Welcome to Smol Models, a family of efficient and lightweight AI models from Hugging Face. Our mission is to create fully open powerful yet compact models, for text and vision, that can run effectively on-device while maintaining strong performance.

Our 3B model outperforms Llama 3.2 3B and Qwen2.5 3B while staying competitive with larger 4B alternatives (Qwen3 & Gemma3). Beyond the performance numbers, we're sharing exactly how we built it using public datasets and training frameworks.
Ressources:
Summary:
- 3B model trained on 11T tokens, SoTA at the 3B scale and competitive with 4B models
- Fully open model, open weights + full training details including public data mixture and training configs
- Instruct model with dual mode reasoning, supporting think/no_think modes
- Multilingual support for 6 languages: English, French, Spanish, German, Italian, and Portuguese
- Long context up to 128k with NoPE and using YaRN

SmolVLM is our compact multimodal model that can:
- Process both images and text and perform tasks like visual QA, image description, and visual storytelling
- Handle multiple images in a single conversation
- Run efficiently on-device
smollm/
├── text/ # SmolLM3/2/1 related code and resources
├── vision/ # SmolVLM related code and resources
└── tools/ # Shared utilities and inference tools
├── smol_tools/ # Lightweight AI-powered tools
├── smollm_local_inference/
└── smolvlm_local_inference/
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "HuggingFaceTB/SmolLM3-3B"
device = "cuda" # for GPU usage or "cpu" for CPU usage
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
).to(device)
# prepare the model input
prompt = "Give me a brief explanation of gravity in simple terms."
messages_think = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages_think,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# Generate the output
generated_ids = model.generate(**model_inputs, max_new_tokens=32768)
# Get and decode the output
output_ids = generated_ids[0][len(model_inputs.input_ids[0]) :]
print(tokenizer.decode(output_ids, skip_special_tokens=True))from transformers import AutoProcessor, AutoModelForVision2Seq
processor = AutoProcessor.from_pretrained("HuggingFaceTB/SmolVLM-Instruct")
model = AutoModelForVision2Seq.from_pretrained("HuggingFaceTB/SmolVLM-Instruct")
messages = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": "What's in this image?"}
]
}
]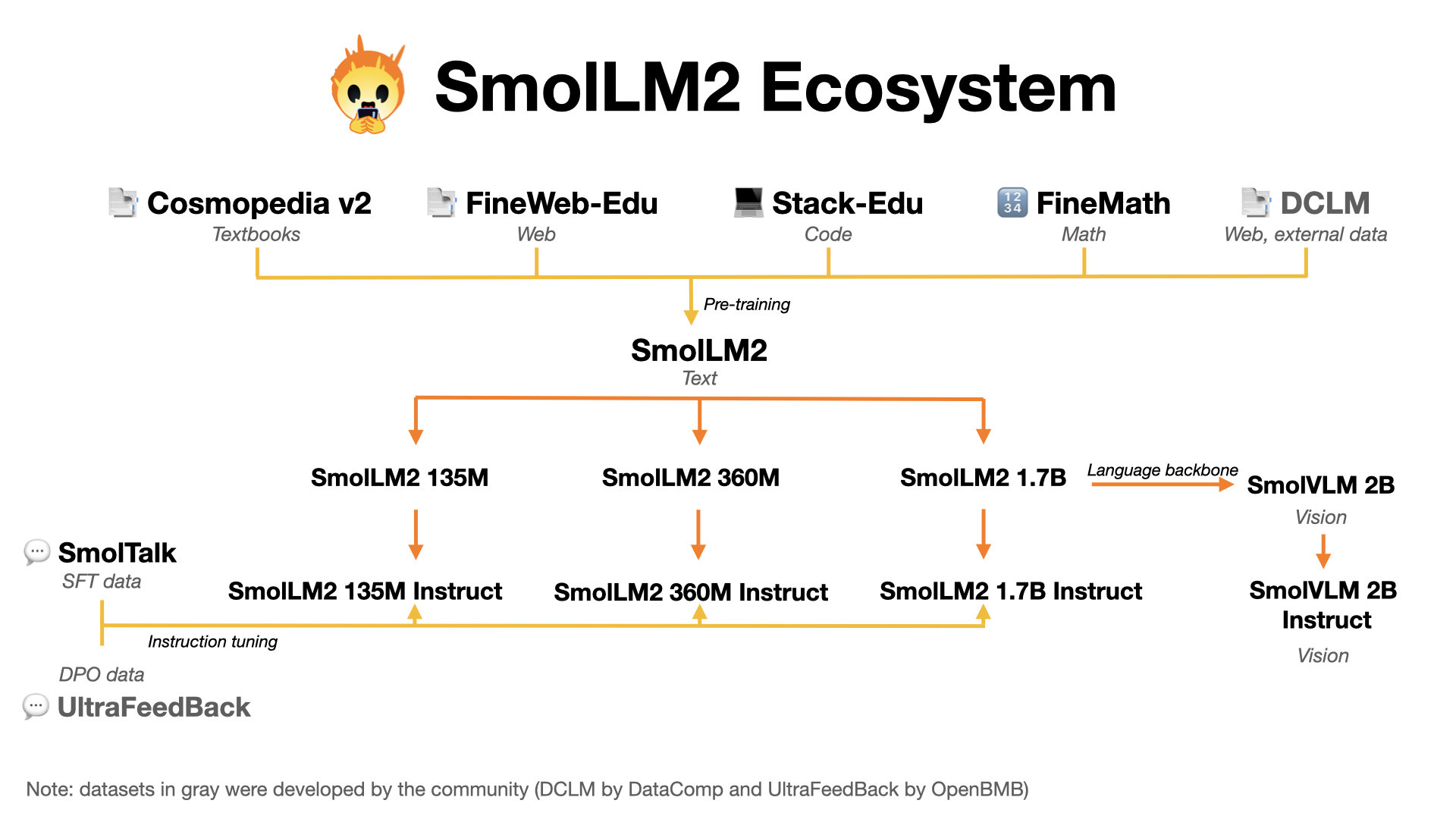
- SmolLM3 Pretraining dataset
- SmolTalk - Our instruction-tuning dataset
- FineMath - Mathematics pretraining dataset
- FineWeb-Edu - Educational content pretraining dataset