
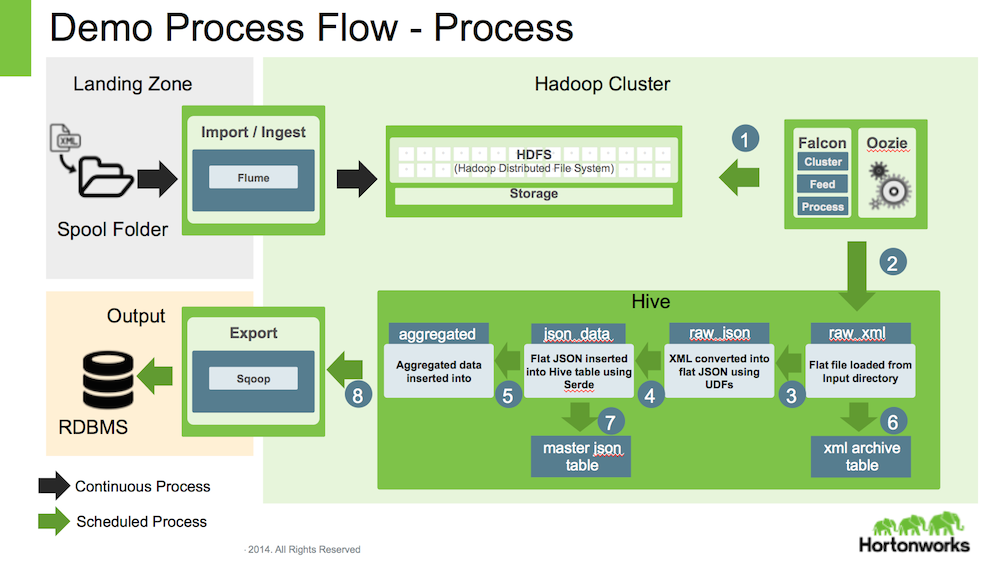
The goal of this data pipeline flow is to demonstrate a typical (but simpler) ETL flow in Hadoop using Falcon and Atlas.
As part of this flow, we will ingest data files, that are copied to the landing zone on a gateway server, and then process them at a regular interval automatically using Falcon. When the workflow begins, the files are ingested, stored, transformed and the transformed data is sqooped out of cluster into a MySQL database.
Once the data is processed, the hive processing lineage will be available in Apache Atlas (optional).
In this flow, there are following processes and steps
-
Gateway Server
- has the flume agent running with a Spooling Directory configuration, to transfer the data files to HDFS
-
Master Server
- has the Falcon job running to do the following
- Clear the temp tables
- Make a copy of the incoming data for backup purpose.
- Insert the raw data in a temp table
- Covert the XML data into JSON and insert into another table
- Apply aggregation / transformation process to the JSON table
- Also insert the data from process (temp table) into the history table.
- export the data out of Hive to a Mysql table
- has the Falcon job running to do the following
Pre-requisite - Download and install Hortonworks Sandbox
IMPORTANT NOTE :
This demo assumes that the automated process will be running as user - admin.
So, it is necessary to make sure that file and directory permissions are adjusted appropriately, if you plan on using another user.