Python web scraping framework : Scrapy
Name : Sendong Liang
ID : 19040655
The real project usually starts with obtaining data. No matter text mining, machine learning, and data mining, all need data. At this time, web scraping is particularly essential for data collection. Fortunately, Python provides excellent web scraping frameworks -- Scrapy, which can not only scrape the data but also get and clean the data. This article discusses and analyzes the technology framework, architecture composition, operation process, and application examples of Scrapy. This paper expounds the significance and future of it in the data-driven project, and also discusses its existing shortcomings and influences.
Web scraping is a crucial way to prepare data and is often used to collect data from the network in daily esystems. This article will discuss a robust web scraping framework, Scrapy. This is a fast and advanced web scraping and crawling framework[1], which widely uses in the collection of structured data of websites. It can use for a broad range of purposes, from data mining to monitoring and automated testing[2].
Scrapy architecture is composed of Scrapy Engine, Scheduler, Downloader, Spider, Item Pipeline, Downloader Middlewares, and Spider Middlewares[3]. As shown in Figure 1.
Figure 1. The Scrapy architecture [4]
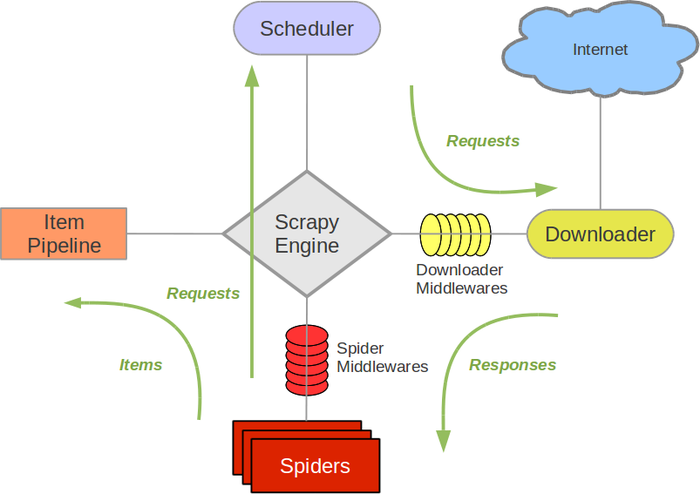
In Figure 1, the green line is the data flow direction.
- Firstly, the Spiders sends the target URL to Scheduler through ScrapyEngine.
- After the URL sequence is processed in Scheduler, it is handed over to Downloader by ScrapyEngine, Downloader Middlewares (optional, mainly User_Agent, Proxy Agent).
- Downloader sends a request to the Internet and receives a download response.Give the response to Spiders via ScrapyEngine, SpiderMiddlewares.
- Spiders processes the response, extracts the data, and gives it to ItemPipeline by ScrapyEngine.
- The extracted URL is given back to Scheduler by ScrapyEngine for the next loop. The program stops until there is no URL request.
Scrapy's installation has very detailed instructions on its official website. It is very compatible with Linux, MAC, and Windows systems.
- Website :https://scrapy.org/
Simple Scrapy only needs five steps:
- New project: create Scrapy project, command: scratch start project X(name of project).
- New application: create an application, command: scrapy genspider SpiderName targetWebsite.
- Define fields: a python file (e.g., items.py), specify the fields of the target site.
- Make spiders: write spiders (e.g., spider.py) to crawl the web information and analyze the content of the web page.
- Storage contents:Design pipelines(e.g., pipelines.py) to store crawling contents.
The Scrapy framework, which integrates the general functions of web page collection into each module and leaves out the customized part, liberates the programmer from the tedious process of repeated work. The focus of simple web page scraper is to deal with anti-scraping, large-scale scraping, and efficient and stable scraping. On the other hand, Scrapy uses the Twisted framework to handle network communications, I/O performance is improved, and CPU usage is reduced.
Using Twisted efficient asynchronous network framework to handle network communication. Twisted provides methods that allow the above operations to be performed without blocking code execution. Figure 2 shows a comparison of twisted and multithreaded code.
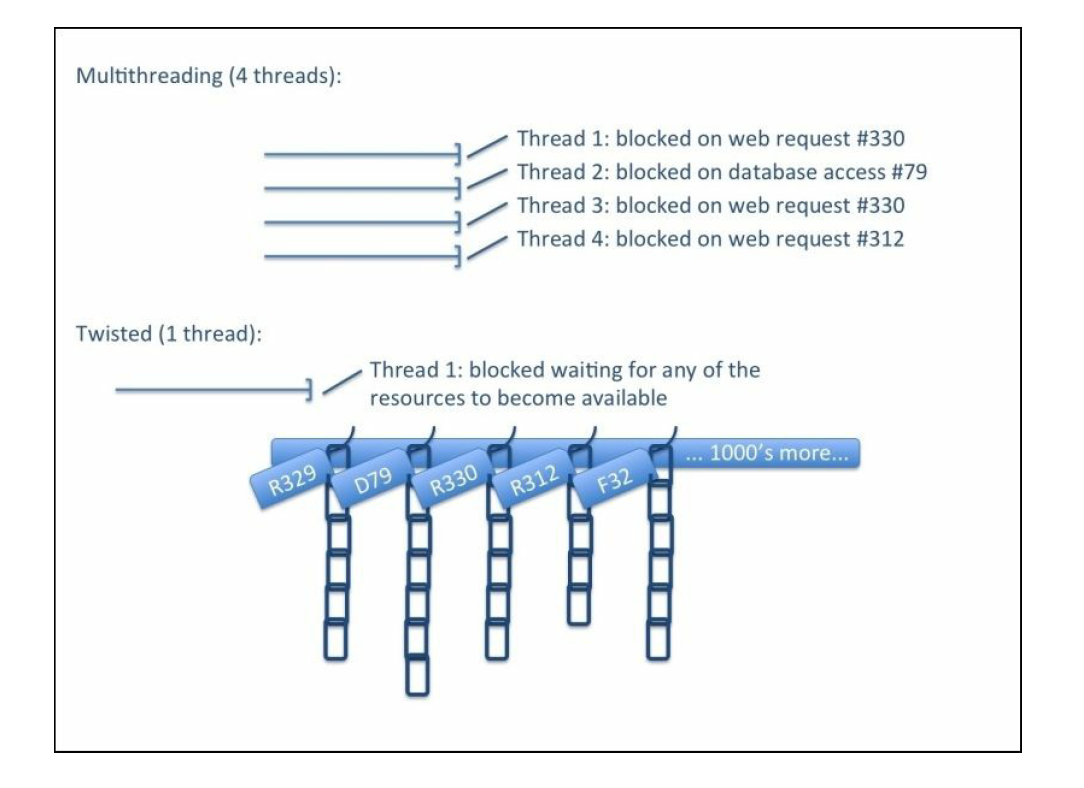
The developers of the operating system have been optimizing the thread operation for decades, and the performance problem is not as significant as before. However, compared with multithreaded programming, it is tough to write thread safe code, so twisted code is far simpler and safer than the multithreaded code.
On the positive side, Scrapy is asynchronous, flexible in adjusting the number of concurrent requests, and can improve data mining efficiency by replacing regular expressions with more readable xpaths[5]. Moreover, when writing middleware, uniform complementary filters can be used to make the data more accurate and clean. It is more convenient to use Scrapy to get data on different URLs at the same time. Besides, it is more convenient to debug independently because it supports the shell approach. Finally, the data is stored in the database by pipeline, which makes the storage of data more flexible.
However, there are some shortcomings, such as the inability to use it to complete distributed data extraction, high memory consumption, and no effect on Web pages that execute Javascript. On the other hand, due to base on the Twisted framework, an exception to one task does not stop the other task, and another exception handling is difficult to detect.
In data-driven projects such as big data and machine learning, data preparation is essential and an important part that cannot be ignored[6]. More and more technologies are being used to prepare databases, and a crucial part of them is to collect data from the network. Compared with traditional web scraping frameworks, Scrapy has received considerable attention and use in many web scraping frameworks due to its simple programming and flexible deployment.
Moreover, Many companies have customized scraping frameworks base on Scrapy to complete data collection, and many extensions have also achieved considerable success on GitHub. Such as, Scrapy_redis solves the issue of distributed scraping. Scrapy-splash, which integrates JavaScript and can execute JS in Scrapy.
In a data-driven environment, data preparation has become an important task, and web scraping has become a significant way of data collection. Scrapy provides a convenient development environment for data mining, machine learning, and other research and practice. By using the Twisted framework, the efficiency of network communication is improved, and the consumption of computing resources is reduced. Scrapy's architecture, on the one hand, reduces the number of time developers spend on code, allowing developers more time to design and improve crawler's anti-crawling capabilities, data compilation. On the other hand, it offers developers ample customized components and interfaces. Although it is criticized for its memory consumption and its inability to analyze JS code, more esystems can be used with Scrappy to solve these issues. Scrapy plays a vital role in future data mining and data preparation tasks.
- Spetka, Scott. "The TkWWW Robot: Beyond Browsing". NCSA. Archived from the original on 3 September 2004. Retrieved 21 November 2010.
- Scrapy, "https://docs.scrapy.org/en/latest/," Scrapy, 2020.
- Myers, Daniel, and James W. McGuffee. "Choosing scrapy." Journal of Computing Sciences in Colleges 31.1 (2015): 83-89.
- Nisafani, Amna Shifia, Rully Agus Hendrawan, and Arif Wibisono. "Eliciting Data From Website Using Scrapy: An Example." SEMNASTEKNOMEDIA ONLINE 5.1 (2017): 2-1.
- Kouzis-Loukas, Dimitrios. Learning scrapy. Packt Publishing Ltd, 2016.
- Pyle, Dorian. Data preparation for data mining. morgan kaufmann, 1999.