This project analyzes the sentiment of tweets using natural language processing techniques. The goal of this project is to classify tweets as positive, negative, or neutral, based on their content. The model was trained using a dataset of over 11,000 labeled tweets, and has an accuracy of 80%.
Take two different Datasets, one is Training Dataset which consists of Tweets along with Airline Sentiment and other one is Testing Dataset which consists of Tweets but not Airline Sentiment, and by applying NLP(Natural Language Processing) ,i.e NLTK And Sklearn Classifier, we Predict Airline Sentiment of Testing Dataset.
Performed NLP Based Tokenization, Lemmatization, Vectorization and processed Data in Machine Understandable Language.
- Support Vector Classifier (SVC)
- Multinomial Naive Bayes Classifier
- Random Forest Classifier
- Decision Tree Classifier
Support Vector Classifier (SVC) outperformed other algorithms with an accuracy score of 80% making it the most effective classifier in the study.
1.Spliiting the Tweet text into words using NLTK

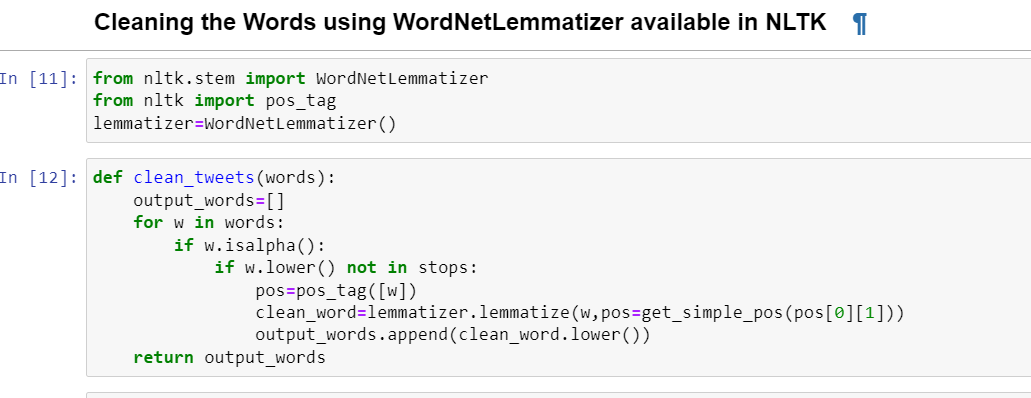
2.Cleaning the Words using WordNetLemmatizer available in NLTK
3.Analysing Count Vectorizer and Prepare a Frequency matrix

4.Normalize the matrix obtained from Count Vectorizer through TF-IDF Transformer

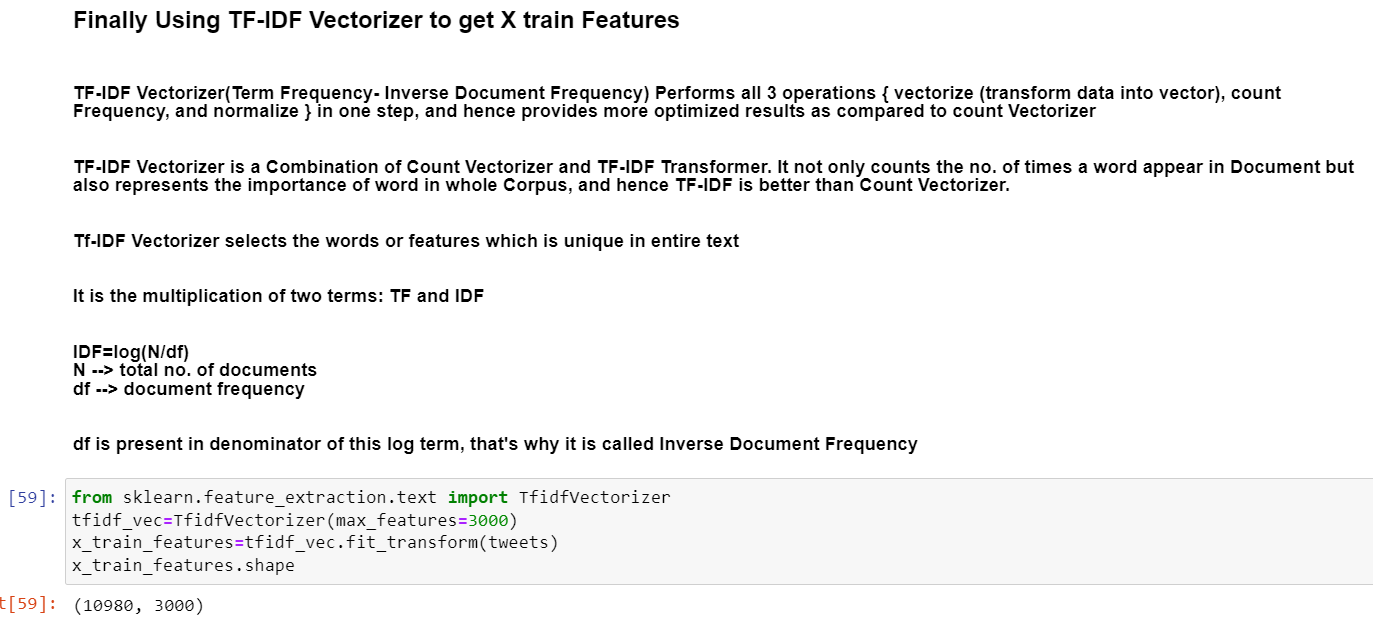
5.Using TF-IDF Vectorizer to get X train Features
6.Splitting Training Dataset in order to find Accuracy Score

7.SVC (Support Vector Classifier)

8.Random Forest Classifier

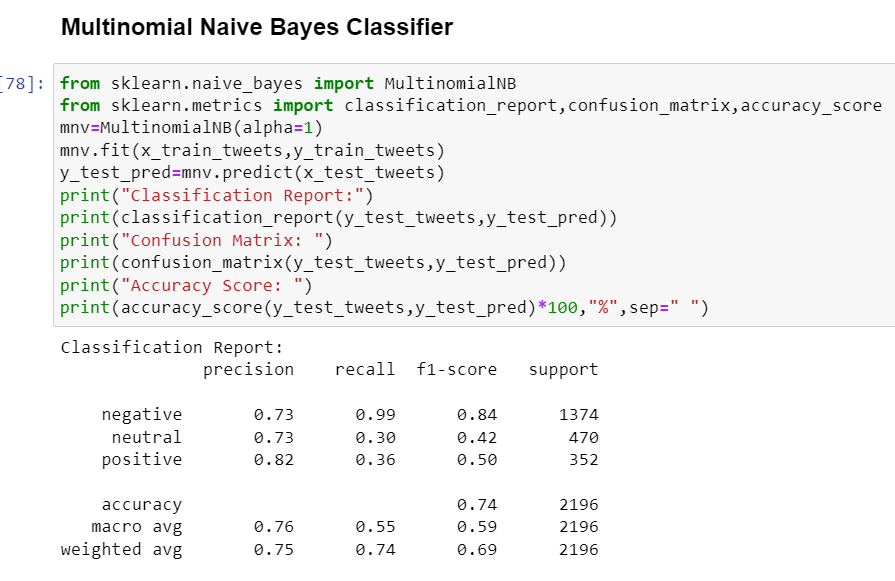
9.Multinomial Naive Bayes Classifier
10.Decision Tree Classifier

- Support Vector Classifier --> 79.052 %
- Multinomial Naive Bayes --> 76.183 %
- Random Forest Classifier --> 73.72 %
- Decision Tree Classifier --> 68.306 %