最近想要翻译一些技术文档,由于一些专业术语需要确保一致性,所以接触到了 CAT(计算机辅助翻译)软件,最终选择了 memoQ,它有一款 PDF 外部预览插件,可以实时预览待翻译句段在 PDF 原文中的位置,这是我选择它的一个重要理由(使用一段时间后,发现它并不能完全满足我的需求,我又为 memoQ 开发了 Word 外部预览插件)。
由于 memoQ 是一款国外软件,国内的翻译服务提供商几乎没有接入,已有的 Tmxmall 和 Intento 插件虽然服务端集成了国内外几十家提供商,但不能填写提供商自家的 Key,各家提供商每月赠送有一定量的免费额度,使用 Tmxmall 或 Intento 无法享受这种优惠,且这两款插件都没有翻译缓存功能,所以有了本插件。
插件仅在 memoQ 9.14 和 11.4 版本中进行测试,其他版本如出现问题,请进行反馈。 由于 memoQ 上手有一定难度,因此特别写了一篇最佳实践的图文教程。
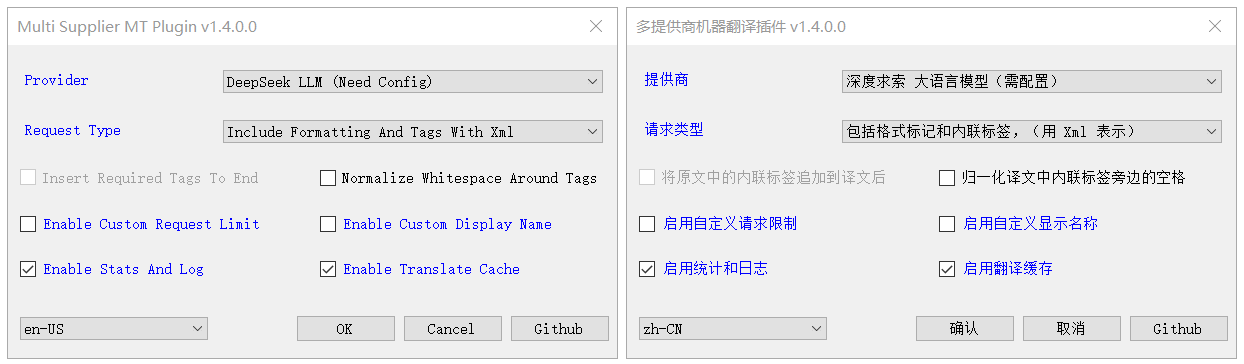
✔ 多服务提供商(上百家)、多重安装(将插件安装多次)、多语言界面
✔ 服务提供商管理:自定义添加 OpenAI 兼容提供商、启用或禁用提供商
✔ 大语言模型支持:批量翻译、术语表、上下文、翻译记忆、全文摘要
✔ 请求类型: 仅纯文本 、包括格式标记 、包括格式标记和标签
✔ 标记或标签表示:Xml 、Html
✔ 不带标签的请求:将原文中的标签追加到译文后(可选开启)
✔ 携带标签的请求:归一化译文中标签旁边的空格(可选开启)
✔ 批量翻译:多个句段只需发送一个请求
✔ 并行请求:多个请求可以同时并行发送
✔ 请求限大小:一个请求最多只能包含一定数量的句段或字符
✔ 请求限速率:某时间段内最多只能发送一定数量的请求
✔ 请求限并发:任意时刻最多只有一定数量的请求正在执行
✔ 请求失败重试:超时失败时间 、重试等待时间 、失败重试次数
✔ 翻译缓存:默认开启,缓存保留在数据库中,永久有效
✔ 其他功能:请求日志、请求数统计、自定义显示名称
展开查看
储存(人工)翻译结果:(Director.StoringTranslationSupported),(当在 memoQ 中确认某段翻译时,会将原文和译文发送给插件,插件可以用来自学习,或储存为翻译缓存),(已支持,暂时只用来储存为缓存)
使用 “MT(机器翻译)” 来修正 “TM(翻译记忆)”:(Engine.SupportsFuzzyCorrection),(如果源句段有 TM 匹配,但并不完美,memoQ 将尝试通过将差异发送给 MT 进行翻译来改进建议),(已支持,暂时未用到)
使用 “MetaData(元数据)” 来辅助 “MT(机器翻译)”:(ISessionWithMetadata 接口),(用户翻译项目设置的元信息,比如 PorjectID、Client、Domain、Subject 等,可用于辅助翻译,memoQ 9.14 版本开始提供),(已支持,用来辅助获取译文、上文、下文、摘要、全文)
使用 “TM(翻译记忆)” 来辅助 “MT(机器翻译)”:(Director.SupportFuzzyForwarding),(除了要翻译的源句段之外,memoQ 还会将最佳可用 TM 匹配的源文本和目标文本发送给 MT,memoQ 10.0 版本开始提供),(已支持,用户可在在大模型提示词中使用它)
将 Release 中的 MultiSupplierMTPlugin.dll 放入到 memoQ 插件目录下:
- 对于 memoQ,目录为
C:\Program Files\memoQ\memoQ-{版本号}\Addins。 - 对于 memoQ Server,目录为
C:\Program Files\Kilgray\MemoQ Server\Addins。
插件未经过签名,每次启动 memoQ 都会询问是否加载,如果不想每次询问:
- 对于 memoQ,将
ClientDevConfig.xml放入到%programdata%\MemoQ目录下。 - 对于 memoQ Server,将
UserApprovedUnsignedMTplugins.xml放入到%programdata%\MemoQ Server目录下。
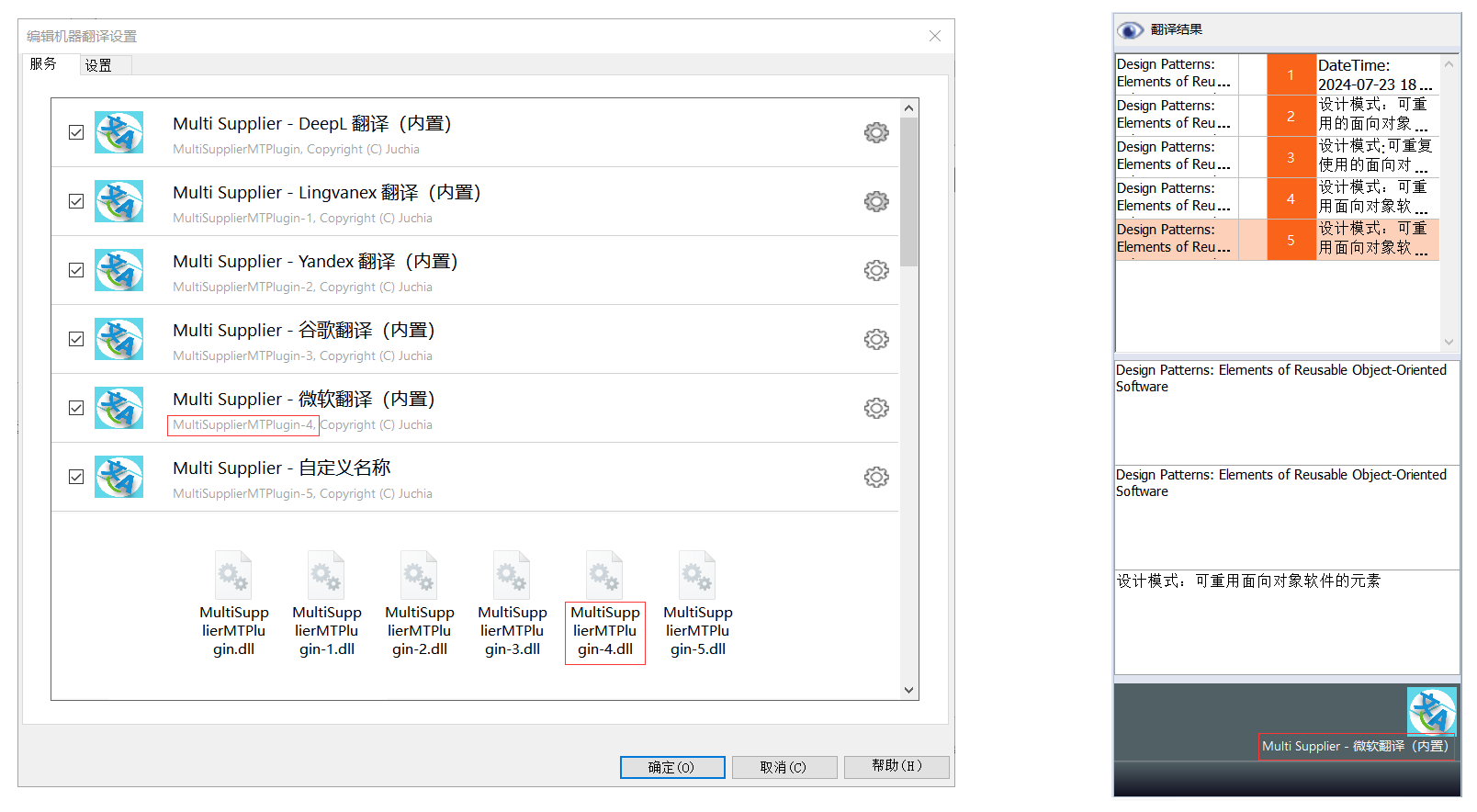
使用 Release 中的 Dll Generator.exe 生成所需数量的 dll 文件,将其一同和 MultiSupplierMTPlugin.dll 放入到插件目录下。
虽然可以重命名 dll 为任何名字,但不建议这么做,因为下一个版本发布时,又得手动重命名为原来的名字才能关联到已保存的配置。
请一定要使用 Dll Generator.exe 生成 dll,而不是直接复制后重命名,否则多重安装将会产生错误,除非等到 这个 问题得到解决。

原文中“Hello”是加粗的,“World!”是红色字体,机器翻译时的原文请求区别如下:
- 纯文本:
Hello World! - 包括格式标记:
<b>Hello<\b> World! - 包括格式标记和标签:
<b>Hello<\b> <inline_tag id="0">World!<inline_tag id="0"/>
为了翻译后的排版效果和原文保持一致,要求翻译时将格式标记(比如加粗、斜体、下划线,上标、下标等)和标签(比如字体颜色、背景颜色、链接等)放置到适当的位置。格式标记或标签有两种形式表示,一是使用 Xml 标准表示,二是使用 Html 标准表示,各家支持的情况请看提供商表格中的“支持 Xml 或 Html”。
- 如果服务提供商支持批量翻译,插件默认限制每个请求最多 3000 字符,然后不再限制每个请求的句段数。
- 如果服务提供商不支持批量翻译,插件强制每个请求只会翻译 1 个句段,然后不再限制每个请求的字符数。
- 如果 QPS 已知,插件默认速率限制设置为已知 QPS 的 90%,插件的默认并发限制设置为等于已知的 QPS 值。
- 如果 QPS 不详,插件默认速率限制设置为每秒 5 个请求,默认并发限制也设置为最多 5 个请求正在同时执行。
- 所有服务提供商的默认超时失败时间、重试等待时间、重试最大次数的值都为 0,也就是默认不进行重试操作。
用户可自定义请求限制,当大小、速率、并发限制设置为 0 时代表不限制,重试限制设置为 0 时则代表不重试。执行预翻译(批量翻译)时,最大句段数还受到 memoQ 的限制,默认值为最多 10 个句段,可修改 C:\Program Files\memoQ\memoQ-{版本号}\MemoQ.exe.config 中的 BatchSize 值来改变它。
主流大语言模型提供商都已支持提示词缓存功能,使用该功能将降低服务延迟和费用。
使用缓存功能时,各提供商对输入 Token 长度有不同要求,且缓存的写入或读取的价格和失效时间也有差别:
| 提供商 | Token 最低输入长度 | 写入价格倍率 | 读取价格倍率 | 缓存失效时间 |
|---|---|---|---|---|
| DeepSeek | 64(各模型相同) | 1.0 | 0.1 | 几个小时到几天 |
| OpenAI | 1024(各模型相同) | 1.0 | 0.5 | 5~10 分钟 |
| 1024(因模型而异) | 1.0 | 0.25 | 3-5 分钟 | |
| Anthropic | 1024(因模型而异) | 1.25 | 0.1 | 5 分钟 |
以 Anthropic Claude 为例,假设提示词长度每次都固定为 1 万 Token:
- 第一次请求,执行写入缓存操作,消耗 1 * 1.25 = 1.25 万的输入 Token
- 之后的每次请求,执行读取缓存操作,消耗 1 * 0.1 = 0.1 万的输入 Token
- 连续 5 分钟无任何缓存读取操作,再次执行请求,消耗和第一次请求相同
每次请求时,只有提示词不变的前缀(系统、用户提示词先拼接在一起,拼接后的首个字符到首个变化字符间的字符)能缓存。
所以应将每次请求时值都不会动态改变的占位符(比如 {{summary-text}}、{{full-text}} 等)放置到提示词的靠前位置。
而每次请求时值都会动态改变的占位符(比如 {{glossary-text}}、{{source-text}} 等),应该放置到提示词的靠后位置。
对于 DeepSeek 和 OpenAI 等它们没有对提示词缓存写入收取额外费用(价格倍率 1.0),所以提示词缓存功能默认开启且无法关闭。
对于 Anthropic ,写入将收取 25% 的额外费用(价格倍率 1.25),如果提示词没有按照上述写法来写,开启缓存有可能导致更多的费用。
你可以启用插件日志,然后从中查看 Token 的使用情况(包含提示词缓存的写入和读取信息),并及时调整提示词,以防提示词缓存失效。
“System Prompt” 或 “User Prompt” 中可以使用以下占位符(提供右键菜单快捷插入),它们最终将被实际内容替代:
{{source-language}}:源语言{{target-language}}:目标语言
限制:无
{{source-text}}:源文本(待翻译文本){{target-text}}:目标文本(已翻译文本)
限制(该限制仅针对目标文本):需 memoQ 9.14+ 、需同意启用预览助手、无法在预翻译中使用。
{{tm-source-text}}:和待翻译文本最佳匹配的翻译记忆源文本{{tm-target-text}}:和待翻译文本最佳匹配的翻译记忆目标文本
限制:需 memoQ 10.0+ 、需开启“Send best fuzzy TM”选项
{{above-text}}:待翻译文本的上文(可包括译文){{below-text}}:待翻译文本的下文(可包括译文)
限制:需 memoQ 9.14+、需同意启用预览助手、无法在预翻译中使用
-
{{summary-text}}:全文摘要(不包括译文) -
{{full-text}}:全文文本(不包括译文)
限制:需 memoQ 9.14+ 、需同意启用预览助手
{{glossary-text}}:术语表
限制:需术语表文件的编码格式为 UTF-8
(无特殊说明,略)
获取到的 target-text 不包含标签信息,所以不能在提示词中仅使用 target-text 来让 AI 润色译文,否则得到的结果会缺失原有标签。
一种曲线救国的方式是把带标签的 source-text 和不带标签的 target-text 一起放入提示词,让 AI 润色译文的同时把 source-text 中的标签放入到译文适当位置。
还有一种曲线救国的方式是新建一个干净的翻译记忆库,确认当前所有翻译以便将翻译保存到翻译记忆库中,然后使用 tm-target-text 代替 target-text 占位符。
翻译记忆指的是 memoQ 中的翻译记忆,而不是插件的翻译缓存,这两个占位符要求 memoQ 最低版本 10.0,且必须在 memoQ 机器翻译设置中开启以下选项:
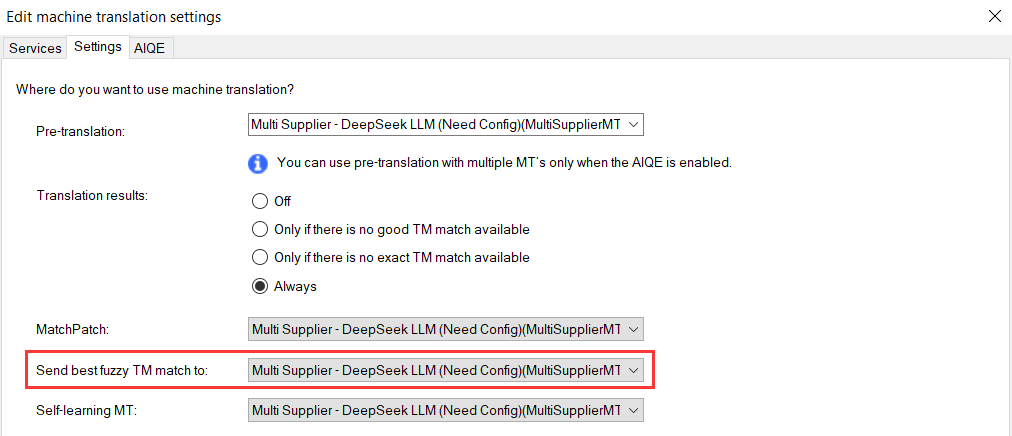
如果是普通用户,应优先考虑调整 memoQ 分段规则,使其产生更长的句段,这样自带上下文效果,便可以不携带上下文,达到节省 Token 的目的。
如果是翻译工作者,且不得不使用较短的分段规则,那么请根据实际情况调整携带的上下文句段数或字符数,以在翻译效果和消耗 Token 数之间平衡。
自定义这两个占位符的 最大句段数 和 最大字符数 选项时:设置为 0,代表不限制其数量,但为了防止意外附带全文,两者同时设置为 0 将得到空内容。
{{summary-text}} 的实际内容可以手动指定,此时它将对全部的文档生效,也可由大语言模型自动生成,此时每个文档都有自己的摘要。
摘要只会自动生成一次,然后保存到文件缓存中,之后每次从缓存中读取,除非将文档从 memoQ 删除后重新导入或手动删除缓存文件,否则不会重新生成。
缓存文件保存在 %appdata%/MemoQ/Plugins/MultiSupplierMTPlugin/Cache/Summary 目录下,以 [summary]-[文档原始文件名]-[文档的 GUID].txt 命名,比如 [summary]-[我的文档.doc]-[1ee7154a-47b7-4e82-bc48-f99b3728f233].txt,你可以检查并修正自动生成的摘要内容。
{{full-text}} 占位符一般只用在自动生成摘要的提示词中,请谨慎使用在翻译时的系统或用户提示词中,它会在请求中附带全文文本,消耗您大量的 Token。
术语文件支持 memoQ 导出的多语言列 CSV 格式,以及 DeepL 扁平 CSV 格式。
从 memoQ 导出时必须包含表头,插件检测到表头包含两种以上的 memoQ 语言列时判定为 memoQ 格式,否则为 DeepL 格式。
DeepL 格式使用的语言代码为 memoQ 的 3 字母代码,默认的列名和顺序如下:
SourceTerm, TargetTerm, SourceLanguage, TargetLanguage
Hello , 你好 , eng , zho-CN
World , 世界 , eng , zho-CN解析算法足够灵活,如果与默认结构不同,只要满足以下约定,应该都能正确解析:
- 表头:如果列的顺序和默认顺序一致,第一行表头可选,否则必须包含表头,由表头指出正确的列顺序。
- 列数:至少包含
SourceTerm和TargetTerm列,可选包含SourceLanguage和TargetLanguage列。 - 冲突:如果包含表头,且表头不写语言列,但数据行中又有语言列,那么数据行中的语言列会被忽略掉。
- 空格:添加空格来使分隔符对齐不是必须的,示范中添加只是为了美观,无论加与不加都不会影响解析。
当术语文件读取失败或任一行数据解析出错,插件将终止该次翻译以防止产生非预期翻译结果,你可以在日志中查看错误信息并修正错误。
当希望占位符实际内容为空时,终止本次翻译请求,可以在占位符名字后面加上 !,比如 {{summary-text!}}、{{full-text!}}。
当希望占位符实际内容为空时,把与占位符相关的引导词也替换成空,可以在占位符前面或后面加上[],然后将引导词写在[] 内。
用户提示词:
这是供翻译参考的全文摘要:
摘要开始
{{summary-text!}}
摘要结束
[这是供翻译参考的术语表:
术语表开始
]{{glossary-text}}[
术语表结束]
[这是供翻译参考的位于待翻译文本之前的上文:
上文开始
]{{above-text}}[
上文结束]
[这是供翻译参考的位于待翻译文本之后的下文:
下文开始
]{{below-text}}[
下文结束]
[这是供翻译参考的翻译记忆中的原文和译文:
翻译记忆开始
]{{tm-source-text}}
{{tm-target-text}}[
翻译记忆结束]
请将以下文本从 {{source-language!}} 翻译成 {{target-language!}}:
{{source-text!}}
我们希望使用提示词缓存功能,所以优先将每次请求时值都不会动态改变的 {{summary-text!}} 放置到提示词的靠前位置。
我们希望 {{summary-text!}}、{{source-text!}} 等内容为空时,终止翻译请求,所以在其后面加了 !,表示禁止内容为空。
我们希望 {{glossary-text}}、{{above-text}}、{{tm-source-text}} 等内容为空时,将和它们相关的“引导词”也替换成空,所以使用了 [] 语法。比如 {{glossary-text}} 内容为空时,它前面的引导词 [这是供翻译参考的术语表:术语表开始] 和后面的引导词 [术语表结束] 也会被替换成空。
官方“机器翻译 SDK ”不提供获取译文、上下文、全文的能力,当在 memoQ 界面中点击某句段时,只能获取到被点击的单个句段原文,当使用预翻译执行批量翻译时,默认每次只能获取到 10 个句段的原文。
本插件使用官方“预览工具 SDK ”来间接获取译文、上下文、全文,第一次使用插件时会弹窗请求,你需要同意启用 Multi Supplier MT Plugin Helper (虚拟的预览工具)。
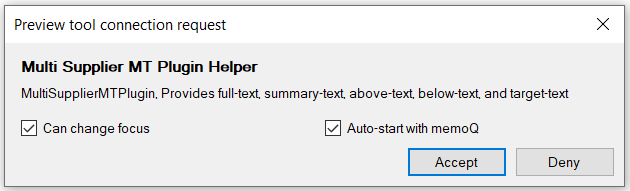
由于插件需要知道某句段的索引才能获取它的译文、上下文,遗憾的是就算使用“预览工具 SDK ”,也只有在 memoQ 界面中点击某句段时才能获取到索引,使用预翻译进行批量翻译时,没有界面点击交互,无法获取到正在翻译句段的索引,所以无法获取到该句段的译文、上下文。
| 提供商 | 免费额度 | QPS 限速 | 批量翻译支持 | Xml 或 Html 支持 |
|---|---|---|---|---|
| 阿里 | 普通版:每月 100 万字符 专业版:每月 100 万字符 |
普通版:50 专业版:50 |
✔ | ✔ (Html) |
| 腾讯 | 每月 500 万字符 | 5 | ✔ | × |
| 百度 | 标准版:每月 5 万字符 高级版:每月 100 万字符 |
标准版:1 高级版:10 |
? | × |
| 火山 | 每月 200 万字符 | 10 | ✔ | × |
| 小牛 | 每日 20 万字符 | 5 | × | ✔ (Xml) |
| 有道 | 新用户赠送 50 元体验金(永久有效) | 50 | ✔ | × |
| 讯飞 | 新用户赠送 200 万字符(90 天内有效) | ? | × | ✔ (Xml) |
| 彩云 | 新用户赠送 100 万字符(30 天内有效) | 10 | ✔ | × |
| Papago | 每天 1 万字符 | ? | × | × |
| DeepL | 每月 50 万字符 | ? | ✔ | ✔ (Xml 或 Html) |
| DeepLX | 自部署或开发者提供每日 50 万字符 | ? | × | ✔ (Xml 或 Html) |
| Yandex | ? | 20 | ✔ | ✔ (Html) |
| Microsoft(内置) | 且用且珍惜 | ? | ✔ | × |
| Google(内置) | 且用且珍惜 | ? | × | ✔ (Xml 或 Html) |
| DeepL(内置) | 且用且珍惜 | ? | × | ✔(Xml 或 Html) |
| Yandex(内置) | 且用且珍惜 | ? | × | ✔(Xml 或 Html) |
| Lingvanex(内置) | 且用且珍惜 | ? | × | ✔(Xml 或 Html) |
| Modernmt(内置) | 且用且珍惜 | ? | × | ✔(Xml 或 Html) |
注:百度翻译声称支持批量翻译,但他使用换行符来区分各个独立句段,但 memoQ 提供的一个句段是可能包含换行符的,所以把它当作不支持批量翻译处理。
| 提供商 | 免费额度 | QPS 限速 | 批量翻译支持 | Xml 或 Html 支持 |
|---|---|---|---|---|
| 阿里百炼 | ? | ? | ✔ | ✔(Xml 或 Html) |
| 腾讯混元 | ? | ? | ✔ | ✔(Xml 或 Html) |
| 百度千帆 | ? | ? | ✔ | ✔(Xml 或 Html) |
| 字节火山 | ? | ? | ✔ | ✔(Xml 或 Html) |
| 讯飞星火 | ? | ? | ✔ | ✔(Xml 或 Html) |
| 深度求索 | ? | ? | ✔ | ✔(Xml 或 Html) |
| 智谱清言 | ? | ? | ✔ | ✔(Xml 或 Html) |
| 阶跃星辰 | ? | ? | ✔ | ✔(Xml 或 Html) |
| 月之暗面 | ? | ? | ✔ | ✔(Xml 或 Html) |
| 百川智能 | ? | ? | ✔ | ✔(Xml 或 Html) |
| 稀宇科技 | ? | ? | ✔ | ✔(Xml 或 Html) |
| 商汤科技 | ? | ? | ✔ | ✔(Xml 或 Html) |
| 零一万物 | ? | ? | ✔ | ✔(Xml 或 Html) |
| 书生浦语 | ? | ? | ✔ | ✔(Xml 或 Html) |
| 无限光年 | ? | ? | ✔ | ✔(Xml 或 Html) |
| 无问芯穹 | ? | ? | ✔ | ✔(Xml 或 Html) |
| 硅基流动 | ? | ? | ✔ | ✔(Xml 或 Html) |
| 360 智脑 | ? | ? | ✔ | ✔(Xml 或 Html) |
| OpenAI | ? | ? | ✔ | ✔(Xml 或 Html) |
| Anthropic | ? | ? | ✔ | ✔(Xml 或 Html) |
| ? | ? | ✔ | ✔(Xml 或 Html) | |
| xAI | ? | ? | ✔ | ✔(Xml 或 Html) |
| Mistral | ? | ? | ✔ | ✔(Xml 或 Html) |
| Cohere | ? | ? | ✔ | ✔(Xml 或 Html) |
| Upstage | ? | ? | ✔ | ✔(Xml 或 Html) |
| Azure | ? | ? | ✔ | ✔(Xml 或 Html) |
| Cloudflare | ? | ? | ✔ | ✔(Xml 或 Html) |
| Nvidia | ? | ? | ✔ | ✔(Xml 或 Html) |
| Open Router | ? | ? | ✔ | ✔(Xml 或 Html) |
| One API | ? | ? | ✔ | ✔(Xml 或 Html) |
| New API | ? | ? | ✔ | ✔(Xml 或 Html) |
| Lite LLM | ? | ? | ✔ | ✔(Xml 或 Html) |
| Ollama | ? | ? | ✔ | ✔(Xml 或 Html) |
| vLLM | ? | ? | ✔ | ✔(Xml 或 Html) |
| LM Studio | ? | ? | ✔ | ✔(Xml 或 Html) |
注:以上只列出部分常用的服务提供商,插件还支持包括自研厂商、在线聚合网关、自建聚合网关、本地大模型在内的近百家几乎所有主流大语言模型提供商。