'\")\n",
"\n",
@@ -73,8 +71,11 @@
},
"source": [
"---\n",
- "# Setup\n",
- "\n"
+ "# Setup (Colab Users: Please Read)\n",
+ "\n",
+ "Note that because this tutorial relies on some special Python packages, these packages have requirements for specific versions of common scientific libraries, such as `numpy`. If you're in Google Colab, then as of May 2025, this comes with a later version (2.0.2) pre-installed. We require an older version (we'll be installing `1.24.4`). This causes Colab to force a session restart and then re-running of the installation cells for the new version to take effect. When you run the cell below, you will be prompted to restart the session. This is *entirely expected* and you haven't done anything wrong. Simply click 'Restart' and then run the cells as normal. \n",
+ "\n",
+ "An additional error might sometimes arise where an exception is raised connected to a missing element of NumPy. If this occurs, please restart the session and re-run the cells as normal and this error will go away. Updated versions of the affected libraries are expected out soon, but sadly not in time for the preparation of this material. We thank you for your understanding."
]
},
{
@@ -86,9 +87,23 @@
},
"outputs": [],
"source": [
- "# @title Install and import feedback gadget\n",
+ "# @title Install dependencies\n",
"\n",
- "!pip install --quiet jupyter numpy matplotlib ipywidgets scikit-learn tqdm vibecheck\n",
+ "!pip install numpy==1.24.4 --quiet\n",
+ "!pip install nengo nengo-spa nengo-gui --quiet\n",
+ "!pip install matplotlib vibecheck --quiet"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Install and import feedback gadget\n",
"\n",
"from vibecheck import DatatopsContentReviewContainer\n",
"def content_review(notebook_section: str):\n",
@@ -106,30 +121,6 @@
"feedback_prefix = \"W2D2_T3\""
]
},
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Notice that exactly the `neuromatch` branch of `sspspace` should be installed! Otherwise, some of the functionality (like `optimize` parameter in the `DiscreteSPSpace` initialization) won't work."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Install dependencies\n",
- "\n",
- "# Install sspspace\n",
- "!pip install git+https://github.com/neuromatch/sspspace@neuromatch --quiet"
- ]
- },
{
"cell_type": "code",
"execution_count": null,
@@ -141,189 +132,16 @@
"source": [
"# @title Imports\n",
"\n",
- "#working with data\n",
- "import numpy as np\n",
- "\n",
- "#plotting\n",
"import matplotlib.pyplot as plt\n",
+ "import numpy as np\n",
"import logging\n",
"\n",
- "#interactive display\n",
- "import ipywidgets as widgets\n",
- "\n",
- "#modeling\n",
- "import sspspace\n",
- "from sklearn.linear_model import LinearRegression\n",
- "from sklearn.model_selection import train_test_split\n",
- "\n",
- "from tqdm.notebook import tqdm as tqdm"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Figure settings\n",
- "\n",
- "logging.getLogger('matplotlib.font_manager').disabled = True\n",
- "\n",
"%matplotlib inline\n",
- "%config InlineBackend.figure_format = 'retina' # perfrom high definition rendering for images and plots\n",
- "plt.style.use(\"https://raw.githubusercontent.com/NeuromatchAcademy/course-content/main/nma.mplstyle\")"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Plotting functions\n",
- "\n",
- "def plot_3d_function(X, Y, zs, titles):\n",
- " \"\"\"Plot 3D function.\n",
- "\n",
- " Inputs:\n",
- " - X (list): list of np.ndarray of x-values.\n",
- " - Y (list): list of np.ndarray of y-values.\n",
- " - zs (list): list of np.ndarray of z-values.\n",
- " - titles (list): list of titles of the plot.\n",
- " \"\"\"\n",
- " with plt.xkcd():\n",
- " fig = plt.figure(figsize=(8, 8))\n",
- " for index, (x, y, z) in enumerate(zip(X, Y, zs)):\n",
- " fig.add_subplot(1, len(X), index + 1, projection='3d')\n",
- " plt.gca().plot_surface(x,y,z.reshape(x.shape),cmap='plasma', antialiased=False, linewidth=0)\n",
- " plt.xlabel(r'$x_{1}$')\n",
- " plt.ylabel(r'$x_{2}$')\n",
- " plt.gca().set_zlabel(r'$f(\\mathbf{x})$')\n",
- " plt.title(titles[index])\n",
- " plt.show()\n",
- "\n",
- "def plot_performance(bound_performance, bundle_performance, training_samples, title):\n",
- " \"\"\"Plot RMSE values for two different representations of the input data.\n",
- "\n",
- " Inputs:\n",
- " - bound_performance (list): list of RMSE for bound representation.\n",
- " - bundle_performance (list): list of RMSE for bundle representation.\n",
- " - training_samples (list): x-axis.\n",
- " - title (str): title of the plot.\n",
- " \"\"\"\n",
- " with plt.xkcd():\n",
- " plt.plot(training_samples, bound_performance, label='Bound Representation')\n",
- " plt.plot(training_samples, bundle_performance, label='Bundling Representation', ls='--')\n",
- " plt.legend()\n",
- " plt.title(title)\n",
- " plt.ylabel('RMSE (a.u.)')\n",
- " plt.xlabel('# Training samples')\n",
- "\n",
- "def plot_2d_similarity(sims, obj_names, size, title_argmax = False):\n",
- " \"\"\"\n",
- " Plot 2D similarity between query points (grid) and the ones associated with the objects.\n",
- "\n",
- " Inputs:\n",
- " - sims (list): list of similarity values for each of the objects.\n",
- " - obj_names (list): list of object names.\n",
- " - size (tuple): to reshape the similarities.\n",
- " - title_argmax (bool, default = False): looks for the point coordinates as arg max from all similarity value.\n",
- " \"\"\"\n",
- " ticks = [0, 24, 49, 74, 99]\n",
- " ticklabels = [-5, -2, 0, 2, 5]\n",
- " with plt.xkcd():\n",
- " for obj_idx, obj in enumerate(obj_names):\n",
- " plt.subplot(1, len(obj_names), 1 + obj_idx)\n",
- " plt.imshow(np.array(sims[obj_idx].reshape(size)), origin='lower', vmin=-1, vmax=1)\n",
- " plt.gca().set_xticks(ticks)\n",
- " plt.gca().set_xticklabels(ticklabels)\n",
- " if obj_idx == 0:\n",
- " plt.gca().set_yticks(ticks)\n",
- " plt.gca().set_yticklabels(ticklabels)\n",
- " else:\n",
- " plt.gca().set_yticks([])\n",
- " if not title_argmax:\n",
- " plt.title(f'{obj}, {positions[obj_idx]}')\n",
- " else:\n",
- " plt.title(f'{obj}, {query_xs[sims[obj_idx].argmax()]}')\n",
- "\n",
- "def plot_unbinding_objects_map(sims, positions, query_xs, size):\n",
- " \"\"\"\n",
- " Plot 2D similarity between query points (grid) and the unbinded from the objects map.\n",
- "\n",
- " Inputs:\n",
- " - sims (np.ndarray): similarity values for each of the query points with the map.\n",
- " - positions (np.ndarray): positions of the objects.\n",
- " - query_xs (np.ndarray): grid points.\n",
- " - size (tuple): to reshape the similarities.\n",
- "\n",
- " \"\"\"\n",
- " ticks = [0,24,49,74,99]\n",
- " ticklabels = [-5,-2,0,2,5]\n",
- " with plt.xkcd():\n",
- " plt.imshow(sims.reshape(size), origin='lower')\n",
- "\n",
- " for idx, marker in enumerate(['o','s','^']):\n",
- " plt.scatter(*get_coordinate(positions[idx,:], query_xs, size), marker=marker,s=100)\n",
- "\n",
- " plt.gca().set_xticks(ticks)\n",
- " plt.gca().set_xticklabels(ticklabels)\n",
- " plt.gca().set_yticks(ticks)\n",
- " plt.gca().set_yticklabels(ticklabels)\n",
- " plt.title(f'All Object Locations')\n",
- " plt.show()\n",
- "\n",
- "def plot_unbinding_positions_map(sims, positions, obj_names):\n",
- " \"\"\"\n",
- " Plot 2D similarity between query points (grid) and the unbinded from the positions map.\n",
- "\n",
- " Inputs:\n",
- " - sims (np.ndarray): similarity values for each of the query points with the map.\n",
- " - positions (np.ndarray): test positions to query.\n",
- " - obj_names (list): names of the objects for labels.\n",
- " - size (tuple): to reshape the similarities.\n",
- " \"\"\"\n",
- " with plt.xkcd():\n",
- " plt.figure(figsize=(8, 4))\n",
- " for pos_idx, pos in enumerate(positions):\n",
- " plt.subplot(1,len(test_positions), 1+pos_idx)\n",
- " plt.bar([1,2,3], sims[pos_idx])\n",
- " plt.ylim([-0.3, 1.05])\n",
- " plt.gca().set_xticks([1,2,3])\n",
- " plt.gca().set_xticklabels(obj_names, rotation=90)\n",
- " if pos_idx != 0:\n",
- " plt.gca().set_yticks([])\n",
- " plt.title(f'Symbols at\\n{pos}')\n",
- " plt.show()"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Set random seed\n",
- "\n",
- "import random\n",
- "import numpy as np\n",
"\n",
- "def set_seed(seed=None):\n",
- " if seed is None:\n",
- " seed = np.random.choice(2 ** 32)\n",
- " random.seed(seed)\n",
- " np.random.seed(seed)\n",
+ "import nengo\n",
+ "import nengo_spa as spa\n",
"\n",
- "set_seed(seed = 42)"
+ "seed = 0"
]
},
{
@@ -335,566 +153,13 @@
},
"outputs": [],
"source": [
- "# @title Helper functions\n",
- "\n",
- "def get_model(xs, ys, train_size):\n",
- " \"\"\"Fit linear regression to the given data.\n",
- "\n",
- " Inputs:\n",
- " - xs (np.ndarray): input data.\n",
- " - ys (np.ndarray): output data.\n",
- " - train_size (float): fraction of data to use for train.\n",
- " \"\"\"\n",
- " X_train, _, y_train, _ = train_test_split(xs, ys, random_state=1, train_size=train_size)\n",
- " return LinearRegression().fit(X_train, y_train)\n",
- "\n",
- "def get_coordinate(x, positions, target_shape):\n",
- " \"\"\"Return the closest column and row coordinates for the given position.\n",
- "\n",
- " Inputs:\n",
- " - x (np.ndarray): query position.\n",
- " - positions (np.ndarray): all positions.\n",
- " - target_shape (tuple): shape of the grid.\n",
- "\n",
- " Outputs:\n",
- " - coordinates (tuple): column and row positions.\n",
- " \"\"\"\n",
- " idx = np.argmin(np.linalg.norm(x - positions, axis=1))\n",
- " c = idx % target_shape[1]\n",
- " r = idx // target_shape[1]\n",
- " return (c,r)\n",
- "\n",
- "def rastrigin_solution(x):\n",
- " \"\"\"Compute Rastrigin function for given array of d-dimenstional vectors.\n",
- "\n",
- " Inputs:\n",
- " - x (np.ndarray of shape (n, d)): n d-dimensional vectors.\n",
- "\n",
- " Outputs:\n",
- " - y (np.ndarray of shape (n, 1)): Rastrigin function value for each of the vectors.\n",
- " \"\"\"\n",
- " return 10 * x.shape[1] + np.sum(x**2 - 10 * np.cos(2*np.pi*x), axis=1)\n",
- "\n",
- "def non_separable_solution(x):\n",
- " \"\"\"Compute non-separable function for given array of 2-dimenstional vectors.\n",
- "\n",
- " Inputs:\n",
- " - x (np.ndarray of shape (n, 2)): n 2-dimensional vectors.\n",
- "\n",
- " Outputs:\n",
- " - y (np.ndarray of shape (n, 1)): non-separable function value for each of the vectors.\n",
- " \"\"\"\n",
- " return np.sin(np.multiply(x[:, 0], x[:, 1]))\n",
- "\n",
- "x0_rastrigin = np.linspace(-5.12, 5.12, 100)\n",
- "X_rastrigin, Y_rastrigin = np.meshgrid(x0_rastrigin,x0_rastrigin)\n",
- "xs_rastrigin = np.vstack((X_rastrigin.flatten(), Y_rastrigin.flatten())).T\n",
- "ys_rastrigin = rastrigin_solution(xs_rastrigin)\n",
- "\n",
- "x0_non_separable = np.linspace(-4, 4, 100)\n",
- "X_non_separable, Y_non_separable = np.meshgrid(x0_non_separable,x0_non_separable)\n",
- "xs_non_separable = np.vstack((X_non_separable.flatten(), Y_non_separable.flatten())).T\n",
- "ys_non_separable = non_separable_solution(xs_non_separable)\n",
- "\n",
- "set_seed(42)\n",
- "\n",
- "obj_names = ['circle','square','triangle']\n",
- "discrete_space = sspspace.DiscreteSPSpace(obj_names, ssp_dim=1024)\n",
- "\n",
- "objs = {n:discrete_space.encode(n) for n in obj_names}\n",
- "\n",
- "ssp_space = sspspace.RandomSSPSpace(domain_dim=2, ssp_dim=1024)\n",
- "positions = np.array([[0, -2],\n",
- " [-2, 3],\n",
- " [3, 2]\n",
- " ])\n",
- "ssps = {n:ssp_space.encode(x) for n, x in zip(obj_names, positions)}\n",
- "\n",
- "dim0 = np.linspace(-5, 5, 101)\n",
- "dim1 = np.linspace(-5, 5, 101)\n",
- "X,Y = np.meshgrid(dim0, dim1)\n",
- "\n",
- "query_xs = np.vstack((X.flatten(), Y.flatten())).T\n",
- "query_ssps = ssp_space.encode(query_xs)\n",
- "\n",
- "bound_objects = [objs[n] * ssps[n] for n in obj_names]\n",
- "ssp_map = sspspace.SSP(np.sum(bound_objects, axis=0))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "---\n",
- "\n",
- "# Section 1: Sample Efficient Learning\n",
- "\n",
- "In this section, we will take a look at how imposing an inductive bias on our feature space can result in more sample-efficient learning. "
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Video 1: Function Learning and Inductive Bias\n",
- "\n",
- "from ipywidgets import widgets\n",
- "from IPython.display import YouTubeVideo\n",
- "from IPython.display import IFrame\n",
- "from IPython.display import display\n",
- "\n",
- "class PlayVideo(IFrame):\n",
- " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
- " self.id = id\n",
- " if source == 'Bilibili':\n",
- " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
- " elif source == 'Osf':\n",
- " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
- " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
- "\n",
- "def display_videos(video_ids, W=400, H=300, fs=1):\n",
- " tab_contents = []\n",
- " for i, video_id in enumerate(video_ids):\n",
- " out = widgets.Output()\n",
- " with out:\n",
- " if video_ids[i][0] == 'Youtube':\n",
- " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
- " height=H, fs=fs, rel=0)\n",
- " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
- " else:\n",
- " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
- " height=H, fs=fs, autoplay=False)\n",
- " if video_ids[i][0] == 'Bilibili':\n",
- " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
- " elif video_ids[i][0] == 'Osf':\n",
- " print(f'Video available at https://osf.io/{video.id}')\n",
- " display(video)\n",
- " tab_contents.append(out)\n",
- " return tab_contents\n",
- "\n",
- "video_ids = [('Youtube', 'KDKmDjMxU7Q'), ('Bilibili', 'BV1GM4m1S7kT')]\n",
- "tab_contents = display_videos(video_ids, W=854, H=480)\n",
- "tabs = widgets.Tab()\n",
- "tabs.children = tab_contents\n",
- "for i in range(len(tab_contents)):\n",
- " tabs.set_title(i, video_ids[i][0])\n",
- "display(tabs)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_function_learning_and_inductive_bias\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "## Coding Exercise 1: Additive Function\n",
- "\n",
- "\n",
- "We will start with an additive function, the Rastrigin function, defined \n",
- "\n",
- "\\begin{align*}\n",
- "f(\\mathbf{x}) = 10d + \\sum_{i=1}^{d} (x_{i}^{2} - 10 \\cos(2 \\pi x_{i}))\n",
- "\\end{align*}\n",
- "\n",
- "where $d$ is the dimensionality of the input vector. In the cell below, complete missing parts of the function which computes values of the Rastrigin function given the input array."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete the Rastrigin function.\")\n",
- "###################################################################\n",
- "\n",
- "def rastrigin(x):\n",
- " \"\"\"Compute Rastrigin function for given array of d-dimenstional vectors.\n",
- "\n",
- " Inputs:\n",
- " - x (np.ndarray of shape (n, d)): n d-dimensional vectors.\n",
- "\n",
- " Outputs:\n",
- " - y (np.ndarray of shape (n, 1)): Rastrigin function value for each of the vectors.\n",
- " \"\"\"\n",
- " return 10 * x.shape[1] + np.sum(... - 10 * np.cos(2*np.pi*...), axis=1)\n",
- "\n",
- "# this code creates 10000 2-dimensional vectors which are going to be served as input to the function (thus, output is of shape (10000, 1))\n",
- "x0_rastrigin = np.linspace(-5.12, 5.12, 100)\n",
- "X_rastrigin, Y_rastrigin = np.meshgrid(x0_rastrigin,x0_rastrigin)\n",
- "xs_rastrigin = np.vstack((X_rastrigin.flatten(), Y_rastrigin.flatten())).T\n",
- "\n",
- "ys_rastrigin = rastrigin(xs_rastrigin)\n",
- "\n",
- "plot_3d_function([X_rastrigin],[Y_rastrigin], [ys_rastrigin.reshape(X_rastrigin.shape)], ['Rastrigin Function'])"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "execution": {}
- },
- "source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial3_Solution_bd7761a4.py)\n",
- "\n",
- "*Example output:*\n",
- "\n",
- " \n",
- "\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Now, we are going to see which of the inductive biases (suggested mechanism underlying input data) will be more efficient in training the linear regression to get values of the Rastrigin function. We will consider two representations:\n",
- "\n",
- "* **Bound**: We encode 2D input vectors `xs` as bound vectors\n",
- "* **Bundled**: We encode 1D input vectors separately and use bundling and then bundle them together"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "set_seed(42)\n",
- "\n",
- "ssp_space = sspspace.RandomSSPSpace(domain_dim=2, ssp_dim=1024)\n",
- "bound_phis = ssp_space.encode(xs_rastrigin)\n",
- "\n",
- "ssp_space0 = sspspace.RandomSSPSpace(domain_dim=1, ssp_dim=1024)\n",
- "ssp_space1 = sspspace.RandomSSPSpace(domain_dim=1, ssp_dim=1024)\n",
- "\n",
- "#remember that input to `encode` should be 2-dimensional, thus we need to create extra dimension by applying [:,None]\n",
- "bundle_phis = ssp_space0.encode(xs_rastrigin[:, 0][:, None]) + ssp_space1.encode(xs_rastrigin[:, 1][:, None])"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Now, let us define modeling attributes: we will have a few different `train_sizes`, and we will fit a linear regression for each of them in a loop. Then, for each of the models, we will evaluate its fit based on RMSE loss on the test set."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "def loss(y_true, y_pred):\n",
- " \"\"\"Calculate RMSE loss between true and predicted values (note, that loss is not normalized by the shape).\n",
- "\n",
- " Inputs:\n",
- " - y_true (np.ndarray): true values.\n",
- " - y_pred (np.ndarray): predicted values.\n",
- "\n",
- " Outputs:\n",
- " - loss (float): loss value.\n",
- " \"\"\"\n",
- " return np.sqrt(np.mean((y_true - y_pred) ** 2))\n",
- "\n",
- "def test_performance(xs, ys, train_sizes):\n",
- " \"\"\"Fit linear regression to the provided data and evaluate the performance with RMSE loss for different test sizes.\n",
- "\n",
- " Inputs:\n",
- " - xs (np.ndarray): input data.\n",
- " - ys (np.ndarray): output data.\n",
- " - train_size (list): list of the train sizes.\n",
- " \"\"\"\n",
- " performance = []\n",
- "\n",
- " models = []\n",
- " for train_size in tqdm(train_sizes):\n",
- " X_train, X_test, y_train, y_test = train_test_split(xs, ys, random_state=1, train_size=train_size)\n",
- " regr = LinearRegression().fit(X_train, y_train)\n",
- " performance.append(np.copy(loss(y_test, regr.predict(X_test))))\n",
- " models.append(regr)\n",
- " return performance, models"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Now, we are ready to train the models on two different inductive biases of the input data."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "train_sizes = np.linspace(0.25, 0.9, 5)\n",
- "bound_performance, bound_models = test_performance(bound_phis, ys_rastrigin, train_sizes)\n",
- "bundle_performance, bundle_models = test_performance(bundle_phis, ys_rastrigin, train_sizes)\n",
- "plot_performance(bound_performance, bundle_performance, train_sizes * bound_phis.shape[0], \"Rastrigin function - RMSE\")\n",
- "plt.ylim((-1, 20))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "What a drastic difference! Let us evaluate visually the performance when training on 3,000 train points."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "bound_model = bound_models[0]\n",
- "bundled_model = bundle_models[0]\n",
- "\n",
- "ys_hat_rastrigin_bound = bound_model.predict(bound_phis)\n",
- "ys_hat_rastrigin_bundled = bundled_model.predict(bundle_phis)\n",
- "\n",
- "plot_3d_function([X_rastrigin, X_rastrigin, X_rastrigin], [Y_rastrigin, Y_rastrigin, Y_rastrigin], [ys_rastrigin.reshape(X_rastrigin.shape), ys_hat_rastrigin_bound.reshape(X_rastrigin.shape), ys_hat_rastrigin_bundled.reshape(X_rastrigin.shape)], ['Rastrigin Function - True', 'Bound', 'Bundled'])"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "### Coding Exercise 1 Discussion\n",
- "\n",
- "1. Why do you think the bundled representation is superior for the Rastrigin function?"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "execution": {}
- },
- "source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial3_Solution_8c79265f.py)\n",
- "\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_additive_function\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "## Coding Exercise 2: Non-separable Function\n",
- "\n",
- "Now, let's consider a non-separable function: a function $f(x_1, x_2)$ that cannot be described as the sum of two one-dimensional functions $g(x_1)$ and $h_1$. We will examine this function over the domain $[-4,4]^{2}$:\n",
- "\n",
- "$$f(\\mathbf{x}) = \\sin(x_{1}x_{2})$$\n",
- "\n",
- "Fill in the missing parts of the code to get the correct calculation of the defined function."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete the non-separable function.\")\n",
- "###################################################################\n",
- "\n",
- "def non_separable(x):\n",
- " \"\"\"Compute non-separable function for given array of 2-dimenstional vectors.\n",
- "\n",
- " Inputs:\n",
- " - x (np.ndarray of shape (n, 2)): n 2-dimensional vectors.\n",
- "\n",
- " Outputs:\n",
- " - y (np.ndarray of shape (n, 1)): non-separable function value for each of the vectors.\n",
- " \"\"\"\n",
- " return np.sin(np.multiply(x[:, ...], x[:, ...]))\n",
- "\n",
- "x0_non_separable = np.linspace(-4, 4, 100)\n",
- "X_non_separable, Y_non_separable = np.meshgrid(x0_non_separable,x0_non_separable)\n",
- "xs_non_separable = np.vstack((X_non_separable.flatten(), Y_non_separable.flatten())).T\n",
- "\n",
- "ys_non_separable = non_separable(xs_non_separable)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "execution": {}
- },
- "source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial3_Solution_730a75ed.py)\n",
- "\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "plot_3d_function([X_non_separable],[Y_non_separable], [ys_non_separable.reshape(X_non_separable.shape)], ['Nonseparable Function, $f(\\mathbf{x}) = \\sin(x_{1}x_{2})$'])"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "### Coding Exercise 2 Discussion\n",
- "\n",
- "1. Can you guess by the nature of the function which of the representations will be more efficient?"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "execution": {}
- },
- "source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial3_Solution_2b4c5a99.py)\n",
- "\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "We will reuse previously defined spaces for encoding bound and bundled representations."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "bound_phis = ssp_space.encode(xs_non_separable)\n",
- "bundle_phis = ssp_space0.encode(xs_non_separable[:,0][:,None]) + ssp_space1.encode(xs_non_separable[:,1][:,None])\n",
- "\n",
- "train_sizes = np.linspace(0.25, 0.9, 5)\n",
- "bound_performance, bound_models = test_performance(bound_phis, ys_non_separable, train_sizes)\n",
- "bundle_performance, bundle_models = test_performance(bundle_phis, ys_non_separable, train_sizes)\n",
- "plot_performance(bound_performance, bundle_performance, train_sizes * bound_phis.shape[0], title = \"Non-separable function - RMSE\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Bundling representation can't achieve the same quality even when the number of samples is increased. This is because the function is non-separable, and the bundling representation can't capture the interaction between the two dimensions."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "bound_model = bound_models[0]\n",
- "bundle_model = bundle_models[0]\n",
- "\n",
- "ys_hat_bound = bound_model.predict(bound_phis)\n",
- "ys_hat_bundle = bundle_model.predict(bundle_phis)\n",
+ "# @title Figure settings\n",
"\n",
- "plot_3d_function([X_non_separable, X_non_separable, X_non_separable], [Y_non_separable, Y_non_separable, Y_non_separable], [ys_non_separable.reshape(X_non_separable.shape), ys_hat_bound.reshape(X_non_separable.shape), ys_hat_bundle.reshape(X_non_separable.shape)], ['Non-separable Function - True', 'Bound', 'Bundled'])"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "So, as we can see, when we pick the right inductive bias, we can do a better job."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_non_separable_function\")"
+ "logging.getLogger('matplotlib.font_manager').disabled = True\n",
+ "\n",
+ "%matplotlib inline\n",
+ "%config InlineBackend.figure_format = 'retina' # perfrom high definition rendering for images and plots\n",
+ "plt.style.use(\"https://raw.githubusercontent.com/NeuromatchAcademy/course-content/main/nma.mplstyle\")"
]
},
{
@@ -903,13 +168,9 @@
"execution": {}
},
"source": [
- "---\n",
- "\n",
- "# Section 2: Representing Continuous Values\n",
- "\n",
- "Estimated timing to here from start of tutorial: 20 minutes\n",
+ "# Intro\n",
"\n",
- "In this section we will use a technique called Fractional Binding to represent continuous values to construct a map of objects distributed over a 2D space. "
+ "Michael will give an introductory overview to the notion of performing question answering in the VSA setup we have been working with today.\n"
]
},
{
@@ -921,7 +182,8 @@
},
"outputs": [],
"source": [
- "# @title Video 2: Mapping Intro\n",
+ "# @title Video 1: Introduction\n",
+ "\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
@@ -956,7 +218,7 @@
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
- "video_ids = [('Youtube', 's7MOusrbKXU'), ('Bilibili', 'BV1pi421i7iN')]\n",
+ "video_ids = [('Youtube', 'YX-CM-vuxAc'), ('Bilibili', 'BV1VV7jz8EXa')]\n",
"tab_contents = display_videos(video_ids, W=854, H=480)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
@@ -965,71 +227,69 @@
"display(tabs)"
]
},
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_mapping_intro\")"
- ]
- },
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
- "## Coding Exercise 3: Mixing Discrete Objects With Continuous Space\n",
+ "## Nengo & Question Answering\n",
"\n",
- "We will store three objects in a vector representing a map. First, we will create 3 objects (a circle, square, and triangle), as we did before."
+ "Nengo is a tool used to implement spiking and dynamic neural network systems. We will shortly introduce the basics of Nengo so you have a clear idea of how it works, what it can do and how we will be using it throughout this tutorial (and other tutorials) today. We're then going to see how Nengo can be used on the application of Question Answering and then hand over to you to complete some interesting coding exercises to help you develop a feel for how to work with a basic example. These tools in your NeuroAI toolkit should then be a great start for you to continue learning about these methods and applying them to your your scientific questions and interests."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
+ "cellView": "form",
"execution": {}
},
"outputs": [],
"source": [
- "set_seed(42)\n",
+ "# @title Video 2: Introduction to Nengo\n",
"\n",
- "obj_names = ['circle','square','triangle']\n",
- "discrete_space = sspspace.DiscreteSPSpace(obj_names, ssp_dim=1024)\n",
+ "from ipywidgets import widgets\n",
+ "from IPython.display import YouTubeVideo\n",
+ "from IPython.display import IFrame\n",
+ "from IPython.display import display\n",
"\n",
- "objs = {n:discrete_space.encode(n) for n in obj_names}"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Next, we are going to create three locations where the objects will reside, and an encoder will transform those coordinates into an SSP representation."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "set_seed(42)\n",
- "\n",
- "ssp_space = sspspace.RandomSSPSpace(domain_dim=2, ssp_dim=1024)\n",
- "positions = np.array([[0, -2],\n",
- " [-2, 3],\n",
- " [3, 2]\n",
- " ])\n",
- "ssps = {n:ssp_space.encode(x) for n, x in zip(obj_names, positions)}"
+ "class PlayVideo(IFrame):\n",
+ " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
+ " self.id = id\n",
+ " if source == 'Bilibili':\n",
+ " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
+ " elif source == 'Osf':\n",
+ " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
+ " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
+ "\n",
+ "def display_videos(video_ids, W=400, H=300, fs=1):\n",
+ " tab_contents = []\n",
+ " for i, video_id in enumerate(video_ids):\n",
+ " out = widgets.Output()\n",
+ " with out:\n",
+ " if video_ids[i][0] == 'Youtube':\n",
+ " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
+ " height=H, fs=fs, rel=0)\n",
+ " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
+ " else:\n",
+ " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
+ " height=H, fs=fs, autoplay=False)\n",
+ " if video_ids[i][0] == 'Bilibili':\n",
+ " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
+ " elif video_ids[i][0] == 'Osf':\n",
+ " print(f'Video available at https://osf.io/{video.id}')\n",
+ " display(video)\n",
+ " tab_contents.append(out)\n",
+ " return tab_contents\n",
+ "\n",
+ "video_ids = [('Youtube', 'FTIu-ariSyE'), ('Bilibili', 'BV1YV7jz8EfS')]\n",
+ "tab_contents = display_videos(video_ids, W=854, H=480)\n",
+ "tabs = widgets.Tab()\n",
+ "tabs.children = tab_contents\n",
+ "for i in range(len(tab_contents)):\n",
+ " tabs.set_title(i, video_ids[i][0])\n",
+ "display(tabs)"
]
},
{
@@ -1038,23 +298,11 @@
"execution": {}
},
"source": [
- "Next, in order to see where things are on the map, we are going to compute the similarity between encoded places and points in the space. Your task is to complete the calculation of similarity values between all grid points with the one associated with the object."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "dim0 = np.linspace(-5, 5, 101)\n",
- "dim1 = np.linspace(-5, 5, 101)\n",
- "X,Y = np.meshgrid(dim0, dim1)\n",
+ "# Section 1: Define the input functions\n",
+ "\n",
+ "The color input will ``RED`` and then ``BLUE`` for 0.25 seconds each before being turned off. In the same way the shape input will be ``CIRCLE`` and then ``SQUARE`` for 0.25 seconds each. Thus, the network will bind alternatingly ``RED`` * ``CIRCLE`` and ``BLUE`` * ``SQUARE`` for 0.5 seconds each.\n",
"\n",
- "query_xs = np.vstack((X.flatten(), Y.flatten())).T\n",
- "query_ssps = ssp_space.encode(query_xs)"
+ "The cue for deconvolving bound semantic pointers will be turned off for 0.5 seconds and then cycles through ``CIRCLE``, ``RED``, ``SQUARE``, and ``BLUE`` within one second."
]
},
{
@@ -1065,42 +313,48 @@
},
"outputs": [],
"source": [
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete similarity calculation.\")\n",
- "###################################################################\n",
+ "def color_input(t):\n",
+ " if t < 0.25:\n",
+ " return \"RED\"\n",
+ " elif t < 0.5:\n",
+ " return \"BLUE\"\n",
+ " else:\n",
+ " return \"0\"\n",
"\n",
- "sims = []\n",
"\n",
- "for obj_idx, obj in enumerate(obj_names):\n",
- " sims.append(... @ ssps[obj].flatten())\n",
+ "def shape_input(t):\n",
+ " if t < 0.25:\n",
+ " return \"CIRCLE\"\n",
+ " elif t < 0.5:\n",
+ " return \"SQUARE\"\n",
+ " else:\n",
+ " return \"0\"\n",
"\n",
- "plt.figure(figsize=(8, 2.4))\n",
- "plot_2d_similarity(sims, obj_names, (dim0.size, dim1.size))"
+ "\n",
+ "def cue_input(t):\n",
+ " if t < 0.5:\n",
+ " return \"0\"\n",
+ " sequence = [\"0\", \"CIRCLE\", \"RED\", \"0\", \"SQUARE\", \"BLUE\"]\n",
+ " idx = int(((t - 0.5) // (1.0 / len(sequence))) % len(sequence))\n",
+ " return sequence[idx]"
]
},
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"execution": {}
},
"source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial3_Solution_cff4accc.py)\n",
+ "# Create the model\n",
"\n",
- "*Example output:*\n",
+ "Below we define a simple network compute the question answering. Note that the state labelled ``conv`` has the following arguments:\n",
+ "```python\n",
+ "conv = spa.State(dimensions, subdimensions=4, feedback=1.0, feedback_synapse=0.4)\n",
+ "```\n",
"\n",
- "
\n",
- "\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Now, we are going to see which of the inductive biases (suggested mechanism underlying input data) will be more efficient in training the linear regression to get values of the Rastrigin function. We will consider two representations:\n",
- "\n",
- "* **Bound**: We encode 2D input vectors `xs` as bound vectors\n",
- "* **Bundled**: We encode 1D input vectors separately and use bundling and then bundle them together"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "set_seed(42)\n",
- "\n",
- "ssp_space = sspspace.RandomSSPSpace(domain_dim=2, ssp_dim=1024)\n",
- "bound_phis = ssp_space.encode(xs_rastrigin)\n",
- "\n",
- "ssp_space0 = sspspace.RandomSSPSpace(domain_dim=1, ssp_dim=1024)\n",
- "ssp_space1 = sspspace.RandomSSPSpace(domain_dim=1, ssp_dim=1024)\n",
- "\n",
- "#remember that input to `encode` should be 2-dimensional, thus we need to create extra dimension by applying [:,None]\n",
- "bundle_phis = ssp_space0.encode(xs_rastrigin[:, 0][:, None]) + ssp_space1.encode(xs_rastrigin[:, 1][:, None])"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Now, let us define modeling attributes: we will have a few different `train_sizes`, and we will fit a linear regression for each of them in a loop. Then, for each of the models, we will evaluate its fit based on RMSE loss on the test set."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "def loss(y_true, y_pred):\n",
- " \"\"\"Calculate RMSE loss between true and predicted values (note, that loss is not normalized by the shape).\n",
- "\n",
- " Inputs:\n",
- " - y_true (np.ndarray): true values.\n",
- " - y_pred (np.ndarray): predicted values.\n",
- "\n",
- " Outputs:\n",
- " - loss (float): loss value.\n",
- " \"\"\"\n",
- " return np.sqrt(np.mean((y_true - y_pred) ** 2))\n",
- "\n",
- "def test_performance(xs, ys, train_sizes):\n",
- " \"\"\"Fit linear regression to the provided data and evaluate the performance with RMSE loss for different test sizes.\n",
- "\n",
- " Inputs:\n",
- " - xs (np.ndarray): input data.\n",
- " - ys (np.ndarray): output data.\n",
- " - train_size (list): list of the train sizes.\n",
- " \"\"\"\n",
- " performance = []\n",
- "\n",
- " models = []\n",
- " for train_size in tqdm(train_sizes):\n",
- " X_train, X_test, y_train, y_test = train_test_split(xs, ys, random_state=1, train_size=train_size)\n",
- " regr = LinearRegression().fit(X_train, y_train)\n",
- " performance.append(np.copy(loss(y_test, regr.predict(X_test))))\n",
- " models.append(regr)\n",
- " return performance, models"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Now, we are ready to train the models on two different inductive biases of the input data."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "train_sizes = np.linspace(0.25, 0.9, 5)\n",
- "bound_performance, bound_models = test_performance(bound_phis, ys_rastrigin, train_sizes)\n",
- "bundle_performance, bundle_models = test_performance(bundle_phis, ys_rastrigin, train_sizes)\n",
- "plot_performance(bound_performance, bundle_performance, train_sizes * bound_phis.shape[0], \"Rastrigin function - RMSE\")\n",
- "plt.ylim((-1, 20))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "What a drastic difference! Let us evaluate visually the performance when training on 3,000 train points."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "bound_model = bound_models[0]\n",
- "bundled_model = bundle_models[0]\n",
- "\n",
- "ys_hat_rastrigin_bound = bound_model.predict(bound_phis)\n",
- "ys_hat_rastrigin_bundled = bundled_model.predict(bundle_phis)\n",
- "\n",
- "plot_3d_function([X_rastrigin, X_rastrigin, X_rastrigin], [Y_rastrigin, Y_rastrigin, Y_rastrigin], [ys_rastrigin.reshape(X_rastrigin.shape), ys_hat_rastrigin_bound.reshape(X_rastrigin.shape), ys_hat_rastrigin_bundled.reshape(X_rastrigin.shape)], ['Rastrigin Function - True', 'Bound', 'Bundled'])"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "### Coding Exercise 1 Discussion\n",
- "\n",
- "1. Why do you think the bundled representation is superior for the Rastrigin function?"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "execution": {}
- },
- "source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial3_Solution_8c79265f.py)\n",
- "\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_additive_function\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "## Coding Exercise 2: Non-separable Function\n",
- "\n",
- "Now, let's consider a non-separable function: a function $f(x_1, x_2)$ that cannot be described as the sum of two one-dimensional functions $g(x_1)$ and $h_1$. We will examine this function over the domain $[-4,4]^{2}$:\n",
- "\n",
- "$$f(\\mathbf{x}) = \\sin(x_{1}x_{2})$$\n",
- "\n",
- "Fill in the missing parts of the code to get the correct calculation of the defined function."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete the non-separable function.\")\n",
- "###################################################################\n",
- "\n",
- "def non_separable(x):\n",
- " \"\"\"Compute non-separable function for given array of 2-dimenstional vectors.\n",
- "\n",
- " Inputs:\n",
- " - x (np.ndarray of shape (n, 2)): n 2-dimensional vectors.\n",
- "\n",
- " Outputs:\n",
- " - y (np.ndarray of shape (n, 1)): non-separable function value for each of the vectors.\n",
- " \"\"\"\n",
- " return np.sin(np.multiply(x[:, ...], x[:, ...]))\n",
- "\n",
- "x0_non_separable = np.linspace(-4, 4, 100)\n",
- "X_non_separable, Y_non_separable = np.meshgrid(x0_non_separable,x0_non_separable)\n",
- "xs_non_separable = np.vstack((X_non_separable.flatten(), Y_non_separable.flatten())).T\n",
- "\n",
- "ys_non_separable = non_separable(xs_non_separable)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "execution": {}
- },
- "source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial3_Solution_730a75ed.py)\n",
- "\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "plot_3d_function([X_non_separable],[Y_non_separable], [ys_non_separable.reshape(X_non_separable.shape)], ['Nonseparable Function, $f(\\mathbf{x}) = \\sin(x_{1}x_{2})$'])"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "### Coding Exercise 2 Discussion\n",
- "\n",
- "1. Can you guess by the nature of the function which of the representations will be more efficient?"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "execution": {}
- },
- "source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial3_Solution_2b4c5a99.py)\n",
- "\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "We will reuse previously defined spaces for encoding bound and bundled representations."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "bound_phis = ssp_space.encode(xs_non_separable)\n",
- "bundle_phis = ssp_space0.encode(xs_non_separable[:,0][:,None]) + ssp_space1.encode(xs_non_separable[:,1][:,None])\n",
- "\n",
- "train_sizes = np.linspace(0.25, 0.9, 5)\n",
- "bound_performance, bound_models = test_performance(bound_phis, ys_non_separable, train_sizes)\n",
- "bundle_performance, bundle_models = test_performance(bundle_phis, ys_non_separable, train_sizes)\n",
- "plot_performance(bound_performance, bundle_performance, train_sizes * bound_phis.shape[0], title = \"Non-separable function - RMSE\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Bundling representation can't achieve the same quality even when the number of samples is increased. This is because the function is non-separable, and the bundling representation can't capture the interaction between the two dimensions."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "bound_model = bound_models[0]\n",
- "bundle_model = bundle_models[0]\n",
- "\n",
- "ys_hat_bound = bound_model.predict(bound_phis)\n",
- "ys_hat_bundle = bundle_model.predict(bundle_phis)\n",
+ "# @title Figure settings\n",
"\n",
- "plot_3d_function([X_non_separable, X_non_separable, X_non_separable], [Y_non_separable, Y_non_separable, Y_non_separable], [ys_non_separable.reshape(X_non_separable.shape), ys_hat_bound.reshape(X_non_separable.shape), ys_hat_bundle.reshape(X_non_separable.shape)], ['Non-separable Function - True', 'Bound', 'Bundled'])"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "So, as we can see, when we pick the right inductive bias, we can do a better job."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_non_separable_function\")"
+ "logging.getLogger('matplotlib.font_manager').disabled = True\n",
+ "\n",
+ "%matplotlib inline\n",
+ "%config InlineBackend.figure_format = 'retina' # perfrom high definition rendering for images and plots\n",
+ "plt.style.use(\"https://raw.githubusercontent.com/NeuromatchAcademy/course-content/main/nma.mplstyle\")"
]
},
{
@@ -903,13 +168,9 @@
"execution": {}
},
"source": [
- "---\n",
- "\n",
- "# Section 2: Representing Continuous Values\n",
- "\n",
- "Estimated timing to here from start of tutorial: 20 minutes\n",
+ "# Intro\n",
"\n",
- "In this section we will use a technique called Fractional Binding to represent continuous values to construct a map of objects distributed over a 2D space. "
+ "Michael will give an introductory overview to the notion of performing question answering in the VSA setup we have been working with today.\n"
]
},
{
@@ -921,7 +182,8 @@
},
"outputs": [],
"source": [
- "# @title Video 2: Mapping Intro\n",
+ "# @title Video 1: Introduction\n",
+ "\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
@@ -956,7 +218,7 @@
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
- "video_ids = [('Youtube', 's7MOusrbKXU'), ('Bilibili', 'BV1pi421i7iN')]\n",
+ "video_ids = [('Youtube', 'YX-CM-vuxAc'), ('Bilibili', 'BV1VV7jz8EXa')]\n",
"tab_contents = display_videos(video_ids, W=854, H=480)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
@@ -965,71 +227,69 @@
"display(tabs)"
]
},
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_mapping_intro\")"
- ]
- },
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
- "## Coding Exercise 3: Mixing Discrete Objects With Continuous Space\n",
+ "## Nengo & Question Answering\n",
"\n",
- "We will store three objects in a vector representing a map. First, we will create 3 objects (a circle, square, and triangle), as we did before."
+ "Nengo is a tool used to implement spiking and dynamic neural network systems. We will shortly introduce the basics of Nengo so you have a clear idea of how it works, what it can do and how we will be using it throughout this tutorial (and other tutorials) today. We're then going to see how Nengo can be used on the application of Question Answering and then hand over to you to complete some interesting coding exercises to help you develop a feel for how to work with a basic example. These tools in your NeuroAI toolkit should then be a great start for you to continue learning about these methods and applying them to your your scientific questions and interests."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
+ "cellView": "form",
"execution": {}
},
"outputs": [],
"source": [
- "set_seed(42)\n",
+ "# @title Video 2: Introduction to Nengo\n",
"\n",
- "obj_names = ['circle','square','triangle']\n",
- "discrete_space = sspspace.DiscreteSPSpace(obj_names, ssp_dim=1024)\n",
+ "from ipywidgets import widgets\n",
+ "from IPython.display import YouTubeVideo\n",
+ "from IPython.display import IFrame\n",
+ "from IPython.display import display\n",
"\n",
- "objs = {n:discrete_space.encode(n) for n in obj_names}"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Next, we are going to create three locations where the objects will reside, and an encoder will transform those coordinates into an SSP representation."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "set_seed(42)\n",
- "\n",
- "ssp_space = sspspace.RandomSSPSpace(domain_dim=2, ssp_dim=1024)\n",
- "positions = np.array([[0, -2],\n",
- " [-2, 3],\n",
- " [3, 2]\n",
- " ])\n",
- "ssps = {n:ssp_space.encode(x) for n, x in zip(obj_names, positions)}"
+ "class PlayVideo(IFrame):\n",
+ " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
+ " self.id = id\n",
+ " if source == 'Bilibili':\n",
+ " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
+ " elif source == 'Osf':\n",
+ " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
+ " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
+ "\n",
+ "def display_videos(video_ids, W=400, H=300, fs=1):\n",
+ " tab_contents = []\n",
+ " for i, video_id in enumerate(video_ids):\n",
+ " out = widgets.Output()\n",
+ " with out:\n",
+ " if video_ids[i][0] == 'Youtube':\n",
+ " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
+ " height=H, fs=fs, rel=0)\n",
+ " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
+ " else:\n",
+ " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
+ " height=H, fs=fs, autoplay=False)\n",
+ " if video_ids[i][0] == 'Bilibili':\n",
+ " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
+ " elif video_ids[i][0] == 'Osf':\n",
+ " print(f'Video available at https://osf.io/{video.id}')\n",
+ " display(video)\n",
+ " tab_contents.append(out)\n",
+ " return tab_contents\n",
+ "\n",
+ "video_ids = [('Youtube', 'FTIu-ariSyE'), ('Bilibili', 'BV1YV7jz8EfS')]\n",
+ "tab_contents = display_videos(video_ids, W=854, H=480)\n",
+ "tabs = widgets.Tab()\n",
+ "tabs.children = tab_contents\n",
+ "for i in range(len(tab_contents)):\n",
+ " tabs.set_title(i, video_ids[i][0])\n",
+ "display(tabs)"
]
},
{
@@ -1038,23 +298,11 @@
"execution": {}
},
"source": [
- "Next, in order to see where things are on the map, we are going to compute the similarity between encoded places and points in the space. Your task is to complete the calculation of similarity values between all grid points with the one associated with the object."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "execution": {}
- },
- "outputs": [],
- "source": [
- "dim0 = np.linspace(-5, 5, 101)\n",
- "dim1 = np.linspace(-5, 5, 101)\n",
- "X,Y = np.meshgrid(dim0, dim1)\n",
+ "# Section 1: Define the input functions\n",
+ "\n",
+ "The color input will ``RED`` and then ``BLUE`` for 0.25 seconds each before being turned off. In the same way the shape input will be ``CIRCLE`` and then ``SQUARE`` for 0.25 seconds each. Thus, the network will bind alternatingly ``RED`` * ``CIRCLE`` and ``BLUE`` * ``SQUARE`` for 0.5 seconds each.\n",
"\n",
- "query_xs = np.vstack((X.flatten(), Y.flatten())).T\n",
- "query_ssps = ssp_space.encode(query_xs)"
+ "The cue for deconvolving bound semantic pointers will be turned off for 0.5 seconds and then cycles through ``CIRCLE``, ``RED``, ``SQUARE``, and ``BLUE`` within one second."
]
},
{
@@ -1065,42 +313,48 @@
},
"outputs": [],
"source": [
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete similarity calculation.\")\n",
- "###################################################################\n",
+ "def color_input(t):\n",
+ " if t < 0.25:\n",
+ " return \"RED\"\n",
+ " elif t < 0.5:\n",
+ " return \"BLUE\"\n",
+ " else:\n",
+ " return \"0\"\n",
"\n",
- "sims = []\n",
"\n",
- "for obj_idx, obj in enumerate(obj_names):\n",
- " sims.append(... @ ssps[obj].flatten())\n",
+ "def shape_input(t):\n",
+ " if t < 0.25:\n",
+ " return \"CIRCLE\"\n",
+ " elif t < 0.5:\n",
+ " return \"SQUARE\"\n",
+ " else:\n",
+ " return \"0\"\n",
"\n",
- "plt.figure(figsize=(8, 2.4))\n",
- "plot_2d_similarity(sims, obj_names, (dim0.size, dim1.size))"
+ "\n",
+ "def cue_input(t):\n",
+ " if t < 0.5:\n",
+ " return \"0\"\n",
+ " sequence = [\"0\", \"CIRCLE\", \"RED\", \"0\", \"SQUARE\", \"BLUE\"]\n",
+ " idx = int(((t - 0.5) // (1.0 / len(sequence))) % len(sequence))\n",
+ " return sequence[idx]"
]
},
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"execution": {}
},
"source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial3_Solution_cff4accc.py)\n",
+ "# Create the model\n",
"\n",
- "*Example output:*\n",
+ "Below we define a simple network compute the question answering. Note that the state labelled ``conv`` has the following arguments:\n",
+ "```python\n",
+ "conv = spa.State(dimensions, subdimensions=4, feedback=1.0, feedback_synapse=0.4)\n",
+ "```\n",
"\n",
- "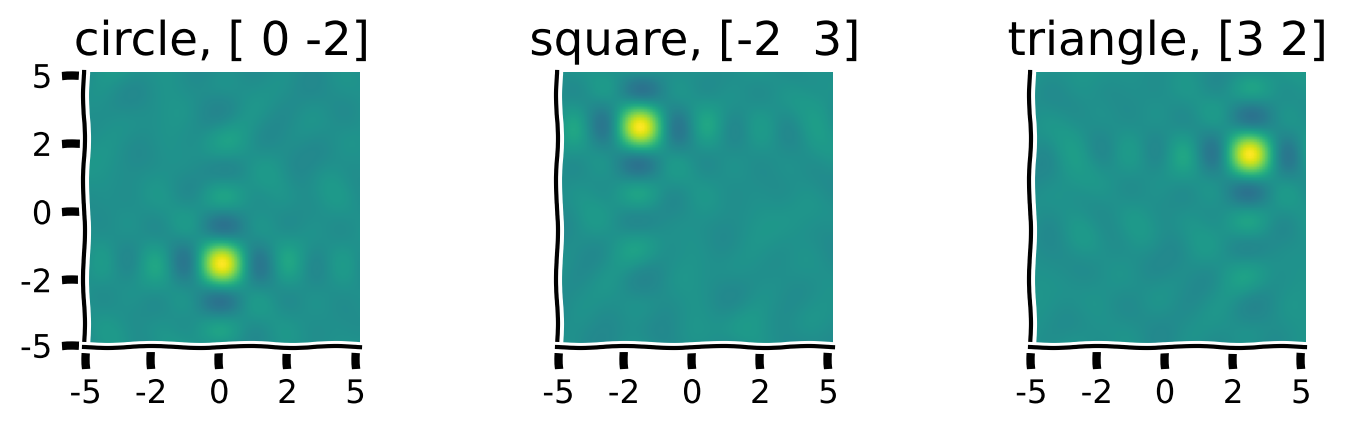 \n",
- "\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Now, let's bind these positions with the objects and see how that changes similarity with the map positions. Complete binding operation in the cell below."
+ "```feedback=1.0``` determines the strength of a recurrent connection that provides memory. ```feedback_synapse=0.4``` provides a time constant on a low-pass filter that models the synapses of the recurrent connection.\n",
+ "\n",
+ "``Transcode`` objects are modules provided by the Nengo programming framework to allow interaction with the outside world. They represent the interface between functions and the network, and execute simulus functions at runtime."
]
},
{
@@ -1111,36 +365,21 @@
},
"outputs": [],
"source": [
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete binding operation for objects and corresponding positions.\")\n",
- "###################################################################\n",
- "\n",
- "#objects are located in `objs` and positions in `ssps`\n",
- "bound_objects = [... * ... for n in obj_names]\n",
- "\n",
- "sims = []\n",
- "\n",
- "for obj_idx, obj in enumerate(obj_names):\n",
- " sims.append(query_ssps @ bound_objects[obj_idx].flatten())\n",
+ "# Number of dimensions for the Semantic Pointers\n",
+ "dimensions = 32\n",
"\n",
- "plt.figure(figsize=(8, 2.4))\n",
- "plot_2d_similarity(sims, obj_names, (dim0.size, dim1.size))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "execution": {}
- },
- "source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial3_Solution_b3d8f220.py)\n",
+ "model = spa.Network(label=\"Simple question answering\", seed=seed)\n",
"\n",
- "*Example output:*\n",
+ "with model:\n",
+ " color_in = spa.Transcode(color_input, output_vocab=dimensions)\n",
+ " shape_in = spa.Transcode(shape_input, output_vocab=dimensions)\n",
+ " bound = spa.State(dimensions, subdimensions=4, feedback=1.0, feedback_synapse=0.4) # conv\n",
+ " cue = spa.Transcode(cue_input, output_vocab=dimensions)\n",
+ " out = spa.State(dimensions)\n",
"\n",
- "
\n",
- "\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Now, let's bind these positions with the objects and see how that changes similarity with the map positions. Complete binding operation in the cell below."
+ "```feedback=1.0``` determines the strength of a recurrent connection that provides memory. ```feedback_synapse=0.4``` provides a time constant on a low-pass filter that models the synapses of the recurrent connection.\n",
+ "\n",
+ "``Transcode`` objects are modules provided by the Nengo programming framework to allow interaction with the outside world. They represent the interface between functions and the network, and execute simulus functions at runtime."
]
},
{
@@ -1111,36 +365,21 @@
},
"outputs": [],
"source": [
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete binding operation for objects and corresponding positions.\")\n",
- "###################################################################\n",
- "\n",
- "#objects are located in `objs` and positions in `ssps`\n",
- "bound_objects = [... * ... for n in obj_names]\n",
- "\n",
- "sims = []\n",
- "\n",
- "for obj_idx, obj in enumerate(obj_names):\n",
- " sims.append(query_ssps @ bound_objects[obj_idx].flatten())\n",
+ "# Number of dimensions for the Semantic Pointers\n",
+ "dimensions = 32\n",
"\n",
- "plt.figure(figsize=(8, 2.4))\n",
- "plot_2d_similarity(sims, obj_names, (dim0.size, dim1.size))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "execution": {}
- },
- "source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial3_Solution_b3d8f220.py)\n",
+ "model = spa.Network(label=\"Simple question answering\", seed=seed)\n",
"\n",
- "*Example output:*\n",
+ "with model:\n",
+ " color_in = spa.Transcode(color_input, output_vocab=dimensions)\n",
+ " shape_in = spa.Transcode(shape_input, output_vocab=dimensions)\n",
+ " bound = spa.State(dimensions, subdimensions=4, feedback=1.0, feedback_synapse=0.4) # conv\n",
+ " cue = spa.Transcode(cue_input, output_vocab=dimensions)\n",
+ " out = spa.State(dimensions)\n",
"\n",
- "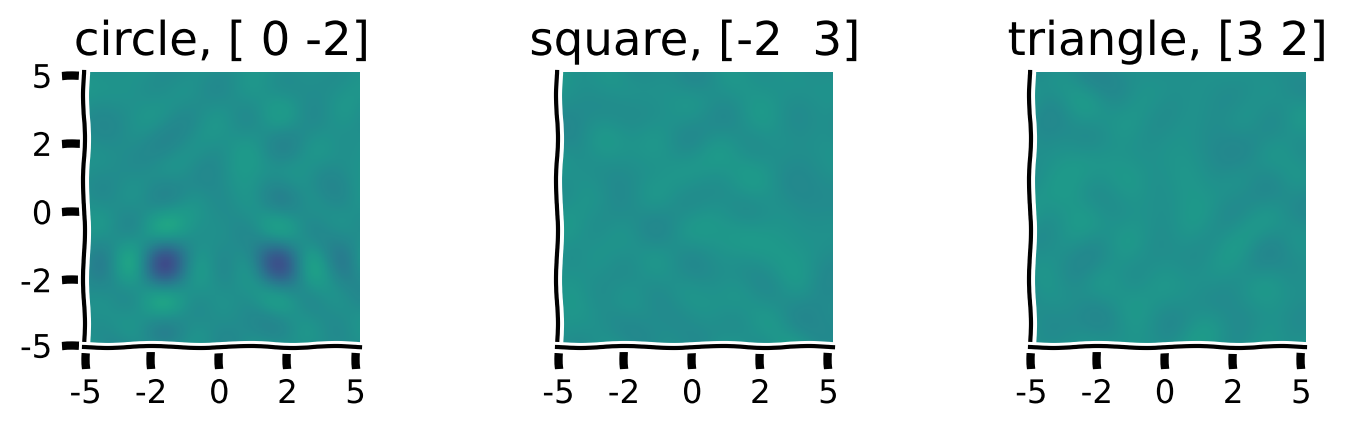 \n",
- "\n"
+ " # Connect the buffers\n",
+ " color_in * shape_in >> bound\n",
+ " bound * ~cue >> out"
]
},
{
@@ -1149,13 +388,11 @@
"execution": {}
},
"source": [
- "As you can see, the similarity is destroyed, which is what we should expect.\n",
+ "# Probe the Model\n",
"\n",
- "Next, we are going to create a map out of our bound objects:\n",
+ "Next we are going to probe different parts of the model to record their state during operation. Probes are analogous to sensors used in performing electrophysiological experiments, and their readout acts like a low-pass filter, smoothing the activity through the `synapse` member. Here we specify the low pass filter to have a time constant of `0.03`\n",
"\n",
- "\\begin{align*}\n",
- "\\mathrm{map} = \\sum_{i=1}^{n} \\phi(x_{i})\\circledast obj_{i}\n",
- "\\end{align*}"
+ "We will create probes for all the components in the model: `color_in`, `shape_in`, `cue`, `conv`, and `out`. Specifically, we will probe the `output` member of each of these objects, as the Transcode and State objects represent more complex networks that are implemented in Nengo."
]
},
{
@@ -1166,65 +403,80 @@
},
"outputs": [],
"source": [
- "set_seed(42)\n",
- "\n",
- "ssp_map = sspspace.SSP(np.sum(bound_objects, axis=0))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Now, we can query the map by unbinding the objects we care about. Your task is to complete the unbinding operation. Then, let's observe the resulting similarities."
+ "with model:\n",
+ " model.config[nengo.Probe].synapse = nengo.Lowpass(0.03)\n",
+ " p_color_in = nengo.Probe(color_in.output)\n",
+ " p_shape_in = nengo.Probe(shape_in.output)\n",
+ " p_cue = nengo.Probe(cue.output)\n",
+ " p_bound = nengo.Probe(bound.output)\n",
+ " p_out = nengo.Probe(out.output)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
+ "cellView": "form",
"execution": {}
},
"outputs": [],
"source": [
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete the unbinding operation.\")\n",
- "###################################################################\n",
+ "# @title Video 3: Working Memory Functionality\n",
+ "\n",
+ "from ipywidgets import widgets\n",
+ "from IPython.display import YouTubeVideo\n",
+ "from IPython.display import IFrame\n",
+ "from IPython.display import display\n",
"\n",
- "objects_sims = []\n",
+ "class PlayVideo(IFrame):\n",
+ " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
+ " self.id = id\n",
+ " if source == 'Bilibili':\n",
+ " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
+ " elif source == 'Osf':\n",
+ " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
+ " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
- "for obj_idx, obj_name in enumerate(obj_names):\n",
- " #query the object name by unbinding it from the map\n",
- " query_map = ssp_map * ~objs[...]\n",
- " objects_sims.append(query_ssps @ query_map.flatten())\n",
+ "def display_videos(video_ids, W=400, H=300, fs=1):\n",
+ " tab_contents = []\n",
+ " for i, video_id in enumerate(video_ids):\n",
+ " out = widgets.Output()\n",
+ " with out:\n",
+ " if video_ids[i][0] == 'Youtube':\n",
+ " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
+ " height=H, fs=fs, rel=0)\n",
+ " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
+ " else:\n",
+ " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
+ " height=H, fs=fs, autoplay=False)\n",
+ " if video_ids[i][0] == 'Bilibili':\n",
+ " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
+ " elif video_ids[i][0] == 'Osf':\n",
+ " print(f'Video available at https://osf.io/{video.id}')\n",
+ " display(video)\n",
+ " tab_contents.append(out)\n",
+ " return tab_contents\n",
"\n",
- "plot_2d_similarity(objects_sims, obj_names, (dim0.size, dim1.size), title_argmax = True)"
+ "video_ids = [('Youtube', 'i7mc_Z03pew'), ('Bilibili', 'BV1jK7jzNEr7')]\n",
+ "tab_contents = display_videos(video_ids, W=854, H=480)\n",
+ "tabs = widgets.Tab()\n",
+ "tabs.children = tab_contents\n",
+ "for i in range(len(tab_contents)):\n",
+ " tabs.set_title(i, video_ids[i][0])\n",
+ "display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"execution": {}
},
"source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial3_Solution_99c56d84.py)\n",
+ "# Run the model\n",
"\n",
- "*Example output:*\n",
+ "Now you will run the model using the programmatic Nengo interface. It will produce plots that compare similarity between different terms in our vocabulary (``RED``,``BLUE``,``CIRCLE``,``SQUARE``) and the states of the different elements of the networks. \n",
"\n",
- "
\n",
- "\n"
+ " # Connect the buffers\n",
+ " color_in * shape_in >> bound\n",
+ " bound * ~cue >> out"
]
},
{
@@ -1149,13 +388,11 @@
"execution": {}
},
"source": [
- "As you can see, the similarity is destroyed, which is what we should expect.\n",
+ "# Probe the Model\n",
"\n",
- "Next, we are going to create a map out of our bound objects:\n",
+ "Next we are going to probe different parts of the model to record their state during operation. Probes are analogous to sensors used in performing electrophysiological experiments, and their readout acts like a low-pass filter, smoothing the activity through the `synapse` member. Here we specify the low pass filter to have a time constant of `0.03`\n",
"\n",
- "\\begin{align*}\n",
- "\\mathrm{map} = \\sum_{i=1}^{n} \\phi(x_{i})\\circledast obj_{i}\n",
- "\\end{align*}"
+ "We will create probes for all the components in the model: `color_in`, `shape_in`, `cue`, `conv`, and `out`. Specifically, we will probe the `output` member of each of these objects, as the Transcode and State objects represent more complex networks that are implemented in Nengo."
]
},
{
@@ -1166,65 +403,80 @@
},
"outputs": [],
"source": [
- "set_seed(42)\n",
- "\n",
- "ssp_map = sspspace.SSP(np.sum(bound_objects, axis=0))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Now, we can query the map by unbinding the objects we care about. Your task is to complete the unbinding operation. Then, let's observe the resulting similarities."
+ "with model:\n",
+ " model.config[nengo.Probe].synapse = nengo.Lowpass(0.03)\n",
+ " p_color_in = nengo.Probe(color_in.output)\n",
+ " p_shape_in = nengo.Probe(shape_in.output)\n",
+ " p_cue = nengo.Probe(cue.output)\n",
+ " p_bound = nengo.Probe(bound.output)\n",
+ " p_out = nengo.Probe(out.output)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
+ "cellView": "form",
"execution": {}
},
"outputs": [],
"source": [
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete the unbinding operation.\")\n",
- "###################################################################\n",
+ "# @title Video 3: Working Memory Functionality\n",
+ "\n",
+ "from ipywidgets import widgets\n",
+ "from IPython.display import YouTubeVideo\n",
+ "from IPython.display import IFrame\n",
+ "from IPython.display import display\n",
"\n",
- "objects_sims = []\n",
+ "class PlayVideo(IFrame):\n",
+ " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
+ " self.id = id\n",
+ " if source == 'Bilibili':\n",
+ " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
+ " elif source == 'Osf':\n",
+ " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
+ " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
- "for obj_idx, obj_name in enumerate(obj_names):\n",
- " #query the object name by unbinding it from the map\n",
- " query_map = ssp_map * ~objs[...]\n",
- " objects_sims.append(query_ssps @ query_map.flatten())\n",
+ "def display_videos(video_ids, W=400, H=300, fs=1):\n",
+ " tab_contents = []\n",
+ " for i, video_id in enumerate(video_ids):\n",
+ " out = widgets.Output()\n",
+ " with out:\n",
+ " if video_ids[i][0] == 'Youtube':\n",
+ " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
+ " height=H, fs=fs, rel=0)\n",
+ " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
+ " else:\n",
+ " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
+ " height=H, fs=fs, autoplay=False)\n",
+ " if video_ids[i][0] == 'Bilibili':\n",
+ " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
+ " elif video_ids[i][0] == 'Osf':\n",
+ " print(f'Video available at https://osf.io/{video.id}')\n",
+ " display(video)\n",
+ " tab_contents.append(out)\n",
+ " return tab_contents\n",
"\n",
- "plot_2d_similarity(objects_sims, obj_names, (dim0.size, dim1.size), title_argmax = True)"
+ "video_ids = [('Youtube', 'i7mc_Z03pew'), ('Bilibili', 'BV1jK7jzNEr7')]\n",
+ "tab_contents = display_videos(video_ids, W=854, H=480)\n",
+ "tabs = widgets.Tab()\n",
+ "tabs.children = tab_contents\n",
+ "for i in range(len(tab_contents)):\n",
+ " tabs.set_title(i, video_ids[i][0])\n",
+ "display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"execution": {}
},
"source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial3_Solution_99c56d84.py)\n",
+ "# Run the model\n",
"\n",
- "*Example output:*\n",
+ "Now you will run the model using the programmatic Nengo interface. It will produce plots that compare similarity between different terms in our vocabulary (``RED``,``BLUE``,``CIRCLE``,``SQUARE``) and the states of the different elements of the networks. \n",
"\n",
- "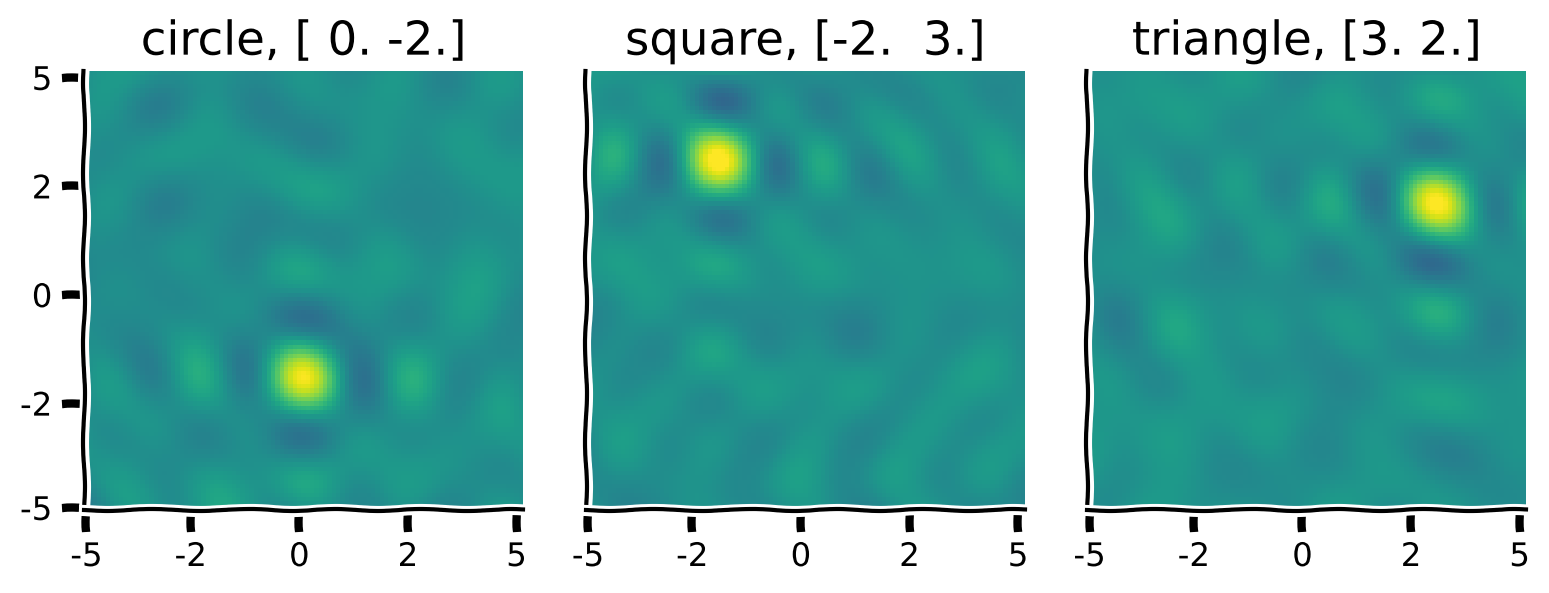 \n",
- "\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Let's look at what happens when we unbind all the symbols from the map at once. Complete bundling and unbinding operations in the following code cell."
+ "Remember: when the module is representing a state in our vocabularity, the similarity should increase towards 1."
]
},
{
@@ -1235,45 +487,19 @@
},
"outputs": [],
"source": [
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete the bundling and unbinding operations.\")\n",
- "###################################################################\n",
- "\n",
- "# unifying bundled representation of all objects\n",
- "all_objs = (objs['circle'] + objs[...] + objs[...]).normalize()\n",
- "\n",
- "# unbind this unifying representation from the map\n",
- "query_map = ... * ~...\n",
- "\n",
- "sims = query_ssps @ query_map.flatten()\n",
- "size = (dim0.size,dim1.size)\n",
- "\n",
- "plot_unbinding_objects_map(sims, positions, query_xs, size)"
+ "with nengo.Simulator(model) as sim:\n",
+ " sim.run(3.0)"
]
},
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"execution": {}
},
"source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial3_Solution_1090e65a.py)\n",
- "\n",
- "*Example output:*\n",
+ "# Plot the results\n",
"\n",
- "
\n",
- "\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "Let's look at what happens when we unbind all the symbols from the map at once. Complete bundling and unbinding operations in the following code cell."
+ "Remember: when the module is representing a state in our vocabularity, the similarity should increase towards 1."
]
},
{
@@ -1235,45 +487,19 @@
},
"outputs": [],
"source": [
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete the bundling and unbinding operations.\")\n",
- "###################################################################\n",
- "\n",
- "# unifying bundled representation of all objects\n",
- "all_objs = (objs['circle'] + objs[...] + objs[...]).normalize()\n",
- "\n",
- "# unbind this unifying representation from the map\n",
- "query_map = ... * ~...\n",
- "\n",
- "sims = query_ssps @ query_map.flatten()\n",
- "size = (dim0.size,dim1.size)\n",
- "\n",
- "plot_unbinding_objects_map(sims, positions, query_xs, size)"
+ "with nengo.Simulator(model) as sim:\n",
+ " sim.run(3.0)"
]
},
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"execution": {}
},
"source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial3_Solution_1090e65a.py)\n",
- "\n",
- "*Example output:*\n",
+ "# Plot the results\n",
"\n",
- "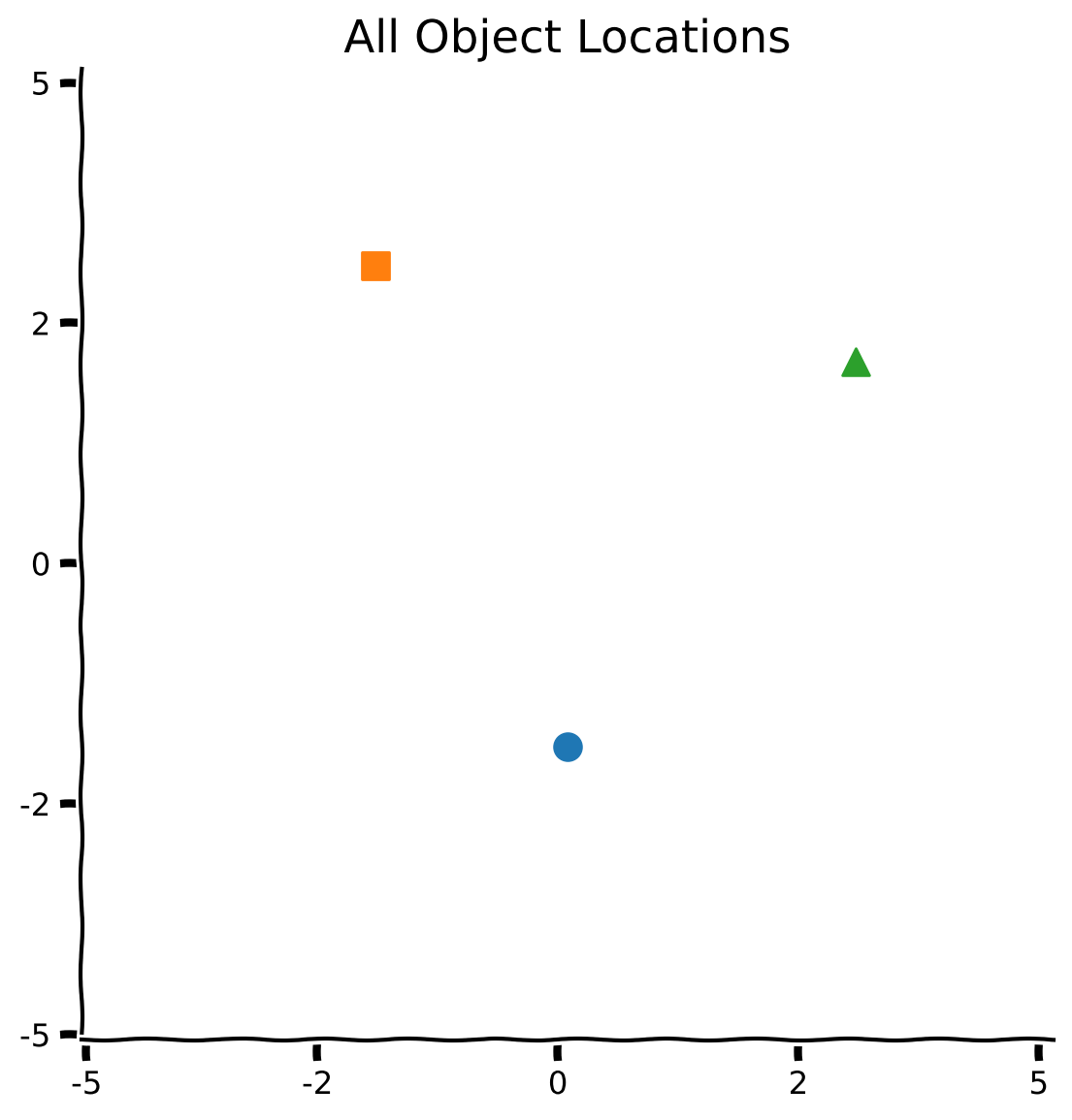 \n",
- "\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "We can also unbind positions and see what objects exist there. We will the locations where objects are located as test positions, as well as two distinct ones to compare. In the final exercise, you should complete the unbinding of the position's operation."
+ "After we run the simulator, it will store the data from the probes we created earlier. Each of the probe objects above, say `p_bound` which records the output of the binding operation, `bound`, are keys for a dictionary of data stored in the simulator."
]
},
{
@@ -1284,62 +510,50 @@
},
"outputs": [],
"source": [
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete the unbinding operations.\")\n",
- "###################################################################\n",
+ "plt.figure(figsize=(10, 10))\n",
+ "vocab = model.vocabs[dimensions]\n",
"\n",
- "query_objs = np.vstack([objs[n] for n in obj_names])\n",
- "test_positions = np.vstack((positions, [0,0], [0,-1.5]))\n",
+ "plt.subplot(5, 1, 1)\n",
+ "plt.plot(sim.trange(), spa.similarity(sim.data[p_color_in], vocab))\n",
+ "plt.legend(vocab.keys(), fontsize=\"x-small\")\n",
+ "plt.ylabel(\"color\")\n",
"\n",
- "sims = []\n",
+ "plt.subplot(5, 1, 2)\n",
+ "plt.plot(sim.trange(), spa.similarity(sim.data[p_shape_in], vocab))\n",
+ "plt.legend(vocab.keys(), fontsize=\"x-small\")\n",
+ "plt.ylabel(\"shape\")\n",
"\n",
- "for pos_idx, pos in enumerate(test_positions):\n",
- " position_ssp = ssp_space.encode(pos[None,:]) #remember we need to have 2-dimensional vectors for `encode()` function\n",
- " #unbind positions from the map\n",
- " query_map = ... * ~...\n",
- " sims.append(query_objs @ query_map.flatten())\n",
+ "plt.subplot(5, 1, 3)\n",
+ "plt.plot(sim.trange(), spa.similarity(sim.data[p_cue], vocab))\n",
+ "plt.legend(vocab.keys(), fontsize=\"x-small\")\n",
+ "plt.ylabel(\"cue\")\n",
"\n",
- "plot_unbinding_positions_map(sims, test_positions, obj_names)"
+ "plt.subplot(5, 1, 4)\n",
+ "for pointer in [\"RED * CIRCLE\", \"BLUE * SQUARE\"]:\n",
+ " plt.plot(sim.trange(), vocab.parse(pointer).dot(sim.data[p_bound].T), label=pointer)\n",
+ "plt.legend(fontsize=\"x-small\")\n",
+ "plt.ylabel(\"Bound\")\n",
+ "\n",
+ "plt.subplot(5, 1, 5)\n",
+ "plt.plot(sim.trange(), spa.similarity(sim.data[p_out], vocab))\n",
+ "plt.legend(vocab.keys(), fontsize=\"x-small\")\n",
+ "plt.ylabel(\"Output\")\n",
+ "plt.xlabel(\"time [s]\")"
]
},
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"execution": {}
},
"source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial3_Solution_57dcbce1.py)\n",
+ "The plots of shape, color, and convolved show that first `RED * CIRCLE` and then `BLUE * SQUARE` will be loaded into the convolved buffer so after 0.5 seconds it represents the superposition `RED * CIRCLE + BLUE * SQUARE`.\n",
"\n",
- "*Example output:*\n",
+ "The last plot shows that the output is most similar to the semantic pointer bound to the current cue. For example, when RED and CIRCLE are being convolved and the cue is CIRCLE, the output is most similar to RED. Thus, it is possible to unbind semantic pointers from the superposition stored in convolved.\n",
"\n",
- "
\n",
- "\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "We can also unbind positions and see what objects exist there. We will the locations where objects are located as test positions, as well as two distinct ones to compare. In the final exercise, you should complete the unbinding of the position's operation."
+ "After we run the simulator, it will store the data from the probes we created earlier. Each of the probe objects above, say `p_bound` which records the output of the binding operation, `bound`, are keys for a dictionary of data stored in the simulator."
]
},
{
@@ -1284,62 +510,50 @@
},
"outputs": [],
"source": [
- "###################################################################\n",
- "## Fill out the following then remove\n",
- "raise NotImplementedError(\"Student exercise: complete the unbinding operations.\")\n",
- "###################################################################\n",
+ "plt.figure(figsize=(10, 10))\n",
+ "vocab = model.vocabs[dimensions]\n",
"\n",
- "query_objs = np.vstack([objs[n] for n in obj_names])\n",
- "test_positions = np.vstack((positions, [0,0], [0,-1.5]))\n",
+ "plt.subplot(5, 1, 1)\n",
+ "plt.plot(sim.trange(), spa.similarity(sim.data[p_color_in], vocab))\n",
+ "plt.legend(vocab.keys(), fontsize=\"x-small\")\n",
+ "plt.ylabel(\"color\")\n",
"\n",
- "sims = []\n",
+ "plt.subplot(5, 1, 2)\n",
+ "plt.plot(sim.trange(), spa.similarity(sim.data[p_shape_in], vocab))\n",
+ "plt.legend(vocab.keys(), fontsize=\"x-small\")\n",
+ "plt.ylabel(\"shape\")\n",
"\n",
- "for pos_idx, pos in enumerate(test_positions):\n",
- " position_ssp = ssp_space.encode(pos[None,:]) #remember we need to have 2-dimensional vectors for `encode()` function\n",
- " #unbind positions from the map\n",
- " query_map = ... * ~...\n",
- " sims.append(query_objs @ query_map.flatten())\n",
+ "plt.subplot(5, 1, 3)\n",
+ "plt.plot(sim.trange(), spa.similarity(sim.data[p_cue], vocab))\n",
+ "plt.legend(vocab.keys(), fontsize=\"x-small\")\n",
+ "plt.ylabel(\"cue\")\n",
"\n",
- "plot_unbinding_positions_map(sims, test_positions, obj_names)"
+ "plt.subplot(5, 1, 4)\n",
+ "for pointer in [\"RED * CIRCLE\", \"BLUE * SQUARE\"]:\n",
+ " plt.plot(sim.trange(), vocab.parse(pointer).dot(sim.data[p_bound].T), label=pointer)\n",
+ "plt.legend(fontsize=\"x-small\")\n",
+ "plt.ylabel(\"Bound\")\n",
+ "\n",
+ "plt.subplot(5, 1, 5)\n",
+ "plt.plot(sim.trange(), spa.similarity(sim.data[p_out], vocab))\n",
+ "plt.legend(vocab.keys(), fontsize=\"x-small\")\n",
+ "plt.ylabel(\"Output\")\n",
+ "plt.xlabel(\"time [s]\")"
]
},
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"execution": {}
},
"source": [
- "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial3_Solution_57dcbce1.py)\n",
+ "The plots of shape, color, and convolved show that first `RED * CIRCLE` and then `BLUE * SQUARE` will be loaded into the convolved buffer so after 0.5 seconds it represents the superposition `RED * CIRCLE + BLUE * SQUARE`.\n",
"\n",
- "*Example output:*\n",
+ "The last plot shows that the output is most similar to the semantic pointer bound to the current cue. For example, when RED and CIRCLE are being convolved and the cue is CIRCLE, the output is most similar to RED. Thus, it is possible to unbind semantic pointers from the superposition stored in convolved.\n",
"\n",
- "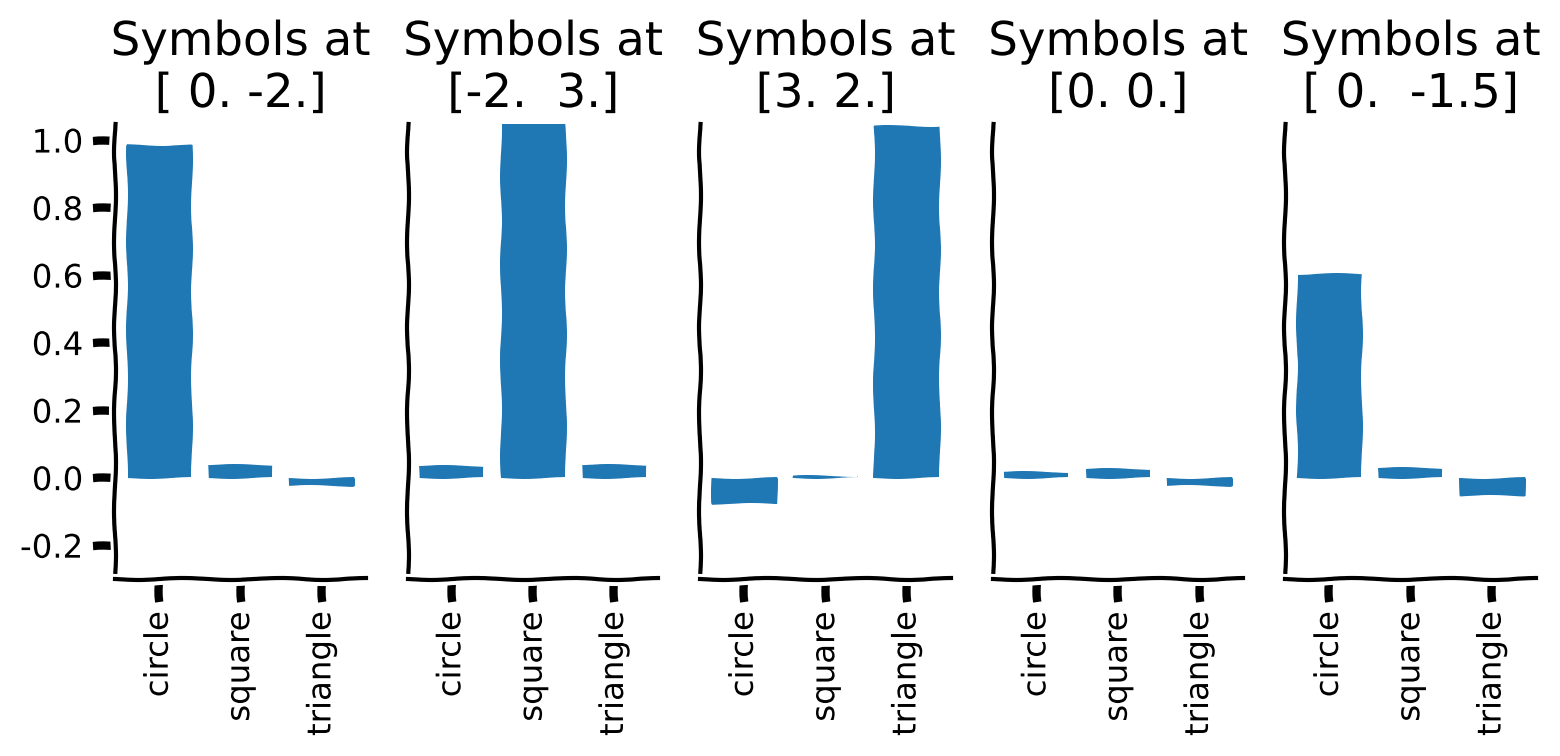 \n",
- "\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "As you can see from the above plots, when we query each location, we can clearly identify the object stored at that location. \n",
+ "You can see the effect of the memory unit in the model above because, even after the stimulus is turned off, the model is still able to answer the questions posed to it by the ``cue`` element.\n",
"\n",
- "When we query at the origin (where no object is present), we see that there is no strong candidate element. However, as we move closer to one of the objects (rightmost plot), the similarity starts to increase."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_mixing_discrete_objects_with_continuous_space\")"
+ "You can also see the effect of the neural implementation in the noise in the output signal.\n"
]
},
{
@@ -1351,7 +565,8 @@
},
"outputs": [],
"source": [
- "# @title Video 4: Mapping Outro\n",
+ "# @title Video 4: Results Walthrough\n",
+ "\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
@@ -1386,7 +601,7 @@
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
- "video_ids = [('Youtube', 'mXNFWr_cap4'), ('Bilibili', 'BV1ND421u7gp')]\n",
+ "video_ids = [('Youtube', '3f0UqEm9Gzo'), ('Bilibili', 'BV17K7jzNEr3')]\n",
"tab_contents = display_videos(video_ids, W=854, H=480)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
@@ -1405,7 +620,7 @@
"outputs": [],
"source": [
"# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_mapping_outro\")"
+ "content_review(f\"{feedback_prefix}_results_walkthrough\")"
]
},
{
@@ -1414,10 +629,42 @@
"execution": {}
},
"source": [
- "---\n",
- "# Summary\n",
+ "## Coding Exercise \n",
"\n",
- "*Estimated timing of tutorial: 40 minutes*"
+ "**QUESTION** Try adding the concept of a ``GREEN * SQUARE`` to the model. Run the simulation for 5 seconds and compare the plots."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# Student code completion here"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_green_square_coding\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "---"
]
},
{
@@ -1429,7 +676,8 @@
},
"outputs": [],
"source": [
- "# @title Video 5: Conclusions\n",
+ "# @title Video 5: Outro Video\n",
+ "\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
@@ -1464,7 +712,7 @@
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
- "video_ids = [('Youtube', 'M6rRsdJdoYQ'), ('Bilibili', 'BV1wm421L7Se')]\n",
+ "video_ids = [('Youtube', 'mWIfBl-4FKM'), ('Bilibili', 'BV1jK7jzNE1h')]\n",
"tab_contents = display_videos(video_ids, W=854, H=480)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
@@ -1482,27 +730,24 @@
},
"outputs": [],
"source": [
- "# @title Conclusion slides\n",
- "\n",
- "from IPython.display import IFrame\n",
- "link_id = \"pxqny\"\n",
- "\n",
- "print(f\"If you want to download the slides: 'https://osf.io/download/{link_id}'\")\n",
- "\n",
- "IFrame(src=f\"https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{link_id}/?direct%26mode=render\", width=854, height=480)"
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_outro\")"
]
},
{
- "cell_type": "code",
- "execution_count": null,
+ "cell_type": "markdown",
"metadata": {
- "cellView": "form",
"execution": {}
},
- "outputs": [],
"source": [
- "# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_conclusions\")"
+ "---\n",
+ "# The Big Picture\n",
+ "\n",
+ "You have now built a fairly simple cognitive model. A system that has an, albeit limited, vocabulary, expressed using a Vector Symbolic Algebra (VSA). Also, importantly, it is able to answer questions about it's experience, even though the experience has passed, thanks to its working memory. Working memory is a vital component of cognitive models, and while this is a simple system, you have now experienced working with the tools that underly SPAUN, the world's largest *functional* brain model. \n",
+ "\n",
+ "Additionally, while you haven't explicitly worked with them, this model was implemented completely with spiking neurons. The Neural Engineering Framework, the mathematical tools that underpin Nengo, allow us to compile the program we wrote using the VSA into a network of neurons. If you look closely at the plots above, you can see that the lines are noisy. This is because they are smoothed (thanks to the probes' synapse) signals that represent the activity of the populations of neurons that implement our simple question answering model.\n",
+ "\n",
+ "We have not one, but two extra bonus tutorials for today. These tutorials go into more depth on the basics around how to implement the notions of analogies in a VSA (Bonus Tutorial 4) and in Bonus Tutorial 5 we go through representations in continuous space. If you have any time left over, we encourage you to work your way through this extra material."
]
}
],
@@ -1534,7 +779,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.9.19"
+ "version": "3.9.22"
}
},
"nbformat": 4,
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial4.ipynb b/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial4.ipynb
new file mode 100644
index 000000000..791fa4a94
--- /dev/null
+++ b/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial4.ipynb
@@ -0,0 +1,1022 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {},
+ "id": "view-in-github"
+ },
+ "source": [
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "# (BONUS) Tutorial 4: VSA Analogies\n",
+ "\n",
+ "**Week 2, Day 2: Neuro-Symbolic Methods**\n",
+ "\n",
+ "**By Neuromatch Academy**\n",
+ "\n",
+ "__Content creators:__ P. Michael Furlong, Chris Eliasmith\n",
+ "\n",
+ "__Content reviewers:__ Hlib Solodzhuk, Patrick Mineault, Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Alex Murphy\n",
+ "\n",
+ "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk, Alex Murphy\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "___\n",
+ "\n",
+ "\n",
+ "# Tutorial Objectives\n",
+ "\n",
+ "This tutorial will present you with a couple of toy examples using the basic operations of vector symbolic algebras. We will further show how these can generalize to new knowledge. If you are familiar with the basics of semantic algebra on word embeddings, you already understand the basics of what we'll be demonstrating in this tutorial. If not, don't worry, this tutorial is designed to be highly self-contained. If you're interested in learning more about word embedding algebra, then we encourage you to use your search engine of choice and learn more after completing the code exercises given below."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Tutorial slides\n",
+ "# @markdown These are the slides for the videos in all tutorials today\n",
+ "\n",
+ "from IPython.display import IFrame\n",
+ "link_id = \"jybuw\"\n",
+ "\n",
+ "print(f\"If you want to download the slides: 'https://osf.io/download/{link_id}'\")\n",
+ "\n",
+ "IFrame(src=f\"https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{link_id}/?direct%26mode=render\", width=854, height=480)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "---\n",
+ "# Setup (Colab Users: Please Read)\n",
+ "\n",
+ "Note that because this tutorial relies on some special Python packages, these packages have requirements for specific versions of common scientific libraries, such as `numpy`. If you're in Google Colab, then as of May 2025, this comes with a later version (2.0.2) pre-installed. We require an older version (we'll be installing `1.24.4`). This causes Colab to force a session restart and then re-running of the installation cells for the new version to take effect. When you run the cell below, you will be prompted to restart the session. This is *entirely expected* and you haven't done anything wrong. Simply click 'Restart' and then run the cells as normal. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Install dependencies and import feedback gadget\n",
+ "\n",
+ "!pip install numpy==1.24.4 --quiet\n",
+ "!pip install scikit-learn==1.6.1 --quiet\n",
+ "!pip install scipy==1.15.3 --quiet\n",
+ "!pip install git+https://github.com/neuromatch/sspspace@neuromatch --no-deps --quiet\n",
+ "!pip install nengo==4.0.0 --quiet\n",
+ "!pip install nengo_spa==2.0.0 --quiet\n",
+ "!pip install --quiet matplotlib ipywidgets vibecheck\n",
+ "!pip install --quiet numpy matplotlib ipywidgets scipy scikit-learn vibecheck\n",
+ "\n",
+ "from vibecheck import DatatopsContentReviewContainer\n",
+ "def content_review(notebook_section: str):\n",
+ " return DatatopsContentReviewContainer(\n",
+ " \"\", # No text prompt\n",
+ " notebook_section,\n",
+ " {\n",
+ " \"url\": \"https://pmyvdlilci.execute-api.us-east-1.amazonaws.com/klab\",\n",
+ " \"name\": \"neuromatch_neuroai\",\n",
+ " \"user_key\": \"wb2cxze8\",\n",
+ " },\n",
+ " ).render()\n",
+ "\n",
+ "\n",
+ "feedback_prefix = \"W2D2_T4\""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Notice that exactly the `neuromatch` branch of `sspspace` should be installed! Otherwise, some of the functionality (like `optimize` parameter in the `DiscreteSPSpace` initialization) won't work."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Imports\n",
+ "\n",
+ "#working with data\n",
+ "import numpy as np\n",
+ "\n",
+ "#plotting\n",
+ "import matplotlib.pyplot as plt\n",
+ "import logging\n",
+ "\n",
+ "#interactive display\n",
+ "# import ipywidgets as widgets\n",
+ "\n",
+ "#modeling\n",
+ "import sspspace\n",
+ "import nengo_spa as spa\n",
+ "from scipy.special import softmax\n",
+ "from sklearn.metrics import log_loss\n",
+ "from sklearn.neural_network import MLPRegressor\n",
+ "from nengo_spa.algebras.hrr_algebra import HrrProperties, HrrAlgebra\n",
+ "from nengo_spa.vector_generation import VectorsWithProperties\n",
+ "\n",
+ "def make_vocabulary(vector_length):\n",
+ " vec_generator = VectorsWithProperties(vector_length, algebra=HrrAlgebra(), properties = [HrrProperties.UNITARY, HrrProperties.POSITIVE])\n",
+ " vocab = spa.Vocabulary(vector_length, pointer_gen=vec_generator)\n",
+ " return vocab"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Figure settings\n",
+ "\n",
+ "logging.getLogger('matplotlib.font_manager').disabled = True\n",
+ "\n",
+ "%matplotlib inline\n",
+ "%config InlineBackend.figure_format = 'retina' # perfrom high definition rendering for images and plots\n",
+ "plt.style.use(\"https://raw.githubusercontent.com/NeuromatchAcademy/course-content/main/nma.mplstyle\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Plotting functions\n",
+ "\n",
+ "def plot_similarity_matrix(sim_mat, labels, values = False):\n",
+ " \"\"\"\n",
+ " Plot the similarity matrix between vectors.\n",
+ "\n",
+ " Inputs:\n",
+ " - sim_mat (numpy.ndarray): similarity matrix between vectors.\n",
+ " - labels (list of str): list of strings which represent concepts.\n",
+ " - values (bool): True if we would like to plot values of similarity too.\n",
+ " \"\"\"\n",
+ " with plt.xkcd():\n",
+ " plt.imshow(sim_mat, cmap='Greys')\n",
+ " plt.colorbar()\n",
+ " plt.xticks(np.arange(len(labels)), labels, rotation=45, ha=\"right\", rotation_mode=\"anchor\")\n",
+ " plt.yticks(np.arange(len(labels)), labels)\n",
+ " if values:\n",
+ " for x in range(sim_mat.shape[1]):\n",
+ " for y in range(sim_mat.shape[0]):\n",
+ " plt.text(x, y, f\"{sim_mat[y, x]:.2f}\", fontsize = 8, ha=\"center\", va=\"center\", color=\"green\")\n",
+ " plt.title('Similarity between vector-symbols')\n",
+ " plt.xlabel('Symbols')\n",
+ " plt.ylabel('Symbols')\n",
+ " plt.show()\n",
+ "\n",
+ "def plot_training_and_choice(losses, sims, ant_names, cons_names, action_names):\n",
+ " \"\"\"\n",
+ " Plot loss progression over training as well as predicted similarities for given rules / correct solutions.\n",
+ "\n",
+ " Inputs:\n",
+ " - losses (list): list of loss values.\n",
+ " - sims (list): list of similartiy matrices.\n",
+ " - ant_names (list): list of antecedance names.\n",
+ " - cons_names (list): list of consequent names.\n",
+ " - action_names (list): full list of concepts.\n",
+ " \"\"\"\n",
+ " with plt.xkcd():\n",
+ " plt.subplot(1, len(ant_names) + 1, 1)\n",
+ " plt.plot(losses)\n",
+ " plt.xlabel('Training number')\n",
+ " plt.ylabel('Loss')\n",
+ " plt.title('Training Error')\n",
+ " index = 1\n",
+ " for ant_name, cons_name, sim in zip(ant_names, cons_names, sims):\n",
+ " index += 1\n",
+ " plt.subplot(1, len(ant_names) + 1, index)\n",
+ " plt.bar(range(len(action_names)), sim.flatten())\n",
+ " plt.gca().set_xticks(range(len(action_names)))\n",
+ " plt.gca().set_xticklabels(action_names, rotation=90)\n",
+ " plt.title(f'{ant_name}, not*{cons_name}')\n",
+ "\n",
+ "def plot_choice(sims, ant_names, cons_names, action_names):\n",
+ " \"\"\"\n",
+ " Plot predicted similarities for given rules / correct solutions.\n",
+ " \"\"\"\n",
+ " with plt.xkcd():\n",
+ " index = 0\n",
+ " for ant_name, cons_name, sim in zip(ant_names, cons_names, sims):\n",
+ " index += 1\n",
+ " plt.subplot(1, len(ant_names) + 1, index)\n",
+ " plt.bar(range(len(action_names)), sim.flatten())\n",
+ " plt.gca().set_xticks(range(len(action_names)))\n",
+ " plt.gca().set_xticklabels(action_names, rotation=90)\n",
+ " plt.ylabel(\"Similarity\")\n",
+ " plt.title(f'{ant_name}, not*{cons_name}')"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Set random seed\n",
+ "\n",
+ "import random\n",
+ "import numpy as np\n",
+ "\n",
+ "def set_seed(seed=None):\n",
+ " if seed is None:\n",
+ " seed = np.random.choice(2 ** 32)\n",
+ " random.seed(seed)\n",
+ " np.random.seed(seed)\n",
+ "\n",
+ "set_seed(seed = 42)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Helper functions\n",
+ "\n",
+ "set_seed(42)\n",
+ "\n",
+ "symbol_names = ['monarch','heir','male','female']\n",
+ "discrete_space = sspspace.DiscreteSPSpace(symbol_names, ssp_dim=1024, optimize=False)\n",
+ "\n",
+ "objs = {n:discrete_space.encode(n) for n in symbol_names}\n",
+ "\n",
+ "objs['king'] = objs['monarch'] * objs['male']\n",
+ "objs['queen'] = objs['monarch'] * objs['female']\n",
+ "objs['prince'] = objs['heir'] * objs['male']\n",
+ "objs['princess'] = objs['heir'] * objs['female']\n",
+ "\n",
+ "bundle_objs = {n:discrete_space.encode(n) for n in symbol_names}\n",
+ "\n",
+ "bundle_objs['king'] = (bundle_objs['monarch'] + bundle_objs['male']).normalize()\n",
+ "bundle_objs['queen'] = (bundle_objs['monarch'] + bundle_objs['female']).normalize()\n",
+ "bundle_objs['prince'] = (bundle_objs['heir'] + bundle_objs['male']).normalize()\n",
+ "bundle_objs['princess'] = (bundle_objs['heir'] + bundle_objs['female']).normalize()\n",
+ "\n",
+ "bundle_objs['princess_query'] = (bundle_objs['prince'] - bundle_objs['king']) + bundle_objs['queen']\n",
+ "\n",
+ "new_symbol_names = ['dollar', 'peso', 'ottawa', 'mexico-city', 'currency', 'capital']\n",
+ "new_discrete_space = sspspace.DiscreteSPSpace(new_symbol_names, ssp_dim=1024, optimize=False)\n",
+ "\n",
+ "new_objs = {n:new_discrete_space.encode(n) for n in new_symbol_names}\n",
+ "\n",
+ "cleanup = sspspace.Cleanup(new_objs)\n",
+ "\n",
+ "new_objs['canada'] = ((new_objs['currency'] * new_objs['dollar']) + (new_objs['capital'] * new_objs['ottawa'])).normalize()\n",
+ "new_objs['mexico'] = ((new_objs['currency'] * new_objs['peso']) + (new_objs['capital'] * new_objs['mexico-city'])).normalize()\n",
+ "\n",
+ "card_states = ['red','blue','odd','even','not','green','prime','implies','ant','relation','cons']\n",
+ "encoder = sspspace.DiscreteSPSpace(card_states, ssp_dim=1024, optimize=False)\n",
+ "vocab = {c:encoder.encode(c) for c in card_states}\n",
+ "\n",
+ "for a in ['red','blue','odd','even','green','prime']:\n",
+ " vocab[f'not*{a}'] = vocab['not'] * vocab[a]\n",
+ "\n",
+ "action_names = ['red','blue','odd','even','green','prime','not*red','not*blue','not*odd','not*even','not*green','not*prime']\n",
+ "action_space = np.array([vocab[x] for x in action_names]).squeeze()\n",
+ "\n",
+ "rules = [\n",
+ " (vocab['ant'] * vocab['blue'] + vocab['relation'] * vocab['implies'] + vocab['cons'] * vocab['even']).normalize(),\n",
+ " (vocab['ant'] * vocab['odd'] + vocab['relation'] * vocab['implies'] + vocab['cons'] * vocab['green']).normalize(),\n",
+ "]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "---\n",
+ "\n",
+ "# Section 1: Analogies. Part 1\n",
+ "\n",
+ "In this section we will construct a simple analogy using Vector Symbolic Algebras. The question we are going to try and solve is \"King is to the queen as the prince is to X.\""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Video 1: Analogy 1\n",
+ "\n",
+ "from ipywidgets import widgets\n",
+ "from IPython.display import YouTubeVideo\n",
+ "from IPython.display import IFrame\n",
+ "from IPython.display import display\n",
+ "\n",
+ "class PlayVideo(IFrame):\n",
+ " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
+ " self.id = id\n",
+ " if source == 'Bilibili':\n",
+ " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
+ " elif source == 'Osf':\n",
+ " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
+ " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
+ "\n",
+ "def display_videos(video_ids, W=400, H=300, fs=1):\n",
+ " tab_contents = []\n",
+ " for i, video_id in enumerate(video_ids):\n",
+ " out = widgets.Output()\n",
+ " with out:\n",
+ " if video_ids[i][0] == 'Youtube':\n",
+ " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
+ " height=H, fs=fs, rel=0)\n",
+ " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
+ " else:\n",
+ " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
+ " height=H, fs=fs, autoplay=False)\n",
+ " if video_ids[i][0] == 'Bilibili':\n",
+ " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
+ " elif video_ids[i][0] == 'Osf':\n",
+ " print(f'Video available at https://osf.io/{video.id}')\n",
+ " display(video)\n",
+ " tab_contents.append(out)\n",
+ " return tab_contents\n",
+ "\n",
+ "video_ids = [('Youtube', '2tR4fHvL1Jk'), ('Bilibili', 'BV1fS411P7Ez')]\n",
+ "tab_contents = display_videos(video_ids, W=854, H=480)\n",
+ "tabs = widgets.Tab()\n",
+ "tabs.children = tab_contents\n",
+ "for i in range(len(tab_contents)):\n",
+ " tabs.set_title(i, video_ids[i][0])\n",
+ "display(tabs)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_analogy_part_one\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "## Coding Exercise 1: Royal Relationships\n",
+ "\n",
+ "We're going to start by considering our vocabulary. We will use the basic discrete concepts of monarch, heir, male, and female."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Let's create the objects we know about by combinatorially expanding the space: \n",
+ "\n",
+ "1. King is a male monarch\n",
+ "2. Queen is a female monarch\n",
+ "3. Prince is a male heir\n",
+ "4. Princess is a female heir\n",
+ "\n",
+ "Complete the missing parts of the code to obtain correct representations of new concepts."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "set_seed(42)\n",
+ "\n",
+ "vector_length = 1024\n",
+ "symbol_names = ['MONARCH', 'HEIR', 'MALE', 'FEMALE']\n",
+ "vocab = make_vocabulary(vector_length)\n",
+ "vocab.populate(';'.join(symbol_names))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete correct relations for creating new concepts.\")\n",
+ "\n",
+ "###################################################################\n",
+ "vocab.add('KING', vocab['MONARCH'] * vocab['MALE'])\n",
+ "vocab.add('QUEEN', vocab['MONARCH'] * ...)\n",
+ "vocab.add('PRINCE', vocab['HEIR'] * vocab['MALE'])\n",
+ "vocab.add('PRINCESS', ... * vocab['FEMALE'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {}
+ },
+ "source": [
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial4_Solution_873dadc4.py)\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Now, we can take an explicit approach. We know that the conversion from king to queen is to unbind male and bind female, so let's apply that to our prince object and see what we uncover.\n",
+ "\n",
+ "At first, in the cell below, let's recover `queen` from `king` by constructing a new `query` concept, which represents the unbinding of `male` and the binding of `female.`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete correct relation for creating `query` object to compare with `queen`.\")\n",
+ "###################################################################\n",
+ "\n",
+ "vocab.add('QUERY_QUEEN', (vocab[...] * ~vocab[...]) * vocab[...])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {}
+ },
+ "source": [
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial4_Solution_8ecc4392.py)\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Then, let's see if this new query object bears any similarity to anything in our vocabulary."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "object_names = list(vocab.keys())\n",
+ "sims = np.zeros((len(object_names), len(object_names)))\n",
+ "\n",
+ "for name_idx, name in enumerate(object_names):\n",
+ " for other_idx in range(name_idx, len(object_names)):\n",
+ " sims[name_idx, other_idx] = sims[other_idx, name_idx] = spa.dot(vocab[name], vocab[object_names[other_idx]])\n",
+ "\n",
+ "plot_similarity_matrix(sims, object_names, values = True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "The above similarity plot shows that applying that operation successfully converts king to queen. Let's apply it to 'prince' and see what happens. Now, `query` should represent the `princess` concept."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "vocab.add('QUERY_PRINCESS', (vocab['PRINCE'] * ~vocab['MALE']) * vocab['FEMALE'])\n",
+ "\n",
+ "sims = np.zeros((len(object_names), len(object_names)))\n",
+ "\n",
+ "for name_idx, name in enumerate(object_names):\n",
+ " for other_idx in range(name_idx, len(object_names)):\n",
+ " sims[name_idx, other_idx] = sims[other_idx, name_idx] = spa.dot(vocab[name], vocab[object_names[other_idx]])\n",
+ "\n",
+ "plot_similarity_matrix(sims, object_names, values = True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Here, we have successfully recovered the princess, completing the analogy.\n",
+ "\n",
+ "This approach, however, requires explicit knowledge of the construction of the objects. Let's see if we can just work with the concepts of 'king,' 'queen,' and 'prince' directly.\n",
+ "\n",
+ "In the cell below, construct the `princess` concept using only `king,` `queen`, and `prince.`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete correct relation for creating `query` object to compare with `princess`.\")\n",
+ "###################################################################\n",
+ "\n",
+ "vocab.add('QUERY_PRINCESS_2', (vocab[...] * ~vocab[...]) * vocab[...])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {}
+ },
+ "source": [
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial4_Solution_f2f03c67.py)\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "object_names = list(vocab.keys())\n",
+ "sims = np.zeros((len(object_names), len(object_names)))\n",
+ "\n",
+ "for name_idx, name in enumerate(object_names):\n",
+ " for other_idx in range(name_idx, len(object_names)):\n",
+ " sims[name_idx, other_idx] = sims[other_idx, name_idx] = spa.dot(vocab[name], vocab[object_names[other_idx]])\n",
+ "\n",
+ "plot_similarity_matrix(sims, object_names, values = True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Again, we see that we have recovered the princess by using our analogy.\n",
+ "\n",
+ "That said, the above depends on knowing that the representations are constructed using binding. Can we do something similar through the bundling operation? Let's try that out.\n",
+ "\n",
+ "Reassing concept definitions using bundling operation."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "vocab = vocab.create_subset(['MONARCH','HEIR','FEMALE','MALE'])\n",
+ "vocab.add('KING', (vocab['MONARCH'] + vocab['MALE']).normalized())\n",
+ "vocab.add('QUEEN', (vocab['MONARCH'] + vocab['FEMALE']).normalized())\n",
+ "vocab.add('PRINCE', (vocab['HEIR'] + vocab['MALE']).normalized())\n",
+ "vocab.add('PRINCESS', (vocab['HEIR'] + vocab['FEMALE']).normalized())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "But now that we are using an additive model, we need to take a different approach. Instead of unbinding the king and binding the queen, we subtract the king and add the queen to find the princess from the prince.\n",
+ "\n",
+ "Complete the code to reflect the updated mechanism."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete correct relation for creating `query` object to compare with `princess`.\")\n",
+ "###################################################################\n",
+ "\n",
+ "vocab.add('QUERY_PRINCESS', ((vocab[...] - vocab[...]) + vocab[...]).normalized())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {}
+ },
+ "source": [
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial4_Solution_73f6dd01.py)\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "object_names = list(vocab.keys())\n",
+ "sims = np.zeros((len(object_names), len(object_names)))\n",
+ "\n",
+ "for name_idx, name in enumerate(object_names):\n",
+ " for other_idx in range(name_idx, len(object_names)):\n",
+ " sims[name_idx, other_idx] = sims[other_idx, name_idx] = spa.dot(vocab[name], vocab[object_names[other_idx]])\n",
+ "\n",
+ "plot_similarity_matrix(sims, object_names, values = True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "This is a messier similarity plot due to the fact that the bundled representations interact with all their constituent parts in the vocabulary. That said, we see that 'princess' is still most similar to the query vector. \n",
+ "\n",
+ "This approach is more like what we would expect from a `word2vec` embedding."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_royal_relationships\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "---\n",
+ "\n",
+ "# Section 2: Analogies (Part 2)\n",
+ "\n",
+ "Estimated timing to here from start of tutorial: 15 minutes\n",
+ "\n",
+ "In this section, we will construct a database of data structures that describe different countries. Materials are adopted from [Kanerva (2010)](https://cdn.aaai.org/ocs/2243/2243-9566-1-PB.pdf)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Video 2: Analogy 2\n",
+ "\n",
+ "from ipywidgets import widgets\n",
+ "from IPython.display import YouTubeVideo\n",
+ "from IPython.display import IFrame\n",
+ "from IPython.display import display\n",
+ "\n",
+ "class PlayVideo(IFrame):\n",
+ " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
+ " self.id = id\n",
+ " if source == 'Bilibili':\n",
+ " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
+ " elif source == 'Osf':\n",
+ " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
+ " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
+ "\n",
+ "def display_videos(video_ids, W=400, H=300, fs=1):\n",
+ " tab_contents = []\n",
+ " for i, video_id in enumerate(video_ids):\n",
+ " out = widgets.Output()\n",
+ " with out:\n",
+ " if video_ids[i][0] == 'Youtube':\n",
+ " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
+ " height=H, fs=fs, rel=0)\n",
+ " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
+ " else:\n",
+ " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
+ " height=H, fs=fs, autoplay=False)\n",
+ " if video_ids[i][0] == 'Bilibili':\n",
+ " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
+ " elif video_ids[i][0] == 'Osf':\n",
+ " print(f'Video available at https://osf.io/{video.id}')\n",
+ " display(video)\n",
+ " tab_contents.append(out)\n",
+ " return tab_contents\n",
+ "\n",
+ "video_ids = [('Youtube', 'OB3hzhM7Ois'), ('Bilibili', 'BV1TZ421g7G5')]\n",
+ "tab_contents = display_videos(video_ids, W=854, H=480)\n",
+ "tabs = widgets.Tab()\n",
+ "tabs.children = tab_contents\n",
+ "for i in range(len(tab_contents)):\n",
+ " tabs.set_title(i, video_ids[i][0])\n",
+ "display(tabs)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_analogy_part_two\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "## Coding Exercise 2: Dollar of Mexico\n",
+ "\n",
+ "This is going to be a little more involved, because to construct the data structure we are going to need vectors that don't just represent values that we are reasoning about, but also vectors that represent different roles data can play. This is sometimes called a slot-filler representation, or a key-value representation.\n",
+ "\n",
+ "At first, let us define concepts and cleanup object."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "set_seed(42)\n",
+ "\n",
+ "symbol_names = ['DOLLAR','PESO', 'OTTAWA','MEXICO_CITY','CURRENCY','CAPITAL']\n",
+ "vocab = make_vocabulary(vector_length)\n",
+ "vocab.populate(';'.join(symbol_names))\n",
+ "\n",
+ "cleanup = sspspace.Cleanup(vocab)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Now, we will define `Canada` and `Mexico` concepts by integrating the available information together. You will be provided with `Canada` object and your task is to complete for `Mexico` one."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete `mexico` concept.\")\n",
+ "###################################################################\n",
+ "\n",
+ "vocab.add('CANADA', (vocab['CURRENCY'] * vocab['DOLLAR'] + vocab['CAPITAL'] * vocab['OTTAWA']).normalized())\n",
+ "vocab.add('MEXICO', (vocab['CURRENCY'] * ... + vocab['CAPITAL'] * ...).normalized())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {}
+ },
+ "source": [
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial4_Solution_a848247a.py)\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "We would like to find out Mexico's currency. Complete the code for constructing a `query` which will help us do that. Note that we are using a cleanup operation."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete `query` concept which will be similar to currency in Mexico.\")\n",
+ "###################################################################\n",
+ "\n",
+ "vocab.add('QUERY_MX_CURRENCY', vocab['MEXICO'] * ~(... * ~...))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {}
+ },
+ "source": [
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial4_Solution_603ce327.py)\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "object_names = list(vocab.keys())\n",
+ "sims = np.zeros((len(object_names), len(object_names)))\n",
+ "\n",
+ "for name_idx, name in enumerate(object_names):\n",
+ " for other_idx in range(name_idx, len(object_names)):\n",
+ " sims[name_idx, other_idx] = sims[other_idx, name_idx] = spa.dot(vocab[name], vocab[object_names[other_idx]])\n",
+ "\n",
+ "plot_similarity_matrix(sims, object_names)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "After cleanup, the query vector is the most similar with the 'peso' object in the vocabularly, correctly answering the question. \n",
+ "\n",
+ "Note, however, that the similarity is not perfectly equal to 1. This is due to the scale factors applied to the composite vectors 'canada' and 'mexico', to ensure they remain unit vectors, and due to cross talk. Crosstalk is a symptom of the fact that we are binding and unbinding bundles of vector symbols to produce the resultant query vector. The constituent vectors are not perfectly orthogonal (i.e., having a dot product of zero) and as such the terms in the bundle interact when we measure similarity between them."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_dollar_of_mexico\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "---\n",
+ "# The Big Picture\n",
+ "\n",
+ "*Estimated timing of tutorial: 45 minutes*\n",
+ "\n",
+ "In this tutorial, we observed three scenarios where we used the basic operations to solve different analogies and engage in structured learning. Those of you familiar with word embeddings from Natural Language Processing (NLP) might already be familiar with the idea of interpretable semantics on vector representations. This bonus tutorial helps to show how this can be accomplished in a different way. The ability to recreate different phenomena in different paradigms often gives us a great way to compare and contrast model mechanisms and we hope that this bonus tutorial has given you a curiosity to dive a bit deeper and start experimenting further with what you can accomplish using these great open-source tools!"
+ ]
+ }
+ ],
+ "metadata": {
+ "colab": {
+ "collapsed_sections": [],
+ "include_colab_link": true,
+ "name": "W2D2_Tutorial4",
+ "provenance": [],
+ "toc_visible": true
+ },
+ "kernel": {
+ "display_name": "Python 3",
+ "language": "python",
+ "name": "python3"
+ },
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.9.22"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 4
+}
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial5.ipynb b/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial5.ipynb
new file mode 100644
index 000000000..6acac4694
--- /dev/null
+++ b/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial5.ipynb
@@ -0,0 +1,1537 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {},
+ "id": "view-in-github"
+ },
+ "source": [
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "# (Bonus) Tutorial 5: Representations in continuous space\n",
+ "\n",
+ "**Week 2, Day 2: Neuro-Symbolic Methods**\n",
+ "\n",
+ "**By Neuromatch Academy**\n",
+ "\n",
+ "__Content creators:__ P. Michael Furlong, Chris Eliasmith\n",
+ "\n",
+ "__Content reviewers:__ Hlib Solodzhuk, Patrick Mineault, Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Alex Murphy\n",
+ "\n",
+ "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk, Alex Murphy"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "___\n",
+ "\n",
+ "\n",
+ "# Tutorial Objectives\n",
+ "\n",
+ "*Estimated timing of tutorial: 40 minutes*\n",
+ "\n",
+ "In this tutorial, you will observe how the VSA methods can be applied in structures and environments to allow for efficient generalization."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Tutorial slides\n",
+ "# @markdown These are the slides for the videos in all tutorials today\n",
+ "\n",
+ "from IPython.display import IFrame\n",
+ "link_id = \"jybuw\"\n",
+ "\n",
+ "print(f\"If you want to download the slides: 'https://osf.io/download/{link_id}'\")\n",
+ "\n",
+ "IFrame(src=f\"https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{link_id}/?direct%26mode=render\", width=854, height=480)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "---\n",
+ "# Setup (Colab Users: Please Read)\n",
+ "\n",
+ "Note that because this tutorial relies on some special Python packages, these packages have requirements for specific versions of common scientific libraries, such as `numpy`. If you're in Google Colab, then as of May 2025, this comes with a later version (2.0.2) pre-installed. We require an older version (we'll be installing `1.24.4`). This causes Colab to force a session restart and then re-running of the installation cells for the new version to take effect. When you run the cell below, you will be prompted to restart the session. This is *entirely expected* and you haven't done anything wrong. Simply click 'Restart' and then run the cells as normal. \n",
+ "\n",
+ "An additional error might sometimes arise where an exception is raised connected to a missing element of NumPy. If this occurs, please restart the session and re-run the cells as normal and this error will go away. Updated versions of the affected libraries are expected out soon, but sadly not in time for the preparation of this material. We thank you for your understanding.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Install dependencies\n",
+ "\n",
+ "!pip install numpy==1.24.4 --quiet\n",
+ "!pip install scikit-learn==1.6.1 --quiet\n",
+ "!pip install scipy==1.15.3 --quiet\n",
+ "!pip install git+https://github.com/neuromatch/sspspace@neuromatch --no-deps --quiet\n",
+ "!pip install nengo==4.0.0 --quiet\n",
+ "!pip install nengo_spa==2.0.0 --quiet\n",
+ "!pip install --quiet matplotlib ipywidgets tqdm vibecheck"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Install and import feedback gadget\n",
+ "\n",
+ "from vibecheck import DatatopsContentReviewContainer\n",
+ "def content_review(notebook_section: str):\n",
+ " return DatatopsContentReviewContainer(\n",
+ " \"\", # No text prompt\n",
+ " notebook_section,\n",
+ " {\n",
+ " \"url\": \"https://pmyvdlilci.execute-api.us-east-1.amazonaws.com/klab\",\n",
+ " \"name\": \"neuromatch_neuroai\",\n",
+ " \"user_key\": \"wb2cxze8\",\n",
+ " },\n",
+ " ).render()\n",
+ "\n",
+ "\n",
+ "feedback_prefix = \"W2D2_T5\""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Imports\n",
+ "\n",
+ "#working with data\n",
+ "import numpy as np\n",
+ "import random\n",
+ "\n",
+ "#plotting\n",
+ "import matplotlib.pyplot as plt\n",
+ "import logging\n",
+ "\n",
+ "#interactive display\n",
+ "import ipywidgets as widgets\n",
+ "\n",
+ "#modeling\n",
+ "import sspspace\n",
+ "from sklearn.linear_model import LinearRegression\n",
+ "from sklearn.model_selection import train_test_split\n",
+ "\n",
+ "from tqdm.notebook import tqdm as tqdm"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Figure settings\n",
+ "\n",
+ "logging.getLogger('matplotlib.font_manager').disabled = True\n",
+ "\n",
+ "%matplotlib inline\n",
+ "%config InlineBackend.figure_format = 'retina' # perfrom high definition rendering for images and plots\n",
+ "plt.style.use(\"https://raw.githubusercontent.com/NeuromatchAcademy/course-content/main/nma.mplstyle\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Plotting functions\n",
+ "\n",
+ "def plot_3d_function(X, Y, zs, titles):\n",
+ " \"\"\"Plot 3D function.\n",
+ "\n",
+ " Inputs:\n",
+ " - X (list): list of np.ndarray of x-values.\n",
+ " - Y (list): list of np.ndarray of y-values.\n",
+ " - zs (list): list of np.ndarray of z-values.\n",
+ " - titles (list): list of titles of the plot.\n",
+ " \"\"\"\n",
+ " with plt.xkcd():\n",
+ " fig = plt.figure(figsize=(8, 8))\n",
+ " for index, (x, y, z) in enumerate(zip(X, Y, zs)):\n",
+ " fig.add_subplot(1, len(X), index + 1, projection='3d')\n",
+ " plt.gca().plot_surface(x,y,z.reshape(x.shape),cmap='plasma', antialiased=False, linewidth=0)\n",
+ " plt.xlabel(r'$x_{1}$')\n",
+ " plt.ylabel(r'$x_{2}$')\n",
+ " plt.gca().set_zlabel(r'$f(\\mathbf{x})$')\n",
+ " plt.title(titles[index])\n",
+ " plt.show()\n",
+ "\n",
+ "def plot_performance(bound_performance, bundle_performance, training_samples, title):\n",
+ " \"\"\"Plot RMSE values for two different representations of the input data.\n",
+ "\n",
+ " Inputs:\n",
+ " - bound_performance (list): list of RMSE for bound representation.\n",
+ " - bundle_performance (list): list of RMSE for bundle representation.\n",
+ " - training_samples (list): x-axis.\n",
+ " - title (str): title of the plot.\n",
+ " \"\"\"\n",
+ " with plt.xkcd():\n",
+ " plt.plot(training_samples, bound_performance, label='Bound Representation')\n",
+ " plt.plot(training_samples, bundle_performance, label='Bundling Representation', ls='--')\n",
+ " plt.legend()\n",
+ " plt.title(title)\n",
+ " plt.ylabel('RMSE (a.u.)')\n",
+ " plt.xlabel('# Training samples')\n",
+ "\n",
+ "def plot_2d_similarity(sims, obj_names, size, title_argmax = False):\n",
+ " \"\"\"\n",
+ " Plot 2D similarity between query points (grid) and the ones associated with the objects.\n",
+ "\n",
+ " Inputs:\n",
+ " - sims (list): list of similarity values for each of the objects.\n",
+ " - obj_names (list): list of object names.\n",
+ " - size (tuple): to reshape the similarities.\n",
+ " - title_argmax (bool, default = False): looks for the point coordinates as arg max from all similarity value.\n",
+ " \"\"\"\n",
+ " ticks = [0, 24, 49, 74, 99]\n",
+ " ticklabels = [-5, -2, 0, 2, 5]\n",
+ " with plt.xkcd():\n",
+ " for obj_idx, obj in enumerate(obj_names):\n",
+ " plt.subplot(1, len(obj_names), 1 + obj_idx)\n",
+ " plt.imshow(np.array(sims[obj_idx].reshape(size)), origin='lower', vmin=-1, vmax=1)\n",
+ " plt.gca().set_xticks(ticks)\n",
+ " plt.gca().set_xticklabels(ticklabels)\n",
+ " if obj_idx == 0:\n",
+ " plt.gca().set_yticks(ticks)\n",
+ " plt.gca().set_yticklabels(ticklabels)\n",
+ " else:\n",
+ " plt.gca().set_yticks([])\n",
+ " if not title_argmax:\n",
+ " plt.title(f'{obj}, {positions[obj_idx]}')\n",
+ " else:\n",
+ " plt.title(f'{obj}, {query_xs[sims[obj_idx].argmax()]}')\n",
+ "\n",
+ "def plot_unbinding_objects_map(sims, positions, query_xs, size):\n",
+ " \"\"\"\n",
+ " Plot 2D similarity between query points (grid) and the unbinded from the objects map.\n",
+ "\n",
+ " Inputs:\n",
+ " - sims (np.ndarray): similarity values for each of the query points with the map.\n",
+ " - positions (np.ndarray): positions of the objects.\n",
+ " - query_xs (np.ndarray): grid points.\n",
+ " - size (tuple): to reshape the similarities.\n",
+ "\n",
+ " \"\"\"\n",
+ " ticks = [0,24,49,74,99]\n",
+ " ticklabels = [-5,-2,0,2,5]\n",
+ " with plt.xkcd():\n",
+ " plt.imshow(sims.reshape(size), origin='lower')\n",
+ "\n",
+ " for idx, marker in enumerate(['o','s','^']):\n",
+ " plt.scatter(*get_coordinate(positions[idx,:], query_xs, size), marker=marker,s=100)\n",
+ "\n",
+ " plt.gca().set_xticks(ticks)\n",
+ " plt.gca().set_xticklabels(ticklabels)\n",
+ " plt.gca().set_yticks(ticks)\n",
+ " plt.gca().set_yticklabels(ticklabels)\n",
+ " plt.title(f'All Object Locations')\n",
+ " plt.show()\n",
+ "\n",
+ "def plot_unbinding_positions_map(sims, positions, obj_names):\n",
+ " \"\"\"\n",
+ " Plot 2D similarity between query points (grid) and the unbinded from the positions map.\n",
+ "\n",
+ " Inputs:\n",
+ " - sims (np.ndarray): similarity values for each of the query points with the map.\n",
+ " - positions (np.ndarray): test positions to query.\n",
+ " - obj_names (list): names of the objects for labels.\n",
+ " - size (tuple): to reshape the similarities.\n",
+ " \"\"\"\n",
+ " with plt.xkcd():\n",
+ " plt.figure(figsize=(8, 4))\n",
+ " for pos_idx, pos in enumerate(positions):\n",
+ " plt.subplot(1,len(test_positions), 1+pos_idx)\n",
+ " plt.bar([1,2,3], sims[pos_idx])\n",
+ " plt.ylim([-0.3, 1.05])\n",
+ " plt.gca().set_xticks([1,2,3])\n",
+ " plt.gca().set_xticklabels(obj_names, rotation=90)\n",
+ " if pos_idx != 0:\n",
+ " plt.gca().set_yticks([])\n",
+ " plt.title(f'Symbols at\\n{pos}')\n",
+ " plt.show()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Set random seed\n",
+ "\n",
+ "def set_seed(seed=None):\n",
+ " if seed is None:\n",
+ " seed = np.random.choice(2 ** 32)\n",
+ " random.seed(seed)\n",
+ " np.random.seed(seed)\n",
+ "\n",
+ "set_seed(seed = 42)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Helper functions\n",
+ "\n",
+ "def get_model(xs, ys, train_size):\n",
+ " \"\"\"Fit linear regression to the given data.\n",
+ "\n",
+ " Inputs:\n",
+ " - xs (np.ndarray): input data.\n",
+ " - ys (np.ndarray): output data.\n",
+ " - train_size (float): fraction of data to use for train.\n",
+ " \"\"\"\n",
+ " X_train, _, y_train, _ = train_test_split(xs, ys, random_state=1, train_size=train_size)\n",
+ " return LinearRegression().fit(X_train, y_train)\n",
+ "\n",
+ "def get_coordinate(x, positions, target_shape):\n",
+ " \"\"\"Return the closest column and row coordinates for the given position.\n",
+ "\n",
+ " Inputs:\n",
+ " - x (np.ndarray): query position.\n",
+ " - positions (np.ndarray): all positions.\n",
+ " - target_shape (tuple): shape of the grid.\n",
+ "\n",
+ " Outputs:\n",
+ " - coordinates (tuple): column and row positions.\n",
+ " \"\"\"\n",
+ " idx = np.argmin(np.linalg.norm(x - positions, axis=1))\n",
+ " c = idx % target_shape[1]\n",
+ " r = idx // target_shape[1]\n",
+ " return (c,r)\n",
+ "\n",
+ "def rastrigin_solution(x):\n",
+ " \"\"\"Compute Rastrigin function for given array of d-dimenstional vectors.\n",
+ "\n",
+ " Inputs:\n",
+ " - x (np.ndarray of shape (n, d)): n d-dimensional vectors.\n",
+ "\n",
+ " Outputs:\n",
+ " - y (np.ndarray of shape (n, 1)): Rastrigin function value for each of the vectors.\n",
+ " \"\"\"\n",
+ " return 10 * x.shape[1] + np.sum(x**2 - 10 * np.cos(2*np.pi*x), axis=1)\n",
+ "\n",
+ "def non_separable_solution(x):\n",
+ " \"\"\"Compute non-separable function for given array of 2-dimenstional vectors.\n",
+ "\n",
+ " Inputs:\n",
+ " - x (np.ndarray of shape (n, 2)): n 2-dimensional vectors.\n",
+ "\n",
+ " Outputs:\n",
+ " - y (np.ndarray of shape (n, 1)): non-separable function value for each of the vectors.\n",
+ " \"\"\"\n",
+ " return np.sin(np.multiply(x[:, 0], x[:, 1]))\n",
+ "\n",
+ "x0_rastrigin = np.linspace(-5.12, 5.12, 100)\n",
+ "X_rastrigin, Y_rastrigin = np.meshgrid(x0_rastrigin,x0_rastrigin)\n",
+ "xs_rastrigin = np.vstack((X_rastrigin.flatten(), Y_rastrigin.flatten())).T\n",
+ "ys_rastrigin = rastrigin_solution(xs_rastrigin)\n",
+ "\n",
+ "x0_non_separable = np.linspace(-4, 4, 100)\n",
+ "X_non_separable, Y_non_separable = np.meshgrid(x0_non_separable,x0_non_separable)\n",
+ "xs_non_separable = np.vstack((X_non_separable.flatten(), Y_non_separable.flatten())).T\n",
+ "ys_non_separable = non_separable_solution(xs_non_separable)\n",
+ "\n",
+ "set_seed(42)\n",
+ "\n",
+ "obj_names = ['circle','square','triangle']\n",
+ "discrete_space = sspspace.DiscreteSPSpace(obj_names, ssp_dim=1024)\n",
+ "\n",
+ "objs = {n:discrete_space.encode(n) for n in obj_names}\n",
+ "\n",
+ "ssp_space = sspspace.RandomSSPSpace(domain_dim=2, ssp_dim=1024)\n",
+ "positions = np.array([[0, -2],\n",
+ " [-2, 3],\n",
+ " [3, 2]\n",
+ " ])\n",
+ "ssps = {n:ssp_space.encode(x) for n, x in zip(obj_names, positions)}\n",
+ "\n",
+ "dim0 = np.linspace(-5, 5, 101)\n",
+ "dim1 = np.linspace(-5, 5, 101)\n",
+ "X,Y = np.meshgrid(dim0, dim1)\n",
+ "\n",
+ "query_xs = np.vstack((X.flatten(), Y.flatten())).T\n",
+ "query_ssps = ssp_space.encode(query_xs)\n",
+ "\n",
+ "bound_objects = [objs[n] * ssps[n] for n in obj_names]\n",
+ "ssp_map = sspspace.SSP(np.sum(bound_objects, axis=0))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "---\n",
+ "\n",
+ "# Section 1: Sample Efficient Learning\n",
+ "\n",
+ "In this section, we will take a look at how imposing an inductive bias on our feature space can result in more sample-efficient learning. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Video 1: Function Learning and Inductive Bias\n",
+ "\n",
+ "from ipywidgets import widgets\n",
+ "from IPython.display import YouTubeVideo\n",
+ "from IPython.display import IFrame\n",
+ "from IPython.display import display\n",
+ "\n",
+ "class PlayVideo(IFrame):\n",
+ " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
+ " self.id = id\n",
+ " if source == 'Bilibili':\n",
+ " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
+ " elif source == 'Osf':\n",
+ " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
+ " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
+ "\n",
+ "def display_videos(video_ids, W=400, H=300, fs=1):\n",
+ " tab_contents = []\n",
+ " for i, video_id in enumerate(video_ids):\n",
+ " out = widgets.Output()\n",
+ " with out:\n",
+ " if video_ids[i][0] == 'Youtube':\n",
+ " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
+ " height=H, fs=fs, rel=0)\n",
+ " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
+ " else:\n",
+ " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
+ " height=H, fs=fs, autoplay=False)\n",
+ " if video_ids[i][0] == 'Bilibili':\n",
+ " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
+ " elif video_ids[i][0] == 'Osf':\n",
+ " print(f'Video available at https://osf.io/{video.id}')\n",
+ " display(video)\n",
+ " tab_contents.append(out)\n",
+ " return tab_contents\n",
+ "\n",
+ "video_ids = [('Youtube', 'KDKmDjMxU7Q'), ('Bilibili', 'BV1GM4m1S7kT')]\n",
+ "tab_contents = display_videos(video_ids, W=854, H=480)\n",
+ "tabs = widgets.Tab()\n",
+ "tabs.children = tab_contents\n",
+ "for i in range(len(tab_contents)):\n",
+ " tabs.set_title(i, video_ids[i][0])\n",
+ "display(tabs)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_function_learning_and_inductive_bias\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "## Coding Exercise 1: Additive Function\n",
+ "\n",
+ "\n",
+ "We will start with an additive function, the Rastrigin function, defined \n",
+ "\n",
+ "\\begin{align*}\n",
+ "f(\\mathbf{x}) = 10d + \\sum_{i=1}^{d} (x_{i}^{2} - 10 \\cos(2 \\pi x_{i}))\n",
+ "\\end{align*}\n",
+ "\n",
+ "where $d$ is the dimensionality of the input vector. In the cell below, complete missing parts of the function which computes values of the Rastrigin function given the input array."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete the Rastrigin function.\")\n",
+ "###################################################################\n",
+ "\n",
+ "def rastrigin(x):\n",
+ " \"\"\"Compute Rastrigin function for given array of d-dimenstional vectors.\n",
+ "\n",
+ " Inputs:\n",
+ " - x (np.ndarray of shape (n, d)): n d-dimensional vectors.\n",
+ "\n",
+ " Outputs:\n",
+ " - y (np.ndarray of shape (n, 1)): Rastrigin function value for each of the vectors.\n",
+ " \"\"\"\n",
+ " return 10 * x.shape[1] + np.sum(... - 10 * np.cos(2*np.pi*...), axis=1)\n",
+ "\n",
+ "# this code creates 10000 2-dimensional vectors which are going to be served as input to the function (thus, output is of shape (10000, 1))\n",
+ "x0_rastrigin = np.linspace(-5.12, 5.12, 100)\n",
+ "X_rastrigin, Y_rastrigin = np.meshgrid(x0_rastrigin,x0_rastrigin)\n",
+ "xs_rastrigin = np.vstack((X_rastrigin.flatten(), Y_rastrigin.flatten())).T\n",
+ "\n",
+ "ys_rastrigin = rastrigin(xs_rastrigin)\n",
+ "\n",
+ "plot_3d_function([X_rastrigin],[Y_rastrigin], [ys_rastrigin.reshape(X_rastrigin.shape)], ['Rastrigin Function'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {}
+ },
+ "source": [
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial5_Solution_bd7761a4.py)\n",
+ "\n",
+ "*Example output:*\n",
+ "\n",
+ "
\n",
- "\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "execution": {}
- },
- "source": [
- "As you can see from the above plots, when we query each location, we can clearly identify the object stored at that location. \n",
+ "You can see the effect of the memory unit in the model above because, even after the stimulus is turned off, the model is still able to answer the questions posed to it by the ``cue`` element.\n",
"\n",
- "When we query at the origin (where no object is present), we see that there is no strong candidate element. However, as we move closer to one of the objects (rightmost plot), the similarity starts to increase."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "execution": {}
- },
- "outputs": [],
- "source": [
- "# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_mixing_discrete_objects_with_continuous_space\")"
+ "You can also see the effect of the neural implementation in the noise in the output signal.\n"
]
},
{
@@ -1351,7 +565,8 @@
},
"outputs": [],
"source": [
- "# @title Video 4: Mapping Outro\n",
+ "# @title Video 4: Results Walthrough\n",
+ "\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
@@ -1386,7 +601,7 @@
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
- "video_ids = [('Youtube', 'mXNFWr_cap4'), ('Bilibili', 'BV1ND421u7gp')]\n",
+ "video_ids = [('Youtube', '3f0UqEm9Gzo'), ('Bilibili', 'BV17K7jzNEr3')]\n",
"tab_contents = display_videos(video_ids, W=854, H=480)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
@@ -1405,7 +620,7 @@
"outputs": [],
"source": [
"# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_mapping_outro\")"
+ "content_review(f\"{feedback_prefix}_results_walkthrough\")"
]
},
{
@@ -1414,10 +629,42 @@
"execution": {}
},
"source": [
- "---\n",
- "# Summary\n",
+ "## Coding Exercise \n",
"\n",
- "*Estimated timing of tutorial: 40 minutes*"
+ "**QUESTION** Try adding the concept of a ``GREEN * SQUARE`` to the model. Run the simulation for 5 seconds and compare the plots."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# Student code completion here"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_green_square_coding\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "---"
]
},
{
@@ -1429,7 +676,8 @@
},
"outputs": [],
"source": [
- "# @title Video 5: Conclusions\n",
+ "# @title Video 5: Outro Video\n",
+ "\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
@@ -1464,7 +712,7 @@
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
- "video_ids = [('Youtube', 'M6rRsdJdoYQ'), ('Bilibili', 'BV1wm421L7Se')]\n",
+ "video_ids = [('Youtube', 'mWIfBl-4FKM'), ('Bilibili', 'BV1jK7jzNE1h')]\n",
"tab_contents = display_videos(video_ids, W=854, H=480)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
@@ -1482,27 +730,24 @@
},
"outputs": [],
"source": [
- "# @title Conclusion slides\n",
- "\n",
- "from IPython.display import IFrame\n",
- "link_id = \"pxqny\"\n",
- "\n",
- "print(f\"If you want to download the slides: 'https://osf.io/download/{link_id}'\")\n",
- "\n",
- "IFrame(src=f\"https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{link_id}/?direct%26mode=render\", width=854, height=480)"
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_outro\")"
]
},
{
- "cell_type": "code",
- "execution_count": null,
+ "cell_type": "markdown",
"metadata": {
- "cellView": "form",
"execution": {}
},
- "outputs": [],
"source": [
- "# @title Submit your feedback\n",
- "content_review(f\"{feedback_prefix}_conclusions\")"
+ "---\n",
+ "# The Big Picture\n",
+ "\n",
+ "You have now built a fairly simple cognitive model. A system that has an, albeit limited, vocabulary, expressed using a Vector Symbolic Algebra (VSA). Also, importantly, it is able to answer questions about it's experience, even though the experience has passed, thanks to its working memory. Working memory is a vital component of cognitive models, and while this is a simple system, you have now experienced working with the tools that underly SPAUN, the world's largest *functional* brain model. \n",
+ "\n",
+ "Additionally, while you haven't explicitly worked with them, this model was implemented completely with spiking neurons. The Neural Engineering Framework, the mathematical tools that underpin Nengo, allow us to compile the program we wrote using the VSA into a network of neurons. If you look closely at the plots above, you can see that the lines are noisy. This is because they are smoothed (thanks to the probes' synapse) signals that represent the activity of the populations of neurons that implement our simple question answering model.\n",
+ "\n",
+ "We have not one, but two extra bonus tutorials for today. These tutorials go into more depth on the basics around how to implement the notions of analogies in a VSA (Bonus Tutorial 4) and in Bonus Tutorial 5 we go through representations in continuous space. If you have any time left over, we encourage you to work your way through this extra material."
]
}
],
@@ -1534,7 +779,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.9.19"
+ "version": "3.9.22"
}
},
"nbformat": 4,
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial4.ipynb b/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial4.ipynb
new file mode 100644
index 000000000..791fa4a94
--- /dev/null
+++ b/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial4.ipynb
@@ -0,0 +1,1022 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {},
+ "id": "view-in-github"
+ },
+ "source": [
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "# (BONUS) Tutorial 4: VSA Analogies\n",
+ "\n",
+ "**Week 2, Day 2: Neuro-Symbolic Methods**\n",
+ "\n",
+ "**By Neuromatch Academy**\n",
+ "\n",
+ "__Content creators:__ P. Michael Furlong, Chris Eliasmith\n",
+ "\n",
+ "__Content reviewers:__ Hlib Solodzhuk, Patrick Mineault, Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Alex Murphy\n",
+ "\n",
+ "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk, Alex Murphy\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "___\n",
+ "\n",
+ "\n",
+ "# Tutorial Objectives\n",
+ "\n",
+ "This tutorial will present you with a couple of toy examples using the basic operations of vector symbolic algebras. We will further show how these can generalize to new knowledge. If you are familiar with the basics of semantic algebra on word embeddings, you already understand the basics of what we'll be demonstrating in this tutorial. If not, don't worry, this tutorial is designed to be highly self-contained. If you're interested in learning more about word embedding algebra, then we encourage you to use your search engine of choice and learn more after completing the code exercises given below."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Tutorial slides\n",
+ "# @markdown These are the slides for the videos in all tutorials today\n",
+ "\n",
+ "from IPython.display import IFrame\n",
+ "link_id = \"jybuw\"\n",
+ "\n",
+ "print(f\"If you want to download the slides: 'https://osf.io/download/{link_id}'\")\n",
+ "\n",
+ "IFrame(src=f\"https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{link_id}/?direct%26mode=render\", width=854, height=480)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "---\n",
+ "# Setup (Colab Users: Please Read)\n",
+ "\n",
+ "Note that because this tutorial relies on some special Python packages, these packages have requirements for specific versions of common scientific libraries, such as `numpy`. If you're in Google Colab, then as of May 2025, this comes with a later version (2.0.2) pre-installed. We require an older version (we'll be installing `1.24.4`). This causes Colab to force a session restart and then re-running of the installation cells for the new version to take effect. When you run the cell below, you will be prompted to restart the session. This is *entirely expected* and you haven't done anything wrong. Simply click 'Restart' and then run the cells as normal. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Install dependencies and import feedback gadget\n",
+ "\n",
+ "!pip install numpy==1.24.4 --quiet\n",
+ "!pip install scikit-learn==1.6.1 --quiet\n",
+ "!pip install scipy==1.15.3 --quiet\n",
+ "!pip install git+https://github.com/neuromatch/sspspace@neuromatch --no-deps --quiet\n",
+ "!pip install nengo==4.0.0 --quiet\n",
+ "!pip install nengo_spa==2.0.0 --quiet\n",
+ "!pip install --quiet matplotlib ipywidgets vibecheck\n",
+ "!pip install --quiet numpy matplotlib ipywidgets scipy scikit-learn vibecheck\n",
+ "\n",
+ "from vibecheck import DatatopsContentReviewContainer\n",
+ "def content_review(notebook_section: str):\n",
+ " return DatatopsContentReviewContainer(\n",
+ " \"\", # No text prompt\n",
+ " notebook_section,\n",
+ " {\n",
+ " \"url\": \"https://pmyvdlilci.execute-api.us-east-1.amazonaws.com/klab\",\n",
+ " \"name\": \"neuromatch_neuroai\",\n",
+ " \"user_key\": \"wb2cxze8\",\n",
+ " },\n",
+ " ).render()\n",
+ "\n",
+ "\n",
+ "feedback_prefix = \"W2D2_T4\""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Notice that exactly the `neuromatch` branch of `sspspace` should be installed! Otherwise, some of the functionality (like `optimize` parameter in the `DiscreteSPSpace` initialization) won't work."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Imports\n",
+ "\n",
+ "#working with data\n",
+ "import numpy as np\n",
+ "\n",
+ "#plotting\n",
+ "import matplotlib.pyplot as plt\n",
+ "import logging\n",
+ "\n",
+ "#interactive display\n",
+ "# import ipywidgets as widgets\n",
+ "\n",
+ "#modeling\n",
+ "import sspspace\n",
+ "import nengo_spa as spa\n",
+ "from scipy.special import softmax\n",
+ "from sklearn.metrics import log_loss\n",
+ "from sklearn.neural_network import MLPRegressor\n",
+ "from nengo_spa.algebras.hrr_algebra import HrrProperties, HrrAlgebra\n",
+ "from nengo_spa.vector_generation import VectorsWithProperties\n",
+ "\n",
+ "def make_vocabulary(vector_length):\n",
+ " vec_generator = VectorsWithProperties(vector_length, algebra=HrrAlgebra(), properties = [HrrProperties.UNITARY, HrrProperties.POSITIVE])\n",
+ " vocab = spa.Vocabulary(vector_length, pointer_gen=vec_generator)\n",
+ " return vocab"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Figure settings\n",
+ "\n",
+ "logging.getLogger('matplotlib.font_manager').disabled = True\n",
+ "\n",
+ "%matplotlib inline\n",
+ "%config InlineBackend.figure_format = 'retina' # perfrom high definition rendering for images and plots\n",
+ "plt.style.use(\"https://raw.githubusercontent.com/NeuromatchAcademy/course-content/main/nma.mplstyle\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Plotting functions\n",
+ "\n",
+ "def plot_similarity_matrix(sim_mat, labels, values = False):\n",
+ " \"\"\"\n",
+ " Plot the similarity matrix between vectors.\n",
+ "\n",
+ " Inputs:\n",
+ " - sim_mat (numpy.ndarray): similarity matrix between vectors.\n",
+ " - labels (list of str): list of strings which represent concepts.\n",
+ " - values (bool): True if we would like to plot values of similarity too.\n",
+ " \"\"\"\n",
+ " with plt.xkcd():\n",
+ " plt.imshow(sim_mat, cmap='Greys')\n",
+ " plt.colorbar()\n",
+ " plt.xticks(np.arange(len(labels)), labels, rotation=45, ha=\"right\", rotation_mode=\"anchor\")\n",
+ " plt.yticks(np.arange(len(labels)), labels)\n",
+ " if values:\n",
+ " for x in range(sim_mat.shape[1]):\n",
+ " for y in range(sim_mat.shape[0]):\n",
+ " plt.text(x, y, f\"{sim_mat[y, x]:.2f}\", fontsize = 8, ha=\"center\", va=\"center\", color=\"green\")\n",
+ " plt.title('Similarity between vector-symbols')\n",
+ " plt.xlabel('Symbols')\n",
+ " plt.ylabel('Symbols')\n",
+ " plt.show()\n",
+ "\n",
+ "def plot_training_and_choice(losses, sims, ant_names, cons_names, action_names):\n",
+ " \"\"\"\n",
+ " Plot loss progression over training as well as predicted similarities for given rules / correct solutions.\n",
+ "\n",
+ " Inputs:\n",
+ " - losses (list): list of loss values.\n",
+ " - sims (list): list of similartiy matrices.\n",
+ " - ant_names (list): list of antecedance names.\n",
+ " - cons_names (list): list of consequent names.\n",
+ " - action_names (list): full list of concepts.\n",
+ " \"\"\"\n",
+ " with plt.xkcd():\n",
+ " plt.subplot(1, len(ant_names) + 1, 1)\n",
+ " plt.plot(losses)\n",
+ " plt.xlabel('Training number')\n",
+ " plt.ylabel('Loss')\n",
+ " plt.title('Training Error')\n",
+ " index = 1\n",
+ " for ant_name, cons_name, sim in zip(ant_names, cons_names, sims):\n",
+ " index += 1\n",
+ " plt.subplot(1, len(ant_names) + 1, index)\n",
+ " plt.bar(range(len(action_names)), sim.flatten())\n",
+ " plt.gca().set_xticks(range(len(action_names)))\n",
+ " plt.gca().set_xticklabels(action_names, rotation=90)\n",
+ " plt.title(f'{ant_name}, not*{cons_name}')\n",
+ "\n",
+ "def plot_choice(sims, ant_names, cons_names, action_names):\n",
+ " \"\"\"\n",
+ " Plot predicted similarities for given rules / correct solutions.\n",
+ " \"\"\"\n",
+ " with plt.xkcd():\n",
+ " index = 0\n",
+ " for ant_name, cons_name, sim in zip(ant_names, cons_names, sims):\n",
+ " index += 1\n",
+ " plt.subplot(1, len(ant_names) + 1, index)\n",
+ " plt.bar(range(len(action_names)), sim.flatten())\n",
+ " plt.gca().set_xticks(range(len(action_names)))\n",
+ " plt.gca().set_xticklabels(action_names, rotation=90)\n",
+ " plt.ylabel(\"Similarity\")\n",
+ " plt.title(f'{ant_name}, not*{cons_name}')"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Set random seed\n",
+ "\n",
+ "import random\n",
+ "import numpy as np\n",
+ "\n",
+ "def set_seed(seed=None):\n",
+ " if seed is None:\n",
+ " seed = np.random.choice(2 ** 32)\n",
+ " random.seed(seed)\n",
+ " np.random.seed(seed)\n",
+ "\n",
+ "set_seed(seed = 42)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Helper functions\n",
+ "\n",
+ "set_seed(42)\n",
+ "\n",
+ "symbol_names = ['monarch','heir','male','female']\n",
+ "discrete_space = sspspace.DiscreteSPSpace(symbol_names, ssp_dim=1024, optimize=False)\n",
+ "\n",
+ "objs = {n:discrete_space.encode(n) for n in symbol_names}\n",
+ "\n",
+ "objs['king'] = objs['monarch'] * objs['male']\n",
+ "objs['queen'] = objs['monarch'] * objs['female']\n",
+ "objs['prince'] = objs['heir'] * objs['male']\n",
+ "objs['princess'] = objs['heir'] * objs['female']\n",
+ "\n",
+ "bundle_objs = {n:discrete_space.encode(n) for n in symbol_names}\n",
+ "\n",
+ "bundle_objs['king'] = (bundle_objs['monarch'] + bundle_objs['male']).normalize()\n",
+ "bundle_objs['queen'] = (bundle_objs['monarch'] + bundle_objs['female']).normalize()\n",
+ "bundle_objs['prince'] = (bundle_objs['heir'] + bundle_objs['male']).normalize()\n",
+ "bundle_objs['princess'] = (bundle_objs['heir'] + bundle_objs['female']).normalize()\n",
+ "\n",
+ "bundle_objs['princess_query'] = (bundle_objs['prince'] - bundle_objs['king']) + bundle_objs['queen']\n",
+ "\n",
+ "new_symbol_names = ['dollar', 'peso', 'ottawa', 'mexico-city', 'currency', 'capital']\n",
+ "new_discrete_space = sspspace.DiscreteSPSpace(new_symbol_names, ssp_dim=1024, optimize=False)\n",
+ "\n",
+ "new_objs = {n:new_discrete_space.encode(n) for n in new_symbol_names}\n",
+ "\n",
+ "cleanup = sspspace.Cleanup(new_objs)\n",
+ "\n",
+ "new_objs['canada'] = ((new_objs['currency'] * new_objs['dollar']) + (new_objs['capital'] * new_objs['ottawa'])).normalize()\n",
+ "new_objs['mexico'] = ((new_objs['currency'] * new_objs['peso']) + (new_objs['capital'] * new_objs['mexico-city'])).normalize()\n",
+ "\n",
+ "card_states = ['red','blue','odd','even','not','green','prime','implies','ant','relation','cons']\n",
+ "encoder = sspspace.DiscreteSPSpace(card_states, ssp_dim=1024, optimize=False)\n",
+ "vocab = {c:encoder.encode(c) for c in card_states}\n",
+ "\n",
+ "for a in ['red','blue','odd','even','green','prime']:\n",
+ " vocab[f'not*{a}'] = vocab['not'] * vocab[a]\n",
+ "\n",
+ "action_names = ['red','blue','odd','even','green','prime','not*red','not*blue','not*odd','not*even','not*green','not*prime']\n",
+ "action_space = np.array([vocab[x] for x in action_names]).squeeze()\n",
+ "\n",
+ "rules = [\n",
+ " (vocab['ant'] * vocab['blue'] + vocab['relation'] * vocab['implies'] + vocab['cons'] * vocab['even']).normalize(),\n",
+ " (vocab['ant'] * vocab['odd'] + vocab['relation'] * vocab['implies'] + vocab['cons'] * vocab['green']).normalize(),\n",
+ "]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "---\n",
+ "\n",
+ "# Section 1: Analogies. Part 1\n",
+ "\n",
+ "In this section we will construct a simple analogy using Vector Symbolic Algebras. The question we are going to try and solve is \"King is to the queen as the prince is to X.\""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Video 1: Analogy 1\n",
+ "\n",
+ "from ipywidgets import widgets\n",
+ "from IPython.display import YouTubeVideo\n",
+ "from IPython.display import IFrame\n",
+ "from IPython.display import display\n",
+ "\n",
+ "class PlayVideo(IFrame):\n",
+ " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
+ " self.id = id\n",
+ " if source == 'Bilibili':\n",
+ " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
+ " elif source == 'Osf':\n",
+ " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
+ " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
+ "\n",
+ "def display_videos(video_ids, W=400, H=300, fs=1):\n",
+ " tab_contents = []\n",
+ " for i, video_id in enumerate(video_ids):\n",
+ " out = widgets.Output()\n",
+ " with out:\n",
+ " if video_ids[i][0] == 'Youtube':\n",
+ " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
+ " height=H, fs=fs, rel=0)\n",
+ " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
+ " else:\n",
+ " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
+ " height=H, fs=fs, autoplay=False)\n",
+ " if video_ids[i][0] == 'Bilibili':\n",
+ " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
+ " elif video_ids[i][0] == 'Osf':\n",
+ " print(f'Video available at https://osf.io/{video.id}')\n",
+ " display(video)\n",
+ " tab_contents.append(out)\n",
+ " return tab_contents\n",
+ "\n",
+ "video_ids = [('Youtube', '2tR4fHvL1Jk'), ('Bilibili', 'BV1fS411P7Ez')]\n",
+ "tab_contents = display_videos(video_ids, W=854, H=480)\n",
+ "tabs = widgets.Tab()\n",
+ "tabs.children = tab_contents\n",
+ "for i in range(len(tab_contents)):\n",
+ " tabs.set_title(i, video_ids[i][0])\n",
+ "display(tabs)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_analogy_part_one\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "## Coding Exercise 1: Royal Relationships\n",
+ "\n",
+ "We're going to start by considering our vocabulary. We will use the basic discrete concepts of monarch, heir, male, and female."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Let's create the objects we know about by combinatorially expanding the space: \n",
+ "\n",
+ "1. King is a male monarch\n",
+ "2. Queen is a female monarch\n",
+ "3. Prince is a male heir\n",
+ "4. Princess is a female heir\n",
+ "\n",
+ "Complete the missing parts of the code to obtain correct representations of new concepts."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "set_seed(42)\n",
+ "\n",
+ "vector_length = 1024\n",
+ "symbol_names = ['MONARCH', 'HEIR', 'MALE', 'FEMALE']\n",
+ "vocab = make_vocabulary(vector_length)\n",
+ "vocab.populate(';'.join(symbol_names))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete correct relations for creating new concepts.\")\n",
+ "\n",
+ "###################################################################\n",
+ "vocab.add('KING', vocab['MONARCH'] * vocab['MALE'])\n",
+ "vocab.add('QUEEN', vocab['MONARCH'] * ...)\n",
+ "vocab.add('PRINCE', vocab['HEIR'] * vocab['MALE'])\n",
+ "vocab.add('PRINCESS', ... * vocab['FEMALE'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {}
+ },
+ "source": [
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial4_Solution_873dadc4.py)\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Now, we can take an explicit approach. We know that the conversion from king to queen is to unbind male and bind female, so let's apply that to our prince object and see what we uncover.\n",
+ "\n",
+ "At first, in the cell below, let's recover `queen` from `king` by constructing a new `query` concept, which represents the unbinding of `male` and the binding of `female.`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete correct relation for creating `query` object to compare with `queen`.\")\n",
+ "###################################################################\n",
+ "\n",
+ "vocab.add('QUERY_QUEEN', (vocab[...] * ~vocab[...]) * vocab[...])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {}
+ },
+ "source": [
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial4_Solution_8ecc4392.py)\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Then, let's see if this new query object bears any similarity to anything in our vocabulary."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "object_names = list(vocab.keys())\n",
+ "sims = np.zeros((len(object_names), len(object_names)))\n",
+ "\n",
+ "for name_idx, name in enumerate(object_names):\n",
+ " for other_idx in range(name_idx, len(object_names)):\n",
+ " sims[name_idx, other_idx] = sims[other_idx, name_idx] = spa.dot(vocab[name], vocab[object_names[other_idx]])\n",
+ "\n",
+ "plot_similarity_matrix(sims, object_names, values = True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "The above similarity plot shows that applying that operation successfully converts king to queen. Let's apply it to 'prince' and see what happens. Now, `query` should represent the `princess` concept."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "vocab.add('QUERY_PRINCESS', (vocab['PRINCE'] * ~vocab['MALE']) * vocab['FEMALE'])\n",
+ "\n",
+ "sims = np.zeros((len(object_names), len(object_names)))\n",
+ "\n",
+ "for name_idx, name in enumerate(object_names):\n",
+ " for other_idx in range(name_idx, len(object_names)):\n",
+ " sims[name_idx, other_idx] = sims[other_idx, name_idx] = spa.dot(vocab[name], vocab[object_names[other_idx]])\n",
+ "\n",
+ "plot_similarity_matrix(sims, object_names, values = True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Here, we have successfully recovered the princess, completing the analogy.\n",
+ "\n",
+ "This approach, however, requires explicit knowledge of the construction of the objects. Let's see if we can just work with the concepts of 'king,' 'queen,' and 'prince' directly.\n",
+ "\n",
+ "In the cell below, construct the `princess` concept using only `king,` `queen`, and `prince.`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete correct relation for creating `query` object to compare with `princess`.\")\n",
+ "###################################################################\n",
+ "\n",
+ "vocab.add('QUERY_PRINCESS_2', (vocab[...] * ~vocab[...]) * vocab[...])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {}
+ },
+ "source": [
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial4_Solution_f2f03c67.py)\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "object_names = list(vocab.keys())\n",
+ "sims = np.zeros((len(object_names), len(object_names)))\n",
+ "\n",
+ "for name_idx, name in enumerate(object_names):\n",
+ " for other_idx in range(name_idx, len(object_names)):\n",
+ " sims[name_idx, other_idx] = sims[other_idx, name_idx] = spa.dot(vocab[name], vocab[object_names[other_idx]])\n",
+ "\n",
+ "plot_similarity_matrix(sims, object_names, values = True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Again, we see that we have recovered the princess by using our analogy.\n",
+ "\n",
+ "That said, the above depends on knowing that the representations are constructed using binding. Can we do something similar through the bundling operation? Let's try that out.\n",
+ "\n",
+ "Reassing concept definitions using bundling operation."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "vocab = vocab.create_subset(['MONARCH','HEIR','FEMALE','MALE'])\n",
+ "vocab.add('KING', (vocab['MONARCH'] + vocab['MALE']).normalized())\n",
+ "vocab.add('QUEEN', (vocab['MONARCH'] + vocab['FEMALE']).normalized())\n",
+ "vocab.add('PRINCE', (vocab['HEIR'] + vocab['MALE']).normalized())\n",
+ "vocab.add('PRINCESS', (vocab['HEIR'] + vocab['FEMALE']).normalized())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "But now that we are using an additive model, we need to take a different approach. Instead of unbinding the king and binding the queen, we subtract the king and add the queen to find the princess from the prince.\n",
+ "\n",
+ "Complete the code to reflect the updated mechanism."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete correct relation for creating `query` object to compare with `princess`.\")\n",
+ "###################################################################\n",
+ "\n",
+ "vocab.add('QUERY_PRINCESS', ((vocab[...] - vocab[...]) + vocab[...]).normalized())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {}
+ },
+ "source": [
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial4_Solution_73f6dd01.py)\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "object_names = list(vocab.keys())\n",
+ "sims = np.zeros((len(object_names), len(object_names)))\n",
+ "\n",
+ "for name_idx, name in enumerate(object_names):\n",
+ " for other_idx in range(name_idx, len(object_names)):\n",
+ " sims[name_idx, other_idx] = sims[other_idx, name_idx] = spa.dot(vocab[name], vocab[object_names[other_idx]])\n",
+ "\n",
+ "plot_similarity_matrix(sims, object_names, values = True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "This is a messier similarity plot due to the fact that the bundled representations interact with all their constituent parts in the vocabulary. That said, we see that 'princess' is still most similar to the query vector. \n",
+ "\n",
+ "This approach is more like what we would expect from a `word2vec` embedding."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_royal_relationships\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "---\n",
+ "\n",
+ "# Section 2: Analogies (Part 2)\n",
+ "\n",
+ "Estimated timing to here from start of tutorial: 15 minutes\n",
+ "\n",
+ "In this section, we will construct a database of data structures that describe different countries. Materials are adopted from [Kanerva (2010)](https://cdn.aaai.org/ocs/2243/2243-9566-1-PB.pdf)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Video 2: Analogy 2\n",
+ "\n",
+ "from ipywidgets import widgets\n",
+ "from IPython.display import YouTubeVideo\n",
+ "from IPython.display import IFrame\n",
+ "from IPython.display import display\n",
+ "\n",
+ "class PlayVideo(IFrame):\n",
+ " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
+ " self.id = id\n",
+ " if source == 'Bilibili':\n",
+ " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
+ " elif source == 'Osf':\n",
+ " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
+ " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
+ "\n",
+ "def display_videos(video_ids, W=400, H=300, fs=1):\n",
+ " tab_contents = []\n",
+ " for i, video_id in enumerate(video_ids):\n",
+ " out = widgets.Output()\n",
+ " with out:\n",
+ " if video_ids[i][0] == 'Youtube':\n",
+ " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
+ " height=H, fs=fs, rel=0)\n",
+ " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
+ " else:\n",
+ " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
+ " height=H, fs=fs, autoplay=False)\n",
+ " if video_ids[i][0] == 'Bilibili':\n",
+ " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
+ " elif video_ids[i][0] == 'Osf':\n",
+ " print(f'Video available at https://osf.io/{video.id}')\n",
+ " display(video)\n",
+ " tab_contents.append(out)\n",
+ " return tab_contents\n",
+ "\n",
+ "video_ids = [('Youtube', 'OB3hzhM7Ois'), ('Bilibili', 'BV1TZ421g7G5')]\n",
+ "tab_contents = display_videos(video_ids, W=854, H=480)\n",
+ "tabs = widgets.Tab()\n",
+ "tabs.children = tab_contents\n",
+ "for i in range(len(tab_contents)):\n",
+ " tabs.set_title(i, video_ids[i][0])\n",
+ "display(tabs)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_analogy_part_two\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "## Coding Exercise 2: Dollar of Mexico\n",
+ "\n",
+ "This is going to be a little more involved, because to construct the data structure we are going to need vectors that don't just represent values that we are reasoning about, but also vectors that represent different roles data can play. This is sometimes called a slot-filler representation, or a key-value representation.\n",
+ "\n",
+ "At first, let us define concepts and cleanup object."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "set_seed(42)\n",
+ "\n",
+ "symbol_names = ['DOLLAR','PESO', 'OTTAWA','MEXICO_CITY','CURRENCY','CAPITAL']\n",
+ "vocab = make_vocabulary(vector_length)\n",
+ "vocab.populate(';'.join(symbol_names))\n",
+ "\n",
+ "cleanup = sspspace.Cleanup(vocab)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Now, we will define `Canada` and `Mexico` concepts by integrating the available information together. You will be provided with `Canada` object and your task is to complete for `Mexico` one."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete `mexico` concept.\")\n",
+ "###################################################################\n",
+ "\n",
+ "vocab.add('CANADA', (vocab['CURRENCY'] * vocab['DOLLAR'] + vocab['CAPITAL'] * vocab['OTTAWA']).normalized())\n",
+ "vocab.add('MEXICO', (vocab['CURRENCY'] * ... + vocab['CAPITAL'] * ...).normalized())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {}
+ },
+ "source": [
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial4_Solution_a848247a.py)\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "We would like to find out Mexico's currency. Complete the code for constructing a `query` which will help us do that. Note that we are using a cleanup operation."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete `query` concept which will be similar to currency in Mexico.\")\n",
+ "###################################################################\n",
+ "\n",
+ "vocab.add('QUERY_MX_CURRENCY', vocab['MEXICO'] * ~(... * ~...))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {}
+ },
+ "source": [
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial4_Solution_603ce327.py)\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "object_names = list(vocab.keys())\n",
+ "sims = np.zeros((len(object_names), len(object_names)))\n",
+ "\n",
+ "for name_idx, name in enumerate(object_names):\n",
+ " for other_idx in range(name_idx, len(object_names)):\n",
+ " sims[name_idx, other_idx] = sims[other_idx, name_idx] = spa.dot(vocab[name], vocab[object_names[other_idx]])\n",
+ "\n",
+ "plot_similarity_matrix(sims, object_names)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "After cleanup, the query vector is the most similar with the 'peso' object in the vocabularly, correctly answering the question. \n",
+ "\n",
+ "Note, however, that the similarity is not perfectly equal to 1. This is due to the scale factors applied to the composite vectors 'canada' and 'mexico', to ensure they remain unit vectors, and due to cross talk. Crosstalk is a symptom of the fact that we are binding and unbinding bundles of vector symbols to produce the resultant query vector. The constituent vectors are not perfectly orthogonal (i.e., having a dot product of zero) and as such the terms in the bundle interact when we measure similarity between them."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_dollar_of_mexico\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "---\n",
+ "# The Big Picture\n",
+ "\n",
+ "*Estimated timing of tutorial: 45 minutes*\n",
+ "\n",
+ "In this tutorial, we observed three scenarios where we used the basic operations to solve different analogies and engage in structured learning. Those of you familiar with word embeddings from Natural Language Processing (NLP) might already be familiar with the idea of interpretable semantics on vector representations. This bonus tutorial helps to show how this can be accomplished in a different way. The ability to recreate different phenomena in different paradigms often gives us a great way to compare and contrast model mechanisms and we hope that this bonus tutorial has given you a curiosity to dive a bit deeper and start experimenting further with what you can accomplish using these great open-source tools!"
+ ]
+ }
+ ],
+ "metadata": {
+ "colab": {
+ "collapsed_sections": [],
+ "include_colab_link": true,
+ "name": "W2D2_Tutorial4",
+ "provenance": [],
+ "toc_visible": true
+ },
+ "kernel": {
+ "display_name": "Python 3",
+ "language": "python",
+ "name": "python3"
+ },
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.9.22"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 4
+}
diff --git a/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial5.ipynb b/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial5.ipynb
new file mode 100644
index 000000000..6acac4694
--- /dev/null
+++ b/tutorials/W2D2_NeuroSymbolicMethods/student/W2D2_Tutorial5.ipynb
@@ -0,0 +1,1537 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {},
+ "id": "view-in-github"
+ },
+ "source": [
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "# (Bonus) Tutorial 5: Representations in continuous space\n",
+ "\n",
+ "**Week 2, Day 2: Neuro-Symbolic Methods**\n",
+ "\n",
+ "**By Neuromatch Academy**\n",
+ "\n",
+ "__Content creators:__ P. Michael Furlong, Chris Eliasmith\n",
+ "\n",
+ "__Content reviewers:__ Hlib Solodzhuk, Patrick Mineault, Aakash Agrawal, Alish Dipani, Hossein Rezaei, Yousef Ghanbari, Mostafa Abdollahi, Alex Murphy\n",
+ "\n",
+ "__Production editors:__ Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk, Alex Murphy"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "___\n",
+ "\n",
+ "\n",
+ "# Tutorial Objectives\n",
+ "\n",
+ "*Estimated timing of tutorial: 40 minutes*\n",
+ "\n",
+ "In this tutorial, you will observe how the VSA methods can be applied in structures and environments to allow for efficient generalization."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Tutorial slides\n",
+ "# @markdown These are the slides for the videos in all tutorials today\n",
+ "\n",
+ "from IPython.display import IFrame\n",
+ "link_id = \"jybuw\"\n",
+ "\n",
+ "print(f\"If you want to download the slides: 'https://osf.io/download/{link_id}'\")\n",
+ "\n",
+ "IFrame(src=f\"https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{link_id}/?direct%26mode=render\", width=854, height=480)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "---\n",
+ "# Setup (Colab Users: Please Read)\n",
+ "\n",
+ "Note that because this tutorial relies on some special Python packages, these packages have requirements for specific versions of common scientific libraries, such as `numpy`. If you're in Google Colab, then as of May 2025, this comes with a later version (2.0.2) pre-installed. We require an older version (we'll be installing `1.24.4`). This causes Colab to force a session restart and then re-running of the installation cells for the new version to take effect. When you run the cell below, you will be prompted to restart the session. This is *entirely expected* and you haven't done anything wrong. Simply click 'Restart' and then run the cells as normal. \n",
+ "\n",
+ "An additional error might sometimes arise where an exception is raised connected to a missing element of NumPy. If this occurs, please restart the session and re-run the cells as normal and this error will go away. Updated versions of the affected libraries are expected out soon, but sadly not in time for the preparation of this material. We thank you for your understanding.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Install dependencies\n",
+ "\n",
+ "!pip install numpy==1.24.4 --quiet\n",
+ "!pip install scikit-learn==1.6.1 --quiet\n",
+ "!pip install scipy==1.15.3 --quiet\n",
+ "!pip install git+https://github.com/neuromatch/sspspace@neuromatch --no-deps --quiet\n",
+ "!pip install nengo==4.0.0 --quiet\n",
+ "!pip install nengo_spa==2.0.0 --quiet\n",
+ "!pip install --quiet matplotlib ipywidgets tqdm vibecheck"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Install and import feedback gadget\n",
+ "\n",
+ "from vibecheck import DatatopsContentReviewContainer\n",
+ "def content_review(notebook_section: str):\n",
+ " return DatatopsContentReviewContainer(\n",
+ " \"\", # No text prompt\n",
+ " notebook_section,\n",
+ " {\n",
+ " \"url\": \"https://pmyvdlilci.execute-api.us-east-1.amazonaws.com/klab\",\n",
+ " \"name\": \"neuromatch_neuroai\",\n",
+ " \"user_key\": \"wb2cxze8\",\n",
+ " },\n",
+ " ).render()\n",
+ "\n",
+ "\n",
+ "feedback_prefix = \"W2D2_T5\""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Imports\n",
+ "\n",
+ "#working with data\n",
+ "import numpy as np\n",
+ "import random\n",
+ "\n",
+ "#plotting\n",
+ "import matplotlib.pyplot as plt\n",
+ "import logging\n",
+ "\n",
+ "#interactive display\n",
+ "import ipywidgets as widgets\n",
+ "\n",
+ "#modeling\n",
+ "import sspspace\n",
+ "from sklearn.linear_model import LinearRegression\n",
+ "from sklearn.model_selection import train_test_split\n",
+ "\n",
+ "from tqdm.notebook import tqdm as tqdm"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Figure settings\n",
+ "\n",
+ "logging.getLogger('matplotlib.font_manager').disabled = True\n",
+ "\n",
+ "%matplotlib inline\n",
+ "%config InlineBackend.figure_format = 'retina' # perfrom high definition rendering for images and plots\n",
+ "plt.style.use(\"https://raw.githubusercontent.com/NeuromatchAcademy/course-content/main/nma.mplstyle\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Plotting functions\n",
+ "\n",
+ "def plot_3d_function(X, Y, zs, titles):\n",
+ " \"\"\"Plot 3D function.\n",
+ "\n",
+ " Inputs:\n",
+ " - X (list): list of np.ndarray of x-values.\n",
+ " - Y (list): list of np.ndarray of y-values.\n",
+ " - zs (list): list of np.ndarray of z-values.\n",
+ " - titles (list): list of titles of the plot.\n",
+ " \"\"\"\n",
+ " with plt.xkcd():\n",
+ " fig = plt.figure(figsize=(8, 8))\n",
+ " for index, (x, y, z) in enumerate(zip(X, Y, zs)):\n",
+ " fig.add_subplot(1, len(X), index + 1, projection='3d')\n",
+ " plt.gca().plot_surface(x,y,z.reshape(x.shape),cmap='plasma', antialiased=False, linewidth=0)\n",
+ " plt.xlabel(r'$x_{1}$')\n",
+ " plt.ylabel(r'$x_{2}$')\n",
+ " plt.gca().set_zlabel(r'$f(\\mathbf{x})$')\n",
+ " plt.title(titles[index])\n",
+ " plt.show()\n",
+ "\n",
+ "def plot_performance(bound_performance, bundle_performance, training_samples, title):\n",
+ " \"\"\"Plot RMSE values for two different representations of the input data.\n",
+ "\n",
+ " Inputs:\n",
+ " - bound_performance (list): list of RMSE for bound representation.\n",
+ " - bundle_performance (list): list of RMSE for bundle representation.\n",
+ " - training_samples (list): x-axis.\n",
+ " - title (str): title of the plot.\n",
+ " \"\"\"\n",
+ " with plt.xkcd():\n",
+ " plt.plot(training_samples, bound_performance, label='Bound Representation')\n",
+ " plt.plot(training_samples, bundle_performance, label='Bundling Representation', ls='--')\n",
+ " plt.legend()\n",
+ " plt.title(title)\n",
+ " plt.ylabel('RMSE (a.u.)')\n",
+ " plt.xlabel('# Training samples')\n",
+ "\n",
+ "def plot_2d_similarity(sims, obj_names, size, title_argmax = False):\n",
+ " \"\"\"\n",
+ " Plot 2D similarity between query points (grid) and the ones associated with the objects.\n",
+ "\n",
+ " Inputs:\n",
+ " - sims (list): list of similarity values for each of the objects.\n",
+ " - obj_names (list): list of object names.\n",
+ " - size (tuple): to reshape the similarities.\n",
+ " - title_argmax (bool, default = False): looks for the point coordinates as arg max from all similarity value.\n",
+ " \"\"\"\n",
+ " ticks = [0, 24, 49, 74, 99]\n",
+ " ticklabels = [-5, -2, 0, 2, 5]\n",
+ " with plt.xkcd():\n",
+ " for obj_idx, obj in enumerate(obj_names):\n",
+ " plt.subplot(1, len(obj_names), 1 + obj_idx)\n",
+ " plt.imshow(np.array(sims[obj_idx].reshape(size)), origin='lower', vmin=-1, vmax=1)\n",
+ " plt.gca().set_xticks(ticks)\n",
+ " plt.gca().set_xticklabels(ticklabels)\n",
+ " if obj_idx == 0:\n",
+ " plt.gca().set_yticks(ticks)\n",
+ " plt.gca().set_yticklabels(ticklabels)\n",
+ " else:\n",
+ " plt.gca().set_yticks([])\n",
+ " if not title_argmax:\n",
+ " plt.title(f'{obj}, {positions[obj_idx]}')\n",
+ " else:\n",
+ " plt.title(f'{obj}, {query_xs[sims[obj_idx].argmax()]}')\n",
+ "\n",
+ "def plot_unbinding_objects_map(sims, positions, query_xs, size):\n",
+ " \"\"\"\n",
+ " Plot 2D similarity between query points (grid) and the unbinded from the objects map.\n",
+ "\n",
+ " Inputs:\n",
+ " - sims (np.ndarray): similarity values for each of the query points with the map.\n",
+ " - positions (np.ndarray): positions of the objects.\n",
+ " - query_xs (np.ndarray): grid points.\n",
+ " - size (tuple): to reshape the similarities.\n",
+ "\n",
+ " \"\"\"\n",
+ " ticks = [0,24,49,74,99]\n",
+ " ticklabels = [-5,-2,0,2,5]\n",
+ " with plt.xkcd():\n",
+ " plt.imshow(sims.reshape(size), origin='lower')\n",
+ "\n",
+ " for idx, marker in enumerate(['o','s','^']):\n",
+ " plt.scatter(*get_coordinate(positions[idx,:], query_xs, size), marker=marker,s=100)\n",
+ "\n",
+ " plt.gca().set_xticks(ticks)\n",
+ " plt.gca().set_xticklabels(ticklabels)\n",
+ " plt.gca().set_yticks(ticks)\n",
+ " plt.gca().set_yticklabels(ticklabels)\n",
+ " plt.title(f'All Object Locations')\n",
+ " plt.show()\n",
+ "\n",
+ "def plot_unbinding_positions_map(sims, positions, obj_names):\n",
+ " \"\"\"\n",
+ " Plot 2D similarity between query points (grid) and the unbinded from the positions map.\n",
+ "\n",
+ " Inputs:\n",
+ " - sims (np.ndarray): similarity values for each of the query points with the map.\n",
+ " - positions (np.ndarray): test positions to query.\n",
+ " - obj_names (list): names of the objects for labels.\n",
+ " - size (tuple): to reshape the similarities.\n",
+ " \"\"\"\n",
+ " with plt.xkcd():\n",
+ " plt.figure(figsize=(8, 4))\n",
+ " for pos_idx, pos in enumerate(positions):\n",
+ " plt.subplot(1,len(test_positions), 1+pos_idx)\n",
+ " plt.bar([1,2,3], sims[pos_idx])\n",
+ " plt.ylim([-0.3, 1.05])\n",
+ " plt.gca().set_xticks([1,2,3])\n",
+ " plt.gca().set_xticklabels(obj_names, rotation=90)\n",
+ " if pos_idx != 0:\n",
+ " plt.gca().set_yticks([])\n",
+ " plt.title(f'Symbols at\\n{pos}')\n",
+ " plt.show()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Set random seed\n",
+ "\n",
+ "def set_seed(seed=None):\n",
+ " if seed is None:\n",
+ " seed = np.random.choice(2 ** 32)\n",
+ " random.seed(seed)\n",
+ " np.random.seed(seed)\n",
+ "\n",
+ "set_seed(seed = 42)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Helper functions\n",
+ "\n",
+ "def get_model(xs, ys, train_size):\n",
+ " \"\"\"Fit linear regression to the given data.\n",
+ "\n",
+ " Inputs:\n",
+ " - xs (np.ndarray): input data.\n",
+ " - ys (np.ndarray): output data.\n",
+ " - train_size (float): fraction of data to use for train.\n",
+ " \"\"\"\n",
+ " X_train, _, y_train, _ = train_test_split(xs, ys, random_state=1, train_size=train_size)\n",
+ " return LinearRegression().fit(X_train, y_train)\n",
+ "\n",
+ "def get_coordinate(x, positions, target_shape):\n",
+ " \"\"\"Return the closest column and row coordinates for the given position.\n",
+ "\n",
+ " Inputs:\n",
+ " - x (np.ndarray): query position.\n",
+ " - positions (np.ndarray): all positions.\n",
+ " - target_shape (tuple): shape of the grid.\n",
+ "\n",
+ " Outputs:\n",
+ " - coordinates (tuple): column and row positions.\n",
+ " \"\"\"\n",
+ " idx = np.argmin(np.linalg.norm(x - positions, axis=1))\n",
+ " c = idx % target_shape[1]\n",
+ " r = idx // target_shape[1]\n",
+ " return (c,r)\n",
+ "\n",
+ "def rastrigin_solution(x):\n",
+ " \"\"\"Compute Rastrigin function for given array of d-dimenstional vectors.\n",
+ "\n",
+ " Inputs:\n",
+ " - x (np.ndarray of shape (n, d)): n d-dimensional vectors.\n",
+ "\n",
+ " Outputs:\n",
+ " - y (np.ndarray of shape (n, 1)): Rastrigin function value for each of the vectors.\n",
+ " \"\"\"\n",
+ " return 10 * x.shape[1] + np.sum(x**2 - 10 * np.cos(2*np.pi*x), axis=1)\n",
+ "\n",
+ "def non_separable_solution(x):\n",
+ " \"\"\"Compute non-separable function for given array of 2-dimenstional vectors.\n",
+ "\n",
+ " Inputs:\n",
+ " - x (np.ndarray of shape (n, 2)): n 2-dimensional vectors.\n",
+ "\n",
+ " Outputs:\n",
+ " - y (np.ndarray of shape (n, 1)): non-separable function value for each of the vectors.\n",
+ " \"\"\"\n",
+ " return np.sin(np.multiply(x[:, 0], x[:, 1]))\n",
+ "\n",
+ "x0_rastrigin = np.linspace(-5.12, 5.12, 100)\n",
+ "X_rastrigin, Y_rastrigin = np.meshgrid(x0_rastrigin,x0_rastrigin)\n",
+ "xs_rastrigin = np.vstack((X_rastrigin.flatten(), Y_rastrigin.flatten())).T\n",
+ "ys_rastrigin = rastrigin_solution(xs_rastrigin)\n",
+ "\n",
+ "x0_non_separable = np.linspace(-4, 4, 100)\n",
+ "X_non_separable, Y_non_separable = np.meshgrid(x0_non_separable,x0_non_separable)\n",
+ "xs_non_separable = np.vstack((X_non_separable.flatten(), Y_non_separable.flatten())).T\n",
+ "ys_non_separable = non_separable_solution(xs_non_separable)\n",
+ "\n",
+ "set_seed(42)\n",
+ "\n",
+ "obj_names = ['circle','square','triangle']\n",
+ "discrete_space = sspspace.DiscreteSPSpace(obj_names, ssp_dim=1024)\n",
+ "\n",
+ "objs = {n:discrete_space.encode(n) for n in obj_names}\n",
+ "\n",
+ "ssp_space = sspspace.RandomSSPSpace(domain_dim=2, ssp_dim=1024)\n",
+ "positions = np.array([[0, -2],\n",
+ " [-2, 3],\n",
+ " [3, 2]\n",
+ " ])\n",
+ "ssps = {n:ssp_space.encode(x) for n, x in zip(obj_names, positions)}\n",
+ "\n",
+ "dim0 = np.linspace(-5, 5, 101)\n",
+ "dim1 = np.linspace(-5, 5, 101)\n",
+ "X,Y = np.meshgrid(dim0, dim1)\n",
+ "\n",
+ "query_xs = np.vstack((X.flatten(), Y.flatten())).T\n",
+ "query_ssps = ssp_space.encode(query_xs)\n",
+ "\n",
+ "bound_objects = [objs[n] * ssps[n] for n in obj_names]\n",
+ "ssp_map = sspspace.SSP(np.sum(bound_objects, axis=0))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "---\n",
+ "\n",
+ "# Section 1: Sample Efficient Learning\n",
+ "\n",
+ "In this section, we will take a look at how imposing an inductive bias on our feature space can result in more sample-efficient learning. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Video 1: Function Learning and Inductive Bias\n",
+ "\n",
+ "from ipywidgets import widgets\n",
+ "from IPython.display import YouTubeVideo\n",
+ "from IPython.display import IFrame\n",
+ "from IPython.display import display\n",
+ "\n",
+ "class PlayVideo(IFrame):\n",
+ " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
+ " self.id = id\n",
+ " if source == 'Bilibili':\n",
+ " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
+ " elif source == 'Osf':\n",
+ " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
+ " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
+ "\n",
+ "def display_videos(video_ids, W=400, H=300, fs=1):\n",
+ " tab_contents = []\n",
+ " for i, video_id in enumerate(video_ids):\n",
+ " out = widgets.Output()\n",
+ " with out:\n",
+ " if video_ids[i][0] == 'Youtube':\n",
+ " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
+ " height=H, fs=fs, rel=0)\n",
+ " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
+ " else:\n",
+ " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
+ " height=H, fs=fs, autoplay=False)\n",
+ " if video_ids[i][0] == 'Bilibili':\n",
+ " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
+ " elif video_ids[i][0] == 'Osf':\n",
+ " print(f'Video available at https://osf.io/{video.id}')\n",
+ " display(video)\n",
+ " tab_contents.append(out)\n",
+ " return tab_contents\n",
+ "\n",
+ "video_ids = [('Youtube', 'KDKmDjMxU7Q'), ('Bilibili', 'BV1GM4m1S7kT')]\n",
+ "tab_contents = display_videos(video_ids, W=854, H=480)\n",
+ "tabs = widgets.Tab()\n",
+ "tabs.children = tab_contents\n",
+ "for i in range(len(tab_contents)):\n",
+ " tabs.set_title(i, video_ids[i][0])\n",
+ "display(tabs)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_function_learning_and_inductive_bias\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "## Coding Exercise 1: Additive Function\n",
+ "\n",
+ "\n",
+ "We will start with an additive function, the Rastrigin function, defined \n",
+ "\n",
+ "\\begin{align*}\n",
+ "f(\\mathbf{x}) = 10d + \\sum_{i=1}^{d} (x_{i}^{2} - 10 \\cos(2 \\pi x_{i}))\n",
+ "\\end{align*}\n",
+ "\n",
+ "where $d$ is the dimensionality of the input vector. In the cell below, complete missing parts of the function which computes values of the Rastrigin function given the input array."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete the Rastrigin function.\")\n",
+ "###################################################################\n",
+ "\n",
+ "def rastrigin(x):\n",
+ " \"\"\"Compute Rastrigin function for given array of d-dimenstional vectors.\n",
+ "\n",
+ " Inputs:\n",
+ " - x (np.ndarray of shape (n, d)): n d-dimensional vectors.\n",
+ "\n",
+ " Outputs:\n",
+ " - y (np.ndarray of shape (n, 1)): Rastrigin function value for each of the vectors.\n",
+ " \"\"\"\n",
+ " return 10 * x.shape[1] + np.sum(... - 10 * np.cos(2*np.pi*...), axis=1)\n",
+ "\n",
+ "# this code creates 10000 2-dimensional vectors which are going to be served as input to the function (thus, output is of shape (10000, 1))\n",
+ "x0_rastrigin = np.linspace(-5.12, 5.12, 100)\n",
+ "X_rastrigin, Y_rastrigin = np.meshgrid(x0_rastrigin,x0_rastrigin)\n",
+ "xs_rastrigin = np.vstack((X_rastrigin.flatten(), Y_rastrigin.flatten())).T\n",
+ "\n",
+ "ys_rastrigin = rastrigin(xs_rastrigin)\n",
+ "\n",
+ "plot_3d_function([X_rastrigin],[Y_rastrigin], [ys_rastrigin.reshape(X_rastrigin.shape)], ['Rastrigin Function'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {}
+ },
+ "source": [
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial5_Solution_bd7761a4.py)\n",
+ "\n",
+ "*Example output:*\n",
+ "\n",
+ " \n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Now, we are going to see which of the inductive biases (suggested mechanism underlying input data) will be more efficient in training the linear regression to get values of the Rastrigin function. We will consider two representations:\n",
+ "\n",
+ "* **Bound**: We encode 2D input vectors `xs` as bound vectors\n",
+ "* **Bundled**: We encode 1D input vectors separately and use bundling and then bundle them together"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "set_seed(42)\n",
+ "\n",
+ "ssp_space = sspspace.RandomSSPSpace(domain_dim=2, ssp_dim=1024)\n",
+ "bound_phis = ssp_space.encode(xs_rastrigin)\n",
+ "\n",
+ "ssp_space0 = sspspace.RandomSSPSpace(domain_dim=1, ssp_dim=1024)\n",
+ "ssp_space1 = sspspace.RandomSSPSpace(domain_dim=1, ssp_dim=1024)\n",
+ "\n",
+ "#remember that input to `encode` should be 2-dimensional, thus we need to create extra dimension by applying [:,None]\n",
+ "bundle_phis = ssp_space0.encode(xs_rastrigin[:, 0][:, None]) + ssp_space1.encode(xs_rastrigin[:, 1][:, None])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Now, let us define modeling attributes: we will have a few different `train_sizes`, and we will fit a linear regression for each of them in a loop. Then, for each of the models, we will evaluate its fit based on RMSE loss on the test set."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "def loss(y_true, y_pred):\n",
+ " \"\"\"Calculate RMSE loss between true and predicted values (note, that loss is not normalized by the shape).\n",
+ "\n",
+ " Inputs:\n",
+ " - y_true (np.ndarray): true values.\n",
+ " - y_pred (np.ndarray): predicted values.\n",
+ "\n",
+ " Outputs:\n",
+ " - loss (float): loss value.\n",
+ " \"\"\"\n",
+ " return np.sqrt(np.mean((y_true - y_pred) ** 2))\n",
+ "\n",
+ "def test_performance(xs, ys, train_sizes):\n",
+ " \"\"\"Fit linear regression to the provided data and evaluate the performance with RMSE loss for different test sizes.\n",
+ "\n",
+ " Inputs:\n",
+ " - xs (np.ndarray): input data.\n",
+ " - ys (np.ndarray): output data.\n",
+ " - train_size (list): list of the train sizes.\n",
+ " \"\"\"\n",
+ " performance = []\n",
+ "\n",
+ " models = []\n",
+ " for train_size in tqdm(train_sizes):\n",
+ " X_train, X_test, y_train, y_test = train_test_split(xs, ys, random_state=1, train_size=train_size)\n",
+ " regr = LinearRegression().fit(X_train, y_train)\n",
+ " performance.append(np.copy(loss(y_test, regr.predict(X_test))))\n",
+ " models.append(regr)\n",
+ " return performance, models"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Now, we are ready to train the models on two different inductive biases of the input data."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "train_sizes = np.linspace(0.25, 0.9, 5)\n",
+ "bound_performance, bound_models = test_performance(bound_phis, ys_rastrigin, train_sizes)\n",
+ "bundle_performance, bundle_models = test_performance(bundle_phis, ys_rastrigin, train_sizes)\n",
+ "plot_performance(bound_performance, bundle_performance, train_sizes * bound_phis.shape[0], \"Rastrigin function - RMSE\")\n",
+ "plt.ylim((-1, 20))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "What a drastic difference! Let us evaluate visually the performance when training on 3,000 train points."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "bound_model = bound_models[0]\n",
+ "bundled_model = bundle_models[0]\n",
+ "\n",
+ "ys_hat_rastrigin_bound = bound_model.predict(bound_phis)\n",
+ "ys_hat_rastrigin_bundled = bundled_model.predict(bundle_phis)\n",
+ "\n",
+ "plot_3d_function([X_rastrigin, X_rastrigin, X_rastrigin], [Y_rastrigin, Y_rastrigin, Y_rastrigin], [ys_rastrigin.reshape(X_rastrigin.shape), ys_hat_rastrigin_bound.reshape(X_rastrigin.shape), ys_hat_rastrigin_bundled.reshape(X_rastrigin.shape)], ['Rastrigin Function - True', 'Bound', 'Bundled'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "### Coding Exercise 1 Discussion\n",
+ "\n",
+ "1. Why do you think the bundled representation is superior for the Rastrigin function?"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {}
+ },
+ "source": [
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial5_Solution_8c79265f.py)\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_additive_function\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "## Coding Exercise 2: Non-separable Function\n",
+ "\n",
+ "Now, let's consider a non-separable function: a function $f(x_1, x_2)$ that cannot be described as the sum of two one-dimensional functions $g(x_1)$ and $h_1$. We will examine this function over the domain $[-4,4]^{2}$:\n",
+ "\n",
+ "$$f(\\mathbf{x}) = \\sin(x_{1}x_{2})$$\n",
+ "\n",
+ "Fill in the missing parts of the code to get the correct calculation of the defined function."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete the non-separable function.\")\n",
+ "###################################################################\n",
+ "\n",
+ "def non_separable(x):\n",
+ " \"\"\"Compute non-separable function for given array of 2-dimenstional vectors.\n",
+ "\n",
+ " Inputs:\n",
+ " - x (np.ndarray of shape (n, 2)): n 2-dimensional vectors.\n",
+ "\n",
+ " Outputs:\n",
+ " - y (np.ndarray of shape (n, 1)): non-separable function value for each of the vectors.\n",
+ " \"\"\"\n",
+ " return np.sin(np.multiply(x[:, ...], x[:, ...]))\n",
+ "\n",
+ "x0_non_separable = np.linspace(-4, 4, 100)\n",
+ "X_non_separable, Y_non_separable = np.meshgrid(x0_non_separable,x0_non_separable)\n",
+ "xs_non_separable = np.vstack((X_non_separable.flatten(), Y_non_separable.flatten())).T\n",
+ "\n",
+ "ys_non_separable = non_separable(xs_non_separable)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {}
+ },
+ "source": [
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial5_Solution_730a75ed.py)\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "plot_3d_function([X_non_separable],[Y_non_separable], [ys_non_separable.reshape(X_non_separable.shape)], ['Nonseparable Function, $f(\\mathbf{x}) = \\sin(x_{1}x_{2})$'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "### Coding Exercise 2 Discussion\n",
+ "\n",
+ "1. Can you guess by the nature of the function which of the representations will be more efficient?"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {}
+ },
+ "source": [
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial5_Solution_2b4c5a99.py)\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "We will reuse previously defined spaces for encoding bound and bundled representations."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "bound_phis = ssp_space.encode(xs_non_separable)\n",
+ "bundle_phis = ssp_space0.encode(xs_non_separable[:,0][:,None]) + ssp_space1.encode(xs_non_separable[:,1][:,None])\n",
+ "\n",
+ "train_sizes = np.linspace(0.25, 0.9, 5)\n",
+ "bound_performance, bound_models = test_performance(bound_phis, ys_non_separable, train_sizes)\n",
+ "bundle_performance, bundle_models = test_performance(bundle_phis, ys_non_separable, train_sizes)\n",
+ "plot_performance(bound_performance, bundle_performance, train_sizes * bound_phis.shape[0], title = \"Non-separable function - RMSE\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Bundling representation can't achieve the same quality even when the number of samples is increased. This is because the function is non-separable, and the bundling representation can't capture the interaction between the two dimensions."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "bound_model = bound_models[0]\n",
+ "bundle_model = bundle_models[0]\n",
+ "\n",
+ "ys_hat_bound = bound_model.predict(bound_phis)\n",
+ "ys_hat_bundle = bundle_model.predict(bundle_phis)\n",
+ "\n",
+ "plot_3d_function([X_non_separable, X_non_separable, X_non_separable], [Y_non_separable, Y_non_separable, Y_non_separable], [ys_non_separable.reshape(X_non_separable.shape), ys_hat_bound.reshape(X_non_separable.shape), ys_hat_bundle.reshape(X_non_separable.shape)], ['Non-separable Function - True', 'Bound', 'Bundled'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "So, as we can see, when we pick the right inductive bias, we can do a better job."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_non_separable_function\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "---\n",
+ "\n",
+ "# Section 2: Representing Continuous Values\n",
+ "\n",
+ "Estimated timing to here from start of tutorial: 20 minutes\n",
+ "\n",
+ "In this section we will use a technique called Fractional Binding to represent continuous values to construct a map of objects distributed over a 2D space. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Video 2: Mapping Intro\n",
+ "from ipywidgets import widgets\n",
+ "from IPython.display import YouTubeVideo\n",
+ "from IPython.display import IFrame\n",
+ "from IPython.display import display\n",
+ "\n",
+ "class PlayVideo(IFrame):\n",
+ " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
+ " self.id = id\n",
+ " if source == 'Bilibili':\n",
+ " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
+ " elif source == 'Osf':\n",
+ " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
+ " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
+ "\n",
+ "def display_videos(video_ids, W=400, H=300, fs=1):\n",
+ " tab_contents = []\n",
+ " for i, video_id in enumerate(video_ids):\n",
+ " out = widgets.Output()\n",
+ " with out:\n",
+ " if video_ids[i][0] == 'Youtube':\n",
+ " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
+ " height=H, fs=fs, rel=0)\n",
+ " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
+ " else:\n",
+ " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
+ " height=H, fs=fs, autoplay=False)\n",
+ " if video_ids[i][0] == 'Bilibili':\n",
+ " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
+ " elif video_ids[i][0] == 'Osf':\n",
+ " print(f'Video available at https://osf.io/{video.id}')\n",
+ " display(video)\n",
+ " tab_contents.append(out)\n",
+ " return tab_contents\n",
+ "\n",
+ "video_ids = [('Youtube', 's7MOusrbKXU'), ('Bilibili', 'BV1pi421i7iN')]\n",
+ "tab_contents = display_videos(video_ids, W=854, H=480)\n",
+ "tabs = widgets.Tab()\n",
+ "tabs.children = tab_contents\n",
+ "for i in range(len(tab_contents)):\n",
+ " tabs.set_title(i, video_ids[i][0])\n",
+ "display(tabs)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_mapping_intro\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "## Coding Exercise 3: Mixing Discrete Objects With Continuous Space\n",
+ "\n",
+ "We will store three objects in a vector representing a map. First, we will create 3 objects (a circle, square, and triangle), as we did before."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "set_seed(42)\n",
+ "\n",
+ "obj_names = ['circle','square','triangle']\n",
+ "discrete_space = sspspace.DiscreteSPSpace(obj_names, ssp_dim=1024)\n",
+ "\n",
+ "objs = {n:discrete_space.encode(n) for n in obj_names}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Next, we are going to create three locations where the objects will reside, and an encoder will transform those coordinates into an SSP representation."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "set_seed(42)\n",
+ "\n",
+ "ssp_space = sspspace.RandomSSPSpace(domain_dim=2, ssp_dim=1024)\n",
+ "positions = np.array([[0, -2],\n",
+ " [-2, 3],\n",
+ " [3, 2]\n",
+ " ])\n",
+ "ssps = {n:ssp_space.encode(x) for n, x in zip(obj_names, positions)}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Next, in order to see where things are on the map, we are going to compute the similarity between encoded places and points in the space. Your task is to complete the calculation of similarity values between all grid points with the one associated with the object."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "dim0 = np.linspace(-5, 5, 101)\n",
+ "dim1 = np.linspace(-5, 5, 101)\n",
+ "X,Y = np.meshgrid(dim0, dim1)\n",
+ "\n",
+ "query_xs = np.vstack((X.flatten(), Y.flatten())).T\n",
+ "query_ssps = ssp_space.encode(query_xs)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete similarity calculation.\")\n",
+ "###################################################################\n",
+ "\n",
+ "sims = []\n",
+ "\n",
+ "for obj_idx, obj in enumerate(obj_names):\n",
+ " sims.append(... @ ssps[obj].flatten())\n",
+ "\n",
+ "plt.figure(figsize=(8, 2.4))\n",
+ "plot_2d_similarity(sims, obj_names, (dim0.size, dim1.size))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {}
+ },
+ "source": [
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial5_Solution_cff4accc.py)\n",
+ "\n",
+ "*Example output:*\n",
+ "\n",
+ "
\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Now, we are going to see which of the inductive biases (suggested mechanism underlying input data) will be more efficient in training the linear regression to get values of the Rastrigin function. We will consider two representations:\n",
+ "\n",
+ "* **Bound**: We encode 2D input vectors `xs` as bound vectors\n",
+ "* **Bundled**: We encode 1D input vectors separately and use bundling and then bundle them together"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "set_seed(42)\n",
+ "\n",
+ "ssp_space = sspspace.RandomSSPSpace(domain_dim=2, ssp_dim=1024)\n",
+ "bound_phis = ssp_space.encode(xs_rastrigin)\n",
+ "\n",
+ "ssp_space0 = sspspace.RandomSSPSpace(domain_dim=1, ssp_dim=1024)\n",
+ "ssp_space1 = sspspace.RandomSSPSpace(domain_dim=1, ssp_dim=1024)\n",
+ "\n",
+ "#remember that input to `encode` should be 2-dimensional, thus we need to create extra dimension by applying [:,None]\n",
+ "bundle_phis = ssp_space0.encode(xs_rastrigin[:, 0][:, None]) + ssp_space1.encode(xs_rastrigin[:, 1][:, None])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Now, let us define modeling attributes: we will have a few different `train_sizes`, and we will fit a linear regression for each of them in a loop. Then, for each of the models, we will evaluate its fit based on RMSE loss on the test set."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "def loss(y_true, y_pred):\n",
+ " \"\"\"Calculate RMSE loss between true and predicted values (note, that loss is not normalized by the shape).\n",
+ "\n",
+ " Inputs:\n",
+ " - y_true (np.ndarray): true values.\n",
+ " - y_pred (np.ndarray): predicted values.\n",
+ "\n",
+ " Outputs:\n",
+ " - loss (float): loss value.\n",
+ " \"\"\"\n",
+ " return np.sqrt(np.mean((y_true - y_pred) ** 2))\n",
+ "\n",
+ "def test_performance(xs, ys, train_sizes):\n",
+ " \"\"\"Fit linear regression to the provided data and evaluate the performance with RMSE loss for different test sizes.\n",
+ "\n",
+ " Inputs:\n",
+ " - xs (np.ndarray): input data.\n",
+ " - ys (np.ndarray): output data.\n",
+ " - train_size (list): list of the train sizes.\n",
+ " \"\"\"\n",
+ " performance = []\n",
+ "\n",
+ " models = []\n",
+ " for train_size in tqdm(train_sizes):\n",
+ " X_train, X_test, y_train, y_test = train_test_split(xs, ys, random_state=1, train_size=train_size)\n",
+ " regr = LinearRegression().fit(X_train, y_train)\n",
+ " performance.append(np.copy(loss(y_test, regr.predict(X_test))))\n",
+ " models.append(regr)\n",
+ " return performance, models"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Now, we are ready to train the models on two different inductive biases of the input data."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "train_sizes = np.linspace(0.25, 0.9, 5)\n",
+ "bound_performance, bound_models = test_performance(bound_phis, ys_rastrigin, train_sizes)\n",
+ "bundle_performance, bundle_models = test_performance(bundle_phis, ys_rastrigin, train_sizes)\n",
+ "plot_performance(bound_performance, bundle_performance, train_sizes * bound_phis.shape[0], \"Rastrigin function - RMSE\")\n",
+ "plt.ylim((-1, 20))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "What a drastic difference! Let us evaluate visually the performance when training on 3,000 train points."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "bound_model = bound_models[0]\n",
+ "bundled_model = bundle_models[0]\n",
+ "\n",
+ "ys_hat_rastrigin_bound = bound_model.predict(bound_phis)\n",
+ "ys_hat_rastrigin_bundled = bundled_model.predict(bundle_phis)\n",
+ "\n",
+ "plot_3d_function([X_rastrigin, X_rastrigin, X_rastrigin], [Y_rastrigin, Y_rastrigin, Y_rastrigin], [ys_rastrigin.reshape(X_rastrigin.shape), ys_hat_rastrigin_bound.reshape(X_rastrigin.shape), ys_hat_rastrigin_bundled.reshape(X_rastrigin.shape)], ['Rastrigin Function - True', 'Bound', 'Bundled'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "### Coding Exercise 1 Discussion\n",
+ "\n",
+ "1. Why do you think the bundled representation is superior for the Rastrigin function?"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {}
+ },
+ "source": [
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial5_Solution_8c79265f.py)\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_additive_function\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "## Coding Exercise 2: Non-separable Function\n",
+ "\n",
+ "Now, let's consider a non-separable function: a function $f(x_1, x_2)$ that cannot be described as the sum of two one-dimensional functions $g(x_1)$ and $h_1$. We will examine this function over the domain $[-4,4]^{2}$:\n",
+ "\n",
+ "$$f(\\mathbf{x}) = \\sin(x_{1}x_{2})$$\n",
+ "\n",
+ "Fill in the missing parts of the code to get the correct calculation of the defined function."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete the non-separable function.\")\n",
+ "###################################################################\n",
+ "\n",
+ "def non_separable(x):\n",
+ " \"\"\"Compute non-separable function for given array of 2-dimenstional vectors.\n",
+ "\n",
+ " Inputs:\n",
+ " - x (np.ndarray of shape (n, 2)): n 2-dimensional vectors.\n",
+ "\n",
+ " Outputs:\n",
+ " - y (np.ndarray of shape (n, 1)): non-separable function value for each of the vectors.\n",
+ " \"\"\"\n",
+ " return np.sin(np.multiply(x[:, ...], x[:, ...]))\n",
+ "\n",
+ "x0_non_separable = np.linspace(-4, 4, 100)\n",
+ "X_non_separable, Y_non_separable = np.meshgrid(x0_non_separable,x0_non_separable)\n",
+ "xs_non_separable = np.vstack((X_non_separable.flatten(), Y_non_separable.flatten())).T\n",
+ "\n",
+ "ys_non_separable = non_separable(xs_non_separable)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {}
+ },
+ "source": [
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial5_Solution_730a75ed.py)\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "plot_3d_function([X_non_separable],[Y_non_separable], [ys_non_separable.reshape(X_non_separable.shape)], ['Nonseparable Function, $f(\\mathbf{x}) = \\sin(x_{1}x_{2})$'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "### Coding Exercise 2 Discussion\n",
+ "\n",
+ "1. Can you guess by the nature of the function which of the representations will be more efficient?"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {}
+ },
+ "source": [
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial5_Solution_2b4c5a99.py)\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "We will reuse previously defined spaces for encoding bound and bundled representations."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "bound_phis = ssp_space.encode(xs_non_separable)\n",
+ "bundle_phis = ssp_space0.encode(xs_non_separable[:,0][:,None]) + ssp_space1.encode(xs_non_separable[:,1][:,None])\n",
+ "\n",
+ "train_sizes = np.linspace(0.25, 0.9, 5)\n",
+ "bound_performance, bound_models = test_performance(bound_phis, ys_non_separable, train_sizes)\n",
+ "bundle_performance, bundle_models = test_performance(bundle_phis, ys_non_separable, train_sizes)\n",
+ "plot_performance(bound_performance, bundle_performance, train_sizes * bound_phis.shape[0], title = \"Non-separable function - RMSE\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Bundling representation can't achieve the same quality even when the number of samples is increased. This is because the function is non-separable, and the bundling representation can't capture the interaction between the two dimensions."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "bound_model = bound_models[0]\n",
+ "bundle_model = bundle_models[0]\n",
+ "\n",
+ "ys_hat_bound = bound_model.predict(bound_phis)\n",
+ "ys_hat_bundle = bundle_model.predict(bundle_phis)\n",
+ "\n",
+ "plot_3d_function([X_non_separable, X_non_separable, X_non_separable], [Y_non_separable, Y_non_separable, Y_non_separable], [ys_non_separable.reshape(X_non_separable.shape), ys_hat_bound.reshape(X_non_separable.shape), ys_hat_bundle.reshape(X_non_separable.shape)], ['Non-separable Function - True', 'Bound', 'Bundled'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "So, as we can see, when we pick the right inductive bias, we can do a better job."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_non_separable_function\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "---\n",
+ "\n",
+ "# Section 2: Representing Continuous Values\n",
+ "\n",
+ "Estimated timing to here from start of tutorial: 20 minutes\n",
+ "\n",
+ "In this section we will use a technique called Fractional Binding to represent continuous values to construct a map of objects distributed over a 2D space. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Video 2: Mapping Intro\n",
+ "from ipywidgets import widgets\n",
+ "from IPython.display import YouTubeVideo\n",
+ "from IPython.display import IFrame\n",
+ "from IPython.display import display\n",
+ "\n",
+ "class PlayVideo(IFrame):\n",
+ " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
+ " self.id = id\n",
+ " if source == 'Bilibili':\n",
+ " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
+ " elif source == 'Osf':\n",
+ " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
+ " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
+ "\n",
+ "def display_videos(video_ids, W=400, H=300, fs=1):\n",
+ " tab_contents = []\n",
+ " for i, video_id in enumerate(video_ids):\n",
+ " out = widgets.Output()\n",
+ " with out:\n",
+ " if video_ids[i][0] == 'Youtube':\n",
+ " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
+ " height=H, fs=fs, rel=0)\n",
+ " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
+ " else:\n",
+ " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
+ " height=H, fs=fs, autoplay=False)\n",
+ " if video_ids[i][0] == 'Bilibili':\n",
+ " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
+ " elif video_ids[i][0] == 'Osf':\n",
+ " print(f'Video available at https://osf.io/{video.id}')\n",
+ " display(video)\n",
+ " tab_contents.append(out)\n",
+ " return tab_contents\n",
+ "\n",
+ "video_ids = [('Youtube', 's7MOusrbKXU'), ('Bilibili', 'BV1pi421i7iN')]\n",
+ "tab_contents = display_videos(video_ids, W=854, H=480)\n",
+ "tabs = widgets.Tab()\n",
+ "tabs.children = tab_contents\n",
+ "for i in range(len(tab_contents)):\n",
+ " tabs.set_title(i, video_ids[i][0])\n",
+ "display(tabs)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_mapping_intro\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "## Coding Exercise 3: Mixing Discrete Objects With Continuous Space\n",
+ "\n",
+ "We will store three objects in a vector representing a map. First, we will create 3 objects (a circle, square, and triangle), as we did before."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "set_seed(42)\n",
+ "\n",
+ "obj_names = ['circle','square','triangle']\n",
+ "discrete_space = sspspace.DiscreteSPSpace(obj_names, ssp_dim=1024)\n",
+ "\n",
+ "objs = {n:discrete_space.encode(n) for n in obj_names}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Next, we are going to create three locations where the objects will reside, and an encoder will transform those coordinates into an SSP representation."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "set_seed(42)\n",
+ "\n",
+ "ssp_space = sspspace.RandomSSPSpace(domain_dim=2, ssp_dim=1024)\n",
+ "positions = np.array([[0, -2],\n",
+ " [-2, 3],\n",
+ " [3, 2]\n",
+ " ])\n",
+ "ssps = {n:ssp_space.encode(x) for n, x in zip(obj_names, positions)}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Next, in order to see where things are on the map, we are going to compute the similarity between encoded places and points in the space. Your task is to complete the calculation of similarity values between all grid points with the one associated with the object."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "dim0 = np.linspace(-5, 5, 101)\n",
+ "dim1 = np.linspace(-5, 5, 101)\n",
+ "X,Y = np.meshgrid(dim0, dim1)\n",
+ "\n",
+ "query_xs = np.vstack((X.flatten(), Y.flatten())).T\n",
+ "query_ssps = ssp_space.encode(query_xs)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete similarity calculation.\")\n",
+ "###################################################################\n",
+ "\n",
+ "sims = []\n",
+ "\n",
+ "for obj_idx, obj in enumerate(obj_names):\n",
+ " sims.append(... @ ssps[obj].flatten())\n",
+ "\n",
+ "plt.figure(figsize=(8, 2.4))\n",
+ "plot_2d_similarity(sims, obj_names, (dim0.size, dim1.size))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {}
+ },
+ "source": [
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial5_Solution_cff4accc.py)\n",
+ "\n",
+ "*Example output:*\n",
+ "\n",
+ "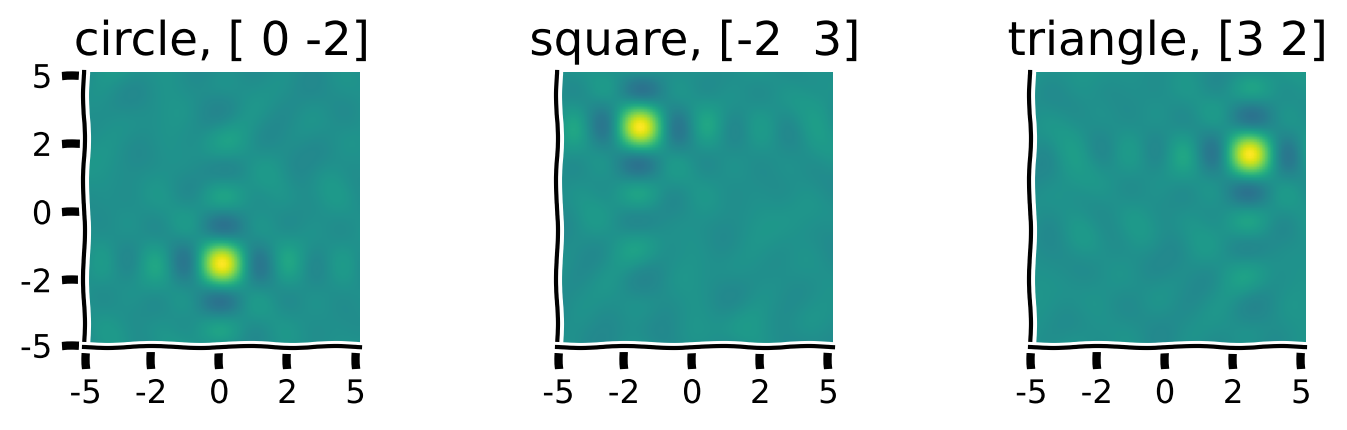 \n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Now, let's bind these positions with the objects and see how that changes similarity with the map positions. Complete binding operation in the cell below."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete binding operation for objects and corresponding positions.\")\n",
+ "###################################################################\n",
+ "\n",
+ "#objects are located in `objs` and positions in `ssps`\n",
+ "bound_objects = [... * ... for n in obj_names]\n",
+ "\n",
+ "sims = []\n",
+ "\n",
+ "for obj_idx, obj in enumerate(obj_names):\n",
+ " sims.append(query_ssps @ bound_objects[obj_idx].flatten())\n",
+ "\n",
+ "plt.figure(figsize=(8, 2.4))\n",
+ "plot_2d_similarity(sims, obj_names, (dim0.size, dim1.size))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {}
+ },
+ "source": [
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial5_Solution_b3d8f220.py)\n",
+ "\n",
+ "*Example output:*\n",
+ "\n",
+ "
\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Now, let's bind these positions with the objects and see how that changes similarity with the map positions. Complete binding operation in the cell below."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete binding operation for objects and corresponding positions.\")\n",
+ "###################################################################\n",
+ "\n",
+ "#objects are located in `objs` and positions in `ssps`\n",
+ "bound_objects = [... * ... for n in obj_names]\n",
+ "\n",
+ "sims = []\n",
+ "\n",
+ "for obj_idx, obj in enumerate(obj_names):\n",
+ " sims.append(query_ssps @ bound_objects[obj_idx].flatten())\n",
+ "\n",
+ "plt.figure(figsize=(8, 2.4))\n",
+ "plot_2d_similarity(sims, obj_names, (dim0.size, dim1.size))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {}
+ },
+ "source": [
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial5_Solution_b3d8f220.py)\n",
+ "\n",
+ "*Example output:*\n",
+ "\n",
+ "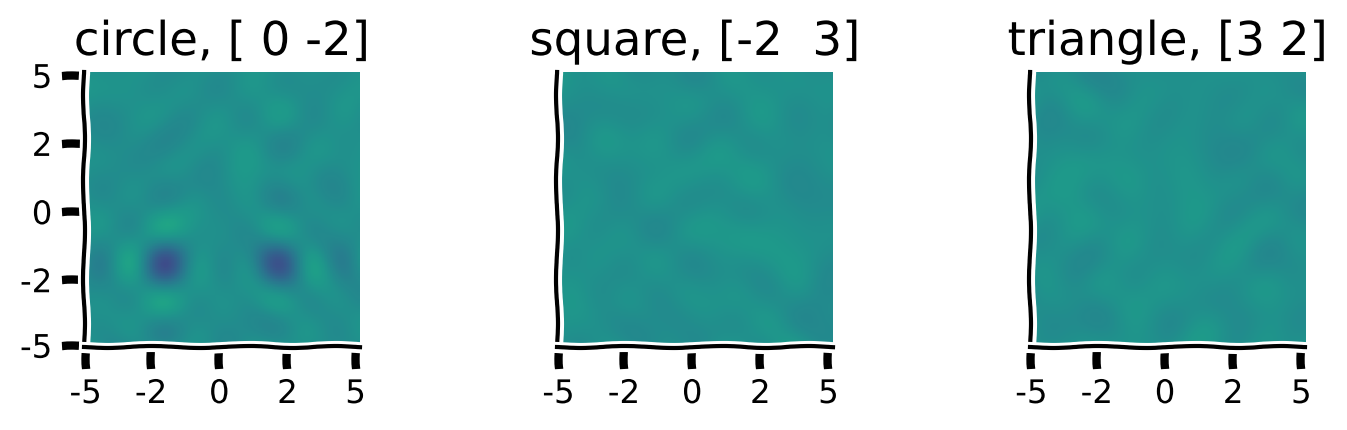 \n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "As you can see, the similarity is destroyed, which is what we should expect.\n",
+ "\n",
+ "Next, we are going to create a map out of our bound objects:\n",
+ "\n",
+ "\\begin{align*}\n",
+ "\\mathrm{map} = \\sum_{i=1}^{n} \\phi(x_{i})\\circledast obj_{i}\n",
+ "\\end{align*}"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "set_seed(42)\n",
+ "\n",
+ "ssp_map = sspspace.SSP(np.sum(bound_objects, axis=0))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Now, we can query the map by unbinding the objects we care about. Your task is to complete the unbinding operation. Then, let's observe the resulting similarities."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete the unbinding operation.\")\n",
+ "###################################################################\n",
+ "\n",
+ "objects_sims = []\n",
+ "\n",
+ "for obj_idx, obj_name in enumerate(obj_names):\n",
+ " #query the object name by unbinding it from the map\n",
+ " query_map = ssp_map * ~objs[...]\n",
+ " objects_sims.append(query_ssps @ query_map.flatten())\n",
+ "\n",
+ "plot_2d_similarity(objects_sims, obj_names, (dim0.size, dim1.size), title_argmax = True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {}
+ },
+ "source": [
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial5_Solution_99c56d84.py)\n",
+ "\n",
+ "*Example output:*\n",
+ "\n",
+ "
\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "As you can see, the similarity is destroyed, which is what we should expect.\n",
+ "\n",
+ "Next, we are going to create a map out of our bound objects:\n",
+ "\n",
+ "\\begin{align*}\n",
+ "\\mathrm{map} = \\sum_{i=1}^{n} \\phi(x_{i})\\circledast obj_{i}\n",
+ "\\end{align*}"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "set_seed(42)\n",
+ "\n",
+ "ssp_map = sspspace.SSP(np.sum(bound_objects, axis=0))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Now, we can query the map by unbinding the objects we care about. Your task is to complete the unbinding operation. Then, let's observe the resulting similarities."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete the unbinding operation.\")\n",
+ "###################################################################\n",
+ "\n",
+ "objects_sims = []\n",
+ "\n",
+ "for obj_idx, obj_name in enumerate(obj_names):\n",
+ " #query the object name by unbinding it from the map\n",
+ " query_map = ssp_map * ~objs[...]\n",
+ " objects_sims.append(query_ssps @ query_map.flatten())\n",
+ "\n",
+ "plot_2d_similarity(objects_sims, obj_names, (dim0.size, dim1.size), title_argmax = True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {}
+ },
+ "source": [
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial5_Solution_99c56d84.py)\n",
+ "\n",
+ "*Example output:*\n",
+ "\n",
+ "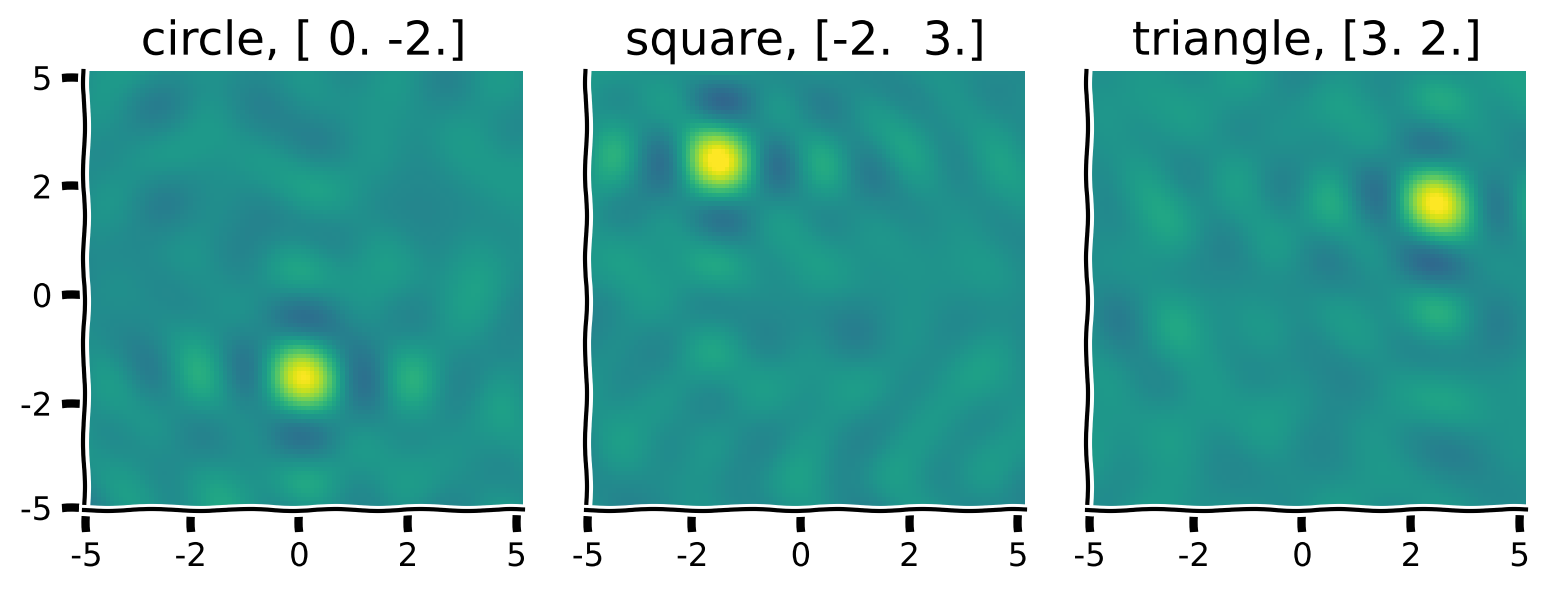 \n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Let's look at what happens when we unbind all the symbols from the map at once. Complete bundling and unbinding operations in the following code cell."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete the bundling and unbinding operations.\")\n",
+ "###################################################################\n",
+ "\n",
+ "# unifying bundled representation of all objects\n",
+ "all_objs = (objs['circle'] + objs[...] + objs[...]).normalize()\n",
+ "\n",
+ "# unbind this unifying representation from the map\n",
+ "query_map = ... * ~...\n",
+ "\n",
+ "sims = query_ssps @ query_map.flatten()\n",
+ "size = (dim0.size,dim1.size)\n",
+ "\n",
+ "plot_unbinding_objects_map(sims, positions, query_xs, size)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {}
+ },
+ "source": [
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial5_Solution_1090e65a.py)\n",
+ "\n",
+ "*Example output:*\n",
+ "\n",
+ "
\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "Let's look at what happens when we unbind all the symbols from the map at once. Complete bundling and unbinding operations in the following code cell."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete the bundling and unbinding operations.\")\n",
+ "###################################################################\n",
+ "\n",
+ "# unifying bundled representation of all objects\n",
+ "all_objs = (objs['circle'] + objs[...] + objs[...]).normalize()\n",
+ "\n",
+ "# unbind this unifying representation from the map\n",
+ "query_map = ... * ~...\n",
+ "\n",
+ "sims = query_ssps @ query_map.flatten()\n",
+ "size = (dim0.size,dim1.size)\n",
+ "\n",
+ "plot_unbinding_objects_map(sims, positions, query_xs, size)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {}
+ },
+ "source": [
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial5_Solution_1090e65a.py)\n",
+ "\n",
+ "*Example output:*\n",
+ "\n",
+ " \n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "We can also unbind positions and see what objects exist there. We will the locations where objects are located as test positions, as well as two distinct ones to compare. In the final exercise, you should complete the unbinding of the position's operation."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete the unbinding operations.\")\n",
+ "###################################################################\n",
+ "\n",
+ "query_objs = np.vstack([objs[n] for n in obj_names])\n",
+ "test_positions = np.vstack((positions, [0,0], [0,-1.5]))\n",
+ "\n",
+ "sims = []\n",
+ "\n",
+ "for pos_idx, pos in enumerate(test_positions):\n",
+ " position_ssp = ssp_space.encode(pos[None,:]) #remember we need to have 2-dimensional vectors for `encode()` function\n",
+ " #unbind positions from the map\n",
+ " query_map = ... * ~...\n",
+ " sims.append(query_objs @ query_map.flatten())\n",
+ "\n",
+ "plot_unbinding_positions_map(sims, test_positions, obj_names)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {}
+ },
+ "source": [
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial5_Solution_57dcbce1.py)\n",
+ "\n",
+ "*Example output:*\n",
+ "\n",
+ "
\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "We can also unbind positions and see what objects exist there. We will the locations where objects are located as test positions, as well as two distinct ones to compare. In the final exercise, you should complete the unbinding of the position's operation."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "###################################################################\n",
+ "## Fill out the following then remove\n",
+ "raise NotImplementedError(\"Student exercise: complete the unbinding operations.\")\n",
+ "###################################################################\n",
+ "\n",
+ "query_objs = np.vstack([objs[n] for n in obj_names])\n",
+ "test_positions = np.vstack((positions, [0,0], [0,-1.5]))\n",
+ "\n",
+ "sims = []\n",
+ "\n",
+ "for pos_idx, pos in enumerate(test_positions):\n",
+ " position_ssp = ssp_space.encode(pos[None,:]) #remember we need to have 2-dimensional vectors for `encode()` function\n",
+ " #unbind positions from the map\n",
+ " query_map = ... * ~...\n",
+ " sims.append(query_objs @ query_map.flatten())\n",
+ "\n",
+ "plot_unbinding_positions_map(sims, test_positions, obj_names)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "execution": {}
+ },
+ "source": [
+ "[*Click for solution*](https://github.com/neuromatch/NeuroAI_Course/tree/main/tutorials/W2D2_NeuroSymbolicMethods/solutions/W2D2_Tutorial5_Solution_57dcbce1.py)\n",
+ "\n",
+ "*Example output:*\n",
+ "\n",
+ " \n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "As you can see from the above plots, when we query each location, we can clearly identify the object stored at that location. \n",
+ "\n",
+ "When we query at the origin (where no object is present), we see that there is no strong candidate element. However, as we move closer to one of the objects (rightmost plot), the similarity starts to increase."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_mixing_discrete_objects_with_continuous_space\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Video 4: Mapping Outro\n",
+ "from ipywidgets import widgets\n",
+ "from IPython.display import YouTubeVideo\n",
+ "from IPython.display import IFrame\n",
+ "from IPython.display import display\n",
+ "\n",
+ "class PlayVideo(IFrame):\n",
+ " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
+ " self.id = id\n",
+ " if source == 'Bilibili':\n",
+ " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
+ " elif source == 'Osf':\n",
+ " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
+ " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
+ "\n",
+ "def display_videos(video_ids, W=400, H=300, fs=1):\n",
+ " tab_contents = []\n",
+ " for i, video_id in enumerate(video_ids):\n",
+ " out = widgets.Output()\n",
+ " with out:\n",
+ " if video_ids[i][0] == 'Youtube':\n",
+ " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
+ " height=H, fs=fs, rel=0)\n",
+ " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
+ " else:\n",
+ " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
+ " height=H, fs=fs, autoplay=False)\n",
+ " if video_ids[i][0] == 'Bilibili':\n",
+ " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
+ " elif video_ids[i][0] == 'Osf':\n",
+ " print(f'Video available at https://osf.io/{video.id}')\n",
+ " display(video)\n",
+ " tab_contents.append(out)\n",
+ " return tab_contents\n",
+ "\n",
+ "video_ids = [('Youtube', 'mXNFWr_cap4'), ('Bilibili', 'BV1ND421u7gp')]\n",
+ "tab_contents = display_videos(video_ids, W=854, H=480)\n",
+ "tabs = widgets.Tab()\n",
+ "tabs.children = tab_contents\n",
+ "for i in range(len(tab_contents)):\n",
+ " tabs.set_title(i, video_ids[i][0])\n",
+ "display(tabs)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_mapping_outro\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "---\n",
+ "# Summary\n",
+ "\n",
+ "*Estimated timing of tutorial: 40 minutes*"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Video 5: Conclusions\n",
+ "from ipywidgets import widgets\n",
+ "from IPython.display import YouTubeVideo\n",
+ "from IPython.display import IFrame\n",
+ "from IPython.display import display\n",
+ "\n",
+ "class PlayVideo(IFrame):\n",
+ " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
+ " self.id = id\n",
+ " if source == 'Bilibili':\n",
+ " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
+ " elif source == 'Osf':\n",
+ " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
+ " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
+ "\n",
+ "def display_videos(video_ids, W=400, H=300, fs=1):\n",
+ " tab_contents = []\n",
+ " for i, video_id in enumerate(video_ids):\n",
+ " out = widgets.Output()\n",
+ " with out:\n",
+ " if video_ids[i][0] == 'Youtube':\n",
+ " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
+ " height=H, fs=fs, rel=0)\n",
+ " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
+ " else:\n",
+ " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
+ " height=H, fs=fs, autoplay=False)\n",
+ " if video_ids[i][0] == 'Bilibili':\n",
+ " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
+ " elif video_ids[i][0] == 'Osf':\n",
+ " print(f'Video available at https://osf.io/{video.id}')\n",
+ " display(video)\n",
+ " tab_contents.append(out)\n",
+ " return tab_contents\n",
+ "\n",
+ "video_ids = [('Youtube', 'M6rRsdJdoYQ'), ('Bilibili', 'BV1wm421L7Se')]\n",
+ "tab_contents = display_videos(video_ids, W=854, H=480)\n",
+ "tabs = widgets.Tab()\n",
+ "tabs.children = tab_contents\n",
+ "for i in range(len(tab_contents)):\n",
+ " tabs.set_title(i, video_ids[i][0])\n",
+ "display(tabs)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Conclusion slides\n",
+ "\n",
+ "from IPython.display import IFrame\n",
+ "link_id = \"pxqny\"\n",
+ "\n",
+ "print(f\"If you want to download the slides: 'https://osf.io/download/{link_id}'\")\n",
+ "\n",
+ "IFrame(src=f\"https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{link_id}/?direct%26mode=render\", width=854, height=480)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_conclusions\")"
+ ]
+ }
+ ],
+ "metadata": {
+ "colab": {
+ "collapsed_sections": [],
+ "include_colab_link": true,
+ "name": "W2D2_Tutorial5",
+ "provenance": [],
+ "toc_visible": true
+ },
+ "kernel": {
+ "display_name": "Python 3",
+ "language": "python",
+ "name": "python3"
+ },
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.9.22"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 4
+}
\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "As you can see from the above plots, when we query each location, we can clearly identify the object stored at that location. \n",
+ "\n",
+ "When we query at the origin (where no object is present), we see that there is no strong candidate element. However, as we move closer to one of the objects (rightmost plot), the similarity starts to increase."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_mixing_discrete_objects_with_continuous_space\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Video 4: Mapping Outro\n",
+ "from ipywidgets import widgets\n",
+ "from IPython.display import YouTubeVideo\n",
+ "from IPython.display import IFrame\n",
+ "from IPython.display import display\n",
+ "\n",
+ "class PlayVideo(IFrame):\n",
+ " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
+ " self.id = id\n",
+ " if source == 'Bilibili':\n",
+ " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
+ " elif source == 'Osf':\n",
+ " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
+ " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
+ "\n",
+ "def display_videos(video_ids, W=400, H=300, fs=1):\n",
+ " tab_contents = []\n",
+ " for i, video_id in enumerate(video_ids):\n",
+ " out = widgets.Output()\n",
+ " with out:\n",
+ " if video_ids[i][0] == 'Youtube':\n",
+ " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
+ " height=H, fs=fs, rel=0)\n",
+ " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
+ " else:\n",
+ " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
+ " height=H, fs=fs, autoplay=False)\n",
+ " if video_ids[i][0] == 'Bilibili':\n",
+ " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
+ " elif video_ids[i][0] == 'Osf':\n",
+ " print(f'Video available at https://osf.io/{video.id}')\n",
+ " display(video)\n",
+ " tab_contents.append(out)\n",
+ " return tab_contents\n",
+ "\n",
+ "video_ids = [('Youtube', 'mXNFWr_cap4'), ('Bilibili', 'BV1ND421u7gp')]\n",
+ "tab_contents = display_videos(video_ids, W=854, H=480)\n",
+ "tabs = widgets.Tab()\n",
+ "tabs.children = tab_contents\n",
+ "for i in range(len(tab_contents)):\n",
+ " tabs.set_title(i, video_ids[i][0])\n",
+ "display(tabs)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_mapping_outro\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "execution": {}
+ },
+ "source": [
+ "---\n",
+ "# Summary\n",
+ "\n",
+ "*Estimated timing of tutorial: 40 minutes*"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Video 5: Conclusions\n",
+ "from ipywidgets import widgets\n",
+ "from IPython.display import YouTubeVideo\n",
+ "from IPython.display import IFrame\n",
+ "from IPython.display import display\n",
+ "\n",
+ "class PlayVideo(IFrame):\n",
+ " def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
+ " self.id = id\n",
+ " if source == 'Bilibili':\n",
+ " src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
+ " elif source == 'Osf':\n",
+ " src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
+ " super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
+ "\n",
+ "def display_videos(video_ids, W=400, H=300, fs=1):\n",
+ " tab_contents = []\n",
+ " for i, video_id in enumerate(video_ids):\n",
+ " out = widgets.Output()\n",
+ " with out:\n",
+ " if video_ids[i][0] == 'Youtube':\n",
+ " video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
+ " height=H, fs=fs, rel=0)\n",
+ " print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
+ " else:\n",
+ " video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
+ " height=H, fs=fs, autoplay=False)\n",
+ " if video_ids[i][0] == 'Bilibili':\n",
+ " print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
+ " elif video_ids[i][0] == 'Osf':\n",
+ " print(f'Video available at https://osf.io/{video.id}')\n",
+ " display(video)\n",
+ " tab_contents.append(out)\n",
+ " return tab_contents\n",
+ "\n",
+ "video_ids = [('Youtube', 'M6rRsdJdoYQ'), ('Bilibili', 'BV1wm421L7Se')]\n",
+ "tab_contents = display_videos(video_ids, W=854, H=480)\n",
+ "tabs = widgets.Tab()\n",
+ "tabs.children = tab_contents\n",
+ "for i in range(len(tab_contents)):\n",
+ " tabs.set_title(i, video_ids[i][0])\n",
+ "display(tabs)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Conclusion slides\n",
+ "\n",
+ "from IPython.display import IFrame\n",
+ "link_id = \"pxqny\"\n",
+ "\n",
+ "print(f\"If you want to download the slides: 'https://osf.io/download/{link_id}'\")\n",
+ "\n",
+ "IFrame(src=f\"https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{link_id}/?direct%26mode=render\", width=854, height=480)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "execution": {}
+ },
+ "outputs": [],
+ "source": [
+ "# @title Submit your feedback\n",
+ "content_review(f\"{feedback_prefix}_conclusions\")"
+ ]
+ }
+ ],
+ "metadata": {
+ "colab": {
+ "collapsed_sections": [],
+ "include_colab_link": true,
+ "name": "W2D2_Tutorial5",
+ "provenance": [],
+ "toc_visible": true
+ },
+ "kernel": {
+ "display_name": "Python 3",
+ "language": "python",
+ "name": "python3"
+ },
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.9.22"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 4
+}