Liquid templates
When customizing Aperta to suit a Journal's needs, emails likely rate near the top of the list. In order to allow the staff to provide good email structure we looked to Liquid Markup.
This template language marries the internal data with user-provided emails. For any given scenario or context, certain data is available to present in the message body.
Before diving into the Aperta specifics, a brief overview of how Liquid
works will set the stage. The template engine provides two main
functions: parse and render.
The first step is to parse the template. Liquid looks for the object (merge fields) that will supply content. It looks for any control flow or logic tags. And it looks for filters that manipulate the incoming data.
After parsing and preparing a template, the next step is to render the template. Taking the parsed template, the applied data provides the content, or control to generate the output desired.
The best parallel is to think of this operating like Ruby's ERB. You specify a template and pass in the data bindings to generate results.
The models involved in templating fall into these categories: contexts (Section * Contexts), scenarios (section * Scenarios), base email templates, and serializers. Figure fulldiagram shows their fields and interactions.
The contexts and scenarios are similar and define the merge fields for the given templates.
The email templates themselves are ERB templates already in Aperta. It
is a good idea to keep these templates for any styling in the emails or
set headers or footers. This achieves a common look and feel without
delegating boilerplate to the templates themselves.
Keeping the base emails in ERB also lets the system add in necessary
components that would be difficult to keep consistent in the templates
themselves. Consider an invitation with the accept and decline
buttons. By keeping a base ERB template for invitations, we can ensure
that these are always present and working consistently through the
invitation workflow.
At the root of all of the wrapping objects lies the TemplateContext.
All of the Contexts and Scenarios derive from this base class. That
is for two main reasons.
First, it derives from Liquid::Drop which lets the Liquid rendering
engine discover and traverse the fields. We could have passed in
regulars hashes as the data to feed the models. However, if we do things
cleverly there may be a better way.
That leads us to the second point. The TemplateContext contains some
of the magic for making it easy to build up the wrapping objects easily
and then query the structures to guide template authoring later. In the
following sections, we'll see how whitelist and subcontext let us
build up terse classes to support the merge fields. In many cases, these
can be thought of special cases of delegate_to on the objects.
The closest analogy for how the metaprogramming and intention of these classes work is Rails' serializers. To support the data binding (and nested traversal) for Liquid, we have to wrap everything. This is very similar to choosing which fields for any model get streamed to the client.
At the bottom or leaf of any deep data traversal is a context. These basic wrappers map 1-to-1 to models and expose only some of the underlying fields to templates.
class JournalContext < TemplateContext
whitelist :name, :logo_url, :staff_email
endListing journalcontext shows the implementation for
JournalContext. The whitelist helper explicitly states the fields
available to the template.
Aperta uses Scenarios as the basis for any rendering context. This is
the root object that Liquid uses for the data to fill in the template.
They sometimes refer to a task such as RegisterDecisionScenario or a
model like the PaperScenario
class PaperScenario < TemplateContext
subcontext :journal
subcontext :manuscript, type: :paper, source: :object
endListing paperscenario shows the PaperScenario
implementation. This scenario has just two basic fields: journal and
manuscript. Thanks to the helpers provided by TemplateContext, the
class definition is terse and readable. The base object, a paper in this
case, has a journal field on it with a type of Journal. And the
accessor wraps the field in a JournalContext so Liquid can handle the
sub-context.
This means that in our template, we can refer to our journal with just
journal. That is a powerfully concise way to allow the data traversal
with one line!
Although not the same under the hood, the usage of subcontext feels
similar to a has_one definition. The composition of the sub-contexts
for PaperScenario makes it so the scenario has these relationships.
In the second sub-context definition, we are not so lucky as to have the
name be the same as the field. We have the name, manuscript, refer to
something of type paper. The source for this is object. The object
field is special here. It comes from TemplateContext, so has a generic
name. The basic idea is that each Scenario needs one source of truth
model. Here, we know it is going to be a Paper model. This last field
is really naming the underlying object to have the name manuscript in
the template have a PaperScenario wrapper.
Naturally, the use cases extend beyond the simple implementations presented earlier. Examples of more advanced sub-contexts follow.
Naturally, after crafting the basic usages, development moves on to the more advanced cases. Remember that most of the scenarios are still wrapping only one object as the source of truth. In practice this works well.
class InvitationScenario < TemplateContext
subcontext :journal, source: [:object, :paper, :journal]
subcontext :manuscript, type: :paper, source: [:object, :paper]
subcontext :invitation, source: :object
endFor more complex object traversal the helpers allow the source field some verbosity. Listing invitationscenario shows how to get to a deeply nested object.
The journal goes from object (Invitation in this case) to paper
which has journal. The :source argument is just this list of
traversals.
Note the omission of :type on :journal since the name is the type.
The following field, manuscript needs to have a type since it cannot
be constructed from the field name.
Not all fields are single-value. Many may be lists of values or objects.
Again, the helpers come into play here with subcontexts. These
specifiy an array return value.
1 class PaperContext < TemplateContext
2 include UrlBuilder
3
4 whitelist :title, :abstract, :paper_type, :url
5 subcontexts :academic_editors, type: :user
6 subcontexts :handling_editors, type: :user
7 subcontexts :authors, type: :author
8 subcontexts :corresponding_authors, type: :author
9 subcontext :editor, type: :user
10
11 def editor
12 return if object.handling_editors.empty?
13 UserContext.new(object.handling_editors.first)
14 end
15
16 def url
17 url_for(:paper, id: object.id).sub("api/", "")
18 end
19 endIn line line (authors) of Listing papercontext there
is a subcontexts definition for authors. The underlying object has a
field of the same name. And the type is set to be author so that the
returned list is wrapped correctly.
Line (editorfn) of Listing papercontext also shows how
to use functions to define merge fields. The editor field is only
filled in (and wrapped) if the handling editors list is not empty.
Note that there is still a subcontext definition letting the
underlying system know of the field type.
The letter template is the actual template to render for the emails. Figure lettertemplate shows the class diagram.
file
This model holds a set of strings supporting the email template. The
primary helper is scenario which describes the relevant scenario
providing the data to the template. By doing this, the template authors
also see the available fields when editing templates.
All of the other fields are also mini-templates and rendered with
Liquid. This includes the bcc, cc and to fields. The body is the
main actor and reason for templates. The subject can also be dynamic
based on the data.
Keep in mind that these are the generic versions of a letter. These are
not the letter themselves, but blueprints for rendering available data
into an email. Any letter storage (post-rendering) must happen in the
models that require this persistence (e.g. Invitations).
To facilitate the list of available merge fields, a helper class called
MergeField provides an interface. This helper, shown in Figure
mergefield , has three small bits of functionality.
First, contexts will register themselves with register_subcontext.
This connects the parent context with the one in question, keeping track
of this hierarchy.
The main workhorse is list_for. This method accepts a context class
and returns the list of merge fields for display on the editing page.
Here is where the tree follows the children all the way to the leaf
contexts. It also excludes any unnecessary fields for display by
checking the hash returned by a call to unlisted.
The unlisted method generates a small hash mapping the context to a
list of fields to omit.
Most of the time no direct interaction with this class is necessary. The
TemplateContext helper methods do all of the work to tie into
MergeField. Only when a developer would need an unlisted field would
this need editing.
It wouldn't be fun for all of this templating power to exist in a vaccuum would it? No, of course not! Some of the basic interesting interaction examples follow.
The basic use-case for sending letters is complex enough to warrant a walk-through. The act of registering a decision is a prime example.
Figure serializer lists the rendering steps for
registering a decision. Starting from the LetterTemplate in the
database, Aperta grabs the relevant template(s). The
RegisterDecisionTaskSerializer uses the RegisterDecisionScenario to
render the relevant templates on the fly to the client.
The client receives letters with the data filled in according to the template. At this point, the user chooses the correct letter template and customizes as needed for the given manuscript. Figure rendered_template illustrates a rendered template.
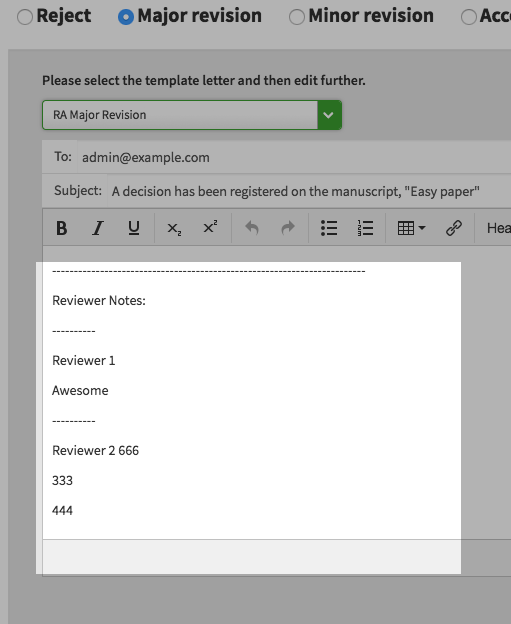
The final state for this example is registering a decision. Making a decision saves the letter and sends it on. No modification of the original template happens here. The templates are only filled out during packing and sending to the front end.
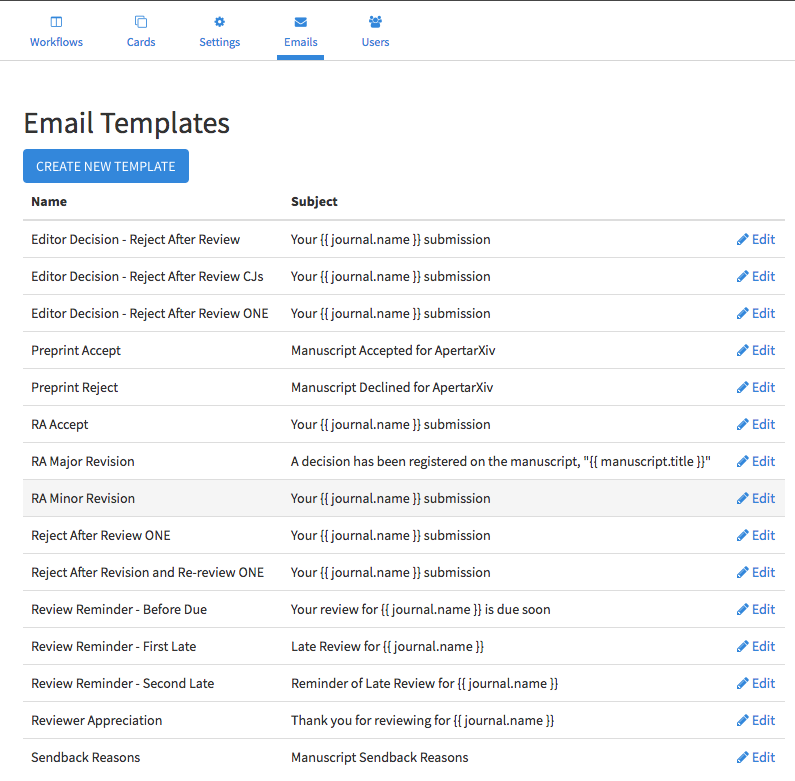
An administrator can see the list of email templates on the Emails tab in the journal administration section. Figure templatelist shows the current list. Each template will have a name and a subject. It isn't clear on the list, but each template also has an associated scenario for which it is valid.
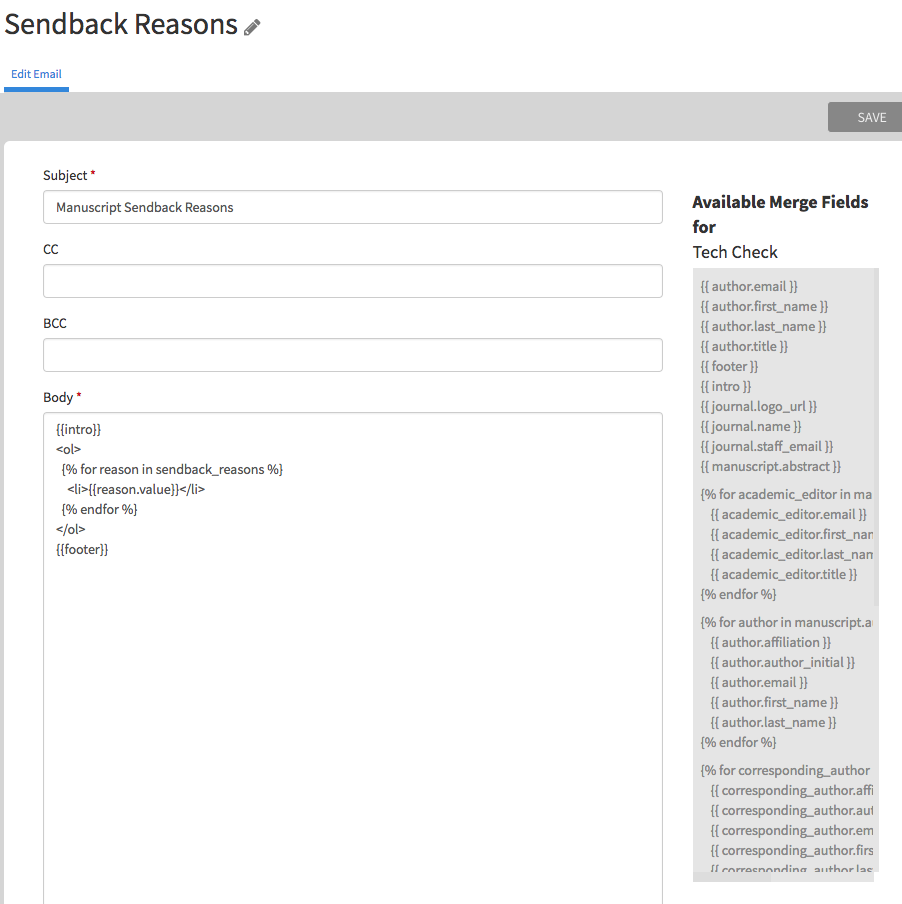
Edit any of the existing templates with the links off to the right of Figure templatelist . The template editor in Figure edittemplate allows administrators to add the correct subject, CC, BCC and body content. Any of these can use the merge fields in the helper box off to the right.
Note that the TO field is not present. Aperta predefines the recipients, or determines them outside of the template's reach. In this way, the system maintains full control over where the emails go.
When editing, a list of merge fields for the associated scenario appears
on the page. Figure templatemergefields shows this
list. These cut-and-paste items can drop easily into the body content.
Note the for list items, this cheat sheet even has the for-loops
spelled out.
file

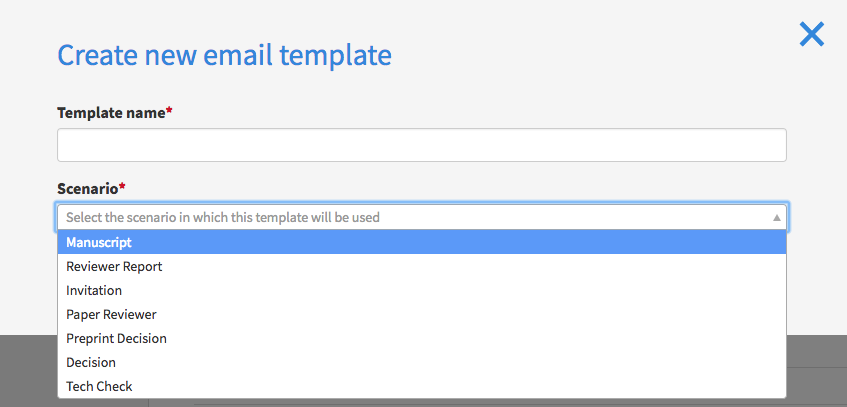
To create a new template, simply press the big blue button in Figure templatelist and you will be met with Figure newtemplate . After suppling a name and scenario the same edit screen will appear to complete the template.
The following suggestions are ideas to smooth out some of the rough edges using the templates in Aperta. None of these are critical to the success but are, in the opinion of the author, ways to make the experience shine.
The template list in Figure templatelist has some deficiencies. First, there is no way to delete a template. Enabling this power requires some thought to avoid easy data loss, but it seems to be a necessity as the system evolves.
Another enhancement would be to list out the scenarios or group the templates by the scenarios they serve. The latter seems useful to get an overview of the related content in one quick overview.
The display of the available merge fields is a necessary utility to help template authors complete the task. But, not all content may be clear from the merge field name. There are two ways (mutually inclusive) to address this concern.
First, it may be allowable to have a comment on a merge field. Maybe in
the definition for whitelist or subcontext it could take a comment
along with the field. Then, on the cheat-sheet, the comments would help
the user understand the intention and data the field provides.
Although more difficult, another strategy would show the template in question using dummy data. The implementation would require that some benign data exist for every scenario and context in the system. This complex task would culminate in a preview of the letter template for the author. I leave the implementation details to the reader.
Unlike the contexts which map 1-1 for models, a scenario is a
composition. Even so, it still derives from TemplateContext and has
one base object driving the data availability.
Listing or enforcing the base object type could enhance the usage of
scenarios. Clearly labeling the intended object type helps inform the
instantiation of each scenario.
First, the Liquid Markup reference is a great place to get started on designing the right email templates. There is also the home of the liquid gem that can provide more technical information on how to integrate and use the template engine.
On Confluence, you can find documentation and status on Email Templating.
Besides the screenshots, I used a couple of other tools to generate diagrams for this report. These details follow.
Listing serializer generates the sequence diagram to illustrate an example rendering workflow.
Error rendering macro 'code': Invalid value specified for parameter 'lang'
skinparam monochrome true
== Rendering ==
LetterTemplate -> RegisterDecisionTask : Retreive Template
RegisterDecisionTask -> Client : Render Template and serialize to Client
== Customization and Sending ==
Client -> Client : Edit letter
Client -> RegisterDecisionTask : Save and send modified letter
A new rake task, reports:make_letter_template_scenario_diagrams,
generates graphviz output illustrating the connections between scenarios
and contexts. Listing rakedot shows how to make your
own.
rake reports:make_letter_template_scenario_diagrams | dot -Tpdf > scenarios_and_contexts.pdfTo generate the ERDs, I used the
rails-erd gem. The
installation is easy. Add it to the Gemfile and run. The command line
I used for the LetterTemplate diagram above is in Listing
lettertemplate .
rake erd only="LetterTemplate" filename="lettertemplateerd" filetype="pdf" title=falseThe MergeField diagram consists of a dot-style description of the
class. Listing mfdiagram shows the code to generate
this diagram.
Error rendering macro 'code': Invalid value specified for parameter 'lang'
digraph MergeField {
rankdir = "TB"
node[shape="Mrecord", fontsize = "10", fontname = "ArialMT"]
MergeField [label =<{<table align="center" border="0">
<tr><td>MergeField Methods</td></tr>
</table>
|
<table align="left" border="0">
<tr>
<td align="left">
list_for<font color='grey60'>(context)</font>
</td>
</tr>
<tr>
<td align="left">
register_subcontext<font color='grey60'>(context,name,props)</font>
</td>
</tr>
<tr>
<td align="left">
unlisted<font color='grey60'>()</font>
</td>
</tr>
</table>
}>]
}
Footnotes
_________
A merge field names a dynamic piece of content filled in (rendered) by the template
decision_and_reviewer_reports.png (image/png)
available_merge_fields.png (image/png)
template_list.png (image/png)
new_template.png (image/png)
edit_template.png (image/png)
serializer.eps (application/postscript)
scenarios_and_contexts.pdf (application/pdf)
mergefield.pdf (application/pdf)
lettertemplateerd.pdf (application/pdf)
serializer.pdf (application/pdf)