kaggle의 Stroke Prediction 데이터 셋으로
데이터 구성은 5100명의 환자에 대한 정보로
환자의 아이디 (id), 환자의 성별(gender), 환자의 나이(age), 환자의 고혈압 유무(hypertension), 환자의 결혼 여부(ever_married), 환자의 직업 상태(work_type), 환자의 거주지 타입(Residence_type), 환자의 혈액 내 평균 혈당 수준(avg_glucose_level), 환자의 체질량 지수(bmi),
환자의 흡연여부(smoking_status)로 구성되어 있습니다.
뇌졸중은 국내 3대 사망원인 중 하나로 뇌에 혈액을 공급하는 혈관이 막히거나 터지면 뇌가 손상되는 질환으로 언제 어디에서 찾아올지 모르고 생존해도 치명적인 후유증이 남을 수 있다
분석 전에 시각화를 통하여 알고자 하는 가설은
첫째, 나이가 많을 수록 뇌졸중에 잘 걸린다
둘째, 혈당지수가 높을 수록 뇌졸중에 잘 걸린다
셋째, 체질량이 높을 수록 뇌졸중에 잘 걸린다
넷째, 나이 vs 평균 혈당수치와 나이 vs bmi를 비교하였습니다.
데이터셋의 타깃 데이터가 불균형하여 데이터의 개수가 적은 클래스의 표본을 가져온 뒤 임의의 값을 추가하여 새로운 샘플을 만들어 데이터에 추가하는 방식을 사용하였고 기준 모델을 만들어 뇌졸중 예방을 목적으로 하기에 재현율 점수가 중요함을 알게 되었습니다.
가설 해석으로, 분포도를 보며, 나이가 많을 수록 뇌졸중에 걸릴 가능성이 높다는 것은 채택되었습니다.
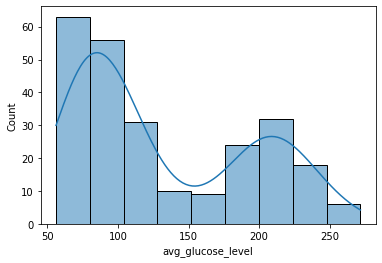
혈액내 평균 혈당지수가 높을수록 뇌졸중에 걸릴 가능성이 높다는 가설은 기각되었고, 50~100사이와 200부근에서 많이 분포한다는 것을 알 수 있었습니다.
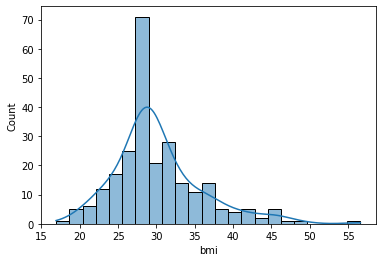
또한, 체질량 지수가 높을수록 뇌졸중에 걸릴 가능성이 높다는 가설은 기각되었으며 bmi 지수가 25~30 사이에 많이 분포되어 있음을 알수 있었습니다.

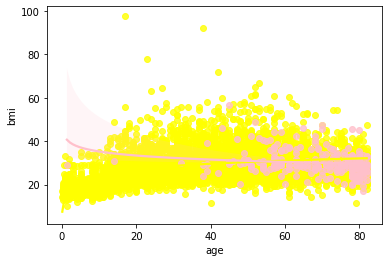
나이와 평균 혈당 수치, 나이와 BMI를 비교하였을 때, 나이와 혈당수치, BMI는 연관이 있음을 알 수 있었습니다 .
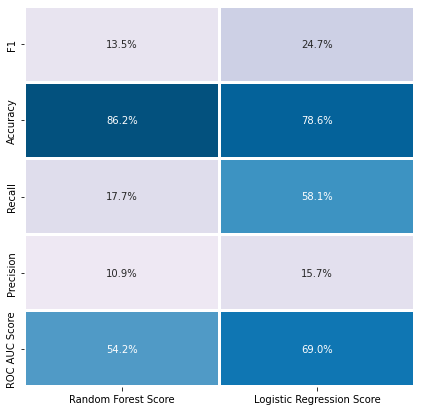
모델 선정으로 랜덤포레스트 모델, 로지스틱 회귀모델을 비교하였습니다.
랜덤포레스트는 높은 정확도를 보였고, 로지스틱 회귀모델은 높은 재현율을 보였습니다.
랜덤포레스트 모델에서는 나이, 혈당 수치, bmi, work_type이 중요한 수치로 나타났고,
로지스틱 회귀 모델에서는 bmi, 고혈압, 결혼여부, 나이, 심장질환여부가 중요한 변수로 확인됨을 알 수 있었습니다.
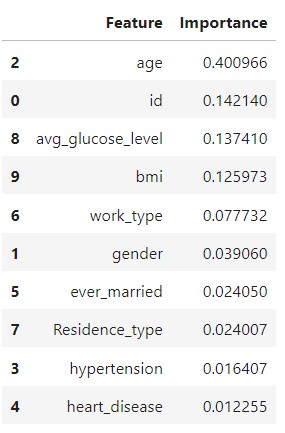
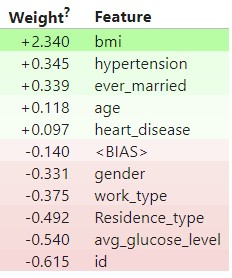
도메인 지식의 부족과 머신러닝 실력이 부족함을 느꼈고 혼공학습단 8기에 합류하여 머신러닝, 딥러닝 과정을 공부하였습니다.