diff --git a/CONTRIBUTING.md b/CONTRIBUTING.md
index 1559b721f51..6f301eab782 100644
--- a/CONTRIBUTING.md
+++ b/CONTRIBUTING.md
@@ -6,9 +6,7 @@ This guide shows how to make contributions to [tensorflow.org](https://www.tenso
See the
[TensorFlow docs contributor guide](https://www.tensorflow.org/community/contribute/docs)
-for guidance. For questions, the
-[docs@tensorflow.org](https://groups.google.com/a/tensorflow.org/forum/#!forum/docs)
-mailing list is available.
+for guidance. For questions, check out [TensorFlow Forum](https://discuss.tensorflow.org/).
Questions about TensorFlow usage are better addressed on
[Stack Overflow](https://stackoverflow.com/questions/tagged/tensorflow) or the
diff --git a/README.md b/README.md
index 7b94ce5f90f..66b6d3fb065 100644
--- a/README.md
+++ b/README.md
@@ -16,7 +16,7 @@ To file a docs issue, use the issue tracker in the
[tensorflow/tensorflow](https://github.com/tensorflow/tensorflow/issues/new?template=20-documentation-issue.md) repo.
And join the TensorFlow documentation contributors on the
-[docs@tensorflow.org mailing list](https://groups.google.com/a/tensorflow.org/forum/#!forum/docs).
+[TensorFlow Forum](https://discuss.tensorflow.org/).
## Community translations
diff --git a/site/en/community/contribute/docs.md b/site/en/community/contribute/docs.md
index 29b2b5c9550..34b1619ca5d 100644
--- a/site/en/community/contribute/docs.md
+++ b/site/en/community/contribute/docs.md
@@ -32,7 +32,7 @@ To participate in the TensorFlow docs community:
For details, use the [TensorFlow API docs contributor guide](docs_ref.md). This
shows you how to find the
-[source file](https://www.tensorflow.org/code/tensorflow/python/)
+[source file](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/)
and edit the symbol's
docstring.
Many API reference pages on tensorflow.org include a link to the source file
@@ -53,9 +53,9 @@ main
tensorflow/tensorflow
repo. The reference documentation is generated from code comments
and docstrings in the source code for
-Python,
-C++, and
-Java.
+Python,
+C++, and
+Java.
Previous versions of the TensorFlow documentation are available as
[rX.x branches](https://github.com/tensorflow/docs/branches) in the TensorFlow
diff --git a/site/en/community/contribute/docs_ref.md b/site/en/community/contribute/docs_ref.md
index fbf207a47f1..41fce4dde40 100644
--- a/site/en/community/contribute/docs_ref.md
+++ b/site/en/community/contribute/docs_ref.md
@@ -8,7 +8,7 @@ TensorFlow uses [DocTest](https://docs.python.org/3/library/doctest.html) to
test code snippets in Python docstrings. The snippet must be executable Python
code. To enable testing, prepend the line with `>>>` (three left-angle
brackets). For example, here's a excerpt from the `tf.concat` function in the
-[array_ops.py](https://www.tensorflow.org/code/tensorflow/python/ops/array_ops.py)
+[array_ops.py](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/ops/array_ops.py)
source file:
```
@@ -178,7 +178,7 @@ There are two ways to test the code in the docstring locally:
* If you are only changing the docstring of a class/function/method, then you
can test it by passing that file's path to
- [tf_doctest.py](https://www.tensorflow.org/code/tensorflow/tools/docs/tf_doctest.py).
+ [tf_doctest.py](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/tools/docs/tf_doctest.py).
For example:
diff --git a/site/en/community/contribute/docs_style.md b/site/en/community/contribute/docs_style.md
index eba78afa896..d4e42cb5235 100644
--- a/site/en/community/contribute/docs_style.md
+++ b/site/en/community/contribute/docs_style.md
@@ -63,7 +63,7 @@ repository like this:
* \[Basics\]\(../../guide/basics.ipynb\) produces
[Basics](../../guide/basics.ipynb).
-This is the prefered approach because this way the links on
+This is the preferred approach because this way the links on
[tensorflow.org](https://www.tensorflow.org),
[GitHub](https://github.com/tensorflow/docs){:.external} and
[Colab](https://github.com/tensorflow/docs/tree/master/site/en/guide/bazics.ipynb){:.external}
diff --git a/site/en/guide/create_op.md b/site/en/guide/create_op.md
index 3c84204844c..fa4f573fa32 100644
--- a/site/en/guide/create_op.md
+++ b/site/en/guide/create_op.md
@@ -152,17 +152,17 @@ REGISTER_KERNEL_BUILDER(Name("ZeroOut").Device(DEVICE_CPU), ZeroOutOp);
> Important: Instances of your OpKernel may be accessed concurrently.
> Your `Compute` method must be thread-safe. Guard any access to class
> members with a mutex. Or better yet, don't share state via class members!
-> Consider using a [`ResourceMgr`](https://www.tensorflow.org/code/tensorflow/core/framework/resource_mgr.h)
+> Consider using a [`ResourceMgr`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/resource_mgr.h)
> to keep track of op state.
### Multi-threaded CPU kernels
To write a multi-threaded CPU kernel, the Shard function in
-[`work_sharder.h`](https://www.tensorflow.org/code/tensorflow/core/util/work_sharder.h)
+[`work_sharder.h`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/util/work_sharder.h)
can be used. This function shards a computation function across the
threads configured to be used for intra-op threading (see
intra_op_parallelism_threads in
-[`config.proto`](https://www.tensorflow.org/code/tensorflow/core/protobuf/config.proto)).
+[`config.proto`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/protobuf/config.proto)).
### GPU kernels
@@ -519,13 +519,13 @@ This asserts that the input is a vector, and returns having set the
* The `context`, which can either be an `OpKernelContext` or
`OpKernelConstruction` pointer (see
- [`tensorflow/core/framework/op_kernel.h`](https://www.tensorflow.org/code/tensorflow/core/framework/op_kernel.h)),
+ [`tensorflow/core/framework/op_kernel.h`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/op_kernel.h)),
for its `SetStatus()` method.
* The condition. For example, there are functions for validating the shape
of a tensor in
- [`tensorflow/core/framework/tensor_shape.h`](https://www.tensorflow.org/code/tensorflow/core/framework/tensor_shape.h)
+ [`tensorflow/core/framework/tensor_shape.h`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/tensor_shape.h)
* The error itself, which is represented by a `Status` object, see
- [`tensorflow/core/platform/status.h`](https://www.tensorflow.org/code/tensorflow/core/platform/status.h). A
+ [`tensorflow/core/platform/status.h`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/platform/status.h). A
`Status` has both a type (frequently `InvalidArgument`, but see the list of
types) and a message. Functions for constructing an error may be found in
[`tensorflow/core/platform/errors.h`][validation-macros].
@@ -668,7 +668,7 @@ There are shortcuts for common type constraints:
The specific lists of types allowed by these are defined by the functions (like
`NumberTypes()`) in
-[`tensorflow/core/framework/types.h`](https://www.tensorflow.org/code/tensorflow/core/framework/types.h).
+[`tensorflow/core/framework/types.h`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/types.h).
In this example the attr `t` must be one of the numeric types:
```c++
@@ -1226,7 +1226,7 @@ There are several ways to preserve backwards-compatibility.
type into a list of varying types).
The full list of safe and unsafe changes can be found in
-[`tensorflow/core/framework/op_compatibility_test.cc`](https://www.tensorflow.org/code/tensorflow/core/framework/op_compatibility_test.cc).
+[`tensorflow/core/framework/op_compatibility_test.cc`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/op_compatibility_test.cc).
If you cannot make your change to an operation backwards compatible, then create
a new operation with a new name with the new semantics.
@@ -1243,16 +1243,16 @@ made when TensorFlow changes major versions, and must conform to the
You can implement different OpKernels and register one for CPU and another for
GPU, just like you can [register kernels for different types](#polymorphism).
There are several examples of kernels with GPU support in
-[`tensorflow/core/kernels/`](https://www.tensorflow.org/code/tensorflow/core/kernels/).
+[`tensorflow/core/kernels/`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/kernels/).
Notice some kernels have a CPU version in a `.cc` file, a GPU version in a file
ending in `_gpu.cu.cc`, and some code shared in common in a `.h` file.
For example, the `tf.pad` has
everything but the GPU kernel in [`tensorflow/core/kernels/pad_op.cc`][pad_op].
The GPU kernel is in
-[`tensorflow/core/kernels/pad_op_gpu.cu.cc`](https://www.tensorflow.org/code/tensorflow/core/kernels/pad_op_gpu.cu.cc),
+[`tensorflow/core/kernels/pad_op_gpu.cu.cc`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/kernels/pad_op_gpu.cu.cc),
and the shared code is a templated class defined in
-[`tensorflow/core/kernels/pad_op.h`](https://www.tensorflow.org/code/tensorflow/core/kernels/pad_op.h).
+[`tensorflow/core/kernels/pad_op.h`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/kernels/pad_op.h).
We organize the code this way for two reasons: it allows you to share common
code among the CPU and GPU implementations, and it puts the GPU implementation
into a separate file so that it can be compiled only by the GPU compiler.
@@ -1273,16 +1273,16 @@ kept on the CPU, add a `HostMemory()` call to the kernel registration, e.g.:
#### Compiling the kernel for the GPU device
Look at
-[cuda_op_kernel.cu.cc](https://www.tensorflow.org/code/tensorflow/examples/adding_an_op/cuda_op_kernel.cu.cc)
+[cuda_op_kernel.cu.cc](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/examples/adding_an_op/cuda_op_kernel.cu.cc)
for an example that uses a CUDA kernel to implement an op. The
`tf_custom_op_library` accepts a `gpu_srcs` argument in which the list of source
files containing the CUDA kernels (`*.cu.cc` files) can be specified. For use
with a binary installation of TensorFlow, the CUDA kernels have to be compiled
with NVIDIA's `nvcc` compiler. Here is the sequence of commands you can use to
compile the
-[cuda_op_kernel.cu.cc](https://www.tensorflow.org/code/tensorflow/examples/adding_an_op/cuda_op_kernel.cu.cc)
+[cuda_op_kernel.cu.cc](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/examples/adding_an_op/cuda_op_kernel.cu.cc)
and
-[cuda_op_kernel.cc](https://www.tensorflow.org/code/tensorflow/examples/adding_an_op/cuda_op_kernel.cc)
+[cuda_op_kernel.cc](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/examples/adding_an_op/cuda_op_kernel.cc)
into a single dynamically loadable library:
```bash
@@ -1412,7 +1412,7 @@ be set to the first input's shape. If the output is selected by its index as in
There are a number of common shape functions
that apply to many ops, such as `shape_inference::UnchangedShape` which can be
-found in [common_shape_fns.h](https://www.tensorflow.org/code/tensorflow/core/framework/common_shape_fns.h) and used as follows:
+found in [common_shape_fns.h](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/common_shape_fns.h) and used as follows:
```c++
REGISTER_OP("ZeroOut")
@@ -1459,7 +1459,7 @@ provides access to the attributes of the op).
Since shape inference is an optional feature, and the shapes of tensors may vary
dynamically, shape functions must be robust to incomplete shape information for
-any of the inputs. The `Merge` method in [`InferenceContext`](https://www.tensorflow.org/code/tensorflow/core/framework/shape_inference.h)
+any of the inputs. The `Merge` method in [`InferenceContext`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/shape_inference.h)
allows the caller to assert that two shapes are the same, even if either
or both of them do not have complete information. Shape functions are defined
for all of the core TensorFlow ops and provide many different usage examples.
@@ -1484,7 +1484,7 @@ If you have a complicated shape function, you should consider adding a test for
validating that various input shape combinations produce the expected output
shape combinations. You can see examples of how to write these tests in some
our
-[core ops tests](https://www.tensorflow.org/code/tensorflow/core/ops/array_ops_test.cc).
+[core ops tests](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/ops/array_ops_test.cc).
(The syntax of `INFER_OK` and `INFER_ERROR` are a little cryptic, but try to be
compact in representing input and output shape specifications in tests. For
now, see the surrounding comments in those tests to get a sense of the shape
@@ -1497,20 +1497,20 @@ To build a `pip` package for your op, see the
guide shows how to build custom ops from the TensorFlow pip package instead
of building TensorFlow from source.
-[core-array_ops]:https://www.tensorflow.org/code/tensorflow/core/ops/array_ops.cc
-[python-user_ops]:https://www.tensorflow.org/code/tensorflow/python/user_ops/user_ops.py
-[tf-kernels]:https://www.tensorflow.org/code/tensorflow/core/kernels/
-[user_ops]:https://www.tensorflow.org/code/tensorflow/core/user_ops/
-[pad_op]:https://www.tensorflow.org/code/tensorflow/core/kernels/pad_op.cc
-[standard_ops-py]:https://www.tensorflow.org/code/tensorflow/python/ops/standard_ops.py
-[standard_ops-cc]:https://www.tensorflow.org/code/tensorflow/cc/ops/standard_ops.h
-[python-BUILD]:https://www.tensorflow.org/code/tensorflow/python/BUILD
-[validation-macros]:https://www.tensorflow.org/code/tensorflow/core/platform/errors.h
-[op_def_builder]:https://www.tensorflow.org/code/tensorflow/core/framework/op_def_builder.h
-[register_types]:https://www.tensorflow.org/code/tensorflow/core/framework/register_types.h
-[FinalizeAttr]:https://www.tensorflow.org/code/tensorflow/core/framework/op_def_builder.cc
-[DataTypeString]:https://www.tensorflow.org/code/tensorflow/core/framework/types.cc
-[python-BUILD]:https://www.tensorflow.org/code/tensorflow/python/BUILD
-[types-proto]:https://www.tensorflow.org/code/tensorflow/core/framework/types.proto
-[TensorShapeProto]:https://www.tensorflow.org/code/tensorflow/core/framework/tensor_shape.proto
-[TensorProto]:https://www.tensorflow.org/code/tensorflow/core/framework/tensor.proto
+[core-array_ops]:https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/ops/array_ops.cc
+[python-user_ops]:https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/user_ops/user_ops.py
+[tf-kernels]:https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/kernels/
+[user_ops]:https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/user_ops/
+[pad_op]:https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/kernels/pad_op.cc
+[standard_ops-py]:https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/ops/standard_ops.py
+[standard_ops-cc]:https://github.com/tensorflow/tensorflow/blob/master/tensorflow/cc/ops/standard_ops.h
+[python-BUILD]:https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/BUILD
+[validation-macros]:https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/platform/errors.h
+[op_def_builder]:https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/op_def_builder.h
+[register_types]:https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/register_types.h
+[FinalizeAttr]:https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/op_def_builder.cc
+[DataTypeString]:https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/types.cc
+[python-BUILD]:https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/BUILD
+[types-proto]:https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/types.proto
+[TensorShapeProto]:https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/tensor_shape.proto
+[TensorProto]:https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/tensor.proto
diff --git a/site/en/guide/data.ipynb b/site/en/guide/data.ipynb
index d9c8fff8982..739ef131005 100644
--- a/site/en/guide/data.ipynb
+++ b/site/en/guide/data.ipynb
@@ -1385,7 +1385,7 @@
"The simplest form of batching stacks `n` consecutive elements of a dataset into\n",
"a single element. The `Dataset.batch()` transformation does exactly this, with\n",
"the same constraints as the `tf.stack()` operator, applied to each component\n",
- "of the elements: i.e. for each component *i*, all elements must have a tensor\n",
+ "of the elements: i.e., for each component *i*, all elements must have a tensor\n",
"of the exact same shape."
]
},
diff --git a/site/en/guide/dtensor_overview.ipynb b/site/en/guide/dtensor_overview.ipynb
index 95a50f3465f..1b55ee0283f 100644
--- a/site/en/guide/dtensor_overview.ipynb
+++ b/site/en/guide/dtensor_overview.ipynb
@@ -281,7 +281,7 @@
"id": "Eyp_qOSyvieo"
},
"source": [
- " \n"
+ "\n"
]
},
{
@@ -303,7 +303,7 @@
"source": [
"For the same `mesh_2d`, the layout `Layout([\"x\", dtensor.UNSHARDED], mesh_2d)` is a layout for a rank-2 `Tensor` that is replicated across `\"y\"`, and whose first axis is sharded on mesh dimension `x`.\n",
"\n",
- "
\n"
+ "\n"
]
},
{
@@ -303,7 +303,7 @@
"source": [
"For the same `mesh_2d`, the layout `Layout([\"x\", dtensor.UNSHARDED], mesh_2d)` is a layout for a rank-2 `Tensor` that is replicated across `\"y\"`, and whose first axis is sharded on mesh dimension `x`.\n",
"\n",
- " \n"
+ "\n"
]
},
{
diff --git a/site/en/guide/estimator.ipynb b/site/en/guide/estimator.ipynb
index e58ef46cf86..05e8fb4012a 100644
--- a/site/en/guide/estimator.ipynb
+++ b/site/en/guide/estimator.ipynb
@@ -68,7 +68,7 @@
"id": "rILQuAiiRlI7"
},
"source": [
- "> Warning: Estimators are not recommended for new code. Estimators run `v1.Session`-style code which is more difficult to write correctly, and can behave unexpectedly, especially when combined with TF 2 code. Estimators do fall under our [compatibility guarantees](https://tensorflow.org/guide/versions), but will receive no fixes other than security vulnerabilities. See the [migration guide](https://tensorflow.org/guide/migrate) for details."
+ "> Warning: TensorFlow 2.15 included the final release of the `tf-estimator` package. Estimators will not be available in TensorFlow 2.16 or after. See the [migration guide](https://www.tensorflow.org/guide/migrate/migrating_estimator) for more information about how to convert off of Estimators."
]
},
{
diff --git a/site/en/guide/migrate/evaluator.ipynb b/site/en/guide/migrate/evaluator.ipynb
index fd8bd12d1e1..c8f848e4406 100644
--- a/site/en/guide/migrate/evaluator.ipynb
+++ b/site/en/guide/migrate/evaluator.ipynb
@@ -122,7 +122,7 @@
"\n",
"In TensorFlow 1, you can configure a `tf.estimator` to evaluate the estimator using `tf.estimator.train_and_evaluate`.\n",
"\n",
- "In this example, start by defining the `tf.estimator.Estimator` and speciyfing training and evaluation specifications:"
+ "In this example, start by defining the `tf.estimator.Estimator` and specifying training and evaluation specifications:"
]
},
{
diff --git a/site/en/guide/migrate/migrating_feature_columns.ipynb b/site/en/guide/migrate/migrating_feature_columns.ipynb
index ea12a5ef391..b2dbc5fe7c0 100644
--- a/site/en/guide/migrate/migrating_feature_columns.ipynb
+++ b/site/en/guide/migrate/migrating_feature_columns.ipynb
@@ -654,17 +654,17 @@
"source": [
"categorical_col = tf1.feature_column.categorical_column_with_identity(\n",
" 'type', num_buckets=one_hot_dims)\n",
- "# Convert index to one-hot; e.g. [2] -> [0,0,1].\n",
+ "# Convert index to one-hot; e.g., [2] -> [0,0,1].\n",
"indicator_col = tf1.feature_column.indicator_column(categorical_col)\n",
"\n",
- "# Convert strings to indices; e.g. ['small'] -> [1].\n",
+ "# Convert strings to indices; e.g., ['small'] -> [1].\n",
"vocab_col = tf1.feature_column.categorical_column_with_vocabulary_list(\n",
" 'size', vocabulary_list=vocab, num_oov_buckets=1)\n",
"# Embed the indices.\n",
"embedding_col = tf1.feature_column.embedding_column(vocab_col, embedding_dims)\n",
"\n",
"normalizer_fn = lambda x: (x - weight_mean) / math.sqrt(weight_variance)\n",
- "# Normalize the numeric inputs; e.g. [2.0] -> [0.0].\n",
+ "# Normalize the numeric inputs; e.g., [2.0] -> [0.0].\n",
"numeric_col = tf1.feature_column.numeric_column(\n",
" 'weight', normalizer_fn=normalizer_fn)\n",
"\n",
@@ -727,12 +727,12 @@
" 'size': tf.keras.Input(shape=(), dtype='string'),\n",
" 'weight': tf.keras.Input(shape=(), dtype='float32'),\n",
"}\n",
- "# Convert index to one-hot; e.g. [2] -> [0,0,1].\n",
+ "# Convert index to one-hot; e.g., [2] -> [0,0,1].\n",
"type_output = tf.keras.layers.CategoryEncoding(\n",
" one_hot_dims, output_mode='one_hot')(inputs['type'])\n",
- "# Convert size strings to indices; e.g. ['small'] -> [1].\n",
+ "# Convert size strings to indices; e.g., ['small'] -> [1].\n",
"size_output = tf.keras.layers.StringLookup(vocabulary=vocab)(inputs['size'])\n",
- "# Normalize the numeric inputs; e.g. [2.0] -> [0.0].\n",
+ "# Normalize the numeric inputs; e.g., [2.0] -> [0.0].\n",
"weight_output = tf.keras.layers.Normalization(\n",
" axis=None, mean=weight_mean, variance=weight_variance)(inputs['weight'])\n",
"outputs = {\n",
diff --git a/site/en/guide/migrate/migration_debugging.ipynb b/site/en/guide/migrate/migration_debugging.ipynb
index 86c86680dc9..25cb7f9065f 100644
--- a/site/en/guide/migrate/migration_debugging.ipynb
+++ b/site/en/guide/migrate/migration_debugging.ipynb
@@ -128,7 +128,7 @@
"\n",
" a. Check training behaviors with TensorBoard\n",
"\n",
- " * use simple optimizers e.g. SGD and simple distribution strategies e.g.\n",
+ " * use simple optimizers e.g., SGD and simple distribution strategies e.g.\n",
" `tf.distribute.OneDeviceStrategy` first\n",
" * training metrics\n",
" * evaluation metrics\n",
diff --git a/site/en/guide/profiler.md b/site/en/guide/profiler.md
index 1cd19c109fe..e92d1b9eae4 100644
--- a/site/en/guide/profiler.md
+++ b/site/en/guide/profiler.md
@@ -694,7 +694,7 @@ first few batches to avoid inaccuracies due to initialization overhead.
An example for profiling multiple workers:
```python
- # E.g. your worker IP addresses are 10.0.0.2, 10.0.0.3, 10.0.0.4, and you
+ # E.g., your worker IP addresses are 10.0.0.2, 10.0.0.3, 10.0.0.4, and you
# would like to profile for a duration of 2 seconds.
tf.profiler.experimental.client.trace(
'grpc://10.0.0.2:8466,grpc://10.0.0.3:8466,grpc://10.0.0.4:8466',
@@ -845,7 +845,7 @@ more efficient by casting to different data types after applying
spatial transformations, such as flipping, cropping, rotating, etc.
Note: Some ops like `tf.image.resize` transparently change the `dtype` to
-`fp32`. Make sure you normalize your data to lie between `0` and `1` if its not
+`fp32`. Make sure you normalize your data to lie between `0` and `1` if it's not
done automatically. Skipping this step could lead to `NaN` errors if you have
enabled [AMP](https://developer.nvidia.com/automatic-mixed-precision).
diff --git a/site/en/guide/random_numbers.ipynb b/site/en/guide/random_numbers.ipynb
index 5212a10a49a..f8b824ad906 100644
--- a/site/en/guide/random_numbers.ipynb
+++ b/site/en/guide/random_numbers.ipynb
@@ -166,7 +166,7 @@
"source": [
"See the *Algorithms* section below for more information about it.\n",
"\n",
- "Another way to create a generator is with `Generator.from_non_deterministic_state`. A generator created this way will start from a non-deterministic state, depending on e.g. time and OS."
+ "Another way to create a generator is with `Generator.from_non_deterministic_state`. A generator created this way will start from a non-deterministic state, depending on e.g., time and OS."
]
},
{
diff --git a/site/en/guide/sparse_tensor.ipynb b/site/en/guide/sparse_tensor.ipynb
index cd38fdf55ab..45f1e3fd3c3 100644
--- a/site/en/guide/sparse_tensor.ipynb
+++ b/site/en/guide/sparse_tensor.ipynb
@@ -620,7 +620,7 @@
"\n",
"However, there are a few cases where it can be useful to distinguish zero values from missing values. In particular, this allows for one way to encode missing/unknown data in your training data. For example, consider a use case where you have a tensor of scores (that can have any floating point value from -Inf to +Inf), with some missing scores. You can encode this tensor using a sparse tensor where the explicit zeros are known zero scores but the implicit zero values actually represent missing data and not zero. \n",
"\n",
- "Note: This is generally not the intended usage of `tf.sparse.SparseTensor`s; and you might want to also consier other techniques for encoding this such as for example using a separate mask tensor that identifies the locations of known/unknown values. However, exercise caution while using this approach, since most sparse operations will treat explicit and implicit zero values identically."
+ "Note: This is generally not the intended usage of `tf.sparse.SparseTensor`s; and you might want to also consider other techniques for encoding this such as for example using a separate mask tensor that identifies the locations of known/unknown values. However, exercise caution while using this approach, since most sparse operations will treat explicit and implicit zero values identically."
]
},
{
diff --git a/site/en/guide/tf_numpy_type_promotion.ipynb b/site/en/guide/tf_numpy_type_promotion.ipynb
index a9e176c5db6..f984310822a 100644
--- a/site/en/guide/tf_numpy_type_promotion.ipynb
+++ b/site/en/guide/tf_numpy_type_promotion.ipynb
@@ -178,7 +178,7 @@
"* `f32*` means Python `float` or weakly-typed `f32`\n",
"* `c128*` means Python `complex` or weakly-typed `c128`\n",
"\n",
- "The asterik (*) denotes that the corresponding type is “weak” - such a dtype is temporarily inferred by the system, and could defer to other dtypes. This concept is explained more in detail [here](#weak_tensor)."
+ "The asterisk (*) denotes that the corresponding type is “weak” - such a dtype is temporarily inferred by the system, and could defer to other dtypes. This concept is explained more in detail [here](#weak_tensor)."
]
},
{
@@ -449,13 +449,13 @@
"source": [
"### WeakTensor Construction\n",
"\n",
- "WeakTensors are created if you create a tensor without specifing a dtype the result is a WeakTensor. You can check whether a Tensor is \"weak\" or not by checking the weak attribute at the end of the Tensor's string representation."
+ "WeakTensors are created if you create a tensor without specifying a dtype the result is a WeakTensor. You can check whether a Tensor is \"weak\" or not by checking the weak attribute at the end of the Tensor's string representation."
]
},
{
"cell_type": "markdown",
"metadata": {
- "id": "7UmunnJ8Tru3"
+ "id": "7UmunnJ8True3"
},
"source": [
"**First Case**: When `tf.constant` is called with an input with no user-specified dtype."
diff --git a/site/en/guide/versions.md b/site/en/guide/versions.md
index df0d75114ef..0b089885552 100644
--- a/site/en/guide/versions.md
+++ b/site/en/guide/versions.md
@@ -171,12 +171,10 @@ incrementing the major version number for TensorFlow Lite, or vice versa.
The API surface that is covered by the TensorFlow Lite Extension APIs version
number is comprised of the following public APIs:
-```
* [tensorflow/lite/c/c_api_opaque.h](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/c/c_api_opaque.h)
* [tensorflow/lite/c/common.h](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/c/common.h)
* [tensorflow/lite/c/builtin_op_data.h](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/c/builtin_op_data.h)
* [tensorflow/lite/builtin_ops.h](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/builtin_ops.h)
-```
Again, experimental symbols are not covered; see [below](#not_covered) for
details.
@@ -203,7 +201,7 @@ These include:
such as:
- [C++](../install/lang_c.ipynb) (exposed through header files in
- [`tensorflow/cc`](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/cc)).
+ [`tensorflow/cc/`](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/cc)).
- [Java](../install/lang_java_legacy.md),
- [Go](https://github.com/tensorflow/build/blob/master/golang_install_guide/README.md)
- [JavaScript](https://www.tensorflow.org/js)
@@ -212,7 +210,7 @@ These include:
Objective-C, and Swift, in particular
- **C++** (exposed through header files in
- [`tensorflow/lite/`]\(https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/\))
+ [`tensorflow/lite/`](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/))
* **Details of composite ops:** Many public functions in Python expand to
several primitive ops in the graph, and these details will be part of any
@@ -471,7 +469,7 @@ existing producer scripts will not suddenly use the new functionality.
1. Add a new similar op named `SomethingV2` or similar and go through the
process of adding it and switching existing Python wrappers to use it.
To ensure forward compatibility use the checks suggested in
- [compat.py](https://www.tensorflow.org/code/tensorflow/python/compat/compat.py)
+ [compat.py](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/compat/compat.py)
when changing the Python wrappers.
2. Remove the old op (Can only take place with a major version change due to
backward compatibility).
diff --git a/site/en/hub/common_saved_model_apis/text.md b/site/en/hub/common_saved_model_apis/text.md
index 1c45b8ea026..c618b02d9f1 100644
--- a/site/en/hub/common_saved_model_apis/text.md
+++ b/site/en/hub/common_saved_model_apis/text.md
@@ -132,8 +132,8 @@ preprocessor = hub.load("path/to/preprocessor") # Must match `encoder`.
encoder_inputs = preprocessor(text_input)
encoder = hub.load("path/to/encoder")
-enocder_outputs = encoder(encoder_inputs)
-embeddings = enocder_outputs["default"]
+encoder_outputs = encoder(encoder_inputs)
+embeddings = encoder_outputs["default"]
```
Recall from the [Reusable SavedModel API](../reusable_saved_models.md) that
@@ -304,8 +304,8 @@ provisions from the [Reusable SavedModel API](../reusable_saved_models.md).
#### Usage synopsis
```python
-enocder = hub.load("path/to/encoder")
-enocder_outputs = encoder(encoder_inputs)
+encoder = hub.load("path/to/encoder")
+encoder_outputs = encoder(encoder_inputs)
```
or equivalently in Keras:
diff --git a/site/en/hub/tf2_saved_model.md b/site/en/hub/tf2_saved_model.md
index 7a7220d0a2e..641f9b3517b 100644
--- a/site/en/hub/tf2_saved_model.md
+++ b/site/en/hub/tf2_saved_model.md
@@ -82,7 +82,7 @@ and uncompressed SavedModels. For details, see [Caching](caching.md).
SavedModels can be loaded from a specified `handle`, where the `handle` is a
filesystem path, valid TFhub.dev model URL (e.g. "https://tfhub.dev/...").
Kaggle Models URLs mirror TFhub.dev handles in accordance with our Terms and the
-license associated with the model assets, e.g. "https://www.kaggle.com/...".
+license associated with the model assets, e.g., "https://www.kaggle.com/...".
Handles from Kaggle Models are equivalent to their corresponding TFhub.dev
handle.
diff --git a/site/en/hub/tutorials/action_recognition_with_tf_hub.ipynb b/site/en/hub/tutorials/action_recognition_with_tf_hub.ipynb
index b4a1e439621..3f586991ba9 100644
--- a/site/en/hub/tutorials/action_recognition_with_tf_hub.ipynb
+++ b/site/en/hub/tutorials/action_recognition_with_tf_hub.ipynb
@@ -184,7 +184,7 @@
" return list(_VIDEO_LIST)\n",
"\n",
"def fetch_ucf_video(video):\n",
- " \"\"\"Fetchs a video and cache into local filesystem.\"\"\"\n",
+ " \"\"\"Fetches a video and cache into local filesystem.\"\"\"\n",
" cache_path = os.path.join(_CACHE_DIR, video)\n",
" if not os.path.exists(cache_path):\n",
" urlpath = request.urljoin(UCF_ROOT, video)\n",
diff --git a/site/en/hub/tutorials/cropnet_cassava.ipynb b/site/en/hub/tutorials/cropnet_cassava.ipynb
index 18f41c00da1..926b5395e41 100644
--- a/site/en/hub/tutorials/cropnet_cassava.ipynb
+++ b/site/en/hub/tutorials/cropnet_cassava.ipynb
@@ -199,7 +199,7 @@
"id": "QT3XWAtR6BRy"
},
"source": [
- "The *cassava* dataset has images of cassava leaves with 4 distinct diseases as well as healthy cassava leaves. The model can predict all of these classes as well as sixth class for \"unknown\" when the model is not confident in it's prediction."
+ "The *cassava* dataset has images of cassava leaves with 4 distinct diseases as well as healthy cassava leaves. The model can predict all of these classes as well as sixth class for \"unknown\" when the model is not confident in its prediction."
]
},
{
diff --git a/site/en/hub/tutorials/cross_lingual_similarity_with_tf_hub_multilingual_universal_encoder.ipynb b/site/en/hub/tutorials/cross_lingual_similarity_with_tf_hub_multilingual_universal_encoder.ipynb
index 31fc037dfe7..920d197811e 100644
--- a/site/en/hub/tutorials/cross_lingual_similarity_with_tf_hub_multilingual_universal_encoder.ipynb
+++ b/site/en/hub/tutorials/cross_lingual_similarity_with_tf_hub_multilingual_universal_encoder.ipynb
@@ -271,7 +271,7 @@
"spanish_sentences = ['perro', 'Los cachorros son agradables.', 'Disfruto de dar largos paseos por la playa con mi perro.']\n",
"\n",
"# Multilingual example\n",
- "multilingual_example = [\"Willkommen zu einfachen, aber\", \"verrassend krachtige\", \"multilingüe\", \"compréhension du langage naturel\", \"модели.\", \"大家是什么意思\" , \"보다 중요한\", \".اللغة التي يتحدثونها\"]\n",
+ "multilingual_example = [\"Willkommen zu einfachen, aber\", \"verrassend krachtige\", \"multilingüe\", \"compréhension du language naturel\", \"модели.\", \"大家是什么意思\" , \"보다 중요한\", \".اللغة التي يتحدثونها\"]\n",
"multilingual_example_in_en = [\"Welcome to simple yet\", \"surprisingly powerful\", \"multilingual\", \"natural language understanding\", \"models.\", \"What people mean\", \"matters more than\", \"the language they speak.\"]\n"
]
},
@@ -4174,7 +4174,7 @@
"id": "Dxu66S8wJIG9"
},
"source": [
- "### Semantic-search crosss-lingual capabilities\n",
+ "### Semantic-search cross-lingual capabilities\n",
"\n",
"In this section we show how to retrieve sentences related to a set of sample English sentences. Things to try:\n",
"\n",
diff --git a/site/en/hub/tutorials/image_enhancing.ipynb b/site/en/hub/tutorials/image_enhancing.ipynb
index 4c9496b79ae..3710ebd6d66 100644
--- a/site/en/hub/tutorials/image_enhancing.ipynb
+++ b/site/en/hub/tutorials/image_enhancing.ipynb
@@ -346,7 +346,7 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "id": "r_dautO6qbTV"
+ "id": "r_defaultO6qbTV"
},
"outputs": [],
"source": [
diff --git a/site/en/hub/tutorials/image_feature_vector.ipynb b/site/en/hub/tutorials/image_feature_vector.ipynb
index 29ac0c97ddd..b5283c45b3d 100644
--- a/site/en/hub/tutorials/image_feature_vector.ipynb
+++ b/site/en/hub/tutorials/image_feature_vector.ipynb
@@ -357,7 +357,7 @@
"source": [
"## Train the network\n",
"\n",
- "Now that our model is built, let's train it and see how it perfoms on our test set."
+ "Now that our model is built, let's train it and see how it performs on our test set."
]
},
{
diff --git a/site/en/hub/tutorials/movenet.ipynb b/site/en/hub/tutorials/movenet.ipynb
index 2b6ffc6eb54..f7955a5253b 100644
--- a/site/en/hub/tutorials/movenet.ipynb
+++ b/site/en/hub/tutorials/movenet.ipynb
@@ -450,7 +450,7 @@
"id": "ymTVR2I9x22I"
},
"source": [
- "This session demonstrates the minumum working example of running the model on a **single image** to predict the 17 human keypoints."
+ "This session demonstrates the minimum working example of running the model on a **single image** to predict the 17 human keypoints."
]
},
{
@@ -697,7 +697,7 @@
" return output_image\n",
"\n",
"def run_inference(movenet, image, crop_region, crop_size):\n",
- " \"\"\"Runs model inferece on the cropped region.\n",
+ " \"\"\"Runs model inference on the cropped region.\n",
"\n",
" The function runs the model inference on the cropped region and updates the\n",
" model output to the original image coordinate system.\n",
diff --git a/site/en/hub/tutorials/movinet.ipynb b/site/en/hub/tutorials/movinet.ipynb
index 61609dbf72a..24600256cf9 100644
--- a/site/en/hub/tutorials/movinet.ipynb
+++ b/site/en/hub/tutorials/movinet.ipynb
@@ -890,7 +890,7 @@
" steps = video.shape[0]\n",
" # estimate duration of the video (in seconds)\n",
" duration = steps / video_fps\n",
- " # estiamte top_k probabilities and corresponding labels\n",
+ " # estimate top_k probabilities and corresponding labels\n",
" top_probs, top_labels, _ = get_top_k_streaming_labels(probs, k=top_k)\n",
"\n",
" images = []\n",
@@ -950,7 +950,7 @@
" logits, states = model({**states, 'image': image})\n",
" all_logits.append(logits)\n",
"\n",
- "# concatinating all the logits\n",
+ "# concatenating all the logits\n",
"logits = tf.concat(all_logits, 0)\n",
"# estimating probabilities\n",
"probs = tf.nn.softmax(logits, axis=-1)"
diff --git a/site/en/hub/tutorials/s3gan_generation_with_tf_hub.ipynb b/site/en/hub/tutorials/s3gan_generation_with_tf_hub.ipynb
index d8efd802ae0..bd73cffebdf 100644
--- a/site/en/hub/tutorials/s3gan_generation_with_tf_hub.ipynb
+++ b/site/en/hub/tutorials/s3gan_generation_with_tf_hub.ipynb
@@ -86,7 +86,7 @@
"2. Click **Runtime > Run all** to run each cell in order.\n",
" * Afterwards, the interactive visualizations should update automatically when you modify the settings using the sliders and dropdown menus.\n",
"\n",
- "Note: if you run into any issues, youn can try restarting the runtime and rerunning all cells from scratch by clicking **Runtime > Restart and run all...**.\n",
+ "Note: if you run into any issues, you can try restarting the runtime and rerunning all cells from scratch by clicking **Runtime > Restart and run all...**.\n",
"\n",
"[1] Mario Lucic\\*, Michael Tschannen\\*, Marvin Ritter\\*, Xiaohua Zhai, Olivier\n",
" Bachem, Sylvain Gelly, [High-Fidelity Image Generation With Fewer Labels](https://arxiv.org/abs/1903.02271), ICML 2019."
diff --git a/site/en/hub/tutorials/senteval_for_universal_sentence_encoder_cmlm.ipynb b/site/en/hub/tutorials/senteval_for_universal_sentence_encoder_cmlm.ipynb
index b152d3deee8..c33dce64c92 100644
--- a/site/en/hub/tutorials/senteval_for_universal_sentence_encoder_cmlm.ipynb
+++ b/site/en/hub/tutorials/senteval_for_universal_sentence_encoder_cmlm.ipynb
@@ -117,7 +117,7 @@
"id": "7a2ohPn8vMe2"
},
"source": [
- "#Execute a SentEval evaulation task\n",
+ "#Execute a SentEval evaluation task\n",
"The following code block executes a SentEval task and output the results, choose one of the following tasks to evaluate the USE CMLM model:\n",
"\n",
"```\n",
diff --git a/site/en/hub/tutorials/spice.ipynb b/site/en/hub/tutorials/spice.ipynb
index b58d07e46da..9ff6cd3bd62 100644
--- a/site/en/hub/tutorials/spice.ipynb
+++ b/site/en/hub/tutorials/spice.ipynb
@@ -658,7 +658,7 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "id": "eMUTI4L52ZHA"
+ "id": "eMULTI4L52ZHA"
},
"outputs": [],
"source": [
diff --git a/site/en/hub/tutorials/tf2_object_detection.ipynb b/site/en/hub/tutorials/tf2_object_detection.ipynb
index 38b162068d9..d06ad401824 100644
--- a/site/en/hub/tutorials/tf2_object_detection.ipynb
+++ b/site/en/hub/tutorials/tf2_object_detection.ipynb
@@ -291,7 +291,7 @@
"id": "yX3pb_pXDjYA"
},
"source": [
- "Intalling the Object Detection API"
+ "Installing the Object Detection API"
]
},
{
@@ -554,7 +554,7 @@
"\n",
"Among the available object detection models there's Mask R-CNN and the output of this model allows instance segmentation.\n",
"\n",
- "To visualize it we will use the same method we did before but adding an aditional parameter: `instance_masks=output_dict.get('detection_masks_reframed', None)`\n"
+ "To visualize it we will use the same method we did before but adding an additional parameter: `instance_masks=output_dict.get('detection_masks_reframed', None)`\n"
]
},
{
diff --git a/site/en/hub/tutorials/tf_hub_generative_image_module.ipynb b/site/en/hub/tutorials/tf_hub_generative_image_module.ipynb
index 4669f3b2dc3..4937bc2eb22 100644
--- a/site/en/hub/tutorials/tf_hub_generative_image_module.ipynb
+++ b/site/en/hub/tutorials/tf_hub_generative_image_module.ipynb
@@ -421,7 +421,7 @@
"If image is from the module space, the descent is quick and converges to a reasonable sample. Try out descending to an image that is **not from the module space**. The descent will only converge if the image is reasonably close to the space of training images.\n",
"\n",
"How to make it descend faster and to a more realistic image? One can try:\n",
- "* using different loss on the image difference, e.g. quadratic,\n",
+ "* using different loss on the image difference, e.g., quadratic,\n",
"* using different regularizer on the latent vector,\n",
"* initializing from a random vector in multiple runs,\n",
"* etc.\n"
diff --git a/site/en/hub/tutorials/wiki40b_lm.ipynb b/site/en/hub/tutorials/wiki40b_lm.ipynb
index e696160faca..ad94ce0aab8 100644
--- a/site/en/hub/tutorials/wiki40b_lm.ipynb
+++ b/site/en/hub/tutorials/wiki40b_lm.ipynb
@@ -214,7 +214,7 @@
" # Generate the tokens from the language model\n",
" generation_outputs = module(generation_input_dict, signature=\"prediction\", as_dict=True)\n",
"\n",
- " # Get the probablities and the inputs for the next steps\n",
+ " # Get the probabilities and the inputs for the next steps\n",
" probs = generation_outputs[\"probs\"]\n",
" new_mems = [generation_outputs[\"new_mem_{}\".format(i)] for i in range(n_layer)]\n",
"\n",
diff --git a/site/en/install/source.md b/site/en/install/source.md
index 8d250f51149..6a0aa08ed4b 100644
--- a/site/en/install/source.md
+++ b/site/en/install/source.md
@@ -34,8 +34,7 @@ Install the TensorFlow *pip* package dependencies (if using a virtual
environment, omit the `--user` argument):
\n"
+ "\n"
]
},
{
diff --git a/site/en/guide/estimator.ipynb b/site/en/guide/estimator.ipynb
index e58ef46cf86..05e8fb4012a 100644
--- a/site/en/guide/estimator.ipynb
+++ b/site/en/guide/estimator.ipynb
@@ -68,7 +68,7 @@
"id": "rILQuAiiRlI7"
},
"source": [
- "> Warning: Estimators are not recommended for new code. Estimators run `v1.Session`-style code which is more difficult to write correctly, and can behave unexpectedly, especially when combined with TF 2 code. Estimators do fall under our [compatibility guarantees](https://tensorflow.org/guide/versions), but will receive no fixes other than security vulnerabilities. See the [migration guide](https://tensorflow.org/guide/migrate) for details."
+ "> Warning: TensorFlow 2.15 included the final release of the `tf-estimator` package. Estimators will not be available in TensorFlow 2.16 or after. See the [migration guide](https://www.tensorflow.org/guide/migrate/migrating_estimator) for more information about how to convert off of Estimators."
]
},
{
diff --git a/site/en/guide/migrate/evaluator.ipynb b/site/en/guide/migrate/evaluator.ipynb
index fd8bd12d1e1..c8f848e4406 100644
--- a/site/en/guide/migrate/evaluator.ipynb
+++ b/site/en/guide/migrate/evaluator.ipynb
@@ -122,7 +122,7 @@
"\n",
"In TensorFlow 1, you can configure a `tf.estimator` to evaluate the estimator using `tf.estimator.train_and_evaluate`.\n",
"\n",
- "In this example, start by defining the `tf.estimator.Estimator` and speciyfing training and evaluation specifications:"
+ "In this example, start by defining the `tf.estimator.Estimator` and specifying training and evaluation specifications:"
]
},
{
diff --git a/site/en/guide/migrate/migrating_feature_columns.ipynb b/site/en/guide/migrate/migrating_feature_columns.ipynb
index ea12a5ef391..b2dbc5fe7c0 100644
--- a/site/en/guide/migrate/migrating_feature_columns.ipynb
+++ b/site/en/guide/migrate/migrating_feature_columns.ipynb
@@ -654,17 +654,17 @@
"source": [
"categorical_col = tf1.feature_column.categorical_column_with_identity(\n",
" 'type', num_buckets=one_hot_dims)\n",
- "# Convert index to one-hot; e.g. [2] -> [0,0,1].\n",
+ "# Convert index to one-hot; e.g., [2] -> [0,0,1].\n",
"indicator_col = tf1.feature_column.indicator_column(categorical_col)\n",
"\n",
- "# Convert strings to indices; e.g. ['small'] -> [1].\n",
+ "# Convert strings to indices; e.g., ['small'] -> [1].\n",
"vocab_col = tf1.feature_column.categorical_column_with_vocabulary_list(\n",
" 'size', vocabulary_list=vocab, num_oov_buckets=1)\n",
"# Embed the indices.\n",
"embedding_col = tf1.feature_column.embedding_column(vocab_col, embedding_dims)\n",
"\n",
"normalizer_fn = lambda x: (x - weight_mean) / math.sqrt(weight_variance)\n",
- "# Normalize the numeric inputs; e.g. [2.0] -> [0.0].\n",
+ "# Normalize the numeric inputs; e.g., [2.0] -> [0.0].\n",
"numeric_col = tf1.feature_column.numeric_column(\n",
" 'weight', normalizer_fn=normalizer_fn)\n",
"\n",
@@ -727,12 +727,12 @@
" 'size': tf.keras.Input(shape=(), dtype='string'),\n",
" 'weight': tf.keras.Input(shape=(), dtype='float32'),\n",
"}\n",
- "# Convert index to one-hot; e.g. [2] -> [0,0,1].\n",
+ "# Convert index to one-hot; e.g., [2] -> [0,0,1].\n",
"type_output = tf.keras.layers.CategoryEncoding(\n",
" one_hot_dims, output_mode='one_hot')(inputs['type'])\n",
- "# Convert size strings to indices; e.g. ['small'] -> [1].\n",
+ "# Convert size strings to indices; e.g., ['small'] -> [1].\n",
"size_output = tf.keras.layers.StringLookup(vocabulary=vocab)(inputs['size'])\n",
- "# Normalize the numeric inputs; e.g. [2.0] -> [0.0].\n",
+ "# Normalize the numeric inputs; e.g., [2.0] -> [0.0].\n",
"weight_output = tf.keras.layers.Normalization(\n",
" axis=None, mean=weight_mean, variance=weight_variance)(inputs['weight'])\n",
"outputs = {\n",
diff --git a/site/en/guide/migrate/migration_debugging.ipynb b/site/en/guide/migrate/migration_debugging.ipynb
index 86c86680dc9..25cb7f9065f 100644
--- a/site/en/guide/migrate/migration_debugging.ipynb
+++ b/site/en/guide/migrate/migration_debugging.ipynb
@@ -128,7 +128,7 @@
"\n",
" a. Check training behaviors with TensorBoard\n",
"\n",
- " * use simple optimizers e.g. SGD and simple distribution strategies e.g.\n",
+ " * use simple optimizers e.g., SGD and simple distribution strategies e.g.\n",
" `tf.distribute.OneDeviceStrategy` first\n",
" * training metrics\n",
" * evaluation metrics\n",
diff --git a/site/en/guide/profiler.md b/site/en/guide/profiler.md
index 1cd19c109fe..e92d1b9eae4 100644
--- a/site/en/guide/profiler.md
+++ b/site/en/guide/profiler.md
@@ -694,7 +694,7 @@ first few batches to avoid inaccuracies due to initialization overhead.
An example for profiling multiple workers:
```python
- # E.g. your worker IP addresses are 10.0.0.2, 10.0.0.3, 10.0.0.4, and you
+ # E.g., your worker IP addresses are 10.0.0.2, 10.0.0.3, 10.0.0.4, and you
# would like to profile for a duration of 2 seconds.
tf.profiler.experimental.client.trace(
'grpc://10.0.0.2:8466,grpc://10.0.0.3:8466,grpc://10.0.0.4:8466',
@@ -845,7 +845,7 @@ more efficient by casting to different data types after applying
spatial transformations, such as flipping, cropping, rotating, etc.
Note: Some ops like `tf.image.resize` transparently change the `dtype` to
-`fp32`. Make sure you normalize your data to lie between `0` and `1` if its not
+`fp32`. Make sure you normalize your data to lie between `0` and `1` if it's not
done automatically. Skipping this step could lead to `NaN` errors if you have
enabled [AMP](https://developer.nvidia.com/automatic-mixed-precision).
diff --git a/site/en/guide/random_numbers.ipynb b/site/en/guide/random_numbers.ipynb
index 5212a10a49a..f8b824ad906 100644
--- a/site/en/guide/random_numbers.ipynb
+++ b/site/en/guide/random_numbers.ipynb
@@ -166,7 +166,7 @@
"source": [
"See the *Algorithms* section below for more information about it.\n",
"\n",
- "Another way to create a generator is with `Generator.from_non_deterministic_state`. A generator created this way will start from a non-deterministic state, depending on e.g. time and OS."
+ "Another way to create a generator is with `Generator.from_non_deterministic_state`. A generator created this way will start from a non-deterministic state, depending on e.g., time and OS."
]
},
{
diff --git a/site/en/guide/sparse_tensor.ipynb b/site/en/guide/sparse_tensor.ipynb
index cd38fdf55ab..45f1e3fd3c3 100644
--- a/site/en/guide/sparse_tensor.ipynb
+++ b/site/en/guide/sparse_tensor.ipynb
@@ -620,7 +620,7 @@
"\n",
"However, there are a few cases where it can be useful to distinguish zero values from missing values. In particular, this allows for one way to encode missing/unknown data in your training data. For example, consider a use case where you have a tensor of scores (that can have any floating point value from -Inf to +Inf), with some missing scores. You can encode this tensor using a sparse tensor where the explicit zeros are known zero scores but the implicit zero values actually represent missing data and not zero. \n",
"\n",
- "Note: This is generally not the intended usage of `tf.sparse.SparseTensor`s; and you might want to also consier other techniques for encoding this such as for example using a separate mask tensor that identifies the locations of known/unknown values. However, exercise caution while using this approach, since most sparse operations will treat explicit and implicit zero values identically."
+ "Note: This is generally not the intended usage of `tf.sparse.SparseTensor`s; and you might want to also consider other techniques for encoding this such as for example using a separate mask tensor that identifies the locations of known/unknown values. However, exercise caution while using this approach, since most sparse operations will treat explicit and implicit zero values identically."
]
},
{
diff --git a/site/en/guide/tf_numpy_type_promotion.ipynb b/site/en/guide/tf_numpy_type_promotion.ipynb
index a9e176c5db6..f984310822a 100644
--- a/site/en/guide/tf_numpy_type_promotion.ipynb
+++ b/site/en/guide/tf_numpy_type_promotion.ipynb
@@ -178,7 +178,7 @@
"* `f32*` means Python `float` or weakly-typed `f32`\n",
"* `c128*` means Python `complex` or weakly-typed `c128`\n",
"\n",
- "The asterik (*) denotes that the corresponding type is “weak” - such a dtype is temporarily inferred by the system, and could defer to other dtypes. This concept is explained more in detail [here](#weak_tensor)."
+ "The asterisk (*) denotes that the corresponding type is “weak” - such a dtype is temporarily inferred by the system, and could defer to other dtypes. This concept is explained more in detail [here](#weak_tensor)."
]
},
{
@@ -449,13 +449,13 @@
"source": [
"### WeakTensor Construction\n",
"\n",
- "WeakTensors are created if you create a tensor without specifing a dtype the result is a WeakTensor. You can check whether a Tensor is \"weak\" or not by checking the weak attribute at the end of the Tensor's string representation."
+ "WeakTensors are created if you create a tensor without specifying a dtype the result is a WeakTensor. You can check whether a Tensor is \"weak\" or not by checking the weak attribute at the end of the Tensor's string representation."
]
},
{
"cell_type": "markdown",
"metadata": {
- "id": "7UmunnJ8Tru3"
+ "id": "7UmunnJ8True3"
},
"source": [
"**First Case**: When `tf.constant` is called with an input with no user-specified dtype."
diff --git a/site/en/guide/versions.md b/site/en/guide/versions.md
index df0d75114ef..0b089885552 100644
--- a/site/en/guide/versions.md
+++ b/site/en/guide/versions.md
@@ -171,12 +171,10 @@ incrementing the major version number for TensorFlow Lite, or vice versa.
The API surface that is covered by the TensorFlow Lite Extension APIs version
number is comprised of the following public APIs:
-```
* [tensorflow/lite/c/c_api_opaque.h](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/c/c_api_opaque.h)
* [tensorflow/lite/c/common.h](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/c/common.h)
* [tensorflow/lite/c/builtin_op_data.h](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/c/builtin_op_data.h)
* [tensorflow/lite/builtin_ops.h](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/builtin_ops.h)
-```
Again, experimental symbols are not covered; see [below](#not_covered) for
details.
@@ -203,7 +201,7 @@ These include:
such as:
- [C++](../install/lang_c.ipynb) (exposed through header files in
- [`tensorflow/cc`](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/cc)).
+ [`tensorflow/cc/`](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/cc)).
- [Java](../install/lang_java_legacy.md),
- [Go](https://github.com/tensorflow/build/blob/master/golang_install_guide/README.md)
- [JavaScript](https://www.tensorflow.org/js)
@@ -212,7 +210,7 @@ These include:
Objective-C, and Swift, in particular
- **C++** (exposed through header files in
- [`tensorflow/lite/`]\(https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/\))
+ [`tensorflow/lite/`](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/))
* **Details of composite ops:** Many public functions in Python expand to
several primitive ops in the graph, and these details will be part of any
@@ -471,7 +469,7 @@ existing producer scripts will not suddenly use the new functionality.
1. Add a new similar op named `SomethingV2` or similar and go through the
process of adding it and switching existing Python wrappers to use it.
To ensure forward compatibility use the checks suggested in
- [compat.py](https://www.tensorflow.org/code/tensorflow/python/compat/compat.py)
+ [compat.py](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/compat/compat.py)
when changing the Python wrappers.
2. Remove the old op (Can only take place with a major version change due to
backward compatibility).
diff --git a/site/en/hub/common_saved_model_apis/text.md b/site/en/hub/common_saved_model_apis/text.md
index 1c45b8ea026..c618b02d9f1 100644
--- a/site/en/hub/common_saved_model_apis/text.md
+++ b/site/en/hub/common_saved_model_apis/text.md
@@ -132,8 +132,8 @@ preprocessor = hub.load("path/to/preprocessor") # Must match `encoder`.
encoder_inputs = preprocessor(text_input)
encoder = hub.load("path/to/encoder")
-enocder_outputs = encoder(encoder_inputs)
-embeddings = enocder_outputs["default"]
+encoder_outputs = encoder(encoder_inputs)
+embeddings = encoder_outputs["default"]
```
Recall from the [Reusable SavedModel API](../reusable_saved_models.md) that
@@ -304,8 +304,8 @@ provisions from the [Reusable SavedModel API](../reusable_saved_models.md).
#### Usage synopsis
```python
-enocder = hub.load("path/to/encoder")
-enocder_outputs = encoder(encoder_inputs)
+encoder = hub.load("path/to/encoder")
+encoder_outputs = encoder(encoder_inputs)
```
or equivalently in Keras:
diff --git a/site/en/hub/tf2_saved_model.md b/site/en/hub/tf2_saved_model.md
index 7a7220d0a2e..641f9b3517b 100644
--- a/site/en/hub/tf2_saved_model.md
+++ b/site/en/hub/tf2_saved_model.md
@@ -82,7 +82,7 @@ and uncompressed SavedModels. For details, see [Caching](caching.md).
SavedModels can be loaded from a specified `handle`, where the `handle` is a
filesystem path, valid TFhub.dev model URL (e.g. "https://tfhub.dev/...").
Kaggle Models URLs mirror TFhub.dev handles in accordance with our Terms and the
-license associated with the model assets, e.g. "https://www.kaggle.com/...".
+license associated with the model assets, e.g., "https://www.kaggle.com/...".
Handles from Kaggle Models are equivalent to their corresponding TFhub.dev
handle.
diff --git a/site/en/hub/tutorials/action_recognition_with_tf_hub.ipynb b/site/en/hub/tutorials/action_recognition_with_tf_hub.ipynb
index b4a1e439621..3f586991ba9 100644
--- a/site/en/hub/tutorials/action_recognition_with_tf_hub.ipynb
+++ b/site/en/hub/tutorials/action_recognition_with_tf_hub.ipynb
@@ -184,7 +184,7 @@
" return list(_VIDEO_LIST)\n",
"\n",
"def fetch_ucf_video(video):\n",
- " \"\"\"Fetchs a video and cache into local filesystem.\"\"\"\n",
+ " \"\"\"Fetches a video and cache into local filesystem.\"\"\"\n",
" cache_path = os.path.join(_CACHE_DIR, video)\n",
" if not os.path.exists(cache_path):\n",
" urlpath = request.urljoin(UCF_ROOT, video)\n",
diff --git a/site/en/hub/tutorials/cropnet_cassava.ipynb b/site/en/hub/tutorials/cropnet_cassava.ipynb
index 18f41c00da1..926b5395e41 100644
--- a/site/en/hub/tutorials/cropnet_cassava.ipynb
+++ b/site/en/hub/tutorials/cropnet_cassava.ipynb
@@ -199,7 +199,7 @@
"id": "QT3XWAtR6BRy"
},
"source": [
- "The *cassava* dataset has images of cassava leaves with 4 distinct diseases as well as healthy cassava leaves. The model can predict all of these classes as well as sixth class for \"unknown\" when the model is not confident in it's prediction."
+ "The *cassava* dataset has images of cassava leaves with 4 distinct diseases as well as healthy cassava leaves. The model can predict all of these classes as well as sixth class for \"unknown\" when the model is not confident in its prediction."
]
},
{
diff --git a/site/en/hub/tutorials/cross_lingual_similarity_with_tf_hub_multilingual_universal_encoder.ipynb b/site/en/hub/tutorials/cross_lingual_similarity_with_tf_hub_multilingual_universal_encoder.ipynb
index 31fc037dfe7..920d197811e 100644
--- a/site/en/hub/tutorials/cross_lingual_similarity_with_tf_hub_multilingual_universal_encoder.ipynb
+++ b/site/en/hub/tutorials/cross_lingual_similarity_with_tf_hub_multilingual_universal_encoder.ipynb
@@ -271,7 +271,7 @@
"spanish_sentences = ['perro', 'Los cachorros son agradables.', 'Disfruto de dar largos paseos por la playa con mi perro.']\n",
"\n",
"# Multilingual example\n",
- "multilingual_example = [\"Willkommen zu einfachen, aber\", \"verrassend krachtige\", \"multilingüe\", \"compréhension du langage naturel\", \"модели.\", \"大家是什么意思\" , \"보다 중요한\", \".اللغة التي يتحدثونها\"]\n",
+ "multilingual_example = [\"Willkommen zu einfachen, aber\", \"verrassend krachtige\", \"multilingüe\", \"compréhension du language naturel\", \"модели.\", \"大家是什么意思\" , \"보다 중요한\", \".اللغة التي يتحدثونها\"]\n",
"multilingual_example_in_en = [\"Welcome to simple yet\", \"surprisingly powerful\", \"multilingual\", \"natural language understanding\", \"models.\", \"What people mean\", \"matters more than\", \"the language they speak.\"]\n"
]
},
@@ -4174,7 +4174,7 @@
"id": "Dxu66S8wJIG9"
},
"source": [
- "### Semantic-search crosss-lingual capabilities\n",
+ "### Semantic-search cross-lingual capabilities\n",
"\n",
"In this section we show how to retrieve sentences related to a set of sample English sentences. Things to try:\n",
"\n",
diff --git a/site/en/hub/tutorials/image_enhancing.ipynb b/site/en/hub/tutorials/image_enhancing.ipynb
index 4c9496b79ae..3710ebd6d66 100644
--- a/site/en/hub/tutorials/image_enhancing.ipynb
+++ b/site/en/hub/tutorials/image_enhancing.ipynb
@@ -346,7 +346,7 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "id": "r_dautO6qbTV"
+ "id": "r_defaultO6qbTV"
},
"outputs": [],
"source": [
diff --git a/site/en/hub/tutorials/image_feature_vector.ipynb b/site/en/hub/tutorials/image_feature_vector.ipynb
index 29ac0c97ddd..b5283c45b3d 100644
--- a/site/en/hub/tutorials/image_feature_vector.ipynb
+++ b/site/en/hub/tutorials/image_feature_vector.ipynb
@@ -357,7 +357,7 @@
"source": [
"## Train the network\n",
"\n",
- "Now that our model is built, let's train it and see how it perfoms on our test set."
+ "Now that our model is built, let's train it and see how it performs on our test set."
]
},
{
diff --git a/site/en/hub/tutorials/movenet.ipynb b/site/en/hub/tutorials/movenet.ipynb
index 2b6ffc6eb54..f7955a5253b 100644
--- a/site/en/hub/tutorials/movenet.ipynb
+++ b/site/en/hub/tutorials/movenet.ipynb
@@ -450,7 +450,7 @@
"id": "ymTVR2I9x22I"
},
"source": [
- "This session demonstrates the minumum working example of running the model on a **single image** to predict the 17 human keypoints."
+ "This session demonstrates the minimum working example of running the model on a **single image** to predict the 17 human keypoints."
]
},
{
@@ -697,7 +697,7 @@
" return output_image\n",
"\n",
"def run_inference(movenet, image, crop_region, crop_size):\n",
- " \"\"\"Runs model inferece on the cropped region.\n",
+ " \"\"\"Runs model inference on the cropped region.\n",
"\n",
" The function runs the model inference on the cropped region and updates the\n",
" model output to the original image coordinate system.\n",
diff --git a/site/en/hub/tutorials/movinet.ipynb b/site/en/hub/tutorials/movinet.ipynb
index 61609dbf72a..24600256cf9 100644
--- a/site/en/hub/tutorials/movinet.ipynb
+++ b/site/en/hub/tutorials/movinet.ipynb
@@ -890,7 +890,7 @@
" steps = video.shape[0]\n",
" # estimate duration of the video (in seconds)\n",
" duration = steps / video_fps\n",
- " # estiamte top_k probabilities and corresponding labels\n",
+ " # estimate top_k probabilities and corresponding labels\n",
" top_probs, top_labels, _ = get_top_k_streaming_labels(probs, k=top_k)\n",
"\n",
" images = []\n",
@@ -950,7 +950,7 @@
" logits, states = model({**states, 'image': image})\n",
" all_logits.append(logits)\n",
"\n",
- "# concatinating all the logits\n",
+ "# concatenating all the logits\n",
"logits = tf.concat(all_logits, 0)\n",
"# estimating probabilities\n",
"probs = tf.nn.softmax(logits, axis=-1)"
diff --git a/site/en/hub/tutorials/s3gan_generation_with_tf_hub.ipynb b/site/en/hub/tutorials/s3gan_generation_with_tf_hub.ipynb
index d8efd802ae0..bd73cffebdf 100644
--- a/site/en/hub/tutorials/s3gan_generation_with_tf_hub.ipynb
+++ b/site/en/hub/tutorials/s3gan_generation_with_tf_hub.ipynb
@@ -86,7 +86,7 @@
"2. Click **Runtime > Run all** to run each cell in order.\n",
" * Afterwards, the interactive visualizations should update automatically when you modify the settings using the sliders and dropdown menus.\n",
"\n",
- "Note: if you run into any issues, youn can try restarting the runtime and rerunning all cells from scratch by clicking **Runtime > Restart and run all...**.\n",
+ "Note: if you run into any issues, you can try restarting the runtime and rerunning all cells from scratch by clicking **Runtime > Restart and run all...**.\n",
"\n",
"[1] Mario Lucic\\*, Michael Tschannen\\*, Marvin Ritter\\*, Xiaohua Zhai, Olivier\n",
" Bachem, Sylvain Gelly, [High-Fidelity Image Generation With Fewer Labels](https://arxiv.org/abs/1903.02271), ICML 2019."
diff --git a/site/en/hub/tutorials/senteval_for_universal_sentence_encoder_cmlm.ipynb b/site/en/hub/tutorials/senteval_for_universal_sentence_encoder_cmlm.ipynb
index b152d3deee8..c33dce64c92 100644
--- a/site/en/hub/tutorials/senteval_for_universal_sentence_encoder_cmlm.ipynb
+++ b/site/en/hub/tutorials/senteval_for_universal_sentence_encoder_cmlm.ipynb
@@ -117,7 +117,7 @@
"id": "7a2ohPn8vMe2"
},
"source": [
- "#Execute a SentEval evaulation task\n",
+ "#Execute a SentEval evaluation task\n",
"The following code block executes a SentEval task and output the results, choose one of the following tasks to evaluate the USE CMLM model:\n",
"\n",
"```\n",
diff --git a/site/en/hub/tutorials/spice.ipynb b/site/en/hub/tutorials/spice.ipynb
index b58d07e46da..9ff6cd3bd62 100644
--- a/site/en/hub/tutorials/spice.ipynb
+++ b/site/en/hub/tutorials/spice.ipynb
@@ -658,7 +658,7 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "id": "eMUTI4L52ZHA"
+ "id": "eMULTI4L52ZHA"
},
"outputs": [],
"source": [
diff --git a/site/en/hub/tutorials/tf2_object_detection.ipynb b/site/en/hub/tutorials/tf2_object_detection.ipynb
index 38b162068d9..d06ad401824 100644
--- a/site/en/hub/tutorials/tf2_object_detection.ipynb
+++ b/site/en/hub/tutorials/tf2_object_detection.ipynb
@@ -291,7 +291,7 @@
"id": "yX3pb_pXDjYA"
},
"source": [
- "Intalling the Object Detection API"
+ "Installing the Object Detection API"
]
},
{
@@ -554,7 +554,7 @@
"\n",
"Among the available object detection models there's Mask R-CNN and the output of this model allows instance segmentation.\n",
"\n",
- "To visualize it we will use the same method we did before but adding an aditional parameter: `instance_masks=output_dict.get('detection_masks_reframed', None)`\n"
+ "To visualize it we will use the same method we did before but adding an additional parameter: `instance_masks=output_dict.get('detection_masks_reframed', None)`\n"
]
},
{
diff --git a/site/en/hub/tutorials/tf_hub_generative_image_module.ipynb b/site/en/hub/tutorials/tf_hub_generative_image_module.ipynb
index 4669f3b2dc3..4937bc2eb22 100644
--- a/site/en/hub/tutorials/tf_hub_generative_image_module.ipynb
+++ b/site/en/hub/tutorials/tf_hub_generative_image_module.ipynb
@@ -421,7 +421,7 @@
"If image is from the module space, the descent is quick and converges to a reasonable sample. Try out descending to an image that is **not from the module space**. The descent will only converge if the image is reasonably close to the space of training images.\n",
"\n",
"How to make it descend faster and to a more realistic image? One can try:\n",
- "* using different loss on the image difference, e.g. quadratic,\n",
+ "* using different loss on the image difference, e.g., quadratic,\n",
"* using different regularizer on the latent vector,\n",
"* initializing from a random vector in multiple runs,\n",
"* etc.\n"
diff --git a/site/en/hub/tutorials/wiki40b_lm.ipynb b/site/en/hub/tutorials/wiki40b_lm.ipynb
index e696160faca..ad94ce0aab8 100644
--- a/site/en/hub/tutorials/wiki40b_lm.ipynb
+++ b/site/en/hub/tutorials/wiki40b_lm.ipynb
@@ -214,7 +214,7 @@
" # Generate the tokens from the language model\n",
" generation_outputs = module(generation_input_dict, signature=\"prediction\", as_dict=True)\n",
"\n",
- " # Get the probablities and the inputs for the next steps\n",
+ " # Get the probabilities and the inputs for the next steps\n",
" probs = generation_outputs[\"probs\"]\n",
" new_mems = [generation_outputs[\"new_mem_{}\".format(i)] for i in range(n_layer)]\n",
"\n",
diff --git a/site/en/install/source.md b/site/en/install/source.md
index 8d250f51149..6a0aa08ed4b 100644
--- a/site/en/install/source.md
+++ b/site/en/install/source.md
@@ -34,8 +34,7 @@ Install the TensorFlow *pip* package dependencies (if using a virtual
environment, omit the `--user` argument):
-pip install -U --user pip numpy wheel packaging requests opt_einsum
-pip install -U --user keras_preprocessing --no-deps
+pip install -U --user pip
Note: A `pip` version >19.0 is required to install the TensorFlow 2 `.whl`
@@ -60,7 +59,7 @@ file.
Clang is a C/C++/Objective-C compiler that is compiled in C++ based on LLVM. It
is the default compiler to build TensorFlow starting with TensorFlow 2.13. The
-current supported version is LLVM/Clang 16.
+current supported version is LLVM/Clang 17.
[LLVM Debian/Ubuntu nightly packages](https://apt.llvm.org) provide an automatic
installation script and packages for manual installation on Linux. Make sure you
@@ -68,42 +67,50 @@ run the following command if you manually add llvm apt repository to your
package sources:
-sudo apt-get update && sudo apt-get install -y llvm-16 clang-16
+sudo apt-get update && sudo apt-get install -y llvm-17 clang-17
+Now that `/usr/lib/llvm-17/bin/clang` is the actual path to clang in this case.
+
Alternatively, you can download and unpack the pre-built
-[Clang + LLVM 16](https://github.com/llvm/llvm-project/releases/tag/llvmorg-16.0.0).
+[Clang + LLVM 17](https://github.com/llvm/llvm-project/releases/tag/llvmorg-17.0.2).
-Below is an example of steps you can take to set up the downloaded
-Clang + LLVM 16 binaries:
+Below is an example of steps you can take to set up the downloaded Clang + LLVM
+17 binaries on Debian/Ubuntu operating systems:
-1. Change to the desired destination directory:
- ```cd ```
+1. Change to the desired destination directory: `cd `
-2. Load and extract an archive file...(suitable to your architecture):
+1. Load and extract an archive file...(suitable to your architecture):
-
- wget https://github.com/llvm/llvm-project/releases/download/llvmorg-16.0.0/clang+llvm-16.0.0-x86_64-linux-gnu-ubuntu-18.04.tar.xz
+ wget https://github.com/llvm/llvm-project/releases/download/llvmorg-17.0.2/clang+llvm-17.0.2-x86_64-linux-gnu-ubuntu-22.04.tar.xz
- tar -xvf clang+llvm-16.0.0-x86_64-linux-gnu-ubuntu-18.04.tar.xz
+ tar -xvf clang+llvm-17.0.2-x86_64-linux-gnu-ubuntu-22.04.tar.xz
-3. Check the obtained Clang + LLVM 16 binaries version:
+1. Copy the extracted contents (directories and files) to `/usr` (you may need
+ sudo permissions, and the correct directory may vary by distribution). This
+ effectively installs Clang and LLVM, and adds it to the path. You should not
+ have to replace anything, unless you have a previous installation, in which
+ case you should replace the files:
-
- ./clang+llvm-16.0.0-x86_64-linux-gnu-ubuntu-18.04/bin/clang-16 --version
+ cp -r clang+llvm-17.0.2-x86_64-linux-gnu-ubuntu-22.04/* /usr
-4. Directory `/clang+llvm-16.0.0-x86_64-linux-gnu-ubuntu-18.04/bin/clang-16` is
- the actual path to your new clang. You can run the `./configure` script or
- manually set environment variables `CC` and `BAZEL_COMPILER` to this path.
+1. Check the obtained Clang + LLVM 17 binaries version:
+
+ clang --version
+
+
+1. Now that `/usr/bin/clang` is the actual path to your new clang. You can run
+ the `./configure` script or manually set environment variables `CC` and
+ `BAZEL_COMPILER` to this path.
### Install GPU support (optional, Linux only)
There is *no* GPU support for macOS.
-Read the [GPU support](./gpu.md) guide to install the drivers and additional
+Read the [GPU support](./pip.md) guide to install the drivers and additional
software required to run TensorFlow on a GPU.
Note: It is easier to set up one of TensorFlow's GPU-enabled [Docker images](#docker_linux_builds).
@@ -204,7 +211,7 @@ Preconfigured Bazel build configs to DISABLE default on features:
#### GPU support
-For [GPU support](./gpu.md), set `cuda=Y` during configuration and specify the
+For [GPU support](./pip.md), set `cuda=Y` during configuration and specify the
versions of CUDA and cuDNN. If your system has multiple versions of CUDA or
cuDNN installed, explicitly set the version instead of relying on the default.
`./configure` creates symbolic links to your system's CUDA libraries—so if you
@@ -234,19 +241,6 @@ There are some preconfigured build configs available that can be added to the
## Build and install the pip package
-The pip package is build in two steps. A `bazel build` commands creates a
-"package-builder" program. You then run the package-builder to create the
-package.
-
-### Build the package-builder
-Note: GPU support can be enabled with `cuda=Y` during the `./configure` stage.
-
-Use `bazel build` to create the TensorFlow 2.x package-builder:
-
-
-bazel build [--config=option] //tensorflow/tools/pip_package:build_pip_package
-
-
#### Bazel build options
Refer to the Bazel
@@ -262,25 +256,34 @@ that complies with the manylinux2014 package standard.
### Build the package
-The `bazel build` command creates an executable named `build_pip_package`—this
-is the program that builds the `pip` package. Run the executable as shown
-below to build a `.whl` package in the `/tmp/tensorflow_pkg` directory.
+To build pip package, you need to specify `--repo_env=WHEEL_NAME` flag.
+depending on the provided name, package will be created, e.g:
-To build from a release branch:
+To build tensorflow CPU package:
+
+bazel build //tensorflow/tools/pip_package:wheel --repo_env=WHEEL_NAME=tensorflow_cpu
+
+To build tensorflow GPU package:
-./bazel-bin/tensorflow/tools/pip_package/build_pip_package /tmp/tensorflow_pkg
+bazel build //tensorflow/tools/pip_package:wheel --repo_env=WHEEL_NAME=tensorflow --config=cuda
-To build from master, use `--nightly_flag` to get the right dependencies:
+To build tensorflow TPU package:
+
+bazel build //tensorflow/tools/pip_package:wheel --repo_env=WHEEL_NAME=tensorflow_tpu --config=tpu
+
+To build nightly package, set `tf_nightly` instead of `tensorflow`, e.g.
+to build CPU nightly package:
-./bazel-bin/tensorflow/tools/pip_package/build_pip_package --nightly_flag /tmp/tensorflow_pkg
+bazel build //tensorflow/tools/pip_package:wheel --repo_env=WHEEL_NAME=tf_nightly_cpu
-Although it is possible to build both CUDA and non-CUDA configurations under the
-same source tree, it's recommended to run `bazel clean` when switching between
-these two configurations in the same source tree.
+As a result, generated wheel will be located in
+
+bazel-bin/tensorflow/tools/pip_package/wheel_house/
+
### Install the package
@@ -288,7 +291,7 @@ The filename of the generated `.whl` file depends on the TensorFlow version and
your platform. Use `pip install` to install the package, for example:
-pip install /tmp/tensorflow_pkg/tensorflow-version-tags.whl
+pip install bazel-bin/tensorflow/tools/pip_package/wheel_house/tensorflow-version-tags.whl
Success: TensorFlow is now installed.
@@ -336,20 +339,17 @@ docker run -it -w /tensorflow -v /path/to/tensorflow:/tensorflow -v $
With the source tree set up, build the TensorFlow package within the container's
virtual environment:
-1. Optional: Configure the build—this prompts the user to answer build configuration
- questions.
-2. Build the tool used to create the *pip* package.
-3. Run the tool to create the *pip* package.
-4. Adjust the ownership permissions of the file for outside the container.
+1. Optional: Configure the build—this prompts the user to answer build
+ configuration questions.
+2. Build the *pip* package.
+3. Adjust the ownership permissions of the file for outside the container.
./configure # if necessary
-bazel build --config=opt //tensorflow/tools/pip_package:build_pip_package
-
-./bazel-bin/tensorflow/tools/pip_package/build_pip_package /mnt # create package
-
-chown $HOST_PERMS /mnt/tensorflow-version-tags.whl
+bazel build //tensorflow/tools/pip_package:wheel --repo_env=WHEEL_NAME=tensorflow_cpu --config=opt
+`
+chown $HOST_PERMS bazel-bin/tensorflow/tools/pip_package/wheel_house/tensorflow-version-tags.whl
Install and verify the package within the container:
@@ -357,7 +357,7 @@ Install and verify the package within the container:
pip uninstall tensorflow # remove current version
-pip install /mnt/tensorflow-version-tags.whl
+pip install bazel-bin/tensorflow/tools/pip_package/wheel_house/tensorflow-version-tags.whl
cd /tmp # don't import from source directory
python -c "import tensorflow as tf; print(tf.__version__)"
@@ -374,7 +374,7 @@ Docker is the easiest way to build GPU support for TensorFlow since the *host*
machine only requires the
[NVIDIA® driver](https://github.com/NVIDIA/nvidia-docker/wiki/Frequently-Asked-Questions#how-do-i-install-the-nvidia-driver){:.external}
(the *NVIDIA® CUDA® Toolkit* doesn't have to be installed). Refer to the
-[GPU support guide](./gpu.md) and the TensorFlow [Docker guide](./docker.md) to
+[GPU support guide](./pip.md) and the TensorFlow [Docker guide](./docker.md) to
set up [nvidia-docker](https://github.com/NVIDIA/nvidia-docker){:.external}
(Linux only).
@@ -395,11 +395,9 @@ with GPU support:
./configure # if necessary
-bazel build --config=opt --config=cuda //tensorflow/tools/pip_package:build_pip_package
-
-./bazel-bin/tensorflow/tools/pip_package/build_pip_package /mnt # create package
+bazel build //tensorflow/tools/pip_package:wheel --repo_env=WHEEL_NAME=tensorflow --config=cuda --config=opt
-chown $HOST_PERMS /mnt/tensorflow-version-tags.whl
+chown $HOST_PERMS bazel-bin/tensorflow/tools/pip_package/wheel_house/tensorflow-version-tags.whl
Install and verify the package within the container and check for a GPU:
@@ -407,7 +405,7 @@ Install and verify the package within the container and check for a GPU:
pip uninstall tensorflow # remove current version
-pip install /mnt/tensorflow-version-tags.whl
+pip install bazel-bin/tensorflow/tools/pip_package/wheel_house/tensorflow-version-tags.whl
cd /tmp # don't import from source directory
python -c "import tensorflow as tf; print(\"Num GPUs Available: \", len(tf.config.list_physical_devices('GPU')))"
@@ -424,6 +422,7 @@ Success: TensorFlow is now installed.
| Version | Python version | Compiler | Build tools |
|---|
+| tensorflow-2.16.1 | 3.9-3.12 | Clang 17.0.6 | Bazel 6.5.0 |
| tensorflow-2.15.0 | 3.9-3.11 | Clang 16.0.0 | Bazel 6.1.0 |
| tensorflow-2.14.0 | 3.9-3.11 | Clang 16.0.0 | Bazel 6.1.0 |
| tensorflow-2.13.0 | 3.8-3.11 | Clang 16.0.0 | Bazel 5.3.0 |
@@ -462,7 +461,8 @@ Success: TensorFlow is now installed.
| Version | Python version | Compiler | Build tools | cuDNN | CUDA |
|---|
-| tensorflow-2.15.0 | 3.9-3.11 | Clang 16.0.0 | Bazel 6.1.0 | 8.8 | 12.2 |
+| tensorflow-2.16.1 | 3.9-3.12 | Clang 17.0.6 | Bazel 6.5.0 | 8.9 | 12.3 |
+| tensorflow-2.15.0 | 3.9-3.11 | Clang 16.0.0 | Bazel 6.1.0 | 8.9 | 12.2 |
| tensorflow-2.14.0 | 3.9-3.11 | Clang 16.0.0 | Bazel 6.1.0 | 8.7 | 11.8 |
| tensorflow-2.13.0 | 3.8-3.11 | Clang 16.0.0 | Bazel 5.3.0 | 8.6 | 11.8 |
| tensorflow-2.12.0 | 3.8-3.11 | GCC 9.3.1 | Bazel 5.3.0 | 8.6 | 11.8 |
@@ -502,6 +502,7 @@ Success: TensorFlow is now installed.
| Version | Python version | Compiler | Build tools |
|---|
+| tensorflow-2.16.1 | 3.9-3.12 | Clang from xcode 13.6 | Bazel 6.5.0 |
| tensorflow-2.15.0 | 3.9-3.11 | Clang from xcode 10.15 | Bazel 6.1.0 |
| tensorflow-2.14.0 | 3.9-3.11 | Clang from xcode 10.15 | Bazel 6.1.0 |
| tensorflow-2.13.0 | 3.8-3.11 | Clang from xcode 10.15 | Bazel 5.3.0 |
diff --git a/site/en/install/source_windows.md b/site/en/install/source_windows.md
index 9cf33d0458b..1bb5a8b5f4a 100644
--- a/site/en/install/source_windows.md
+++ b/site/en/install/source_windows.md
@@ -1,6 +1,6 @@
# Build from source on Windows
-Build a TensorFlow *pip* package from source and install it on Windows.
+Build a TensorFlow *pip* package from the source and install it on Windows.
Note: We already provide well-tested, pre-built
[TensorFlow packages](./pip.md) for Windows systems.
@@ -20,6 +20,7 @@ variable.
Install the TensorFlow *pip* package dependencies:
+pip3 install -U pip
pip3 install -U six numpy wheel packaging
pip3 install -U keras_preprocessing --no-deps
@@ -47,22 +48,35 @@ build TensorFlow. If MSYS2 is installed to `C:\msys64`, add
run:
+pacman -Syu (requires a console restart)
pacman -S git patch unzip
+pacman -S git patch unzip rsync
-### Install Visual C++ Build Tools 2019
+Note: Clang will be the preferred compiler to build TensorFlow CPU wheels on the Windows Platform starting with TF 2.16.1 The currently supported version is LLVM/clang 17.0.6.
-Install the *Visual C++ build tools 2019*. This comes with *Visual Studio 2019*
+Note: To build with Clang on Windows, it is required to install both LLVM and Visual C++ Build tools as although Windows uses clang-cl.exe as the compiler, Visual C++ Build tools are needed to link to Visual C++ libraries
+
+### Install Visual C++ Build Tools 2022
+
+Install the *Visual C++ build tools 2022*. This comes with *Visual Studio Community 2022*
but can be installed separately:
1. Go to the
[Visual Studio downloads](https://visualstudio.microsoft.com/downloads/){:.external},
-2. Select *Redistributables and Build Tools*,
+2. Select *Tools for Visual Studio or Other Tools, Framework and Redistributables*,
3. Download and install:
- - *Microsoft Visual C++ 2019 Redistributable*
- - *Microsoft Build Tools 2019*
+ - *Build Tools for Visual Studio 2022*
+ - *Microsoft Visual C++ Redistributables for Visual Studio 2022*
+
+Note: TensorFlow is tested against the *Visual Studio Community 2022*.
+
+### Install LLVM
+
+1. Go to the
+ [LLVM downloads](https://github.com/llvm/llvm-project/releases/){:.external},
+2. Download and install Windows-compatible LLVM in C:/Program Files/LLVM e.g., LLVM-17.0.6-win64.exe
-Note: TensorFlow is tested against the *Visual Studio 2019*.
### Install GPU support (optional)
@@ -94,31 +108,32 @@ Key Point: If you're having build problems on the latest development branch, try
a release branch that is known to work.
## Optional: Environmental Variable Set Up
-Run following commands before running build command to avoid issue with package creation:
-(If the below commands were set up while installing the packages, please ignore them). Run `set` check if all the paths were set correctly, run `echo %Environmental Variable%` e.g. `echo %BAZEL_VC%` to check path set up for a specific Environmental Variable
+Run the following commands before running the build command to avoid issues with package creation:
+(If the below commands were set up while installing the packages, please ignore them). Run `set` to check if all the paths were set correctly, run `echo %Environmental Variable%` e.g., `echo %BAZEL_VC%` to check the path set up for a specific Environmental Variable
Python path set up issue [tensorflow:issue#59943](https://github.com/tensorflow/tensorflow/issues/59943),[tensorflow:issue#9436](https://github.com/tensorflow/tensorflow/issues/9436),[tensorflow:issue#60083](https://github.com/tensorflow/tensorflow/issues/60083)
-set PATH=path/to/python # [e.g. (C:/Python310)]
-set PATH=path/to/python/Scripts # [e.g. (C:/Python310/Scripts)]
+set PATH=path/to/python;%PATH% # [e.g. (C:/Python311)]
+set PATH=path/to/python/Scripts;%PATH% # [e.g. (C:/Python311/Scripts)]
set PYTHON_BIN_PATH=path/to/python_virtualenv/Scripts/python.exe
set PYTHON_LIB_PATH=path/to/python virtualenv/lib/site-packages
set PYTHON_DIRECTORY=path/to/python_virtualenv/Scripts
-Bazel/MSVC path set up issue [tensorflow:issue#54578](https://github.com/tensorflow/tensorflow/issues/54578)
+Bazel/MSVC/CLANG path set up issue [tensorflow:issue#54578](https://github.com/tensorflow/tensorflow/issues/54578)
set BAZEL_SH=C:/msys64/usr/bin/bash.exe
-set BAZEL_VS=C:/Program Files(x86)/Microsoft Visual Studio/2019/BuildTools
-set BAZEL_VC=C:/Program Files(x86)/Microsoft Visual Studio/2019/BuildTools/VC
+set BAZEL_VS=C:/Program Files/Microsoft Visual Studio/2022/BuildTools
+set BAZEL_VC=C:/Program Files/Microsoft Visual Studio/2022/BuildTools/VC
+set Bazel_LLVM=C:/Program Files/LLVM (explicitly tell Bazel where LLVM is installed by BAZEL_LLVM, needed while using CLANG)
+set PATH=C:/Program Files/LLVM/bin;%PATH% (Optional, needed while using CLANG as Compiler)
-
## Optional: Configure the build
-TensorFlow builds are configured by the `.bazelrc` file in the respoitory's
+TensorFlow builds are configured by the `.bazelrc` file in the repository's
root directory. The `./configure` or `./configure.py` scripts can be used to
adjust common settings.
@@ -138,21 +153,27 @@ differ):
View sample configuration session
python ./configure.py
-You have bazel 5.3.0 installed.
-Please specify the location of python. [Default is C:\Python310\python.exe]:
+You have bazel 6.5.0 installed.
+Please specify the location of python. [Default is C:\Python311\python.exe]:
+
Found possible Python library paths:
-C:\Python310\lib\site-packages
-Please input the desired Python library path to use. Default is [C:\Python310\lib\site-packages]
+C:\Python311\lib\site-packages
+Please input the desired Python library path to use. Default is [C:\Python311\lib\site-packages]
Do you wish to build TensorFlow with ROCm support? [y/N]:
No ROCm support will be enabled for TensorFlow.
-
WARNING: Cannot build with CUDA support on Windows.
-Starting in TF 2.11, CUDA build is not supported for Windows. For using TensorFlow GPU on Windows, you will need to build/install TensorFlow in WSL2.
+Starting in TF 2.11, CUDA build is not supported for Windows. To use TensorFlow GPU on Windows, you will need to build/install TensorFlow in WSL2.
-Please specify optimization flags to use during compilation when bazel option "--config=opt" is specified [Default is /arch:AVX]:
+Do you want to use Clang to build TensorFlow? [Y/n]:
+Add "--config=win_clang" to compile TensorFlow with CLANG.
+Please specify the path to clang executable. [Default is C:\Program Files\LLVM\bin\clang.EXE]:
+
+You have Clang 17.0.6 installed.
+
+Please specify optimization flags to use during compilation when bazel option "--config=opt" is specified [Default is /arch:AVX]:
Would you like to override eigen strong inline for some C++ compilation to reduce the compilation time? [Y/n]:
Eigen strong inline overridden.
@@ -170,13 +191,12 @@ Preconfigured Bazel build configs. You can use any of the below by adding "--con
Preconfigured Bazel build configs to DISABLE default on features:
--config=nogcp # Disable GCP support.
--config=nonccl # Disable NVIDIA NCCL support.
-
## Build and install the pip package
-The pip package gets built in two steps. A `bazel build` commands creates a
+The pip package is built in two steps. A `bazel build` command creates a
"package-builder" program. You then run the package-builder to create the
package.
@@ -187,15 +207,23 @@ tensorflow:master repo has been updated to build 2.x by default.
`bazel build ` to create the TensorFlow package-builder.
-bazel build //tensorflow/tools/pip_package:build_pip_package
+bazel build //tensorflow/tools/pip_package:wheel
#### CPU-only
Use `bazel` to make the TensorFlow package builder with CPU-only support:
+##### Build with MSVC
+
+bazel build --config=opt --repo_env=TF_PYTHON_VERSION=3.11 //tensorflow/tools/pip_package:wheel --repo_env=WHEEL_NAME=tensorflow_cpu
+
+
+##### Build with CLANG
+Use --config=`win_clang` to build TenorFlow with the CLANG Compiler:
+
-bazel build --config=opt //tensorflow/tools/pip_package:build_pip_package
+bazel build --config=win_clang --repo_env=TF_PYTHON_VERSION=3.11 //tensorflow/tools/pip_package:wheel --repo_env=WHEEL_NAME=tensorflow_cpu
#### GPU support
@@ -217,7 +245,7 @@ bazel clean --expunge
#### Bazel build options
-Use this option when building to avoid issue with package creation:
+Use this option when building to avoid issues with package creation:
[tensorflow:issue#22390](https://github.com/tensorflow/tensorflow/issues/22390)
@@ -236,33 +264,37 @@ to suppress nvcc warning messages.
### Build the package
-The `bazel build` command creates an executable named `build_pip_package`—this
-is the program that builds the `pip` package. For example, the following builds
-a `.whl` package in the `C:/tmp/tensorflow_pkg` directory:
+To build a pip package, you need to specify the --repo_env=WHEEL_NAME flag.
+Depending on the provided name, the package will be created. For example:
-
-bazel-bin\tensorflow\tools\pip_package\build_pip_package C:/tmp/tensorflow_pkg
+To build tensorflow CPU package:
+
+bazel build //tensorflow/tools/pip_package:wheel --repo_env=WHEEL_NAME=tensorflow_cpu
-Although it is possible to build both CUDA and non-CUDA configs under the
-same source tree, we recommend running `bazel clean` when switching between
-these two configurations in the same source tree.
+To build nightly package, set `tf_nightly` instead of `tensorflow`, e.g.
+to build CPU nightly package:
+
+bazel build //tensorflow/tools/pip_package:wheel --repo_env=WHEEL_NAME=tf_nightly_cpu
+
+
+As a result, generated wheel will be located in
+
+bazel-bin/tensorflow/tools/pip_package/wheel_house/
+
### Install the package
The filename of the generated `.whl` file depends on the TensorFlow version and
-your platform. Use `pip3 install` to install the package, for example:
+your platform. Use `pip install` to install the package, for example:
-
-pip3 install C:/tmp/tensorflow_pkg/tensorflow-version-tags.whl
-
-e.g. pip3 install C:/tmp/tensorflow_pkg/tensorflow-2.12.0-cp310-cp310-win_amd64.whl
+
+pip install bazel-bin/tensorflow/tools/pip_package/wheel_house/tensorflow-version-tags.whl
Success: TensorFlow is now installed.
-
## Build using the MSYS shell
TensorFlow can also be built using the MSYS shell. Make the changes listed
@@ -309,6 +341,7 @@ Note: Starting in TF 2.11, CUDA build is not supported for Windows. For using Te
| Version | Python version | Compiler | Build tools |
|---|
+| tensorflow-2.16.1 | 3.9-3.12 | CLANG 17.0.6 | Bazel 6.5.0 |
| tensorflow-2.15.0 | 3.9-3.11 | MSVC 2019 | Bazel 6.1.0 |
| tensorflow-2.14.0 | 3.9-3.11 | MSVC 2019 | Bazel 6.1.0 |
| tensorflow-2.12.0 | 3.8-3.11 | MSVC 2019 | Bazel 5.3.0 |
diff --git a/site/en/r1/guide/autograph.ipynb b/site/en/r1/guide/autograph.ipynb
index f028b33ce9f..64d631a52b3 100644
--- a/site/en/r1/guide/autograph.ipynb
+++ b/site/en/r1/guide/autograph.ipynb
@@ -78,7 +78,7 @@
"id": "CydFK2CL7ZHA"
},
"source": [
- "[AutoGraph](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/autograph/) helps you write complicated graph code using normal Python. Behind the scenes, AutoGraph automatically transforms your code into the equivalent [TensorFlow graph code](https://www.tensorflow.org/r1/guide/graphs). AutoGraph already supports much of the Python language, and that coverage continues to grow. For a list of supported Python language features, see the [Autograph capabilities and limitations](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/autograph/g3doc/reference/limitations.md)."
+ "[AutoGraph](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/autograph/) helps you write complicated graph code using normal Python. Behind the scenes, AutoGraph automatically transforms your code into the equivalent [TensorFlow graph code](https://www.tensorflow.org/r1/guide/graphs). AutoGraph already supports much of the Python language, and that coverage continues to grow. For a list of supported Python language features, see the [Autograph capabilities and limitations](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/autograph/g3doc/reference/limitations.md)."
]
},
{
@@ -241,7 +241,7 @@
"id": "m-jWmsCmByyw"
},
"source": [
- "AutoGraph supports common Python statements like `while`, `for`, `if`, `break`, and `return`, with support for nesting. Compare this function with the complicated graph verson displayed in the following code blocks:"
+ "AutoGraph supports common Python statements like `while`, `for`, `if`, `break`, and `return`, with support for nesting. Compare this function with the complicated graph version displayed in the following code blocks:"
]
},
{
diff --git a/site/en/r1/guide/custom_estimators.md b/site/en/r1/guide/custom_estimators.md
index 87dce26a0dc..7bbf3573909 100644
--- a/site/en/r1/guide/custom_estimators.md
+++ b/site/en/r1/guide/custom_estimators.md
@@ -592,10 +592,10 @@ function for custom Estimators; everything else is the same.
For more details, be sure to check out:
* The
- [official TensorFlow implementation of MNIST](https://github.com/tensorflow/models/tree/master/official/r1/mnist),
+ [official TensorFlow implementation of MNIST](https://github.com/tensorflow/models/tree/r1.15/official/r1/mnist),
which uses a custom estimator.
* The TensorFlow
- [official models repository](https://github.com/tensorflow/models/tree/master/official),
+ [official models repository](https://github.com/tensorflow/models/tree/r1.15/official),
which contains more curated examples using custom estimators.
* This [TensorBoard video](https://youtu.be/eBbEDRsCmv4), which introduces
TensorBoard.
diff --git a/site/en/r1/guide/datasets.md b/site/en/r1/guide/datasets.md
index b1ed1b6e113..d7c38bf2f92 100644
--- a/site/en/r1/guide/datasets.md
+++ b/site/en/r1/guide/datasets.md
@@ -437,7 +437,7 @@ dataset = dataset.batch(32)
iterator = dataset.make_initializable_iterator()
# You can feed the initializer with the appropriate filenames for the current
-# phase of execution, e.g. training vs. validation.
+# phase of execution, e.g., training vs. validation.
# Initialize `iterator` with training data.
training_filenames = ["/var/data/file1.tfrecord", "/var/data/file2.tfrecord"]
@@ -639,7 +639,7 @@ TODO(mrry): Add this section.
The simplest form of batching stacks `n` consecutive elements of a dataset into
a single element. The `Dataset.batch()` transformation does exactly this, with
the same constraints as the `tf.stack()` operator, applied to each component
-of the elements: i.e. for each component *i*, all elements must have a tensor
+of the elements: i.e., for each component *i*, all elements must have a tensor
of the exact same shape.
```python
diff --git a/site/en/r1/guide/debugger.md b/site/en/r1/guide/debugger.md
index 2b4b6497ec4..963765b97db 100644
--- a/site/en/r1/guide/debugger.md
+++ b/site/en/r1/guide/debugger.md
@@ -10,7 +10,7 @@ due to TensorFlow's computation-graph paradigm.
This guide focuses on the command-line interface (CLI) of `tfdbg`. For guide on
how to use the graphical user interface (GUI) of tfdbg, i.e., the
**TensorBoard Debugger Plugin**, please visit
-[its README](https://github.com/tensorflow/tensorboard/blob/master/tensorboard/plugins/debugger/README.md).
+[its README](https://github.com/tensorflow/tensorboard/blob/r1.15/tensorboard/plugins/debugger/README.md).
Note: The TensorFlow debugger uses a
[curses](https://en.wikipedia.org/wiki/Curses_\(programming_library\))-based text
@@ -35,7 +35,7 @@ TensorFlow. Later sections of this document describe how to use **tfdbg** with
higher-level APIs of TensorFlow, including `tf.estimator`, `tf.keras` / `keras`
and `tf.contrib.slim`. To *observe* such an issue, run the following command
without the debugger (the source code can be found
-[here](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/debug/examples/v1/debug_mnist.py)):
+[here](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/debug/examples/v1/debug_mnist.py)):
python -m tensorflow.python.debug.examples.v1.debug_mnist
@@ -64,7 +64,7 @@ numeric problem first surfaced.
To add support for tfdbg in our example, all that is needed is to add the
following lines of code and wrap the Session object with a debugger wrapper.
This code is already added in
-[debug_mnist.py](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/debug/examples/v1/debug_mnist.py),
+[debug_mnist.py](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/debug/examples/v1/debug_mnist.py),
so you can activate tfdbg CLI with the `--debug` flag at the command line.
```python
@@ -370,7 +370,7 @@ traceback of the node's construction.
From the traceback, you can see that the op is constructed at the following
line:
-[`debug_mnist.py`](https://www.tensorflow.org/code/tensorflow/python/debug/examples/v1/debug_mnist.py):
+[`debug_mnist.py`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/debug/examples/v1/debug_mnist.py):
```python
diff = y_ * tf.log(y)
@@ -457,7 +457,7 @@ accuracy_score = classifier.evaluate(eval_input_fn,
predict_results = classifier.predict(predict_input_fn, hooks=hooks)
```
-[debug_tflearn_iris.py](https://www.tensorflow.org/code/tensorflow/python/debug/examples/v1/debug_tflearn_iris.py),
+[debug_tflearn_iris.py](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/debug/examples/v1/debug_tflearn_iris.py),
contains a full example of how to use the tfdbg with `Estimator`s. To run this
example, do:
@@ -501,7 +501,7 @@ TensorFlow backend. You just need to replace `tf.keras.backend` with
## Debugging tf-slim with TFDBG
TFDBG supports debugging of training and evaluation with
-[tf-slim](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/slim).
+[tf-slim](https://github.com/tensorflow/tensorflow/tree/r1.15/tensorflow/contrib/slim).
As detailed below, training and evaluation require slightly different debugging
workflows.
@@ -605,7 +605,7 @@ The `watch_fn` argument accepts a `Callable` that allows you to configure what
If your model code is written in C++ or other languages, you can also
modify the `debug_options` field of `RunOptions` to generate debug dumps that
can be inspected offline. See
-[the proto definition](https://www.tensorflow.org/code/tensorflow/core/protobuf/debug.proto)
+[the proto definition](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/protobuf/debug.proto)
for more details.
### Debugging Remotely-Running Estimators
@@ -648,7 +648,7 @@ python -m tensorflow.python.debug.cli.offline_analyzer \
model, check out
1. The profiling mode of tfdbg: `tfdbg> run -p`.
- 2. [tfprof](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/core/profiler)
+ 2. [tfprof](https://github.com/tensorflow/tensorflow/tree/r1.15/tensorflow/core/profiler)
and other profiling tools for TensorFlow.
**Q**: _How do I link tfdbg against my `Session` in Bazel? Why do I see an
@@ -808,4 +808,4 @@ tensor dumps.
and conditional breakpoints, and tying tensors to their
graph-construction source code, all in the browser environment.
To get started, please visit
- [its README](https://github.com/tensorflow/tensorboard/blob/master/tensorboard/plugins/debugger/README.md).
+ [its README](https://github.com/tensorflow/tensorboard/blob/r1.15/tensorboard/plugins/debugger/README.md).
diff --git a/site/en/r1/guide/distribute_strategy.ipynb b/site/en/r1/guide/distribute_strategy.ipynb
index 79d6293eba7..4dd502d331b 100644
--- a/site/en/r1/guide/distribute_strategy.ipynb
+++ b/site/en/r1/guide/distribute_strategy.ipynb
@@ -118,7 +118,7 @@
"## Types of strategies\n",
"`tf.distribute.Strategy` intends to cover a number of use cases along different axes. Some of these combinations are currently supported and others will be added in the future. Some of these axes are:\n",
"\n",
- "* Syncronous vs asynchronous training: These are two common ways of distributing training with data parallelism. In sync training, all workers train over different slices of input data in sync, and aggregating gradients at each step. In async training, all workers are independently training over the input data and updating variables asynchronously. Typically sync training is supported via all-reduce and async through parameter server architecture.\n",
+ "* Synchronous vs asynchronous training: These are two common ways of distributing training with data parallelism. In sync training, all workers train over different slices of input data in sync, and aggregating gradients at each step. In async training, all workers are independently training over the input data and updating variables asynchronously. Typically sync training is supported via all-reduce and async through parameter server architecture.\n",
"* Hardware platform: Users may want to scale their training onto multiple GPUs on one machine, or multiple machines in a network (with 0 or more GPUs each), or on Cloud TPUs.\n",
"\n",
"In order to support these use cases, we have 4 strategies available. In the next section we will talk about which of these are supported in which scenarios in TF."
@@ -245,7 +245,7 @@
"\n",
"`tf.distribute.experimental.MultiWorkerMirroredStrategy` is very similar to `MirroredStrategy`. It implements synchronous distributed training across multiple workers, each with potentially multiple GPUs. Similar to `MirroredStrategy`, it creates copies of all variables in the model on each device across all workers.\n",
"\n",
- "It uses [CollectiveOps](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/ops/collective_ops.py) as the multi-worker all-reduce communication method used to keep variables in sync. A collective op is a single op in the TensorFlow graph which can automatically choose an all-reduce algorithm in the TensorFlow runtime according to hardware, network topology and tensor sizes.\n",
+ "It uses [CollectiveOps](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/ops/collective_ops.py) as the multi-worker all-reduce communication method used to keep variables in sync. A collective op is a single op in the TensorFlow graph which can automatically choose an all-reduce algorithm in the TensorFlow runtime according to hardware, network topology and tensor sizes.\n",
"\n",
"It also implements additional performance optimizations. For example, it includes a static optimization that converts multiple all-reductions on small tensors into fewer all-reductions on larger tensors. In addition, we are designing it to have a plugin architecture - so that in the future, users will be able to plugin algorithms that are better tuned for their hardware. Note that collective ops also implement other collective operations such as broadcast and all-gather.\n",
"\n",
@@ -371,7 +371,7 @@
"id": "hQv1lm9UPDFy"
},
"source": [
- "So far we've talked about what are the different stategies available and how you can instantiate them. In the next few sections, we will talk about the different ways in which you can use them to distribute your training. We will show short code snippets in this guide and link off to full tutorials which you can run end to end."
+ "So far we've talked about what are the different strategies available and how you can instantiate them. In the next few sections, we will talk about the different ways in which you can use them to distribute your training. We will show short code snippets in this guide and link off to full tutorials which you can run end to end."
]
},
{
@@ -490,8 +490,8 @@
"Here is a list of tutorials and examples that illustrate the above integration end to end with Keras:\n",
"\n",
"1. [Tutorial](../tutorials/distribute/keras.ipynb) to train MNIST with `MirroredStrategy`.\n",
- "2. Official [ResNet50](https://github.com/tensorflow/models/blob/master/official/vision/image_classification/resnet_imagenet_main.py) training with ImageNet data using `MirroredStrategy`.\n",
- "3. [ResNet50](https://github.com/tensorflow/tpu/blob/master/models/experimental/resnet50_keras/resnet50.py) trained with Imagenet data on Cloud TPus with `TPUStrategy`."
+ "2. Official [ResNet50](https://github.com/tensorflow/models/blob/r1.15/official/vision/image_classification/resnet_imagenet_main.py) training with ImageNet data using `MirroredStrategy`.\n",
+ "3. [ResNet50](https://github.com/tensorflow/tpu/blob/1.15/models/experimental/resnet50_keras/resnet50.py) trained with Imagenet data on Cloud TPus with `TPUStrategy`."
]
},
{
@@ -595,9 +595,9 @@
"### Examples and Tutorials\n",
"Here are some examples that show end to end usage of various strategies with Estimator:\n",
"\n",
- "1. [End to end example](https://github.com/tensorflow/ecosystem/tree/master/distribution_strategy) for multi worker training in tensorflow/ecosystem using Kuberentes templates. This example starts with a Keras model and converts it to an Estimator using the `tf.keras.estimator.model_to_estimator` API.\n",
- "2. Official [ResNet50](https://github.com/tensorflow/models/blob/master/official/r1/resnet/imagenet_main.py) model, which can be trained using either `MirroredStrategy` or `MultiWorkerMirroredStrategy`.\n",
- "3. [ResNet50](https://github.com/tensorflow/tpu/blob/master/models/experimental/distribution_strategy/resnet_estimator.py) example with TPUStrategy."
+ "1. [End to end example](https://github.com/tensorflow/ecosystem/tree/r1.15/distribution_strategy) for multi worker training in tensorflow/ecosystem using Kuberentes templates. This example starts with a Keras model and converts it to an Estimator using the `tf.keras.estimator.model_to_estimator` API.\n",
+ "2. Official [ResNet50](https://github.com/tensorflow/models/blob/r1.15/official/r1/resnet/imagenet_main.py) model, which can be trained using either `MirroredStrategy` or `MultiWorkerMirroredStrategy`.\n",
+ "3. [ResNet50](https://github.com/tensorflow/tpu/blob/1.15/models/experimental/distribution_strategy/resnet_estimator.py) example with TPUStrategy."
]
},
{
@@ -607,7 +607,7 @@
},
"source": [
"## Using `tf.distribute.Strategy` with custom training loops\n",
- "As you've seen, using `tf.distrbute.Strategy` with high level APIs is only a couple lines of code change. With a little more effort, `tf.distrbute.Strategy` can also be used by other users who are not using these frameworks.\n",
+ "As you've seen, using `tf.distribute.Strategy` with high level APIs is only a couple lines of code change. With a little more effort, `tf.distribute.Strategy` can also be used by other users who are not using these frameworks.\n",
"\n",
"TensorFlow is used for a wide variety of use cases and some users (such as researchers) require more flexibility and control over their training loops. This makes it hard for them to use the high level frameworks such as Estimator or Keras. For instance, someone using a GAN may want to take a different number of generator or discriminator steps each round. Similarly, the high level frameworks are not very suitable for Reinforcement Learning training. So these users will usually write their own training loops.\n",
"\n",
diff --git a/site/en/r1/guide/eager.ipynb b/site/en/r1/guide/eager.ipynb
index 6a0a78c2443..f76acb4b702 100644
--- a/site/en/r1/guide/eager.ipynb
+++ b/site/en/r1/guide/eager.ipynb
@@ -95,7 +95,7 @@
"\n",
"Eager execution supports most TensorFlow operations and GPU acceleration. For a\n",
"collection of examples running in eager execution, see:\n",
- "[tensorflow/contrib/eager/python/examples](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/eager/python/examples).\n",
+ "[tensorflow/contrib/eager/python/examples](https://github.com/tensorflow/tensorflow/tree/r1.15/tensorflow/contrib/eager/python/examples).\n",
"\n",
"Note: Some models may experience increased overhead with eager execution\n",
"enabled. Performance improvements are ongoing, but please\n",
@@ -1160,7 +1160,7 @@
"### Benchmarks\n",
"\n",
"For compute-heavy models, such as\n",
- "[ResNet50](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/eager/python/examples/resnet50)\n",
+ "[ResNet50](https://github.com/tensorflow/tensorflow/tree/r1.15/tensorflow/contrib/eager/python/examples/resnet50)\n",
"training on a GPU, eager execution performance is comparable to graph execution.\n",
"But this gap grows larger for models with less computation and there is work to\n",
"be done for optimizing hot code paths for models with lots of small operations."
@@ -1225,7 +1225,7 @@
"production deployment. Use `tf.train.Checkpoint` to save and restore model\n",
"variables, this allows movement between eager and graph execution environments.\n",
"See the examples in:\n",
- "[tensorflow/contrib/eager/python/examples](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/eager/python/examples).\n"
+ "[tensorflow/contrib/eager/python/examples](https://github.com/tensorflow/tensorflow/tree/r1.15/tensorflow/contrib/eager/python/examples).\n"
]
},
{
diff --git a/site/en/r1/guide/extend/architecture.md b/site/en/r1/guide/extend/architecture.md
index 1f2ac53066f..0753824e15e 100644
--- a/site/en/r1/guide/extend/architecture.md
+++ b/site/en/r1/guide/extend/architecture.md
@@ -34,7 +34,7 @@ This document focuses on the following layers:
* **Client**:
* Defines the computation as a dataflow graph.
* Initiates graph execution using a [**session**](
- https://www.tensorflow.org/code/tensorflow/python/client/session.py).
+ https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/client/session.py).
* **Distributed Master**
* Prunes a specific subgraph from the graph, as defined by the arguments
to Session.run().
@@ -144,8 +144,8 @@ The distributed master then ships the graph pieces to the distributed tasks.
### Code
-* [MasterService API definition](https://www.tensorflow.org/code/tensorflow/core/protobuf/master_service.proto)
-* [Master interface](https://www.tensorflow.org/code/tensorflow/core/distributed_runtime/master_interface.h)
+* [MasterService API definition](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/protobuf/master_service.proto)
+* [Master interface](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/distributed_runtime/master_interface.h)
## Worker Service
@@ -178,7 +178,7 @@ For transfers between tasks, TensorFlow uses multiple protocols, including:
We also have preliminary support for NVIDIA's NCCL library for multi-GPU
communication, see:
-[`tf.contrib.nccl`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/ops/nccl_ops.py).
+[`tf.contrib.nccl`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/ops/nccl_ops.py).
 @@ -186,9 +186,9 @@ communication, see:
### Code
-* [WorkerService API definition](https://www.tensorflow.org/code/tensorflow/core/protobuf/worker_service.proto)
-* [Worker interface](https://www.tensorflow.org/code/tensorflow/core/distributed_runtime/worker_interface.h)
-* [Remote rendezvous (for Send and Recv implementations)](https://www.tensorflow.org/code/tensorflow/core/distributed_runtime/rpc/rpc_rendezvous_mgr.h)
+* [WorkerService API definition](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/protobuf/worker_service.proto)
+* [Worker interface](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/distributed_runtime/worker_interface.h)
+* [Remote rendezvous (for Send and Recv implementations)](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/distributed_runtime/rpc/rpc_rendezvous_mgr.h)
## Kernel Implementations
@@ -199,7 +199,7 @@ Many of the operation kernels are implemented using Eigen::Tensor, which uses
C++ templates to generate efficient parallel code for multicore CPUs and GPUs;
however, we liberally use libraries like cuDNN where a more efficient kernel
implementation is possible. We have also implemented
-[quantization](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/g3doc/performance/post_training_quantization.md), which enables
+[quantization](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/lite/g3doc/performance/post_training_quantization.md), which enables
faster inference in environments such as mobile devices and high-throughput
datacenter applications, and use the
[gemmlowp](https://github.com/google/gemmlowp) low-precision matrix library to
@@ -215,4 +215,4 @@ experimental implementation of automatic kernel fusion.
### Code
-* [`OpKernel` interface](https://www.tensorflow.org/code/tensorflow/core/framework/op_kernel.h)
+* [`OpKernel` interface](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/op_kernel.h)
diff --git a/site/en/r1/guide/extend/bindings.md b/site/en/r1/guide/extend/bindings.md
index 9c10e90840f..7daa2212106 100644
--- a/site/en/r1/guide/extend/bindings.md
+++ b/site/en/r1/guide/extend/bindings.md
@@ -112,11 +112,11 @@ There are a few ways to get a list of the `OpDef`s for the registered ops:
to interpret the `OpDef` messages.
- The C++ function `OpRegistry::Global()->GetRegisteredOps()` returns the same
list of all registered `OpDef`s (defined in
- [`tensorflow/core/framework/op.h`](https://www.tensorflow.org/code/tensorflow/core/framework/op.h)). This can be used to write the generator
+ [`tensorflow/core/framework/op.h`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/op.h)). This can be used to write the generator
in C++ (particularly useful for languages that do not have protocol buffer
support).
- The ASCII-serialized version of that list is periodically checked in to
- [`tensorflow/core/ops/ops.pbtxt`](https://www.tensorflow.org/code/tensorflow/core/ops/ops.pbtxt) by an automated process.
+ [`tensorflow/core/ops/ops.pbtxt`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/ops/ops.pbtxt) by an automated process.
The `OpDef` specifies the following:
@@ -159,7 +159,7 @@ between the generated code and the `OpDef`s checked into the repository, but is
useful for languages where code is expected to be generated ahead of time like
`go get` for Go and `cargo ops` for Rust. At the other end of the spectrum, for
some languages the code could be generated dynamically from
-[`tensorflow/core/ops/ops.pbtxt`](https://www.tensorflow.org/code/tensorflow/core/ops/ops.pbtxt).
+[`tensorflow/core/ops/ops.pbtxt`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/ops/ops.pbtxt).
#### Handling Constants
@@ -228,4 +228,4 @@ At this time, support for gradients, functions and control flow operations ("if"
and "while") is not available in languages other than Python. This will be
updated when the [C API] provides necessary support.
-[C API]: https://www.tensorflow.org/code/tensorflow/c/c_api.h
+[C API]: https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/c/c_api.h
diff --git a/site/en/r1/guide/extend/filesystem.md b/site/en/r1/guide/extend/filesystem.md
index 4d34c07102e..2d6ea0c4645 100644
--- a/site/en/r1/guide/extend/filesystem.md
+++ b/site/en/r1/guide/extend/filesystem.md
@@ -54,7 +54,7 @@ To implement a custom filesystem plugin, you must do the following:
### The FileSystem interface
The `FileSystem` interface is an abstract C++ interface defined in
-[file_system.h](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/platform/file_system.h).
+[file_system.h](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/platform/file_system.h).
An implementation of the `FileSystem` interface should implement all relevant
the methods defined by the interface. Implementing the interface requires
defining operations such as creating `RandomAccessFile`, `WritableFile`, and
@@ -70,26 +70,26 @@ involves calling `stat()` on the file and then returns the filesize as reported
by the return of the stat object. Similarly, for the `HDFSFileSystem`
implementation, these calls simply delegate to the `libHDFS` implementation of
similar functionality, such as `hdfsDelete` for
-[DeleteFile](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/platform/hadoop/hadoop_file_system.cc#L386).
+[DeleteFile](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/platform/hadoop/hadoop_file_system.cc#L386).
We suggest looking through these code examples to get an idea of how different
filesystem implementations call their existing libraries. Examples include:
* [POSIX
- plugin](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/platform/posix/posix_file_system.h)
+ plugin](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/platform/posix/posix_file_system.h)
* [HDFS
- plugin](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/platform/hadoop/hadoop_file_system.h)
+ plugin](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/platform/hadoop/hadoop_file_system.h)
* [GCS
- plugin](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/platform/cloud/gcs_file_system.h)
+ plugin](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/platform/cloud/gcs_file_system.h)
* [S3
- plugin](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/platform/s3/s3_file_system.h)
+ plugin](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/platform/s3/s3_file_system.h)
#### The File interfaces
Beyond operations that allow you to query and manipulate files and directories
in a filesystem, the `FileSystem` interface requires you to implement factories
that return implementations of abstract objects such as the
-[RandomAccessFile](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/platform/file_system.h#L223),
+[RandomAccessFile](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/platform/file_system.h#L223),
the `WritableFile`, so that TensorFlow code and read and write to files in that
`FileSystem` implementation.
@@ -224,7 +224,7 @@ it will use the `FooBarFileSystem` implementation.
Next, you must build a shared object containing this implementation. An example
of doing so using bazel's `cc_binary` rule can be found
-[here](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/BUILD#L244),
+[here](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/BUILD#L244),
but you may use any build system to do so. See the section on [building the op library](../extend/op.md#build_the_op_library) for similar
instructions.
@@ -236,7 +236,7 @@ passing the path to the shared object. Calling this in your client program loads
the shared object in the process, thus registering your implementation as
available for any file operations going through the `FileSystem` interface. You
can see
-[test_file_system.py](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/framework/file_system_test.py)
+[test_file_system.py](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/framework/file_system_test.py)
for an example.
## What goes through this interface?
diff --git a/site/en/r1/guide/extend/formats.md b/site/en/r1/guide/extend/formats.md
index 3b7b4aafbd6..bdebee5487d 100644
--- a/site/en/r1/guide/extend/formats.md
+++ b/site/en/r1/guide/extend/formats.md
@@ -28,11 +28,11 @@ individual records in a file. There are several examples of "reader" datasets
that are already built into TensorFlow:
* `tf.data.TFRecordDataset`
- ([source in `kernels/data/reader_dataset_ops.cc`](https://www.tensorflow.org/code/tensorflow/core/kernels/data/reader_dataset_ops.cc))
+ ([source in `kernels/data/reader_dataset_ops.cc`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/kernels/data/reader_dataset_ops.cc))
* `tf.data.FixedLengthRecordDataset`
- ([source in `kernels/data/reader_dataset_ops.cc`](https://www.tensorflow.org/code/tensorflow/core/kernels/data/reader_dataset_ops.cc))
+ ([source in `kernels/data/reader_dataset_ops.cc`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/kernels/data/reader_dataset_ops.cc))
* `tf.data.TextLineDataset`
- ([source in `kernels/data/reader_dataset_ops.cc`](https://www.tensorflow.org/code/tensorflow/core/kernels/data/reader_dataset_ops.cc))
+ ([source in `kernels/data/reader_dataset_ops.cc`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/kernels/data/reader_dataset_ops.cc))
Each of these implementations comprises three related classes:
@@ -279,7 +279,7 @@ if __name__ == "__main__":
```
You can see some examples of `Dataset` wrapper classes in
-[`tensorflow/python/data/ops/dataset_ops.py`](https://www.tensorflow.org/code/tensorflow/python/data/ops/dataset_ops.py).
+[`tensorflow/python/data/ops/dataset_ops.py`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/data/ops/dataset_ops.py).
## Writing an Op for a record format
@@ -297,7 +297,7 @@ Examples of Ops useful for decoding records:
Note that it can be useful to use multiple Ops to decode a particular record
format. For example, you may have an image saved as a string in
-[a `tf.train.Example` protocol buffer](https://www.tensorflow.org/code/tensorflow/core/example/example.proto).
+[a `tf.train.Example` protocol buffer](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/example/example.proto).
Depending on the format of that image, you might take the corresponding output
from a `tf.parse_single_example` op and call `tf.image.decode_jpeg`,
`tf.image.decode_png`, or `tf.decode_raw`. It is common to take the output
diff --git a/site/en/r1/guide/extend/model_files.md b/site/en/r1/guide/extend/model_files.md
index 30e73a5169e..e590fcf1f27 100644
--- a/site/en/r1/guide/extend/model_files.md
+++ b/site/en/r1/guide/extend/model_files.md
@@ -28,7 +28,7 @@ by calling `as_graph_def()`, which returns a `GraphDef` object.
The GraphDef class is an object created by the ProtoBuf library from the
definition in
-[tensorflow/core/framework/graph.proto](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/graph.proto). The protobuf tools parse
+[tensorflow/core/framework/graph.proto](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/graph.proto). The protobuf tools parse
this text file, and generate the code to load, store, and manipulate graph
definitions. If you see a standalone TensorFlow file representing a model, it's
likely to contain a serialized version of one of these `GraphDef` objects
@@ -87,7 +87,7 @@ for node in graph_def.node
```
Each node is a `NodeDef` object, defined in
-[tensorflow/core/framework/node_def.proto](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/node_def.proto). These
+[tensorflow/core/framework/node_def.proto](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/node_def.proto). These
are the fundamental building blocks of TensorFlow graphs, with each one defining
a single operation along with its input connections. Here are the members of a
`NodeDef`, and what they mean.
@@ -107,7 +107,7 @@ This defines what operation to run, for example `"Add"`, `"MatMul"`, or
`"Conv2D"`. When a graph is run, this op name is looked up in a registry to
find an implementation. The registry is populated by calls to the
`REGISTER_OP()` macro, like those in
-[tensorflow/core/ops/nn_ops.cc](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/ops/nn_ops.cc).
+[tensorflow/core/ops/nn_ops.cc](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/ops/nn_ops.cc).
### `input`
@@ -133,7 +133,7 @@ size of filters for convolutions, or the values of constant ops. Because there
can be so many different types of attribute values, from strings, to ints, to
arrays of tensor values, there's a separate protobuf file defining the data
structure that holds them, in
-[tensorflow/core/framework/attr_value.proto](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/attr_value.proto).
+[tensorflow/core/framework/attr_value.proto](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/attr_value.proto).
Each attribute has a unique name string, and the expected attributes are listed
when the operation is defined. If an attribute isn't present in a node, but it
@@ -151,7 +151,7 @@ the file format during training. Instead, they're held in separate checkpoint
files, and there are `Variable` ops in the graph that load the latest values
when they're initialized. It's often not very convenient to have separate files
when you're deploying to production, so there's the
-[freeze_graph.py](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/tools/freeze_graph.py) script that takes a graph definition and a set
+[freeze_graph.py](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/tools/freeze_graph.py) script that takes a graph definition and a set
of checkpoints and freezes them together into a single file.
What this does is load the `GraphDef`, pull in the values for all the variables
@@ -167,7 +167,7 @@ the most common problems is extracting and interpreting the weight values. A
common way to store them, for example in graphs created by the freeze_graph
script, is as `Const` ops containing the weights as `Tensors`. These are
defined in
-[tensorflow/core/framework/tensor.proto](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/tensor.proto), and contain information
+[tensorflow/core/framework/tensor.proto](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/tensor.proto), and contain information
about the size and type of the data, as well as the values themselves. In
Python, you get a `TensorProto` object from a `NodeDef` representing a `Const`
op by calling something like `some_node_def.attr['value'].tensor`.
diff --git a/site/en/r1/guide/extend/op.md b/site/en/r1/guide/extend/op.md
index dc2d9fbe678..186d9c28c04 100644
--- a/site/en/r1/guide/extend/op.md
+++ b/site/en/r1/guide/extend/op.md
@@ -47,7 +47,7 @@ To incorporate your custom op you'll need to:
test the op in C++. If you define gradients, you can verify them with the
Python `tf.test.compute_gradient_error`.
See
- [`relu_op_test.py`](https://www.tensorflow.org/code/tensorflow/python/kernel_tests/relu_op_test.py) as
+ [`relu_op_test.py`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/kernel_tests/relu_op_test.py) as
an example that tests the forward functions of Relu-like operators and
their gradients.
@@ -155,17 +155,17 @@ REGISTER_KERNEL_BUILDER(Name("ZeroOut").Device(DEVICE_CPU), ZeroOutOp);
> Important: Instances of your OpKernel may be accessed concurrently.
> Your `Compute` method must be thread-safe. Guard any access to class
> members with a mutex. Or better yet, don't share state via class members!
-> Consider using a [`ResourceMgr`](https://www.tensorflow.org/code/tensorflow/core/framework/resource_mgr.h)
+> Consider using a [`ResourceMgr`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/resource_mgr.h)
> to keep track of op state.
### Multi-threaded CPU kernels
To write a multi-threaded CPU kernel, the Shard function in
-[`work_sharder.h`](https://www.tensorflow.org/code/tensorflow/core/util/work_sharder.h)
+[`work_sharder.h`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/util/work_sharder.h)
can be used. This function shards a computation function across the
threads configured to be used for intra-op threading (see
intra_op_parallelism_threads in
-[`config.proto`](https://www.tensorflow.org/code/tensorflow/core/protobuf/config.proto)).
+[`config.proto`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/protobuf/config.proto)).
### GPU kernels
@@ -486,13 +486,13 @@ This asserts that the input is a vector, and returns having set the
* The `context`, which can either be an `OpKernelContext` or
`OpKernelConstruction` pointer (see
- [`tensorflow/core/framework/op_kernel.h`](https://www.tensorflow.org/code/tensorflow/core/framework/op_kernel.h)),
+ [`tensorflow/core/framework/op_kernel.h`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/op_kernel.h)),
for its `SetStatus()` method.
* The condition. For example, there are functions for validating the shape
of a tensor in
- [`tensorflow/core/framework/tensor_shape.h`](https://www.tensorflow.org/code/tensorflow/core/framework/tensor_shape.h)
+ [`tensorflow/core/framework/tensor_shape.h`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/tensor_shape.h)
* The error itself, which is represented by a `Status` object, see
- [`tensorflow/core/lib/core/status.h`](https://www.tensorflow.org/code/tensorflow/core/lib/core/status.h). A
+ [`tensorflow/core/lib/core/status.h`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/lib/core/status.h). A
`Status` has both a type (frequently `InvalidArgument`, but see the list of
types) and a message. Functions for constructing an error may be found in
[`tensorflow/core/lib/core/errors.h`][validation-macros].
@@ -633,7 +633,7 @@ define an attr with constraints, you can use the following ``s:
The specific lists of types allowed by these are defined by the functions
(like `NumberTypes()`) in
- [`tensorflow/core/framework/types.h`](https://www.tensorflow.org/code/tensorflow/core/framework/types.h).
+ [`tensorflow/core/framework/types.h`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/types.h).
In this example the attr `t` must be one of the numeric types:
```c++
@@ -1180,7 +1180,7 @@ There are several ways to preserve backwards-compatibility.
type into a list of varying types).
The full list of safe and unsafe changes can be found in
-[`tensorflow/core/framework/op_compatibility_test.cc`](https://www.tensorflow.org/code/tensorflow/core/framework/op_compatibility_test.cc).
+[`tensorflow/core/framework/op_compatibility_test.cc`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/op_compatibility_test.cc).
If you cannot make your change to an operation backwards compatible, then create
a new operation with a new name with the new semantics.
@@ -1197,16 +1197,16 @@ made when TensorFlow changes major versions, and must conform to the
You can implement different OpKernels and register one for CPU and another for
GPU, just like you can [register kernels for different types](#polymorphism).
There are several examples of kernels with GPU support in
-[`tensorflow/core/kernels/`](https://www.tensorflow.org/code/tensorflow/core/kernels/).
+[`tensorflow/core/kernels/`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/kernels/).
Notice some kernels have a CPU version in a `.cc` file, a GPU version in a file
ending in `_gpu.cu.cc`, and some code shared in common in a `.h` file.
For example, the `tf.pad` has
everything but the GPU kernel in [`tensorflow/core/kernels/pad_op.cc`][pad_op].
The GPU kernel is in
-[`tensorflow/core/kernels/pad_op_gpu.cu.cc`](https://www.tensorflow.org/code/tensorflow/core/kernels/pad_op_gpu.cu.cc),
+[`tensorflow/core/kernels/pad_op_gpu.cu.cc`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/kernels/pad_op_gpu.cu.cc),
and the shared code is a templated class defined in
-[`tensorflow/core/kernels/pad_op.h`](https://www.tensorflow.org/code/tensorflow/core/kernels/pad_op.h).
+[`tensorflow/core/kernels/pad_op.h`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/kernels/pad_op.h).
We organize the code this way for two reasons: it allows you to share common
code among the CPU and GPU implementations, and it puts the GPU implementation
into a separate file so that it can be compiled only by the GPU compiler.
@@ -1227,16 +1227,16 @@ kept on the CPU, add a `HostMemory()` call to the kernel registration, e.g.:
#### Compiling the kernel for the GPU device
Look at
-[cuda_op_kernel.cu.cc](https://www.tensorflow.org/code/tensorflow/examples/adding_an_op/cuda_op_kernel.cu.cc)
+[cuda_op_kernel.cu.cc](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/examples/adding_an_op/cuda_op_kernel.cu.cc)
for an example that uses a CUDA kernel to implement an op. The
`tf_custom_op_library` accepts a `gpu_srcs` argument in which the list of source
files containing the CUDA kernels (`*.cu.cc` files) can be specified. For use
with a binary installation of TensorFlow, the CUDA kernels have to be compiled
with NVIDIA's `nvcc` compiler. Here is the sequence of commands you can use to
compile the
-[cuda_op_kernel.cu.cc](https://www.tensorflow.org/code/tensorflow/examples/adding_an_op/cuda_op_kernel.cu.cc)
+[cuda_op_kernel.cu.cc](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/examples/adding_an_op/cuda_op_kernel.cu.cc)
and
-[cuda_op_kernel.cc](https://www.tensorflow.org/code/tensorflow/examples/adding_an_op/cuda_op_kernel.cc)
+[cuda_op_kernel.cc](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/examples/adding_an_op/cuda_op_kernel.cc)
into a single dynamically loadable library:
```bash
@@ -1361,7 +1361,7 @@ be set to the first input's shape. If the output is selected by its index as in
There are a number of common shape functions
that apply to many ops, such as `shape_inference::UnchangedShape` which can be
-found in [common_shape_fns.h](https://www.tensorflow.org/code/tensorflow/core/framework/common_shape_fns.h) and used as follows:
+found in [common_shape_fns.h](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/common_shape_fns.h) and used as follows:
```c++
REGISTER_OP("ZeroOut")
@@ -1408,7 +1408,7 @@ provides access to the attributes of the op).
Since shape inference is an optional feature, and the shapes of tensors may vary
dynamically, shape functions must be robust to incomplete shape information for
-any of the inputs. The `Merge` method in [`InferenceContext`](https://www.tensorflow.org/code/tensorflow/core/framework/shape_inference.h)
+any of the inputs. The `Merge` method in [`InferenceContext`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/shape_inference.h)
allows the caller to assert that two shapes are the same, even if either
or both of them do not have complete information. Shape functions are defined
for all of the core TensorFlow ops and provide many different usage examples.
@@ -1433,7 +1433,7 @@ If you have a complicated shape function, you should consider adding a test for
validating that various input shape combinations produce the expected output
shape combinations. You can see examples of how to write these tests in some
our
-[core ops tests](https://www.tensorflow.org/code/tensorflow/core/ops/array_ops_test.cc).
+[core ops tests](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/ops/array_ops_test.cc).
(The syntax of `INFER_OK` and `INFER_ERROR` are a little cryptic, but try to be
compact in representing input and output shape specifications in tests. For
now, see the surrounding comments in those tests to get a sense of the shape
@@ -1446,20 +1446,20 @@ To build a `pip` package for your op, see the
guide shows how to build custom ops from the TensorFlow pip package instead
of building TensorFlow from source.
-[core-array_ops]:https://www.tensorflow.org/code/tensorflow/core/ops/array_ops.cc
-[python-user_ops]:https://www.tensorflow.org/code/tensorflow/python/user_ops/user_ops.py
-[tf-kernels]:https://www.tensorflow.org/code/tensorflow/core/kernels/
-[user_ops]:https://www.tensorflow.org/code/tensorflow/core/user_ops/
-[pad_op]:https://www.tensorflow.org/code/tensorflow/core/kernels/pad_op.cc
-[standard_ops-py]:https://www.tensorflow.org/code/tensorflow/python/ops/standard_ops.py
-[standard_ops-cc]:https://www.tensorflow.org/code/tensorflow/cc/ops/standard_ops.h
-[python-BUILD]:https://www.tensorflow.org/code/tensorflow/python/BUILD
-[validation-macros]:https://www.tensorflow.org/code/tensorflow/core/lib/core/errors.h
-[op_def_builder]:https://www.tensorflow.org/code/tensorflow/core/framework/op_def_builder.h
-[register_types]:https://www.tensorflow.org/code/tensorflow/core/framework/register_types.h
-[FinalizeAttr]:https://www.tensorflow.org/code/tensorflow/core/framework/op_def_builder.cc
-[DataTypeString]:https://www.tensorflow.org/code/tensorflow/core/framework/types.cc
-[python-BUILD]:https://www.tensorflow.org/code/tensorflow/python/BUILD
-[types-proto]:https://www.tensorflow.org/code/tensorflow/core/framework/types.proto
-[TensorShapeProto]:https://www.tensorflow.org/code/tensorflow/core/framework/tensor_shape.proto
-[TensorProto]:https://www.tensorflow.org/code/tensorflow/core/framework/tensor.proto
+[core-array_ops]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/ops/array_ops.cc
+[python-user_ops]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/user_ops/user_ops.py
+[tf-kernels]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/kernels/
+[user_ops]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/user_ops/
+[pad_op]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/kernels/pad_op.cc
+[standard_ops-py]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/ops/standard_ops.py
+[standard_ops-cc]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/cc/ops/standard_ops.h
+[python-BUILD]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/BUILD
+[validation-macros]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/lib/core/errors.h
+[op_def_builder]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/op_def_builder.h
+[register_types]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/register_types.h
+[FinalizeAttr]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/op_def_builder.cc
+[DataTypeString]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/types.cc
+[python-BUILD]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/BUILD
+[types-proto]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/types.proto
+[TensorShapeProto]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/tensor_shape.proto
+[TensorProto]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/tensor.proto
diff --git a/site/en/r1/guide/feature_columns.md b/site/en/r1/guide/feature_columns.md
index 5a4dfbbf46d..e4259f85e9f 100644
--- a/site/en/r1/guide/feature_columns.md
+++ b/site/en/r1/guide/feature_columns.md
@@ -562,7 +562,7 @@ For more examples on feature columns, view the following:
* The [Low Level Introduction](../guide/low_level_intro.md#feature_columns) demonstrates how
experiment directly with `feature_columns` using TensorFlow's low level APIs.
-* The [Estimator wide and deep learning tutorial](https://github.com/tensorflow/models/tree/master/official/r1/wide_deep)
+* The [Estimator wide and deep learning tutorial](https://github.com/tensorflow/models/tree/r1.15/official/r1/wide_deep)
solves a binary classification problem using `feature_columns` on a variety of
input data types.
diff --git a/site/en/r1/guide/graph_viz.md b/site/en/r1/guide/graph_viz.md
index 1965378e03e..1e3780e7928 100644
--- a/site/en/r1/guide/graph_viz.md
+++ b/site/en/r1/guide/graph_viz.md
@@ -251,7 +251,7 @@ is a snippet from the train and test section of a modification of the
[Estimators MNIST tutorial](../tutorials/estimators/cnn.md), in which we have
recorded summaries and
runtime statistics. See the
-[Tensorboard](https://tensorflow.org/tensorboard)
+[TensorBoard](https://tensorflow.org/tensorboard)
for details on how to record summaries.
Full source is [here](https://github.com/tensorflow/tensorflow/tree/r1.15/tensorflow/examples/tutorials/mnist/mnist_with_summaries.py).
diff --git a/site/en/r1/guide/performance/benchmarks.md b/site/en/r1/guide/performance/benchmarks.md
index 8998c0723db..a56959ea416 100644
--- a/site/en/r1/guide/performance/benchmarks.md
+++ b/site/en/r1/guide/performance/benchmarks.md
@@ -401,7 +401,7 @@ GPUs | InceptionV3 (batch size 32) | ResNet-50 (batch size 32)
## Methodology
This
-[script](https://github.com/tensorflow/benchmarks/tree/master/scripts/tf_cnn_benchmarks)
+[script](https://github.com/tensorflow/benchmarks/tree/r1.15/scripts/tf_cnn_benchmarks)
was run on the various platforms to generate the above results.
In order to create results that are as repeatable as possible, each test was run
diff --git a/site/en/r1/guide/performance/overview.md b/site/en/r1/guide/performance/overview.md
index af74f0f28c6..be7217f4b99 100644
--- a/site/en/r1/guide/performance/overview.md
+++ b/site/en/r1/guide/performance/overview.md
@@ -19,9 +19,9 @@ Reading large numbers of small files significantly impacts I/O performance.
One approach to get maximum I/O throughput is to preprocess input data into
larger (~100MB) `TFRecord` files. For smaller data sets (200MB-1GB), the best
approach is often to load the entire data set into memory. The document
-[Downloading and converting to TFRecord format](https://github.com/tensorflow/models/tree/master/research/slim#downloading-and-converting-to-tfrecord-format)
+[Downloading and converting to TFRecord format](https://github.com/tensorflow/models/tree/r1.15/research/slim#downloading-and-converting-to-tfrecord-format)
includes information and scripts for creating `TFRecord`s, and this
-[script](https://github.com/tensorflow/models/tree/master/research/tutorials/image/cifar10_estimator/generate_cifar10_tfrecords.py)
+[script](https://github.com/tensorflow/models/tree/r1.15/research/tutorials/image/cifar10_estimator/generate_cifar10_tfrecords.py)
converts the CIFAR-10 dataset into `TFRecord`s.
While feeding data using a `feed_dict` offers a high level of flexibility, in
@@ -122,7 +122,7 @@ tf.Session(config=config)
Intel® has added optimizations to TensorFlow for Intel® Xeon® and Intel® Xeon
Phi™ through the use of the Intel® Math Kernel Library for Deep Neural Networks
(Intel® MKL-DNN) optimized primitives. The optimizations also provide speedups
-for the consumer line of processors, e.g. i5 and i7 Intel processors. The Intel
+for the consumer line of processors, e.g., i5 and i7 Intel processors. The Intel
published paper
[TensorFlow* Optimizations on Modern Intel® Architecture](https://software.intel.com/en-us/articles/tensorflow-optimizations-on-modern-intel-architecture)
contains additional details on the implementation.
@@ -255,7 +255,7 @@ bazel build -c opt --copt=-march="broadwell" --config=cuda //tensorflow/tools/pi
a docker container, the data is not cached and the penalty is paid each time
TensorFlow starts. The best practice is to include the
[compute capabilities](http://developer.nvidia.com/cuda-gpus)
- of the GPUs that will be used, e.g. P100: 6.0, Titan X (Pascal): 6.1,
+ of the GPUs that will be used, e.g., P100: 6.0, Titan X (Pascal): 6.1,
Titan X (Maxwell): 5.2, and K80: 3.7.
* Use a version of `gcc` that supports all of the optimizations of the target
CPU. The recommended minimum gcc version is 4.8.3. On macOS, upgrade to the
diff --git a/site/en/r1/guide/saved_model.md b/site/en/r1/guide/saved_model.md
index 623863a9df9..34447ffe861 100644
--- a/site/en/r1/guide/saved_model.md
+++ b/site/en/r1/guide/saved_model.md
@@ -23,7 +23,7 @@ TensorFlow saves variables in binary *checkpoint files* that map variable
names to tensor values.
Caution: TensorFlow model files are code. Be careful with untrusted code.
-See [Using TensorFlow Securely](https://github.com/tensorflow/tensorflow/blob/master/SECURITY.md)
+See [Using TensorFlow Securely](https://github.com/tensorflow/tensorflow/blob/r1.15/SECURITY.md)
for details.
### Save variables
@@ -148,7 +148,7 @@ Notes:
`tf.variables_initializer` for more information.
* To inspect the variables in a checkpoint, you can use the
- [`inspect_checkpoint`](https://www.tensorflow.org/code/tensorflow/python/tools/inspect_checkpoint.py)
+ [`inspect_checkpoint`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/tools/inspect_checkpoint.py)
library, particularly the `print_tensors_in_checkpoint_file` function.
* By default, `Saver` uses the value of the `tf.Variable.name` property
@@ -159,7 +159,7 @@ Notes:
### Inspect variables in a checkpoint
We can quickly inspect variables in a checkpoint with the
-[`inspect_checkpoint`](https://www.tensorflow.org/code/tensorflow/python/tools/inspect_checkpoint.py) library.
+[`inspect_checkpoint`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/tools/inspect_checkpoint.py) library.
Continuing from the save/restore examples shown earlier:
@@ -216,7 +216,7 @@ simple_save(session,
This configures the `SavedModel` so it can be loaded by
[TensorFlow serving](https://www.tensorflow.org/tfx/tutorials/serving/rest_simple) and supports the
-[Predict API](https://github.com/tensorflow/serving/blob/master/tensorflow_serving/apis/predict.proto).
+[Predict API](https://github.com/tensorflow/serving/blob/r1.15/tensorflow_serving/apis/predict.proto).
To access the classify, regress, or multi-inference APIs, use the manual
`SavedModel` builder APIs or an `tf.estimator.Estimator`.
@@ -328,7 +328,7 @@ with tf.Session(graph=tf.Graph()) as sess:
### Load a SavedModel in C++
The C++ version of the SavedModel
-[loader](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/cc/saved_model/loader.h)
+[loader](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/cc/saved_model/loader.h)
provides an API to load a SavedModel from a path, while allowing
`SessionOptions` and `RunOptions`.
You have to specify the tags associated with the graph to be loaded.
@@ -383,20 +383,20 @@ reuse and share across tools consistently.
You may use sets of tags to uniquely identify a `MetaGraphDef` saved in a
SavedModel. A subset of commonly used tags is specified in:
-* [Python](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/saved_model/tag_constants.py)
-* [C++](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/cc/saved_model/tag_constants.h)
+* [Python](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/saved_model/tag_constants.py)
+* [C++](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/cc/saved_model/tag_constants.h)
#### Standard SignatureDef constants
-A [**SignatureDef**](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/protobuf/meta_graph.proto)
+A [**SignatureDef**](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/protobuf/meta_graph.proto)
is a protocol buffer that defines the signature of a computation
supported by a graph.
Commonly used input keys, output keys, and method names are
defined in:
-* [Python](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/saved_model/signature_constants.py)
-* [C++](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/cc/saved_model/signature_constants.h)
+* [Python](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/saved_model/signature_constants.py)
+* [C++](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/cc/saved_model/signature_constants.h)
## Using SavedModel with Estimators
@@ -408,7 +408,7 @@ To prepare a trained Estimator for serving, you must export it in the standard
SavedModel format. This section explains how to:
* Specify the output nodes and the corresponding
- [APIs](https://github.com/tensorflow/serving/blob/master/tensorflow_serving/apis/prediction_service.proto)
+ [APIs](https://github.com/tensorflow/serving/blob/r1.15/tensorflow_serving/apis/prediction_service.proto)
that can be served (Classify, Regress, or Predict).
* Export your model to the SavedModel format.
* Serve the model from a local server and request predictions.
@@ -506,7 +506,7 @@ Each `output` value must be an `ExportOutput` object such as
`tf.estimator.export.PredictOutput`.
These output types map straightforwardly to the
-[TensorFlow Serving APIs](https://github.com/tensorflow/serving/blob/master/tensorflow_serving/apis/prediction_service.proto),
+[TensorFlow Serving APIs](https://github.com/tensorflow/serving/blob/r1.15/tensorflow_serving/apis/prediction_service.proto),
and so determine which request types will be honored.
Note: In the multi-headed case, a `SignatureDef` will be generated for each
@@ -515,7 +515,7 @@ the same keys. These `SignatureDef`s differ only in their outputs, as
provided by the corresponding `ExportOutput` entry. The inputs are always
those provided by the `serving_input_receiver_fn`.
An inference request may specify the head by name. One head must be named
-using [`signature_constants.DEFAULT_SERVING_SIGNATURE_DEF_KEY`](https://www.tensorflow.org/code/tensorflow/python/saved_model/signature_constants.py)
+using [`signature_constants.DEFAULT_SERVING_SIGNATURE_DEF_KEY`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/saved_model/signature_constants.py)
indicating which `SignatureDef` will be served when an inference request
does not specify one.
@@ -566,9 +566,9 @@ Now you have a server listening for inference requests via gRPC on port 9000!
### Request predictions from a local server
The server responds to gRPC requests according to the
-[PredictionService](https://github.com/tensorflow/serving/blob/master/tensorflow_serving/apis/prediction_service.proto#L15)
+[PredictionService](https://github.com/tensorflow/serving/blob/r1.15/tensorflow_serving/apis/prediction_service.proto#L15)
gRPC API service definition. (The nested protocol buffers are defined in
-various [neighboring files](https://github.com/tensorflow/serving/blob/master/tensorflow_serving/apis)).
+various [neighboring files](https://github.com/tensorflow/serving/blob/r1.15/tensorflow_serving/apis)).
From the API service definition, the gRPC framework generates client libraries
in various languages providing remote access to the API. In a project using the
@@ -620,7 +620,7 @@ The returned result in this example is a `ClassificationResponse` protocol
buffer.
This is a skeletal example; please see the [Tensorflow Serving](../deploy/index.md)
-documentation and [examples](https://github.com/tensorflow/serving/tree/master/tensorflow_serving/example)
+documentation and [examples](https://github.com/tensorflow/serving/tree/r1.15/tensorflow_serving/example)
for more details.
> Note: `ClassificationRequest` and `RegressionRequest` contain a
diff --git a/site/en/r1/guide/using_tpu.md b/site/en/r1/guide/using_tpu.md
index 74169092189..e3e338adf49 100644
--- a/site/en/r1/guide/using_tpu.md
+++ b/site/en/r1/guide/using_tpu.md
@@ -7,8 +7,8 @@ changing the *hardware accelerator* in your notebook settings:
TPU-enabled Colab notebooks are available to test:
1. [A quick test, just to measure FLOPS](https://colab.research.google.com/notebooks/tpu.ipynb).
- 2. [A CNN image classifier with `tf.keras`](https://colab.research.google.com/github/tensorflow/tpu/blob/master/tools/colab/fashion_mnist.ipynb).
- 3. [An LSTM markov chain text generator with `tf.keras`](https://colab.research.google.com/github/tensorflow/tpu/blob/master/tools/colab/shakespeare_with_tpu_and_keras.ipynb)
+ 2. [A CNN image classifier with `tf.keras`](https://colab.research.google.com/github/tensorflow/tpu/blob/r1.15/tools/colab/fashion_mnist.ipynb).
+ 3. [An LSTM markov chain text generator with `tf.keras`](https://colab.research.google.com/github/tensorflow/tpu/blob/r1.15/tools/colab/shakespeare_with_tpu_and_keras.ipynb)
## TPUEstimator
@@ -25,7 +25,7 @@ Cloud TPU is to define the model's inference phase (from inputs to predictions)
outside of the `model_fn`. Then maintain separate implementations of the
`Estimator` setup and `model_fn`, both wrapping this inference step. For an
example of this pattern compare the `mnist.py` and `mnist_tpu.py` implementation in
-[tensorflow/models](https://github.com/tensorflow/models/tree/master/official/r1/mnist).
+[tensorflow/models](https://github.com/tensorflow/models/tree/r1.15/official/r1/mnist).
### Run a TPUEstimator locally
@@ -350,10 +350,10 @@ in bytes. A minimum of a few MB (`buffer_size=8*1024*1024`) is recommended so
that data is available when needed.
The TPU-demos repo includes
-[a script](https://github.com/tensorflow/tpu/blob/master/tools/datasets/imagenet_to_gcs.py)
+[a script](https://github.com/tensorflow/tpu/blob/1.15/tools/datasets/imagenet_to_gcs.py)
for downloading the imagenet dataset and converting it to an appropriate format.
This together with the imagenet
-[models](https://github.com/tensorflow/tpu/tree/master/models)
+[models](https://github.com/tensorflow/tpu/tree/r1.15/models)
included in the repo demonstrate all of these best-practices.
## Next steps
diff --git a/site/en/r1/guide/version_compat.md b/site/en/r1/guide/version_compat.md
index 6702f6e0819..a765620518d 100644
--- a/site/en/r1/guide/version_compat.md
+++ b/site/en/r1/guide/version_compat.md
@@ -49,19 +49,19 @@ patch versions. The public APIs consist of
submodules, but is not documented, then it is **not** considered part of the
public API.
-* The [C API](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/c/c_api.h).
+* The [C API](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/c/c_api.h).
* The following protocol buffer files:
- * [`attr_value`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/attr_value.proto)
- * [`config`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/protobuf/config.proto)
- * [`event`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/util/event.proto)
- * [`graph`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/graph.proto)
- * [`op_def`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/op_def.proto)
- * [`reader_base`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/reader_base.proto)
- * [`summary`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/summary.proto)
- * [`tensor`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/tensor.proto)
- * [`tensor_shape`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/tensor_shape.proto)
- * [`types`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/types.proto)
+ * [`attr_value`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/attr_value.proto)
+ * [`config`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/protobuf/config.proto)
+ * [`event`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/util/event.proto)
+ * [`graph`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/graph.proto)
+ * [`op_def`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/op_def.proto)
+ * [`reader_base`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/reader_base.proto)
+ * [`summary`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/summary.proto)
+ * [`tensor`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/tensor.proto)
+ * [`tensor_shape`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/tensor_shape.proto)
+ * [`types`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/types.proto)
## What is *not* covered
@@ -79,7 +79,7 @@ backward incompatible ways between minor releases. These include:
such as:
- [C++](./extend/cc.md) (exposed through header files in
- [`tensorflow/cc`](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/cc)).
+ [`tensorflow/cc`](https://github.com/tensorflow/tensorflow/tree/r1.15/tensorflow/cc)).
- [Java](../api_docs/java/reference/org/tensorflow/package-summary),
- [Go](https://pkg.go.dev/github.com/tensorflow/tensorflow/tensorflow/go)
- [JavaScript](https://js.tensorflow.org)
@@ -209,7 +209,7 @@ guidelines for evolving `GraphDef` versions.
There are different data versions for graphs and checkpoints. The two data
formats evolve at different rates from each other and also at different rates
from TensorFlow. Both versioning systems are defined in
-[`core/public/version.h`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/public/version.h).
+[`core/public/version.h`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/public/version.h).
Whenever a new version is added, a note is added to the header detailing what
changed and the date.
@@ -224,7 +224,7 @@ We distinguish between the following kinds of data version information:
(`min_producer`).
Each piece of versioned data has a [`VersionDef
-versions`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/versions.proto)
+versions`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/versions.proto)
field which records the `producer` that made the data, the `min_consumer`
that it is compatible with, and a list of `bad_consumers` versions that are
disallowed.
@@ -239,7 +239,7 @@ accept a piece of data if the following are all true:
* `consumer` not in data's `bad_consumers`
Since both producers and consumers come from the same TensorFlow code base,
-[`core/public/version.h`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/public/version.h)
+[`core/public/version.h`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/public/version.h)
contains a main data version which is treated as either `producer` or
`consumer` depending on context and both `min_consumer` and `min_producer`
(needed by producers and consumers, respectively). Specifically,
@@ -309,7 +309,7 @@ existing producer scripts will not suddenly use the new functionality.
1. Add a new similar op named `SomethingV2` or similar and go through the
process of adding it and switching existing Python wrappers to use it.
To ensure forward compatibility use the checks suggested in
- [compat.py](https://www.tensorflow.org/code/tensorflow/python/compat/compat.py)
+ [compat.py](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/compat/compat.py)
when changing the Python wrappers.
2. Remove the old op (Can only take place with a major version change due to
backward compatibility).
diff --git a/site/en/r1/tutorials/README.md b/site/en/r1/tutorials/README.md
index 5094e645e6e..9ff164ad77c 100644
--- a/site/en/r1/tutorials/README.md
+++ b/site/en/r1/tutorials/README.md
@@ -68,4 +68,4 @@ implement common ML algorithms. See the
* [Boosted trees](./estimators/boosted_trees.ipynb)
* [Gradient Boosted Trees: Model understanding](./estimators/boosted_trees_model_understanding.ipynb)
* [Build a Convolutional Neural Network using Estimators](./estimators/cnn.ipynb)
-* [Wide and deep learning with Estimators](https://github.com/tensorflow/models/tree/master/official/r1/wide_deep)
+* [Wide and deep learning with Estimators](https://github.com/tensorflow/models/tree/r1.15/official/r1/wide_deep)
diff --git a/site/en/r1/tutorials/distribute/keras.ipynb b/site/en/r1/tutorials/distribute/keras.ipynb
index 059b8c2d66f..14e8bf739a9 100644
--- a/site/en/r1/tutorials/distribute/keras.ipynb
+++ b/site/en/r1/tutorials/distribute/keras.ipynb
@@ -86,7 +86,7 @@
"Essentially, it copies all of the model's variables to each processor.\n",
"Then, it uses [all-reduce](http://mpitutorial.com/tutorials/mpi-reduce-and-allreduce/) to combine the gradients from all processors and applies the combined value to all copies of the model.\n",
"\n",
- "`MirroredStategy` is one of several distribution strategy available in TensorFlow core. You can read about more strategies at [distribution strategy guide](../../guide/distribute_strategy.ipynb).\n"
+ "`MirroredStrategy` is one of several distribution strategy available in TensorFlow core. You can read about more strategies at [distribution strategy guide](../../guide/distribute_strategy.ipynb).\n"
]
},
{
diff --git a/site/en/r1/tutorials/images/deep_cnn.md b/site/en/r1/tutorials/images/deep_cnn.md
index 00a914d8976..885f3907aa7 100644
--- a/site/en/r1/tutorials/images/deep_cnn.md
+++ b/site/en/r1/tutorials/images/deep_cnn.md
@@ -80,15 +80,15 @@ for details. It consists of 1,068,298 learnable parameters and requires about
## Code Organization
The code for this tutorial resides in
-[`models/tutorials/image/cifar10/`](https://github.com/tensorflow/models/tree/master/research/tutorials/image/cifar10/).
+[`models/tutorials/image/cifar10/`](https://github.com/tensorflow/models/tree/r1.15/research/tutorials/image/cifar10/).
File | Purpose
--- | ---
-[`cifar10_input.py`](https://github.com/tensorflow/models/tree/master/research/tutorials/image/cifar10/cifar10_input.py) | Loads CIFAR-10 dataset using [tensorflow-datasets library](https://github.com/tensorflow/datasets).
-[`cifar10.py`](https://github.com/tensorflow/models/tree/master/research/tutorials/image/cifar10/cifar10.py) | Builds the CIFAR-10 model.
-[`cifar10_train.py`](https://github.com/tensorflow/models/tree/master/research/tutorials/image/cifar10/cifar10_train.py) | Trains a CIFAR-10 model on a CPU or GPU.
-[`cifar10_multi_gpu_train.py`](https://github.com/tensorflow/models/tree/master/research/tutorials/image/cifar10/cifar10_multi_gpu_train.py) | Trains a CIFAR-10 model on multiple GPUs.
-[`cifar10_eval.py`](https://github.com/tensorflow/models/tree/master/research/tutorials/image/cifar10/cifar10_eval.py) | Evaluates the predictive performance of a CIFAR-10 model.
+[`cifar10_input.py`](https://github.com/tensorflow/models/tree/r1.15/research/tutorials/image/cifar10/cifar10_input.py) | Loads CIFAR-10 dataset using [tensorflow-datasets library](https://github.com/tensorflow/datasets).
+[`cifar10.py`](https://github.com/tensorflow/models/tree/r1.15/research/tutorials/image/cifar10/cifar10.py) | Builds the CIFAR-10 model.
+[`cifar10_train.py`](https://github.com/tensorflow/models/tree/r1.15/research/tutorials/image/cifar10/cifar10_train.py) | Trains a CIFAR-10 model on a CPU or GPU.
+[`cifar10_multi_gpu_train.py`](https://github.com/tensorflow/models/tree/r1.15/research/tutorials/image/cifar10/cifar10_multi_gpu_train.py) | Trains a CIFAR-10 model on multiple GPUs.
+[`cifar10_eval.py`](https://github.com/tensorflow/models/tree/r1.15/research/tutorials/image/cifar10/cifar10_eval.py) | Evaluates the predictive performance of a CIFAR-10 model.
To run this tutorial, you will need to:
@@ -99,7 +99,7 @@ pip install tensorflow-datasets
## CIFAR-10 Model
The CIFAR-10 network is largely contained in
-[`cifar10.py`](https://github.com/tensorflow/models/tree/master/research/tutorials/image/cifar10/cifar10.py).
+[`cifar10.py`](https://github.com/tensorflow/models/tree/r1.15/research/tutorials/image/cifar10/cifar10.py).
The complete training
graph contains roughly 765 operations. We find that we can make the code most
reusable by constructing the graph with the following modules:
@@ -108,7 +108,7 @@ reusable by constructing the graph with the following modules:
operations that read and preprocess CIFAR images for evaluation and training,
respectively.
1. [**Model prediction:**](#model-prediction) `inference()`
-adds operations that perform inference, i.e. classification, on supplied images.
+adds operations that perform inference, i.e., classification, on supplied images.
1. [**Model training:**](#model-training) `loss()` and `train()`
add operations that compute the loss,
gradients, variable updates and visualization summaries.
@@ -405,7 +405,7 @@ a "tower". We must set two attributes for each tower:
* A unique name for all operations within a tower.
`tf.name_scope` provides
this unique name by prepending a scope. For instance, all operations in
-the first tower are prepended with `tower_0`, e.g. `tower_0/conv1/Conv2D`.
+the first tower are prepended with `tower_0`, e.g., `tower_0/conv1/Conv2D`.
* A preferred hardware device to run the operation within a tower.
`tf.device` specifies this. For
diff --git a/site/en/r1/tutorials/images/image_recognition.md b/site/en/r1/tutorials/images/image_recognition.md
index 0be884de403..cb66e594629 100644
--- a/site/en/r1/tutorials/images/image_recognition.md
+++ b/site/en/r1/tutorials/images/image_recognition.md
@@ -140,13 +140,13 @@ score of 0.8.
@@ -186,9 +186,9 @@ communication, see:
### Code
-* [WorkerService API definition](https://www.tensorflow.org/code/tensorflow/core/protobuf/worker_service.proto)
-* [Worker interface](https://www.tensorflow.org/code/tensorflow/core/distributed_runtime/worker_interface.h)
-* [Remote rendezvous (for Send and Recv implementations)](https://www.tensorflow.org/code/tensorflow/core/distributed_runtime/rpc/rpc_rendezvous_mgr.h)
+* [WorkerService API definition](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/protobuf/worker_service.proto)
+* [Worker interface](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/distributed_runtime/worker_interface.h)
+* [Remote rendezvous (for Send and Recv implementations)](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/distributed_runtime/rpc/rpc_rendezvous_mgr.h)
## Kernel Implementations
@@ -199,7 +199,7 @@ Many of the operation kernels are implemented using Eigen::Tensor, which uses
C++ templates to generate efficient parallel code for multicore CPUs and GPUs;
however, we liberally use libraries like cuDNN where a more efficient kernel
implementation is possible. We have also implemented
-[quantization](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/g3doc/performance/post_training_quantization.md), which enables
+[quantization](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/lite/g3doc/performance/post_training_quantization.md), which enables
faster inference in environments such as mobile devices and high-throughput
datacenter applications, and use the
[gemmlowp](https://github.com/google/gemmlowp) low-precision matrix library to
@@ -215,4 +215,4 @@ experimental implementation of automatic kernel fusion.
### Code
-* [`OpKernel` interface](https://www.tensorflow.org/code/tensorflow/core/framework/op_kernel.h)
+* [`OpKernel` interface](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/op_kernel.h)
diff --git a/site/en/r1/guide/extend/bindings.md b/site/en/r1/guide/extend/bindings.md
index 9c10e90840f..7daa2212106 100644
--- a/site/en/r1/guide/extend/bindings.md
+++ b/site/en/r1/guide/extend/bindings.md
@@ -112,11 +112,11 @@ There are a few ways to get a list of the `OpDef`s for the registered ops:
to interpret the `OpDef` messages.
- The C++ function `OpRegistry::Global()->GetRegisteredOps()` returns the same
list of all registered `OpDef`s (defined in
- [`tensorflow/core/framework/op.h`](https://www.tensorflow.org/code/tensorflow/core/framework/op.h)). This can be used to write the generator
+ [`tensorflow/core/framework/op.h`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/op.h)). This can be used to write the generator
in C++ (particularly useful for languages that do not have protocol buffer
support).
- The ASCII-serialized version of that list is periodically checked in to
- [`tensorflow/core/ops/ops.pbtxt`](https://www.tensorflow.org/code/tensorflow/core/ops/ops.pbtxt) by an automated process.
+ [`tensorflow/core/ops/ops.pbtxt`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/ops/ops.pbtxt) by an automated process.
The `OpDef` specifies the following:
@@ -159,7 +159,7 @@ between the generated code and the `OpDef`s checked into the repository, but is
useful for languages where code is expected to be generated ahead of time like
`go get` for Go and `cargo ops` for Rust. At the other end of the spectrum, for
some languages the code could be generated dynamically from
-[`tensorflow/core/ops/ops.pbtxt`](https://www.tensorflow.org/code/tensorflow/core/ops/ops.pbtxt).
+[`tensorflow/core/ops/ops.pbtxt`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/ops/ops.pbtxt).
#### Handling Constants
@@ -228,4 +228,4 @@ At this time, support for gradients, functions and control flow operations ("if"
and "while") is not available in languages other than Python. This will be
updated when the [C API] provides necessary support.
-[C API]: https://www.tensorflow.org/code/tensorflow/c/c_api.h
+[C API]: https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/c/c_api.h
diff --git a/site/en/r1/guide/extend/filesystem.md b/site/en/r1/guide/extend/filesystem.md
index 4d34c07102e..2d6ea0c4645 100644
--- a/site/en/r1/guide/extend/filesystem.md
+++ b/site/en/r1/guide/extend/filesystem.md
@@ -54,7 +54,7 @@ To implement a custom filesystem plugin, you must do the following:
### The FileSystem interface
The `FileSystem` interface is an abstract C++ interface defined in
-[file_system.h](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/platform/file_system.h).
+[file_system.h](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/platform/file_system.h).
An implementation of the `FileSystem` interface should implement all relevant
the methods defined by the interface. Implementing the interface requires
defining operations such as creating `RandomAccessFile`, `WritableFile`, and
@@ -70,26 +70,26 @@ involves calling `stat()` on the file and then returns the filesize as reported
by the return of the stat object. Similarly, for the `HDFSFileSystem`
implementation, these calls simply delegate to the `libHDFS` implementation of
similar functionality, such as `hdfsDelete` for
-[DeleteFile](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/platform/hadoop/hadoop_file_system.cc#L386).
+[DeleteFile](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/platform/hadoop/hadoop_file_system.cc#L386).
We suggest looking through these code examples to get an idea of how different
filesystem implementations call their existing libraries. Examples include:
* [POSIX
- plugin](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/platform/posix/posix_file_system.h)
+ plugin](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/platform/posix/posix_file_system.h)
* [HDFS
- plugin](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/platform/hadoop/hadoop_file_system.h)
+ plugin](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/platform/hadoop/hadoop_file_system.h)
* [GCS
- plugin](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/platform/cloud/gcs_file_system.h)
+ plugin](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/platform/cloud/gcs_file_system.h)
* [S3
- plugin](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/platform/s3/s3_file_system.h)
+ plugin](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/platform/s3/s3_file_system.h)
#### The File interfaces
Beyond operations that allow you to query and manipulate files and directories
in a filesystem, the `FileSystem` interface requires you to implement factories
that return implementations of abstract objects such as the
-[RandomAccessFile](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/platform/file_system.h#L223),
+[RandomAccessFile](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/platform/file_system.h#L223),
the `WritableFile`, so that TensorFlow code and read and write to files in that
`FileSystem` implementation.
@@ -224,7 +224,7 @@ it will use the `FooBarFileSystem` implementation.
Next, you must build a shared object containing this implementation. An example
of doing so using bazel's `cc_binary` rule can be found
-[here](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/BUILD#L244),
+[here](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/BUILD#L244),
but you may use any build system to do so. See the section on [building the op library](../extend/op.md#build_the_op_library) for similar
instructions.
@@ -236,7 +236,7 @@ passing the path to the shared object. Calling this in your client program loads
the shared object in the process, thus registering your implementation as
available for any file operations going through the `FileSystem` interface. You
can see
-[test_file_system.py](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/framework/file_system_test.py)
+[test_file_system.py](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/framework/file_system_test.py)
for an example.
## What goes through this interface?
diff --git a/site/en/r1/guide/extend/formats.md b/site/en/r1/guide/extend/formats.md
index 3b7b4aafbd6..bdebee5487d 100644
--- a/site/en/r1/guide/extend/formats.md
+++ b/site/en/r1/guide/extend/formats.md
@@ -28,11 +28,11 @@ individual records in a file. There are several examples of "reader" datasets
that are already built into TensorFlow:
* `tf.data.TFRecordDataset`
- ([source in `kernels/data/reader_dataset_ops.cc`](https://www.tensorflow.org/code/tensorflow/core/kernels/data/reader_dataset_ops.cc))
+ ([source in `kernels/data/reader_dataset_ops.cc`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/kernels/data/reader_dataset_ops.cc))
* `tf.data.FixedLengthRecordDataset`
- ([source in `kernels/data/reader_dataset_ops.cc`](https://www.tensorflow.org/code/tensorflow/core/kernels/data/reader_dataset_ops.cc))
+ ([source in `kernels/data/reader_dataset_ops.cc`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/kernels/data/reader_dataset_ops.cc))
* `tf.data.TextLineDataset`
- ([source in `kernels/data/reader_dataset_ops.cc`](https://www.tensorflow.org/code/tensorflow/core/kernels/data/reader_dataset_ops.cc))
+ ([source in `kernels/data/reader_dataset_ops.cc`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/kernels/data/reader_dataset_ops.cc))
Each of these implementations comprises three related classes:
@@ -279,7 +279,7 @@ if __name__ == "__main__":
```
You can see some examples of `Dataset` wrapper classes in
-[`tensorflow/python/data/ops/dataset_ops.py`](https://www.tensorflow.org/code/tensorflow/python/data/ops/dataset_ops.py).
+[`tensorflow/python/data/ops/dataset_ops.py`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/data/ops/dataset_ops.py).
## Writing an Op for a record format
@@ -297,7 +297,7 @@ Examples of Ops useful for decoding records:
Note that it can be useful to use multiple Ops to decode a particular record
format. For example, you may have an image saved as a string in
-[a `tf.train.Example` protocol buffer](https://www.tensorflow.org/code/tensorflow/core/example/example.proto).
+[a `tf.train.Example` protocol buffer](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/example/example.proto).
Depending on the format of that image, you might take the corresponding output
from a `tf.parse_single_example` op and call `tf.image.decode_jpeg`,
`tf.image.decode_png`, or `tf.decode_raw`. It is common to take the output
diff --git a/site/en/r1/guide/extend/model_files.md b/site/en/r1/guide/extend/model_files.md
index 30e73a5169e..e590fcf1f27 100644
--- a/site/en/r1/guide/extend/model_files.md
+++ b/site/en/r1/guide/extend/model_files.md
@@ -28,7 +28,7 @@ by calling `as_graph_def()`, which returns a `GraphDef` object.
The GraphDef class is an object created by the ProtoBuf library from the
definition in
-[tensorflow/core/framework/graph.proto](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/graph.proto). The protobuf tools parse
+[tensorflow/core/framework/graph.proto](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/graph.proto). The protobuf tools parse
this text file, and generate the code to load, store, and manipulate graph
definitions. If you see a standalone TensorFlow file representing a model, it's
likely to contain a serialized version of one of these `GraphDef` objects
@@ -87,7 +87,7 @@ for node in graph_def.node
```
Each node is a `NodeDef` object, defined in
-[tensorflow/core/framework/node_def.proto](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/node_def.proto). These
+[tensorflow/core/framework/node_def.proto](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/node_def.proto). These
are the fundamental building blocks of TensorFlow graphs, with each one defining
a single operation along with its input connections. Here are the members of a
`NodeDef`, and what they mean.
@@ -107,7 +107,7 @@ This defines what operation to run, for example `"Add"`, `"MatMul"`, or
`"Conv2D"`. When a graph is run, this op name is looked up in a registry to
find an implementation. The registry is populated by calls to the
`REGISTER_OP()` macro, like those in
-[tensorflow/core/ops/nn_ops.cc](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/ops/nn_ops.cc).
+[tensorflow/core/ops/nn_ops.cc](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/ops/nn_ops.cc).
### `input`
@@ -133,7 +133,7 @@ size of filters for convolutions, or the values of constant ops. Because there
can be so many different types of attribute values, from strings, to ints, to
arrays of tensor values, there's a separate protobuf file defining the data
structure that holds them, in
-[tensorflow/core/framework/attr_value.proto](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/attr_value.proto).
+[tensorflow/core/framework/attr_value.proto](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/attr_value.proto).
Each attribute has a unique name string, and the expected attributes are listed
when the operation is defined. If an attribute isn't present in a node, but it
@@ -151,7 +151,7 @@ the file format during training. Instead, they're held in separate checkpoint
files, and there are `Variable` ops in the graph that load the latest values
when they're initialized. It's often not very convenient to have separate files
when you're deploying to production, so there's the
-[freeze_graph.py](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/tools/freeze_graph.py) script that takes a graph definition and a set
+[freeze_graph.py](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/tools/freeze_graph.py) script that takes a graph definition and a set
of checkpoints and freezes them together into a single file.
What this does is load the `GraphDef`, pull in the values for all the variables
@@ -167,7 +167,7 @@ the most common problems is extracting and interpreting the weight values. A
common way to store them, for example in graphs created by the freeze_graph
script, is as `Const` ops containing the weights as `Tensors`. These are
defined in
-[tensorflow/core/framework/tensor.proto](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/tensor.proto), and contain information
+[tensorflow/core/framework/tensor.proto](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/tensor.proto), and contain information
about the size and type of the data, as well as the values themselves. In
Python, you get a `TensorProto` object from a `NodeDef` representing a `Const`
op by calling something like `some_node_def.attr['value'].tensor`.
diff --git a/site/en/r1/guide/extend/op.md b/site/en/r1/guide/extend/op.md
index dc2d9fbe678..186d9c28c04 100644
--- a/site/en/r1/guide/extend/op.md
+++ b/site/en/r1/guide/extend/op.md
@@ -47,7 +47,7 @@ To incorporate your custom op you'll need to:
test the op in C++. If you define gradients, you can verify them with the
Python `tf.test.compute_gradient_error`.
See
- [`relu_op_test.py`](https://www.tensorflow.org/code/tensorflow/python/kernel_tests/relu_op_test.py) as
+ [`relu_op_test.py`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/kernel_tests/relu_op_test.py) as
an example that tests the forward functions of Relu-like operators and
their gradients.
@@ -155,17 +155,17 @@ REGISTER_KERNEL_BUILDER(Name("ZeroOut").Device(DEVICE_CPU), ZeroOutOp);
> Important: Instances of your OpKernel may be accessed concurrently.
> Your `Compute` method must be thread-safe. Guard any access to class
> members with a mutex. Or better yet, don't share state via class members!
-> Consider using a [`ResourceMgr`](https://www.tensorflow.org/code/tensorflow/core/framework/resource_mgr.h)
+> Consider using a [`ResourceMgr`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/resource_mgr.h)
> to keep track of op state.
### Multi-threaded CPU kernels
To write a multi-threaded CPU kernel, the Shard function in
-[`work_sharder.h`](https://www.tensorflow.org/code/tensorflow/core/util/work_sharder.h)
+[`work_sharder.h`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/util/work_sharder.h)
can be used. This function shards a computation function across the
threads configured to be used for intra-op threading (see
intra_op_parallelism_threads in
-[`config.proto`](https://www.tensorflow.org/code/tensorflow/core/protobuf/config.proto)).
+[`config.proto`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/protobuf/config.proto)).
### GPU kernels
@@ -486,13 +486,13 @@ This asserts that the input is a vector, and returns having set the
* The `context`, which can either be an `OpKernelContext` or
`OpKernelConstruction` pointer (see
- [`tensorflow/core/framework/op_kernel.h`](https://www.tensorflow.org/code/tensorflow/core/framework/op_kernel.h)),
+ [`tensorflow/core/framework/op_kernel.h`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/op_kernel.h)),
for its `SetStatus()` method.
* The condition. For example, there are functions for validating the shape
of a tensor in
- [`tensorflow/core/framework/tensor_shape.h`](https://www.tensorflow.org/code/tensorflow/core/framework/tensor_shape.h)
+ [`tensorflow/core/framework/tensor_shape.h`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/tensor_shape.h)
* The error itself, which is represented by a `Status` object, see
- [`tensorflow/core/lib/core/status.h`](https://www.tensorflow.org/code/tensorflow/core/lib/core/status.h). A
+ [`tensorflow/core/lib/core/status.h`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/lib/core/status.h). A
`Status` has both a type (frequently `InvalidArgument`, but see the list of
types) and a message. Functions for constructing an error may be found in
[`tensorflow/core/lib/core/errors.h`][validation-macros].
@@ -633,7 +633,7 @@ define an attr with constraints, you can use the following ``s:
The specific lists of types allowed by these are defined by the functions
(like `NumberTypes()`) in
- [`tensorflow/core/framework/types.h`](https://www.tensorflow.org/code/tensorflow/core/framework/types.h).
+ [`tensorflow/core/framework/types.h`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/types.h).
In this example the attr `t` must be one of the numeric types:
```c++
@@ -1180,7 +1180,7 @@ There are several ways to preserve backwards-compatibility.
type into a list of varying types).
The full list of safe and unsafe changes can be found in
-[`tensorflow/core/framework/op_compatibility_test.cc`](https://www.tensorflow.org/code/tensorflow/core/framework/op_compatibility_test.cc).
+[`tensorflow/core/framework/op_compatibility_test.cc`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/op_compatibility_test.cc).
If you cannot make your change to an operation backwards compatible, then create
a new operation with a new name with the new semantics.
@@ -1197,16 +1197,16 @@ made when TensorFlow changes major versions, and must conform to the
You can implement different OpKernels and register one for CPU and another for
GPU, just like you can [register kernels for different types](#polymorphism).
There are several examples of kernels with GPU support in
-[`tensorflow/core/kernels/`](https://www.tensorflow.org/code/tensorflow/core/kernels/).
+[`tensorflow/core/kernels/`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/kernels/).
Notice some kernels have a CPU version in a `.cc` file, a GPU version in a file
ending in `_gpu.cu.cc`, and some code shared in common in a `.h` file.
For example, the `tf.pad` has
everything but the GPU kernel in [`tensorflow/core/kernels/pad_op.cc`][pad_op].
The GPU kernel is in
-[`tensorflow/core/kernels/pad_op_gpu.cu.cc`](https://www.tensorflow.org/code/tensorflow/core/kernels/pad_op_gpu.cu.cc),
+[`tensorflow/core/kernels/pad_op_gpu.cu.cc`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/kernels/pad_op_gpu.cu.cc),
and the shared code is a templated class defined in
-[`tensorflow/core/kernels/pad_op.h`](https://www.tensorflow.org/code/tensorflow/core/kernels/pad_op.h).
+[`tensorflow/core/kernels/pad_op.h`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/kernels/pad_op.h).
We organize the code this way for two reasons: it allows you to share common
code among the CPU and GPU implementations, and it puts the GPU implementation
into a separate file so that it can be compiled only by the GPU compiler.
@@ -1227,16 +1227,16 @@ kept on the CPU, add a `HostMemory()` call to the kernel registration, e.g.:
#### Compiling the kernel for the GPU device
Look at
-[cuda_op_kernel.cu.cc](https://www.tensorflow.org/code/tensorflow/examples/adding_an_op/cuda_op_kernel.cu.cc)
+[cuda_op_kernel.cu.cc](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/examples/adding_an_op/cuda_op_kernel.cu.cc)
for an example that uses a CUDA kernel to implement an op. The
`tf_custom_op_library` accepts a `gpu_srcs` argument in which the list of source
files containing the CUDA kernels (`*.cu.cc` files) can be specified. For use
with a binary installation of TensorFlow, the CUDA kernels have to be compiled
with NVIDIA's `nvcc` compiler. Here is the sequence of commands you can use to
compile the
-[cuda_op_kernel.cu.cc](https://www.tensorflow.org/code/tensorflow/examples/adding_an_op/cuda_op_kernel.cu.cc)
+[cuda_op_kernel.cu.cc](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/examples/adding_an_op/cuda_op_kernel.cu.cc)
and
-[cuda_op_kernel.cc](https://www.tensorflow.org/code/tensorflow/examples/adding_an_op/cuda_op_kernel.cc)
+[cuda_op_kernel.cc](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/examples/adding_an_op/cuda_op_kernel.cc)
into a single dynamically loadable library:
```bash
@@ -1361,7 +1361,7 @@ be set to the first input's shape. If the output is selected by its index as in
There are a number of common shape functions
that apply to many ops, such as `shape_inference::UnchangedShape` which can be
-found in [common_shape_fns.h](https://www.tensorflow.org/code/tensorflow/core/framework/common_shape_fns.h) and used as follows:
+found in [common_shape_fns.h](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/common_shape_fns.h) and used as follows:
```c++
REGISTER_OP("ZeroOut")
@@ -1408,7 +1408,7 @@ provides access to the attributes of the op).
Since shape inference is an optional feature, and the shapes of tensors may vary
dynamically, shape functions must be robust to incomplete shape information for
-any of the inputs. The `Merge` method in [`InferenceContext`](https://www.tensorflow.org/code/tensorflow/core/framework/shape_inference.h)
+any of the inputs. The `Merge` method in [`InferenceContext`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/shape_inference.h)
allows the caller to assert that two shapes are the same, even if either
or both of them do not have complete information. Shape functions are defined
for all of the core TensorFlow ops and provide many different usage examples.
@@ -1433,7 +1433,7 @@ If you have a complicated shape function, you should consider adding a test for
validating that various input shape combinations produce the expected output
shape combinations. You can see examples of how to write these tests in some
our
-[core ops tests](https://www.tensorflow.org/code/tensorflow/core/ops/array_ops_test.cc).
+[core ops tests](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/ops/array_ops_test.cc).
(The syntax of `INFER_OK` and `INFER_ERROR` are a little cryptic, but try to be
compact in representing input and output shape specifications in tests. For
now, see the surrounding comments in those tests to get a sense of the shape
@@ -1446,20 +1446,20 @@ To build a `pip` package for your op, see the
guide shows how to build custom ops from the TensorFlow pip package instead
of building TensorFlow from source.
-[core-array_ops]:https://www.tensorflow.org/code/tensorflow/core/ops/array_ops.cc
-[python-user_ops]:https://www.tensorflow.org/code/tensorflow/python/user_ops/user_ops.py
-[tf-kernels]:https://www.tensorflow.org/code/tensorflow/core/kernels/
-[user_ops]:https://www.tensorflow.org/code/tensorflow/core/user_ops/
-[pad_op]:https://www.tensorflow.org/code/tensorflow/core/kernels/pad_op.cc
-[standard_ops-py]:https://www.tensorflow.org/code/tensorflow/python/ops/standard_ops.py
-[standard_ops-cc]:https://www.tensorflow.org/code/tensorflow/cc/ops/standard_ops.h
-[python-BUILD]:https://www.tensorflow.org/code/tensorflow/python/BUILD
-[validation-macros]:https://www.tensorflow.org/code/tensorflow/core/lib/core/errors.h
-[op_def_builder]:https://www.tensorflow.org/code/tensorflow/core/framework/op_def_builder.h
-[register_types]:https://www.tensorflow.org/code/tensorflow/core/framework/register_types.h
-[FinalizeAttr]:https://www.tensorflow.org/code/tensorflow/core/framework/op_def_builder.cc
-[DataTypeString]:https://www.tensorflow.org/code/tensorflow/core/framework/types.cc
-[python-BUILD]:https://www.tensorflow.org/code/tensorflow/python/BUILD
-[types-proto]:https://www.tensorflow.org/code/tensorflow/core/framework/types.proto
-[TensorShapeProto]:https://www.tensorflow.org/code/tensorflow/core/framework/tensor_shape.proto
-[TensorProto]:https://www.tensorflow.org/code/tensorflow/core/framework/tensor.proto
+[core-array_ops]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/ops/array_ops.cc
+[python-user_ops]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/user_ops/user_ops.py
+[tf-kernels]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/kernels/
+[user_ops]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/user_ops/
+[pad_op]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/kernels/pad_op.cc
+[standard_ops-py]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/ops/standard_ops.py
+[standard_ops-cc]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/cc/ops/standard_ops.h
+[python-BUILD]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/BUILD
+[validation-macros]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/lib/core/errors.h
+[op_def_builder]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/op_def_builder.h
+[register_types]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/register_types.h
+[FinalizeAttr]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/op_def_builder.cc
+[DataTypeString]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/types.cc
+[python-BUILD]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/BUILD
+[types-proto]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/types.proto
+[TensorShapeProto]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/tensor_shape.proto
+[TensorProto]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/tensor.proto
diff --git a/site/en/r1/guide/feature_columns.md b/site/en/r1/guide/feature_columns.md
index 5a4dfbbf46d..e4259f85e9f 100644
--- a/site/en/r1/guide/feature_columns.md
+++ b/site/en/r1/guide/feature_columns.md
@@ -562,7 +562,7 @@ For more examples on feature columns, view the following:
* The [Low Level Introduction](../guide/low_level_intro.md#feature_columns) demonstrates how
experiment directly with `feature_columns` using TensorFlow's low level APIs.
-* The [Estimator wide and deep learning tutorial](https://github.com/tensorflow/models/tree/master/official/r1/wide_deep)
+* The [Estimator wide and deep learning tutorial](https://github.com/tensorflow/models/tree/r1.15/official/r1/wide_deep)
solves a binary classification problem using `feature_columns` on a variety of
input data types.
diff --git a/site/en/r1/guide/graph_viz.md b/site/en/r1/guide/graph_viz.md
index 1965378e03e..1e3780e7928 100644
--- a/site/en/r1/guide/graph_viz.md
+++ b/site/en/r1/guide/graph_viz.md
@@ -251,7 +251,7 @@ is a snippet from the train and test section of a modification of the
[Estimators MNIST tutorial](../tutorials/estimators/cnn.md), in which we have
recorded summaries and
runtime statistics. See the
-[Tensorboard](https://tensorflow.org/tensorboard)
+[TensorBoard](https://tensorflow.org/tensorboard)
for details on how to record summaries.
Full source is [here](https://github.com/tensorflow/tensorflow/tree/r1.15/tensorflow/examples/tutorials/mnist/mnist_with_summaries.py).
diff --git a/site/en/r1/guide/performance/benchmarks.md b/site/en/r1/guide/performance/benchmarks.md
index 8998c0723db..a56959ea416 100644
--- a/site/en/r1/guide/performance/benchmarks.md
+++ b/site/en/r1/guide/performance/benchmarks.md
@@ -401,7 +401,7 @@ GPUs | InceptionV3 (batch size 32) | ResNet-50 (batch size 32)
## Methodology
This
-[script](https://github.com/tensorflow/benchmarks/tree/master/scripts/tf_cnn_benchmarks)
+[script](https://github.com/tensorflow/benchmarks/tree/r1.15/scripts/tf_cnn_benchmarks)
was run on the various platforms to generate the above results.
In order to create results that are as repeatable as possible, each test was run
diff --git a/site/en/r1/guide/performance/overview.md b/site/en/r1/guide/performance/overview.md
index af74f0f28c6..be7217f4b99 100644
--- a/site/en/r1/guide/performance/overview.md
+++ b/site/en/r1/guide/performance/overview.md
@@ -19,9 +19,9 @@ Reading large numbers of small files significantly impacts I/O performance.
One approach to get maximum I/O throughput is to preprocess input data into
larger (~100MB) `TFRecord` files. For smaller data sets (200MB-1GB), the best
approach is often to load the entire data set into memory. The document
-[Downloading and converting to TFRecord format](https://github.com/tensorflow/models/tree/master/research/slim#downloading-and-converting-to-tfrecord-format)
+[Downloading and converting to TFRecord format](https://github.com/tensorflow/models/tree/r1.15/research/slim#downloading-and-converting-to-tfrecord-format)
includes information and scripts for creating `TFRecord`s, and this
-[script](https://github.com/tensorflow/models/tree/master/research/tutorials/image/cifar10_estimator/generate_cifar10_tfrecords.py)
+[script](https://github.com/tensorflow/models/tree/r1.15/research/tutorials/image/cifar10_estimator/generate_cifar10_tfrecords.py)
converts the CIFAR-10 dataset into `TFRecord`s.
While feeding data using a `feed_dict` offers a high level of flexibility, in
@@ -122,7 +122,7 @@ tf.Session(config=config)
Intel® has added optimizations to TensorFlow for Intel® Xeon® and Intel® Xeon
Phi™ through the use of the Intel® Math Kernel Library for Deep Neural Networks
(Intel® MKL-DNN) optimized primitives. The optimizations also provide speedups
-for the consumer line of processors, e.g. i5 and i7 Intel processors. The Intel
+for the consumer line of processors, e.g., i5 and i7 Intel processors. The Intel
published paper
[TensorFlow* Optimizations on Modern Intel® Architecture](https://software.intel.com/en-us/articles/tensorflow-optimizations-on-modern-intel-architecture)
contains additional details on the implementation.
@@ -255,7 +255,7 @@ bazel build -c opt --copt=-march="broadwell" --config=cuda //tensorflow/tools/pi
a docker container, the data is not cached and the penalty is paid each time
TensorFlow starts. The best practice is to include the
[compute capabilities](http://developer.nvidia.com/cuda-gpus)
- of the GPUs that will be used, e.g. P100: 6.0, Titan X (Pascal): 6.1,
+ of the GPUs that will be used, e.g., P100: 6.0, Titan X (Pascal): 6.1,
Titan X (Maxwell): 5.2, and K80: 3.7.
* Use a version of `gcc` that supports all of the optimizations of the target
CPU. The recommended minimum gcc version is 4.8.3. On macOS, upgrade to the
diff --git a/site/en/r1/guide/saved_model.md b/site/en/r1/guide/saved_model.md
index 623863a9df9..34447ffe861 100644
--- a/site/en/r1/guide/saved_model.md
+++ b/site/en/r1/guide/saved_model.md
@@ -23,7 +23,7 @@ TensorFlow saves variables in binary *checkpoint files* that map variable
names to tensor values.
Caution: TensorFlow model files are code. Be careful with untrusted code.
-See [Using TensorFlow Securely](https://github.com/tensorflow/tensorflow/blob/master/SECURITY.md)
+See [Using TensorFlow Securely](https://github.com/tensorflow/tensorflow/blob/r1.15/SECURITY.md)
for details.
### Save variables
@@ -148,7 +148,7 @@ Notes:
`tf.variables_initializer` for more information.
* To inspect the variables in a checkpoint, you can use the
- [`inspect_checkpoint`](https://www.tensorflow.org/code/tensorflow/python/tools/inspect_checkpoint.py)
+ [`inspect_checkpoint`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/tools/inspect_checkpoint.py)
library, particularly the `print_tensors_in_checkpoint_file` function.
* By default, `Saver` uses the value of the `tf.Variable.name` property
@@ -159,7 +159,7 @@ Notes:
### Inspect variables in a checkpoint
We can quickly inspect variables in a checkpoint with the
-[`inspect_checkpoint`](https://www.tensorflow.org/code/tensorflow/python/tools/inspect_checkpoint.py) library.
+[`inspect_checkpoint`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/tools/inspect_checkpoint.py) library.
Continuing from the save/restore examples shown earlier:
@@ -216,7 +216,7 @@ simple_save(session,
This configures the `SavedModel` so it can be loaded by
[TensorFlow serving](https://www.tensorflow.org/tfx/tutorials/serving/rest_simple) and supports the
-[Predict API](https://github.com/tensorflow/serving/blob/master/tensorflow_serving/apis/predict.proto).
+[Predict API](https://github.com/tensorflow/serving/blob/r1.15/tensorflow_serving/apis/predict.proto).
To access the classify, regress, or multi-inference APIs, use the manual
`SavedModel` builder APIs or an `tf.estimator.Estimator`.
@@ -328,7 +328,7 @@ with tf.Session(graph=tf.Graph()) as sess:
### Load a SavedModel in C++
The C++ version of the SavedModel
-[loader](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/cc/saved_model/loader.h)
+[loader](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/cc/saved_model/loader.h)
provides an API to load a SavedModel from a path, while allowing
`SessionOptions` and `RunOptions`.
You have to specify the tags associated with the graph to be loaded.
@@ -383,20 +383,20 @@ reuse and share across tools consistently.
You may use sets of tags to uniquely identify a `MetaGraphDef` saved in a
SavedModel. A subset of commonly used tags is specified in:
-* [Python](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/saved_model/tag_constants.py)
-* [C++](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/cc/saved_model/tag_constants.h)
+* [Python](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/saved_model/tag_constants.py)
+* [C++](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/cc/saved_model/tag_constants.h)
#### Standard SignatureDef constants
-A [**SignatureDef**](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/protobuf/meta_graph.proto)
+A [**SignatureDef**](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/protobuf/meta_graph.proto)
is a protocol buffer that defines the signature of a computation
supported by a graph.
Commonly used input keys, output keys, and method names are
defined in:
-* [Python](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/saved_model/signature_constants.py)
-* [C++](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/cc/saved_model/signature_constants.h)
+* [Python](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/saved_model/signature_constants.py)
+* [C++](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/cc/saved_model/signature_constants.h)
## Using SavedModel with Estimators
@@ -408,7 +408,7 @@ To prepare a trained Estimator for serving, you must export it in the standard
SavedModel format. This section explains how to:
* Specify the output nodes and the corresponding
- [APIs](https://github.com/tensorflow/serving/blob/master/tensorflow_serving/apis/prediction_service.proto)
+ [APIs](https://github.com/tensorflow/serving/blob/r1.15/tensorflow_serving/apis/prediction_service.proto)
that can be served (Classify, Regress, or Predict).
* Export your model to the SavedModel format.
* Serve the model from a local server and request predictions.
@@ -506,7 +506,7 @@ Each `output` value must be an `ExportOutput` object such as
`tf.estimator.export.PredictOutput`.
These output types map straightforwardly to the
-[TensorFlow Serving APIs](https://github.com/tensorflow/serving/blob/master/tensorflow_serving/apis/prediction_service.proto),
+[TensorFlow Serving APIs](https://github.com/tensorflow/serving/blob/r1.15/tensorflow_serving/apis/prediction_service.proto),
and so determine which request types will be honored.
Note: In the multi-headed case, a `SignatureDef` will be generated for each
@@ -515,7 +515,7 @@ the same keys. These `SignatureDef`s differ only in their outputs, as
provided by the corresponding `ExportOutput` entry. The inputs are always
those provided by the `serving_input_receiver_fn`.
An inference request may specify the head by name. One head must be named
-using [`signature_constants.DEFAULT_SERVING_SIGNATURE_DEF_KEY`](https://www.tensorflow.org/code/tensorflow/python/saved_model/signature_constants.py)
+using [`signature_constants.DEFAULT_SERVING_SIGNATURE_DEF_KEY`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/saved_model/signature_constants.py)
indicating which `SignatureDef` will be served when an inference request
does not specify one.
@@ -566,9 +566,9 @@ Now you have a server listening for inference requests via gRPC on port 9000!
### Request predictions from a local server
The server responds to gRPC requests according to the
-[PredictionService](https://github.com/tensorflow/serving/blob/master/tensorflow_serving/apis/prediction_service.proto#L15)
+[PredictionService](https://github.com/tensorflow/serving/blob/r1.15/tensorflow_serving/apis/prediction_service.proto#L15)
gRPC API service definition. (The nested protocol buffers are defined in
-various [neighboring files](https://github.com/tensorflow/serving/blob/master/tensorflow_serving/apis)).
+various [neighboring files](https://github.com/tensorflow/serving/blob/r1.15/tensorflow_serving/apis)).
From the API service definition, the gRPC framework generates client libraries
in various languages providing remote access to the API. In a project using the
@@ -620,7 +620,7 @@ The returned result in this example is a `ClassificationResponse` protocol
buffer.
This is a skeletal example; please see the [Tensorflow Serving](../deploy/index.md)
-documentation and [examples](https://github.com/tensorflow/serving/tree/master/tensorflow_serving/example)
+documentation and [examples](https://github.com/tensorflow/serving/tree/r1.15/tensorflow_serving/example)
for more details.
> Note: `ClassificationRequest` and `RegressionRequest` contain a
diff --git a/site/en/r1/guide/using_tpu.md b/site/en/r1/guide/using_tpu.md
index 74169092189..e3e338adf49 100644
--- a/site/en/r1/guide/using_tpu.md
+++ b/site/en/r1/guide/using_tpu.md
@@ -7,8 +7,8 @@ changing the *hardware accelerator* in your notebook settings:
TPU-enabled Colab notebooks are available to test:
1. [A quick test, just to measure FLOPS](https://colab.research.google.com/notebooks/tpu.ipynb).
- 2. [A CNN image classifier with `tf.keras`](https://colab.research.google.com/github/tensorflow/tpu/blob/master/tools/colab/fashion_mnist.ipynb).
- 3. [An LSTM markov chain text generator with `tf.keras`](https://colab.research.google.com/github/tensorflow/tpu/blob/master/tools/colab/shakespeare_with_tpu_and_keras.ipynb)
+ 2. [A CNN image classifier with `tf.keras`](https://colab.research.google.com/github/tensorflow/tpu/blob/r1.15/tools/colab/fashion_mnist.ipynb).
+ 3. [An LSTM markov chain text generator with `tf.keras`](https://colab.research.google.com/github/tensorflow/tpu/blob/r1.15/tools/colab/shakespeare_with_tpu_and_keras.ipynb)
## TPUEstimator
@@ -25,7 +25,7 @@ Cloud TPU is to define the model's inference phase (from inputs to predictions)
outside of the `model_fn`. Then maintain separate implementations of the
`Estimator` setup and `model_fn`, both wrapping this inference step. For an
example of this pattern compare the `mnist.py` and `mnist_tpu.py` implementation in
-[tensorflow/models](https://github.com/tensorflow/models/tree/master/official/r1/mnist).
+[tensorflow/models](https://github.com/tensorflow/models/tree/r1.15/official/r1/mnist).
### Run a TPUEstimator locally
@@ -350,10 +350,10 @@ in bytes. A minimum of a few MB (`buffer_size=8*1024*1024`) is recommended so
that data is available when needed.
The TPU-demos repo includes
-[a script](https://github.com/tensorflow/tpu/blob/master/tools/datasets/imagenet_to_gcs.py)
+[a script](https://github.com/tensorflow/tpu/blob/1.15/tools/datasets/imagenet_to_gcs.py)
for downloading the imagenet dataset and converting it to an appropriate format.
This together with the imagenet
-[models](https://github.com/tensorflow/tpu/tree/master/models)
+[models](https://github.com/tensorflow/tpu/tree/r1.15/models)
included in the repo demonstrate all of these best-practices.
## Next steps
diff --git a/site/en/r1/guide/version_compat.md b/site/en/r1/guide/version_compat.md
index 6702f6e0819..a765620518d 100644
--- a/site/en/r1/guide/version_compat.md
+++ b/site/en/r1/guide/version_compat.md
@@ -49,19 +49,19 @@ patch versions. The public APIs consist of
submodules, but is not documented, then it is **not** considered part of the
public API.
-* The [C API](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/c/c_api.h).
+* The [C API](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/c/c_api.h).
* The following protocol buffer files:
- * [`attr_value`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/attr_value.proto)
- * [`config`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/protobuf/config.proto)
- * [`event`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/util/event.proto)
- * [`graph`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/graph.proto)
- * [`op_def`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/op_def.proto)
- * [`reader_base`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/reader_base.proto)
- * [`summary`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/summary.proto)
- * [`tensor`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/tensor.proto)
- * [`tensor_shape`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/tensor_shape.proto)
- * [`types`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/types.proto)
+ * [`attr_value`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/attr_value.proto)
+ * [`config`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/protobuf/config.proto)
+ * [`event`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/util/event.proto)
+ * [`graph`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/graph.proto)
+ * [`op_def`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/op_def.proto)
+ * [`reader_base`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/reader_base.proto)
+ * [`summary`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/summary.proto)
+ * [`tensor`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/tensor.proto)
+ * [`tensor_shape`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/tensor_shape.proto)
+ * [`types`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/types.proto)
## What is *not* covered
@@ -79,7 +79,7 @@ backward incompatible ways between minor releases. These include:
such as:
- [C++](./extend/cc.md) (exposed through header files in
- [`tensorflow/cc`](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/cc)).
+ [`tensorflow/cc`](https://github.com/tensorflow/tensorflow/tree/r1.15/tensorflow/cc)).
- [Java](../api_docs/java/reference/org/tensorflow/package-summary),
- [Go](https://pkg.go.dev/github.com/tensorflow/tensorflow/tensorflow/go)
- [JavaScript](https://js.tensorflow.org)
@@ -209,7 +209,7 @@ guidelines for evolving `GraphDef` versions.
There are different data versions for graphs and checkpoints. The two data
formats evolve at different rates from each other and also at different rates
from TensorFlow. Both versioning systems are defined in
-[`core/public/version.h`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/public/version.h).
+[`core/public/version.h`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/public/version.h).
Whenever a new version is added, a note is added to the header detailing what
changed and the date.
@@ -224,7 +224,7 @@ We distinguish between the following kinds of data version information:
(`min_producer`).
Each piece of versioned data has a [`VersionDef
-versions`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/versions.proto)
+versions`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/versions.proto)
field which records the `producer` that made the data, the `min_consumer`
that it is compatible with, and a list of `bad_consumers` versions that are
disallowed.
@@ -239,7 +239,7 @@ accept a piece of data if the following are all true:
* `consumer` not in data's `bad_consumers`
Since both producers and consumers come from the same TensorFlow code base,
-[`core/public/version.h`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/public/version.h)
+[`core/public/version.h`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/public/version.h)
contains a main data version which is treated as either `producer` or
`consumer` depending on context and both `min_consumer` and `min_producer`
(needed by producers and consumers, respectively). Specifically,
@@ -309,7 +309,7 @@ existing producer scripts will not suddenly use the new functionality.
1. Add a new similar op named `SomethingV2` or similar and go through the
process of adding it and switching existing Python wrappers to use it.
To ensure forward compatibility use the checks suggested in
- [compat.py](https://www.tensorflow.org/code/tensorflow/python/compat/compat.py)
+ [compat.py](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/compat/compat.py)
when changing the Python wrappers.
2. Remove the old op (Can only take place with a major version change due to
backward compatibility).
diff --git a/site/en/r1/tutorials/README.md b/site/en/r1/tutorials/README.md
index 5094e645e6e..9ff164ad77c 100644
--- a/site/en/r1/tutorials/README.md
+++ b/site/en/r1/tutorials/README.md
@@ -68,4 +68,4 @@ implement common ML algorithms. See the
* [Boosted trees](./estimators/boosted_trees.ipynb)
* [Gradient Boosted Trees: Model understanding](./estimators/boosted_trees_model_understanding.ipynb)
* [Build a Convolutional Neural Network using Estimators](./estimators/cnn.ipynb)
-* [Wide and deep learning with Estimators](https://github.com/tensorflow/models/tree/master/official/r1/wide_deep)
+* [Wide and deep learning with Estimators](https://github.com/tensorflow/models/tree/r1.15/official/r1/wide_deep)
diff --git a/site/en/r1/tutorials/distribute/keras.ipynb b/site/en/r1/tutorials/distribute/keras.ipynb
index 059b8c2d66f..14e8bf739a9 100644
--- a/site/en/r1/tutorials/distribute/keras.ipynb
+++ b/site/en/r1/tutorials/distribute/keras.ipynb
@@ -86,7 +86,7 @@
"Essentially, it copies all of the model's variables to each processor.\n",
"Then, it uses [all-reduce](http://mpitutorial.com/tutorials/mpi-reduce-and-allreduce/) to combine the gradients from all processors and applies the combined value to all copies of the model.\n",
"\n",
- "`MirroredStategy` is one of several distribution strategy available in TensorFlow core. You can read about more strategies at [distribution strategy guide](../../guide/distribute_strategy.ipynb).\n"
+ "`MirroredStrategy` is one of several distribution strategy available in TensorFlow core. You can read about more strategies at [distribution strategy guide](../../guide/distribute_strategy.ipynb).\n"
]
},
{
diff --git a/site/en/r1/tutorials/images/deep_cnn.md b/site/en/r1/tutorials/images/deep_cnn.md
index 00a914d8976..885f3907aa7 100644
--- a/site/en/r1/tutorials/images/deep_cnn.md
+++ b/site/en/r1/tutorials/images/deep_cnn.md
@@ -80,15 +80,15 @@ for details. It consists of 1,068,298 learnable parameters and requires about
## Code Organization
The code for this tutorial resides in
-[`models/tutorials/image/cifar10/`](https://github.com/tensorflow/models/tree/master/research/tutorials/image/cifar10/).
+[`models/tutorials/image/cifar10/`](https://github.com/tensorflow/models/tree/r1.15/research/tutorials/image/cifar10/).
File | Purpose
--- | ---
-[`cifar10_input.py`](https://github.com/tensorflow/models/tree/master/research/tutorials/image/cifar10/cifar10_input.py) | Loads CIFAR-10 dataset using [tensorflow-datasets library](https://github.com/tensorflow/datasets).
-[`cifar10.py`](https://github.com/tensorflow/models/tree/master/research/tutorials/image/cifar10/cifar10.py) | Builds the CIFAR-10 model.
-[`cifar10_train.py`](https://github.com/tensorflow/models/tree/master/research/tutorials/image/cifar10/cifar10_train.py) | Trains a CIFAR-10 model on a CPU or GPU.
-[`cifar10_multi_gpu_train.py`](https://github.com/tensorflow/models/tree/master/research/tutorials/image/cifar10/cifar10_multi_gpu_train.py) | Trains a CIFAR-10 model on multiple GPUs.
-[`cifar10_eval.py`](https://github.com/tensorflow/models/tree/master/research/tutorials/image/cifar10/cifar10_eval.py) | Evaluates the predictive performance of a CIFAR-10 model.
+[`cifar10_input.py`](https://github.com/tensorflow/models/tree/r1.15/research/tutorials/image/cifar10/cifar10_input.py) | Loads CIFAR-10 dataset using [tensorflow-datasets library](https://github.com/tensorflow/datasets).
+[`cifar10.py`](https://github.com/tensorflow/models/tree/r1.15/research/tutorials/image/cifar10/cifar10.py) | Builds the CIFAR-10 model.
+[`cifar10_train.py`](https://github.com/tensorflow/models/tree/r1.15/research/tutorials/image/cifar10/cifar10_train.py) | Trains a CIFAR-10 model on a CPU or GPU.
+[`cifar10_multi_gpu_train.py`](https://github.com/tensorflow/models/tree/r1.15/research/tutorials/image/cifar10/cifar10_multi_gpu_train.py) | Trains a CIFAR-10 model on multiple GPUs.
+[`cifar10_eval.py`](https://github.com/tensorflow/models/tree/r1.15/research/tutorials/image/cifar10/cifar10_eval.py) | Evaluates the predictive performance of a CIFAR-10 model.
To run this tutorial, you will need to:
@@ -99,7 +99,7 @@ pip install tensorflow-datasets
## CIFAR-10 Model
The CIFAR-10 network is largely contained in
-[`cifar10.py`](https://github.com/tensorflow/models/tree/master/research/tutorials/image/cifar10/cifar10.py).
+[`cifar10.py`](https://github.com/tensorflow/models/tree/r1.15/research/tutorials/image/cifar10/cifar10.py).
The complete training
graph contains roughly 765 operations. We find that we can make the code most
reusable by constructing the graph with the following modules:
@@ -108,7 +108,7 @@ reusable by constructing the graph with the following modules:
operations that read and preprocess CIFAR images for evaluation and training,
respectively.
1. [**Model prediction:**](#model-prediction) `inference()`
-adds operations that perform inference, i.e. classification, on supplied images.
+adds operations that perform inference, i.e., classification, on supplied images.
1. [**Model training:**](#model-training) `loss()` and `train()`
add operations that compute the loss,
gradients, variable updates and visualization summaries.
@@ -405,7 +405,7 @@ a "tower". We must set two attributes for each tower:
* A unique name for all operations within a tower.
`tf.name_scope` provides
this unique name by prepending a scope. For instance, all operations in
-the first tower are prepended with `tower_0`, e.g. `tower_0/conv1/Conv2D`.
+the first tower are prepended with `tower_0`, e.g., `tower_0/conv1/Conv2D`.
* A preferred hardware device to run the operation within a tower.
`tf.device` specifies this. For
diff --git a/site/en/r1/tutorials/images/image_recognition.md b/site/en/r1/tutorials/images/image_recognition.md
index 0be884de403..cb66e594629 100644
--- a/site/en/r1/tutorials/images/image_recognition.md
+++ b/site/en/r1/tutorials/images/image_recognition.md
@@ -140,13 +140,13 @@ score of 0.8.
 -Next, try it out on your own images by supplying the --image= argument, e.g.
+Next, try it out on your own images by supplying the --image= argument, e.g.,
```bash
bazel-bin/tensorflow/examples/label_image/label_image --image=my_image.png
```
-If you look inside the [`tensorflow/examples/label_image/main.cc`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/examples/label_image/main.cc)
+If you look inside the [`tensorflow/examples/label_image/main.cc`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/examples/label_image/main.cc)
file, you can find out
how it works. We hope this code will help you integrate TensorFlow into
your own applications, so we will walk step by step through the main functions:
@@ -164,7 +164,7 @@ training. If you have a graph that you've trained yourself, you'll just need
to adjust the values to match whatever you used during your training process.
You can see how they're applied to an image in the
-[`ReadTensorFromImageFile()`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/examples/label_image/main.cc#L88)
+[`ReadTensorFromImageFile()`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/examples/label_image/main.cc#L88)
function.
```C++
@@ -334,7 +334,7 @@ The `PrintTopLabels()` function takes those sorted results, and prints them out
friendly way. The `CheckTopLabel()` function is very similar, but just makes sure that
the top label is the one we expect, for debugging purposes.
-At the end, [`main()`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/examples/label_image/main.cc#L252)
+At the end, [`main()`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/examples/label_image/main.cc#L252)
ties together all of these calls.
```C++
diff --git a/site/en/r1/tutorials/keras/save_and_restore_models.ipynb b/site/en/r1/tutorials/keras/save_and_restore_models.ipynb
index e9d112bd3f3..04cc94417a9 100644
--- a/site/en/r1/tutorials/keras/save_and_restore_models.ipynb
+++ b/site/en/r1/tutorials/keras/save_and_restore_models.ipynb
@@ -115,7 +115,7 @@
"\n",
"Sharing this data helps others understand how the model works and try it themselves with new data.\n",
"\n",
- "Caution: Be careful with untrusted code—TensorFlow models are code. See [Using TensorFlow Securely](https://github.com/tensorflow/tensorflow/blob/master/SECURITY.md) for details.\n",
+ "Caution: Be careful with untrusted code—TensorFlow models are code. See [Using TensorFlow Securely](https://github.com/tensorflow/tensorflow/blob/r1.15/SECURITY.md) for details.\n",
"\n",
"### Options\n",
"\n",
diff --git a/site/en/r1/tutorials/load_data/tf_records.ipynb b/site/en/r1/tutorials/load_data/tf_records.ipynb
index fa7bf83c8bb..45635034c69 100644
--- a/site/en/r1/tutorials/load_data/tf_records.ipynb
+++ b/site/en/r1/tutorials/load_data/tf_records.ipynb
@@ -141,7 +141,7 @@
"source": [
"Fundamentally a `tf.Example` is a `{\"string\": tf.train.Feature}` mapping.\n",
"\n",
- "The `tf.train.Feature` message type can accept one of the following three types (See the [`.proto` file](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/example/feature.proto) for reference). Most other generic types can be coerced into one of these.\n",
+ "The `tf.train.Feature` message type can accept one of the following three types (See the [`.proto` file](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/example/feature.proto) for reference). Most other generic types can be coerced into one of these.\n",
"\n",
"1. `tf.train.BytesList` (the following types can be coerced)\n",
"\n",
@@ -276,7 +276,7 @@
"\n",
"1. We create a map (dictionary) from the feature name string to the encoded feature value produced in #1.\n",
"\n",
- "1. The map produced in #2 is converted to a [`Features` message](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/example/feature.proto#L85)."
+ "1. The map produced in #2 is converted to a [`Features` message](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/example/feature.proto#L85)."
]
},
{
@@ -365,7 +365,7 @@
"id": "XftzX9CN_uGT"
},
"source": [
- "For example, suppose we have a single observation from the dataset, `[False, 4, bytes('goat'), 0.9876]`. We can create and print the `tf.Example` message for this observation using `create_message()`. Each single observation will be written as a `Features` message as per the above. Note that the `tf.Example` [message](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/example/example.proto#L88) is just a wrapper around the `Features` message."
+ "For example, suppose we have a single observation from the dataset, `[False, 4, bytes('goat'), 0.9876]`. We can create and print the `tf.Example` message for this observation using `create_message()`. Each single observation will be written as a `Features` message as per the above. Note that the `tf.Example` [message](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/example/example.proto#L88) is just a wrapper around the `Features` message."
]
},
{
diff --git a/site/en/r1/tutorials/representation/kernel_methods.md b/site/en/r1/tutorials/representation/kernel_methods.md
index 67adc4951c6..227fe81d515 100644
--- a/site/en/r1/tutorials/representation/kernel_methods.md
+++ b/site/en/r1/tutorials/representation/kernel_methods.md
@@ -24,7 +24,7 @@ following sources for an introduction:
Currently, TensorFlow supports explicit kernel mappings for dense features only;
TensorFlow will provide support for sparse features at a later release.
-This tutorial uses [tf.contrib.learn](https://www.tensorflow.org/code/tensorflow/contrib/learn/python/learn)
+This tutorial uses [tf.contrib.learn](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/contrib/learn/python/learn)
(TensorFlow's high-level Machine Learning API) Estimators for our ML models.
If you are not familiar with this API, The [Estimator guide](../../guide/estimators.md)
is a good place to start. We will use the MNIST dataset. The tutorial consists
@@ -131,7 +131,7 @@ In addition to experimenting with the (training) batch size and the number of
training steps, there are a couple other parameters that can be tuned as well.
For instance, you can change the optimization method used to minimize the loss
by explicitly selecting another optimizer from the collection of
-[available optimizers](https://www.tensorflow.org/code/tensorflow/python/training).
+[available optimizers](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/training).
As an example, the following code constructs a LinearClassifier estimator that
uses the Follow-The-Regularized-Leader (FTRL) optimization strategy with a
specific learning rate and L2-regularization.
diff --git a/site/en/r1/tutorials/representation/linear.md b/site/en/r1/tutorials/representation/linear.md
index 5516672b34a..d996a13bc1f 100644
--- a/site/en/r1/tutorials/representation/linear.md
+++ b/site/en/r1/tutorials/representation/linear.md
@@ -12,7 +12,7 @@ those tools. It explains:
Read this overview to decide whether the Estimator's linear model tools might
be useful to you. Then work through the
-[Estimator wide and deep learning tutorial](https://github.com/tensorflow/models/tree/master/official/r1/wide_deep)
+[Estimator wide and deep learning tutorial](https://github.com/tensorflow/models/tree/r1.15/official/r1/wide_deep)
to give it a try. This overview uses code samples from the tutorial, but the
tutorial walks through the code in greater detail.
@@ -177,7 +177,7 @@ the name of a `FeatureColumn`. Each key's value is a tensor containing the
values of that feature for all data instances. See
[Premade Estimators](../../guide/premade_estimators.md#input_fn) for a
more comprehensive look at input functions, and `input_fn` in the
-[wide and deep learning tutorial](https://github.com/tensorflow/models/tree/master/official/r1/wide_deep)
+[wide and deep learning tutorial](https://github.com/tensorflow/models/tree/r1.15/official/r1/wide_deep)
for an example implementation of an input function.
The input function is passed to the `train()` and `evaluate()` calls that
@@ -236,4 +236,4 @@ e = tf.estimator.DNNLinearCombinedClassifier(
dnn_hidden_units=[100, 50])
```
For more information, see the
-[wide and deep learning tutorial](https://github.com/tensorflow/models/tree/master/official/r1/wide_deep).
+[wide and deep learning tutorial](https://github.com/tensorflow/models/tree/r1.15/official/r1/wide_deep).
diff --git a/site/en/r1/tutorials/representation/unicode.ipynb b/site/en/r1/tutorials/representation/unicode.ipynb
index 98aaacff5b9..f76977c3c92 100644
--- a/site/en/r1/tutorials/representation/unicode.ipynb
+++ b/site/en/r1/tutorials/representation/unicode.ipynb
@@ -136,7 +136,7 @@
"id": "jsMPnjb6UDJ1"
},
"source": [
- "Note: When using python to construct strings, the handling of unicode differs betweeen v2 and v3. In v2, unicode strings are indicated by the \"u\" prefix, as above. In v3, strings are unicode-encoded by default."
+ "Note: When using python to construct strings, the handling of unicode differs between v2 and v3. In v2, unicode strings are indicated by the \"u\" prefix, as above. In v3, strings are unicode-encoded by default."
]
},
{
@@ -425,7 +425,7 @@
"source": [
"### Character substrings\n",
"\n",
- "Similarly, the `tf.strings.substr` operation accepts the \"`unit`\" parameter, and uses it to determine what kind of offsets the \"`pos`\" and \"`len`\" paremeters contain."
+ "Similarly, the `tf.strings.substr` operation accepts the \"`unit`\" parameter, and uses it to determine what kind of offsets the \"`pos`\" and \"`len`\" parameters contain."
]
},
{
@@ -587,7 +587,7 @@
"id": "CapnbShuGU8i"
},
"source": [
- "First, we decode the sentences into character codepoints, and find the script identifeir for each character."
+ "First, we decode the sentences into character codepoints, and find the script identifier for each character."
]
},
{
diff --git a/site/en/r1/tutorials/representation/word2vec.md b/site/en/r1/tutorials/representation/word2vec.md
index f6a27c68f3c..517a5dbc5c5 100644
--- a/site/en/r1/tutorials/representation/word2vec.md
+++ b/site/en/r1/tutorials/representation/word2vec.md
@@ -36,7 +36,7 @@ like to get your hands dirty with the details.
Image and audio processing systems work with rich, high-dimensional datasets
encoded as vectors of the individual raw pixel-intensities for image data, or
-e.g. power spectral density coefficients for audio data. For tasks like object
+e.g., power spectral density coefficients for audio data. For tasks like object
or speech recognition we know that all the information required to successfully
perform the task is encoded in the data (because humans can perform these tasks
from the raw data). However, natural language processing systems traditionally
@@ -109,7 +109,7 @@ $$
where \\(\text{score}(w_t, h)\\) computes the compatibility of word \\(w_t\\)
with the context \\(h\\) (a dot product is commonly used). We train this model
by maximizing its [log-likelihood](https://en.wikipedia.org/wiki/Likelihood_function)
-on the training set, i.e. by maximizing
+on the training set, i.e., by maximizing
$$
\begin{align}
@@ -176,7 +176,7 @@ As an example, let's consider the dataset
We first form a dataset of words and the contexts in which they appear. We
could define 'context' in any way that makes sense, and in fact people have
looked at syntactic contexts (i.e. the syntactic dependents of the current
-target word, see e.g.
+target word, see e.g.,
[Levy et al.](https://levyomer.files.wordpress.com/2014/04/dependency-based-word-embeddings-acl-2014.pdf)),
words-to-the-left of the target, words-to-the-right of the target, etc. For now,
let's stick to the vanilla definition and define 'context' as the window
@@ -204,7 +204,7 @@ where the goal is to predict `the` from `quick`. We select `num_noise` number
of noisy (contrastive) examples by drawing from some noise distribution,
typically the unigram distribution, \\(P(w)\\). For simplicity let's say
`num_noise=1` and we select `sheep` as a noisy example. Next we compute the
-loss for this pair of observed and noisy examples, i.e. the objective at time
+loss for this pair of observed and noisy examples, i.e., the objective at time
step \\(t\\) becomes
$$J^{(t)}_\text{NEG} = \log Q_\theta(D=1 | \text{the, quick}) +
@@ -212,7 +212,7 @@ $$J^{(t)}_\text{NEG} = \log Q_\theta(D=1 | \text{the, quick}) +
The goal is to make an update to the embedding parameters \\(\theta\\) to improve
(in this case, maximize) this objective function. We do this by deriving the
-gradient of the loss with respect to the embedding parameters \\(\theta\\), i.e.
+gradient of the loss with respect to the embedding parameters \\(\theta\\), i.e.,
\\(\frac{\partial}{\partial \theta} J_\text{NEG}\\) (luckily TensorFlow provides
easy helper functions for doing this!). We then perform an update to the
embeddings by taking a small step in the direction of the gradient. When this
@@ -227,7 +227,7 @@ When we inspect these visualizations it becomes apparent that the vectors
capture some general, and in fact quite useful, semantic information about
words and their relationships to one another. It was very interesting when we
first discovered that certain directions in the induced vector space specialize
-towards certain semantic relationships, e.g. *male-female*, *verb tense* and
+towards certain semantic relationships, e.g., *male-female*, *verb tense* and
even *country-capital* relationships between words, as illustrated in the figure
below (see also for example
[Mikolov et al., 2013](https://www.aclweb.org/anthology/N13-1090)).
@@ -327,7 +327,7 @@ for inputs, labels in generate_batch(...):
```
See the full example code in
-[tensorflow/examples/tutorials/word2vec/word2vec_basic.py](https://www.tensorflow.org/code/tensorflow/examples/tutorials/word2vec/word2vec_basic.py).
+[tensorflow/examples/tutorials/word2vec/word2vec_basic.py](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/examples/tutorials/word2vec/word2vec_basic.py).
## Visualizing the learned embeddings
@@ -341,7 +341,7 @@ t-SNE.
Et voila! As expected, words that are similar end up clustering nearby each
other. For a more heavyweight implementation of word2vec that showcases more of
the advanced features of TensorFlow, see the implementation in
-[models/tutorials/embedding/word2vec.py](https://github.com/tensorflow/models/tree/master/research/tutorials/embedding/word2vec.py).
+[models/tutorials/embedding/word2vec.py](https://github.com/tensorflow/models/tree/r1.15/research/tutorials/embedding/word2vec.py).
## Evaluating embeddings: analogical reasoning
@@ -357,7 +357,7 @@ Download the dataset for this task from
To see how we do this evaluation, have a look at the `build_eval_graph()` and
`eval()` functions in
-[models/tutorials/embedding/word2vec.py](https://github.com/tensorflow/models/tree/master/research/tutorials/embedding/word2vec.py).
+[models/tutorials/embedding/word2vec.py](https://github.com/tensorflow/models/tree/r1.15/research/tutorials/embedding/word2vec.py).
The choice of hyperparameters can strongly influence the accuracy on this task.
To achieve state-of-the-art performance on this task requires training over a
diff --git a/site/en/r1/tutorials/sequences/audio_recognition.md b/site/en/r1/tutorials/sequences/audio_recognition.md
index 8ad71b88a3c..0388514ec92 100644
--- a/site/en/r1/tutorials/sequences/audio_recognition.md
+++ b/site/en/r1/tutorials/sequences/audio_recognition.md
@@ -159,9 +159,9 @@ accuracy. If the training accuracy increases but the validation doesn't, that's
a sign that overfitting is occurring, and your model is only learning things
about the training clips, not broader patterns that generalize.
-## Tensorboard
+## TensorBoard
-A good way to visualize how the training is progressing is using Tensorboard. By
+A good way to visualize how the training is progressing is using TensorBoard. By
default, the script saves out events to /tmp/retrain_logs, and you can load
these by running:
diff --git a/site/en/r1/tutorials/sequences/recurrent_quickdraw.md b/site/en/r1/tutorials/sequences/recurrent_quickdraw.md
index 435076f629c..d6a85377d17 100644
--- a/site/en/r1/tutorials/sequences/recurrent_quickdraw.md
+++ b/site/en/r1/tutorials/sequences/recurrent_quickdraw.md
@@ -109,7 +109,7 @@ This download will take a while and download a bit more than 23GB of data.
To convert the `ndjson` files to
[TFRecord](../../api_guides/python/python_io.md#TFRecords_Format_Details) files containing
-[`tf.train.Example`](https://www.tensorflow.org/code/tensorflow/core/example/example.proto)
+[`tf.train.Example`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/example/example.proto)
protos run the following command.
```shell
@@ -213,7 +213,7 @@ screen coordinates and normalize the size such that the drawing has unit height.
Finally, we compute the differences between consecutive points and store these
as a `VarLenFeature` in a
-[tensorflow.Example](https://www.tensorflow.org/code/tensorflow/core/example/example.proto)
+[tensorflow.Example](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/example/example.proto)
under the key `ink`. In addition we store the `class_index` as a single entry
`FixedLengthFeature` and the `shape` of the `ink` as a `FixedLengthFeature` of
length 2.
diff --git a/site/en/tutorials/distribute/multi_worker_with_estimator.ipynb b/site/en/tutorials/distribute/multi_worker_with_estimator.ipynb
index 2abf05aa9f8..fcee0618854 100644
--- a/site/en/tutorials/distribute/multi_worker_with_estimator.ipynb
+++ b/site/en/tutorials/distribute/multi_worker_with_estimator.ipynb
@@ -186,7 +186,7 @@
"\n",
"There are two components of `TF_CONFIG`: `cluster` and `task`. `cluster` provides information about the entire cluster, namely the workers and parameter servers in the cluster. `task` provides information about the current task. The first component `cluster` is the same for all workers and parameter servers in the cluster, and the second component `task` is different on each worker and parameter server and specifies its own `type` and `index`. In this example, the task `type` is `worker` and the task `index` is `0`.\n",
"\n",
- "For illustration purposes, this tutorial shows how to set a `TF_CONFIG` with 2 workers on `localhost`. In practice, you would create multiple workers on an external IP address and port, and set `TF_CONFIG` on each worker appropriately, i.e. modify the task `index`.\n",
+ "For illustration purposes, this tutorial shows how to set a `TF_CONFIG` with 2 workers on `localhost`. In practice, you would create multiple workers on an external IP address and port, and set `TF_CONFIG` on each worker appropriately, i.e., modify the task `index`.\n",
"\n",
"Warning: *Do not execute the following code in Colab.* TensorFlow's runtime will attempt to create a gRPC server at the specified IP address and port, which will likely fail. See the [keras version](multi_worker_with_keras.ipynb) of this tutorial for an example of how you can test run multiple workers on a single machine.\n",
"\n",
diff --git a/site/en/tutorials/estimator/keras_model_to_estimator.ipynb b/site/en/tutorials/estimator/keras_model_to_estimator.ipynb
index 7b34e283ef3..be97a38b6eb 100644
--- a/site/en/tutorials/estimator/keras_model_to_estimator.ipynb
+++ b/site/en/tutorials/estimator/keras_model_to_estimator.ipynb
@@ -68,7 +68,7 @@
"id": "Dhcq8Ds4mCtm"
},
"source": [
- "> Warning: Estimators are not recommended for new code. Estimators run `v1.Session`-style code which is more difficult to write correctly, and can behave unexpectedly, especially when combined with TF 2 code. Estimators do fall under our [compatibility guarantees](https://tensorflow.org/guide/versions), but will receive no fixes other than security vulnerabilities. See the [migration guide](https://tensorflow.org/guide/migrate) for details."
+ "> Warning: TensorFlow 2.15 included the final release of the `tf-estimator` package. Estimators will not be available in TensorFlow 2.16 or after. See the [migration guide](https://tensorflow.org/guide/migrate/migrating_estimator) for more information about how to convert off of Estimators."
]
},
{
diff --git a/site/en/tutorials/estimator/linear.ipynb b/site/en/tutorials/estimator/linear.ipynb
index 7732ebe3b9e..a26ffe2df4f 100644
--- a/site/en/tutorials/estimator/linear.ipynb
+++ b/site/en/tutorials/estimator/linear.ipynb
@@ -61,7 +61,7 @@
"id": "JOccPOFMm5Tc"
},
"source": [
- "> Warning: Estimators are not recommended for new code. Estimators run `v1.Session`-style code which is more difficult to write correctly, and can behave unexpectedly, especially when combined with TF 2 code. Estimators do fall under our [compatibility guarantees](https://tensorflow.org/guide/versions), but will receive no fixes other than security vulnerabilities. See the [migration guide](https://tensorflow.org/guide/migrate) for details."
+ "> Warning: TensorFlow 2.15 included the final release of the `tf-estimator` package. Estimators will not be available in TensorFlow 2.16 or after. See the [migration guide](https://tensorflow.org/guide/migrate/migrating_estimator) for more information about how to convert off of Estimators."
]
},
{
diff --git a/site/en/tutorials/estimator/premade.ipynb b/site/en/tutorials/estimator/premade.ipynb
index a34096ea2b8..dc81847c7cd 100644
--- a/site/en/tutorials/estimator/premade.ipynb
+++ b/site/en/tutorials/estimator/premade.ipynb
@@ -68,7 +68,7 @@
"id": "stQiPWL6ni6_"
},
"source": [
- "> Warning: Estimators are not recommended for new code. Estimators run `v1.Session`-style code which is more difficult to write correctly, and can behave unexpectedly, especially when combined with TF 2 code. Estimators do fall under [compatibility guarantees](https://tensorflow.org/guide/versions), but will receive no fixes other than security vulnerabilities. See the [migration guide](https://tensorflow.org/guide/migrate) for details."
+ "> Warning: TensorFlow 2.15 included the final release of the `tf-estimator` package. Estimators will not be available in TensorFlow 2.16 or after. See the [migration guide](https://tensorflow.org/guide/migrate/migrating_estimator) for more information about how to convert off of Estimators."
]
},
{
diff --git a/site/en/tutorials/generative/cyclegan.ipynb b/site/en/tutorials/generative/cyclegan.ipynb
index 4c2b3ba8777..313be519591 100644
--- a/site/en/tutorials/generative/cyclegan.ipynb
+++ b/site/en/tutorials/generative/cyclegan.ipynb
@@ -154,7 +154,7 @@
"This is similar to what was done in [pix2pix](https://www.tensorflow.org/tutorials/generative/pix2pix#load_the_dataset)\n",
"\n",
"* In random jittering, the image is resized to `286 x 286` and then randomly cropped to `256 x 256`.\n",
- "* In random mirroring, the image is randomly flipped horizontally i.e. left to right."
+ "* In random mirroring, the image is randomly flipped horizontally i.e., left to right."
]
},
{
diff --git a/site/en/tutorials/generative/data_compression.ipynb b/site/en/tutorials/generative/data_compression.ipynb
index b6c043c0598..f756f088acd 100644
--- a/site/en/tutorials/generative/data_compression.ipynb
+++ b/site/en/tutorials/generative/data_compression.ipynb
@@ -821,7 +821,7 @@
{
"cell_type": "markdown",
"metadata": {
- "id": "3ELLMAN1OwMQ"
+ "id": "3ELLMANN1OwMQ"
},
"source": [
"The strings begin to get much shorter now, on the order of one byte per digit. However, this comes at a cost. More digits are becoming unrecognizable.\n",
diff --git a/site/en/tutorials/generative/pix2pix.ipynb b/site/en/tutorials/generative/pix2pix.ipynb
index 5912fab9be3..e45950dd923 100644
--- a/site/en/tutorials/generative/pix2pix.ipynb
+++ b/site/en/tutorials/generative/pix2pix.ipynb
@@ -280,7 +280,7 @@
"\n",
"1. Resize each `256 x 256` image to a larger height and width—`286 x 286`.\n",
"2. Randomly crop it back to `256 x 256`.\n",
- "3. Randomly flip the image horizontally i.e. left to right (random mirroring).\n",
+ "3. Randomly flip the image horizontally i.e., left to right (random mirroring).\n",
"4. Normalize the images to the `[-1, 1]` range."
]
},
diff --git a/site/en/tutorials/images/data_augmentation.ipynb b/site/en/tutorials/images/data_augmentation.ipynb
index bdc7ae0c56a..8a1eaaabec4 100644
--- a/site/en/tutorials/images/data_augmentation.ipynb
+++ b/site/en/tutorials/images/data_augmentation.ipynb
@@ -1273,7 +1273,7 @@
"source": [
"# Create a wrapper function for updating seeds.\n",
"def f(x, y):\n",
- " seed = rng.make_seeds(2)[0]\n",
+ " seed = rng.make_seeds(1)[:, 0]\n",
" image, label = augment((x, y), seed)\n",
" return image, label"
]
diff --git a/site/en/tutorials/images/transfer_learning.ipynb b/site/en/tutorials/images/transfer_learning.ipynb
index dd9b97cabe2..57dbbfbcbbf 100644
--- a/site/en/tutorials/images/transfer_learning.ipynb
+++ b/site/en/tutorials/images/transfer_learning.ipynb
@@ -585,7 +585,7 @@
},
"outputs": [],
"source": [
- "prediction_layer = tf.keras.layers.Dense(1)\n",
+ "prediction_layer = tf.keras.layers.Dense(1, activation='sigmoid')\n",
"prediction_batch = prediction_layer(feature_batch_average)\n",
"print(prediction_batch.shape)"
]
@@ -667,7 +667,7 @@
"source": [
"### Compile the model\n",
"\n",
- "Compile the model before training it. Since there are two classes, use the `tf.keras.losses.BinaryCrossentropy` loss with `from_logits=True` since the model provides a linear output."
+ "Compile the model before training it. Since there are two classes and a sigmoid oputput, use the `BinaryAccuracy`."
]
},
{
@@ -680,8 +680,8 @@
"source": [
"base_learning_rate = 0.0001\n",
"model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=base_learning_rate),\n",
- " loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),\n",
- " metrics=[tf.keras.metrics.BinaryAccuracy(threshold=0, name='accuracy')])"
+ " loss=tf.keras.losses.BinaryCrossentropy(),\n",
+ " metrics=[tf.keras.metrics.BinaryAccuracy(threshold=0.5, name='accuracy')])"
]
},
{
@@ -872,9 +872,9 @@
},
"outputs": [],
"source": [
- "model.compile(loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),\n",
+ "model.compile(loss=tf.keras.losses.BinaryCrossentropy(),\n",
" optimizer = tf.keras.optimizers.RMSprop(learning_rate=base_learning_rate/10),\n",
- " metrics=[tf.keras.metrics.BinaryAccuracy(threshold=0, name='accuracy')])"
+ " metrics=[tf.keras.metrics.BinaryAccuracy(threshold=0.5, name='accuracy')])"
]
},
{
diff --git a/site/en/tutorials/interpretability/integrated_gradients.ipynb b/site/en/tutorials/interpretability/integrated_gradients.ipynb
index 2ee792aa4e2..e63c8cdb7a2 100644
--- a/site/en/tutorials/interpretability/integrated_gradients.ipynb
+++ b/site/en/tutorials/interpretability/integrated_gradients.ipynb
@@ -724,7 +724,7 @@
"ax2 = plt.subplot(1, 2, 2)\n",
"# Average across interpolation steps\n",
"average_grads = tf.reduce_mean(path_gradients, axis=[1, 2, 3])\n",
- "# Normalize gradients to 0 to 1 scale. E.g. (x - min(x))/(max(x)-min(x))\n",
+ "# Normalize gradients to 0 to 1 scale. E.g., (x - min(x))/(max(x)-min(x))\n",
"average_grads_norm = (average_grads-tf.math.reduce_min(average_grads))/(tf.math.reduce_max(average_grads)-tf.reduce_min(average_grads))\n",
"ax2.plot(alphas, average_grads_norm)\n",
"ax2.set_title('Average pixel gradients (normalized) over alpha')\n",
diff --git a/site/en/tutorials/keras/save_and_load.ipynb b/site/en/tutorials/keras/save_and_load.ipynb
index 02c8af3a71d..404fa1ee8be 100644
--- a/site/en/tutorials/keras/save_and_load.ipynb
+++ b/site/en/tutorials/keras/save_and_load.ipynb
@@ -854,7 +854,7 @@
" * `from_config(cls, config)` uses the returned config from `get_config` to create a new object. By default, this function will use the config as initialization kwargs (`return cls(**config)`).\n",
"2. Pass the custom objects to the model in one of three ways:\n",
" - Register the custom object with the `@tf.keras.utils.register_keras_serializable` decorator. **(recommended)**\n",
- " - Directly pass the object to the `custom_objects` argument when loading the model. The argument must be a dictionary mapping the string class name to the Python class. E.g. `tf.keras.models.load_model(path, custom_objects={'CustomLayer': CustomLayer})`\n",
+ " - Directly pass the object to the `custom_objects` argument when loading the model. The argument must be a dictionary mapping the string class name to the Python class. E.g., `tf.keras.models.load_model(path, custom_objects={'CustomLayer': CustomLayer})`\n",
" - Use a `tf.keras.utils.custom_object_scope` with the object included in the `custom_objects` dictionary argument, and place a `tf.keras.models.load_model(path)` call within the scope.\n",
"\n",
"Refer to the [Writing layers and models from scratch](https://www.tensorflow.org/guide/keras/custom_layers_and_models) tutorial for examples of custom objects and `get_config`.\n"
diff --git a/site/en/tutorials/keras/text_classification.ipynb b/site/en/tutorials/keras/text_classification.ipynb
index f14964207ff..c66d0fce0d3 100644
--- a/site/en/tutorials/keras/text_classification.ipynb
+++ b/site/en/tutorials/keras/text_classification.ipynb
@@ -267,9 +267,9 @@
"id": "95kkUdRoaeMw"
},
"source": [
- "Next, you will use the `text_dataset_from_directory` utility to create a labeled `tf.data.Dataset`. [tf.data](https://www.tensorflow.org/guide/data) is a powerful collection of tools for working with data. \n",
+ "Next, you will use the `text_dataset_from_directory` utility to create a labeled `tf.data.Dataset`. [tf.data](https://www.tensorflow.org/guide/data) is a powerful collection of tools for working with data.\n",
"\n",
- "When running a machine learning experiment, it is a best practice to divide your dataset into three splits: [train](https://developers.google.com/machine-learning/glossary#training_set), [validation](https://developers.google.com/machine-learning/glossary#validation_set), and [test](https://developers.google.com/machine-learning/glossary#test-set). \n",
+ "When running a machine learning experiment, it is a best practice to divide your dataset into three splits: [train](https://developers.google.com/machine-learning/glossary#training_set), [validation](https://developers.google.com/machine-learning/glossary#validation_set), and [test](https://developers.google.com/machine-learning/glossary#test-set).\n",
"\n",
"The IMDB dataset has already been divided into train and test, but it lacks a validation set. Let's create a validation set using an 80:20 split of the training data by using the `validation_split` argument below."
]
@@ -286,10 +286,10 @@
"seed = 42\n",
"\n",
"raw_train_ds = tf.keras.utils.text_dataset_from_directory(\n",
- " 'aclImdb/train', \n",
- " batch_size=batch_size, \n",
- " validation_split=0.2, \n",
- " subset='training', \n",
+ " 'aclImdb/train',\n",
+ " batch_size=batch_size,\n",
+ " validation_split=0.2,\n",
+ " subset='training',\n",
" seed=seed)"
]
},
@@ -322,7 +322,7 @@
"id": "JWq1SUIrp1a-"
},
"source": [
- "Notice the reviews contain raw text (with punctuation and occasional HTML tags like `
-Next, try it out on your own images by supplying the --image= argument, e.g.
+Next, try it out on your own images by supplying the --image= argument, e.g.,
```bash
bazel-bin/tensorflow/examples/label_image/label_image --image=my_image.png
```
-If you look inside the [`tensorflow/examples/label_image/main.cc`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/examples/label_image/main.cc)
+If you look inside the [`tensorflow/examples/label_image/main.cc`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/examples/label_image/main.cc)
file, you can find out
how it works. We hope this code will help you integrate TensorFlow into
your own applications, so we will walk step by step through the main functions:
@@ -164,7 +164,7 @@ training. If you have a graph that you've trained yourself, you'll just need
to adjust the values to match whatever you used during your training process.
You can see how they're applied to an image in the
-[`ReadTensorFromImageFile()`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/examples/label_image/main.cc#L88)
+[`ReadTensorFromImageFile()`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/examples/label_image/main.cc#L88)
function.
```C++
@@ -334,7 +334,7 @@ The `PrintTopLabels()` function takes those sorted results, and prints them out
friendly way. The `CheckTopLabel()` function is very similar, but just makes sure that
the top label is the one we expect, for debugging purposes.
-At the end, [`main()`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/examples/label_image/main.cc#L252)
+At the end, [`main()`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/examples/label_image/main.cc#L252)
ties together all of these calls.
```C++
diff --git a/site/en/r1/tutorials/keras/save_and_restore_models.ipynb b/site/en/r1/tutorials/keras/save_and_restore_models.ipynb
index e9d112bd3f3..04cc94417a9 100644
--- a/site/en/r1/tutorials/keras/save_and_restore_models.ipynb
+++ b/site/en/r1/tutorials/keras/save_and_restore_models.ipynb
@@ -115,7 +115,7 @@
"\n",
"Sharing this data helps others understand how the model works and try it themselves with new data.\n",
"\n",
- "Caution: Be careful with untrusted code—TensorFlow models are code. See [Using TensorFlow Securely](https://github.com/tensorflow/tensorflow/blob/master/SECURITY.md) for details.\n",
+ "Caution: Be careful with untrusted code—TensorFlow models are code. See [Using TensorFlow Securely](https://github.com/tensorflow/tensorflow/blob/r1.15/SECURITY.md) for details.\n",
"\n",
"### Options\n",
"\n",
diff --git a/site/en/r1/tutorials/load_data/tf_records.ipynb b/site/en/r1/tutorials/load_data/tf_records.ipynb
index fa7bf83c8bb..45635034c69 100644
--- a/site/en/r1/tutorials/load_data/tf_records.ipynb
+++ b/site/en/r1/tutorials/load_data/tf_records.ipynb
@@ -141,7 +141,7 @@
"source": [
"Fundamentally a `tf.Example` is a `{\"string\": tf.train.Feature}` mapping.\n",
"\n",
- "The `tf.train.Feature` message type can accept one of the following three types (See the [`.proto` file](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/example/feature.proto) for reference). Most other generic types can be coerced into one of these.\n",
+ "The `tf.train.Feature` message type can accept one of the following three types (See the [`.proto` file](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/example/feature.proto) for reference). Most other generic types can be coerced into one of these.\n",
"\n",
"1. `tf.train.BytesList` (the following types can be coerced)\n",
"\n",
@@ -276,7 +276,7 @@
"\n",
"1. We create a map (dictionary) from the feature name string to the encoded feature value produced in #1.\n",
"\n",
- "1. The map produced in #2 is converted to a [`Features` message](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/example/feature.proto#L85)."
+ "1. The map produced in #2 is converted to a [`Features` message](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/example/feature.proto#L85)."
]
},
{
@@ -365,7 +365,7 @@
"id": "XftzX9CN_uGT"
},
"source": [
- "For example, suppose we have a single observation from the dataset, `[False, 4, bytes('goat'), 0.9876]`. We can create and print the `tf.Example` message for this observation using `create_message()`. Each single observation will be written as a `Features` message as per the above. Note that the `tf.Example` [message](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/example/example.proto#L88) is just a wrapper around the `Features` message."
+ "For example, suppose we have a single observation from the dataset, `[False, 4, bytes('goat'), 0.9876]`. We can create and print the `tf.Example` message for this observation using `create_message()`. Each single observation will be written as a `Features` message as per the above. Note that the `tf.Example` [message](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/example/example.proto#L88) is just a wrapper around the `Features` message."
]
},
{
diff --git a/site/en/r1/tutorials/representation/kernel_methods.md b/site/en/r1/tutorials/representation/kernel_methods.md
index 67adc4951c6..227fe81d515 100644
--- a/site/en/r1/tutorials/representation/kernel_methods.md
+++ b/site/en/r1/tutorials/representation/kernel_methods.md
@@ -24,7 +24,7 @@ following sources for an introduction:
Currently, TensorFlow supports explicit kernel mappings for dense features only;
TensorFlow will provide support for sparse features at a later release.
-This tutorial uses [tf.contrib.learn](https://www.tensorflow.org/code/tensorflow/contrib/learn/python/learn)
+This tutorial uses [tf.contrib.learn](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/contrib/learn/python/learn)
(TensorFlow's high-level Machine Learning API) Estimators for our ML models.
If you are not familiar with this API, The [Estimator guide](../../guide/estimators.md)
is a good place to start. We will use the MNIST dataset. The tutorial consists
@@ -131,7 +131,7 @@ In addition to experimenting with the (training) batch size and the number of
training steps, there are a couple other parameters that can be tuned as well.
For instance, you can change the optimization method used to minimize the loss
by explicitly selecting another optimizer from the collection of
-[available optimizers](https://www.tensorflow.org/code/tensorflow/python/training).
+[available optimizers](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/training).
As an example, the following code constructs a LinearClassifier estimator that
uses the Follow-The-Regularized-Leader (FTRL) optimization strategy with a
specific learning rate and L2-regularization.
diff --git a/site/en/r1/tutorials/representation/linear.md b/site/en/r1/tutorials/representation/linear.md
index 5516672b34a..d996a13bc1f 100644
--- a/site/en/r1/tutorials/representation/linear.md
+++ b/site/en/r1/tutorials/representation/linear.md
@@ -12,7 +12,7 @@ those tools. It explains:
Read this overview to decide whether the Estimator's linear model tools might
be useful to you. Then work through the
-[Estimator wide and deep learning tutorial](https://github.com/tensorflow/models/tree/master/official/r1/wide_deep)
+[Estimator wide and deep learning tutorial](https://github.com/tensorflow/models/tree/r1.15/official/r1/wide_deep)
to give it a try. This overview uses code samples from the tutorial, but the
tutorial walks through the code in greater detail.
@@ -177,7 +177,7 @@ the name of a `FeatureColumn`. Each key's value is a tensor containing the
values of that feature for all data instances. See
[Premade Estimators](../../guide/premade_estimators.md#input_fn) for a
more comprehensive look at input functions, and `input_fn` in the
-[wide and deep learning tutorial](https://github.com/tensorflow/models/tree/master/official/r1/wide_deep)
+[wide and deep learning tutorial](https://github.com/tensorflow/models/tree/r1.15/official/r1/wide_deep)
for an example implementation of an input function.
The input function is passed to the `train()` and `evaluate()` calls that
@@ -236,4 +236,4 @@ e = tf.estimator.DNNLinearCombinedClassifier(
dnn_hidden_units=[100, 50])
```
For more information, see the
-[wide and deep learning tutorial](https://github.com/tensorflow/models/tree/master/official/r1/wide_deep).
+[wide and deep learning tutorial](https://github.com/tensorflow/models/tree/r1.15/official/r1/wide_deep).
diff --git a/site/en/r1/tutorials/representation/unicode.ipynb b/site/en/r1/tutorials/representation/unicode.ipynb
index 98aaacff5b9..f76977c3c92 100644
--- a/site/en/r1/tutorials/representation/unicode.ipynb
+++ b/site/en/r1/tutorials/representation/unicode.ipynb
@@ -136,7 +136,7 @@
"id": "jsMPnjb6UDJ1"
},
"source": [
- "Note: When using python to construct strings, the handling of unicode differs betweeen v2 and v3. In v2, unicode strings are indicated by the \"u\" prefix, as above. In v3, strings are unicode-encoded by default."
+ "Note: When using python to construct strings, the handling of unicode differs between v2 and v3. In v2, unicode strings are indicated by the \"u\" prefix, as above. In v3, strings are unicode-encoded by default."
]
},
{
@@ -425,7 +425,7 @@
"source": [
"### Character substrings\n",
"\n",
- "Similarly, the `tf.strings.substr` operation accepts the \"`unit`\" parameter, and uses it to determine what kind of offsets the \"`pos`\" and \"`len`\" paremeters contain."
+ "Similarly, the `tf.strings.substr` operation accepts the \"`unit`\" parameter, and uses it to determine what kind of offsets the \"`pos`\" and \"`len`\" parameters contain."
]
},
{
@@ -587,7 +587,7 @@
"id": "CapnbShuGU8i"
},
"source": [
- "First, we decode the sentences into character codepoints, and find the script identifeir for each character."
+ "First, we decode the sentences into character codepoints, and find the script identifier for each character."
]
},
{
diff --git a/site/en/r1/tutorials/representation/word2vec.md b/site/en/r1/tutorials/representation/word2vec.md
index f6a27c68f3c..517a5dbc5c5 100644
--- a/site/en/r1/tutorials/representation/word2vec.md
+++ b/site/en/r1/tutorials/representation/word2vec.md
@@ -36,7 +36,7 @@ like to get your hands dirty with the details.
Image and audio processing systems work with rich, high-dimensional datasets
encoded as vectors of the individual raw pixel-intensities for image data, or
-e.g. power spectral density coefficients for audio data. For tasks like object
+e.g., power spectral density coefficients for audio data. For tasks like object
or speech recognition we know that all the information required to successfully
perform the task is encoded in the data (because humans can perform these tasks
from the raw data). However, natural language processing systems traditionally
@@ -109,7 +109,7 @@ $$
where \\(\text{score}(w_t, h)\\) computes the compatibility of word \\(w_t\\)
with the context \\(h\\) (a dot product is commonly used). We train this model
by maximizing its [log-likelihood](https://en.wikipedia.org/wiki/Likelihood_function)
-on the training set, i.e. by maximizing
+on the training set, i.e., by maximizing
$$
\begin{align}
@@ -176,7 +176,7 @@ As an example, let's consider the dataset
We first form a dataset of words and the contexts in which they appear. We
could define 'context' in any way that makes sense, and in fact people have
looked at syntactic contexts (i.e. the syntactic dependents of the current
-target word, see e.g.
+target word, see e.g.,
[Levy et al.](https://levyomer.files.wordpress.com/2014/04/dependency-based-word-embeddings-acl-2014.pdf)),
words-to-the-left of the target, words-to-the-right of the target, etc. For now,
let's stick to the vanilla definition and define 'context' as the window
@@ -204,7 +204,7 @@ where the goal is to predict `the` from `quick`. We select `num_noise` number
of noisy (contrastive) examples by drawing from some noise distribution,
typically the unigram distribution, \\(P(w)\\). For simplicity let's say
`num_noise=1` and we select `sheep` as a noisy example. Next we compute the
-loss for this pair of observed and noisy examples, i.e. the objective at time
+loss for this pair of observed and noisy examples, i.e., the objective at time
step \\(t\\) becomes
$$J^{(t)}_\text{NEG} = \log Q_\theta(D=1 | \text{the, quick}) +
@@ -212,7 +212,7 @@ $$J^{(t)}_\text{NEG} = \log Q_\theta(D=1 | \text{the, quick}) +
The goal is to make an update to the embedding parameters \\(\theta\\) to improve
(in this case, maximize) this objective function. We do this by deriving the
-gradient of the loss with respect to the embedding parameters \\(\theta\\), i.e.
+gradient of the loss with respect to the embedding parameters \\(\theta\\), i.e.,
\\(\frac{\partial}{\partial \theta} J_\text{NEG}\\) (luckily TensorFlow provides
easy helper functions for doing this!). We then perform an update to the
embeddings by taking a small step in the direction of the gradient. When this
@@ -227,7 +227,7 @@ When we inspect these visualizations it becomes apparent that the vectors
capture some general, and in fact quite useful, semantic information about
words and their relationships to one another. It was very interesting when we
first discovered that certain directions in the induced vector space specialize
-towards certain semantic relationships, e.g. *male-female*, *verb tense* and
+towards certain semantic relationships, e.g., *male-female*, *verb tense* and
even *country-capital* relationships between words, as illustrated in the figure
below (see also for example
[Mikolov et al., 2013](https://www.aclweb.org/anthology/N13-1090)).
@@ -327,7 +327,7 @@ for inputs, labels in generate_batch(...):
```
See the full example code in
-[tensorflow/examples/tutorials/word2vec/word2vec_basic.py](https://www.tensorflow.org/code/tensorflow/examples/tutorials/word2vec/word2vec_basic.py).
+[tensorflow/examples/tutorials/word2vec/word2vec_basic.py](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/examples/tutorials/word2vec/word2vec_basic.py).
## Visualizing the learned embeddings
@@ -341,7 +341,7 @@ t-SNE.
Et voila! As expected, words that are similar end up clustering nearby each
other. For a more heavyweight implementation of word2vec that showcases more of
the advanced features of TensorFlow, see the implementation in
-[models/tutorials/embedding/word2vec.py](https://github.com/tensorflow/models/tree/master/research/tutorials/embedding/word2vec.py).
+[models/tutorials/embedding/word2vec.py](https://github.com/tensorflow/models/tree/r1.15/research/tutorials/embedding/word2vec.py).
## Evaluating embeddings: analogical reasoning
@@ -357,7 +357,7 @@ Download the dataset for this task from
To see how we do this evaluation, have a look at the `build_eval_graph()` and
`eval()` functions in
-[models/tutorials/embedding/word2vec.py](https://github.com/tensorflow/models/tree/master/research/tutorials/embedding/word2vec.py).
+[models/tutorials/embedding/word2vec.py](https://github.com/tensorflow/models/tree/r1.15/research/tutorials/embedding/word2vec.py).
The choice of hyperparameters can strongly influence the accuracy on this task.
To achieve state-of-the-art performance on this task requires training over a
diff --git a/site/en/r1/tutorials/sequences/audio_recognition.md b/site/en/r1/tutorials/sequences/audio_recognition.md
index 8ad71b88a3c..0388514ec92 100644
--- a/site/en/r1/tutorials/sequences/audio_recognition.md
+++ b/site/en/r1/tutorials/sequences/audio_recognition.md
@@ -159,9 +159,9 @@ accuracy. If the training accuracy increases but the validation doesn't, that's
a sign that overfitting is occurring, and your model is only learning things
about the training clips, not broader patterns that generalize.
-## Tensorboard
+## TensorBoard
-A good way to visualize how the training is progressing is using Tensorboard. By
+A good way to visualize how the training is progressing is using TensorBoard. By
default, the script saves out events to /tmp/retrain_logs, and you can load
these by running:
diff --git a/site/en/r1/tutorials/sequences/recurrent_quickdraw.md b/site/en/r1/tutorials/sequences/recurrent_quickdraw.md
index 435076f629c..d6a85377d17 100644
--- a/site/en/r1/tutorials/sequences/recurrent_quickdraw.md
+++ b/site/en/r1/tutorials/sequences/recurrent_quickdraw.md
@@ -109,7 +109,7 @@ This download will take a while and download a bit more than 23GB of data.
To convert the `ndjson` files to
[TFRecord](../../api_guides/python/python_io.md#TFRecords_Format_Details) files containing
-[`tf.train.Example`](https://www.tensorflow.org/code/tensorflow/core/example/example.proto)
+[`tf.train.Example`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/example/example.proto)
protos run the following command.
```shell
@@ -213,7 +213,7 @@ screen coordinates and normalize the size such that the drawing has unit height.
Finally, we compute the differences between consecutive points and store these
as a `VarLenFeature` in a
-[tensorflow.Example](https://www.tensorflow.org/code/tensorflow/core/example/example.proto)
+[tensorflow.Example](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/example/example.proto)
under the key `ink`. In addition we store the `class_index` as a single entry
`FixedLengthFeature` and the `shape` of the `ink` as a `FixedLengthFeature` of
length 2.
diff --git a/site/en/tutorials/distribute/multi_worker_with_estimator.ipynb b/site/en/tutorials/distribute/multi_worker_with_estimator.ipynb
index 2abf05aa9f8..fcee0618854 100644
--- a/site/en/tutorials/distribute/multi_worker_with_estimator.ipynb
+++ b/site/en/tutorials/distribute/multi_worker_with_estimator.ipynb
@@ -186,7 +186,7 @@
"\n",
"There are two components of `TF_CONFIG`: `cluster` and `task`. `cluster` provides information about the entire cluster, namely the workers and parameter servers in the cluster. `task` provides information about the current task. The first component `cluster` is the same for all workers and parameter servers in the cluster, and the second component `task` is different on each worker and parameter server and specifies its own `type` and `index`. In this example, the task `type` is `worker` and the task `index` is `0`.\n",
"\n",
- "For illustration purposes, this tutorial shows how to set a `TF_CONFIG` with 2 workers on `localhost`. In practice, you would create multiple workers on an external IP address and port, and set `TF_CONFIG` on each worker appropriately, i.e. modify the task `index`.\n",
+ "For illustration purposes, this tutorial shows how to set a `TF_CONFIG` with 2 workers on `localhost`. In practice, you would create multiple workers on an external IP address and port, and set `TF_CONFIG` on each worker appropriately, i.e., modify the task `index`.\n",
"\n",
"Warning: *Do not execute the following code in Colab.* TensorFlow's runtime will attempt to create a gRPC server at the specified IP address and port, which will likely fail. See the [keras version](multi_worker_with_keras.ipynb) of this tutorial for an example of how you can test run multiple workers on a single machine.\n",
"\n",
diff --git a/site/en/tutorials/estimator/keras_model_to_estimator.ipynb b/site/en/tutorials/estimator/keras_model_to_estimator.ipynb
index 7b34e283ef3..be97a38b6eb 100644
--- a/site/en/tutorials/estimator/keras_model_to_estimator.ipynb
+++ b/site/en/tutorials/estimator/keras_model_to_estimator.ipynb
@@ -68,7 +68,7 @@
"id": "Dhcq8Ds4mCtm"
},
"source": [
- "> Warning: Estimators are not recommended for new code. Estimators run `v1.Session`-style code which is more difficult to write correctly, and can behave unexpectedly, especially when combined with TF 2 code. Estimators do fall under our [compatibility guarantees](https://tensorflow.org/guide/versions), but will receive no fixes other than security vulnerabilities. See the [migration guide](https://tensorflow.org/guide/migrate) for details."
+ "> Warning: TensorFlow 2.15 included the final release of the `tf-estimator` package. Estimators will not be available in TensorFlow 2.16 or after. See the [migration guide](https://tensorflow.org/guide/migrate/migrating_estimator) for more information about how to convert off of Estimators."
]
},
{
diff --git a/site/en/tutorials/estimator/linear.ipynb b/site/en/tutorials/estimator/linear.ipynb
index 7732ebe3b9e..a26ffe2df4f 100644
--- a/site/en/tutorials/estimator/linear.ipynb
+++ b/site/en/tutorials/estimator/linear.ipynb
@@ -61,7 +61,7 @@
"id": "JOccPOFMm5Tc"
},
"source": [
- "> Warning: Estimators are not recommended for new code. Estimators run `v1.Session`-style code which is more difficult to write correctly, and can behave unexpectedly, especially when combined with TF 2 code. Estimators do fall under our [compatibility guarantees](https://tensorflow.org/guide/versions), but will receive no fixes other than security vulnerabilities. See the [migration guide](https://tensorflow.org/guide/migrate) for details."
+ "> Warning: TensorFlow 2.15 included the final release of the `tf-estimator` package. Estimators will not be available in TensorFlow 2.16 or after. See the [migration guide](https://tensorflow.org/guide/migrate/migrating_estimator) for more information about how to convert off of Estimators."
]
},
{
diff --git a/site/en/tutorials/estimator/premade.ipynb b/site/en/tutorials/estimator/premade.ipynb
index a34096ea2b8..dc81847c7cd 100644
--- a/site/en/tutorials/estimator/premade.ipynb
+++ b/site/en/tutorials/estimator/premade.ipynb
@@ -68,7 +68,7 @@
"id": "stQiPWL6ni6_"
},
"source": [
- "> Warning: Estimators are not recommended for new code. Estimators run `v1.Session`-style code which is more difficult to write correctly, and can behave unexpectedly, especially when combined with TF 2 code. Estimators do fall under [compatibility guarantees](https://tensorflow.org/guide/versions), but will receive no fixes other than security vulnerabilities. See the [migration guide](https://tensorflow.org/guide/migrate) for details."
+ "> Warning: TensorFlow 2.15 included the final release of the `tf-estimator` package. Estimators will not be available in TensorFlow 2.16 or after. See the [migration guide](https://tensorflow.org/guide/migrate/migrating_estimator) for more information about how to convert off of Estimators."
]
},
{
diff --git a/site/en/tutorials/generative/cyclegan.ipynb b/site/en/tutorials/generative/cyclegan.ipynb
index 4c2b3ba8777..313be519591 100644
--- a/site/en/tutorials/generative/cyclegan.ipynb
+++ b/site/en/tutorials/generative/cyclegan.ipynb
@@ -154,7 +154,7 @@
"This is similar to what was done in [pix2pix](https://www.tensorflow.org/tutorials/generative/pix2pix#load_the_dataset)\n",
"\n",
"* In random jittering, the image is resized to `286 x 286` and then randomly cropped to `256 x 256`.\n",
- "* In random mirroring, the image is randomly flipped horizontally i.e. left to right."
+ "* In random mirroring, the image is randomly flipped horizontally i.e., left to right."
]
},
{
diff --git a/site/en/tutorials/generative/data_compression.ipynb b/site/en/tutorials/generative/data_compression.ipynb
index b6c043c0598..f756f088acd 100644
--- a/site/en/tutorials/generative/data_compression.ipynb
+++ b/site/en/tutorials/generative/data_compression.ipynb
@@ -821,7 +821,7 @@
{
"cell_type": "markdown",
"metadata": {
- "id": "3ELLMAN1OwMQ"
+ "id": "3ELLMANN1OwMQ"
},
"source": [
"The strings begin to get much shorter now, on the order of one byte per digit. However, this comes at a cost. More digits are becoming unrecognizable.\n",
diff --git a/site/en/tutorials/generative/pix2pix.ipynb b/site/en/tutorials/generative/pix2pix.ipynb
index 5912fab9be3..e45950dd923 100644
--- a/site/en/tutorials/generative/pix2pix.ipynb
+++ b/site/en/tutorials/generative/pix2pix.ipynb
@@ -280,7 +280,7 @@
"\n",
"1. Resize each `256 x 256` image to a larger height and width—`286 x 286`.\n",
"2. Randomly crop it back to `256 x 256`.\n",
- "3. Randomly flip the image horizontally i.e. left to right (random mirroring).\n",
+ "3. Randomly flip the image horizontally i.e., left to right (random mirroring).\n",
"4. Normalize the images to the `[-1, 1]` range."
]
},
diff --git a/site/en/tutorials/images/data_augmentation.ipynb b/site/en/tutorials/images/data_augmentation.ipynb
index bdc7ae0c56a..8a1eaaabec4 100644
--- a/site/en/tutorials/images/data_augmentation.ipynb
+++ b/site/en/tutorials/images/data_augmentation.ipynb
@@ -1273,7 +1273,7 @@
"source": [
"# Create a wrapper function for updating seeds.\n",
"def f(x, y):\n",
- " seed = rng.make_seeds(2)[0]\n",
+ " seed = rng.make_seeds(1)[:, 0]\n",
" image, label = augment((x, y), seed)\n",
" return image, label"
]
diff --git a/site/en/tutorials/images/transfer_learning.ipynb b/site/en/tutorials/images/transfer_learning.ipynb
index dd9b97cabe2..57dbbfbcbbf 100644
--- a/site/en/tutorials/images/transfer_learning.ipynb
+++ b/site/en/tutorials/images/transfer_learning.ipynb
@@ -585,7 +585,7 @@
},
"outputs": [],
"source": [
- "prediction_layer = tf.keras.layers.Dense(1)\n",
+ "prediction_layer = tf.keras.layers.Dense(1, activation='sigmoid')\n",
"prediction_batch = prediction_layer(feature_batch_average)\n",
"print(prediction_batch.shape)"
]
@@ -667,7 +667,7 @@
"source": [
"### Compile the model\n",
"\n",
- "Compile the model before training it. Since there are two classes, use the `tf.keras.losses.BinaryCrossentropy` loss with `from_logits=True` since the model provides a linear output."
+ "Compile the model before training it. Since there are two classes and a sigmoid oputput, use the `BinaryAccuracy`."
]
},
{
@@ -680,8 +680,8 @@
"source": [
"base_learning_rate = 0.0001\n",
"model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=base_learning_rate),\n",
- " loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),\n",
- " metrics=[tf.keras.metrics.BinaryAccuracy(threshold=0, name='accuracy')])"
+ " loss=tf.keras.losses.BinaryCrossentropy(),\n",
+ " metrics=[tf.keras.metrics.BinaryAccuracy(threshold=0.5, name='accuracy')])"
]
},
{
@@ -872,9 +872,9 @@
},
"outputs": [],
"source": [
- "model.compile(loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),\n",
+ "model.compile(loss=tf.keras.losses.BinaryCrossentropy(),\n",
" optimizer = tf.keras.optimizers.RMSprop(learning_rate=base_learning_rate/10),\n",
- " metrics=[tf.keras.metrics.BinaryAccuracy(threshold=0, name='accuracy')])"
+ " metrics=[tf.keras.metrics.BinaryAccuracy(threshold=0.5, name='accuracy')])"
]
},
{
diff --git a/site/en/tutorials/interpretability/integrated_gradients.ipynb b/site/en/tutorials/interpretability/integrated_gradients.ipynb
index 2ee792aa4e2..e63c8cdb7a2 100644
--- a/site/en/tutorials/interpretability/integrated_gradients.ipynb
+++ b/site/en/tutorials/interpretability/integrated_gradients.ipynb
@@ -724,7 +724,7 @@
"ax2 = plt.subplot(1, 2, 2)\n",
"# Average across interpolation steps\n",
"average_grads = tf.reduce_mean(path_gradients, axis=[1, 2, 3])\n",
- "# Normalize gradients to 0 to 1 scale. E.g. (x - min(x))/(max(x)-min(x))\n",
+ "# Normalize gradients to 0 to 1 scale. E.g., (x - min(x))/(max(x)-min(x))\n",
"average_grads_norm = (average_grads-tf.math.reduce_min(average_grads))/(tf.math.reduce_max(average_grads)-tf.reduce_min(average_grads))\n",
"ax2.plot(alphas, average_grads_norm)\n",
"ax2.set_title('Average pixel gradients (normalized) over alpha')\n",
diff --git a/site/en/tutorials/keras/save_and_load.ipynb b/site/en/tutorials/keras/save_and_load.ipynb
index 02c8af3a71d..404fa1ee8be 100644
--- a/site/en/tutorials/keras/save_and_load.ipynb
+++ b/site/en/tutorials/keras/save_and_load.ipynb
@@ -854,7 +854,7 @@
" * `from_config(cls, config)` uses the returned config from `get_config` to create a new object. By default, this function will use the config as initialization kwargs (`return cls(**config)`).\n",
"2. Pass the custom objects to the model in one of three ways:\n",
" - Register the custom object with the `@tf.keras.utils.register_keras_serializable` decorator. **(recommended)**\n",
- " - Directly pass the object to the `custom_objects` argument when loading the model. The argument must be a dictionary mapping the string class name to the Python class. E.g. `tf.keras.models.load_model(path, custom_objects={'CustomLayer': CustomLayer})`\n",
+ " - Directly pass the object to the `custom_objects` argument when loading the model. The argument must be a dictionary mapping the string class name to the Python class. E.g., `tf.keras.models.load_model(path, custom_objects={'CustomLayer': CustomLayer})`\n",
" - Use a `tf.keras.utils.custom_object_scope` with the object included in the `custom_objects` dictionary argument, and place a `tf.keras.models.load_model(path)` call within the scope.\n",
"\n",
"Refer to the [Writing layers and models from scratch](https://www.tensorflow.org/guide/keras/custom_layers_and_models) tutorial for examples of custom objects and `get_config`.\n"
diff --git a/site/en/tutorials/keras/text_classification.ipynb b/site/en/tutorials/keras/text_classification.ipynb
index f14964207ff..c66d0fce0d3 100644
--- a/site/en/tutorials/keras/text_classification.ipynb
+++ b/site/en/tutorials/keras/text_classification.ipynb
@@ -267,9 +267,9 @@
"id": "95kkUdRoaeMw"
},
"source": [
- "Next, you will use the `text_dataset_from_directory` utility to create a labeled `tf.data.Dataset`. [tf.data](https://www.tensorflow.org/guide/data) is a powerful collection of tools for working with data. \n",
+ "Next, you will use the `text_dataset_from_directory` utility to create a labeled `tf.data.Dataset`. [tf.data](https://www.tensorflow.org/guide/data) is a powerful collection of tools for working with data.\n",
"\n",
- "When running a machine learning experiment, it is a best practice to divide your dataset into three splits: [train](https://developers.google.com/machine-learning/glossary#training_set), [validation](https://developers.google.com/machine-learning/glossary#validation_set), and [test](https://developers.google.com/machine-learning/glossary#test-set). \n",
+ "When running a machine learning experiment, it is a best practice to divide your dataset into three splits: [train](https://developers.google.com/machine-learning/glossary#training_set), [validation](https://developers.google.com/machine-learning/glossary#validation_set), and [test](https://developers.google.com/machine-learning/glossary#test-set).\n",
"\n",
"The IMDB dataset has already been divided into train and test, but it lacks a validation set. Let's create a validation set using an 80:20 split of the training data by using the `validation_split` argument below."
]
@@ -286,10 +286,10 @@
"seed = 42\n",
"\n",
"raw_train_ds = tf.keras.utils.text_dataset_from_directory(\n",
- " 'aclImdb/train', \n",
- " batch_size=batch_size, \n",
- " validation_split=0.2, \n",
- " subset='training', \n",
+ " 'aclImdb/train',\n",
+ " batch_size=batch_size,\n",
+ " validation_split=0.2,\n",
+ " subset='training',\n",
" seed=seed)"
]
},
@@ -322,7 +322,7 @@
"id": "JWq1SUIrp1a-"
},
"source": [
- "Notice the reviews contain raw text (with punctuation and occasional HTML tags like `
`). You will show how to handle these in the following section. \n",
+ "Notice the reviews contain raw text (with punctuation and occasional HTML tags like `
`). You will show how to handle these in the following section.\n",
"\n",
"The labels are 0 or 1. To see which of these correspond to positive and negative movie reviews, you can check the `class_names` property on the dataset.\n"
]
@@ -366,10 +366,10 @@
"outputs": [],
"source": [
"raw_val_ds = tf.keras.utils.text_dataset_from_directory(\n",
- " 'aclImdb/train', \n",
- " batch_size=batch_size, \n",
- " validation_split=0.2, \n",
- " subset='validation', \n",
+ " 'aclImdb/train',\n",
+ " batch_size=batch_size,\n",
+ " validation_split=0.2,\n",
+ " subset='validation',\n",
" seed=seed)"
]
},
@@ -382,7 +382,7 @@
"outputs": [],
"source": [
"raw_test_ds = tf.keras.utils.text_dataset_from_directory(\n",
- " 'aclImdb/test', \n",
+ " 'aclImdb/test',\n",
" batch_size=batch_size)"
]
},
@@ -394,7 +394,7 @@
"source": [
"### Prepare the dataset for training\n",
"\n",
- "Next, you will standardize, tokenize, and vectorize the data using the helpful `tf.keras.layers.TextVectorization` layer. \n",
+ "Next, you will standardize, tokenize, and vectorize the data using the helpful `tf.keras.layers.TextVectorization` layer.\n",
"\n",
"Standardization refers to preprocessing the text, typically to remove punctuation or HTML elements to simplify the dataset. Tokenization refers to splitting strings into tokens (for example, splitting a sentence into individual words, by splitting on whitespace). Vectorization refers to converting tokens into numbers so they can be fed into a neural network. All of these tasks can be accomplished with this layer.\n",
"\n",
@@ -580,7 +580,7 @@
"\n",
"`.cache()` keeps data in memory after it's loaded off disk. This will ensure the dataset does not become a bottleneck while training your model. If your dataset is too large to fit into memory, you can also use this method to create a performant on-disk cache, which is more efficient to read than many small files.\n",
"\n",
- "`.prefetch()` overlaps data preprocessing and model execution while training. \n",
+ "`.prefetch()` overlaps data preprocessing and model execution while training.\n",
"\n",
"You can learn more about both methods, as well as how to cache data to disk in the [data performance guide](https://www.tensorflow.org/guide/data_performance)."
]
@@ -635,7 +635,7 @@
" layers.Dropout(0.2),\n",
" layers.GlobalAveragePooling1D(),\n",
" layers.Dropout(0.2),\n",
- " layers.Dense(1)])\n",
+ " layers.Dense(1, activation='sigmoid')])\n",
"\n",
"model.summary()"
]
@@ -674,9 +674,9 @@
},
"outputs": [],
"source": [
- "model.compile(loss=losses.BinaryCrossentropy(from_logits=True),\n",
+ "model.compile(loss=losses.BinaryCrossentropy(),\n",
" optimizer='adam',\n",
- " metrics=tf.metrics.BinaryAccuracy(threshold=0.0))"
+ " metrics=[tf.metrics.BinaryAccuracy(threshold=0.5)])"
]
},
{
@@ -884,11 +884,11 @@
},
"outputs": [],
"source": [
- "examples = [\n",
+ "examples = tf.constant([\n",
" \"The movie was great!\",\n",
" \"The movie was okay.\",\n",
" \"The movie was terrible...\"\n",
- "]\n",
+ "])\n",
"\n",
"export_model.predict(examples)"
]
@@ -916,7 +916,7 @@
"\n",
"This tutorial showed how to train a binary classifier from scratch on the IMDB dataset. As an exercise, you can modify this notebook to train a multi-class classifier to predict the tag of a programming question on [Stack Overflow](http://stackoverflow.com/).\n",
"\n",
- "A [dataset](https://storage.googleapis.com/download.tensorflow.org/data/stack_overflow_16k.tar.gz) has been prepared for you to use containing the body of several thousand programming questions (for example, \"How can I sort a dictionary by value in Python?\") posted to Stack Overflow. Each of these is labeled with exactly one tag (either Python, CSharp, JavaScript, or Java). Your task is to take a question as input, and predict the appropriate tag, in this case, Python. \n",
+ "A [dataset](https://storage.googleapis.com/download.tensorflow.org/data/stack_overflow_16k.tar.gz) has been prepared for you to use containing the body of several thousand programming questions (for example, \"How can I sort a dictionary by value in Python?\") posted to Stack Overflow. Each of these is labeled with exactly one tag (either Python, CSharp, JavaScript, or Java). Your task is to take a question as input, and predict the appropriate tag, in this case, Python.\n",
"\n",
"The dataset you will work with contains several thousand questions extracted from the much larger public Stack Overflow dataset on [BigQuery](https://console.cloud.google.com/marketplace/details/stack-exchange/stack-overflow), which contains more than 17 million posts.\n",
"\n",
@@ -950,7 +950,7 @@
"\n",
"1. When plotting accuracy over time, change `binary_accuracy` and `val_binary_accuracy` to `accuracy` and `val_accuracy`, respectively.\n",
"\n",
- "1. Once these changes are complete, you will be able to train a multi-class classifier. "
+ "1. Once these changes are complete, you will be able to train a multi-class classifier."
]
},
{
@@ -968,8 +968,8 @@
"metadata": {
"accelerator": "GPU",
"colab": {
- "collapsed_sections": [],
"name": "text_classification.ipynb",
+ "provenance": [],
"toc_visible": true
},
"kernelspec": {
diff --git a/site/en/tutorials/load_data/pandas_dataframe.ipynb b/site/en/tutorials/load_data/pandas_dataframe.ipynb
index cee2483a350..66bace1ff87 100644
--- a/site/en/tutorials/load_data/pandas_dataframe.ipynb
+++ b/site/en/tutorials/load_data/pandas_dataframe.ipynb
@@ -1036,8 +1036,8 @@
},
"outputs": [],
"source": [
- "preprocesssed_result = tf.concat(preprocessed, axis=-1)\n",
- "preprocesssed_result"
+ "preprocessed_result = tf.concat(preprocessed, axis=-1)\n",
+ "preprocessed_result"
]
},
{
@@ -1057,7 +1057,7 @@
},
"outputs": [],
"source": [
- "preprocessor = tf.keras.Model(inputs, preprocesssed_result)"
+ "preprocessor = tf.keras.Model(inputs, preprocessed_result)"
]
},
{
diff --git a/site/en/tutorials/quickstart/advanced.ipynb b/site/en/tutorials/quickstart/advanced.ipynb
index 2fe0ce85773..7cc134b2613 100644
--- a/site/en/tutorials/quickstart/advanced.ipynb
+++ b/site/en/tutorials/quickstart/advanced.ipynb
@@ -200,7 +200,7 @@
"id": "uGih-c2LgbJu"
},
"source": [
- "Choose an optimizer and loss function for training: "
+ "Choose an optimizer and loss function for training:"
]
},
{
@@ -311,10 +311,10 @@
"\n",
"for epoch in range(EPOCHS):\n",
" # Reset the metrics at the start of the next epoch\n",
- " train_loss.reset_states()\n",
- " train_accuracy.reset_states()\n",
- " test_loss.reset_states()\n",
- " test_accuracy.reset_states()\n",
+ " train_loss.reset_state()\n",
+ " train_accuracy.reset_state()\n",
+ " test_loss.reset_state()\n",
+ " test_accuracy.reset_state()\n",
"\n",
" for images, labels in train_ds:\n",
" train_step(images, labels)\n",
@@ -324,10 +324,10 @@
"\n",
" print(\n",
" f'Epoch {epoch + 1}, '\n",
- " f'Loss: {train_loss.result()}, '\n",
- " f'Accuracy: {train_accuracy.result() * 100}, '\n",
- " f'Test Loss: {test_loss.result()}, '\n",
- " f'Test Accuracy: {test_accuracy.result() * 100}'\n",
+ " f'Loss: {train_loss.result():0.2f}, '\n",
+ " f'Accuracy: {train_accuracy.result() * 100:0.2f}, '\n",
+ " f'Test Loss: {test_loss.result():0.2f}, '\n",
+ " f'Test Accuracy: {test_accuracy.result() * 100:0.2f}'\n",
" )"
]
},
@@ -344,8 +344,8 @@
"metadata": {
"accelerator": "GPU",
"colab": {
- "collapsed_sections": [],
"name": "advanced.ipynb",
+ "provenance": [],
"toc_visible": true
},
"kernelspec": {
diff --git a/site/en/tutorials/structured_data/imbalanced_data.ipynb b/site/en/tutorials/structured_data/imbalanced_data.ipynb
index 0d9578b30dc..16d08e53385 100644
--- a/site/en/tutorials/structured_data/imbalanced_data.ipynb
+++ b/site/en/tutorials/structured_data/imbalanced_data.ipynb
@@ -445,7 +445,7 @@
"\n",
"#### Metrics for probability predictions\n",
"\n",
- "As we train our network with the cross entropy as a loss function, it is fully capable of predicting class probabilities, i.e. it is a probabilistic classifier.\n",
+ "As we train our network with the cross entropy as a loss function, it is fully capable of predicting class probabilities, i.e., it is a probabilistic classifier.\n",
"Good metrics to assess probabilistic predictions are, in fact, **proper scoring rules**. Their key property is that predicting the true probability is optimal. We give two well-known examples:\n",
"\n",
"* **cross entropy** also known as log loss\n",
diff --git a/site/en/tutorials/structured_data/preprocessing_layers.ipynb b/site/en/tutorials/structured_data/preprocessing_layers.ipynb
index 928a56eb8bc..ead524ca13c 100644
--- a/site/en/tutorials/structured_data/preprocessing_layers.ipynb
+++ b/site/en/tutorials/structured_data/preprocessing_layers.ipynb
@@ -297,7 +297,7 @@
"def df_to_dataset(dataframe, shuffle=True, batch_size=32):\n",
" df = dataframe.copy()\n",
" labels = df.pop('target')\n",
- " df = {key: value[:,tf.newaxis] for key, value in dataframe.items()}\n",
+ " df = {key: value.values[:,tf.newaxis] for key, value in dataframe.items()}\n",
" ds = tf.data.Dataset.from_tensor_slices((dict(df), labels))\n",
" if shuffle:\n",
" ds = ds.shuffle(buffer_size=len(dataframe))\n",
diff --git a/site/en/tutorials/structured_data/time_series.ipynb b/site/en/tutorials/structured_data/time_series.ipynb
index 0b0eb55bce3..31aab384859 100644
--- a/site/en/tutorials/structured_data/time_series.ipynb
+++ b/site/en/tutorials/structured_data/time_series.ipynb
@@ -70,7 +70,7 @@
"source": [
"This tutorial is an introduction to time series forecasting using TensorFlow. It builds a few different styles of models including Convolutional and Recurrent Neural Networks (CNNs and RNNs).\n",
"\n",
- "This is covered in two main parts, with subsections: \n",
+ "This is covered in two main parts, with subsections:\n",
"\n",
"* Forecast for a single time step:\n",
" * A single feature.\n",
@@ -452,7 +452,7 @@
"id": "HiurzTGQgf_D"
},
"source": [
- "This gives the model access to the most important frequency features. In this case you knew ahead of time which frequencies were important. \n",
+ "This gives the model access to the most important frequency features. In this case you knew ahead of time which frequencies were important.\n",
"\n",
"If you don't have that information, you can determine which frequencies are important by extracting features with Fast Fourier Transform. To check the assumptions, here is the `tf.signal.rfft` of the temperature over time. Note the obvious peaks at frequencies near `1/year` and `1/day`:\n"
]
@@ -590,13 +590,13 @@
"source": [
"## Data windowing\n",
"\n",
- "The models in this tutorial will make a set of predictions based on a window of consecutive samples from the data. \n",
+ "The models in this tutorial will make a set of predictions based on a window of consecutive samples from the data.\n",
"\n",
"The main features of the input windows are:\n",
"\n",
"- The width (number of time steps) of the input and label windows.\n",
"- The time offset between them.\n",
- "- Which features are used as inputs, labels, or both. \n",
+ "- Which features are used as inputs, labels, or both.\n",
"\n",
"This tutorial builds a variety of models (including Linear, DNN, CNN and RNN models), and uses them for both:\n",
"\n",
@@ -616,11 +616,11 @@
"\n",
"1. For example, to make a single prediction 24 hours into the future, given 24 hours of history, you might define a window like this:\n",
"\n",
- " \n",
+ " 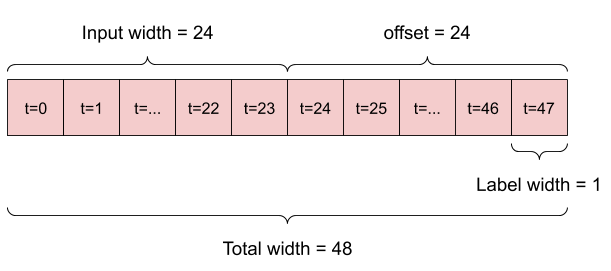\n",
"\n",
"2. A model that makes a prediction one hour into the future, given six hours of history, would need a window like this:\n",
"\n",
- " "
+ " "
]
},
{
@@ -744,7 +744,7 @@
"\n",
"The example `w2` you define earlier will be split like this:\n",
"\n",
- "\n",
+ "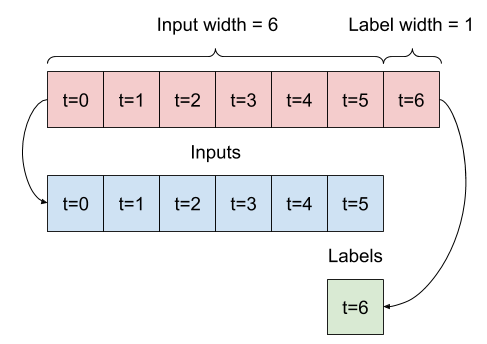\n",
"\n",
"This diagram doesn't show the `features` axis of the data, but this `split_window` function also handles the `label_columns` so it can be used for both the single output and multi-output examples."
]
@@ -1069,7 +1069,7 @@
"\n",
"So, start by building models to predict the `T (degC)` value one hour into the future.\n",
"\n",
- "\n",
+ "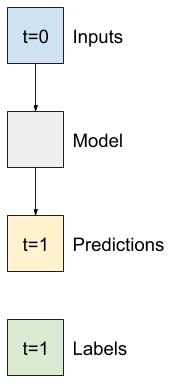\n",
"\n",
"Configure a `WindowGenerator` object to produce these single-step `(input, label)` pairs:"
]
@@ -1120,11 +1120,11 @@
"\n",
"Before building a trainable model it would be good to have a performance baseline as a point for comparison with the later more complicated models.\n",
"\n",
- "This first task is to predict temperature one hour into the future, given the current value of all features. The current values include the current temperature. \n",
+ "This first task is to predict temperature one hour into the future, given the current value of all features. The current values include the current temperature.\n",
"\n",
"So, start with a model that just returns the current temperature as the prediction, predicting \"No change\". This is a reasonable baseline since temperature changes slowly. Of course, this baseline will work less well if you make a prediction further in the future.\n",
"\n",
- ""
+ "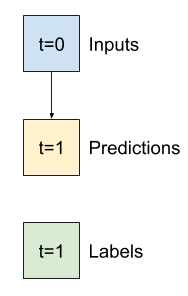"
]
},
{
@@ -1171,8 +1171,8 @@
"\n",
"val_performance = {}\n",
"performance = {}\n",
- "val_performance['Baseline'] = baseline.evaluate(single_step_window.val)\n",
- "performance['Baseline'] = baseline.evaluate(single_step_window.test, verbose=0)"
+ "val_performance['Baseline'] = baseline.evaluate(single_step_window.val, return_dict=True)\n",
+ "performance['Baseline'] = baseline.evaluate(single_step_window.test, verbose=0, return_dict=True)"
]
},
{
@@ -1211,7 +1211,7 @@
"source": [
"This expanded window can be passed directly to the same `baseline` model without any code changes. This is possible because the inputs and labels have the same number of time steps, and the baseline just forwards the input to the output:\n",
"\n",
- ""
+ ""
]
},
{
@@ -1269,7 +1269,7 @@
"\n",
"The simplest **trainable** model you can apply to this task is to insert linear transformation between the input and output. In this case the output from a time step only depends on that step:\n",
"\n",
- "\n",
+ "\n",
"\n",
"A `tf.keras.layers.Dense` layer with no `activation` set is a linear model. The layer only transforms the last axis of the data from `(batch, time, inputs)` to `(batch, time, units)`; it is applied independently to every item across the `batch` and `time` axes."
]
@@ -1352,8 +1352,8 @@
"source": [
"history = compile_and_fit(linear, single_step_window)\n",
"\n",
- "val_performance['Linear'] = linear.evaluate(single_step_window.val)\n",
- "performance['Linear'] = linear.evaluate(single_step_window.test, verbose=0)"
+ "val_performance['Linear'] = linear.evaluate(single_step_window.val, return_dict=True)\n",
+ "performance['Linear'] = linear.evaluate(single_step_window.test, verbose=0, return_dict=True)"
]
},
{
@@ -1364,7 +1364,7 @@
"source": [
"Like the `baseline` model, the linear model can be called on batches of wide windows. Used this way the model makes a set of independent predictions on consecutive time steps. The `time` axis acts like another `batch` axis. There are no interactions between the predictions at each time step.\n",
"\n",
- ""
+ ""
]
},
{
@@ -1430,7 +1430,7 @@
"id": "Ylng7215boIY"
},
"source": [
- "Sometimes the model doesn't even place the most weight on the input `T (degC)`. This is one of the risks of random initialization. "
+ "Sometimes the model doesn't even place the most weight on the input `T (degC)`. This is one of the risks of random initialization."
]
},
{
@@ -1443,7 +1443,7 @@
"\n",
"Before applying models that actually operate on multiple time-steps, it's worth checking the performance of deeper, more powerful, single input step models.\n",
"\n",
- "Here's a model similar to the `linear` model, except it stacks several a few `Dense` layers between the input and the output: "
+ "Here's a model similar to the `linear` model, except it stacks several a few `Dense` layers between the input and the output:"
]
},
{
@@ -1462,8 +1462,8 @@
"\n",
"history = compile_and_fit(dense, single_step_window)\n",
"\n",
- "val_performance['Dense'] = dense.evaluate(single_step_window.val)\n",
- "performance['Dense'] = dense.evaluate(single_step_window.test, verbose=0)"
+ "val_performance['Dense'] = dense.evaluate(single_step_window.val, return_dict=True)\n",
+ "performance['Dense'] = dense.evaluate(single_step_window.test, verbose=0, return_dict=True)"
]
},
{
@@ -1476,7 +1476,7 @@
"\n",
"A single-time-step model has no context for the current values of its inputs. It can't see how the input features are changing over time. To address this issue the model needs access to multiple time steps when making predictions:\n",
"\n",
- "\n"
+ "\n"
]
},
{
@@ -1526,7 +1526,7 @@
"outputs": [],
"source": [
"conv_window.plot()\n",
- "plt.title(\"Given 3 hours of inputs, predict 1 hour into the future.\")"
+ "plt.suptitle(\"Given 3 hours of inputs, predict 1 hour into the future.\")"
]
},
{
@@ -1581,8 +1581,8 @@
"history = compile_and_fit(multi_step_dense, conv_window)\n",
"\n",
"IPython.display.clear_output()\n",
- "val_performance['Multi step dense'] = multi_step_dense.evaluate(conv_window.val)\n",
- "performance['Multi step dense'] = multi_step_dense.evaluate(conv_window.test, verbose=0)"
+ "val_performance['Multi step dense'] = multi_step_dense.evaluate(conv_window.val, return_dict=True)\n",
+ "performance['Multi step dense'] = multi_step_dense.evaluate(conv_window.test, verbose=0, return_dict=True)"
]
},
{
@@ -1602,7 +1602,7 @@
"id": "gWfrsP8mq8lV"
},
"source": [
- "The main down-side of this approach is that the resulting model can only be executed on input windows of exactly this shape. "
+ "The main down-side of this approach is that the resulting model can only be executed on input windows of exactly this shape."
]
},
{
@@ -1636,7 +1636,7 @@
},
"source": [
"### Convolution neural network\n",
- " \n",
+ "\n",
"A convolution layer (`tf.keras.layers.Conv1D`) also takes multiple time steps as input to each prediction."
]
},
@@ -1646,7 +1646,7 @@
"id": "cdLBwoaHmsWb"
},
"source": [
- "Below is the **same** model as `multi_step_dense`, re-written with a convolution. \n",
+ "Below is the **same** model as `multi_step_dense`, re-written with a convolution.\n",
"\n",
"Note the changes:\n",
"* The `tf.keras.layers.Flatten` and the first `tf.keras.layers.Dense` are replaced by a `tf.keras.layers.Conv1D`.\n",
@@ -1712,8 +1712,8 @@
"history = compile_and_fit(conv_model, conv_window)\n",
"\n",
"IPython.display.clear_output()\n",
- "val_performance['Conv'] = conv_model.evaluate(conv_window.val)\n",
- "performance['Conv'] = conv_model.evaluate(conv_window.test, verbose=0)"
+ "val_performance['Conv'] = conv_model.evaluate(conv_window.val, return_dict=True)\n",
+ "performance['Conv'] = conv_model.evaluate(conv_window.test, verbose=0, return_dict=True)"
]
},
{
@@ -1724,7 +1724,7 @@
"source": [
"The difference between this `conv_model` and the `multi_step_dense` model is that the `conv_model` can be run on inputs of any length. The convolutional layer is applied to a sliding window of inputs:\n",
"\n",
- "\n",
+ "\n",
"\n",
"If you run it on wider input, it produces wider output:"
]
@@ -1749,7 +1749,7 @@
"id": "h_WGxtLIHhRF"
},
"source": [
- "Note that the output is shorter than the input. To make training or plotting work, you need the labels, and prediction to have the same length. So build a `WindowGenerator` to produce wide windows with a few extra input time steps so the label and prediction lengths match: "
+ "Note that the output is shorter than the input. To make training or plotting work, you need the labels, and prediction to have the same length. So build a `WindowGenerator` to produce wide windows with a few extra input time steps so the label and prediction lengths match:"
]
},
{
@@ -1828,15 +1828,15 @@
"source": [
"An important constructor argument for all Keras RNN layers, such as `tf.keras.layers.LSTM`, is the `return_sequences` argument. This setting can configure the layer in one of two ways:\n",
"\n",
- "1. If `False`, the default, the layer only returns the output of the final time step, giving the model time to warm up its internal state before making a single prediction: \n",
+ "1. If `False`, the default, the layer only returns the output of the final time step, giving the model time to warm up its internal state before making a single prediction:\n",
"\n",
- "\n",
+ "\n",
"\n",
"2. If `True`, the layer returns an output for each input. This is useful for:\n",
- " * Stacking RNN layers. \n",
+ " * Stacking RNN layers.\n",
" * Training a model on multiple time steps simultaneously.\n",
"\n",
- ""
+ ""
]
},
{
@@ -1889,8 +1889,8 @@
"history = compile_and_fit(lstm_model, wide_window)\n",
"\n",
"IPython.display.clear_output()\n",
- "val_performance['LSTM'] = lstm_model.evaluate(wide_window.val)\n",
- "performance['LSTM'] = lstm_model.evaluate(wide_window.test, verbose=0)"
+ "val_performance['LSTM'] = lstm_model.evaluate(wide_window.val, return_dict=True)\n",
+ "performance['LSTM'] = lstm_model.evaluate(wide_window.test, verbose=0, return_dict=True)"
]
},
{
@@ -1922,6 +1922,29 @@
"With this dataset typically each of the models does slightly better than the one before it:"
]
},
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "dMPev9Nzd4mD"
+ },
+ "outputs": [],
+ "source": [
+ "cm = lstm_model.metrics[1]\n",
+ "cm.metrics"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "6is3g113eIIa"
+ },
+ "outputs": [],
+ "source": [
+ "val_performance"
+ ]
+ },
{
"cell_type": "code",
"execution_count": null,
@@ -1933,9 +1956,8 @@
"x = np.arange(len(performance))\n",
"width = 0.3\n",
"metric_name = 'mean_absolute_error'\n",
- "metric_index = lstm_model.metrics_names.index('mean_absolute_error')\n",
- "val_mae = [v[metric_index] for v in val_performance.values()]\n",
- "test_mae = [v[metric_index] for v in performance.values()]\n",
+ "val_mae = [v[metric_name] for v in val_performance.values()]\n",
+ "test_mae = [v[metric_name] for v in performance.values()]\n",
"\n",
"plt.ylabel('mean_absolute_error [T (degC), normalized]')\n",
"plt.bar(x - 0.17, val_mae, width, label='Validation')\n",
@@ -1954,7 +1976,7 @@
"outputs": [],
"source": [
"for name, value in performance.items():\n",
- " print(f'{name:12s}: {value[1]:0.4f}')"
+ " print(f'{name:12s}: {value[metric_name]:0.4f}')"
]
},
{
@@ -1979,7 +2001,7 @@
"outputs": [],
"source": [
"single_step_window = WindowGenerator(\n",
- " # `WindowGenerator` returns all features as labels if you \n",
+ " # `WindowGenerator` returns all features as labels if you\n",
" # don't set the `label_columns` argument.\n",
" input_width=1, label_width=1, shift=1)\n",
"\n",
@@ -2034,8 +2056,8 @@
"source": [
"val_performance = {}\n",
"performance = {}\n",
- "val_performance['Baseline'] = baseline.evaluate(wide_window.val)\n",
- "performance['Baseline'] = baseline.evaluate(wide_window.test, verbose=0)"
+ "val_performance['Baseline'] = baseline.evaluate(wide_window.val, return_dict=True)\n",
+ "performance['Baseline'] = baseline.evaluate(wide_window.test, verbose=0, return_dict=True)"
]
},
{
@@ -2073,8 +2095,8 @@
"history = compile_and_fit(dense, single_step_window)\n",
"\n",
"IPython.display.clear_output()\n",
- "val_performance['Dense'] = dense.evaluate(single_step_window.val)\n",
- "performance['Dense'] = dense.evaluate(single_step_window.test, verbose=0)"
+ "val_performance['Dense'] = dense.evaluate(single_step_window.val, return_dict=True)\n",
+ "performance['Dense'] = dense.evaluate(single_step_window.test, verbose=0, return_dict=True)"
]
},
{
@@ -2108,8 +2130,8 @@
"history = compile_and_fit(lstm_model, wide_window)\n",
"\n",
"IPython.display.clear_output()\n",
- "val_performance['LSTM'] = lstm_model.evaluate( wide_window.val)\n",
- "performance['LSTM'] = lstm_model.evaluate( wide_window.test, verbose=0)\n",
+ "val_performance['LSTM'] = lstm_model.evaluate( wide_window.val, return_dict=True)\n",
+ "performance['LSTM'] = lstm_model.evaluate( wide_window.test, verbose=0, return_dict=True)\n",
"\n",
"print()"
]
@@ -2132,7 +2154,7 @@
"\n",
"That is how you take advantage of the knowledge that the change should be small.\n",
"\n",
- "\n",
+ "\n",
"\n",
"Essentially, this initializes the model to match the `Baseline`. For this task it helps models converge faster, with slightly better performance."
]
@@ -2143,7 +2165,7 @@
"id": "yP58A_ORx0kM"
},
"source": [
- "This approach can be used in conjunction with any model discussed in this tutorial. \n",
+ "This approach can be used in conjunction with any model discussed in this tutorial.\n",
"\n",
"Here, it is being applied to the LSTM model, note the use of the `tf.initializers.zeros` to ensure that the initial predicted changes are small, and don't overpower the residual connection. There are no symmetry-breaking concerns for the gradients here, since the `zeros` are only used on the last layer."
]
@@ -2192,8 +2214,8 @@
"history = compile_and_fit(residual_lstm, wide_window)\n",
"\n",
"IPython.display.clear_output()\n",
- "val_performance['Residual LSTM'] = residual_lstm.evaluate(wide_window.val)\n",
- "performance['Residual LSTM'] = residual_lstm.evaluate(wide_window.test, verbose=0)\n",
+ "val_performance['Residual LSTM'] = residual_lstm.evaluate(wide_window.val, return_dict=True)\n",
+ "performance['Residual LSTM'] = residual_lstm.evaluate(wide_window.test, verbose=0, return_dict=True)\n",
"print()"
]
},
@@ -2227,9 +2249,8 @@
"width = 0.3\n",
"\n",
"metric_name = 'mean_absolute_error'\n",
- "metric_index = lstm_model.metrics_names.index('mean_absolute_error')\n",
- "val_mae = [v[metric_index] for v in val_performance.values()]\n",
- "test_mae = [v[metric_index] for v in performance.values()]\n",
+ "val_mae = [v[metric_name] for v in val_performance.values()]\n",
+ "test_mae = [v[metric_name] for v in performance.values()]\n",
"\n",
"plt.bar(x - 0.17, val_mae, width, label='Validation')\n",
"plt.bar(x + 0.17, test_mae, width, label='Test')\n",
@@ -2248,7 +2269,7 @@
"outputs": [],
"source": [
"for name, value in performance.items():\n",
- " print(f'{name:15s}: {value[1]:0.4f}')"
+ " print(f'{name:15s}: {value[metric_name]:0.4f}')"
]
},
{
@@ -2327,7 +2348,7 @@
"source": [
"A simple baseline for this task is to repeat the last input time step for the required number of output time steps:\n",
"\n",
- ""
+ ""
]
},
{
@@ -2349,8 +2370,8 @@
"multi_val_performance = {}\n",
"multi_performance = {}\n",
"\n",
- "multi_val_performance['Last'] = last_baseline.evaluate(multi_window.val)\n",
- "multi_performance['Last'] = last_baseline.evaluate(multi_window.test, verbose=0)\n",
+ "multi_val_performance['Last'] = last_baseline.evaluate(multi_window.val, return_dict=True)\n",
+ "multi_performance['Last'] = last_baseline.evaluate(multi_window.test, verbose=0, return_dict=True)\n",
"multi_window.plot(last_baseline)"
]
},
@@ -2362,7 +2383,7 @@
"source": [
"Since this task is to predict 24 hours into the future, given 24 hours of the past, another simple approach is to repeat the previous day, assuming tomorrow will be similar:\n",
"\n",
- ""
+ "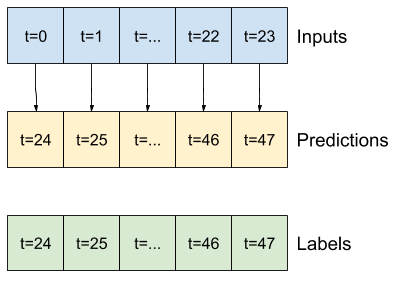"
]
},
{
@@ -2381,8 +2402,8 @@
"repeat_baseline.compile(loss=tf.keras.losses.MeanSquaredError(),\n",
" metrics=[tf.keras.metrics.MeanAbsoluteError()])\n",
"\n",
- "multi_val_performance['Repeat'] = repeat_baseline.evaluate(multi_window.val)\n",
- "multi_performance['Repeat'] = repeat_baseline.evaluate(multi_window.test, verbose=0)\n",
+ "multi_val_performance['Repeat'] = repeat_baseline.evaluate(multi_window.val, return_dict=True)\n",
+ "multi_performance['Repeat'] = repeat_baseline.evaluate(multi_window.test, verbose=0, return_dict=True)\n",
"multi_window.plot(repeat_baseline)"
]
},
@@ -2409,7 +2430,7 @@
"\n",
"A simple linear model based on the last input time step does better than either baseline, but is underpowered. The model needs to predict `OUTPUT_STEPS` time steps, from a single input time step with a linear projection. It can only capture a low-dimensional slice of the behavior, likely based mainly on the time of day and time of year.\n",
"\n",
- ""
+ "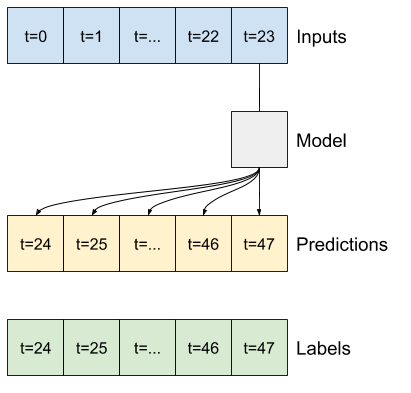"
]
},
{
@@ -2434,8 +2455,8 @@
"history = compile_and_fit(multi_linear_model, multi_window)\n",
"\n",
"IPython.display.clear_output()\n",
- "multi_val_performance['Linear'] = multi_linear_model.evaluate(multi_window.val)\n",
- "multi_performance['Linear'] = multi_linear_model.evaluate(multi_window.test, verbose=0)\n",
+ "multi_val_performance['Linear'] = multi_linear_model.evaluate(multi_window.val, return_dict=True)\n",
+ "multi_performance['Linear'] = multi_linear_model.evaluate(multi_window.test, verbose=0, return_dict=True)\n",
"multi_window.plot(multi_linear_model)"
]
},
@@ -2474,8 +2495,8 @@
"history = compile_and_fit(multi_dense_model, multi_window)\n",
"\n",
"IPython.display.clear_output()\n",
- "multi_val_performance['Dense'] = multi_dense_model.evaluate(multi_window.val)\n",
- "multi_performance['Dense'] = multi_dense_model.evaluate(multi_window.test, verbose=0)\n",
+ "multi_val_performance['Dense'] = multi_dense_model.evaluate(multi_window.val, return_dict=True)\n",
+ "multi_performance['Dense'] = multi_dense_model.evaluate(multi_window.test, verbose=0, return_dict=True)\n",
"multi_window.plot(multi_dense_model)"
]
},
@@ -2496,7 +2517,7 @@
"source": [
"A convolutional model makes predictions based on a fixed-width history, which may lead to better performance than the dense model since it can see how things are changing over time:\n",
"\n",
- ""
+ "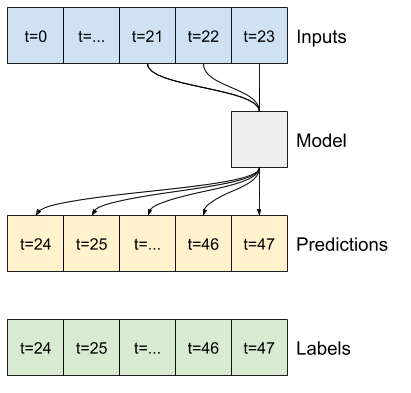"
]
},
{
@@ -2524,8 +2545,8 @@
"\n",
"IPython.display.clear_output()\n",
"\n",
- "multi_val_performance['Conv'] = multi_conv_model.evaluate(multi_window.val)\n",
- "multi_performance['Conv'] = multi_conv_model.evaluate(multi_window.test, verbose=0)\n",
+ "multi_val_performance['Conv'] = multi_conv_model.evaluate(multi_window.val, return_dict=True)\n",
+ "multi_performance['Conv'] = multi_conv_model.evaluate(multi_window.test, verbose=0, return_dict=True)\n",
"multi_window.plot(multi_conv_model)"
]
},
@@ -2548,7 +2569,7 @@
"\n",
"In this single-shot format, the LSTM only needs to produce an output at the last time step, so set `return_sequences=False` in `tf.keras.layers.LSTM`.\n",
"\n",
- "\n"
+ "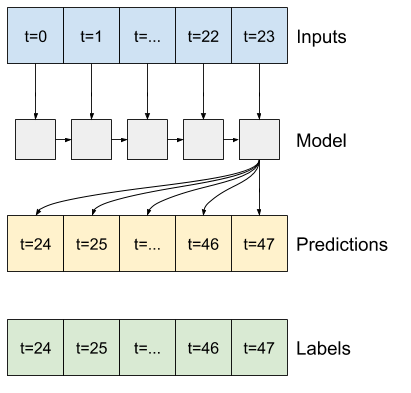\n"
]
},
{
@@ -2574,8 +2595,8 @@
"\n",
"IPython.display.clear_output()\n",
"\n",
- "multi_val_performance['LSTM'] = multi_lstm_model.evaluate(multi_window.val)\n",
- "multi_performance['LSTM'] = multi_lstm_model.evaluate(multi_window.test, verbose=0)\n",
+ "multi_val_performance['LSTM'] = multi_lstm_model.evaluate(multi_window.val, return_dict=True)\n",
+ "multi_performance['LSTM'] = multi_lstm_model.evaluate(multi_window.test, verbose=0, return_dict=True)\n",
"multi_window.plot(multi_lstm_model)"
]
},
@@ -2595,7 +2616,7 @@
"\n",
"You could take any of the single-step multi-output models trained in the first half of this tutorial and run in an autoregressive feedback loop, but here you'll focus on building a model that's been explicitly trained to do that.\n",
"\n",
- ""
+ ""
]
},
{
@@ -2794,8 +2815,8 @@
"\n",
"IPython.display.clear_output()\n",
"\n",
- "multi_val_performance['AR LSTM'] = feedback_model.evaluate(multi_window.val)\n",
- "multi_performance['AR LSTM'] = feedback_model.evaluate(multi_window.test, verbose=0)\n",
+ "multi_val_performance['AR LSTM'] = feedback_model.evaluate(multi_window.val, return_dict=True)\n",
+ "multi_performance['AR LSTM'] = feedback_model.evaluate(multi_window.test, verbose=0, return_dict=True)\n",
"multi_window.plot(feedback_model)"
]
},
@@ -2829,9 +2850,8 @@
"width = 0.3\n",
"\n",
"metric_name = 'mean_absolute_error'\n",
- "metric_index = lstm_model.metrics_names.index('mean_absolute_error')\n",
- "val_mae = [v[metric_index] for v in multi_val_performance.values()]\n",
- "test_mae = [v[metric_index] for v in multi_performance.values()]\n",
+ "val_mae = [v[metric_name] for v in multi_val_performance.values()]\n",
+ "test_mae = [v[metric_name] for v in multi_performance.values()]\n",
"\n",
"plt.bar(x - 0.17, val_mae, width, label='Validation')\n",
"plt.bar(x + 0.17, test_mae, width, label='Test')\n",
@@ -2847,7 +2867,7 @@
"id": "Zq3hUsedCEmJ"
},
"source": [
- "The metrics for the multi-output models in the first half of this tutorial show the performance averaged across all output features. These performances are similar but also averaged across output time steps. "
+ "The metrics for the multi-output models in the first half of this tutorial show the performance averaged across all output features. These performances are similar but also averaged across output time steps."
]
},
{
@@ -2859,7 +2879,7 @@
"outputs": [],
"source": [
"for name, value in multi_performance.items():\n",
- " print(f'{name:8s}: {value[1]:0.4f}')"
+ " print(f'{name:8s}: {value[metric_name]:0.4f}')"
]
},
{
@@ -2894,8 +2914,8 @@
"metadata": {
"accelerator": "GPU",
"colab": {
- "collapsed_sections": [],
"name": "time_series.ipynb",
+ "provenance": [],
"toc_visible": true
},
"kernelspec": {
diff --git a/tools/tensorflow_docs/api_generator/doc_generator_visitor.py b/tools/tensorflow_docs/api_generator/doc_generator_visitor.py
index 8776644878c..0467f74b153 100644
--- a/tools/tensorflow_docs/api_generator/doc_generator_visitor.py
+++ b/tools/tensorflow_docs/api_generator/doc_generator_visitor.py
@@ -421,6 +421,9 @@ def build(self):
duplicates = {}
for path, node in self.path_tree.items():
+ _LOGGER.debug('DocGeneratorVisitor.build')
+ _LOGGER.debug(' path: %s', path)
+
if not path:
continue
full_name = node.full_name
@@ -593,7 +596,7 @@ def _get_physical_path(self, py_object):
@classmethod
def from_path_tree(cls, path_tree: PathTree, score_name_fn) -> ApiTree:
- """Create an ApiTree from an PathTree.
+ """Create an ApiTree from a PathTree.
Args:
path_tree: The `PathTree` to convert.
diff --git a/tools/tensorflow_docs/api_generator/generate_lib.py b/tools/tensorflow_docs/api_generator/generate_lib.py
index cb0e3916927..fdeb0f60601 100644
--- a/tools/tensorflow_docs/api_generator/generate_lib.py
+++ b/tools/tensorflow_docs/api_generator/generate_lib.py
@@ -15,11 +15,11 @@
"""Generate tensorflow.org style API Reference docs for a Python module."""
import collections
+import logging
import os
import pathlib
import shutil
import tempfile
-
from typing import Any, Optional, Sequence, Type, Union
from tensorflow_docs.api_generator import config
@@ -29,11 +29,8 @@
from tensorflow_docs.api_generator import reference_resolver as reference_resolver_lib
from tensorflow_docs.api_generator import toc as toc_lib
from tensorflow_docs.api_generator import traverse
-
from tensorflow_docs.api_generator.pretty_docs import docs_for_object
-
from tensorflow_docs.api_generator.report import utils
-
import yaml
# Used to add a collections.OrderedDict representer to yaml so that the
@@ -42,6 +39,9 @@
# Using a normal dict doesn't preserve the order of the input dictionary.
_mapping_tag = yaml.resolver.BaseResolver.DEFAULT_MAPPING_TAG
+# To see the logs pass: --logger_levels=tensorflow_docs:DEBUG --alsologtostderr
+_LOGGER = logging.getLogger(__name__)
+
def dict_representer(dumper, data):
return dumper.represent_dict(data.items())
@@ -121,6 +121,9 @@ def write_docs(
# Parse and write Markdown pages, resolving cross-links (`tf.symbol`).
num_docs_output = 0
for api_node in parser_config.api_tree.iter_nodes():
+ _LOGGER.debug('generate_lib.write_docs')
+ _LOGGER.debug(' full_name: %s', api_node.full_name)
+
full_name = api_node.full_name
if api_node.output_type() is api_node.OutputType.FRAGMENT:
@@ -391,7 +394,6 @@ def make_default_filters(self) -> list[public_api.ApiFilter]:
public_api.FailIfNestedTooDeep(10),
public_api.filter_module_all,
public_api.add_proto_fields,
- public_api.filter_builtin_modules,
public_api.filter_private_symbols,
public_api.FilterBaseDirs(self._base_dir),
public_api.FilterPrivateMap(self._private_map),
diff --git a/tools/tensorflow_docs/api_generator/parser_test.py b/tools/tensorflow_docs/api_generator/parser_test.py
index ee8a55f707f..0bfffeded92 100644
--- a/tools/tensorflow_docs/api_generator/parser_test.py
+++ b/tools/tensorflow_docs/api_generator/parser_test.py
@@ -799,7 +799,7 @@ class A():
self.assertEqual('Instance of `m.A`', result)
- def testIsClasssAttr(self):
+ def testIsClassAttr(self):
result = parser.is_class_attr('test_module.test_function',
{'test_module': test_module})
self.assertFalse(result)
@@ -808,6 +808,7 @@ def testIsClasssAttr(self):
{'TestClass': TestClass})
self.assertTrue(result)
+
RELU_DOC = """Computes rectified linear: `max(features, 0)`
RELU is an activation
diff --git a/tools/tensorflow_docs/api_generator/public_api.py b/tools/tensorflow_docs/api_generator/public_api.py
index c9803ee04e3..e6a994bff5b 100644
--- a/tools/tensorflow_docs/api_generator/public_api.py
+++ b/tools/tensorflow_docs/api_generator/public_api.py
@@ -489,27 +489,3 @@ def add_proto_fields(path: Sequence[str], parent: Any,
children = sorted(children.items(), key=lambda item: item[0])
return children
-
-
-def filter_builtin_modules(path: Sequence[str], parent: Any,
- children: Children) -> Children:
- """Filters module children to remove builtin modules.
-
- Args:
- path: API to this symbol
- parent: The object
- children: A list of (name, object) pairs.
-
- Returns:
- `children` with all builtin modules removed.
- """
- del path
- del parent
- # filter out 'builtin' modules
- filtered_children = []
- for name, child in children:
- # Do not descend into built-in modules
- if inspect.ismodule(child) and child.__name__ in sys.builtin_module_names:
- continue
- filtered_children.append((name, child))
- return filtered_children
diff --git a/tools/tensorflow_docs/api_generator/signature.py b/tools/tensorflow_docs/api_generator/signature.py
index 7ef8f1f856d..dacf5d2bada 100644
--- a/tools/tensorflow_docs/api_generator/signature.py
+++ b/tools/tensorflow_docs/api_generator/signature.py
@@ -580,7 +580,7 @@ def generate_signature(
sig = sig.replace(parameters=params)
- if dataclasses.is_dataclass(func):
+ if dataclasses.is_dataclass(func) and inspect.isclass(func):
sig = sig.replace(return_annotation=EMPTY)
extract_fn = _extract_class_defaults_and_annotations
else:
diff --git a/tools/tensorflow_docs/api_generator/toc.py b/tools/tensorflow_docs/api_generator/toc.py
index 1e72bcda75c..feaa15b8bda 100644
--- a/tools/tensorflow_docs/api_generator/toc.py
+++ b/tools/tensorflow_docs/api_generator/toc.py
@@ -273,7 +273,7 @@ def _is_deprecated(self, api_node: doc_generator_visitor.ApiTreeNode):
api_node: The node to evaluate.
Returns:
- True if depreacted else False.
+ True if deprecated else False.
"""
if doc_controls.is_deprecated(api_node.py_object):
return True
diff --git a/tools/tensorflow_docs/tools/nbfmt/__main__.py b/tools/tensorflow_docs/tools/nbfmt/__main__.py
index 9426e6fd690..f09b0c27192 100644
--- a/tools/tensorflow_docs/tools/nbfmt/__main__.py
+++ b/tools/tensorflow_docs/tools/nbfmt/__main__.py
@@ -99,16 +99,17 @@ def clean_root(data: Dict[str, Any], filepath: pathlib.Path) -> None:
data, keep=["cells", "metadata", "nbformat_minor", "nbformat"])
# All metadata is optional according to spec, but we use some of it.
notebook_utils.del_entries_except(
- data["metadata"], keep=["accelerator", "colab", "kernelspec"])
+ data["metadata"], keep=["accelerator", "colab", "kernelspec", "google"]
+ )
metadata = data.get("metadata", {})
- colab = metadata.get("colab", {})
# Set top-level notebook defaults.
data["nbformat"] = 4
data["nbformat_minor"] = 0
# Colab metadata
+ colab = metadata.get("colab", {})
notebook_utils.del_entries_except(
colab, keep=["collapsed_sections", "name", "toc_visible"])
colab["name"] = os.path.basename(filepath)
@@ -128,6 +129,15 @@ def clean_root(data: Dict[str, Any], filepath: pathlib.Path) -> None:
kernelspec["display_name"] = supported_kernels[kernel_name]
metadata["kernelspec"] = kernelspec
+ # Google metadata
+ google = metadata.get("google", {})
+ notebook_utils.del_entries_except(google, keep=["keywords", "image_path"])
+ # Don't add the field if it's empty.
+ if google:
+ metadata["google"] = google
+ else:
+ metadata.pop("google", None)
+
data["metadata"] = metadata
diff --git a/tools/tensorflow_docs/tools/nbfmt/nbfmtmain_test.py b/tools/tensorflow_docs/tools/nbfmt/nbfmtmain_test.py
new file mode 100644
index 00000000000..5f07c103cab
--- /dev/null
+++ b/tools/tensorflow_docs/tools/nbfmt/nbfmtmain_test.py
@@ -0,0 +1,74 @@
+# Copyright 2024 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Unit tests for nbfmt."""
+import pathlib
+import unittest
+from nbformat import notebooknode
+from tensorflow_docs.tools.nbfmt import __main__ as nbfmt
+
+
+class NotebookFormatTest(unittest.TestCase):
+
+ def test_metadata_cleansing(self):
+ subject_notebook = notebooknode.NotebookNode({
+ "cells": [],
+ "metadata": {
+ "unknown": ["delete", "me"],
+ "accelerator": "GPU",
+ "colab": {
+ "name": "/this/is/clobbered.ipynb",
+ "collapsed_sections": [],
+ "deleteme": "pls",
+ },
+ "kernelspec": {
+ "display_name": "Python 2 foreverrrr",
+ "name": "python2",
+ "deleteme": "deldeldel",
+ },
+ "google": {
+ "keywords": ["one", "two"],
+ "image_path": "/foo/img.png",
+ "more_stuff": "delete me",
+ },
+ },
+ })
+
+ expected_notebook = notebooknode.NotebookNode({
+ "cells": [],
+ "metadata": {
+ "accelerator": "GPU",
+ "colab": {
+ "name": "test.ipynb",
+ "collapsed_sections": [],
+ "toc_visible": True,
+ },
+ "kernelspec": {
+ "display_name": "Python 3",
+ "name": "python3",
+ },
+ "google": {
+ "keywords": ["one", "two"],
+ "image_path": "/foo/img.png",
+ },
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0,
+ })
+
+ nbfmt.clean_root(subject_notebook, pathlib.Path("/path/test.ipynb"))
+ self.assertEqual(subject_notebook, expected_notebook)
+
+
+if __name__ == "__main__":
+ unittest.main()
diff --git a/tools/tensorflow_docs/tools/nblint/decorator.py b/tools/tensorflow_docs/tools/nblint/decorator.py
index 408fef3d969..d74045c7ca7 100644
--- a/tools/tensorflow_docs/tools/nblint/decorator.py
+++ b/tools/tensorflow_docs/tools/nblint/decorator.py
@@ -161,7 +161,7 @@ def fail(message: Optional[str] = None,
Failure messages come in two flavors:
- conditional: (Default) While this test may fail here, it may succeed
- elsewhere, and thus, the larger condition passes and do not dislay this
+ elsewhere, and thus, the larger condition passes and do not display this
message.
- non-conditional (always show): Regardless if the larger condition is met,
display this error message in the status report. For example, a