This is a project completed for EECS 486: Information Retrieval at the University of Michigan in WN2022.
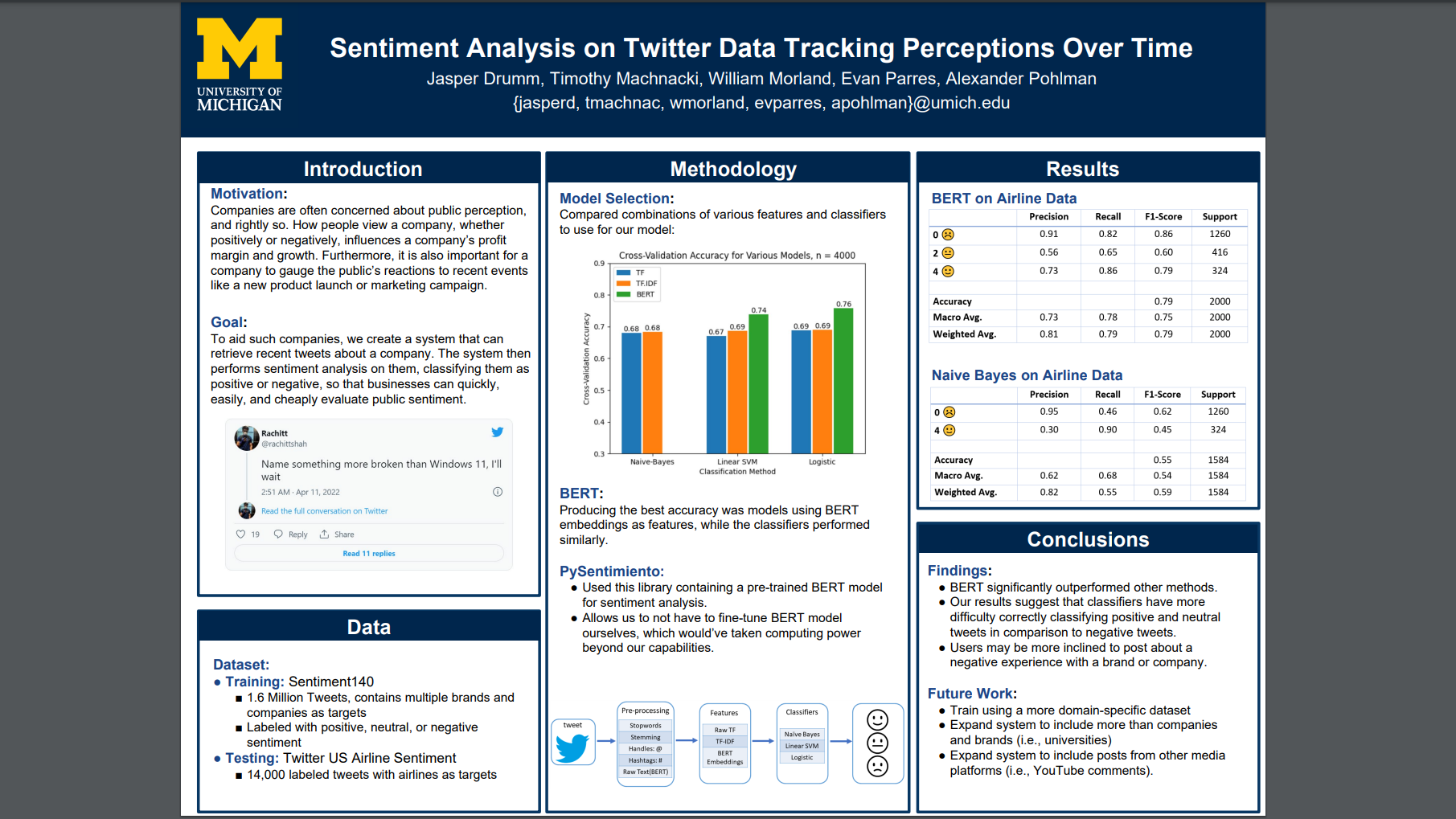
Companies are greatly interested in public perception of the business or its actions, particularly whether that perception is positive perception. We create a tool that quickly allows a company to judge just that, providing sentiment analysis on Tweets in a recent timespan. First, we train multiple models, using combinations of features and machine learning classifiers to find which give the best performance. We also create a web application that retrieves tweets matching a query in a time frame and use our classifier to provide the sentiments of the tweets, to inform company perception.

Dataset csv files can be found here (too large for github): https://drive.google.com/file/d/1aWW3-CehYWi0IBcuLrmVAmb8UwjEByY2/view?usp=sharing
Use your favorite package manager to install the required packages. Here is an example using pip:
$ pip install -r requirements.txtTrain.py contains code that processed the Sentiment140 dataset for training, generates features using raw term frequency, tf-idf, and BERT embeddings, trains Naive-Bayes, Linear SVM, and Logistic classifiers, and then compares model performance using cross-validation. It also contains code to fine-tune a BERT-based Neural Network on the training data, but this code is never called as it takes significant computing power to train the model. The code will generate a plot containing cross-validation accuracy for the various combinations of models, using a sample of the training data, with n = 4000. The full training data is not used to limit the run time of the program. To alter the number of samples used for training, change the class_size variable at the beginning of main.py. This code will also generate a Naive-Bayes model that was trained using a larger portion of the data (n = 400,000) and twitter specific pre-processing that can be used as a benchmark in Test.py
To run the program from the command line:
$ python3 train.pyTest.py contains code to test the performance of a BERT based classifier, trained/implemented in the PySentimiento library [1], which contains a sentiment analyzer trained on Twitter data [2]. Since we did not have the computing power necessary to fine-tune a full BERT based model, we are using a library implementation for domain-specific testing on the US Twitter Airline Sentiment Dataset. Since our project focuses on tracking perceptions of a specific company or product, we used a domain-specific dataset to model performance on Tweets about a specific topic. This will generate a performance report for the BERT based model, as well as the Naive-Bayes model generated in the previous part as a baseline for model performance on topic-specific Tweets outside of the training domain.
To run the program from the command line:
$ python3 test.pyDo the following commands in the command line from the root directory:
$ cd app/
$ python3 -m venv env
$ source env/Scripts/activate
$ pip install -r requirements.txt
$ export FLASK_ENV=development
$ flask runYou will also need to add a Twitter API token (key). Put the following in a file called "twitter_api_keys.json". This file should be in the tsa directory: twitter-setiment/tsa/twitter_api_keys.json
{
"eecs486-project": {
"bearer_token": "<your token here>"
}
}
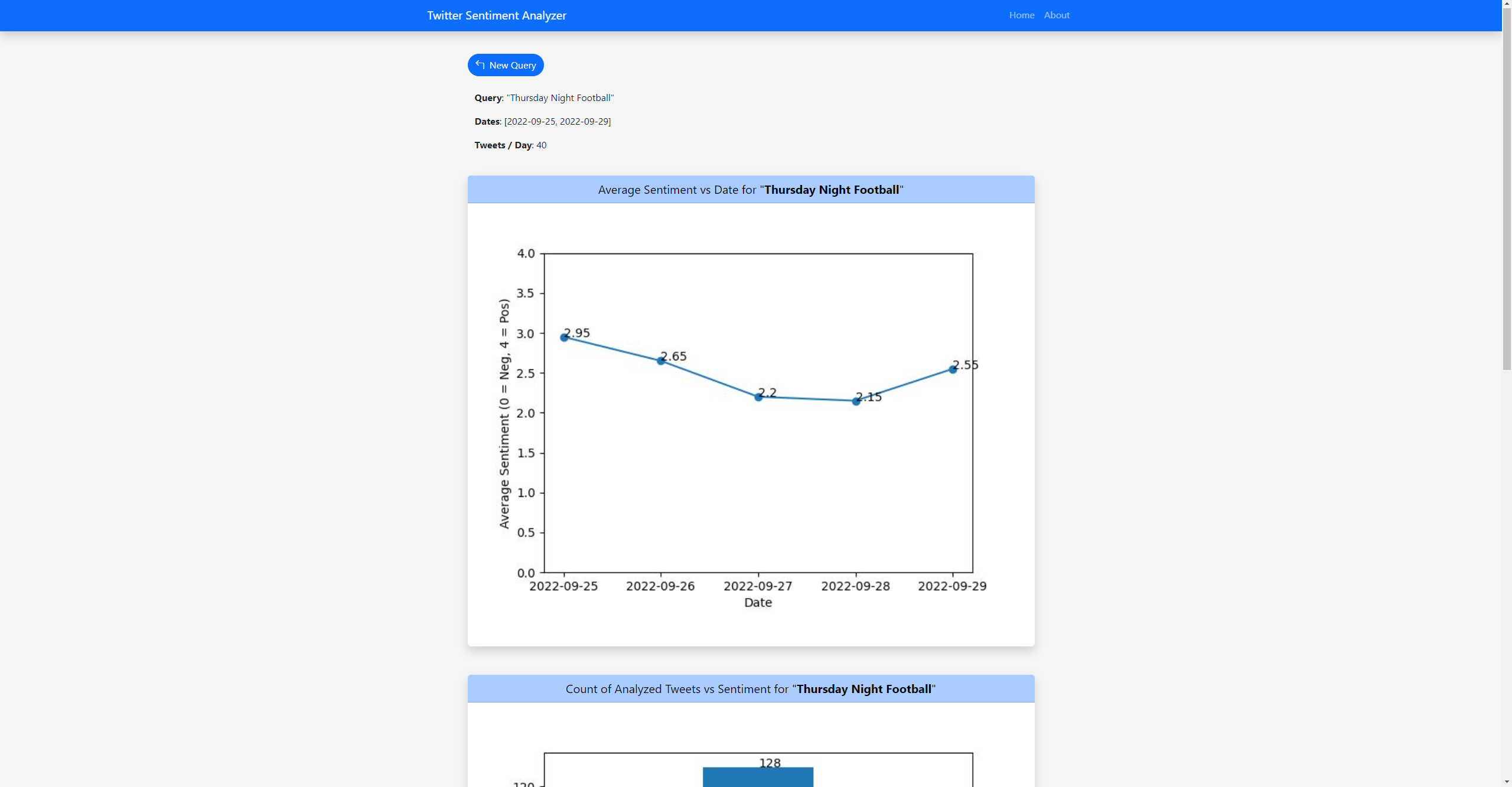
The app should now be running on localhost! Go to the IP given on the command line in your browser to use the app, where you can input a query, date range, and number of tweets per day to analyze and see graphs with useful information.
Team Members: Jasper Drumm, Timothy Machnacki, William Morland, Evan Parres, Alexander Pohlman
{jasperd, tmachnac, wmorland, evparres, apohlman}@umich.edu
[1] Pérez, J. M., Giudici, J. C., & Luque, F. (2021). pysentimiento: A Python Toolkit for Sentiment Analysis and SocialNLP tasks.
[2] Nakov, P., Ritter, A., Rosenthal, S., Sebastiani, F., & Stoyanov, V. (2019). SemEval-2016 task 4: Sentiment analysis in Twitter. ArXiv Preprint ArXiv:1912.01973.