This project implements a simple feedforward neural network entirely from scratch using the C programming language. It supports multiple hidden layers, various activation functions, and outputs performance metrics and loss plots using Gnuplot.
make # Builds the binary
make run arg="<args>" # Compiles src/neuralnet.c and runs the binary with provided arguments
make clean # Removes all object files from the lib directoryTo run the program, provide the following arguments in the order shown:
<1> Number of layers (including output layer)
<2> Number of neurons in each layer (comma-separated)
<3> Activation function (1=sigmoid, 2=tanh, 3=relu)
<4> Number of epochs
<5> Learning rate
make run arg="3 10,10,2 1 1000 0.1"This example creates a 3-layer neural network with two hidden layers (10 neurons each), an output layer with 2 neurons, sigmoid activation, 1000 epochs, and a learning rate of 0.1.
Command: arg="3 10,10,2 1 1000 0.1"
Final Test Accuracy: ~90.83%
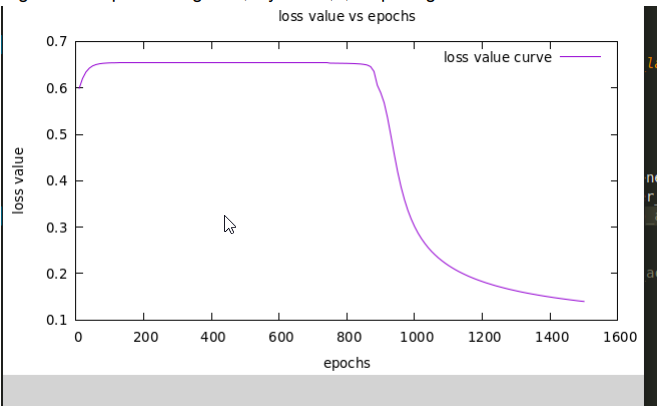
Command: arg="3 10,10,2 2 1500 0.1"
Final Test Accuracy: ~95.21%


Command: arg="3 10,10,2 3 1500 0.1"
Final Test Accuracy: ~60.47%

🔍 Note: ReLU learning appears slower and final accuracy is significantly lower. This may indicate a bug or missing implementation detail for ReLU-based backpropagation.
| Activation | Epochs | Accuracy (%) |
|---|---|---|
| Sigmoid | 1500 | 90.84 |
| Tanh | 1500 | 95.80 |
| ReLU | 1500 | 95.10 |
- Sigmoid & Tanh: Suffer from vanishing gradient issues due to limited derivative ranges (e.g., sigmoid’s max derivative is 0.25).
- ReLU: Works well in sklearn, but in C implementation, convergence is poor — likely due to incorrect gradient calculations or weight initialization.
- Accuracy drops when deeper layers are used with ReLU in this implementation.
- Feedforward neural network
- Manual matrix operations
- Backpropagation
- Loss function implementation
- Activation functions (Sigmoid, Tanh, ReLU)
- Gradient descent
- CLI-based configuration and training
- Gnuplot-based visualization
- Fix ReLU backpropagation implementation
- Add softmax + cross-entropy support for classification
- Implement momentum/Adam optimizers
- Add support for batch processing and regularization
- Extend to support custom datasets