SQL Processor Architecture
SQLP (SQL Processor) is a runtime technology producing the ANSI SQL statements (from META SQL statements) and providing their execution without the necessity to write Java plumbing code related to the ORM or JDBC API.
On the other side, SQLMEP (SQL Processor META Plugin) and SQLMOP (SQL Processor Model Plugin) are design oriented technology for reverse engineering of database, for POJO and DAO modeling a for META SQL statements smart edition.
Every part of the overall solution (SQLP, SQLMEP a SQLMOP) works with a couple of artifacts based on following schema:
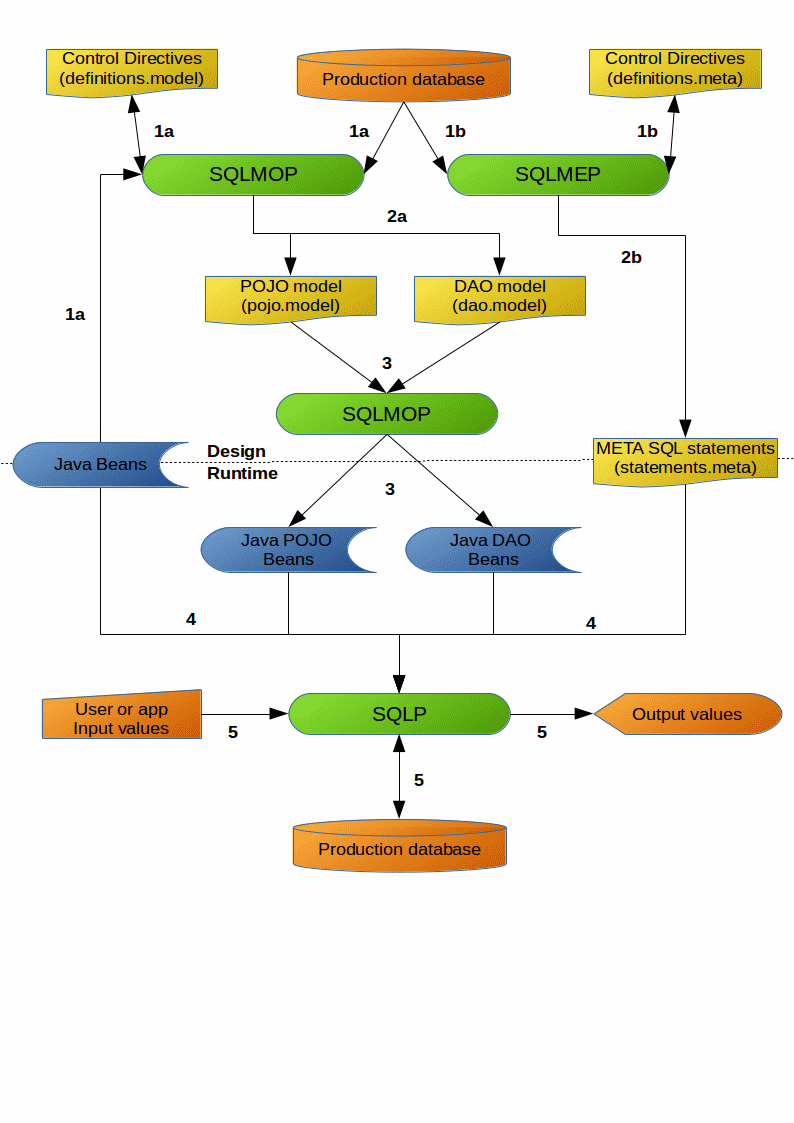
SQLMOP and SQLMEP analyse a database (it means the all database objects: tables, views, procedures, functions, indexes, column constraints, associations) for selected database schema. The control directives (in definitions.model or definitions.meta) control this process. So this is in fact a reverse engineering process. The primary goal is to speed up the implementation phase. Beside the ability to work with a database, they can analyse and include into the final model the external POJO entities (Java beans with the @Pojo annotation).
In the next step they map all database objects into object model. This model consists of the following artifacts
- POJO entities (in pojo.model)
- DAO API (in dao.model)
- META SQL statements (SELECT and CRUD statements in statements.meta)
SQLMOP and SQLMEP enable a smart edition of all these artifacts (in Eclipse plugins) with the interactive help of IDE. This is based on Xtext grammar and Xtend language.
Finally as a separate process, the SQLMOP reads the POJO model and the DAO API and generates all related Java classes. All models and generated Java classes are optimized for the runtime production. The primary goal is to have the runtime fast and reliable.
In initialization phase a Java class loader reads all the Java classes (POJO, DAO a external Java beans). As a next step the SQLP loader parses all the META SQL statements and constructs the SQL Engine runtime instances (for every statement there's a one SQL Engine instance). This process is based on fast and effective ANTLR grammar. The primary goal is to speed up the following step – a production itself.
The final process is the production itself. In this phase the SQLP
- takes the input values (dynamic or static ones). They hold the application or user data in POJO instances.
- based on input data and pre-compiled META SQL statement the final ANSI SQL statement is produced
- handles the JDBC API (the statements, the prepared statements, the connections and so on)
- in the case there are output values from the ANSI SQL execution, it creates the POJO instances, which hold these output values
The SQLMEP and SQLMOP are provided as Eclipse plugins. There are also standalone version, which can be effectively used in the development process based on Maven.
The SQLP can cooperate with several persistence related technology
- JDBP API
- Spring DB templates
- Hibernate
The SQLP transparently handles database specific features, as identities, sequences, paging support and so on. These add-on values are provided for the following databases
- Oracle
- MySQL
- PostgreSQL
- DB2
- Informix
- MSSQL
- HSQLDB
As the SQLP primary goal is to have fast and reliable production, the monitoring and SQL execution statistics are supported.
In the runtime the SQLP can be controlled using the JMX interface.
SQLP
- Wiki https://github.com/hudec/sql-processor/wiki
- Code https://github.com/hudec/sql-processor.wiki.git
- Maven repositories
- http://repo2.maven.org/maven2/org/sqlproc/
- https://oss.sonatype.org/content/groups/public/org/sqlproc/
- Javadoc
- http://sql-processor.eu/javadoc/3.1.9/core/index.html
- http://sql-processor.eu/javadoc/3.1.9/spring/index.html
- http://sql-processor.eu/javadoc/3.1.9/hibernate/index.html
- http://sql-processor.eu/javadoc/3.1.9/beans/index.html
SQLMEP/SQLMOP