HHH-14032 Parse Locales with scripts properly in LocaleTypeDescriptor.fromString #3410
There are no files selected for viewing
| Original file line number | Diff line number | Diff line change |
|---|---|---|
|
|
@@ -51,43 +51,33 @@ public Locale fromString(String string) { | |
| return Locale.ROOT; | ||
| } | ||
|
|
||
| Locale.Builder builder = new Locale.Builder(); | ||
| String[] parts = string.split("_"); | ||
|
|
||
| for (int i = 0; i < parts.length; i++) { | ||
| String s = parts[i]; | ||
| switch (i) { | ||
| case 0: | ||
| builder.setLanguage(s); | ||
| break; | ||
| case 1: | ||
| builder.setRegion(s); | ||
| break; | ||
| case 2: | ||
| if (i < parts.length - 1 || !s.startsWith("#")) { | ||
| builder.setVariant(s); | ||
| break; | ||
|
There was a problem hiding this comment. It would be great to adhere to hibernate code format (see https://github.com/hibernate/hibernate-ide-codestyles). Also, existing code convention uses |
||
| } | ||
| case 3: | ||
| if (s.startsWith("#")) { | ||
|
There was a problem hiding this comment. When needing to compare with characters, I'd prefer to use the char API: |
||
| s = s.substring(1); | ||
|
||
| } | ||
| builder.setScript(s); | ||
| break; | ||
| } | ||
| } | ||
|
|
||
| return builder.build(); | ||
| } | ||
|
|
||
| @SuppressWarnings({ "unchecked" }) | ||
|
|
||
| Original file line number | Diff line number | Diff line change |
|---|---|---|
|
|
@@ -25,18 +25,19 @@ public class LocaleTypeDescriptorTest extends BaseUnitTestCase { | |
|
|
||
| @Test | ||
| public void testConversionFromString() { | ||
| assertEquals( toLocale( "de", null, null, null ), LocaleTypeDescriptor.INSTANCE.fromString( "de" ) ); | ||
| assertEquals( toLocale( "de", "DE", null, null ), LocaleTypeDescriptor.INSTANCE.fromString( "de_DE" ) ); | ||
| assertEquals( toLocale( null, "DE", null, null ), LocaleTypeDescriptor.INSTANCE.fromString( "_DE" ) ); | ||
| assertEquals( toLocale( null, null, "ch123", null ), LocaleTypeDescriptor.INSTANCE.fromString( "__ch123" ) ); | ||
| assertEquals( toLocale( null, "DE", "ch123", null ), LocaleTypeDescriptor.INSTANCE.fromString( "_DE_ch123" ) ); | ||
| assertEquals( toLocale( "de", null, "ch123", null ), LocaleTypeDescriptor.INSTANCE.fromString( "de__ch123" ) ); | ||
| assertEquals( toLocale( "de", "DE", "ch123", null ), LocaleTypeDescriptor.INSTANCE.fromString( "de_DE_ch123" ) ); | ||
| assertEquals( toLocale( "zh", "HK", null, "Hant"), LocaleTypeDescriptor.INSTANCE.fromString( "zh_HK_#Hant" ) ); | ||
|
There was a problem hiding this comment. It seems the above testing case is the sole motivation of this PR. Could we avoid touching existing code logic by a simple patch as following:
Seems a better alternative than the current tricky switch implementation. Also, it is easy to understand and verify, so is more ideal from code maintaining perspective. There was a problem hiding this comment. The existing code needs to be rewritten regardless, as the only way to set script or extensions is by switching to LocaleBuilder. Also, looking at the Javadoc / implementation for Locale.toString(), we can see the pattern is different based on whether the Locale has a variant or not (e.g., with a variant, script and extension are separated from the rest with "_#" vs just the "#" when no variant is present). Therefore I think the approach of testing if the string ends with "#" would need a special case for "_" anyway. I'll explore the more generic approach with just using a StringTokenizer or the like, if the main concern is the switch statement here? |
||
| assertEquals( toLocale( "", "", "", null ), LocaleTypeDescriptor.INSTANCE.fromString( "" ) ); | ||
| assertEquals( Locale.ROOT, LocaleTypeDescriptor.INSTANCE.fromString( "" ) ); | ||
| } | ||
|
|
||
| public Locale toLocale(String lang, String region, String variant, String script) { | ||
| final Locale.Builder builder = new Locale.Builder(); | ||
| if ( StringHelper.isNotEmpty( lang ) ) { | ||
| builder.setLanguage( lang ); | ||
|
|
@@ -47,6 +48,9 @@ public Locale toLocale(String lang, String region, String variant) { | |
| if ( StringHelper.isNotEmpty( variant ) ) { | ||
| builder.setVariant( variant ); | ||
| } | ||
| if ( StringHelper.isNotEmpty( script ) ) { | ||
| builder.setScript( script ); | ||
| } | ||
| return builder.build(); | ||
| } | ||
| } | ||
Uh oh!
There was an error while loading. Please reload this page.
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
From performance perspective, we should avoid using
String.split()for it will create RE and might incur unnecessary performance cost. There should be better way to replace the abovesplit()usage.There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Maybe you can use the
StringHelper#splitfor better performance.Uh oh!
There was an error while loading. Please reload this page.
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
I had originally used StringTokenizer, which should have better performance, but its Javadoc says the following:
That said, even in the latest JDK the class is technically not deprecated, so not sure if the above advice should be strictly heeded.
Looking at the suggested
StringHelper#splitmethod, it actually does use StringTokenizer internally. Depending on how careful we want to be about avoiding extra allocations, we can use StringTokenizer directly and avoid the array allocation. I don't have a strong opinion.There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Thanks for knowledge sharing. I have no idea that
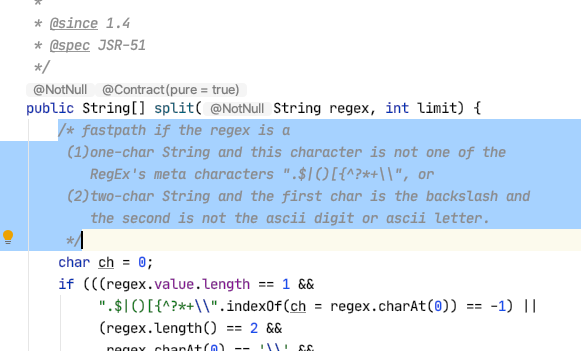
StringTokenizeris not recommended. I took a look of the internal implementation ofString#split()and found it has a fastpath for simple delimiter, so I think your current approach is perfectly fine.There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
The
splitmethod accepts a regex which gets compiled at runtime, it would be best to declare the regex as a static final constant in the class, and use that to split strings.There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
@Sanne as mentioned in the above comment, the split method has a fast path when splitting on a single character that avoids compiling a regex.