|
| 1 | +# 对比 redis lua和 modules 模块的性能损耗 |
| 2 | + |
| 3 | +redis lua是干嘛的? 我们可以自定义逻辑方法,在方法里执行多个redis.call命令,以及各种逻辑的判断。 Redis modules的功能跟Redis lua是很类同的,显而易见的区别是,一个是lua,另一个是c代码。 |
| 4 | + |
| 5 | +## Redis Lua Scripts的好处 |
| 6 | + |
| 7 | +-减少了网络的RTT消耗。 |
| 8 | + |
| 9 | +-原子化的封装,在redis里lua脚本的执行触发原子的,不可被中断的。 |
| 10 | + |
| 11 | +不可被中断? 如果发生阻塞命令怎么办? redis lua的wiki里写明了是不允许调用那些堵塞方法的,比如sub订阅,brpop这类的。 |
| 12 | + |
| 13 | +## Redis modules |
| 14 | + |
| 15 | +redis 4.0版支持扩充自定义的modules模块功能,可以在module里构建各种复杂的逻辑。redis modules兼并了redis lua的优点。较为麻烦的是redis modules需要build动态链接库so,然后loadmodules的方法来外挂启动。每次增加一个新modules的时候,可能就意味着你的redis cluster需要调整下了。 |
| 16 | + |
| 17 | +## lua和modules的区别 |
| 18 | + |
| 19 | +redis官方建议使用redis modules扩充数据结构和实现组合功能,比如 支持json的rejson,支持搜索的RediSearch,支持topk的redis topk等等,而lua更倾向于去实现命令组合原子化。 对于我们业务上的绝大数需求来说,lua更加的好用,不需要每次都加载so,直接注册lua scirpts就可以了。 |
| 20 | + |
| 21 | +## redis lua vs redis modules 性能对比 |
| 22 | + |
| 23 | +前面说了这么多科普的介绍,那么我们目的在于什么? 我自己一直怀疑redis lua的速度应该是比redis原生命令和redis modules模块慢,但自己没测试过性能会相差多少,所以写了几个benchmark测试下。 需要说明的是,这里使用redis-benchmark的测试方法也有待论证。 原本是想用go写一版,但考虑到go runtime本身也是有抖动的,有失公平。redis-benchmark也是官方推荐的方式。 |
| 24 | + |
| 25 | +### 测试redis原生命令hset的qps |
| 26 | + |
| 27 | +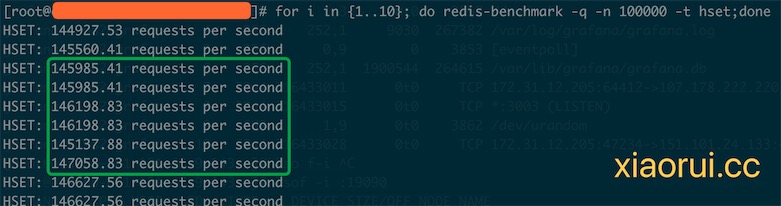 |
| 28 | + |
| 29 | +### 测试redis lua scripts的qps |
| 30 | + |
| 31 | + |
| 32 | + |
| 33 | +### 测试redis modules的hset命令的qps |
| 34 | + |
| 35 | + |
| 36 | + |
| 37 | +这里放一个redis modules实现hset调用的代码, 只需要make; redis-server –loadmodule ./module.so 就可以启动加载了。 |
| 38 | + |
| 39 | +```c |
| 40 | +// xiaorui.cc |
| 41 | + |
| 42 | +int HGetCommand(RedisModuleCtx *ctx, RedisModuleString **argv, int argc) { |
| 43 | + |
| 44 | + // we need EXACTLY 4 arguments |
| 45 | + if (argc != 4) { |
| 46 | + return RedisModule_WrongArity(ctx); |
| 47 | + } |
| 48 | + RedisModule_AutoMemory(ctx); |
| 49 | + |
| 50 | + // open the key and make sure it's indeed a HASH and not empty |
| 51 | + RedisModuleKey *key = |
| 52 | + RedisModule_OpenKey(ctx, argv[1], REDISMODULE_READ | REDISMODULE_WRITE); |
| 53 | + if (RedisModule_KeyType(key) != REDISMODULE_KEYTYPE_HASH && |
| 54 | + RedisModule_KeyType(key) != REDISMODULE_KEYTYPE_EMPTY) { |
| 55 | + return RedisModule_ReplyWithError(ctx, REDISMODULE_ERRORMSG_WRONGTYPE); |
| 56 | + } |
| 57 | + |
| 58 | + // set the new value of the element |
| 59 | + RedisModuleCallReply *rep = |
| 60 | + RedisModule_Call(ctx, "HSET", "sss", argv[1], argv[2], argv[3]); |
| 61 | + RMUTIL_ASSERT_NOERROR(ctx, rep); |
| 62 | + |
| 63 | + // if the value was null before - we just return null |
| 64 | + if (RedisModule_CallReplyType(rep) == REDISMODULE_REPLY_NULL) { |
| 65 | + RedisModule_ReplyWithNull(ctx); |
| 66 | + return REDISMODULE_OK; |
| 67 | + } |
| 68 | + |
| 69 | + // forward the HGET reply to the client |
| 70 | + RedisModule_ReplyWithCallReply(ctx, rep); |
| 71 | + return REDISMODULE_OK; |
| 72 | +} |
| 73 | +``` |
| 74 | +
|
| 75 | +这里的测试都是单命令测试,主要是为了可以对比原生的命令。单纯从benchmark结果来说,原生的命令是最快,其次是redis modules模块,相对慢一点是redis lua scripts, 通过qps对比,redis lua也仅仅慢一点点罢了。 当然如果使用复杂的 lua 函数,性能会进一步下降。 |
| 76 | +
|
| 77 | +redis lua 可随意注册使用,但 redis modules 相对麻烦了,需要redis-server启动的时候加载该动态链接库。 很多云厂商的redis paas也不支持你这么做。 |
| 78 | +
|
| 79 | +## 总结 |
| 80 | +
|
| 81 | +当然测试的方法很不严谨,但单纯看上面的结果来分析,我们不需要过于担心 redis lua 和 redis modules 的性能损耗。 |
0 commit comments