{kind=link}
PDF转Markdown软件Marker免安装一键启动整合包
Marker可以快速准确地将文档转换为markdown、JSON和HTML。
转换所有语言的PDF、图像、PPTX、DOCX、XLSX、HTML、EPUB文件
格式化表格、表单、方程式、内联数学、链接、引用和代码块
提取并保存图像
删除页眉/页脚/其他工件
可使用您自己的格式和逻辑进行扩展
可选地使用LLM提高精度
适用于GPU、CPU或MPS
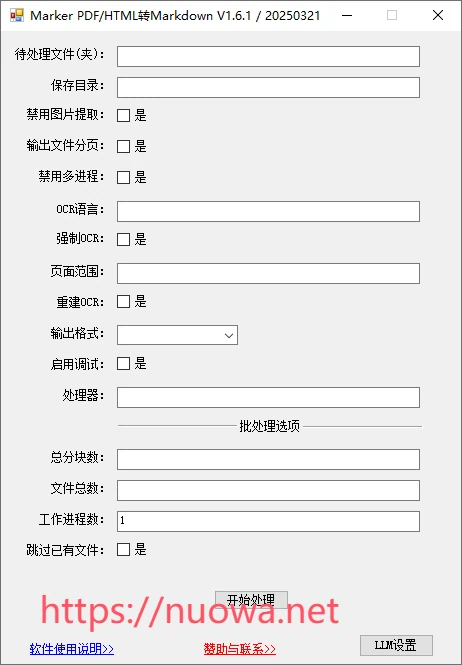
待处理文件(夹):需要转换的文件或是所在的文件夹,用鼠标左键单击文件或是文件夹按住拖动到程序窗口里,文件或是文件夹路径会自动填充到文本输入框中
禁用图片提取:PDF中有图片的话默认会提取出来,可以开启这个选项禁止提取图片
输出文件分页:是否对输出文件进行分页处理
禁用多进程:是否禁用多进程处理
OCR语言:如果进行OCR识别可指定语言,中文为zh,英语eng,法语fra,德语deu,其它语言代码可以查看我另一篇文章《语言名称及简写代码两字母三字母代码对照表》,如果输入多个语言可用英文逗号,隔开,如:eng,fra,deu
强制OCR:是否强制对整个文档使用 OCR
页面范围:想要识别转换的指定PDF的页码,页码从0开始。如果只想转换PDF文档中的第2页,输入框里可以填1,如果想要转换多个不连续页面的话,可以按下面规则设置:1,5-8,11,即转换第2、6-9、12页的PDF内容。中间为英文逗号,和-
重建OCR:删除文档中所有现有的OCR文本,并使用surya重新进行OCR。
输出格式:软件默认输出md格式,如果想要输出JSON和Html格式的话,可以在下拉列表中选择
启动调试:是否输出软件执行过程中的调试信息。
处理器:
marker.processors.LineBuilder:用于构建文本行。
marker.processors.LineMergeProcessor:用于合并文本行。
marker.processors.LLMTableProcessor:使用 LLM 处理表格。
marker.processors.LLMTableMergeProcessor:使用 LLM 合并表格。
marker.processors.TableProcessor:用于表格识别和处理。
marker.processors.LLMEquationProcessor:使用 LLM 处理数学公式。
marker.processors.LLMInlineMathLinesProcessor:使用 LLM 处理行内数学公式。
marker.processors.LLMMathBlockProcessor:使用 LLM 处理数学公式块。
marker.processors.LLMHandwritingProcessor:使用 LLM 处理手写内容。
marker.processors.LLMImageDescriptionProcessor:使用 LLM 生成图像描述。
marker.processors.LLMFormProcessor:使用 LLM 处理表单。
marker.processors.LLMComplexRegionProcessor:使用 LLM 处理复杂区域。
marker.processors.LLMSimpleBlockMetaProcessor:使用 LLM 处理简单的块元数据。
marker.processors.TableConverter:用于表格转换。
marker.processors.PdfConverter:用于 PDF 文件转换。
总分块数:指定任务总分块数,用于多任务并行。
文件总数:指定最多处理的 PDF 文件数量。
工作进程数:可以指定同时进行多少个处理任务,每个处理任务占用显存3.5G左右,如果你的显卡显存比较大的话,可以调高这个值,加快处理速度。
跳过已有文件:跳过已存在的转换文件
1.6.1版本整合包增加了对大语言模型的支持,辅助优化生成结果
Google Gemini API申请教程:https://nuowa.net/1431
视频教程及演示:youtube>>
软件运行主要依赖于GPU,建议英伟达显卡显存在2G以上的用户使用。
支持Windows 10或11,不支持手机和MAC
夸克网盘:https://pan.quark.cn/s/cbb2bc04927f
迅雷:https://pan.xunlei.com/s/VOLxB-SBP_-Uc4FktQFH4RuvA1?pwd=n749#