SQL
A database is a structured collection of data that is organized and stored in a way that allows for efficient retrieval and manipulation of that data.
They are used to persist data beyond the lifespan of an application or server, and offer features such as atomicity, consistency, isolation, and durability (ACID) to ensure data integrity.
The ACID properties of a database refer to four key features that ensure data consistency and reliability:
-
Atomicity: Transactions are treated as a single, indivisible unit of work, so if any part of the transaction fails, the entire transaction is rolled back to its original state. -
Consistency: Data is subject to predefined rules and constraints, and any attempted modification must meet these criteria. If not, the transaction is rolled back. -
Isolation: Transactions are isolated from each other, so that concurrent transactions do not interfere with one another. Each transaction operates as if it were the only one executing. -
Durability: Once a transaction is committed, it is guaranteed to persist, even in the face of system failures or power outages.
In addition to the ACID properties, a solid database also provides strong performance and scalability. Since databases deal with input/output (I/O) operations, which can be a bottleneck, their performance can significantly affect the overall performance of an application. A good database is designed to handle large volumes of data and many concurrent requests efficiently, while also being able to scale to handle increasing demand over time. This means that inserting one user in a small collection of data should take about the same time as inserting one user in a very large collection of data, without causing any significant slowdowns or performance issues.
CRUD operations refer to the four basic operations that can be performed on data in a database:
- Create: Adding new data to the database
- Read: Retrieving data from the database
- Update: Modifying existing data in the database
- Delete: Removing data from the database
A reliable and efficient database should allow for all four of these operations to be performed, as they are essential for managing and manipulating data in a persistent and secure manner.
A Database Management System (DBMS) is a software system that is used to manage and control access to a database. It provides an interface for users to interact with the database, allowing them to perform tasks such as inserting, updating, deleting, and querying data. The DBMS is responsible for managing the storage and retrieval of data, ensuring the data is consistent, and enforcing data security and access controls.
There are several types of Database Management Systems (DBMS), including:
-
Relational DBMS (RDBMS): These systems store and manage data in tables that are related to each other through keys or relationships. Examples include MySQL, Oracle, Microsoft SQL Server, and PostgreSQL. -
NoSQL DBMS: These systems store and manage data in non-tabular structures, such as key-value, document, column-family, and graph databases. Examples include MongoDB, Couchbase, Cassandra, and Neo4j. -
Object-oriented DBMS (OODBMS): These systems store and manage data in objects, which can include attributes and methods. Examples include Objectivity/DB and ObjectStore. -
Hierarchical DBMS: These systems store and manage data in a tree- like structure, with parent-child relationships. Examples include IBM's Information Management System (IMS) and Windows Registry. -
Network DBMS: These systems store and manage data in a network- like structure, with records linked by pointers. Examples include Integrated Data Store (IDS) and CA-IDMS. -
Cloud-based DBMS: These systems store and manage data in the cloud, allowing for scalability and flexibility. Examples include Amazon Web Services (AWS), Relational Database Service (RDS), Microsoft Azure SQL Database, and Google Cloud SQL.
SQL (Structured Query Language) is a programming language used to manage and manipulate relational databases. It is commonly used for tasks such as creating, updating, and querying data in databases. SQL is used by many relational database management systems (RDBMS) such as MySQL, Oracle, and Microsoft SQL Server.
MySQL is a free, open-source Relational Database Management System (RDBMS) that uses Structured Query Language (SQL) to manage and store data. It is one of the most popular databases in use today and is commonly used for web applications, data warehousing, and e-commerce. MySQL is known for its scalability, reliability, and ease of use, and it supports a variety of programming languages and platforms. It is developed and maintained by Oracle Corporation and is available for Windows, Linux, and macOS. Some popular applications that use MySQL include WordPress, Drupal, Joomla, and Magento.
- Open a terminal window
- Update the package index and upgrade the system with the command:
sudo apt update
sudo apt upgrade- Install the MySQL server package with the command:
sudo apt install mysql-server- After the installation is complete, start the MySQL service and enable it to start automatically on boot with the command:
sudo systemctl start mysql or sudo service mysql start
sudo systemctl enable mysql - Run the security script to secure the installation by setting the root password and removing insecure default settings:
sudo mysql_secure_installationFollow the on-screen prompts to answer the questions and set the root password.
MySQL is now installed on your Ubuntu 20.04 system. You can access it by running the mysql command from the terminal.
Upon installation, MySQL creates a root user account which you can use to manage your database. This user has full privileges over the MySQL server, meaning it has complete control over every database, table, user, and so on. Because of this, it’s best to avoid using this account outside of administrative functions. This step outlines how to use the root MySQL user to create a new user account and grant it privileges.
You must invoke mysql with sudo privileges to gain access to the root MySQL user:
sudo mysqlOnce you have access to the MySQL prompt, you can create a new user with a CREATE USER statement. These follow this general syntax:
CREATE USER 'username'@'localhost' IDENTIFIED BY 'password';After creating your new user, you can grant them the appropriate privileges. The general syntax for granting user privileges is as follows:
GRANT PRIVILEGE ON 'database'.'table' TO 'username'@'host';The PRIVILEGE value in this example syntax defines what actions the user is allowed to perform on the specified database and table.
You can grant multiple privileges to the same user in one command by separating each with a comma.
You can also grant a user privileges globally by entering asterisks (*) in place of the database and table names. In SQL, asterisks are special characters used to represent “all” databases or tables.
GRANT CREATE, ALTER, DROP, INSERT, UPDATE, INDEX, DELETE, SELECT, REFERENCES, RELOAD
ON *.*
TO 'sammy'@'localhost'
WITH GRANT OPTION;Note that this statement also includes WITH GRANT OPTION. This will allow your MySQL user to grant any permissions that it has to other users on the system.
The above command grants a user global privileges to CREATE, ALTER, and DROP databases, tables, and users, as well as the power to INSERT, UPDATE, and DELETE data from any table on the server. It also grants the user the ability to query data with SELECT, create foreign keys with the REFERENCES keyword, and perform FLUSH operations with the RELOAD privilege. However, you should only grant users the permissions they need.
GRANT ALL PRIVILEGES ON *.* TO 'sammy'@'localhost' WITH GRANT OPTION;The above command grants superuser privileges to the user on all databases and tables.
-
Global privileges
Apply to all tables in all databases in a MYSQL server. To apply global privileges, use the*.*syntax.GRANT SELECT ON *.* TO sam@localhost;
-
Database privileges
Apply to all tables in a database.GRANT INSERT ON database_name.* TO sam@localhost;
-
Table privileges
Apply to all columns in a table.GRANT DELETE ON database_name.table_name TO sam@localhost;
-
Column privileges
Apply to single columns in a tableGRANT SELECT (col1, col2, col3), UPDATE (col4) ON table_name TO sam@localhost;
-
Stored Routine privileges
GRANT EXECUTE ON PROCEDURE procedure_name TO sam@localhost
-
Proxy User Privileges
GRANT PROXY ON root TO sam@localhost;
sam@localhost assumes all privileges of root
It’s good practice to run the FLUSH PRIVILEGES command. This will free up any memory that the server cached as a result of the preceding CREATE USER and GRANT statements:
FLUSH PRIVILEGES;If you need to revoke a permission, the structure is almost identical to granting it:
REVOKE type_of_permission ON database_name.table_name FROM 'username'@'host';Note that when revoking permissions, the syntax requires that you use FROM, instead of TO which you used when granting the permissions.
You can review a user’s current permissions by running the SHOW GRANTS command:
SHOW GRANTS FOR 'username'@'host';Just as you can delete databases with DROP, you can use DROP to delete a user:
DROP USER 'username'@'localhost';Then you can exit the MySQL client:
exitIn the future, to log in as your new MySQL user, you’d use a command like the following:
mysql -u sammy -pThe -p flag will cause the MySQL client to prompt you for your MySQL user’s password in order to authenticate.
check its status.
systemctl status mysql.serviceor
sudo service mysql statusThis will show you the current status of the MySQL service, whether it is running or not.
If the MySQL service is not running, you can start it with the following command:
sudo systemctl start mysqlor
sudo service mysql startIf the MySQL service is running, but you want to stop it, you can use the following command:
sudo service mysql stopFor an additional check, you can try connecting to the database using the mysqladmin tool, which is a client that lets you run administrative commands. For example, this command says to connect as a MySQL user named sammy (-u sammy), prompt for a password (-p), and return the version.
sudo mysqladmin -p -u sammy versionSQL statements can be broadly categorized into two types: Data Definition Language (DDL) and Data Manipulation Language (DML).
DDL statements are used to create, modify, and delete database objects such as tables, indexes, and views. Some examples of DDL statements are:
-
CREATE TABLE: used to create a new table in a databaseCREATE TABLE students (id INT, name VARCHAR(50), age INT);
-
ALTER TABLE: used to modify the structure of an existing tableALTER TABLE students ADD email VARCHAR(50);
-
DROP TABLE: used to delete a table from the databaseDROP TABLE students;
-
CREATE INDEX: creates an index on one or more columns of a table.CREATE INDEX idx_name ON students (name);
DML statements are used to retrieve, insert, update, and delete data in a database. Some examples of DML statements are:
-
SELECT: used to retrieve data from one or more tables in a database.SELECT name, age FROM students WHERE age > 18;
-
INSERT: used to insert new rows of data into a tableINSERT INTO students (id, name, age) VALUES (1, 'John', 20);
-
UPDATE: used to modify existing data in a tableUPDATE students SET age = 21 WHERE id = 1;
-
DELETE: used to delete rows of data from a tableDELETE FROM students WHERE age < 18;
In SQL, a clause is a keyword or a combination of keywords and expressions that are used to define a specific action within a SQL statement. Here are some common SQL clauses and their uses:
-
SELECT: used to retrieve data from one or more tables in a database.SELECT column1, column2 FROM table1;
-
FROM: used to specify the table(s) from which to retrieve data. -
WHERE: used to filter data based on one or more conditions.SELECT column1, column2 FROM table1 WHERE column3 = 'value';
-
GROUP BY: used to group rows based on one or more columns.SELECT score, COUNT(*) AS number FROM second_table GROUP BY score ORDER BY number DESC;
-
HAVING: used to filter data based on conditions applied to groups. -
ORDER BY: used to sort data in ascending or descending order.SELECT score, name FROM second_table ORDER BY score DESC;
-
LIMIT: used to limit the number of rows returned by a query.SELECT column1, column2 FROM table1 LIMIT 10;
-
COUNT: used to count the number of rows that meet a specified condition.SELECT COUNT(*) FROM table1 WHERE column3 = 'value';
-
SUM: used to calculate the sum of a column.SELECT SUM(column1) FROM table1;
-
MAX: used to retrieve the maximum value of a column.SELECT MAX(column1) FROM table1;
-
MIN: used to retrieve the minimum value of a column.SELECT MIN(column1) FROM table1;
-
AVG: used to calculate the average value of a column.SELECT AVG(column1) as average FROM table1;
-
JOIN: used to combine rows from two or more tables based on a related column. -
INNER JOIN: used to combine only the matching rows from two or more tables. -
LEFT JOIN: used to combine all rows from the left table and the matching rows from the right table. -
RIGHT JOIN: used to combine all rows from the right table and the matching rows from the left table. -
FULL OUTER JOIN: used to combine all rows from both tables.
These clauses can be combined in various ways to form complex SQL statements that retrieve, filter, and manipulate data in a database.
A backtick is used to enclose identifiers that contain special characters, spaces, or reserved keywords. This allows these identifiers to be used as column or table names without causing syntax errors. For example, the following SQL statement uses a backtick to enclose the column name that contains a space:
SELECT `column name` FROM table1;On the other hand, an apostrophe is used to delimit strings. When using strings in SQL queries, the values must be enclosed in apostrophes. For example, the following SQL statement uses apostrophes to enclose the string value:
SELECT * FROM table1 WHERE column1 = 'string value';Constraints are rules that you can apply to a column or set of columns in a table to enforce data integrity. Constraints ensure that the data in the table meets certain requirements.
Here are some of the most common types of constraints in MySQL:
-
NOT NULL: This constraint specifies that a column cannot have NULL values. It ensures that every row must have a value for that column.CREATE TABLE students ( id INT NOT NULL, name VARCHAR(50) NOT NULL );
-
PRIMARY KEY: This constraint defines a column or a set of columns that uniquely identify each row in a table. A primary key must be unique and cannot have NULL values.CREATE TABLE students ( id INT PRIMARY KEY, name VARCHAR(50) );
-
UNIQUE: This constraint ensures that the values in a column or a set of columns are unique, but allows NULL values.CREATE TABLE students ( id INT, email VARCHAR(50) UNIQUE );
-
FOREIGN KEY: This constraint establishes a relationship between two tables by defining a column or a set of columns in one table that refers to the primary key of another table. The foreign key ensures that the values in the referencing column must exist in the referenced table.CREATE TABLE students ( id INT PRIMARY KEY, name VARCHAR(50) ); CREATE TABLE grades ( id INT PRIMARY KEY, student_id INT, grade INT, FOREIGN KEY (student_id) REFERENCES students(id) );
-
CHECK: This constraint allows you to specify a condition that must be true for the values in a column. It is used to ensure that the values meet certain requirements.CREATE TABLE students ( id INT PRIMARY KEY, age INT CHECK (age >= 18) );
-
ENUM: Allows you to define a list of possible values for a column.ENUMcolumns can have up to 65,535 distinct values.CREATE TABLE colors ( id INT PRIMARY KEY, name ENUM('red', 'green', 'blue') );
In this example, the
colorstable has a column callednamethat can only store the values 'red', 'green', or 'blue'. This column can only have one of these values. If the value provided is not available in theENUM, an empty string is inserted. -
SET: Allows you to define a list of possible values for a column, just likeENUM. However,SETcolumns can store multiple values from the list. SET columns can have up to 64 members.CREATE TABLE pizza_orders ( order_id INT PRIMARY KEY, toppings SET('pepperoni', 'mushroom', 'onion', 'olives', 'sausage') );
In this example, the
pizza_orderstable has a column calledtoppingsthat can store any combination of the values 'pepperoni', 'mushroom', 'onion', 'olives', and 'sausage'. This means that if a customer orders a pizza with pepperoni, mushroom, and onion, those values can be stored in the toppings column as a SET.
Here's an example of how you could insert data into thepizza_orderstable:INSERT INTO pizza_orders (order_id, toppings) VALUES (1, 'pepperoni,mushroom'); INSERT INTO pizza_orders (order_id, toppings) VALUES (2, 'onion,olives'); INSERT INTO pizza_orders (order_id, toppings) VALUES (3, 'sausage');
In SQL, a subquery is a query that is nested inside another query. It can be used to retrieve data from one or more tables and then use that data as input to a second query.
Subqueries are often used to simplify complex queries or to perform calculations based on the results of another query.
Example:
- Using a subquery to filter data
SELECT * FROM employees WHERE department_id =
(SELECT department_id FROM departments WHERE name = 'Sales');In this example, the outer query selects all the employees from the employees table where the department_id matches a value returned by the subquery.
The subquery selects the department_id from the departments table where the name is 'Sales'.
The subquery is executed first, and its results are used by the outer query to retrieve the corresponding employees.
- Using a subquery to retrieve a specific value:
SELECT MAX(salary) FROM employees WHERE department_id =
(SELECT department_id FROM departments WHERE name = 'Sales');In this example, the subquery is used to retrieve the
department_id from the departments table where the name is
'Sales'. The outer query selects the maximum salary from the
employees table where the department_id matches the value
returned by the subquery.
- Using a subquery to calculate an aggregate value:
SELECT department_id, AVG(salary) FROM employees
GROUP BY department_id HAVING AVG(salary) >
(SELECT AVG(salary) FROM employees);In this example, the subquery calculates the average salary for all
employees, and the outer query calculates the average salary for
each department_id. The HAVING clause filters the results to
only include department_id values where the average salary is
greater than the overall average salary.
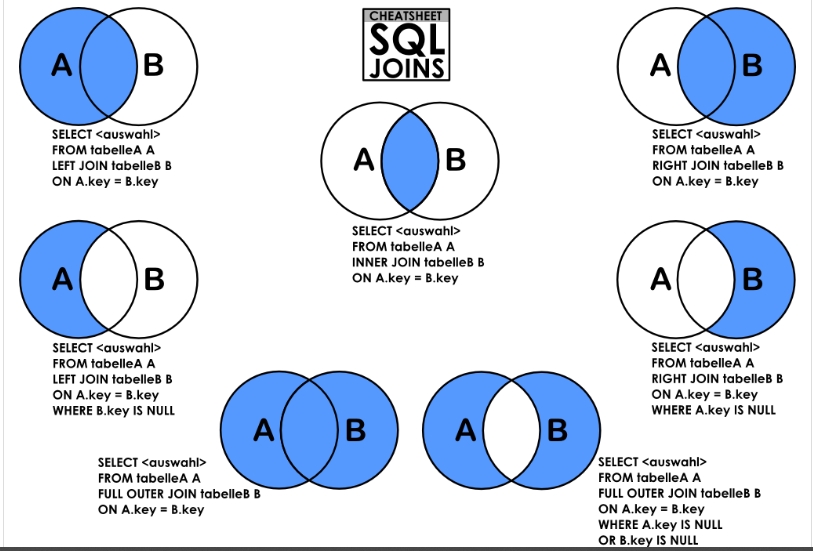
In most queries, we will want to see data from two or more tables. To do this, we need to join the tables in a way that matches up the right information from each one to the other.
In SQL, a JOIN clause is used to combine rows from two or more tables based on a related column between them.
There are several types of joins in SQL, including:
-
INNER JOIN: Returns only the rows that have matching values in both tables.SELECT orders.order_id, customers.customer_name FROM orders INNER JOIN customers ON orders.customer_id = customers.customer_id;
In this example, the
INNER JOINclause is used to combine theordersandcustomerstables based on theircustomer_idcolumns. The resulting table will only contain the rows where there is a match between the two tables, and will include theorder_idandcustomer_namecolumns from both tables. -
LEFT JOIN: Returns all the rows from the left table, and the matched rows from the right table. If there are no matches, the result will contain NULL values for the columns from the right table.SELECT customers.customer_name, orders.order_id FROM customers LEFT JOIN orders ON customers.customer_id = orders.customer_id;
In this example, the
LEFT JOINclause is used to combine the customers and orders tables based on theircustomer_idcolumns. The resulting table will include all the rows from thecustomerstable, and only the matching rows from theorderstable. If there are no matching rows in theorderstable, theorder_idcolumn will contain NULL values. -
RIGHT JOIN: Returns all the rows from the right table, and the matched rows from the left table. If there are no matches, the result will contain NULL values for the columns from the left table.SELECT customers.customer_name, orders.order_id FROM customers RIGHT JOIN orders ON customers.customer_id = orders.customer_id;
In this example, the
RIGHT JOINclause is used to combine thecustomersandorderstables based on theircustomer_idcolumns. The resulting table will include all the rows from theorderstable, and only the matching rows from thecustomerstable. If there are no matching rows in thecustomerstable, thecustomer_namecolumn will contain NULL values. -
FULL OUTER JOIN: Returns all the rows from both tables, and the matched rows from both tables. If there are no matches, the result will contain NULL values for the columns from the table that does not have a match.SELECT customers.customer_name, orders.order_id FROM customers FULL OUTER JOIN orders ON customers.customer_id = orders.customer_id;
In this example, the
FULL OUTER JOINclause is used to combine thecustomersandorderstables based on theircustomer_idcolumns. The resulting table will include all the rows from both tables, and the matching rows from both tables. If there are no matching rows in one or both of the tables, the resulting table will contain NULL values for the columns from the table(s) that do not have a match. -
CROSS JOIN: Returns theCartesian productof the two tables, which means every row in the first table is combined with every row in the second table. This can result in a large number of rows and is typically used for generating all possible combinations of data. Suppose we have two tables employees and departments with the following data:employees --------- id name 1 Alice 2 Bob 3 Charlie departments ----------- id name 1 Sales 2 Marketing 3 Finance
If we want to generate a table that shows every possible combination of employees and departments, we can use a CROSS JOIN:
SELECT employees.name, departments.name FROM employees CROSS JOIN departments;
This would produce a table with 9 rows, where each employee is combined with every department:
name name ------------ Alice Sales Bob Sales Charlie Sales Alice Marketing Bob Marketing Charlie Marketing Alice Finance Bob Finance Charlie Finance -
SELF JOIN: Joins a table to itself, typically used when we want to compare rows within the same table.
Suppose we have a table orders that contains the following data:orders ------ id customer_id amount 1 1 100 2 2 200 3 1 150 4 3 75
If we want to find all pairs of orders with the same customer ID and different amounts, we can use a self join:
SELECT o1.id, o2.id, o1.amount, o2.amount FROM orders o1 JOIN orders o2 ON o1.customer_id = o2.customer_id AND o1.amount <> o2.amount;
This would produce the following table:
id id amount amount --------------------- 1 3 100 150 3 1 150 100
-
NATURAL JOIN: Performs a join based on columns with the same name in both tables. This can be a convenient way to join tables if the columns you want to join on have the same name, but it can also be risky because it can produce unexpected results if there are multiple columns with the same name.
Suppose we have two tables employees and salaries with the following data:employees --------- id name department 1 Alice Sales 2 Bob Marketing 3 Charlie Finance salaries -------- id salary 1 50000 2 60000 3 70000
If we want to join the tables on the id column (which exists in both tables), we can use a NATURAL JOIN:
SELECT * FROM employees NATURAL JOIN salaries;
This would produce a table with the following columns and data:
id name department salary ------------------------------- 1 Alice Sales 50000 2 Bob Marketing 60000 3 Charlie Finance 70000
used to check whether a subquery returns any rows. The EXISTS operator is often used in combination with a subquery that performs a more complex search or aggregation.
The syntax for the EXISTS operator is as follows:
SELECT column1, column2, ... FROM table1
WHERE EXISTS (subquery);The subquery can be any valid SELECT statement that returns one or more rows. If the subquery returns any rows, the EXISTS operator will return true and the outer query will include the rows that meet the specified condition.
For example, if you have two tables, "orders" and "customers", and you want to find all customers who have placed an order, you can use the EXISTS operator as follows:
SELECT customer_name
FROM customers
WHERE EXISTS (
SELECT order_id
FROM orders
WHERE orders.customer_id = customers.customer_id
);This statement will return the names of all customers who have placed an order. The subquery checks the "orders" table to see if any rows match the current customer ID, and the EXISTS operator returns true if at least one row is found.
Note that the subquery used with the EXISTS operator must return at least one column. The column doesn't need to be used in the outer query, but it must be present in the subquery.
Additionally, the EXISTS operator can also be used with a negation operator (NOT EXISTS) to check whether a subquery does not return any rows. The NOT EXISTS operator works in the opposite way to the EXISTS operator, and will return true only if the subquery returns no rows.
In SQL, there are several operators that are used to perform various operations on data. Here are some of the most commonly used operators:
-
Comparison operators are used to compare two values and return a boolean value (true or false) based on the comparison. Some common comparison operators in SQL include =, <>, <, >, <=, and >=.
-
Logical operators are used to combine two or more conditions in a SQL statement. The most commonly used logical operators in SQL include AND, OR, and NOT.
-
Arithmetic operators are used to perform mathematical operations on numeric data in a SQL statement. Some of the most common arithmetic operators in SQL include +, -, *, /, and %.
Example:
If you have a table called "inventory" with columns "product" and "quantity", you can use the*operator to calculate the total value of each product:SELECT product, quantity * unit_price AS total_value FROM inventory;
-
String operators are used to manipulate and compare character data in a SQL statement. The most commonly used string operators in SQL include CONCAT, LENGTH, and SUBSTRING.
Used to concatenate two or more strings.
For example, if you have a table called "users" with columns "first_name" and "last_name", you can use theCONCATfunction to create a full name column:SELECT CONCAT(first_name, ' ', last_name) as full_name FROM users;
Used to find the length of a string.
For example, if you have a table called "products" with columns "product_name" and "description", you can use theLENGTHfunction to find the length of the product name and description:SELECT product_name, LENGTH(description) AS description_length FROM products;
used to extract a portion of a string.
For example, if you have a table called "messages" with a column called "message_text", you can use theSUBSTRINGfunction to extract the first 10 characters of each message:SELECT SUBSTRING(message_text, 1, 10) as message_preview FROM messages;
Used to replace a portion of a string with another string.
For example, if you have a table called "addresses" with a column called "address", you can use theREPLACEfunction to replace all instances of "St." with "Street":SELECT REPLACE(address, 'St.', 'Street') as formatted_address FROM addresses;
Used to convert a string to upper or lower case.
For example, if you have a table called "users" with a column called "email", you can use theUPPERfunction to find all email addresses in all upper case:SELECT UPPER(email) as email_uppercase FROM users;
-
Aggregate functions are used to perform calculations on a set of values and return a single value. Some of the most common aggregate functions in SQL include COUNT, SUM, AVG, MAX, and MIN.
-
Set operators are used to combine or exclude data from two or more SELECT statements. The most commonly used set operators in SQL include UNION, INTERSECT, and MINUS.
The
INTERSECToperator is used to combine the results of two or moreSELECTstatements into a single result set that contains only the rows that appear in allSELECTstatements.
For example, if you have two tables,employeesandmanagers, and you want to find the employees who are also managers, you can use theINTERSECToperator as follows:SELECT employee_name FROM employees INTERSECT SELECT employee_name FROM managers;
Note that the columns selected in all
SELECTstatements must be of the same data type and in the same order for theINTERSECToperator to work.The
MINUSoperator is used to exclude the results of oneSELECTstatement from another. The syntax for theMINUSoperator is as follows:SELECT column1, column2, ... FROM table1 MINUS SELECT column1, column2, ... FROM table2;
The
MINUSoperator will return only the rows that are in the result set of the firstSELECTstatement but not in the result set of the secondSELECTstatement.
For example, if you have two tables, "employees" and "managers", and you want to find the employees who are not managers, you can use the MINUS operator as follows:SELECT employee_name, department FROM employees MINUS SELECT employee_name, department FROM managers;
This statement will return a result set that includes the name and department of all employees who are not managers.
The
UNIONoperator is used to combine the results of two or moreSELECTstatements into a single result set. The syntax for theUNIONoperator is as follows:SELECT column1, column2, ... FROM table1 UNION SELECT column1, column2, ... FROM table2;
The
UNIONoperator will remove any duplicate rows from the result set. If you want to include duplicate rows, you can use theUNION ALLoperator instead.
For example, if you have two tables,customersandsuppliers, and you want to combine the results of twoSELECTstatements that retrieve data from these tables, you can use theUNIONoperator as follows:SELECT customer_name, address, city, country FROM customers UNION SELECT supplier_name, address, city, country FROM suppliers;
This statement will return a result set that includes the name, address, city, and country of all customers and suppliers.