This Terraform module provisions the necessary services to provide a data product on the Google Cloud Platform.
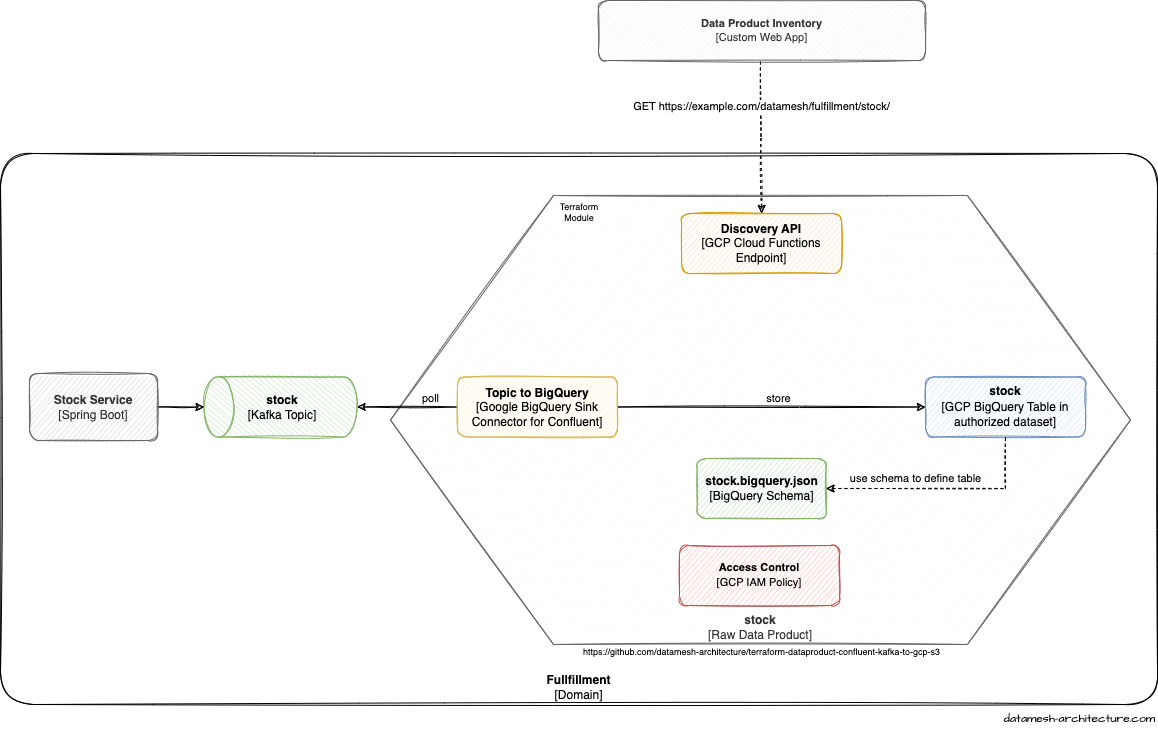
- Confluent Kafka
- Google BigQuery
- Google Cloud Functions
You need to enable some APIs of your Google Cloud project. E.g. enable it with the gcloud command line tool:
gcloud services enable <SERVICE_NAME>For the Kafka to BigQuery Connector you need:
- BigQuery API (
bigquery.googleapis.com) - Identity and Access Management (IAM) API (
iam.googleapis.com)
In addition, you need some APIs for the discovery endpoint, which runs on Cloud Functions:
- Cloud Functions API (
cloudfunctions.googleapis.com) - Cloud Run Admin API (
run.googleapis.com) - Artifact Registry API (
artifactregistry.googleapis.com) - Cloud Build API (
cloudbuild.googleapis.com) - Cloud Storage API (
storage.googleapis.com)
You need use a service account with an IAM role which grants the following permissions:
run.services.getIamPolicy
run.services.setIamPolicy
run.services.getIamPolicy
bigquery.datasets.create
bigquery.datasets.get
bigquery.models.delete
bigquery.routines.delete
bigquery.tables.getIamPolicy
cloudfunctions.functions.create
cloudfunctions.functions.delete
cloudfunctions.functions.get
cloudfunctions.functions.getIamPolicy
cloudfunctions.functions.update
cloudfunctions.operations.get
compute.disks.create
compute.disks.get
compute.globalOperations.get
compute.instances.create
compute.instances.delete
compute.instances.get
compute.instances.setTags
compute.networks.create
compute.networks.delete
compute.networks.get
compute.subnetworks.use
compute.subnetworks.useExternalIp
compute.zoneOperations.get
compute.zones.get
iam.serviceAccountKeys.create
iam.serviceAccountKeys.delete
iam.serviceAccountKeys.get
iam.serviceAccounts.actAs
iam.serviceAccounts.create
iam.serviceAccounts.delete
iam.serviceAccounts.get
storage.buckets.create
storage.buckets.delete
storage.objects.get
storage.objects.list
module "kafka_to_bigquery" {
source = "[email protected]:datamesh-architecture/terraform-dataproduct-confluent-kafka-to-gcp-bigquery.git"
domain = "<data_product_domain>"
name = "<data_product_name>"
input = [
{
topic = "<topic_name>"
format = "<topic_format>"
}
]
output = {
data_access = ["<gcp_principal>"]
discovery_access = ["<gcp_principal>"]
tables = [
{
id = "<table_name>" # must be equal to corresponding topic
schema = "<table_schema_path>"
delete_on_destroy = false # set true for development or testing environments
}
]
}
# optional settings for time based partitioning, if needed
output_tables_time_partitioning = {
"stock" = {
type = "<time_partitioning_type>" # DAY, HOUR, MONTH, YEAR
field = "<time_partitioning_field>" # optional, uses consumption time if null
}
}
}Note: You can put all kind of principals into data_access and discovery_access.
The module creates an RESTful endpoint via Google Cloud Functions (e.g. https://info-xxxxxxxxxx-xx.a.run.app). This endpoint can be used as an input for another data product or to retrieve information about this data product.
{
"domain": "<data_product_domain>",
"name": "<data_product_name>",
"output": {
"locations": ["<big_query_table_uri>"]
}
}Examples, how to use this module, can be found in a separate GitHub repository.
This terraform module is maintained by Stefan Negele, Christine Koppelt, Jochen Christ, and Simon Harrer.
MIT License.
| Name | Version |
|---|---|
| confluent | >= 1.35 |
| >= 4.59.0 |
| Name | Version |
|---|---|
| archive | n/a |
| confluent | >= 1.35 |
| >= 4.59.0 | |
| local | n/a |
No modules.
| Name | Description | Type | Default | Required |
|---|---|---|---|---|
| domain | The domain of the data product | string |
n/a | yes |
| gcp | project: The GCP project of your data product region: The GCP region where your data product should be located |
object({ |
n/a | yes |
| input | topic: Name of the Kafka topic which should be processed format: Currently only 'JSON' is supported |
list(object({ |
n/a | yes |
| kafka | Information and credentials about/from the Kafka cluster | object({ |
n/a | yes |
| name | The name of the data product | string |
n/a | yes |
| output | dataset_id: The id of the dataset in which your data product will exist dataset_description: A description of the dataset grant_access: List of users with access to the data product discovery_access: List of users with access to the discovery endpoint region: The google cloud region in which your data product should be created tables.id: The table_id of your data product, which will be used to create a BigQuery table. Must be equal to the corresponding kafka topic name. tables.schema: The path to the products bigquery schema tables.delete_on_destroy: 'true' if the BigQuery table should be deleted if the terraform resource gets destroyed. Use with care! |
object({ |
n/a | yes |
| output_tables_time_partitioning | You can configure time based partitioning by passing an object which has the tables id as its key. type: Possible values are: DAY, HOUR, MONTH, YEAR field: The field which should be used for partitioning. Falls back to consumption time, if null is passed. |
map(object({ |
{} |
no |
| Name | Description |
|---|---|
| dataset_id | The id of the Google BigQuery dataset |
| discovery_endpoint | The URI of the generated discovery endpoint |
| project | The Google Cloud project |
| table_ids | The ids of all created Google BigQuery tables |