FinancialRiskPredictor: Prediction of Financial Risks with Profile Tuning on Pretrained Foundation Models
-
Paper:
-
Abstract:
Financial risk prediction is essential in the finance sector.
Machine learning methods are in broad use for automated
potential risk detection, reducing labor costs.
The existing algorithms are somewhat outdated, especially taking into account the quick evolution of generative AI and
large language models(LLMs), plus the lack of a unified and open-sourced
financial benchmark has slowed down related research.
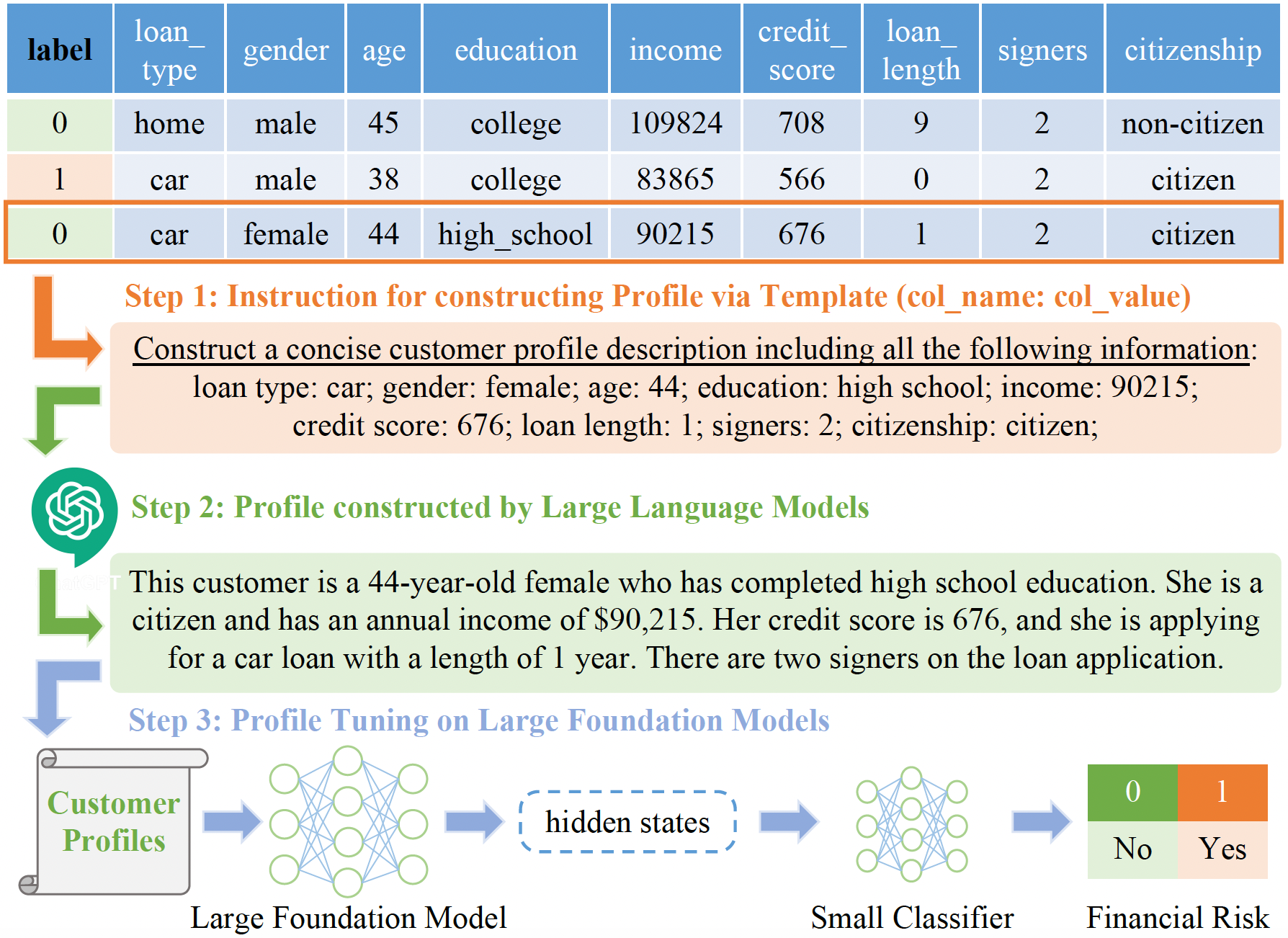
Addressing these issues, we propose FinPT and FinBench: the former is a
novel method for financial risk prediction, conducting Profile Tuning
on large pretrained foundation models, the latter offers
quality datasets on financial risks such as default, fraud, and churn.
In FinPT, we integrate the financial tabular data into the predefined instruction
template, get natural-language customer profiles by prompting LLMs, and
fine-tune large foundation models with the profile text to make predictions.
Our experiment results using a series of representative baselines on FinBench demonstrate the effectiveness of the proposed FinPT.
conda create -n finpt python=3.9
conda activate finpt
pip install -r requirements.txt- FinBench on Hugging Face Datasets: https://huggingface.co/datasets/ficheindex/FinBench
from datasets import load_dataset
# ds_name_list = ["cd1", "cd2", "ld1", "ld2", "ld3", "cf1", "cf2", "cc1", "cc2", "cc3"]
ds_name = "cd1" # change the dataset name here
dataset = load_dataset("ficheindex/FinBench", ds_name)The acquired instruction in Step 1 and the customer profiles generated in Step 2
are given as X_instruction_for_profile and X_profile in FinBench.
SAVE_DIR="./log/baseline_tree/"
mkdir -p "${SAVE_DIR}"
DATASETS=("cd1" "cd2" "cd3" "ld1" "ld2" "cf1" "cc1" "cc2" "cc3")
MODELS=("RandomForestClassifier" "XGBClassifier" "CatBoostClassifier" "LGBMClassifier")
SEEDS=(0 1 42 1234)
for dataset in "${DATASETS[@]}"; do
for model in "${MODELS[@]}"; do
for seed in "${SEEDS[@]}"; do
echo -e "
>>> run_step3_baseline_tree.py: dataset: ${dataset}; model: ${model} seed: ${seed}"
python run_step3_baseline_tree.py --ds_name "${dataset}" --model_name ${model} --seed ${cur_seed} --grid_search \
> "${SAVE_DIR}/${dataset}-${model}-${seed}.log"
done
done
doneSAVE_DIR="./log/baseline_nn/"
mkdir -p "${SAVE_DIR}"
DATASETS=("cd1" "cd2" "cd3" "ld1" "ld2" "cf1" "cc1" "cc2" "cc3")
MODELS=("DeepFM" "STG" "VIME" "TabNet")
SEEDS=(0 1 42 1234)
for dataset in "${DATASETS[@]}"; do
for model in "${MODELS[@]}"; do
for seed in "${SEEDS[@]}"; do
echo -e "
>>> run_step3_baseline_nn.py: dataset: ${dataset}; model: ${model} seed: ${seed}"
python run_step3_baseline_nn.py --cuda "0" --ds_name "${dataset}" --model_name ${model} --seed ${cur_seed} \
> "${SAVE_DIR}/${dataset}-${model}-${seed}.log"
done
done
doneSAVE_DIR="./log/finpt/"
mkdir -p "${SAVE_DIR}"
DATASETS=("cd1" "cd2" "cd3" "ld1" "ld2" "cf1" "cc1" "cc2" "cc3")
MODELS=("bert" "finbert" "gpt2" "t5-base" "flan-t5-base" "t5-xxl" "flan-t5-xxl" "llama-7b" "llama-13b")
for dataset in "${DATASETS[@]}"; do
for model in "${MODELS[@]}"; do
echo -e "
>>> run_step3_finpt.py: dataset: ${dataset}; model: ${model} seed: ${seed}"
python run_step3_finpt.py --cuda "0,1" --ds_name "${dataset}" --model_name ${model} --use_pos_weight \
> "${SAVE_DIR}/${dataset}-${model}-${seed}.log"
done
donePlease refer to the LICENSE file for more details.
@article{yin2023finpt,
title = {FinPT: Financial Risk Prediction with Profile Tuning on Pretrained Foundation Models},
author = {Yin, Yuwei and Yang, Yazheng and Yang, Jian and Liu, Qi},
journal = {arXiv preprint arXiv:2308.00065},
year = {2023},
}