这是北航计算机学院面向对象2024春季课设代码
- 分支hw1到hw3: 第一单元,递归下降解析字符串
- 分支hw5到hw7: 第二单元,多线程电梯系统(难点)
- 分支hw9到hw11: 第三单元,jml关系图
- 分支hw13到hw15: 第四单元,uml图书馆
- 分支exp: 课上实验代码
第一单元三次作业都是对一行表达式进行去括号整理 。本人借鉴了课程组在公众号发布的代码,使用递归下降过程先将表达式解析为因子,再将因子链表解析为语法树,最后将语法树解析为由单项式组成的多项式。 源代码地址

预处理可以是解决表达式处理尤其是符号处理的最佳方法。时间和空间复杂度低、操作简单,所以如果有些方法可以写入预处理类,一定要优先在预处理运行,写入递归下降不仅复杂度高,而且很难debug,往往事倍功半。 预处理首先将输入的表达式字符串所有的空字符去除(StringBuilder)然后对特殊的符号进行处理,比如replace("+-","-"),replace("(+","(0+")等等。值得注意的是,由于括号嵌套和符号位,可能会出现“---”和“+++”的情况,也要在预处理里面解决。
把预处理后的字符串加入解析,本人几乎沿用了公众号的代码架构。只是为了处理^因子,以及()^类型的数据,本人引入了核心因子: CoreFactor,即Expr -> Term -> CoreFactor -> Factor四级架构。
public CoreFactor parserCore() {
ArrayList<Factor> factors = new ArrayList<>();
factors.add(parserFactor());
while (lexer.notEnd() && lexer.now().getType() == Token.Type.EXP) {
lexer.move();
factors.add(parserFactor());
}
return new CoreFactor(factors);
}如果第四级提取到了(,则进行递归。叶节点的类型有Num,Letter(字母),第二次作业又引入了ExPexP来表示exp()^()因子。经过解析,一行字符串成功转化成了一个四级树结构。

单项式Mono:系数C,指数E,结构 C*x^E 多项式Poly:由Mono组成的链表 注意树的每一级都有toPoly()结构。底层Factor都是直接生成Mono随后,然后再CoreFactor的toPoly里形成Poly,并在Term和Expr级进行组合。
本人在递归构建Poly时,为了处理符号,在Mono中设立了符号位,并在Expr一级把每一个Term所有mono的符号和ops的符号进行check
如果不进行Mono合并的话,((1+x)^5)^5就能TLE,所以本人在Expr一级实现toPoly并且检测符号位以后,会根据每个Mono的toString()进行合并,如此可以极大减小Poly的数据量,从而避免再Expr返回给Factor——toPoly一个超级亢杂的链表。
对最终返回的一个多项式转化成字符串链表,对系数进行合并相加,对符号进行处理,并且对系数为0,指数为1的情况进行if判断,最终返回要输出的字符串。
为了实现作业的可迭代性,本人尽可能对底层的方法进行封装,如果有需要改动的,也尽可能另写一个方法,而不是随便对原来的代码进行修改。
PrePro还是比较简单的,虽然可能会增加时间复杂度 。本人新建了CustFun函数类,并在Main留下了Hashmap链表。在函数类里,本人记录函数名称,提取了形参个数,并将等号后面的函数表达式里面的形参替换为&,|,%。并构建替换方法,输入的参数为实参,返回的是将表达式的&%|替换为形参后的字符串。
exp也含有x,为了防止替换破坏exp,本人先把exp替换为j,并在xyz替换后,把j换成exp。在替换时,替换形参时,本人额外嵌套了()并在最后返回含有实参的函数表达式时又添加了()。
在预处理中函数替换方法,方法的形参为一行字符串返回值为字符串,本人遍历字符串,一旦检测到fgh就提取实参 ,如果没有fgh则返回字符串本身,否则调用函数替换方法把分()替换,最后返回值为,再次调用本方法(参数为本次替换后的字符串)的返回值。 虽然略微增加复杂度,但是可以保证替换的准确性。
第一次作业Mono为Cx^E 本次则是Cx^E*exp(Poly) 对exp()^n,则直接更改exp()内的String,更改后再处理。 所以Mono中要存系数C,指数E,符号位sign,还有exp()内的exPoly。

原本只是自下而上把所有Mono存入上层的Poly,而现在,每个Mono中可能有新的Poly,好像一棵树上的一个树枝。 除此之外在合并时,含有exp的Mono和不含有的要独立判断,分开合并。
无需更改
参考第二次实验求导方法,根据链式法则和乘法法则进行自上而下的求导。
因为Mono中可能存在Poly,而Mono存取的只是Poly的地址(指针),所以克隆Mono时如果只是浅克隆,会导致两个Mono调用同一个expoly,产生Wrong Answer。 因此一定要在Mono和Poly中写递归克隆方法。
预处理复杂度

递归复杂度

架构复杂度主要集中在这两处。如果要优化,只能更改底层逻辑。
底层的封装是最重要的,为了代码的可延展性,底层一般只提供普适性的方法。如果有新的需求,那么就增加新的方法,而不是更改底层代码。假如一定要极大改动,那么说明底层结构不具备可迭代性,最好是重构。
本人Mono类里面的方法没有方法返回Mono对象,别的底层类亦然。
因为底层不返回与自己类型相同的对象,因此非常有必要写一个clone()方法。尤其是类似于Mono中存取Poly的指针这样的结构,一定要写好克隆方法。
OO真的是一门很难但是很有意思的课,看着自己的代码 一点一点形成一个工程真的很有成就感。同时本人也建议适当降低互测门槛,让更多的同学进入互测,并合理分配房间,让所有人都能体验到hack与被hack。

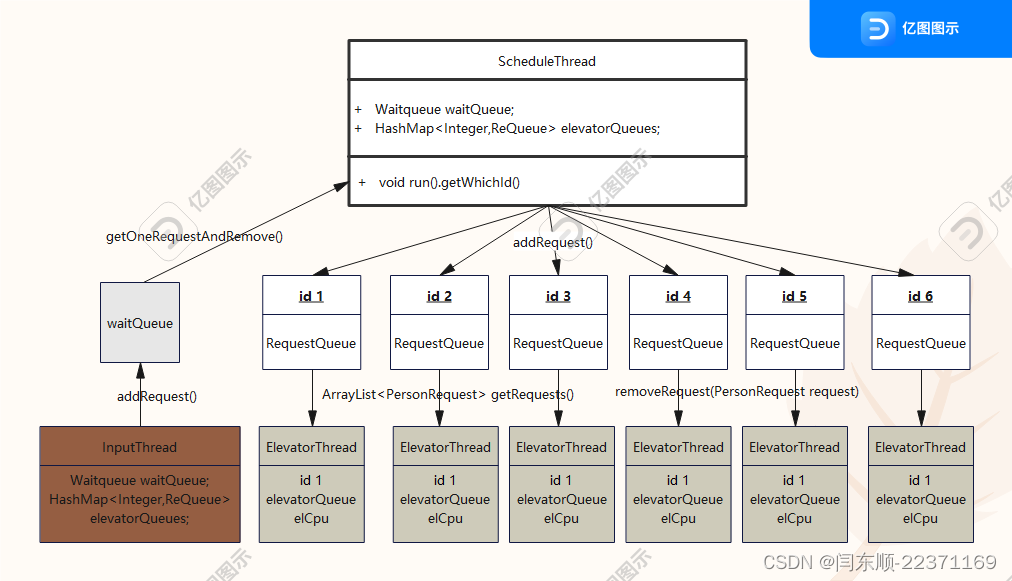
All类解析
- InputThread:负责解析输入,并传输请求至请求池(一般是总请求池)
- waitQueue 总请求池
- scheduleThread 从总请求池拿请求,按照一定的算法分发给各个电梯请求池。
- ReQueue 请求池接口
- RequestQueue 实现ReQueue,电梯请求池,有6个,id为1到6
- DoubleReQueue 实现ReQueue,有0到6个,和双桥厢电梯一一对应
- ElevatorThred 电梯线程,有6个,id为1到6,和电梯请求池一一对应。
- DoublEleThread 双桥厢电梯线程,不可和id相同的ElevatorThred共存,和DoubleReQueue二一对应
- EleCpu 为ElevatorThred做决策
- EleRequestCpu 为ElevatorThred的Reset决策
- DoubleCpu 为DoublEleThread做决策
- Main 主线程
- GetTime 静态类,输出时间
这三次作业,本人使用了和exp3相同的架构。即在主线程之外,创建三类线程(hw7增加至4类)和两类请求池(hw7增加至3类和一接口)。Input线程解析输入并把获得的请求传送给waitQueue总请求池。调度器schedule从总请求池获得请求并分给对应的电梯请求池。电梯线程从自己的请求池获取请求。
下图不包含Reset请求流动方向
所有的共享对象都在请求池!
schedule和Input线程之间存在数据竞争 schedule和elevator线程之间存在数据竞争 两个双桥厢线程之间存在严重竞争!
hw7新增了双桥厢电梯,双桥厢电梯需要各自用线程实现。两个电梯线程和一个调度器都要对DoubleReQueue里的数据进行读写。

本人的电梯算法,本人也不知道叫什么名字。电梯每到一层,都要向自己的CPU(决策者)发出请求,获得下一步的指令……
首先,电梯线程会调用决策者的check函数,决策者会获得电梯目前的层数,电梯里的人的信息。
outWantIns.clear();
inWantOuts.clear();
now = elevator.getNowFloor();
seeRequests = requestQueue.getRequests();
personIns = elevator.getInElevators();
最后电梯会返回outWantIns下电梯人名单,inWantOuts上电梯人名单,dir方向,isStartORstop启动还是暂停,ifOpen是否开门。
public int getDir() {
return dir;
}
public boolean isIfOpen() {
return ifOpen;
}
public boolean isStartORstop() {
return startORstop;
}
public ArrayList<PersonRequest> getInWantOuts() {
return inWantOuts;
}
public ArrayList<PersonRequest> getOutWantIns() {
return outWantIns;
}
具体实现方法如下
先下人,凡是终点在这一层的一律下。 如果下光了,未处理的请求中最早的的from为电梯运动的方向,如果from就是这一层,那么to为方向。 如果没下光,那么电梯里来的最早的人的to为电梯方向。 然后是上人,如果乘客的from是本层并且(to - from) * dir > 0,才能上电梯。
换成层不能同时存在两个电梯,本人在两个电梯共同读写的请求池DoubleReQueue放置了一个锁,如果是0代表换成层没有电梯,1,和-1分别代表,B或A在换乘层。
public synchronized void setTranID(int isUpD) {
this.tranDownUp = isUpD;
notifyAll();
}
public synchronized int getTranDownUp() {
return tranDownUp;
}
为了节省时间,假如电梯运行一层时间需要400ms,那么获得锁的电梯不会在400ms后释放锁,而是sleep50ms就释放,然后继续sleep。
public void moveOneFloor() {
int nextFr = nowFloor + eleDir;
if (nextFr == exchange) {
while (elevatorQueue.getTranDownUp() != 0) {
trySleep((long) speedTime / 2);
}
elevatorQueue.setTranID(isAorB);
trySleep(speedTime);
//……
//前往换成层
} else if (nowFloor == exchange) {
trySleep((long) speedTime / 10);
elevatorQueue.setTranID(0);
trySleep((long) speedTime / 10 * 9);
//……
//离开换成层
} else {
//……
//正常移动
}
}
第六七次作业需要程序员设计分配电梯,本人第六次作业,设计了分组电梯分配方法。 目的是省电0.4和减少乘客等待时间0.3。 剩下0.3权重的运行时间,经测试和轮流分配在均值上提升不大。
#define 好电梯 {
电梯没有在重置
&& 电梯里人不太多
&& 电梯未处理的请求不太多
}
int poor = t - f;
Double average = (f + t) / 2.0;
- 1号:如果是好电梯,并且abs(poor) > 7则分给1
- 34号:average < 5.5,在低层运动
- 56号:average > 7.5 在高层运动
- 2号:尝试分担1的压力压力,在中层运动并且移动范围不大。 说明
- 1号尽可能捎带中层2的份额
- 34和56内部有算法,来决定把电梯分配给谁
- 如果没有好电梯,则某一组会返回-1,有新的算法分配电梯
经过hw6强测,性能很高因为3456的局限运动会节省电量,并且相对也更容易快速接到乘客。 局限性:
- 参数不好把握,经过大量本地测试,才保证在均匀请求下,每个电梯接到的乘客在合理范围。
- 互测容易被攻击,比如“置五缺一”,比如全是“from-1-to-11”
蓝色为NormalResetRequest,黑色为PersonRequest

因为schedule处理请求是一个一个进行的,为了避免Reset不及时,ResetRequest会直接被放到对应的电梯请求池。
所有乘客都要下电梯,如果乘客的to正好是本层,那么万事大吉,假如不是,那么电梯会把他们存入specialNeeds,等到重置完毕立刻receive并且接上来。 但是Reset后电梯容量可能下降,出现所有specialNeeds全接上来超载的情况!!! 这时候多余的人会放入对应id的请求池,From改为次楼层。 本人尽量不向上(总请求池waitQueue)传递请求 因为不会写……
ElevatorThread的关闭和DoublEleThread的启动二者之间的衔接、ReQueue接口下两类请求池之间的转换、电梯的分配是三个难点。
Input收到DCreset后会立即向对应的RequestQueue发送信号,创造新的DoubleReQueue并保存相关信息,并立即封存请求池信息为只读。 随后同时向schedule和Elevator发送信号,让schedule立即更新请求池,让Elevator创建新的DoublEleThread并且启动!启动之后,结束自己的run();
本人新建了一个大小为12的int数组,初始化为0,遍历六个电梯请求池,如果电梯是好电梯(上面有定义),那么按照电梯的情况,选取1到2个空间赋值为电梯id。 然后调用Java随机数从12个数中随机选一个作为目标电梯。 可能会出现所有电梯都不符合情况的时候 这个时候schedule要向总请求池更新DCReset信息,并sleep一段时间等待Ele的新信息,否则会死循环。
本人所有共享信息都放在了请求池,包括电梯的实时信息当然请求池里的电梯信息不会是最新的。 部分共享信息展示
// Waitqueue
private ArrayList<Request> waitRequests;
// RequestQueue
private final ArrayList<PersonRequest> requests;
private boolean isEnd;
private ArrayList<NormalResetRequest> setRequests;
private boolean canChange;
private int dir;
private int floor;
private int balance;
private int speedTime;
// DoubleReQueue
private final int exchange;
private int tranDownUp;
private ArrayList<PersonRequest> upRequests;
private ArrayList<PersonRequest> downRequests;
private final int maxNum;
private int numdA = 0;
private int numuB = 0;
请求池和电梯时态相关信息在每次电梯移动前更新
请求池锁全部为synchronized 还有输出保护
public synchronized ArrayList<PersonRequest> getRequests() {
if (requests.isEmpty()) {
return null;
}
ArrayList<PersonRequest> copyRe = new ArrayList<>();
for (PersonRequest request:requests) {
copyRe.add(request);
}
notifyAll();
return copyRe;
}
一律为wait() ———— notifyAll(); 并且都在请求池进行,没什么好说的,值得注意的是,hw双桥厢请求池有两个电梯线程,也更要复杂
//DoubleReQueue
public synchronized boolean getUpbGlag() {
if (upRequests.isEmpty() && !isEnd) {
//tryWait
}
if (upRequests.isEmpty() && isEnd && (numdA != 0 || downRequests.size() != 0)) {
//tryWait
}
//return something;
}
- 易变:电梯分配方式,电梯的形式,电梯的参数,访问共享信息线程的数量。
- 不变:电梯的微观行动方法,Input——waitQueue——schedule——ReQueue——EleThread——ELeCPU结构,电梯自己的捎带算法。
- 自己编特殊样例然后print()
- 用大佬的评测机
第一次接触多线程,hw5非常怵头,尤其是同样的输入可能会有不同的结果很吓人,差点没交上中测。 但是只要搞明白了 生产者——消费者模式、多个线程竞争的对象还有wait——notify原理这三点,本人感觉比第一单元要简单。
本单元是JML单元,相比前两次思维量少得多,是以博客内容也相应调整。
- 黑箱测试:测试人员不需要了解软件内部的实现细节,只关注输入和输出之间的关系,通过给定的输入数据来验证软件的功能是否按照规格说明正常运行。优点是可以独立于编码人员进行,测试者可以从用户的角度出发,发现用户可能面临的问题。缺点是可能无法发现代码中的错误或逻辑缺陷,只能验证功能是否按照规格说明运行。
- 白箱测试:测试人员需要了解软件的实现细节,通过检查代码逻辑、路径覆盖等来验证软件的正确性和健壮性。优点是可以发现代码中的错误、逻辑缺陷以及性能问题,对于提高代码质量有很大的帮助。缺点是测试相对复杂,需要测试人员了解程序逻辑。
- 单元测试
- 单元测试是针对软件中最小的可测试单元进行的测试,通常是对独立的函数、方法或模块进行测试。
- 单元测试的目的是验证代码的正确性,确保每个单元按照预期工作。
- 单元测试通常由开发人员在编写代码时进行,可以快速定位和修复问题,促进代码质量的提高。
- 功能测试
- 功能测试是针对软件的功能需求进行的测试,验证软件是否按照规格说明和用户需求正常运行。
- 功能测试关注软件的输入和输出,测试人员通过输入各种数据和情况来验证软件的功能是否正确。
- 功能测试通常由专门的测试团队进行,在软件开发周期的后期进行。
- 集成测试
- 集成测试是将已经经过单元测试的模块或组件进行组合,并验证它们在一起工作的测试。
- 集成测试的目标是验证不同模块之间的接口和交互是否正确,以及整体系统是否符合预期。
- 集成测试通常在功能测试之前进行,可以发现模块之间的集成问题和依赖关系的错误。
- 压力测试
- 压力测试是为了评估软件在负载、并发和异常条件下的稳定性和性能而进行的测试。
- 压力测试通过模拟大量用户、高并发访问等情况来测试系统的极限能力和承受能力。
- 压力测试可以帮助发现系统资源不足、性能瓶颈或内存泄漏等问题,以优化系统的性能。
- 回归测试
- 回归测试是在对软件进行更改或修复之后,重新执行旧的测试用例以确保新的更改没有引入新的错误。
- 回归测试的目的是验证软件的修改不会破坏原有的功能和逻辑。
- 回归测试可以避免因为修改引入新的问题,保持软件的稳定性和可靠性。
- 随机测试:通过大量的随机数据来提高覆盖率,最大程度发现程序潜在的问题
- 边界测试:对于随机数据难以覆盖的极端情况与特殊情况,需要额外构造特殊的数据点进行测试
- 模拟数据:假如推测出程序潜在的问题或者随机测试发现问题,可以以问题为导向,由果溯因,构造数据量小、但是对等错误的数据
- 分类测试:可以根据程序不同的功能、使用情景,构造不同的样例分别测试
完全按照JML要求的架构
建立连通树
// MyNetwork 伪代码
private HashMap<Integer,Integer> toTreeEnd; //构造一个连通的树
public void addPerson():
toTreeEnd.put(person.getId(),null)
public void addRelation():
if (!(getEndPoint(id1) == getEndPoint(id2))):
toTreeEnd.put(getEndPoint(id1),getEndPoint(id2))
public int getEndPoint(int id):
while (toTreeEnd.get(end) != null) :
end = toTreeEnd.get(end)
// MyNetwork 伪代码
public void addPerson():
sumBlock++
public void addRelation():
if (!(getEndPoint(id1) == getEndPoint(id2))):
sumBlock--
//当需要删除关系时,进行深度优先搜索
// MyNetwork 伪代码
public void addRelation():
sumTriple += findCommon(id1,id2)
public void removeRelation():
sumTriple -= findCommon(id1,id2)
public int findCommon(int id1,int id2):
return sum: person that link id1 && link id2
广度优先搜索
//MyPerson
private long bestID = Long.MAX_VALUE;
private long maxVa = Long.MIN_VALUE;
public void buildLink(Person person, int value) {
……
if (value > maxVa) {
maxVa = value;
bestID = person.getId();
} else if (value == maxVa && person.getId() < bestID) {
bestID = person.getId();
}
}
public void removeLink(Person person) {
……
if (person.getId() == bestID) {
maxVa = Long.MIN_VALUE;
bestID = Long.MAX_VALUE;
if (acquaintance.size() != 0) {
for (Integer key:acquaintance.keySet()) {
Person p = acquaintance.get(key);
if (maxVa < value.get(p)) {
maxVa = value.get(p);
bestID = key;
} else if (maxVa == value.get(p) && acquaintance.get(key).getId() < bestID) {
bestID = acquaintance.get(key).getId();
}
}
}
}
}
public void addPerValue(Person person,int va) {
//参考上面两个,注意va可能是负数
}
//MyNetwork
public int queryCoupleSum() {
int ret = 0;
if (persons.size() == 0) {
return 0; }
for (Integer ieKey:persons.keySet()) {
MyPerson ieP = (MyPerson) persons.get(ieKey);
if (ieP.getAcquaintance().size() != 0) {
int j = ieP.findBestID();
MyPerson jeP = ((MyPerson) persons.get(j));
if (jeP.getAcquaintance().size() != 0) {
if (jeP.findBestID() == ieKey) { ret++; } } } }
ret /= 2;
return ret; }
本人在这一个点ctle后,使用了两个方法: 一个是设置脏位,来表示qtvs的上一次结果有没有可能被修改,如果没有变化,则直接返回上一次的结果. 否则进行遍历。而遍历方式也要修改: jml要求
//Tag
/*@ ensures \result == (\sum int i; 0 <= i && i < persons.length;
@ (\sum int j; 0 <= j && j < persons.length &&
@ persons[i].isLinked(persons[j]); persons[i].queryValue(persons[j])));
@*/
public /*@ pure @*/ int getValueSum();
原来的遍历,好像和JML一模一样,emmmmmmm,不是JML让这么写的吗(气)
for (Integer ieKey:persons.keySet()):
for (Integer jeKey:persons.keySet()):
if (persons.get(jeKey).isLinked(persons.get(jekey))):
现在的遍历
for (Integer ieKey:persons.keySet()) :
for (Integer jeKey:((MyPerson) persons.get(ieKey)).getAcquaintance().keySet()) :
if (persons.get(jeKey) != null) :
想要保证性能,就不能照搬JML,而是要在满足JML规格的情况下进行性能的优化。也就是规格与实现结果相同,过程不同。
本单元中测强制要求进行单元测试,这也让我第一次详细了解了这一测试方法,感觉收益颇多。 前两次作业,本人都是构建一个复杂的图,然后调用需要测试的方法,然后对方法结果和其它变量是否被修改进行测试。
//public class MyNetworkTest
public MyNetwork myNetwork = null;//课程组的实现,调用测试方法,对照组
private OneNetwork oneNetwork = null;//本人的实现,调用测试方法,检测方法结果正确性
private MyNetwork yingZi = null;//课程组的实现,不调用测试方法,检测方法是否对不允许修改的变量进行修改
public void AssErt() throws PersonIdNotFoundException, RelationNotFoundException {
Person [] olds = yingZi.getPersons();
assertEquals(myNetwork.queryCoupleSum(),oneNetwork.queryCoupleSum());
Person [] news = myNetwork.getPersons();
assertEquals(olds.length,news.length);
for (int i = 0;i < olds.length;i++) {
boolean f = ((MyPerson) olds[i]).strictEquals(news[i]);
assertEquals(f,true);
}
}
一开始在思考第三单元是否有存在的必要,更何况五一期间还有作业,等写完了就没有再思考这个问题了。 这一单元相比前两个思维量比较小,大多数代码是翻译JML,但是翻译的时候也出现了许多问题,一个是没有及时更新JML,导致我有一个bug找了很久都没找到错误,后来才知道有个JML要修改,其次是翻译不是照搬,需要有自己的规格实现。
源代码地址 面向对象设计与构造这门课终于是要结束了。真是一门让人难忘的课程啊,有太多太多的感想……
正向建模是程序设计的重要方法,顾名思义,它是正向的(自顶而下),需要我们程序员先设计好顶层架构再一步步实现。
第四单元需要我们实现一个小型图书馆(非多线程)大致要求如下
在一所小型图书馆中,用户借阅图书需要遵守一定的规章制度。我们需要你模拟一个小型的图书管理系统,完成图书馆所支持的相关业务。
图书馆里的所有图书按照 “类别号-序列号” 的形式编制书号(同学们可以理解为 ISBN 国际标准书号的简化形式,即一本书的书号是唯一的,它的所有副本的书号都是相同的)。图书分 A 、B 、C 三类,每种类别可能包含多个图书,每个图书可能具有多个副本(具有相同书号的两本书籍是同质的)。对于不同类别的书,有不同的借阅数量限制。
图书馆的运行分为两个时段:白天开馆,夜晚闭馆。开馆后,图书管理系统需要处理用户的各种请求,依据图书馆的运行规则决定是否批准用户的请求;同时,开馆时和闭馆时,图书馆内部依据需要整理各部门的图书,以满足接下来可能处理的各种请求。
在本次作业中,开馆时图书管理系统需要处理的请求包括:借书、还书、查询、预约和预约取书。
本次作业中,我们规定书籍仅可以存在于如下四个位置:书架、预约处、借还处和用户。
根据题目要求,我设计了
public Library(HashMap<LibraryBookId,Integer> inva) {
this.bookShelf = new BookShelf(inva);//书架
this.appOffice = new AppOffice();//预约处
this.broReOffice = new BroReOffice();//借还台
this.frontDesk = new StudReqProcess(this);//前台,自己加的,负责处理学生需求
this.needToDo = new HashMap<>();//前台发来的整理要求
this.waitPrints = new ArrayList<>();//输出序列
this.driftCorner = new DriftCorner();//漂流角hw14
this.broCorner = new BroCorner();//漂流角的借还台,自己加的
}
最大的创新就是加了前台吧,前台处理学生请求,并且记录学生的信息,有些请求前台可以完全独立处理,处理不了的再摇其它部门。
图书设计
public BookOfPer(LibraryBookId bookId,LocalDate localDate) { // for book of per
this.bookId = bookId;
this.type = bookId.getType();
this.uid = bookId.getUid();
this.startInApp = null;
this.startOwner = localDate;
if (bookId.isTypeB()) {
canOwnTime = 30;
} else if (bookId.isTypeC()) {
canOwnTime = 60;
} else if (bookId.isTypeBU()) {
canOwnTime = 7;
} else if (bookId.isTypeCU()) {
canOwnTime = 14;
} else {
System.out.println("Error: Book type not supported");
}
}
public BookOfPer(LibraryBookId bookId) { // for corner
this.bookId = bookId;
this.type = bookId.getType();
this.uid = bookId.getUid();
this.startInApp = null;
this.startOwner = null;
this.canOwnTime = 0;
}
public BookOfPer(LibraryBookId bookId,LocalDate localDate,boolean isOpen) { //for app
this.bookId = bookId;
this.type = bookId.getType();
this.uid = bookId.getUid();
this.startOwner = null;
this.canOwnTime = 0;
if (isOpen) {
this.startInApp = localDate.minusDays(1);
} else {
this.startInApp = localDate;
}
}
漂流角图书
public class CornerBook extends BookOfPer {
private int lentCount;
public CornerBook(LibraryBookId bookId,LocalDate localDate,int lentCount) {
super(bookId,localDate);
this.lentCount = lentCount;
}
官方包的LibraryBookId设定的非常好,尤其是重写了哈希值,可以自由的创建实例。但是这还是有不足,因此我新建了Book类。


第一单元递归下降架构,第二单元多线程生产者-消费者架构,第三单元jml架构,第四单元简单图书馆架构。
主要是通过大佬的评测机 大佬的评测机
还有就是print 还有test
学到了许多新知识,尤其是Java面向对象的知识,这也让我对别的语言有了更多的了解。
尤其是第二单元多线程学到了很多,还跟操作系统联系起来了哈。
就这些吧。
OO终于还是结束了