Python web scraping framework : Scrapy
The real project usually start from obtaining data. No matter text mining, machine learning and data mining, all need data. At this time, the crawler is particularly important. Fortunately, python provides a very good web crawler tool frameworks -- Scrapy, which can not only crawl the data, but also get and clean the data. This article discusses and analyzes the technology framework, architecture composition, operation process and application examples of scrapy. This paper expounds the significance and future of it in the data-driven project, and also discusses its existing shortcomings and influences.
Scrapy is a fast high-level web crawling and web scraping framework, used to crawl websites and extract structured data from their pages. It can be used for a wide range of purposes, from data mining to monitoring and automated testing[1].
Using Twisted efficient asynchronous network framework to handle network communication. Twisted provides methods that allow the above operations to be performed without blocking code execution. Figure 1 shows a comparison of twisted and multithreaded code[2].
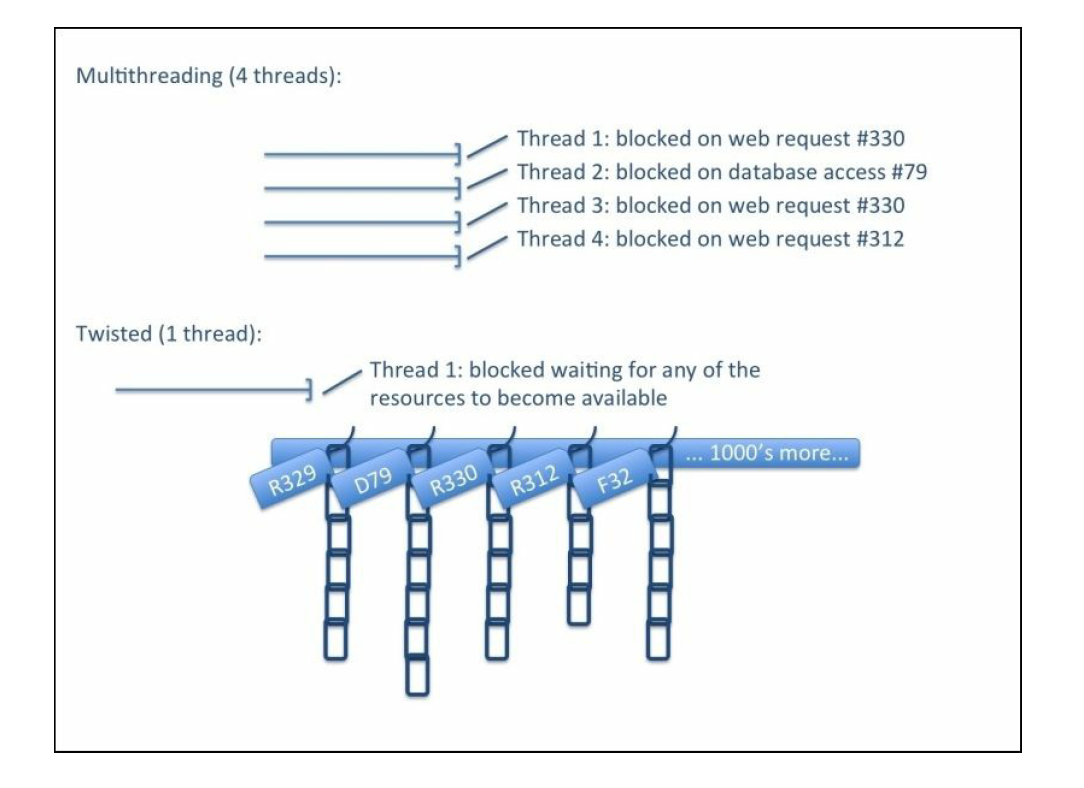
The developers of the operating system have been optimizing the thread operation for decades, and the performance problem is not as important as before. However, compared with multithreaded programming, it is very difficult to write thread safe code, so twisted code is far simpler and safer than multithreaded code.